Podstawy podejmowania decyzji i inЕјynierii wiedzy
Architektura systemu ekspertowego: definicje systemu ekspertowego, metody reprezentacji wiedzy, metody pozyskiwania wiedzy, metody wnioskowania w systemach ekspertowych, elementy badania poprawnoЕ›ci bazy wiedzy.
System ekspertowy to:
program komputerowy posiadajД…cy wiadomoЕ›ci w formie bazy wiedzy i przeprowadzajД…cy wnioskowanie z moЕјliwoЕ›ciД… rozwiД…zywania problemГіw i doradztwa.
program komputerowy, ktГіry prezentuje sobД…, w pewnej Е›ciЕ›le okreЕ›lonej dziedzinie, stopieЕ„ doЕ›wiadczenia w rozwiД…zywaniu problemГіw porГіwnywalny ze stopniem doЕ›wiadczenia i wiedzy eksperta
CechД… charakterystycznД… systemu eksperckiego jest wyrГіЕјnienie reprezentacji wiedzy o dziedzinie, ktГіrej dotyczy system oraz mechanizmu rozumowania na podstawie zasobГіw wiedzy z tej dziedziny. System ekspercki w swej strukturze zawiera takie elementy, ktГіre umoЕјliwiajД… jego dziaЕ‚anie w sposГіb porГіwnywalny z najlepszymi specjalistami tzn. ma zdolnoЕ›Д‡:
Zadawania pytaЕ„ w celu uzyskania odpowiednich informacji od uЕјytkownika
WyjaЕ›niania sposobu rozumowania na ЕјД…danie uЕјytkownika
Uzasadniania otrzymanych konkluzji
Modyfikowania sposobu dziaЕ‚aЕ„
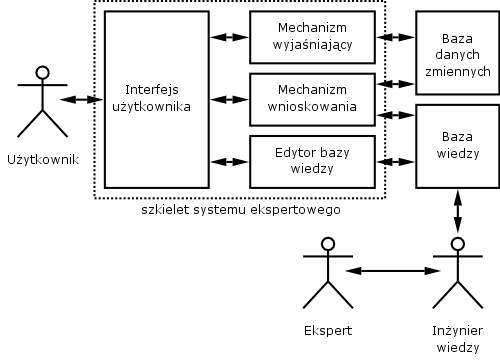
W systemie eksperckim wyrГіЕјnia siД™ nastД™pujД…ce elementy gЕ‚Гіwne :
elementy programu wykonywane podczas wspГіЕ‚dziaЕ‚ania uЕјytkownika z systemem eksperckim
procedury sterowania dialogiem pomiД™dzy uЕјytkownikiem systemu a systemem eksperckim
procedury wnioskowania
procedury objaЕ›niania
procedury aktualizacji bazy wiedzy
elementy nie wykonywane stanowiД…ce odpowiednie bazy a wiД™c
baza wiedzy
baza danych staЕ‚ych
baza danych zmiennych
W skЕ‚ad systemu eksperckiego wchodzД…:
baza wiedzy - zawiera reprezentację wiedzy z danej dziedziny niezbędnej w procesie rozwiązywania problemów decyzyjnym. Reprezentacja wiedzy w bazie wiedzy może mieć charakter deklaratywny (reguły, fakty) lub proceduralny (procedury, funkcje)
moduЕ‚ wnioskowania - zadaniem moduЕ‚y jest przeszukiwanie elementГіw bazy wiedzy, ustalenie kolejnoЕ›ci ich analizowania i sprawdzenie warunkГіw ich stosowalnoЕ›ci
baza danych staЕ‚ych i baza danych zmiennych - stanowiД… zbiory danych (stwierdzeЕ„) zorganizowanych wedЕ‚ug ustalonego sposobu. Baza danych zmiennych zawiera odpowiedzi uЕјytkownika oraz wnioski poЕ›rednie wyznaczone przez ukЕ‚ad wnioskowania a takЕјe wykaz dziaЕ‚aЕ„ zawieszonych ze wzglД™du na brak okreЕ›lonych stwierdzeЕ„ w bazie
interfejs uЕјytkownika - umoЕјliwia prowadzenie dialogu uЕјytkownika z systemem. Interfejs uЕјytkownika jest czД™sto dzielony na interfejs wejЕ›ciowy i wyjЕ›ciowy
moduЕ‚ pozyskiwania wiedzy - umoЕјliwia pozyskiwanie i gromadzenie wiedzy w celu zwiД™kszenia efektywnoЕ›ci systemu
