Zasoby podzielne i niepodzielne. Sposoby ochrony zasobów niepodzielnych. Procedura TAS, zasuwki, semafory.
Zasoby systemu - zbiór układów wewnętrznych maszyny cyfrowej oraz zbiór programów pomocniczych i podprogramów bibliotecznych niezbędnych do realizacji procesów.
Zasób podzielny - to taki, który można oddać innemu klientowi do wykorzystania a potem powrócić do obsługi klient, którą się uprzednio przerwało ( w systemach komputerowych takim zasobem jest procesor).
Zasób niepodzielny - jest to zasób, z którego nie może jednocześnie korzystać więcej niż jeden klient ( przykładem takiego zasobu może być drukarka).
Sposoby ochrony zasobów niepodzielnych :
a) Procedura TAS (m) - często realizowana w postaci jednego rozkazu maszynowego.
Poczatek
Zablokuj dostęp do zmiennej m;
Jeżeli m=0 to
Poczatek
m:=1;
licznik:=licznik+2;
Koniec
W przeciwnym razie
Licznik := licznik +1;
Odblokuj dostęp do zmiennej m.;
Koniec
Zmienna licznik - licznik rozkazów komputera.
Przykład:
Jeśli mamy zasób p i używamy do jego zabezpieczania procedury TAS to:
P=1 - zasób jest zajęty
P=0 - zasób jest wolny
b) Zasuwka - zmienna p wraz ze stowarzyszoną z nią kolejką f(p). Ta metoda, w przeciwieństwie do poprzedniej , porządkuje procesy żądające dostępu do zasobu.
Procedura zamknięcia zasuwki:
Jeżeli p=0 to p:=1
W przeciwnym razie zawieś program i dołącz do kolejki f(p)
Procedura otwarcia zasuwki:
Jeżeli f(p)< >0
To wprowadź kolejny program z kolejki w stan aktywny i usuń z kolejki
W przeciwnym razie p:=0
Semafor- z semaforem s są związane: wartość zmiennej semaforowej e(s) i kolejka f(s) procesów czekających na dostęp do zasobu. Dla semafora można zdefiniować 2 procedury: wejścia P(s) -umożliwiająca dostęp do zasobu i wyjścia V(s) - wykonuje się zwalniając niepotrzebny już procesowi zasób.
Zmiennej semaforowej nadaje się wartość początkową, która zależy od konkretnego problemu, rozwiązywanego tą metodą.
Procedura P(s)
Początek
e(S):=e(s)-1;
Jeżeli e(s)<0 to
początek
komentarz niech r jest procesem pytającym;
stan(r)=zawieszony;
proces r do kolejki f(s)
koniec
Koniec
Procedura V(s)
Początek
e(s):=e(s)+1;
Jeżeli e(s)<=0 to
Początek
Wyprowadź z kolejki f(s) pierwszy proces;
Komentarz niech q będzie procesem wyprowadzonym;
Stan(q)=aktywny
Koniec
Koniec
Wnioski:
Jeżeli po wykonaniu operacji e(s):=e(s)-1 w procedurze P(s) wartość e(s) jest mniejsza od 0 , znaczy to, że zasób jest zajęty.
Jeżeli po wykonaniu operacji e(s):=e(s)+1 w procedurze V(s) wartość e(s) jest mniejsza lub równa 0, to znaczy ,że jest kolejka procesów czekających na zwolnienie zasobu.
Zadanie o producencie i konsumencie.
Typowe zadanie, w którym wymagana jest synchronizacja pomiędzy procesami.
program `PRODUCENT' produkuje dane (np. generuje, pobiera, przygotowuje wstępnie do obróbki)
program `KONSUMENT' konsumuje (wykorzystuje) dane wyprodukowanie przez producenta
Rozwiązanie 1:
Program producenta (cykliczny):
produkuj dane
czekaj na konsumenta P(k)
przekaż dane
powiadom o przekazaniu danych V(p)
Program konsumenta (cykliczny):
sprawdź, czy dane są dostępne P(p)
pobierz dane
obrabiaj dane
powiadom o gotowości konsumenta V(k)
Wykorzystywane semafory:
p - gotowość danych producenta (binarny, e0 = 0)
k - gotowość konsumenta do przyjęcia danych (binarny, e0 = 1)
Problemy:
jeśli producent będzie szybszy od konsumenta, będzie miał duże przestoje
synchronizacja większej ilości programów wymaga mnożenia semaforów
Rozwiązanie 2:
Zastosowanie bufora danych.
W tym rozwiązaniu należy wprowadzić dodatkowe założenie, że konsument po pobraniu elementu usuwa go z bufora.
Program producenta (cykliczny):
generuj dane
sprawdź wolne miejsce
w buforze P (wolne)wstaw element do bufora
V (zajęte)
Program konsumenta (cykliczny):
sprawdź, czy są dane
w buforze P (zajęte)pobierz dane z bufora
V (wolne)obrabiaj dane
Zastosowane semafory:
wolne - ilość wolnego miejsca
w buforze (e0 = n, gdzie n - pojemność bufora)
zajęte - ilość danych w buforze
(e0 = 0)
Problem:
Jeśli buforem jest zasób niepodzielny (np. dysk), należy synchronizować dostęp do niego za pomocą oddzielnego semafora.
