
PRZETWARZANIE ZAPYTAŃ TO:
PRZETWARZANIE ZAPYTAŃ TO:
przekształcenie zapytania zapisanego w
języku wysokiego poziomu, zazwyczaj SQL,
w poprawną efektywną sekwencję operacji
niskiego poziomu (operacje algebry relacji)
oraz wykonanie tej sekwencji operacji w celu
uzyskania poszukiwanych danych

Zapytanie jest poddawane
przetwarzaniu w następujących
etapach:
1. Analiza składniowa
2. Poprawność zapytania względem informacji
przechowywanej w słowniku bazy danych
3. Optymalizacja zapytania
4. Wykonanie zapytania
5. Zwrot do użytkownika wyników zapytania lub
komunikatów o błędach
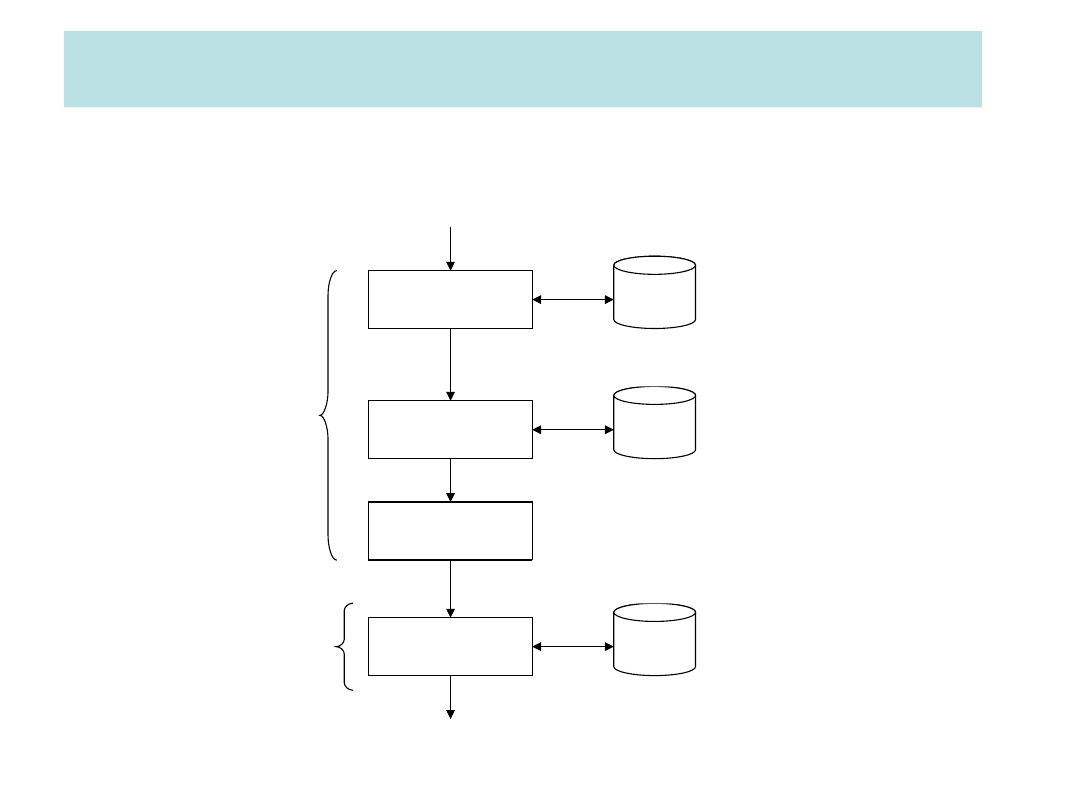
Fazy procesu przetwarzania
Fazy procesu przetwarzania
zapytania
zapytania
Rozkład
Rozkład
zapytania
zapytania
Optymaliza
Optymaliza
cja
cja
zapytania
zapytania
Generowani
Generowani
e kodu
e kodu
Wykonanie
Wykonanie
zapytania
zapytania
Kompilacja
Kompilacja
Wykonanie
Wykonanie
Wynik
Wynik
zapytani
zapytani
a
a
Katalog
Katalog
systemowy
systemowy
Statystyki bazy
Statystyki bazy
danych
danych
Główna baza
Główna baza
danych
danych
Wygenerowany
Wygenerowany
kod
kod
Plan
Plan
wykonania
wykonania
Wyrażenie algebry relacji
Wyrażenie algebry relacji
Zapytanie w języku
Zapytanie w języku
wysokiego
wysokiego
poziomu (SQL)
poziomu (SQL)

OPTYMALIZACJA ZAPYTAŃ
OPTYMALIZACJA ZAPYTAŃ
• Optymalizacja dynamiczna – powtarzanie
rozkładu i optymalizacji za każdym razem, gdy
zapytanie jest wykonywane.
• Optymalizacja statyczna – analiza składni,
kontrola poprawności i optymalizacja jest
wykonywana tylko raz (podejście podobne do
stosowanego w kompilatorach języków
programowania).
• Można stosować połączenie tych strategii,
wówczas ponowna optymalizacja ma miejsce
wówczas, gdy system wykryje, że w statystykach
zaszły poważne zmiany od ostatniej kompilacji.
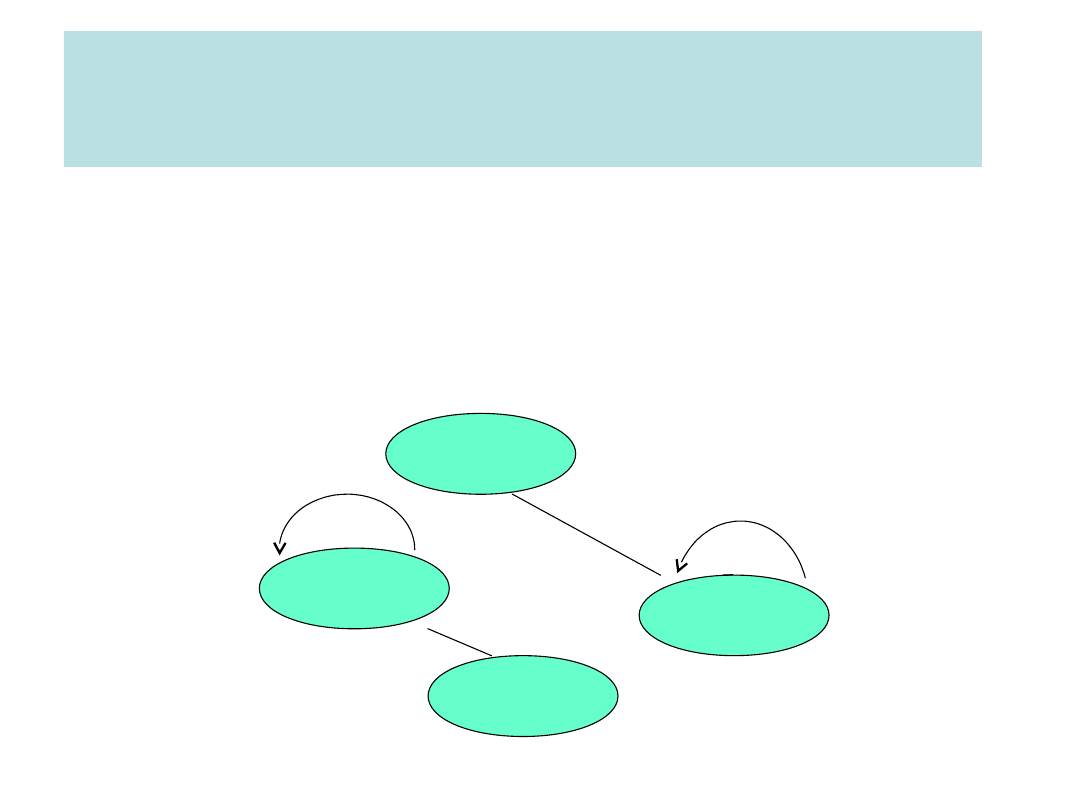
Rozkład zapytania - przykład drzewa
Rozkład zapytania - przykład drzewa
algebry relacji
algebry relacji
Persone
l
Biuro
liście
Operacje
pośredni
e
Stanowisko=’dyrekto
r’
miasto=’Londy
n’
nrbiura=biuronr
Korzeń
SELECT *
SELECT *
FROM Personel, Biuro
FROM Personel, Biuro
WHERE nrbiura=biuronr AND
WHERE nrbiura=biuronr AND
(stanowisko=’dyrektor’ AND miasto=’Londyn’)
(stanowisko=’dyrektor’ AND miasto=’Londyn’)

Etap normalizacji
Etap normalizacji
• Koniunktywna postać normalna – składa
się z ciągu czynników połączonych operatorem
koniunkcji. Każdy czynnik składa się z kilku
członów połączonych operatorami alternatywy.
• Dysjunktywna postać normalna – składa
się z ciągu składników połączonych
operatorem alternatywy. Każdy składnik składa
się z kilku członów połączonych operatorem
koniunkcji.

