
Routing- podstawowe
informacje
Opracował Dominik Walkowski
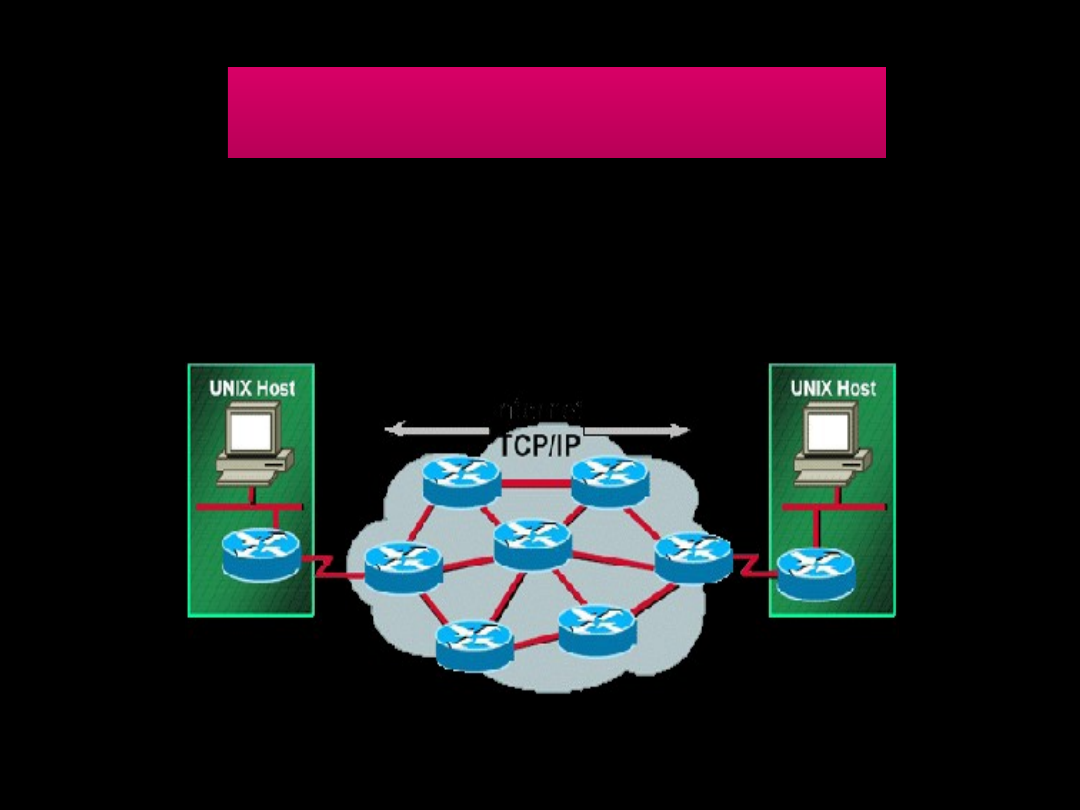
Co to jest Routing?
Co to jest Routing?
Routing
powstał wraz z rozwojem wielkości sieci
komputerowych. Powstał problem jak połączyć ze sobą sieci
znajdujące się daleko od siebie. Routery są zatem urządzeniami,
które pozwalają nam łączyć różne sieci za sobą.
Jak można się łatwo domyślić istnieje wiele możliwości
połączenia wielu sieci ze sobą, stosuje się także nadmiarowe
połączenia w celu zwiększenia niezawodności funkcjonowania
sieci. Routery mają za zdanie przesyłać pakiety z jednej sieci
do drugiej wybierając najbardziej optymalną trasę –
pozwalającą na najszybsze dotarcie wiadomości do adresata.
Routery są węzłami sieci operującymi w trzeciej (sieciowej)
warstwie modelu OSI. Są to urządzenia wyposażone
najczęściej w kilka interfejsów sieciowych LAN, porty
obsługujące sieci WAN, pracujący wydajnie procesor i
specjalne oprogramowanie zawiadujące ruchem pakietów
przepływających przez router. Jak sama nazwa wskazuje
(router to trasa), routery wyznaczają pakietom marszruty,
kierując je do odpowiedniego
interfejsu.

