
Rozdział 8.
Bezpieczeństwo
Bezpieczeństwo danych jest jednym z najważniejszych zagadnień programowania sieciowego, ponieważ coraz
więcej firm decyduje się na obsługę klientów za pośrednictwem sieci i ich Intranety zapełniane są tajnymi
danymi. Bezpieczeństwo danych zajmuje się ochroną tajnych informacji przed niepowołanymi użytkownikami.
W przypadku aplikacji sieciowych bezpieczeństwo rozpatrujemy jako:
•
Uwierzytelnienie
— możliwość weryfikacji tożsamości biorących udział w wymianie informacji.
•
Autoryzacja
— udostępnienie zasobów systemu wybranej grupie użytkowników lub programów.
•
Poufność
— pewność, że przesyłane dane mogą odczytać tylko przez nas określeni użytkownicy.
•
Integralność
— możliwość sprawdzenia, czy informacja nie została zmieniona podczas transmisji.
Wymienione powyżej aspekty bezpieczeństwa można zilustrować prostym przykładem: klient chce być pewien,
że jest połączony z właściwym serwerem (uwierzytelnienie) i żadna informacja (np. numer karty kredytowej) nie
zostanie przechwycona (poufność). Firma, sprzedając usługę lub przesyłając tajne informacje poprzez sieć do
pracowników, chce zabezpieczyć dane przed nieuprawnionymi użytkownikami. Ponadto obie strony (klient
firmy i jej pracownik) chcą mieć pewność, że otrzymali niezmienioną informację.
Wiarygodność, autoryzacja, poufność i integralność są zapewniane przy użyciu technologii certyfikatów
cyfrowych. Certyfikaty cyfrowe pozwalają serwerom i klientom na używanie zaawansowanych technik
kryptograficznych do zapewnienia identyfikacji i kodowania protekcyjnego. Java zawiera wbudowany zestaw
narzędzi wspomagających użycie certyfikatów cyfrowych, co sprawia, że serwlety są wspaniałą platformą do
obsługi bezpiecznych aplikacji sieciowych używających technologii certyfikatów cyfrowych.
Bezpieczeństwo powinno również zapewnić ochronę danych przechowywanych na serwerze przed krakerami.
Java od podstaw została zaprojektowana jako bezpieczny, sieciowo-zorientowany język, w którym istnieje
możliwość wykorzystania komponentów gwarantujących bezpieczeństwo własnych i obcych danych na
serwerze.
Niniejszy rozdział przedstawia podstawy zabezpieczania danych w sieci i użycia technik certyfikatów cyfrowych
w serwletach. Opisano tu również sposoby zabezpieczania serwera podczas uruchamiania serwletów
pochodzących z niepewnych źródeł. W stosunku do poprzednich rozdziałów przedstawiono tu mniej
przykładów, gdyż podejmuje on problem wyższego poziomu, a wiele poruszonych tu tematów wymaga
implementacji obsługi serwera. Serwlety potraktowano tu jako dodatki.
Autorzy niniejszej książki nie biorą odpowiedzialności za problemy związane z bezpieczeństwem danych, które
mogą pojawić się po zastosowaniu rad tu zawartych. Szerszy opis dotyczący problematyki bezpieczeństwa w
sieci można znaleźć w książce
Web
Security
&
Commerce
napisanej przez Simsona Garfinkela i Gene Spafford
(O'Reilly). Oczywiście, oni także nie wezmą na siebie odpowiedzialności.
W tym rozdziale:
• Uwierzytelnienie poprzez
HTTP
• Uwierzytelnienie w oparciu
o formularz
• Uwierzytelnienie
niestandardowe
• Certyfikaty cyfrowe
• Protokół bezpiecznej
transmisji danych(SSL)

Uwierzytelnienie poprzez HTTP
W rozdziale 4, „Odczytywanie informacji” wspomniano, że protokół HTTP posiada wbudowaną obsługę
uwierzytelnienia — zwaną
uwierzytelnieniem
podstawowym
, która jest oparta o prosty model wezwanie-
odpowiedź, nazwa_użytkownika-hasło. Korzystając z tej techniki serwer zarządza bazą danych zawierającą
nazwy użytkowników i hasła dostępu oraz identyfikuje określone zasoby (pliki, katalogi, serwlety, itp.) jako
chronione. Gdy użytkownik zażąda dostępu do zastrzeżonych zasobów, serwer odpowie żądaniem podania
nazwy użytkownika i hasła. W tym momencie przeglądarka zwykle wyświetla okno dialogowe zawierające pola,
w które użytkownik wpisuje swoją nazwę i hasło, po czym dane te przesyłane są do serwera. Jeśli przesłane
serwerowi informacje istnieją w jego bazie danych, dostęp do zasobów chronionych jest przyznawany. Cały
opisany tu proces uwierzytelnienia odbywa się na serwerze.
Uwierzytelnienie podstawowe nie zapewnia poufności i integralności, co sprawia, że jest to słaby system
zabezpieczenia dostępu do danych. Problem polega na tym, że przesyłane poprzez sieć hasła są kodowane za
pomocą powszechnie znanej metody Base64. Każdy monitorując strumień danych TCP/IP ma pełny i
natychmiastowy dostęp do przesyłanej informacji łącznie z nazwą użytkownika i hasłem chyba, że zostanie
wykorzystana dodatkowa metoda kryptografii SSL (omówiona w dalszej części rozdziału). Ponadto hasła są
przechowywane na serwerze w postaci czystego tekstu czyniąc je łatwym łupem dla każdego, kto włamie się do
systemu plików serwera. Strony zabezpieczone opisaną tu metodą nie mogą zostać uznane za bezpieczne.
Uwierzytelnienie
szyfrowane
(typu
digest
) bazuje na schemacie omówionej metody, ale poprzez sieć przesyłany
jest łańcuch tworzony za pomocą algorytmu szyfrowania MD5 z nazwy użytkownika, hasła, URI, metody
żądania HTTP i losowo generowanej przez serwer
wartości
jednokrotnego
użycia
(
nounce
). Obie strony
transakcji (klient i serwer) znają hasło i na jego podstawie generują szyfr. Dostęp do danych jest dozwolony,
jeśli łańcuchy klienta i serwera są zgodne. Transakcje zabezpieczone w ten sposób są bezpieczniejsze, gdyż
łańcuch jest ważny tylko dla jednego żądania i jednej wartości jednokrotnego użycia (
nonce
value
). Niestety, tak
jak w poprzedniej metodzie, serwer nadal zawiera bazę danych z oryginalnymi (nie zaszyfrowanymi) hasłami.
Poza tym niewiele przeglądarek obsługuje tą technikę.
Podsumowując można stwierdzić, że uwierzytelnianie za pomocą protokołu HTTP jest użyteczne w
środowiskach wymagających niskiego poziomu bezpieczeństwa danych. Dobrym przykładem takiego
środowiska jest płatna witryna gazety internetowej, gdzie twórcom bardziej zależy na dostępności serwisu niż na
ścisłym bezpieczeństwie danych. W tym przypadku uwierzytelnianie za pomocą HTTP jest wystarczającą
metodą.
Konfiguracja uwierzytelnienia HTTP
W starszych interfejsach Servlet API (wersje wcześniejsze niż 2.2) sposób konfiguracji uwierzytelnienia różnił
się w zależności od typu serwera. Począwszy od wersji 2.2 sposób uwierzytelniania został znormalizowany. W
pliku opisu rozmieszczenia
web.xml
określa się metodę zabezpieczenia danych. Za pomocą tego pliku można
stosować wybraną metodę zabezpieczenia w różnych serwerach.
Instalacja mechanizmu zabezpieczeń dla interfejsu Servlet API 2.2 na serwerze nie jest konieczna, aby zapewnić
kompatybilność z tym interfejsem. Zalecana jest implementacja pełnego systemu bezpieczeństwa, ale kontener
serwletu może użyć tylko część mechanizmu bezpieczeństwa lub nie użyć go wcale. Implementacja pełnego
mechanizmu bezpieczeństwa na serwerze jest wymagana tylko wtedy, gdy chcemy, aby serwer był
kompatybilny z bardziej zaawansowaną platformą Java 2 (Enterprise Edition — J2EE),w której Servlet API 2.2
stanowi tylko część systemu. Poza tym, bezpieczeństwo jest jednym z najnowszych i nie do końca poznanych
aspektów interfejsu Servlet API 2.2, co sprawia, że serwery sieciowe mogą różnić się pod względem
implementacji mechanizmów bezpieczeństwa. Aby mieć pewność, że witryna pozostanie bezpieczna, należy ją
co najmniej raz przetestować podczas przenoszenia danych pomiędzy serwerami.
*
Plik opisu rozmieszczenia jest również znany jako deskryptor rozmieszczenia - te dwa określenia można stosować
zamiennie.

