Wykład 1
Czym zajmuje się technologia informacyjna
Technologia informacyjna to dziedzina wiedzy obejmująca informatykę (włącznie ze sprzętem komputerowym oraz oprogramowaniem używanym do tworzenia, przesyłania, prezentowania i zabezpieczania informacji), telekomunikację, narzędzia i inne technologie związane z informacją. Dostarcza ona użytkownikowi narzędzi, za pomocą których może on pozyskiwać informacje, selekcjonować je, analizować, przetwarzać, zarządzać i przekazywać innym ludziom
Jaka jest różnica pomiędzy urządzeniami cyfrowymi i analogowymi
Urządzenia cyfrowe operują na liczbach (wartościach skończonych), natomiast w urządzeniach analogowych liczby są zastępowane jakimiś wielkościami fizycznymi np. długość. Urządzenia analogowe są bardziej dokładne niż cyfrowe ponieważ nie występują w nich błędy zaokrągleń charakterystycznych dla urządzeń cyfrowych. Natomiast urządzenia cyfrowe są mniej czułe na błędy niż urządzenia analogowe.
Wyjaśnij pojęcie algorytmu
Algorytm jest to skończony uporządkowany ciąg jasno zdefiniowanych czynności, koniecznych do wykonania pewnego rodzaju zadań. Przykładem algorytmu z życia codziennego może być książka kucharska która składa się z przepisów (algorytmów) które pozwalają nam krok po kroku stworzyć potrawę analogicznie jest z algorytmami w informatyce.
Wyjaśnij dlaczego kluczową ideą w konstrukcji komputera uniwersalnego było przechowywanie programów i danych w pamięci
Kluczową ideą przy konstruowaniu komputera uniwersalnego było przechowywanie programów i danych w pamięci, ponieważ umożliwiało to skuteczne usprawnienie pracy takiego komputera. Komputer chcąc wykonać operacje nie musi czekać aż niezbędne dane zostaną wprowadzone przez użytkownika, pobiera je bezpośrednio z pamięci. Przechowywanie danych daje mu także możliwość wykonywania kilku niezależnych procesów jednocześnie. W przypadku, gdy np. nasz komputer nie może wykonać jakieś operacji ze względu na przebieg innej może dane z oczekującego procesu zapisać pamięci i zlecić wykonanie, gdy będzie to już możliwe np. drukowanie.
Wykład 2
Spróbuj zdefiniować pojęcie dane
Dane są zdefiniowane jako "to wszystko co jest/może być przetwarzane umysłowo lub komputerowo". W informatyce zbiory liczb i tekstów o różnych formach
Dlaczego sposób reprezentowania informacji jest ważny dla wygody jej przetwarzania
Ponieważ wygodniej jest przetwarzać informacje zrozumiałe od razu niż najpierw tłumaczenie ich na język zrozumiały w tym wypadku dla komputera.
Wymień i krótko scharakteryzuj podstawowe typy danych
Dane logiczne - tak/nie, prawda/fałsz, posiadają dwie wartości
Dane alfanumeryczne - tekst (alfabet i liczby)
Dane numeryczne - to liczby na których można wykonywać operacje arytmetyczne
Dane graficzne
Dane muzyczne
Co to jest bit i bajt. Wyjaśnij jak to możliwe, że ciąg bitów pozwala reprezentować przesłać dowolną wiadomość
Bit - binary unit, czyli jednostka dwójkowa, najmniejsza jednostka informacji pozwalająca odróżnić dwie sytuacje. Bajt to ciąg 8 bitów.
Jakie znasz operatory logiczne? Podaj jakie wartości są zwracane przez te operatory dla 2 argumentów
Koniunkcja (AND, iloczyn logiczny)
x y w
0 0 0
0 1 0
1 0 0
1 1 1
Alternatywa (OR, suma logiczna)
x y w
0 0 0
0 1 1
1 0 1
1 1 1
Iloczyn przestawny (XOR)
x y w
0 0 0
0 1 1
1 0 1
1 1 0
Negacja (NOT)
x w
0 1
1 0Co to są bramki logiczne? Narysuj znane Ci symbole bramek logicznych
Bramki logiczne to urządzania które na podstawie wartości wejściowych tworzą wartość wyjściową zgodnie z pewną operacją logiczną.
Bramka NOT:
Bramka AND:
Bramka OR
Bramka NAND
Bramka NOR
Bramka EXOR
Bramka EXNOR
Co to jest przerzutnik? Dlaczego przerzutniki są ważnymi układami w technologii przetwarzania informacji?
