Część III - Relacyjne bazy danych
W trzeciej części książki zajmiemy się tworzeniem i wykorzystywaniem baz danych. W kolejnych rozdziałach zaprojektujemy, utworzymy i wypełnimy danymi przykładową bazę Dziennik klasowy. Pokażemy, jak modyfikować informacje przechowywane w naszej bazie, oraz jak tworzyć coraz bardziej skomplikowane zestawienia i raporty.
W każdej bazie danych można wyodrębnić dwa składniki:
model danych,
system zarządzania bazą danych (w skrócie SZBD).
Termin model danych w książce rozumiany będzie szeroko, tzn. jako zbiór zasad dotyczących struktury danych, i ich związków z rzeczywistością.
Pod pojęciem SZBD rozumieć będziemy zbiór narzędzi (aplikacji) umożliwiający dostęp do danych, w szczególności ich odczyt i modyfikację. Przykładową bazę Dziennik klasowy utworzymy korzystając z systemu zarządzania bazą danych Access firmy Microsoft.
Rozdział 17 — Tabele jako zbiory danych
SZBD przechowuje informacje (dane) w tabelach. Tabela charakteryzowana jest przez unikalną w skali bazy danych nazwę. Każda tabela składa się z kolumn o określonej, unikalnej w skali tabeli nazwie. W każdej kolumnie można przechowywać dane określonego typu.
Aby utworzyć nową tabelę należy z dostępnych obiektów bazy danych wybrać obiekt Tabele, kliknąc przycisk Nowy (w rezultacie wywołamy okno przedstawione na rys. 17.1), a następnie z listy dostępnych możliwości wybrać Widok Projekt.
Rys 17.1 Tworzenie nowej tabeli w Widoku Projekt
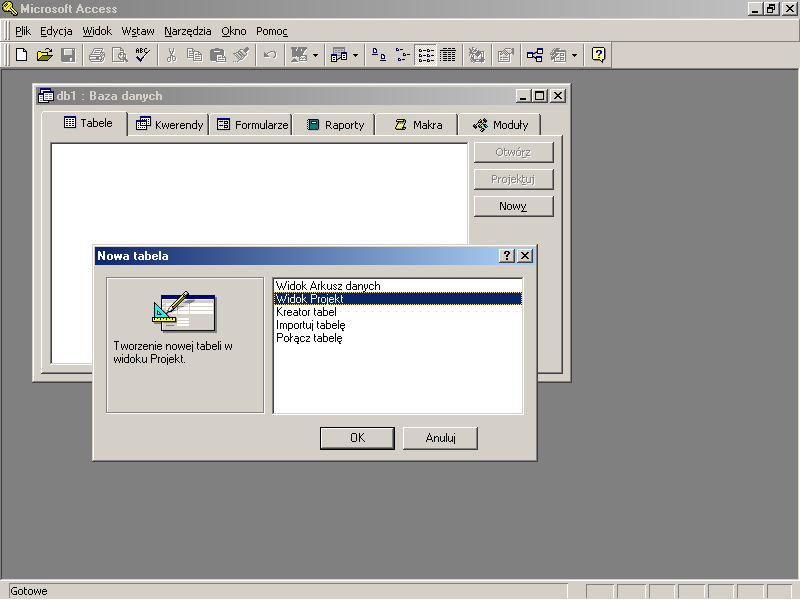
Utwórzmy tabelę Matematyka, w której zapiszemy informacje o ocenach uczniów z tego przedmiotu.
