
Zarządzanie Projektem
Teleinformatycznym
Wymiarowanie projektów
dr inż. Konrad Jackowski
e-mail:
konrad.jackowski@pwr.wroc.pl
C3 111

Metody algorytmiczne szacowania
wielkości projektu
• Precyzyjne oszacowanie wielkości tworzonego systemu informatycznego
jest podstawą poprawnego planowania projektu
– Zapotrzebowania na zasoby
– Kosztów bezpośrednich (wynagrodzeń)
– Czasu trawania
• Modele algorytmiczne szacowania wymagają opisu danego przedsięwzięcia
za pomocą szeregu atrybutów liczbowych i opisowych. Odpowiedni
algorytm daje w wyniku spodziewany nakład pracy
• W metodach algorytmicznych podstawowym parametrem oszacowań jest
liczba osobomiesięcy (PM – person per month)
• Wartość tego parametru jest iloczynem „wielkości” systemu praz
„produktywności” zespołu programistów
–
Oszacowanie „wielkości” systemu realizowane z wykorzystaniem
dedykowanych algorytmów szacowania
–
„Produktywność” jest parametrem empirycznym

Miary wielkości systemu informatycznego
• Typy miar wielkości systemu
–
Wolumenowe
–
Funkcyjne
• Miary wolumenowe odnoszą się bezpośrednio do jednostek określających
rozmiar
–
Liczbę linii kodu (LOC – Line of COde, KLOC – 1000 * LOC)
–
Liczbę stron dokumentacji systemowej
• Miary funkcyjne bazują na identyfikacji funkcjonalności systemu
–
Metoda punktów funkcyjnych (FP Functional Points)
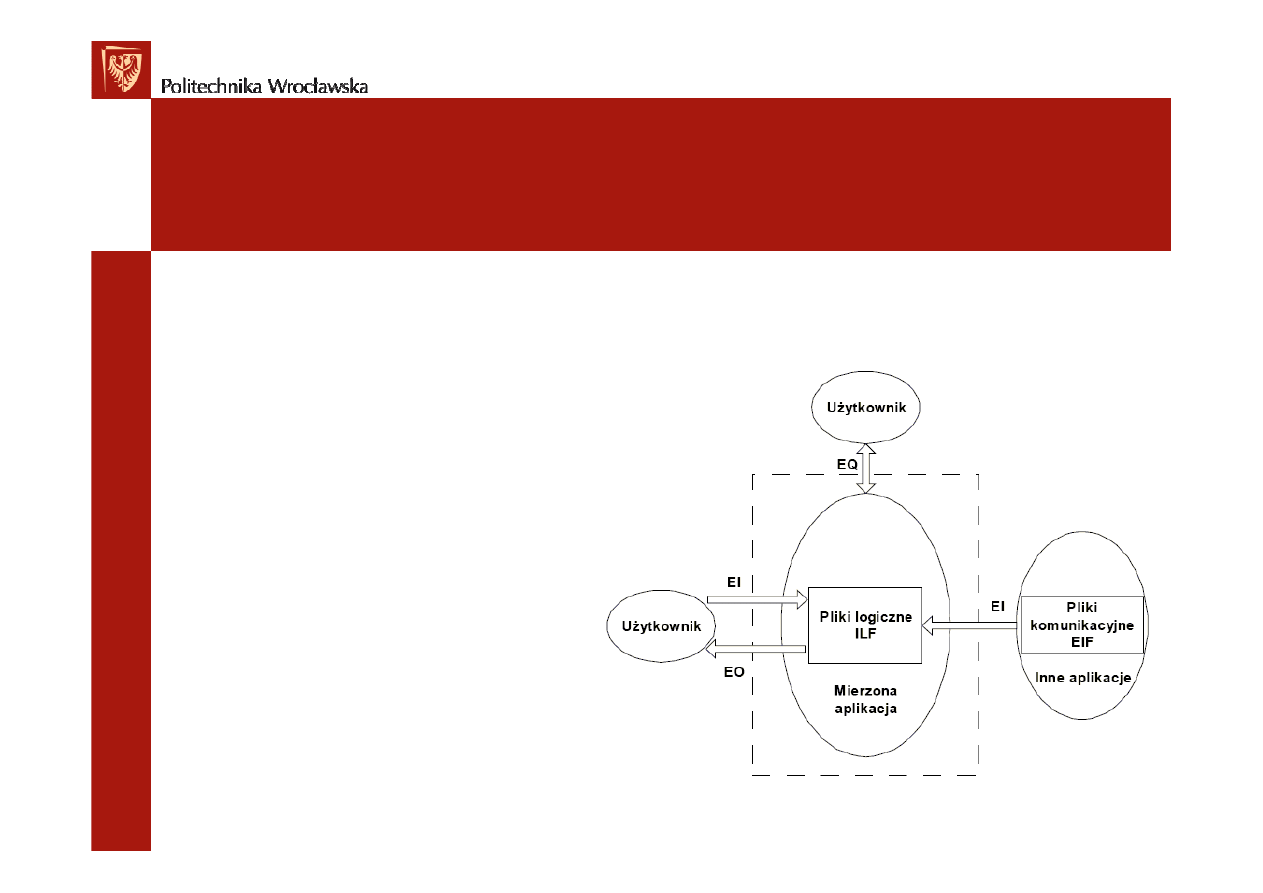
Metoda punktów funkcyjnych
• Szacowanie liczby punktów funkcyjnych bazuje na
–
Liczbie funkcjonalności związanej z obsługą transakcji
• wejść do systemu
• wyjść z systemu
• interakcji użytkownika
z system
–
Liczbie funkcjonalności związanej
z obsługą danych
• plików logicznych,
w których przechowywane
są dane
• zewnętrznych
interfejsów

•
EI- (external input) zewnętrzne wejście reprezentujące dane pobierane przez
system. Zewnętrzne wejście modyfikuje pliki ILF. Przykładem EI są formularze
•
EO- (external output) zewnętrzne wyjście reprezentujące dane od systemu do
otoczenia (np. użytkownika lub innego systemu). Zewnętrzne wyjście nie zawsze
modyfikuje pliki ILF. Przykładem EO są raporty
•
EQ- (external inquiry) zewnętrzne zapytanie oznaczające jednoczesny przepływ
informacji z i do systemu oraz reprezentujące zapytanie pochodzące z otoczenia
systemu. Dane zwracane przez system nie mogą być danymi przetworzonymi,
natomiast operacja EQ nie może zmieniać plików ILF. Najprostszym przykładem tej
operacji jest wyszukiwanie danych
•
ILF- (internal logical file) to grupa logicznie powiązanych danych określonych przez
użytkownika lub danych kontrolnych utrzymanych i działających ramach badanego
systemu. Przykładem jest baza danych
•
EIF- (external interface file) jest grupą logicznie powiązanych danych lub informacji
kontrolnych odnoszących się do systemu, lecz utrzymywanych w ramach innej
aplikacji. Dane EIF muszą być danymi ILF dla innej aplikacji
Metoda punktów funkcyjnych
Obiekty występujące w modelu

Identyfikacja funkcjonalności związanych
z obsługą danych
•
Identyfikacja plików danych i interfejsów
(obiektów ILF i EIF)
–
Identyfikacja połączonym baz danych
–
Identyfikacja tabel w bazie
–
Identyfikacja plików
przechowujących dane
–
Identyfikacja systemów, z którymi
mają być wymieniane dane
•
Dla każdego ILD i EIF należy
zidentyfikować podstawowe zawarte w
nim grupy danych (RET - record element
type)
•
Jeżeli nie istnieje możliwość
zdefiniowania RET, należy przyjąć, że
RET = ILE lub EIF
•
Dla każdego RET należy zidentyfikować
wszystkie unikalne i niepowtarzalne pola
DET- (data element type)
Liczba DET:18
Liczba RET:4
Imi
ę
Nazwisko
Tytu
ł
naukowy
Data wst
ą
pienia do PTI
Cz
ł
onek
wprowadzaj
ą
cy
Nazwa zainteresowania
Czy w teorii
Czy w praktyce
Zainteresowania
Ulica
Nr domu
Nr mieszkania
Miejscowo
ść
Kod pocztowy
Województwo
Adres
Imi
ę
Nazwisko
Numer cz
ł
onkowski
Tytu
ł
naukowy
Data wst
ą
pienia do PTI
Dane osobowe
DET
RET
Przyk
ł
ad wyznaczenia RET i DET dla jednego
pliku ILF