Rozwiązanie 3:
Program producenta (cykliczny):
generuj dane
sprawdź wolne miejsce w buforze ( P (wolne) )
sprawdź, czy bufor jest dostępny ( P ( buf ) )
wstaw element do bufora ( V (zajęte) )
zwolnij bufor ( V ( buf ) )
Program konsumenta (cykliczny):
sprawdź, czy są dane w buforze ( P (zajęte) )
sprawdź, czy bufor jest dostępny ( P ( buf ) )
pobierz dane z bufora ( V (wolne) )
zwolnij bufor ( V ( buf ) )
obrabiaj dane
Zastosowane semafory:
buf - udostępnia bufor 1 procesowi (binarny, e0 = 1)
wolne - ilość wolnego miejsca w buforze (e0 = n, gdzie n - pojemność bufora)
zajęte - ilość danych w buforze
(e0 = 0)
W ostatnich dwóch rozwiązaniach wykorzystano mechanizm dostępu do bufora taki, że można dowolnie dodawać zarówno programy producentów, jak i konsumentów (nie mając założeń o kolejności dostępu do bufora).
W pierwszym przykładzie wykorzystano tzw. synchronizację przez zdarzenia. To znaczy, że proces 2 czeka, aż proces 1 dostarczy dane i wyśle sygnał o ich gotowości.
W pozostałych przypadkach zachodzą:
synchronizacja: producent składuje dane w buforze, jeśli jest wolne miejsce;
w przeciwnym przypadku celukomunikacja: konsument pobiera dane z bufora (jeżeli są), a następnie daje znać
o tym producentowi
Gospodarka zasobami, pojęcia wzajemnej blokady, obszarów zdrowych i chorych. Metody ochrony przed wzajemną blokadą.
Pojęcia:
Etap procesu - fragment, w którym potrzebne do realizacji procesu zasoby są stałe (np. w tym fragmencie proces będzie używał tylko drukarki i stacja dysków nie będzie mu potrzebna)
Gospodarka zasobami - polityka (sposób) przydziału zasobów procesom. Celem gospodarki zasobami jest:
- minimalizacja czasu realizacji procesów
- uniknięcie wzajemnej blokady (ang. deadlock)
Problemy zostaną omówione na przykładach.
Przykład 1 (minimalizacja czasu realizacji)
Kilka programów na jednym komputerze można wykonywać po kolei, ale następstwem takiego działania jest nieracjonalne wykorzystanie zasobów, np. podczas transmisji danych z RAMu na dysk koprocesor matematyczny nie jest potrzebny i mógłby wykonywać obliczenia dla innego programu. Logicznym jest dopuszczenie do współbieżnej realizacji programów. Prowadzi to do kilku równolegle realizowanych procesów korzystających w razie potrzeby z zasobów komputera. W przypadku, gdy jakiś proces będzie żądał dostępu do zasobu uprzednio przydzielonego innemu procesowi, żądający zostanie zatrzymany aż do chwili zwolnienia potrzebnego zasobu, a potem ponownie znajdzie się w stanie aktywnym.
Przykład 2 (wzajemna blokada)
Rozpatrzmy dwa programy P1 i P2, generujące procesy I1 i I2, do których realizacji potrzebne są zasoby Z1 i Z2. Obydwa zasoby są niepodzielne. Każdy z procesów dzieli się na 5 etapów, przy czym zapotrzebowanie na zasoby oznaczmy (Z1,Z2) np.: (0,1) - proces korzysta z zasobu Z2, a nie używa zasobu Z1.
Etapy procesu I1: (0,0),(0,1),(1,1),(1,0),(0,0)
Etapy procesu I2: (0,0),(1,0),(1,1),(0,1),(0,0)
Nie będę rysował wykresu stanów, myślę, że każdy z was jest w stanie sam sobie go narysować i zaznaczyć stany realizowalne i nierealizowalne.
Wymienię tylko stan niebezpieczny: 1. I1=(0,1) I2=(1,0)
Uogólniając:
Niech będzie dany zbiór programów:
P = {P1,P2,…,Pn}
i odpowiadający mu zbiór procesów:
I = {I1,I2,…In}
oraz zbiór klas zasobów systemu, w którym te procesy mają być realizowane:
Z = {Z1,Z2,…Zn}
Każda z klas zasobów składa się z określonej liczby elementów, np. w klasie Z1 jest x1 elementów.
Całkowity obszar systemu:
Przyjmujemy w dalszych rozważaniach, że wektor ten jest dany i niezmienny w czasie. Każdemu procesowi Ii przyporządkujemy wektor zasobów przydzielonych:
gdzie składowe aik określają ilość zasobów klasy k, przydzielonych procesowi Ii,
oraz wektor zasobów potrzebnych do zakończenia procesu Ii:
gdzie składowe bik określają ilość zasobów klasy k, potrzebnych do zakończenia procesu Ii.