moduЕ‚ objaЕ›niania - uzasadnia decyzje podejmowane przez moduЕ‚ wnioskowania systemu eksperckiego poprzez przedstawienie toku rozumowania
METODY POZYSKIWANIA WIEDZY:
bezpoЕ›rednie zapisywanie wiedzy tzn. uczenie na pamiД™Д‡. Metoda ta nie wymaga Ејadnego dziaЕ‚ania typu wnioskowanie lub transformowanie wiedzy od uczД…cego siД™ systemu
pozyskiwanie wiedzy na podstawie instrukcji. Metoda ta wymaga udziaЕ‚u nauczyciela w procesie pozyskiwania wiedzy i polega na wykorzystaniu ЕєrГіdeЕ‚ wiedzy wskazanych przez nauczyciela oraz przeksztaЕ‚ceniu wiedzy do postaci akceptowalnej przez system
pozyskiwanie wiedzy na podstawie analogii. Metoda ta polega na przeksztaЕ‚ceniu istniejД…cej wiedzy w bazie wiedzy w celu umoЕјliwienie opisu faktГіw podobnych do faktu opisanego uprzednio
pozyskiwanie wiedzy na podstawie przykładów. Jest to szczególny przypadek uczenia indukcyjnego. Polega na generowaniu ogólnego opisu pojęć na podstawie zbioru przykładów oraz kontrprzykładów obiektów reprezentujących te pojęcia. Przykłady mogą być określone przez eksperta na podstawie wcześniej utworzonych baz danych
pozyskiwanie wiedzy na podstawie odkrywania i obserwacji. Metoda ta jest czД™sto nazywana uczeniem bez nauczyciela i stanowi ogГіlny przypadek uczenia indukcyjnego ktГіry wymaga zwiД™kszonego udziaЕ‚u uczД…cego w procesie uczenia.
METODY REPREZENTACJI WIEDZY - to metody zapisania pozyskanej wiedzy w maszynach cyfrowych, w sposГіb najbliЕјszy sposobowi rozumowania czЕ‚owieka. P
powinna umożliwiać prosty, kompletny (wyczerpujący), zwięzły, zrozumiały i wyraźny zapis wiedzy.
metody bazujД…ce na bezpoЕ›rednim zastosowaniu logiki takie jak: rachunek zadaЕ„, rachunek predykatГіw
metody wykorzystujД…ce zapis stwierdzeЕ„
metody bazujД…ce na sieciach semantycznych
metody wykorzystujД…ce systemy reguЕ‚owe i zapis reguЕ‚
ramy
tabele decyzyjne
drzewa decyzyjne
metody przybliЕјonej reprezentacji wiedzy.
PodziaЕ‚ reprezentacji wiedzy ze wzglД™du na techniki zapisu wiedzy :
reprezentacja proceduralna - polega na okreЕ›leniu zbioru procedur ktГіrych dziaЕ‚anie reprezentuje wiedzД™ o dziedzinie
reprezentacja deklaratywna - zbiГіr specyficznych dla danej dziedziny faktГіw stwierdzeЕ„ i reguЕ‚(wykЕ‚ady PiЕ‚ota)
Wnioskowanie - proces, w ktГіrym na podstawie zadaЕ„ uznanych za prawdziwe dochodzi siД™ do nowego zdanie dotД…d nieuznanego (konkluzji).
METODY WNIOSKOWANIA
wnioskowanie logiczne
dedukcja
abdukcja
indukcja
wnioskowanie na bazie niespГіjnoЕ›ci
wnioskowanie nie monotoniczne
wnioskowanie pochodne od logiki
wstecz
wprzГіd
mieszane
algorytmy dopasowania wzorca
metody szukania
wnioskowanie przez analogiД™
metody uczenia parametrycznego i strukturalnego
Ze wzglД™du na metodД™ prowadzenia procesu wnioskowania systemy ekspertowe dzieli siД™ na:
z logikД… dwuwartoЕ›ciowД… (Boole'a),
z logikД… wielowartoЕ›ciowД…,
zlogikД… rozmytД….
