Ćwiczenia 6. Weryfikacja
Zadanie. Niech Yt = α0 + α1X1t + α2X2t + α3X3t + α4X4t + ξt, gdzie:
Yt - zmiany produkcji w przedsiębiorstwie [mld zł],
X1t - zatrudnienie [tys. osób],
X2t - wartość maszyn i urządzeń [mld zł],
X3t - czas przestoju maszyn [l. dni],
X4t - nakłady inwestycyjne [mln zł],
t € [1991 - 2000].
Lata |
Yt |
X1t |
X2t |
X3t |
X4t |
1991 |
10 |
6 |
8 |
14 |
12 |
1992 |
10 |
6 |
8 |
14 |
12 |
1993 |
16 |
10 |
12 |
18 |
12 |
1994 |
16 |
10 |
12 |
18 |
14 |
1995 |
12 |
8 |
8 |
18 |
10 |
1996 |
14 |
10 |
8 |
18 |
12 |
1997 |
20 |
12 |
14 |
24 |
14 |
1998 |
20 |
12 |
16 |
24 |
12 |
1999 |
20 |
12 |
16 |
26 |
12 |
2000 |
22 |
14 |
18 |
26 |
10 |
Parametry modelu oszacowano klasyczną metodą najmniejszych kwadratów. Rezultaty poniżej.
Ordinary Least Squares Estimation
***************************************************************************
I.
Dependent variable is Y
10 observations used for estimation from 1991 to 2000
II.
Regressor Coefficient Standard Error T-Ratio[Prob]
C -3.97930 1.022100 -3.8933[0.011]
X1 0.86241 0.105200 8.1979[0.000]
X2 0.37075 0.061860 5.9935[0.002]
X3 0.16983 0.066925 2.5377[0.052]
X4 0.29246 0.070716 4.1357[0.009]
***************************************************************************
III.
1. R-Squared 0.99785 6. R-Bar-Squared 0.99614
2. S.E. of Regression 0.27483 7. F-stat. F(4,5) 581.2805[0.000]
3. Mean of Dependent Variable 16.0000 8. S.D. of Dependent Variable 4.4222
4. Residual Sum of Squares 0.37766
5. DW-statistic 2.87240
***************************************************************************
IV. Diagnostic Tests
***************************************************************************
* Test Statistics * LM Version * F Version *
***************************************************************************
* A:Serial Correlation *CHSQ(1)= 3.1360[0.077]**************F(1,4)= 1.8275[0.248] *
* B:Functional Form *CHSQ(1)= 0.64114[0.423]*************F(1,4)= 0.27402[0.628]*
* C:Normality *CHSQ(2)= 0.80713[0.668]*************Not applicable *
* D:Heteroscedasticity*CHSQ(1)= 0.48283[0.487]*************F(1,8)= 0.40586[0.542]*
***************************************************************************
A: Lagrange multiplier test of residual serial correlation
B:Ramsey's RESET test using the square of the fitted values
C:Based on a test of skewness and kurtosis of residuals
D:Based on the regression of squared residuals on squared fitted values
V. Residuals and Fitted Values of Regression
***************************************************************************
Based on OLS regression of Y on: C X1 X2 X3 X4
10 observations used for estimation from 1991 to 2000
***************************************************************************
Observation Actual Fitted Residual
1991 10.0000 10.0484 -0.048359
1992 10.0000 10.0484 -0.048359
1993 16.0000 15.6603 0.339670
1994 16.0000 16.2453 -0.245250
1995 12.0000 11.8676 0.132410
1996 14.0000 14.1773 -0.177320
1997 20.0000 19.7306 0.269430
1998 20.0000 19.8872 0.112840
1999 20.0000 20.2268 -0.226830
2000 22.0000 22.1082 -0.108230
***************************************************************************
Z łatwością zauważymy istotną wadę oszacowanego modelu, wystarczy przyjąć założenie o niezmienność w czasie zatrudnienia, wartości majątku produktywnego oraz nakładów inwestycyjnych by stwierdzić, że przyrost liczby dni przestoju maszyn powodował równoczesny wzrost wielkości produkcji, teza trudna do obrony.
