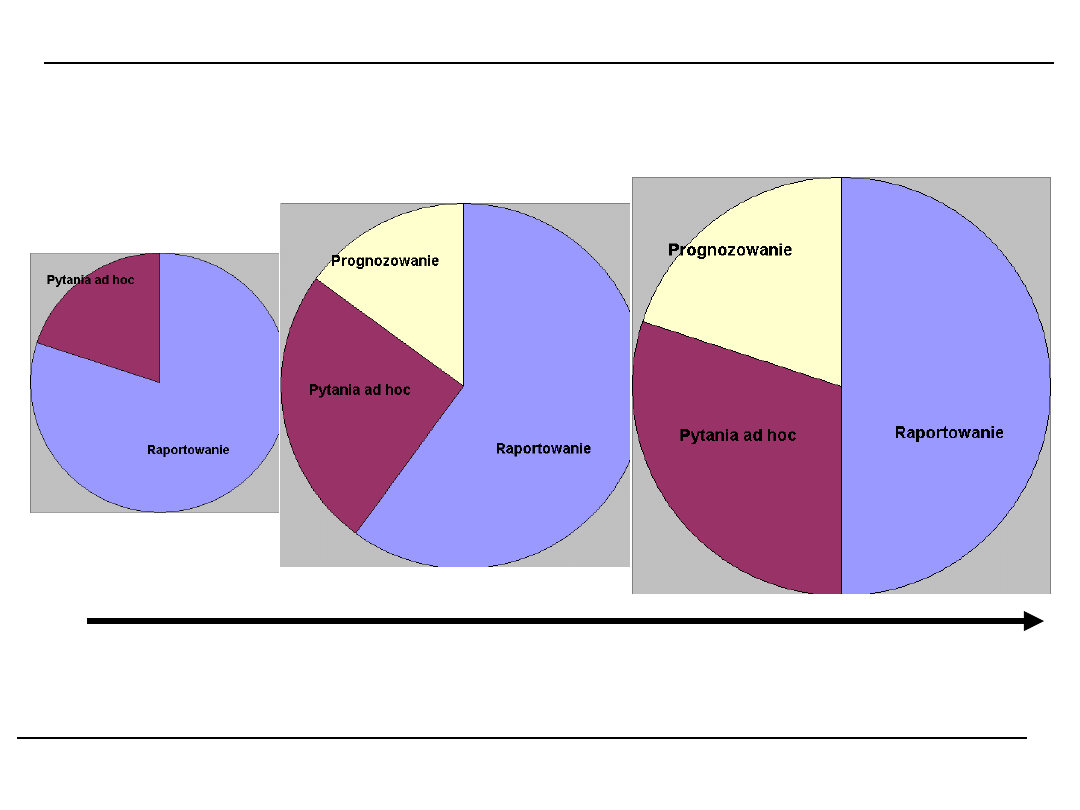
Stopnie zaawansowania analizy danych
Co się stało? Dlaczego się stało? Co się stanie?
Proste pytania Odkrywanie przez człowieka Odkrywanie
wspomagane maszynowo
?

Co to jest analiza danych?
Analiza danych jest to metodyczny proces
realizowany
przy
pomocy
specjalizowanych narzędzi zmierzający do
sformułowania nowej wiedzy w sposób
zrozumiały i przydatny dla jej właściciela.
Analiza
wspomagana
komputerowo
realizowana jest z reguły na ogromnych
zbiorach danych i opiera się na tzw.
algorytmach drążenia danych

Co to jest analiza danych?
Proces analizy danych:
Ustalenie rodzaju i struktury reprezentacji
która będzie używana
Ustalenie sposobów pomiaru, porównywania
danych i oceny wyników
Wybranie
algorytmu
optymalizującego
funkcję oceny
Określenie jakie zasady zarządzania danymi
są potrzebne do uruchomienia algorytmów.

Klasyfikacja analizy danych wg rodzajów
zadań
1. Eksploracyjna analiza danych – bez
założeń dotyczących celu,
2. Modelowanie opisowe – celem jest
scharakteryzowanie wszystkich danych
lub procesu tworzącego dane
3. Modelowanie predykcyjne
4. Odkrywanie wzorców i reguł
5. Wyszukiwanie według zadanego wzorca

Klasyfikacja analizy danych – stosowane
techniki
1. Eksploracyjna analiza danych opiera się na
technikach
interaktywnych
i
wizualnych
(różnego rodzaju wykresy, techniki rzutowania
na przestrzenie o mniejszej liczbie wymiarów),
2. Modelowanie
opisowe
–
rozkłady
prawdopodobieństwa (estymacja gęstości),
analiza skupień, segmentacja, modelowanie
zależności
3. Modelowanie predykcyjne – analiza szeregów
czasowych, analiza trendów,
4. Odkrywanie wzorców i reguł – algorytmy
formułowania i weryfikacji reguł
5. Wyszukiwanie według zadanego wzorca –
analiza miar podobieństwa i obliczanie
odległości miedzy obiektami

Dwa rodzaje DATA MINING
1. Zorientowany na weryfikację hipotez stawianych
przez użytkownika (veryfication oriented)
2. Zorientowany na odkrywanie wiedzy
(znajdowanie nowych reguł i wzorców)
Metody zorientowane na weryfikację to najczęściej
tradycyjne metody statystyki: miary
dopasowania, testy statystyczne, analiza
wariancji,
Metody zorientowane na odkrywanie wiedzy są
związane z problemami selekcji hipotez bardziej
niż z ich weryfikacją, bardziej z identyfikacją niż
z oceną.
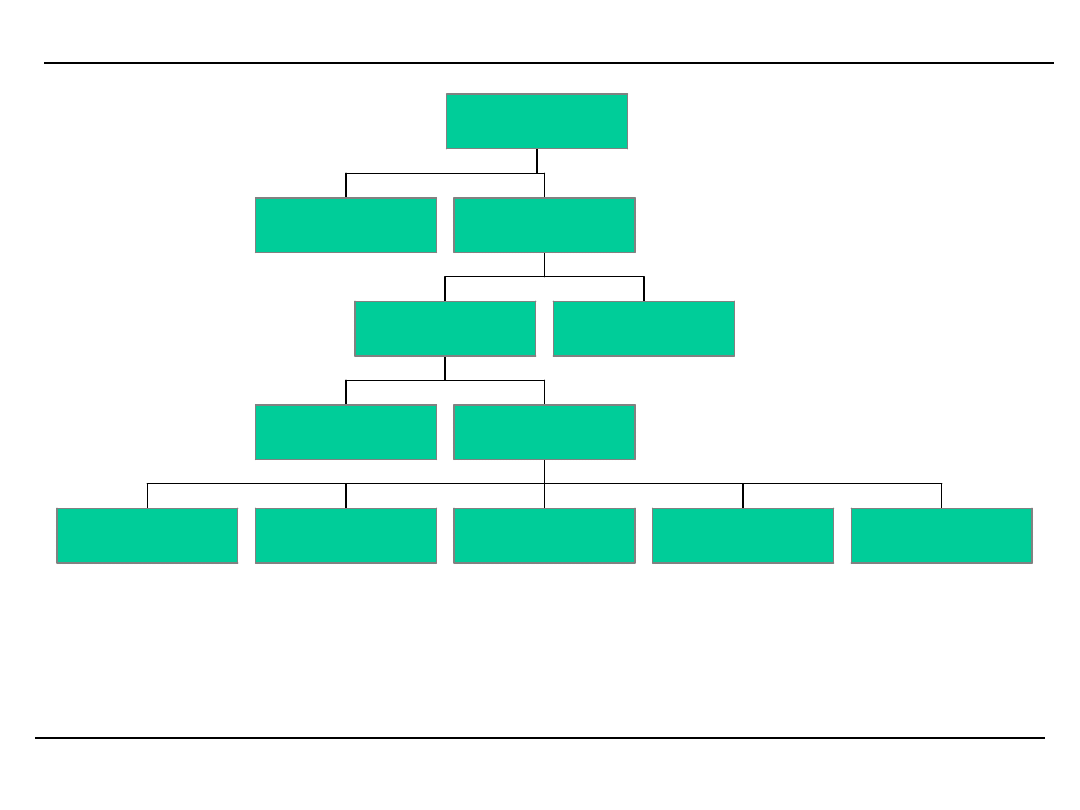
Taksonomia metod DATA MINING
w e ry fi k a c ja
re g re s ja
re g u ły a s o c ja c ji
s ie c i n e u ro n o w e
d rz e w a d e c y z y jn e
s ie c i in fo rm a c y jn e
s ie c i B a y e s o w s k ie
k la s y fi k a c ja
p ro g n o z a
o p is
o d k ry w a n ie
m e to d y D M

Analiza danych – obszary zastosowań
Praktycznie wszystkie dziedziny życia:
• Marketing – segmentacja klientów
• Finanse – reguły zależności
• Demografia – techniki wizualizacji, trendy
• Zmiany klimatu – trendy, grupowanie (3 wzorce
rozkładów ciśnienia)
• Katalogowanie
gwiazd
–
grupowanie
segmentacja
• Zagadnienia techniczne – statystyczna kontrola
procesów
• Ruch drogowy – przyczyna powstawania korków
i wypadków drogowych - analiza zależności
• ...

Komputerowa analiza danych
Komputerowo
wspomagana
analiza
danych jest przydatna wtedy gdy
chcemy
zaoszczędzić
czas
i
zredukować
wysiłek
ale
jest
konieczna w przypadku:
1.bardzo dużych ilości danych.
Wall-mart – 20 mln transakcji dziennie
AT&T – 300 mln rozmów dziennie
2. ciągłej aktualizacji danych
3. specyfiki gromadzonych danych
4. specyfiki źródeł danych

DATA MINING w środowisku OLAP
Data Mining czyli wydobywanie wiedzy z baz
danych i hurtowni danych jest najbardziej
zaawansowanym działaniem analitycznym. Polega
ono na automatycznej analizie danych zawartych w
składnicach danych w celu poszukiwania nieznanej
wcześniej wiedzy.
(moduł Oracle Discoverer, Mining model w MS
OLAP server, Scenario w środowisku COGNOS)
DEFINICJA:
drążenie danych (data mining) jest procesem
wydobywania wiedzy ukrytej w dużych zbiorach
danych, hurtowniach danych lub innych
repozytoriach informacji.
[Han J., Kamber M.:
Data Mining: Concepts and Techniques, Academic
Press, 2001.]