Chociaż routerem może być też zwykły komputer
dysponujący kilkoma kartami sieciowymi i specjalnym
oprogramowaniem, to jest to najczęściej dedykowany
komputer,
dysponujący
rozwiązaniami
znacznie
zwiększającymi wydajność tego rodzaju węzłów sieci. Jest to
szczególnie istotne w przypadku routerów obsługujących
duży ruch. Przez lata routing IP ewoluował od pakietów
obsługiwanych
programowo,
poprzez
przekazywanie
realizowane przez specjalizowane układy scalone ASIC, dalej
przekazywanie przez układy ASIC z szybkością danego
interfejsu, aż do wprowadzanego obecnie przekazywania
realizowanego przez procesory sieciowe z szybkością
interfejsu. Routery są stosowane zarówno w sieciach LAN, jak
i sieciach WAN.
Router Cisco 2621

W sieciach LAN są używane, gdy siec komputerową chcemy
podzielić na dwie lub więcej podsieci, czyli poddać operacji
segmentowania.
Segmentacja
sieci
powoduje,
że
poszczególne podsieci są od siebie odseparowane, zatem
pakiety rozgłoszeniowe (broadcast) nie przenikają z jednej
podsieci do drugiej dzięki czemu zwiększamy przepustowość
każdej z podsieci.
Routery dostępowe są węzłami sieci ekspediujące przez
łącze WAN pakiety generowane przez stacje pracujące w sieci
LAN do innego routera pracującego po drugiej stronie tego
łącza. Oczywiście może zdarzyć się i tak, że jeden router
obsługuje zarówno pakiety lokalne, jak i te kierowane na
zewnątrz.

