
1
WOJSKOWA AKADEMIA TECHNICZNA
im. Jarosława Dąbrowskiego
SYSTEMY DIALOGOWE
SPRAWOZDANIE Z ĆWICZENIA nr 3
Temat:
Urządzenie automatycznego rozpoznawania sygnału mowy
metodą rozpoznawania wzorców
(projekt dla małego słownika)
Wykonał: plut. pchor. Radosław WOŹNIAK
Grupa: I9G1S1

2
1.
TREŚĆ ZADANIA
1)
Założenia:
- mały słownik wyrazów rozpoznawanych: 10 słów,
- jednostka fonetyczna: całe słowo.
2)
Przygotować dane:
-
sformułować słownik wyrazów rozpoznawanych;
-
dokonać rejestracji wszystkich słów (każde słowo 15-krotnie, w
oddzielnym pliku .wav);
-
do rejestracji przyjąć: f
s
= 22050 Hz, 16 bitów/próbka, kodowanie
PCM, mono;
3)
Zdefiniować wzór testowy(obserwacja) (współrzędne wektora obserwacji,
np.: energia, długość – liczba próbek, liczba przejść przez zero,
współczynniki FFT (widmo) od 3 do 10, współczynniki LPC, itp.)
4)
Opracować procedurę uczenia - utworzyć wzorce słów:
-
zdefiniować wzorzec,
-
określić ciąg uczący,
-
dokonać estymacji parametrów wzorców
5)
Opracować procedurę rozpoznawania
6)
Dokonać weryfikacji i testowania urządzenia:
-
określić ciąg testowy
-
wyznaczyć statystyki rozpoznawania (estymatory
prawdopodobieństwa poprawnego rozpoznania, analiza błędów
rozpoznawania)
-
zaproponować kierunki zmian w celu poprawienia jakości
zbudowanego urządzenia ARM
Dokonać implementacji urządzenia w środowisku MATLAB.
3
2. WYNIKI
W celu realizacji zadania został sformułowany słownik składający się z 10
wyrazów (nagranych po 15 razy każdy). Zgodnie z zaleceniami każdy wyraz został
zapisany w oddzielnym pliku typu wav. Przy nagrywaniu przyjąłem częstotliwość
próbkowania wynoszącą 22kHz, rozdzielczość 16bitów na próbkę oraz tryb mono.
Nagrane wyrazy to:
beta;
koc;
drukarka;
borowiki;
komputer;
daktyloskopia;
mysz;
rower;
spacja;
wideo;
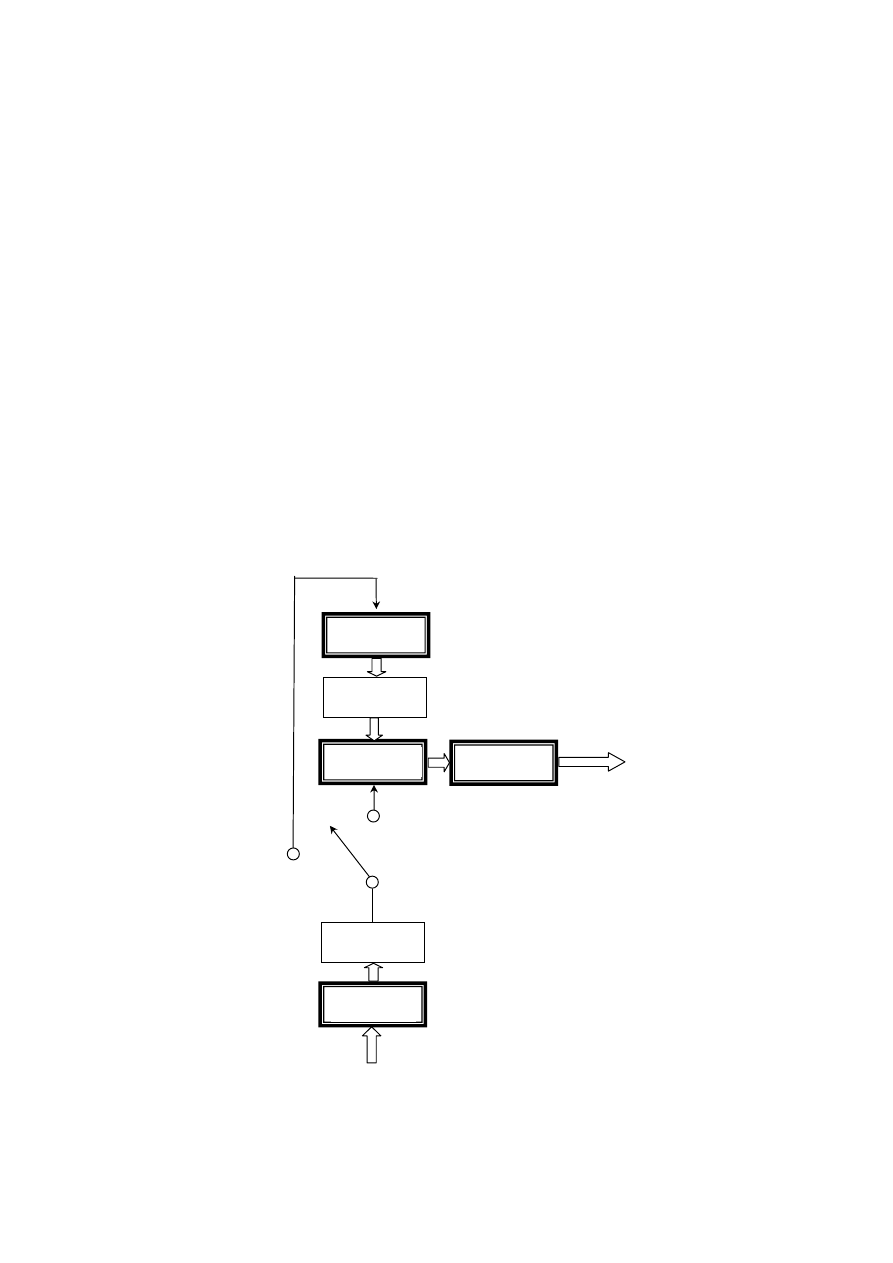
System rozpoznawania wyrazów został zaimplementowany zgodnie z
uproszczoną strukturą rozpoznawania sygnału mowy metodą rozpoznawania
wzorców.
WZORCE
PROCEDURA
UCZENIA
UKŁAD
PORÓWNANIA
OBSERWA-
CJA
mowy