Jaka wiedza nas interesuje? Czyli cele Data Mining
Głównym celem drążenia danych jest odkrycie i
sformalizowanie wiedzy. Menedżerowie i eksperci
zainteresowani są przede wszystkim wiedzą:
nową,
nietrywialną i
użyteczną.
Biznesowe DM to proces odkrywania i interpretacji
wzorców w danych w celu rozwiązywania
problemów biznesowych

Cele szczegółowe Data Mining
•gdy nie jest dostępna żadna wiedza podstawowa
lub gdy ekspert dysponujący wiedzą o dziedzinie
jest niedostępny, ale dysponujemy dużą ilością
danych interesujące może być odkrycie wszelkiej
wiedzy. Rezultaty tego procesu są wtedy podstawą
dalszych badań z wykorzystaniem ekspertów
erudytów zmierzających do skonkretyzowania i
uszczegółowienia wiedzy.
•gdy dostępna jest wiedza eksperta, który zna
dziedzinę lub jest dostępna bogata wiedza
podręcznikowa odkrycie w danych potwierdzenia
znanej wiedzy jest niewystarczające.

Cele szczegółowe Data Mining - historia
obiektów
Głównym zadaniem wykorzystania technik analizy
danych oraz drążenia danych w bazach danych
przechowujących historię obiektów jest opisanie
charakterystyk ewolucji obiektów przede wszystkim
w celu:
rozpoznania reguł zachowania się obiektów w
krótkim
okresie czasu czyli w konkretnej
sytuacji (jeśli kupił X to
czy kupi Y?),
rozpoznania reguł zmian (ewolucji) zachowań
obiektów (jak
zmieniają się upodobania
klientów),
dokonania wiarygodnej predykcji zachowania się
obiektów (kupi – nie kupi),
postawienia diagnozy rozwojowej (co z tego
wyniknie? Co z niego będzie?).

Jak są realizowane szczegółowe zadania DM
• Definicja celu
• Selekcja danych
• Przygotowanie danych
• Eksploracja danych
• Odkrywanie wzorców
• Przypisanie wzorców do celów
• Prezentacja
• Rangowanie rozwiązań
• Monitorowanie wykonania

Cel pragmatyczny Data Mining
• Użytkownicy
oczekują
przede
wszystkim
dostarczenia im wiedzy dającej przewagę nad
innymi uczestnikami rynku, aplikacja której
stwarza szansę na postęp w rozwoju organizacji.
• Z ich punktu widzenia drążenie danych ma dwa
podstawowe cele:
znalezienie i wytłumaczenie odchyleń od
znanych prawideł w bardzo dużej ilości danych
niemożliwej do przetworzenia tradycyjnymi
metodami w rozsądnym czasie,
odkrycie związków trudnych do wytłumaczenia
(non-trivial) i przypadków niespodziewanych
(emergency patterns).

Cel pragmatyczny Data Mining c.d.
Na takich założeniach opiera się na przykład
analiza tzw. sekwencji rzadkich. Zakłada ona, że
sukcesów w procesie drążenia danych poszukiwać
przede wszystkim w możliwości wyjścia poza
stwierdzenie oczywistych reguł i oczywistych
wzorców i znajdowaniu reguł niespodziewanych. W
przeciwnym przypadku badanie nie będzie w stanie
dostarczyć decydentom wiedzy, której nie byłby w
stanie dać ekspert w danej dziedzinie, i która
dawałaby jakąkolwiek przewagę konkurencyjną.

Podział systemów Data Mining c.d.
1. Ze względu na źródła:
RBD, obiektowe BD, HD, Temporalne Bd,
tekstowe BD, GIS, WWW
2. Ze względu na rodzaj odkrywanej wiedzy:
klasyfikacja,
dyskryminacja,
grupowanie,
związki zależności, zależności przyczynowo-
skutkowe, ewolucja (jeden system może
obejmować kilka funkcjonalności)
3. Ze względu na wykorzystywane techniki:
Ze
wspomaganiem
użytkownika:
interakcyjne, objaśniające, sterowane przez
człowieka, uczenie z nadzorem.
Bez
wspomagania:
sieci
neuronowe,
rozpoznawanie
wzorców,
statystyczne,
maszynowe uczenie się
4. Ze względu na dziedzinę: giełdowe, medyczne,
telekomunikacja, badania DNA, analiza e-mail,
analiza serwisów WWW i wiele, wiele innych...

Cel pragmatyczny Data Mining c.d.
Na takich założeniach opiera się na przykład
analiza tzw. sekwencji rzadkich. Zakłada ona, że
sukcesów w procesie drążenia danych poszukiwać
przede wszystkim w możliwości wyjścia poza
stwierdzenie oczywistych reguł i oczywistych
wzorców i znajdowaniu reguł niespodziewanych. W
przeciwnym przypadku badanie nie będzie w stanie
dostarczyć decydentom wiedzy, której nie byłby w
stanie dać ekspert w danej dziedzinie, i która
dawałaby jakąkolwiek przewagę konkurencyjną.
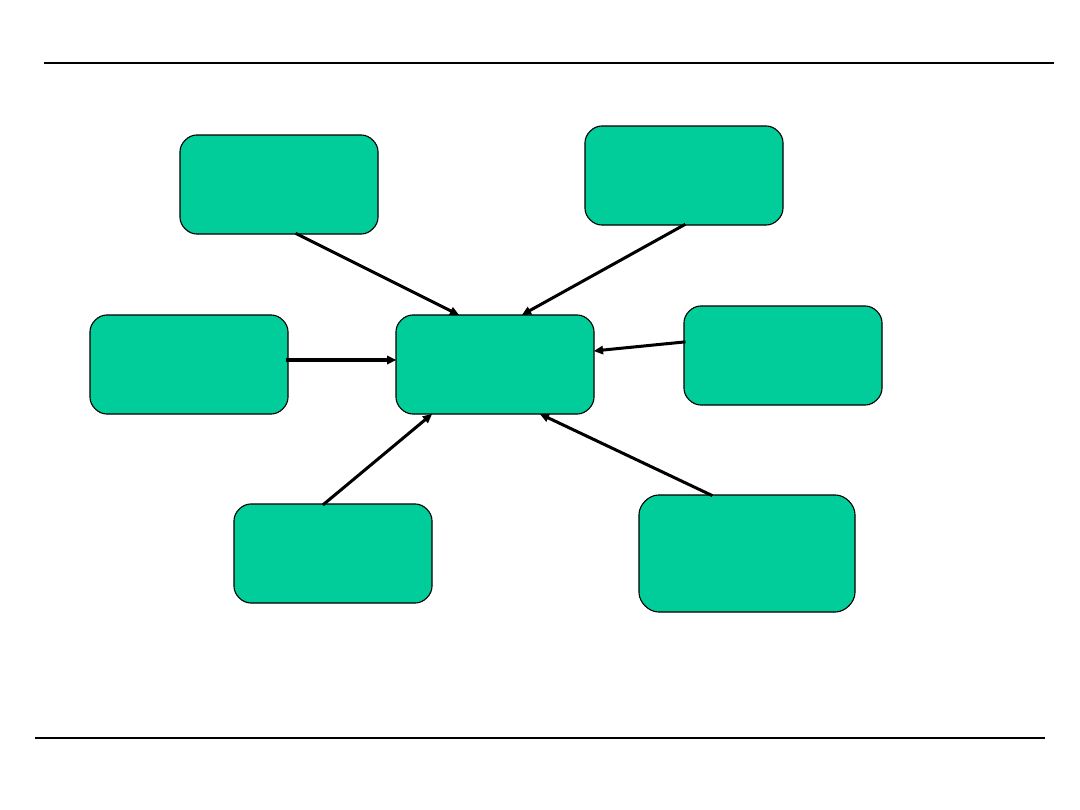
Związki Data Mining z innymi dziedzinami
nauki
Data Mining
Nauka
o informacji
Wizualizacja
Podejmowanie
decyzji
Technologia
BD
Statystyka
Maszynowe
uczenie
OBSZAR
ANALIZY
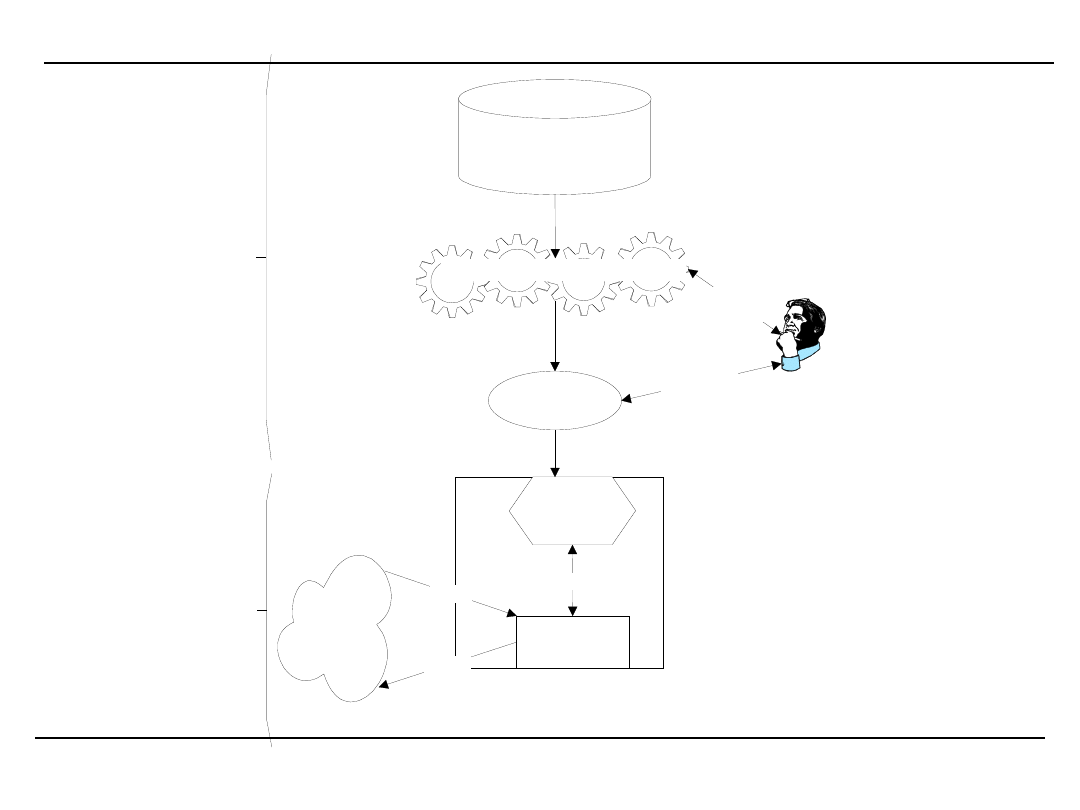
Miejsce analizy danych w cyklu uczenia
STRATEGIA
DZIAŁANIE
WYNIK DZIAŁANIA
DANE
INFORMACJA
WIEDZA