Uwierzytelnienie w oparciu o rolę
Za pomocą znaczników (umieszczonych w pliku rozmieszczenia aplikacji sieciowej) można określić strony, do
których dostęp mają tylko użytkownicy posiadający specjalne uprawnienia. W ten sposób zapewniamy dostęp
wszystkim użytkownikom do witryny, ale niektóre strony zawarte w witrynie możemy udostępniać przez nas
wybranym użytkownikom. Jednym ze sposobów zapewnienia ograniczonego dostępu jest skorzystanie z metody
uwierzytelnienia
opartego
o
rolę
. W tej metodzie, zezwolenia dostępu są przyznawane abstrakcyjnemu
podmiotowi
security
role
, a dostęp do danych mają tylko użytkownicy (lub grupy użytkowników) należący do
określonej roli. Można, na przykład, utworzyć witrynę w ten sposób, aby strony zawierające informacje o
wynagrodzeniach były dostępne tylko użytkownikom w roli manager. W pliku opisu rozmieszczenia określany
jest tylko sposób dostępu do danych w zależności od roli użytkownika, a konkretne przypisanie ról
użytkownikom (lub grupom użytkowników) ma miejsce podczas wdrażania aplikacji, przy pomocy narzędzi
serwerowych. To przypisanie można realizować w oparciu o informacje zawarte w plikach tekstowych, tabelach
baz danych, systemie operacyjnym, itd.
Ograniczanie dostępu do serwletu
Załóżmy, że chcemy zapewnić ograniczony dostęp do serwletu, co pokazano w przykładzie 8.1. (Za pomocą
omawianej metody można zabezpieczać nie tylko serwlety, ale również pliki i inne aplikacje).
Przykład 8.1.
Czy jesteś pewien, że masz pozwolenie na czytanie tego przykładu?
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class SalaryServer extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType ("text/plain");
PrintWriter out = res.getWriter();
out.println("Informacja ściśle tajna:"); out.println("Każdy zarabia więcej od Ciebie!");
}
}
Załóżmy, że posiadamy bazę danych użytkowników naszego serwera, zawierającą listę identyfikatorów, haseł i
ról. Nie wszystkie serwery obsługują taką bazę danych, a te, które to robią, implementują ją w dowolny sposób.
W przypadku serwera Tomcat 3.2 dane użytkowników są umieszczane w pliku
conf/tomcat-users.xml
,
pokazanym w przykładzie 8.2. Kolejne wersje Tomcata pozwolą na bezpieczniejszy zapis informacji (nasza
wersja umieszcza dane w postaci niezaszyfrowanej).
Przykład 8.2.
Plik
conf/tomcat-users.xml
<tomcat-users>
<user name="Dilbert" password="dnrc" roles="engineer" />
<user name="Willy" password="iluvalice" roles="engineer,slacker" />
<user name="MrPointyHair" password="MrPointyHair" roles="manager,slacker" />
</tomcat-users>
Należy zauważyć, że tylko
MrPointyHair
jest w roli
manager
. Zakładając, że potrafi podłączyć swój
komputer do sieci, powinien być jedyną osobą mającą dostęp do naszego tajnego serwletu. Określimy to w pliku
web.xml
, pokazanym w przykładzie 8.3.
Zwróćmy uwagę na to, że istotne znaczenie ma kolejność wystąpienia znaczników w pliku
web.xml
. Należy
zawsze stosować znaczniki w następującym porządku:
<security-constraint>
,
<login-config>
, a

następnie
<security-role>
. Nie bez znaczenia jest również kolejność występowania elementów wewnątrz
tych znaczników. Tworząc pliki
web.xml
najłatwiej skorzystać z pomocy narzędzi graficznych, które
automatycznie „zadbają” o odpowiednią strukturę pliku.
Przykład 8.3.
Ograniczenie dostępu za pomocą uwierzytelniania podstawowego.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web_app_2_2.dtd">
<web-app>
<servlet>
<servlet_name>
secret
</servlet-name>
<servlet-class>
SalaryServer
</servlet-class>
</servlet>
<security-constraint>
<web-resource-collection>
<web-resource-name>
SecretProtection
</web-resource-name>
<url-pattern>
/servlet/SalaryServer
</url-pattern>
<url-pattern>
/servlet/secret
</url-pattern>
<http-method>
GET
</http-method>
<http-method>
POST
</http-method>
</web-resource-collection>
<auth-constraint>
<role-name>
manager
</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>
BASIC <!-- BASIC, DIGEST, FORM, CLIENT-CERT -->

</auth-method>
<realm-name>
Default <!-- Opcjonalne, użyteczne tylko dla BASIC -->
</realm-name>
</login-config>
<security-role>
<role-name>
manager
</role-name>
</security-role>
</web-app>
Za pomocą tego pliku opisu rozmieszczenia zabezpieczono wszystkie metody
GET
i
POST
, które udostępniają
/servlet/secret
i
/servlet/SalaryServer
użytkownikom w roli
manager
, zalogowanym za pomocą
uwierzytelnienia podstawowego. Pozostała część witryny jest dostępna bez ograniczeń.
Znacznik
<security-constraint>
chroni dostęp do danych, których ścieżki dostępu znajdują się
wewnątrz znacznika
<web-resource-collection>
w ten sposób, że dostęp jest zapewniony tylko
użytkownikom, których role umieszczono wewnątrz znacznika
<auth-constraint>.
Każdy znacznik
<web-resource-collection>
zawiera nazwę, chronione adresy URL oraz kilka metod HTTP o
ograniczonym dostępie. Dla wzorców adresów URL można użyć identycznych symboli wieloznacznych, jakich
używa się do mapowania serwletu — co opisano w rozdziale 2 „Podstawy serwletu HTTP”. Powinno się
wyznaczyć metody chronione, przynajmniej
GET
i
POST
. Jeśli nie wpiszemy znacznika
<http-method>
, to
wszystkie metody zostaną uznane za chronione. Znacznik
<auth-constraint>
zawiera nazwy ról
użytkowników, którym udostępnia się zbiór zasobów.
Znacznik
<login-config>
określa sposób logowania się, którego używa aplikacja. W tym przypadku
określamy podstawowe uwierzytelnienie za pomocą dyrektywy
Default
. W znaczniku
<auth-method>
umieszcza się wartości
BASIC
,
DIGEST
,
FORM
i
CLIENT-CERT
, które odpowiadają typom uwierzytelnienia:
podstawowemu, szyfrowanemu, w oparciu o formularz i przy użyciu certyfikatów klienckich. O
uwierzytelnieniach w oparciu o formularz i przy użyciu certyfikatów klienckich będzie mowa w dalszej części
rozdziału. Znacznik
<realm-name>
określa zakres użycia loginu (tu zawarta jest informacja określająca
uprawnienia poszczególnych ról). Ten znacznik jest używany tylko w uwierzytelnieniu podstawowym i
szyfrowanym.
Znacznik
<security-role>
zawiera listę ról, która może być użyta przez aplikację.
W omówionej metodzie nie ma możliwości udostępniania zasobów wszystkim z pominięciem użytkowników z
„czarnej listy”. Najprostszym wyjściem z tej sytuacji może być utworzenie grupy użytkowników nie należących
do „czarnej listy”.
Teraz, gdy plik
web.xml
jest już gotowy, wszystkie żądania dostępu do chronionych danych zostaną
przechwycone przez serwer i dane uwierzytelniające użytkownika zostaną sprawdzone. Dostęp jest
przydzielany, jeśli uprawnienia są ważne, a serwer przypisuje użytkownikowi rolę
manager
. W przeciwnym
razie dostęp jest zabroniony, a okno dialogowe przeglądarki poprosi użytkownika o kolejną próbę zalogowania
się.
Wyszukiwanie informacji uwierzytelnienia
Serwlet może odczytać informację na temat uwierzytelnienia dzięki dwóm metodom przedstawionym w
rozdziale 4:
getRemoteUser()
i
getAuthType()
. Serwlet API 2.2 zawiera dodatkową metodę
getUserPrincipal()
, która zwraca obiekt implementujący interfejs
java.security.Principal
public java.security.Principal HttpServletRequest.getUserPrincipal()
Principal
to termin techniczny określający uwierzytelniany podmiot. Może nim być użytkownik, grupa,
korporacja lub po prostu identyfikator. Interfejs
Principal
zawiera metodę
getName()
zwracającą nazwę
podmiotu. Metoda
getUserPrincipal()
służy do określenia uwierzytelnionej tożsamości użytkownika,