Przerzutnik jest to podstawowy element pamiętający każdego układu cyfrowego, przeznaczonego do przechowywania i ewentualnego przetwarzania informacji. Przerzutnik zdolny jest do zapamiętania jednego bitu informacji. Przerzutnik jest ważnym układem, gdyż idealnie nadaje się do zapamiętania jednego bitu. Pamiętana w nim wartość to wartość znajdująca się na wyjściu. Inne układy mogą łatwo zmieniać pamiętaną w przerzutniku wartość, przesyłając impulsy na jego odpowiednie wejścia. Podobnie inne układy mogą wykorzystywać wyjście przerzutnika jako swoje wejście i w ten sposób odczytywać zapamiętaną w nim wartość.
Wymień znane CI sposoby przechowywania informacji
Taśmy i karty dziurkowane (obecnie już praktycznie nieużywane), karty magnetyczne (także o znaczeniu historycznym), taśmy magnetyczne na szpulach i w kasetach, bębny, dyskietki (magnetyczne "dyski miękkie"), dyski twarde (magnetyczne), dyski optyczne: CD-ROM, CD-R, CD-RW, DVD-ROM, DVD-R, DVD-RW, DVD+R, DVD+RW, HD DVD, BD-ROM, BD-R, BD-RW, DMD, EVD, HVD. dyski magnetooptyczne, rejestry procesora, pamięć cache (pamięć podręczna), pamięć operacyjna - aktualnie RAM i jej różne odmiany PRAM, MRAM, FRAM, ROM - Read-Only Memory (pamięć tylko do odczytu), PROM - Programmable Read-Only Memory (programowalna pamięć tylko do odczytu), EPROM - Erasable-Programmable Read-Only Memory (kasowalno-programowalna pamięć tylko do odczytu (kasowana promieniowaniem ultrafioletowym) EEPROM - Electrically Erasable-Programmable Read-Only Memory (elektrycznie kasowalno-programowalna pamięć tylko do odczytu (kasowana elektrycznie), Flash EEPROM - (błyskawicznie działająca elektrycznie kasowalno-programowalna pamięć kasowana elektrycznie).
Co definiują standardy reprezentacji danych alfanumerycznych? Jakie znasz standardy reprezentacji danych alfanumerycznych? Czym różnią się one między sobą?
Standardy definiują sposób uporządkowania znaków. ASCII, ANSI, EBCDIC, UNICODE. Różnią się sposobem reprezentowania danych, ilością możliwych do zakodowania znaków, wielkością jednego zakodowanego znaku.
Zamień dwójkową (dziesiętną, szesnastkową) liczbę X (np. 11010101) w kodzie naturalnym na jej dziesiętny (szesnastkowy, dwójkowy) odpowiednik.
Wyjaśnij na czym polegają błędy przepełnienia i niedomiaru oraz jakie są przyczyny ich występowania.
Błędy przepełnienia polegają na tym że wartości które chcemy zapamiętać w określonej przestrzeni (są zbyt duże) natomiast błędy niedomiaru polegają na tym że ułamki są zbyt małe aby można było zapisać je w przeznaczonym miejscu (inaczej potrzeba większej ilość bitów niż jest na to przeznaczona)
Dodaj do siebie dwie naturalne liczby dwójkowe X i Y (np. 01010101 i 00111011).
+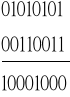
w dodawaniu liczb binarnych należy pamiętać o takich zasadach, że : 0+0=0 0+1=1 1+0=1 1+1=0 i „1” zapisujemy w pamięci lub inaczej „przenosimy o jedną pozycję dalej”
W jaki sposób zapisujemy ułamki w naturalnym kodzie dwójkowym
Aby zapisać w notacji binarnej wartości ułamkowe wykorzystać musimy kropkę pozycyjną, która pełni taką samą role jak przecinek w notacji dziesiątkowej. Cyfry na lewo od kropki reprezentują część całkowitą. Cyfry po prawej stronie kropki reprezentują część ułamkową liczby i interpretuje się je tak jak pozostałe bity z tą różnicą, że ich pozycjom przypisuje się wagi ułamkowe. Pierwsza pozycja po kropce ma wagę ½, druga - wagę ¼, następna - ⅛ i tak dalej. Zwróćmy uwagę, że jest to w zasadzie naturalne rozszerzenie konwencji stosowanej poprzednio: każdej pozycji przypisuje się wagę dwa razy większą niż waga pozycji z jej prawej strony.
Dodaj do siebie dwie liczby rzeczywiste ( z ułamkami) liczby dwójkowe X i Y reprezentowane w kodzie naturalnym (np. 10101.111 i 11011.0011)
10101.111
+ 11011.0011
110001.0001
Zapisz liczbę X w n -bitowej notacji uzupełnieniowej do dwóch (np. -7 w kodzie 4-bitowym).
