
Statystyka w analizie i planowaniu eksperymentu
Wykład 7
Uzupełnienie informacji o regresji i zagadnienia
pokrewne
Przemysław Biecek
Dla 1 roku studentów Biotechnologii
Słów kilka o estymatorach
Estymator
Estymator to funkcja próby.
Estymatory używane są aby na podstawie próby wyestymować
(ocenić) wartość pewnego, nieznanego, parametru populacji.
Poznaliśmy już między innymi następujące estymatory:
średniej ˆ
µ oznaczany najczęściej przez ¯
x ,
częstości ˆ
p,
wariancji ˆ
σ
2
oznaczany najczęściej przez S
2
,
współczynników modelu regresji ˆ
β
1
, ˆ
β
0
,
korelacji ˆ
ρ.
2/28

Słów kilka o estymatorach
Ta sama wartość może być oceniana na różne sposoby.
Przykładowo do tej pory poznaliśmy dwa estymatory wariancji,
S
2
1
=
1
n
P
i
(x
i
− ¯
x )
2
,
S
2
2
=
1
n−1
P
i
(x
i
− ¯
x )
2
.
Gdy estymatorów jest więcej niż jeden, naturalnymi pytaniami są:
Który z nich jest lepszy?
Jak porównywać te estymatory?
3/28

Słów kilka o estymatorach
Dwa popularne kryteria to obciążoność i wariancja.
Obciążenie estymatora parametru θ wyznacza się następująco
bias
θ
= θE
θ
(ˆ
θ)
gdzie ˆ
θ oznacza estymator parametru θ (estymator a nie ocenę!).
Estymator jest nieobciążony, jeżeli jego obciążenie wynosi 0.
Estymator jest obciążony jeżeli jego obciążenie jest różne od
zera.
Estymator jest asymptotycznie nieobciążony, jeżeli jego
obciążenie maleje do zera wraz z rozmiarem próby.
4/28

Słów kilka o estymatorach
Wariancja estymatora opisuje jak duży jest rozrzut estymatora.
Wariancje estymatora można wyznaczyć ze wzoru
var
θ
= E
θ
(θ − ˆ
θ)
2
.
gdzie ˆ
θ oznacza estymator parametru θ (estymator a nie ocenę!).
Jeżeli jakiś estymator ma mniejszą wariancję niż każdy inny
estymator (dla każdego θ) to mówimy, że jest on estymatorem o
minimalnej wariancji.
5/28

Obciążenie estymatora
Który z tych estymatorów jest nieobciążony?
estymator A
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
estymator B
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
6/28

Wariancja estymatora
Który z tych estymatorów ma mniejszą wariancję?
estymator A
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
estymator B
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
7/28
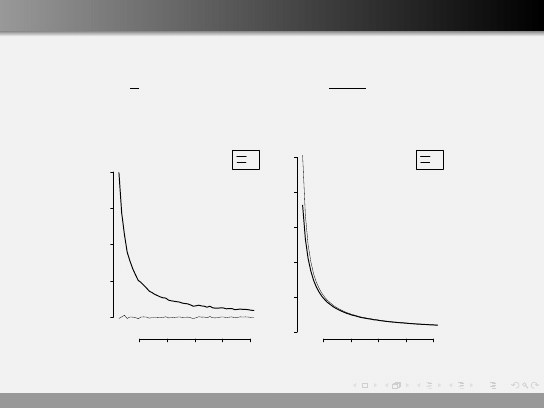
Porównanie estymatorów wariancji
S
2
1
=
1
n
X
i
(x
i
− ¯
x )
2
S
2
2
=
1
n − 1
X
i
(x
i
− ¯
x )
2
20
40
60
80
100
0.00
0.05
0.10
0.15
0.20
n
bias
S1
S2
20
40
60
80
100
0.0
0.1
0.2
0.3
0.4
0.5
n
wariancja
S1
S2
8/28
Współczynnik korelacji Spearmana
Co robić, gdy dane nie maja rozkładu normalnego lub obecne są
wartości odstające?
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−2
0
2
4
6
8
10
−2
0
2
4
6
8
10
cor = 0.8
x
y
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−2
0
2
4
6
8
10
−2
0
2
4
6
8
10
cor = 0.01
x
y
9/28

Współczynnik korelacji Spearmana
W tej sytuacji nie należy używać współczynnika Pearsona.
Używa się współczynnika Spearmana, który korelacje pomiędzy
obserwacjami wyznacza na podstawie rang tych obserwacji
ρ
Spearmana
= cor (r (X ), r (Y ))
Ranga obserwacji x
i
odpowiada indeksowi tej obserwacji w
uporządkowanej próbie.
10/28

Współczynnik korelacji Spearmana
Mamy próbę X
X = (−53, 124, −19, −46, 87, 16, −13, 6, −68, −97)
i próbę Y
Y = (−3, 117, −38, 105, 244, 115, 102, −31, −10, −136)
Wyznaczamy rangi dla tych elementów
r (X ) = (3, 10, 5, 4, 9, 8, 6, 7, 2, 1)
r (Y ) = (5, 9, 2, 7, 10, 8, 6, 3, 4, 1)
I liczymy korelacje rang.
11/28

