
Inżynieria oprogramowania
część IX – Architektury systemów rozproszonych
mgr inż. Piotr Greniewski
Europejska Wyższa Szkoła Informatyczno-
Ekonomiczna

Slajd nr 2
©Ian Sommerville 2000 - Inżynieria oprogramowania
Materiały do wykładu
Wykład opracowano na podstawie książki:
Inżynieria oprogramowania - Jan Sommerville
Wydawnictwa Naukowo – Techniczne
Warszawa 2003 r.
Prawa własności:
Rysunki, diagramy oraz układ prezentowanych treści są
własnością:
©Ian Sommerville 2000
.
Prezentacja stanowi tłumaczenie prezentacji autora
książki pobranej z witryny
http:/www.software-
engin.com.
Zgodnie z wolą autora: ”wykładowcy mają prawo
dowolnie modyfikować i adoptować tę prezentacje”
(Przedmowa – Witryna WWW – punkt 2 ) co też czynię.

Slajd nr 3
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Zawartość:
Architektury wieloprocesorowe
Architektury klient-serwer
Architektury obiektów rozproszonych
CORBA

Slajd nr 4
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Niemal wszystkie współczesne systemy
komputerowe są systemami rozproszonymi.
W systemie rozproszonym przetwarzanie jest
wykonywane na kilku komputerach i nie jest
przydzielone do jednej maszyny.
Inżynieria systemów rozproszonych ma wiele
wspólnego z innymi inżynieriami
oprogramowania.
Inżynierowie oprogramowania muszą znać
zagadnienia związane z tymi systemami gdyż
są one szeroko stosowane.

Slajd nr 5
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Do niedawna wielkie systemy były w
większości
scentralizowane
i działały na
komputerach głównych
do których były
podłączone
terminale
.
Terminale
nie posiadały mocy obliczeniowej.
Za całość przetwarzanej informacji
odpowiadał
komputer główny
.
Projektanci nie musieli zajmować się
sprawami związanymi z przetwarzaniem
rozproszonym.

Slajd nr 6
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Obecnie istnieją trzy rodzaje systemów:
Systemy osobiste
, które nie są rozproszone i są
przeznaczone do pracy na komputerze osobistym lub
stacji roboczej. Przykładami takich systemów są:
procesory tekstów, arkusze kalkulacyjne ...
Systemy wbudowane
, które działają na jednym
procesorze lub na zintegrowanej grupie procesorów.
Przykładami takich systemów są systemy sterowania
sprzętem domowym, systemy sterujące ...
Systemy rozproszone
, w których oprogramowanie
działa na luźno zintegrowanej grupie
współpracujących procesorów połączonych siecią.
Przykłady: systemy bankomatów, systemy rezerwacji
miejsc, systemy pracy grupowej ...

Slajd nr 7
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Obecnie dość łatwo możemy rozróżnić do
której grupy należy system.
Szybki rozwój sieci łączności bezprzewodowej
może doprowadzić do zatarcia granic
pomiędzy grupami systemów.
Będzie możliwe stała lub czasowa integracja
różnych systemów.

Slajd nr 8
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Istotne cechy systemu rozproszonego:
Współdzielenie zasobów
Otwartość
Współbieżność
Skalowalność
Odporność na awarie
Przezroczystość

Slajd nr 9
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Współdzielenie zasobów
. System rozproszony
umożliwia współdzielenie zasobów
sprzętowych i programowych umieszczonych
na różnych komputerach w sieci, np. dysków,
drukarek, plików, kompilatorów itd.
Współdzielenie zasobów było znane w
systemie wielodostępnym, ale tam zasoby
znajdowały się na jednym komputerze.

Slajd nr 10
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Otwartość
. Otwartość systemu mierzy się
łatwością rozszerzania go o nowe nie należące
do niego zasoby. Systemy rozproszone są
otwarte i zwykle zawierają sprzęt i
oprogramowanie różnych producentów.
Współbieżność
. W systemie współbieżnym
kilka procesów może działać na różnych
komputerach w tym samym czasie. Te procesy
mogą (ale nie muszą) komunikować się w
czasie swej normalnej pracy.

Slajd nr 11
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Skalowalność
. Systemy rozproszone powinny być
skalowane w sensie zwiększania możliwości
poprzez dodawanie nowych zasobów. W praktyce
skalowalność jest ograniczona przez sieć łączącą
komputery.
Odporność na awarie
. Dostępność wielu
komputerów i związana z tym możliwość
powielania informacji powinna oznaczać, że
systemy rozproszone powinny być odporne na
pewne awarie sprzętowe i programowe. W
większości systemów rozproszonych, gdy nastąpi
awaria, oferuje się gorsze usługi. Całkowity zanik
usługi zdarza się jedynie w wypadku awarii sieci.

Slajd nr 12
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Przezroczystość
. Polega na ukryciu przed
użytkownikiem rozproszonej natury systemu.
Celem projektu systemu może być
zapewnienie użytkownikom całkowicie
przezroczystego dostępu do usług i
wykluczenia potrzeby jakiejkolwiek informacji
o rozproszeniu systemu. Powinno się
udostępniać użytkownikom pewną wiedzę o
rozproszeniu systemu co pozwala na lepsze
korzystanie z jego zasobów.

Slajd nr 13
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Wady systemów rozproszonych:
Złożoność
Mniejsze bezpieczeństwo
Problemy z administrowaniem
Nieprzewidywalność

Slajd nr 14
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Złożoność
. Systemy rozproszone są bardziej
skomplikowane niż systemy scentralizowane.
Utrudnione jest zrozumienie pojawiających się
właściwości i testowania systemu.
Efektywność systemu nie zależy od szybkości
jednego procesora ale raczej od
przepustowości sieci i szybkości różnych
procesorów. Przenoszenie zasobów z jednej
części systemu do innej może drastycznie
wpływać na efektywność systemu.

