
Technologie mikroelektroniczne
Wstęp
1. Podstawy fizyki półprzewodników
1.1. Model pasmowy ciała stałego
1.2. Model pasmowy półprzewodnika
1.3. Półprzewodnik domieszkowany
1.4. Złącze PN
2. Budowa i działanie tranzystora MOS
3. Procesy technologiczne wytwarzania układów scalonych
3.1. Wytwarzanie podłoży krzemowych
3.2. Wytwarzanie nowych warstw
3.3. Odwzorowanie kształtów na powierzchni
3.4. Zmiana własności materiału
3.5. Ogólne zasady przeprowadzania procesów technologicznych
4. Proces technologiczny produkcji tranzystora MOS i inwertera CMOS
4.1. Proces wykonania tranzystora NMOS
4.2. Proces wytwarzania inwertera CMOS
Podsumowanie
Bibliografia
„Nie ma na tyle skompilkowanych problemów, których
nie można by rozwiązać bez komputera.”
Matematycy podczas prezentacji pierwszego na świecie
komputera ogólego zastosowania, 1947

2
Wstęp
Jesteśmy już na półmetku naszego kursu. Potrafisz już zbudować działający cyfro-
wy układ elektroniczny — począwszy od pomysłu, aż do schematu, na którym są
już podstawowe przyrządy. Gdyby nie było układów scalonych, to w tym miej-
scu zakończylibyśmy nasz kurs. Co najwyżej poświęciłbym jeszcze kilka stron, aby
opowiedzieć o tym, jak dobrać tranzystory do takiego układu, jak je zlutować, jak
zbadać, czy taki układ działa, jak wyszukać błędy, zachęciłbym jeszcze do wyko-
nania tego układu i na tym koniec. Ty zapewne poszedłbyś do sklepu, kupił od-
powiednią liczbę tranzystorów, uzbroił się w dużą dawkę cierpliwość, poskładał
układ według otrzymanego schematu i przy odrobinie szczęścia zobaczyłbyś swoje
dzieło w działaniu. Na szczęście układy scalone istnieją.
Jak wspomniałem, umiesz już przejść od pomysłu układu do jego schematu elek-
trycznego złożonego z tranzystorów. A więc do całości brakuje ci już jedynie wie-
dzy na temat tego, jak zbudowany jest sam tranzystor MOS i jak go wykonać. Do
tej pory tranzystor MOS traktowaliśmy jak „czarną skrzynkę” — wiesz jak działa,
do czego służy, jak nim sterować, ale nie wiesz, jak jest zbudowany, co jest w je-
go wnętrzu. Gdyby nie istniały układy scalone, wiedza ta nie byłaby ci do niczego
potrzebna — kupiłbyś w sklepie gotowy tranzystor i nie interesowałoby ciebie jak
on jest wykonany, ważne byłoby, że działa. Jednak w układach scalonych będziesz
musiał wykonywać właśnie pojedyncze tranzystory i aby móc je wykonać, musisz
poznać ich budowę. Od tego zaczniemy ten moduł — konkretnie od pokazania
co znajduje się wewnątrz tranzystora MOS, jak jest on zbudowany. W dalszej czę-
ści zajmiemy się technologią wykonania takiego tranzystora — najpierw opowiem
o procesach technologicznych, które stosuje się do podczas wytworzenia tranzysto-
ra, a następnie, krok po kroku, pokażę jak się go wykonuje. Na koniec przedstawię
sposób wykonania najprostszej bramki CMOS, czyli inwertera.
Podobnie jak poprzednio, przed nami sporo pracy — i to bardzo ważnej pracy. Po-
cieszę cię jednak, że najtrudniejsze masz już za sobą! Zapraszam do lektury.
3
1. Podstawy fizyki półprzewodników
Współczesne tranzystory, a co za tym idzie i układy scalone, buduje się z materiału
półprzewodnikowego, którym najczęściej jest krzem. Zanim więc poznamy budo-
wę samego tranzystora MOS, musimy najpierw poznać podstawy fizyki półprze-
wodników, czyli podstawowe zjawiska, jakie wykorzystuje się do budowy przyrzą-
dów elektronicznych. Wiem, że większość osób wręcz alergicznie reaguje na słowo
fizyka i choć właśnie zawodowo zajmuję się fizyką półprzewodników, to obiecuję,
że powiem na jej temat tylko tyle, ile potrzeba.
1.1. Model pasmowy ciała stałego
Półprzewodniki to nazwa pewnej grupy materiałów. Generalnie materiały można
podzielić na trzy grupy:
— przewodniki,
— półprzewodniki,
— izolatory.
Pierwsza grupa to materiały doskonale przewodzące prąd (przykładem mogą być
metale, np. miedź). Ostatnia grupa, to materiały izolacyjne, a więc praktycznie nie-
przewodzące prądu (np. szkło, większość tworzyw sztucznych). Natomiast półprze-
wodniki to taka pośrednia grupa materiałów, które przewodzą prąd, ale nie najle-
piej. Nie wiem, czy kiedykolwiek zastanawiałeś się, czemu jedne materiały prze-
wodzą prąd, a inne nie. Odpowiedź na to pytanie nie jest taka prosta, ale spróbuję
możliwie prosto to wytłumaczyć. Oczywiście zajmiemy się wyłącznie materiałami
stałymi, przewodnictwo w cieczach i gazach w ogóle nas nie będzie interesowało.
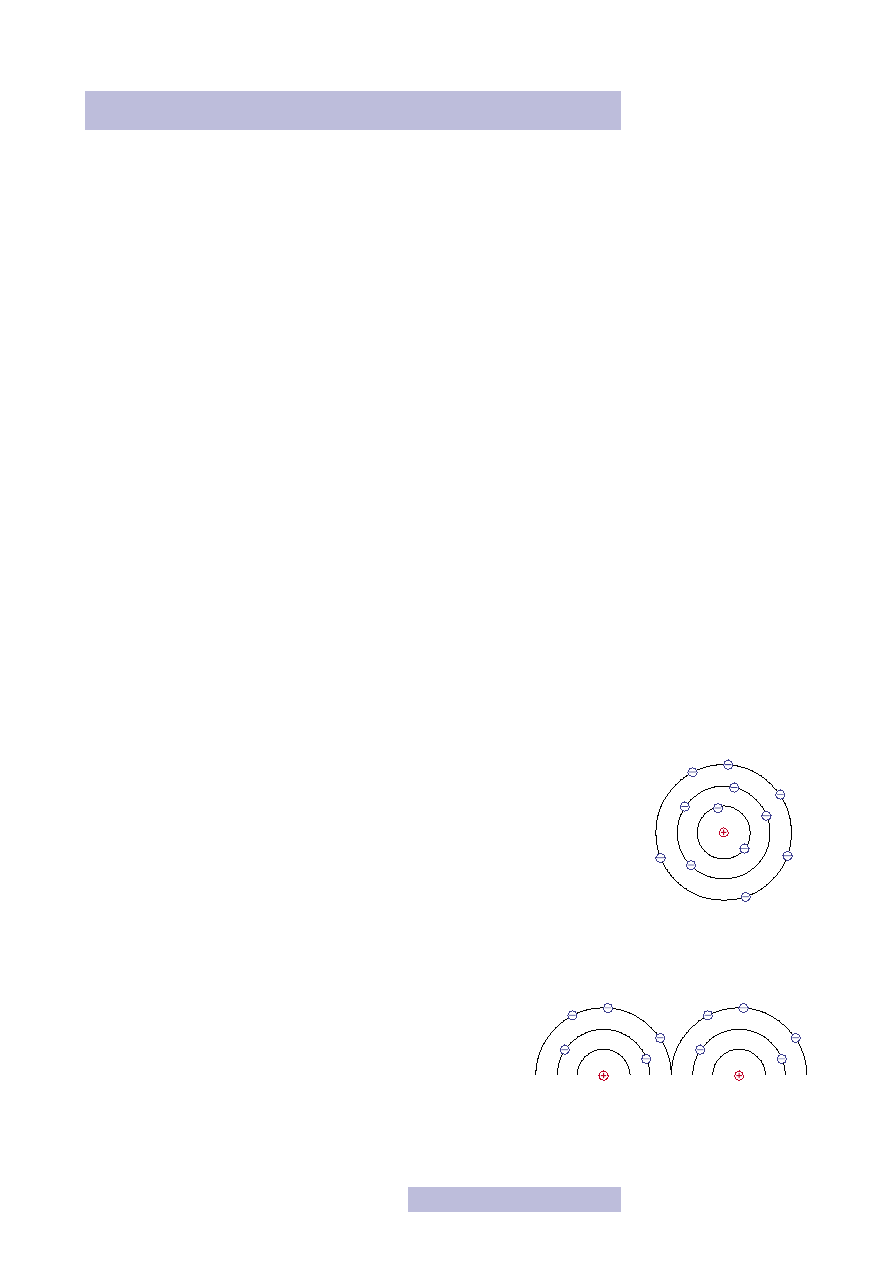
Przypomnijmy, każdy materiał składa się z atomów, a atom z jądra i krążących wo-
kół niego elektronów (rys. 1). Elektrony znajdują się na powłokach. Liczba elektro-
nów na każdej powłoce jest ściśle określona, podobnie odległość powłok od jądra.
Tak więc elektrony nie mogą krążyć wokół jądra gdzie chcą, lecz wyłącznie w pre-
cyzyjnie określonych miejscach! Im dalej od jądra znajduje się elektron, tym ma
większą energię, jeśli więc chcemy przenieść elektron na dalszą powłokę, musimy
dostarczyć mu energii. Natomiast kiedy elektron spada na bliższą, to musi energię
oddać. Zapewne nie raz zastanawiałeś się, czemu przedmioty spadają, woda rozle-
wa się, a gorąca herbata stygnie. Wynika to z faktu, że każdy układ fizyczny dąży
do jak najmniejszej energii. I podobnie jest z atomami — one też chcą mieć jak naj-
niższą energię, dlatego elektrony najpierw zajmują wszystkie możliwe miejsca naj-
bliżej jądra, a dopiero później dalsze. Zatem elektrony na ostatnich powłokach
mają największą energię i jednocześnie najłatwiej „oderwać” je od
atomu. W ciele stałym, w przeciwieństwie do gazów i cieczy, atomy
są ze sobą związane. Mówiąc nieprecyzyjnie, ich ostatnie powłoki
łączą się ze sobą tak, że elektrony mogą bez zmiany energii poru-
szać się między atomami. Mówi się wówczas o powstaniu tzw. pasm
energetycznych (rys. 2). Ostatnie (licząc od jądra atomu) pasmo, na którym znaj-
dują się elektrony nazywane jest pasmem walencyjnym, natomiast pierwsze, które
nie jest w całości obsadzone (są wolne miejsca dla elektronów) nazywane jest pa-
Rysunek 1
Model atomu
Rysunek 2
Powstanie pasm
energetycznych
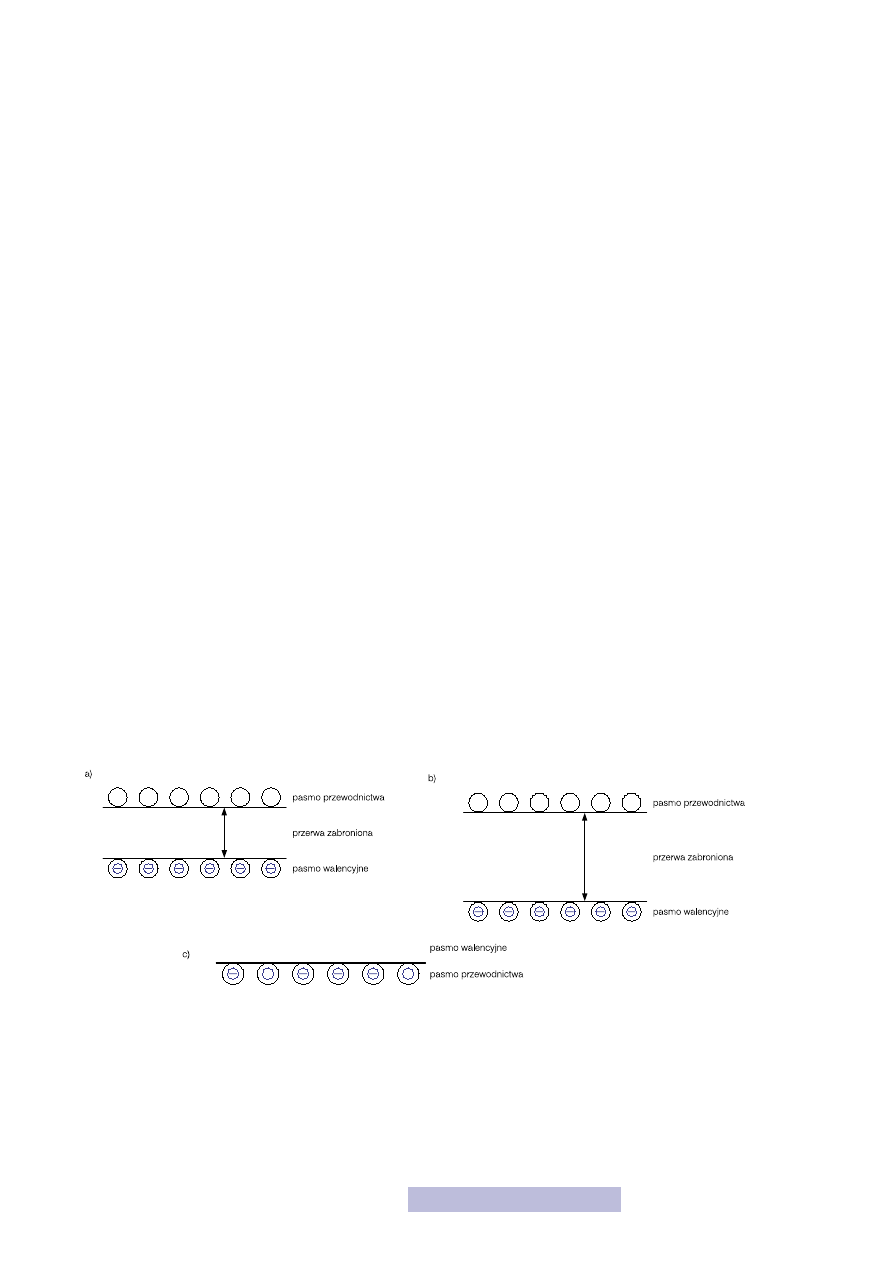
4
smem przewodnictwa. Zatem pasmo przewodnictwa może być położone dalej od
pasma walencyjnego lub oba pasma mogą się pokrywać. Jeśli ostatnie pasmo jest
całkowicie zapełnione, to jest ono walencyjne, a kolejne, całkowicie puste jest pa-
smem przewodnictwa. Natomiast gdy ostatnie pasmo nie jest całkowicie zapełnio-
ne, to oczywiście spełnia warunki bycia zarówno pasmem walencyjnym, jak i pa-
smem przewodnictwa.
Prąd to uporządkowany ruch ładunków. Jądro atomu ma ładunek dodatni, ale jest
duże i nie bardzo może się poruszać, często nawet tkwi w sieci krystalicznej. Na-
tomiast poruszać mogą się elektrony — są bardzo małe i ujemnie naładowane. Jed-
nak nie wszystkie! Te leżące bliżej jądra są z nim mocno związane i trudno je „wy-
rwać”. Za przepływ prądu odpowiadają tylko elektrony leżące na zewnątrz atomu.
Stwierdzenie na zewnątrz atomu jest bardzo nieprecyzyjne i powinienem powie-
dzieć leżące w paśmie przewodnictwa. Elektrony znajdujące się właśnie w paśmie
przewodnictwa mogą poruszać się między atomami, powodując przepływ prądu.
I właśnie od liczby tych elektronów w paśmie przewodnictwa zależy czy dany ma-
teriał jest przewodnikiem, czy izolatorem, czy wreszcie półprzewodnikiem. Im jest
ich więcej, tym oczywiście dany materiał lepiej przewodzi prąd.
W przewodnikach, np. metalach, ostatnie pasmo nie jest całkowicie zapełnione
przez elektrony — oznacza to, że pasmo przewodnictwa pokrywa się z pasmem
walencyjnym (rys. 3a). Zatem w paśmie przewodnictwa znajduje się sporo elektro-
nów i dlatego materiały te dobrze przewodzą prąd. Zupełnie inaczej wygląda sytu-
acja w przypadku półprzewodników i izolatorów. Tam pasmo przewodnictwa jest
puste i obie grupy materiałów słabo przewodzą prąd! Jaka jest więc między nimi
różnica? Otóż różnicą jest energetyczna odległość pasma przewodnictwa od pa-
sma walencyjnego — w półprzewodnikach (rys. 3b) jest ona znacznie mniejsza niż
w izolatorach (rys. 3c). Odległość energetyczna między pasmem przewodnictwa
a pasmem walencyjnym nazwana jest przerwą zabronioną. W obszarze przerwy za-
bronionej nie może znaleźć się żaden elektron! Zatem, aby go przenieść do pasma
przewodnictwa, należy dostarczyć większej energii niż wynosi wartość przerwy.
Zatem, aby półprzewodnik lub izolator zaczął przewodzić, należy przenieść część
elektronów z pasma walencyjnego do przewodnictwa, czyli należy dostarczyć im
energii większej niż wynosi wartość przerwy zabroniona. Jeśli tej energii będzie
mniej, to nic się nie stanie.
I to cała tajemnica pasmowego modelu ciała stałego! Najważniejsze, abyś zapamię-
tał co to jest pasmo przewodnictwa i pasmo walencyjne oraz jak one wyglądają
w poszczególnych grupach materiałów. W dalszej części skupimy się wyłącznie na
własnościach półprzewodników.