rys. 17.2 Projekt tabeli Matematyka
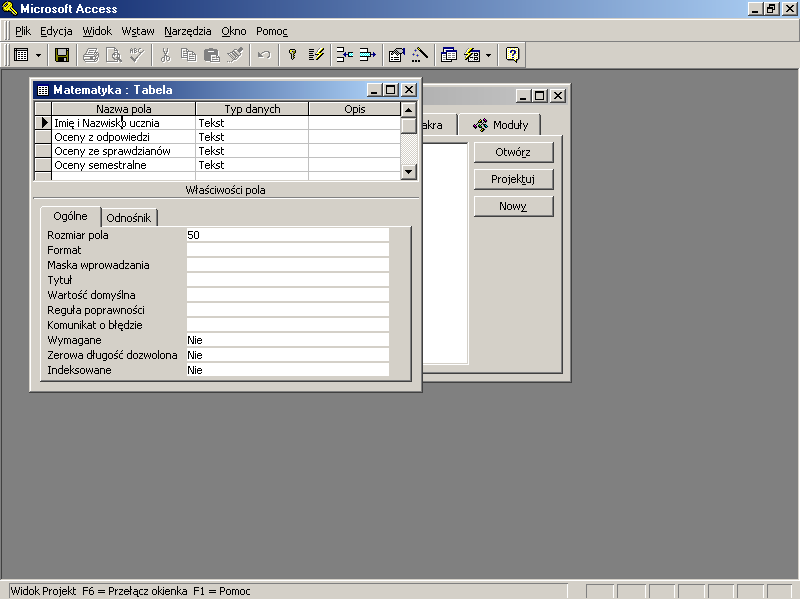
Zaprojektowaliśmy tabelę składająca się czterech kolumn, w każdej z nich będziemy przechowywać inne informacje o konkretnym uczniu. Wypełnijmy tabelę przykładowymi danymi:
rys. 17.3 Tabela Matematyka
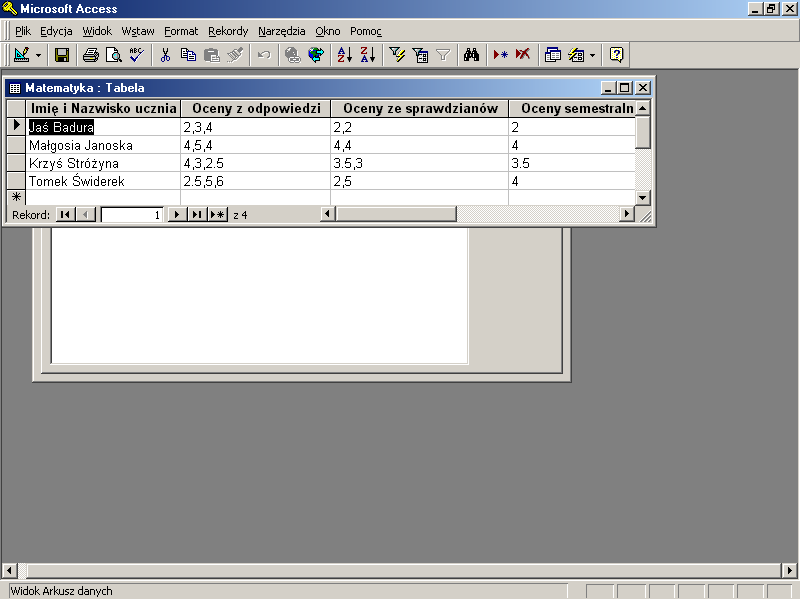
Każdy wiersz w tabeli Matematyka zawiera zbiór informacji o konkretnym uczniu (np. wiersz drugi o Małgosi Janoskiej). Informacje o uczniach podzielona są, według ich rodzaju, na kolumny. I tak, w kolumnie pierwszej przechowywane są dane o imieniu i nazwisku ucznia, w kolumnie drugiej — o ocenach z odpowiedzi ustnych, w kolumnie trzeciej — o ocenach ze sprawdzianów, a w ostatniej kolumnie przechowujemy informacje o ocenach semestralnych ucznia.
Wyodrębnianie danych elementarnych
Pierwszym naszym zadaniem, jako projektantów bazy danych, powinno być określenie danych elementarnych na potrzeby naszego modelu danych. Pod pojęciem danych elementarnych będziemy rozumieć podstawowe, niepodzielne 'cegiełki' informacji, z których możemy zbudować pełną informację o modelowanym fragmencie rzeczywistości. Pojedyncze dane elementarne będziemy przechowywać w odpowiednich kolumnach tabeli.
Ponieważ SZBD wspomagają łączenie danych, natomiast wyodrębnianie danych z fragmentu pojedynczej kolumny jest dość skomplikowane, powinniśmy zawsze do pojedynczej kolumny wpisywać najmniejszą (elementarną) informację o obiekcie.
