Rozwiá zanie zestawu E:
Zadanie 1:
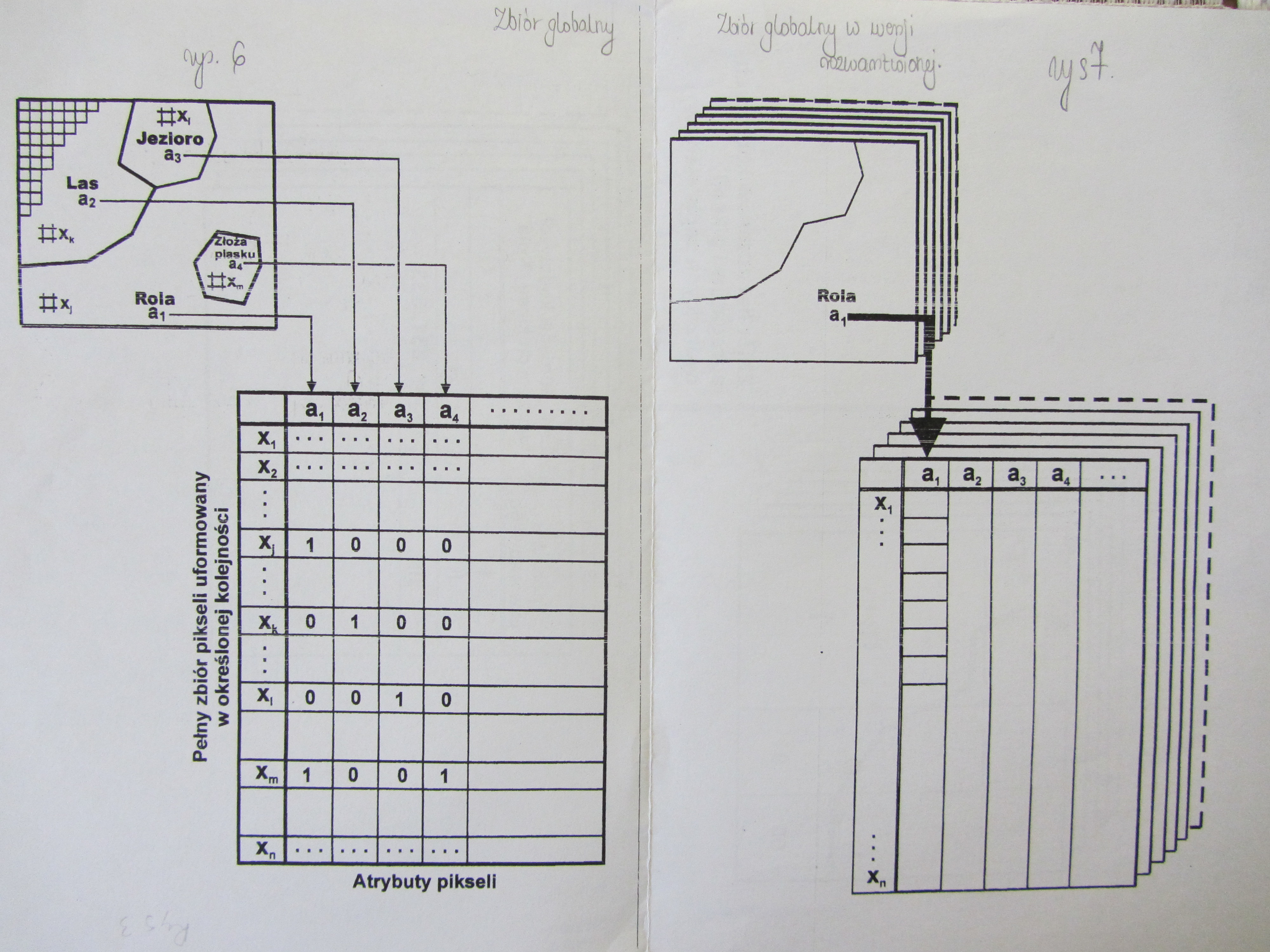
Rastrowy zbiû°r globalny
Model rastrowy (mozaikowy). - ziarniste widzenie przestrzeni, polega na arbitralnym podzieleniu obrazu na maée elementy - piksele. Dzielenie to nazywamy teselacjá
.
