(c) Instytut Informatyki Politechniki Poznańskiej
1
Optymalizacja polece
ń
SQL
Cz
ęść
2.
Statystyki i histogramy,
metody dost
ę
pu do danych
(c) Instytut Informatyki Politechniki Poznańskiej
2
Statystyki (1)
•
Informacje, opisuj
ą
ce dane i struktury obiektów bazy danych.
•
Przechowywane w słowniku danych.
•
U
ż
ywane przez optymalizator do oszacowania:
• selektywno
ś
ci predykatów polecenia,
• kosztu u
ż
ycia
ś
cie
ż
ek dost
ę
pu,
• kosztu operacji I/O i czasu procesora,
• kosztu planu wykonania polecenia
.
•
Tylko
aktualne
statystyki u
ż
yteczne!
• Statystyki s
ą
statyczne – nie s
ą
automatycznie uaktualniane przy
zmianie danych.
(c) Instytut Informatyki Politechniki Poznańskiej
3
Statystyki (2)
•
Przykłady statystyk:
• dla relacji:
• liczba rekordów,
• liczba bloków,
•
ś
rednia długo
ść
rekordu,
• dla atrybutu relacji:
• liczba ró
ż
nych warto
ś
ci,
• liczba rekordów, w których atrybut ma warto
ść
pust
ą
,
• rozkład warto
ś
ci (histogram),
• dla indeksu:
• liczba bloków-li
ś
ci,
• wysoko
ść
drzewa,
• wska
ź
nik zgrupowania indeksu,
• statystyki systemowe:
• wykorzystanie procesora,
• liczba operacji we/wy.
(c) Instytut Informatyki Politechniki Poznańskiej
4
Statystyki (3)
•
Statystyki mog
ą
by
ć
gromadzone automatycznie (przez
dedykowany proces SZBD) lub r
ę
cznie (na
żą
danie u
ż
ytkownika)
przy u
ż
yciu pakietu DBMS_STATS.
•
W przypadku braku statystyk dla obiektów u
ż
ywanych w zapytaniu
przed wykonaniem zapytania optymalizator realizuje dynamiczne
próbkowanie statystyk.
(c) Instytut Informatyki Politechniki Poznańskiej
5
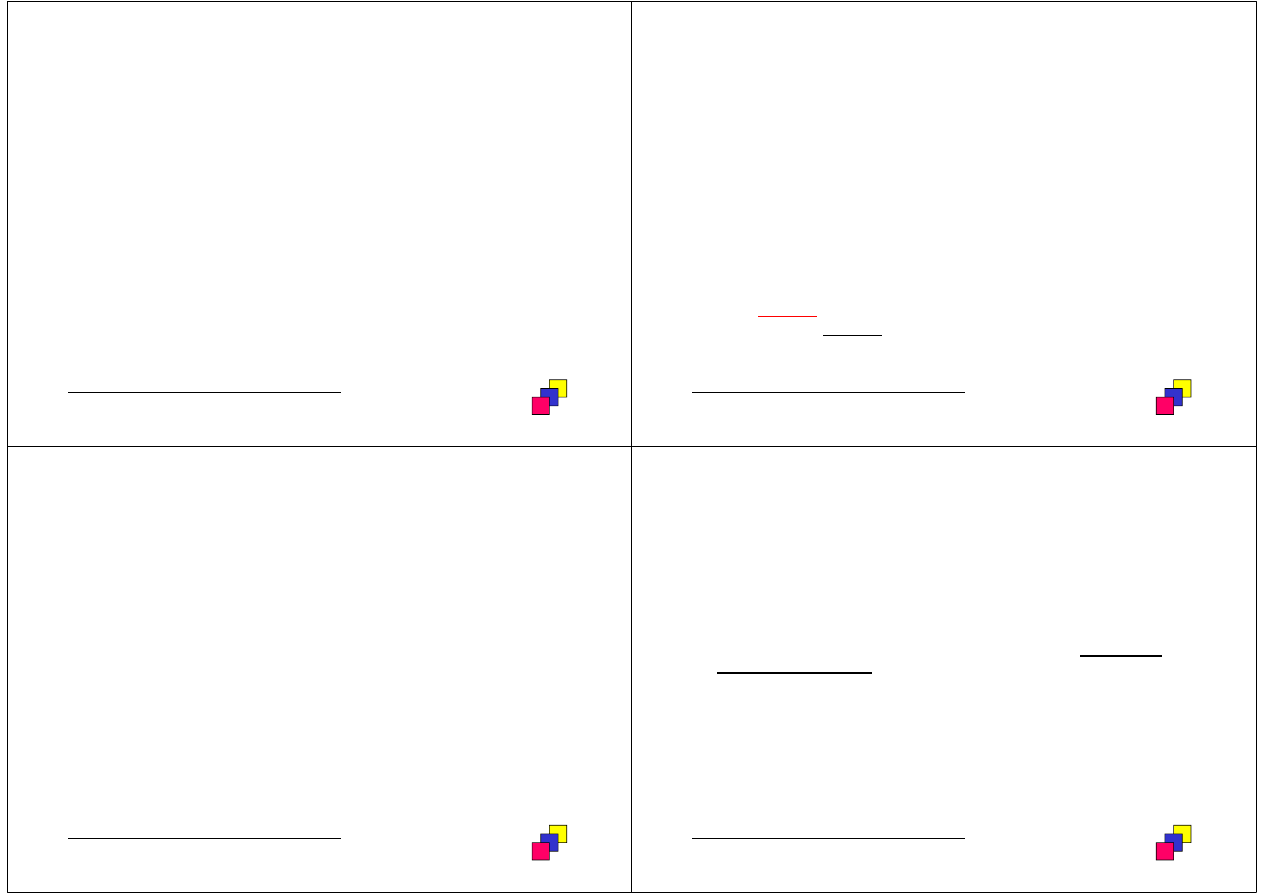
Histogramy (1)
•
Histogram – szczegółowa statystyka opisuj
ą
ca rozkład warto
ś
ci
okre
ś
lonej kolumny relacji.