podczas gdy
getRemoteUser()
do zapewnienia kompatybilności ze skryptami CGI. Metoda
IsUserInRole()
została także wprowadzona w Servlet API 2.2. Ta metoda zwraca wartość
true
, gdy
użytkownik należy do określonej roli:
public boolean HttpServletRequest.isUserInRole(String role)
Ta metoda pozwala na wykonanie pewnych decyzji wewnątrz serwletu. Załóżmy, że deskryptor rozmieszczenia
pozwala uzyskać dostęp wielu różnym rolom. Wywołanie tej metody pozwala serwletowi na zróżnicowanie
dostępu do danych zależności od uwierzytelnionej roli użytkownika.
W deskryptorze rozmieszczeń (pliku opisu rozmieszczenia) można utworzyć pseudonimy, (można sprawić, by
zasięg roli
mgr
będzie taki sam, jak zasięg roli
manager)
. Ma to zastosowanie podczas integracji serwletów
pochodzących z innych aplikacji sieciowych, które używają innych nazw ról niż nasz serwlet. Pseudonimy są
konfigurowane osobno dla każdego serwletu, za pomocą znacznika
<security-role-ref>
wewnątrz
znacznika
<servlet>
, jak pokazano w poniższym fragmencie
web.xml
:
<servlet>
<servlet-name>
secret
</servlet-name>
<servlet-class>
SalaryViewer
</servlet-class>
<security-role-ref>
<role-name>
mgr <!-- Nazwa używana przez serwlet -->
</role-name>
<role-link>
manager <!-- Nazwa używana przez deskryptor rozmieszczenia -->
</role-link>
</security-role-ref>
</servlet>
Może istnieć dowolna ilość znaczników
<security-role-ref>
. Należy pamiętać, że dane pseudonimy są
ważne tylko podczas dostępu do serwletu poprzez jego zarejestrowaną nazwę.
W przykładzie 8.4 serwlet wyświetla klientowi jego nazwę, podmiot, rodzaj uwierzytelnienia (
BASIC
,
DIGEST
,
FORM
,
CLIENT-CERT
) oraz przynależność do roli
manager
. Aby uruchomić ten serwlet należy zainstalować
go na serwerze sieciowym i zabezpieczyć korzystając ze schematu objaśnionego w poprzednim podpunkcie
(należy przy tym upewnić się, że dostęp do nowego
<url-pattern>
jest ograniczony).
Przykład 8.4.
Szpiegowanie informacji uwierzytelniania
import java.io.*;
import java.security.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class AuthenticationSnoop extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
out.println("<HTML><HEAD><TITLE>AuthenticationSnoop</TITLE></HEAD><BODY>");
out.println("<PRE>");
out.println("Nazwa Uzytkownika: "+ req.getRemoteUser());
String name = (req.getUserPrincipal() == null) ?
null : req.getUserPrincipal().getName();
out.println("Nazwa Podmiotu: " + name);
out.println("Typ uwierzytelnienia: " + req.getAuthType());
out.println("Przynależność do roli Manager: " + req.isUserInRole("manager"));
out.println("</PRE>");
out.println("</BODY></HTML>");
. }
}
Po wykonaniu programu powinniśmy zobaczyć na ekranie:
This is a password protected resource
Nazwa Użytkownika: jhunter
Nazwa Podmiotu: jhunter
Typ Uwierzytelnienia: BASIC
Przynależność do roli Manager: false
Uwierzytelnienie w oparciu o formularz
Zamiast uwierzytelnienia poprzez HTTP, serwlety mogą używać formularzy HTML. Użycie tej techniki
pozwala użytkownikom wejść na chronioną witrynę poprzez odpowiednio zaprojektowaną, przyjazną
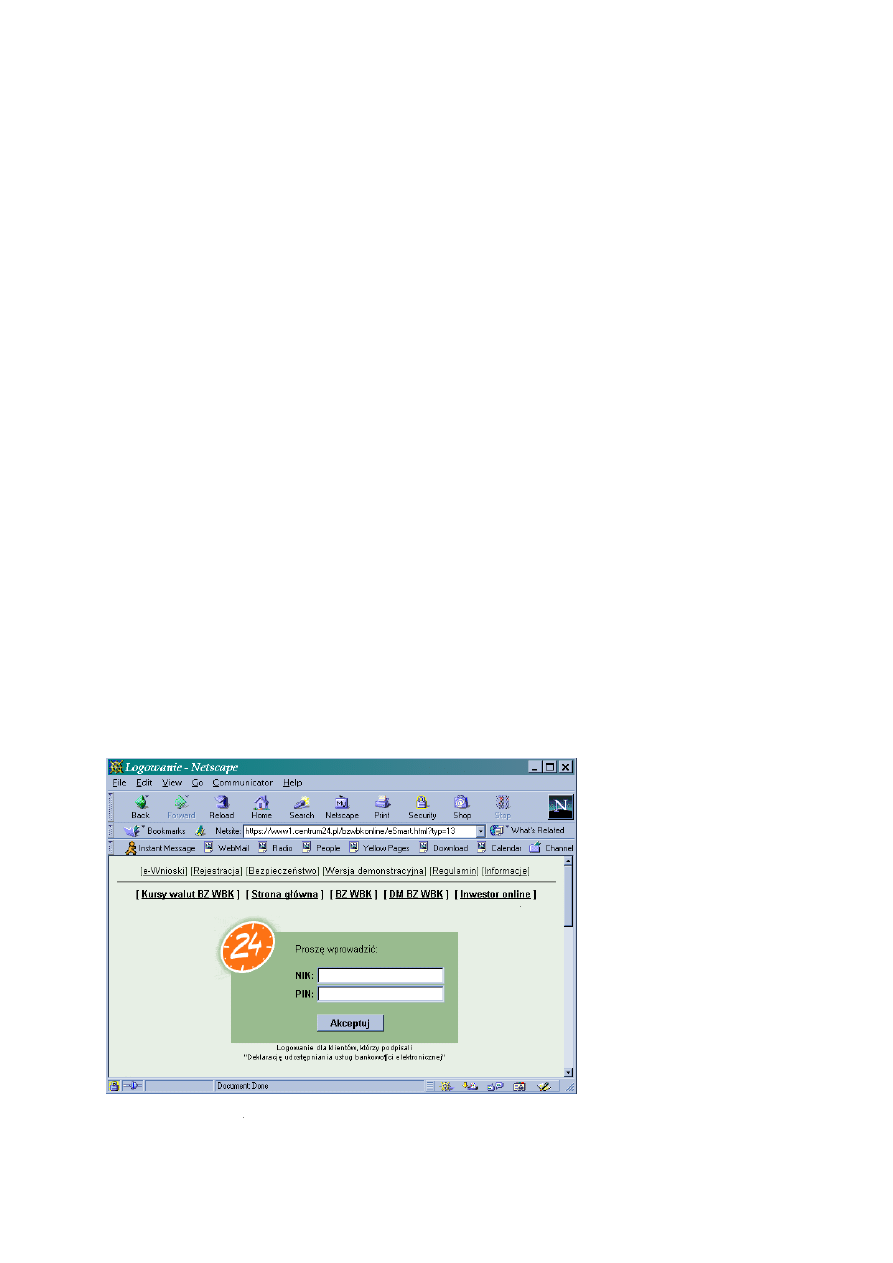
użytkownikowi stronę logującą. Wyobraźmy sobie, że prowadzimy bank internetowy. Lepiej utworzyć
niestandardowy formularz logujący (rys. 8.1), który poprosi o odpowiednie dane, niż korzystać z obskurnego
okna przeglądarki.
Wiele banków i innych serwisów online wybrało uwierzytelnienie oparte o formularz. Implementacja takiego
systemu jest stosunkowo prostym zadaniem, ponieważ takie uwierzytelnienie jest wbudowane w Servlet API
2.2. Aby przekształcić uwierzytelnienie z podstawowego na oparte o formularz należy zamienić fragment pliku
web.xml
<login-config>
z przykładu 8.3 na fragment z przykładu 8.5.