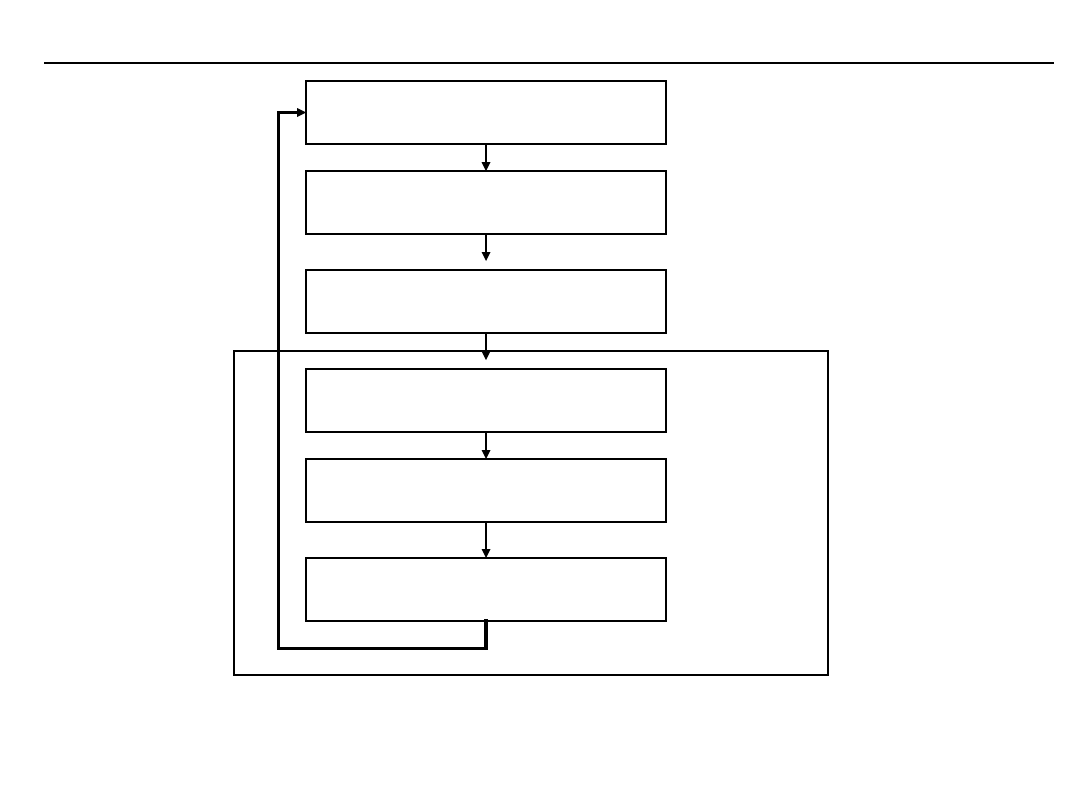
Miejsce DM w procesie odkrywania i aplikacji
wiedzy (1)
Ogólnie proces odkrywania i aplikacji wiedzy
można przedstawić jako iterację działań:
zrozumienie dziedziny i sformułowanie
problemu
przygotowanie danych
drążenie danych
przetwarzanie odkrytych wzorców i reguł
wdrożenie uzyskanej wiedzy.

Miejsce DM w procesie odkrywania i aplikacji
wiedzy (2)
W nieco innym ujęciu:
oczyszczane danych
integracja danych
selekcja danych
przekształcenie danych
drążenie danych
ocena uzyskanych rezultatów
prezentacja
aplikacja wiedzy

Tryby pracy modułów Data Mining
Mówi się o dwóch trybach pracy w DM:
•off-line oraz
•on-line.
Wybór trybu zależy od celu badania.

Charakterystyka trybu off-line (1)
Tryb off-line jest ukierunkowany na zdobycie
wiedzy. W trybie off-line odkrywanie i aplikacja
wiedzy jest:
•zwykle procesem długotrwałym lecz dokładnym i
kompletnym. Ograniczenia czasowe są bardzo
słabe, a prowadzone obliczenia mogą trwać
stosunkowo długo (godziny, dni).
• Odkryta wiedza ma charakter długotrwały
(tygodnie, miesiące, lata) i może mieć wpływ na
wszystkie elementy organizacji oraz na wszystkie
szczeble zarządzania organizacją.
• Udział wiedzy a priori może być ograniczony do
wskazania celu drążenia oraz zasad, według
których drążenie ma się odbywać.

Charakterystyka trybu off-line (2)
•Algorytmy mogą pracować na dużych zbiorach
danych i nie muszą korzystać z metod przybliżonych,
natomiast ich optymalność jest sprawą drugorzędną.
•Na tym etapie realizowane są takie zadania jak:
ekstrakcja reguł, grupowanie (tworzenie klas),
wyszukiwanie częstych sekwencji itd.
•Wiedzę zdobytą w tym trybie daje podstawę do pracy
eksperta i budowy finalnej bazy reguł, wzorców, klas
itp., wykorzystywanej w pracy w trybie on-line.

Charakterystyka trybu on-line
Tryb on-line przewidywany jest do szybkiej reakcji
(ułamki sekund, sekundy) na zaistniałą sytuację. W
takich przypadkach konieczne jest:
•przyjęcie dużego udziału wiedzy wstępnej (przede
wszystkim tej uzyskanej w procesie drążenia danych w
trybie
off-line
oraz
wiedzy
fundamentalnej
–
podręcznikowej),
•zastosowanie
szybkich,
chociaż
przybliżonych
algorytmów.
Ten tryb pracy systemu wykorzystywany jest przede
wszystkim do klasyfikowania kolejnych pojawiających
się przypadków.
Na podstawie wyników przeprowadzonej analizy
realizowane są działania dostosowujące bieżącą pracę
organizacji do pojawiających się w otoczeniu
organizacji sytuacji poprzez wspieraną wiedzą (mądrą)
reakcję na odbierane sygnały.
Schemat pracy on i off-line
Zweryfikowana
wiedza
Narzędzia odkrywania wiedzy
T
ry
b
p
ra
cy
o
f
-l
in
e
T
ry
b
p
ra
cy
o
n
-l
in
e
Konsultacje
z ekspertem
Konsultacje
z ekspertem
Repozytorium danych
O
R
G
A
N
IZ
A
C
JA
Baza wiedzy
organizacji
otoczenie
organizacji
komórka
decyzyjna
konsultacja
sygnał
reakcja

Najważniejsze zagadnienia badawcze w DM (1)
• możliwości wydobywania różnych rodzajów
wiedzy,
• budowa języków dla DM (tak jak SQL dla BD),
• metody i narzędzia prezentacji i wizualizacji
efektów DM,
• operowanie na niepełnych i zaszumionych
danych,
• pomiar wartości wiedzy.

Najważniejsze zagadnienia badawcze w DM (2)
Zagadnienia wydajności:
•Efektywność i skalowalność algorytmów,
•Równoległe, rozproszone i przyrostowe
drążenie danych.
Praca z różnorodnymi źródłami danych
•Relacyjne,
tekstowe,
multimedialne,
obiektowe,
hypertekstowe,
przestrzenne,
temporalne źródła danych,
•Heterogeniczne BD,
•źródła nieustrukturalizowane,
•lokalne i rozległe (w tym Internet) źródła
danych.

Co to jest „Golden Search”?
„Golden Search” jest odpowiednikiem
znalezienia żyły złota. Wśród wielu jałowych
danych czasami uda nam się znaleźć jakąś
regułę, która umożliwi nam radykalną zmianę z
zarządzaniu organizacją, albo zmianę podejścia
do klienta, albo wykrywanie pewnych zjawisk
itp. Eksploatacja tej wiedzy przed konkurencją
– zanim wiedza ta stanie się powszechna -
umożliwi nam uzyskanie dodatkowego zysku.

Przykłady „Golden Search” z dziedziny bankowości
Po długookresowej, żmudnej i wyczerpującej
analizie zachowań klientów banków udało się
sformułować regułę:
Jeśli klient jest związany z bankiem co najmniej
czterema usługami (konto, karta, kredyt, ...) to
mimo obniżenia jakości jego obsługi i
podniesienia jej kosztów nie przechodzi on do
konkurencji.
Konsekwencje łatwe do przewidzenia...

Przykłady „Golden Search” z dziedziny
telekomunikacji
Analiza zgromadzonych danych o rozmowach
telefonicznych (czas, czas trwania, ilość)
wykazała że posiadacze najdroższych
abonamentów wykorzystują je tylko w drobnej
części.
Po ustaleniu docelowej grupy takich
snobistycznych klientów skonstruowano dla
nich jeszcze droższe oferty, odpowiednio
marketingowo opakowano (abonament VIP,
złoty, brylantowy, ...) i sprzedano.

Przykłady „Golden Search” z dziedziny sprzedaży
detalicznej
Analiza koszyków klientów wykazała, że pewne
towary kupowane są w grupach (wędlina-
nabiał, piwo-krakersy, orzeszki itp.)
Spowodowało to rozłożenie towarów w sklepie
w taki sposób aby trzeba było przejść jak
najdłuższą drogę pomiędzy nimi. Wzrasta
wtedy szansa na dokonanie przez klienta
dodatkowych zakupów.

Warunki pomyślnego wdrożenia projektu DM
• istnieje wsparcie finansowe aplikacji,
• jest uzasadnione podejrzenie że w ramach
prowadzonego biznesu istnieje możliwość
pozyskania nowej wiedzy,
• cele są określone i możliwe do osiągnięcia,
• efekty mogą mieć znaczący wpływ na
prowadzoną działalność,
• jest dostępna wiedza podstawowa,
• istnieją wiarygodne źródła danych o dobrej
jakości za długi okres czasu,
• właściwi ludzie - znawcy danej dziedziny,
fachowcy od zarządzania informacją,
statystycy i eksperci Data Mining.