Analiza semantyczna
Analiza semantyczna
• Analiza semantyczna ma na celu odrzucenie
tych spośród znormalizowanych zapytań, które
są źle sformułowane lub sprzeczne.
• Zapytanie jest źle sformułowane, jeżeli
jego elementy nie prowadzą do
wygenerowania wyniku, co może się zdarzyć
na skutek pominięcia specyfiki złączenia.
• Zapytanie jest sprzeczne – jeżeli jego
warunek nie może być spełniony przez żaden
wiersz.

Budujemy graf połączeń relacji – jeśli graf
Budujemy graf połączeń relacji – jeśli graf
nie jest spójny, to zapytanie jest źle
nie jest spójny, to zapytanie jest źle
sformułowane
sformułowane
•tworzymy wierzchołek dla każdej relacji
i dla
każdego wyniku
•dodajemy krawędzie pomiędzy
wierzchołkami,
które reprezentują złączenia
•dodajemy
krawędzie, które reprezentują
operacje
rzutowania
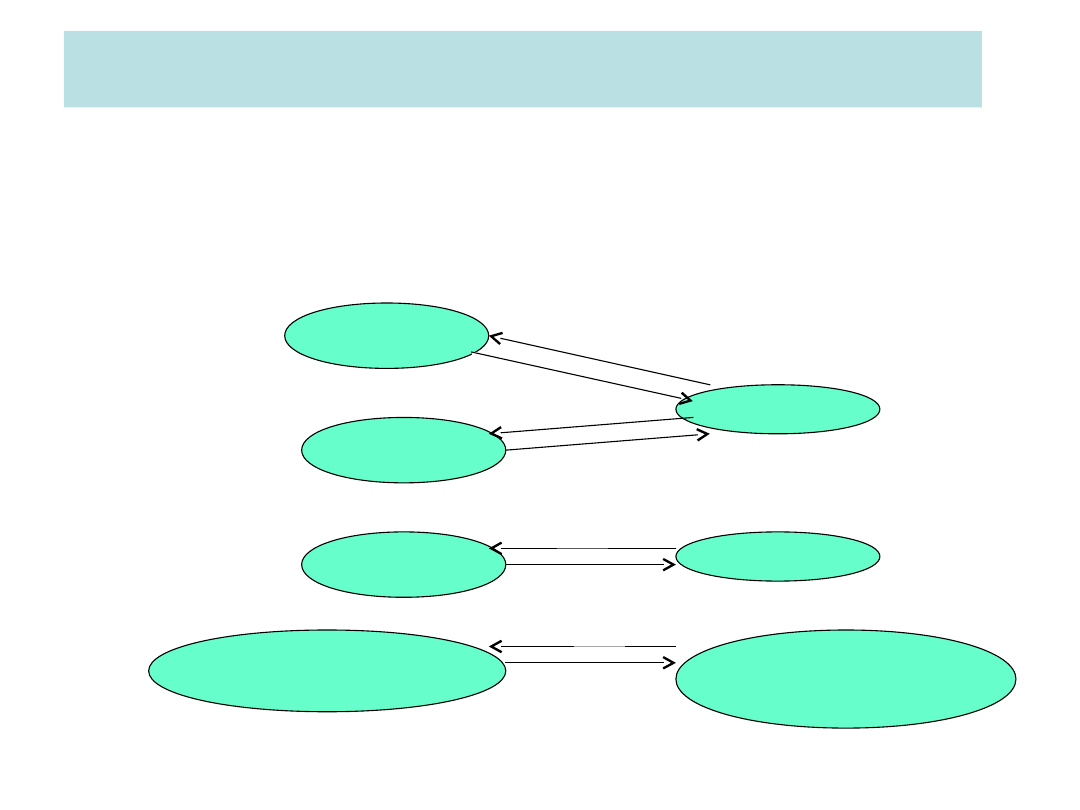
Analiza semantyczna - zapytanie
Analiza semantyczna - zapytanie
sformułowane nie poprawnie
sformułowane nie poprawnie
Analiza semantyczna - zapytanie
Analiza semantyczna - zapytanie
sformułowane nie poprawnie
sformułowane nie poprawnie
SELECT p.nr_nieruch, p.ulica
FROM Klient c, Wizyta w, Nieruchomosc p
WHERE c.nr_kli=w.nr_kli AND c.czynsz>=500 AND
c.typ=’mieszkanie’ AND p.nrwlasciciela=’KTOS’;
WYNIK
c
p
w

Analiza semantyczna - zapytanie
Analiza semantyczna - zapytanie
sprzeczne
sprzeczne
Budujemy znormalizowany graf połączeń
Budujemy znormalizowany graf połączeń
atrybutów – jeżeli graf zawiera cykl o
atrybutów – jeżeli graf zawiera cykl o
ujemnej wadze - zapytanie jest sprzeczne
ujemnej wadze - zapytanie jest sprzeczne
• tworzymy wierzchołek dla każdego odwołania do
atrybutu oraz do stałej 0
• tworzymy skierowaną krawędź pomiędzy
wierzchołkami reprezentującymi złączenie
• tworzymy
skierowaną krawędź pomiędzy
wierzchołkiem atrybutu i wierzchołkiem stałej 0 -
reprezentującą selekcję
• krawędzi a→b przypisujemy wagę c jeśli
reprezentuje ona warunek nierówności (a≤b+c)
• krawędzi 0→a przypisujemy wagę –c, jeśli
reprezentuje ona warunek nierówności (a≥c)
Analiza semantyczna - zapytanie
Analiza semantyczna - zapytanie
sprzeczne
sprzeczne
c.czynsz
0
c.typ
mieszkani
e
200
-500
-
mieszkanie
w.nr_kli
c.nr_kli
p.nr_nieruch
w.nr_nieruch
0
0
0
0
SELECT p.nr_nieruch, p.ulica
FROM Klient c, Wizyta w, Nieruchomosc p
WHERE c.czynsz>=500 AND c.nr_kli=w.nr_kli AND
w.nr_nieruch=p.nr_nieruch AND c.typ=’mieszkanie’ AND
c.czynsz<200;

UPRASZCZANIE
UPRASZCZANIE
• wykrycie powtarzających się warunków i wspólnych
podwyrażeń
• przekształcenie
zapytania
do
semantycznie
równoważnej, lecz prostszej i łatwiejszej do obliczeń
postaci
• Zazwyczaj na tym etapie uwzględnia się również
ograniczenia dostępu, definicje perspektyw i więzy
integralności
• Jeśli użytkownik nie ma odpowiednich praw dostępu
do elementów składowych zapytania, to całe
zapytanie musi zostać odrzucone

Istnieją dwie klasy optymalizatorów
Istnieją dwie klasy optymalizatorów
używanych we współczesnych
używanych we współczesnych
relacyjnych SZBD
relacyjnych SZBD
• optymalizatory
oparte
na
składni
(nazywane też opartymi na heurystyce) -
wybierają plan wykonania na podstawie
składni instrukcji SQL. Decyzja jest
podejmowana
na
podstawie
takich
wielkości jak: postać i kolejność warunków
w klauzuli WHERE.
.
• optymalizatory oparte na statystyce
(oparte na koszcie)

OPTYMALIZACJA ZAPYTAŃ
OPTYMALIZACJA ZAPYTAŃ
• Zapytania są kompilowane - plany wykonań są
tworzone na etapie kompilacji i składowane do
późniejszego użycia.
• Zapytania interpretowane – wszystkie zapytania są
interpretowane w czasie wykonania.
• Zapytania kompilowane są wykonywane szybciej niż
interpretowane - ponieważ w przypadku powtórnego
zapytania kompilacja nie musi być wykonana
ponownie.
• Jeśli jednak baza danych jest przedmiotem wielu
zapytań kierowanych do niej ad hoc, to zapytania
interpretowane są bardziej elastyczne, ponieważ nie
są przedmiotem wcześniejszego etapu kompilacji.