В Ze wzglД™du na rodzaj przetwarzanej informacji systemy ekspertowe dzielД… siД™ na dwie grupy:
systemy z wiedzД… pewnД…, czyli zdeterminowanД…,
systemy z wiedzД… niepewnД…, w przetwarzaniu, ktГіrej wykorzystuje siД™ przede wszystkim aparat probabilistyczny.
BADANIA POPRAWNOЕљCI BAZY WIEDZY
SpГіjnoЕ›Д‡ - wykrywanie reguЕ‚ zbД™dnych, sprzecznych, pochЕ‚aniajД…cych, ze sprzecznym warunkiem oraz zapД™tlonych, kompletnoЕ›Д‡ bazy reguЕ‚ - poszukiwanie reguЕ‚ brakujД…cych.
SpГіjnoЕ›Д‡ reguЕ‚:
SprzecznoЕ›Д‡: dwie reguЕ‚y sД… sprzeczne, jeЕ›li ich czД™Е›ci warunkowe sД… rГіwnoczeЕ›nie speЕ‚nione lub nie speЕ‚nione we wszystkich moЕјliwych przypadkach oraz ich konkluzje sД… rГіЕјne. PrzykЕ‚ad: (a,L) ^ (c, 3)=>(d,H), (a,L) ^ (c, 3) =>(d,L)
ReguЕ‚y pochЕ‚aniajД…ce - jedna reguЕ‚a jest pochЕ‚aniana wГіwczas, gdy czД™Е›Д‡ warunkowa pierwszej reguЕ‚y jest speЕ‚niona, jeЕ›li jest speЕ‚niona czД™Е›Д‡ warunkowa drugiej reguЕ‚y i konkluzje obu reguЕ‚ sД… identyczne. PrzykЕ‚ad: (a,L) ^ (c, 3)=>(d,H), (c,3)=>(d,H)
Niepotrzebne warunki: dwie reguЕ‚y majД… niepotrzebne warynki, jeЕ›li obie sД… pochЕ‚aniane przez trzeciД… reguЕ‚Д™. PrzykЕ‚ad: (a,L)^(b,D)^(c,5)=>(d,H), (a,R)^(b,D)^(c,5)=>(d,H).
ZapД™tlenie reguЕ‚: Zestaw reguЕ‚ tworzy pД™tlД™ jeЕ›li zapД™tlenie tych reguЕ‚ jest cykliczne. PrzykЕ‚ad: (a,L)^(c,5)=>(d,H), (d,H)=>(f,2), (f,2)^(g,4)=>(c,5)
Wielokrotne odwoЕ‚ywanie do jednego atrybutu: WystД™puje wtedy, gdy w czД™Е›ci warunkowej sД… czЕ‚ony zawierajД…ce ten sam atrybut. PrzykЕ‚ad: (a,L)^(a,R)=>(d,H)
Teoria zbiorГіw rozmytych - definicje zbioru, liczby i przykЕ‚ady operacji, przykЕ‚ad wnioskowania rozmytego.
Teoria zbiorów rozmytych jest uogólnieniem klasycznej teorii zbiorów. Teoria klasyczna mówi ze element należy bądź nie należy do zbioru. Czyli funkcja przynależności według klasycznej teorii zbiorów może przyjmować tylko wartość 0 lub 1. W teorii zbiorów rozmytych element może częściowo należeć do jakiegoś zbioru a przynależność tę można wyrazić z pomocą liczby rzeczywistej z zakresu 0 do 1Tojęcie ZBIORÓW ROZMYTYCH jako uogólnienie zbiorów zwykłych (nie rozmytych) zostało wprowadzone przez L. Zadehaw w 1965r. Tradycyjny sposób reprezentowania elementu x zbioru A odbywa się za pośrednictwem funkcji charakterystycznej μ(x) równej jeden, gdy element należy do zbioru A lub zero gdy element nie należy do tego zbioru. W systemach rozmytych element może należeć do każdego zbioru częściowo. Stopień przynależności do zbioru A stanowiący uogólnienie funkcji charakterystycznej jest zwany funkcją przynależności μ(x), przy czym μ(x) ∈ [0, 1]
Operacje na liczbach rozmytych
WprowadЕєmy definicjД™ liczby rozmytej (Zadeh 1965).