Realizowalny stan systemu to taki stan, który spełnia poniższe warunki:
Bi <= X dla i ε [1,n]
Ai <= Bi dla i ε [1,n]
<= X lub R >= 0
gdzie R = X -
- wektor rezerwy.
Analizując stany:
Stan 1 - I1=(1,0), I2=(0,1)
Stan 2 - I1=(1,1), I2=(1,1)
Stan 3 - I1=(0,1), I2=(1,0)
Stwierdzamy, że stan 1 jest realizowalny, stan 2 jest nierealizowalny i stan 3 jest realizowalny.
Wprowadźmy pojęcie zdrowego ciągu procesów:
Niech będzie dany zbiór m procesów:
I1,I2,I3,…,Ix,…,Im
Uporządkujmy go według pewnej funkcji porządkującej S:
S(x) = k, gdzie x - indeks procesu,
k - miejsce kolejne procesu w uporządkowanym ciągu procesów
Przykładowo, mając dany ciąg uporządkowany: I5,I23,…,I3, wiemy, że uporządkowanie takie nastąpiło, ponieważ:
S(5) = 1, S(23) = 2,…, S(3) = m.
Niech procesy będą określone przez swoje stany, a więc proces Ii przez wektory Ai i Bi.
Jeżeli można znaleźć taką funkcję S porządkującą ciąg procesów, w wyniku której otrzymamy ciąg:
IS1, IS2,…, ISi, …, ISm
gdzie S1, S2, …, Si, …, Sm są wskaźnikami wynikającymi z funkcji S, że dla każdego i ε [1,m] zachodzi zależność:
Bi - Ai <= R +
to ciąg taki nazywamy CIĄGIEM ZDROWYM.
Jeżeli dany obszar jest realizowalny i można znaleźć dla niego ciąg zdrowy, to ten sam obszar jest OBSZAREM ZDROWYM. (obszar chory jest przeciwieństwem zdrowego)
Metody ochrony przed wzajemną blokadą
Metody dynamiczne
Przed przydziałem zasobu procesowi następuje kontrola, czy po przydziale system nie znajdzie się w obszarze niebezpiecznym, to znaczy, czy dla obszaru, do którego wchodzi, istnieje zdrowy ciąg procesów.
Polityka bankiera
Ze zbioru procesów wybiera się taki proces Ik, że:
Bk(t0) - Ak(t0) <= R(t0)
i przydziela mu się wszystkie potrzebne zasoby. Proces Ik kończy się i zwraca wszystkie zasoby, które posiadał, tj. Bk(t0), zatem rezerwa zwiększa się i wynosi:
R(t1) = R(t0) + Ak(t0)
następnie wybiera się taki proces Il, że:
B2(t1) - A2(t1) <= R(t0) + Ak(t0)
itd. Aż do zrealizowania ostatniego procesu.
Przydziały globalne
Realizuje się tylko tyle procesów, aby potrzebne im zasoby można było przydzielić z góry; po zakończeniu wszystkich realizuje się następną grupę procesów, itd.
Metoda klas uporządkowanych
Klasy zasobów porządkuje się w pewnej kolejności i przyjmuje zasadę, że nie przydziela się procesowi zasobu niższej klasy, jeżeli nie posiada lub poprzednio nie posiadał zasobów klasy wyższej.
Struktury B-drzew i zadanie o optymalnej strukturze drzewa.
Metoda drzew binarnych jest stosowana przede wszystkim wtedy, gdy przeszukiwany zbiór znajduje się całkowicie w pamięci operacyjnej. Gdy zbiór znajduje się w pamięci zewnętrznej zasadnicze znaczenie ma liczba transmisji z pam. Zewnętrznej do pam. Operacyjnej - każda taka operacja wymaga ~ 104 razy więcej czasu niż operacja porównania.
Przyjmijmy, że węzły drzewa są przechowywane w pamięci pomocniczej (np. dyskowej). Użycie drzewa binarnego dla, powiedzmy miliona obiektów wymaga średnio około log2106 =~ 20 kroków szukania. Ponieważ w każdym kroku wymaga się dostępu do dysku (=opóźnienie czasowe), to znacznie bardziej pożądana byłaby taka organizacja pamięci, która zmniejszałaby liczbę odwołań. Idealnym rozwiązaniem jest drzewo wielokierunkowe. Wraz z dostępem do pojedynczego obiektu w pam. Pomocniczej pobieramy bez dodatkowych kosztów cała grupę danych. Sugeruje to podzielenie drzewa na poddrzewa stanowiące jednostki o jednoczesnym dostępie. Te poddrzewa to strony.
W/w idea doprowadziła do koncepcji B-drzew wykorzystywanych do szukania rekordów w bazach danych.
Drzewo nazywamy B-drzewem klasy t(h,m), jeżeli jest ono drzewem pustym (h=0) lub spełnione są warunki:
Wszystkie drogi prowadzące z korzenia drzewa do liści są jednakowej długości = h, liczbę h nazywamy wysokością drzewa.