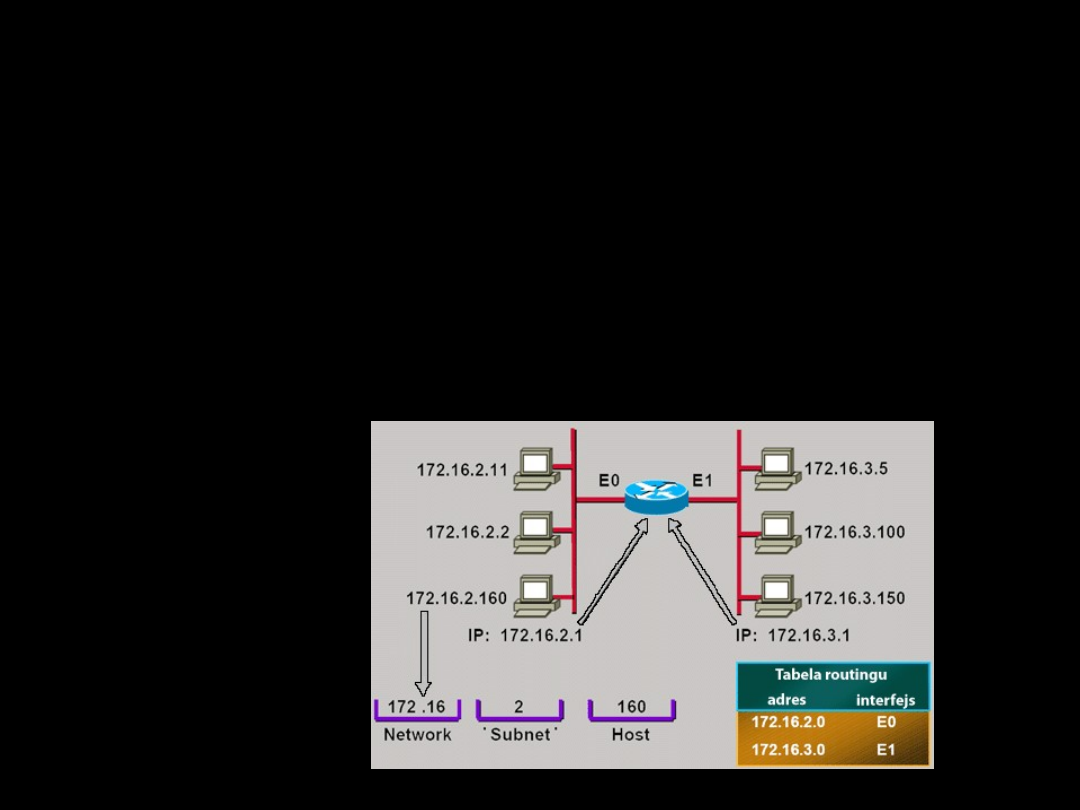
Routery nie interesują się adresami MAC ( w przypadku
sieci Ethernet jest to 48 bitowa liczba przypisywana
każdej karcie sieciowej ), a po odebraniu pakietu
odczytują i poddają analizie adres budowany w obszarze
warstwy sieciowej. W sieciach pracujących z protokołem
IP do każdego komputera pracującego w sieci
przypisywany jest jego adres IP. Adres taki składa się
zawsze z dwóch części: jedna definiuje adres sieci, a
druga to adres komputera pracującego w tej sieci. O tym
jak długa jest część adresu IP przeznaczona na adres
sieci decyduje maska podsieci i tak np. adres
148.81.40.10 przy masce 255.255.255.0 oznacza, że
stacja docelowa jest zainstalowana w sieci 148.81.40.0, a
adres stacji w tej sieci to 148.81.40.10. Routery dokonują
operacji logicznej AND przychodzących do nich adresów
IP z maskami jakie mają zdefiniowane na swoich
interfejsach, obliczając w ten sposób adres sieci i
wysyłają dany pakiet do właściwej sieci. Gdy obliczony
adres sieci nie należy do sieci podłączonej do danego
routera przekazuje on go wtedy do innego routera ( na
tzw. adres default ), który prawdopodobnie będzie lepiej
wiedział dokąd skierować dany pakiet.
Routery posiadają tabele routingu i mają zdolność „uczenia się”
topologii sieci, wymieniając informacje z innymi routerami
zainstalowanymi w sieci. Ponieważ prawie wszystkie operacje są
z odbieraniem i wysyłaniem pakietów do odpowiednich
interfejsów są realizowane w routerze przez oprogramowanie, to
tego rodzaju węzły sieci pracują dużo wolniej niż np. przełączniki
(switch). Protokoły routingu (trasowania) wyznaczają pakietom
marszruty opierając się na różnych algorytmach. Mogą to być
algorytmy statyczne lub dynamiczne, single path lub multipath,
płaskie lub hierarchiczne, host inteligent lub router inteligent,
intradomain lub interdomain i opierające się na technologii link
state lub distance vector.