Definicja. LiczbД… rozmytД… A nazywamy zbiГіr rozmyty okreЕ›lony na zbiorze liczb rzeczywistych R co zapisujemy:
A вЉ† R., Ој: R в†’ [0,1]
Podstawowe operacje na liczbach rozmytych można zdefiniować stosując zasadę rozszerzania (Zadeh 1965):
Definicja. Niech dana bД™dzie pewna operacja dwuargumentowa na
liczbach rzeczywistych:
* : R x R в†’ R
Ponadto, niech A i B będą liczbami rozmytymi A, B ⊆ R, wtedy operację `*' można rozszerzyć na argumenty rozmyte A i B w następujący sposób:
Ој(z) = min {Ој(x), Ој(y)}
OPERACJE NA ZBIORACH ROZMYTYCH
Suma logiczna A в€Є B
Ој(x) = Ој(x) в€Є Ој(y) = Max [A(x), B(x)]
gdzie znak в€Є oznacza operator Max
przykЕ‚ad:
A= {, , , }
B= {, , , }
C = A в€Є B
C = {, , , }
Iloczyn logiczny zbiorów A ∩B
μ∩ (x) = μ(x) ∩ μ(x) = Min [A(x), B(x)]
przy czym symbol ∩ oznacza operator Min
C = A ∩B
C = {, , , }
Negacja zbioru A
Ој(x) = 1 - Ој(x)
w odrГіЕјnieniu od zbiorГіw zwykЕ‚ych gdzie negacja elementГіw naleЕјД…cych do zbioru tworzyЕ‚a zbiГіr pusty, negacja w odniesieniu do zbiorГіw rozmytych definiuje zbiГіr niepusty o elementach z funkcjami przynaleЕјnoЕ›ci naleЕјД…cymi rГіwnieЕј do przedziaЕ‚u
[0, 1]
RГіwnoЕ›Д‡ zbioru A i B
Zbiory rozmyte A(x) i B(x) sД… sobie rГіwne, gdy dla wszystkich elementГіw xi obu zbiorГіw zachodzi Ој(xi) = Ој(xi)
Operacja koncentracji CON(A)
Ој(x) = [Ој(x)]ВІ
jest to szczegГіlnie czД™sto uЕјywana operacja w dziaЕ‚aniach na zmiennej lingwistycznej gdzie utoЕјsamia siД™ ja z intensyfikatorem „bardzo”
Operacja rozciД…gania DIL(A)
Ој(x) = [Ој(x)]
operacja ta w znaczeniu lingwistycznym oznacza „mniej wiД™cej”
Iloczyn algebraiczny A*B
Ој(x) = Ој(x) * Ој(x)
Suma ograniczona dwu zbiorГіw rozmytych A|+|B
Ој(x) = min {1, Ој(x) + Ој(x)}
RГіЕјnica ograniczona dwu zbiorГіw rozmytych A|-|B
Ој(x) = max {0, Ој(x) - Ој(x)}
Iloczyn ograniczony dwu zbiorГіw rozmytych A|*|B
Ој(x) = max {0, Ој(x) + Ој(x) - 1}
Normalizacja zbioru NORM(A)
Ој(x) =
ZbiГіr A zawiera siД™ w zbiorze B to jest AвЉ‚B jeЕ›li dla wszystkich elementГіw zachodzi nierГіwnoЕ›Д‡:
μ(xi) ≤ μ(xi)
Zbiory rozmyte (ang. fuzzy sets) są wykorzystywane do formalnego określania nieostrych, nieprecyzyjnych lub wieloznacznych pojęć, np. "wysokie drzewo", "piękny krajobraz", itd. Mają one swoje źródło w rozwoju teorii sterowania, teorii systemów i zw. logik wielowartościowych. Zauważono, bowiem, że chociaż umysł ludzki jest zdolny do rozumowania w kategoriach przybliżonych, to mimo to jest w stanie przetwarzać dane przybliżone i niejednoznaczne oraz wyznaczać przybliżone rozwiązania, czego nie są w stanie zrobić komputery działające w oparciu o ścisłe reguły. W teorii zbiorów rozmytych funkcja charakterystyczna została uogólniona i nazywa się funkcją przynależności. Przyporządkowuje ona każdemu elementowi zbioru wartości z przedziału [0,1], zamiast tylko jedną z wartości z dwuelementowego zbioru {0,1}, jak to jest w klasycznej teorii zbiory.