OPTYMALIZACJA ZAPYTAŃ
OPTYMALIZACJA ZAPYTAŃ
W SYSTEMIE ORACLE
W SYSTEMIE ORACLE
• Optymalizacja oparta na regułach - wykorzystuje
15 reguł, które zostały przedstawione w kolejności
spodziewanego wpływu na efektywność.
Optymalizator może wybrać konkretną ścieżkę
dostępu do tabeli tylko wówczas, gdy zapytanie
zawiera odpowiedni warunek lub istnieje struktura
umożliwiająca określony sposób dostępu
• Optymalizator oparty na analizie kosztów –
wybiera strategię wykonania zapytania wymagającą
najmniejszych zasobów do przetworzenia wszystkich
wierszy, do których odwołuje się zapytanie.
Użytkownik może wybrać, czy optymalizowanym
zasobem ma być przepustowość, czy czas
odpowiedzi.

OPTYMALIZACJA ZAPYTAŃ SYSTEMIE
OPTYMALIZACJA ZAPYTAŃ SYSTEMIE
ORACLE
ORACLE
1
Jeden wiersz wg identyfikatora wiersza
2
Jeden wiersz wg indeksu grupującego
3
Jeden wiersz wg indeksu haszującego dla klucza unikalnego lub
głównego
4
Jeden wiersz wg klucza unikalnego lub głównego
5
Wykorzystanie klastra
6
Grupujący klucz haszujący
7
Klucz indeksu grupującego
8
Klucz złożony
9
Indeks wg pierwszej kolumny
10
Poszukiwanie zakresu dla kolumny z indeksem
11
Poszukiwanie bez ograniczeń dla kolumny z indeksami
12
Złączenie przez scalanie posortowanych relacji
13
MAX lub MIN dla kolumny z indeksem
14
ORDER BY dla kolumny z indeksem
15
Przeszukiwanie całej tablicy

OPTYMALIZACJA ZAPYTAŃ
OPTYMALIZACJA ZAPYTAŃ
W SYSTEMIE ORACLE
W SYSTEMIE ORACLE
• Działanie optymalizatora opartego na analizie kosztów zależy od
zgromadzonych statystyk dla tabel, klastrów oraz indeksów.
• Sam Oracle nie zbiera tych statystyk automatycznie – generuje je i
uaktualnia tylko na polecenie użytkownika.
• Proces gromadzenia statystyk jest regulowany przez liczne opcje,
gdy tylko jest to możliwe.
• Gdy zostanie wyznaczony optymalny plan wykonania zapytania,
można go zapisać poleceniem CREATE OUTLINE, które pozwala
przechować atrybuty wykorzystane przez optymalizator do
stworzenia planu wykonania.
• W trakcie późniejszych wykonań zapytania, optymalizator korzysta
z zapisanych atrybutów i wykonuje gotowy plan zapytania,
zamiast generować go od nowa.
• System Oracle pozwala obejrzeć plan wykonania wybrany przez
optymalizator poleceniem EXPLAIN PLAN. Przydaje się to
szczególnie wtedy, gdy efektywność wykonania zapytania nie
spełnia naszych oczekiwań. Wynik polecenia EXPLAIN PLAN jest
zapisywany w tabeli bazy danych (domyślnie PLAN_TABLE).

Transakcje
•
Transakcja
Transakcja
-
- pewna ilość poleceń przesłana do
systemu zarządzania celem przetworzenia jako całość
•
Sesja
składa się z jednej lub większej liczby transakcji
•
Transakcje wykonywane są współbieżnie - jeżeli do
bazy danych ma jednocześnie dostęp kilku
użytkowników
•
Transakcje współbieżne
mogą być przeprowadzane na
jeden z dwóch sposobów
:
–
Szeregowo - w momencie zakończenia jednej
transakcji uruchamiamy następną
–
Równolegle - wszystkie transakcje są realizowane
jednocześnie - po jednej czynności na transakcję

Kontrola współbieżności
•
Mechanizm blokowania
(locking) - umożliwia
przyznanie wybranej transakcji całkowitej
kontroli nad analizowanym elementem bazy,
uniemożliwiając pozostałym transakcjom
odczytywanie, czy modyfikowanie zawartych w
nim danych
•
Transakcje modyfikujące dane ustawiają
zazwyczaj blokady wyłączności lub blokady
zapisu, które gwarantują, że żadna inna
transakcja nie dokona odczytu lub zmiany
danych aż do momentu zniesienia blokady

Rozróżniamy dwa główne typy blokad:
•
Blokada do odczytu
Blokada do odczytu – daje dostęp tylko do
odczytu danych i chroni zablokowane dane przed
modyfikacją.
–
Ten typ blokady stosujemy, gdy chcemy zastosować
zapytanie na tabeli bez potrzeby dokonywania w niej
zmian
–
Ważne jest by inni użytkownicy nie zmieniali tabeli w
czasie gdy ją oglądamy
•
Blokada do zapisu -
Blokada do zapisu - umożliwia dostęp do
elementów danych zarówno w celu ich odczytu,
jak i zapisu
–
uniemożliwia ona innym transakcjom jakikolwiek odczyt
i zapis dla tego elementu danych

BLOKADY
•
blokady wyłączności
blokady wyłączności
–
–
zabezpieczają wybrany element
zabezpieczają wybrany element
bazy danych zarówno przed zapisem jak i przed odczytem
bazy danych zarówno przed zapisem jak i przed odczytem
•
blokady wspólne
blokady wspólne
- umożliwiają wszystkim transakcjom
odczyt danego elementu, lecz tylko jednej z nich – zapis
•
blokowanie dwufazowe
- nowa transakcja otrzymuje na
początek tylko blokadę wspólną, która w momencie
uruchomienia polecenia modyfikującego może zostać
zastąpiona blokadą
wyłączności
–
skraca czas trwania blokad wyłączności
–
przyspiesza współbieżne wykonywanie transakcji

Ziarnistość blokady
•
Ziarnistość blokady
- rozmiar elementu bazy
danych, na który zostaje nałożona blokada
–
zależy od systemu zarządzania i od rodzaju
przeprowadzanej operacji
•
Im mniejsza ziarnistość, tym lepiej obsługiwane
jest współbieżne przetwarzanie transakcji
•
Zmniejszenie ziarnistości - więcej czasu
procesora na obsługę blokad

Poziomy izolacji
•
SERIALIZABLE - transakcje są w pełni odizolowane od
pozostałych
•
REPEATABLE READ - transakcja mogąca odczytywać te same
dane wiele razy, za pomocą predykatu WHERE - powtórne
wykonanie tego samego zapytania może zwrócić inne wiersze
Efekt ten znany jest jako fantom
•
READ COMMITTED - transakcje mogą odczytywać pewne dane
wielokrotnie, lecz w tym wypadku odczyt zwraca zawsze te
same wiersze
Efekt ten znany jest jako bezpowtórzeniowość odczytu
•
READ UNCOMMITTED - transakcja wielokrotnie odczytująca te
same dane, uwzględniając poprawki wprowadzone przez inne
transakcje, które nie zakończyły się jeszcze sukcesem
Efekt ten znany jest jako brudny odczyt
•
SERIALIZABLE - domyślny poziom izolacji

Poziomy izolacji
Aby wyznaczyć jeden z poziomów należy użyć
polecenia:
SET TRANSACTION ISOLATION LEVEL
poziom_izolacji
Przykład
SET TRANSACTION ISOLATION
LEVEL REPEATABLE READ