Podstawowe zasady
routingu.
Podstawowe zasady
routingu.
Algorytmy routingu wykorzystują różne metryki w celu określenia
najlepszej ścieżki. Każdy algorytm routingu na swój sposób dokonuje
interpretacji najlepszego wyboru. Algorytm routingu generuje liczbę,
zwaną wartością metryki, dla każdej ścieżki w sieci. Zaawansowane
algorytmy routingu opierają wybór trasy na wielu metrykach, tworząc
z nich pojedynczą metrykę złożoną. Zwykle mniejsze wartości metryk
wskazują preferowane ścieżki. Metryki mogą być obliczane na
podstawie pojedynczego parametru charakteryzującego ścieżkę lub
kilku różnych parametrów. Poniżej przedstawiono parametry
najczęściej wykorzystywane przez protokoły routingu:
Szerokość pasma — przepustowość łącza w kontekście
transmitowanych danych.
Zwykle połączenie
Ethernet o paśmie 10 Mb/s jest bardziej pożądane od łącza
dzierżawionego o paśmie 64 kb/s.
Opóźnienie — czas potrzebny do przesłania pakietu w
każdym łączu na drodze ze źródła do celu.
Opóźnienie zależy od szerokości pasma łączy pośrednich, ilości
danych, które mogą być tymczasowo
przechowywane w każdym routerze, przeciążenia sieci oraz fizycznej
odległości.
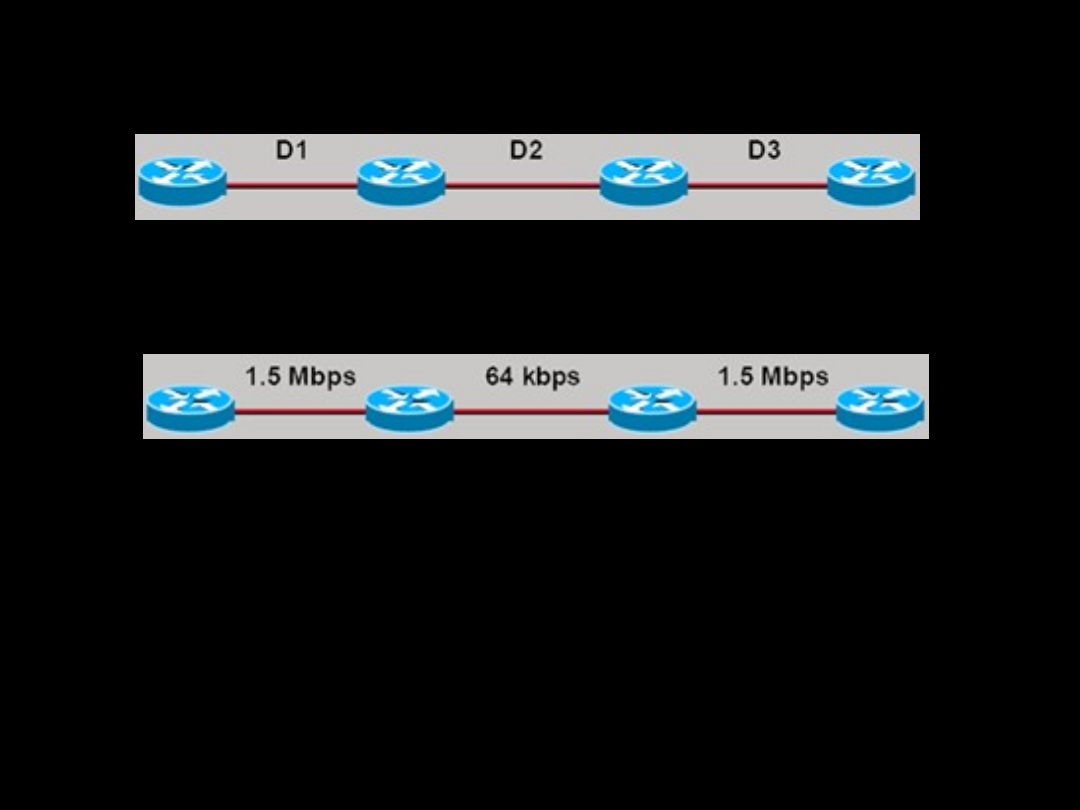
metryka liczona na podstawie
opóźnień
D1+D2+D3
metryka liczona na podstawie
przepustowości
64 kbps

·
Obciążenie — aktywność występująca w ramach
zasobu sieciowego, takiego jak router czy łącze.
· Niezawodność — zazwyczaj tym mianem określana
jest stopa błędów występujących w danym łączu
sieciowym.
· Liczba przeskoków — liczba routerów, przez które
musi być przesłany pakiet, zanim dotrze do punktu
docelowego. Każdy router, przez który muszą zostać
przesłane dane, odpowiada pojedynczemu przeskokowi.
Ścieżka, której liczba przeskoków wynosi cztery, wskazuje,
że dane przesyłane tą ścieżką muszą pokonać cztery
routery nim dotrą do punktu docelowego. Jeśli istnieje kilka
różnych ścieżek, preferowana jest ścieżka o najmniejszej
liczbie przeskoków.
Impulsy zegarowe — opóźnienie na łączu danych
mierzone impulsami zegarowymi komputera IBM PC.
Jeden impuls to około 1/18 sekundy.
· Koszt — dowolna wartość przypisana przez
administratora sieci, zwykle oparta na szerokości
pasma,
wydatku pieniężnym lub innej mierze.