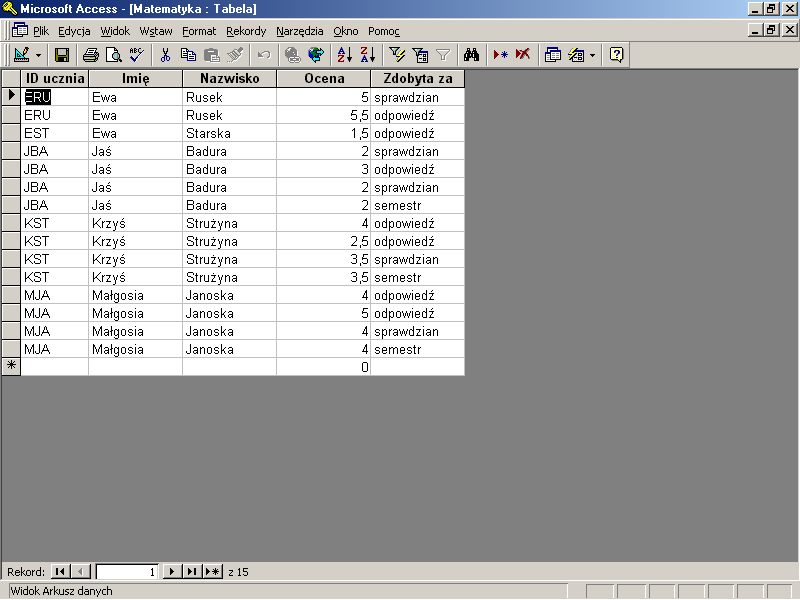
Wróćmy do projektu tabeli Matematyka. Analizując go pod kątem wyodrębniania danych elementarnych, zauważymy, że w pierwszej kolumnie przechowujemy dane o nazwisku i imieniu ucznia. Zastanówmy się, czy w obrębie bazy danych nie będziemy wykorzystywać danych o imieniu w oderwaniu od nazwiska ucznia (lub odwrotnie)? Prawdopodobnie tak, więc pamiętając o umieszczonej powyżej wskazówce, powinniśmy zmienić projekt tabeli Matematyka zastępując kolumnę Imię i nazwisko ucznia dwiema kolumnami — w jednej przechowamy informacje o imieniu, w drugiej o nazwisku ucznia. Przyjrzyjmy się pozostałym kolumnom. Oceny podzieliliśmy na oceny z odpowiedzi, oceny ze sprawdzianów i oceny semestralne. Jeżeli nawet informacja o tym, kiedy została zdobyta konkretna ocena nie musi być zachowana w bazie, to taki sposób przechowywania danych uniemożliwi (a w każdym razie utrudni) obliczenia np. średniej każdego ucznia z danego przedmiotu (pamiętajmy o tym, że wyodrębniania danych z fragmentów kolumn jest stosunkowo trudne). Bogatsi o nową wiedzę na temat modeli baz danych utworzyliśmy nowy, wolny od powyższych błędów, projekt tabeli Matematyka.
rys. 17.4 Nowy projekt tabeli Matematyka
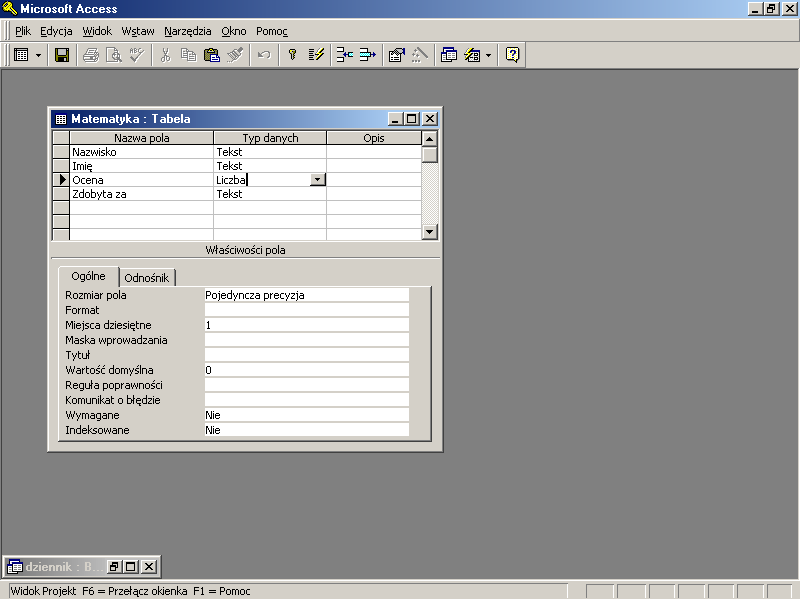
Pomocą przy wyodrębnieniu danych elementarnych może być pole Typ Danych widoczne w widoku Projekt. Jeżeli Access nie zawiera odpowiedniego dla naszego typu elementarnego typu danych, to najprawdopodobniej pomyliliśmy się przy jego określaniu.