•
Rodzaje:
• histogram o zrównowa
ż
onej wysoko
ś
ci (ang. height balanced) – zbiór
warto
ś
ci kolumny dzielony jest na przedziały o tej samej (w
przybli
ż
eniu) liczbie rekordów; przykład (zakres warto
ś
ci: <1, 100>,
liczba przedziałów: 10):
• równomierny rozkład warto
ś
ci atrybutu:
• nierównomierny rozkład warto
ś
ci atrybutu:
1 10 20 30 40 50 60 70 80 90 100
1 10 10 10 30 40 40 40 65 80 100
(c) Instytut Informatyki Politechniki Poznańskiej
6
Histogramy (2)
•
Rodzaje (cd):
• histogram cz
ę
stotliwo
ś
ci (ang. frequency) – ka
ż
da warto
ść
kolumny
odpowiada jednemu przedziałowi, ka
ż
dy przedział zawiera liczb
ę
wyst
ą
pie
ń
tej warto
ś
ci; tworzony wtedy, gdy liczba warto
ś
ci kolumny
jest mniejsza b
ą
d
ź
równa
żą
danej liczbie przedziałów histogramu.
•
Histogramy nale
ż
y tworzy
ć
tylko dla kolumn z nierównomiernym
rozkładem warto
ś
ci (ang. skewed data), cz
ę
sto u
ż
ywanych w
warunkach zapytania.
•
Gdy zmieni si
ę
rozkład danych kolumny, konieczne jest ponowne
wygenerowanie histogramu,
(c) Instytut Informatyki Politechniki Poznańskiej
7
R
ę
czne zbieranie statystyk
•
Metody:
• na podstawie pełnych danych,
• szacowanie na podstawie próbki, próbka okre
ś
lana w
procentach liczby rekordów.
•
Procedury zbieraj
ą
ce statystyki:
• DBMS_STATS.GATHER_INDEX_STATS – dla indeksu,
• DBMS_STATS.GATHER_TABLE_STATS – dla relacji.
•
Procedury usuwaj
ą
ce statystyki:
• DBMS_STATS.DELETE_INDEX_STATS – dla indeksu,
• DBMS_STATS.DELETE_TABLE_STATS – dla relacji,
• DBMS_STATS.DELETE_COLUMN_STATS – dla kolumny.
(c) Instytut Informatyki Politechniki Poznańskiej
8
Zbieranie statystyk dla indeksu
•
je
ś
li warto
ść
<procentowa_wielko
ść
_próbki> okre
ś
lono jako:
• null, wówczas statystyki zbierane na podstawie pełnych danych,
• liczb
ę
z przedziału <0,00001; 100>, wówczas szacowanie na podstawie
próbki o zadanym rozmiarze,
• DBMS_STATS.AUTO_SAMPLE_SIZE – rozmiar próbki dobiera system.
•
Uwaga! Od Oracle10g statystyki dot. indeksów s
ą
gromadzone automatycz-
nie podczas tworzenia lub przebudowy indeksu.
exec DBMS_STATS.GATHER_INDEX_STATS(
ownname => <nazwa_schematu>, indname => <nazwa_indeksu>,
estimate_percent => <procentowa_wielko
ść
_próbki>);
exec DBMS_STATS.GATHER_INDEX_STATS(
ownname => 'SCOTT', indname => 'PK_PRAC', estimate_percent => 20);
(c) Instytut Informatyki Politechniki Poznańskiej
9
Zbieranie statystyk dla relacji (1)
•
METHOD_OPT – okre
ś
la zakres zbieranych statystyk:
• FOR TABLE – tylko statystyki dla tabeli bez statystyk dla kolumn,
• FOR ALL COLUMNS [<klauzula SIZE>] – statystyki dla tabeli i statystyki
dla wszystkich kolumn,
• FOR ALL INDEXED COLUMNS [<klauzula SIZE>] – statystyki dla tabeli i
statystyki dla poindeksowanych kolumn,
• FOR COLUMNS [<klauzula SIZE>] kolumna1 [<klauzula SIZE>], kolumna2
[<klauzula SIZE>], ... – statystyki dla tabeli i statystyki dla wskazanych
kolumn.