Slajd nr 15
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Mniejsze bezpieczeństwo
. Z systemu można
korzystać za pośrednictwem wielu komputerów,
a ruch w sieci może być podsłuchiwany.
Zarządzanie bezpieczeństwem w systemie
rozproszonym jest znacznie trudniejsze
Problemy z administrowaniem
. W sieci mogą
istnieć komputery różnych typów, posiadające
różne systemy operacyjne. Awarie jednej
maszyny mogą rozszerzać się na inne maszyny i
powodować niespodziewane konsekwencje.
Oznacza to administrowanie i pielęgnacja
takiego systemu wymagają większego wysiłku.

Slajd nr 16
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Nieprzewidywalność
. Wszyscy użytkownicy
WWW wiedzą, jak nieprzewidywalny jest czas
reakcji systemu rozproszonego. Czas
odpowiedzi zależy od całkowitego obciążenia
systemu, jego organizacji i obciążenia sieci.
Wszystko to może zmieniać się w bardzo
krótkich i nieprzewidywalnych okresach.
Każde zlecenie może mieć znacząco inny czas
reakcji na żądanie użytkownika.
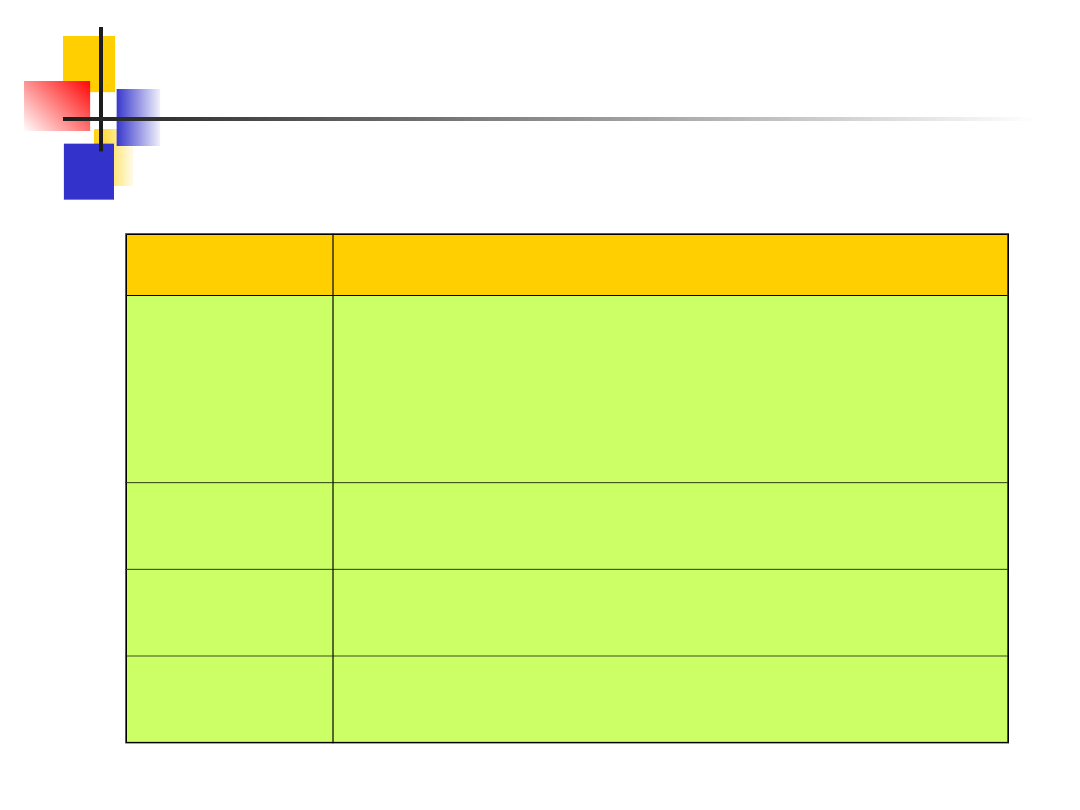
Slajd nr 17
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Zagadnienia projektowania systemów rozproszonych
Zagadnienia
projektowe
Opis
Identyfikacja
zasobów
Zasoby systemu rozproszonego są umieszczone na różnych
komputerach, należy więc opracować jednolity schemat
nazewnictwa aby użytkownicy mogli znajdować i
wykorzystywać potrzebne im zasoby. Dobrym przykładem
jest URL (Uniform Resource Locator) służący do
identyfikacji stron WWW. Bez jednolitego schematu
większość zasobów będzie niedostępna
Komunikacja
Dostępność sieci i efektywna implementacja protokołu
TCP/IP oznacza, że jest to najskuteczniejszy sposób
komunikacji komputerów w systemach rozproszonych.
Jakość usług
Jakość usług oferowanych przez system odzwierciedla jego
efektywność dostępność i niezawodność. Mają na nią wpływ
również inne czynniki.
Architektury
oprogramowania
W architekturze opisuje się jak funkcjonalność programu
użytkowego rozproszono na kilku logicznych komponentach
oraz jak te komponenty rozproszono na procesorach.

Slajd nr 18
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury systemów rozproszonych
Omówimy dwa rodzaje architektur systemów
rozproszonych:
Architektura klient-serwer
. W tym podejściu system
jest postrzegany jako zbiór usług oferowanych
klientom. W takich systemach odmiennie traktuje
się serwery i klientów
Architektura obiektów rozproszonych
. W tym
podejściu nie istnieje rozróżnienie pomiędzy
klientami i serwerami. System jest postrzegany jako
zbiór komunikujących się obiektów, których
położenie jest nieistotne. Nie ma różnicy pomiędzy
dostawcą i użytkownikiem usług.

Slajd nr 19
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury wieloprocesorowe
Najprostszym modelem systemu rozproszonego
jest system wieloprocesowy, składający się z
wielu procesów działających na jednym lub
wielu procesorach.
Model ten powszechnie występuje w systemach
czasu rzeczywistego.
Systemy takie zbierają informacje i na ich
podstawie podejmują decyzje i wysyłają sygnały
do efektorów które zmieniają środowisko.
Z logicznego punktu widzenia procesy zajmujące
się zbieraniem informacji, podejmowaniem
decyzji i sterowaniem efektorami mogłyby
działać na jednym procesorze.

