METODY NUMERYCZNE W ELEKTROTECHNICE
Metody numeryczne - dział matematyki stosowanej, zajmujący się opracowywaniem i badaniem metod przybliżonego rozwiązywania problemów obliczeniowych w modelach matematycznych innych dziedzin nauki
Przykładowe zastosowania:
elektrotechnika - obliczanie parametrów obwodów elektrycznych
medycyna - tomografia komputerowa, opracowywanie nowych leków
chemia - konstruowanie nowych cząsteczek
inżynieria - przemysł samochodowy i lotniczy
informatyka - konstruowanie nowych procesorów
W obrębie klasycznych metod numerycznych możemy wyróżnić m.in. takie zagadnienia jak:
analiza błędów zaokrągleń
interpolacja
aproksymacja
rozwiązywanie równań i układów równań nieliniowych
całkowanie i różniczkowanie numeryczne
rozwiązywanie układów równań liniowych
obliczanie wartości własnych i wektorów własnych macierzy
rozwiązywanie zagadnień dla równań różniczkowych zwyczajnych i cząstkowych
rozwiązywanie równań całkowych i układów równań całkowych
(każdy wynik musi podlegać weryfikacji!)
Reprezentacja liczb w maszynie cyfrowej
Liczby całkowite (stałopozycyjne = stałoprzecinkowe):
![]()
, gdzie ei = 0 lub 1
Jeżeli rejestr ma d-bitów, wówczas liczba całkowita n może zawierać się w przedziale
-2d-1 < n < 2d-1-1
przykład: Zapisać liczbę 18 w systemie dwójkowym:
![]()
, może być zatem przechowywana w słowie o długości D + 1 > 5 bitów jako
![]()
Liczby rzeczywiste (zmiennopozycyjne):
![]()
, gdzie ½ < m < 1, m-mantysa, i-cecha
![]()
W maszynie cyfrowej mantysa zapisywana jest w t-bitach mt
![]()
w wyniku zaokrąglenia do t-bitów mantysy
![]()
Zmiennopozycyjna reprezentacja liczby rzeczywistej x oznaczana jest symbolem rd(x) i jest równa
![]()
![]()
! |
Gdy elementy macierzy są rzędu μ lub n musimy dokonać przekształcenia całego układu. Uciekamy się od operacji na małych liczbach. |
Nie prowadzi się operacji na małych liczbach, co oznacza, że:
![]()
, gdzie ![]()
liczbę 2-t nazywamy dokładnością maszynową
przykład: Liczba 18,5 daje się przedstawić w postaci:
![]()
może być więc przechowywana w słowie o długości d + 1 > 11 bitów o t > 6 bitach mantysy:
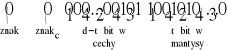
0,5781525
W sytuacji, gdy elementy macierzy są < 1, np. mV, musimy wtedy dokonać przeskalowania całego układu (np. poprzez pomnożenie macierzy przez jakąś liczbę).
Błędy obliczeń
Przy obliczeniach wykonywanych na maszynach cyfrowych spotyka się trzy podstawowe rodzaje błędów:
błędy wejściowe (danych wejściowych) - występujące, gdy dane wprowadzane do pamięci maszyny cyfrowej odbiegają od dokładnych wartości tych danych. Źródłem tych błędów jest najczęściej skończona długość słów binarnych reprezentujących liczby i w związku z tym nieuniknione jest wstępne ich zaokrąglenie
błędy odcięcia - powstają podczas obliczeń na skutek zmniejszenia liczby działań, na przykład przy obliczaniu sum nieskończonych. Chcąc obliczyć wartość wyrażenia ex równego szeregowi:
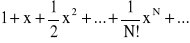
zastępuje je sumą częściową o odpowiednio dobranej wartości N: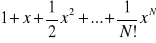
Jeżeli liczba N będzie niedostatecznie duża, to uzyskana w ten sposób wartość liczby ex będzie obliczona niedokładnie, a popełniony w ten sposób błąd jest właśnie błędem odcięcia. Błędy tego typu powstają też często przy obliczaniu wielkości będących granicami. Podobnie zastąpienie wartości pochodnej funkcji jej ilorazem różnicowym powoduje powstanie błędu odcięcia. W wielu przypadkach daje się uniknąć błędu wejściowego i odcięcia przez ograniczenie danych.
Lemat Wilkinsona:
Błędy zaokrągleń powstające podczas wykonywania działań zmiennopozycyjnych są równoważne zastępczemu zaburzeniu liczb, na których wykonujemy działania. W przypadku działań arytmetycznych otrzymujemy:
![]()
![]()
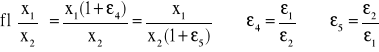
gdzie εi są co do modułu niewiększe niż dokładność maszyny ε. Przedrostek fl oznacza, że są to wyniki działań wyznaczone przy użyciu maszyny cyfrowej.
Oszacowanie błędów w obliczeniach iteracyjnych:
Wiele algorytmów obliczeniowych polega na wyznaczeniu ciągu liczb zbieżnego do poszukiwanej wartości.
Przykład:
wyznaczyć wartość funkcji ![]()
, przekształcając do równania iteracyjnego. Można to uczynić obliczając ciąg y0, y1, y2..., gdzie y0 jest dowolnie wybraną liczbą, natomiast każdy element ciągu yi jest dany wzorem:
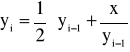
, dla i = 1, 2, 3, ...
(niewiadoma musi być po obu stronach równania)
![]()
![]()
![]()
![]()
, współczynnik przed funkcją (tutaj 1) musi być < 1 dlatego:
![]()
![]()
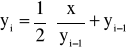
- iteracja i-ta
np. 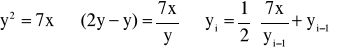
takiego równania nie da się rozwiązać bo 7/2
ale można zrobić tak:
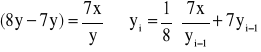
jeśli założyć, że działania wykonywane są dokładnie, to ciąg y0, y1, y2, ... będzie zbieżny do liczby x, ponieważ ![]()
, to
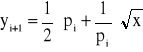
, a ciąg po > 0
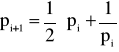
, przy i = 1, 2, 3, ... jest zbieżny do 1
Przykład:
rozwiązanie iteracyjne
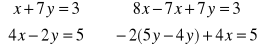
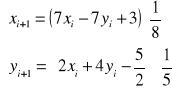
wszystkie składniki przy niewiadomych są < 1 (7/8, -7/8, 3/5)
przyjmujemy dowolnie xi = 1, yi = 2
Działania potrzebne do wyznaczania kolejnych wartości ciągu y0, y1, y2, ... nazywamy iteracją. Informację o tym czy w kolejnej iteracji nastąpiło przybliżenie do rozwiązania uzyskujemy obliczając wyrażenie:
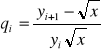
W przypadku dokładnych działań, gdy ![]()
i ![]()
, więc qi < 0 dla i = 1, 2, 3, ... jeśli pi>1/3. Oznacza to, że maleje wartość bezwzględna różnicy ![]()
odpowiednio dużego numeru iteracji i.
Dla obliczeń wykonywanych na maszynie cyfrowej, mamy:
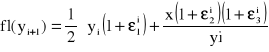
, gdzie ![]()
, k = 1, 2, 3, ...
Dla liczby ![]()
uzyskamy 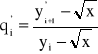
Jeżeli yi jest już dostatecznie dobrym przybliżeniem liczby ![]()
, a więc pi jest bliskie jedności, to pierwszy składnik powyższego wyrażenia ma pomijalnie małą wartość, natomiast drugi ze składników wynika z błędów zaokrągleń i może mieć tym większą wartość im bliższe jedności jest pi.
Przykład: dla liczby 4 x=4
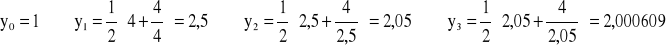
Algorytm:
zmienne rzeczywiste x, y, eps
y:= x/4; {pierwsze przybliżenie}
repeat
y:= 0,5*(y+(x/y));
until abs (x-sqr(y))<=eps {eps jest zakładaną dokładnością obliczeń)
Uwarunkowanie zadania i stabilność algorytmów.
Załóżmy, że mamy skończoną liczbę danych rzeczywistych, x = ( x1, x2, ... xn ), na ich podstawie chcemy obliczyć skończenie wiele wyników rzeczywistych y = ( y1, y2, ... ym ). Będziemy więc chcieli określić wartość y według odwzorowania y = φ (x), gdzie ϕ: D → Rm jest ciągłym odwzorowaniem i D ⊆ Rm.
Algorytm to jednoznaczny przepis obliczania wartości odwzorowania φ (x) składający się ze skończonej liczby kroków.
Jeśli zadanie rozwiązujemy numerycznie to zamiast dokładnymi wartościami x1, x2, ... xn posługujemy się reprezentacjami rd (x1), rd (x2), ..., rd (xn). Operacje elementarne nie są więc realizowane dokładnie tylko przez odwzorowanie zastępcze fl. Ta niewielka zmiana danych powoduje, że różne algorytmy rozwiązania tego samego zadania dają na ogół niejednakowe wyniki. Dużą rolę odgrywa tu przenoszenie błędów zaokrągleń. Często niewielkie zmiany danych powodują duże względne zmiany rozwiązania zadania. Zadanie takie nazywamy źle uwarunkowanym. Wielkości charakteryzujące wpływ zaburzeń danych na zaburzenia rozwiązania nazywamy wskaźnikami uwarunkowania zadania.
Przykład:
![]()
Zerami tego wielomianu będą liczby naturalne 1, 2, ..., 20. Gdy zakłócimy np. a19 = - 210 i jego wartość wynosi a19(ε) = - (210 + 2-23), czyli a19 (ε) = a19 (1+ε). Otrzymujemy wtedy wielomian wε(x) = w (x) - 2-23, który posiada już pierwiastki zespolone i np. najbliższe pierwiastkowi 15 wielomianu w(x) są pierwiastki 13,992358137 ± 2,518830070j.