exec DBMS_STATS.GATHER_TABLE_STATS(
ownname => <nazwa_schematu>, tabname => <nazwa_relacji>,
estimate_percent => <procentowa_wielko
ść
_próbki>,
method_opt => <rodzaj_statystyk>,
cascade =>
<DBMS_STATS.AUTO_CASCADE
|
TRUE | FALSE> );
(c) Instytut Informatyki Politechniki Poznańskiej
10
Zbieranie statystyk dla relacji (2)
•
<klauzula SIZE> – SIZE { liczba | REPEAT | AUTO | SKEWONLY }:
• liczba – liczba przedziałów w histogramie, zakres: <1, 254>,
• REPEAT – powtórzenie zbierania histogramów dla kolumn, które maj
ą
ju
ż
histogramy,
• AUTO – SZBD okre
ś
li, dla których kolumn zbiera
ć
histogramy na podstawie
obci
ąż
enia i rozkładu danych kolumny,
• SKEWONLY – SZBD okre
ś
li, dla których kolumn zbiera
ć
histogramy tylko na
podstawie rozkładu danych kolumny (bez analizy obci
ąż
enia).
•
FOR ALL COLUMNS SIZE AUTO – warto
ść
domy
ś
lna dla par. METHOD_OPT:
• statystyki tabeli,
• podstawowe statystyki wszystkich kolumn tabeli,
• histogramy dla kolumn wyznaczonych na podstawie wcze
ś
niejszych
obserwacji dotycz
ą
cych obci
ąż
enia i rozkładu warto
ś
ci.
(c) Instytut Informatyki Politechniki Poznańskiej
11
Zbieranie statystyk dla relacji (3)
exec DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'SCOTT', tabname => 'PRACOWNICY',
estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE,
method_opt => 'FOR COLUMNS placa_pod SIZE AUTO, nazwisko SIZE AUTO');
exec DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'SCOTT', tabname => 'PRACOWNICY',
method_opt => 'FOR ALL INDEXED COLUMNS',
cascade => TRUE);
•
Uwaga! Od Oracle12c statystyki dotycz
ą
ce tabel zostaj
ą
zebrane automatycznie
w sytuacji, gdy tabela, do której ładowane s
ą
dane
ś
cie
ż
k
ą
bezpo
ś
redni
ą
(polecenie INSERT /*+ APPEND */, dane umieszczane od razu w plikach bazy
danych z pomini
ę
ciem bufora bazy danych), była poprzednio pusta:
• tabela została dopiero co utworzona i nie posiada jeszcze rekordów, lub
• usuni
ę
to z tabeli wszystkie rekordy.
(c) Instytut Informatyki Politechniki Poznańskiej
12
Statystyki w słowniku bazy danych
•
Dla relacji:
• USER_TABLES, USER_TAB_STATISTICS
•
Dla kolumn:
• USER_TAB_COLUMNS, USER_TAB_COL_STATISTICS,
USER_TAB_HISTOGRAMS
•
Dla indeksów:
• USER_INDEXES, USER_IND_STATISTICS
SELECT num_rows, blocks, last_analyzed, sample_size
FROM USER_TAB_STATISTICS
WHERE table_name = 'PRACOWNICY';
SELECT num_distinct, low_value, high_value, num_buckets, histogram
FROM USER_TAB_COL_STATISTICS
WHERE table_name = 'PRACOWNICY'
AND column_name = 'NAZWISKO';
(c) Instytut Informatyki Politechniki Poznańskiej
13
Usuwanie statystyk
exec DBMS_STATS.DELETE_INDEX_STATS(
ownname => <nazwa_schematu>, indname => <nazwa_indeksu>);
exec DBMS_STATS.DELETE_TABLE_STATS(
ownname => <nazwa_schematu>, tabname => <nazwa_relacji>);
exec DBMS_STATS.DELETE_COLUMN_STATS(
ownname => <nazwa_schematu>, tabname => <nazwa_relacji>,
colname => <nazwa_kolumny>, col_stat_type => <rodzaj_usuwanych_statystyk>);
•
COL_STAT_TYPE:
• HISTOGRAM – usuwany jest histogram dla kolumny, podstawowe
statystyki kolumny pozostaj
ą
,
• ALL – usuwane s
ą
wszystkie statystyki dla kolumny (warto
ść
domy
ś
lna).
(c) Instytut Informatyki Politechniki Poznańskiej
14
Metody dost
ę
pu do danych
•
Okre
ś
laj
ą
, w jaki sposób dane polecenia SQL s
ą
odczytywane z
miejsca ich fizycznej lokalizacji.