Protokoły routingu projektowane są z
myślą o realizacji jednego lub kilku z
poniższych
założeń:
Protokoły routingu projektowane są z
myślą o realizacji jednego lub kilku z
poniższych
założeń:
Optymalizacja
—
optymalizacja
określa
skuteczność
protokołu
routingu
w
wyborze
najlepszej ścieżki.
Ścieżka
zależeć
będzie
od
metryk
i
ich
wag
wykorzystanych w obliczeniach. Na przykład jeden
algorytm może wykorzystywać metryki liczby przeskoków i
opóźnienia, przypisując metrykom opóźnienia większą
wagę.
Prostota i niski narzut — im prostszy jest algorytm,
tym wydajniej będzie przetwarzany przez procesor i
pamięć routera. Ten parametr jest istotny, gdyż umożliwia
rozrost sieci do dużych rozmiarów, takich jak w przypadku
Internetu.
Odporność na błędy i stabilność — algorytm
routingu powinien funkcjonować poprawnie w
obliczu
niecodziennych
albo
nieprzewidzianych
okoliczności, takich jak awarie sprzętu komputerowego,
duże obciążenie i błędy implementacji.

Elastyczność — algorytm routingu powinien
szybko dostosowywać się do różnorakich zmian
zachodzących w sieci. Zmiany te obejmują dostępność
routerów, wielkość pamięci poszczególnych routerów,
zmiany pasma i opóźnień występujących w sieci.
Szybka zbieżność — zbieżnością określa się
proces uzgadniania dostępnych tras pomiędzy
wszystkimi routerami. Kiedy jakieś zdarzenie w sieci
zmieni dostępność routera, niezbędne są aktualizacje w
celu przywrócenia łączności w sieci. Algorytmy routingu,
które charakteryzuje niska zbieżność, mogą spowodować,
że dane nie zostaną dostarczone
.
C.D
C.D

Algorytmy trasowania:
Algorytmy trasowania:
Algorytm statyczny — nie jest właściwie algorytmem.
Wszystkie trasy routingu wyznacza na stałe sam
administrator systemu. Jeśli topologia sieci zmieni się, należy
odpowiednio ręcznie zmienić konfigurację routingu.
Algorytmy dynamiczne — śledzą cały czas topologię
sieci – pracują w czasie rzeczywistym i modyfikują w
razie potrzeby tabele routingu zakładane przez router.
Algorytmy single i multi path — Niektóre protokoły
trasowania wyznaczają pakietom kilka dróg dostepu do
stacji przeznaczenia, czyli wspierają multipleksowanie.
Algorytm single path definiuje tylko jedną ścieżkę dostępu do
adresata. Algorytm multi path pozwala przesyłać pakiety
przez wiele niezależnych ścieżek, co nie tylko zwiększa
szybkość transmisji pakietów, ale też chroni system routingu
przed skutkami awarii.

Algorytmy płaskie i hierarchiczne — W pierwszym
przypadku wszystkie routery są równorzędne. Można to
porównać do sieci typu peer-to-peer. Nie ma tutaj (ze względu
na strukturę logiczną) nadrzędnych i podrzędnych routerów.
Algorytmy hierarchiczne postrzegają sieć jako strukturę
zhierarchizowaną, dzieląc je na domeny. Pakiety krążącymi w
obrębie każdej domeny zawiaduje wtedy właściwy router,
przekazując je routerowi nadrzędnemu lub podrzędnemu
Algorytmy host inteligent i router intelligent —
Niektóre algorytmy zakładają, że całą drogę pakietu
do stacji przeznaczenia wyznaczy od razu stacja nadająca
( source routing czyli host intelligent ).