Metodę badania przenoszenia błędów można rozbudować do analizy różniczkowej błędów algorytmu.
Niech δx1 = rd (xi) - xi dla i = 1, 2, ..., n
![]()
dla j = 1, 2, ..., m
We wzorze tym, czynnikiem określającym wrażliwość yj na bezwzględną zmianę δxi jest ![]()
Analogiczny wzór można wyprowadzić dla przenoszenia się błędów względnych. Jeśli ![]()
dla j = 0,1, 2, ..., m i ![]()
dla i = 1, 2, ..., n to
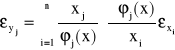
, gdzie 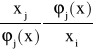
nazywamy wskaźnikiem uwarunkowania. Jeśli wskaźniki uwarunkowania co do wartości bezwzględnej są duże to zadanie jest źle uwarunkowane.
Przykład:
Badamy uwarunkowanie sumy y = a + b + c ![]()
![]()
= 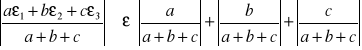
, gdzie ε jest
największą z wartości ε1, ε2 i ε3, gdzie ![]()
jest wskaźnikiem uwarunkowania zadania.
Stabilność numeryczna algorytmów
Algorytm jest stabilny, jeżeli posiada tę własność, że małe błędy powstałe w pewnym kroku algorytmu nie są powiększane w innych krokach oraz nie powodują poważnego ograniczenia dokładności wszystkich obliczeń. Oznacza to, że algorytm jest numerycznie stabilny, gdy zwiększając dokładność obliczeń można wyznaczyć (z dowolną dokładnością) istniejące rozwiązanie zadania. Numeryczną stabilność zadania łatwo sprawdzić rozwiązując zadanie raz z dokładnością np. 10-6, a potem z dokładnością 10-12.
INTERPOLACJA:
Dana jest funkcja y = f (x), ![]()
, dla której znana jest tablica wartości w punktach zwanych węzłami interpolacji. Należy wyznaczyć taką funkcję W(x), aby:
W(x0) = Y0, W(x1) = Y1, ..., W(xn) = Yn
interpolacja funkcji f(x)
Zadaniem interpolacji jest wyznaczenie przybliżonych wartości funkcji zwanej funkcją interpolową w punktach nie będących węzłami interpolacji. Przybliżoną wartość funkcji obliczamy za pomocą funkcji zwanej funkcją interpolującą, która w węzłach ma te same wartości co funkcja interpolowana.
Funkcja interpolująca jest funkcją pewnej klasy. Najczęściej będzie to wielomian algebraiczny, wielomian trygonometryczny, funkcja wymierna i funkcja sklejana.
Interpolację stosuje się najczęściej, gdy nie znamy analitycznej postaci funkcji (jest ona tylko stablicowana) lub gdy jej postać analityczna jest zbyt skomplikowana.
Najczęściej stosowaną metodą wyznaczania funkcji W(x) jest jej dobór w postaci kombinacji liniowej n+1 funkcji bazowych ![]()
![]()
wyrażenie to nazywamy wielomianem uogólnionym.
Wprowadzając macierz bazową
![]()
i macierz współczynników 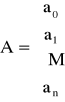
mamy ![]()
warunek W(x0) = Y0, W(x1) = Y1, ..., W(xn) = Yn
można zapisać w postaci układu równań liniowych X · A = Y, gdzie
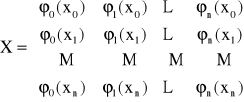
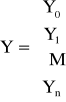
Jeśli macierz X nie jest osobliwa (da się odwrócić), to:
A = X-1·Y
co ostatecznie daje
W(x) = Φ(x) · X-1· Y
Interpolacja wielomianowa
W praktyce często używa się bazy złożonej z jednomianów
![]()
Baza dla funkcji ciągłych na odcinku skończonym [xo, xn] jest bazą zamkniętą, tzn., że każda funkcja tej klasy może być przedstawiona w postaci szeregu złożonego z funkcji bazowych. Wielomian interpolacyjny ma w tym przypadku postać:
![]()
dodatkowo musi być spełniony warunek:
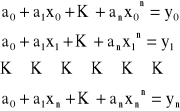
Powyższy układ równań ma jedyne rozwiązanie względem a1, jeżeli wartości x0, x1, ..., xn są od siebie różne
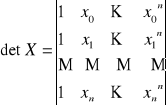
Macierz X-1 dla bazy wielomianowej ![]()
nazywana jest macierzą Lagrange'a
Zauważyć należy, że każdy zbiór węzłów równoodległych xi+1 - xi = h = const. można sprowadzić do zbioru podstawowego podstawiając ![]()
, wówczas ![]()
, a macierz Φ przyjmuje postać
![]()
Interpolacja Lagrange'a
Przedstawiony powyżej sposób podejścia do interpolacji nie jest zbyt efektywny, ponieważ macierz X jest macierzą pełną i nie zawsze dobrze uwarunkowaną, co oznacza, że numeryczna procedura jej odwracania może być obarczona dużym błędem.
W interpolacji wielomianowej Lagrange'a dla n+1 węzłów interpolacji
![]()
przyjmuje się funkcje bazowe w postaci
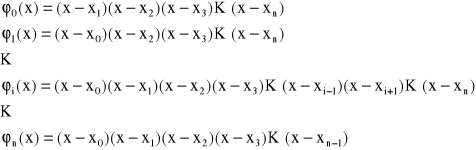
Funkcje te są wielomianami stopnia n zbudowanymi w ten sposób, że w funkcji bazowej φ1 brakuje czynnika (x-xi). Zatem wielomian interpolacji wyraża się następującym wzorem:
![]()
współczynniki a0 ... an tego wielomianu wyznaczamy z równania:
X · A = Y, przy czym macierz X ma postać:
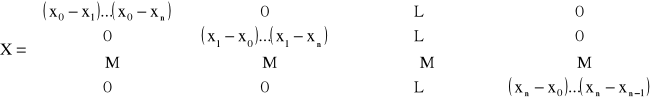
Macierz posiada tylko główną przekątną niezerową w związku z tym układ równań X · A = Y rozwiązuje się natychmiastowo

Można więc wielomian interpolacyjny Lagrange'a zapisać w postaci ułamka:
![]()
lub krócej
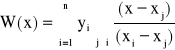
, j = 0, 1, ..., n
Przykład:
Wyznaczyć wielomian interpolacyjny Lagrange'a funkcji f (x) = ex w przedziale [0,2 ; 0,5] mając dane:
f (0,2) = 1,2214, f (0,4) = 1,4918, f (0,5) = 1,6487
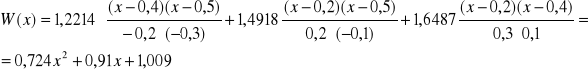
algorytm do wyznaczania wielomianu Lagrange'a dla podanego punktu:
begin
fx:=0;
for i:=0 to n do
begin
p:=1;
for k:=0 to n do
if k<>i then p:=p*(xx-x[k])/(x[i]-x[k]);
fx:=fx+f[i]*p
end;
end;
Należy pamiętać, ze przed przystąpieniem do obliczeń należy sprawdzić czy w wektorze x wartości się nie powtarzają, ponieważ grozi to wystąpieniem błędu dzielenia przez zero.
Różnice skończone
Dla funkcji stabelaryzowanej przy stałym kroku h = xi+1 - xi można wyprowadzić pojęcie różnicy skończonej rzędu k
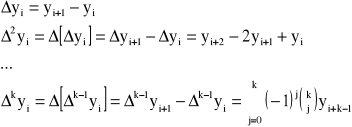
Przykład: Dla funkcji danej w postaci tablicy zbudować tablicę różnic skończonych.
NR |
x |
y |
Δy |
Δ2y |
Δ3y |
Δ4y |
Δ5y |
0 |
1,2 |
1,728 |
0,469 |
0,078 |
0,006 |
0 |
0 |
1 |
1,3 |
2,197 |
0,547 |
0,084 |
0,006 |
0 |
|
2 |
1,4 |
2,744 |
0,631 |
0,090 |
0,006 |
|
|
3 |
1,5 |
3,375 |
0,721 |
0,096 |
|
|
|
4 |
1,6 |
4,096 |
0,817 |
|
|
|
|
5 |
1,7 |
4,913 |
|
|
|
|
|
Wzory interpolacyjne dla argumentów równoodległych
Dla zbioru węzłów tworzących ciąg arytmetyczny x0, x1 = x0 + h, x2 = x0 + 2h, ..., xn = x0 + nh dane są wartości funkcji f(x0), f(x1), ..., f(xn). Szukany wielomian interpolacyjny zapisać możemy w następujący sposób:
W(x) = a0 + a1q + a2q(q - 1) + a3q(q - 1)(q - 2) + ... + anq(q - 1)(q - 2)...(q - n +1),
gdzie ![]()
Dla:
x = x0: q = 0
x = x1: q = 1
x = x2: q = 2
...