Rysunek 8.1. Strona logująca do banku online
Przykład 8.5.
Konfiguracja uwierzytelnienia opartego o formularz
<login-config>
<auth-method>
FORM <!-- BASIC, DIGEST, FORM, CLIENT-CERT Æ
</auth-method>
<form-login-config> <!-- Przydatne tylko dla FORM -->
<form-login-page>
/loginpage.html
</form-login-page>
<form-error-page>
/errorpage.html
</form-error-page>
</form-login-config>
</login-config>
Należy zauważyć, że wewnątrz znacznika
<auth-method>
zmieniono tryb
BASIC
na
FORM
. To oznacza, że
w aplikacji sieciowej należy użyć uwierzytelnienia za pomocą formularza HTML. Znacznik
<realm-name>
zamieniono na
<form-login-config>
. Ten znacznik określa stronę logującą i stronę błędnego logowania
używane w procesie uwierzytelnienia. Obie strony powinny być dobrze zaprojektowane i opisowe, przy czym
strona logująca powinna prosić użytkownika o podanie danych, a strona błędnego logowania informować serwer
o błędnych danych. Obie ścieżki adresów URL muszą być umieszczone w
context
root
.
Za każdym razem, gdy serwer otrzymuje żądanie do chronionych danych, sprawdza czy użytkownik nie jest już
zalogowany. Serwer może na przykład przeszukiwać obiekt
HttpSession
w celu znalezienia obiektu
Principal
. Jeśli serwer odnajdzie ten obiekt, porównuje zawarte w nim role do tych, które mają dostęp do
danych. Dostęp przyznawany jest tylko temu użytkownikowi, którego rola jest umieszczona w obiekcie
Principal
. Jeśli serwer nie zlokalizuje obiektu
Principal
albo ten obiekt nie zawiera uprawnionych ról,
klient jest przekierowywany na stronę logującą (ale najpierw serwer zapisuje żądany adres URL w obiekcie
użytkownika
HttpSession
).
Strona logująca zawiera formularz, gdzie użytkownik wprowadza nazwę i hasło, które są przesyłane do serwera.
Dostęp do zasobów jest możliwy tylko wtedy, gdy nazwa użytkownika i hasło są ważne i należą do
uprawnionych ról obiektu
Principal
. Wówczas serwer przekierowuje użytkownika do chronionych zasobów,
a w przeciwnym przypadku do strony błędnego logowania.
Strona logująca musi zawierać formularz ze specjalnymi wartościami, aby zapewnić dostarczenie właściwych
danych do serwera. Formularz musi być zadeklarowany jako metoda POST dla URL
j_security_check
(nie należy poprzedzać go ukośnikiem, chociaż niektóre serwery mogą uznać to za błąd) z nazwą użytkownika
przesłaną w zmiennej
j_username
i hasłem w
j_password
, na przykład:
<FORM METHOD=POST ACTION="j_security_check">
Username: <INPUT TYPE=TEXT NAME="j_username"><br>
Password: <INPUT TYPE=PASSWORD NAME="j_password"><br>
<INPUT TYPE=SUBMIT>
</FORM>
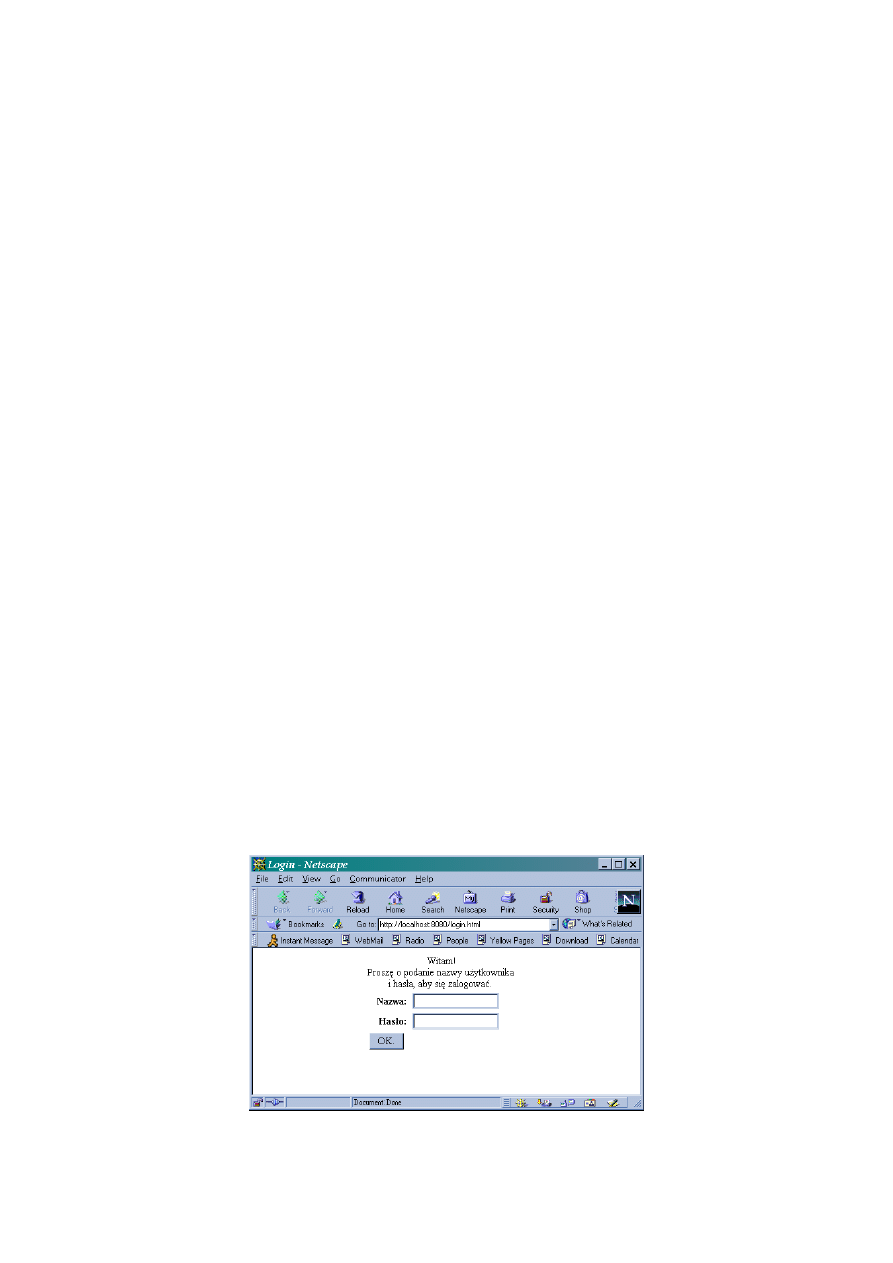
Przykład 8.6 przedstawia plik
loginpage
.
html
, który generuje formularz pokazany na rysunku 8.2.
Przykład 8.6.
Plik
loginpage
.
html
<HTML>
<TITLE>Login</TITLE>
<BODY>
<FORM METHOD=POST ACTION=j_security_check>
<CENTER>
<TABLE BORDER=0>
<TR><TD COLSPAN=2>
<P ALIGN=center>
Witam! Proszę o podanie nazwy użytkownika <br>
i hasła aby się zalogować.
</TD></TR>
<TR><TD>
<P ALIGN=right><B>Nazwa:</B>
</TD>
<TD>
<P><INPUT TYPE=TEXT NAME="j_username" VALUE="" SIZE=15>
</TD></TR>
<TR><TD>
<P ALIGN=RIGHT><B>Hasło:</B>
</TD>
<TD>
<P><INPUT TYPE=PASSWORD NAME="j_password" VALUE="" SIZE=15>
</TD></TR>
<TR><TD>
<CENTER>
<INPUT TYPE=submit VALUE=" OK. ">
</CENTER>
</TD></TR>
</TABLE>
</FORM>
</BODY></HTML>
Rysunek 8.2 przedstawia wygenerowany formularz.
Rysunek 8.2. Formularz logujący przyjazny dla użytkownika

Strona błędnego logowania określona w sekcji
<login-config>
pliku
web
.
xml
może być jakimkolwiek
plikiem HTML. Nie przewidziano specjalnych znaczników, by ten plik dołączyć. Niestety, nie ma też dostępu do
żadnych specjalnych informacji mówiących o tym, dlaczego dostęp do danych jest zabroniony i wskazujących
użytkownikowi stronę, za pomocą której powinien spróbować zalogować się ponownie. Przykład 8.7 ilustruje
prostą stronę błędnego logowania.
Przykład 8.7.
Plik
errorpage
.
html
<HTML>
<TITLE> Login Denied <TITLE>
<BODY>
Niestety, operacja logowania nie powiodła się.
Proszę wrócić do poprzedniej strony i spróbować jeszcze raz.
</BODY></HTML>
W porównaniu z uwierzytelnieniem podstawowym, logowanie przez formularz jest lepsze, ponieważ
użytkownik może wejść do witryny poprzez przyjazną i przejrzystą stronę logującą. W obu uwierzytelnieniach
hasło jest przesyłane jako tekst jawny chyba, że kanał komunikacyjny zostanie zabezpieczony innymi metodami.
Oba omówione uwierzytelnienia nie zapewniają mechanizmu wylogowania. W przypadku uwierzytelnienia
opartego o formularz można wywołać metodę
session.Invalidate()
, ale nie gwarantuje to
zamierzonego efektu. W obu sposobach serwer sprawdza ważność użytkowników nawet wówczas, gdy kontrola
nie powinna być dokonywana przez serwer (na przykład: niektóre banki wymagają podania numeru konta, hasła
i PIN-u, by umożliwić dostęp). Aby rozwiązać ten problem, należy skorzystać z uwierzytelnienia
niestandardowego.
Uwierzytelnienie niestandardowe
Zwykle uwierzytelnienie klienta odbywa się w serwerze sieciowym. Deskryptor rozmieszczenia przekazuje
serwerowi informację o zastrzeżonych zasobach i sposobie przydzielania dostępu.
Często takie podejście jest wystarczające, ale czasem pożądany system ochrony nie może być
zaimplementowany na serwerze. Może być to spowodowane tym, że lista użytkowników jest zapisana w
formacie nieznanym serwerowi albo udostępnianie zasobów użytkownikom odbywa się za pomocą wspólnego
hasła. Aby poradzić sobie w takich sytuacjach, można skorzystać z serwletów. Serwlety mogą pobierać
informacje o użytkownikach ze specjalnie sformatowanego pliku lub relacyjnej bazy danych. Dodatkowo można
zastosować określony system ochrony (standardowy lub niestandardowy). Za pomocą tych serwletów można
dodawać, usuwać lub zmieniać dane użytkowników.
Serwlety używają kodu stanu i nagłówków HTTP do zarządzania własnym systemem ochrony. Serwlet
otrzymuje zakodowane dane użytkownika w nagłówku
Authorization
. Odmawia dostępu danemu
użytkownikowi poprzez przesłanie statusu
SC_UNAUTHORIZED
i nagłówka
WWW-Authenticate
,
opisującego określone dane użytkownika. Serwer zazwyczaj obsługuje wyżej opisane zdarzenia bez udziału
serwletu, ale nie ogranicza dostępu do danych, gdy autoryzacja jest przeprowadzona w serwlecie.
Nagłówek
Authorization
przesłany przez klienta zawiera jego nazwę i hasło. W podstawowym schemacie
autoryzacji, nagłówek
Authorization
zawiera łańcuch tekstowy
username:password
, zakodowany za
pomocą kodera Base64. Na przykład, nazwa
webmaster
i hasło
try2gueSS
są przesyłane w nagłówku
Authorization
o wartości:
Authorization: BASIC d2VibWFzdGVyOnRyeTJndWVTUw
Serwlet może przesłać nagłówek
WWW-Authenticate
, aby poinformować klienta o sposobie autoryzacji i o
obszarze weryfikacji użytkowników. Obszar stanowi zbiór kont użytkowników i chronionych zasobów. Na
przykład, do przesłania klientowi informacji, aby użył uwierzytelnienia podstawowego w dziedzinie
Admin
,
nagłówek
WWW-Authenticate
wygląda następująco:
WWW-Authenticate: BASIC realm="Admin"

W przykładzie 8.8 pokazano, jak serwlet wykonuje niestandardową autoryzację, otrzymując nagłówek
Authorization
i wysyłając status
SC_UNAUTHORIZED
oraz nagłówek
WWW-Authenticate
. Tak
skonfigurowany serwlet ogranicza dostęp do „ściśle tajnego zbioru” tylko do grona użytkowników, których
rozpozna na liście. W tym przykładzie, lista jest przechowywana w prostej
tablicy mieszającej
, a jej
zawartość jest zakodowana. Listę użytkowników można także dołączyć poprzez zewnętrzną relacyjną bazę
danych.
Aby odczytać nazwę i hasło zakodowane za pomocą Base64, należy skorzystać z dekodera Base64. Na szczęście
jest on dostępny w darmowej wersji. W naszym serwlecie użyjemy własnej klasy
com.oreilly.servlet.Base64Decoder
dostępnej na stronie
http://www.servlets.com
. Szczegóły
dotyczące kodowania Base64 można znaleźć na stronie
http://www.ietf.org/rfc/rfc1521.txt*
Przykład 8.8.
Bezpieczeństwo w serwlecie.
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
import com.oreilly.servlet.Base64Decoder;
public classs CustomAuth extends HttpServlet {
Hashtable users = new Hashtable();
public void init (ServletConfig config) throws ServletException {
super.init(config);
// Nazwy i hasła są tajne!
users.put("Wallace:cheese", "allowed");
users.put("Gromit:sheepnapper", "allowed");
users.put("Penguin:evil", "allowed");
}
public void doGet (httpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain");
PrintWriter out = res.getWriter();
// pobierz nagłówek autoryzacji
String auth = req.GetHeader("Authorization");
//Czy zezwalamy na dostęp temu użytkownikowi?
if(!allowUser(auth)) {
//nie zezwalamy, nie jest autoryzowany
res.setHeader("WWW-Autheticate", "BASIC realm=\"users\"");
res.sendError(res.S.C._UNAUTHORIZED);
//można zaoferować mu wpisanie na listę zatwierdzonych użytkowników
}
else{
//dopuszczony, wiec pokażmy mu tajne rzeczy
out.println("Ściśle tajne rzeczy");
}
}
*
Można także użyć klasy
sun.misc.BASE64Decoder, która towarzyszy JDK.