Identyfikacja funkcjonalności związanych
z obsługą wejścia wyjścia (transakcji)
•
Identyfikacja wszystkich wejść i wyjść do i z systemu oraz zapytań
•
Identyfikacja wszystkich funkcji realizujących obsługę transakcji w zidentyfikowanych
elementach
•
Przy identyfikacji transakcji należy kierować się następującymi zasadami
–
Wszystkie funkcje obsługujące transakcje są procesami elementarnymi i są realizowane
nierozerwalnie w tej samej chwili
–
Z punktu widzenie użytkownika funkcje te są najmniejszymi czynnościami i akcjami, jakie
wykonuje system
–
Transakcje związane z wejściem EI mogą zapisywać dane w jednym lub więcej plikach ILF
–
Transakcje związane w wyjściem EO tworzą dane, które są przekazywane na zewnątrz
systemu (ekran, system zewnętrzny/powiązany). Mogą pobierać dane z wielu plików ILF
lub EIF.
•
Liczba transakcji to parametr FTR
•
Przykłady
–
Dodanie nowego użytkownika
–
Modyfikacja danych adresowych
–
Wyszukanie produktu w bazie
–
Zapis pliku na dysku

Szacowanie złożoności implementacji
• Dla każdego zidentyfikowanego pliku lub interfejsu szacuje się złożoność
(trudność) implementacji związanych z nim funkcji
• Oszacowanie bazuje na liczbach DET i RET i jest wyznaczane dla każdego
obiektu niezależnie na podstawie poniższej tabeli
Z
ł
o
ż
ony
Z
ł
o
ż
ony
Ś
redni
>5
Z
ł
o
ż
ony
Ś
redni
Prosty
2-5
Ś
redni
Prosty
Prosty
1
>50
20-50
1-19
Liczba DET
Liczba RET

Szacowanie złożoności implementacji
• Dla każdego zidentyfikowanego EI, EO i EQ szacuje się złożoność (trudność)
implementacji związanych z nim funkcji na podstawie
–
liczby transakcji FTR
–
Liczby jednostek danych, które są w nim wykorzystywane DET
• Dla EI
Dla EU i EQ
Z
ł
o
ż
ony
Z
ł
o
ż
ony
Ś
redni
>2
Z
ł
o
ż
ony
Ś
redni
Prosty
1-2
Ś
redni
Prosty
Prosty
0-1
>15
5-15
1-4
Liczba DET
Liczba
FTR
Z
ł
o
ż
ony
Z
ł
o
ż
ony
Ś
redni
>2
Z
ł
o
ż
ony
Ś
redni
Prosty
1-2
Ś
redni
Prosty
Prosty
0-1
>19
6-19
1-5
Liczba DET
Liczba
FTR

Szacowanie złożoności implementacji
• Na podstawie złożoności implementacji funkcjonalności określa się
dla każdej funkcjonalności odpowiadającą jej liczbę
nieunormowanych punktów funkcyjnych
• Całkowita liczba nieunormowanych punktów funkcyjnych UFC
systemu jest sumą tych punktów dla wszystkich funkcjonalności
6
7
6
10
15
Z
ł
o
ż
ony
4
5
4
7
10
Ś
redni
3
4
3
5
7
Prosty
EQ
EO
EI
EIF
ILF
Zło
ż
ono
ść

•
Po zakończeniu tych czynności przyszedł czas na wyliczenie tzw. czynnika
korygującego (VAF)
–
VAF określa złożoność przedsięwzięcia
–
Przyjmuje wartości od 0,65 do 1,35
–
Wartość jego wylicza się na podstawie czternastu współczynników (TDi) i stałej
0,65 według wzoru:
– Współczynniki TDI wyznacza się arbitralnie na podstawie ankiety
– Mogą przyjmować wartości punktowe od 0 do 5,
• gdzie 0 oznacza brak reprezentacji lub wpływu danej charakterystyki,
• natomiast 5 oznacza silny wpływ danej charakterystyki
(
)
∑
+
=
i
TD
VAF
*
01
,
0
65
,
0
Uwzględnienie złożoności projektu

1.
Przesyłanie danych - zależy od ilości urządzeń komunikacyjnych
pomagających w transferze lub wymianie informacji z systemem.
2.
Przetwarzanie rozproszone - charakteryzuje w jaki sposób traktuje się
rozproszone dane oraz funkcje przetwarzania.
3.
Wydajność- odpowiada na pytanie czy użytkownik wymaga określonego
czasu odpowiedzi lub określonej szybkości przesyłania danych.
4.
Obciążenie platformy sprzętowej - zależy od obciążenia obecnej
platformy sprzętowej, jeśli aplikacja lub system będzie na niej
wykorzystywany.
5.
Stopa transakcji - charakteryzuje częstość realizacji transakcji w
interesującym nas czasie.
6.
Wprowadzanie danych on-line- określa ilość informacji wprowadzanych
on-line.
7.
Wydajność użytkownika końcowego- odpowiada na pytanie czy system
ma być zaprojektowany z punktu widzenia użytkownika końcowego.
Uwzględnienie złożoności projektu

8.
Aktualizacja on-line - charakteryzuje ile plików jest aktualizowanych podczas
transakcji on-line.
9.
Przetwarzanie złożone - udziela odpowiedzi na pytanie czy w aplikacji tudzież
systemie występuje znaczące przetwarzanie logiczne lub matematyczne.
10.
Wielokrotna używalność - mówi nam czy aplikację należy zaprojektować dla
pojedynczego użytkownika czy też dla większej ich grupy.
11.
Łatwość instalacji - odpowiada na pytanie jak łatwa jest konwersja danych z
poprzedniego systemu i instalacja nowego systemu.
12.
Łatwość obsługi - określa sprawność i/lub zautomatyzowanie procedur
uruchamiania, tworzenia kopii zapasowych oraz odzyskiwania informacji.
13.
Wielokrotna lokalizacja- odpowiada czy system należy projektować w celu
instalacji w wielu miejscach dla wielu organizacji.
14.
Łatwość wprowadzania zmian - mówi nam czy system należy projektować mając
na celu łatwe wprowadzanie zmian.
Uwzględnienie złożoności projektu

Po obliczeniu czynnika korygującego końcowym
działaniem jest obliczenie ostatecznej liczby punktów
funkcyjnych (PF), które scharakteryzują badany lub
projektowany przez nas system. Owych obliczeń
dokonuje się za pomocą wzoru:
VAF
UPC
PF
*
=
Liczba punktów funkcyjnych

• Najważniejszą zaletą w przypadku metody punktów funkcyjnych jest
stosowanie jednostek umownych zamiast programowych, a pośrednio
przez to uniezależnienie tej metody od rodzaju języka
programistycznego.
• Takie rozwiązanie w znacznym stopniu zmniejszyło subiektywność
analizy spowodowaną jednostkami programowymi.
• Kolejną ważną zaletą jest to, iż owa metoda jest dedykowana dla
systemów baz danych, które w dzisiejszych czasach obejmują ok. 70%
wszystkich systemów SI.
• Bardzo znacznym argumentem przemawiającym na korzyść tego
systemu jest możliwość określenia jego złożoności już we wczesnej
fazie projektowania. Dzięki temu możemy uniknąć dużych strat
finansowych spowodowanych nierealnym oszacowaniem wymaganych
zasobów finansowych i osobowych.
Metoda punktów funkcyjnych

