
1
SYSTEM PLIKÓW
powiązane ze sobą informacje
przechowywane są oddzielnie
(różne pliki)
te same dane są powielane w
wielu różnych plikach
(np.różnych formatach)
coraz większa liczba informacji
przestaje być możliwa do
zarządzania w sposób efektywny
wielodostępowość, prawa i
transakcje
2
DBMS-SZBD
Współdzielenie danych
Efektywne mechanizmy wielodostępu.
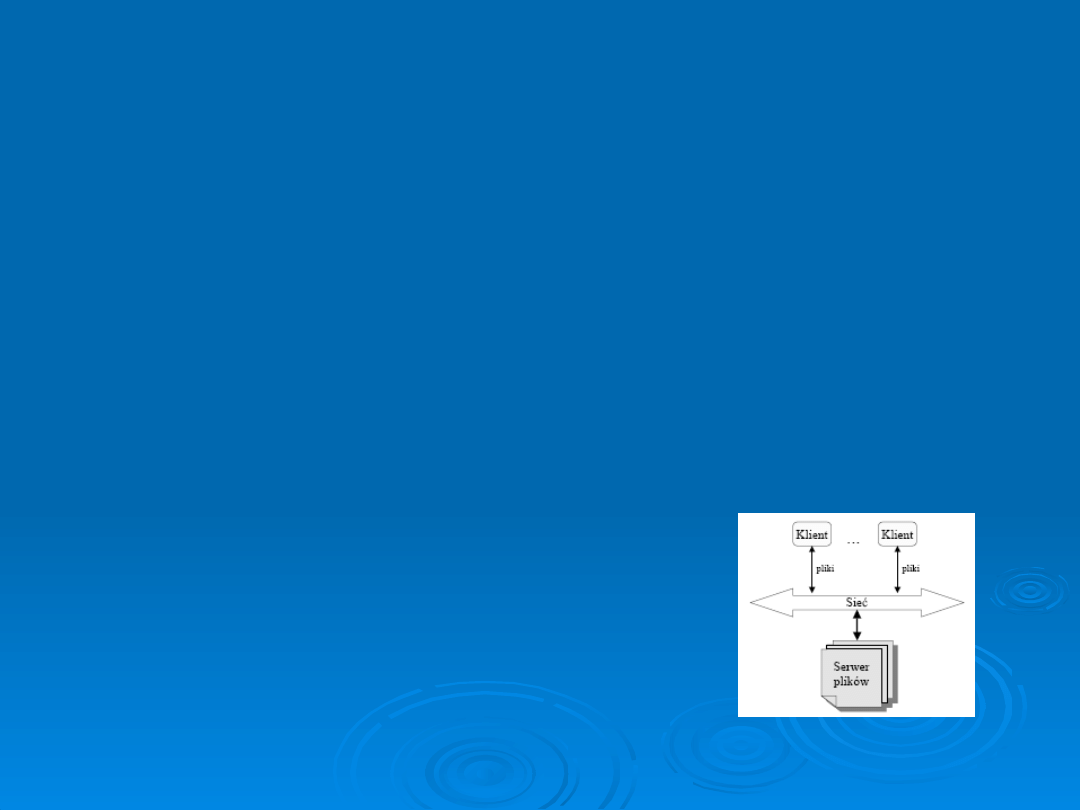
Model klient-serwer: programy używane przez użytkowników (klienci)
są oddzielone od programu bezpośrednio wykonującego operacje na
danych (serwera);
umożliwia to uruchamianie klientów na innych komputerach niż serwer,
zwiększa bezpieczeństwo,
odciąża serwer od końcowej obróbki i prezentacji danych.
Integracja danych
Centralne składowanie wszystkich danych dotyczących danego obszaru
działalności umożliwia uniknięcie zbędnych powtórzeń tych samych
informacji
Integralność danych (prawidłową postać)
Bezpieczeństwo danych
Autoryzacja użytkowników
Brak dostępu do „maszyny”
Abstrakcja i niezależność danych
Ukrycie wew. mechanizmów działania systemu przed użytkownikiem