Warunki pomyślnego wdrożenia projektu DM c.d.
• zakres aplikacji jest ściśle wyznaczony i
sensownie ograniczony,
• pierwsze rezultaty powinny pojawić się w
okresie 3-6 miesięcy
• nie należy rozbudzać nadmiernych
oczekiwań. W wielu przypadkach uzyskana
wiedza będzie trudna do wykorzystania.
• proces data mining wtedy możemy uznać za
zakończony powodzeniem gdy zrozumiemy
efekty drążenia danych i będziemy wiedzieli
jak uzyskana wiedze zaaplikować.
• podobne kryteria można przyjąć dla budowy
projektu budowy HD

UWAGA – dane zbierane są WSZĘDZIE
1. Operacje bankowe
2. Operacje wykonywane za pomocą kart
płatniczych
3. Telefonia
4. Telefonia komórkowa (SMSy, rozmowy)
5. Wszelkie działania w sieciach lokalnych i
rozległych
6. Zakupy, programy lojalnościowe
7. Ubezpieczenia
8. Biblioteki i wypożyczalnie
9. ....
TOTALNA INWIGILACJA – to nie jest s-f to
nasza rzeczywistość
APLIKACJE
SYSTEMY WSPOMAGANIA
DECYZJI
OPTYMALIZACJ A ZAPYTAŃ
SYSTEMY
EKSPERTOWE
INTELIGENTNY
INTERFEJ S
REGUŁY INTEGRALNOŚCI
PROJ EKT BAZY
DANYCH
BAZA DANYCH
BAZA WIEDZY
OSTATECZNY
ZBIÓR REGUŁ
REGUŁY
FILTRY
SEMAN-
TYCZNE
FILTRY
WZORCÓW
FILTRY
STATY-
STYCZNE
FILTRY
DANYCH
REGUŁY
REGUŁY
WZORCE ORAZ
NARZĘDZIA
WIZUALIZACJ I I
SELEKCJ I
SPECYFIKACJ A TYPÓW
REGUŁ ORAZ WZORCE
PARAMETRY,
PRZEDZIAŁY,
WARTOŚCI PROGOWE
PRZEGLĄDARKI I FILTRY
WEJ ŚCIA UŻYTKOWNIKA
STEROWANIE
STEROWANIE
STEROWANIE
STEROWANIE
Architektura systemu odkrywania wiedzy z baz
danych

Know-what
(wiedzieć co) – fakty. prowadzenie
obserwacji
i
zdobywanie
doświadczenia
osiągnięcie profesjonalnej biegłości.
Know-why
(wiedzieć dlaczego) – prawa i zasady
zrozumienie przyczyn budowanie łańcuchów
przyczynowo-skutkowych,
wyjaśnianie,
diagnozowanie prewencja i naprawa.
Know-how
(wiedzieć jak) – wiedza praktyczna
umiejętności
pracowników
i
stosowanie
odpowiednich zasad w rozwiązywaniu złożonych
problemów rozwijanie kwalifikacji wysokiego
stopnia umiejętności praktycznych oraz znawstwo.
Know-who
(wiedzieć kto) – osoby posiadające wiedzę
+ wiedza którą dysponują meta-wiedza.
RODZAJE WIEDZY

•Klasyfikacyjna
•Charakteryzująca
•Asocjacyjna
Postaci odkrytej wiedzy
•Zależności funkcyjne i statystyczne
•Zależności funkcjonalne
•Reguły przyczynowe
•Drzewa decyzyjne
•...
RODZAJE ODKRYWANEJ WIEDZY
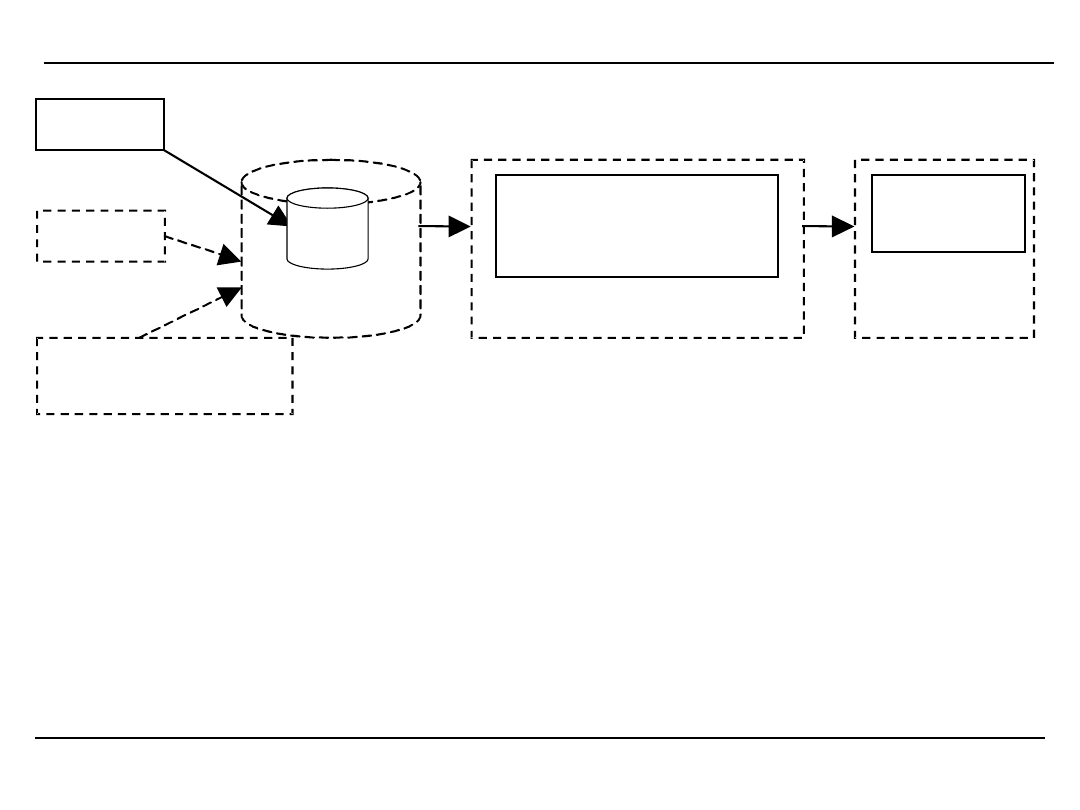
P
rezentacje
procesów
Narzę
dzia analizy procesów
HDP
WMS
Rejestracja zdarzeń z
otoczenia
OLTP
Klasyczne
narzędzia
DataMining
Narzędzi
a
prezenta
cji
HD
ROZSZERZONA ARCHITEKTURA SYSTEMU BI

Uzyskanie wartościowej informacji analitycznej
wymaga zastosowania technik, wykraczających poza
standardowe badania statystyczne i raportowanie.
Do najczęściej wykorzystywanych metod analizy
danych zaliczamy:
•poszukiwanie
związków
i
zależności
(reguł
asocjacji),
•grupowanie,
•klasyfikację,
•analizę szeregów czasowych i sekwencji zdarzeń.
NARZĘDZIA ANALIZY DANYCH

Celem jest przed wszystkim wygenerowanie reguł
opisujących badaną dziedzinę.
Najpopularniejszą grupę reguł stanowią reguły
związków (association rules) w postaci:
Jeśli A to B lub (AB).
POSZUKIWANIE ZWIĄZKÓW I ZALEŻNOŚCI

Ponieważ
każdy
zapis
w
bazie
może
być
interpretowany
jako
reguła,
nie
ma
sensu
generowanie reguł bez żadnych ograniczeń. Liczba
wygenerowanych reguł z ogromnego zbioru danych
może być bardzo duża, a przez to bezużyteczna
wprowadzono miary umożliwiające pomiar istotności
reguły (interestingness measure). Są to:
poziom wsparcia reguły (r_s)
poziom wiarygodności reguły (r_c):
POSZUKIWANIE ISTOTNYCH ZWIĄZKÓW I
ZALEŻNOŚCI
tek
liczba_kro
całkowita_
A
ych
zawierając
tek
liczba_kro
)
(A
rt
rule_suppo
B
B
A
ających
tek_zawier
liczba_kro
A
ających
tek_zawier
liczba_kro
)
(A
dence
rule_confi
B
B

Przykładowo reguła:
Jeśli użytkownik wykonuje akcję A to wykonuje
również akcję B (r_s=0,002 ;r_c=0,5 )
oznacza, że dwóch użytkowników na tysiąc wykonuje
czynność A jak i B oraz, że połowa wykonujących A
wykonuje również B.
Poziom wsparcia i wiarygodności najczęściej jest
określany przez eksperta w danej dziedzinie lub
użytkownika,
który
w
iteracyjnym
procesie
weryfikuje użyteczność znalezionych reguł. Reguła
jest uznawana za interesującą (znaczącą, istotną),
jeśli zarówno poziom wsparcia jak i istotności dla
danej reguły przekracza zadany próg.
POSZUKIWANIE ZWIĄZKÓW I ZALEŻNOŚCI

Grupowanie jest techniką łączenia w klasy (grupy)
obiektów o podobnych charakterystykach. W grupie
powinny znaleźć się obiekty podobne do innych
należących do tej samej grupy oraz niepodobne do
obiektów z innych grup.
Grupowanie może być oparte o odpowiednio dobraną
miarę odległości lub o pewien opis obiektu. Tę drugą
formę grupowania określa się jako grupowanie
konceptualne.
Na
proces
grupowania
konceptualnego składa się:
zbudowanie odpowiednich grup oraz
zbudowanie opisu dla każdej klasy.
Ponieważ proces grupowania nie jest oparty o żadną
wiedzę początkową często określany jest jako
uczeniem lub rozpoznawaniem bez nauczyciela
(unsupervised learning).
GRUPOWANIE

W zastosowaniach biznesowych grupowanie jest
jedną
z
podstawowych
technik
badawczych.
Przykładowo:
•badania rynku i łączenie użytkowników w grupy ma
na celu przede wszystkim segmentację rynku i w
konsekwencji umożliwienie personalizacji kontaktów
z użytkownikami - klientami. Działanie to opiera się
głównie na badaniu cech użytkowników: wieku, płci,
wykształcenia, zawodu, zainteresowań itp.
•grupowanie stron WWW może opierać się o różne
kryteria i może być użyteczne przede wszystkim w
algorytmach wyszukiwarek internetowych oraz dla
dostarczycieli usług internetowych.
CELE GRUPOWANIA
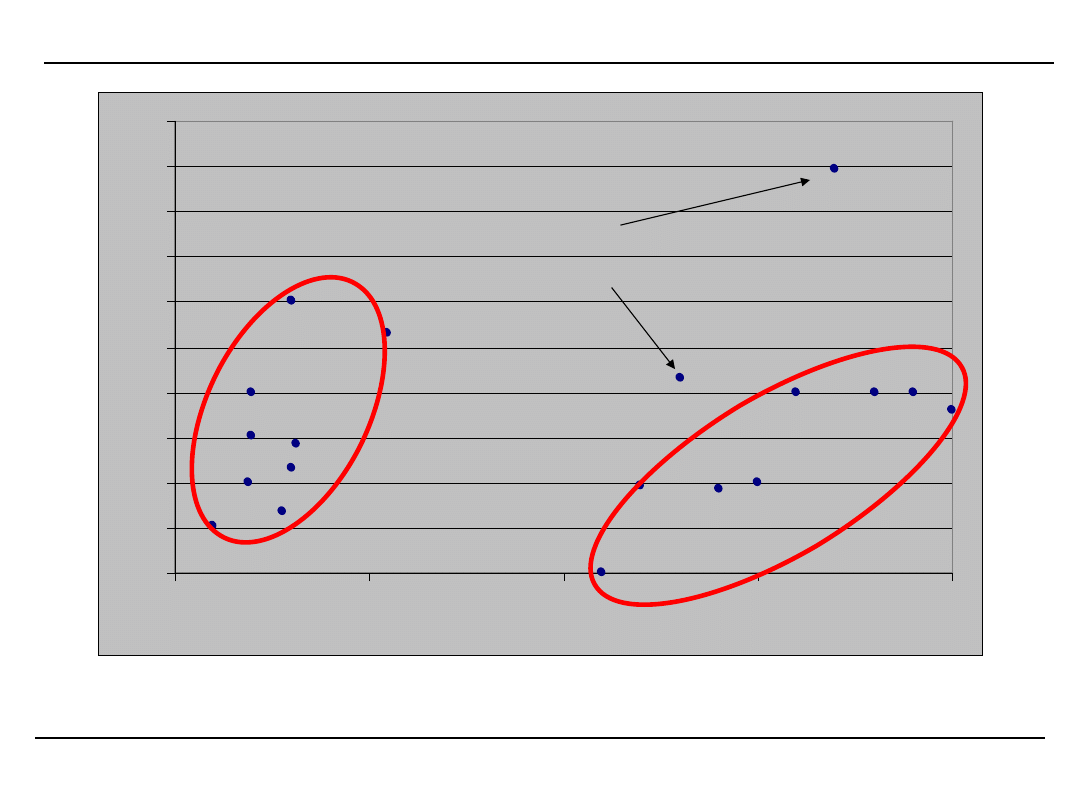
PRZYKŁAD GRUPOWANIA
2
2,5
3
3,5
4
4,5
5
5,5
6
6,5
7
0
5
10
15
20
Przypadki odosobnione