x = xn: q = n
Funkcje bazowe dla wielomianu W(x) przyjęto w postaci:
Φ0(x) = 1 Φ1(x) = q Φ2(x) = q(q - 1)
Φ3(x) = q(q - 1)(q - 2) Φn(x) = q(q - 1)(q - 2)...(q - n + 1)
Otrzymujemy następujący układ równań:
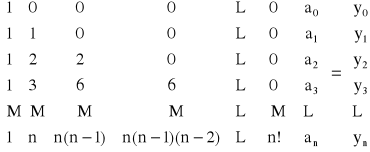
z którego wyznacza się wartości nieznanych współczynników a0, a1, a2, ..., an
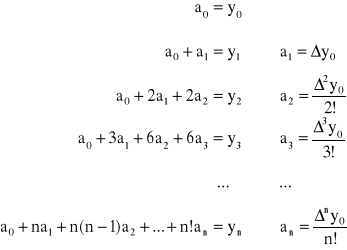
Ostatecznie otrzymujemy I wzór interpolacyjny Newtona w postaci
![]()
Przykład: Dla zależności f(T)=T log p znaleźć wielomian interpolacyjny stopnia 3 i obliczyć odchyłki w węzłach interpolacji
T |
0,8 |
1,0 |
1,2 |
1,4 |
1,6 |
1,8 |
T log p |
0,3566 |
0,9383 |
1,5598 |
2,2169 |
2,9059 |
3,6229 |
Tablica:
T |
T log p |
Δ |
Δ2 |
Δ3 |
błąd [%] |
0,8 |
0,3566 |
0,5817 |
0,0398 |
-0,0042 |
0 |
1,0 |
0,9383 |
0,6215 |
0,0356 |
-0,0037 |
0 |
1,2 |
1,5598 |
0,6571 |
0,0319 |
-0,0039 |
0 |
1,4 |
2,2169 |
0,6890 |
0,0280 |
|
0 |
1,6 |
2,9059 |
0,7170 |
|
|
1,9 |
1,8 |
3,6229 |
|
|
|
4,2 |
przyjmijmy ![]()
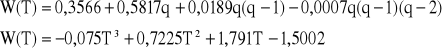
Zauważmy, że I wzór Newtona daje dobrą dokładność w pobliżu punktu T0, natomiast dla punktów leżących niżej w tabeli błąd wzrasta. Jeśli chcielibyśmy wyzerować odchyłki we wszystkich węzłach tabeli trzeba by podwyższyć rząd interpolacji i w efekcie wzór empiryczny staje się wtedy praktycznie mało przydatny. Wzory interpolacyjne stosuje się też do obliczania wartości funkcji w punktach pośrednich tabeli (do zagęszczenia). Aby obliczyć T log p dla T = 1,3 z dokładnością do Δ2 wystarczy przyjąć T0 = 1,2, a wówczas q = 0,5 i znajdujemy ![]()
.
Zadanie takich wartości T = 1,65 byłoby już niewykonalne, ponieważ brakuje różnic. Widać tu ograniczenie tzw. interpolacji w przód, określonej I wzorem Newtona. Do interpolacji wstecz służy II wzór Newtona. Szukamy wielomian interpolacyjny
W(x) = a0 + a1q + a2q(q + 1) + a3q(q + 1)(q + 2) + ... + anq(q + 1)(q + 2)...(q + n - 1),
gdzie ![]()
Współczynniki a0, a1, a2, ..., an wyznaczamy jak poprzednio i dochodzimy do wzoru:
![]()
Przykład: Obliczyć T log p dla T = 1,65 z dokładnością do Δ2
![]()
![]()
3,6229-0,75*0,717-0,75*0,25*0,028=3,0825
for j:=1 to 2 do
for i:=1 to n-j do
z[i,j]:=z[i+1,j-1]-z[i,j-1];
q0:=(x-x0)/h;
k:=int(q,0);
q:=q0-k;
if k>=n then write (`Brak danych')
else wart:=z[k,0]+q*z[k,1]+0.5*q*(q-1)*z[k,2];
Interpolacja trygonometryczna
Załóżmy, że znamy wartości pewnej ciągłej i okresowej funkcji f(x) o okresie 2π w 2n+1 węzłach. Jako bazę interpolacji przyjmujemy zbiór funkcji trygonometrycznych
![]()
Otrzymujemy zatem wielomian interpolacyjny w postaci
![]()
zawierający 2n+1 nieznanych parametrów.
Ze względu na uproszczenie obliczeń najistotniejszy jest przypadek interpolacji funkcji określonej na zbiorze równoodległych węzłów xi∈[0,2π] dobranych według następującej zależności
![]()
, gdzie i = 0, 1, ..., 2n
Czyli
![]()
Warunek interpolacji prowadzi do układu równań liniowych w postaci
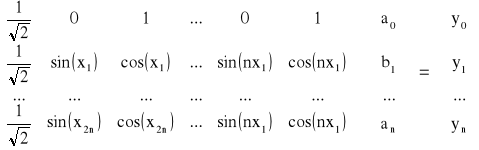
Współczynniki pierwszego wiersza macierzy X wynikają z wartości funkcji sin(hx) i cos (hx) dla x0 = 0. Przedstawiony układ równań rozwiązuje się natychmiastowo, ponieważ macierz X-1 można wyznaczyć z zależności
![]()
Przykład: Daną funkcję f(x) = 7x - x2 przybliżyć wielomianem trygonometrycznym przyjmując n = 3. Współrzędne węzłów interpolacji obliczamy ze wzoru:
![]()
x |
0 |
0,898 |
1,795 |
2,693 |
3,590 |
4,488 |
5,386 |
y |
0 |
5,478 |
9,344 |
11,598 |
12,242 |
11,274 |
8,695 |
Baza interpolacji - zbiór funkcji:
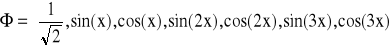
Tworzymy macierz X:
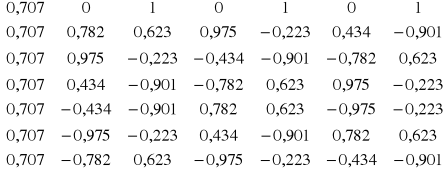
Elementy macierzy X mnożymy przez 2/7, otrzymaną macierz transponujemy i obliczamy współczynniki wzoru interpolacyjnego
![]()
Aproksymacja
jest to przybliżanie funkcji f(x) zwanej aproksymowaną inną funkcją Q(x) zwaną funkcją aproksymującą. Aproksymacja bardzo często występuje w dwóch przypadkach:
gdy funkcja aproksymowana jest przedstawiona w postaci tablicy wartości i poszukujemy dla niej odpowiedniej funkcji ciągłej
gdy funkcję o dosyć skomplikowanym zapisie analitycznym chcemy przedstawić w „prostszej” postaci
Dokonując aproksymacji funkcji f(x) musimy rozwiązać dwa ważne problemy:
dobór odpowiedniej funkcji aproksymującej Q(x)
określenie dokładności dokonanej aproksymacji
Dobór odpowiedniej funkcji aproksymującej Q(x)
Najczęściej stosowane funkcje aproksymujące są dobierane w postaci wielomianów uogólnionych będących kombinacją liniową funkcji q(x)
![]()
Jako funkcje bazowe stosowane są:
jednomiany
funkcje trygonometryczne
wielomiany ortogonalne
Przyjęcie odpowiednich funkcji bazowych powoduje, że aby wyznaczyć funkcję aproksymującą należy wyznaczyć wartości współczynników, a0, a1, ..., am.
Określenie dokładności aproksymacji
Aproksymacja funkcji powoduje powstanie błędów i sposób ich oszacowania wpływa na wybór metody aproksymacji. Jeśli błąd będzie mierzony na dyskretnym zbiorze punktów x0, x1, ..., xn to jest oto aproksymacja punktowa, jeśli będzie mierzony w przedziale (a,b) - aproksymacja integralna lub przedziałowa.
Najczęściej stosowanymi miarami błędów aproksymacji są:
dla aproksymacji średniokwadratowej punktowej
![]()
dla aproksymacji średniokwadratowej integralnej lub przedziałowej
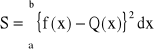
dla aproksymacji jednostajnej
![]()
We wszystkich tych przypadkach zadanie aproksymacji sprowadza się do takiego optymalnego doboru funkcji aproksymującej (dla wielomianu uogólnionych zaś do optymalnego doboru współczynników a0, a1, ..., am) aby zdefiniowane wyżej błędy były minimalne.
Aproksymacja średniokwadratowa
Niech dana będzie funkcja y=f(x), która w pewnym zbiorze X punktów x0, x1, ..., xn przyjmuje wartości y0, y1, ..., yn. Wartości te znane tylko w przybliżeniu z pewnym błędem (np. jako wyniki pomiarów). Poszukujemy takiej funkcji Q(x) przybliżającej daną funkcję f(x), która umożliwi wygładzenie funkcji f(x), czyli pozwoli z zakłóconych błędami danymi wartości funkcji przybliżonej otrzymać gładką funkcję przybliżającą.
Niech ϕj(x), j=0, 1,...,n będzie układem funkcji bazowych. Poszukujemy wielomianu uogólnionego Q(x) będącego najlepszym przybliżeniem średniokwadratowym funkcji f(x) na zbiorze X=(xj). Funkcja przybliżająca ma postać
![]()
Przy czym współczynniki ai są tak określone, aby wyrażenie
![]()
![]()
dla i=0, 1, ..., n
było minimalne. Funkcja w(x) jest z góry ustaloną funkcją wagową.
Aby wyznaczyć współczynniki ai oznaczamy odchylenie
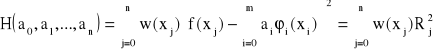
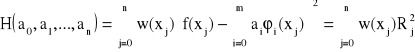
gdzie Rj jest odchyleniem w punkcie xj.