3
MODELE DANYCH
1. Hierarchiczny model danych
2. Sieciowy model danych
3. Relacyjny model danych
4. Obiektowy model danych
5. Obiektowo-relacyjny model danych

4
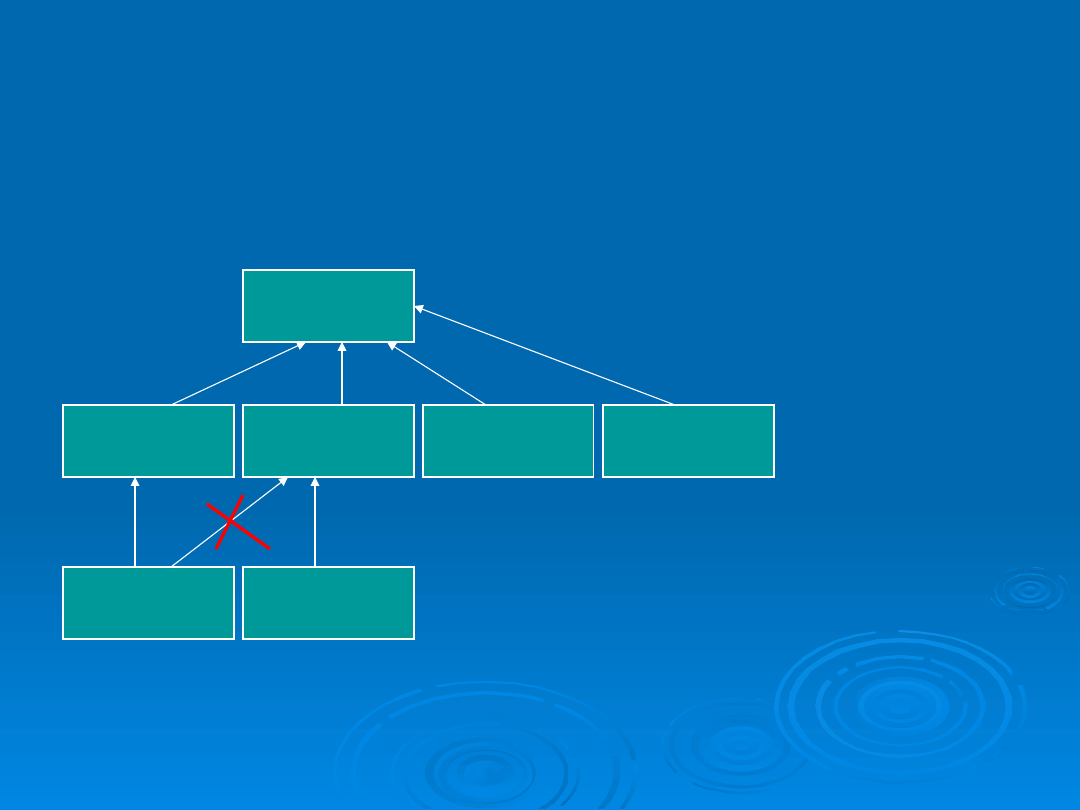
Hierarchiczny model danych
(podobny do systemu plików)
Używa dwóch struktur danych:
rekordu;
Nazwana struktura danych tj. zbiór nazwanych pól
określonego typu
- związków nadrzędny-podrzędny;
Związek jeden-do-wiele między dwoma typami rekordów.
Typ rekordu po stronie jeden w związku jest typem
nadrzędnym
.
rekordy przypominają strukturę drzewa
5
Hierarchiczny model danych
Obywatel
Jan Nowak
Barbara ZyskAndrzej Kruk
dziecko
Kamil Nowak
dziecko
Kamil Nowak
Kamil Nowak
REDUNDANCJA
DANYCH