•
Dost
ę
p do tabeli:
• pełne przegl
ą
dni
ę
cie,
• dost
ę
p przy pomocy adresu rekordu.
•
Dost
ę
p do indeksu:
• unikalne przegl
ą
dni
ę
cie indeksu,
• (odwrócone) zakresowe przegl
ą
dni
ę
cie indeksu,
• przegl
ą
dni
ę
cie indeksu z pomini
ę
ciem kolumn,
• pełne przegl
ą
dni
ę
cie indeksu,
• szybkie pełne przegl
ą
dni
ę
cie indeksu,
• dost
ę
p do indeksu bitmapowego,
• poł
ą
czenie indeksów.
Przy dost
ę
pie do indeksu dane zwykle zwracane w kolejno
ś
ci rosn
ą
cej.
•
Ogólne zasady dost
ę
pu do danych:
• odczyt du
ż
ej cz
ęś
ci rekordów relacji – pełne przegl
ą
dni
ę
cie relacji,
• odczyt pojedynczych rekordów relacji – dost
ę
p za pomoc
ą
indeksu.
(c) Instytut Informatyki Politechniki Poznańskiej
15
Pełne przegl
ą
dniecie tabeli
•
Ang. full table scan
•
Sekwencyjny odczyt wszystkich bloków danych, w których tabela
przechowuje swoje rekordy, odfiltrowanie rekordów nie
spełniaj
ą
cych zdefiniowanych w poleceniu SQL kryteriów selekcji
(np. w klauzuli WHERE).
•
Stosowane gdy:
• brak indeksu dla relacji lub
nie mo
ż
na u
ż
y
ć
istniej
ą
cych
indeksów,
• zostanie odczytana du
ż
a cz
ęść
wszystkich bloków, w których tabela składuje swoje dane,
• rozmiar tabeli jest niewielki.
•
Mo
ż
liwy odczyt wieloblokowy – pobranie w jednej operacji I/O wielu
przyległych bloków danych, bardziej efektywne ni
ż
wiele odczytów
pojedynczych bloków.
DB_FILE_MULTIBLOCK_READ_COUNT
Dost
ę
p do tabeli
(c) Instytut Informatyki Politechniki Poznańskiej
16
Dost
ę
p przy pomocy adresu rekordu
•
Ang. rowid scan
•
Odszukanie rekordu relacji na podstawie dostarczonego adresu
rekordu (rowid).
•
Najszybszy sposób dost
ę
pu
do rekordów tabeli.
•
Ź
ródło adresu rekordu:
• warunek selekcji polecenia SQL,
• pobranie z indeksu tabeli.
SELECT * FROM pracownicy
WHERE rowid = ‘AAAMMUAAEAAAAAtAAG’;
Dost
ę
p do tabeli
(c) Instytut Informatyki Politechniki Poznańskiej
17
Unikalne przegl
ą
dni
ę
cie indeksu
•
Ang. index unique scan
•
Dost
ę
p do indeksu unikalnego, operacja zwraca co najwy
ż
ej jeden
adres rekordu.
•
Stosowane, gdy w poleceniu SQL zastosowano warunek
równo
ś
ciowy z atrybutem, na którym zdefiniowano indeks unikalny
(równie
ż
ograniczenia klucz podstawowy i klucz unikalny).
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
18
Zakresowe przegl
ą
dni
ę
cie indeksu
•
Ang. index range scan
•
Dost
ę
p do indeksu unikalnego (warunek inny ni
ż
równo
ś
ciowy) lub
nieunikalnego, operacja zwraca zakres adresów rekordów.
•
Stosowane, gdy w poleceniu SQL:
• warunek selekcji z kolumnami z cz
ęś
ci wiod
ą
cej indeksu, takie jak:
• kolumna = ‘warto
ść
’, kolumna > ‘warto
ść
’, kolumna < ‘warto
ść
’
(równie
ż
kombinacje powy
ż
szych)
• kolumna like ‘ABC%’ (% nie mo
ż
e by
ć
na pocz
ą
tku wzorca),
• warunek zło
ż
ony z ww. warunków ze spójnikiem AND,
• klauzula ORDER BY lub GROUP BY z atrybutami z cz
ęś
ci wiod
ą
cej
indeksu.
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
19
Odwrócone zakresowe przegl
ą
dni
ę
cie indeksu
•
Ang. index range scan descending
•
Odmiana zakresowego przegl
ą
dni
ę
cia indeksu.
•
Dane zwracane w kolejno
ś
ci malej
ą
cej .
•
Stosowane, gdy:
• w poleceniu konieczne posortowanie danych w porz
ą
dku malej
ą
cym,
• przy poszukiwaniu warto
ś
ci mniejszych ni
ż
warto
ść
wyspecyfikowana.