1) zapisujemy liczbę 7 w kodzie 4 - bitowym 0111
2) przepisujemy bajty od prawej do lewej aż do napotkania pierwszej jedynki (wraz z nią przepisujemy) potem kolejne bity negujemy w wyniku tego otrzymujemy: 1001
Jak w notacji uzupełnieniowej oznaczamy znak liczby
W notacji uzupełnieniowej znak liczby określany jest przez lewy skrajny bit tzw. „bit znaku”. Jeżeli jest on równy 0 to jest to liczba dodatnia, natomiast jeśli 1 to liczba jest ujemna.
Jaką zależnością związane są ciągi reprezentujące wartości dodatnie i ujemne w kodzie uzupełnieniowym do dwóch (Jak przekształcić ciąg bitów w wartość przeciwną?)
W jaki sposób zapisujemy ułamki w naturalnym kodzie dwójkowym
Aby zapisać w notacji binarnej wartości ułamkowe wykorzystać musimy kropkę pozycyjną, która pełni taką samą role jak przecinek w notacji dziesiątkowej. Cyfry na lewo od kropki reprezentują część całkowitą. Cyfry po prawej stronie kropki reprezentują część ułamkową liczby i interpretuje się je tak jak pozostałe bity z tą różnicą, że ich pozycjom przypisuje się wagi ułamkowe. Pierwsza pozycja po kropce ma wagę ½, druga - wagę ¼, następna - ⅛ i tak dalej. Zwróćmy uwagę, że jest to w zasadzie naturalne rozszerzenie konwencji stosowanej poprzednio: każdej pozycji przypisuje się wagę dwa razy większą niż waga pozycji z jej prawej strony.
Jaką wartość liczbową w notacji uzupełnieniowej do dwóch reprezentuje ciąg bitów X (np.1100).
Jest to wartość -4, z tego co zrozumiałem jedynka po lewej stronie oznacza że wartość jest z minusem a trzy bity określają jej wartość.
Jak dodajemy wartości ze znakiem w notacji uzupełnieniowej do dwóch?
Dodajemy tak jak liczby w systemie binarnym z tą różnicą że wszystkie ciągi bitów muszą mieć tą samą długość w tym też wynik. Oznacza to że przy dodawaniu w tym systemie należy odrzuć ewentualny bit wyniku na wskutek przeniesienia ze skrajnie lewej pozycji.
Wyjaśnij dlaczego w systemie uzupełnień do dwóch odejmowanie można sprowadzić do dodawania.
W systemie uzupełnień do dwóch odejmowanie można sprowadzić do dawania ponieważ w tym systemie odjąć liczbę oznacza to samo co dodać liczbę ze znakiem przeciwnym np. 4 - 8 to to samo co 4 + (-8).
Skąd bierze się problem przepełnienia? Jak można wykryć przepełnienie?
W każdym systemie liczbowym istnieje pewne ograniczenie rozmiaru reprezentowanych w nim wartości, problem przepełnienia pojawia się wówczas, gdy chcemy zakodować wartość przekraczająca zakres reprezentowanych w kodzie wartości. Błąd przepełnienia występuje wtedy, gdy wynikiem dodawania dwóch wartości dodatnich jest ciąg bitów reprezentujący wartość ujemną lub, kiedy suma dwóch wartości ujemnych okazuje się dodatnia.
Zapisz liczę X w notacji z nadmiarem Y (np. -7 w notacji z nadmiarem do 8).
Jest to 0001
Wymień jakie elementy ciągów bitów składają się na liczbę w notacji zmiennopozycyjnej.
Najbardziej znaczący bit bajtu to bit znaku (0 wartości dodatnie, 1 wartości ujemne)
Pozostałe bajty dzieli się na dwie grupy zwane polami: pole wykładnika i pole części ułamkowej .
Jaką wartość w notacji zmiennopozycyjnej reprezentuje ciąg bitów X (np. 11010010)?
Bit znaku = 1 - wartość jest ujemna; wykładnik = 101; część ułamkowa = 0010
Zapisz w notacji zmiennopozycyjnej liczbę X (np.2
).
Aby zakodować wartość 1⅛, najpierw wyrażamy ją w notacji binarnej, otrzymując 1.001. Następnie kopiujemy ciąg bitów od lewej do prawej do pola części ułamkowej, rozpoczynając od skrajnie lewej 1. W tym momencie konstruowany bajt wygląda następująco:
_ _ _ _1001. Musimy teraz wypełnić pole wykładnika. W tym celu wyobraźmy sobie zawartość pola części ułamkowej z kropką umieszczoną po jego lewej stronie i określmy, o ile bitów i w którą stronę należy przesunąć kropkę, aby uzyskać wartość 1.001. Wykładnik powinien mieć wartość 1, więc umieszczamy 101 (co oznacza +1 w notacji z nadmiarem cztery) w polu wykładnika. Wreszcie wypełniamy bit znaku zerem, gdyż wartość jest nieujemna. Pełny bajt wygląda zatem następująco: 01011001
Uwaga! Jest pewna subtelność związana z określaniem zawartości pola części ułamkowej, którą łatwo przeoczyć. Metoda postępowania polega na skopiowaniu od lewej do prawej ciągu bitów występującego w reprezentacji binarnej liczby, począwszy od skrajnie lewej 1. Rozważmy proces kodowania liczby ⅜, którą w notacji binarnej zapisuje się za pomocą ciągu 011. Część ułamkowa będzie zatem równa: _ _ _ _1100 a nie: _ _ _ _0110 Jest to spowodowane tym, że wypełnianie pola części ułamkowej rozpoczyna się od skrajnej lewej 1, występującej w reprezentacji binarnej.