Poprzednio oceny musieliśmy wpisywać do pól tekstowych — teraz zadeklarowaliśmy dla kolumny Ocena typ Liczba, zdecydowanie odpowiedniejszy dla tego rodzaju danych.
Zobaczmy, jak wygląda teraz wypełniona danymi tabela Matematyka
rys 17.5 Tabela Matematyka wypełniona danymi elementarnymi
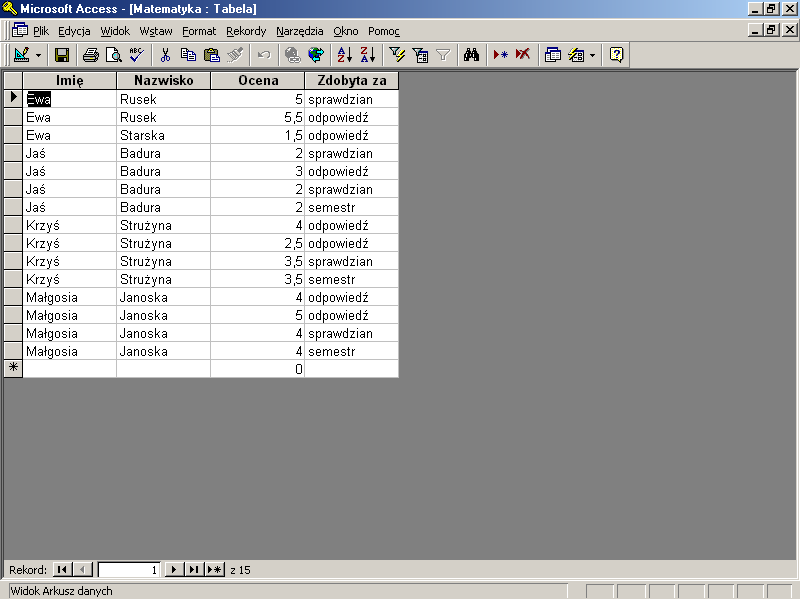
Na pierwszy rzut oka widać, że przybyło wierszy z danymi. Ponieważ ilość informacji przechowywanej w tabeli nie zwiększyła się (a nawet na rysunku 17.5 pokazano jej mniej) możemy być pewni, że pierwszy projekt tabeli, pokazany na rysunkach 17.2 i 17.3 był nieprawidłowy. Analizując nowy układ danych wyraźniej możemy zauważyć, że jeżeli kilkoro uczniów w klasie będzie miało to samo imię, a więc dane w pierwszej tabeli kolumny będą identyczne, to SZBD będzie miał problemy z "pamiętaniem" jakie oceny zdobyła Ewa Rusek, a jakie Ewa Starska. Rozwiązaniem tego problemu jest dodanie kolumny przechowującej unikalne, jednoznacznie identyfikujące ucznia wartości.
rys 17.6 Tabela Matematyka z dodatkową kolumną identyfikującą ucznia
Grupowanie danych w tabelach
Wiemy już, jak powinniśmy zaprojektować pojedynczą tabelę. Zastanówmy się teraz, czy wszystkie informacje powinny być przechowywane w jednej tabeli, czy może powinniśmy podzielić je pomiędzy kilka tabel. Przyjrzyjmy się tabeli Matematyka. Zawiera ona pewne informacje o uczniu, takie jak jego imię i nazwisko, nie związane bezpośrednio z jego ocenami z matematyki. W dodatku nie są to informacje kompletne, nauczyciel chciałby znać nie tylko imię i nazwisko ucznia, ale także wiedzieć gdzie uczeń mieszka, kim są jego rodzice, jak można się z nimi skontaktować itd. Dodajmy te niezbędne dane do tabeli Matematyka.