Dopisywanie nowych użytkowników
bazy danych
•
Bazodanowy identyfikator użytkownika pokrywa się jego
identyfikatorem w systemie operacyjnym
•
System zarządzania posiada własny zbiór identyfikatorów,
różnych od systemowych nazw użytkowników
DO utworzenia nowego identyfikatora Jan_Kowalski z hasłem
Iksiński
służy polecenie
GRANT CONNECT TO Jan_Kowalski
IDENTIFIED BY Iksiński
Uwaga!
identyfikator bazodanowy i odpowiadające mu hasło nie mają w tym
przypadku nic wspólnego z parą użytkownik-hasło potrzebną do
załogowania się do systemu operacyjnego

Połączenie z bazą danych
• CONNECT
- połączenie się z bazą danych
• Standard SQL-92 wprowadza do składni CONNECT daleko
posuniętą elastyczność
• CONNECT AS identyfikator_połączenia
- jeśli wymagana jest
nazwa połączenia
• CONNECT
- jeśli system zarządzania posiada swój własny
algorytm nadawania nazw połączeniom
Uwaga:
Polecenie CONNECT zakłada:
• istnieje sposób na wyznaczenie bazy danych, z której
użytkownik będzie korzystał w danej sesji
• baza została wyznaczona przed próbą uzyskania
połączenia

zerwanie połączenie z bazą danych
•
DISCONNECT
- zamknięcie aktywnego połączenia
DISCONNECT identyfikator__połączenia
jeśli została wcześniej podana nazwa połączenia
DISCONNECT
połączenie domyślne lub połączenie wykorzystujące
identyfikator użytkownika

Połączenie z bazą danych
Istnieją dwie strategie rządzące czasem trwania połączeń
z bazą danych:
•
połączenie w momencie rozpoczęcia pracy i
odłączenie po jej zakończeniu
–
eliminuje konieczność wielokrotnego łączenia i rozłączania
–
uniemożliwia innym użytkownikom wykorzystanie tego
samego połączenia w chwilach bezczynności połączonej osoby
–
stwarza problemy w sytuacji, gdy ilość użytkowników
mogących jednocześnie korzystać z bazy danych jest
znacząco mniejsza od ilości wszystkich użytkowników tej bazy
•
połączenie w momencie uruchomienia pojedynczej
transakcji i odłączenie się natychmiast po jej
zakończeniu
–
tymczasowe tabele istnieją tylko na czas trwania sesji!
–
wymaga większych nakładów czasu procesora na obsługę
połączeń, ale umożliwia jednoczesny dostęp do bazy danych
większej liczbie użytkowników

Cechy transakcji
Każda transakcja powinna mieć
następujące właściwości:
• Niepodzielność
• Spójność
• Izolacja
• Trwałość

Kończenie transakcji
•
Wszystkie transakcje kończą się na jeden z dwóch
sposobów:
–
sukcesem
oznaczającym trwałe wprowadzenie wszystkich
modyfikacji do bazy danych
–
porażką
, oznaczającą odwołanie transakcji i odtworzenie
stanu bazy sprzed jej rozpoczęcia transakcji
•
Z definicji, transakcja zakończona sukcesem nie
może zostać odwołana
•
System zarządzania zapisuje wszystkie
podejmowane przez transakcję czynności w
rejestrze transakcji - aby móc ją odwołać

Operacje COMMIT i ROLLBACK
• COMMIT
[ nazwa tabeli ]
– zapamiętuje tablicę w bazie danych lub
uzupełnia stan bazy danych
– zapamiętuje wszystkie zmiany w bazie danych
od ostatniej operacji COMMIT
• ROLLBACK
– odtwarza stan bazy danych i przywraca jej
status do stanu po ostatniej operacji COMMIT
– zmiany wprowadzone do bazy danych po
ostatniej operacji COMMIT są odwracane

Główne kroki przy wykonywaniu transakcji:
• Uruchom transakcję i przekaż do SPT
• Zapisz transakcję do dziennika – zapisz w
dzienniku informacje początkowe o
transakcji
• Sprowadź rekordy z bazy danych
• Zapisz do dziennika obraz przed transakcją
• Oblicz nowe wartości
• Zapisz do dziennika obraz po transakcji
• Zapisz w dzienniku zatwierdzenie
• Zapisz nowe rekordy do bazy danych

KOPIA ZAPASOWA I ODTWARZANIE
• W przypadku awarii administrator odtwarza dane z
wcześniej wykonanej kopii zapasowej
• Opracowuje strategię sporządzania kopii zapasowej
całej bazy danych, albo jej części - wykonuje się
okresowo używając specjalnych narzędzi SZBD
• Awarie globalne można podzielić na dwie kategorie:
– Awarie systemowe (zasilanie) – dotykają
aktualnie wykonywanych transakcji, ale nie
uszkadzają fizycznej bazy danych (miękkie
awarie)
– Awarie nośników (uszkodzenie dysku) –
uszkodzenie bazy danych lub jej części (awarie
twarde)
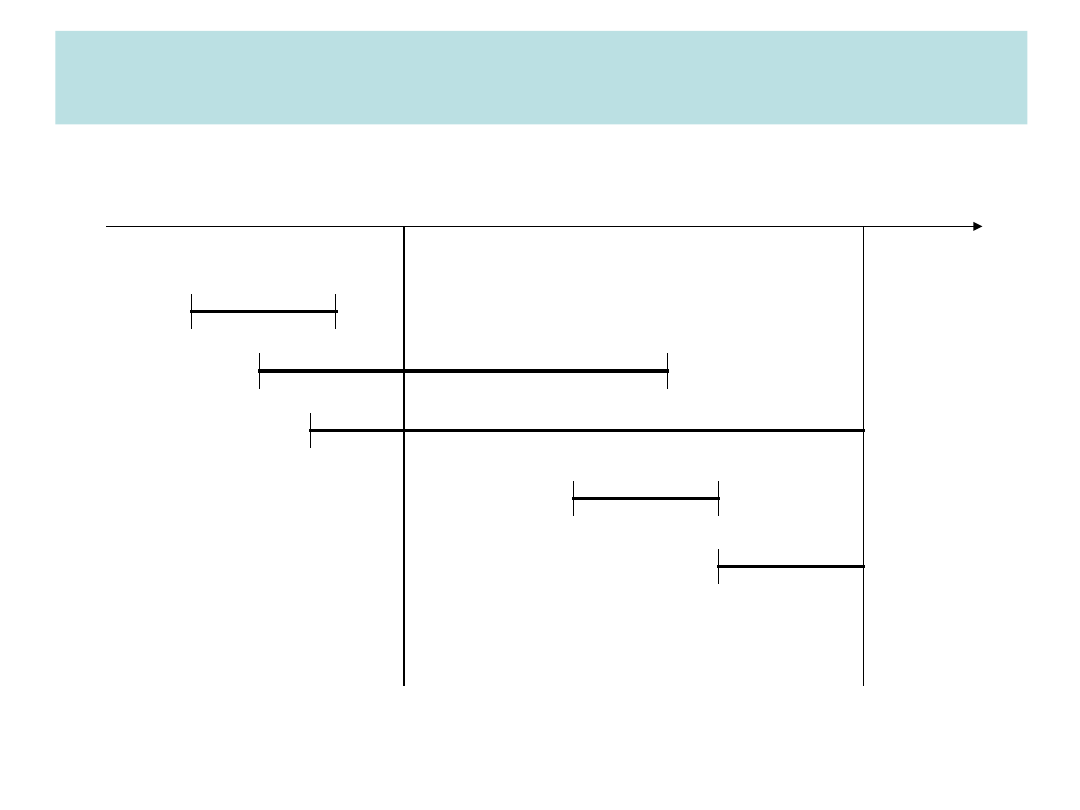
Czas
T
R
A
N
S
A
K
C
J
A
T1
T2
T3
T4
T5
Punkt
kontrolny
Awaria
systemu
ODTWARZANIE TRANSAKCJI