LogicznД… podstawД… pojД™cia podzbioru rozmytego jest logika wielowartoЕ›ciowa. PodzbiГіr rozmyty umoЕјliwia opisanie pojД™Д‡, ktГіrych granica miД™dzy posiadaniem pewnej wЕ‚asnoЕ›ci i jej brakiem jest rozmyta.
Zadania realizowane przez sieci neuronowe - architektura przykЕ‚adowych sieci i metody uczenia.
SIEĆ NEURONOWA - jest równoległym systemem wieloprocesorowym, zorganizowanym na wzór struktur przetwarzania w biologicznej sieci neuronowej (w mózgu człowieka). Podstawowym elementem tej sieci jest prosty procesor dokonujący dwuwartościowej selekcji sumarycznego pobudzenia wejść i wytwarzający jedno z alternatywnych wyjść odpowiadających pobudzeniu podprogowemu i ponad progowemu. Wielkość pobudzenia jest funkcją wag poszczególnych wejść, w procesie uczenia wartości wag są modyfikowane. Procesor realizujący taką funkcję jest nazywany neuronem, przez analogię do sieci biologicznej.
ZADANIA REALIZOWANE PRZEZ SIECI NEURONOWE
Rozpoznawanie wzorcГіw (znakГіw, liter, ksztaЕ‚tГіw, sygnaЕ‚Гіw mowy, sygnaЕ‚Гіw sonarowych) Klasyfikowanie obiektГіw
Prognozowanie i ocena ryzyka ekonomicznego
Prognozowanie zmian cen rynkowych (gieЕ‚dy, waluty)
Ocena zdolnoЕ›ci kredytowej
Ocena wnioskГіw ubezpieczeniowych
Rozpoznawanie wzorГіw podpisГіw
Prognozowanie zapotrzebowania na energiД™ elektrycznД…
Diagnostyka medyczna
DobГіr pracownikГіw
Prognozowanie sprzedaЕјy
Analizowanie zachowaЕ„ klienta w supermarketach
Aproksymowanie wartoЕ›ci funkcji
METODY UCZENIA SIECI
Uczenie pod NADZOREM
Przy tym uczeniu kaЕјdemu wektorowi wejЕ›ciowemu towarzyszy zadany wektor wyjЕ›ciowy. Dane uczД…ce sД… podane w postaci par uczД…cych.
Celem uczenia pod nadzorem minimalizacja odpowiednio zdefiniowanej funkcji celu, ktГіra w wyniku umoЕјliwi dopasowanie wartoЕ›ci aktualnych odpowiedzi neuronГіw wyjЕ›ciowych do wartoЕ›ci ЕјД…danych dla wszystkich par uczД…cych.
Uczenie z KRYTYKIEM
Uczenie z krytykiem jest odmianД… uczenia pod nadzorem, w ktГіrym nie wystД™puje informacja o wartoЕ›ciach ЕјД…danych na wejЕ›ciu systemu a jedynie informacja czy podjД™ta przez system akcja daje wyniki pozytywne w sensie poЕјД…danego zachowania systemu czy negatywne.
Uczenie samoorganizujД…ce siД™ typu HEBBA
W modelu Hebba wykorzystuje siД™ wynik obserwacji neurobiologicznych zgodnie, z ktГіrymi waga powiД…zaЕ„ miД™dzy dwoma neuronami wzrasta przy jednoczesnym stanie pobudzenia obu neuronГіw w przeciwnym wypadku maleje.