//ta metoda sprawdza informacje użytkownika przesłana w nagłówku Authorization
//z baza danych użytkowników zawarta w tablicy mieszającej users
protected boolean allowUser (String auth) throws IOException {
if (auth==null) return false; //brak auth
if(!auth.toUpperCase().startsWith("BASIC"))
return false;//my tylko przeprowadzamy tryb BASIC
//popierz zakodowaną nazwę użytkownika i hasło po "BASIC"
String userpassEncoded = auth.substring(6);
//zdekoduj, używając jakikolwiek dekoder Base64 (my używamy com.oreilly.servlet)
String userpassDecoded = Base64Decoder.decode(userpassEncoded);
//sprawdź nasza listę użytkowników czy ten jest "allowed"
if("allowed".equals(users.get(userPassDecoded)))
return true;
else
return false;
}
Dostęp do serwletu mają wszyscy użytkownicy. W serwlecie dokonuje się proces uwierzytelnienia: dostęp do
chronionych zasobów jest przydzielany użytkownikom których dane uwierzytelniające znajdują się na liście
uprawnionych. Po dokonaniu kilku modyfikacji za pomocą tego serwletu można udostępnić dane użytkownikom
posiadającym hasło grupowe albo, podobnie do anonimowego FTP, można udostępnić zasoby użytkownikowi o
nazwie
anonymous
i haśle, którym jest adres email.
Autoryzację niestandardową można użyć nie tylko do ograniczenia dostępu do pojedynczego serwletu.
Gdybyśmy taką logikę dodali do naszego serwletu
ViewResource
, moglibyśmy zaimplementować
niestandardowy sposób dostępu do pełnego zestawu plików. Reguła mapowania za pomocą przedrostków URL
mogłaby być utworzona w ten sposób, aby ochrona serwletu
ViewResource
udostępniała całą strukturę
katalogów chronionych plików. Gdybyśmy utworzyli specjalną podklasę z
HttpServlet
i dodali do niej tą
logikę, moglibyśmy w łatwy sposób ograniczyć dostęp do każdego serwletu pochodnego tej podklasy. W
metodzie niestandardowej autoryzacji sposób ograniczenia zabezpieczeń serwera nie wpływa na sposób
zabezpieczenia jego serwletów.
Autoryzacja niestandardowa w oparciu o formularz
Serwlety mają możliwość wykonania autoryzacji niestandardowej w oparciu o formularz. Poprzez logowanie
niestandardowe oparte o formularz, aplikacja sieciowa może użyć strony logującej HTML. Na przykład, aby
zalogować się do niektórych aplikacji bankowych, należy oprócz nazwy i hasła podać także numer konta i PIN.
Takiej możliwości nie zapewnia użycie
FORM
<auth-method>
, lecz autoryzacja niestandardowa w oparciu o
formularz. Jest to bardziej skomplikowane zadanie, bo szczegóły procesu logowania muszą być obsługiwane
ręcznie.
Najpierw trzeba stworzyć stronę logującą, którą można napisać tak jak inne formularze HTML. Przykład 8.9
przedstawia plik
login.html
, który generuje formularz pokazany na rysunku 8.3.
Przykład 8.9
Plik
login
.
html
<HTML>
<TITLE Login </TITLE>
<BODY>
<FORM ACTION=/servlet/LoginHandler METHOD=POST>
<CENTER>
<TABLE BORDER=0>

<TR><TD COLSPAN=2>
<P ALIGN=CENTER>
Witamy!<br>
Proszę wprowadzić numer rachunku, <br>
hasło i PIN, aby się zalogować
</TD></TR>
<TR><TD>
<P ALIGN=RIGHT><B> Rachunek:</B>
</TD>
<TD>
<P><INPUT TYPE=TEXT NAME="account" VALUE="" SIZE=15>
</TD></TR>
<TR><TD>
<P ALIGN=RIGHT><B>Hasło: </B>
</TD>
<TD>
<P><INPUT TYPE=TEXT NAME="password" VALUE="" SIZE=15>
</TR></TD>
<TR><TD>
<P ALIGN=RIGHT><B>PIN:</B>
</TD>
<TD>
<P><INPUT TYPE=TEXT NAME="PIN" VALUE="" SIZE=15>
</TR></TD>
<TR><TD COLSPAN=2>
<CENTER>
<INPUT TYPE=SUBMIT VALUE=" OK. ">
</CENTER>
</TD></TR>
</TABLE>
</FORM>
</BODY></HTML>
Rysunek 8.3 przedstawia formularz.

Rysunek 8.3. Przyjazny formularz logowania się do banku
Ten formularz prosi klienta o podanie numeru konta, hasła i kodu PIN, po czym przesyła informację do serwletu
LoginHandler
zatwierdzającego logowanie. Klient może dostać się do tej strony bezpośrednio lub poprzez
link ze strony głównej witryny. Gdyby użytkownik chciał dostać się bezpośrednio do zasobów (bez logowania
się) powinien być automatycznie skierowany na stronę logującą, a po pomyślnym zalogowaniu przekierowany z
powrotem. Proces powinien przebiegać niezauważalnie. Użytkownik odnosi wrażenie, że to jego przeglądarka
otworzyła okno.
Przykład 8.10 przedstawia serwlet implementujący przekierowania. Serwlet ten wysyła tajne informacje tylko
wtedy, gdy obiekt sesji klienta wskazuje zalogowanie. Jeśli tak nie jest, serwlet zapamiętuje żądany URL w sesji
do przyszłego użytku i przekierowuje klienta na stronę logującą.
Przykład 8.10.
Chronione Źródło
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class protectResource extends HttpServlet {
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain";
PrintWriter out = res.getWriter();
//pobierz sesję
HttpSession session = req.getSession();
//czy sesja rozpozna użytkownika jako już zalogowanego?
Object done=sesion.getAttribute("logon.isDone");//zaznacz obiekt
if (done == null) {
//zaprzeczenie logon.isDone znaczy, że użytkownik się nie zalogował
//zapisz zadany URL jako prawdziwy cel i prześlij do login page
session.setAttribute("login.target",
HttpUtils.getRequestURL(req).toString());
res.sendRedirect(„/login.html”);
return;
}

//użytkownik zalogował się i może zobaczyć towary
out.println("Nieopublikowane książki wydawnictwa Helion czekają na ciebie!");
}
}
Ten serwlet sprawdza, czy klient jest już zalogowany szukając obiektu
logon.isDone
. Jeśli taki obiekt
istnieje, serwlet ma pewność, że klient już się zalogował, w związku z czym pozwala mu przeglądać tajne
informacje. Brak tego obiektu oznacza, że klient nie jest zalogowany, wobec czego serwlet zapisuje żądany
adres URL w zmiennej
login.target
i przekierowuje klienta na stronę logującą. W niestandardowej
autoryzacji opartej o formularz należy zapewnić takie zachowanie. Użycie podklas lub klas użytkowych może
uprościć to zadanie.
W naszym przykładowym serwlecie sprawdzana jest ważność numeru konta, hasła i kodu PIN. Jeśli
wprowadzone przez klienta dane są nieprawidłowe, dostęp do informacji jest zabroniony. W przeciwnym
wypadku, fakt ten jest zapisywany w obiekcie sesji i klient jest przekierowywany na żądaną stronę.
Przykład 8.11.
Obsługa logowania.
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public void doPost(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
PrintWriter out = res.getWriter();
//pobierz numer rachunku, hasło i PIN użytkownika
String account = req.getparametr("account");
String password = req.getParametr("password");
String pin = req.getParametr("pin");
//sprawdzenie ważności hasła i nazwy
if (!allowUser(account, password, pin)) {
out.println("<HTML><HEAD><TITLE>Odmowa dostępu</TITLE></HEAD>");
out.println("<BODY>Hasło i login są nieważne. <BR>");
out.println("Możesz <A HREF=\"/login.html\"> sprobować ponownie</A>");
out.println("</BODY></HTML>");
}
else
{
//login ważny, zanotować to w obiekcie sesji.
HttpSession session = req.getSession();
session.setAttribute ("logon.isDone", account); //zaznaczenie obiektu
spróbuj przesłać klienta do strony, na która chciał wejść
try{
String target = (String) session.getAttribute("login.target");
if (target != null {
res.sendRedirect(target);
return;

