
WYKŁAD 0:
Kody binarne: NKB – Naturalny kod binarny, U2.
Podstawowe elementy logiki cyfrowej: bramki, przerzutniki, rejestry, liczniki, multipleksery, pamięci.
WYKŁAD 1: TROCHĘ TEORII.
Komputer
– urządzenie do przetwarzania danych, wyposażone w możliwość wprowadzania,
przechowywania i wyprowadzania danych (wprowadzanie i wyprowadzanie danych może być
realizowane w postaci odpowiedniej dla człowieka np. klawiatura, ekran lub właściwej współpracy
z jakimś obiektem np. czujnik temperatury, grzejnik.
Taksonomie systemów komputerowych
– służą do klasyfikacji architektur komputerowych (podział
na kategorie i określanie własności).
Taksonomia Flynna
– 1968
– prosta; ma znaczenie historyczne. Zakłada, że komputer jest
urządzeniem przetwarzającym strumienie danych na podstawie strumieni instrukcji; klasyfikuje
komputery wg liczby strumieni instrukcji i danych; liczba strumieni może wynosić 1 lub n (więcej
niż 1). Cztery klasy: SISD, SIMD, MISD, MIMD, NISD, NIMD (S-pojedynczy, M-wiele, I-Instrukcje, D-
Dane, N-Zero). Bez strumienia danych urządzenie nie jest komputerem, a bez strumienia instrukcji
to wieloprocesory Dataflow.
Dataflow
– Nie ma jawnych instrukcji. Jednostką przetwarzaną jest
token
(zawiera dane oraz
tag
(metka)
opisujący zawartość (jest odpowiednikiem instrukcji). Procesor za pomocą metki
przekształca cały token – i dane i metkę, tworząc nowy token.
Taksonomia Skillicorna
– 1988 – ilustruje strukturę komputera; stosunkowo mało znana. Każda
architektura stanowi połączenie pewnej liczby składników. Składniki: 1. Procesory instrukcji (IP) –
pobierają i analizują dane; 2. Procesory danych (DP) – wykonują operacje na danych; 3. Hierarchie
pamięci instrukcji (IM) – przechowują instrukcje; 4. Hierarchie pamięci danych (DM) – przechowują
dane. Liczba hierarchii pamięci jest równa liczbie procesorów. Komputer musi zawierać przynajmniej
jeden procesor danych. Spośród 30 możliwych modeli tylko 6 modeli ma sensowne znaczenie (takie
same jak w taksonomii Flynna).
Hierarchia pamięci
–
od góry - 1. Rejestry; 2. Kieszenie (L1-L3); 3. Pamięć operacyjna; 4. Pamięć
masowa (rozsz. p. oper.); 5. Pamięć masowa (system plików); 6. Nośniki wymienne, zasoby
sieciowe.
Maszyna von Neumanna
– Instrukcje tworzące program są przechowywane w pamięci w taki sam
sposób, jak dane. Dostęp do pamięci – poprzez adres. Występuje rejestr licznika instrukcji.
Warianty organizacji hierarchii pamięci w realizacjach maszyny von Neumanna
– 1. „Harvard” –
oddzielne hierarchie pamięci programu i danych. Wysoka wydajność dzięki możliwości
równoczesnego pobierania instrukcji i operacji na hierarchi pamięci danych. Brak możliwości zapisu
instrukcji i operacji na hierarchii pamięci danych. 2. „Princeton” – wspólna hierarchia pamięci
programu i danych. Nie można równocześnie pobierać instrukcji i operować na danych.
Nieograniczone możliwości modyfikacji programu. 3. „Harvard-Princeton” – Łączy zalety Harvard i
Princeton. Oddzielne górne warstwy hierarchii pamięci i wspólne warstwy dolne. Wszystkie
produkowane współcześnie procesory do komputerów mają architekturę Harvard-Princeton z
rozdzielonymi kieszeniami kodu i danych.

WYKŁAD 2: DANE.
Typy danych
– 1. Wartości logiczne (prawda/fałsz). 2. Znaki pisarskie. 3. Liczby (całkowite
nieujemnie i ze znakiem oraz niecałkowite stałopozycyjne i zmiennopozycyjne). 4. Dźwięki i inne
sygnały jednowymiarowe. 5. Obrazy rastrowe.
Binarna reprezentacja danych
– wszystkie komputery działają w systemie binarnym. Wszystkie
dane, na których operuje komputer, są zapisane w postaci ciągów cyfr binarnych – bitów,
interpretowanych najczęściej jako liczby binarne. Wszelkie dane o charakterze nie liczbowym muszą
być zapisane (zakodowane) w postaci liczb lub grup liczb.
Dane w pamięci komputera
– Alfanumeryczne – są one reprezentowane przez liczby, określające
pozycję danego symbolu w tablicy kodowej. Standardy kodowania znaków pisarskich:
ASCII
– cyfry, znaki przestankowe, podstawowe symbole matematyczne oraz małe i wielkie litery
alfabetu łacińskiego, mieszczące się na 128 pozycjach kodowych. Na jego bazie zaprojektowano
wiele kodów rozszerzonych, zawierających 256 pozycji kodowych. Pierwsze 128 są identyczne, a
następne 128 zawiera: litery akcentowane, rozszerzony zestaw symboli matematycznych, litery
alfabetów narodowych. W Polsce: kody ISO8859-2 oraz Microsoft CP1250.
EBCDIC
– używane w systemach firmy IBM.
UNICODE
– reprezentacja wszystkich znaków używanych na świecie.
Jednostki informacji
– 1. Bit – najmniejsza jednostka informacji; 2. Bajt – najmniejsza jednostka
informacji adresowana przez procesor (8 bitów); 3. Słowo; 4. Słowo procesora – obecnie 32 lub 64
bity; 5. Słowo pamięci – obecnie 64 bity, czasem 128.
Zapis danych
– do zapisu
danej logicznej
wystarcza jeden bit. Zapis
liczb całkowitych
nieujemnych
–
Naturalny kod binarny (NKB); Kod BCD – używany do liczb dziesiętnych stałopozycyjnych. Zapis
liczb całkowitych ze znakiem
: Kod uzupełnieniowy do dwóch (U2) – najbardziej znaczący bit ma
wagę ujemną; Kod uzupełnieniowy do jedności (U1) – wartość bezwzględna najbardziej znaczącego
bitu jest o jeden mniejsza niż w U2; Znak-moduł; Zapis spolaryzowany.
Liczby ułamkowe i
mieszane
: Zapis stałopozycyjny – powstaje przez przesunięcie wag w zapisie całkowitoliczbowym.
Używany zwykle w U2.
Liczby całkowite i ułamkowe o bardzo dużym zakresie dynamiki wartości
bezwzględnych:
Zapis zmiennopozycyjny - elementy: Znak liczby; część znacząca; wykładnik. Postać
znormalizowana – jedna z możliwych postaci jako preferowana. Binarny zapis zmiennopozycyjny –
niemal wszystkie komputery posługują się tym zapisem zgodnym ze standardem IEEE754. Bazą jest
liczba 2. Podstawowym formatem jest format double – 64-bitowy.
Konwencje adresowania danych wielobajtowych
– 1. Little Endian – najmniej znaczący bajt pod
najmniejszym adresem. Numeracja bajtów zgodna z wagami bitów. Naturalna dla komputera ale nie
dla człowieka. 2. Big Endian – najbardziej znaczący bajt pod najmniejszym adresem. Kolejność
bajtów naturalna dla człowieka. Możliwe szybkie porównywanie łańcuchów znakowych. Rzutowanie
typów związane ze zmianą długości zmienia wartość adresu.
Dane wektorowe
– współczesne procesory mogą operować na długich słowach danych. Dźwięki i
obrazy są zapisane przy użyciu liczb o małej precyzji. Algorytmy przetwarzania dźwięków i obrazów
wykonują takie same operacje na wszystkich próbkach. Umożliwia lepsze wykorzystanie możliwości
procesora.