Następnie obliczamy pochodne cząstkowe funkcji H względem ai. Z warunku
![]()
, gdzie k = 0, 1, ..., n
otrzymujemy układ m+1 równań o niewiadomych ai zwany układem normalnym
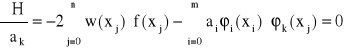
, gdzie k = 0, 1, ..., n
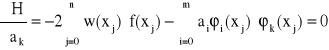
Jeśli wyznacznik tego układu jest różny od zera to rozwiązaniem układu jest minimum funkcji H. W zapisie macierzowym układ przyjmuje postać
![]()
gdzie
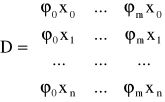
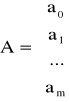
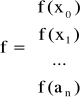
Aproksymacja wielomianowa
Jeżeli za funkcje bazowe przyjmiemy ciąg jednomianów (xi), i = 0, 1, ..., n to układ normalny przyjmuje postać
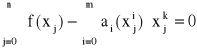
, k = 0, 1, ..., n
co po zmianie kolejności sumowania daje
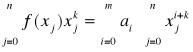
przykład: Odnaleźć zależność między x i y w postaci ax+by=1
x |
1 |
3 |
4 |
6 |
8 |
9 |
11 |
14 |
y |
1 |
2 |
4 |
4 |
5 |
7 |
8 |
9 |
Będziemy rozpatrywać odchylenia zarówno wartości x jak i y, ponieważ wiodą one do różnych wyników. Zakładamy, że dane są obarczone błędami, wówczas minimalizujemy wyrażenia
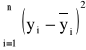
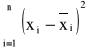
przy czym ![]()
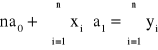
, gdzie: ![]()
, ![]()
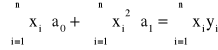
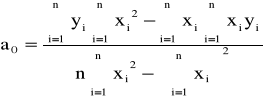
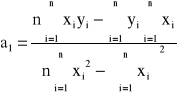
Układ normalny dla danych z tablicy ma rozwiązanie
a0 = 6/11 i a1 = 7/11,
więc ma postać
11y - 7x = 6
Minimalizując w ten sam sposób wyrażenie
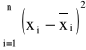
otrzymamy równanie
2x - 3y = -1
Dla obu otrzymanych równań wykresy się pokrywają.
Algorytm
tablice: tab[1..4,1..5], a, p[1..4], s, suma[1..6]
zmienne rzeczywiste: x, y
zmienne indeksowe: i, j, n, k
for j:=1 to n do
begin
write (`Podaj x i y dla węzła:');
readln (x:10:4, y:10:4);
s[1]:=x;
for i:=2 to 6 do s[i]:=x*s[i-1];
for i:=1 to 6 do suma[i]:=suma[i]+s[i];
p[1]:=p[1]+y;
for i:=2 to 4 do p[i]:=p[i]+y*s[i-1];
end;
tab[1,1]:=n;
for i:=1 to 4 do
begin
tab[i,5]:=p[i];
for j:=1 to 4 do
begin
k:=i+j;
if not (k=2 then tab[i,j]:=suma[k-2]
end;
end;
RUKL(tab,a,4,5);
writeln (`Poszukiwane współczynniki to');
for i:=1 to 4 do writeln (a[i]:12:6);
Aproksymacja za pomocą wielomianów ortogonalnych ze wzrostem stopnia wielomianu, obliczenia stają się coraz bardziej pracochłonne a ich wyniki niepewne. Problem ten można usunąć stosując do aproksymacji wielomiany ortogonalne.
Funkcje f(x) i g(x) nazywa się ortogonalnymi na dyskretnym zbiorze punktów x0, x1, ..., xn jeśli
![]()
przy czym
![]()
![]()
Analogicznie ciąg funkcyjny
![]()
nazywamy ortogonalnym na zbiorze punktów x0, x1, ..., xn jeśli
![]()
dla j≠k
Zastosowanie tej metody powoduje, że znika jedna z trudności obliczeniowych przy aproksymacji wielomianowej, mianowicie złe uwarunkowanie macierzy układu normalnego. Przy aproksymacji wielomianami ortogonalnymi macierz układu normalnego jest macierzą diagonalną, a jej elementy położone na głównej przekątnej dane są wzorem
![]()
Załóżmy, że znamy n+1 równoodległych punktów xi (xi = x0+ih, i = 0, 1, ..., n). Za pomocą przekształcenia liniowego
![]()
przeprowadzimy te punkty w kolejne liczby całkowite od 0 do n poszukujemy ciągu wielomianów
![]()
(dolny indeks oznacza stopień i m ≤ n) spełniających warunek ortogonalności
![]()
dla j≠k
przy czym
![]()
gdzie
![]()
Często używa się unormowanego ciągu wielomianów spełniających warunek
![]()
, gdzie k = 0, 1, ..., m
![]()
Co po przekształceniu daje nam wzór na wielomiany Grama, zwane też wielomianami Czebyszewa stopni k = 0, 1, ..., m w postaci
![]()
, gdzie k = 0, 1, ..., m
Wzór aproksymacyjny oparty na wielomianach Grama ma postać:
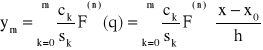
gdzie,
![]()
oraz
![]()
![]()
Przykład:
Na podstawie tablicy wartości f(x) znaleźć najlepszy w sensie aproksymacji średniokwadratowej wielomian przybliżający tę funkcję.
x |
1 |
1,5 |
2 |
2,5 |
3 |
y |
3 |
4,75 |
7 |
9,75 |
13 |
Ponieważ węzły są równoodległe posłużymy się wielomianem Grama. Konstruujemy wielomian aproksymacyjny dla n = 4. Wartości Fk(q), q=1, 2,…, 4.
Obliczamy ze wzoru:
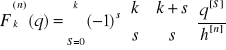
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Zestawienie wyników przedstawia tabela:
q |
xi |
yi |
F0(q) |
F1(q) |
F2(q) |
F3(q) |
F4(q) |
0 |
1 |
3 |
1 |
1 |
1 |
1 |
1 |
1 |
1,5 |
4,75 |
1 |
0,5 |
-0,5 |
-2 |
-4 |
2 |
2 |
7 |
1 |
0 |
-1 |
0 |
6 |
3 |
2,5 |
9,75 |
1 |
-0,5 |
-0,5 |
2 |
-4 |
4 |
3 |
13 |
1 |
-1 |
1 |
-1 |
1 |
Następnie korzystając ze wzorów:
![]()
![]()
Obliczamy ci i si oraz bi= ci / si i ze wzoru:
![]()
otrzymujemy:
ci |
37,5 |
-12,5 |
1,75 |
0 |
0 |
si |
5 |
2,5 |
3,5 |
10 |
70 |
bi |
7,5 |
-5 |
0,5 |
0 |
2 |
dla ![]()
Aproksymacja trygonometryczna
Często spotykamy się z przypadkiem, gdy funkcja f(x) jest okresowa. Taką funkcję wygodniej jest aproksymować, wielomianem trygonometrycznym o bazie:
1, sin x, cos x, sin 2x, cos 2x, …, sin kx, cos kx
Jeżeli f(x) jest funkcją dyskretną określoną w dyskretnym zbiorze równoodległych punktów i ich liczba jest parzysta i wynosi 2L (dla nieparzystej liczby punktów rozumowanie jest analogiczne), niech:
![]()
dla i = 0, 1, …, 2L-1
Baza jest ortogonalna nie tylko na przedziale <0, 2π>, ale też na zbiorze punktów xi, przy czym warunki ortogonalności mają postać:
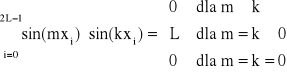
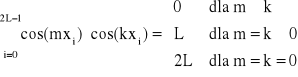
![]()
dla m, k dowolnych, przy czym m i k zmieniają się od 0 do L
Przybliżeniem funkcji f(x) na zbiorze punktów xi jest wielomian trygonometryczny:
![]()
, n<L
Współczynniki aj i bj wielomianu wyznaczamy tak, aby suma kwadratów różnic
![]()
była minimalna.
Korzystając z warunku ortogonalności otrzymujemy rozwiązanie układu normalnego
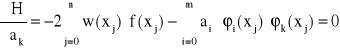
w postaci:
![]()
dla j=1, 2, …, n
![]()
Algorytm:
const max: … {zdefiniowanie stałej}
type zakres: 1…max;
wektor: array[zakres] of real;
procedure APR (N, K: zakres; var y, a, b: wektor);
var i, j: integer;
PI, A0, S1, S2: real;
begin
write(`Podaj wartość y');
for i:=1 to N do readln(Y[I]);
A0:=0.0;
for j:=1 to N do A0:=A0+Y[I];
A0:=A0/N;
PI:=4.0*arctan(1.0)/N;
for i:=1 to K do
begin
S1:=0.0;
S2:=0.0;
for j:=1 to N do
begin
S1:=S1+Y[J]*cos(PI*J*I);
S2:=S2+Y[J]*sin(PI*J*I);
end;
A[I]:=S1*2/N;
B[I]:=S2*2/N;
end;
end;
Szybka transformata Fouriera
Każdą funkcję w tablicy tablicą wartości w n punktach ![]()
, gdzie β = 0, 1, ..., n-1 można przybliżać wielomianem trygonometrycznym w postaci
![]()
, j - czynnik urojony
lub
![]()
gdzie
Θ = 1 ![]()
dla n parzystych
Θ = 1 ![]()
dla n nieparzystych
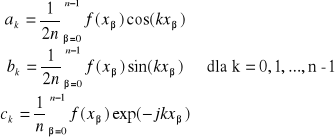
Aproksymacja za pomocą funkcji sklejonych stopnia 3 (funkcji giętych)
Każdą funkcję ![]()
można przedstawić w postaci kombinacyjnej liniowej
![]()
, a ≤ x ≤ b oraz gdzie ![]()
są funkcjami określonymi wzorem:
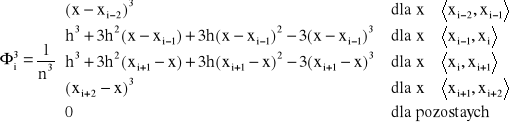
gdzie ![]()
, ![]()
Aproksymacja na przedziale <a,b>
Współczynniki ci dobieramy tak, aby odchylenie kwadratowe dane poniższym wzorem było jak najmniejsze:
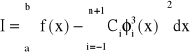
w celu wyznaczenia minimum funkcji I=I(c-1 , c0 , … , cn+1) obliczamy pochodne:
![]()
j = -1 , 0, … , n+1
i przyrównujemy je do zera. Otrzymane równania tworzą układ n+3 równań z n+3 niewiadomymi ci
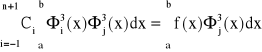
j= -1, 0, 1, … ,n+1
Funkcje ![]()
są liniowo niezależne na przedziale <a,b>, więc układ równań ma rozwiązanie w postaci punktu. Funkcji I osiąga minimum. Układ równań możemy zapisać w postaci:
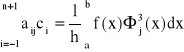
j = -1, 0, 1, … , n+1,
gdzie 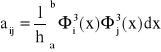
Aproksymacja funkcji określonej na dyskretnym zbiorze punktów
Niech (xi') dla i= 0, 1, … ,n1 ; n1 > n + 3 będzie zbiorem punktów, w których dane są wartości funkcji f(x). Szukane jest minimum wyrażenia:
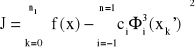
W celu wyznaczenia ci obliczamy pochodne cząstkowe funkcji J = J (c-1, c0,… ,cn+1) względem zmiennych ci i przyrównujemy je do zera.