Rysunek 3
Pasma: a) w półprzewodniku,
b) w izolatorze,
c) w przewodniku
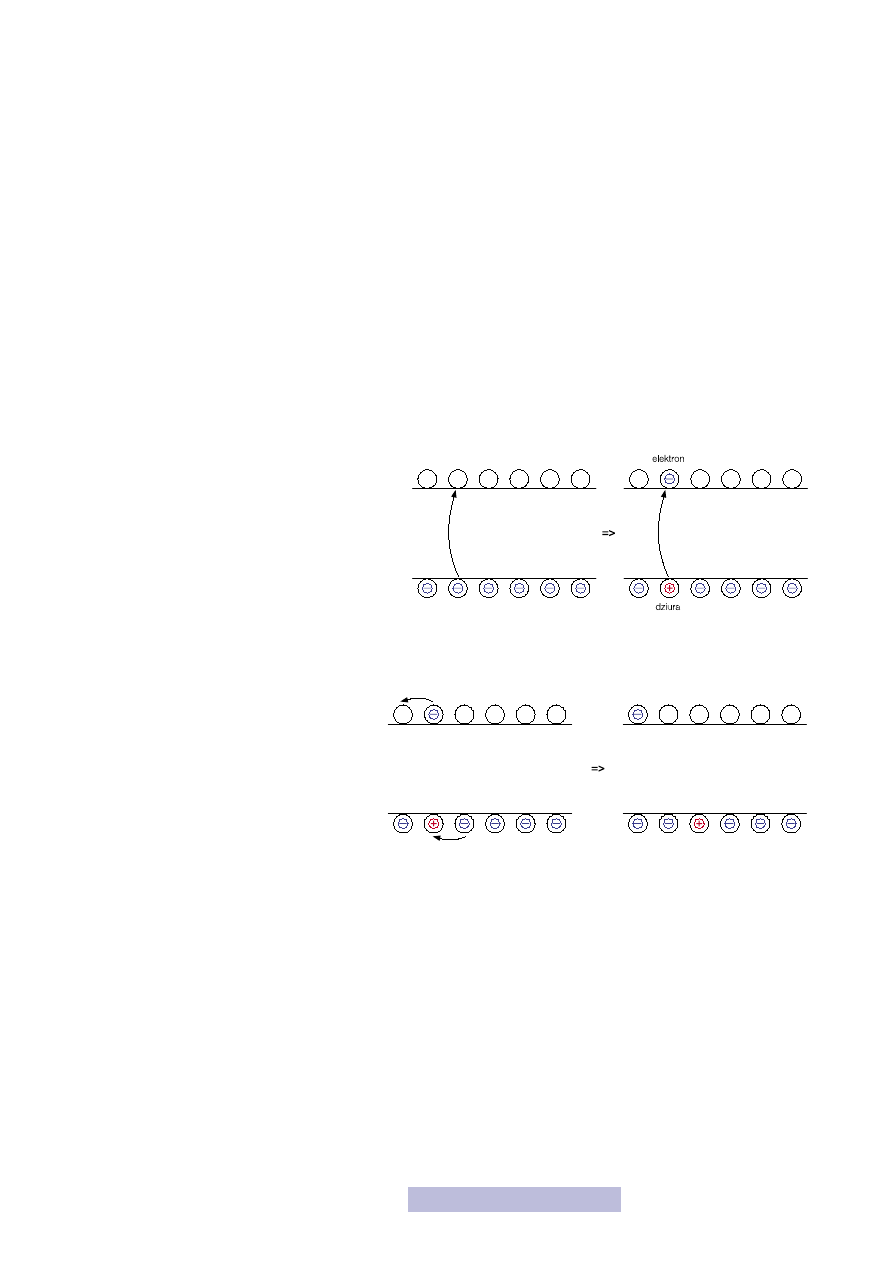
5
1.2. Model pasmowy półprzewodnika
W półprzewodnikach pasmo przewodnictwa jest oddalone od pasma walencyjne-
go o pewną — niedużą — ilość energii. Wystarczy zatem dostarczyć elektrono-
wi z pasma walencyjnego pewną niedużą energię, aby przeskoczył on do pasma
przewodnictwa i półprzewodnik zaczął przewodzić prąd. Nic prostszego, tylko jak
dostarczyć elektronowi tej energii? Stosunkowo prostym i pewnym sposobem jest
podwyższenie temperatury. Im jest ona wyższa, tym elektrony mają większą ener-
gię i chętniej przechodzą na wyższy poziom — do pasma przewodnictwa. Okazu-
je się, że przerwa między pasmami jest na tyle mała, że w normalnej temperaturze
pokojowej część elektronów przechodzi do pasma przewodnictwa i półprzewodnik
przewodzi prąd. Jeśli zacząłbyś podgrzewać półprzewodnik, to coraz lepiej prze-
wodziłbym on prąd, coraz mniejsza byłaby jego rezystywność. Inaczej jest w izola-
torze, tam przerwa jest na tyle duża, że praktycznie w ogóle nie przewodzi on prą-
du, nawet w podwyższonej temperaturze.
Przyjrzyj się jeszcze przez chwilę mechanizmowi przeniesienia elektronu do pasma
przewodnictwa. W wyniku wzrostu temperatury, elektron znajdujący się w pa-
śmie walencyjnym ma coraz większą energię.
Jednak dopóki nie będzie ona większa niż war-
tość przerwy zabronionej (W
g
), to nic nie będzie
się działo. Elektron nadal znajduje się w paśmie
walencyjnym, gdyż nie może znaleźć się w prze-
rwie zabronionej. Kiedy jego dodatkowa energia
przekroczy W
g
, to zostanie przeniesiony do pa-
sma przewodnictwa (rys. 4). Ale w paśmie wa-
lencyjnym zostaje dziura! Jest wolny stan, a więc
pasmo walencyjne też staje się pasmem przewodnictwa! Zatem zysk jest podwójny
— mamy elektron w paśmie przewodnictwa, a pasmo walencyjne też staje się pa-
smem przewodnictwa. Zatem elektrony znajdujące się w paśmie przewodnictwa
i w paśmie walencyjnym mogą przewodzić.
O ile mechanizm przewodzenia elektronów
w paśmie przewodnictwa jest prosty, elek-
trony mają dużo wolnego miejsca i bez prze-
szkód poruszają się, o tyle w paśmie walen-
cyjnym wygląda to ciekawej. Otóż do po-
wstałej luki przeskakują sąsiednie elektrony,
powodując, że luka przemieszcza się (rys. 5).
Luka ta nazywana jest dziurą. Jako że jest to
po prostu brak elektronu, dziura ma ładunek dodatni. W półprzewodnikach prze-
wodzą zatem zarówno elektrony, jak i dziury. Właśnie dzięki istnieniu tych dwóch
mechanizmów przewodzenia półprzewodniki można wykorzystać do budowy pod-
stawowych elementów elektronicznych, o czym za chwilę się przekonasz. Jedyną
wadą czystego półprzewodnika jest to, że wstępuje w nim taka sama liczba dziur
i elektronów, ale ten problem rozwiążemy już w następnym podtemacie.
Typowym i najbardziej znanym materiałem półprzewodnikowych jest oczywiście
krzem. Ale półprzewodnikiem może być również german, węgiel oraz związki, np.
węglik krzemu, krzemogerman czy arsenek galu.
Rysunek 4
Generacja pary dziura–elektron
Rysunek 5
Przewodzenie
w półprzewodniku
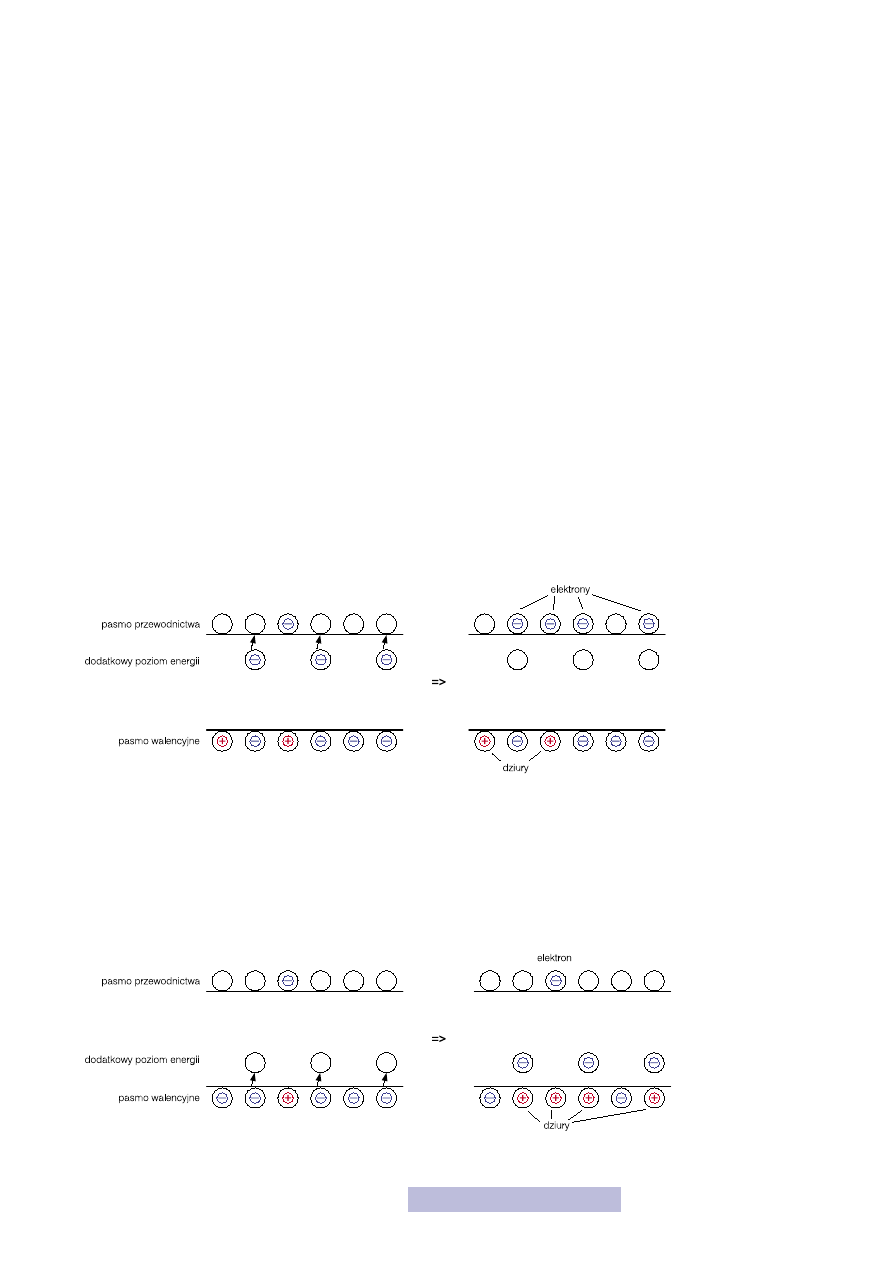
6
1.3. Półprzewodnik domieszkowany
Czysty półprzewodnik na niewiele może się w praktyce przydać. Jedynym prak-
tycznym zastosowaniem, jakie w tej chwili przychodzi mi do głowy jest czujnik
temperatury. Im wyższa temperatura, tym mniejsza rezystancja. Mierząc tę rezy-
stancję, można stwierdzić jaka jest temperatura.
Natomiast najważniejsze z punktu widzenia elektroniki są półprzewodniki do-
mieszkowane. Proces domieszkowania polega na wprowadzeniu do materiału pół-
przewodnikowego innych atomów, które pozwolą na wygenerowanie dodatkowej
dziury albo dodatkowego elektronu. Domieszki dzielimy na dwie grupy:
— domieszki typu N — powodujące wygenerowanie dodatkowych elektronów,
— domieszki typu P — powodujące wygenerowanie dodatkowych dziur.
Typową domieszką typu N jest fosfor, natomiast typu P bor.
Wprowadzenie domieszki powoduje wytworzenie dodatkowego poziomu energe-
tycznego w przerwie zabronionej. Zobaczmy jak to wygląda na przykładzie do-
mieszki typu N (rys. 6). W pobliżu pasma przewodnictwa prowadzony jest dodat-
kowy poziom zawierający elektrony. Odległość od pasma przewodnictwa jest bar-
dzo mała i elektrony z tego dodatkowego pasma bez większego problemu nawet
w niskich temperaturach przechodzą do pasma przewodnictwa. Tak więc w takim
półprzewodniku jest więcej elektronów w paśmie przewodnictwa niż dziur w pa-
śmie walencyjnym. I o to chodziło. Oczywiście im więcej wprowadzimy atomów
domieszki, tym większa będzie przewaga elektronów nad dziurami.
Odwrotnie jest w półprzewodniku typu P. Tam wprowadzony jest dodatkowy pu-
sty poziom w pobliżu pasma walencyjnego (rys. 7). Elektrony znajdujące się w pa-
śmie walencyjnym, nawet w niskich temperaturach posiadają energię, która po-
zwala mi przejść do tego dodatkowego pasma, pozostawiając w paśmie walencyj-
nym dziury. Oczywiście liczba miejsc na elektrony w tym dodatkowym paśmie jest
ograniczona przez liczbę wprowadzonych domieszek. Im jest ich więcej, tym więcej
dziur powstanie.
Rysunek 6
Półprzewodnik domieszkowany
typu N
Rysunek 7
Półprzewodnik domieszkowany
typu P
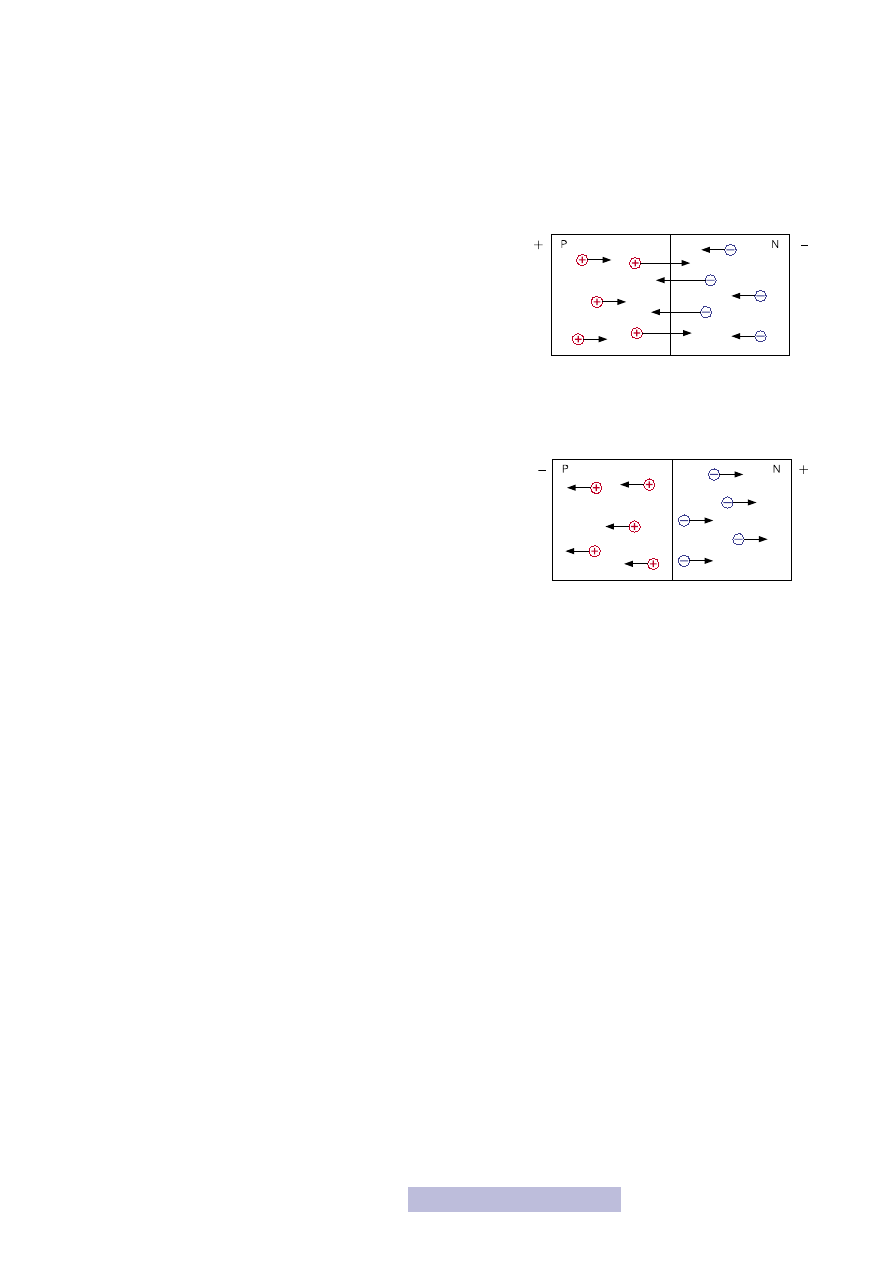
7
1.4. Złącze PN
Ostatnim ważnym dla nas tematem z fizyki półprzewodników jest złącze PN. Jak
sama nazwa wskazuje jest to po prostu połączenie ze sobą dwóch półprzewodników:
typu P i typu N. Okazuje się, że takie złącze ma własności prostujące — w jedną stro-
nę przewodzi prąd, a w drugą nie. Czy to nie przypomina ci własności diody?