Co to jest postać znormalizowana liczby?
Jest to taka metoda postępowania, która eliminuje możliwość reprezentacji tej samej wartości na wiele sposobów. Oznacza również, że w reprezentacji wszystkich niezerowych wartości pole części ułamkowej rozpoczyna się od 1.
Wyjaśnij na czym polegają błędy zaokrąglenia? Jakie są przyczyny występowania błędów zaokrągleń?
Błąd zaokrąglenia polega na tym, że część wartości, którą chcemy zapisać, zostaje zgubiona, gdyż pole części ułamkowej nie jest wystarczająco duże.
Niektórych cyfr nie da się wyrazi niezależnie od tego jak wielu cyfr użyjemy (np. reprezentowanie skończonego rozwinięcia liczby 1/3 w systemie dziesiątkowym, 1/10 w notacji binarnej)
Wyjaśnij dlaczego kolejność wykonywania operacji dodawania przy notacji zmiennopozycyjnej może być istotna?
Przy dodawaniu do bardzo dużej liczby wartości bardzo małej dochodzi wtedy do obcięcia małej wartości . Jest jakby pomijana przy dodawaniu.
Wymień znane Ci techniki reprezentacji obrazów?
Popularne techniki reprezentacji obrazu można podzielić na dwie kategorie:
- techniki wykorzystujące mapę bitową
- techniki wektorowe
Jaki jest cel kompresji danych? Czym różni się kompresja stratna i bezstratna?
Do przechowywania danych i ich przesyłania często jest przydatne (a czasem nawet niezbędne) zmniejszenie rozmiaru danych. Technika realizacji takiego zmniejszenia rozmiaru danych to kompresja danych. Różnica pomiędzy kompresją stratną i bezstratną polega na różnych algorytmach kompresji, rozmiarem skompresowanego pliku. Nie wszystkie dane możemy poddać kompresji stratnej, nadają się do niej tylko pliki video, obrazy i dźwięki- nie wyobrażamy sobie przecież kompresji stratnej pliku .exe
Na czym polega metoda kodowania grupowego?
Kodowanie grupowe polega na zastąpieniu takich ciągów kodem założonym z powtarzającej się wartości i z liczby wystąpień tej wartości w ciągu.
Na czym polega kodowanie względne (relatywne, różnicowe)? Dla jakich rodzajów danych ta metoda daje najlepsze wyniki?
Kodowanie względne polega na zapamiętywaniu różnicy między kolejnymi blokami danych a nie całe bloki. Typowym przykładem jest zbiór ramek filmu.
Na czym polega kodowanie zależne od częstości wystąpień?
Kodowanie zależne od częstości wystąpień jest to jedna z metod zmniejszania rozmiaru danych. Długość ciągu bitów używanego do reprezentacji danego elementu jest uzależniona od częstości wystąpień tego elementu: im częstsze wystąpienia, tym krótszy kod. Tego typu kody są przykładami kodów o zmiennej długości, co oznacza, że różne elementy danych reprezentuje się kodami o różnej długości.
Wyjaśnij idee kodowania słownikowego (Lempela-Ziva)?
Systemy Lempela-Ziva są przykładami kodowań ze słownikiem adaptacyjnym Termin słowni oznacza tutaj pewien zbiór bloków, z których jest zbudowany kompresowany komunikat. Przy kompresji tekstu w języku naturalnym blokami mogą być litery alfabetu. Przy kompresji danych w pamięci komputera za bloki można uważać cyfry binarne 0 i 1. W systemie kodowania ze słownikiem adaptacyjnym słownik może zmieniać się w trakcie procesu kodowania. Na przykład już po zakodowaniu części komunikatu zapisanego w języku angielskim można podjąć decyzję o dołączeniu do słownika tekstu ing i the. Wtedy miejsce potrzebne do zapamiętania przyszłych wystąpień Ing i the można zmniejszyć dzięki zastąpieniu tych wzorców pojedynczym odwołaniem do słownika (zamiast trzech odwołań). W systemach kodowania Lempela-Ziva stosuje się inteligentne i efektywne sposoby adaptacji słownika w trakcie procesu kodowania (lub kompresji). W szczególności w dowolnej chwili słownik składa się z tych wzorców, które już zostały zakodowane (skompresowane).