• Następną ważną zaletą jest możliwość zaangażowania klienta w proces
projektowania systemu. Jest to ważne gdyż w takim przypadku klient
ponosi współodpowiedzialność za niektóre z podjętych decyzji realizacji
systemu i jest lepiej zorientowany w problemach związanych z
wykonaniem poszczególnych funkcji SI, a poza tym jest znacznie większa
możliwość, że klient naprawdę otrzyma produkt spełniający wszystkie
jego wymagania.
• Co ciekawe metoda punktów krytycznych pozwala nie tylko na
oszacowanie wielkości projektu, lecz także umożliwia analizę
produktywności zespołu projektowego. Jest to na tyle ważne, iż dzięki
temu możemy określić produktywność zespołu zgodnie z jej ekonomiczną
definicją.
• Kolejnym ważnym argumentem przemawiającym na korzyść metody FPA
jest możliwość stosowania jej tak do dopiero tworzonych systemów,
jak i do już istniejących. Dzięki temu możemy łatwiej rozwijać nasz
system bez znacznej straty czasu jak i środków finansowych, jeśli
wcześniej już wykonaliśmy taką analizę. Poza tym można porównywać ze
sobą podobne projekty i poprzez to również w zauważalny sposób
przyspieszyć prace rozwojowe/projektowe.
Metoda punktów funkcyjnych

• Pomimo tak wielu zalet metoda punktów krytycznych spotyka się częstą
krytyką. Najważniejszymi powodami są:
– brak jej obiektywności w przypadku wyliczania czynnika
korygującego oraz
– trudność jej stosowania
• Pierwszy powód jest związany z indywidualną oceną wszystkich
czternastu charakterystyk inaczej wyznaczaną przez każdego projektanta
stosującego tą metodę
• Dużym problemem jest określenie zbiorów danych i transakcji. Z tego
względu dwóch różnych informatyków oddzielnie badających ten sam
system może zupełnie inaczej obliczyć liczbę końcową punktów
funkcyjnych.
• Stosowanie tej metody wymaga od projektanta dużej wiedzy,
doświadczenia i wyczucia.
Metoda punktów funkcyjnych

• Brak możliwości odzwierciedlenia złożoności wewnętrznej
projektowanego systemu
. Dotyczy to zarówno
– algorytmów w nim stosowanych, jak i
– stosowania wyszukanych struktur danych.
• Z tego względu metoda FPA nie nadaje się do użytku w
zastosowaniach naukowych, gdzie ów czynnik często jest
najważniejszy.
• W związku z przeznaczeniem tej metody dla systemów baz danych
nie stosuje się jej do badania systemów operacyjnych oraz
systemów czasu rzeczywistego, co jest związane z określoną
funkcjonalnością i wykonywaniem jedynie operacji na
posiadanych danych w systemach bazodanowych
Metoda punktów funkcyjnych

• Ostatnim ważnym mankamentem metody punktów funkcyjnych
jest brak uwzględnienia innych działań związanych z tworzonym
systemem, czyli
– zabezpieczeniem danych,
– przeszkoleniem pracowników,
– tworzeniem dokumentacji
– projektowaniem systemu, aby współdziałał z innymi
aplikacjami.
• Wszystkie te czynniki znacząco podnoszą koszt i czas tworzenia
systemu.
Metoda punktów funkcyjnych

Dla jednego z oddziałów Polskiego Towarzystw
Informatycznego stworzono system, który zawierał
cztery pliki ILF reprezentujące jednostki w systemie.
Pliki ILF zawierały takie jednostki jak „członek
oddziału”, „koło naukowe”, „uczelnia” oraz
„instytucja”. W ramach tych plików należało wyznaczyć
wszystkie elementy RET i DET, a oto jak to zrobiono dla
pliku „członek oddziału”
Metoda punktów funkcyjnych -
przykład
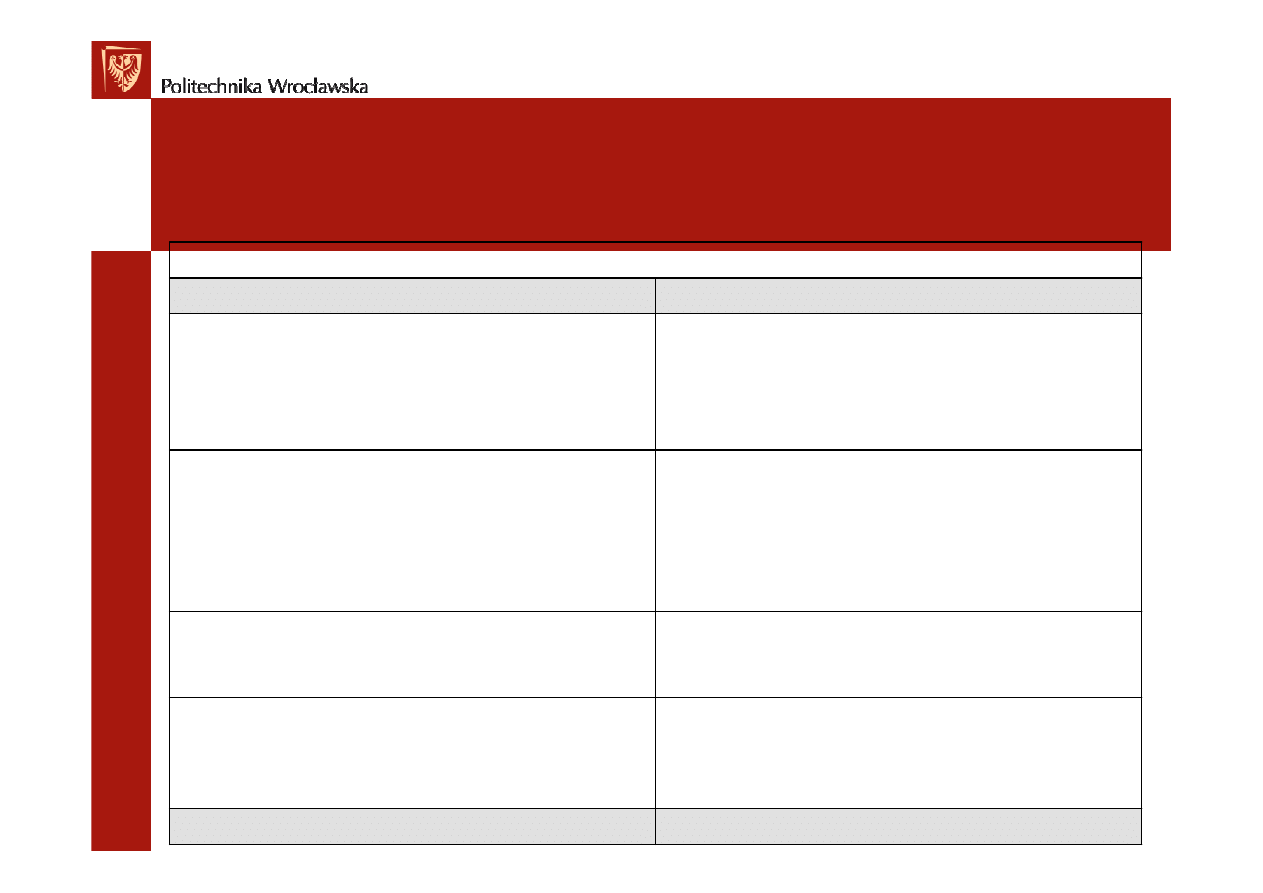
Liczba DET:18
Liczba RET:4
Imię
Nazwisko
Tytuł naukowy
Data wstąpienia do PTI
Czł
ł
ł
łonek wprowadzają
ą
ą
ący
Nazwa zainteresowania
Czy w teorii
Czy w praktyce
Zainteresowania
Ulica
Nr domu
Nr mieszkania
Miejscowość
Kod pocztowy
Województwo
Adres
Imię
Nazwisko
Numer członkowski
Tytuł naukowy
Data wstąpienia do PTI
Dane osobowe
DET
RET
ILF: czł
ł
ł
łonek oddział
ł
ł
łu
Metoda punktów funkcyjnych -
przykład

Po sprawdzeniu złożoności tego pliku ILF w tabeli
dowiedzieliśmy się, że należy on do kategorii „prosty” i
z racji bycia plikiem ILF należy przydzielić za niego
siedem punktów funkcyjnych. Następnie po uzyskaniu
identycznej liczby dla pozostałych plików ILF możemy
stwierdzić, iż nasza liczba punktów funkcyjnych za
pomiar danych jest równa 28.
Metoda punktów funkcyjnych -
przykład