sygnał
ANALIZA
SYGNAŁU
UKŁAD
DECYZYJNY
tryb uczenia
mowa
tryb rozpoznawania
rozpoznana
Rys.1. Uproszczona struktura rozpoznawania sygnału mowy metodą
rozpoznawania wzorców.

4
%tryb uczenia
for
i=1:L
ocena=0;
for
j=1:5
%nazwy plikow ujednolicone
z=wavread([deblank(A(i,:)) int2str(j)]);
%nazwy plików odpowiadaja
zawartosci
z=z/max(abs(z));
%wartosci amplitud w zakresie [-1,+1]
dlugosc=length(z);
%pomiar dlugosci dzwieku
E=z'*z;
%pomiar energii
z1=z(2:dlugosc);
%wspolczynnik do wzoru na ppz
z2=z(1:dlugosc-1);
%wspolczynnik do wzoru na ppz
PPZ = sum(abs(sign(z1)-sign(z2)))/2;
%oblcizenie liczby przejsc
przez zero
MAX=max(abs(z));
%wartosc max
LPC=sum(abs(lpc(z,12)));
%wspolczynnik LPC z 12
parametry=[dlugosc,E,PPZ,MAX,LPC];
%wektor obserwacji
parametry=parametry.*wagi;
%wymnożenie wektora przez odpowiednie
wagi
ocena=ocena+parametry;
end
;
tablica_ocen(i,:)=ocena/5;
end
;
tablica_wynikowa=sum(tablica_ocen')*0.05;
%dopuszczalna roznica wartosci
elementow miedzy wzorcem testowym i rozpoznowalnym
Rys.2
. Listing fragmentu kodu programu odpowiedzialnego za tryb uczenia się
wyrazów przez system.
W trybie testowym do budowy wektora obserwacji wykorzystane zosta
ły takie
wartości jak:
długość sygnału próbki;
en
ergię sygnału:
N
1
n
2
n
z
log
E
liczbę przejść przez zero PPZ
N
2
n
1
n
z
sign
n
z
sign
2
1
PPZ
gdzie:
0
n
z
dla
1
n
z
sign
0
n
z
dla
1
n
z
sign
wartość największą M
n
z
max
M
N
n
1
współczynniki LPC (p=12);
Po obliczeniu wyżej wymienionych wartości dla każdego słowa wzorcowego,
zostały one wymnożone przez odpowiednie wagi w celu polepszenia ich
charakterystyk.
wagi=[1 0.8 0.5 0.2 0.1]
Kolejne liczby wektora
wagi odpowiadają wartością wektora obserwacji.
wagi=[dlugosc, Energia, PPZ, MAX, LPC]

5
Następnie dla każdego wyrazu obliczana jest średnia wszystkich parametrów.
Po zako
ńczeniu etapu uczenia się sumuje tablice ocen i wymnażam przez
współczynnik 0,05, dzięki czemu otrzymuje dopuszczalną różnicę wartości
element
ów, którą wykorzystam do porównania wzorca testowego z rozpoznanym.