Slajd nr 20
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektury wieloprocesorowe
Użycie wielu procesorów poprawia
efektywność i odporność systemu.
Przydział procesów do procesorów może może
być zadany z góry (tak zwykle jest w
systemach krytycznych) albo sterowany przez
dyspozytora, który decyduje o przyznaniu
procesora procesowi.

Slajd nr 21
©Ian Sommerville 2000 - Inżynieria oprogramowania
System wieloprocesorowy do kierowania
ruchem
Na rysunku pokazany jest model systemu
kierowania ruchem.
Zbiór rozproszonych detektorów zbiera informacje
o natężeniu ruchu i przetwarza je lokalnie przed
przesłaniem do centrum sterowania.
Operatorzy na podstawie tej informacji podejmują
decyzje i przekazują polecenia do oddzielnego
procesu sterowania światłami.
W przykładzie wyróżniono trzy logicznie
wydzielone procesy do zarządzania: detektorami,
centrum sterowania i światłami.
Systemy wieloprocesowe nie muszą być
rozproszone.
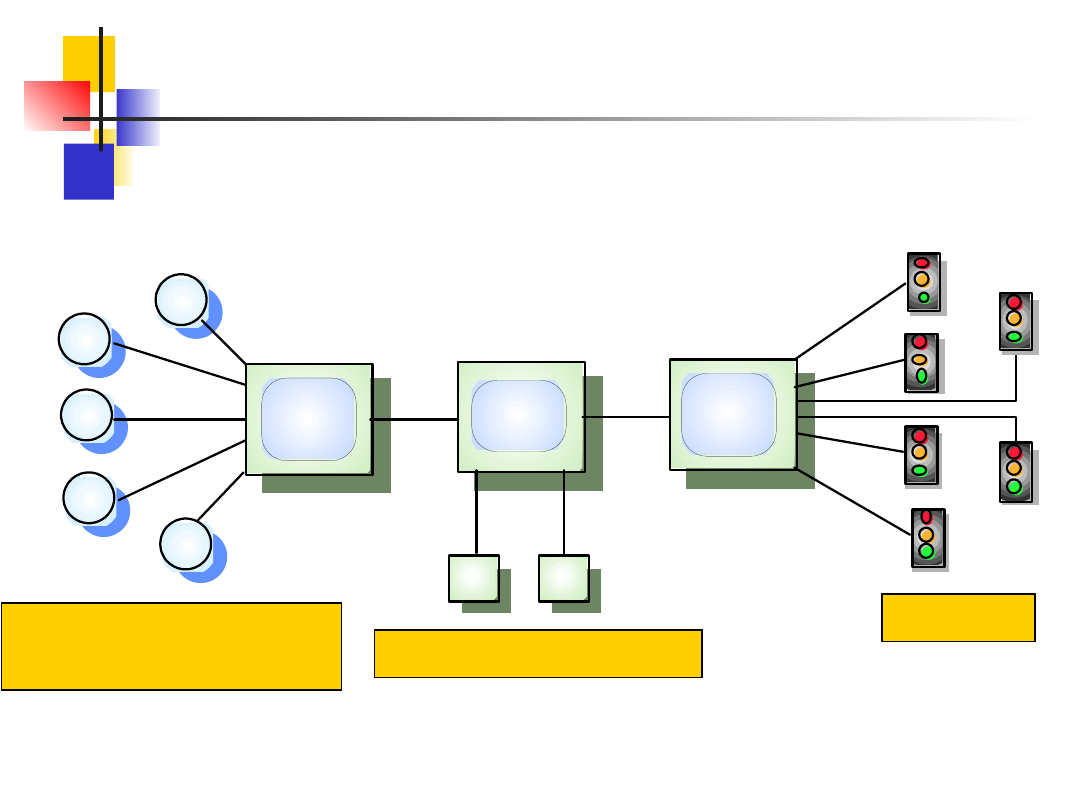
Slajd nr 22
©Ian Sommerville 2000 - Inżynieria oprogramowania
System wieloprocesorowy do kierowania
ruchem
Traffic lights
Light
control
process
Traffic light control
processor
Traffic flow
processor
Operator consoles
Traffic flow sensors
and cameras
Sensor
processor
Sensor
control
process
Display
process
Konsole operatorów
Detektory natężenia
ruchu i kamery
Światła

Slajd nr 23
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Architektoniczny model klient-serwer jest
modelem rozproszonym systemu w którym dane
i przetwarzanie jest rozproszone między zbiór
procesorów. Główne komponenty systemu:
Zbiór samodzielnych procesorów oferujących usługi
innym podsystemom. Przykładami są systemy
realizujące usługi drukowania, serwery plików,
serwery kompilujące.
Zbiór klientów, którzy korzystają z usług oferowanych
przez serwery. Zwykle same w sobie są podsystemami.
Może być kilka współbieżnie działających programów
klient.
Sieć dająca klientowi dostęp do serwerów