Zmieniamy założenie o zbiorze zmiennych objaśniających, pozostawimy zmienne {![]()
, a to rezultat zmiany założenia:
Ordinary Least Squares Estimation
***************************************************************************
Dependent variable is Y
10 observations used for estimation from 1991 to 2000
***************************************************************************
Regressor Coefficient Standard Error T-Ratio[Prob]
C -2.74760 1.242000 -2.2122[0.069]
X1 1.03880 0.109020 9.5292[0.000]
X2 0.44660 0.074785 5.9718[0.001]
X4 0.25000 0.094873 2.6351[0.039]
***************************************************************************
R-Squared 0.99509 R-Bar-Squared 0.99264
S.E. of Regression 0.37949 F-stat. F(3,6) 405.3708[.000]
Mean of Dependent Variable 16.0000 S.D. of Dependent Variable 4.4222
Residual Sum of Squares 0.86408 Equation Log-likelihood -1.9460
Akaike Info. Criterion -5.9460 Schwarz Bayesian Criterion -6.5512
DW-statistic 2.6175
***************************************************************************
Diagnostic Tests
***************************************************************************
* Test Statistics * LM Version * F Version *
***************************************************************************
* A:Serial Correlation*CHSQ(1)= 1.9691[0.161]*F(1,5)=1.2259[0.319]*
* B:Functional Form *CHSQ(1)=0.013243[0.908]*F(1,5)=0.0066304[0.938]*
* C:Normality *CHSQ(2)=0.20934[0.901]* Not applicable *
* D:Heteroscedasticity*CHSQ(1)=0.75721[0.384]*F(1,8)=0.65540[0.442]*
Residuals and Fitted Values of Regression
***************************************************************************
Based on OLS regression of Y on:
C X1 X2 X4
10 observations used for estimation from 1991 to 2000
***************************************************************************
Observation Actual Fitted Residual
1991 10.0000 10.0583 -0.058252
1992 10.0000 10.0583 -0.058252
1993 16.0000 16.0000 0.00000
1994 16.0000 16.5000 -0.50000
1995 12.0000 11.6359 0.36408
1996 14.0000 14.2136 -0.21359
1997 20.0000 19.4709 0.52913
1998 20.0000 19.8641 0.13592
1999 20.0000 19.8641 0.13592
2000 22.0000 22.3350 -0.33495
Zmiana założenia, w rezultacie której ze zbioru zmiennych objaśniających została usunięta zmienna X3t, pozwoliła usunąć tę widoczną wadę modelu jaką była oczywista sprzeczność opisu zmian wielkości produkcji w wyniku zmian między innymi liczby dni przestoju maszyn.
Dopuszczalność modelu ze względu na R2:
Niech wartość dopuszczalna ![]()
jest równa 75%, to ponieważ ![]()
zatem nie ma podstaw do odrzucenia hipotezy ![]()
co oznacza iż model jest wystarczająco zgodny.
Wyrazistość modelu V:
Ustalmy dopuszczalną wartość współczynnika wyrazistości V0 na poziomie 10%. Wartość parametru V jest równa: ![]()
, co oznacza, że ![]()
. Nie ma więc podstaw do odrzucenia hipotezy H0, tzn. rzeczywisty udział standardowego błędu oceny w stosunku do wartości przeciętnej ![]()
zmiennej objaśnianej jest mniejszy od dopuszczalnego.
Istotność ocen parametrów strukturalnych:
Z tablic rozkładu t - Studenta dla parametrów rozkładu (![]()
, wyznaczamy wartość krytyczną statystyki tkr. Jeśli więc ![]()
a liczba stopni swobody n-(k+1)=6, to tkr=2,447: ![]()
, ![]()
, ![]()
, w każdym przypadku wartości statystyki ![]()
dla i=1,2,4 są większe od wartości tkr, co oznacza, iż nie można przyjąć hipotezy H0, należy przyjąć hipotezę alternatywną ![]()
a to znaczy, że otrzymane oceny parametrów strukturalnych są istotnie różne od zera. W konsekwencji wszystkie trzy zmienne objaśniające ![]()
istotnie wpływają na zmiany zmiennej objaśnianej Yt.
Symetria składnika losowego:
Parametry modelu oszacowano na bazie danych o zmiennych modelu z lat 1991-2000. Próba licząca 10 obserwacji jest małą próbą, zatem można przyjąć, że ![]()
ma rozkład dwumianowy o parametrach ![]()
/m jest liczbą reszt dodatnich/. Dla weryfikowanego modelu m=5. Z tablic do sprawdzania hipotezy symetrii w przypadku małej próby statystycznej określamy wartości m1=2 oraz m2=8. Stąd wobec tego, że prawdziwa jest relacja ![]()
, nie więc podstaw do odrzucenia hipotezy H0, składnik losowy jest symetryczny.