Współczynnik korelacji Spearmana
> x
[1] -53 124 -19 -46 87 16 -13 6 -68 -97
> rank(x)
[1] 3 10 5 4 9 8 6 7 2 1
> cor(x,y)
[1] 0.7261815
> cor(x,y, method=’pearson’)
[1] 0.7261815
> cor(x,y, method=’spearman’)
[1] 0.7333333
> cor.test(x,y, method=’spearman’)
Spearman’s rank correlation rho
data: x and y
S = 44, p-value = 0.01976
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.7333333
12/28

Współczynnik korelacji Spearmana
Ile wynosi korelacja w takim przypadku?
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
x
y
które ρ = 0.85 a które ρ = 0.95?
13/28

Współczynnik korelacji Spearmana
Wartości współczynników korelacji Pearsona i Spearmana mogą się
różnić. Ale dla dużych prób, gdy rozkład obserwacji jest normalny
a relacja pomiędzy zmiennymi ma charakter liniowy, to
współczynniki te przyjmują podobne wartości.
Współczynnik Spearmana powinno się stosować, gdy:
rozkład danych nie jest normalny,
obecne są obserwacje odstające,
nie jest dla nas ważna liniowość relacji pomiędzy zmiennymi.
14/28

Regresja nieliniowa
Co zrobić gdy zależność pomiędzy zmiennymi wygląda na
nieliniową?
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
x
y
15/28

Regresja nieliniowa
Mamy kilka możliwości:
wykonać transformacje zmiennych objaśniających,
wykonać transformacje zmiennych objaśnianych,
przybliżać zależność za pomocą prostych na fragmentach
dziedziny x,
wybrać inny model regresji (nieliniowy).
16/28
Regresja nieliniowa
Co dają nam transformacje wielomianowe?
x
0
= x
2
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
x
y
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
0.0
0.2
0.4
0.6
0.8
1.0
x^2
y
17/28
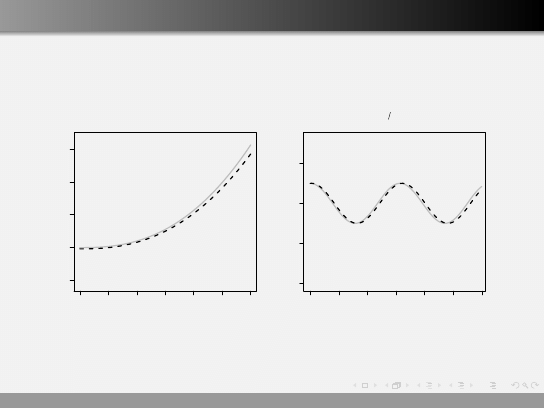
Regresja nieliniowa
Co daje nam logarytmowanie?
y
0
= log (y )
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
0
20
40
60
80
100
120
140
x
y
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.2
0.4
0.6
0.8
1.0
5
10
20
50
100
x
y
18/28

Regresja nieliniowa
Ogólny model gaussowskiej regresji nieliniowej
Y = f (X , θ) + ε,
gdzie
ε ∼ N (0, σ
2
).
Znalezienie ocen parametrów w takim modelu nie jest łatwe,
rozwiązania wyznaczane są korzystając z metod numerycznych.
19/28

Regresja nieliniowa
Ale w R to jest proste!
> x = runif(100)*3
> y = x
2.5
− 5+rnorm(100,0,3)
> model <- nls(y ∼ x
a
− b, start = list(a = 2, b=2))
> summary(model)
Formula: y ∼ x
a
− b
Parameters:
Estimate Std. Error t value Pr(>|t|)
a
2.4281
0.0722
33.6
<2e-16 ***
b
5.1934
0.3729
13.9
<2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.99 on 98 degrees of freedom
Number of iterations to convergence: 4
Achieved convergence tolerance: 3.42e-07
20/28
Regresja nieliniowa
Bardziej skomplikowane zależności
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0.0
0.5
1.0
1.5
2.0
2.5
3.0
−10
−5
0
5
10
y
==
x
2.5
−−
5
++ εε
x
y
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
0
1
2
3
4
5
6
−4
−2
0
2
y
==
sin
((
ππ
2
++
2.5x
))
++ εε
x
y
21/28