}
}
catch (Exception ignored){}
//nie było możliwości przesłania do target. Przekierowanie do strony startowej.
res.sendRedirect ("/");
}
}
protected boolean allowUser (String account, String password, String pin) {
return true;//zaufaj każdemu
}
}
Właściwy sposób kontroli danych w serwlecie jest prosty: serwlet zakłada, że wszystkie dane użytkownika są
ważne. Jeśli logowanie się powiedzie, serwlet zachowuje numer rachunku użytkownika w sesji klienta pod
nazwą
logon.isDone
. Dla chronionych zasobów oznacza to, że klient ma do nich prawo dostępu. Klient
zostaje przekierowany do strony, której adres znajduje się w zmiennej
login.target
. Jeśli z jakiegokolwiek
powodu ta operacja się nie powiedzie, serwlet przekieruje użytkownika na stronę główną.
Certyfikaty cyfrowe
Prawdziwe aplikacje wymagają zabezpieczeń wyższego poziomu niż opisane do tej pory. Wymagają również
zagwarantowania poufności i integralności informacji oraz bardziej niezawodnego systemu uwierzytelniania. To
właśnie oferuje technologia certyfikatów cyfrowych.
Główną koncepcją jest system kryptografii oparty o klucze publiczne. W tym systemie każdy uczestnik wymiany
informacji posiada unikatową parę kluczy używanych do kodowania i dekodowania informacji. Jednym z nich
jest ogólnie dostępny klucz publiczny, a drugim — tajny klucz prywatny. Aby zademonstrować zasadę działania
systemu, załóżmy, że Jaś chce przesłać Krzysiowi tajną informację. Jaś znajduje w swoich zasobach klucz
publiczny Krzysia i za jego pomocą koduje informację. Gdy Krzyś otrzyma wiadomość, użyje swojego klucza
prywatnego do jej zdekodowania. Informacja staje się bezwartościowa dla każdego, kto ją przechwyci i nie
posiada klucza prywatnego Krzysia.
Metody kodowania wykorzystujące klucze cyfrowe istnieją już od kilku lat i są dość dobrze rozwinięte.
Większość z nich działa w oparciu o algorytm RSA stworzony przez Rona Rivesta, Adiego Shamira i Leonarda
Adelmana.
RSA używa dużej ilości liczb pierwszych do generowania unikatowej pary kluczy asymetrycznych
(wiadomość zakodowaną przez jeden klucz można zdekodować używając drugiego). Generowane klucze mogą
różnić się długością, zwykle wyrażaną w ilości bitów składających się na klucz. Klucze 1024- lub 2048-bitowe
są wystarczające do zapewnienia bezpiecznej komunikacji RSA.
Ponieważ klucze składają się z tak wielu znaków, niepraktycznym podejściem byłoby zmuszanie użytkownika
do wpisywania klucza za każdym razem. Zamiast tego, klucze publiczne są przechowywane na dysku w formie
certyfikatów cyfrowych, a klucze prywatne w zakodowanej formie. Certyfikaty cyfrowe mogą być generowane
za pomocą specjalnych programów (takich jak np. pakiet PGP) lub są wydawane przez specjalistyczną firmę.
Pliki z certyfikatami mogą być ładowane przez najbardziej chronione aplikacje (takie jak serwery, przeglądarki i
programy obsługujące pocztę elektroniczną).
Kryptografia kluczy publicznych rozwiązuje problem poufności, ponieważ cały proces komunikacji jest
zakodowany. Metoda ta zapewnia również integralność: w naszym przykładzie Krzyś wie, że wiadomość, którą
otrzymał nie została zmodyfikowana (gdyby tak było, nie byłby w stanie jej zdekodować). Nie rozwiązaliśmy
jeszcze problemu wierzytelności: Krzyś nie ma pewności, że wiadomość, którą odebrał została wysłana przez
Jasia. Ten problem rozwiązuje podpis elektroniczny. Ponieważ klucze prywatne i publiczne są asymetryczne, Jaś
może najpierw użyć własnego klucza prywatnego do zakodowania wiadomości, a następnie zaszyfrować
informację jeszcze raz, za pomocą publicznego klucza Krzysia. Gdy Krzyś odbierze wiadomość, zdekoduje ją
najpierw własnym kluczem prywatnym, a następnie kluczem publicznym Jasia. Teraz Krzyś wie, że jedynym
nadawcą otrzymanej wiadomości mógł być tylko Jaś, bo wiadomość zakodowana jego kluczem prywatnym
może być zdekodowana jedynie za pomocą jego klucza publicznego.
*
Patent USA nr 4.405.829. Utracił ważność 20 września 2000 r.

Prostszym systemem jest użycie kluczy symetrycznych, czyli jednego klucza kodującego i dekodującego.
Klucze asymetryczne mają dużą zaletę: przy przesyłaniu informacji nie trzeba zapewniać bezpieczeństwa kanału
komunikacyjnego. Mają też ogromną wadę: kodowanie i dekodowanie informacji za pomocą tych kluczy
wymaga sporej mocy obliczeniowej. Jako kompromis, wiele systemów kryptograficznych korzysta z
asymetrycznych kluczy prywatnych i publicznych do wzajemnej identyfikacji i poufnego przekazania
oddzielnego klucza symetrycznego do kodowania właściwej informacji. Klucz symetryczny jest zwykle
tworzony w oparciu o standard DES.
Rząd Stanów Zjednoczonych ograniczył rozmiar eksportowanych kluczy symetrycznych do długości 56 bitów
(co daje około 72*10
15
możliwych kombinacji kluczy). Wiadomości zakodowane 56-bitowym kluczem są trudne
do zdekodowania, ale nie ma rzeczy niemożliwych — wyspecjalizowane maszyny potrafią złamać kod w ciągu
kilku godzin. Wewnątrz USA wiele systemów używa 128-bitowych kluczy DES (około 3.40282*10
38
możliwości). Ponieważ nie znaleziono jeszcze sposobu na złamanie kodu informacji zakodowanej kluczem DES
w sposób brutalny, przekazywanie wiadomości z wykorzystaniem kluczy o dużych rozmiarach jest bardzo
bezpieczne.
Pozostaje jeszcze jeden problem: w jaki sposób jeden użytkownik może upewnić się, że ten drugi jest faktycznie
tym, za kogo się podaje? Jaś i Krzyś znają się, więc Krzyś wierzy, że klucz publiczny dostarczony mu osobiście
przez Jasia jest prawdziwy
. Z drugiej strony, jeśli np. Małgosia, nie znając wcześniej Jasia, chciałaby mu
udostępnić swój klucz publiczny, Jaś może podejrzewać, że Małgosia jest w rzeczywistości Markiem. Jeśli
założymy, że Krzyś zna Małgosię, możemy poprosić Krzysia, by za pomocą swojego klucza prywatnego
podpisał klucz publiczny Małgosi. Wówczas, Jaś dostanie klucz Małgosi potwierdzony przez Krzysia, do
którego ma zaufanie.
W rzeczywistości, ta „trzecia strona” potwierdzająca autentyczność nazywana jest Centrum Certyfikacji. Takim
centrum jest np. korporacja VeriSign. Ponieważ VeriSign jest ogólnie znaną organizacją (z powszechnie znanym
kluczem publicznym) klucze zweryfikowane przez to centrum można uznać za pewne. VeriSign oferuje kilka
klas identyfikatorów (wraz ze wzrostem numeru klasy rośnie jego poziom zaufania i cena). Certyfikaty pierwszej
klasy można otrzymać po wypełnieniu odpowiedniego formularza zamieszczonego w witrynie VeriSign.
Certyfikaty wyższych klas są weryfikowane indywidualnie przez pracowników tego centrum certyfikacji, przy
użyciu specjalnych metod weryfikacyjnych.
Wybierając centrum autoryzacji należy zwrócić uwagę na jego prestiż. Certyfikaty VeriSign są dołączone do
przeglądarek MS IE i Netscape, więc każdy użytkownik Internetu będzie je akceptował. Poniżej wypisano
najpopularniejsze centra certyfikacji:
• VeriSign (
http://www.verisign.com
)
• Thawte Consulting (
http://www.thawte.com
)
• Entrust Technologies (
http://www.entrust.com
)
Więcej informacji na temat certyfikatów cyfrowych znajduje się w książce Gail'a L.Granta (McGraw-Hill)
Understanding
Digital
Signatures
, która dostarcza wprowadzenie odpowiednie dla programistów i zwykłych
użytkowników. O powiązaniu kryptografii z Javą traktuje książka Jonathana Knudsena
Java
Cryptography
(O'Reilly).
Protokół bezpiecznej transmisji danych (SSL)
Protokół SSL zajmuje miejsce pomiędzy protokołem poziomu aplikacji (w tym przypadku HTTP) a protokołem
transportowym niskiego poziomu (w przypadku Internetu — prawie wyłącznie TCP/IP). Protokół ten
wykorzystuje klucze publiczne do wymiany kluczy symetrycznych, które służą do zakodowania komunikacji
pomiędzy klientem i serwerem. Po raz pierwszy wykorzystano ten protokół w przeglądarce Netscape Navigator
1. Od tamtej pory SSL jest standardem bezpieczeństwa komunikacji online i jest podstawą nowego protokołu
TLS (który jest tworzony przez IETF). Więcej informacji na temat TLS można uzyskać na stronie
http://www.ietf,org/rfc/rfc2246.txt
.
SSL Version 2.0 jest pierwszą wersją, która zyskała szeroką akceptację. Zawiera ona wsparcie tylko dla
certyfikatów serwerowych, zapewnia uwierzytelnienie serwera, poufność i integralność. Zasady działania
protokołu są następujące:
**
Szczerze mówiąc, ludzie nie spotykają się w ciemnej alejce po to, aby wymienić swoje klucze publiczne. Zamiast tego wymieniają klucze
w cyfrowy sposób (np. za pomocą email) i rozpoznają klucz po kilku pierwszych znakach.