Następnie przechodzimy do transakcji, jakie mają
miejsce w systemie. Nie będziemy wymieniać
wszystkich transakcji, lecz podamy ich jedynie
część. W tej przykładowej tabeli zawierającej
jedynie część transakcji suma punktów
funkcyjnych jest równa 30. Razem z pozostałymi
transakcjami suma ta wzrosła do liczby 63.
Metoda punktów funkcyjnych -
przykład
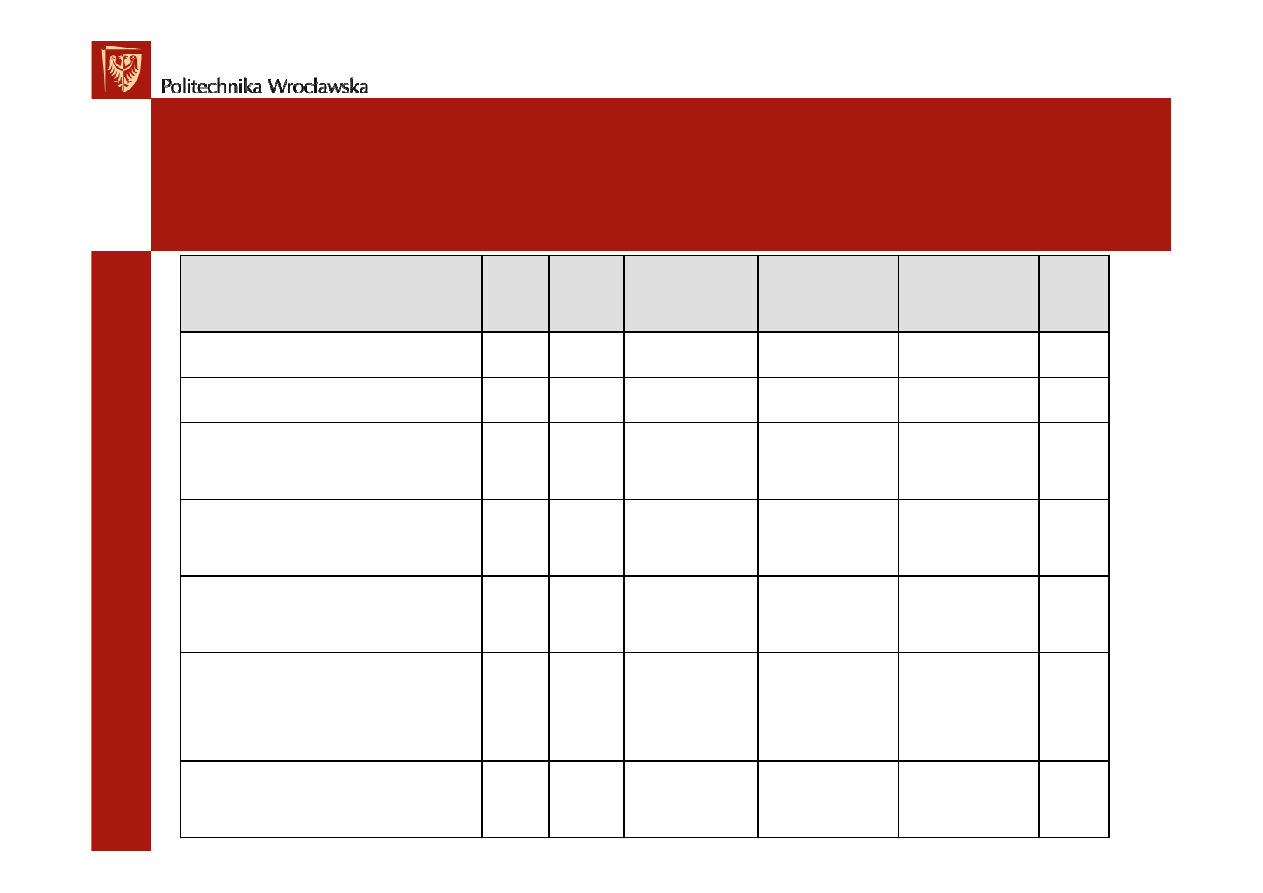
3
Proste
1
4
1
EI
Edycja danych koła naukowego
3
Proste
0
1
1
EQ
Wybranie koła naukowego do
edycji lub usunięcia
3
Proste
1
4
1
EI
Dodanie nowego koła
naukowego
6
Złożone
1
34
3
EI
Usunięcie danych członka
3
Proste
0
4
1
EQ
Wybranie członka do edycji lub
usunięcia
6
Złożone
1
34
3
EI
Edycja danych członka
6
Złożone
1
34
3
EI
Dodanie członka
PF
Złożoność
DET- Gui
DET- dane
FTR
Typ
Transakcje
Metoda punktów funkcyjnych -
przykład

Po ustaleniu punktów
wynikających z pomiaru
danych i transakcji
możemy je zsumować. W
tym przypadku otrzymamy
liczbę NPF równą 91.
Teraz możemy przejść do
liczenia czynnika
korygującego. Projektant
zajmujący się tym
systemem ustalił wartości
kolejnych charakterystyk
następująco.
21
Suma
3
14.
0
13.
0
12.
0
11.
0
10.
0
9.
5
8.
4
7.
5
6.
1
5.
0
4.
3
3.
0
2.
0
1.
Stopień wpływu oszacowany
przez eksperta
Nr kategorii
(charakterystyki)
Metoda punktów funkcyjnych -
przykład

W związku z uzyskaną sumą możemy teraz
wyliczyć czynnik korygujący (VAF), który w tym
przypadku jest równy 0,86 (0,65 + 0,01*21). Po
dokonaniu tego rachunku możemy już śmiało
obliczyć ostateczne punkty funkcyjne naszego
systemu. W tym konkretnym przypadku
ostateczna liczba punktów funkcyjnych jest
równa 78.
• PF=NPF*VAF
• PF=91*0,86
• PF=78
Metoda punktów funkcyjnych -
przykład

• Zadanie do realizacji w ramach projektu
– Wydzielić z projektu wybraną część funkcjonalności
• Powinny dotyczyć jednego obszaru wymagań (np.
administracja danymi użytkownika
• Powinny odnosić się do kilku tabel danych i/lub interfejsów
z zewnętrznymi systemami
– Oszacować złożoność wybranej części systemu metodą
punktów funkcyjnych
– Proszę uzasadnić odpowiedzi na pytania związane z
wyznaczeniem współczynnika korygującego VAF
– Proszę przedstawić komplet tabel oraz szczegóły
zrealizowanych obliczeń
Metoda punktów funkcyjnych

• COCOMO to skrót od COnstructive COst MOdel i oznacza
model szacowania kosztów w procesie tworzenia
oprogramowania
– 1981 r.- Barry Bohem opracowuje pierwszą wersję modelu znaną
pod nazwą COCOMO 81 na podstawie około 60 projektów
informatycznych o różnej złożoności (od 2KLOC do 100KLOC ) i
napisanych w różnych językach programowania.
– 1989 r. – Barry Bohem i Royce zastosowali poprawki w celu
dostosowania modelu do programowania w Adzie.
– 1995 r.- Barry Bohem i inni publikują najnowszą wersję COCOMO
znaną pod nazwą COCOMO 2.
Metody algorytmiczne szacowania
kosztów projektów

Cechy COCOMO
1.
Jeden z częściej wykorzystywanych modeli algorytmicznych.
2.
Celem metody jest oszacowanie całkowitego kosztu przedsięwzięcia na
podstawie oszacowanej liczby linii kodu źródłowego projektu.
3.
Przy ustaleniu oszacowania kosztu bierze się również pod uwagę atrybuty
przedsięwzięcia, produktu, sprzętu i personelu.
4.
COCOMO jest zestawem metod od podstawowych do zaawansowanych.
5.
COCOMO obejmuje także sposoby szacowania harmonogramu.
6.
Metoda ta jest szeroko stosowana.
7.
Liczba wad stosunkowo mała w porównaniu z innymi metodami.
8.
Istnieje możliwość przeliczenia punktów funkcyjnych na liczbę linii kodu, co
może być podstawą dla zastosowania metody COCOMO.
9.
Jest dobrze udokumentowana.
10.
Wersja pierwsza jest dostępna bezpłatnie.
11.
Wspomagana przez komercyjne i bezpłatne narzędzia.