Spróbujmy najpierw przyłożyć do półprzewodnika N mniejszy po-
tencjał (–), a do P większy (+). Jak wiesz, w półprzewodniku typu
N jest zdecydowanie więcej elektronów, które mają ładunek ujemny,
natomiast w półprzewodniku typu P dziur, które są dodatnie. Elek-
trony są więc odpychane z przez przyłożony „–”, a przyciągane po
drugiej stronie przez „+”, a więc elektrony z warstwy N przechodzą
do P (rys. 8). Dziury odwrotnie, są odpychane przez „+”, a przycią-
gane przez „–”, a więc będą przechodziły z P do N. Zatem prąd przez takie złącze
będzie mógł płynąć. Aby łatwiej zapamiętać, kiedy złącze jest stanie przewodzenia,
proponuję ci zapamiętać zasadę trzech P — „Aby złącze było w
P
rzewodzeniu, do
warstwy
P
trzeba przyłożyć
P
lus”.
Teraz zobaczmy co dzieje się, kiedy odwrócimy polaryzację, a więc
do warstwy P przyłożymy „–”, a do N „+” (rys. 9). W tym wypadku
dziury z P są przyciągane przez „–” i nie przechodzą na drugą stro-
nę złącz, a wręcz przeciwnie — uciekają w kierunku „–”. Podobnie
elektrony — nie przechodzą na druga stronę do P, lecz są przyciąga-
ne przez „+” i w jego kierunku się udają. Przez złącze nie może więc
płynąć prąd, mamy więc stan zaporowy.
I tak właśnie działa złącze PN. Jeśli teraz dołożylibyśmy do obu warstw elektro-
dy, do P anodę, a do N katodę, otrzymalibyśmy gotową diodę. Oczywiście mecha-
nizm działania złącza PN jest o wiele bardziej skomplikowany i zachęcam cię do
zapoznania się z nim z dostępnej literatury. Z własności złącza PN będziemy już za
chwilę korzystali przy budowie tranzystora MOS.
Rysunek 8
Złącze PN spolaryzowane
w kierunku przewodzenia
Rysunek 9
Złącze PN spolaryzowane
w kierunku zaporowym
8
2. Budowa i działanie
tranzystora MOS
Przed chwilą poznałeś podstawowe własności materiałów półprzewodnikowych.
Wystarczą one do tego, abyś mógł poznać budowę i zrozumieć działanie tranzy-
stora MOS. Podobnie jak w przypadku bramek CMOS, zbudujemy sobie
taki tranzystor sami, od podstaw.
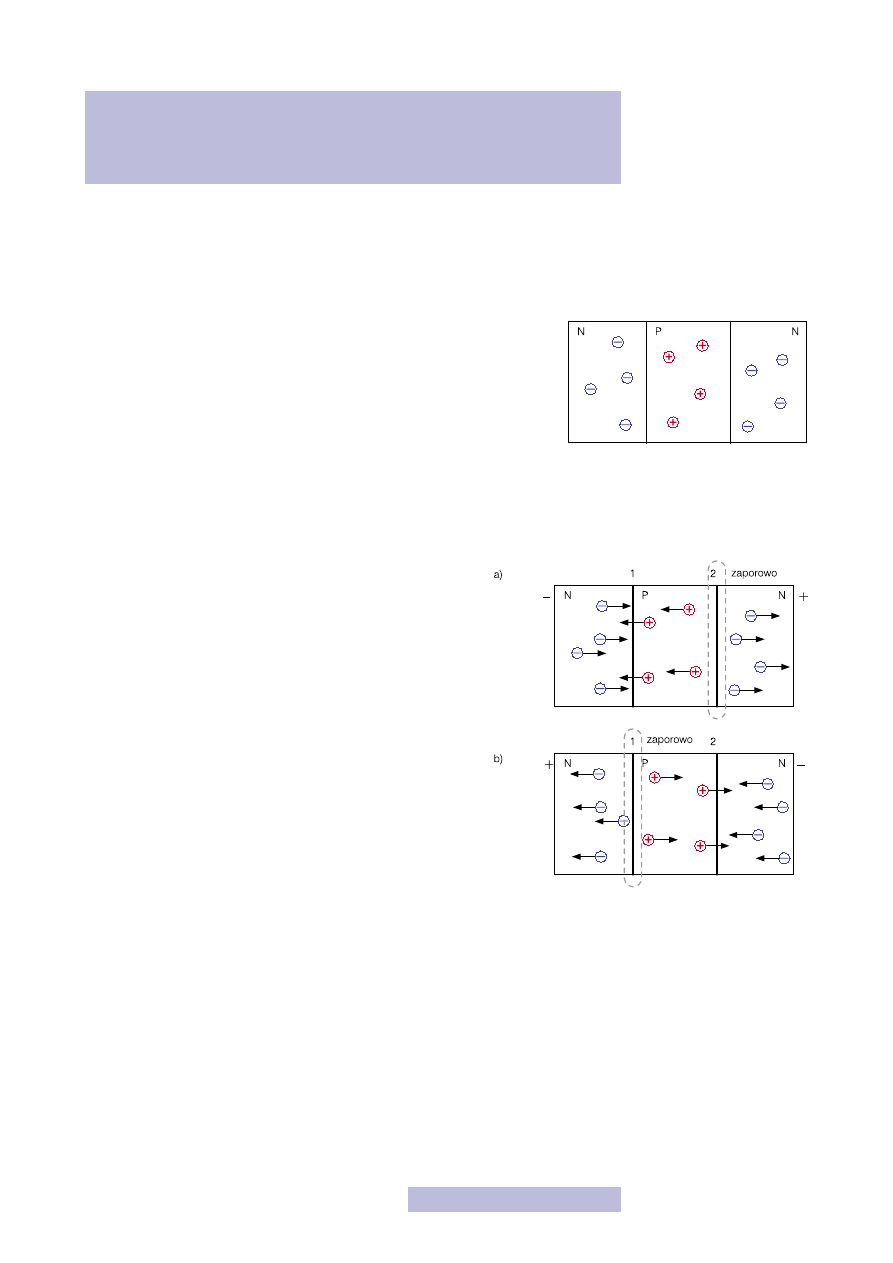
Na początek połączmy ze sobą trzy warstwy półprzewodników, np. N,
P i N (rys. 10). Mamy zatem do czynienia z dwoma złączami, jednym po
lewej (oznaczmy je nr 1), drugim po prawej stronie (oznaczmy je nr 2).
Zobaczmy teraz, co się stanie, jeśli do skrajnych warstw przyłożymy na-
pięcie.
Jeśli do lewej strony struktury podłączymy „–”, a do prawej „+” (rys. 11a), to złą-
cze nr 1 będzie w stanie przewodzenia (minus na N), natomiast złącze nr 2 będzie
w stanie zaporowym (plus na N). Zatem przez tę strukturę nie może płynąć prąd.
Odwróćmy polaryzację, a więc do lewej strony struktury podłączmy „+”, a do pra-
wej „–”. Tym razem złącze nr 1 jest w stanie zaporowym,
a nr 2 w przewodzeniu. Niemniej jednak i tym razem przez
strukturę nie może płynąć prąd.
Jest nieźle, mamy strukturę, przez którą nie płynie prąd bez
względu na polaryzację. Teraz jednak należy coś zrobić, żeby
w pewnych warunkach zaczęła ona przewodzić. Pomysłów
jest wiele i prowadzą one do różnych tranzystorów. My sko-
rzystajmy z następującego: spróbujmy połączyć ze sobą obie
warstwy N. Czym połączyć? Najlepiej metalem, ale z tym
może być ciężko, ponieważ trudno się go potem pozbyć. Na-
tomiast dobry i stosunkowo prostym pomysłem jest połącze-
nie po prostu półprzewodnikiem typu N! A więc trzeba jakoś
wytworzyć w półprzewodniku typu P półprzewodnik typu
N, który połączy ze sobą oba obszary N i będzie mógł mię-
dzy nimi płynąć prąd. Jak to zrobić? Rozwiązaniem jest zna-
ny z drugiego moduły kondensator.
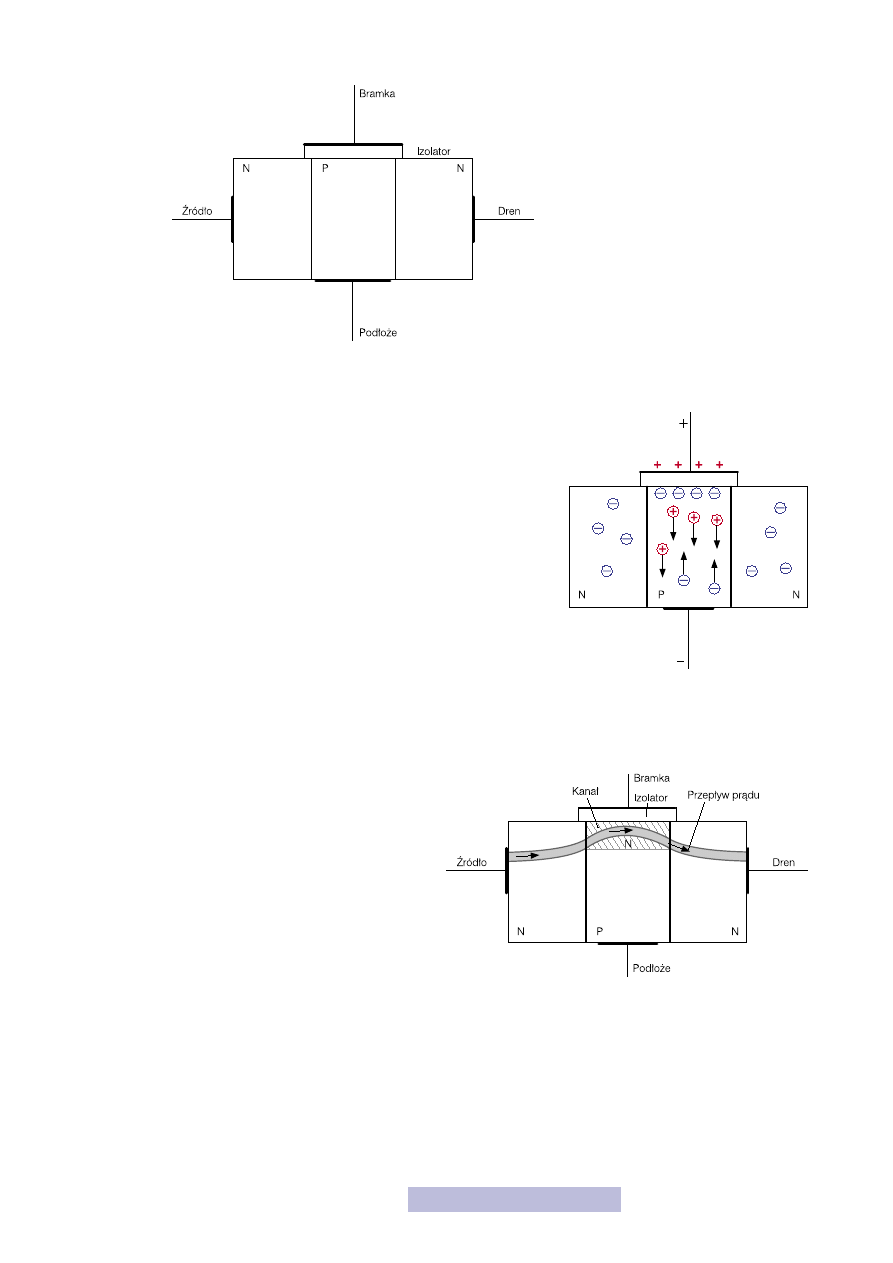
Kładziemy na warstwie typu P izolator. Z jednej strony styka
się on z półprzewodnikiem, z drugiej z dodatkową elektrodą
(rys. 12), którą nazwiemy bramką. Dokładamy jeszcze jedną elektrodę na dole war-
stwy P, którą nazwiemy podłożem. Jeśli już nazywamy wszystkie elektrody, to po le-
wej stronie do warstwy N będzie dołączona elektroda źródła, a po prawej elektroda
drenu. To już chyba bardzo przypomina tranzystor MOS. Zobaczmy jak on działa.
Rysunek 10
Struktura trójwarstwowa
Rysunek 11
Polaryzacja struktury
trójwarstwowej
9
Jeśli między bramką a podłożem napięcie jest równe 0 V, to nic nie będzie się działo,
a więc niezależnie od polaryzacji źródła i drenu, przez strukturę nie popłynie prąd,
ponieważ któreś ze złącz jest w stanie zaporowym, co uzasadniałem przed
chwilą. Teraz przyłóżmy do bramki wyższy potencjał (+) niż do podłoża
(–). „+” przyciąga elektrony, a „–” dziury, a więc pod izolatorem zaczyna-
ją gromadzić się elektrony, a dziury są odpychane w kierunku elektrody
podłoża (rys. 13). Im większe jest to dodatnie napięcie bramka–podłoże,
tym więcej elektronów przypływa pod izolator. Ze względu na izolator nie
mogą one przepłynąć do elektrody bramki, tylko gromadzą się pod nim.
A jak pamiętasz, półprzewodnik jest typu N, gdy ma więcej elektronów niż
dziur. Dziury zostały odepchnięte, elektrony przyciągnięte i w pewnym
momencie okazuje się, że elektronów jest więcej niż dziur, a więc mamy
półprzewodnik typu N, który łączy ze sobą obszary źródła i drenu (rys.
14). Teraz prąd bez przeszkód może płynąć od źródła przez utworzony ka-
nał do drenu. Cały czas płynie po jednym typie półprzewodnika, nie na-
potyka na żadne złącza, przeszkody. I o to właśnie chodziło! Przypomnij
sobie teraz jak działał tranzystor MOS z kanałem typu N (NMOS). Kiedy napięcie
bramka–podłoże było równe 0 V, tranzystor nie przewodził, gdy było dodatnie prze-
wodził. I dokładnie tak samo jest w naszej strukturze. Pozostaje wyjaśnić jeszcze tyl-
ko dwie kwestie, mianowicie: skąd nazwa z kanałem typu N oraz czemu tranzystor
nie przewodzi od razu, tylko po przekroczeniu pew-
nego napięcie progowego. Odpowiedź na pierwsze py-
tanie narzuca się sama, kiedy spojrzysz na rysunek 14
— po prostu tworzy się przewodzący kanał, który jest
półprzewodnikiem typu N. Natomiast czemu nie prze-
wodzi od razu? Otóż, jeśli przyłożysz nieduże napię-
cie bramka–podłoże, to przyciągnięte zostanie za mało
elektronów i odepchnięte za mało dziur. Zatem pół-
przewodnik nadal będzie typu P, ponieważ będzie miał
więcej dziur niż elektronów. Natomiast jeśli napięcie
będzie dostatecznie duże, nastąpi inwersja, a więc bę-
dzie więcej elektronów niż dziur, zmieni się typ pół-
przewodnika i utworzy się kanał, którym będzie mógł popłynąć prąd. Jeśli nadal bę-
dziesz zwiększał napięcie bramka–podłoże, to elektronów będzie coraz więcej, kanał
będzie coraz lepiej przewodził prąd, a więc będzie miał coraz mniejszą rezystancję.
Na koniec pozostaje wyjaśnić jeszcze jak zbudowany jest tranzystor z kanałem typu
P. Otóż niemal identycznie jak z kanałem typu N, zamienione są tylko ze sobą do-
mieszkowania. Pod źródłem i drenem jest półprzewodnik typu P, a pośrodku typu N.
Jeśli napięcie bramka–podłoże wynosi 0 V, to zawsze jedno ze złącz jest spolaryzowa-
ne w kierunku zaporowym. Jeśli przyłożysz ujemne napięcie bramka–podłoże, a więc
Rysunek 12
„Prawie tranzystor” MOS
Rysunek 13
Działanie „prawie NMOS-a”
Rysunek 14
Stan przewodzenia
„prawie NMOS-a”
10
na bramce będzie „–”, a na podłożu „+”, to do bramki przyciągane są do-
datnio naładowane dziur, a odpychane elektrony (rys. 15). Tak więc two-
rzy się warstwa półprzewodnika typu P, która łączy obszary źródła i drenu.
Mamy zatem dokładnie strukturę, która działa jak tranzystor PMOS.
Budowa tranzystora NMOS i PMOS
Choć przedstawione powyżej struktury działają jak opisywane w mo-
dule trzecim tranzystory MOS, to nazywałem je „prawie MOS-y”. I to
„prawie” robi różnicę! Otóż tranzystory MOS, szczególnie te stosowane
w mikroelektronice, wykonuje się w postaci planarnej (a więc cały przy-
rząd leży na powierzchni).