Losowość składnika losowego:
Oznaczmy literą A zdarzenie, że ![]()
, natomiast literą B zdarzenie, że ![]()
. Dla reszt weryfikowanego modelu otrzymujemy ciąg zdarzeń: {B,B,A,B,A,B,A,A,A,B}. W ciągu zdarzeń występuje tylko jedna seria o maksymalnej długości, liczącej trzy takie same zdarzenia, R3=1.
Z tablic testu serii wyznaczamy maksymalną liczbę obserwacji n, dla której prawdopodobieństwo ![]()
. Dla serii o długości k=5, maksymalna liczba obserwacji n jest nie większa aniżeli 10, ponieważ rzeczywista długość serii równa 3 jest mniejsza aniżeli dopuszczalna równa 5, stąd nie ma podstaw do odrzucenia hipotezy o losowości składnika losowego.
Innym stosowanym rozwiązaniem jest tzw. test liczby serii. Sprawdzianem hipotezy o losowości jest liczba rk określająca liczbę wszystkich serii, w analizowanym przypadku rk=7. Z tablic liczby serii, dla wartości n1 /liczba zdarzeń A/ oraz n2 /liczba zdarzeń B/ i poziomu istotności ![]()
określamy wartość krytyczną![]()
. Ponieważ n1=5, n2=5, to dla ![]()
, ![]()
, stąd ![]()
, co oznacza, że przyjmujemy hipotezę o losowości rozkładu składnika losowego. Duża liczba serii potwierdza tezę, że próbkowe obserwacje są losowe.
Stacjonarność składnika losowego:
Na tym etapie weryfikacji zależy nam na odpowiedzi na pytanie o to, czy reszty modelu nie wykazują korelacji w czasie?.
Sprawdzianem hipotezy ![]()
o stacjonarności składnika losowego jest statystyka: 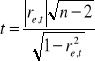
, dla ![]()
, t=0,9042674. Wartość krytyczna ![]()
określona z tablic rozkładu t-Studenta dla poziomu istotności ![]()
oraz n-2=8, stopni swobody jest równa ![]()
. Ponieważ prawdziwa jest nierówność ![]()
nie powodów by odrzucić hipotezę o stacjonarności składnika losowego.
Weryfikacja założenia o wartości przeciętnej /oczekiwanej/ składnika losowego. Ten element procedury weryfikacyjnej dotyczy modeli nieliniowych, które w rezultacie transformacji postaci analitycznej można przedstawić w równoważnej postaci liniowej. Analizowany tu przykład nie wymaga zatem weryfikacji tej własności.
Autokorelacja składnika losowego:
t |
|
|
1 |
-0,058252 |
|
2 |
-0,058252 |
-0,058252 |
3 |
0,000000 |
0,000000 |
4 |
-0,500000 |
-0,500000 |
5 |
0,364080 |
0,364080 |
6 |
-0,213590 |
-0,213590 |
7 |
0,529130 |
0,529130 |
8 |
0,135920 |
0,135920 |
9 |
0,135920 |
0,135920 |
10 |
-0,334950 |
-0,334950 |
Weryfikacja założenia o braku bądź autokorelacji składnika losowego rzędu pierwszego wymaga analizy dwu szeregów reszt {![]()
, w oparciu o nie wyznacza się statystykę DW, jest równa 2,6175. Jej wartość sugeruje autokorelację ujemną. Z tablic rozkładu Durbina -Watsona, dla poziomu ufności ![]()
oraz n i k /k oznacza liczbę zmiennych objaśniających/, określamy wartości dL oraz dU oraz korygujemy statystykę DW.
Dla ![]()
oraz n=10 i k=3, z tablice rozkładu Durbina-Watsona określamy wartości dL=0,525 oraz dU=2,016, skorygowana wartość DW'=4-DW=1,3825. Test nie pozwala na jednoznaczne przyjęcie hipotezy o braku bądź istnieniu hipotezy o autokorelacji, bowiem prawdą jest, że ![]()
, jest to przypadek kiedy test Durbina-Watsona nie wypowiada się jednoznacznie o istnieniu autokorelacji.
Jednoznaczny w takim przypadku jest test Godfreya, dla zdefiniowania statystyki ![]()
, zdefiniujmy macierz Mx=![]()
oraz W, gdzie p=4. w rezultacie otrzymujemy: ![]()
, a wartość statystyki ![]()
. Ponieważ próba statystyczna jest próbą małą, zatem do weryfikacji hipotezy o autokorelacji wykorzystamy statystykę ![]()
, z tablic rozkładu statystyki F dla T1=(n-p-(k+1))=(10-4-4)=2 oraz T2=4, określamy ![]()
=6,94, ponieważ ![]()
nie ma podstaw do odrzucenia hipotezy H0, ostatecznie więc podejrzenie o istnieniu autokorelacji należy odrzucić.