1.
Szacowanie pracochłonności odbywa się tylko na podstawie samego procesu
kodowania programu.
2.
Liczba linii kodu jest trudna do oszacowania i znana dokładnie dopiero w
momencie, gdy system jest już napisany.
3.
Pojęcie „linii kodu” zależy od języka programowania i przyjętych konwencji.
4.
Liczba instrukcji źródłowych jest miarą długości programu i nie bierze pod
uwagę w bezpośredni sposób jego złożoności i możliwości funkcjonalnych.
5.
Szacunki są zwykle obarczone bardzo poważnym błędem (niekiedy ponad 100%).
6.
Miara w postaci liczby linii kodu uniemożliwia wykonywanie badań
porównawczych, gdyż silnie zależy od środków implementacji (języka).
7.
Koncepcja oparta na liniach kodu źródłowego jest całkowicie nieadekwatna dla
nowoczesnych środków programistycznych, np. opartych o programowanie
wizualne.
8.
Zły wybór czynników modyfikujących może prowadzić do znacznych rozbieżności
pomiędzy oczekiwanym i rzeczywistym kosztem przedsięwzięcia.
9.
Ponieważ przedsięwzięcia typu szacowanie nakładów pracy, czasu realizacji oraz
optymalnej liczby pracowników realizowane były bez użycia narzędzi CASE, tak
więc model COCOMO nie jest w pełni adekwatny w przypadku współczesnych
przedsięwzięć.
COCOMO - wady
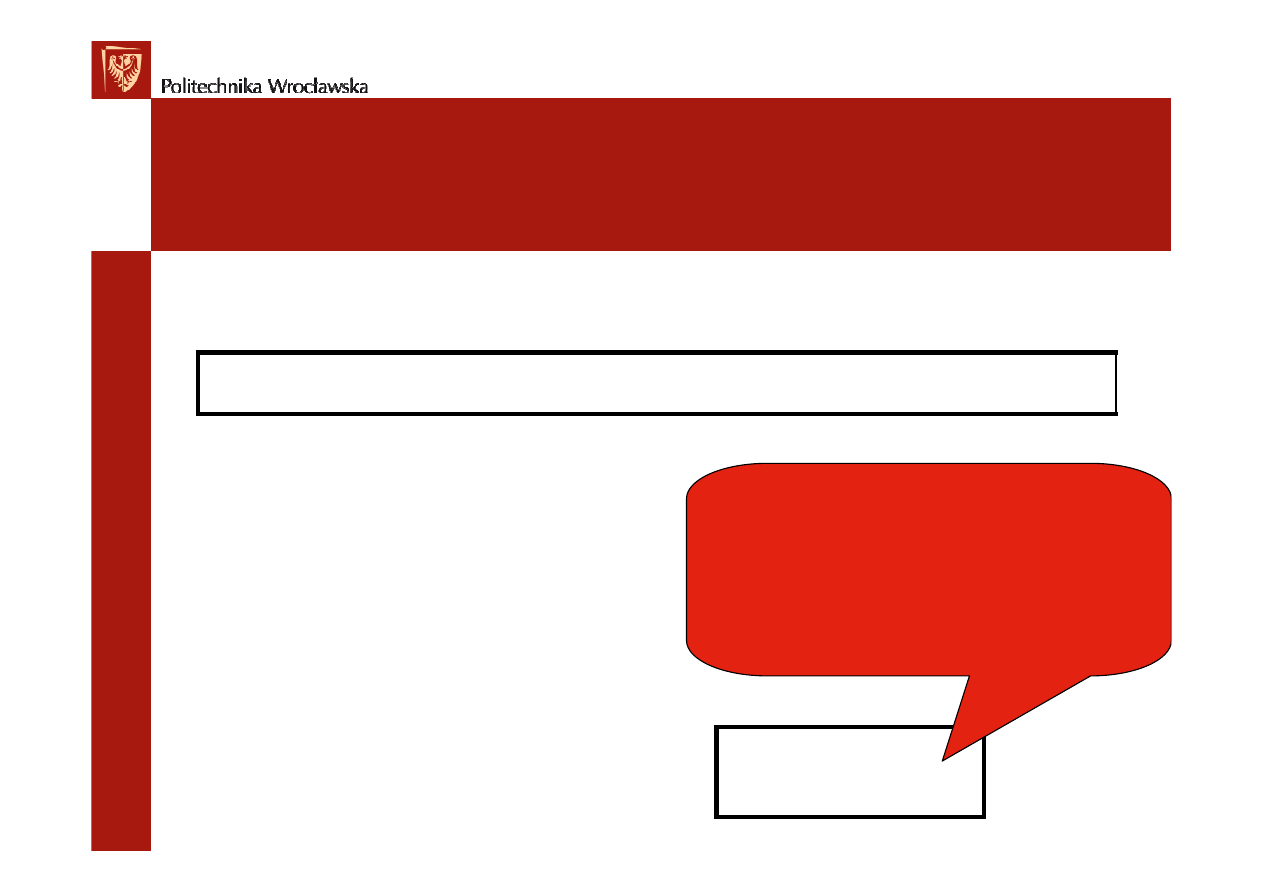
COCOMO - pracochłonność
Podstawowy wzór dla oszacowania nakładów pracy w
metodzie COCOMO to:
• Nakład [osobomiesiące]- pracochłonność projektu w
osobomiesiącach;
• KDSI- oszacowanie liczby linii kodu źródłowego programu
mierzony w tysiącach instrukcji (ang. thousand of delivered
source code instructions
);
• D- współczynnik korygujący zależny od atrybutów procesu
produktu i środowiska tworzenia oprogramowania (w
klasycznym modelu D=1);
• a, b- to współczynniki wyznaczone
eksperymentalnie:
Nakład[osobomiesiące] = a * (KDSI)
b
* D
2.4 ≤ a ≤ 3.6
1.05 ≤ b ≤1.20
Parametry te s
ą
zale
ż
ne od
projektu (klasy) i
ś
rodowiska, a im
bardziej dziedzina problemu jest
nieznana realizatorom, tym
współczynniki wy
ż
sze.

COCOMO – czas realizacji
• Model COCOMO zakłada, że znając nakład pracy można
oszacować czas realizacji przedsięwzięcia, z czego wynika
oczywiście przybliżona wielkość zespołu, który powinien
realizować przedsięwzięcie. Z obserwacji wiadomo, że dla
każdego przedsięwzięcia istnieje optymalna liczba członków
zespołu wykonawców. Zwiększenie tej liczby nie musi wcale
skrócić czas realizacji, lecz może nawet go wydłużyć.
• Fred Brooks twierdzi, że dodanie więcej osób do opóźnionego
projektu oprogramowania zwiększa jego opóźnienie w
stworzeniu.
– dodanie więcej osób zwiększa wymagania na komunikację
między członkami zespołu
– część pracy w projekcie nie jest podzielona- jest
wykonana tylko przez jedną osobę dodanie więcej osób nic
tu nie wnosi.