Jakie znasz sposoby kodowania obrazów? Dlaczego stosujemy wiele różnych formatów zapisu obrazu?
GIF - ogranicza liczbę kolorów do 256 których można przypisać każdemu z pikseli
JPEG w ramach tego standardu: kompresja stratna, kodowanie różnicowe, dyskretna transformata kosinusowa, kodowanie ze zmienną długością kodu.
Stosujemy wiele różnych formatów zapisu obrazów ponieważ każdy format ma jakieś swoje zalety, których nie ma inny a te akurat są nam najbardziej przydatne
Jakie techniki wykorzystuje się do kodowania filmów?
Do kodowania obrazów ruchomych używa się podobnych technik jak przy kodowaniu obrazów. Np. Kodowanie najpierw rozpoczyna się sekwencje klatek obrazu w sposób podobny jak w JPEG a następnie reprezentowanie pozostałego fragmentu za pomocą technik kodowania względnego.
Wyjaśnij w jaki sposób można kodować dźwięk? Czy w wypadku dźwięku kompresja jest niezbędna? Odpowiedź uzasadnij.
Najbardziej ogólną metodą kodowania dźwięku w celu przechowywania komputerze przetwarzania go w komputerze jest próbkowanie amplitudy fali dźwiękowej w regularnych odstępach czasu i zapamiętanie otrzymanych wartości. Na przykład ciąg 0,1,2,1,2,3, 4, 2, 0 może reprezentować falę dźwiękową, której amplituda narasta, na krótko opada, wzrasta do wyższego poziomu, a następnie spada do wartości 0. Aby uzyskać akceptowalną jakość dźwięku, muzykę na współczesnych płytach CD nagrywa się z częstotliwością 44 100 próbek na sekundę i rozróżnia się 65536 poziomów dźwięku. Wartość otrzymaną z każdego próbkowania reprezentuje się za pomocą 16 bitów (32 bitów przy nagraniach stereofonicznych). W efekcie zapamiętanie jednej sekundy muzyki stereofonicznej wymaga ponad miliona bitów pamięci. Pliki muzyczne niepoddane kompresji zajmują bardzo duże obszary pamięci, przez co staja się uciążliwe w przechowywaniu. Problem pamięciorzeności powraca również, gdy chcemy połączyć dźwięk z obrazem np. w filmach. Z tego powodu opracowane zostały techniki kompresji, które w znacznym stopniu zmniejszają wymagania pamięciowe do przechowywania dźwięku. Jedna z tych technik to MP3 dająca możliwość uzyskania 12-krotnej kompresji umożliwiającej swobodne przesyłanie nagrań w Internecie.
W jaki sposób można uporać się z błędami komunikacji?
Opracowano różne techniki kodowania, które umożliwiają wykrywanie, a nawet poprawianie błędów. -Bit parzystości: Prostą metodę wykrywania błędów oparto na następującej zasadzie: Jeśli każdy ciąg bitów, który podlega manipulacjom, ma nieparzystą liczbę jedynek, to po napotkaniu ciągu z parzystą liczbą jedynek wiadomo, że wystąpił błąd.
-Bajt kontrolny, CRC- Z długimi ciągami bitów często związuje się zestaw bitów parzystości, tworząc w ten sposób bajt kontrolny (ang. checkbyte). Każdy bit w bajcie kontrolnym jest bitem parzystości związanym z konkretnym zbiorem bitów z danego ciągu.
-Kod korekcyjny Hamminga- pozwala na wykrywanie i naprawianie błędów
Wykład 3
Na czym polega różnica pomiędzy sieciami LAN i WAN?
Sieć LAN (sieć lokalna, Local area network) - sieć komputerowa składająca się zazwyczaj ze zbioru komputerów znajdujących się w jednym budynku lub kompleksie budynków.
Sieć WAN (sieć rozległa, Wide area network) - sieć łącząca komputer znajdujących się w znacznych odległość np. na dwóch końcach miasta, Ziemi.
Główną różnicą pomiędzy sieciami LAN i WAN polega na technice stosowanej do ustalania ścieżek komunikacyjnych. (Łącze satelitarne nadaje się dobrze do sieci WAN ale nie do sieci LAN)
Czym różnią się sieci otwarte od sieci prawnie zastrzeżonych?
Sieć pierwszego typu nazywa się siecią otwartą, a sieć drugiego typu siecią zamkniętą lub siecią prawnie zastrzeżoną.Internet jest systemem otwartym. Komunikację przez Internet realizuje się za pomocą otwartego zestawu standardów znanych jako pakiet protokołów TCP/IP. Dla odmiany jeśli sieć korzysta z zastrzeżonych prawem protokołów to jest systemem zamkniętym.
Jakie znasz topologie (konfiguracje) sieci?