Uczenie samoorganizujД…ce siД™ typu KONKURENCYJNEGO
W uczeniu typu konkurencyjnego neurony współzawodniczą ze sobą, aby stać się aktywnymi (pobudzonymi). W odróżnieniu do uczenia Hebba gdzie dowolna liczba neuronów może być aktywna w uczeniu konkurencyjnym tylko jeden z neuronów może być aktywny a pozostałe pozostają w stanie spoczynku z tego powodu uczenie to nosi tez nazwę WTA (Winner Takes All). Uczenie typu WTA nie wymaga nauczyciela i odbywa się zwykle z zastosowaniem znormalizowanych wektorów wyjściowych
Uczenie metodД… wstecznej propagacji bЕ‚Д™dГіw:
Pierwszą czynnością w procesie uczenia jest przygotowanie dwóch ciągów danych: uczącego i weryfikującego. Ciąg uczący jest to zbiór takich danych, które w miarę dokładnie charakteryzują dany problem. Jednorazowa porcja danych nazywana jest wektorem uczącym. W jego skład wchodzi wektor wejściowy, czyli te dane wejściowe, które podawane są na wejścia sieci i wektor wyjściowy, czyli takie dane oczekiwane, jakie sieć powinna wygenerować na swoich wyjściach. Po przetworzeniu wektora wejściowego, nauczyciel porównuje wartości otrzymane z wartościami oczekiwanymi i informuje sieć czy odpowiedź jest poprawna, a jeżeli nie, to, jaki powstał błąd odpowiedzi. Błąd ten jest następnie propagowany do sieci, ale w odwrotnej niż wektor wejściowy kolejności (od warstwy wyjściowej do wejściowej) i na jego podstawie następuje taka korekcja wag w każdym neuronie, aby ponowne przetworzenie tego samego wektora wejściowego spowodowało zmniejszenie błędu odpowiedzi. Procedurę taką powtarza się do momentu wygenerowania przez sieć błędu mniejszego niż założony. Wtedy na wejście sieci podaje się kolejny wektor wejściowy i powtarza te czynności. Po przetworzeniu całego ciągu uczącego (proces ten nazywany jest epoką) oblicza się błąd dla epoki i cały cykl powtarzany jest do momentu, aż błąd ten spadnie poniżej dopuszczalnego. Jak to już było zasygnalizowane wcześniej, SSN wykazują tolerancję na nieciągłości, przypadkowe zaburzenia lub wręcz niewielkie braki w zbiorze uczącym. Jest to wynikiem właśnie zdolności do uogólniania wiedzy.
Algorytm uczenia Kohonena:
Sieć Kohonena posiada tylko dwie warstwy: warstwę wejściową oraz warstwę wyjściową, składającą się z neuronów radialnych. Warstwa ta znana jest również jako warstwa tworząca mapę topologiczną, ponieważ takie jest jej najczęstsze zastosowanie. Neurony w warstwie tworzącej mapę topologiczną są rozważane w taki sposób, jakby były rozmieszczone w przestrzeni według jakiegoś ustalonego wzoru.
Sieci Kohonena uczone są przy wykorzystaniu algorytmu iteracyjnego. Rozpoczynając od początkowych, wybranych w sposób losowy centrów radialnych, algorytm stopniowo modyfikuje je w taki sposób, aby odzwierciedlić skupienia występujące w danych uczących.
Siec Hopfielda:
Strukturę sieci Hopfielda można opisać bardzo prosto - jest to układ wielu identycznych elementów połączonych metodą każdy z każdym. Jest, zatem najczęściej rozpatrywana jako struktura jednowarstwowa. W odróżnieniu od sieci warstwowych typu perceptron sieć Hopfielda jest siecią rekurencyjną, gdzie neurony są wielokrotnie pobudzane w jednym cyklu rozpoznawania, co uzyskuje się poprzez pętle sprzężenia zwrotnego.
Wagi poЕ‚Д…czeЕ„ wyliczane sД… w sieci Hopfielda a priori, jej faza uczenia ogranicza siД™ do wyliczenia wartoЕ›ci wag zgodnie zasadД… uczenia Hebba.
ZASTOSOWANIE SIECI NEURONOWYCH
Sztuczne sieci neuronowe mają zastosowanie w działaniach wymagających kojarzenia, rozpoznawania i przewidywania na podstawie poznanych wcześniej danych. SSN znajdują zastosowanie również tam, gdzie ze względu na złożoność opisywanego procesu czy obiektu trudno jest sformułować klasyczny model.
Sztuczne sieci neuronowe stosowane są w wielu problemach, głownie takich, gdzie nie sprawdzają się metody tradycyjne i analityczne. Problemy te można sklasyfikować w kilku grupach, nie zawsze rozłącznych:
- aproksymacja
- autoasocjacja
- klasyfikacja
- podobieЕ„stwo, rozpoznawanie
- analiza czynników głównych - (przykładem zastosowania może być diagnostyka medyczna. Jeśli na wejściu sieci zaprezentujemy objawy występujące u pacjenta, zdefiniujemy czynniki główne jako jednostki chorobowe związane z pewnymi zespołami objawów, to sieć poda na wyjściu w jakim stopniu każda z określonych jednostek chorobowych dotyczy prezentowanego zbioru objawów rozpatrywanego przypadku klinicznego.)