COCOMO – czas realizacji
Wzór na czas realizacji przedsięwzięcia:
• Czas[miesiące] – optymalny czas wykonania w
miesiącach;
• Wartość 2,5 wyznaczona eksperymentalnie;
• Nakład pracy w osobomiesiącach;
• c- parametr zależny od projektu i środowiska;
wyznaczony eksperymentalnie:
Czas[miesiące]= 2,5 * (Nakład)
c
0.32 ≤ c ≤ 0.38
Im bardziej dziedzina
problemu jest nieznana, tym
współczynnik c jest wy
ż
szy.
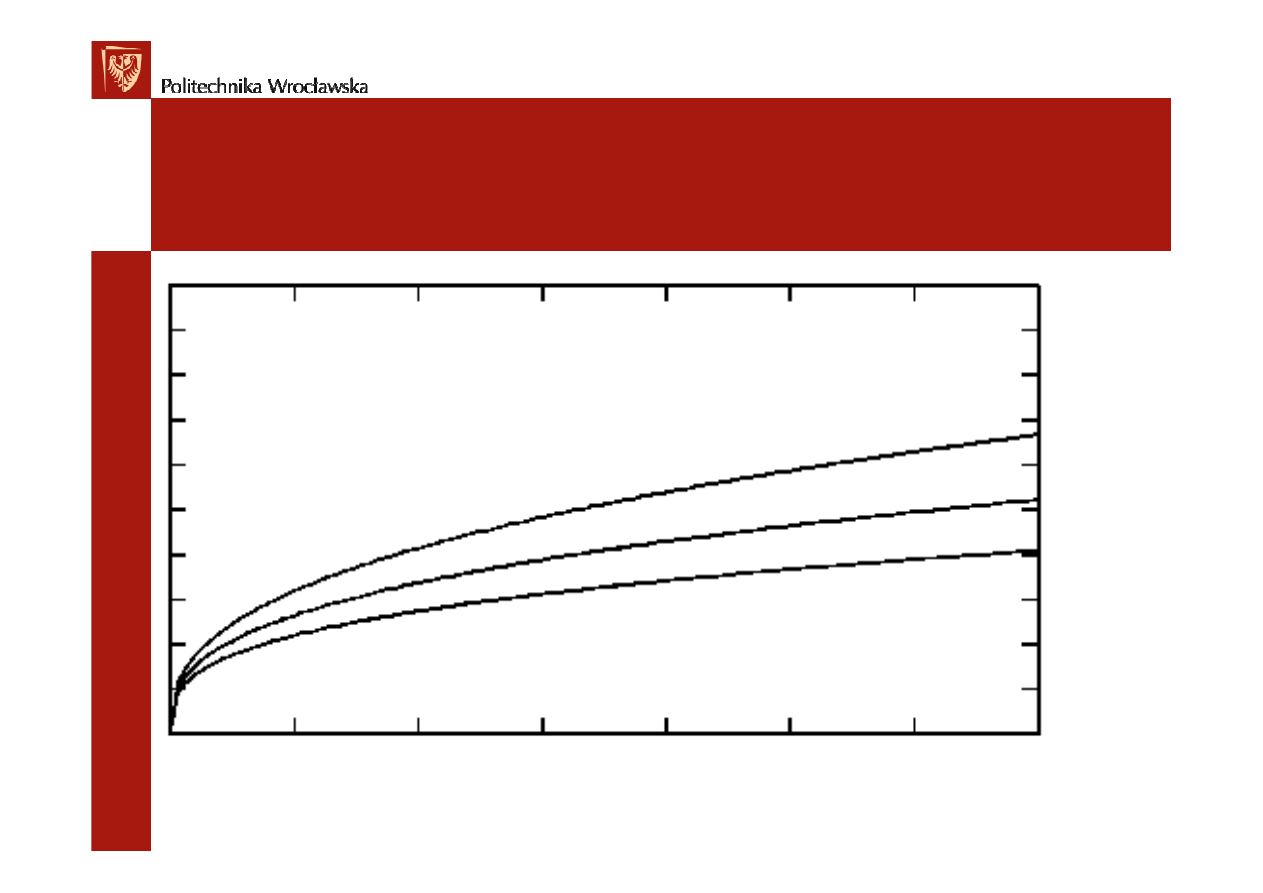
COCOMO – czas realizacji
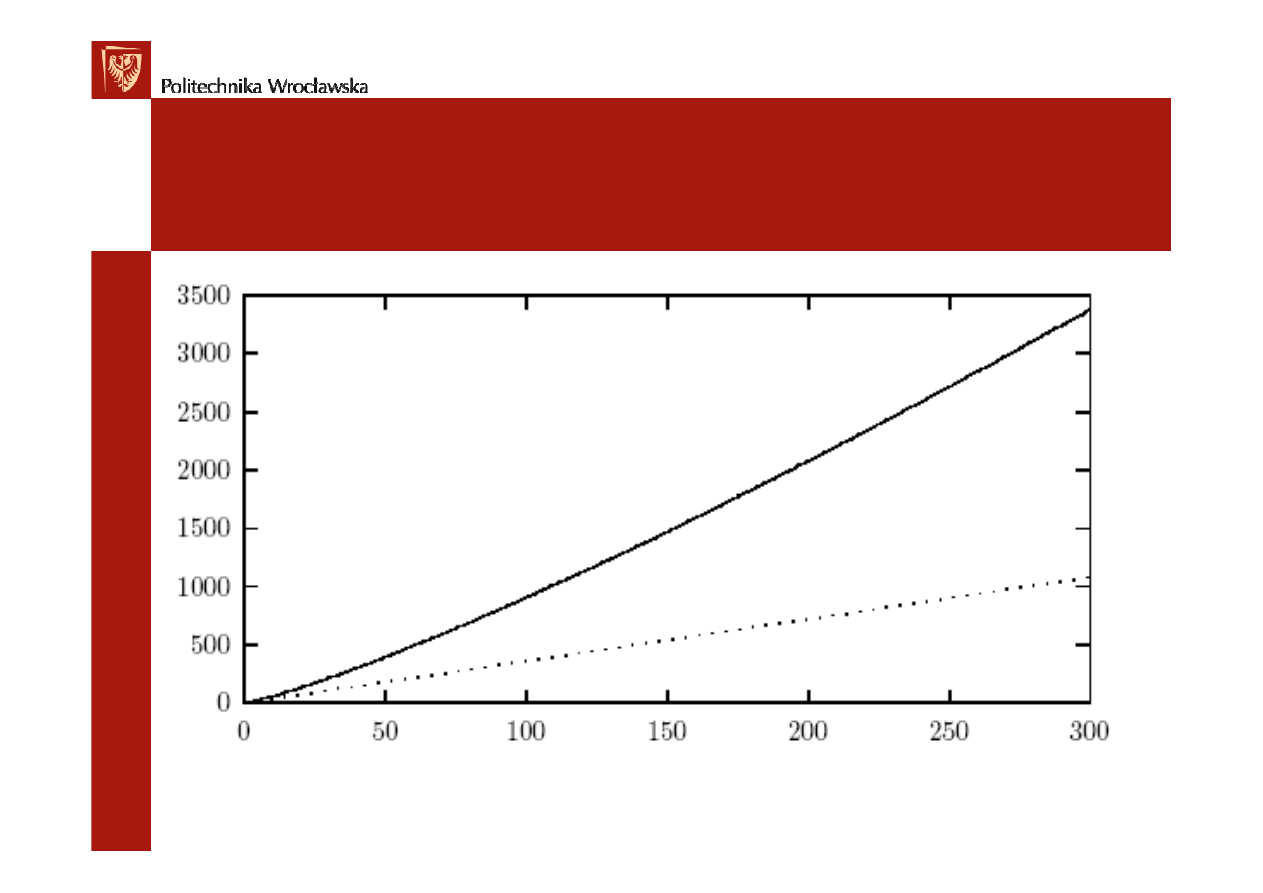
2,5* N
0.38
2,5* N
0.35
2,5* N
0.32
0 500 1000 1500 2000 2500 3000 3500

Otrzymane oszacowania powinny być skorygowane przy
pomocy tzw. czynników modyfikujących.
Tworzy się je biorąc pod uwagę następujące atrybuty
przedsięwzięcia:
•
Wymagania wobec niezawodności systemu
•
Rozmiar bazy danych w stosunku do rozmiaru kodu
•
Złożoność systemu, tj. złożoność struktur danych,
złożoność algorytmów, komunikacja z innymi systemami,
stosowanie obliczeń równoległych
•
Wymagania co do wydajności systemu
•
Ograniczenia pamięci
•
Zmienność sprzętu i oprogramowania systemowego
tworzących środowisko pracy systemu
COCOMO – czas realizacji
COCOMO – czas realizacji
Wzór na wielkość zespołu:
• S- liczebność zespołu projektowego (optymalna ilość pracowników);
• Nakład [osobomiesiące]- pracochłonność projektu w
osobomiesiącach;
• Czas[miesiące] – optymalny czas wykonania w miesiącach;
Wzory i współczynniki stosowane w tej metodzie są empiryczne.
S= Nakład [osobomiesiące] / Czas[miesiące]