Prace poświęcone grupowaniu skupiają się na:
•znalezieniu efektywnych metod wydajnego i
efektywnego grupowania w oparciu o duże bazy
danych w sytuacji występowania bardzo wielu
obiektów,
•
znalezienia
algorytmów
grupowania
w
przestrzeniach wielowymiarowych,
• algorytmów wymagających minimalnej ilości
wiedzy początkowej,
•grupowanie danych obiektów opisanych danymi
numeryczno-symbolicznymi, danymi zakłóconym itp.
ZAGADNIENIA ZWIĄZANE Z GRUPOWANIEM

Klasyfikacja to zbiór działań zmierzających do
zakwalifikowania przypadku do jednej z wcześniej
określonych grup. Klasyfikacja może być dokonana
na podstawie pewnych cech obiektu (np. wiek, płeć,
zainteresowania) lub jego zachowania (początkujący,
ekspert, sprawny użytkownik, hacker itp.).
Klasyfikacja tym się różni od zadania grupowania, że
jest dana pewna wiedza początkowa dotycząca
możliwego podziału na klasy i z tego też powodu
określana
jest
jako
uczenie
pod
nadzorem
(supervised learning) lub uczeniem z nauczycielem.
KLASYFIKACJA

Przykładami reguł czasowo niezależnych są reguły:
Użytkownicy odwiedzający stronę A serwisu X odwiedzają
również stronę B tego serwisu, lub
Klienci kupujący dobro A kupują również dobro B.
Przykład reguły uwzględniającej zależności temporalne:
Użytkownicy odwiedzający stronę A odwiedzają później
(następnie) stronę B lub
Klienci kupujący dobro A kupują dobro B w ciągu 3
miesięcy od zakupu dobra A.
(wszystkie reguły z określonym
poziomem wsparcia i wiarygodności).
Ekstrakcja reguł temporalnych jest znacznie trudniejsza
niż reguł klasycznych jednak są one bardziej użyteczne
dla menedżerów.
Reguły zależne i niezależne czasowo

Pożądane jest odkrycie zmian zachodzących w
zbiorze reguł. Dla możliwości adaptacji systemu
istotniejsze
może
być
stwierdzenie
zmian
parametrów reguł – poziomu wsparcia i poziomu
ufności niż reguły z całego zestawu danych.
Istotniejsza jest zmiana wartości parametrów we
wskazanych przez badającego okresach, aniżeli
informacja z sumy tych okresów. W ten sposób
można wskazać reguły, które mają szansę stać się
dominującymi
w
przyszłości
lub
przeciwnie,
zignorować reguły, których znaczenie maleje.
ZAGADNIENIA ZWIĄZANE Z GRUPOWANIEM

Przykładowo
reguła:
Użytkownik
wykonał
procedurę A oraz procedurę B (r_s=20%,
r_c=50%),
uzyskana z okresu dwuletniego 1999-2000 ma inną
wartość dla badacza i operatora systemu niż para
reguł:
Użytkownik
wykonał
procedurę
A
oraz
procedurę B w roku 1999 (r_s=10%, r_c=30%)
Użytkownik
wykonał
procedurę
A
oraz
procedurę B w roku 2000 (r_s=30%, r_c=80%).
Analiza tych dwóch reguł pozwala bowiem wysnuć
dodatkowy
wniosek:
Udział
użytkowników
wykonujących procedurę A oraz procedurę A łącznie
z B szybko rośnie.
ZAGADNIENIA ZWIĄZANE Z GRUPOWANIEM

Potrzebne narzędzia w zakresie analizy sekwencji zdarzeń:
• Efektywne algorytmy wyszukiwania powtarzających się
sekwencji zdarzeń,
• Określanie podobieństwa sekwencji i znajdowanie
sekwencji podobnych,
• Znajdowanie sekwencji z określonymi ograniczeniami
czasowymi,
• Taksonomia w połączeniu z analizą sekwencji,
• Badanie sekwencji zdarzeń równoległych (np. zdarzeń
politycznych i
gospodarczych),
• Metody klasyfikacji danych symbolicznych,
• Maszynowe uczenie się na podstawie zachowań.
NARZĘDZIA ANALIZY SEKWENCJI

Dostępne narzędzia
Algorytm Apriori:
• poszukiwanie wzorców sekwencji,
• wyszukanie częstych sekwencji zdarzeń,
• generowanie reguł na podstawie sekwencji przy założonym
poziomie
wsparcia i ufności.
Algorytm GSP:
• uwzględnienie czasu, który upłynął pomiędzy realizacjami
poszczególnych
zdarzeń w sekwencji,
• uwzględnienie hierarchii zdarzeń występujących w sekwencjach,
• zniesienie ograniczenia że zdarzenie musi wystąpić w tej samej
transakcji jeśli
zdarzenie wystąpiło w określonym „okienku
czasowym”.
Miara umożliwiająca obliczanie podobieństwa/odległości
między sekwencjami.
NARZĘDZIA ANALIZY SEKWENCJI (2)

Obecnie
podstawowymi
narzędziami
wizualizacji są:
•tabele przestawne,
•wykresy różnego rodzaju
•odpowiednie dla nich raporty i zestawienia
Do analizy sekwencji należałoby zastosować:
•wykresy podobne do wykresów Gantta tak, aby
możliwe byłoby śledzenie zależności pomiędzy
procesami i zdarzeniami.
•wykresy spiralne
•operacje grupowania i rozkładu na hierarchiach
zdarzeń, procesów
•swobodne poruszanie się po osi czasu.
•animacje (schematy animowane)
WIZUALIZACJA ANALIZY SEKWENCJI

Opis Algorytmu Apriori
Do znajdowania częstych wzorców w sekwencjach
oraz generowania na tej podstawie reguł posłużyć
się można jedną z kilku metod. Najwcześniej
opracowany został zaproponowany (1996r) algorytm
Apriori, który następnie wielokrotnie usprawniany i
modyfikowany jest obecnie wykorzystywany również
w pakiecie drążenia danych Clementine programu
SPSS. Algorytm Apriori służy do przeszukiwania
transakcyjnych baz danych w celu:
•wyszukania
często
występujących
sekwencji
zdarzeń (frequent itemsests) czyli sekwencji, które
występują co najmniej tyle razy ile wskazuje
predefiniowany wcześniej poziom,
•generowania na podstawie znalezionych zbiorów
reguł przy założonym poziomie wsparcia i ufności.