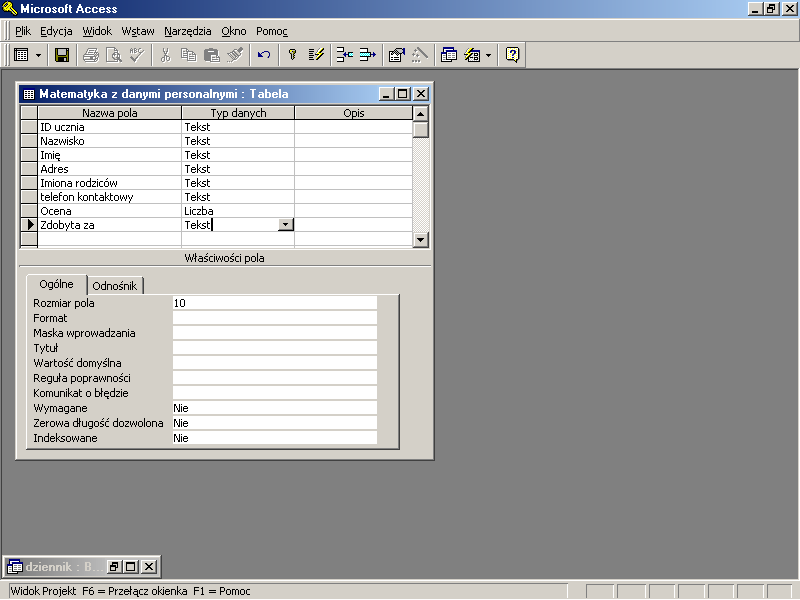
rys 17.7 Projekt tabeli uzupełnionej o dane personalne
Na pierwszy rzut oka projekt tabeli wygląda nieźle — pamiętając o wyodrębnianiu danych elementarnych utworzyliśmy trzy nowe kolumny, jedną, w której przechowywać będziemy informacje o adresie ucznia (ponieważ nie wydaje się, żeby informacje o ulicy, czy kodzie kiedykolwiek była potrzebna jako osobne dane wg. których można by np. wyszukiwać, czy sortować dane), jedną z imionami rodziców i jedną dla przechowywania numeru telefonu kontaktowego. Zobaczmy jednak, jak wygląda nasza nowa tabela wypełniona danymi.
rys 17.8 Tabela Matematyka z danym personalnymi.
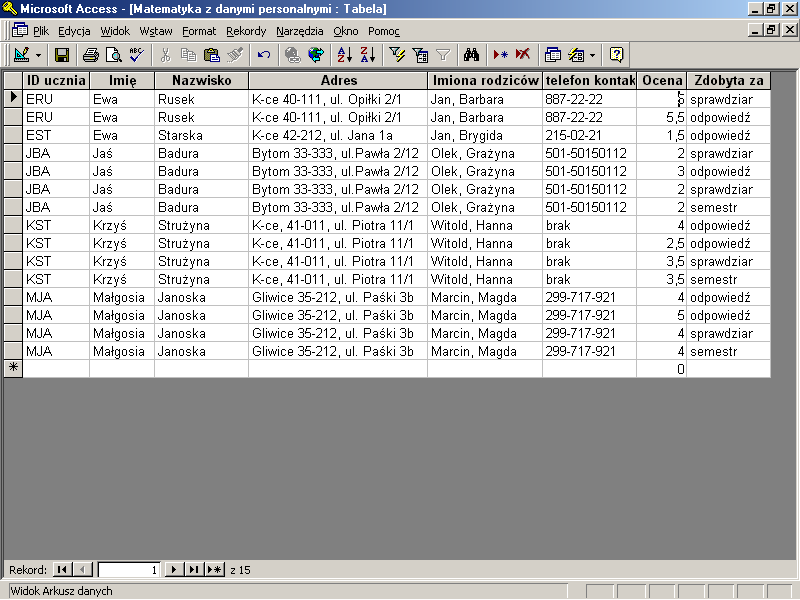
To, czego nie sposób nie zauważyć, to niesamowita nadmiarowość informacji. Dane o adresie, imionach rodziców, numerze telefonu, imieniu i nazwisku powtarzają się dla każdego ucznia tyle razy, ile ocen z matematyki dostał on w tym roku szkolnym. Nietrudno zauważyć, że jeżeli do tej tabeli dopisalibyśmy oceny z innego przedmiotu, sytuacje wyglądałby o wiele gorzej. Szybko doprowadzilibyśmy do tego, że do przechowywania względnie prostej informacji o kilku, czy kilkunastu ocenach z jednego przedmiotu potrzebować będziemy kilkuset kilobajtowego pliku na dysku.