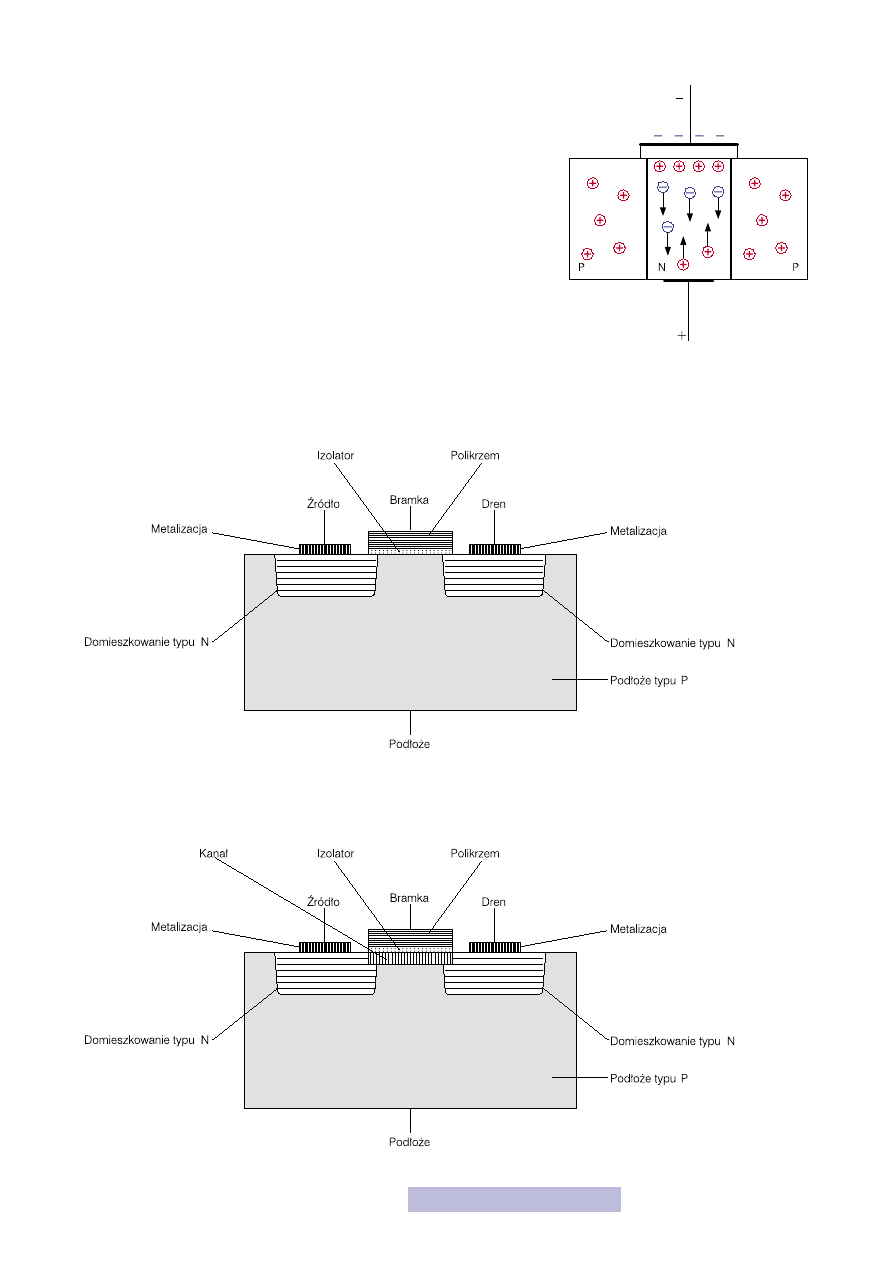
Przyjrzyjmy się najpierw budowie tranzystora z kanałem typu N (rys.
16). Cały przyrząd wykonany jest w półprzewodniku typu P. Obszary
źródła i drenu są to domieszkowane wysepki typu N. Na te wysepki na-
łożona jest warstewka metalu, która stanowi elektrodę źródła i drenu. Na półprze-
wodnik naniesiona jest warstwa izolatora, którym najczęściej jest dwutlenek krze-
mu (SiO
2
), a na niego warstwa silnie domieszkowanego polikrzemu, która stanowi
elektrodę bramki. Działanie jest dokładnie takie jak „prawie MOS-a”.
Budowa tranzystora PMOS jest niemal identyczna jak NMOS-a, z tą różnicą, że
wykonywany jest on na podłożu typu N, a domieszkowania źródła i drenu są typu
P (rys. 17). Pozostałe szczegóły są identyczne.
Rysunek 15
Działanie tranzystora
„prawie PMOS”
Rysunek 16
Budowa tranzystora NMOS
Rysunek 17
Budowa tranzystora PMOS

11
Na koniec chciałbym jeszcze wytłumaczyć, skąd wzięła się nazwa tranzystor MOS.
Otóż MOS jest skrótem od słów
M
etal,
O
xide (tlenek),
S
emiconductor (półprze-
wodnik). Jeśli spojrzysz na konstrukcję bramki, zauważysz, że są tam nałożone są
na siebie półprzewodnik, izolator, którym najczęściej jest właśnie tlenek krzemu
oraz polikrzem. Współcześnie, ze względów technologicznych, metal został zastą-
piony przez polikrzem, jednak nazwa pozostała.
12
3. Procesy technologiczne
wytwarzania układów scalonych
Przed chwilą poznałeś kolejny element w mikroelektronicznej układance — wiesz
już jak zbudowany jest i jak działa tranzystor MOS. Znasz już więc dokładnie bu-
dowę wnętrza „czarnej skrzyneczki”. Do ukończenia układanki brakuje jeszcze
tylko jednego etapu! Jak w praktyce wykonać tranzystor? Tym właśnie zajmiemy
się teraz. Zanim jednak przejdziemy do samej technologii produkcji tranzystorów
MOS, musimy poznać procesy technologiczne, za pomocą których będziemy wy-
twarzali tranzystor, a w konsekwencji układy scalone. Proces wytwarzania układu
scalonego można zamknąć w pewnym schemacie (rys. 18).
Na początku bierzemy płytkę podłożową, na której w pętli wykonujemy następu-
jące operacje:
— zmieniamy własności materiału i/lub wytwarzamy nową warstwę (warstwy) na
powierzchni,
— odwzorowujemy kształty na powierzchni,
— trawimy (usuwamy niepotrzebnych elementów warstw).
Taką pętlę powtarzamy, aż powstanie struktura, którą planowaliśmy. Następnie
powstały układ sprawdzamy, opakowujemy i wysyłamy do klienta.
W tym temacie zajmiemy się dwoma pierwszymi etapami, a więc wytworzeniem
podłoża oraz procesami zachodzącymi w pętli. Pozostałe omówimy w następnym
module.
3.1. Wytwarzanie podłoży krzemowych
Zanim zaczniemy mówić o wytwarzaniu układów scalonych musimy wziąć pod-
łoże, na którym będziemy wytwarzali cały układ. Najczęściej podłożami są płytki
krzemowe (rys. 19) i każdy szanujący się podręcznik mikroelektroniki zawiera opis
ich wytwarzania, stworzony przez Jana Czochralskiego (widziałem nawet kiedyś
Rysunek 18
Schemat wytwarzania układu
scalonego
13
podręcznik w języku japońskim, który zawierał opis tej metody). Pomysł prosty,
mający już niemal 100 lat, ale nadal bezkonkurencyjny.
W technologii układów scalonych stosuje się krzem monokrystaliczny, czyli cała
płytka jest wielkim jednorodnym kryształem. Do tego krzem musi być bardzo wy-
sokiej czystości! Trudno sobie to wyobrazić, ale zanieczyszczeń i defektów musi
być mniej niż 0,000001%! Jest to wręcz niewyobrażalnie mała liczba i oznacza,
że na 10 miliardów atomów krzemu może być tylko jeden atom zanieczyszczenia
lub jeden defekt. Najczystsza sala operacyjna jest dosłownie przesypownią węgla
w porównaniu z czystością, jaka musi być zachowana przy produkcji podłoży krze-
mowych. Natomiast płytki krzemowe są już najczęściej wstępnie domieszkowa-
ne. Praktycznie nie produkuje się płytek z czystego krzemu (byłoby to niezwykle
kosztowe i bezsensowne). Przypomnij sobie budowę tranzystora MOS — widziałeś
tam, że cały obszar jest praktycznie jednego typu, domieszkowane są tylko niewiel-
kie obszary źródła i drenu.
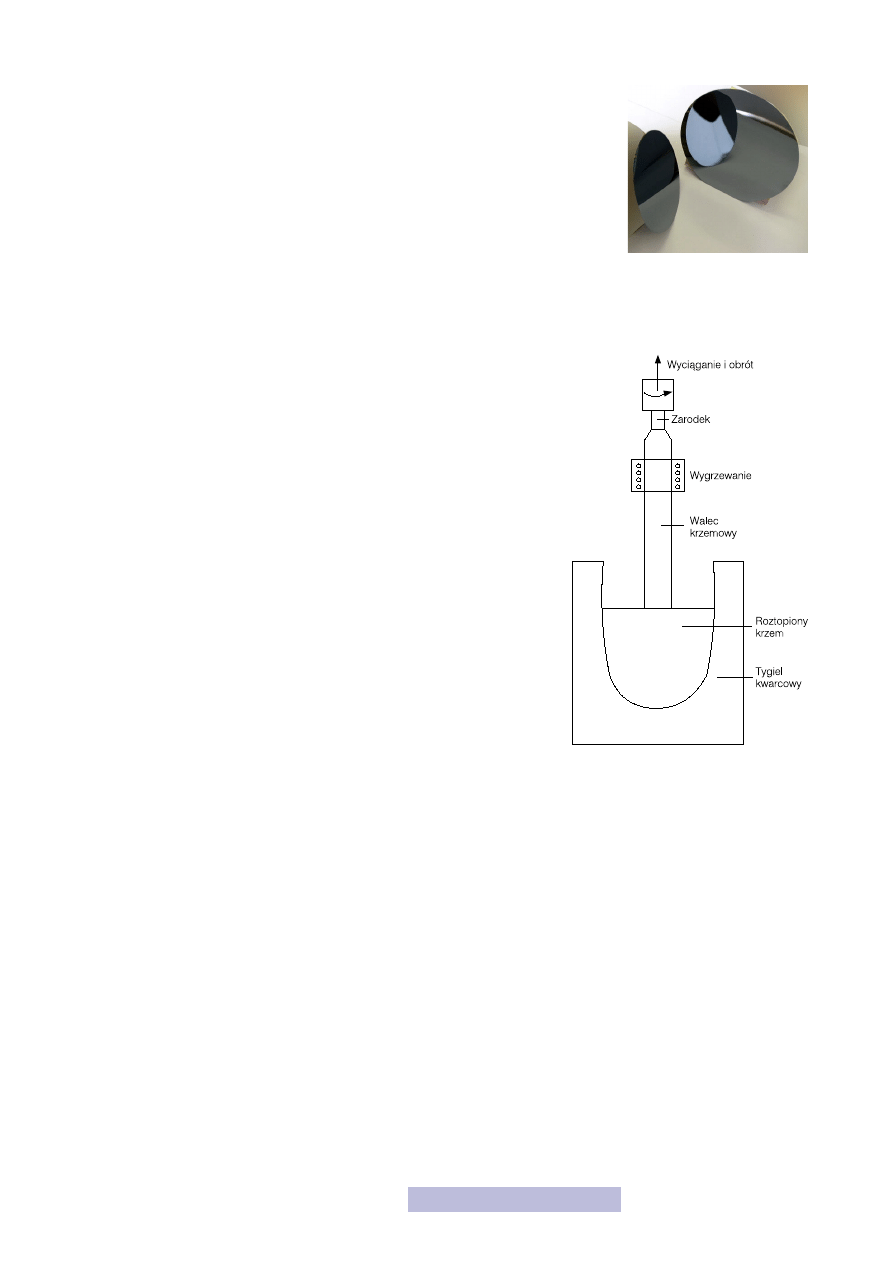
Jak wykonuje się płytkę podłożową? Do tygla wrzuca się czysty, ale nie
monokrystaliczny krzem oraz pierwiastki domieszki. Całość rozgrzewa
się do temperatury topnienia krzemu. Następnie w takim roztworze za-
nurza się mały kawałek bardzo czystego krzemu, zwanego zarodkiem.
Następnie bardzo powoli wyciąga się zarodek do góry, jednocześnie rów-
nie powoli obracając go. W ten sposób wyciąga się okrągły monokrysta-
liczny pręt. Aby poprawić jego czystość i zmniejszyć liczbę defektów czę-
sto po drodze dodatkowo się go wygrzewa.
Na koniec pozostaje pociąć taki pręt na płytki. Oczywiście proces cięcia
jest również niezwykle precyzyjny, aby nie uszkodzić struktury krzemu
oraz nie wprowadzić zanieczyszczeń. Po pocięciu płytki myje się, oczysz-
cza dodatkowo ich powierzchnię, aby miała jak najmniej defektów. Na-
stępnie pakuje się je i wysyła do fabryki układów scalonych, aby wykonać
na nich układy scalone. Takie płytki są poddawane w pętli poszczegól-
nym procesom technologicznym, które teraz omówię.
3.2. Wytwarzanie nowych warstw
Kiedy spojrzysz na budowę tranzystora MOS, od raz możesz dostrzec, że na po-
wierzchni półprzewodnika muszą zostać wytworzone warstwy dwutlenku krzemu,
polikrzemu oraz metalizacje. W rzeczywistości jest ich znacznie więcej, ponieważ
dochodzą warstwy izolujące, zabezpieczające i maskujące. Przyjrzyjmy się możli-
wym procesom wytwarzania nowych warstw na powierzchni płytki podłożowej.
Utlenianie termiczne
Proces utleniania termicznego polega na wytworzeniu na powierzchni półprze-
wodnika warstwy tlenku krzemu. Tlenek powstaje w wyniku reakcji chemicznej
atomów krzemu z tlenem lub parą wodną:
Si + O
2
→ SiO
2
Si + 2H
2
O → SiO
2
+ 2H
2
Aby wytworzyć na powierzchni warstwę dwutlenku krzemu, umieszcza się płytkę
w piecu w atmosferze tlenu (O
2
) lub pary wodnej (H
2
O), podgrzewa do odpowied-
niej temperatury (ok. 1000°C) i czeka. Na powierzchni zachodzą procesy utlenia-
nia i powstaje warstwa dwutlenku krzemu. Tlenek wytworzony w atmosferze tlenu
Rysunek 19
Podłoża krzemowe
Rysunek 20
Wykonanie płytki podłożowej
metodą Czochralskiego
14
ma zdecydowanie lepsze własności izolacyjne, choć proces zachodzi zdecydowanie
wolniej i powstające warstwy są bardzo cienkie. Dlatego jest stosowany najczęściej
jako tlenek bramkowy. Natomiast w atmosferze pary wodnej tlenek powstaje bar-
dzo szybko, jednak jest on kiepskiej jakości, ma wiele defektów. Stosuje się go jako
tlenek maskujący i polowy (o czym powiemy więcej w kolejnym podtemacie). Nie-
wątpliwą zaletą tlenku wytwarzanego metodą termiczną jest doskonała przyczep-
ność do podłoża, jako że tlenek ten powstaje z atomów znajdujących w płytce pod-
łożowej.
CVD
CVD (ang. Chemical Vapor Deposition) jest to proces chemicznego osadzania z fa-
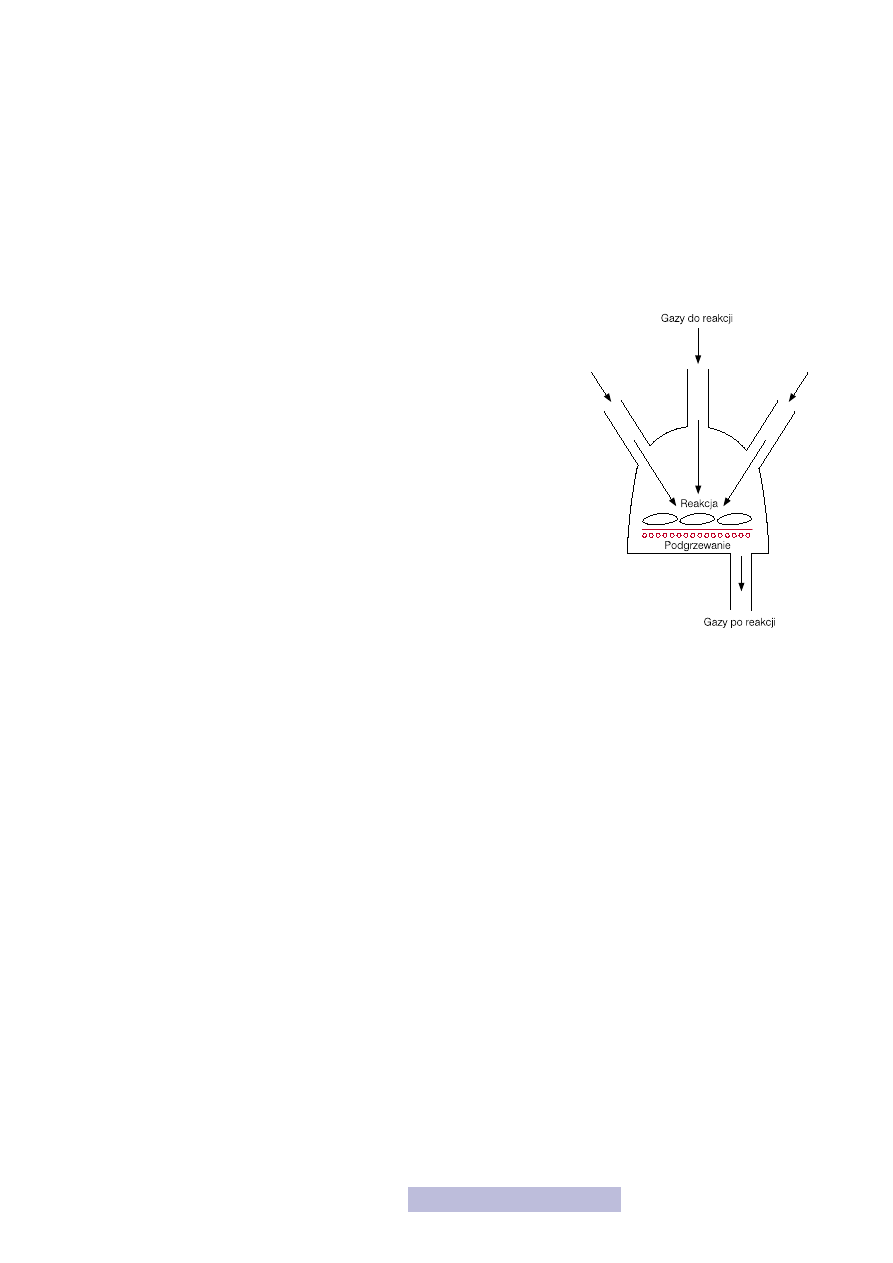
zy lotnej. Jak się on odbywa? Otóż do komory reakcyjnej wkładana jest płytka,
a następnie są do niej dostarczane odpowiednie gazy (reagenty). Reakcja za-
chodzi między wprowadzonymi gazami, najczęściej w podwyższonej tem-
peraturze, a produkt reakcji osadza się na płytce (rys. 21). Atomy krzemu
z płytki w większości przypadków nie biorą udziału w reakcji, stanowią tyl-
ko podłoże, na którym osadza się warstwa. W ten sposób można wytwarzać
warstwy:
— tlenków (głównie maskujące ze względu na kiepską jakość) i azotków,
— krzemu monokrystalicznego i polikrystalicznego (na bramkę),
— metaliczne, szczególnie metali trudno topliwych (metalizacje).