ODTWARZANIE TRANSAKCJI
• Tworzy dwie listy transakcji
– UNDO (transakcje uzyskane z aktualnego rekordu
kontrolnego)
– REDO (pusta lista)
• Przeszukuje (do przodu) dziennik transakcji zaczynając od
rekordu kontrolnego. Jeśli napotka na pozycję BEGIN
TRANSACTION dla danej transakcji dodaje tą transakcję do
listy UNDO
• Jeśli znajdzie COMMIT dla transakcji, przesuwa transakcję z
listy UNDO do REDO
• System ponownie przechodzi przez dziennik, ale tym razem
wstecz, cofając skutki transakcji z listy UNDO
• Posuwa się do przodu i ponownie wykonuje transakcje z listy
REDO
• Kiedy napotka na znak końca dziennika, wtedy lista UNDO
wskazuje transakcje T3 i T5 a REDO T2 i T4

ODTWARZANIE TRANSAKCJI
• System przechodzi ponownie przez dziennik
transakcji -tym razem wstecz - cofając skutki
transakcji z listy UNDO
• Potem posuwa się do przodu i ponownie
wykonuje transakcje z listy REDO
system jest gotowy do pracy – po zakończeniu
wszystkich tych czynności

ODTWARZANIE NOŚNIKÓW
• Błąd danych wiąże się z awarią dysków lub jego
kontrolera – fizyczne uszkodzenie dysku
• Odzyskiwanie danych – ponowne załadowanie
bazy z kopii zapasowej
• Wykorzystanie dziennika transakcji do
ponownego wykonania wszystkich operacji, które
zakończyły się od czasu wykonania kopii