Otrzymane równania tworzą układ:
![]()
, gdzie
![]()
Jeżeli wyznacznik tego układu jest różny od zera to rozwiązując go możemy wyznaczyć współczynniki cj takie, że funkcja J osiągnie minimum.
Metody numeryczne rozwiązywania układów algebraicznych równań liniowych. Rozpatrujemy układ n równań liniowych zawierających n niewiadomych
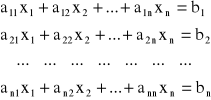
Układ ten można zapisać także w postaci macierzowej A · X = B, gdzie
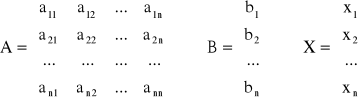
metody dokładne: metoda Cramera, metoda eliminacji Gaussa, metoda Crouta (LU)
metody niedokładne: iteracja prosta, Gaussa-Siedla, metoda sukcesywnej nadrelaksacji (SOR)
O wyborze metody decyduje postać macierzy współczynników A. Jeśli macierz A jest macierzą pełną to na ogół stosujemy metody dokładne. Jeśli macierz współczynników A jest macierzą niepełną (znacząca ilość współczynników jest równa zero) wtedy stosujemy metody iteracyjne.
Macierz A nazywana jest macierzą główną układu, X - wektorem niewiadomych, B - wektorem wyrazów wolnych. Jeśli macierz główna nie jest osobliwa (det A ≠ 0), to układ równań jest oznaczony (posiada dokładnie jedno rozwiązanie).
Gdy macierz A posiada niezerowe elementy tylko na głównej przekątnej, to układ równań rozwiązuje się natychmiastowo.
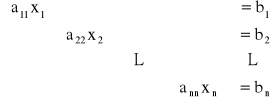
Niewiadome można wtedy obliczyć ![]()
, aii ≠ 0, i = 0, 1, ..., n.
Łatwo rozwiązuje się trójkątne układy równań
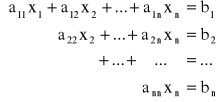
Z ostatniego równania możemy wyznaczyć xn, z przedostatniego xn-1
![]()
a ogólnie 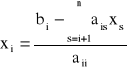
, i = n-1, n-2, ..., 1 przy założeniu, że aii ≠ 0, i = 1, 2, ..., n
PRZYKŁAD:
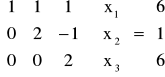
zmienną x3 mamy daną wprost - x3 = 3
![]()
ALGORYTM:
zmienne indeksowe n, i, j, s
zmienne rzeczywiste suma
tablice a[1..n,1..n], b[1..n], c[1..n]
for i:=n downto 1 do
begin
suma:=0;
for s:=i+1 to n do
suma:=suma+a[i,s]*x[s];
x[i]:=(b[i]-suma)/a[i,i];
end;
Wzory Cramera
Jesli oznaczymy symbolem W wyznacznik główny układu równań
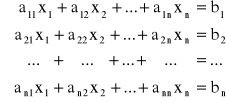
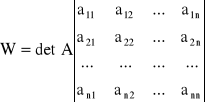
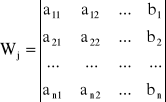
to można wykazać, że ![]()
, W ≠ 0, j = 1, 2, ..., n
Metoda ta należy do metod dokładnych. Ze względu na dużą złożoność obliczeniową praktycznie stosowana do numerycznego rozwiązywania równań.
Metoda eliminacji Gaussa
Metoda polega na zapisaniu układu równań w postaci macierzy C, której n pierwszych kolumn zawiera elementy aij macierzy głównej A, natomiast kolumnę n+1 tworzą dowolne wyrazy bi.
Zakładając, że C11≠0, odejmujemy pierwsze równanie pomnożone przez ![]()
od i-tego równania (i=2,3,...,n) a obliczonymi współczynnikami zastępujemy przednie wartości. W wyniku tej operacji otrzymujemy układ równań i odpowiadającą mu macierz C1.
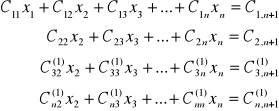
Za pomocą wzorów określających nowe współczynniki
![]()
i=2,3,...,n j=2,3,...,n+1
Jeśli ![]()
, to odejmiemy drugie równanie układu pomnożone przez ![]()
od i-tego równania układu i=3,4,...,n. W wyniku otrzymujemy układ:
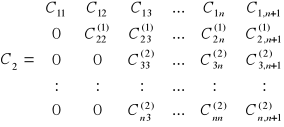
A nowe współczynniki wyrażone są wzorami
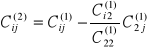
i=3, 4, ..., n j=3, 4, ..., n
Kontynuując takie postępowanie po wykonaniu n kroków dochodzimy do układu trójkątnego
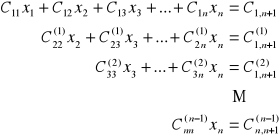

Algorytm dochodzenia od układu trójkątnego do układu równań liniowych
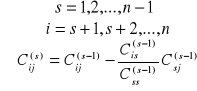
Przykład
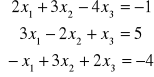
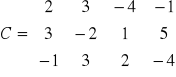
Obliczamy elementy macierzy C1
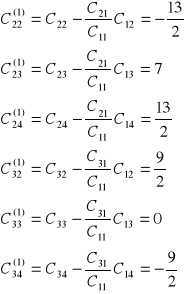
druki krok s=2
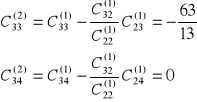
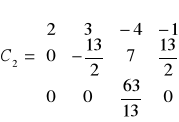
co daje nam macierz C1:
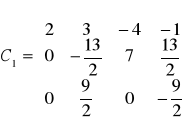
i dalej ze wzorów dla układów trójkątnych mamy x3=0, x2=-1, x1=1
ALGORYTM:
zmienne indeksowe n, i, j, s
zmienne rzeczywiste suma
tablice c[1..n,1..n+1], x[1..n]
for s:=1 to n-1 do
for i:=s+1 to n do
for j:=s+1 to n+1 do
c[i,j]:=c[i,j]-(c[i,s]*c[s,j])/c[s,s];
x[n]:=c[n,n+1]/c[n,n]
for i:=n-1 downto 1 do
begin
suma:=0;
for s:=i+1 to n do
suma:=suma+c[i,s]*x[s];
x[i]:=(c[i,n+1]-suma)/c[i,i];
end;
Metody iteracyjne
Proces iteracyjnego obliczania wrtości x polega na przyjęciu pewnej wartości początkowej Xo, zwanej przybliżeniem początkowym, a następnie wykonaniu określonych operacji arytmetycznych dających w wyniku X1 (zwanym pierwszym przybliżeniem). Kolejne przybliżenia oblicza się wykonując te same operacje na ostatnio obliczonym przybliżeniu. Jeżeli ciąg przybliżeń {Xn} zmierza do X, to proces iteracyjny jest zbieżny i tylko wtedy metoda iteracyjna jest efektywna. Metody iteracyjnego rozwiązywania układów równań liniowych można stosować dla układów typu...
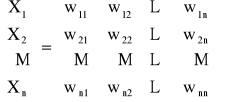
Przykład: Sprowadzić układ do postaci AX=B
2x1+x2+x3=4 x1=-0,5x2-0,5x3+2
x1+x2-x3=1 x2=-x1+x3+1
x1+x2+x3=3 x3=-x1-2x2+4
W pierwszej kolejności macierz A zakładamy na dwie macierze D i R przy czym D zawiera tylko główną przekątną macierzy A, natomiast R pozostałe jej elementy.

A = D + R
Równanie A*X=B sprawdziło się dla
D*X+R*X=B D*X=-R*X+B
Ostatnie równanie pomnożymy lewostronnie przez D-1 i otrzymujemy:
E*X=D-1*R*X+D-1*B
Oznaczając -D-1*R=W i D-1*B=Z dochodzimy dorównania: X=W*X+Z
Wracając do zadania:

ponieważ
więc jak łatwo sprawdzić mamy taki sam układ jaki znaleziono sposobem „naturalnym”
Metoda iteracji prostej (Jakobiego):
Metoda ta dla równania X=W*X+Z polega na przyjęciu zerowego przybliżenia wektora X=Xo, a następnie przeprowadzenia obliczeń iteracyjnych za pomocą zależności:
Xi+1=W*Xi+Z i=0,1,...
Liczba kroków, które należy wykonać, aby uzyskać wymaganą dokładność rozwiązania, jest z reguły dość duża i istotnie zależy od przyjęcia punktu startowego Xo. Punkt ten najczęściej się dobiera na podstawie dodatkowych informacji o fizycznych aspektach problemu.
Przykład: Metodę iteracji prostej wykorzystano do rozwiązania układu równań będącego różnicową aproksymacją równania Laplace`a z warunkami brzegowymi I rodzaju. Równanie to opisuje stacjonarne pole temperatury w pewnym dwuwymiarowym obszarze, na którego brzegach temperatury są znane. Jako przybliżenie zerowe przyjęto wartość temperatur w wnętrzu obszaru T=50°C, wymiary prostokątne a=b=0,8 cm.