Opis Algorytmu Apriori
Konstrukcja algorytmu opiera się na założeniu, że
sekwencja
częsta
musi
składać
się
z
podsekwencji, które również są częste (cechę tę
również określa się jako cechę APRIORI). W ten
sposób można zbudować ogólny algorytm:
1. k=1
2. znajdź bazie wszystkie k-elementowe sekwencje
częste
3. k=k+1
4.
utwórz
k-elementowe
sekwencje
złożone
z
wszystkich
możliwych
znalezionych
sekwencji częstych
5. wygeneruj zgodnie z regułą APRIORI sekwencje
kandydujące do dalszego badania
6. Jeśli liczba_kandydatów>0
przejdź do kroku 2
w przeciwnym przypadku
Stop.
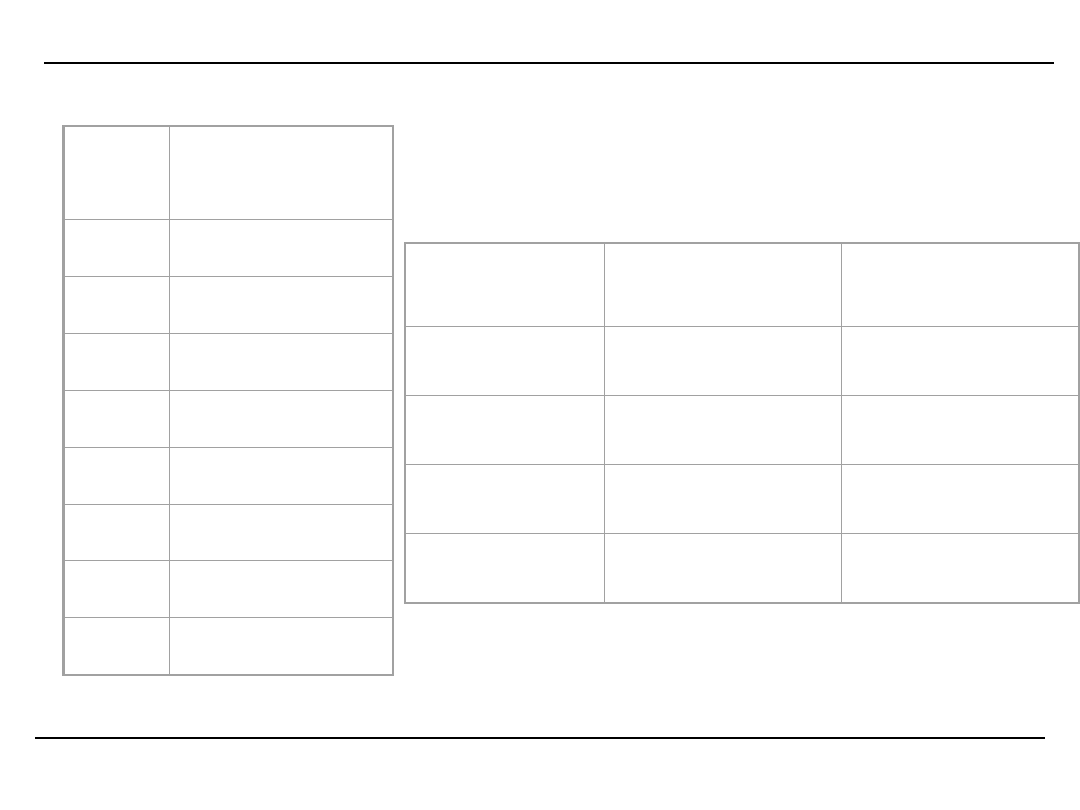
Przykład działania algorytmu Apriori – krok 1 i 2
Przyjmijmy następującą postać bazy:
Id
tran
s
Lista
Zdarzeń
1
A, B, C, D
2
A, D, B, C
3
A, D, C, B
4
B, C, D
5
A, B, C, C
6
D, A
7
A, B, C, B
8
A, C, D
sekwencja
Liczba
wystąpień
Osiągnięty
poziom
wsparcia
{A}
5
Tak
{B}
4
Tak
{C}
5
Tak
{D}
7
Tak
Oraz minimalny poziom
wsparcia =3
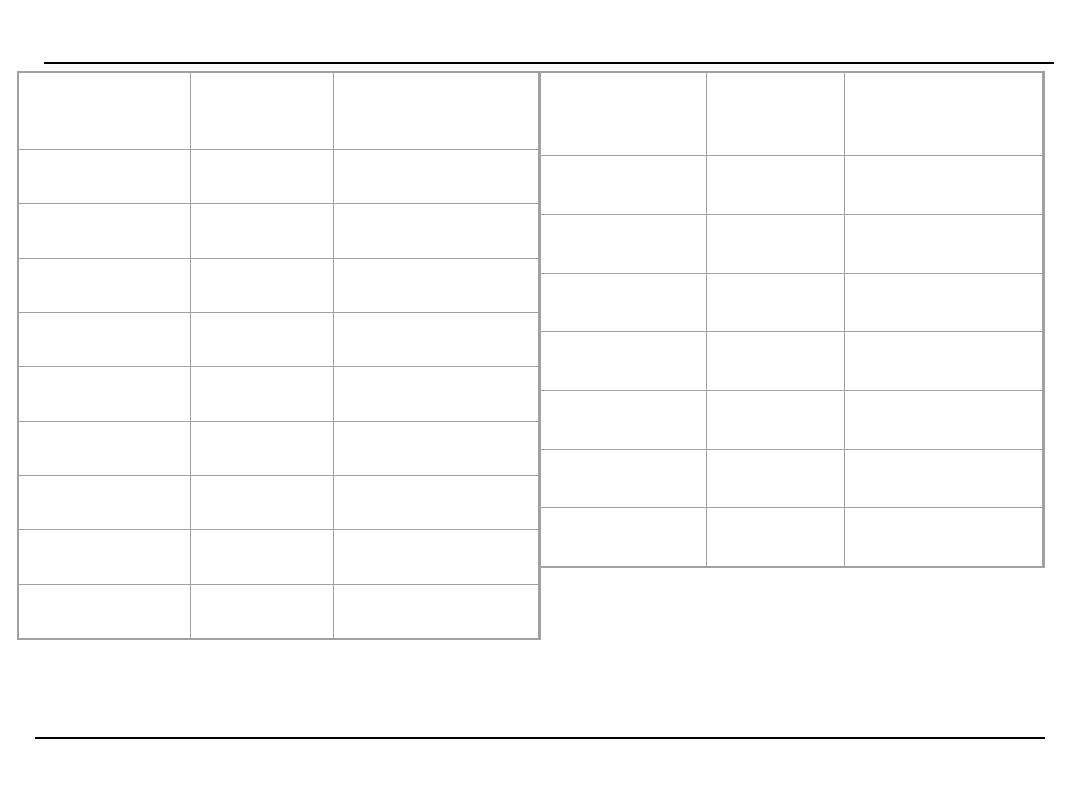
Przykład działania algorytmu Apriori – krok 3, 4
sekwencja
Liczba
wystąpie
ń
Osiągnięty
poziom
wsparcia
{A,A}
0
Nie
{A,B}
6
Tak
{A,C}
7
Tak
{A,D}
4
Tak
{B,A}
0
Nie
{B,B}
0
Nie
{B,C}
6
Tak
{B,D}
2
Nie
{C,A}
0
Nie
sekwencja
Liczba
wystąpi
eń
Osiągnięty
poziom
wsparcia
{C,B}
2
Nie
{C,C}
1
Nie
{C,D}
3
Tak
{D,A}
1
Nie
{D,B}
2
Nie
{D,C}
2
Nie
{D,D}
0
Nie
utwórz k-elementowe sekwencje złożone z wszystkich
możliwych znalezionych sekwencji częstych

Przykład działania algorytmu Apriori – krok 5
Złączenie wygenerowanych sekwencji daje następujący
zbiór sekwencji 3-elementowych:
{{A,B}{A,C}{A,D}{B,C}{C,D}} x {{A,B}{A,C}{A,D}{B,C}
{C,D}} =
A,A,B
A,A,C
A,A,D
A,B,A
A,B,B
A,B,C
A,B,D
A,C,A
A,C,B
A,C,C
A,C,D
A,D,A
A,D,B
A,D,C
A,D,D
B,C,A
B,C,B
B,C,C
B,C,D
C,D,A
C,D,B
C,D,C
C,D,D.
Ponieważ zgodnie z założeniem cechy APRIORI każda podsekwencja
sekwencji częstej też musi być częsta można przystąpić do fazy
usuwania tych sekwencji, które tego warunku nie spełniają.
Przykładowo sekwencja A,A,B składa się z dwóch podsekwencji A,A
oraz A,B i nie może być sekwencją częstą, ponieważ podsekwencja A,A
nie jest sekwencją częstą w związku z tym odrzucana jest z dalszych
badań. Natomiast sekwencja A,C,D składa się z podsekwencji A,C A,D i
C,D i każda z nich jest sekwencją częstą, w związku z czym sekwencja
A,C,D jest kwalifikowana do dalszych badań.
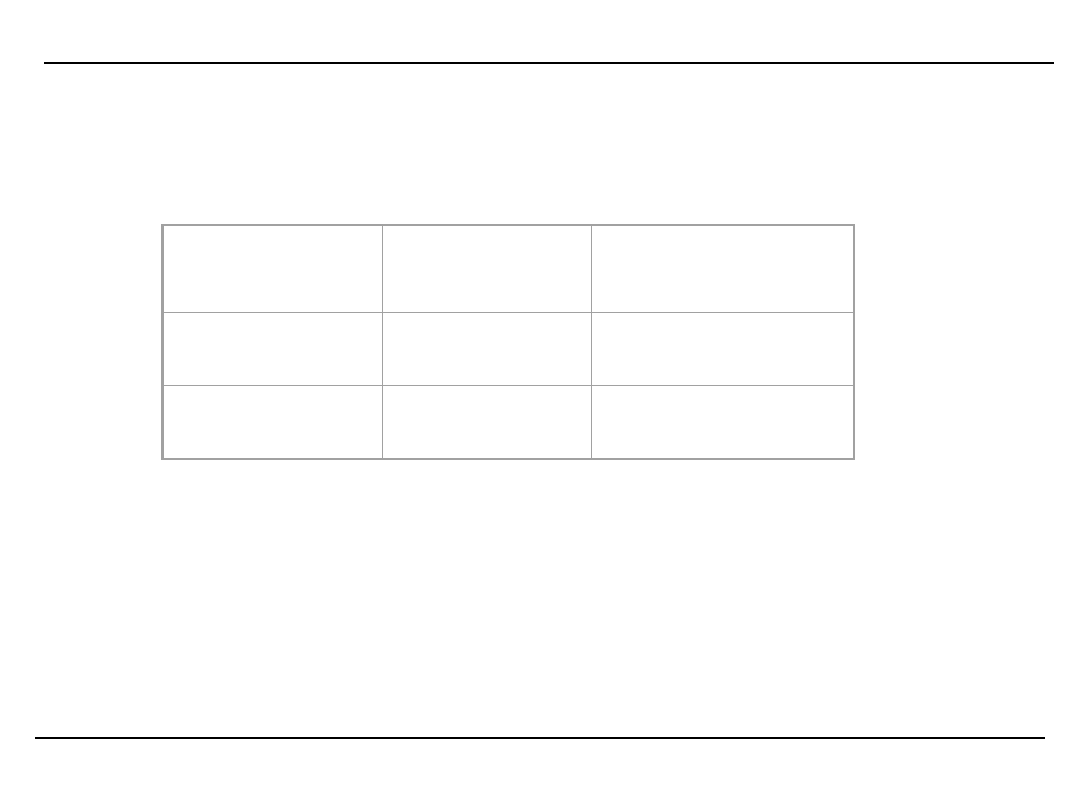
Przykład działania algorytmu Apriori – krok 2
pętla 2
W ten sposób generowany jest następujący zbiór
kandydatów
A,B,C
A,C,D
Liczba wystąpień tych sekwencji w bazie wynosi
odpowiednio
Po porównaniu z wymaganym poziomem wsparcia
pozostaje tylko sekwencja {A,B,C}.
{A,B,C}x{A,B,C} = {A,B,C,A} {A,B,C,B} {A,B,C,C}
{A,B,C,D}
Ponieważ żaden z kandydatów nie składa się z
podsekwencji częstych nie zostaje wygenerowany żaden
kandydat i algorytm kończy działanie.
sekwencja
Liczba
wystąpień
Osiągnięty
poziom
wsparcia
{A,B,C}
3
Tak
{A,C,D}
2
Nie

Generowanie reguł (1)
Proces
generowania
reguł
na
podstawie
znalezionych
sekwencji
wykorzystuje
pojęcie
poziomu wiarygodności reguły (r_c):
gdzie liczba krotek zawierających A B to liczba
transakcji w bazie zawierających sekwencję A oraz
sekwencję B, i odpowiednio liczba krotek
zawierających A to liczba transakcji w bazie
zawierających sekwencję A.
A
ających
tek_zawier
liczba_kro
A
ających
tek_zawier
liczba_kro
)
(A
dence
rule_confi
B
B

Generowanie reguł (2)
W oparciu o tę równość reguły mogą zostać
wygenerowane w ten sposób, że:
dla każdej częstej sekwencji l należy wygenerować
wszystkie niepuste podsekwencje sekwencji l,
dla każdego niepustego podzbioru s sekwencji l
regułą jest s=>(l-s) jeżeli tylko
c
r_
s
encją
tek_z_sekw
liczba_kro
l
encją
tek_z_sekw
liczba_kro

Generowanie reguł (3)
Przykładowo dla przedstawionej bazy danych i
znalezionej sekwencji A,B,C wszystkie niepuste
podsekwencje to {A}, {B}, {C}, {A, B}, {A, C}, {B,
C} a wygenerowane reguły to:
A B => C
r_c = 3/6 = 50%
A C => B
r_c = 3/7 = 42,86%
B C => A
r_c = 3/6 = 50%
A => B C
r_c = 3/5 = 60%
B => A C
r_c = 3/4 = 75%
C => A B
r_c = 3/5 = 60%
Przy minimalnym poziomie wiarygodności reguły na
poziomie 70% jedynie przedostatnia reguła może
zostać uznana za wiarygodną.