%tryb rozpoznawania
for
i=1:L
for
j=6:15
%nazwy plikow ujednolicone
z=wavread([deblank(A(i,:)) int2str(j)]);
%nazwy plików odpowiadaja
zawartosci
z=z/max(abs(z));
%wartosci amplitud w zakresie [-1,+1]
dlugosc=length(z);
%pomiar dlugosci dzwieku
E=z'*z;
%pomiar energii
z1=z(2:dlugosc);
%wspolczynnik do wzoru na ppz
z2=z(1:dlugosc-1);
%wspolczynnik do wzoru na ppz
PPZ = sum(abs(sign(z1)-sign(z2)))/2;
%oblcizenie liczby przejsc
przez zero
MAX=max(abs(z));
%wartosc max
LPC=sum(abs(lpc(z,12)));
%wspolczynnik LPC z 12
parametry2=[dlugosc,E,PPZ,MAX,LPC];
%wektor z badanymi wartosciami
parametry2=parametry2.*wagi;
%wymnożenie wektora przez odpowiednie
wagi
if
sum((tablica_ocen(i,:)-
parametry2)')<=tablica_wynikowa(i)
%porownanie wzorca testowego z wyrazami
badanymi
tablica_koncowa(j-5,i)=1;
%uzupelnianie tablicy poprawnym
rozpozanniem
end
;
end
;
end
;
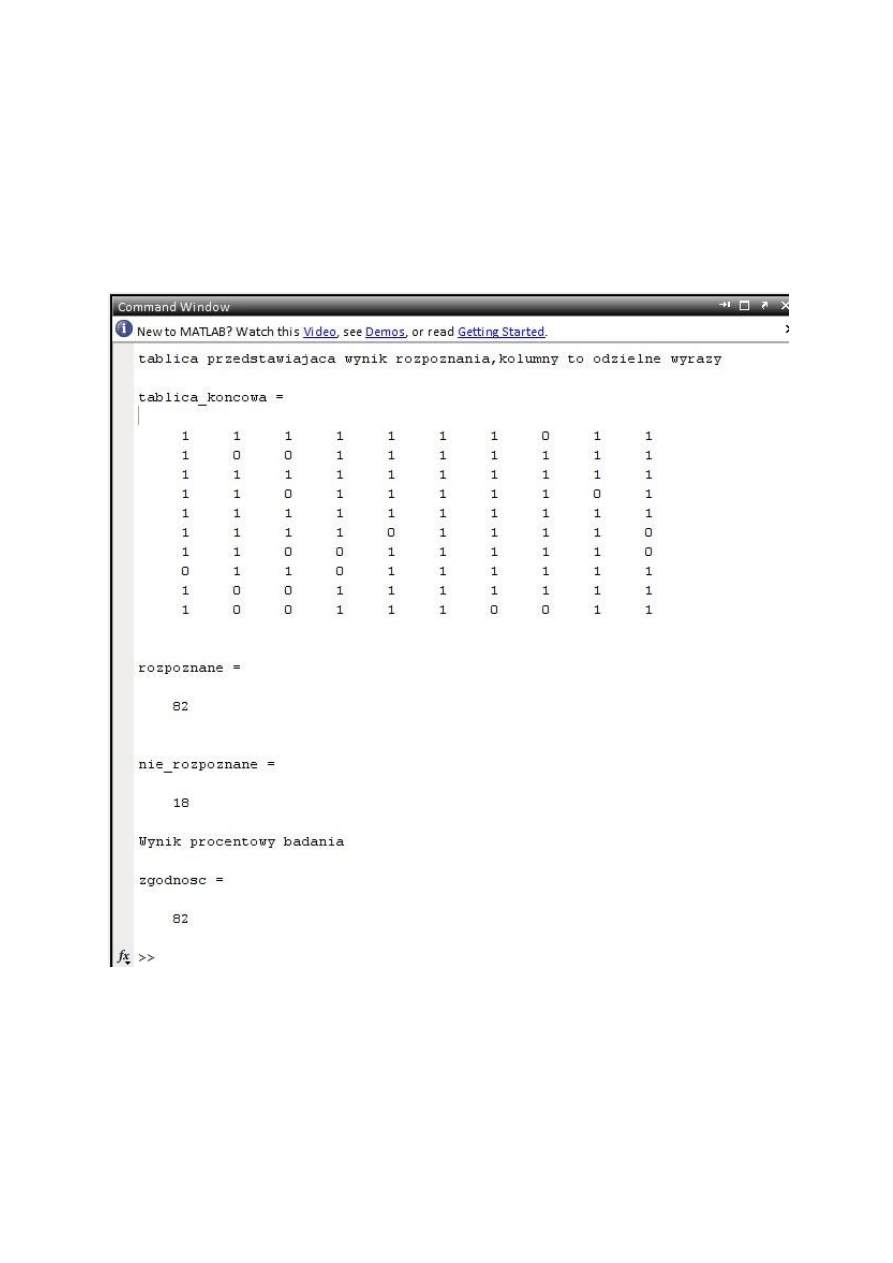
display(
'tablica przedstawiajaca wynik rozpoznania,kolumny to odzielne
wyrazy'
);
tablica_koncowa
rozpoznane=0;
nie_rozpoznane=0;
for
i=1:10
for
j=1:10
if
tablica_koncowa(i,j)==1
%odczytanie wartosci z tablic w celu
obliczenia rozpoznawalnosci
rozpoznane=rozpoznane+1;
else
nie_rozpoznane=nie_rozpoznane+1;
end
;
end
;
end
;
rozpoznane
nie_rozpoznane
display(
'Wynik procentowy badania'
);
zgodnosc=(rozpoznane)/(rozpoznane+nie_rozpoznane)*100
%
Rys.3. Listing fragmentu kodu programu odpowiedzialnego za tryb rozpoznawania
wyrazów przez system oraz opracowanie i wyświetlenie wyników.