1. Użytkownik łączy się z zabezpieczoną witryną przy użyciu protokołu HTTPS (protokół HTTP i
SSL).Adresy URL witryn, które używają protokołu HTTPS, zaczynają się od
https:
zamiast
http:
.
2. Serwer podpisuje kluczem prywatnym swój klucz publiczny i przesyła go przeglądarce.
3. Przeglądarka używa klucza publicznego serwera, by sprawdzić, czy osoba podpisująca klucz jest w
jego posiadaniu.
4. Przeglądarka upewnia się, czy zaufane centrum certyfikacji podpisało klucz. Jeśli nie, przeglądarka
pyta użytkownika, czy klucz można uznać za wiarygodny i postępuje zgodnie z jego zaleceniami.
5. Klient generuje dla tej sesji klucz symetryczny DES, koduje publicznym kluczem serwera i odsyła
serwerowi. Powstały w ten sposób nowy klucz jest użyty do zakodowania transakcji. Klucz
symetryczny jest używany dlatego, że systemy oparte o klucze asymetryczne bardzo obciążają
system.
Wszystkie opisane tu procedury są niewidoczne dla twórców serwerów i serwletów. Należy po prostu otrzymać
odpowiedni certyfikat serwerowy, zainstalować go i odpowiednio skonfigurować serwer. Informacje przesyłane
pomiędzy serwletami i klientami będą od tej pory zakodowane.
Uwierzytelnianie klienta za pomocą SSL
Nasza skrzynka z narzędziami zabezpieczającymi zawiera już solidne systemy kodowania i uwierzytelnienia
serwera, ale słaby system uwierzytelniania klienta. Oczywiście użycie SSL 2.0 stawia nas w dużo lepszej
sytuacji. Serwery wyposażone w SSL mogą jednocześnie używać podstawowych metod uwierzytelniania
omówionych na początku niniejszego rozdziału, ponieważ nie ma możliwości przechwycenia informacji. Nadal
jednak nie mamy dowodu na wiarygodność klienta, bo każdy mógłby zgadnąć lub zawładnąć hasłem i nazwą
użytkownika.
Powyższy problem rozwiązano w nowszej wersji SSL 3.0 poprzez zapewnienie obsługi certyfikatów klienckich.
Te certyfikaty są zarejestrowane jako klienckie, ale niczym nie różnią się od serwerowych. SSL 3.0 z
uwierzytelnieniem klienckim pracuje podobnie do SSL 2.0, ale po uwierzytelnieniu serwera przez klienta,
serwer żąda od niego certyfikatu. Klient przesyła podpisany certyfikat i serwer przeprowadza taką samą
procedurę uwierzytelniającą, jaka odbyła się po stronie klienta (serwer porównuje certyfikat klienta z biblioteką
istniejących certyfikatów lub przechowuje certyfikat, aby zweryfikować użytkownika przy kolejnej wizycie).
Wiele przeglądarek zanim wyśle certyfikat, jako zabezpieczenie, wymaga podania hasła przez użytkownika.
Klientowi raz uwierzytelnionemu serwer udostępni chronione zasoby (serwlety lub pliki) tak, jak za pomocą
uwierzytelnienia HTTP. Cały proces przebiega w sposób niewidoczny dla użytkownika. Ponadto ten sposób
dostarcza dodatkowy poziom uwierzytelnienia, bo serwer wie, że klient posługujący się certyfikatem Jasia
Kowalskiego jest w istocie Jasiem Kowalskim (w dodatku może rozpoznać konkretnego Jasia Kowalskiego
poprzez jego unikatowy certyfikat). Wadami certyfikatów klienckich jest konieczność ich otrzymania i instalacji
przez użytkowników. Ponadto serwery muszą zawierać bazę danych z kluczami publicznymi, a przede
wszystkim obsługiwać SSL 3.0.
Konfigurowanie ochrony za pomocą SSL
Aplikacja sieciowa, która wymaga ochrony za pomocą SSL (HTTPS) może o tym powiadomić serwer przy
użyciu deskryptora rozmieszczenia. Wymaganie SSL modyfikuje plik
web.xml
w ten sposób, że znacznik
<security-constraint>
zawiera znacznik
<user-data-constraint>
wskazujący wymagania
dotyczące systemu zabezpieczeń. Przykład 8.12 przedstawia ten plik.
Przykład 8.12.
Ta kolekcja wymaga bezpiecznego połączenia
<!-- ...itp... -->
<security-constraint>
<web-resource-collection>
<web-resource-name>
SecretProtection
</web-resource-name>
<url-pattern>
/servlet/SalaryServer

</url-pattern>
<url-pattern>
/servlet/secret
</url-pattern>
<url-method>
GET
</url-method>
<url-method>
POST
</url-method>
</web-resource-collection>
<auth-constraint>
<role-name>
manager
</role-name>
</auth-constraint>
<user-data-constraint>
<transport-guarantee>
CONFIDENTIAL
</transport-guarantee>
</user-data-constraint>
</security-constraint>
<!-- ...itp... -->
Dodany znacznik
<user-data-constraint>
informuje o tym, że dostęp do danych jest zapewniany
użytkownikom w roli manager oraz, że użytkownicy muszą łączyć się używając trybu
CONFIDENTIAL
.
Znacznik
<transport-guaratee>
może zawierać jedną z dwóch wartości:
INTEGRAL
albo
CONFIDENTIAL
.
INTEGRAL
wymaga niezmienności danych podczas transmisji. Z kolei
CONFIDENTIAL
wymaga poufności danych. Zastosowanie
CONFIDENTIAL
pociąga za sobą jednoczesne użycie
INTEGRAL
.
Serwer decyduje, które algorytmy kryptograficzne można zakwalifikować jako
INTEGRAL
, a które jako
CONFIDENTIAL
. Większość powszechnie znanych algorytmów SSL zalicza się do obu grup. Jednakże serwer
może zaliczyć algorytmy wykorzystujące kodowanie 56-bitowe DES do
INTEGRAL
(informacja nie może być
naruszona, aby ją zdekodować), a nie do
CONFIDENTIAL
(bo łatwo złamać taki kod)
. W praktyce pomiędzy
tymi trybami jest niewielka różnica, a ogólnie gwarantowanym standardem jest
CONFIDENTIAL
.
Znaczniki
<auth-constraint>
i
<user-data-constraint>
mogą występować razem lub osobno. Na
przykład, strona obsługująca kartę kredytową wymaga komunikacji typu
CONFIDENTIAL
, ale może pozostać
widoczna dla wszystkich użytkowników.
Konfiguracja uwierzytelnienia SSL
SSL 3.0 zyskuje popularność, bo coraz więcej witryn uwierzytelnia użytkowników za pomocą certyfikatów
klienckich. To zapewnia automatyczną i bezpieczną metodę identyfikacji użytkownika klienta. W zależności od
poziomu zaufania powiązanego z certyfikatem klienckim, można uważać mechanizm uwierzytelnienia za
dostatecznie bezpieczny, by wspomagać podpisywanie prawnie wiążących kontraktów lub nawet głosowanie
online.
Można zgadnąć, że uwierzytelnienie oparte o certyfikaty klienckie może być wskazane wewnątrz znacznika
<login-config>:
<login-config>
*
Połączenie klient-serwer poprzez bezpieczną sieć VPN może spotkac się z ograniczeniem CONFIDENTIAL nawet bez użycia SSL.

<auth-method>
CLIENT_CERT <!—Klient musi zostać zidentyfikowany za pomocą certyfikatu X.509 --!>
</auth-method>
</login-config>
Tak określony znacznik jest informacją dla serwera, że wszystkie procesy uwierzytelnienia dla danej aplikacji
będą wykonywane przy użyciu certyfikatów klienckich zamiast tradycyjnych metod: podstawowej lub w oparciu
o formularz. Klient nigdy nie ujrzy strony logującej, mimo że przeglądarka poprosi o hasło do odblokowania
certyfikatu przed przesłaniem do serwera. Jeśli przeglądarka nie otrzyma certyfikatu klienckiego, dostęp do
danych będzie zabroniony.
Wyszukiwanie informacji uwierzytelnienia SSL
Podczas uwierzytelnienia podstawowego i szyfrowanego wszystkie szczegóły dotyczące SSL obsługiwane są
przez serwer w sposób niewidoczny dla serwletów. Innymi słowy, serwlet nie musi spełniać jakichkolwiek
kryteriów, by mieć dostęp do zabezpieczonego serwera! Serwlet może czasami wyszukiwać użytecznych
informacji dotyczących uwierzytelnienia SSL. Na przykład, serwlet może sprawdzić, czy połączenie z klientem
jest bezpieczne używając metody
isSecure()
:
public boolean ServletRequest.isSecure()
Metoda zwraca
true
, jeśli serwer uzna połączenie za bezpieczne. Poziom kodowania zależy od implementacji
serwera. Potrzebne detale można znaleźć w dokumentacji serwera. Niestety, serwlet nie może w standardowy
sposób zażądać właściwego algorytmu kodowania użytego do połączenia, a nawet długości symetrycznego
klucza (40, 56, 128). Taką opcje można ustawić w serwerze jako atrybut o nieokreślonej do tej pory nazwie.
Taka cecha jest oczekiwana w Servlet API 2.3, który używa atrybutów żądania:
javax.servlet.request.cipher_suite
i
javax.servlet.request.key_size
.
Gdy klient zostanie uwierzytelniony za pomocą CLIENT-CERT metoda
getUserPrincipal() zwróci
nazwę jego podmiotu. Nazwa ta jest wzięta z pola certyfikatu
Distinguished
Name
.
Za każdym razem, gdy certyfikat kliencki jest wysyłany do serwera, serwlet może otrzymać go jako atrybut
żądania. Może to pojawić się podczas zwykłego procesu przesłania z potwierdzeniem SSL 3.0, nawet gdy
CLIENT-CERT
nie jest określony.
java.security.cert.X509Certificate cert =
(java.security.cert.X509Certificate)
req.getAttribute(„javax.servlet.request.X509Certificate”);
Dla każdego serwera pracującego na J2SE 1.2 (JDK 1.2) lub obsługującego J2EE 1.2 atrybut żądania
javax.servlet.request.X509Certyficate
zwróci obiekt
java.security.cert.X509Certyficate
reprezentujący certyfikat X.509v3 (instrukcje konfigurujące
można znaleźć w dokumentacji serwera). Serwery pracujące na JDK 1.1, które są niekompatybilne z J2EE 1.2
nie wspierają tego atrybutu, ponieważ JDK 1.1 nie zawiera pakietu
java.security.cert
. Serwlet z
przykładu 8.13 drukuje łańcuch certyfikatu klienta.
Przykład 8.13
Sprawdzanie certyfikatów klienckich
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class X509Snoop extends HttpServlet {
public void doGet (HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType ("text/plain");
PrintWriter out = res.getWriter();
X509Certificate[] certs = (X509Certificate[])