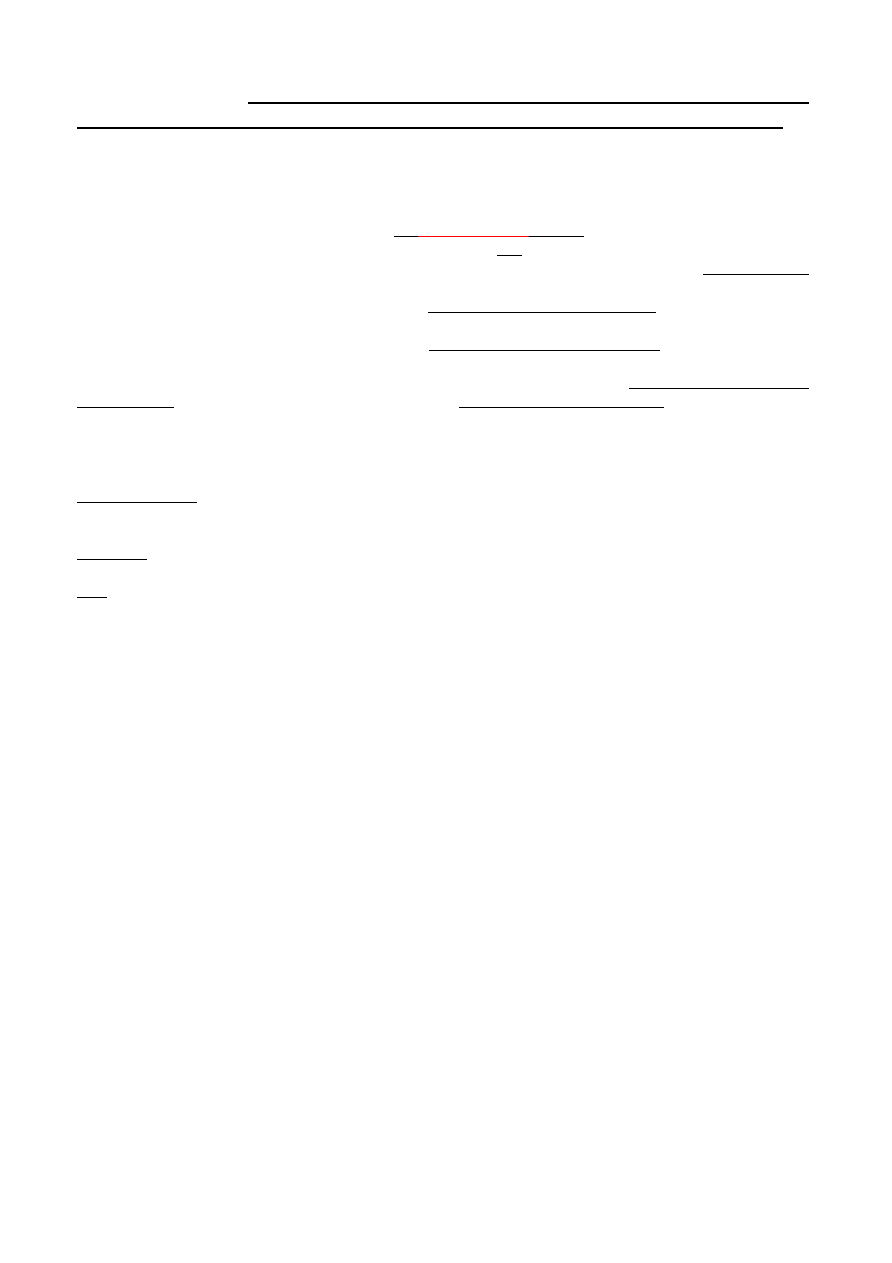
WYKŁAD 3: SYNTEZA UŻYTKOWEGO MODELU PROGRAMOWEGO
KOMPUTERA NA PODSTAWIE WYMAGAŃ JĘZYKÓW WYSOKIEGO POZIOMU.
Języki wysokiego poziomu –
60te: Fortran, Algol; 80te: Pascal, C.
Wymagania języka wysokiego poziomu
–
1.
Klasy pamięci
(sekcje): odpowiadają różnym klasom
obiektów niezbędnych do działania programu. Składa się z: kod (statyczny, obecny w pamięci przez cały
czas życia programu; stały rozmiar; tylko do odczytu; może zawierać instrukcje, stałe); dane statyczne
(czas życia równy czasowi życia programu; stały rozmiar; mogą być podzielone na obszary: stałe,
zmienne zainicjowane, zmienne niezainicjowane); dane dynamiczne automatyczne (argumenty i zmienne
lokalne procedur; tworzone i usuwane w czasie działania programu; kolejność usuwania zawsze
odwrotna do kolejności tworzenia; tworzą stos); dane dynamiczne kontrolowane (tworzone i usuwane
jawnie przez programistę; czas życia nie związany z czasem życia i zagłębianiem procedur, nie wynika ze
struktury wywołań; kolejność tworzenia i usuwania dowolna; tworzą stertę); kod współdzielony i dane
współdzielone – we współczesnych syst. operacyjnych 2. Przekazywanie sterowania: wywołanie procedur
i powroty; przekazywanie parametrów; zmienne lokalne procedur.
Mapa przestrzeni adresowej procesu użytkowego –
kod, dane statyczne, stos i sterta. Sterta rośnie w
górę, stos w dół. Adresy bliskie zera nie są używane. Duże puste obszary w przestrzeni użytkowej.
Licznik instrukcji – rejestr przechowujący adres kolejnej instrukcji, która ma zostać wykonana.
Inkrementowany w czasie pobrania instrukcji. Przy wykonaniu instrukcji skoku, ładowany nową
wartością. Niezbędny w maszynie von Neumanna.
Procedury (wywołanie i powrót) – wywołanie następuje poprzez instrukcję skoku ze śladem. Powrót –
instrukcja powrotu według śladu.
Stos – struktura danych używana do przekazywania sterowania pomiędzy procedurami programu
(parametry wywołania; ślad powrotu; zmienne lokalne).
Model procesora I
–
rejestr licznika instrukcji; rejestr przechowujący wyniki obliczeń (akumulator); stos o
bliżej nieokreślonej realizacji; dostęp do danych przez nazwy lub wartości (stałe).
SLAJD 16.
Kompilacja -
argumenty wywoływanej procedury są wkładane na stos w kolejności od ostatniego do
pierwszego. Dzięki temu tuż przed wywołaniem na wierzchołku stosu jest położony pierwszy argument, a
głębiej na stosie znajdują się kolejne argumenty wywołania. Po przygotowaniu argumentów następuje
skok ze śladem.
Procedura: alokacja zmiennych lokalnych; dostęp do danych przez nazwy; każda instrukcja języka
wysokiego poziomu kompilowana niezależnie od wcześniejszych; wartość funkcji zwracana w rejestrze A;
dealokacja zmiennych lokalnych; powrót przy użyciu instrukcji skoku według śladu.
Operacje na stosie: PUSH – umieszczenie danej na stosie; POP – zdjęcie danej ze stosu i inkrementacja
SP (rejestr wskaźnika stosu).
Model procesora II
–
bardziej realistyczna wersja modelu I; stos w pamięci; rejestr wskaźnika stosu;
jawnie zdefiniowane operacje stosowe; alokacja i dealokacja – zmiana wartości wskaźnika stosu bez
przesłania danej; dostęp do parametrów i zmiennych lokalnych bez nazwy.
SLAJD 24.
Ramka stosu – fragment stosu używany przez procedurę. Część ramki, która jest obecna na stosie w
chwili przekazania sterowania do procedury, nazywa się rekordem aktywacji. Adresy obiektów w ramce
można tworzyć zsumowanie wartości wskaźnika stosu i stałej, jednak wartość wskaźnika stosu może się
zmieniać podczas wykonywania procedury.
Rejestr wskaźnika ramki – służy do adresowania ramki stosu. Zawartość nie zmienia się. Wskazuje ramkę
bieżącej procedury. Każda procedura ustanawia własną wartość wskaźnika ramki. Procedura musi przed
powrotem odtworzyć wskaźnik ramki procedura wołającej.
Operacje na wskaźniku ramki – zapamiętanie wskaźnika ramki na stosie i ustanowienie nowej wartości;
dane ramki stosu są stosowane względem wskaźnika ramki; przed powrotem należy odtworzyć starą
wartość wskaźnika ramki.
Procesory x86
–
akumulator/rejestr wartości; wskaźnik stosu; wskaźnik ramki; licznik instrukcji;
instrukcje w większości dwuargumentowe; dostępne adresowanie rejestrowe pośrednie z
przemieszczeniem.
SLAJD 30
.
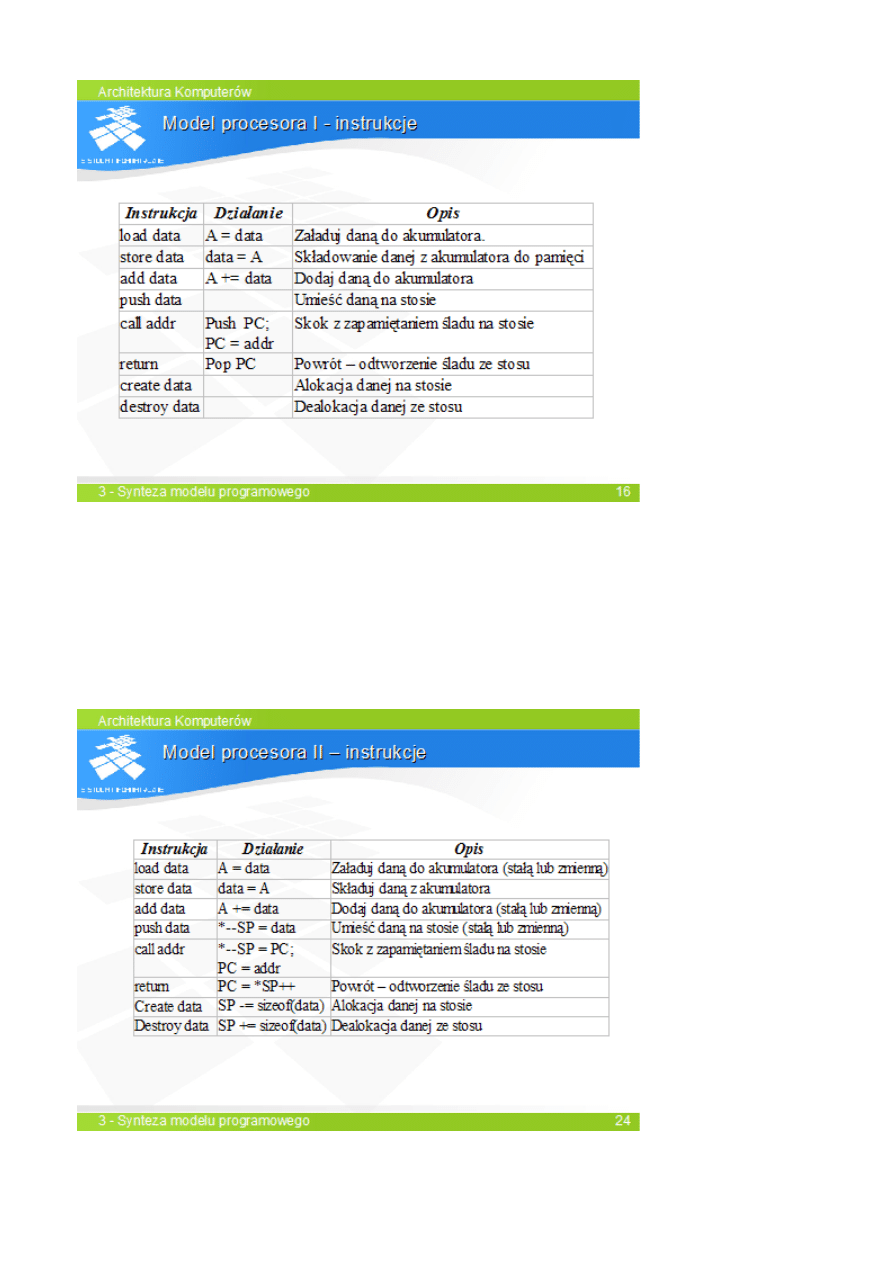
Tabela zawiera opis instrukcji pierwszego modelu procesora.