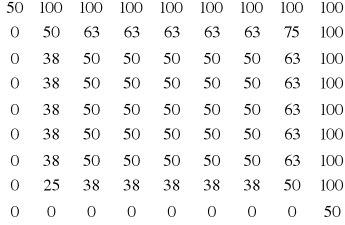
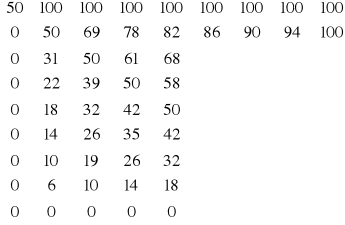
Metoda Gaussa-Seidla
Stanowi ulepszenie metody iteracyjnej prostej polegające na wykorzystaniu obliczonych k pierwszych składowych wektora Xi+1 do obliczenia składowej k+1. Modyfikacja ta znacznie przyspiesza proces obliczania.
Przykład: Rozwiązując układ równań:
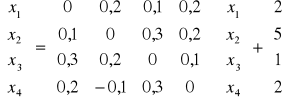
dla uproszczenia zapisu oznaczamy składowe z wektora iteracji „i” symbolem „x”, a składowe wektora i iteracji i+1 symbolem „u”. W metodzie iteracji prostej układ ten zapisujemy:
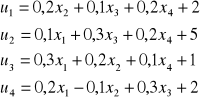
Przyjmujemy teraz punkt startowy np. X0 = [3, 6, 4, 3]T, składowe tego wektora podstawiamy do prawych stron równań wyliczając u1, ..., u4, które w następnej iteracji przejmą rolę punktu startowego. Kolejne przybliżenia otrzymane tą metodą

rozwiązaniem dokładnym jest X = [4,59, 7,49, 4,20, 3,44]
Ten sam układ w metodzie Gaussa - Siedla ma postać:
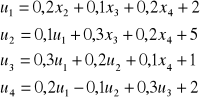
a kolejne przybliżenia:

Formalny zapis algorytmu
Macierz W w równaniu X = W · X + Z przedstawiamy jako sumę dwóch macierzy: górnej trójkątnej Wu i dolnej trójkątnej Wl. Macierz górna trójkątna składa się z elementów macierzy W leżących nad główną przekątną (pozostałe są zerami), natomiast macierz dolna trójkątna składa się z elementów macierzy W leżących pod główną przekątną. Macierz W w tym przykładzie ma zerową główną przekątną
Algorytm metody Gaussa - Siedla realizowany jest następującym wzorem:
![]()
czyli mamy:
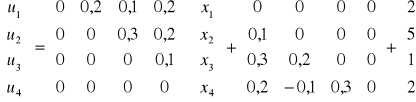
Metoda sukcesywnej nadrelaksacji (SOR)
Jest ulepszeniem metody Gaussa-Seidla mającym poprawić szybkość zbieżności procesu iteracyjnego. Istota polega na sukcesywnym wprowadzaniu w miejsce składowych ui po prawej stronie układu wartości
xi + α (ui - xi) α - współczynnik nadrelaksacji, α∈<1,2>
i - liczba niewiadomych a nie iteracja
Sposób dobory optymalnego współczynnika α nazywanego czynnikiem nadrelaksacyjnym jest trudny do określenia, chociaż wiadomo, że jest on liczbą z przedziału [1 , 2]. Można zauważyć, że dla α=1 otrzymuje się metodę Gaussa - Siedla. Według źródeł literaturowych zaleca się przyjmowanie α rzędu 1,8.
Algorytm metody nadrelaksacyjnej sprowadza się do wzoru:
![]()
Zbieżność metod iteracyjnych
Jeżeli macierz A kwadratowa oraz x jest wektorem niezerowym, wówczas istnieje pewien wektor równoległy do Ax, co oznacza, że istnieje pewna stała λ taka, że:
Ax = λx
Możemy wtedy zapisać równanie charakterystyczne
(A - λI)x = 0, gdzie I - macierz jednostkowa
oraz wielomian charakterystyczny ma postać
p(λ) = det (A - λI)
Jeżeli wielomian macierzy A jest ![]()
, wektora x jest n, wówczas p jest wielomianem m-tego stopnia, którego pierwiastki są pojedyncze i zespolone. Jeżeli wektor λ jest pierwiastkiem wielomianu p wówczas:
![]()
Jeżeli powyższy warunek jest spełniony, oznacza to, że równanie charakterystyczne ma rozwiązanie x≠0.
Zbieżność metod iteracyjnych (2)
Promień spektralny ρ(A) macierzy A jest zdefiniowany jako:
![]()
, gdzie![]()
- oznacza moduł wektora λ
wówczas równanie charakterystyczne jest zbieżne gdy:
![]()
Można wykazać, że:
![]()
ostatecznie dla metod iteracyjnych można zapisać twierdzenie:
Warunkiem koniecznym i wystarczającym zbieżności procesu iteracyjnego danego wzorem
|
Zbieżność metod iteracyjnych
W praktyce jest na ogół wygodniej korzystać z twierdzenia:
Jeżeli norma macierzy W jest mniejsza od jedności to proces iteracyjny określany wzorem Xi+1 = W · Xi + Z jest zbieżny. |
Z przytoczonych twierdzeń wynika, że zbieżność procesu iteracyjnego nie zależy ani od wartości początkowej ![]()
, ani też od wartości danego wektora Z, a wystarczy jedynie spełnienie jednego z następujących warunków:
![]()
norma wierszowa
![]()
norma kolumnowa
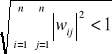
norma energetyczna
Kryterium „stopu” metod iteracyjnych
Obliczenia iteracyjne trwają do momentu kiedy zostanie spełniony warunek
![]()
gdzie: X(i+1) oraz X(i) są kolejnymi przybliżeniami rozwiązania Xi+1 = W · Xi + Z oraz δ jest dokładnością obliczeń - dowolna liczba większa od 0
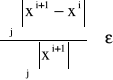
, gdzie ε ∈ <10-1, 10-256> - przyjęta dokładność obliczeń
Numeryczne rozwiązywanie równań nieliniowych
Metoda Newtona
Dany jest układ równań nieliniowych z n niewiadomymi
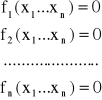
który możemy zapisać w postaci wektorowej
f(x)=0
gdzie:
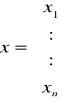
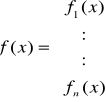
O funkcjach fi(x1...xn) dla i = 1, 2, ..., n zakładamy, że mają ciągłe pochodne pierwszego rzędu w pewnym obszarze zawierającym odosobniony pierwiastek układu równań. Niech
x(k) = {x1(k), ..., xn(k)}
będzie k-tym przybliżeniem pierwiastka a = {a1, ..., an} równania.
Dokładną wartość pierwiastka wyraża wzór a = x(k) + ε(k)
Gdzie ![]()
jest błędem pierwiastka przybliżonego ![]()
. Skoro istnieje ciągła pochodna funkcji f(x) możemy zapisać:
![]()
Zastępując błąd ![]()
przyrostem ![]()
i porównując prawą stronę powyższego wyrażenia do zera otrzymujemy równanie liniowe:
![]()
Wzór ten stanowi zapis rekurencyjny dla metody Newtona w postaci macierzowej.
Pochodna f'(x) jest macierzą Jakobiego
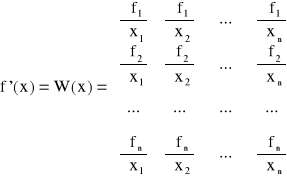
Przyjmując, że ![]()
jest macierzą nieosobliwą możemy równanie liniowe przekształcić do postaci:
![]()
stąd przyjmując dowolną wartość ![]()
otrzymujemy ciąg kolejnych przybliżeń pierwiastka równania ![]()
uzyskanych metodą Newtona.
Metoda iteracji
Dany jest układ równań nieliniowych z n niewiadomymi
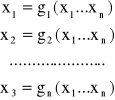
który możemy zapisać w postaci wektorowej
x=g(x)
gdzie:
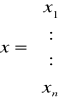
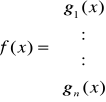
Zakładamy, że funkcja g1, g2, ..., gn są rzeczywiste i ciągłe w pewnym otoczeniu odosobnionego pierwiastka a = {a1, ..., an} układu równań.
Metoda iteracji polega na stosowaniu następującego wzoru
xk+1 = g(x(k))
Po przyjęciu przybliżenia ![]()
, w rezultacie otrzymujemy ciąg kolejnych przybliżeń ![]()
pierwiastka a równania.
Metoda siecznych
Rozpatrujemy układ równań nieliniowych w postaci
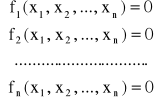
Który możemy ogólnie zapisać w postaci:
f(x)=0
gdzie x jest wektorem n zmiennych.
Metoda iteracji polega na stosowaniu wzoru wyliczającego k-te przybliżenie i-tej zmiennej tych:
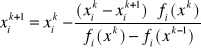
Metoda ma dwie wady:
- potrzebne są 2 zestawy punktów startowych: x0, f(x0), x1, f(x1)
- wykrywamy jeden wektor x-ów (globalny) (jeden zestaw x-ów), a pierwiastki mogą być wielokrotne
Przykład: Dany jest układ równań w postaci
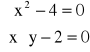
Napisać program wyznaczający rozwiązanie tego układu.