Topologie sieci:
- pierścień;
- magistrala;
- gwiazda;
-nieregularna;
Co to jest router? Jaką rolę w sieci pełnią routery?
Router urządzenie sieciowe pracujące w trzeciej warstwie modelu OSI. Służy do łączenia różnych sieci komputerowych (różnych w sensie informatycznym, czyli np. o różnych klasach, maskach itd.), pełni więc rolę węzła komunikacyjnego. Na podstawie informacji zawartych w pakietach TCP/IP jest w stanie przekazać pakiety z dołączonej do siebie sieci źródłowej do docelowej, rozróżniając ją spośród wielu dołączonych do siebie sieci.
Wyjaśnij pojęcie domena?
Domena jest to skupisko sieci działających w obrębie jednej instytucji np. uczelnia, bank. Każda domena jest systemem autonomicznym, który konfiguruje się zgodnie z wymogami lokalnych władz.
Jak zbudowane są adresy identyfikujące sieci i komputery w Internecie (IP v.4)?
Adres każdego komputera w internecie jest (obecnie IP v.4) 32-bitowym ciągiem złożonym z dwóch części: pierwszej identyfikującej domenę w której znajduje się komputer i drugiej identyfikującej konkretny komputer o obrębie tej domeny. Część adresu określająca domenę, czyli identyfikator sieci jest przydzielana i rejestrowana przez InterNIC (Internet Network Information Center) w chwili tworzenia domeny.
Wyjaśnij terminy adres, host i nazwa domeny. Jak władze domeny mogą rozszerzać jej nazwę?
Adres jest to 32-bitowy ciąg złożony z dwóch części: części identyfikującej domenę, w której znajduje się komputer, i części identyfikującej konkretny komputer w obrębie tej domeny. Część adresu określająca domenę, czyli identyfikator sieci jest przydzielana i rejestrowana przez InterNIC w chwili tworzenia domeny. Host jest to komputer pełniący w sieci rolę gospodarza. Część adresu, która określa konkretną maszynę w obrębie domeny jest nazywana adresem hosta. W ten sposób podkreśla się jego rolę zleceń nadchodzących od innych maszyn. Ta część adresu określana jest przez władze lokalne domeny; zazwyczaj jest to osoba, która pełni funkcję administratora sieci lub administratora systemu. Nazwa domeny jest to unikatowy adres mnemoniczny przydzielany prze InterNIC każdej domenie celem ułatwienia człowiekowi posługiwania się adresami domen. Adres domeny w postaci ciągu bitów jest bowiem dla człowieka mało czytelny. Nazwa domeny może byś swobodnie rozszerzana przez władze lokalne domeny poprzez tworzenie nazw dla poszczególnych komputerów należących do niej.
Co to są klasyfikatory domen? Jakie znasz klasyfikatory domen?
Notacja kropkowa stosowana w adresach mnemonicznych nie ma żadnego związku z notacją kropkową używaną do reprezentacji adresów w postaci ciągów bitów. Poszczególne części w notacji mnemonicznej określają położenie komputera w hierarchicznym systemie klasyfikacji. W szczególności adres transcomp.pr.radom.net określa komputer o nazwie transcomp znajdujący się w instytucji pr, która należy do domeny radom i jest organizacją sieciową net. Oprócz klasy net jest wiele klasyfikatorów domen, w tym: com dla organizacji komercyjnych, edu dla instytucji edukacyjnych, gov dla instytucji rządowych, org dla ogólnie pojętych organizacji ale podział ten jak widać na przykładzie nie jest dziś ściśle przestrzegany. Władze lokalne wielkich domen mogą podjąć decyzję o ich podziale na poddomeny. Wtedy adres mnemoniczny komputera w domenie jest dłuższy. Przypuśćmy, że Uniwersytet Znikąd ma przydzieloną nazwę uz.edu i że zdecydowano się podzielić tę domenę na poddomeny. Wtedy komputer na tym uniwersytecie może mieć adres r2d2.compsc.uz.edu, który oznacza, że komputer r2d2 znajduje się w poddomenie compsc domeny uz w obrębie klasy edu domen organizacji edukacyjnych.
Z jakich części składa się adres poczty elektronicznej?
Adres poczty elektronicznej składa się z ciągów znaków identyfikujących użytkownika po którym umieszcza się symbol @ oraz nazwę komputera przeznaczonego do wykonywania czynności związanych z obsługą poczty elektronicznej w tej domenie
np. Lolek@pr.radom.pl
gdzie:
- Lolek - identyfikator użytkownika
- Pr - nazwa komputera obsługującego pocztę
- radom.pl - identyfikator domeny
Jaką rolę w Internecie pełnią serwery nazw?