W tym układzie router pełni tylko rolę przekaźnika
odbierającego pakiet i przekazując go do innego miejsca. W
algorytmach router intelligent stacja wysyłajaca nie ma
pojęcia, jaką drogę przemierzy pakiet zanim dotrze do
adresata. Obowiązek wyznaczenia pakietowi marszruty
spoczywa na routerach.
Algorytmy trasowania intradomain — operują
wyłącznie w obszarze konkretnej domeny, podczas
gdy algorytmy interdomain zawiadują pakietami biorąc pod
uwagę nie tylko zależności zachodzące między tą domeną i
innymi, otaczającymi ją domenami. Optymalne marszruty
wyznaczane przez algorytm intradomain nie muszą być ( i
najczęściej nie są ) najlepsze, jeśli porównamy je z
optymalnymi marszrutami wypracowanymi przez algorytm
interdomain widzący całą strukturę sieci.

Algorytm link state i distance vector — Algorytm
link state (stanu łącza) rozsyła informacje routingu
do
wszystkich
węzłów
obsługujących
połączenia
międzysieciowe. Każdy ruter wysyła jednak tylko tę część
tabeli routingu, która opisuje stan jego własnych łączy.
Algorytm distance vector wysyła w sieć całą
tabelę routingu, ale tylko do są siadujących z nim
routerów. Algorytm link state jest skomplikowany i trudny
do konfigurowania oraz wymaga większej mocy
obliczeniowej procesora. Odnotowuje za to szybciej
wszelkie zmiany zachodzące w topologii sieci. Nie należy
mylić dwóch pojęć: protokołu używanego do trasowania
pakietów – routing protocol (np. RIP,OSPF) i protokołów
obsługiwanych przez router – routed protocol (np. IP,IPX).
Rutery mogą być jedno i wieloprotokołowe, które potrafią
obsługiwać pakiety generowane przez różne protokoły
warstwy sieciowej.