Slajd nr 24
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Program użytkowy jest modelowany jako zbiór
usług oferowany przez serwery i zbiór
klientów, którzy z tych usług korzystają.
Klienci muszą znać dostępne serwery ale nie
muszą wiedzieć o istnieniu innych klientów.
Klienci i serwery są oddzielnymi procesami
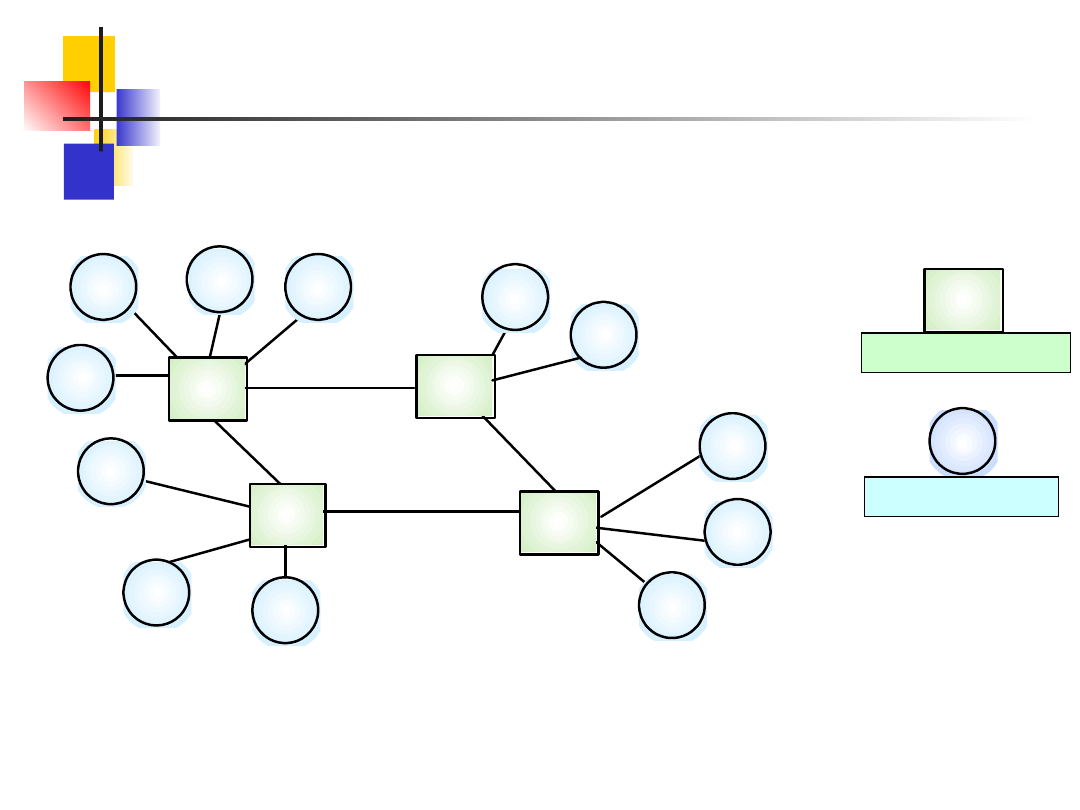
Slajd nr 25
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
s1
s2
s3
s4
c1
c2
c3
c4
c5
c6
c7
c8
c9
c10
c11
c12
Client process
Server process
Proces serwera
Proces klienta

Slajd nr 26
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Procesy i procesory nie muszą być wzajemnie
jednoznacznie przyporządkowane.
Na następnym slajdzie pokazano fizyczną
architekturę systemu z dwoma komputerami
serwerów i sześcioma komputerami klientów.
Mogą na nich działać procesy klientów i
serwerów.
Mówiąc o klientach i serwerach ma się
zazwyczaj na myśli procesy logiczne a nie
fizyczne komputery (procesory) na których
działają.
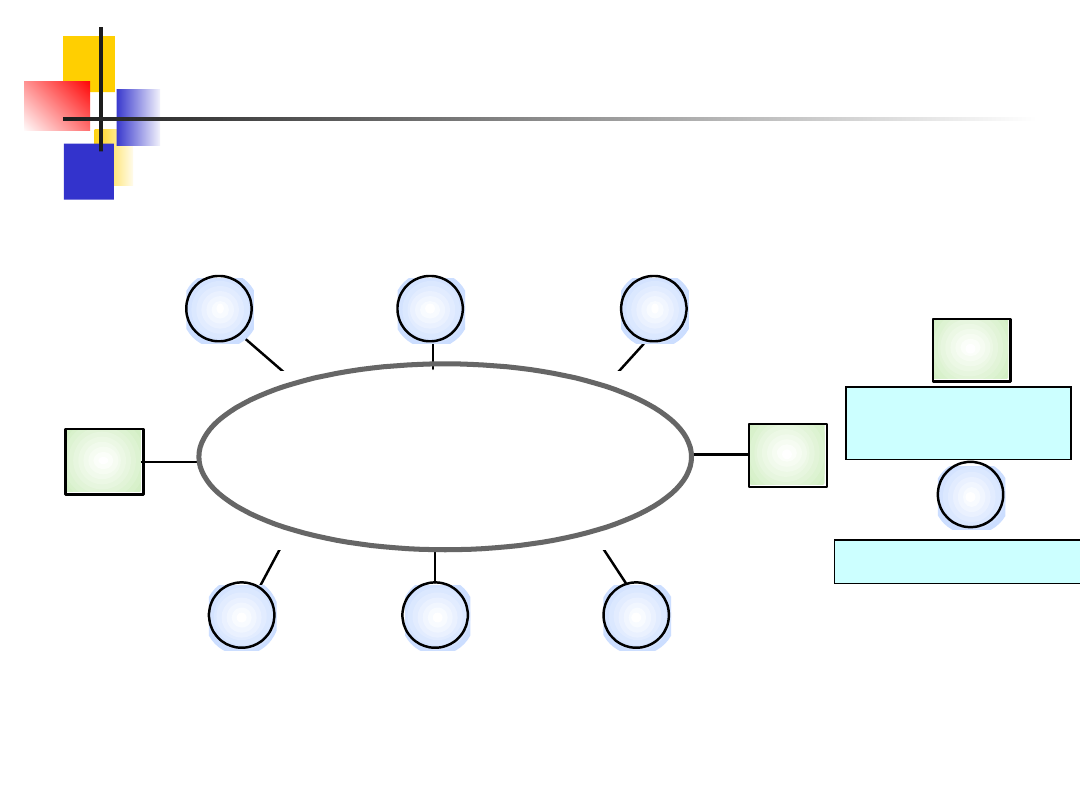
Slajd nr 27
©Ian Sommerville 2000 - Inżynieria oprogramowania
Komputery w sieci klient-serwer
Network
SC1
SC2
CC1
CC2
CC3
CC5
CC6
CC4
Server
computer
Client
computer
s1, s2
s3, s4
c5, c6, c7
c1
c2
c3, c4
c8, c9
c10, c11, c12
Komputer klienta
Komputer
serwera