Każdy wierzchołek, z wyjątkiem korzenia i liści, ma co najmniej m+1 potomków, korzeń jest albo liściem albo ma co najmniej 2 potomków.
Każdy wierzchołek ma co najwyżej 2m+1 potomków.
Z maksymalnym wypełnieniem B-drzewa klasy t(h,m) mamy do czynienia wtedy, gdy w każdym jego wierzchołku zapamiętanych jest 2m elementów, a z minimalnym - gdy w wierzchołkach pośrednich i w liściach zapamiętanych jest m elementów, a w korzeniu zapamiętany jest 1 element. Przy tych 2 skrajnych możliwościach wypełnienia, przy ustalonej liczbie N elementów indeksu, otrzymujemy następujące ograniczenie liczby h poziomów w indeksie zorganizowanym według struktury B-drzewa klasy t(h,m):
Algorytm wyszukiwania elementu w B-drzewie:
Pod p podstaw identyfikator strony korzenia
Czy p jest wartościa niezerową?
- Tak - przejdź do kroku 3
- Nie - koniec algorytmu, brak poszukiwanego elementu.
3. Sprowadź stronę wskazywaną przez p
4. Czy x jest mniejsze od najmniejszego klucza na stronie p?
- Tak - pod p podstaw skrajnie lewy wskaźnik strony potomka, przejdź do kroku 2
- Nie - przejdź do kroku 5
5. Czy na stronie p znajduje się klucz o wartości x?
- Tak - koniec algorytmu, znaleziono szukany element
- Nie - przejdź do kroku 6
6. Czy na stronie p znajduje się klucz o wartości > x?
- Tak - pod p podstaw najbardziej prawą stronę potomka zawierającego wartości kluczy mniejsze bądź równe najmniejszemu kluczowi o wartości większej od x z aktualnej strony i przejdź do kroku 2
- Nie - pod p podstaw skrajnie prawą stronę potomka, przejdź do kroku 2
Złożoność algorytmu rzędu O(logmN).
Dołączanie elementu do B-drzewa
Każde dołączanie musi być poprzedzone algorytmem wyszukiwania i ma sens gdy tamten zakończył się niepomyślnie. Wówczas znana jest strona liścia, do której ma być dołączona dany element. Dołączenie może być bezkolizyjne lub spowodować przepełnienie strony (gdy na stronie zapamiętanych jest już 2m elementów). Gdy bezkolizyjnie to dołączanie tak, by zachować rosnące uporządkowanie wartości klucza na stronie, w drugim przypadku stosuje się metodę kompensacji lub podziału.
Metoda kompensacji - stosujemy wtedy, gdy jedna ze stron sąsiadujących ze stroną przepełnioną zawiera mniej niż 2m elementów. Wtedy porządkujemy elementy z obu stron z uwzględnieniem elementu dołączanego oraz elementu ojca (tj. tego elementu, dla którego wskaźniki znajdujące się po jego obu stronach wskazują strony uczestniczące w kompensacji). Element „środkowy” uporządkowanego ciągu wstawiamy w miejsce elementu ojca. Wszystkie elementy mniejsze od środkowego na jedną z kompensowanych stron, a wszystkie większe na drugą (zachowując uporządkowanie na stronie).
Metoda podziału strony - porządkujemy rosnąco wszystkie elementy rozważanej strony (wraz z dołączanym) otrzymując ciąg 2m+1 elementów. Element środkowy tego ciągu dodajemy do strony ojca, element większe tworzą jedną stronę a elementy większe drugą stronę potomną. Gdy po podziale strona ojca zostanie przepełniona to dzielimy ją tak samo i tak aż do korzenia. Ewentualny podział korzenia spowoduje powstanie dwóch nowych stron i powiększenie wysokości drzewa.
By zachować wysokość drzewa najpierw stosujemy metodę kompensacji jeżeli się da.
Usuwanie elementu z B-drzewa
Ma sens gdy wcześniejsze przeszukiwanie zakończyło się pomyślnie. Wówczas zmienna s wskazuje stronę z elementem do usunięcia. Jeżeli strona ta to liść to element jest usuwany. Może to jednak spowodować niedomiar na stronie (liczba elementów na stronie spadnie poniżej m). Jeżeli ta strona to liść to w miejsce usuniętego elementu wstawiany jest element Emin o najmniejszej wartości klucza z poddrzewa wskazywanego przez wskaźnik p, stojący bezpośrednio po prawej stronie usuwanego elementu. Usunięcie elementu Emin ze strony liścia może spowodować wystąpienie niedomiaru.
Metody usuwania niedomiaru
Łączenie - gdy na stronie s wystąpił niedomiar tzn. ilość elementów j < m , a jednocześnie na stronie sąsiedniej s1 jest k elementów i j+k<2m wtedy łączymy strony s i s1. Elementy strony s1 przenoszoną są na stronę s z zachowaniem uporządkowania. Ze strony rodzica usuwamy element rozdzielający strony s i s1 (i także przenosimy do łączonej strony). Wyłączenie elementu ze strony rodzica może spowodować tam niedomiar. Likwidacja tego niedomiaru może z kolei spowodować niedomiar na stronie jej ojca itd. - w skrajnym przypadku aż do korzenia B-drzewa. Łączenie jest jedyną metodą zmniejszenia wysokości B-drzewa.
