Hipotezy statystyczne - sformułowane przypuszczenia dotyczące rozkładu populacji:
parametryczne - precyzują wartości parametrów w rozkładzie populacji (są najczęściej stosowane)
nieparametryczne - dotyczą rozkładów badanej cechy w populacji generalnej i nie prezentują wartości parametrów tego rozkładu
h0 - podlega weryfikacji
h1 - alternatywna
Do weryfikacji testów używamy testów. Testy - statystyki z próby które wykorzystujemy do weryfikacji hipotez.
Test I rodzaju - h0 jest prawdziwe ale wynik testu ją obalił i przyjęto h1 popełnienie tego błędu jest związane z przyjętym poziomem istotności
Test II rodzaju - h0 jest fałszywa ale wynik testu ją potwierdził i przyjęto tę hipotezę zerową.
Test nieparametryczny - test χ2 bada zgodność rozkładu empirycznego z teoretycznym.
h0 - mówi że rozkład naszej cechy jest zgodny z rozkładem teoretycznym
h1 - mówi że rozkład naszej cechy odbiega od rozkładu teoretycznego
Zależności pomiędzy zmiennymi:
zależność funkcyjna - występuje wówczas gdy zmiana wartości jednej zmiennej powoduje ściśle określoną zmianę wartości pozostałych zmiennych.
zależność stochastyczna - gdy zmiana wartości jednej zmiennej losowej powoduje zmianę rozkładu prawdopodobieństwa drogiej zmiennej losowej czyli w miarę wzrostu wartości jednej zmiennej na ogół rosną wartości drugiej zmiennej.
Wariantem zależności stochastycznej jest zależność korelacyjna, która dotyczy tylko zmiennej zależnej mierzalnej.
brak zależności - zmiana wartości jednej zmiennej nie powoduje zmiany wartości drugiej zmiennej.
Własności prostych regresji:
Proste regresji przecinają się w punktach
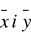
.Współczynniki kierunkowe b1 i b2 prostych regresji mają taki sam znak + lub -. Gdy + to zachodz korelacja dodatnia pomiędzy cechami a więc ze wzrostem wartości jednej zmiennej rośnie wartość drugiej.
Współczynnik kierunkowy b1 wskazuje o ile zmieni się średnio wartość pierwszej zmiennej (zależnej0 gdy wartość drugiej zmiennej (niezależnej) zmieni się o jednostkę w której wyrażona jest ta zmienna. - z b2 jest analogicznie.
Gdy między zmiennymi nie występuje zależność wówczas współczynniki kierunkowe prostych są równe 0: b1 =0 i b2 =0. Wówczas proste regresji przecinają się pod kątem 900.
Jeżeli między zmiennymi występuje liniowa zależność funkcyjna, to proste regresji pokrywają się.
Jeżeli między zmiennymi występuje związek korelacyjny, to proste regresji przecinają się pod pewnym kątem. Gdy wartość tego kąta maleje do 0 to związek korelacyjny dąży do związku funkcyjnego. Im większa wartość tego kąta tym siła związku słabnie ( gdy kąt prosty - brak związku).
Współczynnik korelacji jest kowariancją dwuwymiarowej zmiennej losowej (x, y)podzieloną przez iloczyn odchyleń standardowych zmiennej x i zmiennej y.
Własności korelacji;
Gdy r = 0 wówczas między zmiennymi nie występuje zależność liniowa, może występować zależność nieliniowa.
Gdy r = 1 lub r = -1 to zależność między zmiennymi jest funkcyjna, liniowa.
Jeżeli współczynnik korelacji przybiera wartości z przedziałów 0 < r < 1 lub-1 < r < 0 to zależność między zmiennymi jest korelacyjna.
Im bardziej współczynnik korelacji różni się od 0 więc im bliższy jest wartościom 1 lub -1 tym związek między zmiennymi jest silniejszy.
Znak współczynnika korelacji jest taki sam jak znak współczynników kierunkowych prostych regresji b1 i b2. Znak + oznacz korelację dodatnią a - ujemną.
Współczynnik determinacji r2 (tzw. Określoności) - wyjaśnia jaka część zmienności zmiennej y spowodowana jest regresją, a więc zależnością od zmiennej x.
Współczynnik indeterminacji 1 - r2 - podaje jaka część zmienności zmiennej y nie jest spowodowana regresją, a więc nie jest spowodowana wpływem zmiennej x.
Prosta próba losowa - to taka próba w której każdy element populacji ma jednakową szansę (prawdopodobieństwo) wejścia do próby, a losowanie elementów jest niezależne.
Schematy losowania:
niezależne - ze zwracaniem, - jeden element populacji może zostać wylosowany do próby więcej niż 1 raz
zależne - bez zwracania,
warstwowe - populację dzieli się na części tzw. warstwy tak że każdy element populacji należy dokładnie do jednej z warstw. Elementy dla których określa się badaną cechę A, losuje się z każdej warstwy oddzielnie, stosując losowanie zależne lub niezależne.