Slajd nr 28
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Projekt systemu klient-serwer powinien
odzwierciedlać logiczną strukturę tworzonego
programu użytkowego.
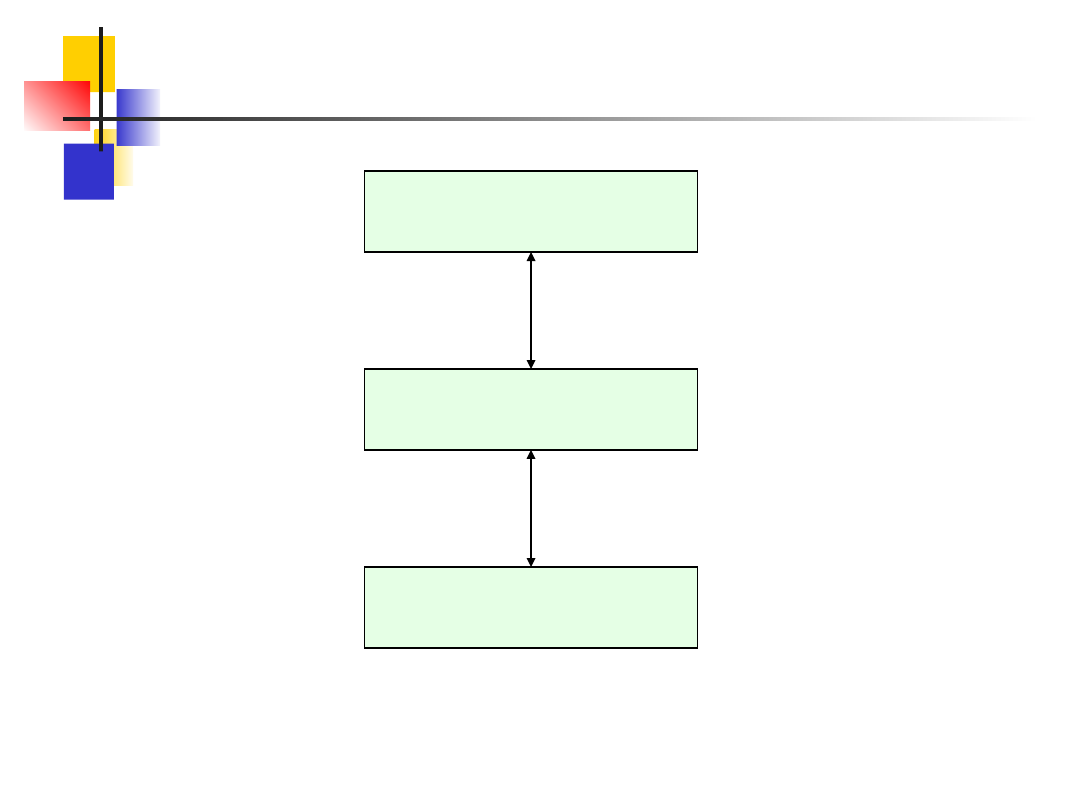
Na następnym slajdzie przedstawiono
program użytkowy złożony z trzech warstw:
Warstwa prezentacji
, dotycząca przedstawiania
informacji użytkownikowi.
Warstwa przetwarzania
, implementująca logikę
programu użytkowego.
Warstwa zarządzania danymi
, odpowiedzialna za
wszystkie operacje na bazie danych.
Slajd nr 29
©Ian Sommerville 2000 - Inżynieria oprogramowania
Warstwy programu użytkowego
Warstwa prezentacji
Warstwa przetwarzania
Warstwa zarządzania
danymi

Slajd nr 30
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
W
systemie
scentralizowanym
nie ma potrzeby
jawnego wydzielenia tych warstw.
Projektując
system rozproszony
, trzeba
wyraźnie je wyróżnić, ponieważ umożliwi to
umieszczenie każdej warstwy na innym
komputerze.
Najprostsza architektura klient-serwer nosi
nazwę
dwuwarstwowej
.
Program użytkowy składa się serwera
(serwerów) i zbioru klientów.

Slajd nr 31
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
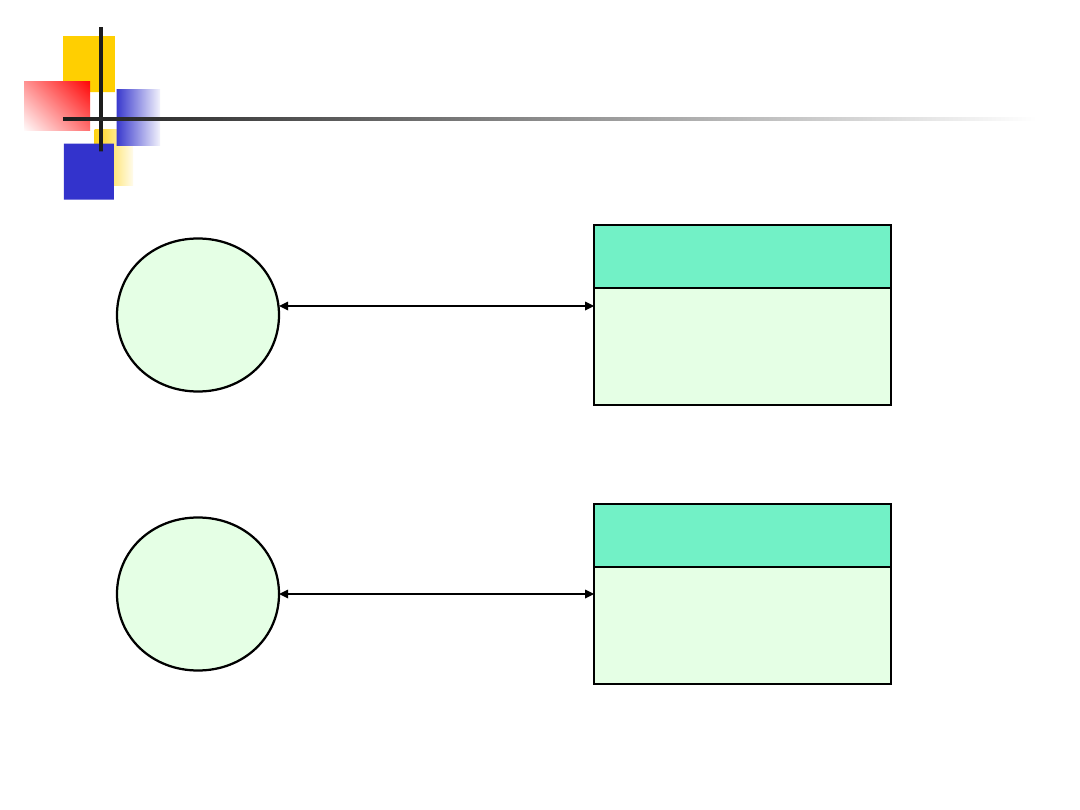
Dwa rodzaje architektury klient-serwer
Model klienta cienkiego
. W tym modelu całość
przetwarzania i zarządzania danymi ma miejsce na
serwerze.Jedynym zadaniem klienta jest
uruchomienie oprogramowania prezentacyjnego.
Model klienta grubego
. W tym modelu serwer
odpowiada jedynie za zarządzanie danymi.
Oprogramowanie u klienta implementuje logikę
programu i kontakt z użytkownikiem systemu.
Slajd nr 32
©Ian Sommerville 2000 - Inżynieria oprogramowania
Klient cienki i klient gruby
Klie
nt
Klie
nt
Serwer
Zarządzanie danymi
Przetwarzanie
Serwer
Zarządzanie danymi
Model klienta cienkiego
Model klienta grubego