1.Zbiû°r globalny
Jeé¥eli na obraz mapy naéoé¥ymy siatká rastra to wszystkie obiekty wyraé¥one bádá za pomocá piksela.
Struktura i cechy zbioru globalnego:
Zbiû°r globalny ma strukturá tablicy. Ma tyle wierszy ile jest pikseli. Ma tyle kolumn ile jest atrybutû°w.
Wymiar tej tablicy jest bardzo dué¥y. Cechy dla pojedynczego piksela mogá siá powtarzaá. Zbiû°r globalny jest zbiorem binarnym a w rzeczywistoéci moé¥e zawieraá dowolne wartoéci (kolory, barwy). Zbiû°r globalny jest zbiorem kompletnym. Zapisuje caéy przeglá d sytuacji. Przyjmuje é¥e coé istnieje albo nie. Moé¥emy wpisywaá wartoéá dowolnych dziedzin.
Jest uniwersalnym zapisem. Wady: jest
bardzo dué¥y, jest nieoszczádny, musimy go selekcjonowaá.
Zaleta: peény zapis éwiata realnego (é¥eby wygenerowaá warstwá trzeba przeprowadziá selekcjá).
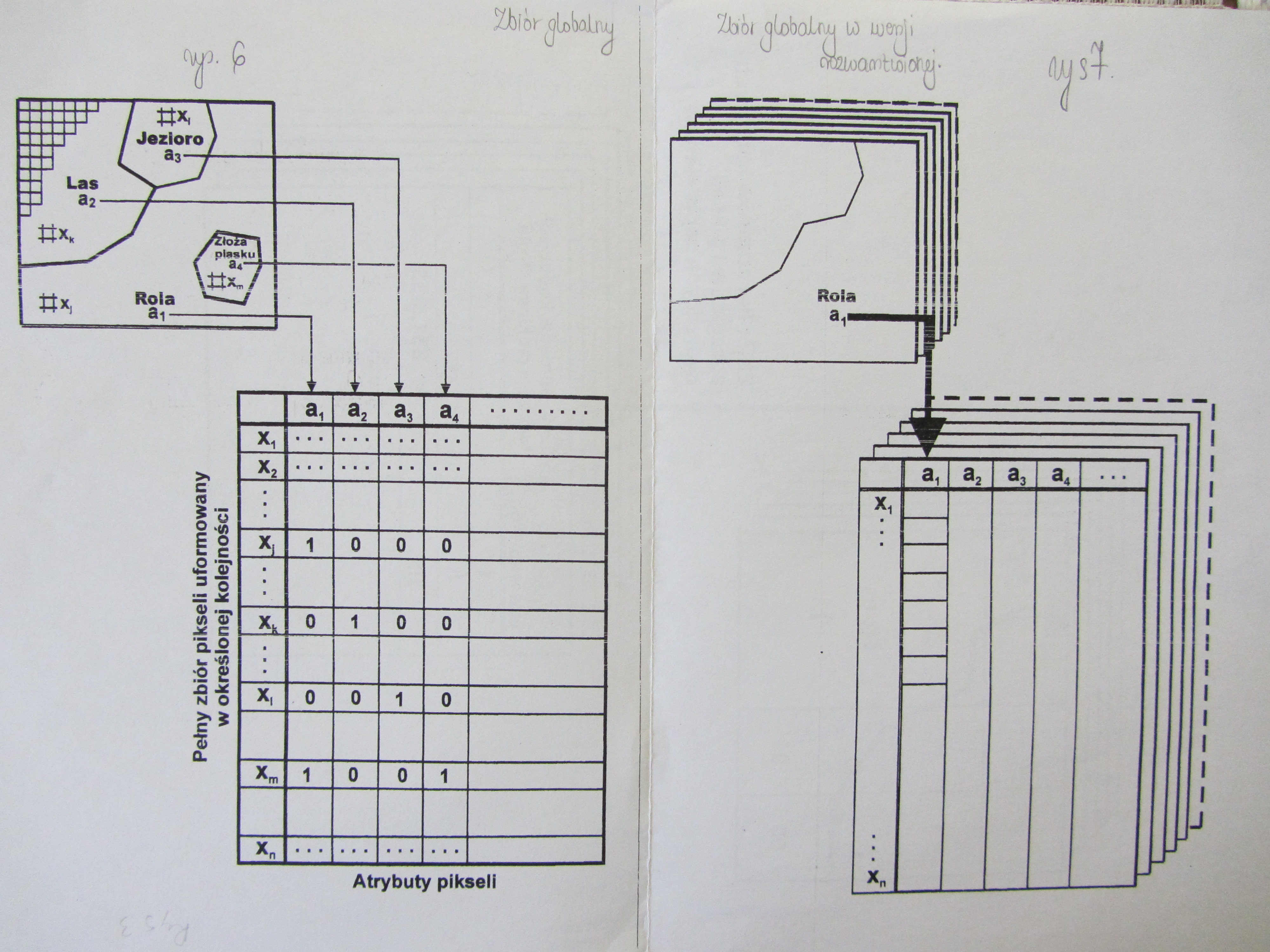
2.Zbiû°r globalny w wersji rozwarstwionej- zbiû°r tablic
(kaé¥da kolejna tablica to kolejny atrybut.) Z jednej tablicy powstaje tyle tablic ile atrybutû°w. Nadal ma dué¥o zer. Generowanie zestawû°w tematycznych musi byá zawiá zane z selekcja. Zbiory warstw tematycznych zespalajá potrzeby generowania zestawieé tematycznych. Takie zbiory powinny byá kompresowane.
Kompresja obrazu- pozbycie siá zer:
Poczá tkowy + liczba powtû°rzeé
Poczá tkowy + koécowy i co tam jest