skalowalność
skalowalność
dostępność
dostępność
łatwość zarządzania
łatwość zarządzania
bezpieczeństwo
bezpieczeństwo
Charakterystyka rozproszonych
Charakterystyka rozproszonych
baz danych
baz danych
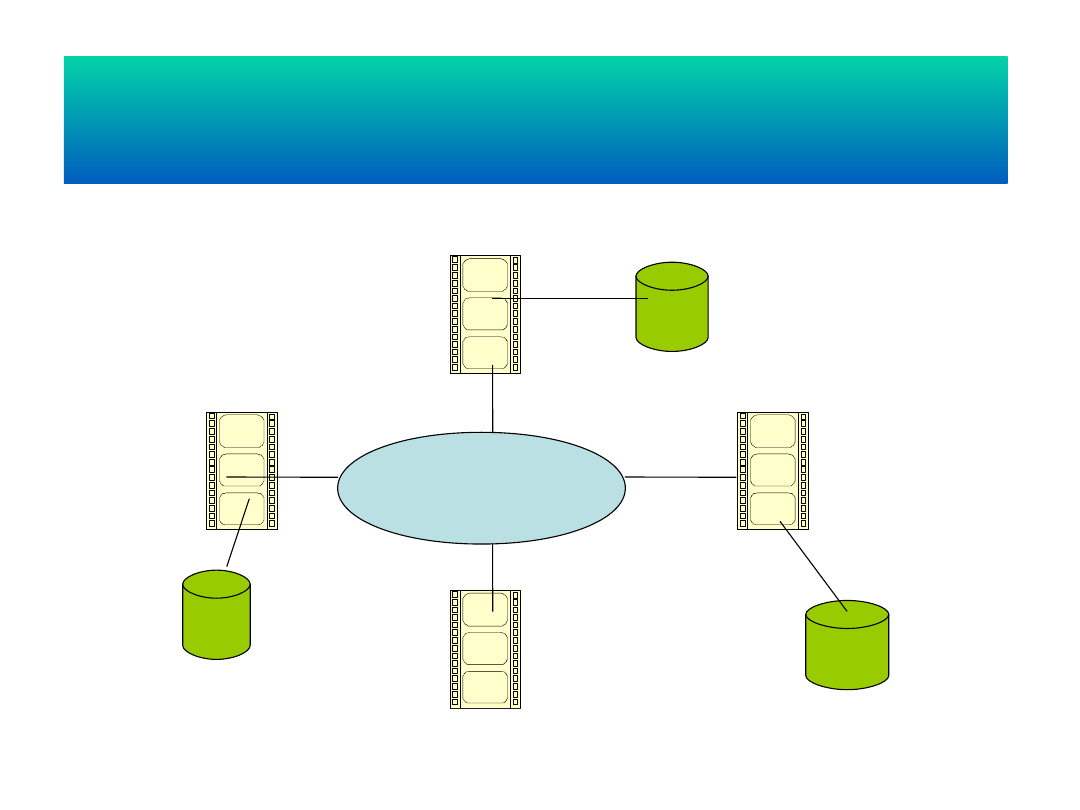
Rozproszony system zarządzania
Rozproszony system zarządzania
bazą danych
bazą danych
Sieć
komputero
wa
BD
BD
BD
Węzeł 2
Węzeł 4
Węzeł 3
Węzeł 1
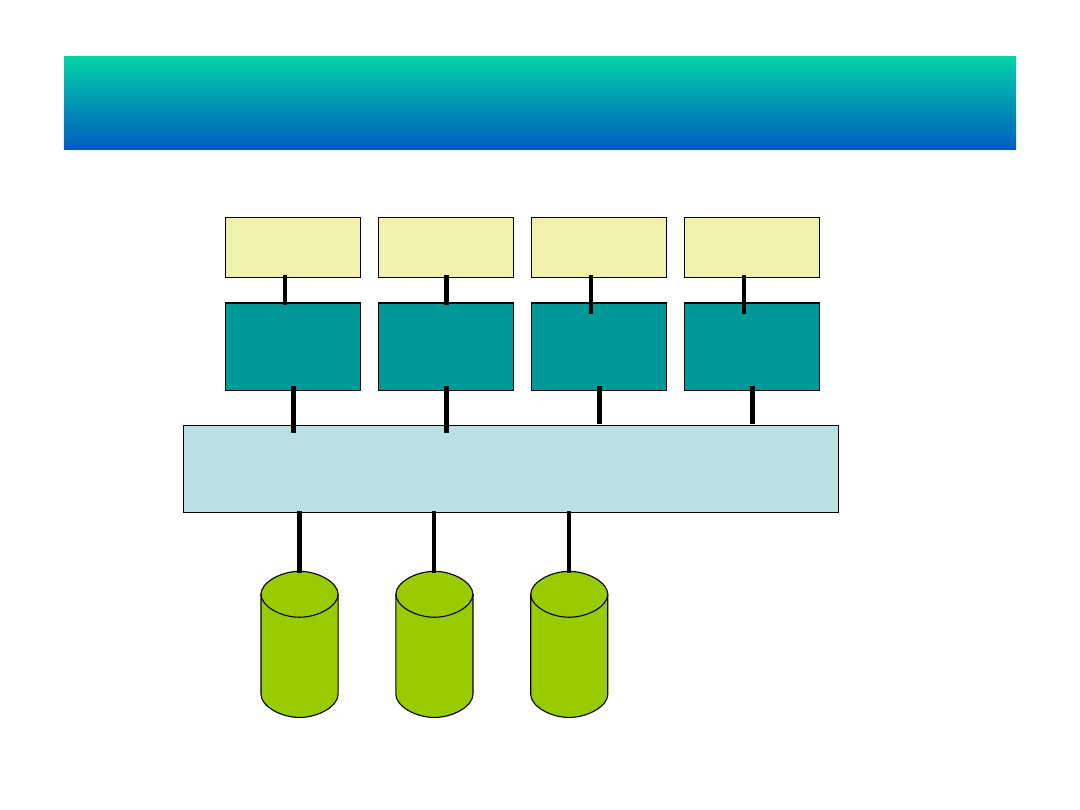
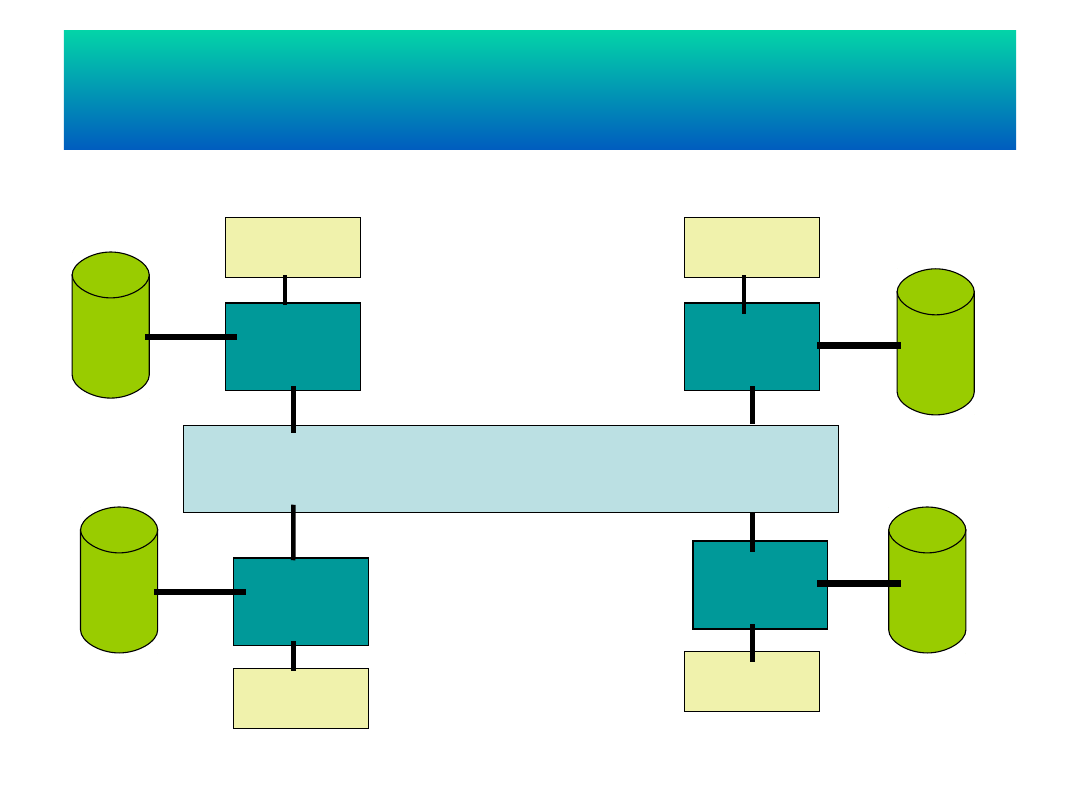
Wieloprzetwarzanie symetryczne SMP
Wieloprzetwarzanie symetryczne SMP
(pamięć dzielona)
(pamięć dzielona)
Sieć komputerowa
proceso
r
proceso
r
proceso
r
proceso
r
pamięć
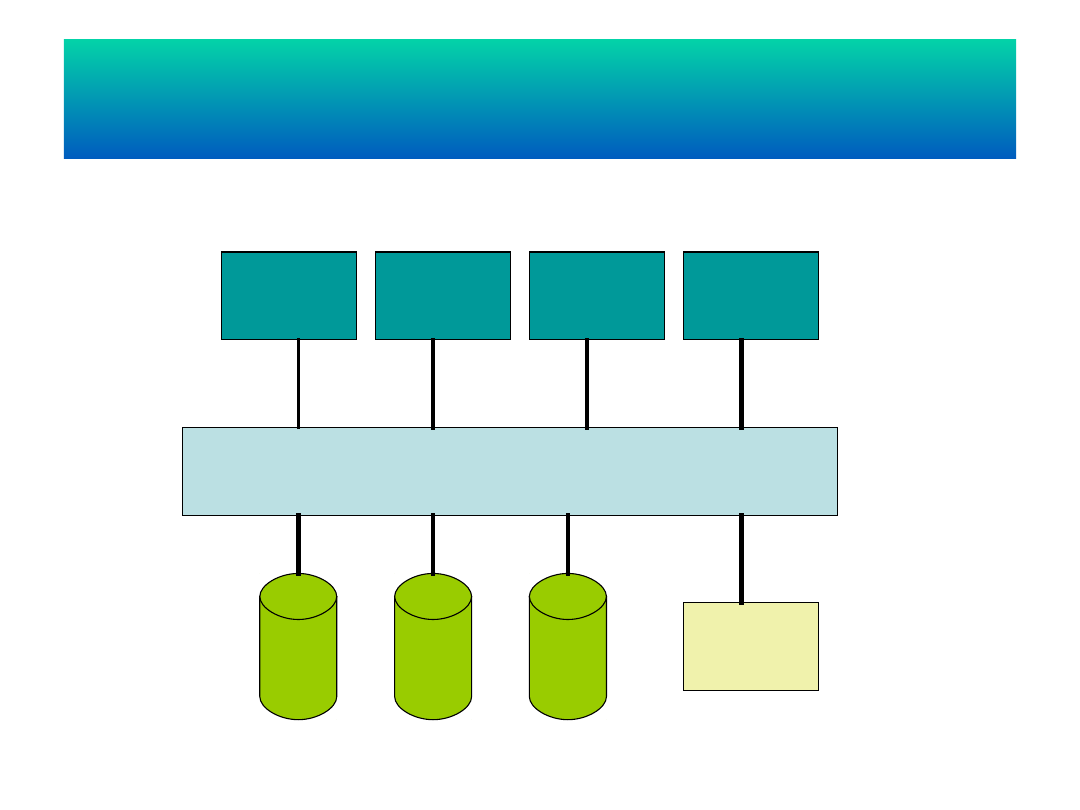
Dzielony dostęp do dysku
Dzielony dostęp do dysku
Sieć komputerowa
proceso
r
proceso
r
proceso
r
proceso
r
pamięć
pamięć
pamięć
pamięć
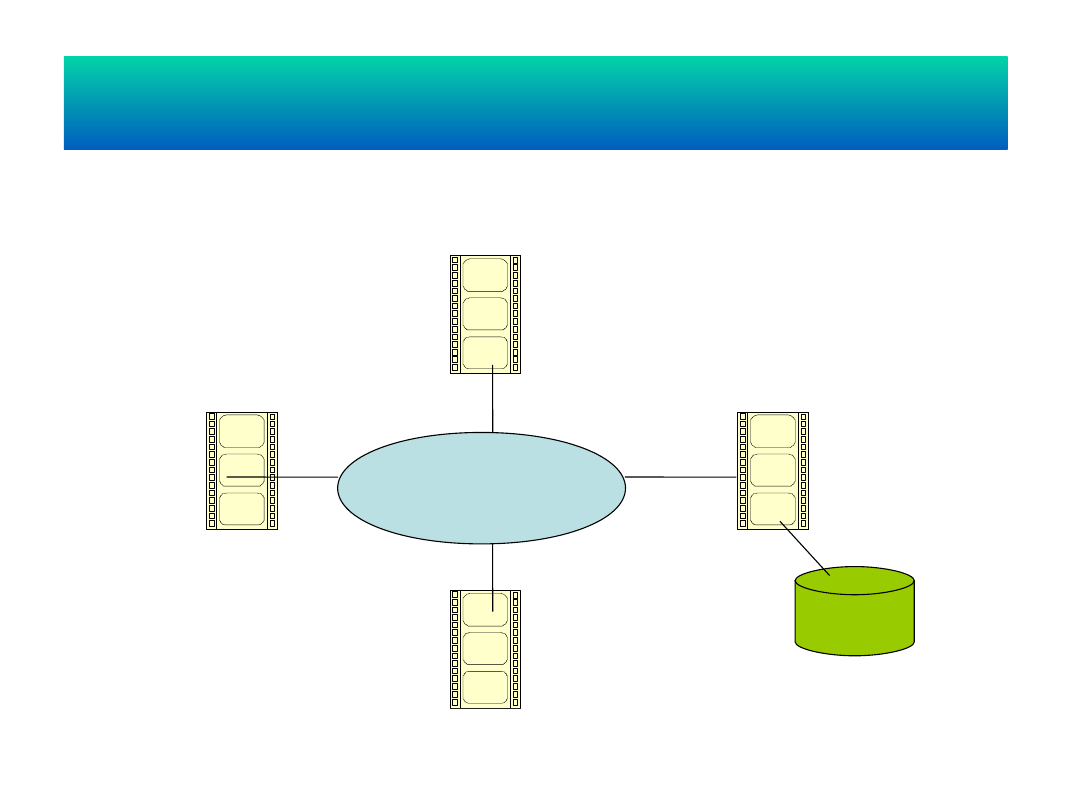
Przetwarzanie masywnie równoległe
Przetwarzanie masywnie równoległe
(MPP - żaden zasób nie jest
(MPP - żaden zasób nie jest
współużytkowany)
współużytkowany)
Sieć komputerowa
proceso
r
proceso
r
pamięć
pamięć
proceso
r
pamięć
proceso
r
pamięć
Przetwarzanie rozproszone
Przetwarzanie rozproszone
Sieć
komputero
wa
BD
Węzeł 2
Węzeł 4
Węzeł 3
Węzeł 1