- kodowanie i dekodowanie
- uogГіlnienie
- optymalizacja - (szukanie wzglД™dnego maksimum i minimum pewnej funkcji, gdy inne metody zawodzД… lub sa zbyt wolne, a maks czy min globalne nie jest konieczne. Problem komiwojaЕјera. W problemach optymalizacyjnych czД™sto wykorzystywane sД… sieci rekurencyjne Hopfielda. )
ZASTOSOWANIE:
- zastosowanie w sterowaniu
- poЕјyczki bankowe - ocena ryzyka przed udzieleniem pozyczki.
- gieЕ‚da - przewidywanie zachowanai siД™ gieЕ‚dy
- rozpoznawanie pisma rД™cznego
- rozpoznawanie znakГіw drukowanych
- walka z przestД™pczoЕ›ciД… (wykrywanie faЕ‚szerstw zwiД…zanych z wykorzystaniem kart kredytowych.)
Algorytmy genetyczne, programowanie genetyczne, programowanie ewolucyjne, podstawowe pojД™cia , strategie algorytmy.
ALGORYTMY GENETYCZNE
SД… to algorytmy optymalizacyjne, ktГіrych zasady dziaЕ‚ania oparte sД… na mechanizmach znanych od stuleci a mianowicie na mechanizmach doboru naturalnego i dziedzicznoЕ›ci. Zasada przeЕјycia najlepszych osobnikГіw zostaЕ‚a przeniesiona wprost do algorytmГіw genetycznych.
Celem optymalizacji jest zwiД™kszenie efektywnoЕ›ci aЕј do osiД…gniД™cia pewnego optimum, takiego rezultatu, ktГіry bД™dzie najbardziej odpowiedni dla badanego przypadku.
Chromosomy sД… to uporzД…dkowane zbiory genГіw, ciД…gi kodowe skЕ‚adajД…ce siД™ z genГіw. W algorytmach genetycznych jako chromosomy bД™dziemy rozumieli binarny ciД…g kodowy.
Genem nazywamy cechД™, znak, detektor. Jest to pojedynczy element genotypu a w szczegГіlnoЕ›ci chromosomu.
Obecnie wyrГіЕјniamy 3 metody poszukiwania: metody analityczne, metody enumeracyjne i metody losowego poszukiwania rozwiД…zaЕ„.
Metody enumeracyjne sД… to metody oparte na przeszukiwaniu caЕ‚ej przestrzeni rozwiД…zaЕ„ i obliczanie dla kaЕјdego punktu wartoЕ›ci funkcji celu.
Dla kaЕјdego punktu w przestrzeni poszukiwaЕ„ wyliczana jest wartoЕ›Д‡ funkcji przystosowania. Wynikiem jest najlepszy zapamiД™tany rezultat.
Algorytmy genetyczne wykorzystujД… elementy losowego wyboru jako przewodnika w prowadzeniu wysoce ukierunkowanego poszukiwania przestrzeni rozwiД…zaЕ„. Takie metody poszukiwaЕ„ z elementami losowego wyboru nazywamy technikami zrandomizowanymi.
Na klasyczny algorytm genetyczny, nazywanym takЕјe elementarnym lub prostym algorytmem genetycznym , skЕ‚adajД… siД™ nastД™pujД…ce kroki:
- inicjacja czyli wybГіr poczД…tkowej populacji chromosomГіw
- ocena przystosowania chromosomГіw
- sprawdzanie warunku zatrzymania,
- selekcja chromosomГіw,
- zastosowanie operatorГіw genetycznych,
- utworzenie nowej populacji
- wynik w postaci „najlepszego” osobnika.
Inicjacja, czyli utworzenie populacji poczД…tkowej, polega na wyborze ЕјД…danej liczby chromosomГіw reprezentowanych przez ciД…gi binarne okreЕ›lonej dЕ‚ugoЕ›ci.
Ocena przystosowania chromosomГіw w populacji polega na obliczeniu wartoЕ›ci funkcji przystosowania (funkcji celu np. f(x)= x^2) dla kaЕјdego chromosomu z tej populacji. Im wiД™ksza jest wartoЕ›Д‡ tej funkcji, tym lepsza ”jakoЕ›Д‡” chromosomu.