Implikacje praktyczne
Analiza koszykowa jest jednym z najczęściej
podawanych przykładów zastosowania algorytmu
Apriori. Polega ona na przewidywaniu jakie towary
znajdą się w jednym koszyku danego klienta.
Na podstawie algorytmu można np. określić z jakim
prawdopodobieństwem jeśli klient kupi mleko to
kupi również płatki owsiane i czy jest to wielkość
istotna z punktu widzenia marketingu.
W tym przypadku kolejność towarów w koszyku nie
jest istotna, ale dla algorytmu nie ma żadnego
znaczenia (wystarczy np. posortować towary w
koszyku wg alfabetu lub numeru)

Implikacje praktyczne (2)
Bardziej zaawansowana analiza polega na
określeniu w jakiej kolejności klient będzie kupował
określone dobra. Np.
Klient X kupił telewizor.
Z prawdopodobieństwem 70% jego następnym
zakupem z grupy RTV będzie DVD
Jeśli klient kupił TV i DVD to z
prawdopodobieństwem 65% następnym zakupem
będzie kamera cyfrowa
Ustalenie takich reguł umożliwia zbudowanie
odpowiednich akcji promocyjnych, programów
lojalnościowych itp.

Ogólna charakterystyka sieci jako składnicy
danych
•Sieć WWW jest obecnie największą znana składnicą
danych – jej wielkość szacuje się na co najmniej
setki terabajtów lub petabajtów i bardzo szybko
przyrasta.
•Złożoność i stopień nieustrukturalizowania danych
w sieci jest bardzo wysoki – znacznie wyższy niż
zwykłego tekstu książkowego,
•Brak
metadanych
–
indeksów,
porządków,
katalogów powoduje olbrzymie kłopoty w z
wyszukaniem informacji,
•Sieć jest bardzo dynamicznym źródłem informacji –
niektóre informacje są w nim obecne zaledwie przez
minuty lub godziny
•Sieć ma najbardziej rozdrobnioną strukturę
użytkowników
•Zaledwie drobna część danych jest użyteczna
(istnieje reguła która mówi że 99% informacji w
sieci jest nieistotna dla 99% jej użytkowników).

DM w sieci – źródła danych(1)
Organizacje komunikujące się ze swym otoczeniem
poprzez sieć mają niespotykane do tej pory
możliwości gromadzenia danych o nim. Ze względu
na źródło (miejsce) pozyskania danych można je
podzielić na:
•dane serwisu a w tym:
•dane o zawartości serwisów WWW,
•dane o strukturze ich zawartości wewnętrznej
oraz powiązań z innymi serwisami,
•pliki zawierające informacje o kliencie oraz
sposobie wykorzystania informacji w serwisach.
Z kolei źródła informacji o kliencie można podzielić
ze względu na sposób pozyskania danych. Wyróżnić
można dwa rodzaje danych:
•pozyskiwane niezależnie od współpracy z klientem,
•pozyskiwane za aprobatą klienta.

DM w sieci – źródła danych(2)
Podstawowym źródłem danych pierwszego typu są
pliki przechowujące dane o logowaniu się
użytkownika do serwisu oraz o działaniach na nim
prowadzonych (weblogs). Struktura tych plików
może zmieniać się w zależności od ustawień
administratora. Możliwe jest jednak co najmniej
określenie:
•danych ułatwiających identyfikację użytkownika:
•numer IP lub adres serwera wysyłającego
żądanie,państwo, miasto,
•pełna nazwa użytkownika w przypadku usług
wymagających autoryzacji,
•czasu odwiedzin,
•kolejnych działań wykonywanych przez klienta
(żądań zgłaszanych przez klienta) (click stream),
są to jednak dane niedokładne ze względu na
możliwość przechowywania (cache) informacji w
przeglądarce klienta.

DM w sieci – pliki logowania
155.158.208.235 - - [16/Nov/2000:14:01:50 +0100] "GET
/webusage/usage_100.html HTTP/1.0" 304 -
155.158.208.235 - - [16/Nov/2000:14:01:51 +0100] "GET
/webusage/daily_usage_100.gif HTTP/1.0" 304 -
155.158.208.235 - - [16/Nov/2000:14:01:52 +0100] "GET
/webusage/ctry_usage_100.gif HTTP/1.0" 304 -
155.158.208.235 - - [16/Nov/2000:14:01:52 +0100] "GET
/webusage/ctry_usage_100.gif HTTP/1.0" 206 5959
155.158.208.235 - -[16/Nov/2000:14:01:52 +0100]
"GET/webusage/daily_usage_100.gif HTTP/1.0" 206 10290
dhcp-edu-155-158-238-57.co.ae.katowice.pl - - [16/Nov/2000:14:02:16
+0100] "GET / HTTP/1.1" 304 -
dhcp-edu-155-158-238-57.co.ae.katowice.pl - - [16/Nov/2000:14:02:16
+0100] "GET /image/clj.jpg HTTP/1.1" 304 -
dhcp-edu-155-158-238-57.co.ae.katowice.pl - - [16/Nov/2000:14:02:16
+0100] "GET /image/left.jpg HTTP/1.1" 304 -
dhcp-edu-155-158-238-57.co.ae.katowice.pl - - [16/Nov/2000:14:02:16
+0100] "GET /image/aem.jpg HTTP/1.1" 304 -
dhcp-edu-155-158-238-57.co.ae.katowice.pl - - [16/Nov/2000:14:02:16
+0100] "GET /image/right.jpg HTTP/1.1" 304 -
dhcp-edu-155-158-238-57.co.ae.katowice.pl - -

DM w sieci – źródła danych(3)
Możliwe jest jednak dzięki nim określenie:
•kolejności odwiedzania stron,
•długości przebywania na każdej stronie,
•rodzaju pobieranych danych (cenniki, informacje o
promocjach, dane techniczne towarów itp.),
•zadawanych przez
użytkownika
zapytań
w
oferowanych przez serwis wyszukiwaniach,
•rodzaju realizowanych zadań i statusu ich
wykonania,
typu przeglądarki.

DM w sieci – źródła danych(4)
Istnieją również dodatkowe możliwości pozyskania
dokładniejszych danych o kliencie, jednak ich
zastosowanie wymaga co najmniej neutralnej
postawy użytkownika. Należą do nich:
•cookies (technika ta wymaga przyzwolenia
przyjmowania ich przez użytkownika),
•dokładniejsze dane o użytkowniku uzyskane
poprzez prowadzenie z nim stałej korespondencji
(wymagane jest podanie przez użytkownika adresu
e-mail),
•identyfikacja klienta w zamian za określone
korzyści (promocje, konkursy, nagrody),
•wypełnianie rozmaitych ankiet lub odpowiedzi na
pytania.

DM w sieci – źródła danych(5)
Dokładniejsze informacje można zdobyć o klientach,
dla których jest realizowane zamówienie poprzez
zaliczenie pocztowe lub kartę płatniczą (miejsce
zamieszkania, płeć, status materialny, wiek).
Informacje te w toku prowadzonych analiz
uzupełniane
są
o
ogólnodostępne
dane
makroekonomiczne, demograficzne, branżowe itp.
pochodzące ze źródeł zewnętrznych: raportów,
roczników statystycznych, almanachów itp.

DM w sieci – wykorzystanie
Wykorzystanie wyników analizy może zostać
podzielone na trzy obszary:
1. wspieranie zarządzania relacjami z klientem
(Client
Relationship Management) poprzez
personalizację
obsługi
klienta,
(np.
wyświetla reklamę i interesujące łącza
na
podstawie analizy skierowanego zapytania)
2. monitorowanie i analiza otoczenia organizacji,
3. analiza i optymalizacja techniczna pracy
serwisu.

DM w sieci – wykorzystanie(1)
Warunkiem optymalizacji obsługi klienta jest jego
personalizacja. Jest ona nieodłącznie związana z
identyfikacją oraz charakterystyką klienta. Te z kolei są
oparte o klasyfikację na podstawie zachowania lub
atrybutów użytkownika. Na podstawie plików logowania
możliwe jest śledzenie poczynań klienta aktualnie
odwiedzającego
stronę
i
klasyfikowanie
go
do
odpowiedniej grupy oraz dostosowywanie zawartości stron
i ścieżek przeglądania stron do typu klienta. W
szczególności można wtedy stwierdzić, że:
•klientowi się spieszy,
•klient szuka określonego towaru/usługi,
•klient zainteresowaniem jest jedynie przeglądnięciem
oferty,
•klient ma (lub nie ma) rozeznania w serwisie,
•klient porównuje różne towary (usługi),
•wielokrotnie pyta o to samo itp.
Najprostsze działanie tego typu to wyświetlenie strony w
języku użytkownika określonym na podstawie jego IP.

DM w sieci – wykorzystanie(1)
Korzystając z wykrytych reguł można konstruować
strony
zawierające
zestawy
towarów
komplementarnych, pozwalać na łatwe porównanie
dóbr substytucyjnych, umieszczać w odpowiednich
miejscach reklamę lub odnośniki itp.
Szczególną uwagę warto zwrócić na rzadką
możliwość sprawdzenia bezpośredniego wpływu
reklamy na zachowanie użytkownika. Możliwe jest
zmierzenie czasu, rodzaju, wielkości użytej reklamy i
zapisu reakcji użytkownika.

DM w sieci – wykorzystanie(2)
Na pracę organizacji powinna mieć również wpływ
zautomatyzowana analiza otoczenia. Obejmować
ona może zmiany w strukturze rynku, zmiany w
wielkości sprzedaży i cenach towarów, badanie
trendów,
wykrywanie
sezonowości
sprzedaży,
badanie
oferty
konkurencyjnych
serwisów,
technologii używanych przez konkurencję, itp.
Działania te, chociaż nie mają natychmiastowego
wpływu pozwalają utrzymać serwis na poziomie nie
odbiegającym od serwisów konkurencyjnych i co
najmniej zatrzymać dotychczasowych klientów.