Zbiû°r globalny w wersji rozwarstwionej jest w dalszym ciá gu wielki i nieoszczádny, dlatego teé¥ powstaé trzeci sposû°b zapisu.
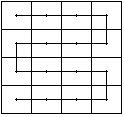
3.Zbiory warstwy tematycznej w oparciu o hierarchiczne rozwiniácie obrazu
Sporzá dza listá agregatû°w (blok) ktû°re caékowicie mieszczá siá w danych obiektach od najwiákszego do najmniejszego agregatu - wynikiem jest lista kodû°w agregatû°w, ktû°re nie dzielá siá dalej bo kolejne elementy majá takie same atrybuty
é£eby zbudowaá kaé¥dá klasá musimy sporzá dziá listá kodû°w drzewa czwû°rkowego. Podziaé przestrzeni jest wiác zgodny z drzewem czwû°rkowym, a zbiû°r warstw tematycznych ma strukturá listy.
|
|
|
|||
|
|
|
|
||
|
|
|
|
||
|
|
|
|
||
|
|
|
|
||
|
|
|
|||
Kolejnoéá narastania kodû°w w schemacie drzewa czwû°rkowego pokrywa siá z kierunkiem przebiegania zgodnym z liniá Peana.
linia fraktalna Peana umoé¥liwia budowá zwiá zkû°w hierarchicznych (blokû°w pikseli), dalsze stopnie o identycznym ksztaécie, wykonuje krû°tkie przebiegi w lokalnej przestrzeni, oscyluje w lokalnej przestrzeni, minimalna liczba skokû°w. Niezmiernie oszczádny zapis.
Kaé¥dy kolejny powstaje z 4 poprzednich
Zalety: - oszczádny zapis przy ué¥yciu stopni podziaéu. - obszar reprezentowany przez max agregaty -regularnoéá -éatwoéá zamiany na wspû°érzádne -pola bádá ce sá siadami majá podobne kody, -hierarchiczna struktura, -wyé¥szy stopieé organizacji.