Niezbędne deklaracje typów:
wektor array[1..2] of Extended;
zmienne:
x, X1, Xn, F, F1, Fn: Extended;
iteracja: LongInt;
Funkcja reprezentująca układ równań
function funkcja (z:word):wektor;
begin
funkcja[1]:=sqrt(z[1])-4;
funkcja[2]:=z[1]*z[2]-2;
end;
Realizacja obliczeń:
Procedure oblicz
Begin
x[1]:=4;
x[2]:=7;
X1[1]:=9;
X1[2]:=11;
Repeat
Inc(iteracje);
F:=funkcja(x);
F1:=funkcja(X1);
xn[1]:=x[1]-((x[1]-x1[1])*F[1])/F[1]-F1[1];
Xn[2]:=x[2]-((x[2]-X1[2])*F[2])/F[2]-F1[2];
Fn:=funkcja(xn);
X1:=x;
x:=Xn;
until (abs(Fn[1]+abs(Fn[2])<=0.0000000001;
Po zakończeniu obliczeń wektor x przechowuje wartości zmiennych, natomiast zmienna iteracje zawiera liczbę wykonanych iteracji.
Rozważania dotyczą numerycznego obliczania wartości:
- całek pojedynczych funkcji ciągłych
- całek pojedynczych funkcji niewłaściwych
- całek funkcji osobliwych
- całek wielokrotnych
- całek Monte Carlo
Całkowanie pojedyncze - metody obliczeń
kwadratury z ustalonymi węzłami
kwadratury Newtona-Cotesa
złożone kwadratury Newtona-Cotesa
metody Romberga
metoda adaptacyjna
b) kwadratury Gaussa
- kwadratury Gaussa
- złożone kwadratury Gaussa
Całki pojedyncze właściwe
Całka oznaczona Riemanna
Niech funkcja f(x) będzie określona i ograniczona na przedziale [a,b]. Dokonajmy podziału przedziału [a,b] takiego, że:
a = x0 < x1 < ... < xn+1 = b
i utwórzmy sumę
![]()
, gdzie ![]()
są dowolnymi punktami pośrednimi
Jeżeli ciąg {SN} dla ![]()
jest zbieżny do tej samej granicy S przy każdym przedziale odcinka [a ; b] takim, że ![]()
niezależnie od wyboru punktów Ci to funkcję f(x) nazywamy całkowalną w przedziale [a ; b], a granicę S ciągu (1) nazywamy:
Całką oznaczoną Riemanna funkcji f o oznaczamy:
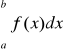
Można wykazać, że funkcja ograniczona w przedziale domkniętym jest całkowalna wtedy i tylko wtedy, gdy jej punkt nieciągłości w przedziale [a ; b] tworzą zbiór miary zero.
Jeżeli przez F(x) oznaczymy funkcję pierwotną funkcji f(x) w przedziale [a,b] (jeżeli F'(x) = f(x)) to ma miejsce wzór
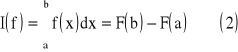
![]()
, gdzie E(f) - reszta kwadratury
Interpretacją graficzną całki oznaczonej jest pole pomiędzy osią OX, krzywą.
Wzór (1) jest inaczej nazywany kwadraturą. Nazwa pochodzi od sumowania wyrazów ciągu, które w najprostszym przypadku graficzną interpretację mają w postaci czworokątów.
Całka oznaczona Riemanna
Interpretacją graficzną całki oznaczonej jest pole powierzchni pomiędzy osią OX a krzywą. Rysunek obok to ilustruje
Wyznaczmy S sumę ciągu n-wyrazów, które są określone jako iloczyn wartości funkcji w punktach xi∈<a,b> oraz współczynników niezależnych od rodzaju funkcji.
Wówczas
![]()
(1) 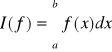
(2)
Można wykazać, że suma ciągu S(f) jest zbieżna do całki oznaczonej I(f) dla ![]()
Uwagi ogólne o całkowaniu numerycznym
Całkowanie numeryczne stosujemy wtedy gdy trudno obliczyć całkę w sposób analityczny lub w przypadku gdy znane są tylko wartości funkcji podcałkowej w punktach zwanych węzłami
W celu przybliżonego obliczenia całki oznaczonej funkcji f(x) na skończonym przedziale ![]()
, funkcję podcałkową f(x) zastępujemy interpolującą funkcją φ(x), którą łatwo można całkować. Funkcja φ(x) będzie wielomianem interpolującym z węzłami interpolacji x0, x1, …, xn. Wówczas całkę możemy zastąpić sumą, współczynniki ai zależą od metody obliczeń
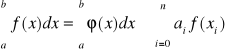
(4)
Kwadratury z ustalonymi węzłami
Kwadratury Newtona-Cotesa
Całkowanie z zastosowaniem kwadratur o ustalonych węzłach polega na zastąpieniu funkcji podcałkowej wielomianem interpolacyjnym Lagrange'a Li(x).
Jeżeli dla skończonego przedziału [a,b] wybierzemy zbiór punktów węzłowych {x0, ..., xn} takich, że:
xi = x0 + i · h
gdzie:
![]()
dla wówczas=(0, 1, …, n)
n - oznacza również stopień wielomianu interpolacyjnego
![]()
(5), gdzie:
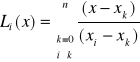
(6)
wówczas
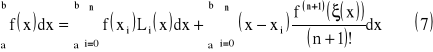
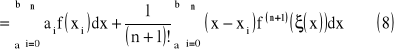
ξ - dowolny punkt pośredni z przedziału (x,xi)
gdzie:
![]()
oraz 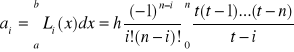
(9)
ostatecznie wzór kwadratury Newtona - Cotesa oraz reszta kwadratury
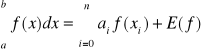
(10)
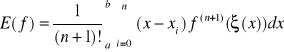
(11)
Twierdzenie 1
Kwadratury Newtona-Cotesa oparte na n+1 węzłach są rzędu
|
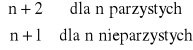
wówczas wzory kwadratur dla n parzystych mają postać
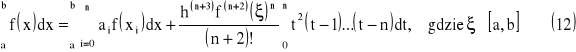
oraz dla nieparzystych mają postać:
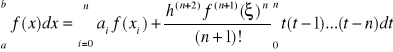
(13)
Kwadratury z ustalonymi węzłami - wzór trapezów
Wyznaczmy wzór kwadratury dla n = 1
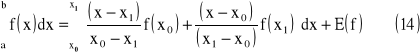
gdzie:
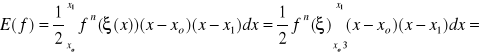
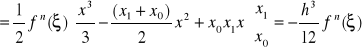
wówczas:
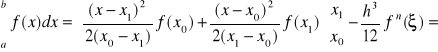
![]()
(16)
Ostatecznie otrzymujemy
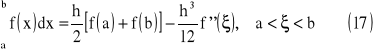
powyższe równanie jest znane jako wzór trapezów - widać, że wzór pozwala dokładnie obliczyć całkę dla dowolnej funkcji, dla której druga pochodna jest zero (wtedy reszta jest 0).
Zauważmy, że dla powyższych rozwiązań końce przedziału całkowania są węzłami kwadratury x0=a oraz xn=b. Wzory kwadratur oparte na tych węzłach nazywamy wzorami zamkniętymi Newtona - Cotesa.
Podobnie wyznaczyć można wzory dla innych n.
Kwadratury Newtona-Cotesa - wzory zamknięte
Poniżej znajdują się wzory zamknięte dla n = (1..3):
wzór trapezów 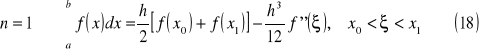
wzór parabol (Simpsona)
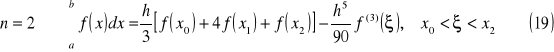
wzór Bessela
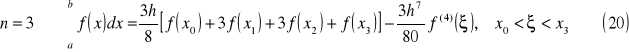
Interpretacja graficzna
wzór parabol (Simpsona)
wzór Bessela
Kwadratury Newtona - Cotesa - wzory otwarte
Wzory kwadratur nie opartych na węzłach będących końcami przedziału całkowania nazywamy wzorami otwartymi Newtona - Cotesa
Jeżeli dla skończonego [a ; b] przedziału wybierzemy zbiór punktów węzłowych {x0, …, xn} takich, że :
![]()
gdzie:
![]()
dla i=(0, …, n)
oraz
![]()
W oparciu o Twierdzenie 1 można również wyznaczyć wzory kwadratur otwartych. Wówczas wzory kwadratur dla n parzystych mają postać
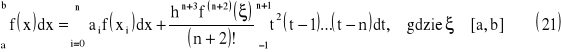
oraz dla n nieparzystych mają postać:
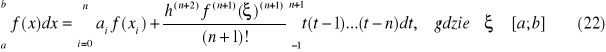
wzór prostokątów
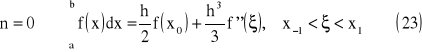
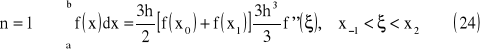
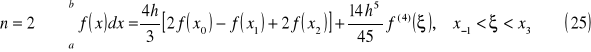
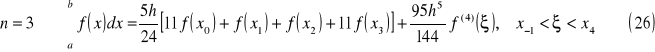
Interpretacja geometryczna
wzór prostokątów
wzór trapezów
Kwadratury Newtona-Cotesa - porównanie
Przykładowe wyniki obliczeń całki
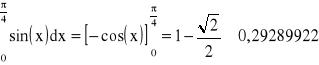
Wyniki obliczeń dla wzorów otwartych i zamkniętych:
n |
0 |
1 |
2 |
3 |
wzory zamknięte |
|
0,27768018 |
0,29293264 |
0,29291070 |
błąd |
|
0,01521303 |
0,00003924 |
0,00001748 |
wzory otwarte |
0,30055887 |
0,29798754 |
0,29285866 |
0,29286923 |
błąd |
0,007666565 |
0,00509432 |
0,00003456 |
0,00002399 |
Kwadratury Newtona-Cotesa - podsumowanie
Kwadratury Newtona-Cotesa dają coraz lepszą dokładność wraz ze wzrostem n. Jednak wraz ze wzrostem n wzór na sumę posiada również rosnącą liczbę czynników. Dlatego kwadratur Newtona-Cotesa nie stosuje się dla dużych n oraz z uwagi na pojawianie się ujemnych współczynników (dla n = 7). Co więcej dla dużych n istnieją funkcje ciągłe, dla których ciąg kwadratur Newtona - Cotesa nie jest zbieżny do całki
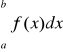
W praktyce nie stosuje się kwadratur Newtona - Cotesa wysokiego rzędu.