Procesor wykonuje pięć instrukcji dotyczących stosu. PUSH umieszcza wartość na stosie. Instrukcja
skoku ze śladem przekazuje sterowanie do procedury po uprzednim zapamiętaniu śladu na stosie.
Instrukcja powrotu według śladu odtwarza ślad ze stosu jednocześnie usuwając go. Instrukcja
aloka
cji danej CREATE przypomina instrukcję PUSH, lecz nie nadaje danej na wierzchołku stosu
żadnej wartości. Instrukcja DESTROY usuwa daną z wierzchołka stosu.
Tablica przedstawia definicję instrukcji modelu, w tym symboliczny opis działania instrukcji
ope
rujących na stosie.
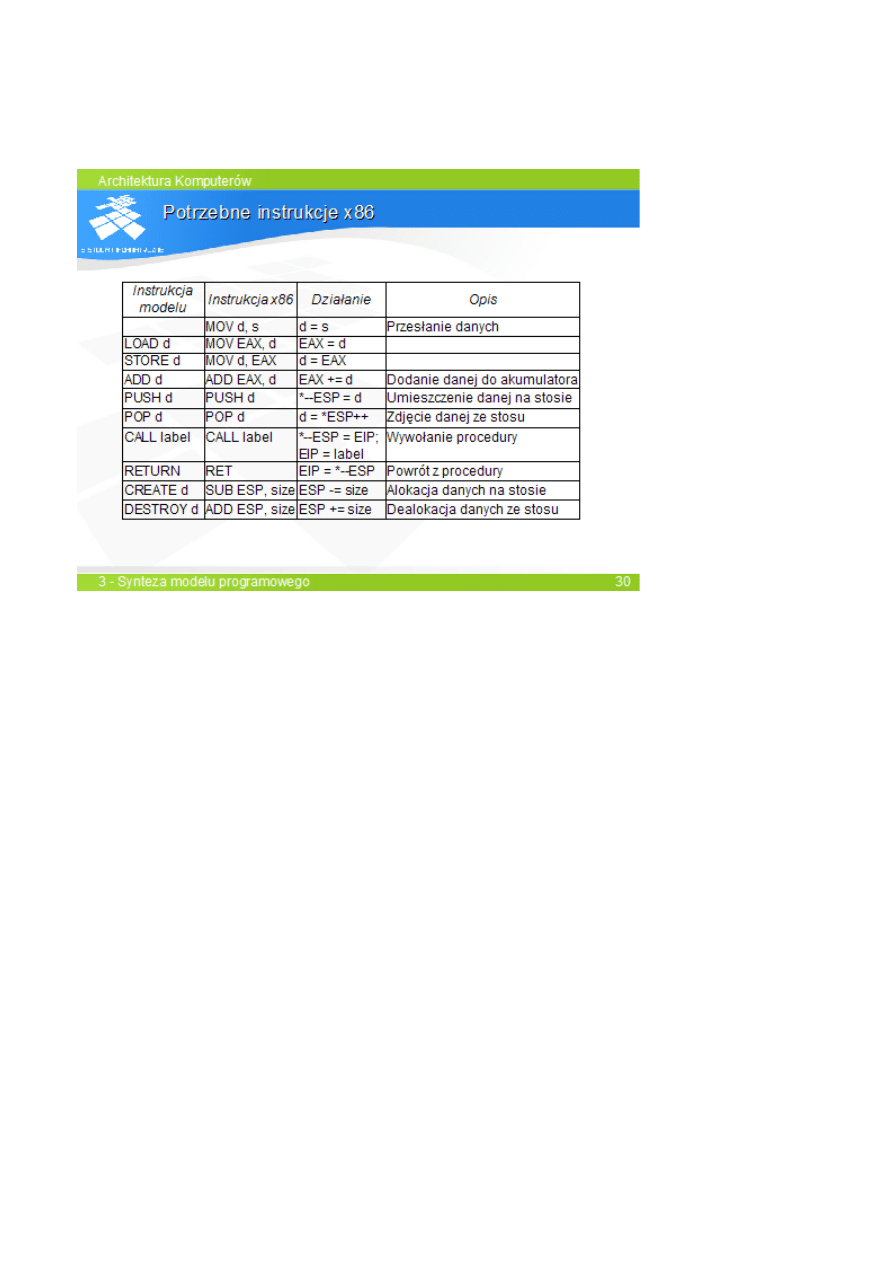
Ponieważ model II różni się od modelu I tylko jawną definicją instrukcji, translacja programu dla
modelu II jest identyczna, jak dla modelu I.
Tabela zawiera zestawienie instrukcji modelu II i ich odpowiedników w x86. instrukcje LOAD i
STOR są zastąpione pojedynczą, dwuargumentową instrukcją przesłania MOV.
Operacje CREATE i DESTROY są realizowane jako odjęcie i dodanie stałej określającej rozmiar
obiektów do wskaźnika stosu.

Wyk
ład 6. Jednostka wykonawcza procesora
Procesor jednocyklowy
- uk
ład sekwencyjny
- model programowy RISC ( z uproszczeniami MIPS)
- architektura HARWARD (program w ROM)
- instrukcje 32- bitowe
- max. cz
ęstotliwość 12 MHz
IM - pa
mięć instrukcji
PC_inc – inkrementuje o 4 licznik instrukcji
nextPC –
ścieżka zawierająca następną zawartość PC (licznika rozkazów/instrukcji)
Wady: nie wykonuje instrukcji skoku ze
śladem
Problemy: niska wydaj
ność, oddzielne pamięci – brak programowalności, nadmiarowość bloków
Procesor wielocyklowy
- model programowy CISC
- zminimalizowana liczba bloków funkcjonalnych (np. sumatorów), wielokrotne wykorzystanie ich
w jednej instrukcji
- instrukcja rozbita na cykle (w k
ażdej fazie każdy blok wykonuje jedną czynność)
- ró
żne instrukcje wykonują się w różnym czasie (CISC)
- skomplikowany uk
ład sterujący
- zw
iększona liczba multiplekserów (z powodu komplikacji dróg przesyłu danych)
- architektura PRINCETON
- wspólna pami
ęć programu i danych
- programowal
ność
- 2-3 odwo
łania do pamięci podczas wykonywania instrukcji
- koniecz
ność zapamiętania pobranej instrukcji (rejestr IR)
- instrukcja wykonuje si
ę w kilku cyklach zegara (średnio 3)
- max. cz
ęstotliwość 30 MHz
- wolniejszy od jednocyklowego
- n
iższe koszty wykonania
- fazy wykonywania instrukcji:
- pobranie instrukcji
- zdekodowanie instrukcji
- pobranie argumentów
- wykonanie operacji
- zapis wyniku
- pami
ęć poza procesorem, połączona z nim szyną
- jednostka interfejsu szyny – do wspó
łpracy procesora z pamięcią
- bloki procesora:
- jednostka steruj
ąca
- zestaw rejestrów
- ALU
- jednostka interfejsu szyny
D
ziałanie:
- przez w
iększość czasu większość bloków procesora jest bezczynna
- aktyw
ność poszczególnych bloków w różnych fazach wykonania instrukcji
- pobranie instrukcji (interfejs szyny)
- dekodowanie instrukcji (jednostka steruj
ąca)
- odczyt argumentów (rejestr lub interfejs szyny)
- wykonanie operacji (ALU)
- zapis wyników (rejestry lub interfejs szyny)
Optymalizacja:
- zw
iększenie liczby ścieżek danych wewnątrz procesora – szybkie wykonanie złożonych instrukcji
z wieloma argumentami
- pobranie instrukcji z wyprzedzeniem – PREFETCH
- dodatkowy rejestr scanPC w jednostce interfejsu szyny
- rejestr instrukcji pobieraj
ącej na zapas – prefetch register -w jednostce interfejsu szyny
- pomini
ęcie fazy pobierania instrukcji, pobranie następnej instrukcji o adresie z scanPC do rejestru
prefetch na zapas w czasie bezczyn
ności
Problemy:
- ró
żna długość instrukcji (CISC) – mechanizm prefetch pobiera 1 słowo z pamięci
- skok uniew
ażnia zawartość rejestru prefetch – niezgodność nextPC z scanPC
-
częsta bezczynność interfejsu szyny (rozwiązanie: kolejka instrukcji, bufor FIFO zamiast
pojedynczego rejestru prefetch
-skok uniew
ażnia kolejkę (trzeba skopiować nextPC do scanPC)
- opó
źnienie skoków (branch penalty) wynika z konieczności przeładowania kolejki instrukcji
- skoki wykonuj
ą się dłużej niż inne instrukcje
- statystycznie 7-14% instrukcji to skoki
rozwi
ązanie: redukcja liczby skoków przez odpowiednie techniki programowania i użycie