DM w sieci – wykorzystanie(3)
Analiza obciążenia serwera i optymalizacja
techniczna pracy serwisu jest najczęstszym
działaniem administratorów systemu. Wyniki analiz
takich jak obciążenia dobowe (ilość użytkowników,
ilość odwiedzanych stron) mają bezpośredni wpływ
na jakość technicznej obsługi użytkownika oraz
natychmiastowe zastosowanie np. w postaci
optymalizacji przechowywania informacji w pamięci
podręcznej serwera.
Coraz częściej analiza zachowania użytkownika
oparta
o
badanie
podobieństwa
sekwencji
wykorzystywana jest do budowania systemów
ochrony serwera.
Pomocna w tym zadaniu może być również analiza:
zachowań
odbiegających
od
normy,
sekwencji/zdarzeń rzadkich, oraz sekwencji/zdarzeń
regularnych.
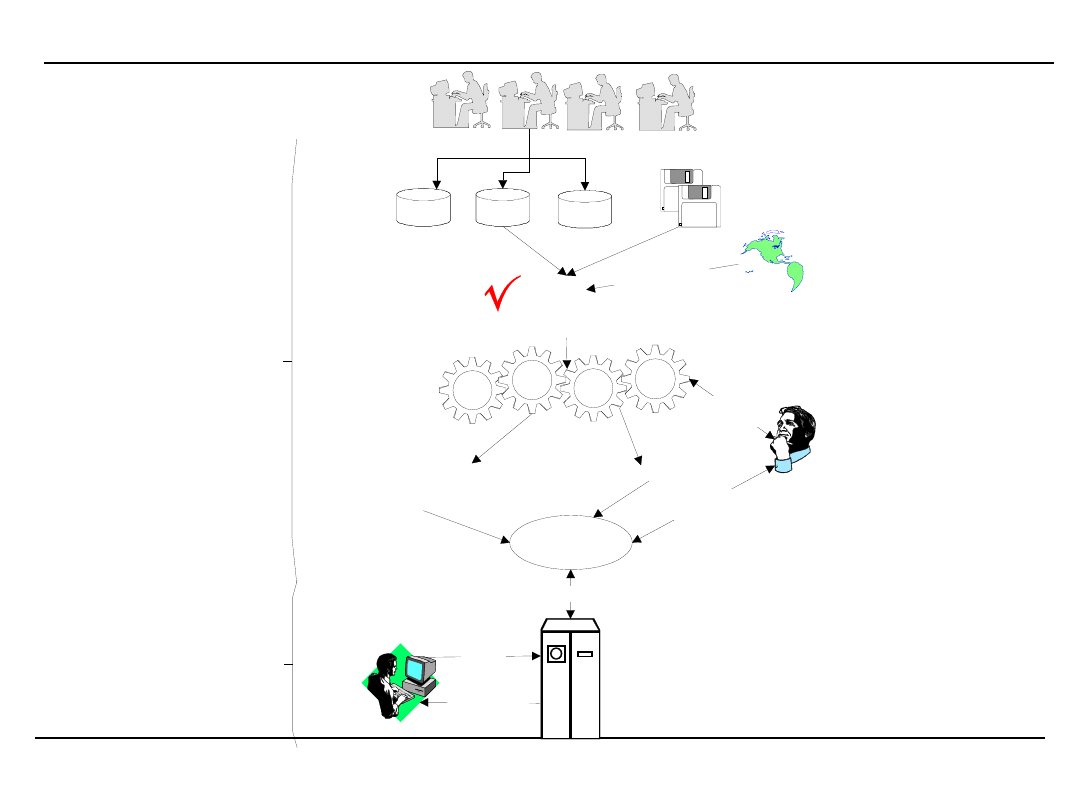
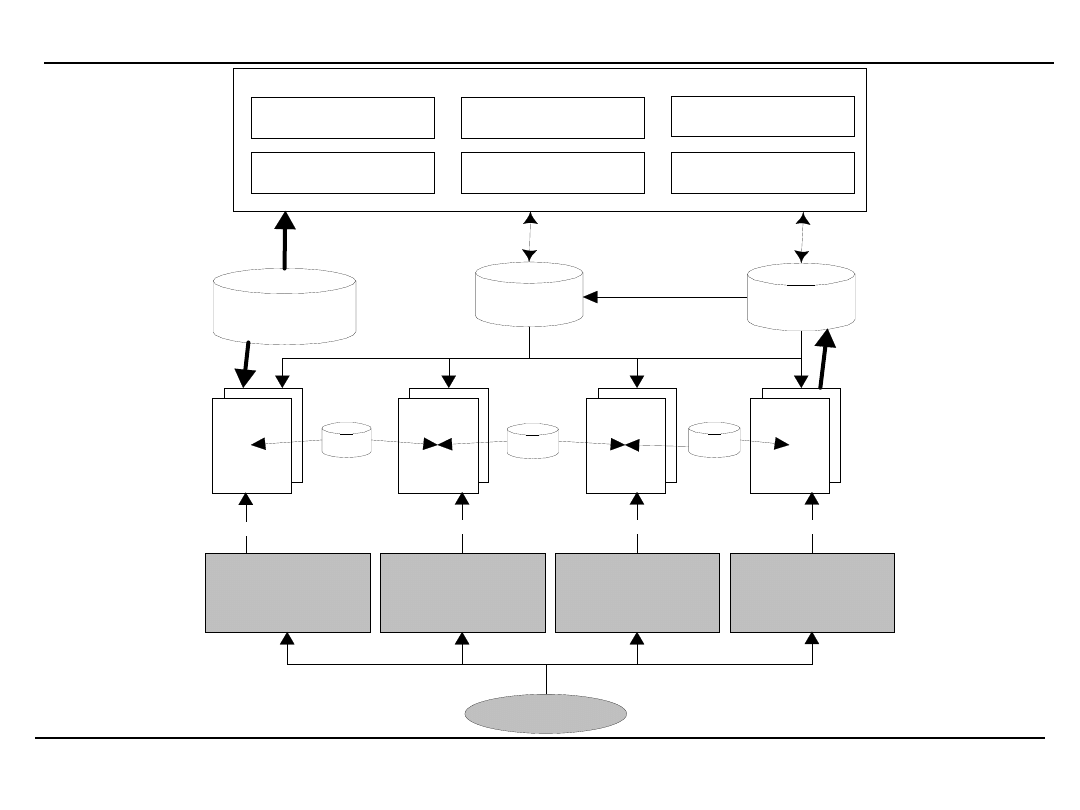
DM w sieci – architektura systemu
Scalanie
Oczyszczanie
Integracja
Dane uzyskane od użytkowników
Dane serwisu
Wyszukiwanie wzorców sekwencji
Grupowanie
Reguły związków
Statystyki serwisu
Wzorce
klasy
reguły
Narzędzia odkrywania wiedzy
Konsultacja z bazą wiedzy
Sygnały
od klienta
Personalizacja
usług
T
ry
b
p
ra
cy
o
f
-l
in
e
T
ry
b
p
ra
cy
o
n
-l
in
e
Konsultacje
z ekspertem
Konsultacje
z ekspertem
Dane zewnętrzne

DM w sieci – jakie informacje są analizowane
Element serwisu
informacyjnego
BD
Liczba kliknięć w reklamy
Liczba wyświetlonych reklam
Strony na które przeszedł
użytkownik
Strony z których przyszedł
Czas sesji
Web logs
BD reklam
Profile użytkowników
Segmentacja rynku
Dane z plików cookie
Element serwisu
biznesowego
BD
Liczba wykonanych
transakcji
Kwota transakcji
Częstotliwość transakcji
Rodzaj pobranych informacji
BD rachunkowości
BD demograficzne
CRM

Zadania DM w sieci
Przed procesem DM w sieci stawia się kilka
kolejnych zadań dotyczących całej sieci. Do ich
realizacji jest jednak bardzo daleko
•Analiza połączeń internetowych w celu określenia
struktury sieci
•Automatyczna klasyfikacja dokumentów w sieci
•Konstrukcja wielowarstwowej, wielowymiarowej i
hierarchicznej struktury informacyjnej sieci
•Analiza wykorzystania zasobów sieci

Problemy rozwiązywane w DM – DNA
Analiza danych biomedycznych i analiza DNA
(człowiek ok. 100 000 genów):
•Określenie sekwencji DNA dla różnych
organizmów, znalezienie sekwencji wspólnych,
ustalenie ich znaczenia,
•Analiza współwystępujących sekwencji genów i ich
wzajemnego wpływu na cechy organizmów,
•Łączenie genów oraz ich stanów z wartościami
parametrów opisującymi organizm oraz
występującymi chorobami
•Wizualizacja i budowanie map genomów

Problemy rozwiązywane w DM – finanse
Analiza danych finansowych:
•Ustalanie wiarygodności kredytowej,
•Przewidywanie możliwych wariantów spłaty
zaciągniętych kredytów
•Ustalanie polityki kredytowej dla poszczególnych
typów klientów,
•Określanie docelowych grup klientów dla
proponowanych usług finansowych,
•Wykrywanie przestępstw finansowych i prania
„brudnych” pieniędzy.

Problemy rozwiązywane w DM – sprzedaż
•Wielowymiarowa analiza sprzedaży wg. produktów,
klientów, marek, czasu, położenia itp.
•analiza efektywności kampanii marketingowych,
•Badanie lojalności klientów,
•Proponowanie zestawów towarów, budowanie list
substytutów i towarów komplementarnych.

Problemy rozwiązywane w DM –
telekomunikacja
•Wizualizacja i budowanie map wykorzystania
możliwości sieci telekomunikacyjnej
•Analiza połączeń i budowanie planów taryfowych
•Wykrywanie zależności między wywoływaniem
określonych numerów a zapotrzebowaniem na inne
usługi (np. zwiększone zapotrzebowanie na karetki
pogotowia poprzedza zwiększone zapotrzebowanie
na straż pożarną i policję - dzięki szybszej
informacji można czasami nawet o kilka minut
przyspieszyć akcję ratowniczą).
•Planowanie obciążenia ruchu w sieci.

Kryteria wyboru systemu DM
•Możliwość wykorzystania wielu źródeł danych (w
większości przypadków ODBC załatwia sprawę),
•Zakres funkcjonalny i stosowane metody (reguły,
drzewa, sieci
Bayesowskie, algorytmy
genetyczne, sieci neuronowe,
specjalizowane
algorytmy itp.),
•Możliwości współpracy (a nie tylko połaczenia) z
bazami
danych,
•Możliwość pracy w środowisku
wieloplatformowym,
•Skalowalność,
•Narzędzia wizualizacji,
•Język dostępu do danych wielowymiarowych.

Produkty
Intelligent Miner
Enterprise Miner
MineSet
Clementine
DBMiner

Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
Wyszukiwarka
Podobne podstrony:
Analiza danych w Systemach Informacji Przestrzennej
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
tabela danych, Inżynieria systemów i analiza systemowa Jacek Domagalski
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Systemy Baz Danych (cz 1 2)
SPSS paca domowa 1 odpowiedzi, Studia, Kognitywistyka UMK, I Semestr, Statystyczna analiza danych
Analiza danych wyjściowych
Metody analizy danych
5 Proszę opisać ujęcie systemowe w analizie mediów
Sciaga3, Cyfrowa Analiza Danych
07 Analiza danych
17 Rejestracja i analiza danych dotyczących z k
Materiał na egzamin, Analiza danych (Program R)
Analiza danych1
Materiały zastane wtórna analiza danych
więcej podobnych podstron