Sprawdzenie warunku zatrzymania. Określenie warunku zatrzymania algorytmu genetycznego zależy od konkretnego zastosowania tego algorytmu i może nastąpić w przypadkach gdy:
- uzyskamy wartoЕ›Д‡ maksymalnД… znanД… wczeЕ›niej
- nie poprawia siД™ uzyskiwana wartoЕ›Д‡ (np. jeЕ›li przez 3 generacje wynik siД™ nie zmieni)
- po określonej liczbie generowanych populacji (np. przetwarzania ma trwać 6 generacji)
Selekcja chromosomów polega na wybraniu, na podstawie obliczonych wartości funkcji przystosowania, tych chromosomów, które będą brały udział w tworzeniu potomków do następnego pokolenia, czyli następnej generacji. Najczęściej stosowana jest metoda ruletki. (na podstawie wzoru wyliczany jest wycinek okręgu dla każdego chromosomu). Selekcja chromosomu może być widziana jako obrót kołem ruletki.
Do operatorГіw genetycznych zaliczamy krzyЕјowanie i mutacjД™.
KrzyЕјowanie polega na wymianie informacji genetycznej (bitГіw) miД™dzy parami chromosomГіw.
- kojarzymy losowo chromosomy w pracy rodzicГіw
- dla kaЕјdej pary wybieramy losowo punkt krzyЕјowania
- i zamieniamy pary potomkГіw
Mutacja polega na wymianie pojedynczego bitu w chromosomie z bardzo maЕ‚ym prawdopodobieЕ„stwem.
- dla kaЕјdego genu w chromosomach potomkГіw sprawdzamy prawdopodobieЕ„stwo mutacji.
Utworzenie nowej populacji. Chromosomy otrzymane w wyniku dziaЕ‚ania operatorГіw genetycznych na chromosomy tymczasowej populacji rodzicielskiej wchodzД… w skЕ‚ad nowej populacji.
Wprowadzenie najlepszego chromosomu. Jeżeli spełniony jest warunek zatrzymania algorytmu genetycznego, należy wprowadzić wynik działania algorytmu w postaci najlepszego chromosomu.
1
Wyszukiwarka
Podobne podstrony:
Egzamin, C. Podstawy podejmowania decyzji i inЕјynierii wiedzy, C
Etap podstawowy XXV Olimpiady Wiedzy Ekologicznej ODPOWIEDZI
inЕј, administracja, II ROK, III Semestr, podstawy budownictwa + inЕјynieria komunikacyjna
Podstawy geodezji Inzynieria Srodowiska S 2013 2014
Podsta~1-wykЕ‚ady, inЕјynieria ochrony Е›rodowiska kalisz, Rok 1 IOS, Ekonomia
Podstawy projektowania inzynierskiego
Katedra InЕјynierii Wiedzy
pytania1, administracja, II ROK, III Semestr, podstawy budownictwa + inЕјynieria komunikacyjna, od Da
Przedszkole2, ZarzД…dzanie i inЕјynieria produkcji, Semestr 6, Podstawy projektowania inЕјynierskiego,
pytania&odp teoretyczne, administracja, II ROK, III Semestr, podstawy budownictwa + inЕјynieria komun
sprawko 3, studia, semestr V, podstawy projektowania inzynierskiego II, Podstawy projektowania inЕјyn
drzewo niezdatnoЕ›ci, Podstawy projektowania inЕјynierskiego
Do kolokwium, Pytania do kolokwium z PPI nr2, PYTANIA DO KOLOKWIUM NR 2 Z WYKЕЃADГ“W „PODSTAWY P
Do kolokwium, Pytania do kolokwium z PPI nr2, PYTANIA DO KOLOKWIUM NR 2 Z WYKЕЃADГ“W „PODSTAWY P
Podstawy politologii konspekt wiedzy
Etap podstawowy XXVI Olimpiady Wiedzy Ekologicznej TEST
Etap podstawowy XXIII Olimpiady Wiedzy Ekologicznej TEST
Etap podstawowy XXIV Olimpiady Wiedzy Ekologicznej TEST
Podstawy Grafiki Inzynierskiej Nieznany
wiД™cej podobnych podstron