instrukcji itercyjnych, wykrywanie krótkich p
ętli – kolejka zmienia się w bufor cykliczny –
wykonanie p
ętli bez pobierania instrukcji z pamięci
Procesor potokowy
- wykonanie pojedynczej instrukcji zajmuje 5 cykli zegarowych
- w k
ażdym cyklu procesor rozpoczyna nową instrukcję i kończy inną
- wydaj
ność 1 sekunda na 1 cykl (widziana z zewnątrz)
-
częstotliwość ok. 33 MHz
- od po
łowy lat 80 XX w. potoki to prawie wszystkie wyprodukowane procesory
- równoleg
łe wykonanie instrukcji zwiększa wydajność ale tworzy problemy z synchronizacją
Stopnie potoku:
IF – pobranie instrukcji
RD – dekodowanie i odczyt argumentów z rejestrów
ALU – obliczanie wyniku w jednostce arytmetyczno-logicznej
MEM – wymiana danych z p
amięcią
WB – zwrotny zapis wyniku do rejestrów
WYK
ŁAD 7 Działanie potokowej jednostki wykonawczej
Potokowa jednostka wykonawcza – MIPS 3000
- jeden z pierwszych mikroprocesorów RISC
- 5 stopni potoku: IF, RD, ALU, MEM, WB
- czas wykonania instrukcji 4 cykle (IF i WB po
pół cyklu)
- architektura HARWARD-PRINCETON (rozdzielone górne warstwy hierarchii pami
ęci, wspólna
pami
ęć operacyjna
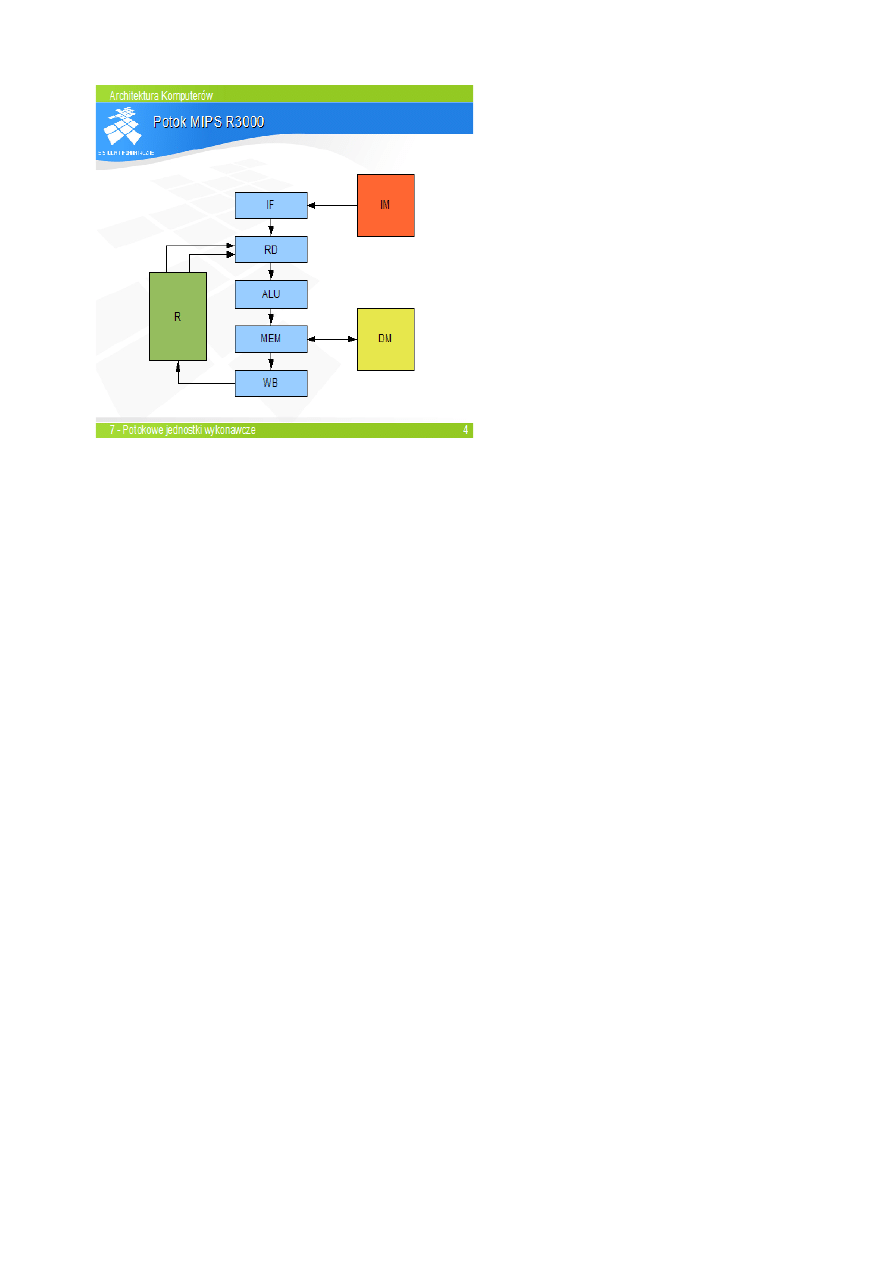
Potok R3000 sk
łada się z pięciu stopni.
Stopie
ń IF pobiera instrukcje z hierarchii
pami
ęci instrukcji (zewnętrznej w stosunku
do procesora).
Stopie
ń RD odczytuje zawartości rejestrów
źródłowych z zestawu rejestrów procesora.
Stopie
ń ALU wykonuje operację
arytmetyczn
ą i ew. skok.
Stopie
ń MEM dokonuje wymiany danych z
hierarchi
ą pamięci danych.
Stopie
ń WB zapisuje wynik operacji
arytmetycznej lub da
ną odczytaną z pamięci
do rejestru.
- aktualizacja PC i rejestrów uniwersalnych w po
łowie cyklu zegara
Problem: kolejna instrukcja mo
że potrzebować jako argument wyniku poprzedniej instrukcji,
jeszcze nie za
kończonej co spowoduje pobranie złej wartości
- hazadr RA-W (read-after-write) niemo
żliwość przewidzenia wartości jaką pobierze druga
instrukcja
- usuwanie hazardu RA-W
-metoda administracyjna – programista sam musi unika
ć sekwencji instrukcji,
koniecz
ność wstawienia między instrukcje instrukcji pustych lub innych nie
pow
iązanych
-wstrzymanie potoku po wykryciu hazardu – instrukcja druga wstrzymana w RD ( IF i RD
stoj
ą), do ALU wstrzyknięta instrukcja pusta, wznowienie instrukcji drugiej gdy instrukcja
pierwsza dojdzie do WB
- obej
ścia – szyny poprowadzone z ALU i MEM do RD, wynik operacji arytmetycznej jest
dos
tępny już w ALU, w razie potrzeby pobranie instrukcji obejścia ALU, MEM, dopiero w
ostatecz
ności z rejestru fizycznego procesora. Obejścia eliminują hazard bez opóźnień.
Instrukcja skoku w potoku
- skok realizowany w ALU
- kolejna instrukcja jest w tym czasie w RD
- w przypadku skoku jest ona anulowana (powoduje opó
źnienie) 1 cykl
wniosek: skoki powoduj
ą opóźnienie
Redukcja opó
źnienia skoków:
- wprowadzenie skoku opó
źnionego (delayed branch) wykonuje przed skokiem niezależną
instrukcj
ę, która miała być wykonana po skoku, 90% szans na znalezienie niepowiązanej ze
skokiem instrukcji
Wydaj
ność potoku
- teoretycznie 1 cykl w sekund
ę, rzeczywista 1.2 cyklu w sekundę
- czynniki opó
źniające wewnątrz potoku:
- hazardy inne ni
ż przez obejścia,
-
ładowanie danych z pamięci
- skoki
-czynniki na zewn
ątrz potoku:
- dos
tęp do hierarchii pamięci > 1 cykl
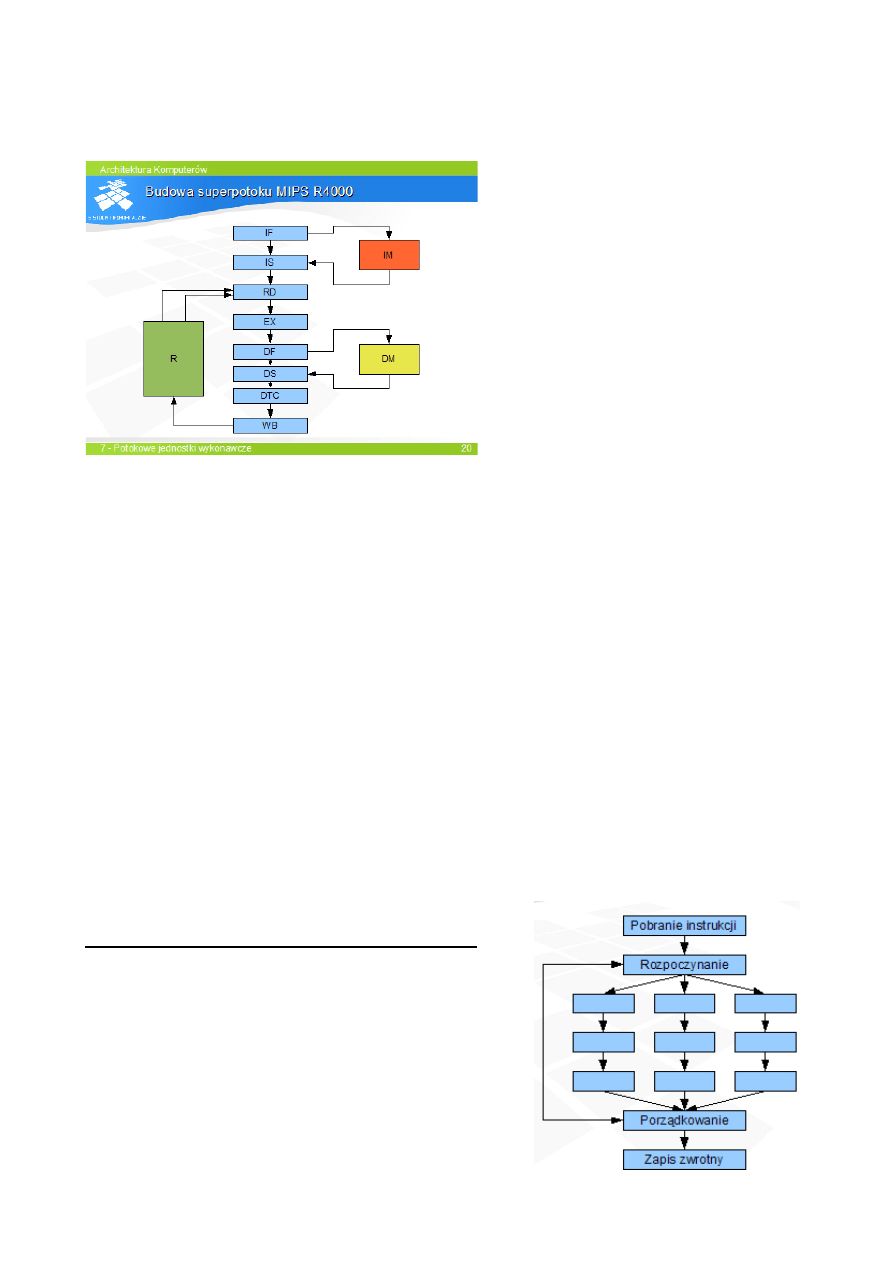
Przyspieszenie potoku mo
że spowodować zmniejszenie wydajności (np. dostęp do hierarchii
pami
ęci niemożliwy w 1 cyklu. Rozwiązanie: wydłużenie potoku, wprowadzenie superpotoku
(powy
żej 6 stopni)
IF- Instruction First – pocz
ątek pobrania
instrukcji
IS – Instruction Second – za
kończenie
pobierania instrukcji
RD- read – odczyt argumentów
EX – execute – odpowiednik ALU w R3000
DF – data first – po
czątek odwołania do
danych
DS – data second – koniec transakcji z
pami
ęcią danych
DTC- data tag check – finalizacja odwo
łania
WB – write back – zapis wyniku do rejestru
Wspó
łpraca z pamięcią
- odwo
łania do pamięci rozbite na dwie fazy
- pami
ęć ma budowę potokową, dostęp w dwóch cyklach zegara, dwa dostępy do pamięci naraz
Opó
źnienie i synchronizacja superpotoku
- problemy synchronizacyjne (hazard) i opó
źnienia takie jak w zwykłym potoku