Slajd nr 33
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Architektura dwuwarstwowa z klientem cienkim
jest najprostszym rozwiązaniem, które można
wykorzystać w scentralizowanych procesach
odziedziczonych ewoluujących w kierunku
architektury klient serwer.
Interfejs użytkownika tych systemów jest
przenoszony na komputer osobisty, a program
użytkowy działa jako serwer i obsługuje
przetwarzanie użytkowe oraz zarządzanie danymi.
Model klienta cienkiego można zaimplementować
tam gdzie klienci są prostymi urządzeniami
sieciowymi. Na takim urządzeniu sieciowym działa
przeglądarka oraz interfejs użytkownika
realizowany przez system.

Slajd nr 34
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Wadą klienta cienkiego
jest duże obciążanie
przetwarzaniem zarówno sieci jak i serwera.
Serwer odpowiada za wszystkie obliczenia co
prowadzi do dużego ruchu sieciowego między
klientem a serwerem.
Współczesne komputery osobiste mają dużą moc
obliczeniową, z której w modelu klienta cienkiego
nie korzysta się.
W modelu klienta grubego
korzysta się z dostępnej
mocy obliczeniowej i przekazuje klientowi
przetwarzanie związane z logiką programu
użytkowego jak i prezentację.
Serwer jest serwerem zarządzającym transakcjami
w bazie danych.

Slajd nr 35
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Przykładem architektury
klienta grubego
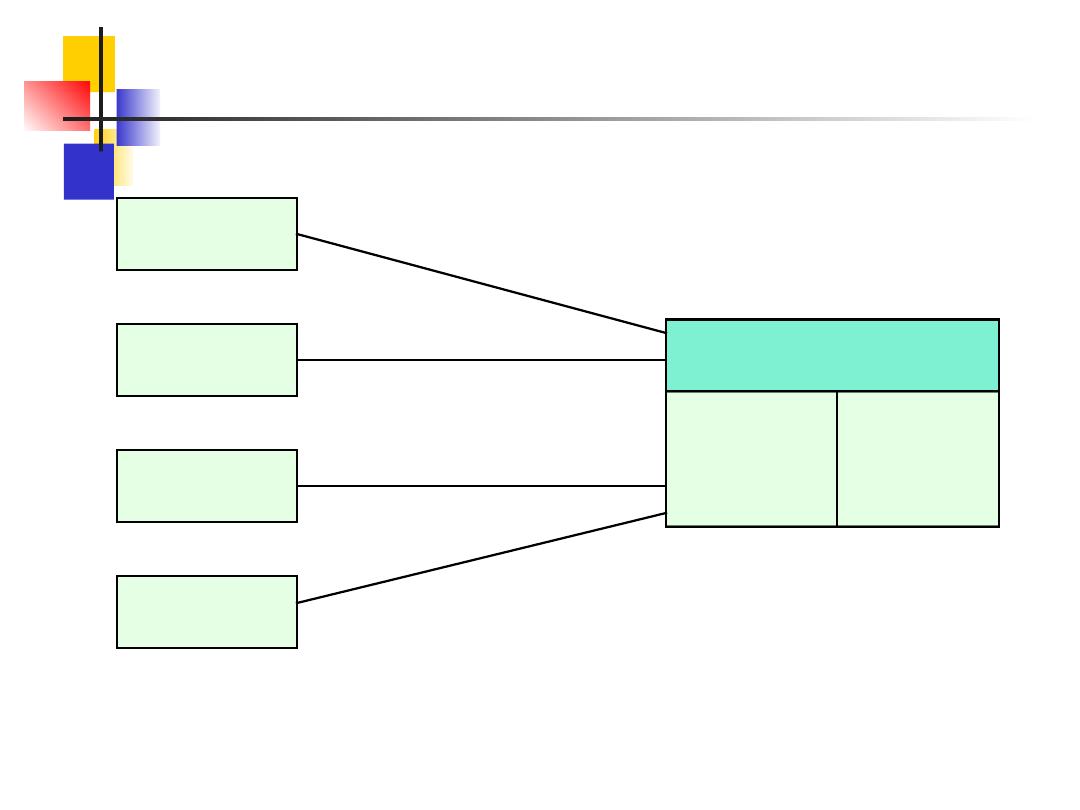
są systemy
bankomatów. Bankomat jest klientem, a serwerem
jest komputer główny obsługujący bazę danych kont
klientów.
Na następnym slajdzie przedstawiono sieć
bankomatów.
Bankomaty nie łączą się bezpośrednio z bazą danych
klientów ale z monitorem przetwarzania zdalnego.
Jest to system zarządzający komunikacją z klientami
zdalnymi, szeregujący transakcje przed
przetwarzaniem ich w bazie.
Zastosowanie transakcji szeregowych umożliwia
odtworzenie systemu po awarii bez uszkadzania bazy.
Slajd nr 36
©Ian Sommerville 2000 - Inżynieria oprogramowania
System klient-serwer do obsługi
bankomatów
Serwer kont
Monitor
przetwarzania
zdalnego
Baza danych
kont
klientów
Bankomat
Bankomat
Bankomat
Bankomat