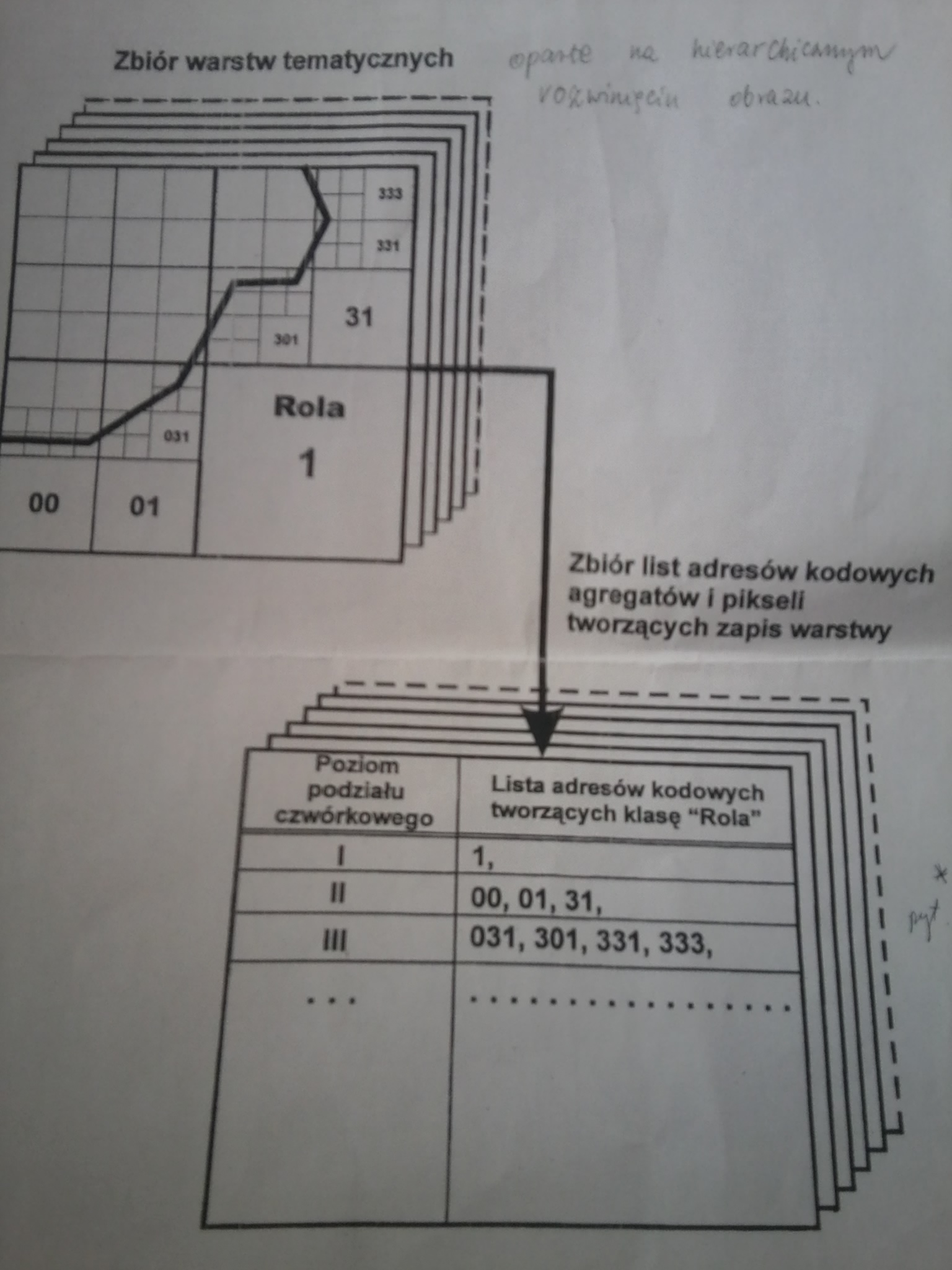
Opis przebiegu zapisu warstwy:
Poszukujemy peénych agregatû°w, rejestrujemy kolejne maksymalne agregaty na poszczegû°lnych poziomach podziaéu, ktû°re mieszczá siá caékowicie w konturach obiektu danej klasy. Kody tych agregatû°w zapisujemy w postaci listy. Takie agregaty nie podlegajá jué¥ dalszemu podziaéowi, poniewaé¥ posiadajá ten sam atrybut. To daje znaczná oszczádnoéá zapisu, poniewaé¥ dué¥e obszary sá reprezentowane przez agregaty o maksymalnej wielkoéci. W miará dopasowywania siá granic obiektu, tworzymy zapis coraz mniejszych agregatû°w. Lista siá powiáksza ale i tak ten zapis jest o wiele bardziej oszczádny, nié¥ zbiû°r globalny lub zbiû°r globalny w wersji rozwarstwionej.