- konieczna w
iększa liczba obejść i większe opóźnienia (ładowania danych i skoków)
Opó
źnienie danych w superpotoku
- przy zastosowaniu obej
ść – opóźnienie 3 cykle
- odwo
łania do pamięci – szczególnie do struktur danych
- wy
ższa częstotliwość powoduje opóźnienia zewnętrzne
Opó
źnienia skoków w superpotokach
- niemo
żliwość użycia skoku opóźniającego 20% szans na znalezienie dwóch instrukcji
nieza
leżnych od skoku
- przewidywanie skoków rozw
iązaniem problemu
Wydaj
ność superpotoków
- 1.5 cyklu na se
kundę (rekompensowane przez wyższą częstotliwość)
- przyrost wydaj
ności z wydłużeniem potoku 50%
Potokowa realizacja procesora CISC
- CISC nie pasuje do koncepcji potoku, rozwi
ązania:
- konstrukcja potoku wykonuj
ącego instrukcje CISC – skomplikowany
- transkodowanie instrukcji CISC na pseudoRISC,
jednostka wykonawcza wykonuje instrukcje RISC
WYK
ŁAD 8 Procesory wielopotokowe (superskalary)

Budowa i dzia
łanie superskalara
- pierwsze stopnie pobieraj
ą i dekodują naraz kilka instrukcji
- instrukcje
są kierowane każda do innego potoku ( nie zawsze da się skierować instrukcje do
k
ażdego potoku)
- stopie
ń porządkujący decyduje o zatwierdzeniu wykonania instrukcji i modyfikuje PC (licznik
instrukcji)
- stopie
ń zapisu – ostatecznie modyfikuje rejestry i pamięci
Rodzaje superskalarów
- pseudosuperskalar
-procesor nie decyduje o równoczesnym wykonaniu instrukcji, decyduje programista lub
kompilator
- przyk
ład: Intel 860
-dwa potoki wykonawcze (sta
ło- i zmiennopozycyjny)
- instrukcje 32 bitowe pobierane parami
- równoczesne wykonanie obu instrukcji gdy pierwsza s
tało a druga
zmiennopozycyjna oraz w kodzie zmiennopozycyjny bit zezwolenia
- superskalar z kolejnym wykonaniem instrukcji
- procesor decyduje o równole
głym wykonaniu instrukcji, równoległe wykonanie możliwe
gdy brak
zależności między instrukcjami do wykonania w tym samym cyklu
-rodzaje potoków:
- 1 potok wszystkie, 2 tylko proste instrukcje
- 1 potok s
tało, 2 zmiennopozycyjne instrukcje
- potoki pracuj
ą sekwencyjnie – wstrzymanie jednego zatrzymuje pozostałe
- instrukcje pobierane po kilka w grupie (2,4), kierowane do wykonania pobierana nas
tępna
grupa instrukcji
- okno instrukcji – stopie
ń szeregujący dobiera instrukcje aby w każdym cyklu rozpocząć tą
sam
ą ilość instrukcji – większa wydajność i komplikacja stopnia szeregującego
- superskalar z kolejnym rozpoczynaniem i niekolejnym
kończeniem
- pobieranie i dekodowanie instrukcji po kilka sztuk w kolej
ności programu
- wstrzymanie jednego potoku nie wstrzymuje pozost
ałych
- kolejno
ść kończenia instrukcji może być inna niż kolejność rozpoczęcia
- w
iększa wydajność, wykorzystanie potoków
- problemy synchronizacyjne
- superskalar z niekolejnym wykonywaniem instrukcji
- zdekodoawne instrukcje trzymane w stopniu szereguj
ącym, kierowane do wykonania gdy gotowe
argumenty
źródłowe
- dowolna kolej
ność wykonania instrukcji
-rodzaje szeregowania: centralny bufor przed rozdzi
ałem na potoki (równe obciążenie przy
identycznych potokach, drogie rozw
iązanie np. Intel P6, AMD K6), bufory w pierwszych stopniach
potoków (stacje rezerwacyjne algorytm Tomasulo, proste w realizacji np. AMD K5)
- PC musi by
ć zawsze aktualny
- instrukcja wykonana gdy poprzednie te
ż wykonane
-stopnie
ń RETIRE za potokami miejsce oczekiwania instrukcji na wykonanie poprzednich
- niemo
żliwość modyfikacji pamięci i kontekstu procesora przed ostatecznym zakończeniem
instrukcji
- 2 ostatnie stopnie RETIRE, ostateczny zapis
- tego typu
są prawie wszystkie dzisiejsze procesory (Intel Pentium 4, Intel Core, AMD K8)
Problemy synchronizacyjne
- hazard WAR (zapis po odczycie)
- hazard WAW (zapis po zapisie
-
źródła hazardów:
Ograniczona liczba rejestrów

Os
zczędne korzystanie ze zmiennych i rejestrów przez programistów
P
ętlowa struktura programów
Rozwi
ązanie: więcej rejestrów niż w modelu programowym
Przemianowywanie rejestrów – dynamiczne przypisanie rejestrów fizycznych do tych z modelu
programowego
WYK
ŁAD 10 Redukcja opóźnień w procesorach superskalarnych
Opó
źnienia w superpotokach i superskalarach
-superpotok – stracone cykle=stracone instrukcje
- superskalar – stracone cykle*potoki=stracone instrukcje