Routing statyczny wydaje się najprostszą formą budowania
informacji o topologii sieci. Administrator wprowadza ręcznie
trasy definiujące routing statyczny, przy tworzeniu których
wymagane jest jedynie podanie adresu sieci docelowej,
interfejsu, przez który pakiet ma zostać wysłany oraz adresu IP
następnego routera na trasie.
ip route sieć_docelowa maska_podsieci {adres_IP |
interfejs} [dystans] [permanent]
Najważniejsze jest dokładne określenie odległej sieci lub
podsieci, do której będą wysyłane pakiety. Zanim dotrą one do
miejsca docelowego, należy podać adres IP lub interfejs, przez
który jest osiągalny router kolejnego skoku. Można również
podać dystans administratorski dla konkretnej trasy. Po
wyłączeniu interfejsu, który prowadzi do wskazanej sieci,
pozycja statyczna jest natychmiast usuwana, co przy częstych
zmianach stanu łącza jest uciążliwe. Opcja permanent
spowoduje zachowanie danej trasy nawet po awarii interfejsu
Routing
statyczny
Routing
statyczny
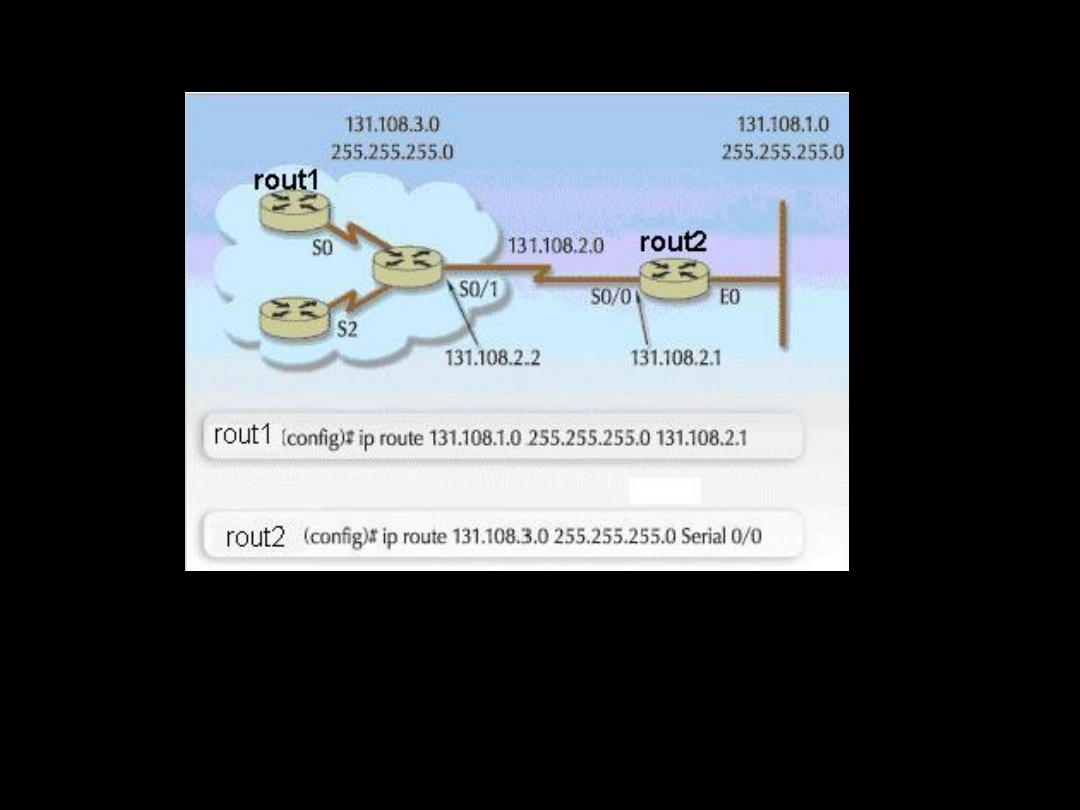
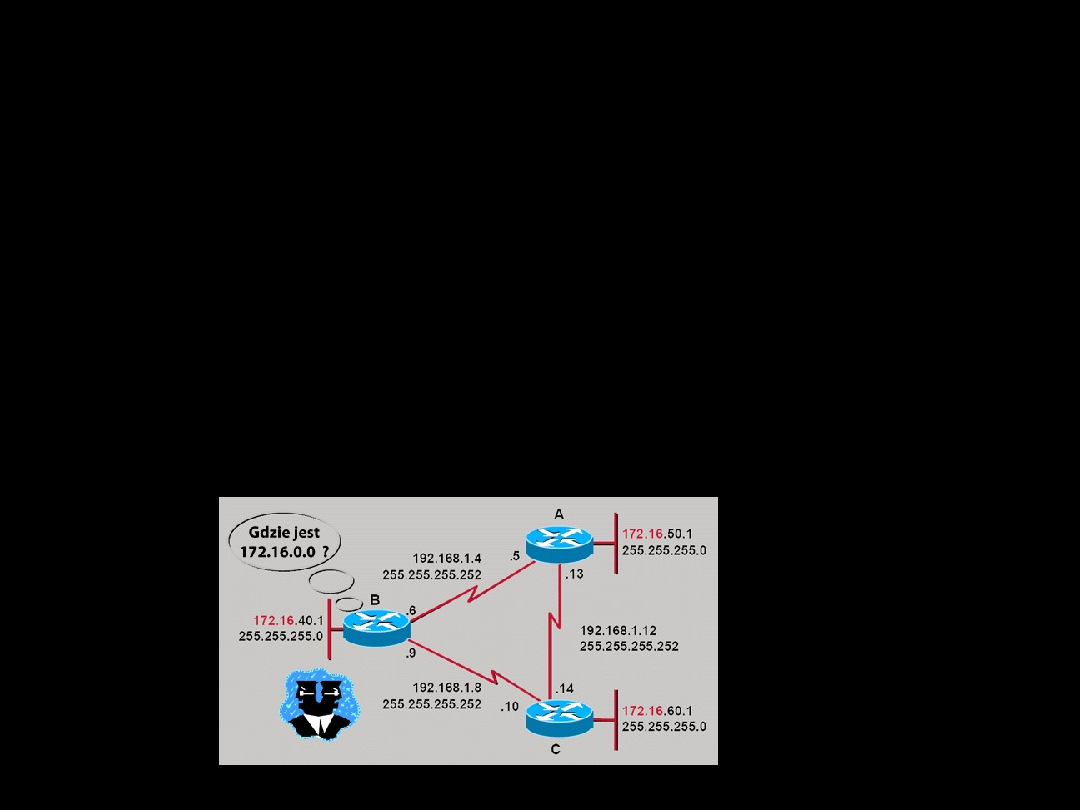
Przykład routingu statycznego