Do weryfikacji hipotezy H0 można wykorzystać statystykę Prob, jeśli przyjmiemy 5% poziom istotności, hipotezę H0 odrzucamy dla Prob![]()
, dla wartości Prob>0,05 nie ma podstaw do odrzucenia H0. Dla analizowanego modelu Prob=0,161, wartość statystyki Prob>0,05, co potwierdza wcześniej otrzymany wynik.
Zgodność rozkładu składnika losowego z rozkładem normalnym:
Obliczona wartość statystyki ![]()
jest równa 0,20934, wartość odczytana z tablic rozkładu ![]()
dla poziomu istotności ![]()
oraz 2 stopni swobody jest równa ![]()
, ponieważ ![]()
, stąd nie ma podstaw do odrzucenia hipotezy H0, składnik losowy jest zgodny z rozkładem normalnym.
Do weryfikacji hipotezy H0 można wykorzystać statystykę Prob, jeśli przyjmiemy 5% poziom istotności, hipotezę H0 odrzucamy dla Prob![]()
, dla wartości Prob>0,05 nie ma podstaw do odrzucenia H0. Dla analizowanego modelu Prob=0,901, wartość statystyki Prob>0,05, co potwierdza wcześniej otrzymany wynik.
Weryfikacja założenia o poprawności przyjętej postaci analitycznej:
Obliczona wartość statystyki ![]()
jest równa 0,013245, wartość odczytana z tablic rozkładu ![]()
dla poziomu istotności ![]()
oraz 1 stopnia swobody jest równa ![]()
, ponieważ ![]()
, stąd nie ma podstaw do odrzucenia hipotezy H0, o liniowej relacji pomiędzy zmiennymi objaśniającymi i zmienną objaśnianą modelu.
Bardziej przydatny staje się test F dla małych prób, wartość statystyki obliczonej ![]()
jest równa 0,0066304, natomiast wartość statystyki odczytanej ![]()
jest równa 6,61, stąd wobec tego, że ![]()
nie ma podstaw do odrzucenia hipotezy o poprawności przyjętej hipotezy o liniowej relacji pomiędzy zmiennymi objaśniającymi i zmienną objaśnianą modelu.
Do weryfikacji hipotezy H0 można wykorzystać statystykę Prob, jeśli przyjmiemy 5% poziom istotności, hipotezę H0 odrzucamy dla Prob![]()
, dla wartości Prob>0,05 nie ma podstaw do odrzucenia H0. Dla analizowanego modelu Prob=0,908, wartość statystyki Prob>0,05, co potwierdza wcześniej otrzymany wynik /w przypadku małej próby Prob=0,938/.
Test na istotność łącznego wpływu zmiennych objaśniających:
Obliczona wartość statystyki F przy parametrach rozkładu (k,n-(k+1)) jest równa 405,3708, wartość odczytana z tablic rozkładu statystyki ![]()
jest równa 4,76, ponieważ ![]()
, stąd nie ma podstaw do przyjęcia hipotezy H0, uznajemy hipotezę alternatywną H1, co oznacza, łączny wpływ zmiennych objaśniających jest statystycznie istotny.
Do weryfikacji hipotezy H0 można wykorzystać statystykę Prob, jeśli przyjmiemy 5% poziom istotności, hipotezę H0 odrzucamy dla Prob![]()
, dla wartości Prob>0,05 nie ma podstaw do odrzucenia H0. Dla analizowanego modelu Prob=0,938, wartość statystyki Prob>0,05, co potwierdza wcześniej otrzymany wynik.
Test stabilności parametrów strukturalnych modelu:
Niech ![]()
, ![]()
, po oszacowaniu modelu na bazie informacji statystycznej opartej na obydwu podzbiorach ![]()
oraz ![]()
otrzymamy dwa ciągi reszt: ![]()
oraz ![]()
. Podział na dwa podzbiory tak niewielkiej próby nie da pozytywnych rezultatów, bowiem w obydwu przypadkach wszystkie reszt są równe zero.
Wyszukiwarka
Podobne podstrony:
cwek 03 5, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
cwek 03 1, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
cwek 03 2, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
wek 03 3, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
model, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
wyklad 4, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
wyklad 6, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
model, Pomoce naukowe, studia, Ekonomia2, III rok Ekonometria
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
uzasadnienie do ustawy budzetowej na 2005r, Pomoce naukowe, studia, Ekonomia2, IV rok Finanse Public
więcej podobnych podstron