Problemy
Problemy
• konstrukcja rozproszonych baz danych
• rozproszone wykonywanie zapytań
• zarządzanie rozproszonymi kartotekami
• rozproszona kontrola współbieżności
• rozproszone zarządzanie blokowaniami
• niezawodność systemów zarządzania
rozproszonymi bazami danych
• wsparcie systemu operacyjnego
• różnorodność baz danych
Charakterystyka rozproszonych baz
Charakterystyka rozproszonych baz
danych
danych

Charakterystyka rozproszonych baz
Charakterystyka rozproszonych baz
danych
danych
FRAGMENTACJA
• aby polepszyć wydajność transakcji
oraz lokalność transakcji
ALOKACJA
• aby zredukować koszt
przetwarzania transakcji
REPLIKACJA
REPLIKACJA
• aby zwiększyć dostępność i
niezawodność
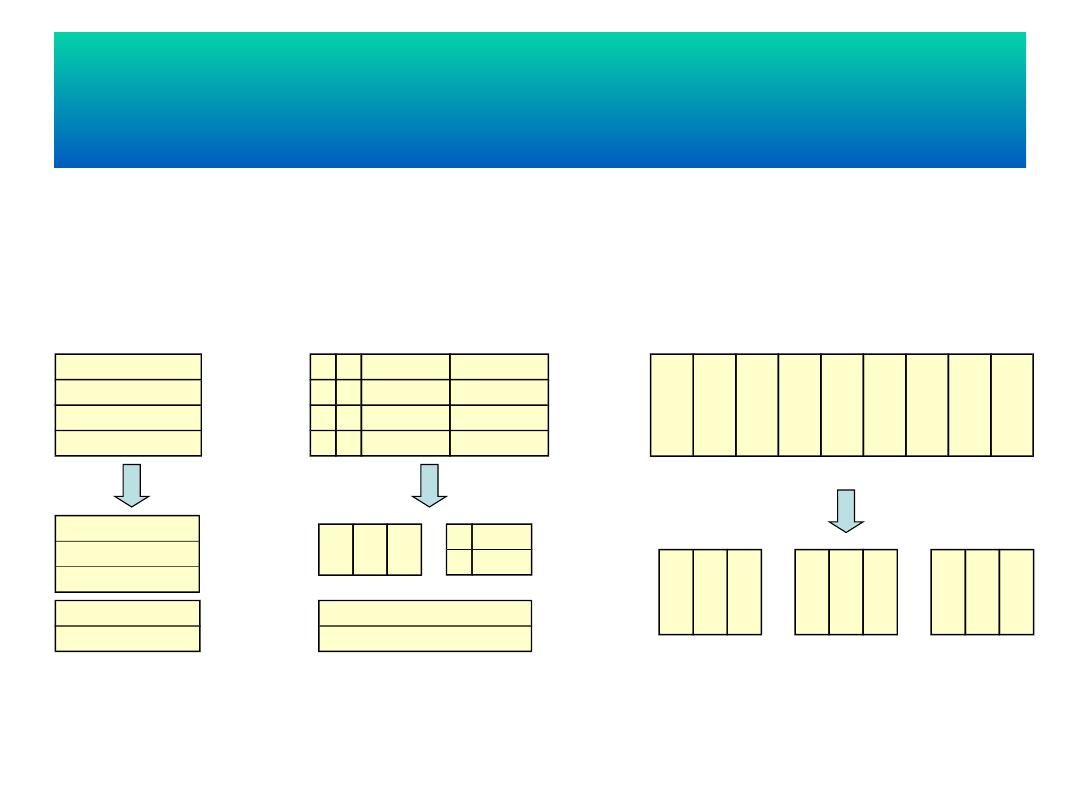
Fragmentacja jest procesem rozdzielenia
zbioru danych na kilka podzbiorów
(nazywanych fragmentami)
Charakterystyka rozproszonych baz
Charakterystyka rozproszonych baz
danych
danych
hybrydowa
(mieszana)
horyzontalna
(pozioma)
wertykal
na
(pionow
a)

Alokacja jest procesem umieszczenia
każdego fragmentu w jednym lub
więcej miejscach (węzłach)
• alokacja bez redundancji
(porcjowa -
każdy fragment jest umieszczony
dokładnie w jednym węźle)
• alokacja z redundancją
(częściowa
lub pełna replikacja - każdy fragment
może być powielony w większej
liczbie węzłów)
Charakterystyka rozproszonych baz
Charakterystyka rozproszonych baz
danych
danych

Rozproszone bazy danych
Rozproszona baza danych
Rozproszona baza danych
logicznie powiązany zbiór danych (oraz opis tych
danych) współużytkowanych przez wiele osób,
fizycznie rozproszony w sieci komputerowej.
Bazując na tej definicji spróbujmy zdefiniować
rozproszony SZBD.
Rozproszony SZBD (RSZBD)
oprogramowanie umożliwiające zarządzanie
rozproszoną bazą danych oraz sprawiające, że fakt
rozproszenia danych jest niewidoczny
(przezroczysty) dla użytkownika.

Cechy i własności rozproszonego
Cechy i własności rozproszonego
SZBD
SZBD
• Zbiór logicznie powiązanych
współużytkowanych danych
• Dane są podzielone na fragmenty (części)
• Poszczególne fragmenty mogą być powielane
• Fragmenty są rozmieszczone na różnych
komputerach
• Komputery są połączone za pomocą sieci
komunikacyjnej
• Dane znajdujące się w każdym z węzłów
systemu znajdują się pod kontrolą lokalnego
SZBD
• Każdy lokalny SZBD może niezależnie
uruchamiać lokalne aplikacje
• Każdy SZBD jest wykorzystywany
w co najmniej
jednej aplikacji globalnej

Zalety RSZBD
• Odzwierciedlenie struktury
organizacyjnej
• Większe możliwości współużytkowania
danych oraz lokalna autonomia
• Zwiększenie dostępności danych
• Większa wiarygodność
• Większa wydajność systemu
• Koszty
• Rozwój modularny

Wady RSZBD
• Złożoność
• Koszty
• Trudniejsze zapewnienie
bezpieczeństwa
• Trudniejsza kontrola integralności
• Brak standardów
• Brak doświadczeń
• Bardziej skomplikowane
projektowanie bazy danych

Homogeniczne i heterogeniczne
RSZBD
•
Homogeniczne
Homogeniczne
– wszystkie węzły wykorzystują tę samą wersję
oprogramowania SZBD,
– projektowanie i zarządzanie proste,
– możliwy przyrostowy rozwój systemu
•
Heterogeniczne
Heterogeniczne
– węzły mogą wykorzystywać różne oprogramowanie
SZBD,
– różne modele danych (relacyjne, sieciowe, hierarchiczne,
obiektowe),
– konieczność tłumaczenia między protokołami i językami
stosowanymi przez różne SZBD,
– odwzorowania struktur danych,