Opó
źnienia skoków (superpotok, superskalar)
-10% instrukcji to skoki
-du
że opóźnienia skoków (nawet kilkanaście cykli)
Spekulatywne wykonanie instrukcji – procesor próbuje przewidzie
ć następną instrukcję po skoku,
wykonuje j
ą, a gdy błędnie przewidzi to anuluje tą instrukcję
Terminologia:
- wykonanie skoku – wykonanie instrukcji skoku która mo
że (nie musi) zmienić PC
- realizacja skoku – zmiana wart
ości PC
Przewidywanie skoków:
- próba przewidzenia czy skok si
ę odbędzie
- spekulatywne wykonanie instrukcji po skoku (zrealizowanym b
ądź nie)
- wykonanie instrukcji skoku jest sprawdzeniem przewidywania
- je
śli przewidywanie było poprawne – skok wykonany bez, lub z mniejszym opóźnieniem,
instrukcje spekulatywne m
ogą być zatwierdzone
- gdy przewidywanie b
łędne - instrukcje wykonane spekulatywnie są anulowane (czas ich
wykonania to opó
źnienie), wykonanie właściwych instrukcji
- przewidzie
ć można wystąpienie instrukcji skoku, czy skok się wykona oraz adres
docelowy skoku
-skok bez spekulacji
statyczny bezwarunkowy, statyczny warunkowy, dynamiczny
Przewidywanie skoków
- statyczne – niepotrzebna historia wykonania programu, po zdekodowaniu instrukcji skoku
- dynamiczne – na podstawie historii programu, przed pobraniem instrukji
Statyczne przewidywanie realizacji skoku
- przez kompilator, programist
ę – oznacza skoki jako prawdopodobne lub
nieprawdopodobne
- przez procesor – 60% skoków w ty
ł jest realizowanych a w przód niezrealizowanych
(statystycznie) procesor korzysta z tej w
łasności
Dynamiczne przewidywanie wyst
ąpienia skoku
- bufor docelowy skoków – BTB (Branch Target Buffor) zawiera informacje o wykonanych
skokach
- BTB pami
ęta adres instrukcji skoku i adres docelowy skoku
- Je
śli adres instrukcji skoku = scanPC – ładowanie instrukcji do której prowadzi skok (co
scanPC)
Ograniczenia BTB: nie przewiduje skoków warunkowych i dynamicznych
Spr
zętowy stos powrotów: niewielki niewidoczny stos, efektywny dla zgłębienia procedur <
pojem
ność stosu
Dynamiczne przewidywanie realizacji skoku: BTB przewiduje skoki warunkowe jako
bezwarunkowe, predyktor decyduje czy skok si
ę wykona
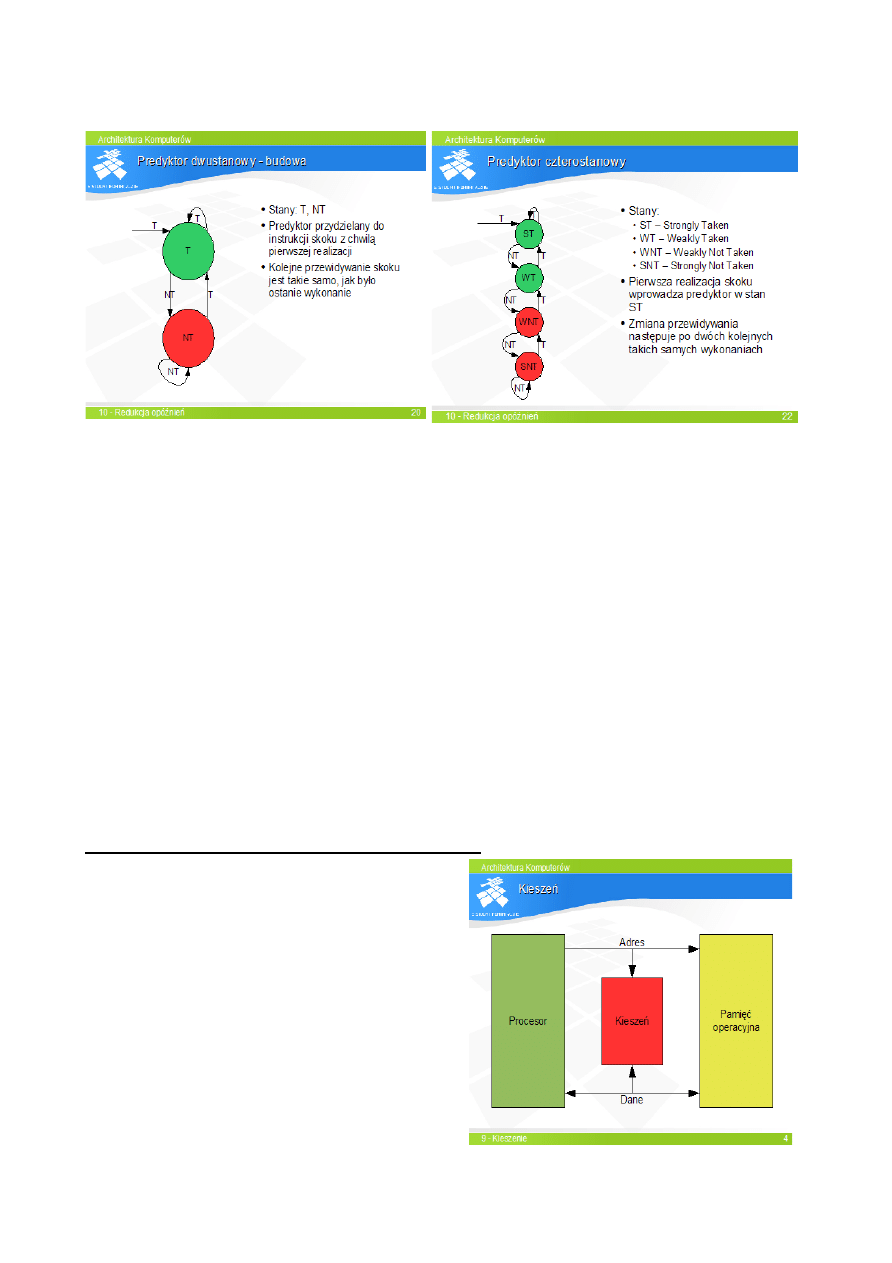
Skróty: T (Taken) – skok zrealizowany, NT (Not Taken) niezrealizowany, PT (Predikt Taken)
przewidywany jako zrealizowany, PNT (Predikt Not Taken) przewidywany jako niezrealizowany.
Ograniczenia: b
łędne przewidywanie ostatniego skoku w pętli, nie przewidują skoków cyklicznych
Predyktory dwupoziomowe:
- przechowuj
ą informację o prawdopodobieństwie warunkowym: jak wykona się skok jeśli był 1
raz zrealizowany i 3 razy zrealizowany
- wybór predyktora na podstawie adresu instrukcji skoku i historii wykona
ń
Predyktor gLocal – okre
śla prawdopodobieństwo skoku na bazie poprzednich wykonań wszystkich
ostatnio wykonanych skoków
Predyktor gShare – okre
śla prawdopodobieństwo skoku na bazie poprzednich wykonań wszystkich
ostatnio wykonanych skoków
Własności: - powolne uczenie się predyktorów, trafność przewidywań ok 95%, gLocal lepiej
przewiduje krótkie p
ętle, gShare lepiej przewiduje przejścia zależne od wartości
Predyktory trójpoziomowe
- hybryda dwóch predyktorów np. gLocal i gShare
- dwa schematy przewidywania skoku, w przypadku b
łędu zmiana realizowanego schematu
- tra
fność powyżej 96%
Redukcja opó
źnień pobierania danych z pamięci
- w superskalarach niezb
ędne pobieranie danych z pamięci do buforów na zapas (data prefetch)
- pobieranie przez procesor (spekulatywne) b
ądź przez oprogramowanie
WYK
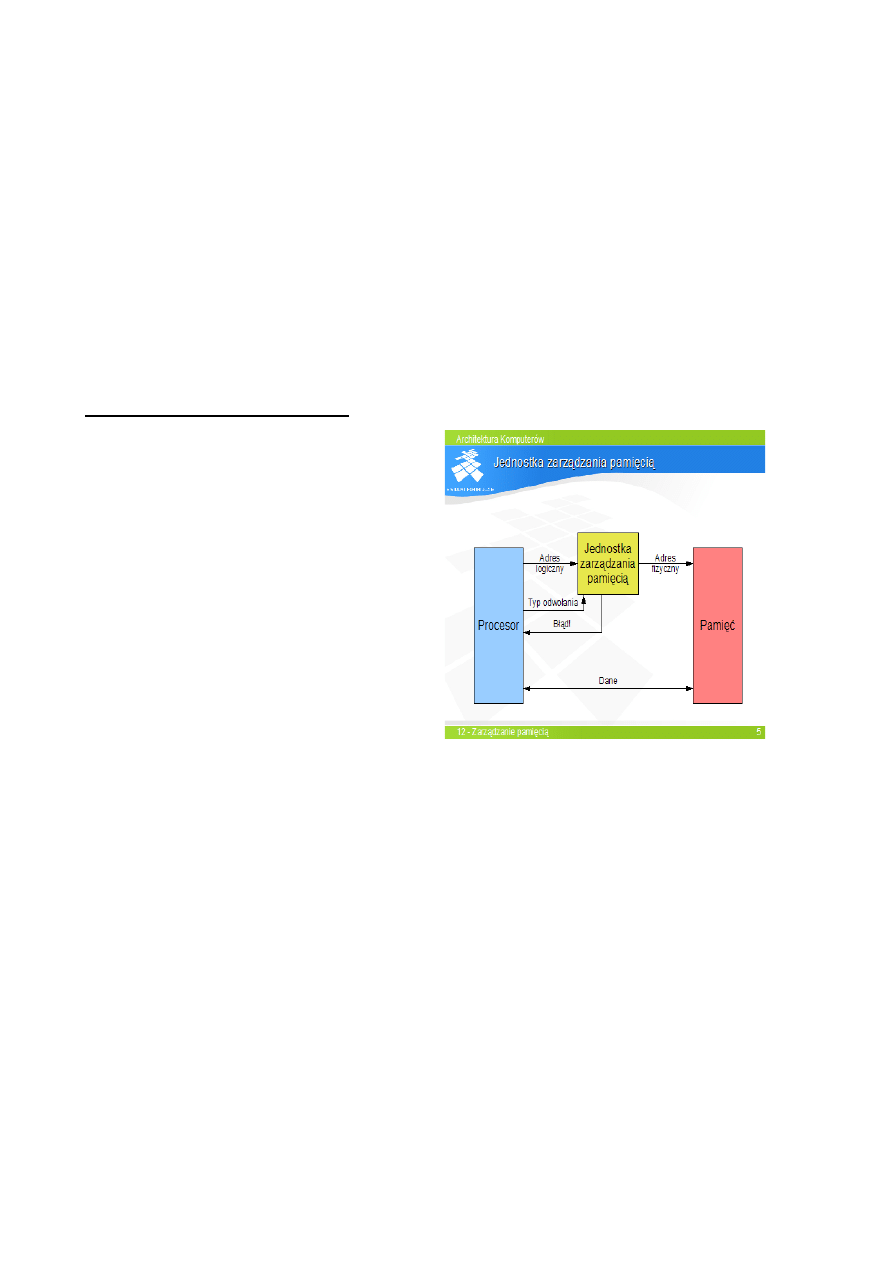
ŁAD 9 Kieszenie jako warstwa hierarchii pamięci
Kieszenie:
- warstwa pami
ęci między rejestrami i RAM
- niewidoczna dla programisty (b
ądź ograniczony
dost
ęp)
- jest buforem RAM

D
ziałanie:
- sprawdzenie obec
ności danej w kieszeni przy każdym odwołaniu CPU do RAM
- brak danej w kieszeni –
ładowanie danej z pamięci do CPU, po drodze zapis danej z adresem do
kieszeni
- dana w kieszeni – odczyt danej z kieszeni (szybsze)
- zasada lokal
ności odwołań – w ograniczonym czasie odwołania procesora na niewielkiej
przestrzeni adresowej – du
że prawdopodobieństwo odwołania do danych sąsiednich.