Największym problemem CVD jest to, że reakcje między gazami zachodzą
nie tylko na powierzchni płytki, ale także w całej objętości komory. Aby ten
efekt zminimalizować, stosuje się często bardzo skomplikowane konstruk-
cje komór reakcyjnych, dodatkowe nawiewy kierujące gazy w odpowiednie
miejsce reakcji, obniżone lub podwyższone ciśnienie, wspomaganie plazmą
i wiele innych metod. Poniżej podaję przykładowe reakcje CVD:
— osadzenie warstwy azotku krzemu (Si
3
N
4
):
3SiCl
2
H
2
+ 4NH
3
(amoniak) → Si
3
N
4
+ 6H
2
+ 6HCl
— osadzenie polikrzemu (rozpad w wysokiej temperaturze silanu):
SiH
4
→ Si + 2H
2
Metoda CVD jest bardzo często stosowana w technologii mikroelektronicznej. Jej
podstawową zaletą jest szybkość, duża wydajność oraz stosunkowo niski koszt.
Epitaksja
Jedną z odmian CVD jest epitaksja. Jest to nanoszenie na warstwę podłoża war-
stwy krzemu. Zapewne zapytasz się: po co nanosić krzem na krzem? Okazuje się,
że często potrzebne są warstwy o całkowicie innych własnościach niż podłoże, któ-
rych nie da się uzyskać przez modyfikację własności podłoża. Klasycznym przykła-
dem jest warstwa o niższym poziomie domieszkowania niż podłoże. Można wpro-
wadzić dodatkowe atomy domieszki do podłoża, lecz praktycznie nie ma sposobu,
aby je usunąć. Dlatego na podłoże należy nanieść warstwę o niższym poziomie
domieszkowania. Innym przykładem jest wytworzenie dużej (głębokiej) warstwy
o bardzo równomiernym poziomie domieszkowania. Metodami modyfikacji po-
wierzchni bardzo trudno jest uzyskać równomierny poziom domieszkowania, na-
tomiast metodą epitaksji można uzyskać bardzo głębokie warstwy o niemal iden-
tycznej koncentracji domieszki.
Jedną z klasycznych reakcji chemicznego osadzania krzemu jest:
SiCl
4
+ 2H
2
→ Si + 4HCl.
Rysunek 21
Schemat CVD
15
Proces zachodzi w atmosferze gazów, które dostarczają odpowiednich atomów do-
mieszki, np. B
2
H
6
(domieszki typu P), PH
3
(domieszka typu N). W ten sposób po-
wstaje warstwa krzemu, odpowiednio domieszkowanego, osadzona na powierzch-
ni płytki podłożowej.
PVD
PVD (ang. Phisical Vapor Deposition) jest to proces fizycznego osadzania mate-
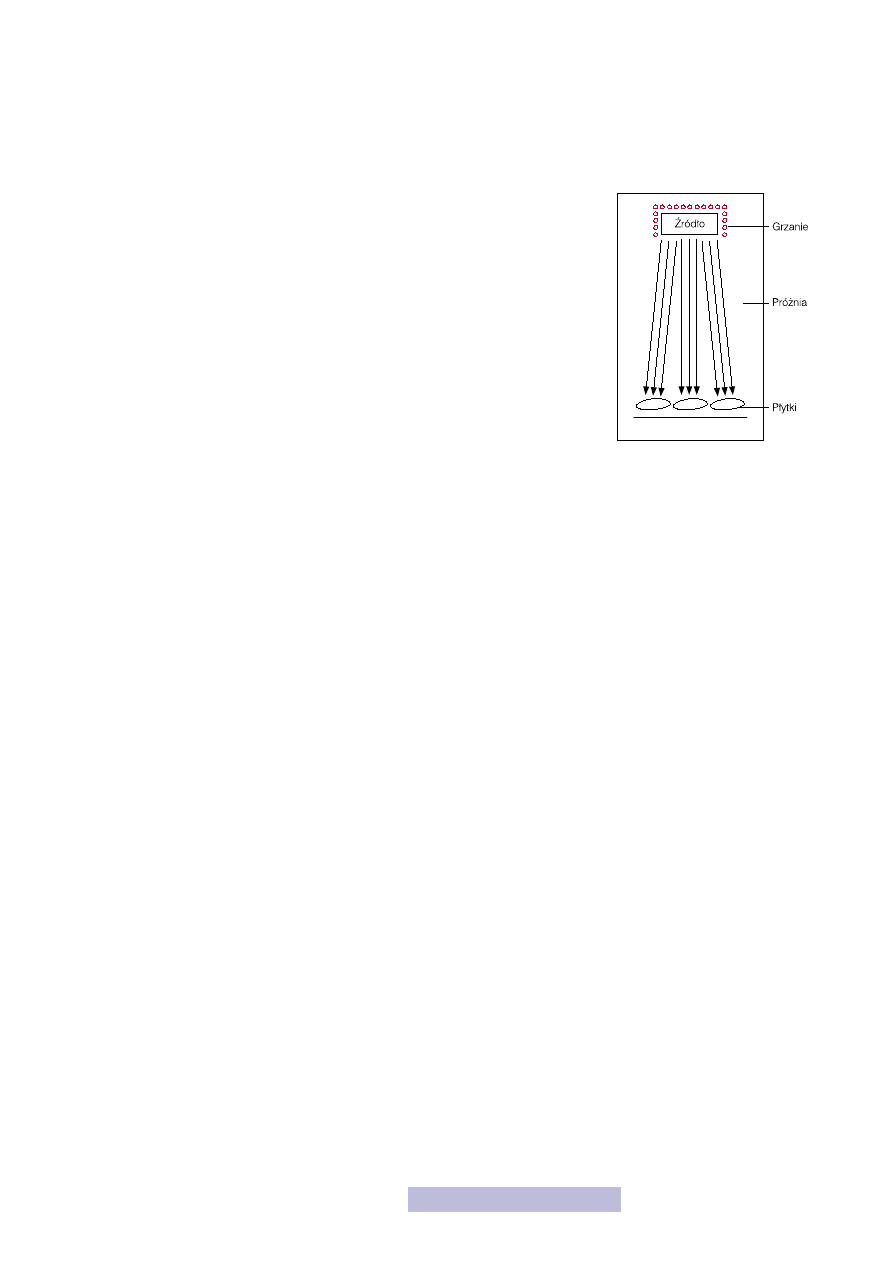
riału z fazy lotnej. Jak on się odbywa? W komorze reakcyjnej (rys. 22), w której
znajduje się płytka panuje bardzo wysoka próżnia. Nanoszony materiał jest od-
parowywany ze źródła, jego atomy poruszają się w komorze, docierając do płyt-
ki i na niej się osadzają. Otrzymuje się w ten sposób najczęściej warstwy meta-
liczne. W tej metodzie nie zachodzą żadne reakcje chemiczne, źródłem jest jeden
materiał, który jest przenoszony i osadzany na płytkę podłożową. Zaletą tej me-
tody jest stosunkowo duża szybkość tworzenia się warstwy, natomiast wadą są
trudności w zapewnieniu stałej grubości warstwy na całej powierzchni płytki.
Przedstawionymi powyżej metodami tworzy się nowe warstwy na powierzchni
płytki podłożowej. Oczywiście każdą warstwę można utworzyć na wiele sposo-
bów, czego przykładem jest choćby pokrycie dwutlenkiem krzemu, który można
uzyskać utlenianiem w atmosferze tlenu, pary wodnej lub CVD. Metodę nano-
szenia warstwy dobiera się na podstawie parametrów, jakie musi spełniać warstwa
oraz parametrów, jakie pozwala uzyskać dana metoda. Oczywiście bardzo ważnym
kryterium jest rachunek ekonomiczny. Jeśli daną warstwę można uzyskać szybciej
i taniej, a do tego spełnia ona zakładane wymagania, to taką właśnie metodę po-
winno się wybrać. Obecnie wiodącą technologią nanoszenia warstw jest CVD.
3.3. Odwzorowanie kształtów na powierzchni
Nowa warstwa najczęściej nanoszona jest na całą powierzchnię płytki podłożowej.
Natomiast przeważnie potrzebujemy jej wyłącznie na niewielkim obszarze (tlenek
bramkowy, metalizacja źródła i drenu itp.). Pozostaje więc pytanie jak usunąć te
nadmiarowe warstwy. Odpowiedzią są właśnie procesy odwzorowywania odpo-
wiednich kształtów na powierzchni, a następnie usunięcia tych, które są zbędne.
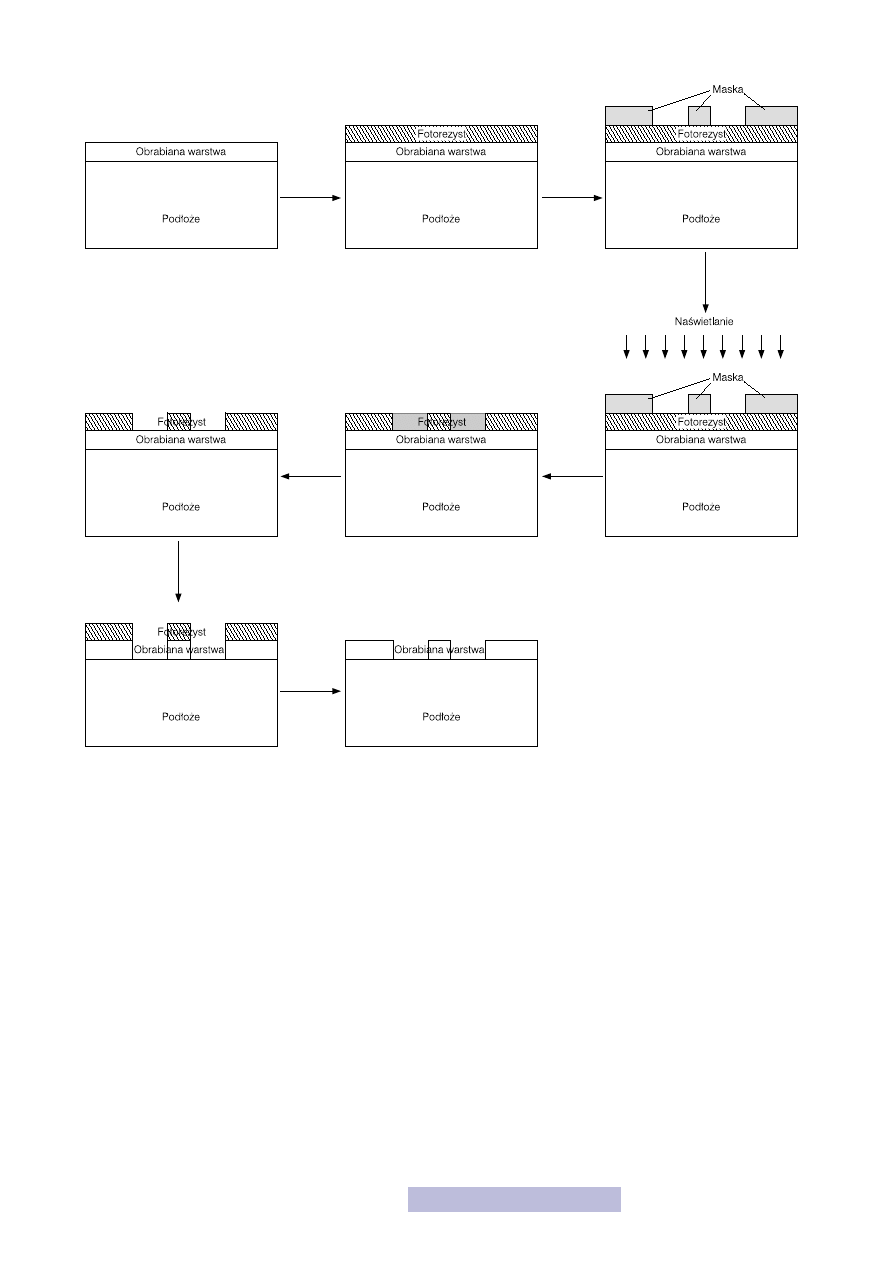
Wykonuje się to w kilku etapach:
— naniesienie na powierzchnię warstwy fotorezystu, a więc materiału światłoczu-
łego,
— nałożenie odpowiedniej maski, przez którą przepuszczane jest światło, powodu-
jące zmianę własności fotorezystu tam, gdzie pada na niego światło oraz pozo-
stawienie bez zmian obszarów, gdzie był on zakryty,
— wywołanie fotorezystu,
— strawienie warstwy niepokrytej fotorezystem,
— usunięcie fotorezystu.
Rysunek 22
Schemat PVD
16
Powyższe procesy, za wyjątkiem trawienia, noszą wspólną nazwę litografii. Są to
najbardziej krytyczne procesy w całym cyklu produkcji układu scalonego. To wła-
śnie jakość litografii decyduje o możliwości wykonania jak najmniejszych elemen-
tów i najczęściej stanowi ograniczenie w dalszym rozwoju technologii. Można po-
wiedzieć, że postęp w mikroelektronice mierzony jest postępem w litografii. Czę-
sto możesz usłyszeć o wymiarze technologii, np. procesor został wykonany w tech-
nologii 90 nm. To jest właśnie minimalny wymiar, jaki można odwzorować w pro-
cesie litografii. Z tego względu, przyjrzyjmy się bliżej jak przebiega ten proces.
Litografia
Proces litografii zaczyna się od nałożenie warstwy fotorezystu. Jest to najczęściej
gęsta ciecz, którą nakłada się równomiernie na całą płytkę. Jest to substancja świa-
tłoczuła, tzn. zmieniająca swoje własności fizyczne pod wpływem światła. Wyróż-
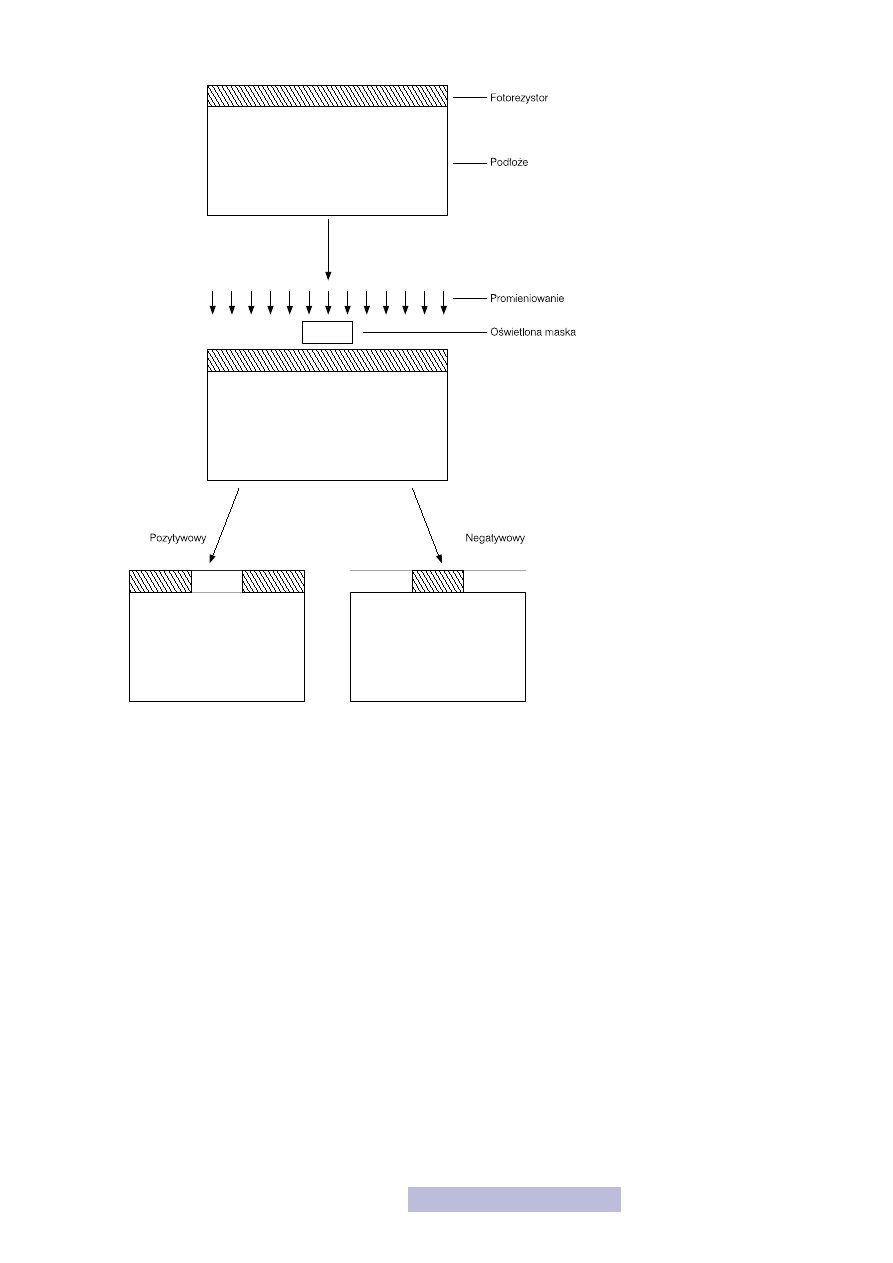
nia się dwa rodzaje fotorezystów:
— pozytywowy,
— negatywowy.