Kompensacja - stosowana, gdy wśród sąsiadów strony s nie ma kandydata do połączenia. Analogicznie do kompensacji przy dołączaniu z tym, że obecnie nie ma oczywiście potrzeby uwzględniania dodatkowego (dołączanego) elementu.
Funkcje mieszające i oparte o nie struktury baz danych, problem kolizji i metody ich rozładowywania.
Funkcja mieszająca jest funkcją nadającą numer indeksowy elementowi bazy danych na podstawie klucza w niej zawartego. Oznaczana jest jako h (K) => hash (Key).
Stosowanie jest ograniczone do baz, w których rzadko występuje zmiana klucza, gdyż za każdym razem należałoby obliczać na nowo wartość funkcji.
Możliwe jest zastosowanie funkcji mieszającej tylko, jeśli baza skonstruowana jest na strukturze indeksowanej bezpośrednio (np. tablica - wektor, czy deque z C++).
Najczęściej stosuje się jedynie tablicę odnośników do odpowiednich rekordów (nie wstawia się do tablicy wg funkcji mieszającej całych rekordów, a jedynie wskaźniki do nich).
Prawidłowo skonstruowana funkcja mieszająca powinna znajdować każdy element tablicy z jednakowym prawdopodobieństwem.
Adresowanie za pomocą funkcji mieszającej:
bezpośrednie
Np. gdy klucz składa się z 2 liter alfabetu (26 znaków), dostajemy maksymalną ilość kombinacji równą 252 + 25 = 650. Obliczenie klucza polega na np. zamianie liter na odpowiadające im liczby 0 - 25
i obliczeniu adresu wg wzoru L1 + 25 * L2.
problem:
bardzo pamięciochłonna metoda, jeśli wiemy, że max. ilość elementów jest mniejsza od max. ilości kluczy
dzielenie modulo
Mając maksymalnie np. 60 kluczy z poprzedniego przykładu tworzymy tablicę o wielkości minimalnie większej od tej wartości taką, aby ilość elementów była liczbą pierwszą (czyli w tym przypadku 61).
Wstawiając element obliczamy jego adres z punktu 1 i dzielimy modulo przez wielkość tablicy.
wada:
nie można zapamiętać więcej rekordów, niż wynosi pojemność tablicy (zwykle mniejsza od maksymalnej ilości kluczy)
problem:
występowanie kolizji
Kolizja:
Przypadek, gdy 2 lub więcej kluczy po obliczeniu adresu `trafia' w ten sam element tablicy.
Klucze takie nazywamy synonimami.
Metody przezwyciężania kolizji:
Metoda listy podwieszanej (nadmiarowej).
Polega na dołączaniu kolejnych `kolizyjnych' elementów w formie listy.
Przykład:
Klucze: 67, 128, 311 przy dzieleniu modulo dają w tablicy 61-elementowej ten sam adres `6' (są synonimami):
0 |
. |
1 |
. |
2 |
. |
3 |
. |
4 |
. |
5 |
. |
6 |
67 => 128 => 311 |
7 |
. |
8 |
. |
Wady:
duże spowolnienie wyszukiwania (skutek przeszukiwania listy)
duże rozrzucenie danych po powierzchni nośnika (skutek stosowania listy - dopisywanie elementu wyklucza możliwość zastosowania ciągłego obszaru pamięci)
marnotrawstwo miejsca (jeśli w tablicy 61-pozycyjnej umieścimy 61 elementów, ale będą występowały kolizje, to niektóre zajmujące miejsce elementy tablicy pozostaną puste, a elementy kolizyjne będą na nośniku w postaci nadmiaru)
Metoda funkcji zwalczającej kolizje.
Polega na wyznaczeniu drugiej funkcji (oznaczanej zwykle jako g (i) ), której argumentem jest numer kolejnej próby wyznaczenia bezkolizyjnego miejsca w tablicy przy wstawianiu elementu
(lub poszukiwaniu go).
Np. elementy z poprzedniego punktu:
Wstawienie elementu 128 => kolizja => dodaj do adresu
wartość z funkcji zwalczającej kolizje
Algorytm postępowania:
Weź klucz rekordu.
Oblicz wartość klucza: h (K) + g (i).
Jeśli pozycja jest wolna - wstaw element.
W przeciwnym wypadku: i++; przejdź do p.2
Wady:
wydłużenie czasu poszukiwania miejsca do wstawienia i wyszukiwania (niewielkie jednak w porównaniu z listą nadmiarową) => minimalizację tego czasu osiągamy zwiększając rozmiar tablicy (zwykle stosowane 2N,
gdzie N - ilość elementów)
Zalety:
możliwość stworzenia ciągłego obszaru tablicy
niezmienna wielkość zajmowanego obszaru na nośniku
Zapis algorytmu w postaci kanonicznej, twierdzenie o realizowalności algorytmu, realizacja szeregowa
i równoległa, definicja przyspieszenia, model komputera sterowanego przepływem argumentów i przykłady realizacji algorytmów w takich systemach
Algorytm - ciąg uporządkowanych operacji w celu osiągnięcia określonego wyniku (definicja początkowa) - niektóre operacje mogą być wykonywane współbieżnie. Wg von Neumana program sprowadza się do ciągu operacji.