Slajd nr 37
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
W modelu klienta grubego przetwarzanie jest
bardziej efektywne niż w modelu klienta cienkiego,
zarządzanie jest natomiast dużo trudniejsze.
Funkcjonalność programów użytkowych jest
rozproszona po wielu różnych komputerach.
Aby zmienić oprogramowanie użytkowe, trzeba
wykonać ponowną instalację na każdym
komputerze klienta.
Pojawienie się języka
Java
i ściąganych
apletów
umożliwiło opracowanie modelu klient-serwer,
który leży pomiędzy modelem klienta cienkiego a
grubego.

Slajd nr 38
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Model zakłada, że części oprogramowania
przetwarzającego mogą być przekazywane klientowi
w postaci apletów Javy, co zmniejsza obciążenie
serwera.
Interfejs użytkownika jest budowany dla
przeglądarki WWW, w której mogą działać aplety.
Powstają problemy związane z tym, że przeglądarki
różnych producentów i ich wersje nie zawsze
wyświetlają w ten sam sposób.
Wcześniejsze wersje starych komputerów mogą nie
być w stanie uruchamiać programów w Javie.
To podejście można stosować gdy wszyscy
użytkownicy systemu mają zgodne przeglądarki
zdolne do uruchamiania Javy.

Slajd nr 39
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Zasadnicza trudność dotycząca
dwuwarstwowego podejścia klient-serwer
polega na tym, że trzy warstwy logiczne
(prezentacja, przetwarzanie użytkowe i
zarządzanie danymi) muszą być
przyporządkowane do dwóch systemów
komputerowych.
Występują kłopoty ze skalowalnością i
efektywnością dla klienta cienkiego i kłopoty z
pielęgnacją dla klienta grubego.
Unikniemy tych kłopotów stosując architekturę
trójwarstwową.

Slajd nr 40
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
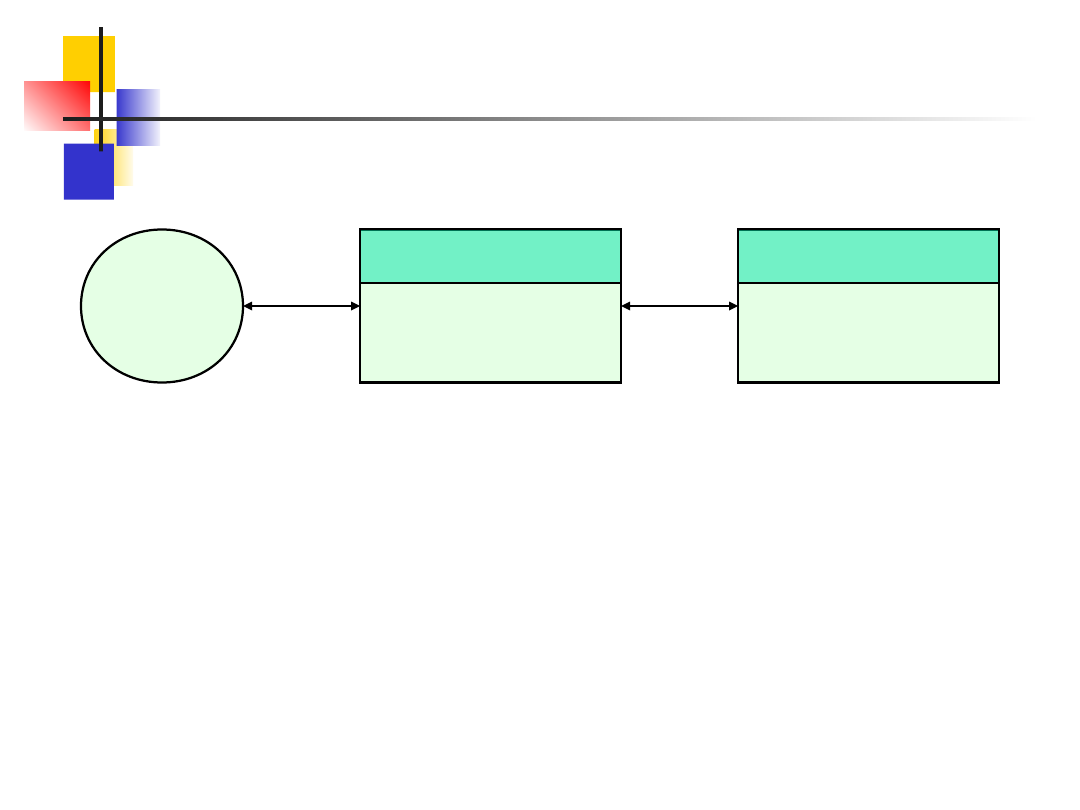
Architektura trójwarstwowa oznacza, że
prezentacja, przetwarzanie użytkowe i
zarządzanie danymi są oddzielnymi
procesami.
Nie oznacza to, że musimy mieć trzy
komputery. Jeden komputer serwera może
obsługiwać zarówno przetwarzanie użytkowe
jak i zarządzanie danymi jako dwa logiczne
serwery.
Gdy potrzeba większej wydajności możemy je
umieścić na różnych serwerach.
Slajd nr 41
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura trójwarstwowa klient-serwer
Serwer
Zarządzanie
danymi
Serwer
Przetwarzanie
użytkowe
Klie
nt
Prezentacja