COCOMO – typy projektów
Wartości wspomnianych wcześniej stałych a, b, c są
zależne od klasy, do której zaliczono dane
przedsięwzięcie. COCOMO oferuje kilka metod
określanych jako:

Metoda podstawowa, poziom wczesnego
prototypowania
:
• Jest to przedsięwzięcie łatwe, wykonywane przez
stosunkowo małe zespoły o podobnym, wysokim poziomie
umiejętności technicznych.
• Podstawą oszacowań są punkty obiektowe.
• Dziedzina problemu jest dobrze znana. Programy
użytkowe są zrozumiałe. Przedsięwzięcie jest
wykonywane przy pomocy dobrze znanych metod i
narzędzi.
• Cechy charakterystyczne tego typu projektu: mały,
typowy, bez ograniczeń czasowych, w stabilnym
środowisku.
COCOMO – typy projektów
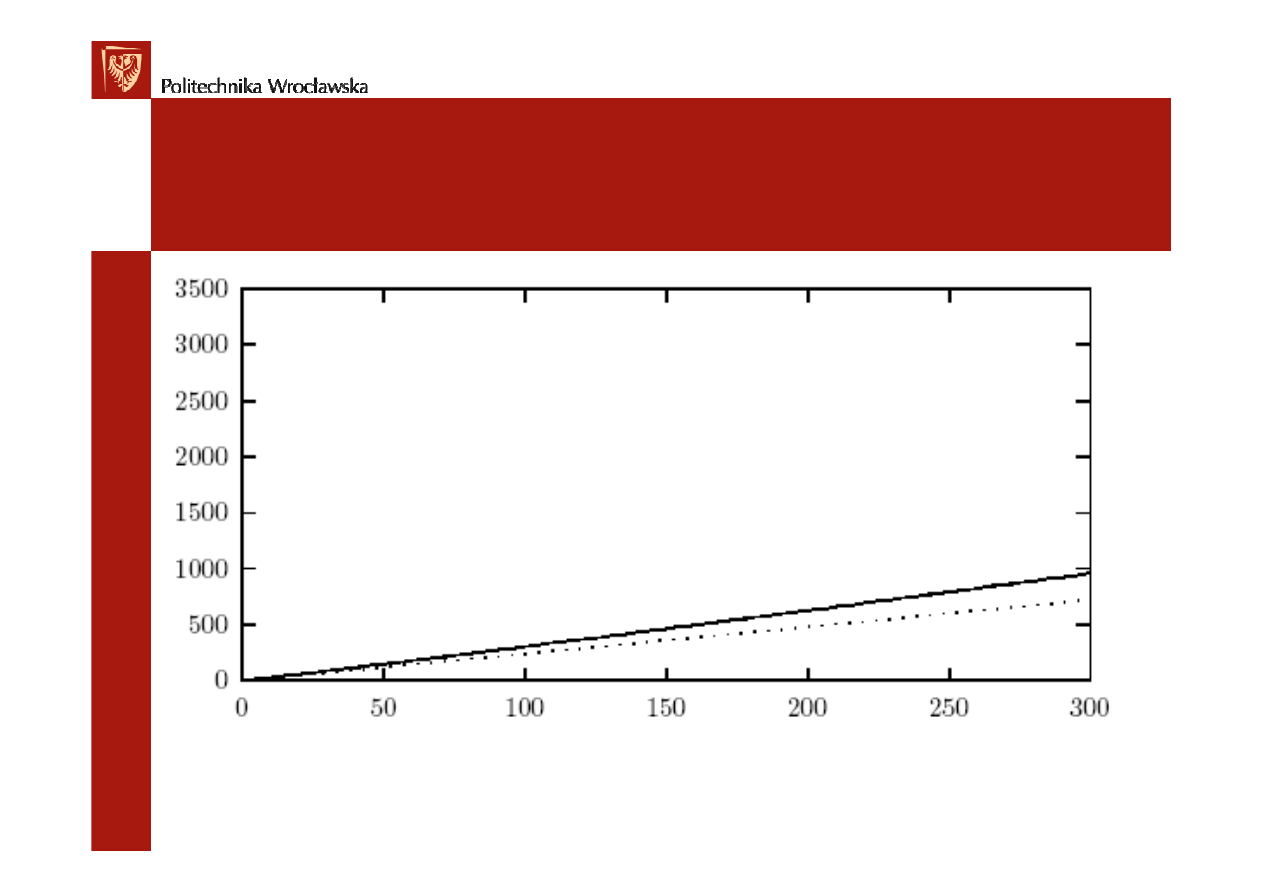
COCOMO – typy projektów
Metoda podstawowa

Metoda pośrednia, przedsięwzięcie niełatwe, poziom
wczesnego projektowania
:
• Jest to bardziej złożone przedsięwzięcie, które
modyfikuje wyniki osiągnięte przez metodę podstawową
poprzez odpowiednie „czynniki napędzające koszty”,
zależne od aspektów złożoności.
• Podstawą oszacowania są punkty funkcjonalne
przeliczane na linie kodu.
• Członkowie zespołu różnią się stopniem zaawansowania.
Pewne aspekty dziedziny problemu, część metod oraz
narzędzi nie są dobrze znane.
• Cechy charakterystyczne tego typu projektu: średni,
typowy, z modyfikacjami, bez szczególnych ograniczeń,
w dobrym środowisku.
COCOMO – typy projektów
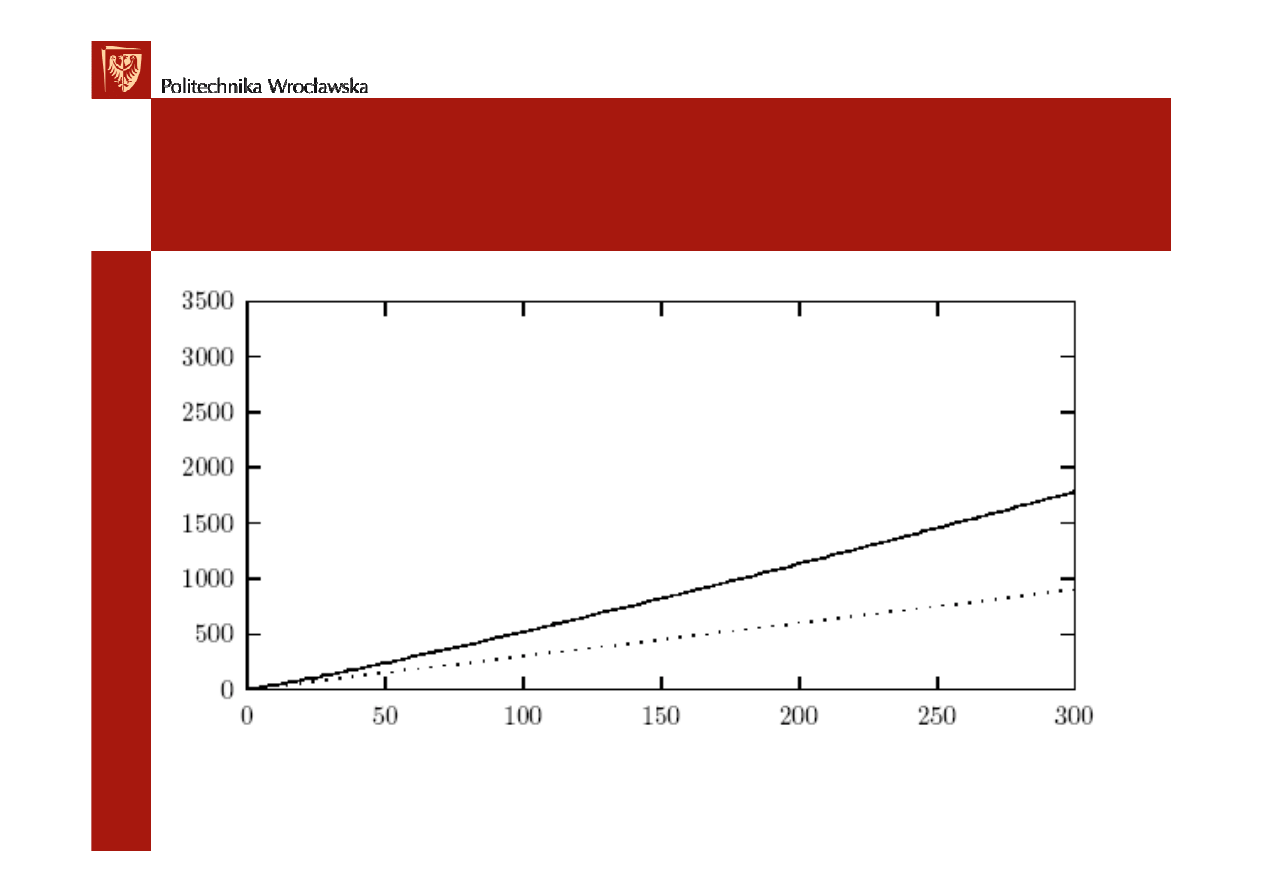
COCOMO – typy projektów
Metoda po
ś
rednia