Np:
Y1 = 01(a1); y2=02(y1,a2); y3=03(y2,a3); y4=o4(y3,a4) - jest to klasyczny algorytm sekwencyjny O - oznacza operacje na Y - to są zmienne a A to dane.
Baza danych
argumentów JAL O1, Klasyczny sposów realizowania
O2 argumentów
O3
O1 O2 O3 O4
a1
a2
a3
y1
y2
y3
y4
y1=O1(a1); y2=02(a2,y1); y2=O3(a3,y1); y4=O4(y3,y4) - należy zaukurważyć, że operacje o2 i o3 mogą być wykonywane równokurwalegle
Komputery sterowane przesyłem danych - dostępność argumentów steruje przesyłem danych ; decyduje o przeprowadzeniu operacji
Kanoniczna postać algorytmu:
Yi=Oi(Dj,Xk) i=1..n j=1..m k=1..p
O - operacja - instrukcja uogólniona
D - dane
X zmienne robocze
Y może to być wektor ale chuj go wie naprawdę co to jest ..
Sposób zapisu algorytmu decyduje o możliwości zrównoleglenia.
Na przykład ... dodawanie liczb może być:
y1= x1+x2;y2=x3+x4;y3=y1+y2 - to sie da zrównoleglić
y=x1+x2+x3+x4 - nie ma jak ...
y1 = x1+x2; y2=y1+x3; y3 = y2+x4 - to sie tez za bardzo nie da zrównoleglić
da sie z tego zrobić macierz nxn w wiersze i kolumny są ponumerowane od y1 do yn. Jedynki znajdują się w sytuacji gdy na przykład y2=o(y3,xilestam). Warunkiem wystarczającym realizowalności algorytmu żeby jedynki znajdowały się powyżej przekątnej głównej
macierz A:
0 |
1 |
1 |
0 |
Y1=o1(a1,y2); y2=o2(a2,y1) - tego algorytmu w ogóle się nie da zrealizować.
Wk
Ar macierz zredukowana przez funkcje redukującą. Ar = (fr (a)) ^sufit(ln[2](n)) jeśli ar ma przekątną główną złożoną z samych zer to algorytm jest realizowalny
Przyślieszenie p = l/lu gdzie l wszystkie operacje a lu zrównoleglone operacje
Statystyczny model komputera jako stanowiska obsługi (M/M/1) i jego analiza. Model sieci komputerowej jako sieci stanowisk M/M/1.
Model stanowiska obsługi (M/M/1)
Na powyższy model składają się:
źródło zgłoszeń - emituje zgłoszenia i przesyła je do wykonania systemowi. Wyróżnia się dwa rodzaje źródeł:
źródło n wymiarowe - zawiera ściśle określoną liczbę zadań - po wyemitowaniu
n zgłoszeń źródło nie generuje kolejnych (prawdopodobieństwo wygenerowania kolejnego zgłoszenia wynosi 0)źródło nieskończenie wymiarowe - liczba wygenerowanych zgłoszeń nie zmienia prawdopodobieństwa pojawienia się kolejnego zgłoszenia (najczęściej spotykane)
kolejka - uporządkowany ciąg zgłoszeń czekających na obsługę. Z każda kolejką związany jest regulamin, który decyduje o kolejności wyboru zgłoszeń do obsługi
regulamin naturalny - o kolejności obsługi decyduje kolejność przybycia
regulamin priorytetowy - kolejność obsługi zależy od priorytetu zgłoszenia
stanowisko obsługi - charakteryzowane jest zmienną losową określającą czas obsługi jednego klienta.
Proces Poissona
Jest to proces losowy spełniający dwa założenia:
liczba zgłoszeń w danej jednostce czasu nie zależy od liczby zgłoszeń jakie pojawiły się przed obserwacją
dla krótkiego odcinka czasu dt prawdopodobieństwo zajścia zdarzenia wynosi λdt
System M/M/1 zbudowany jest z nieskończonego źródła, kolejki o nieograniczonej pojemności i regulaminie naturalnym oraz pojedynczego stanowiska o wykładniczym czasie obsługi.