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
20
Przegl
ą
dni
ę
cie indeksu z pomini
ę
ciem kolumn
•
Ang. index skip scan
•
Operacja korzystaj
ą
ca z indeksu zło
ż
onego dla polecenia, w którym
nie wyst
ę
puje kolumna z pocz
ą
tku cz
ęś
ci wiod
ą
cej klucza
indeksowego:
• indeks dzielony jest na mniejsze podindeksy, liczba podindeksów jest
równa liczbie warto
ś
ci pierwszej kolumny w kluczu indeksowym,
• podindeksy skanowane s
ą
kolejno – operacja zast
ę
puje pełne
przegl
ą
dni
ę
cie relacji.
•
Przykład:
• relacja Pracownicy(id_prac, adres, płe
ć
), indeks o strukturze klucza:
(płe
ć
, id_prac), zapytanie: select * from Pracownicy where id_prac =
100
• indeks zostaje podzielony na dwa podindeksy: dla warto
ś
ci płe
ć
= ‘M’ i
dla warto
ś
ci płe
ć
= ‘K’, podindeksy zostaj
ą
przeskanowane kolejno.
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
21
Pełne przegl
ą
dni
ę
cie indeksu
•
Ang. full index scan
•
Stosowane, gdy:
• w warunku polecenia SQL odwołania do kolumn z klucza indeksowego,
kolumny nie musz
ą
by
ć
cz
ęś
ci
ą
wiod
ą
c
ą
klucza,
• brak odwoła
ń
do poindeksowanych kolumn w warunku polecenia, ale:
• wszystkie kolumny, do których wyst
ę
puje odwołanie w poleceniu (np. w
klauzuli SELECT), znajduj
ą
si
ę
w kluczu indeksowym,
• przynajmniej jedna z tych kolumn nie jest pusta.
•
Odczytywane s
ą
wszystkie li
ś
cie indeksu w porz
ą
dku, bloki indeksu
odczytywane pojedynczo.
•
U
ż
ywane głównie do eliminacji operacji sortowania relacji – dane s
ą
posortowane wg klucza indeksowego.
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
22
Szybkie pełne przegl
ą
dni
ę
cie indeksu
•
Ang. fast full index scan
•
Stosowane, gdy:
• wszystkie kolumny, które s
ą
u
ż
ywane w poleceniu SQL, wyst
ę
puj
ą
w
kluczu indeksowym,
• co najmniej jedna z tych kolumn ma zdefiniowane ograniczenie NOT
NULL.
•
Zast
ę
puje pełne przegl
ą
dni
ę
cie relacji – wynik polecenia SQL
uzyskuje si
ę
bezpo
ś
rednio z indeksu, bez konieczno
ś
ci dost
ę
pu do
relacji.
•
Odczytywane s
ą
wszystkie li
ś
cie indeksu przy zastosowaniu
odczytu wieloblokowego – wi
ę
ksza wydajno
ść
ni
ż
pełne
przegl
ą
dni
ę
cie indeksu, ale nie zostaje zachowane uporz
ą
dkowanie.
•
Nie mo
ż
e by
ć
u
ż
ywany do eliminacji operacji sortowania relacji –
dane nie s
ą
posortowane wg klucza indeksowego.
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
23
Dost
ę
p do indeksu bitmapowego
•
Składa si
ę
z dwóch kroków:
1. dost
ę
p do bitmapy,
2. konwersja bitmapy do adresów rekordów (krok opuszczany w
przypadku mo
ż
liwo
ś
ci realizacji polecenia bez dost
ę
pu do
relacji).
•
W przypadku polece
ń
z warunkiem zło
ż
onym (spójniki AND i OR,
negacja), operacje koniunkcji, alternatywy i negacji wykonywane
bezpo
ś
rednio na bitmapach (widoczne w planie wykonania
polecenia).