6
W procesie rozpoznawania podobnie jak w etapie uczenia, tak
że obliczam
poprzednio
wymienionych wartości dla każdego słowa rozpoznawanego, oraz w celu
polepszenia wykrywania zostają one wymnożone przez odpowiednie wagi.
Sam etap porównywania wzorca testowego i rozpoznanego polega na
odejmowaniu tablicy zbadanych
wyrazów wzorcowych od kolejnych wyrazów
badanych
i porównaniu z dopuszczalną różnicę wartości elementów, którą uzyskałem
po etapie uczenia.
Rys. 5. Zrzut ekranu
uzyskanych obliczeń i wyników.
Końcowy etap polegał na podliczeniu poprawnych i niepoprawnych
rozpoznań, obliczeniu procentowego rozpoznania wyrazów oraz wyświetleniu
wyników.

7
3.
WNIOSKI i SPOSTRZEŻENIA.
Cel ćwiczenia został osiągnięty, ponieważ udało się zaprojektować i wykonać
u
rządzenie automatycznego rozpoznawania sygnału mowy zgodnie z uproszczoną
strukturą rozpoznawania sygnału mowy metodą rozpoznawania wzorców. Wynik
82% poprawnie rozpoznanych wyrazów jest zadowalający przy wykorzystaniu 5
wskaźników. Dzięki temu, że słownik składał się z małej liczby wyrazów,
zdecydowałem się na rozpoznawanie wyrazów w pierwszej kolejności na podstawie
ich długości wartości energii sygnału. Jest to jedna z najłatwiejszych metod przy tak
małej liczbie wyrazów. Jednak wynik nadal nie był wystarczający, dlatego posłużyłem
się także w liczbą przejść przez zero, wartością maksymalną M oraz
współczynnikami LPC. Zapewnie wykorzystanie kolejnych wskaźników jak np.
współczynniki FFT (widmo) lub obliczanie energii sygnału dla kolejnych części
wyrazów.
Błędy w wykryciu wyrazów były spowodowane najprawdopodobniej nienajlepszej
jakości sprzętem do nagrywania oraz brakiem odpowiedniego, wyciszonego miejsca
do nagrywania.
Niedoskonałości wy wykrywaniu można także poszukiwać w
podobieństwie wykorzystanych wyrazów (ich długości – liczby próbek).
W
celu poprawy jakości zbudowanego urządzenia można by było oprócz dodania
wyżej wspomnianych wskaźników, także spróbować zwiększyć liczbę wzorcowych
wyrazów.
Wyszukiwarka
Podobne podstrony:
i9g1s1 wozniak lab4 sd
i9g1s1 wozniak lab5 sd id 20877 Nieznany
i9g1s1 wozniak lab4 sd
i9g1s1 wozniak lab5 sd
Bezpieczenstwo w sieci SD
lab3
020806 WPK Wozniakid 3955
lab3 kalorymetria
Instrukcja Lab3
lab3 6
Tematy ćwiczeń - SD, WAT, SEMESTR V, systemy dialogowe
Pytania Ania Woźnialis i Wojtek Zduńczyk, gik, semestr 7, seminarium, Seminarium
Soczysta pierś z kurczaka po włosku by sd
Naleśniki amerykańskie by sd
Korzenne muffiny jabłkowe by sd
lab3
sprawko z lab3 z auto by pawelekm
Lab3 zadanie 2 schemat organizacyjny
więcej podobnych podstron