Nadmiarowość jest jednym z powodów grupowania danych o różnych obiektach w odrębnych tabelach.
W naszym przykładzie łatwo wyodrębnić elementarne dane opisujące ucznia (ID ucznia, Imię, Nazwisko, Adres, Imiona rodziców, Telefon kontaktowy) od danych opisujących oceny ucznia(ID ucznia, Ocena, Zdobyta za).
Nadmiarowość nie jest jedynym powodem, dla którego powinniśmy grupować dane o poszczególnych typach obiektów w wielu tabelach. W modelu jednorodnym stosunkowo trudno jest zachować spójność i adekwatność danych. W naszym przypadku, jeżeli Małgosia zdecydowałaby się wyprowadzić od rodziców, informację o jej nowym adresie musielibyśmy modyfikować tyle razy, ile ocen ma Małgosia. W nieco bardzie skomplikowanych przypadkach mogłoby się okazać, że jedna, drobna zmiana adresu pociąga za sobą modyfikacje kilkuset, czy kilku tysięcy rekordów. A co, jeżeli dane o adresie zmienimy 123 221 razy, a w 5 891 komórkach pozostaną one niezmienione?
Anomalie przy modyfikacji są kolejnym powodem logicznego grupowania danych w odrębnych tabelach.
Kolejnym utrudnieniem w zarządzaniu jednorodnym modelem danych jest konieczność wprowadzania nowych danych o jednym obiekcie do wielu rekordów. Wracając do naszej tabeli Matematyka — gdyby Krzyś zdecydował się nieroztropnie podać nauczycielowi numer telefonu rodziców, SZBD musiałby wpisać tą informację w liczbę pól równą ilości ocen Krzysia z matematyki.
Anomalie powstałe przy wstawianiu danych są kolejnym powodem logicznego grupowania danych w odrębnych tabelach.
Niestety, to nie koniec wad modelu jednorodnego. Kolejny, poważny mankament związany z przechowywaniem danych w pojedynczej tabeli związany jest z usuwaniem pewnych danych o obiekcie. W naszym przypadku, jeżeli pewien uczeń z klasy nie miałby żadnej oceny z matematyki (co odpowiada sytuacji, w której wszystkie oceny z matematyki zostałby temu uczniowi anulowane) z tabeli usunięte zostały by również dane personalne ucznia.
Anomalie związane z usuwaniem danych są czwartym powodem, dla którego powinno się grupować dane opisujące obiekty różnego rodzaju w osobnych tabelach.
Stosując się do powyższych zaleceń zmieńmy projekt tabeli Matematyka, dzieląc przechowywane w niej dane pomiędzy dwie tabele: tabelę Matematyka i tabelę Uczeń.
rys 17.9 wynik podziału tabeli Matematyka na tabelę Uczeń i tabelę Matematyka
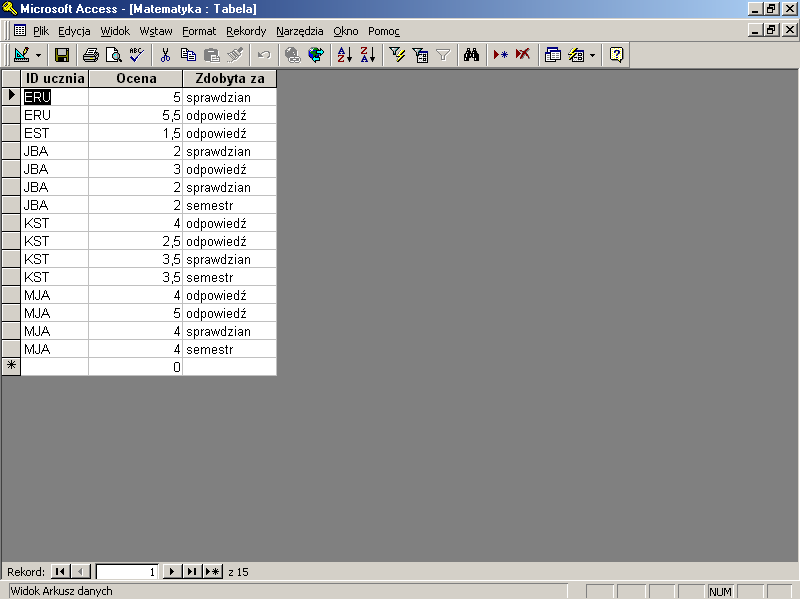
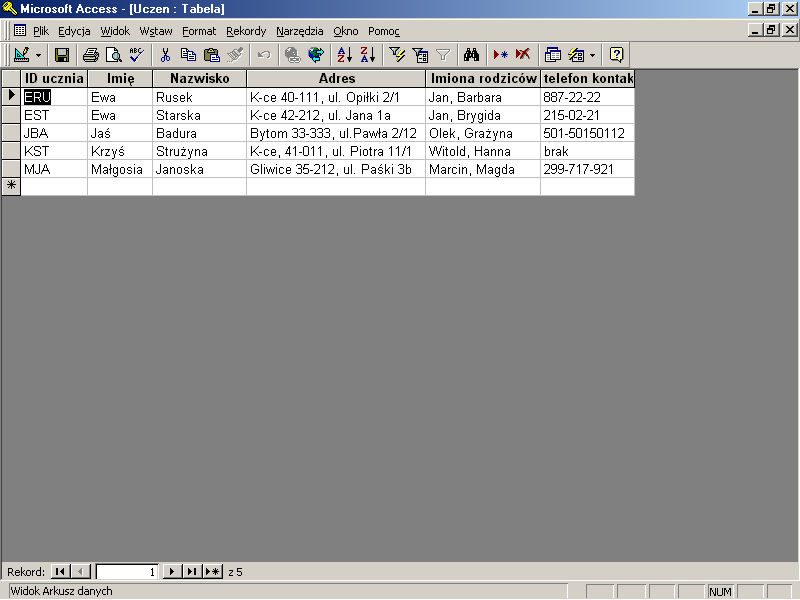