Dost
ę
p do indeksu
(c) Instytut Informatyki Politechniki Poznańskiej
24
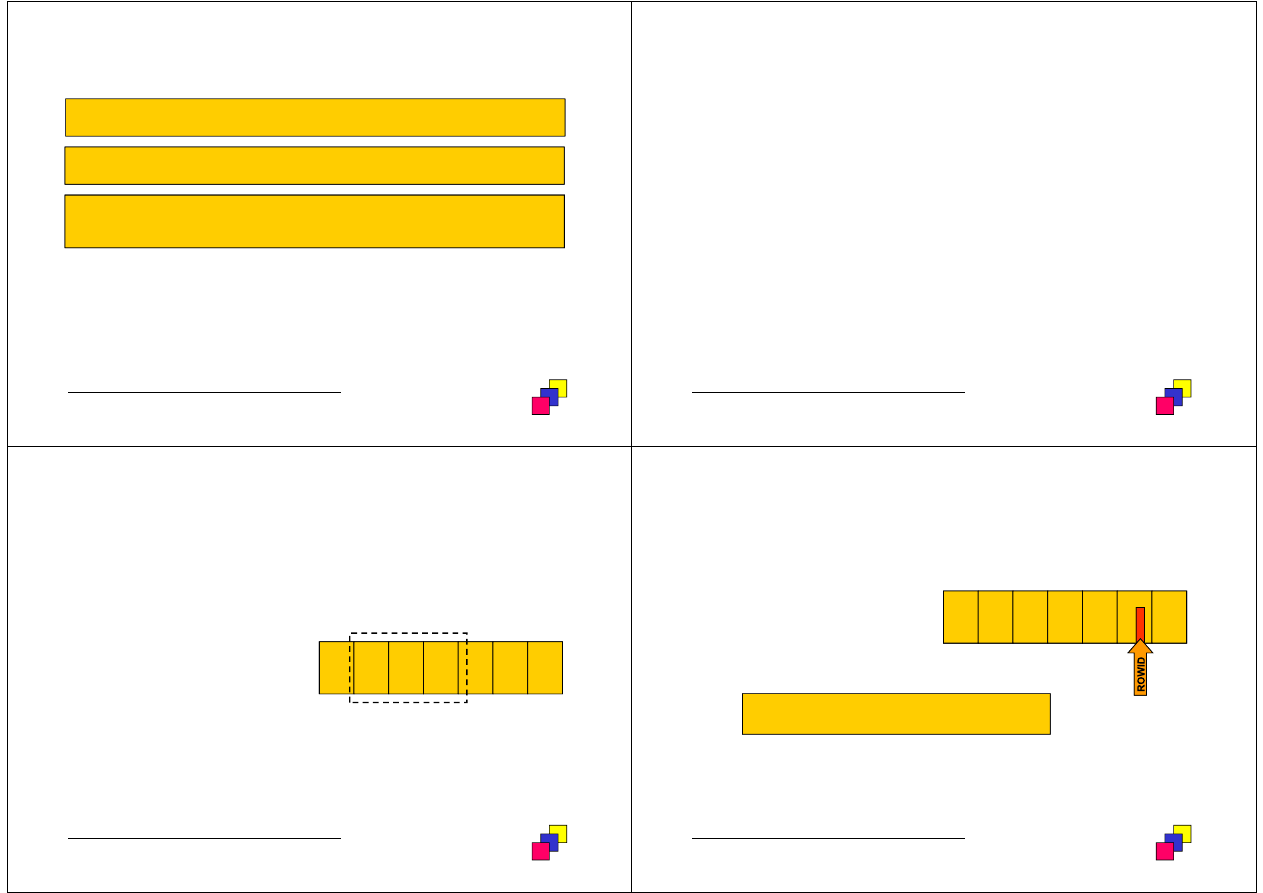
Poł
ą
czenie indeksów
•
Ang. index join
•
Stosowane w przypadku, gdy wszystkie kolumny, u
ż
ywane w
poleceniu SQL, znajduj
ą
si
ę
w kluczach kilku ró
ż
nych indeksów.
•
Wynik polecenia uzyskuje si
ę
tylko z indeksów, bez konieczno
ś
ci
dost
ę
pu do relacji.
•
Nie mo
ż
e by
ć
stosowane do eliminacji operacji sortowania relacji.
•
Przykład:
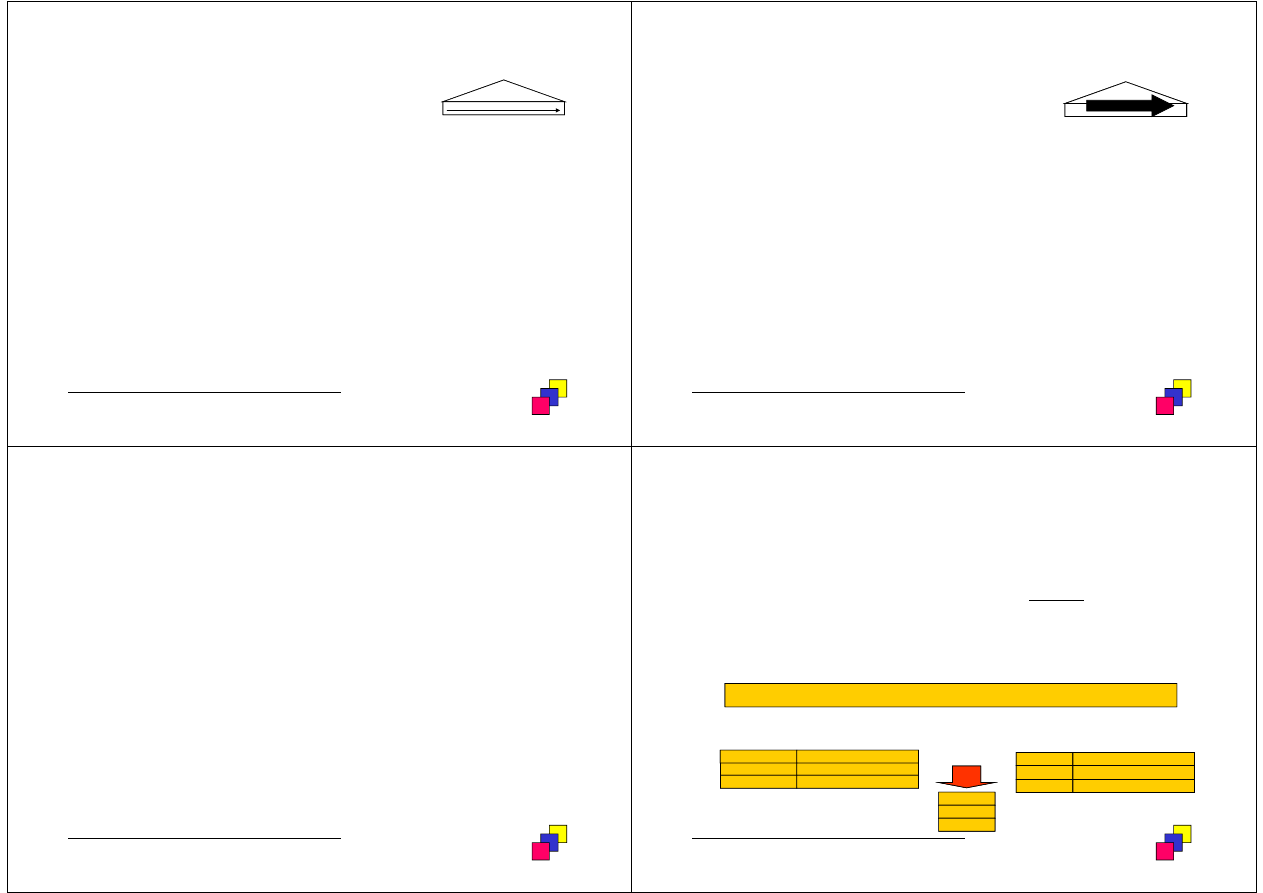
SELECT id_prac FROM pracownicy WHERE placa_pod >1000;
Range scan(indeks na placa_pod)
Fast Full Scan(indeks na id_prac)
1600
1600
00000001.001.001
00000001.001.001
placa_pod
ROWID
120
120
...
...
140
140
join (hash)
120
120
...
...
...
...
2000
2000
00000001.0A1.01E
00000001.0A1.01E
...
...
140
140
ROWID
id_prac
00000001.0A1.01E
00000001.0A1.01E
...
...
00000001.001.001
00000001.001.001
Dost
ę
p do indeksu
Wska
ź
nik zgrupowania indeksu (1)
•
Minimaln
ą
jednostk
ą
operacji I/O jest blok dyskowy a nie rekord
•
Statystyka, pozwalaj
ą
ca na porównanie kosztu operacji
przegl
ą
dni
ę
cia indeksu z kosztem pełnego przegl