Serwer nazw obsługuje zlecenia dotyczące udzielenia informacji o adresach. Wszystkie serwery nazw w całym Internecie tworzą razem system adresowy tłumaczący nazwy mnemoniczne na ich numeryczne odpowiedniki. Gdy ktoś zleci wysłanie komunikatu pod podany adres w postaci mnemonicznej to system serwerów nazw przekształci ten adres do odpowiedniej postaci bitowej zrozumiałej dla oprogramowania Internetu (trwa to kilka sekund).
Wyjaśnij pojęcie hipertekstu. Co to jest „światowa pajęczyna”?
Hipertekst jest tekstem zawierającym słowa, zdania lub obrazy, które są dowiązane do innych dokumentów. Czytelnik dokumentu hipertekstowego, jeśli sobie tego życzy, może uzyskać dostęp do dowiązanych dokumentów, zazwyczaj za pomocą myszy lub klawiatury. „Światowa pajęczyna” jest to pajęczyna powstała na skutek połączenie fragmentów wielu dokumentów tworzących razem powiązane informacje. Dokumenty wchodzące w skład takiej pajęczyny mogą znajdować się na różnych komputerach połączonych siecią. Pajęczyna, która powstała w Internecie, ma zasięg ogólnoświatowy i nazywa się World Wide Web.
Jaką rolę w prezentacji dokumentów pełni oprogramowanie serwerów i klientów?
Pakiety oprogramowania, które asystują czytelnikom hipertekstu w wędrówce po łączach hipertekstowych, można podzielić na dwie kategorie: programy, które pełnią funkcję klientów, i programy, które pełnią funkcję serwerów. Program-klient znajduje się na komputerze czytelnika. Jego zadaniem jest uzyskanie materiałów, których zażąda użytkownik oraz przedstawienie ich w pewien uporządkowany sposób. Klient definiuje interfejs użytkownika, który pozwala użytkownikowi przeglądać sieć. Z tego powodu programy te często nazywa się przeglądarkami lub przeglądarkami stron WWW (ang. browsers).Serwer hipertekstu znajduje się w komputerze zawierającym odczytywane dokumenty. Jego zadaniem jest udostępnianie dokumentów z komputera zgodnie z żądaniami klienta. Krótko mówiąc, użytkownik uzyskuje dostęp do dokumentów hipertekstowych, komunikując się z przeglądarką znajdującą się na jego komputerze. Przeglądarka z kolei realizuje żądania użytkownika, prosząc o ich realizację serwery hipertekstowe rozrzucone po całym Internecie.
Jak wyszukiwarka pozyskuje informacji o zawartości stron internetowych?
Wyszukiwarka pozyskuje informacje o zawartości stron przeszukując wielkie bazy danych, które zawierając dowiązania do stron internetowych. Dokumenty klasyfikuje się w tych bazach za pomocą słów kluczowych. Informacja w nich gromadzone są na dwa sposoby: za pomocą programów zwanych pająkami lub robotami, które po prostu pełzają po sieci WEB, przechodząc po dowiązaniach z jednej strony na drugą i przekazując informacje o odnalezionych stronach. Inny sposób polega na bezpośrednim zawiadamianiu.
Wyjaśnij pojęcie URL. Jak zbudowane są typowe adresy URL?
URL - jednorodny lokalizator zasobu (Uniform resource locator). URL pozwala przeglądarce na kontakt z właściwym serwerem i zamówienie potrzebnego dokumentu. Przykład adresu URL: http://www.pr.radom.net/dzial/dziekanat/index.php
- Protokół wymagany do uzyskania dostępu do dokumentu (http). - Nazwa mnemoniczna hosta, na którym znajduje się dokument. - Ścieżka do katalogu określającego położenie dokumentu w systemie plików hosta. - Nazwa dokumentu
Czym zajmują się protokoły sieciowe?
Protokoły stosowane w sieciach komputerowych definiują szczegóły wykonania każdej czynności, w tym sposób adresowania komunikatów, sposób przekazywania praw do transmisji komunikatów i sposób obsługi czynności związanych z upakowywaniem komunikatów przeznaczonych do transmisji i rozpakowywaniem otrzymanych komunikatów.
Wyjaśnij zasady sterowania uprawnieniami do transmisji systemu Token Ring.
Jeden ze sposobów koordynacji prawa do transmisji komunikatów to protokół token ring stosowany w sieciach o konfiguracji pierścienia. Zgodnie z tym protokołem, każdy komputer przekazuje komunikaty tylko w „prawo”, a odbiera je tylko z „lewej strony”, tak jak to przedstawiono na rysunku. Komunikat z jednego komputera do drugiego jest zatem przekazywany po sieci przeciwnie do ruchu wskazówek zegara aż do chwili, gdy dotrze do miejsca przeznaczenia. Gdy komunikat dochodzi do celu, komputer odbierający kopiuje go, zatrzymuje kopię dla siebie, a drugi egzemplarz przekazuje dalej do pierścienia. Gdy ten egzemplarz dotrze do komputera nadawcy, jest pewność, że komunikat dotarł do miejsca przeznaczenia, nadawca usuwa go zatem z pierścienia.