Podstawowe równania:
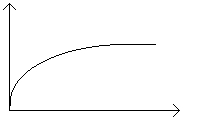
A(x) = 1 - e-λx - dystrybuanta zmiennej losowej opisującej pojawianie się zgłoszeń
(a dokładniej: odstępy czasu między zgłoszeniami)
B(x) = 1 - e-μx - dystrybuanta zmiennej losowej opisującej czas obsługi zgłoszeń
λ - liczba zgłoszeń emitowanych przez źródło
μ - średnia liczba zgłoszeń, które mogą być obsłużone w jednostce
Do analizy dodatkowo oznaczamy:
n - łączna liczba zgłoszeń w systemie
k - długość kolejki (liczba zgłoszeń w kolejce)
s - liczba zgłoszeń na stanowisku obsługi (s=1 stanowisko zajęte)
Pn(t) - prawdopodobieństwo, że w chwili t w systemie znajduje się n zgłoszeń
Pn(t + dt) - prawdopodobieństwo, że w chwili t+dt w systemie znajduje się n zgłoszeń
Prawdopodobieństwo P0(t+dt), że system jest pusty w chwili t+dt może mieć miejsce
w dwóch przypadkach:
w chwili t było jedno zgłoszenie i zostało obsłużone w czasie dt i jednocześnie nie nadeszło zgłoszenie
Pa = P1(t)(μdt)(1 - λdt)
gdy w chwili t system był pusty i w przedziale dt nie przybyło ze źródła żadne zgłoszenie:
Pb = P0(t)(1 - λdt)
(1 - μdt) - żadne zgłoszenie nie opuściło
(1 - λdt) - żadne zgłoszenie nie nadeszło
Obliczanie prawdopodobieństwa jest sumą prawdopodobieństw obu przypadków:
P0(t+dt) = Pa + Pb = P0(t)(1 - λdt) + P1(t)(μdt)(1 - λdt)
Przekształcając powyższe równanie otrzymujemy postać:
[P0(t+dt) - P1(t)]/dt = P1(t)μ - P0(t) λ
dla P0(t+dt)/dt = 0 otrzymujemy P1 = ρP0 , gdzie
(intensywność kanału)
Analogicznie dla systemu z n zgłoszeniami, prawdopodobieństwa przedstawiają się następująco
Pn(t+dt) = Pn-1(t)( λdt)(1 - μdt) + Pn(t)[(1 - λdt)(1 - μdt) + λdt.μdt] + Pn+1(t)(μdt)(1 - λdt)
Po obliczeniach otrzymujemy:
P1 = ρP0
P2 = ρP1= P1 = ρ2P0
ogólnie : Pn = ρnP0
Własności:
średnia liczba zgłoszeń obecnych w systemie w stanie ustalonym
średnia liczba zgłoszeń w kolejce
średnia liczba zgłoszeń przebywających na stanowisku obsługi
E(s)=E(n) - E(k) = ρ
Model sieci komputerowej jako sieci stanowisk (M/M/1)
Gęstość rozkładu odstępów czasu miedzy opuszczeniami Stanowiska Obsługi (pochodna dystrybuanty) wynosi:
po obliczeniach (te wyprowadzenia są po prostu okropne i miejmy nadzieję, że nie będą ich wymagali) :
d(x) = λe-λx=a(x)
Siecią komputerową nazywamy system utworzony z węzłów (komputerów) i krawędzi (łączy transmisyjnych, linii przesyłu informacji). Wyróżniamy:
sieci otwarte - z co najmniej jednym wejściem i jednym wyprowadzeniem
sieci zamknięte - bez wyprowadzeń, bez zmiany krążących programów. W sieciach zamkniętych możemy zmieniać dane, na których operują programy oraz możemy odczytywać wyniki ich pracy, nie możemy natomiast zmieniać samych programów.
Sieci otwarte
λ1 = λ + λ2 (λ2 - dla zgł. Zawracanego)
Stan stacjonarny występuje wtedy gdy ρ<1
Twierdzenie Little'a
E(k) = λE(w), gdzie E(w) - średni czas oczekiwania w kolejce
E(τ) - średni pobyt w systemie
Sieci zamknięte
Zgłoszenia:
1. P20 (2,0) dwa zgłoszenia na stanowisku I (1 w kolejce), brak zgłoszeń na II
2. P11 (1,1) kolejki są puste, na każdym stanowisku jedno zgłoszenie
3. P02 (0,2) dwa zgłoszenia na stanowisku II (1 w kolejce), brak zgłoszeń na I
P20 + P11 + P02 = 1
Sieci otwarte. Metody obliczania rozkładu obciążeń w sieci.
Sieci otwarte - część zgłoszeń opuszcza sieć stanowisk
Twierdzenie Little'a
E(k) - średnia długość kolejki
λ - średni czas oczekiwania w kolejce
E(τ) = E(w) + E(γ)
E(τ) - średni pobyt w systemie
Przykład:
Obliczyć długość kolejek przed I i II kompputerem w nastepującej sieci:
r11
r 12 r 20
λ0
r 21
λ0 = 0.4
μ1 = 4
μ2 = 1
r11 = 0.4
r12 = 0.6
r20 = 0.5
r21 = 0.5
Gdyby ρ1 lub ρ2 były większe do 1 , to dalsze obliczenia nie miałyby sensu.
Sieci zamknięte. Metody obliczania rozkładu obciążeń w sieci.
Sieci zamknięte - krąży stała liczba zagłoszeń pomiędzy stanowiskami.