ą
dni
ę
cia tabeli
•
Okre
ś
la, jak mocno indeks jest "zsynchronizowany" z tabel
ą
:
• mała warto
ść
– rekordy tabeli z tymi samymi (lub zbli
ż
onymi)
warto
ś
ciami poindeksowanej kolumny s
ą
skupione w niewielkiej liczbie
bloków
• du
ż
a warto
ść
– rekordy tabeli z tymi samymi (lub zbli
ż
onymi)
warto
ś
ciami poindeksowanej kolumny s
ą
rozproszone w du
ż
ej liczbie
bloków
(c) Instytut Informatyki Politechniki Poznańskiej
25
Wska
ź
nik zgrupowania indeksu (2)
•
Interpretacja:
• mała warto
ść
(równa lub bliska liczbie bloków tabeli) – dobrze, u
ż
ycie
indeksu jest korzystne w stosunku do pełnego przegl
ą
dni
ę
cia tabeli z
powodu konieczno
ś
ci wykonania mniejszej liczby operacji odczytu
bloków tabeli (odczytu danych) po dost
ę
pie do indeksu (po odczycie
adresów rekordów)
• du
ż
a warto
ść
(równa lub bliska liczbie rekordów tabeli) –
ź
le, u
ż
ycie
indeksu jest niekorzystne w stosunku do pełnego przegl
ą
dni
ę
cia tabeli
z powodu konieczno
ś
ci wykonania wi
ę
kszej liczby operacji odczytu
bloków tabeli po dost
ę
pie do indeksu
•
Słownik
danych
(c) Instytut Informatyki Politechniki Poznańskiej
26