Kiesze
ń pełnoasocjacyjna
- trudna, nieefektowna, ma
łe pojemności niestosowana, brak adresów,
- dzia
ła jak książka telefoniczna: szukamy nazwiska, odczytujemy nr tel, nie przejmujemy się
po
łożeniem nazwiska w książce
charakterystyka:
- w k
ażdej komórce może być dana z dowolnym adresem
- komparator w k
ażdej komórce
konstrukcja:
- dane w kieszeni przechowywane jako bloki (s
łowo*4)
-element kieszeni z danymi + znaczniki (adresu)=linia
-najmniej znacz
ąca część adresu używana do wyboru bajtu/słowa z linii
Kiesze
ń nezpośrenio adresowana
- na bazie szybkiego RAM i komparatora
- prosta, szybka, wydajna, du
ża pojemność
-najmniej w
ażny bit – wybór bajtu z linii
-
środkowa część - adres RAM – wybór linii
D
ziałanie
- w k
ażdym cyklu wybór jednej linii zaadresowanej przez mniej znaczącą część adresu
- trafione – dane transmitowane do procesora
- chybienia – wymiana linii
Kiesze
ń zbiorowo- asocjacyjna
- po
łączenie kieszeni bezpośrednio adresowanych (bloków)
- dana spod okre
ślonego adresu może być w każdym bloku
- zestaw linii w cyklu – zbiór (ma
ła kieszeń pełnoasocjacyjna)
-stopie
ń asocjacywności – liczba bloków
-
złożenie kieszeni pełnoasocjacyjnych
D
ziałanie:
- podobna do bez
pośrednio adresowanej
- chybienie – wyznaczenie 1 linii do zas
tąpienia
- ma
ła wrażliwość na powtarzanie się adresów
Rodzaje kieszeni
- najcz
ęstsze – zbiorowo asocjacyjne
- gdy du
że zapotrzebowanie na szybkość- kieszeń bezpośrednio adresowana
Wspó
łczynniki trafień
- stosunek trafie
ń do liczby odwołań w przedziale czasu
- zal
eży od: pojemności, organizacji wykonywanego programu
- 0-0,9 – zal
eży od pojemności
- 0,9-1 – zal
eży od organizacji i alegoryzmu wymiany
- wy
ższa asocjacyjność => hit ratio
- wysoki hit ratio nie zapewnia do
końca wyrównania wydajności między czasem dostępu do RAM
a czasem cyklu procesora
Kieszenie wielopoziomowe – L1, L2, L3
- L1 – bardzo szybka, ma
ła pojemność
- L2 – wolniejsza (np. 5x) znac
ząco większa
- L3 – wolna, du
ża
Kieszenie inkluzywne:
- przep
ływ danych: L2=>L1=>CPU
- k
ażdy obiekt w wyższej warstwie jest też w niższej
-
całkowita pojemność = pojemność największej warstwy
- L2>>L1 (znacznie w
iększa)
Kieszenie wy
łączne
- L2 zawiera obiekty usun
ięte z L1 (victim cache)
- przep
ływ danych: RAM=>L1=>CPU=>L1=>L2
-
całkowita pojemność – suma pojemności wszystkich warstw
- L2>=L1
WYK
ŁAD 12 Zarządzanie pamięcią
Funkcje systemu zar
ządzania pamięcią:
- sprz
ętowa relokacja – każdy proces widzi
przestrze
ń adresową tak samo
- ochrona – przed ingerencj
ą w kod i dane innego
procesu
- dynamiczna alokacja i dealokacja –
powi
ększanie, zmniejszanie pamięci
przydzielonej procesowi
- wirtualizacja – niezal
eżność dostępności
pami
ęci od jej zajętości
Jednostka zar
ządzania pamięcią
- po
między CPU i RAM
- zamienia adres logiczny z procesora na adres
fizyczny
Prosta relokacja
- pierwsza metoda
- system operuje na adresach fizycznych
Translacja adresu w jednostce relokacji
- sprawdzenie czy adres logiczny znajduje si
ę w obszarze przydzielonym procesowi (między
DATUM, LIMIT)
- DATUM to baza
- je
śli tak – adres fizyczny = adres logiczny + baza
- je
śli nie – zwrócony błąd
alokacja pa
mięci
- rozszerzenie obszaru pa
mięci procesu
- gdy brak miejsca bez
pośrednio za procesem – przemieszczenie dalszych procesów
Wada: fragmentacja p
amięci (zbyt małe puste obszary aby zaalokować nowy proces – fragmentacja
zewn
ętrzna)
Jednostka relokacji:
- 3 z 4 funkcji zar
ządzania pamięcią: relokacja, ochrona, dynamiczna alokacja
- brak wirtualizacji

Segmentacja:
- uogólniona relokacja
- jednostka segmentacji
- przestrze
ń adresowa procesu podzielona na segmenty o różnych długościach:
-kod, dane statyczne (s
tałe, zmienne), stos, sterta
Adresy logiczne w segmentacji
- dwuwymiarowa logiczna przestrze
ń adresowa
- adres logiczny dwu
częściowy: id segmentu, offset
- jednostka segmentacji translatuje adresy w przestrzeni dwuwymiarowej na adresy w przestrzeni
p
ełnowymiarowej - liniowej
Deskryptor segmentu – zawiera informacje o segmencie ( znacznik w
ażności, odmowa dostępu,
rozmiar, liniowy adres bazowy)
Translacja adresu w jednostce segmentacji
- jednostka segmentacji odbiera adres logiczny (id segmentu, offset)
- d
zięki id segmentu odnajduje deskryptor
- b
łąd gdy nieprawidłowości deskryptora
- brak b
łędu – adres liniowy (fizyczny) = liniowy adres bazowy (z deskryptora) + offset
Alokacja pami
ęci
- rozszerzenie segmentu sterty
- alokacja nowego segmentu
P
amięć wirtualna na bazie segmentacji
- podzia
ł programu na wiele segmentów sterty i kodu (niepodzielny segment stosu)
- fragmentacja pami
ęci masowej
Segmentacja wys
tępuje tylko w architekturze x86
Stronicowanie
- podzia
ł logiczny i fizyczny przestrzeni adresowej na bloki (dł. 2'')
- bloki przestrzeni logicznej to strony
- bloki przestrzeni fizycznej to strony fizyczne lub ramki stron
Jednostka stronicowania
- translacja adresu – przypor
ządkowanie stronie logicznej strony wirtualnej
- jednostka stronicowania dzieli adres na strony wirtualnej VPN i adres wewn
ątrz stronicowy
(offset)
- translacja zamienia VPN na PPN (physical page number)
TLB – bufor translacji – przechowuje kilka ostatnio u
żytych deskryptorów (ważnych)
P
amięć wirtualna na bazie stronicowania
- niepotrzebne strony zrzucane na dysk
- brak fragmentacji – sta
ły rozmiar stron
- deskryptory przechowywane w pami
ęci w strukturach tablicowo – drzewiastych
- deskryptor niew
ażny – cały fragment przestrzeni adresowej nieważny
- k
ażdy proces ma własną tablicę deskryptorów
WYK
ŁAD 11 Zarządzanie zasobami komputera
- procesy nie mog
ą sobie przeszkadzać ani się szpiegować oraz mieć dostępu do pamięci innego
procesu bez jego zezwolenia
Zasoby podlegaj
ące ochronie:
- procesor – proces nie mo
że przejąć całego czasu procesora (systemy wieloprocesowe)
- pami
ęć – powinien mieć dostęp tylko do wyznaczonego mu obszaru pamięci, ewentualnie do
danych wspó
łdzielonych ( za zgodą innego procesu), dostęp procesu do jego pamięci tylko we
w
łaściwy sposób)
- wej
ście/wyjście – procesy nie mogą sobie przeszkadzać podczas dostępu do urządzeń
zewn
ętrznych

- zakaz bez
pośrednich odwołań do urządzeń
U
żytkownik i system
- minimum 2 poziomy zaufania:
- poziom u
żytkownika – programy użytkowe, mogą mieć błędy
- poziom systemowy – system operacyjny, powinien dzi
ałać bezbłędnie
Poziomy zaufania:
- 0 – poziom
jądra systemu – pełny dostęp do wszystkich zasobów
- 1,2 – poziom us
ług systemu – (opcjonalny) ograniczony dostęp, lecz o znaczących uprawnieniach
- 3 – poziom u
żytkownika – najbardziej ograniczony, dostęp do zasobów przydzielonych przez
system, na zasadach okre
ślonych przez system
Ochrona procesora:
- dost
ęp do zasobów zależy od poziomu zaufania
- procesor w k
ażdej chwili pracuje z określonym poziomem zaufania
- poziom zaufania przechowywany w rejestrze stanu procesora (1 lub 2 bity)
- dost
ęp do rejestru z informacjami sterującymi tylko na poziomie systemowym
- rejestry systemowe podlegaj
ą ochronie
Egzekwowanie zasad ochrony
- k
ażde naruszenie zasad ochrony musi być wykryte, udaremnione i zgłoszone do OS jako wyjątek
- system mo
że usunąć „szkodliwy” proces
Ochrona czasu procesora
- wymuszenie pr
zełączania procesów w czasie (syst. wieloprocesowe)
- pr
zełączanie procesów na podstawie algorytmu, zgłoszenie wyjątku przez system
- po przej
ęciu sterowania system może usunąć proces
Ochrona ur
ządzeń wejścia/wyjścia
- procesy u
żytkowe całkowicie odizolowane od fizycznych urządzeń
- ur
ządzenia fizyczne obsługuje system
- wyj
ątek: wyłączny dostęp procesu do urządzenia np. DirectX w Windows
Ochrona pami
ęci: proces ma mieć dostęp tylko do przydzielonej mu pamięci
Maszyny wirtualne
- hypervisor – oprogramowanie nadr
zędne do systemów
- system uruchomiony pod innym systemem musi mie
ć mniejszy poziom zaufania niż gospodarz
Obecnie: hypervisior, tzw host (gospodarz) pod którym dzia
ła gość (inny OS), dostęp do niektórych
zasobów tylko w trybie gospodarza
WYK
ŁAD 13 Sytuacje wyjątkowe
Wyj
ątek – zdarzenie w systemie komputerowym wymagające przerwania wykonywania strumienia
instrukcji i przekazania sterowania do systemu operacyjnego
Rodzaje wyj
ątków:
- przerwania – powstaj
ą asynchronicznie poza procesorem, niezależnie od wykonania instrukcji,
sygnalizuj
ą ważne zdarzenia dla systemu operacyjnego (zmiana stanu urządzeń lub upłynięcie
odcinka czasu)
- pu
łapki – powstają w procesorze, zależne od wykonywanych instrukcji (generowane przez nie),
rodzaje: przerwania programowe, sygna
ł o błędzie programu do OD, pułapka śledzenia (przy
tworzeniu programu – debug)
- b
łędy – generowane przez procesor (np. dzielenie przez 0) przez jednostkę wykonawczą i
zar
ządzania pamięcią, wyjątek: błąd transmisji (poza procesorem)
Obs
ługa wyjątków:
- k
ażdy wyjątek musi zostać obsłużony
- na poziomie oprogramowania (reakcja OS na zdarzenie)
- na poziomie procesora (czy
nności przerywające obsługę bieżącego strumienia instrukcji i
wykonanie procedury OS)
Fazy obs
ługi wyjątku przez procesor:
- identyfikacja
źródła wyjątku – w przypadku przerwania (pułapka, błąd – zbędna)
- przerwanie wykonywanych instrukcji: (zapami
ętanie bieżącego stanu procesora
-
załadowanie nowego kontekstu procesora w celu obsługi wyjątku przez OS
- powrót z obs
ługi wyjątku (nie zawsze możliwy) odtworzenie informacji zapamiętanych przy
obs
łudze wyjątku.