Routing dynamiczny
Routing dynamiczny
Routing dynamiczny same się orientują w topologii sieci
w której pracują i same ustalają zasady optymalnych
połączeń między sobą. Powinny też zauważyć zmiany w
topologii sieci (np. awarie, rozbudowa sieci) i
automatycznie
się
do
nich
dostosowywać.
Po
wprowadzeniu przez administratora sieci poleceń
konfiguracyjnych
inicjujących dynamiczny routing,
informacje o trasach są automatycznie uaktualniane
przez protokół routingu za każdym razem, gdy z sieci
otrzymywane są nowe informacje. Informacje o
zmianach są wymieniane między routerami jako proces
uaktualniania. Wyróżniamy dwa podstawowe protokoły
routingu dynamicznego: stanu łącza oraz wektora
odległości. Wektor odległości jest wyznaczany przez
określenie metryki.

Protokoły routingu
wewnętrzne i zewnętrzne
Protokoły routingu
wewnętrzne i zewnętrzne
Wewnętrzne
•Stosowane wewnątrz jednej domeny administracyjnej
•Proste, w małym stopniu obciążają routery
•Mało skalowalne
• RIP (Routing Information Protocol), IGRP (Interior Gateway
Routing Protocol), OSPF (Open Shortest Path First),
Zewnętrzne
•Odpowiadają za wymianę informacji pomiędzy dwiema
niezależnymi
•administracyjnie sieciami
•Dają się skalować, łatwo obsługują duże sieci
•Są skomplikowane, ilość dodatkowych informacji przesyłanych
siecią może
•szybko zablokować pracę małej lub średniej sieci EGP (exterior
gateway protocol), BGP (border gateway protocol)
Można je zamieniać, ale nie jest to mądre, bo zostały
przystosowane
do innego trybu pracy

Protokoły dystans-wektor
Protokoły dystans-wektor
Router regularnie wysyła wszystkim swoim sąsiadom
informacje na temat każdej dostępnej, znanej sobie
sieci:
– Jak daleko do niej jest (dystans)
Czas podroży
Liczba przeskoków
Koszt przesyłu
– Jak się można do niej dostać (wektor)
Zwykle — „wyślij do mnie, bo ja wiem, jak to przesłać dalej”.
Inny router. Np. gdy router docelowy nie obsługuje danego
protokołu routingu.


Dziękuje za uwagę i
cierpliwość
Dobre HEHE :D
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
Wyszukiwarka
Podobne podstrony:
Sem II Transport, Podstawy Informatyki Wykład XXI Object Pascal Komponenty
Podstawy Informatyki Wykład XIX Bazy danych
Podstawy Informatyki Wykład V Struktury systemów komputerowych
1 Epidemiologia i podstawowe informacje o NSid 8500 ppt
Dydaktyka jako nauka podstawowe informacje
Podstawowe informacje o planowa Nieznany (4)
Podstawowe informacje na temat zasad przylaczenia farm wiatrowych
praca dyplomowa 1 strona wzor, Szkoła, prywatne, Podstawy informatyki
Podstawowe informacje
Witaminy - zestawienie podstawowych informacji, administracja, Reszta, Promocja zdrowia
podstawowe informacje o ochronie prawnej wzorów przemysłowych, Studia - Politechnika Śląska, Zarządz
wstęp i podstawowe informacje, Automatyka i Robotyka, Semestr II, Ekologia i zarządzanie środowiskie
Podstawowe informacje o rynkach nieruchomości w UE, Nieruchomości, Nieruchomości - pośrednik
koncepcje zarzadzania 14 2015 studia stacjonarne podstawowe informacje
Pedagogika wczesnoszkolna podstawowe informacje
podstawowe informacje alzheimer Nieznany
przekroj poprzeczny drogi podstawowe informacje z Dz U
więcej podobnych podstron