SELECT clustering_factor FROM user_indexes
WHERE index_name = ‘PRAC_PK’;
Wska
ź
nik zgrupowania indeksu (3)
•
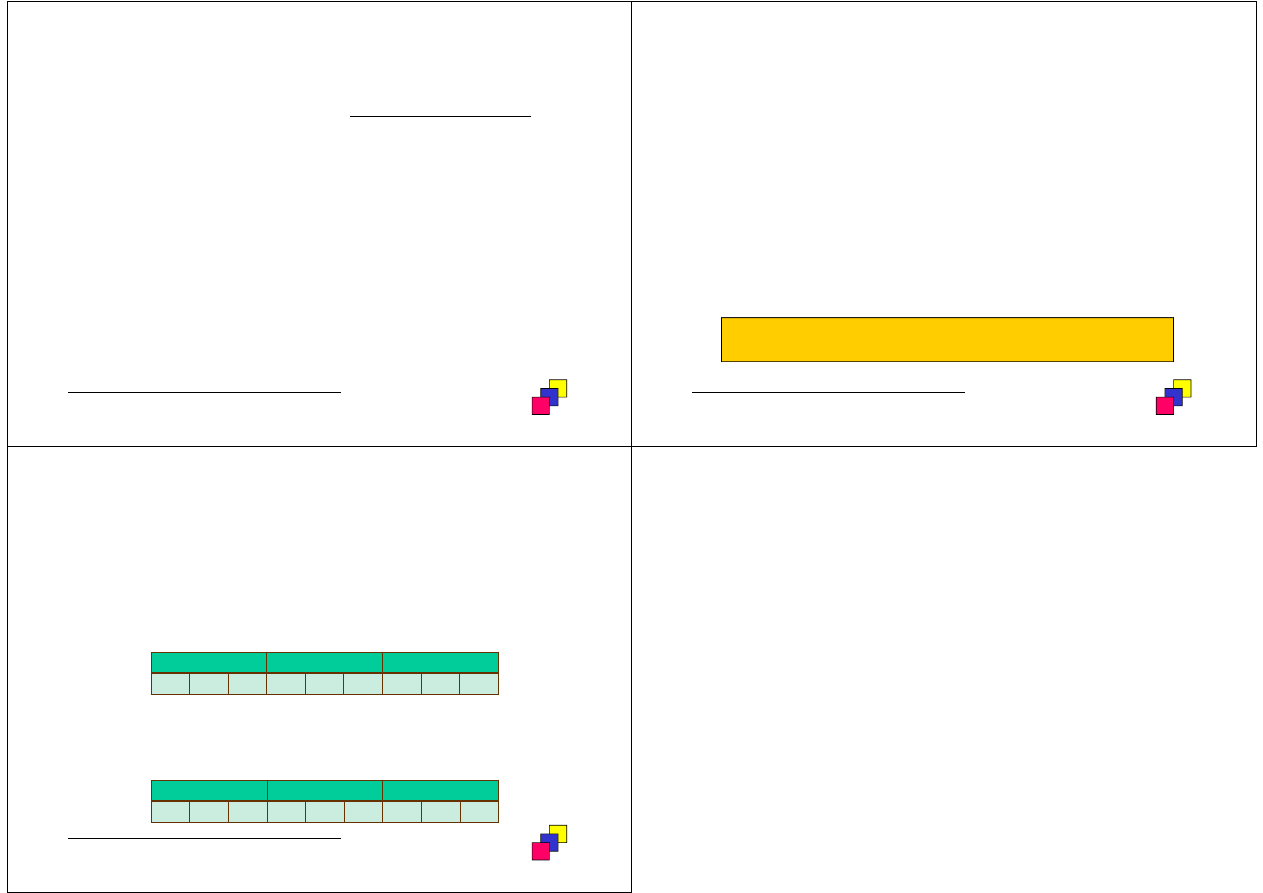
Przykład – tabela posiada 9 rekordów, poindeksowana kolumna K1
posiada trzy warto
ś
ci A, B i C (po trzy rekordy), rekordy zajmuj
ą
3
bloki.
•
Przypadek 1. Mała warto
ść
wska
ź
nika. Niski koszt skanu indeksu –
odczyt A wymaga dost
ę
pu do jednego bloku tabeli
•
Przypadek 2. Du
ż
a warto
ść
wska
ź
nika. Wy
ż
szy koszt skanu indeksu
– odczyt A wymaga dost
ę
pu do wszystkich trzech bloków tabeli
(c) Instytut Informatyki Politechniki Poznańskiej
27
BLOK 1
BLOK 2
BLOK 3
A
A
A
B
B
B
C
C
C
BLOK 1
BLOK 2
BLOK 3
A
B
C
A
B
C
A
B
C
Wyszukiwarka
Podobne podstrony:
19OptymalizacjaSQL czesc 2 zadania
19OptymalizacjaSQL czesc 3
19OptymalizacjaSQL czesc 2 zadaniaid 18608
19OptymalizacjaSQL czesc 1 zadania
19OptymalizacjaSQL czesc 2
19OptymalizacjaSQL czesc 3id 18609
88 Leki przeciwreumatyczne część 2
guzy część szczegółowa rzadsze
11 Resusc 2id 12604 ppt
Stomatologia czesc wykl 12
S II [dalsza część prezentacji]
(65) Leki przeciwreumatyczne (Część 1)
więcej podobnych podstron