W CISC – 2 stosy stos u
żytkownika i stos systemowy
System przerwa
ń
- hierarchia przerwa
ń – piorytet przerwań obsługiwanych przez procesor
- podej
ście jednopoziomowe – blokada lub zezwolenie na przerwania
- wielopoziomowy system przerwa
ń – 3/16 poziomów, wolniejsze urządzenie ma niższy
piorytet
- maska przerwa
ń – aktualny poziom wrażliwości
Zmiany poziomu wr
ażliwości – obsługa przerwania o tym samym bądź niższym piorytecie
- przerwania niemaskowalne – nie zale
żą od poziomu maski przerwań (np. awaria zasilania)
Asynchronicznie przerwanie programowe – to nie przerwanie tylko pu
łapka przerwanie zgłoszone
przez sam procesor
Reset – wyj
ątek o najwyższym priorytecie, natychmiastowe przekazanie sterowania pod określony
adres
Priorytety sytuacji wyj
ątkowych
- na poziomie systemu – wynikaj
ą z pilności zdarzenia: przerwania>pułapki>błędy
- na poziomie procesora – wynikaj
ą z kolejności działań procesora: błędy (stopuje
CPU)>pu
łapki>przerwania
We wspó
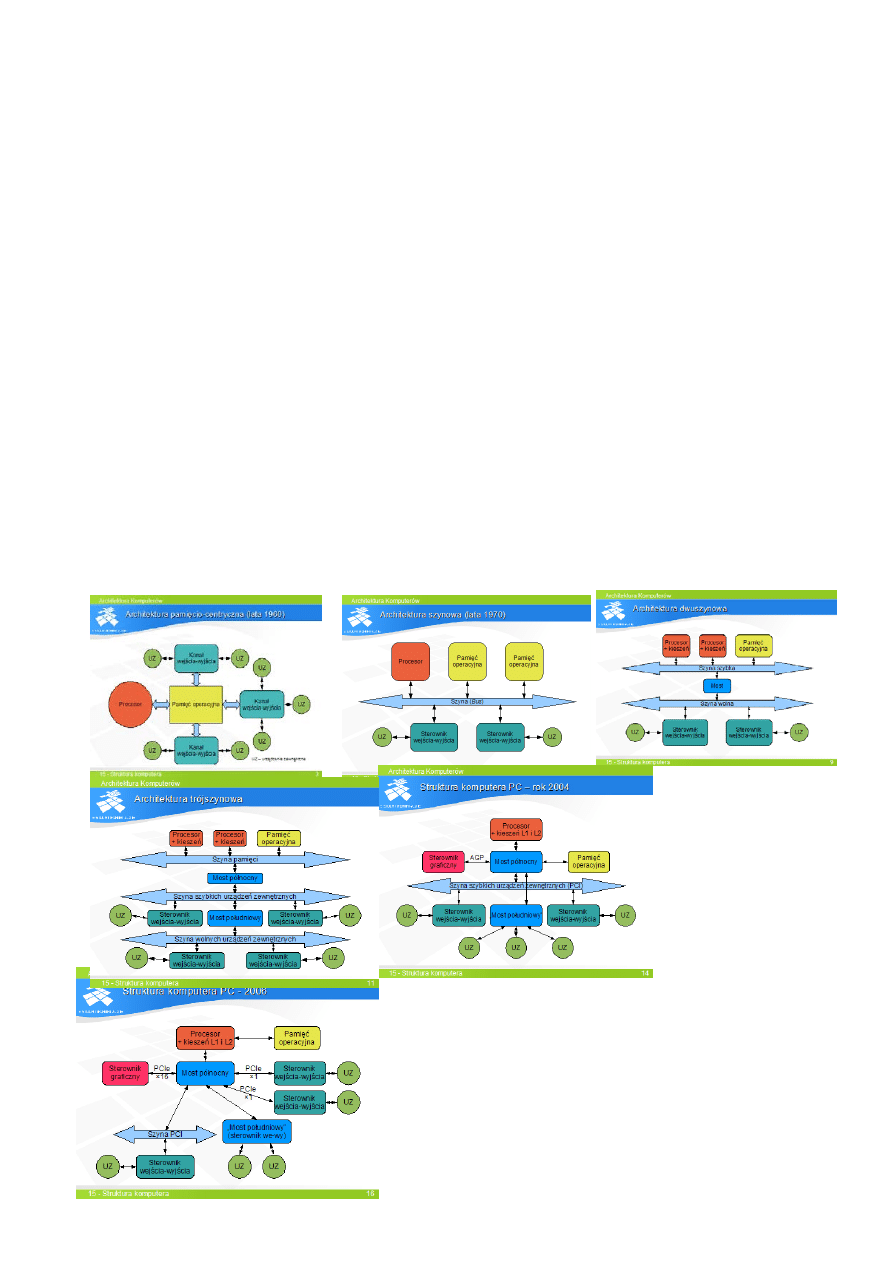
łczesnych komputerach sterownik pamięci
umieszczony jest w procesorze. Most pó
łnocny jest
wyposa
żony w indywidualne łącza dla sterowników
ur
ządzeń zewnętrznych, zrealizowane w standardzie PCI
express. „Most po
łudniowy” jest zintegrowanym
sterownikiem ur
ządzeń zewnętrznych. Szyna PCI została
zachowana w celu umo
żliwienia podłączenia starszych
sterowników ur
ządzeń.
17
Document Outline
- Procesor jednocyklowy
- Procesor wielocyklowy
- Procesor potokowy
- WYKŁAD 8 Procesory wielopotokowe (superskalary)
- WYKŁAD 10 Redukcja opóźnień w procesorach superskalarnych
- WYKŁAD 9 Kieszenie jako warstwa hierarchii pamięci
- WYKŁAD 12 Zarządzanie pamięcią
- WYKŁAD 11 Zarządzanie zasobami komputera
- WYKŁAD 13 Sytuacje wyjątkowe
Wyszukiwarka
Podobne podstrony:
Prawoznawstwo - opracowanie na egzamin, Prawoznawstwo
Opracowania na egzamin z RPE RPE
Fizyka opracowanie na egzamin, wersja 2
Opracowanie na egzamin z fizyki, semestr I(1)
ANTROPOLOGIA OPRACOWANIE NA EGZAMIN
Filozofia opracowanie na egzamin
MAŁE+GRUPY+ OPRACOWANIE NA EGZAMIN, socjologia
Metodologia wykłady - opracowanie na egzamin, studia różne, Opracowania
egz end, opracowania na egzamin obrone, Wstęp do nauki o państwie , prawie i polityce
Opracowania na egzamin z RPE, 3. Celtowie, CELTOWIE
Opracowanie na egzamin
opracowanie na egzamin inżynierski z przedmiotu inżynieria leśna
Mechanika gruntów opracowanie na egzamin
badziewne Opracowanie na egzamin dyplomowy[1], Opracowanie pytań na egzamin dyplomowy
więcej podobnych podstron