Zgłoszenia:
( 2, 0 ) - 2 zgłoszenia z części I, 0 zgłoszeń z części II
( 1, 1 ) - kolejki są puste
( 0, 2 ) - 0 zgłoszeń z części I, 2 zgłoszenia z części II
Równiania systemu:
Np. dla P20 w chwili t + dt
Graf przejść pomiędzy poszczególnymi stami:
μ1 μ1
μ2 μ2
dla węzła ( 2, 0 )
μ2 P11 = μ1 P20
dla węzła ( 0, 2)
μ1 P11 = μ2 P02
Informatyka a genetyka, nanosystemy informatyki,
Kwantowe systemy informatyki
Podstawą działania komputera kwantowego jest zjawisko jądrowego rezonansu.
Jądrowy rezonanas magnetyczny opisuje zachowanie się jąder atomów związanych z pochłanianiem energii w sytuacji gdy atomy znajduja się w polu magnetycznym.
Nieparzysta liczba protonów bądź neutronów.
bez pola magnetycznego z polem magnetycznym
Bo
ustawiają się równoleglr lub antyrównolegle
do kierunku działania pola
Wektor momentu pędu wykonuje ruch obrotowy - Precesja
Częstotliwość pędu zależy od ind. magnetycznej i jest oa wzorem Larusa fo =
-Bo/2
- stała żyromagnetyczna
Większość jąder ustawia się równolegle występuje namagnesowanie gdy dostają energię
Uukład się wzbudza czyli jądra odchylają się o pewien kąt alfa.
Składowe
do działania pola magnetycznego muszą być
równolegle
prostopadle
Powrót do stanu ustalonego nastepuje po spirali
(KOMENTAŻ! -miało być ładniej ale mi nie wyszło)
Echo
Przydaje się do badania struktury wewnętrzne
impuls
echo(pojawia się po sygnale po pewnym czasie)
Zjawisko to wykorzystuje się do budowy komputera kwantowego
Idea komnputera kwantowego rurka z cieczą CHCL3
gubit
bit kwantowy
magnes
Proces obl - wprowadzenie serii odpowiednich impulsów i odczytanie wyników przez echo
CHCL3
H C H C
SPINY ZGODNE SPINY PRZECIWNE
szybko
po wprowadzeniu impulsu zmiennego pola magnetycznego
po ponownym podaniu impulsu
USTAWIŁY SIĘ PRZECIWNIE WRÓCIŁY DO STANU POCZATKOWEGO
a - oznacza spin atomu wodoru = 1 gdy równolegle , 0 gdy antyrównolegle
b - oznacza spin atomu węgla = 1 gdy równolegle , 0 gdy antyrównolegle
b1 = b sumamod a
uzyskane XOR (bramka negacji)
Sprawdzenie
a, b b1 b2 a
0 0 0 0
0 1 1 0
1 0 1 0
1 1 0 1
b b1= b sumamod a b2 = (b smod a) smod a = b
PORÓWNANIE
W komputerze kwantowym do zrealizowania bramki operacje rozmieszczone są w czasie i realizowane jako kolejne impulsy o odpowiednim czasie trwania.
W komputerze klasycznym bramki rozmieszczone w przestrzeni( połączenia między nimi).
Bramka Toffoli - trójbitowa
a
b
c
Realizowana funkcja: c sumamod(a
b)
Podstawy informatyki - egzamin ustny 2002
Źródło zgłoszeń
kolejka
∞ stanowisko
obsługi
Rozkład o ch-terze wykładniczym
t t+dt
P0(t)
(1 - λdt)
P0(t+dt)
P1(t) μdt(1 - λdt)
t t+dt
Pn-1(t)
λdt(1 - μdt)
(1 - λdt)(1 - μdt)
Pn(t) λdt.μdt Pn(t+dt)
Pn+1(t) μdt(1 - λdt)
D(x)
∞
A(x) = 1 - e-λx B(x) = 1 - e-μx
(czas dostępu)
λ2=r1λ1 r1
λ λ1 r r2
∞ μ
μ1
μ2
PRODUCENT
KONSUMENT
czekaj, aż konsument będzie gotowy
sygnalizuj, że konsument jest gotowy
PRODUCENT
KONSUMENT
bufor |
|||||
|
|
|
|
|
|
Czy jest miejsce ?
Tak / Nie
Czy są dane ?
Tak / Nie
1
2
∞
μ2
μ1
2, 0
0, 2
1, 1
Wyszukiwarka
Podobne podstrony:
(33) Leki stosowane w niedokrwistościach megaloblastycznych oraz aplastycznych
33 Przebieg i regulacja procesu translacji
Image Processing with Matlab 33
6 Wielki kryzys 29 33 NSL
33 Postepowanie administracyjne
15 Wyposażenie Auta 1 33
od 33 do 46
33 sobota
MSR 33 KOREFERAT Zysk przypadający na jedną akcje
33 Rama zamknięta ze ściągiem
Eaton VP 33 76 Ball Guide Unit Drawing
02 33 o systemie oceny zgodności
jcic 33
Marthas Vineyard DA 1980 33(2)2 6
33
33 - Kod ramki(1)(1), RAMKI NA CHOMIKA, Gotowe kody do średnich ramek
31 33 doc
2010 02 05 09;33;36
więcej podobnych podstron