Pierwszy z nich pozostaje po wywołaniu w obszarach zaciemnionych, natomiast
drugi w obszarach naświetlanych (rys. 24). Zatem pierwszy daje dokładnie taki
sam obraz jak wyglądała maska i dlatego jest nazywany pozytywowym, natomiast
drugi obraz odwrotny, dlatego jest nazywany negatywowym.
Rysunek 23
Proces odwzorowywania
kształtu na powierzchni
17
Po naniesieniu fotorezystu następuje jego wygrzanie. Powoduje ono utwardzenie
fotorezystu i jego przywarcie do powierzchni płytki. Następnie nakłada się ma-
skę. Maska jest to po prostu płytka, na którą naniesiony jest wzór, który chcemy
uzyskać. Działa ona tak jak klisza fotograficzna — tam, gdzie chcemy, aby świa-
tło przeszło i naświetliło fotorezyst znajduje się otwór, natomiast tam, gdzie nie
chcemy, obszar jest zakryty. Na temat masek, ich konstrukcji, technologii produk-
cji itp., napisano wiele książek. Wytworzenie maski jest procesem niezwykle trud-
nym, a przede wszystkim bardzo kosztownym. Głównie z tego względu wyróżnia
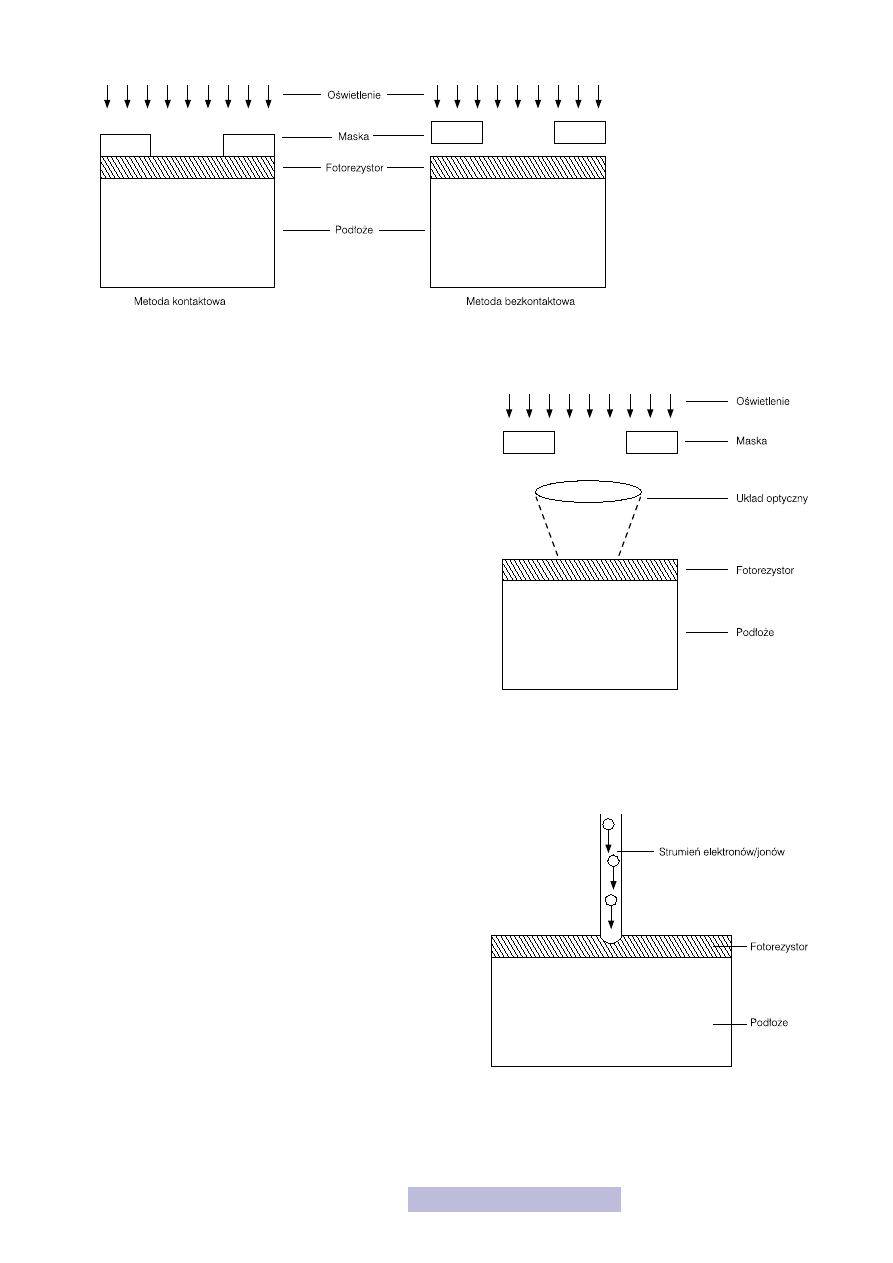
się dwie możliwości ich nakładania (rys. 25):
— kontaktową,
— zbliżeniową.
Rysunek 24
Rodzaje fotorezystów
18
W pierwszym przypadku maskę kładzie się na płytce podłożowej pokrytej foto-
rezystem. Dzięki temu można uzyskać zdecydowanie lepszą rozdzielczość i lepsze
odwzorowanie kształtów, kosztem natomiast jest możliwość uszkodzenia fotorezy-
stu oraz płytki. Dodatkowo w tej metodzie maski zużywają się
zdecydowanie szybciej. Metoda zbliżeniowa polega na umiesz-
czeniu maski bardzo blisko płytki, ale bez styku. Dzięki temu
nie uszkadza się powierzchnia płytki i nie zużywają się maski.
Gorsze jest natomiast odwzorowanie kształtów. W metodzie
zbliżeniowej często poniżej maski umieszcza się dodatkowy
układ optyczny, który pomniejsza obraz (rys. 26). Dzięki temu
można uzyskać jeszcze lepszą rozdzielczość procesu litografii
oraz obniżyć koszty masek, które mogą być wykonane z mniej-
szą dokładnością.
Po nałożeniu maski następuje naświetlenie. Oczywiście zwy-
kłe widzialne światło nie nadaje się do tego celu, ze względu
na zbyt dużą długość fali. Światło widzialne ma zakres długo-
ści fal: 0,38–0,76 µm, natomiast wymiary elementów, które
wykonuje się współcześnie mają poniżej 0,1 µm. Dlatego do
naświetlań stosuje się światło ultrafioletowe, a nawet promie-
niowanie X (rentgenowskie).
Po naświetleniu fotorezyst jest wywoływany, a więc zmyta zostaje ta jego część,
która nie jest już potrzebna. W przypadku fotorezystu pozytywowego będą to ob-
szary naświetlone, natomiast przy negatywowym nienaświetlone (rys. 24).
Przedstawiony proces często nazywany jest fotolitografią.
Inną odmiana litografii jest elektrono- i jonolitografia (rys.
27). Zamiast światła wykorzystuje się w nich strumień elek-
tronów lub jonów, które padają na płytkę pokrytą emulsja
czułą na elektrony lub jony. Dodatkowo nie stosuje się ma-
sek, lecz skanowanie powierzchni płytki strumieniem ładun-
ków. Takie rozwiązanie pozwala na uzyskanie lepszej roz-
dzielczości, jednak jest zdecydowanie kosztowniejsze oraz
wolniejsze.
Po zakończeniu procesu litografii uzyskujemy płytkę, na któ-
rej obszary przeznaczone do wytrawienia są bezpośrednio
dostępne, natomiast pozostałe pokryte są zabezpieczającą
warstwą utwardzonego fotorezystu. W tym momencie moż-
na przystąpić do kolejnego procesu, a więc wytrawiania niepotrzebnych elemen-
tów warstw.
Rysunek 25
Metody nakładania masek
Rysunek 26
Schemat fotolitografii
Rysunek 27
Litografia elektronowa i jonowa
19
Trawienie
Trawienie polega na usunięciu zbędnych elementów warstw niepokrytych fotorezy-
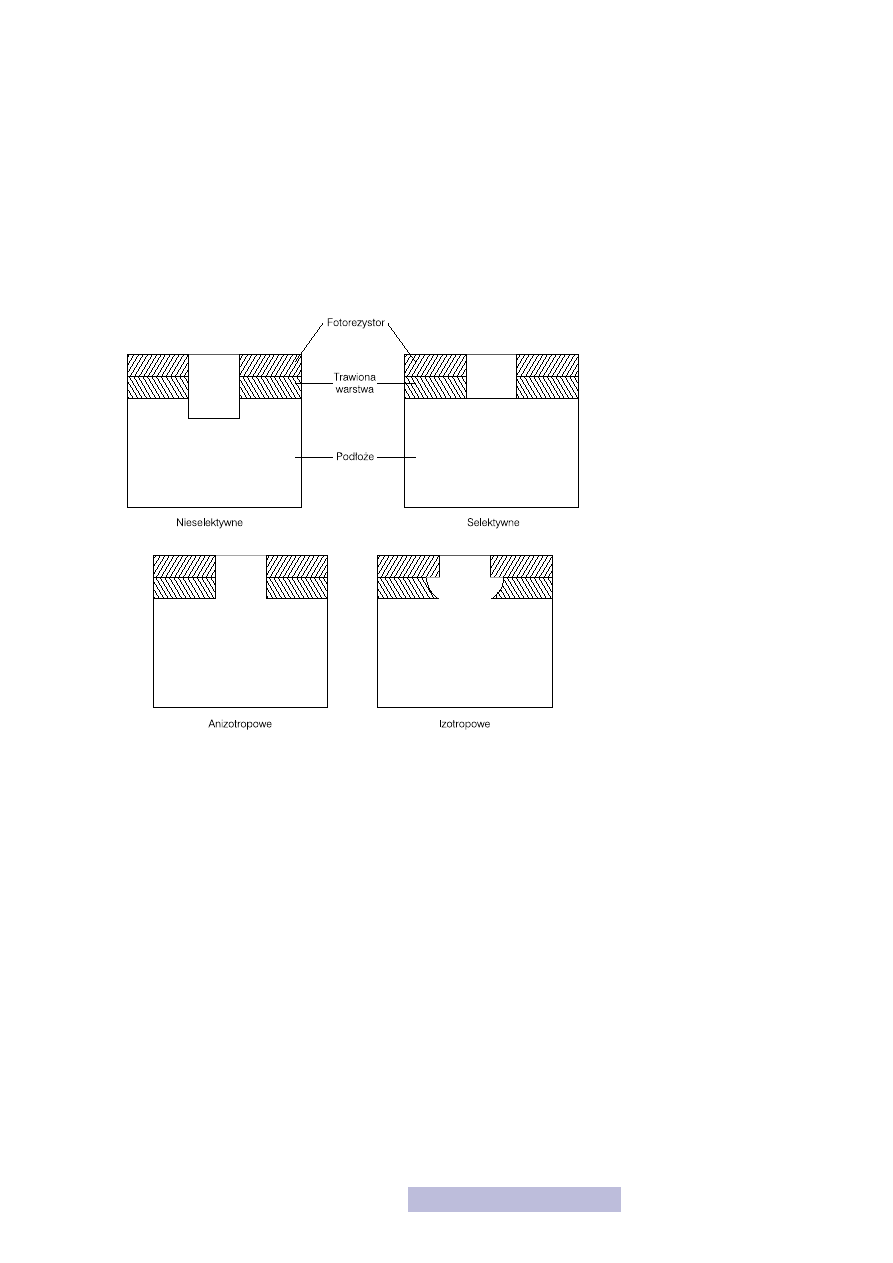
stem. Jedną z najważniejszych cech procesu trawienia jest selektywność, czyli tra-
wienie tylko jednego rodzaju materiału. Przykładem może być trawienie nieosło-
niętego tlenku bramkowego, po zakończeniu którego nie chcemy, aby zaczęło tra-
wić się podłoże krzemowe (rys. 28). Drugą ważną cechą procesu trawienia jest ani-
zotropowość, czyli trawienie tylko w jednym wybranym kierunku (rys. 29). Przeci-
wieństwem trawienia anizotropowego jest trawienie izotropowe, a więc przebiega-
jące w każdym kierunku tak samo. Powstają jednak wówczas bardzo niekorzystne
efekty podtrawienia. Jeśli trawiona warstwa jest gruba, to efekt podtrawienia może
całkowicie wypaczyć otrzymaną strukturę.
Wyróżniamy dwa rodzaje procesów trawienia:
— na mokro,
— na sucho.
Pierwszy z nich polega na zanurzeniu płytki w cieczy trawiącej. Metoda ta jest sto-
sunkowo prosta, tania, zapewnia dobrą selektywność, natomiast ma cechę izotro-
powości. Ciecz obmywa każdą część płytki i trawi w każdy kierunku wybrany ma-
teriał. Oczywiście stosuje się wiele zabiegów, mających na celu ukierunkowanie
procesu trawienia, np. wspomaganie plazmą oraz bombardowanie trawionej po-
wierzchni jonami. Oba zabiegi powodują zwiększenie szybkości reakcji na wybra-
nej powierzchni, a więc w tym samym czasie zostanie ona strawiona w większym
stopniu w wybranym kierunku.
Trawienie na sucho polega na umieszczeniu płytki w komorze próżniowej i bom-
bardowaniu jej powierzchni rozpędzonymi jonami lub cząstkami neutralnymi, np.
argonem. Pędzące atomy przy zderzeniu z płytką wybijają atomy z jej powierzchni.
W miejscach, w których jest fotorezyst, wybijane są jego atomy, natomiast w miej-
scach, w których go nie ma, wybijane są atomy warstwy, powodując zmniejszanie
jej grubości. Jeśli bombardowanie trwa dostatecznie długo, cała warstwa zostanie
usunięta. Trawienie na sucho jest oczywiście anizotropowe, gdyż trawieniu pod-
lega jedynie powierzchnia, na którą padają jony (podtrawienia są znikome). Nato-
Rysunek 28
Trawienie selektywne
i nieselektywne
Rysunek 29
Trawienie izotropowe
i anizotropowe
20
miast nie jest to trawienie selektywne. Po strawieniu jednej warstwy, jony zaczyna-
ją padać na kolejną, powodując wybijanie z niej atomów. Proces trawienia na sucho
trzeba więc precyzyjnie planować, dobierając czas jego trwania, użyte jony, pręd-
kości, do jakich są rozpędzane itp.
W praktyce oba rodzaje trawień często łączy się ze sobą, uzyskując najlepsze efekty.
3.4. Zmiana własności materiału
Ostatnim zabiegiem technologicznym, jaki omówimy jest modyfikacja własności
materiałów. Procesy w tej grupie można podzielić na:
— domieszkowanie,
— wygrzewanie.
Pierwszy z procesów polega na wprowadzeniu atomów domieszki do podłoża.
Może to spowodować zmianę typu półprzewodnika, np. z P na N, ewentualnie
zwiększenie koncentracji domieszki. Natomiast drugi proces ma za zadanie zmie-
nić rozkład domieszki wewnątrz struktury oraz zlikwidować niektóre jej defekty.
Przyjrzymy się najpierw procesom domieszkowania.
Dyfuzja
Proces dyfuzji polega na ruchu atomów w wyniku różnicy ich koncen-
tracji. Jest on szczególnie widoczny w gazach. Jeśli w powietrzu w jed-
nym miejscu pojawi się zapach, to rozprzestrzenia się on. Oczywiście
traci przy tym na „sile”, ale rozprzestrzenia się w każdym kierunku.
Podobnie jest w ciałach stałych — oczywiście proces ten jest w nich
zdecydowanie powolniejszy, lecz zachodzi i jest wykorzystywany wła-
śnie w procesie domieszkowania dyfuzyjnego.