Funkcje RSZBD
• Rozszerzone usługi komunikacyjne
• Rozszerzenie katalogu systemowego
• Przetwarzanie rozproszonych zapytań, ich
optymalizacja, dostęp do odległych danych
• Rozszerzona ochrona bezpieczeństwa
umożliwiająca stosowanie metod autoryzacji,
nadawanie praw dostępu do danych
rozproszonych
• Rozszerzona kontrola wielodostępu - zachowanie
spójności danych
• Rozszerzone możliwości odtwarzania danych po
awarii węzła oraz łączy komunikacyjnych
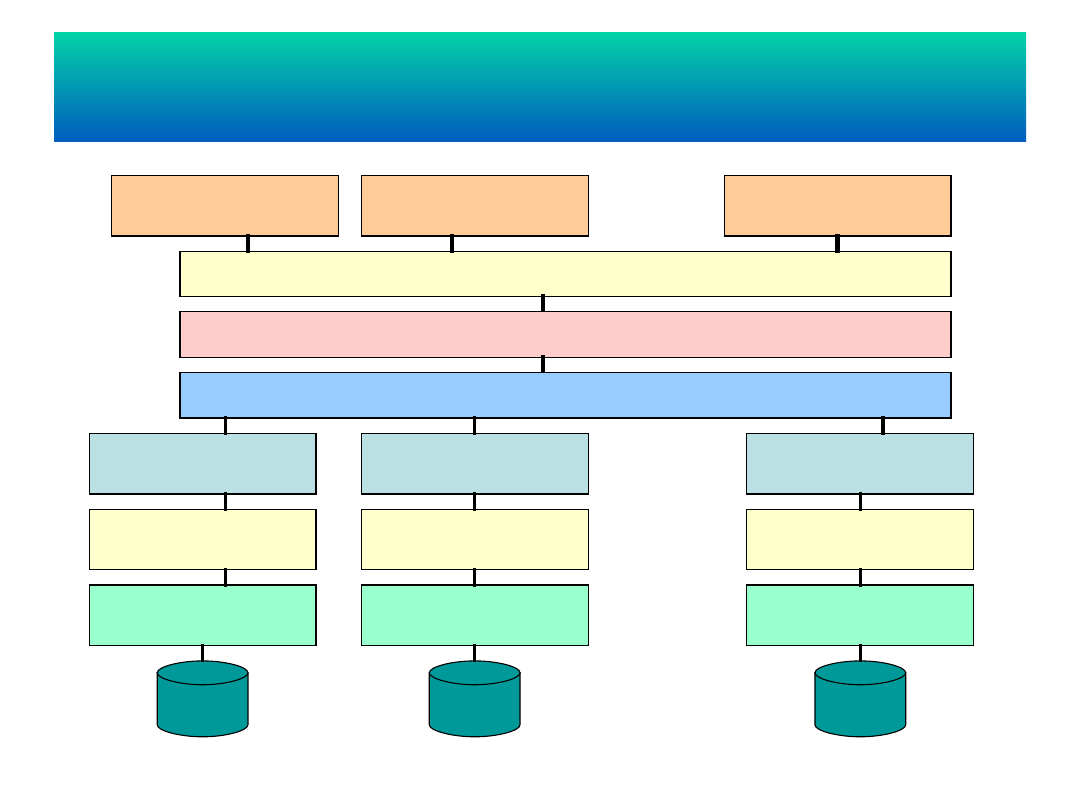
Architektura wzorcowa dla RSZBD
Globalny schemat konceptualny
Globalny schemat
zewnętrzny
Globalny schemat
zewnętrzny
DB
. . .
Globalny schemat
zewnętrzny
Schemat fragmentacji
Schemat alokacji
Lokalny schemat
odwzorowania
Lokalny schemat
konceptualny
Lokalny schemat
wewnętrzny
DB
Lokalny schemat
odwzorowania
Lokalny schemat
konceptualny
Lokalny schemat
wewnętrzny
DB
Lokalny schemat
odwzorowania
Lokalny schemat
konceptualny
Lokalny schemat
wewnętrzny
. . .
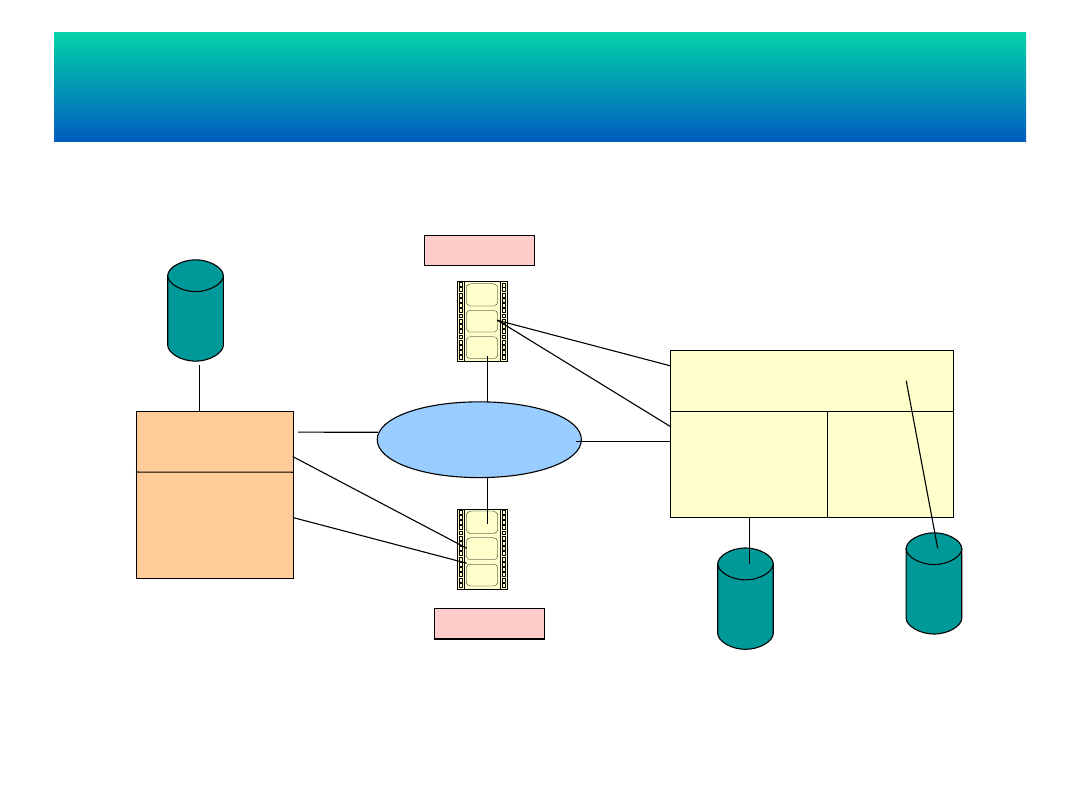
Komponenty rozproszonego
RSZBD
Sieć
komputero
wa
Węzeł 1
Węzeł 3
RSZBD
Komponent
komunikacyjn
y
Globalny katalog
systemowy
LSZBD
Komponent
Lokalny
komunikacyjny SZBD
DB
lokalny
katalog
systemowy
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
Wyszukiwarka
Podobne podstrony:
transakcyjny SQL
6 BERNE ANALIZA TRANSAKCYJNA
C3A4 Transaction in foreign trade Polish ver 2010 10 17
FMP1 Zadania Kursy i transakcje Nieznany
rozliczenia- transakcje sciaga, Finanse i bankowość, finanse cd student
Bezpieczenstwo w transakcjach finansowych
Międzynarodowe Transakcje Gospodarcze SUM opracowanie
MIĘDZYNARODOWE TRANSAKCJE HANDLOWE
cw, 3 transakcje zadania
Przebieg transakcji w handlu zagranicznym, WNPiD, moje, ChomikBox, międzynarodowe transakcje gospod
Analiza Transakcyjna - kwestionariusz, psychologia
49 Olber Adamus Pajak Opracowanie strategii transakcyjnej
06 MANUAL TRANSAXLE (C153)(1)
Congressional Research Services, 'NATO in Afghanistan, A Test of the Transatlantic Alliance', July 2
2 Międzynarodowe Transakcje Gospodarcze
Transakcja wojny chocimskiej
Opracowanie systemu informatycznego z automatycznym zawieraniem transakcji na rynku walutowym(1)
13 manual transaxle
więcej podobnych podstron