Zadanie 2:
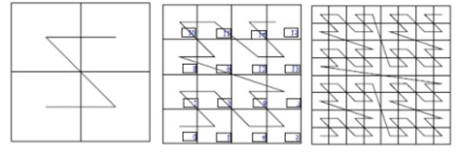
Sposû°b (model rastrowy) - model w ktû°rym zapis przestrzeni 2D jest ukierunkowany na elementy skéadowe obrazu - regularna siatka pû°l elementarnych jest rozwijana do postaci liniowej, a z chwilá uformowania siatki pû°l (zwanej rastrem) kaé¥dy obraz moé¥e byá wyraé¥ony wyéá cznie poprzez geometriá elementû°w siatki;
Wybû°r sposobû°w przebiegania:
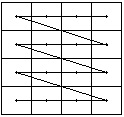
a) wierszowe-
dué¥e skoki
i wiele skokû°w
b) serpentynowy
-eliminuje skoki
ale zaburza kolejnoéá
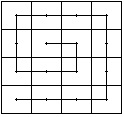
c)spiralny-usuwa skoki, jest zawsze
w tych samych kierunkach, sá tu
martwe przebiegi, zostaéa
wprowadzona asymetria: gástoéá
przebiegania na zewná trz jest inna
nié¥ gástoéá w érodku.
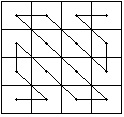
d)diagonalny Cantora (usuwa skoki ale zaburza kolejnoéá,
wprowadza dezintegracjá,
sá tu martwe przebiegi,
sá dué¥e przebiegi).
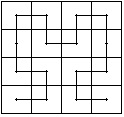
sposoby hierarchiczne:
e) przebieganie Hilberta-kierunek umoé¥liwia
budowá zwiá zkû°w hierarchicznych, oscyluje
w lokalnej przestrzeni, symetryczny
wzgládem linii pén-péd, wadá jest to é¥e
hierarchia jest oparta o obracanie o 90O
f) linia fraktalna Peana-umoé¥liwia budowá zwiá zkû°w hierarchicznych (blokû°w pikseli), dalsze stopnie o identycznym ksztaécie, wykonuje krû°tkie przebiegi w lokalnej przestrzeni, oscyluje w lokalnej przestrzeni, minimalna liczba skokû°w. Niezmiernie oszczádny zapis.
Kaé¥dy kolejny powstaje z 4 poprzednich
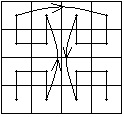
g)kody Gray'a- eliminuje
dué¥e béády, symetryczny
w kierunku linii pén-péd
Zadanie 3:
Nieregularna sieá trû°jká tû°w powstaje géownie jako efekt bezpoérednich pomiarû°w terenowych, gdzie caéy zakres opracowania zapeénia siá trû°jká tami opartymi o punkty pomiarowe. Poniewaé¥ w tych modelach wykorzystywane sá wszystkie punkty charakterystyczne model jest stosunkowo dokéadny.
a) triangulacja Delaunay'a
Trû°jká ty tworzone sá w ten sposû°b aby é¥aden z punktû°w nie naleé¥á cych do niego nie byé
poéoé¥ony wewná trz okrágu opisanego na trû°jká cie
b) Obszar Thiessena stanowi zbiû°r wszystkich punktû°w péaszczyzny, dla ktû°rych odlegéoéá do punktu centralnego jest mniejsza od odlegéoéci do pozostaéychpunktû°w. Ograniczenia tego obszaru stanowiá odcinki symetralnych do bokû°w triangulacji Delaunay'a.