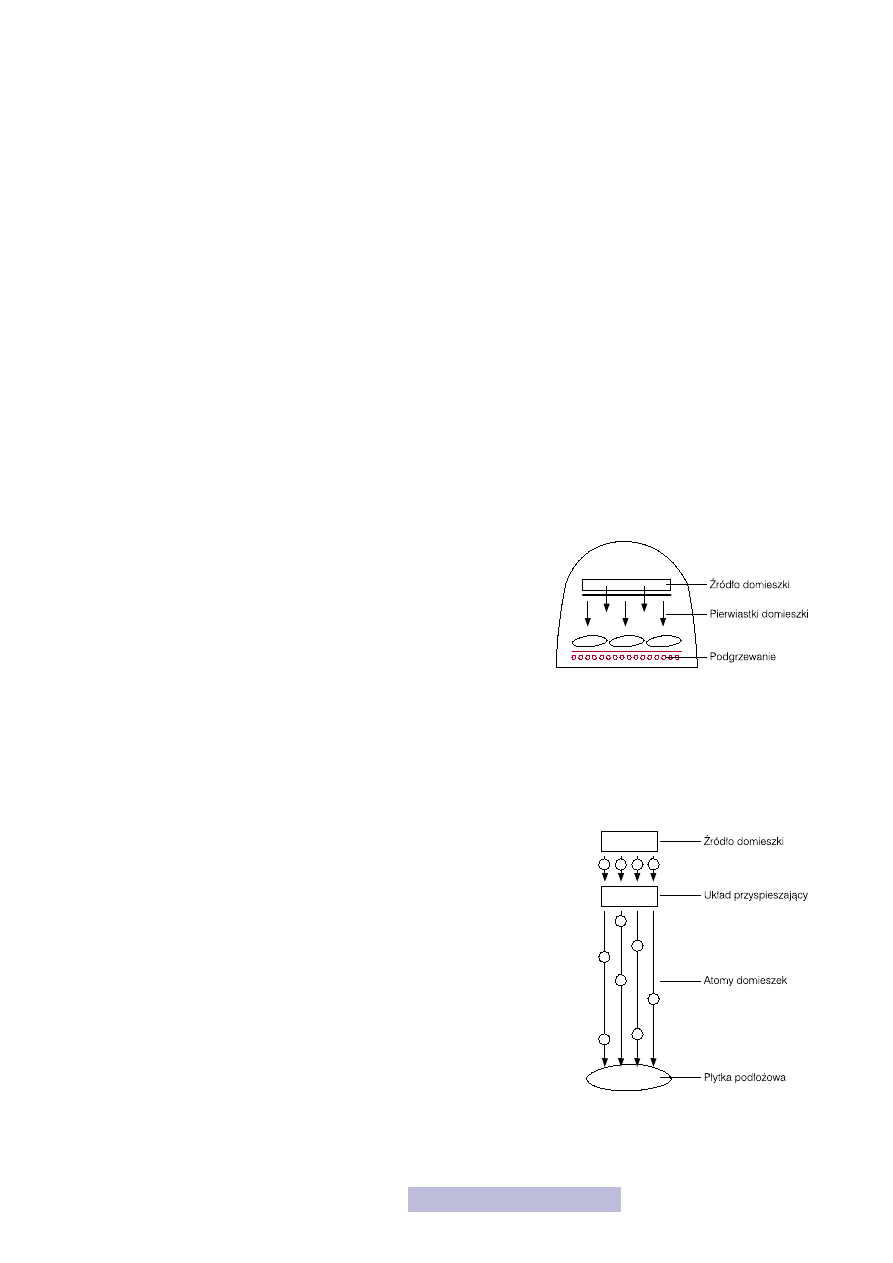
Dyfuzja wykonywana jest w piecu dyfuzyjnym (rys. 30), w którym umieszcza się
płytki podłożowe oraz źródło domieszki. Cały proces przeprowadza się w pod-
wyższonej temperaturze, która znacznie przyspiesza dyfuzję. Źródłem mogą być
zarówno gazy, ciecze, jak i ciała stałe. Zasadą jest dostarczenie do powierzchni
atomów domieszki, które w wyniku zjawiska dyfuzji wnikają do wnętrza struktu-
ry krzemowej i rozchodzą się w niej. W rzeczywistości proces ten zachodzi dwu-
etapowo:
— na powierzchni tworzą się tlenki domieszki,
— następuje odłączenie od nich atomu tlenu i utworzenie tlenków krzemu,
a pozostałe atomy domieszki wnikają do wnętrza płytki i tam dyfundują
w głąb w wyniku różnicy koncentracji.
Proces dyfuzji jest stosunkowo powolny i trudny w kontrolowaniu, dlatego
we współczesnej mikroelektronice jest rzadko stosowany.
Implantacja jonowa
Proces implantacji jonowej jest bardzo zbliżony do przedstawionego już tra-
wienia na sucho. Podobnie jak w przypadku trawienia, pierwiastki są roz-
pędzane i „wbijane” w strukturę krzemu (rys. 31). Jedyna różnica polega na
zastosowanych pierwiastkach oraz ich energiach. W przypadku trawienia
muszą to być duże atomy, niezbyt mocno rozpędzone, które wybiją atomy
z warstwy wierzchniej. Natomiast przy implantacji są to po prosty atomy
domieszki rozpędzone do wysokich energii, tak aby mogły wbić się na pewną głę-
bokość w strukturę.
Rysunek 30
Proces dyfuzji
Rysunek 31
Implantacja jonowa
21
Implantacja jonowa jest obecnie najważniejszym dla mikroelektroniki procesem
domieszkowania. Pozwala bardzo precyzyjnie umieścić odpowiednią liczbę ato-
mów domieszki na odpowiedniej głębokości. Wadą tego procesu jest uszkadzania
struktury przez wbijające się atomy. Jednak po procesie implantacji stosuje się naj-
częściej wygrzewanie, które naprawia powstałe uszkodzenia.
Procesy domieszkowania wykonuje się najczęściej tylko na ograniczonym obszarze.
W procesie dyfuzji wystarczy zamaskować fotorezystem obszary, które nie mają
być domieszkowane. Natomiast przed procesem implantacji jonowej wykonuje się
najczęściej grube tlenki maskujące, które zatrzymują w sobie padające atomy i nie
dają im dojść do powierzchni krzemu.
Wygrzewanie
Ostatnim procesem modyfikującym własności powierzchni jest wygrzewanie. Pro-
ces ten powoduje redyfuzję, czyli przemieszczanie się atomów domieszek wewnątrz
płytki podłożowej. Mówiąc obrazowo, powoduje to „rozmycie” wprowadzonej do-
mieszki. Drugim efektem wygrzewania jest naprawa defektów struktury, szczegól-
nie po procesie implantacji jonowej. Wygrzewanie można prowadzić celowo, ewen-
tualnie przy okazji innych procesów, np. utleniania termicznego.
3.5. Ogólne zasady przeprowadzania procesów technologicznych
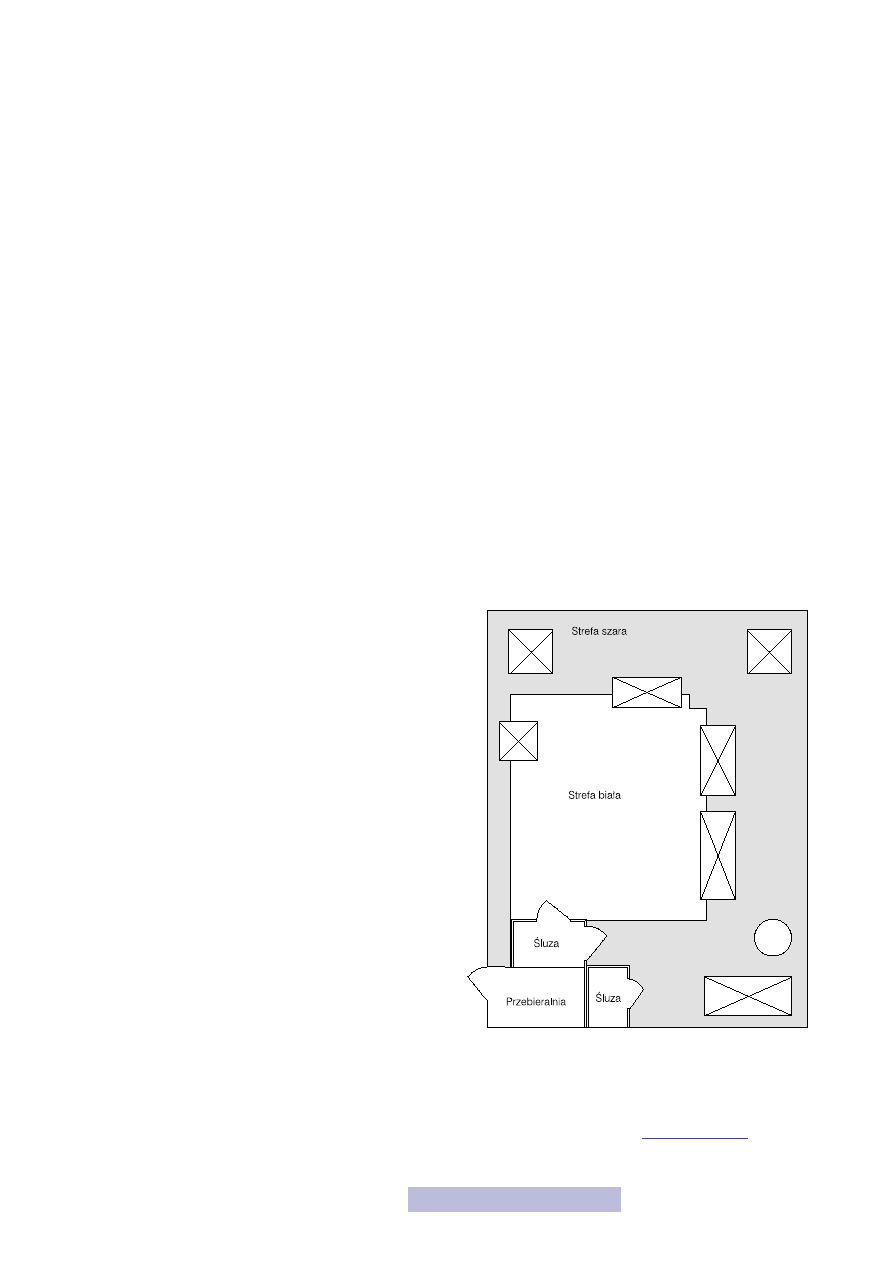
Najważniejszą zasadą prowadzenia procesów technologicznych jest zachowanie
jak największej czystości. Większość procesów prowadzonych jest w tzw. clean-
-roomach, czyli pomieszczeniach o niewyobrażalnej wręcz
czystości. Miarą tej czystości jest liczba zanieczyszczeń,
jaka znajduje się w jednej stopie
1
sześciennej i wynosi ona
od 1 do 1000. Dla porównania w najczystszych salach
operacyjnych liczba zanieczyszczeń to więcej niż dziesiąt-
ki milionów w stopie sześciennej, a więc tysiące razy wię-
cej! Do tego znajdujące się w clean-roomie zanieczyszcze-
nia muszą być bardzo małe, gdyż w przeciwnym wypadku
mogą uszkodzić produkowane elementy.
Aby zapewnić tak ogromną czystość, pomieszczenia mu-
szą być w specjalnych sposób zaprojektowane (rys. 32).
Wyróżnia się w nich dwie strefy:
— białą — o najwyższej czystości,
— szarą — o podwyższonej czystości.
Strefa biała to miejsce, gdzie wykonuje się wszystkie naj-
bardziej krytyczne procesy technologiczne. Aby ich nie
zanieczyścić, człowiek wchodzi do nich tylko w sytu-
acjach absolutnej konieczności, w specjalnych kombi-
nezonach i maskach. Co więcej, zanim wejdzie, nawet
ubrany w kombinezon, poddawany jest w specjalnej ślu-
zie procesowi wielokrotnego nadmuchu powietrzem. Po-
nadto wszystkie urządzenia znajdujące się w strefie białej muszą być wykonane ze
specjalnych materiałów oraz mieć taką konstrukcję, aby nie mogły się w nich gro-
madzić zanieczyszczenia.
W całym clean-roomiem panuje podwyższone ciśnienie, tak aby powietrze ciągle
wydobywało się z pomieszczenia i nie pozwalało na wnikanie do wnętrza zanie-
1
Jedna stopa to 32 cm.
Rysunek 32
Schemat clean-roomu

22
czyszczeń. Powietrze, które dostaje się do pomieszczenia jest ciągle i wielostopnio-
wo filtrowane, oczyszczane, infrastruktura pracuje przez całą dobę, aby utrzymać
tę nieskazitelną czystość. Oczywiście koszty tego są ogromne, dlatego dąży się do
jak największego ograniczenia powierzchni strefy białej. Stąd wokół niej znajduje
się tzw. strefa szara, a więc miejsce o podwyższonej czystości, ale już nie tak kry-
tycznej jak w strefie białej. W strefie szarej znajdują się m.in. urządzenia lub ich czę-
ści, które nie są niezbędne w procesie technologicznym.
Samo zachowanie czystości laboratorium nie jest wystarczające. Do procesów tech-
nologicznych należy używać specjalnych oczyszczanych odczynników chemicznych,
produkowanych wyłącznie na potrzeby przemysłu półprzewodnikowego. Wszyst-
kie użyte materiały, m.in. płytki podłożowe, pojemniki z odczynnikami, zanim
znajdą się w clean-roomie, muszą zostać dodatkowo oczyszczone w strefie szarej.
Drugą ważną zasadą jest umiejętne planowanie procesów technologicznych, szcze-
gólnie ich kolejności. Chodzi o to, aby poszczególne procesy nie wpływały nega-
tywnie na siebie, a ich liczba była jak najmniejsza. Jako przykład można podać fakt,
że wszystkie procesy wykonywane w podwyższonych temperaturach powodują re-
dyfuzję domieszek w podłożu. Dlatego po wykonaniu domieszkowania nie nale-
ży wykonywać utleniania termicznego, tylko nanosić tlenek metodą CVD. Innym
przykładem mogą być procesy litografii, które są krytyczne w technologii mikro-
elektronicznej i ich liczbę należy ograniczyć do minimum. Zatem w jednym proce-
sie litografii należy wykonać możliwie jak największą liczbę odwzorowań.
23
4. Proces technologiczny produkcji
tranzystora MOS i inwertera CMOS
Poznałeś przed chwilą podstawowe procesy technologiczne umożliwiające wytwo-
rzenie tranzystora MOS. Czas wypełnić ostatnią lukę w naszej mikroelektronicznej
układance, a mianowicie poznać proces produkcji tranzystora MOS oraz inwertera
CMOS. Analogicznie wykonuje się pozostałe bramki logiczne, połączenia między
nimi oraz całe układy scalone.
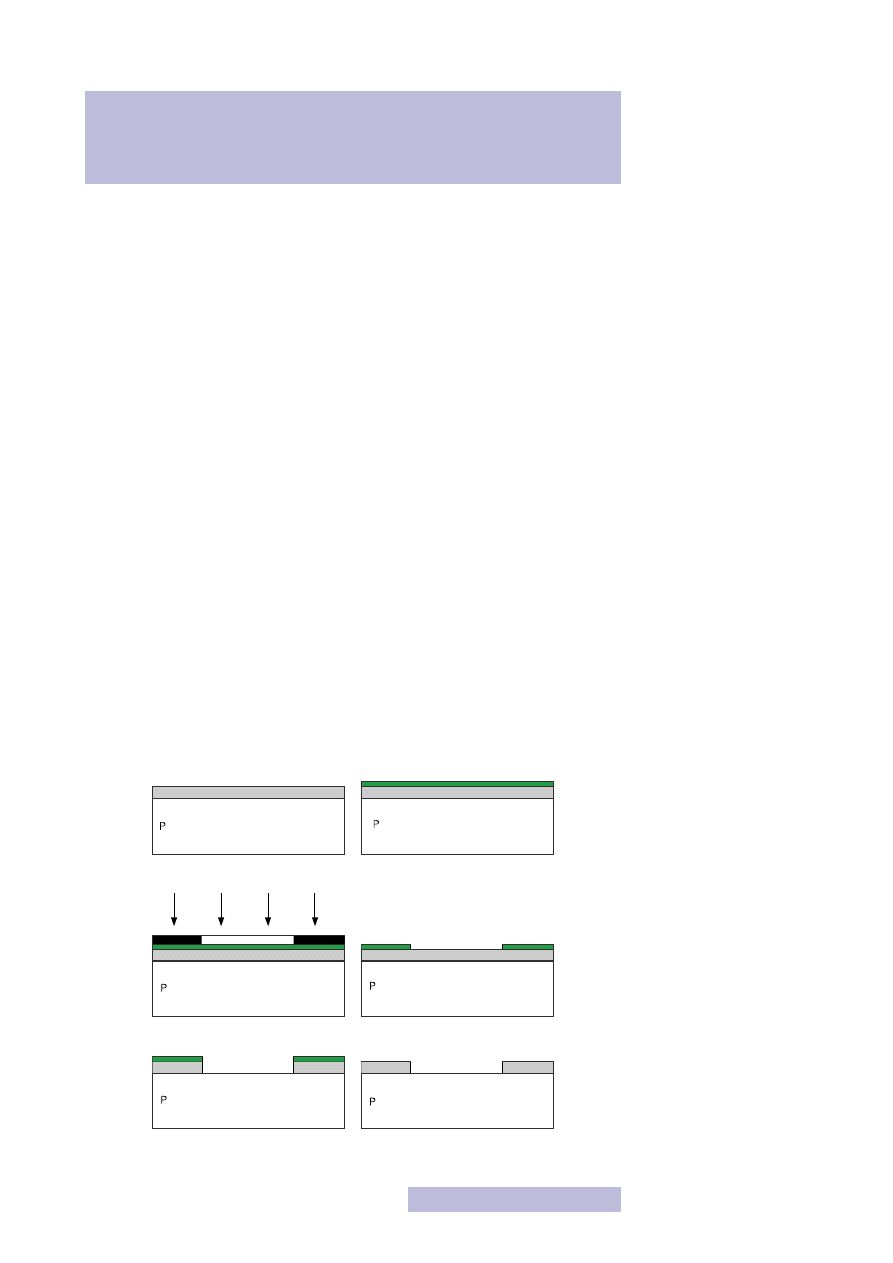
4.1. Proces wykonania tranzystora NMOS
Poniżej został przedstawiony proces technologiczny wykonania tranzystora
NMOS. Należy zwrócić szczególną uwagę na proces nr 14, nazywany
samocentro-
waniem bramki
. Pomysł samocentrowania umożliwia tak ogromną miniaturyzację
poszczególnych przyrządów, jaką obecnie mamy okazję obserwować. Polega on na
wykorzystaniu polikrzemu i tlenku bramkowego jako maski przy procesie dyfuzji!