req.getAttribute("javax.servlet.request.X509Certificate");
if (certs != null) {
for (int i=0; i<certs.length; i++) {
out.println("certyfikat klienta [" + i + "] = " + certs[i].tostoring());
}
}
else {
if („https”.equals(req.getScheme())){
out.println(„To było HTTPS, ale brak certyfikatu,”+”...”);
}
else {
out.println(„to nie był HTTPS,”+
„wiec żaden certyfikat nie jest możliwy”);
}
}
}
}
Zwrócony certyfikat
X509Certyficate
może być użyty do sprawdzenia ważności, wydawcy, numeru
seryjnego, podpisu i tak dalej. Wydruk certyfikatu jako
String
pokazano w przykładzie 8.14. Pierwszy
certyfikat jest kluczem publicznym użytkownika. Drugi z nich to podpis VeriSign potwierdzający autentyczność
pierwszego podpisu.
Przykład 8.14.
Przykładowy certyfikat X509 dla Ramesha Mandavy.
Client Certificate [0] =[
[
Version: V3
Subject: EmailAddress=rmandava@talentportal.com, CN=Ramesh babu mandava, OU=Digital
ID Class 1 –
Netscape, OU=Persona Not Validated, OU="www.verisign.com/repository/RPA Incorp. By Ref.,
LIAB.LTD©98", OU=VeriSign Trust Network, O="VeriSign, INC."
Signature Algorithm: MD5withRSA, OID = 1.2.840.113549.1.1.4
Key: com.sun.net.ssl.internal.ssl.JSA_RSAPublicKey@5b5870e3
Validity: [From: Tue Oct 10 17:00:00 PDT 2000,
To: sun Dec 10 15:59:59 PST 2000]
Issuer: CN=VeriSign Class 1 CA Individual subscriber-Persona not Validated,
OU="www.verisign.com/repository/RPA incorp. By Ref.,LIAB.LTD(c)98", OU=VeriSign Trust
Network, O="VeriSign, Inc."
SerialNumber: [ 1ef11638 5ab8aaa1 bfa2b11b3 c0fb9cd9]
Certificate Extensions: 4
[1]: ObjectId: 2.16.840.1.113730.1.1 Criticality=false
NetscapecertType [
SSL client
]
[2]: ObjectId: 2.5.29.32 Criticality=false
Extension unknown: DER encoded OCTET string =

0000: 04 3D 30 3B 30 39 06 0B 60 86 48 01 86 F8 45 01 .=0;09..'.H...E.
0010: 07 01 08 30 2A 30 28 06 08 2B 06 01 05 05 07 02 ...0*0(..+......
0020: 01 16 1C 68 74 74 70 73 3A 2F 2F 77 77 77 2E 76 ...https:/www.v
0030: 65 72 69 73 69 67 6E 2E 63 6F 6D 2F 72 70 61 erisign.com/rpa
[3]: ObjectId: 2.5.29.31 Criticality=false
Extension unknown: DER encoded OCTET string =
0000: 04 2C 30 2A 30 28 A0 26 A0 24 86 22 68 74 74 70 .,0*0(.&.$."http
0010: 3A 2F 2F 63 72 6C 2E 76 65 72 69 73 69 67 6E 2E ://crl.verisign.
0020: 63 6F 6D 2F 63 6C 61 73 73 31 2E 63 72 6C com/class1.crl
[4]: ObjectId: 2.5.29.19 Criticality=false
BasiConstraints:[
CA:false
PathLen: undefined
]
]
Algorithm: [MD5withRSA]
Signature:
0000: 5E EC 5C F9 96 D5 3F F6 19 8B 66 0A 46 DE 02 FC ^.\...?...f.F...
0010: 52 4E 32 70 5F DA 8B 92 43 F4 19 51 C3 A3 36 7D RN2P^...C...Q..6
0020: 02 4A 5B 35 B6 76 05 F8 FE C0 4F D7 9C B1 5B BA .J[5.v....O...[.
0030: EE 38 A7 98 C5 57 A7 6B 86 B9 B2 A1 4F 25 5F FF .8...W.k....0%_.
0040: OB 19 54 86 D7 14 7A F7 97 A1 E8 E7 D3 89 75 B0 ..T...z.......u.
0050: 72 4F 4B 77 E4 56 5D B2 40 D2 7E 69 26 77 DD F1 rOkw.V].@..i&w..
0060: E6 31 3D F2 EF 5A 11 22 78 23 47 C2 D6 ED DD 14 .1=..Z."x#G.....
0070: 2F E9 2E 46 73 D9 20 72 BF 9B 6C 04 12 0D 68 C7 /..Fs. r..l...h.
]
Client Certificate [1] = [
[
Version: V3
Subject: CN=VeriSign Class 1 CA Individual Subsciber-Persona Not Validated,
OU="www.verisign,com/repository/RPA Incorp. By Ref., LIAB.LTD(c)98", OU=VeriSign Trust
Network, O="VeriSign, Inc."
Signature Algorithm: MD2withRSA, OID = 1.2.840.113549.1.1.2
Key: com.sun.net.ssl.internal.ssl.JSA_RSAPublicKey@9ae870e3
Validity: [From: Mon May 11 17:00:00 PDT 1998,
To: Sun May 12 16:59:59 PST 2008]
Issuer: OU=Class 1 Public Primary Certification Authority, O="VeriSign, Inc.", C=US
SerialNumber: [ d2762e8d 140c3d7d b2a8255d afee0d75 ]
Certificate Extensions: 4
[1]: ObjectId: 2.16.840.1.113730.1.1 Criticality=false
NetscapeCerttype [
SSL CA
S/MIME CA
]

[2]: ObjesctID: 2.5.29.32 Criticality=false
Extension unknown: DER encoded OCTET string =
0000: 04 40 30 3E 30 3C 06 0B 60 86 48 01 86 E8 45 01 .@0>0<..'.H...E.
0010: 07 01 01 30 2D 30 2B 06 08 2B 06 01 05 05 07 02 ...0-0+..+......
0020: 01 16 1F 77 77 77 2E 76 65 72 69 73 69 67 6E 2E ...www.verisign.
0030: 63 6F 6D 2F 72 65 70 6F 73 69 74 6F 72 79 2F 52 com/repository/R
0040: 50 41 PA
[3]: ObjectId: 2.5.29.15 Criticality=false
KeyUsage [
Key_CertSign
Crl_Sign
]
[4]: ObjectId: 2.5.29.19 Criticality=false
BasicConstraints:[
CA:true
PathLen:0
]
]
Algorithm: [MD2withRSA]
Signature:
0000: 88 B8 37 3B DD DA 94 37 00 AD AA 9F E1 81 01 71 ..7;...7.......q
0010: 1E 92 6A 6D 2F F6 F1 9D D3 CA 64 38 DC 1B 98 0C ..jm/.....d8....
0020: 07 86 5B 85 15 6A 0F B9 49 85 A4 95 F1 17 7D 67 ..[..j..I......g
0030: B4 7F 2D 2C DD 9A 42 9E C3 3E B4 8E AA E5 0B 06 ..-,..B..>......
0040: DE F2 56 2A FA 33 C7 BE 19 D7 53 4C C3 BD C8 E3 ..V*.3....SL....
0050: 17 B5 A4 49 42 63 EC C2 A6 17 0F 5D 58 1A 49 3C ...Ibc.....]X.I<
0060: 90 5C 55 A3 65 20 00 FD 18 20 E5 5F 82 A6 B1 A8 .\U.e... ._....
0070: 92 C5 58 6A C1 8D 03 3C EB C3 CD 05 A2 90 AE 6E ..Xj...<.......n
]
Wyszukiwarka
Podobne podstrony:
r08 05 (28)
r08 05 (47)
r08 05 (17)
r08-05-spr, ## Documents ##, Debian GNU Linux
r08-05, informatyka, SQL Server 2000 dla kazdego
r08-05, ## Documents ##, flash5biblia
r08 05 spr spr (2)
r08 05 doc
podrecznik 2 18 03 05
regul praw stan wyjątk 05
05 Badanie diagnostyczneid 5649 ppt
Podstawy zarządzania wykład rozdział 05
05 Odwzorowanie podstawowych obiektów rysunkowych
05 Instrukcje warunkoweid 5533 ppt
05 K5Z7
05 GEOLOGIA jezior iatr morza
05 IG 4id 5703 ppt
więcej podobnych podstron