Metoda detaliczna, przedsięwzięcie trudne, poziom
postarchitektoniczny:
• Bardziej skomplikowana metoda, która obejmuje
przedsięwzięcia realizujące systemy o bardzo złożonych
wymaganiach.
• Podstawą oszacowań jest rozmiar kodu.
• Dziedzina problemu, stosowane narzędzia i metody są w
dużej mierze nieznane. Większość członków zespołu nie
ma doświadczenia w realizacji podobnych zadań. Metoda
ta jest porównywalna z metodą pośrednią.
• Cechy charakterystyczne tego typu projektu: duży,
unikalny, ścisłe limity czasu i kosztu, w złożonym
środowisku.
COCOMO – typy projektów
Metoda detaliczna
COCOMO – typy projektów

COCOMO – przykład
Znając liczbę linii kodu można obliczyć pracochłonność, czas
trwania realizacji oraz optymalną ilość pracowników.
Załóżmy, że program zawiera 20 tysięcy instrukcji źródłowych,
czyli KDSI=20. Podstawiając do wzoru:
Nakład [osobomiesiące] = a * (KDSI)
b
* D
otrzymamy dla kolejnych metod:
Metoda podstawowa
Nakład [osobomiesiące] = 2.4 * (20)
1.05
* 1= 55.75≈ 56
Metoda pośrednia
Nakład [osobomiesiące] = 3 * (20)
1.12
= 85.95 ≈ 86
Metoda detaliczna
Nakład [osobomiesiące] = 3.6 * (20)
1.2
= 131

COCOMO – przykład
Otrzymane dane nakładów posłużą nam w oszacowaniu czasu
potrzebnego na realizację danego projektu.
Podstawiając do wzoru poniżej:
Czas[miesiące]= 2,5 * (Nakład)
c
otrzymamy dla kolejnych metod:
Metoda podstawowa
Czas [miesiące] = 2,5 * (56)
0.32
= 9.06 ≈ 9 miesięcy
Metoda pośrednia
Czas [miesiące] = 2,5 * (86)
0.35
= 11.88 ≈ 12 miesięcy
Metoda detaliczna
Czas [miesiące] = 2,5 * (131)
0.38
= 15.9 ≈ 16 miesięcy

COCOMO – przykład
Na koniec można obliczyć liczebność zespołu projektowego dla
konkretnej metody:
Metoda podstawowa
S= Nakład [osobomiesiące] / Czas[miesiące] = 56 / 9 = 6
Metoda pośrednia
S= Nakład [osobomiesiące] / Czas[miesiące] = 86/ 12 = 7
Metoda detaliczna
S =Nakład [osobomiesiące] / Czas[miesiące] = 131/16
= 8
COCOMO 2
COCOMO 2 jest modelem trójpoziomowym w skład,
którego wchodzą:
Poziom wczesnego prototypowania –
podstawą oszacowania
produktywności programisty są punkty obiektowe na miesiąc.
Bierze się również pod uwagę użycie narzędzi CASE. Formuła
wygląda następująco:
PM - praca w osobomiesiącach;
NOP - liczba punktów obiektowych;
PROD – produktywność;
PM = ( NOP ´ (1 - %reuse/100 ) ) / PROD

COCOMO 2
Poziom wczesnego projektowania -
podstawą opracowania są
punkty funkcyjne przeliczane na linie kodu. Wykładnik B zależy od
pięciu czynników (nadrzędność, elastyczność tworzenia, panowanie
nad ryzykiem, spójność zespołu, dojrzałość procesu) a ich suma jest
dzielona przez 100 i dodawana do 1.01. Cała formuła prezentuje się
w takiej postaci:
A - początkowe oszacowanie, którego wartość wynosi 2.5, rozmiar ten
jest
liczony w tysiącach linii kodu;
PMm – ilość automatycznie generowanego kodu;
PMm = (ASLOC * (AT/100)) / ATPROD;
B – wartość wykładnicza; mieści się w przedziale pomiędzy 1.1 a 1.24
M = PERS * RCPX * RUSE * PDIF * PREX * FCIL * SCED;
PM = A * Wielkość
B
* M + PMm
Powyższe mnożniki M to:
PERS – możliwości personelu
RCPX – niezawodność i złożoność
RUSE – wymagane użycie wielokrotne
PDIF – trudność platformy
PREX – doświadczenie personelu
FCIL – udogodnienia pomocnicze
SCED – wymagany harmonogram

COCOMO 2
Poziom post- architektoniczny –
używa tych samych formuł co
powyższy poziom. Podstawą jest dokładniejsze oszacowanie
rozmiaru kodu poprzez płynność wymagań i zwiększenie pracy.
Ostatnia formuła wygląda następująco:
ESLOC - równoważna liczba wierszy nowego kodu;
ASLOC - liczba linii kodu koniecznych do zmodyfikowania;
DM - procent modyfikowanego projektu;
CM - procent modyfikowanego kodu;
IM - odsetek pierwotnej pracy integracyjnej;
SU - czynnik oparty na koszcie zrozumienia kodu;
AA - czynnik odzwierciedlający koszt ustalenia czy oprogramowanie może
być użyte wielokrotnie;
100
AA)
SU
IM
*
0.3
CM
*
0.3
DM
*
(0.4
*
ASLOC
=
ESLOC
+
+
+
+

COCOMO 2 – czas trwania
Oprócz oszacowania kosztu konieczne jest szacowanie czasu
trwania przedsięwzięcia.
Dla COCOMO 2 wzór na czas wynosi:
PM – oszacowanie pracy;
B – wykładnik (wartość 1 dla wczesnego prototypu);
))
01
.
1
*(
2
.
0
33
.
0
(
)
(
*
0
.
3
−
+
=
B
PM
TDEV

COCOMO 2 - przykład
Dla poziomu wczesnego projektowania mamy następujący przykład,
którego dane wejściowe wyglądają następująco:
Nadrzędność - nowy projekt – 4
Elastyczność tworzenia – klient niezaangażowany – bardo wysoka - 1
Panowanie nad ryzykiem - brak - 5
Spójność zespołu – nowy zespół - 3
Dojrzałość procesu - częściowa – 3
Za pomocą tych danych jesteśmy w stanie wyliczyć wartość wykładniczą
B, która pochodzi ze wzoru
PM = A * Wielkość
B
* M +PMm
Wartość B jak pamiętamy powinna mieścić się w przedziale od 1.1 do 1.24.
Kolejność działania jest następująca: dodajemy wszystkie wartości do
siebie, wynik dzielimy przez 100, teraz dodajemy wartość 1.01 i
otrzymujemy B= 1.17.
Wyszukiwarka
Podobne podstrony:
ZPT 04 Wymiarowanie projektow odblokowany
ZPT 02 Project management processes V2 odblokowany
ZPT 05 Zarzadzanie ryzykiem odblokowany
Projekt cz 1 TOB
Projekt cz 1 Sprawozdanie
Projekt cz 1
Projekt cz 09
projekt cz 1 poprawiony
Bazy danych - podstawowe kroki w projektowaniu cz 2 - wyklady, Zajęcia z Baz Danych - MS Access, cz
Bazy danych - podstawowe kroki w projektowaniu cz 2 - wyklady, Zajęcia z Baz Danych - MS Access, cz
PHP cz 1 v2
05 definiowanie projektuid 5669 Nieznany (2)
projekt cz 2
więcej podobnych podstron