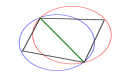
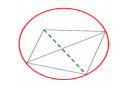
Triangulacja Delaunaya maksymalizuje wartoéá minimalnego ká
ta w trû°jká
cie.( z spoérû°d wszystkich wyselekcjonowanych punktû°w w kole do polaczenia pkt centralny zostanie polaczony z tymi punktami ktû°rych symetralne utworzyéy wielobok thiessen
Najczáéciej stosowany jest algorytm Delaunay'a w ktû°rym wykorzystywane sá poligony Thiessena. Triangulacja powinna byá tak wykonana é¥eby: - tworzone trû°jká ty byéy moé¥liwie zblié¥one do rû°wnobocznych i moé¥liwie maée; - kaé¥dy punkt ze zbioru punktû°w rozproszonych musi byá uwzgládniony; -procedura postápowania musi byá jednoznaczná
Gdy nie sá znane sposoby poéá czenia punktû°w stosuje sie triangulacje Delaunay'a z wykorzystaniem wielobokû°w Thiessena (mamy jak poéá czyá punkty rozproszone)
-trû°jká ty zblié¥one do rû°wnobocznych
-kaé¥dy punkt musi byá wykorzystany
-procedura musi byá jednoznaczna
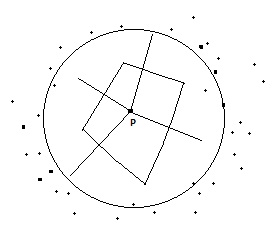
Przebieg tworzenia:
1. obieramy jaká é odlegéoéá R, rû°wná lub wiákszá nié¥ érednia odl miádzy pkt
2. zakreélamy okrá g o promieniu R na kaé¥dym punkcie, w tym okrágu znajda siá punkty kandydujá ce do poéá czenia z tym punktem.
3. éá czymy pkt P ze wszystkimi punktami kandydujá cymi i kreélimy symetralne tych odcinkû°w
4. Z tych symetralnych budujemy najmniejszy wielobok. wielobok ten to wielobok Thiessena. Kaé¥dy punkt zawarty wewná trz tego wieloboku jest blié¥ej punktu P nié¥ innego punktu.
5. Spoérû°d wszystkich pkt wyselekcjonowanych w okrágu punkt P bádzie poéá czony tylko z tymi punktami, ktû°rych symetralne utworzyéy wielobok Thissena, te pkt bádá tworzyéy fragment przyszéej siatki.
6. Resztá punktû°w ktû°re nie utworzyéy wieloboku siá odrzuca.
7. Powyé¥sza procedura powtarza siá dalej dla wszystkich punktû°w rozproszonych
Matematycznie: budujemy ostroséup i zakéadamy, é¥e V=0
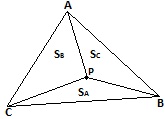
Wysokoéá punktu P jest éredniá waé¥oná z wysokoéci trzech punktû°w, gdzie wagami sá pola trû°jká tû°w leé¥á cych naprzeciwko.