6
Hierarchiczny model danych
Operowanie danymi:
Wykonywane przez wbudowane funkcje dostępu
do bazy danych bądź procedury tworzone
przez zaawansowanych użytkowników
typowe operacje na danych w tym modelu to:
a) wyszukiwanie rekordów określonego typu,
podrzędnych względem danego rekordu, i
spełniających warunki dotyczące zawartości
określonych pól;
b) usuwanie lub dodawanie rekordów i edycja ich
pól

7
Hierarchiczny model danych
Integralność danych
1)
Każdy rekord (z wyjątkiem korzenia) musi być powiązany z
rekordem nadrzędnym właściwego typu:
nie można wstawić rekordu podrzędnego bez jego powiązania z
rekordem nadrzędnym
usunięcie rekordu nadrzędnego wiąże się z usunięciem
wszystkich względem niego podrzędnych.
2) Zawartość każdego pola rekordu musi odpowiadać typowi
danych
z definicji danego typu rekordu.
3) Jeżeli podrzędny typ rekordu musi mieć więcej niż jeden
rekord nadrzędny musi zostać powielony dla każdego
rekordu nadrzędnego
PODOBNY DO SYSTEMU PLIKÓW
Przykładem modelu hierarchicznego są dokumenty XML

8
Sieciowy model danych
rozwinięcie hierarchicznego modelu danych
Używa dwóch struktur danych:
rekordu;
Nazwana struktura danych tj.zbiór nazwanych pól
określonego typu gdzie typ może być typem złożonym
i składać się z kilku typów prostych
- kolekcji („set”);
Jest opisem związku jeden do jednego,jeden-do-wiele,
wiele do wielu między dwoma typami rekordów
SAMI DEFINIUJEMY CAŁĄ STRUKTURĘ: BUDOWĘ REKORDÓW,
BUDOWĘ WEWNĘTRZNĄ TYPÓW PÓL I KOLEKCJE.

9
Sieciowy model danych
Operowanie danymi:
Nawigacja po danych
Sprowadzanie („wyciąganie”)
zawartości bieżących rekordów
Modyfikacje zawartości wystąpień
rekordów i kolekcji

10
Sieciowy model danych
Integralność danych dotyczy określenia:
- członkowstwa w kolekcji:
wymagane
opcjonalne-może nie mieć kolekcji;
- trybu wstawiania;
automatyczny – wstawianie w bieżącej
kolekcji,
ręczny – musimy wskazywać gdzie ma być
wstawiony
sprawdzanie zgodności typów:
integer, char itp.
unikalność pól kluczowych

11
Relacyjny model danych
Opracowany w latach 70 przez E. F.
Codda
Jest do dziś podstawą architektury
większości popularnych SZBD
Model relacyjny oparty jest tylko na
jednej podstawowej strukturze danych -
RELACJI. Jest nią tabela.

12
Relacyjny model danych
RELACJA (tabela) musi spełniać następujący zbiór zasad:
1. Każda relacja (tabela) w bazie danych ma własną, unikalną
nazwę
2. Każda kolumna w relacji (tabeli) ma jednoznaczną nazwę w
ramach tabeli
3. Wszystkie wartości w danej kolumnie muszą być tego
samego typu – muszą należeć do dziedziny.
4. Porządek kolumn w relacji (tabeli) jest nieistotny.
5. Każdy wiersz w relacji musi być rożny. Wiersze relacji(tabeli)
nazywa się „encjami”
klucz główny -kolumna (lub kolumny), której wartości
jednoznacznie identyfikują wiersz
6. Porządek wierszy nie jest istotny.
7. Każde pole (przecięcie wiersza z kolumną) zawiera wartość
„atomową” z dziedziny określonej przez kolumnę. Brakowi
wartości odpowiada wartość specjalna NULL, zgodna z
każdym typem kolumny