Dzięki temu samoczynnie powstaje niedomieszkowany obszar kanału, bez koniecz-
ności późniejszego dopasowywania bramki i domieszkowań. Ponadto proces ten
powoduje dodatkowe domieszkowanie polikrzemowej elektrody bramki (powinna
być ona jak najsilniej domieszkowana). Właśnie od momentu wykorzystania tego
pomysłu zaczął się tak szalony postęp w dziedzinie mikroelektroniki.
Zwróć również uwagę na wykorzystanie tlenków jako substancji izolującej połącze-
nia metaliczne. Pozwala to na uniknięcie ewentualnych zwarć w układzie oraz za-
bezpiecza układ od strony mechanicznej.
1. Utlenianie powierzchni
2. Nałożenie fotorezystu
3. Nałożenie maski i naświetlanie 4. Wywołanie fotorezystu
5. Wytrawienie tlenku
6. Usunięcie fotorezystu
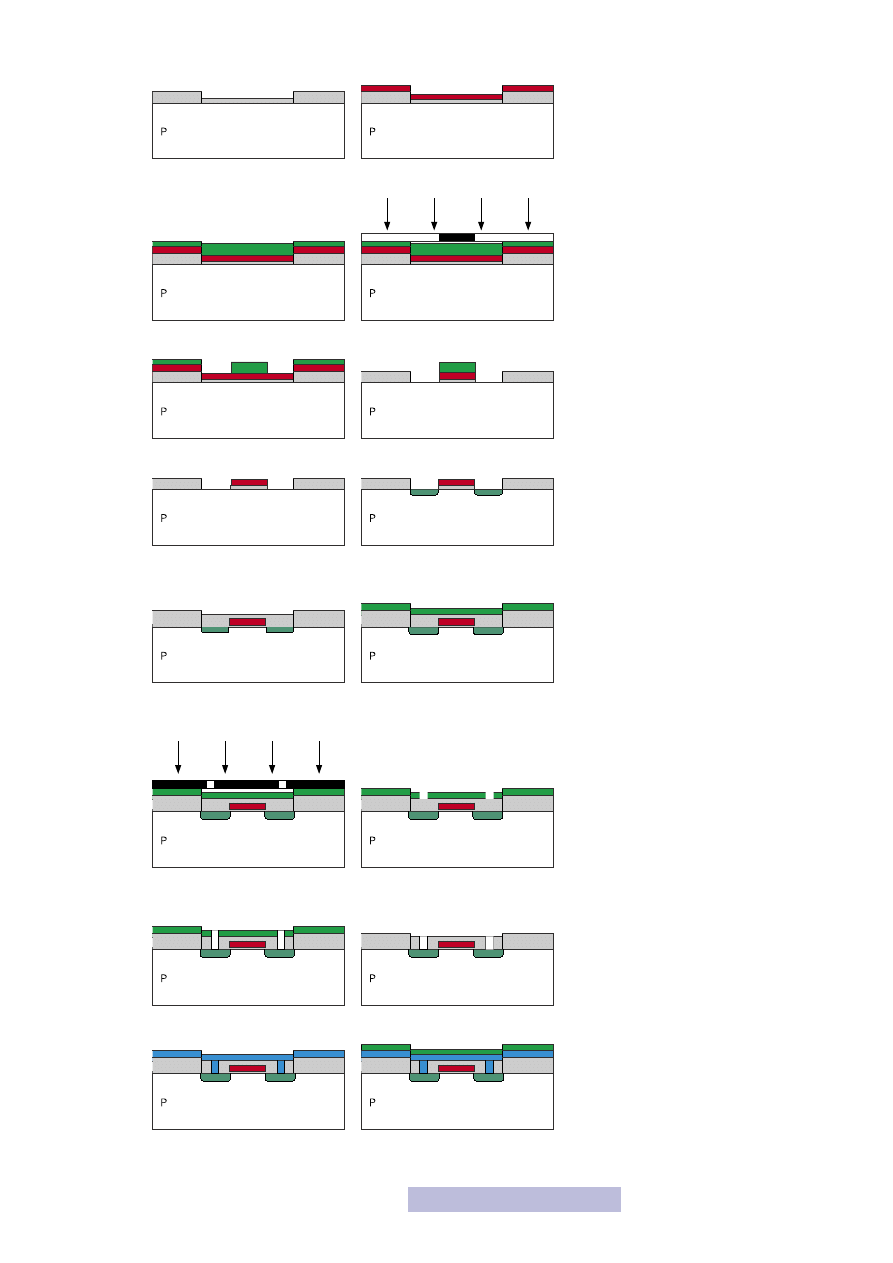
24
7. Nałożenie cienkiego tlenku
8. Nałożenie polikrzemu
9. Nałożenie fotorezystu
10. Nałożenie maski i naświetlenie
11. Wywołanie
12. Wytrawienie polikrzemem
13. Usunięcie fotorezystu
14.
Dyfuzja drenu i źródła
(samocentorwanie)
15.
Nałożenie warstwy
izolacyjnej
16. Nałożenie fotorezystu
17.
Nałożenie maski
i naświetlenie
18. Wywołanie
19. Trawienie tlenku
20. Usunięcie fotorezystu
21. Pokrycie warstwą metalu
22. Pokrycie warstwą fotorezystu
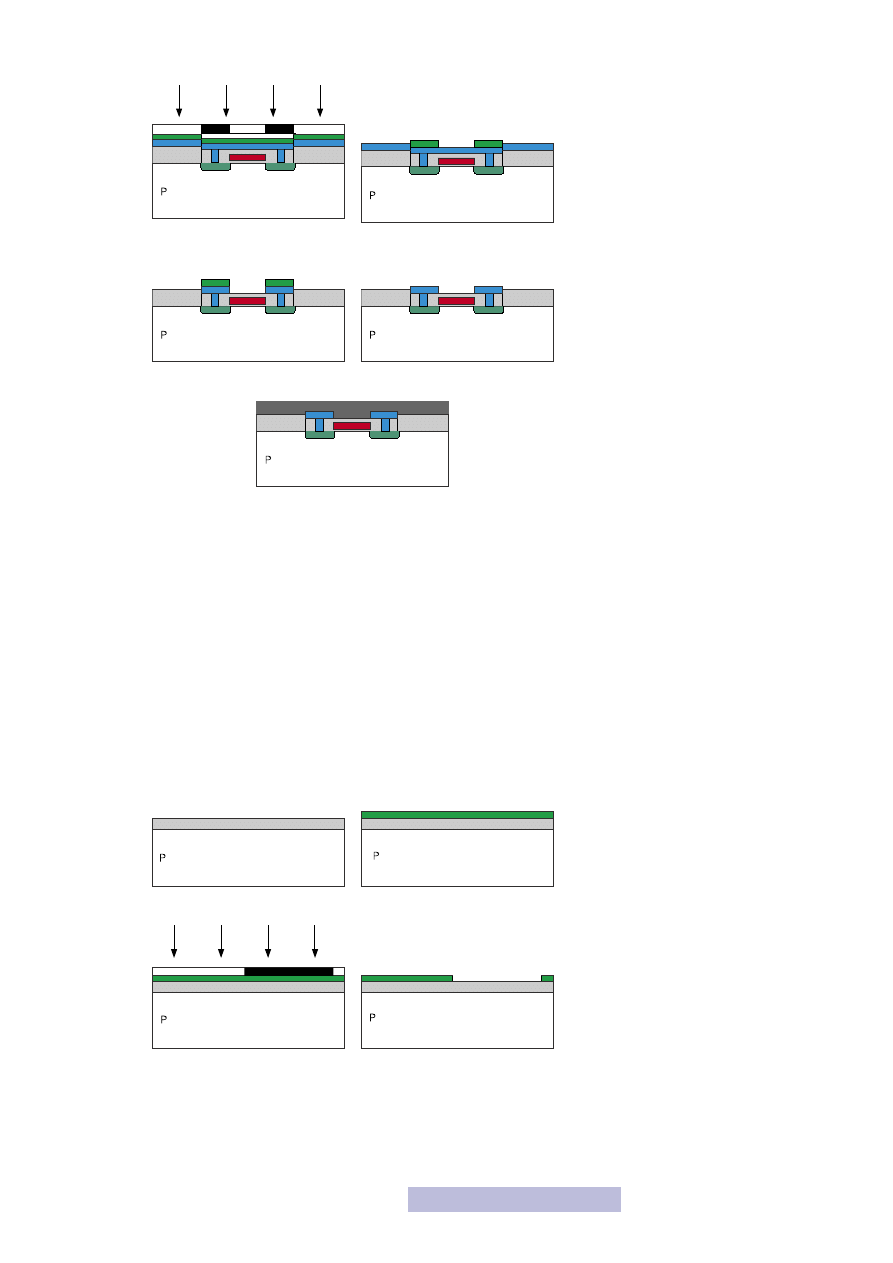
25
23. Nałożenie maski
i naświetlenie
24. Wywołanie fotorezystu
25. Wytrawienie metalizacji
26. Usunięcie fotorezystu
27. Nałożenie warstwy pasywacyjnej
4.2. Proces wytwarzania inwertera CMOS
Poniżej został przedstawiony proces produkcji inwertera CMOS. Polega on na wy-
tworzeniu dwóch tranzystorów MOS: jednego NMOS, drugiego PMOS. Jako że
wiesz już jak tworzy się tranzystor MOS, część etapów została pomięta. Najwięk-
sza różnica między wytworzeniem tych dwóch tranzystorów polega na zaimple-
mentowaniu na początku studni dla tranzystora PMOS. Jak pamiętasz, podłoże
tranzystora PMOS jest typu N, a więc należy wykonać w podłożu typu P duży ob-
szar domieszkowania typu N, w którym zostanie wykonany tranzystor PMOS.
1. Utlenianie powierzchni
2. Pokrycie warstwą fotorezystu
3. Maskowanie i naświetlanie
4. Wywołanie fotorezystu
Rysunek 33
Wytwarzanie tranzystora NMOS
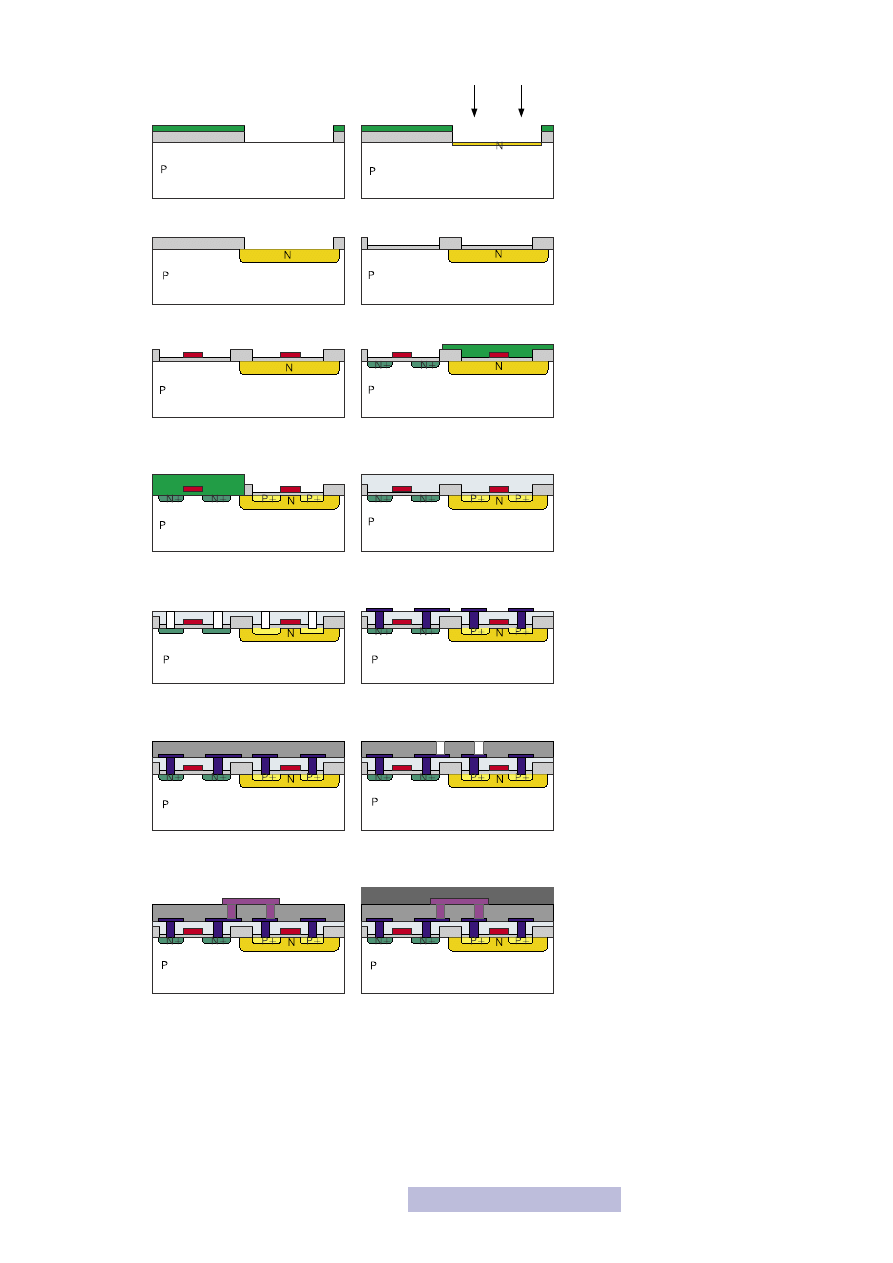
26
5. Wytrawienie tlenku
6. Implantacja jonów
7. Wygrzewanie
8. Wytworzenie tlenku bramkowego
9. Osadzenie, maskowanie
i wytrawianie polikrzemu
10. Wytworzenie tranzystorów NMOS
11. Wytworzenie tranzystorów
PMOS
12. Nałożenie pierwszej warstwy
izolacyjnej
13. Wytrawienie otworów pod
kontakty
14. Kontakty i metalizacja I
15. Nałożenie drugiej warstwy
izolacyjnej
16. Otwory pod przeplotki (VIAs)
17. Przeplotki i metalizacja II
18. Pasywacja końcowa
Rysunek 34
Wytwarzanie inwertera CMOS

27
Podsumowanie
W tym module poznałeś wewnętrzną budowę tranzystora MOS. Teraz już nie tyl-
ko wiesz jak działa tranzystor MOS, ale i to, dlaczego tak działa. Poznałeś również
podstawowe procesy technologiczne, które umożliwiają jego wytworzenie. Na ko-
niec zobaczyłeś jak wygląda proces produkcji tranzystora MOS oraz najprostszej
bramki CMOS, czyli inwertera.
Ułożyłeś więc naszą mikroelektroniczną układankę. Znasz już cały proces — od
pomysłu na układ, przez jego projektowanie, aż do fizycznego wykonania. Myślę,
że wiele pojęć związanych z technologią produkcji układów scalonych (szczególnie
procesorów), z którymi często spotykasz się w literaturze informatycznej, stało się
jasne.

28
Bibliografia
1. Beck R., 1991: Technologia krzemowa, PWN, Warszawa.
2. Europractice. Witryna internetowa.
, stan z 26 wrze-
śnia 2006 r.
3. IBM. Witryna internetowa.
, stan z 26 września 2006 r.
4. Intel. Witryna internetowa.
, stan z 26 września 2006 r.
5. International Technology Roadmap for Semiconductors. Witryna internetowa.
, stan z 26 września 2006 r.
6. Kalisz J., 1998: Podstawy elektroniki cyfrowej, Wydawnictwa Komunikacji
i Łączności, Warszawa.
7. Marciniak W., 1984: Przyrządy półprzewodnikowe i układy scalone, Wydaw-
nictwa Naukowo-Techniczne, Warszawa.
8. Marciniak W., 1991: Przyrządy półprzewodnikowe MOS, Wydawnictwa Na-
ukowo-Techniczne, Warszawa.
9. Massucci J., 2001: Projekt Milenium, Wydawnictwo Amber sp. z o. o., Warszawa.
10. Napieralska M., Jabłoński G., 2002: Podstawy mikroelektroniki, Wydawnic-
twa PŁ, Łódź.
11. University of California, Berkeley. Witryna internetowa.
, stan z 26 września 2006 r.
Document Outline
- Technologie mikroelektroniczne
Wyszukiwarka
Podobne podstrony:
TI moduł 3, Technologie Informacyjne
21 technologie mikroelektroniczne
TI moduł 7, Technologie Informacyjne
TI moduł 1, Technologie Informacyjne
TI moduł 6, Technologie Informacyjne
TI moduł 4, Technologie Informacyjne
Modul 6 Przyszlosc mikroelektroniki
21 Technologie mikroelektroniczne systematyka
MODUL 02 Rynek%20technologii
MODUL 19 Transfer%20technologii%20poprzez%20partnerstwo%20strategiczne
Moduł 7 odpowiedzi, Technologie Informacyjne (TI)
Najważniejsze zagadnienia - Moduł 3, Semestr I, Technologie informacyjne, Moduł 3
Modul 2 Podstawowe elementy stosowane w mikroelektronice
Moduł 3 odpowiedzi, Technologie Informacyjne (TI)
MODUL 06 Ocena%20i%20wybor%20technologii
więcej podobnych podstron