Zadanie 4:
4.1). S=(PRACOWNICY [NAZWISKOPRAC] + STUDENCI [NAZWISKOSTUD]) x LISTACZYTELN [NAZWISKOCZYT]
Komentarz: Najpierw musimy wykonaá dwie projekcje: tabeli PRACOWNICY, tak aby pozostaé jedynie atrybut z nazwiskiem pracownika (NAZWISKOPRAC), oraz tabeli STUDENCI, tak aby pozostaé atrybut z nazwiskiem studenta (NAZWISKOSTUD). Projekcja jest to przeksztaécenie usuwajá ce rû°é¥norodnoéci, jest skreélaniem atrybutû°w i wybieraniem tylko tych, ktû°re nas interesujá . Nastápnie przetworzone tablice po projekcji dodajemy do siebie. Dodawanie daje w wyniku relacje zawierajá ce wszystkie krotki, a powtû°rzenia sá usuwane. W dodawaniu wszystkie operanty muszá mieá takie same atrybuty, dlatego wykonano projekcjá, aby obie dodawane tablice miaéy takie same atrybuty NAZWISKO. Niewaé¥ne tu jest, é¥e nagéû°wki sá rû°é¥ne (NAZWISKOPRAC i NAZWISKOSTUD), moé¥emy wykonywaá operacje na tych tablicach relacji, poniewaé¥ majá atrybuty tego samego typu (nazwisko). Kolejnym krokiem byéo wykonanie projekcji tabeli LISTACZYTELN, tak aby pozostaé tylko atrybut z nazwiskiem (NAZWISKOCZYT). Na koniec wykonano mnoé¥enie pomiádzy wynikowá tabelá z dodawania i wynikowá tabelá po projekcji. Byéo to moé¥liwe, poniewaé¥ posiadaéy one takie same atrybuty. Wynikiem mnoé¥enia jest obszar wspû°lny - krotki, ktû°re wystápujá jednoczeénie w obu relacjach. Jako wynik otrzymaliémy nazwiska studentû°w i pracownikû°w, ktû°rzy choá raz w tym semestrze byli w czytelni.
4.2). S={(PRACOWNICY + STUDENCI) / LISTACZYTELN} [NAZWISKO]
Komentarz: Logiczne jest, é¥e bádziemy te nazwiska poszukiwaá na ogû°lnych listach nazwisk PRACOWNICY i STUDENCI. Musimy wiác stworzyá taká zsumowaná listá, a pû°é¤niej wykreéliá z niej te nazwiska, ktû°re wystápujá w zbiorze czytelnikû°w: LISTACZYTELN. Aby tego dokonaá, najpierw wykonujemy dodawanie dwû°ch tablic relacji: PRACOWNICY i STUDENCI, a nastápnie od tablicy wynikowej odejmujemy listá czytelnikû°w (LISTACZYTELN), aby dowiedzieá siá kogo na tej liécie nie byéo. Musimy w tym przypadku byá bardzo ostroé¥ni i nie wykonywaá projekcji wczeéniej, tylko na samym koécu, poniewaé¥ gdy w dziaéaniach na tablicach relacji wystápuje odejmowanie, to nie moé¥emy robiá wczeéniej projekcji, bo to zlikwidowaéoby rû°é¥norodnoéá. Dlatego teé¥ ostatnim krokiem byéo wykonanie projekcji wzgládem NAZWISKA (mimo ié¥ nagéû°wki w kaé¥dej z tablic byéy rû°é¥ne NAZWISKOSTUD, -PRAC, -CZYT, to dziaéania na tych tablicach byéy moé¥liwe, poniewaé¥ atrybuty byéy takie same). W wyniku otrzymaliémy tabelá z nazwiskami studentû°w i pracownikû°w, ktû°rzy w tym semestrze ani razu nie byli w czytelni.
Wyszukiwarka
Podobne podstrony:
Zadania-rozwiazane zestaw6
Rozwiá zanie zestawu D
Rozwiá zanie zestawu C
Chemia áwiczenia zestawy rozwiá zane, Zestaw nr 7 rozwiazany, Zestaw 7
Rozwiá zanie zestawu E
Rozwiá zane zestawy Viola Milas
rozwiá zania zestawu 8,9
Matematyka Zestaw 2 Rozwiá zany
zestaw B, C rozwiazane (2)
zestaw 07 rozwiazania
Zestaw1 PR rozwiazania id 58873 Nieznany
planimetria zestawy 13 i 14 rozwiá zane- Aksjomat Toruá¿ã
wiácej podobnych podstron