13
Relacyjny model danych
Klucze główne:
Każda relacja musi mieć klucz główny
Klucz główny to jedna lub więcej kolumn tabeli, w których wartości
jednoznacznie identyfikują każdy wiersz tabeli
Dziedzina:
Zbiór danych tego samego typu ze wszystkimi wartościami mogącymi
wystąpić
w wybranej kolumnie.
Klucze obce:
To sposób na łączenie danych przechowywanych w różnych tabelach.
Połączenie to funkcjonuje na zasadzie połączenia klucza obcego jednej
tabeli i klucza głównego drugiej. Wynika stąd, że dziedzina klucza obcego
musi być taka sama jak klucza głównego
Wartość null
Specjalna wartość dla wskazania niepełnej lub nieznanej informacji.
Wprowadza pewną niejednoznaczność do logiki dwuwartościowej (prawda,
fałsz). Konieczność istnienia jest dyskusyjna.

14
Relacyjny model danych
Operowanie danymi
1.
Wstawianie danych
2.
Usuwanie danych
3.
Modyfikacja danych
4.
Wyszukiwanie danych –
oparte na tzw.
algebrze relacyjnej

15
Relacyjny model danych
Selekcja:
jest operacją jednoargumentową
(wykonywana na 1 relacji)
jest określona przez warunek dotyczący
zawartości kolumn danej relacji.
wynikiem jej jest nowa relacja zawierająca
wszystkie encje (wiersze) „wejściowej”
relacji, których wartości kolumn spełniają
założony warunek.
jest to „cięcie poziome” relacji

16
Relacyjny model danych
Rzut:
Jest operacją jednoargumentową
(wykonywana na 1 relacji)
Jest określona jako podzbiór zbioru
kolumn danej relacji,
Wynikiem jest relacja składającą się z
podzbioru kolumn „wejściowej”
relacji.
Jest to „cięcie pionowe” relacji

17
Relacyjny model danych
Iloczyn kartezjański
Operacja dwuargumentowa (2
relacje)
Wynikiem jest relacja, której wiersze
są zbudowane ze wszystkich
kombinacji par wierszy relacji
wyjściowych

18
Relacyjny model danych
Równozłączenie:
Argumentami są dwie relacje,
posiadające kolumny o tych samych
dziedzinach np. klucz główny jednej z
nich i klucz obcy drugiej.
Wynikiem jest relacja otrzymana z
iloczynu kartezjańskiego relacji
„wejściowych” i warunku równości
tych ,,wspólnych'' atrybutów.

19
Relacyjny model danych
Złączenie naturalne
- Argumentami są dwie relacje, posiadające kolumny o
tych samych dziedzinach np. klucz główny jednej z
nich i klucz obcy drugiej.
Wynikiem jest relacja otrzymana z iloczynu
kartezjańskiego relacji „wejściowych” i warunku
równości tych ,,wspólnych'' atrybutów oraz rzutowania
usuwającego powtarzające się kolumny
- Wartości pustych kolumn uzupełnianie są wartościa
NULL
Lewostronne
– dodawane są „nie pasujące” wiersze z
pierwszego argumentu
Prawostronne
- dodawane są „nie pasujące” wiersze z
drugiego argumentu
Obustronne
– dodawane są „nie pasujące” wiersze z
obydwu argumentów

20
Relacyjny model danych
Suma
Argumentami są dwie zgodne relacje,
tj. o tych samych dziedzinach dla
odpowiednich kolumn
Wynikiem jest suma „pionowa”
relacji

21
Relacyjny model danych
Przecięcie
Argumentami są dwie zgodne relacje,
tj. o tych samych dziedzinach dla
odpowiednich kolumn
wynikiem jest relacja zawierająca
encje wspólne dla obu argumentów
( pozostają wiersze występujące w 2
encjach)

22
Relacyjny model danych
Różnica
Argumentami są dwie zgodne relacje,
tj. o tych samych dziedzinach dla
odpowiednich kolumn
Wynikiem jest różnica
„teoriomnogościowa”
( pozostają wiersze występujące w 1 encji a
nie występujące w 2 encji)