Regresja logistyczna
Regresja liniowa służyła nam do opisywania zależności pomiędzy
zmienną ilościową a inną zmienną ilościową, lub zbiorem
zmiennych ilościowych (regresja wieloraka).
W sytuacji gdy zmienną objaśnianą jest zmienna binarna to regresji
liniowej użyć nie możemy.
Zmienne binarne są bardzo częste w rzeczywistych analizach.
Przykładowo gdy interesuje nas odpowiedź myszy na podanie
pewnej ilości inhibitora genu BRCA1. Jeżeli mysz może być tylko w
dwóch stanach, np: żywa/zdechła, chora/zdrowa,
normalna/zmieniona to jak stan myszy opisać ilością podanego
inhibitora?
22/28
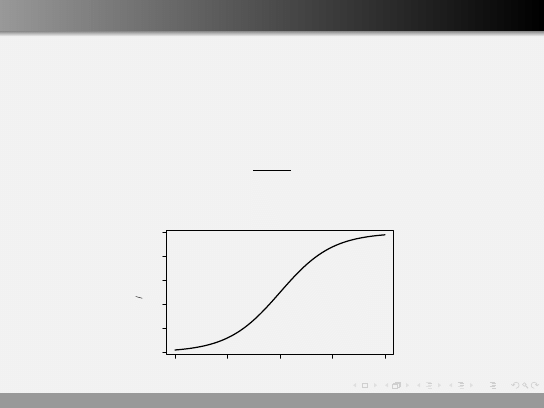
Regresja logistyczna dla jednej zmiennej
W regresji logistycznej modeluje się prawdopodobieństwo
wystąpienia określonego zjawiska za pomocą rozkładu
dwumianowego
Y = B(1, p)
gdzie prawdopodobieństwo p sukcesu określa się następująco
logit(p) = ln(
p
1 − p
) = β
0
+ β
1
X
−4
−2
0
2
4
0.0
0.2
0.4
0.6
0.8
1.0
p
ln
((
p
((
1
−−
p
))))
23/28

Regresja logistyczna
> z
[1] nie zyje nie zyje zyje zyje nie zyje zyje zyje zyje ....
Levels: zyje nie zyje
> x
[1] 4.405359 4.002627 2.417993 2.492061 4.244590 2.798724 ....
> modelRL <- glm(z∼x, family="binomial")
> summary(modelRL)
Call:
glm(formula = z ∼ x, family = "binomial")
Deviance Residuals:
Min
1Q
Median
3Q
Max
-1.37241
-0.24212
-0.03202
0.01613
1.92766
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept)
-21.604
11.221
-1.925
0.0542 .
y
7.342
3.872
1.896
0.0579 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 26.920 on 19 degrees of freedom
Residual deviance: 7.790 on 18 degrees of freedom
AIC: 11.79
Number of Fisher Scoring iterations: 8
24/28

Kocowy model regresji logistycznej?
Na podstawie tych wyników, możemy podać jawną postać modelu.
Pr (z =
0
nie zyje
0
) =
exp(7.3 ∗ x − 21.6)
1 + exp(7.3 ∗ x − 21.6)
●
zyje
nie zyje
1
2
3
4
5
z
ilosc inhibitira [mg]
25/28

Regresja wieloraka / wieloczynnikowa
Do tech chwili mówiliśmy o zależnością pomiędzy parą zmiennych,
ale zmiennych objaśniających może być więcej.
Gdy wiemy, że na jakąś cechę wpływa wiele parametrów i te
parametry możemy kontrolować, wtedy możemy zbudować model
uwzględniający wszystkie parametry.
Przykładowo na obfitość plonów może wpływać nasłonecznienie,
wilgotność, stopień nawożenia. Zamiast budować model dla każdej
z tych zmiennych osobno, możemy zbudować jeden model
całościowo uwzględniający wpływ tych zmiennych.
26/28

Regresja logistyczna
> modelPP <- lm(cena∼powierzchnia+pokoi, data = mieszkania)
> summary(modelPP)
wyświetlamy podsumowanie modelu liniowego
Call:
lm(formula = cena ∼ powierzchnia + pokoi, data = mieszkania)
Residuals:
Min
1Q
Median
3Q
Max
-39705.0 -9386.1 -863.5 9454.3 35097.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept)
82407.1
2569.9
32.066
<2e-16 ***
powierzchnia
2070.9
149.2
13.883
<2e-16 ***
pokoi
840.1
2765.1
-0.304
0.762
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 14110 on 197 degrees of freedom
Multiple R-Squared: 0.8937, Adjusted R-squared: 0.8926
27/28

Co trzeba zapamiętać?
Jakie właściwości mogą mają estymatory, jakimi kryteriami
kierować się przy wyborze estymatora?
Jak na ocenę korelacji wpływa niespełnienie jej założeń i co
robić gdy zmienne nie mają rozkładu normalnego lub
zależność nie jest zależnością liniową.
Jakie rodzaje regresji poznaliśmy, od czego zależy które
metody regresji będziemy stosować?
28/28
Wyszukiwarka
Podobne podstrony:
07 Zagadnienia zrodla poznania II
2013 07 01 BaRD W ST zagadnienia
07 Zagadnienia zrodla poznania IIid 6750 ppt
zagadnienia 07 08
07 zagadnienia na egzamin
zagadnienia na egzamin pisemny 07
Zagadnienia na zaliczenie (mechanika) 07
07. Zagadnienia źródła poznania II, Archiwum, Filozofia
Went I i II zagadnienia egz 06 07, Zagadnienia do egzaminu z wentylacji
Zagadnienia na egzamin03 07
07 Zagadnienia zrodla poznania II
Z zagadnienia żydowskiego w Polsce Przegląd Powszechny 1938 07 t 219
BW 1920 07 Zagadn roli gen Weyganda
więcej podobnych podstron