Jak widać aby obliczyć wartość całki stosując kwadratury Newtona - Cotesa wystarczy wyznaczyć wartość funkcji w punktach węzłowych, a następnie podstawić je do wzoru. Większą trudność sprawia oszacowanie reszty kwadratury, gdyż należy wyznaczyć maksimum pochodnej k rzędu funkcji dla przedziału całkowania.
Obliczyć poniższą całkę stosując metodę Simpsona
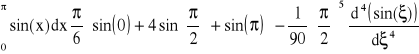
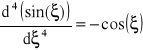
, wtedy ![]()
![]()
wówczas wyniki:
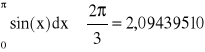
oraz oszacowanie błędu obliczeń:
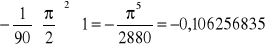
rozwiązanie dokładne:
Kody źródłowe:
przykładowa całkowana funkcja:
function f(x:extender):extender,
begin
result:=sin (2*x*x)+2*cos(3x);
end;
wzór prostokątów:
function calka_n_0_wzor_otwarty(a,b:extended):extended;
var h:extended;
begin
h:=(b-a)/2;
result:=2*h*f(a+h);
end;
wzór trapezów:
function calka_n_1_wzor_zamkniety(a,b:extended):extended;
var h:extended;
begin
h:=(b-a);
result:=(h/2)*(f(a)+f(b));
end;
wzór parabol:
function calka_n_2_wzor_zamkniety(a,b:extended):extended;
var h:extended;
begin
h:=(b-a)/2;
result:=(h/3)*(f(a)+f(a+h)=f(b));
end;
Kwadratury z ustalonymi węzłami
Złożone kwadratury Newtona - Cotesa:
W poprzednim punkcie zostały przedstawione kwadratury Newtona-Cotesa. Wiemy, że błąd kwadratury zależy od długości przedziału całkowania oraz rzędu kwadratury. Dlatego w oparciu właśnie o kwadratury Newtona-Cotesa niskich rzędów zdefiniujemy tzw. wzory złożone Newtona-Cotesa. W celu zwiększenia dokładności obliczeń należy zmniejszyć długość przedziału. Wynika z tego, że dzieląc przedział całkowania na m podprzedziałów i obliczając dla każdego przedziału kwadraturę Newtona-Cotesa niskiego rzędu, następnie, gdy zsumujemy wyniki podprzedziałów, uzyskamy wynik zbieżny do rozwiązania dokładnego, natychmiast zwiększy się dokładność obliczeń.
m=1
Otrzymane w ten sposób kwadratury określono na całym przedziale całkowania nazywamy złożonymi kwadraturami Newtona-Cotesa
Twierdzenie 2:
Podzielmy przedział całkowania [a,b] na m części przy pomocy punktów:
![]()
, dla ![]()
, ![]()
mamy wtedy:
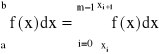
stosując do każdej z całek po prawej stronie równania dowolny wzór kwadratury Newtona-Cotesa ...
Na podstawie poprzedniej zależności możemy wyprowadzić wzory złożonych kwadratur:
złożony wzór prostokątów:
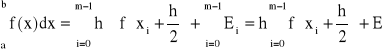
(28)
gdzie błąd przybliżenia ![]()
(29)
oraz ![]()
złożony wzór trapezów:
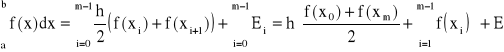
(30)
gdzie błąd przybliżenia ![]()
(31)
oraz ![]()
złożony wzór parabol - dla m parzystych:
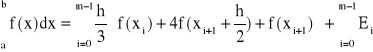
(32)
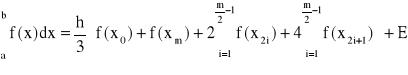
(33)
gdzie błąd przybliżenia ![]()
(34)
oraz ![]()
Podsumowanie:
Z powyższych wzorów wynika, że jeśli funkcja f jest wystarczająco regularna, to całka tej funkcji może być z dowolnie dużą dokładnością przybliżona przy pomocy złożonych kwadratur. Dla złożonych kwadratur Newtona-Cotesa, również największą trudność sprawia oszacowanie błędu obliczeń.
Twierdzenie 3:
Jeżeli ![]()
(jest jednokrotnie całkowalna w przedziale [a,b]), to dla każdego ciągu m złożonych kwadratur Newtona-Cotesa n-tego rzędu dla funkcji f jest zbieżny do całki: 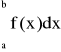
, przy ![]()
inaczej 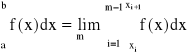
![]()
, ![]()
, ![]()
Przykład:
Obliczyć poniższą całkę:
Rozwiązanie dokładne
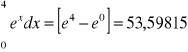
Metoda Simpsona m=1, h=2
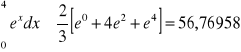
błąd = -3,17143
Metoda Simpsona m=1, h=1
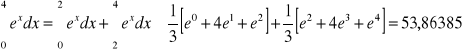
błąd = -0,26570
Metoda Simpsona m=4, h=0,5
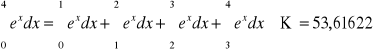
błąd = -0,01807
Przykładowe wyniki obliczeń całki:
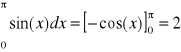
Wyniki obliczeń dla wzorów złożonych w zależności od m:
m |
|
2 |
4 |
8 |
16 |
32 |
64 |
wzór prostokątów |
wynik |
1,110720735 |
1,751785441 |
1,936297295 |
1,983970758 |
1,995986709 |
1,998996147 |
|
błąd |
0,889279265 |
0,248214559 |
0,066102705 |
0,016029242 |
0,004013791 |
0,001003853 |
wzór trapezów |
wynik |
1,570796327 |
1,896118898 |
1,1974231602 |
1,993570344 |
1,998393361 |
1,999598389 |
|
błąd |
0,429203673 |
0,103881102 |
0,025768398 |
0,006429656 |
0,001606639 |
0,000401611 |
wzór parabol |
wynik |
2,094395102 |
2,004559755 |
2,000269170 |
2,000016591 |
2,000001033 |
2,000000065 |
|
błąd |
-0,094395102 |
-0,004559755 |
-0,000269170 |
-0,000016591 |
0,000001033 |
0,000000065 |
Kody źródłowe:
Złożony wzór prostokątów:
function Calka_Prostokat_Zlozony(a,b:extended;m:integer):extended;
var h,x,I_0:extended;
begin
h:=(b-a)/m;
I_0:=0.0;
for i:=0 to m-1 do
begin
x:=a+(i*h);
x:=x+(h/2);
I_0:=I_0+f(x)
end;
result:=I_0*h
end;
Złożony wzór trapezów:
function Calka_Trapez_Zlozony(a,b:extended;m:integer):extended;
var h,x,I_0,I_1:extended;
begin
h:=(b-a)/m;
I_0:=f(a)+f(b);
I_1:=0.0;
for i:=0 to m-1 do
begin
x:=a+(i*h);
I_1:=I_1+f(x);
end;
result:=(0.5*I_0+I_1)*h;
end;
Złożony wzór parabol:
function Calka_Simpson_Zlozony(a,b:extended;m:integer):extended;
var h,x,I_0,I_1,I_2:extended;
begin
h:=(b-a)/m;
I_0:=f(a)+f(b);
I_1:=0.0;
I_2:=0.0;
for i:=0 to m-1 do
begin
x:=a+(i*h);
if (i mod 2)=0
then I_2:=I_2+f(x);
else I_1:=I_1+f(x);
end;
result:=(I_0+2.0*I_2+4.0*I_1)*h/3;
end;
Wyszukiwarka
Podobne podstrony:
Metody numeryczne w elektrotechnice, Metody numeryczne w elektrotechnice
6 spr met numer, semestr5, metody numeryczne, 6 met simplex
Macierze - teoria, Politechnika Radomska, 1 stopień, przed 5 semestrem, metody numeryczne, Wysyłka M
Zadanie 2 Met Num TM 2010, Politechnika Radomska, 1 stopień, przed 5 semestrem, metody numeryczne,
metoda siecznych, Elektrotechnika, SEM3, Metody numeryczne, egzamin metody numeryczn
metoda regula falsi, Elektrotechnika, SEM3, Metody numeryczne, egzamin metody numeryczn
num 4 (1), polibuda, 4 semestr, metody numeryczne(laboratorium, wejściówki kolokwia), ćw4
ZADANIE PROJEKTOWE. 1 Madejski Grzegorz & Michalski Paweł, Elektrotechnika, SEM3, Metody numeryczne
Metody numeryczne, sprawozdanie num new332 pluskwik, Piotr Próchniak gr
Wzory i obliczenia2, Elektrotechnika, SEM3, Metody numeryczne
Notka, Informatyka, Informatyka, Informatyka. Metody numeryczne, Kosma Z - Metody numeryczne dla zas
Metody numeryczne (USM), ozdysk, odzysk, utp, Elektrotechnika B.Płachta, s.I EP z. II st.
Powtorka mat, Elektrotechnika AGH, Semestr III zimowy 2013-2014, Metody Numeryczne, Kolos 1 - ZALICZ
Interpolacja-Lania, Elektrotechnika, SEM3, Metody numeryczne
21.03.2011, Elektrotechnika I stopień PWSZ Leszno, SEMESTR II, Metody Numeryczne, 2. 21.03.2011
R7 Roz Num, metody numeryczne
interpolacja, Elektrotechnika, SEM3, Metody numeryczne, egzamin metody numeryczn
więcej podobnych podstron