Slajd nr 42
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
System bankowy w sieci jest przykładem
trójwarstwowej architektury klient serwer.
Bankowa baza danych o klientach oferuje usługi
zarządzania danymi.
Serwer WWW zapewnia usługi użytkowe, takie
jak udogodnienia do przelewu pieniędzy,
generowanie wyciągów, płacenie rachunków itp.
Komputer użytkownika z przeglądarką sieci
odgrywa rolę klienta.
System jest skalowalny, ponieważ łatwo dodać
nowe serwery WWW w miarę wzrostu liczby
klientów.
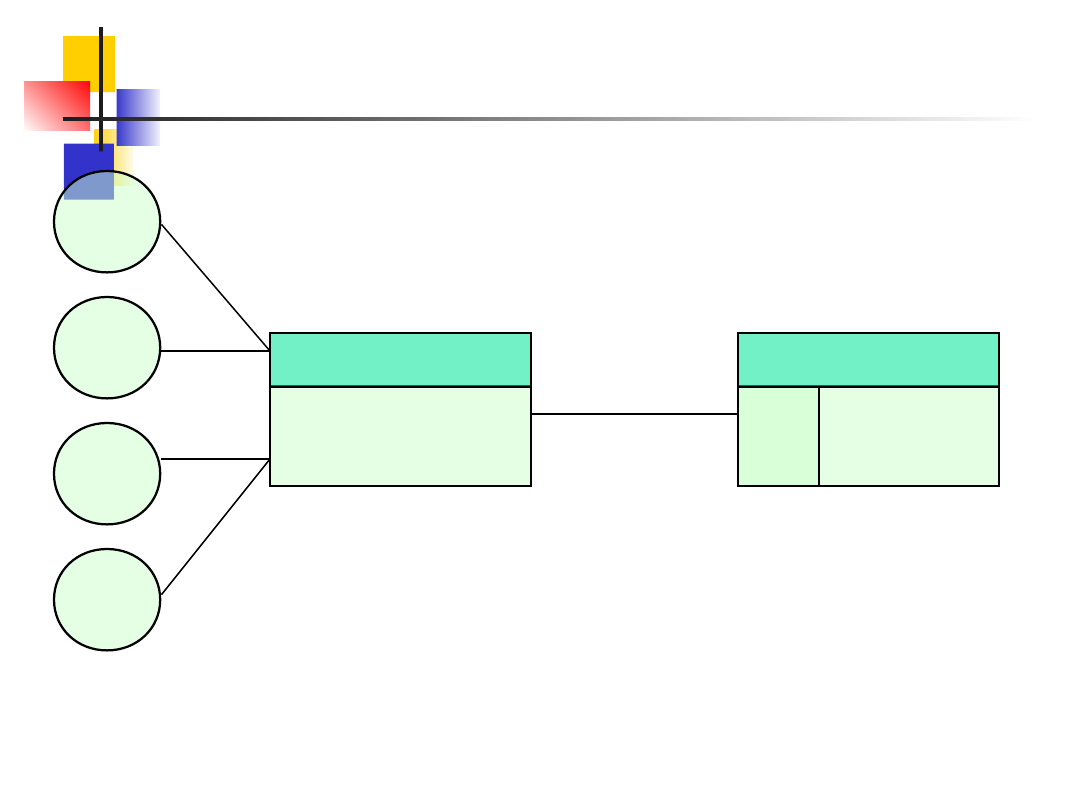
Slajd nr 43
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura rozproszona systemu
bankowego
Serwer WWW
Obsługa
konta
Klie
nt
Klie
nt
Klie
nt
Klie
nt
Serwer bazy danych
SQL
Baza danych
kont klientów
Zapytania SQL

Slajd nr 44
©Ian Sommerville 2000 - Inżynieria oprogramowania
Architektura klient-serwer
Architektura trójwarstwowa klient-serwer umożliwia
optymalizację przekazywania informacji pomiędzy
serwerem WWW a serwerem bazy danych.
Komunikacja pomiędzy tymi serwerami nie musi być
zgodna ze standardami sieci ale opierać się na
szybszych protokołach komunikacyjnych.
Aby wydobyć informacje z bazy używa się języka
SQL.
W uzasadnionych wypadkach można rozszerzyć
model trójwarstwowy do modelu wielowarstwowego.
Systemy wielowarstwowe stosujemy tam, gdzie
programy użytkowe muszą wykorzystywać dane z
różnych baz.

Slajd nr 45
©Ian Sommerville 2000 - Inżynieria oprogramowania
Zastosowanie różnych architektur klient-
serwer
Architektura
Zastosowanie
Architektura
dwuwarstwowa
klient-serwer
z klientami
cienkimi
Systemy odziedziczone w których oddzielenie przetwarzania
od zarządzania danymi jest niepraktyczne lub niemożliwe.
Programy użytkowe wykonujące dużo obliczeń i w małym
stopniu albo wcale zarządzające danymi, np. kompilatory.
Architektura
dwuwarstwowa
klient-serwer
z klientami
grubymi
Programy użytkowe, w których obliczenia są wykonywane u
klienta przez komponenty z półki np. Excel.
Programy wymagające złożonego przetwarzania danych.
Architektura
trójwarstwowa
lub
wielowarstwowa
klient-serwer
Duże programy użytkowe dla tysięcy użytkowników.
Programy użytkowe dla których zarówno dane jak i
programy są płynne.
Programy użytkowe w których integruje się dane z różnych
źródeł.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
Wyszukiwarka
Podobne podstrony:
002 architektur systemow rozproszonychid 2229 ppt
Architektura systemów komputerowych( 09
Architektura systemów komputerowych ppt
10 Reprezentacja liczb w systemie komputerowymid 11082 ppt
09 Podstawy chirurgii onkologicznejid 7979 ppt
09 Choroba niedokrwienna sercaid 7754 ppt
Architecting Presetation Final Release ppt
1 Systematyka rehabilitacjiid 9891 ppt
Wstęp do informatyki z architekturą systemów kompuerowych, Wstęp
System podatkowy Malty ppt
Architekrura Systemów Lab1
09 A Latała Systemy zabezpieczeń
Architekrura SystemAlw Lab5 (1) Nieznany
66 251103 projektant architekt systemow teleinformatycznych
Architekrura Systemów Lab3
tranzystory mosfet(1), Architektura systemów komputerowych, Sentenza, Sentenza
więcej podobnych podstron