W rezultacie otrzymaliśmy dwie tabelę, żadna z informacji przechowywanych w bazie nie została utracona (z wyjątkiem informacji nadmiarowych, ale to poczytujemy sobie za atut, nie wadę nowego rozwiązania), a nasze rozwiązanie wolne jest od anomalii modyfikacji, wstawiania i usuwania danych. Niejasne może pozostawać przeznaczenie tabeli ID ucznia, znajdującej się w obu nowych tabelach. Opisem tej tabeli zajmiemy się w kolejnym rozdziale.
W większych systemach w skład nazwy tabeli wchodzi nazwa użytkownika, który jest jej właścicielem, i nazwa bazy danych, w ramach której tabela została utworzona, tak więc pełna nazwa tabeli Matematyka, utworzonej przez Maćka w ramach bazy Dziennik będzie miała postać Dziennik.Maciek.Matematyka
Problem ten występował również w pierwotnym projekcie tabeli Matematyka, był on jedynie mniej widoczny, ponieważ szansa, że w klasie będzie kilkoro uczniów o takim samym imieniu i nazwisku jest raczej niewielka.
Taki model danych nazywany jest modelem jednorodnym.
Problemem jest również to, że liczba rekordów, które będziemy musieli dopisać do bazy jest zależna od wcześniej wprowadzonych do niej danych.
Nazwy tabeli powinny odzwierciedlać typ obiektu, o którym informacje przechowujemy. Nazwy tabel powinny przybierać formę mianownika l. pojedynczej (a więc tabela Uczeń, a nie Uczniowie)
8 Część I ♦ Podstawy obsługi systemu WhizBang (Nagłówek strony)
C:\My Documents\MATURA\R-17.DOC
Wyszukiwarka
Podobne podstrony:
R-19, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-22, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-21, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-dod A slownik, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-06, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-05, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R-20, materiały stare, stare plyty, Programowamie, Zagadnienia maturalne z informatyki
R07-05, materiały stare, stare plyty, Programowamie, SQL Server 2000 dla kazdego
relacje m tab, materiały stare, stare plyty, Programowamie
R11-3, materiały stare, stare plyty, Programowamie, Windows XP Professional PL. Ćwiczenia praktyczne
R01-3, materiały stare, stare plyty, Programowamie, Windows XP Professional PL. Ćwiczenia praktyczne
R07-3, materiały stare, stare plyty, Programowamie, Windows XP Professional PL. Ćwiczenia praktyczne
Zagadnienia maturalne z informatyki Wydanie II Tom I
Zagadnienia maturalne z informatyki Wydanie II Tom II 2
więcej podobnych podstron