23
Relacyjny model danych
Integralność danych
- Integralność encji:
każda tabela musi posiadać klucz główny (unikalny, różny od null)
Integralność referencyjna:
każda wartość klucza obcego musi być równa jakiejś wartości klucza głównego
występującej w tabeli powiązanej lub NULL.
Reguły postępowania w wypadku usuwania wiersza z tabeli powiązanej:
Restricted: usunięcie wiersza jest zabronione, dopóki nie zostaną usunięte lub
odpowiednio zmodyfikowane wiersze z innych tabel, których wartości kluczy obcych
stałyby się wskutek tej operacji nieważne;
Cascades: usunięcie wiersza powoduje automatyczne usunięcie z innych tabel
wszystkich wierszy, dla których wartości kluczy obcych staną się nieważne;
Nullifies: nieważne wartości kluczy obcych ulegają zastąpieniu przez NULL.

24
Obiektowy model danych
Umożliwia korzystanie z bogatszego
repertuaru struktur danych (klas
tworzonych pod kątem potrzeb danej
aplikacji - abstrakcyjne typy danych np.
wielokąt w SIP) i wiązanie definicji danych
z metodami ich manipulacji poprzez
definiowanie metod.
- Szczegóły operacji są ukryte przed
użytkownikiem
Zagnieżdżone relacje – obiekty złożone z
podobiektów mających swoje własne
wiązania
Dziedziczenie

25
Obiektowy model danych
Obiekt
to ,,pakiet danych i procedur'
Dane to atrybuty obiektu, procedury
definiowane są za pomocą tzw.metod
Każdy obiekt ma swoją tożsamość –
identyfikator, pozwalającą go odróżnić od
innego posiadającego takie same atrybuty.
Metoda
danego obiektu może
modyfikować wartości jego atrybutów,
uzyskiwać informacje o wartościach
atrybutów
tworzyć nowe obiekty i je usuwać
constructor, destructor

26
Obiektowy model danych
Klasa
typ, wzorzec obiektów,
„definicję pewnego typu danych”.
Dziedziczenie
jest sposobem
tworzenia nowych klas, poprzez
modyfikację i/lub wzbogacenie już
istniejącej definicji klasy (lub klas:
wielokrotne dziedziczenie).
Enkapsulacja
- szczegóły
implementacji danego obiektu nie są
bezpośrednio dostępne z zewnątrz.
Document Outline
- SYSTEM PLIKÓW
- DBMS-SZBD
- MODELE DANYCH
- Hierarchiczny model danych (podobny do systemu plików)
- Hierarchiczny model danych
- Hierarchiczny model danych
- Hierarchiczny model danych
- Sieciowy model danych rozwinięcie hierarchicznego modelu danych
- Sieciowy model danych
- Sieciowy model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Relacyjny model danych
- Obiektowy model danych
- Obiektowy model danych
- Obiektowy model danych
Wyszukiwarka
Podobne podstrony:
Fotogrametria i SIP wyklad 2 ZSZ modele danych przestrzennych konspekt
wyklad 2 Prezentacja danych PL
Wykład 3 Określenie danych wyjściowych do projektowania OŚ
ssciaga, Studia PŚK informatyka, Semestr 4, Bazy Danych 2, Bazy Danych Zaliczenie Wykladu, Bazy Dany
1 Dane geograficzne i modele danych geograficznychIid 10310
Wyklad2 Modele systemów informatycznych zarządzania
wykład 6-modele
Wykład 3-4 - Modele komunikowania masowego, Notatki, Dziennikarstwo i komunikacja społeczna, Nauka o
http, www strefawiedzy edu pl file php file= 28 Wyklady Bazy danych3
Technika komputerowa w obrocie towarowym, Wykłady, Baza danych - uporządkowany zbiór danych obsługiw
Psychologia rozwojowa - Brzezińska - wykład 2 - Modele rozwoju, WYKŁAD 2
wyklad03(Bazy danych)
2 Dane geograficzne i modele danych geograficznychIIid 21107
wyklad 4 -modele systemu emerytalnego, Konspekty wykładów
wyklad4 bazy danych i wlasnosc przemyslowa
więcej podobnych podstron