Systematyczne - całą populację dzielimy na n części gdzie n jest liczbą próby. Każda część populacji reprezentowana jest przez taką samą liczbę elementów, które numerujemy od 1 do k. Dla jednej części populacji losujemy 1 element z pośród k elementów. Do próby wchodzi wylosowany element oraz wszystkie te elementy z pozostałych części populacji, które mają ten sam numer.
Dwufazowe - polega na wyborze z populacji dużej próby, dla której określa się cechy B, C, D itd., W drugiej fazie pobiera się próbę do określenia cechy A, wykorzystując informację o cechach B, C, D, itd.
Wielostopniowe - populację dzielimy na duże jednostki, które losujemy, jest to losowanie pierwszego stopnia. Wylosowane jednostki dzielimy na jednostki mniejsze i przeprowadzamy losowanie drugiego stopnia. Wylosowane jednostki drugiego stopnia dzielimy na jeszcze mniejsze i ponownie przeprowadzamy losowanie. Czynności te powtarzamy do momentu uzyskania jednostek najwyższego (podstawowego) stopnia. Wylosowane jednostki najwyższego stopnia wchodzą do próby.
Estymacja punktowa - polega na wyznaczeniu parametru θ populacji generalnej na podstawie estymatora Tn będącego statystyką z próby. Szacunek taki uzupełnia się zwykle podaniem błędu estymatora. θ = Tn - Bn.
Test zgodności χ2 pozwala na weryfikację hipotezy, że populacja ma określoną postać funkcyjną dystrybuanty. Może to być rozkład dla zmiennej losowej zarówno skokowej jak i ciągłej, a jedynym ograniczeniem jest konieczność operowania dużą próbą.
Estymacja statystyczna - rodzaj wnioskowania o wartościach parametrów populacji generalnej na podstawie statystyk określonych dla n-elementowych prób wylosowanych z populacji. Wnioskowanie to polega na tym że znając wyniki uzyskane z próby staramy się ocenić z określonym stopniem dokładności wartości parametrów zmiennej.
3 powody dla których stos. Próby:
Populacja jest nieokreślona, pop. -jest skończona ale tak liczna że jej zbadanie jest pracochłonne i czasochłonne - zbadanie jakiejś cechy - zniszczenie jednostki statystycznej.
Próba musi reprezentować populację generalną.
Próba reprezentatywna - to taka próba z której po odpowiednich przeliczeniach uzyskamy idealny obraz populacji. Otrzymujemy ją przez losowy wybór.
Próba tendencyjna - reprezentatywna daje fałszywy obraz populacji.
Parametry z próby - to statystyki które oblicza się na podstawie wyników z próby, np. średnia arytmetyczna, wariancja
Własności estymatora
nieobciążony - oznacza że przy wielokrotnym losowaniu próby średnia z wartości otrzymywanej przez estymator równa jest wartości szacowanego parametru θ w populacji generalnej.
zgodny - jeżeli jest stochastycznie zbieżny do szacowanego parametru. Im większa próba tym estymator większy.
efektywny - jeżeli mamy zbiór estymatorów nieobciążonych Tn1, Tn2 ... Tni parametru θ to estymatorem najbardziej efektywnym w tym zbiorze będzie ten który ma najmniejszą wariancję.
Efektywność estymatora - najbardziej efektywnego ma wartość =1, natomiast wszystkich pozostałych mieści się 0 < e < 1.
Wyznaczanie liczebności próby - gdy populacja generalna ma rozkład normalny N (, σ i znana jest wariancja tej populacji stosujemy wzór pozwalający na określenie liczebności próby
![]()
![]()
Dla małych prób badanie istotności różnic między średnimi możemy przeprowadzić opierając się na statystyce:
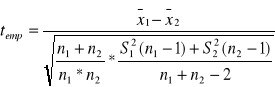
populacje z których pobieramy próby powinny mieć rozkład normalny
populacje powinny mieć jednakowe wariancje, jak w przypadku dużych prób.
Kiedy liczebność dużych prób jest jednakowa, a więc n1 = n2 =n to wzór ma postać 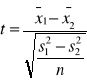
Błąd standardowy dla średnich:
![]()
Błąd średni:
![]()
Wyszukiwarka
Podobne podstrony:
Ekonomika ćw II, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Ekonomika, Ściągi
ststa ściąga I, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Statystyka, ściągi
Ekonomika ćw II duze, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Ekonomika, Ściągi
spółki, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ściąga wg mnie, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZ$D~2, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
tematy sprawozdań, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Statystyka
ZARZĄDZANIE EGZ 2, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZADZANIE EGZ 1a, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZ$D~3, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZ$D~1, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZĄDZANIE EGZ 3a, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
Ekonomika ćw I, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Ekonomika, Ściągi
sciaga egzamin, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
ZARZĄDZANIE EGZ 3, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
spółki, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, ściągi
Aktywa-kolokwium, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, Cwiczenia, ściągi
definicje, Niezbędnik leśnika, WYDZIAŁ LEŚNY, Zarządzanie, Cwiczenia, ściągi
więcej podobnych podstron