Wyjaśnij zasady sterowania uprawnieniami do transmisji systemu w Ethernecie (CSMA/CD).
Do transmisji w Ethernecie stosowany jest protokół CSMA/CD. Polega on na tym iż każdy komunikat transmitowanych przez dowolny komputer jest rozgłaszany do wszystkich komputerów przyłączonych do magistrali. Każdy komputer monitoruje nadchodzące komunikaty, ale zatrzymuje te które są adresowane do niego. Aby wysłać swój komunikat komputer czeka na chwilę ciszy na magistrali wtedy rozpoczyna transmisję cały czas monitorując magistralę. Jeśli inny komputer również rozpocznie transmisję to obie maszyny wykrywają konflikt, przerywają transmisję na krótki czas o losowej długości po czym rozpoczynają transmisję od nowa.
Omów warstwową budowę oprogramowania internetowego. Jakie warstwy biorą udział w transmisji danych?
Głównym zadaniem oprogramowania sieciowego jest dostarczenie abstrakcyjnych narzędzi potrzebnych do transmisji komunikatów przez sieć. W wypadku Internetu zadanie to obejmuje także przekazywanie komunikatów między poszczególnymi sieciami. Warstwy wchodzące w skład transmisji danych: warstwa transportowa; warstwa sieciowa; warstwa aplikacji.
Omów rolę poszczególnych warstw oprogramowania internetowego w trakcie transmisji danych.
Warstwa aplikacji
Jest to najwyższa warstwa w hierarchii oprogramowania internetowego składającą się z modułów programu komunikujących się ze sobą za pośrednictwem Internetu. Warstwa aplikacji przekazuje przeznaczone do transmisji komunikaty warstwie transportowej podając również adresy, pod które mają zostać wysłane. Tradycyjnymi przykładami są np. zbiór podprogramów do transmisji plików przez Internet za pomocą protokołu FTP lub pakiet telnet, opracowany w celu umożliwienia użytkownikom uzyskania postępu do zdalnego komputera w Internecie, tak jakby byli jego lokalnymi użytkownikami.
Warstwa transportowa
Zadaniem warstwy transportowej jest zapewnienie, że komunikat dotrze do warstwy transportowej w miejscu przeznaczenia, skąd zostanie przekazany do odpowiedniej aplikacji. Warstwa ta musi, zatem wykonać wszystkie czynności niezbędne w miejscu wysłania i w miejscu przeznaczenia komunikatu w sposób nieuwzględniający szczegółów związanych z samym przesłaniem komunikatu. Długie komunikaty dzielone są na segmenty o rozmiarze wymaganym przez warstwę sieciową, którym nadaje się kolejne numery, aby w miejscu przeznaczenia można było odtworzyć oryginalny komunikat. Następnie warstwa transportowa dołącza do każdego segmentu adres przeznaczenia i przekazuje powstałe jednostki, zwane pakietami warstwie sieciowej.
Warstwa sieciowa
Warstwa sieciowa zapewnia, że otrzymywane przez nią pakiety będą poprawnie przekazywane między poszczególnymi sieciami w Internecie aż do miejsca przeznaczenia. W odróżnieniu od warstwy transportowej, którą interesuje jedynie miejsce wysłania i przeznaczenia komunikatu, warstwa sieciowa musi nadzorować także kroki pośrednie wykonywane w trakcie wędrówki komunikatu przez Internet. Warstwa sieciowa pakuje pakiet, który otrzymuje od warstwy transportowej, w dodatkowe opakowanie, które zamiast adresu pierwotnego zawiera adres pośredni. Adres pośredni przydzielany jest na podstawie miejsca przeznaczenia danego pakietu, jeśli znajduje się ono w bieżącej sieci to adres pośredni jest taki sam jak miejsca przeznaczenia. Jeśli natomiast miejsce przeznaczenia znajduje się w innej sieci to adres pośredni zgodny jest z adresem routera w bieżącej sieci.
Warstwa kanałowa
Warstwa kanałowa odpowiedzialna jest za obsługę szczegółów komunikacji właściwych dla sieci, w której znajduje się komputer. Zadaniem warstwy kanałowej jest przetłumaczenie adresów internetowych zapisanych na opakowaniu pakietów na odpowiadające im adresy w formacie zgodnym z lokalnym systemem adresowania, a następnie dodać te przetłumaczone adresy do pakietu w postaci dodatkowego opakowania.
Jakie są przyczyny rzadkiego sterowania w sieci modelu OSI.
Nie ma jego czytelnej implementacji, przede wszystkim dlatego, że opracowano go po powstaniu, zaimplementowaniu i rozpowszechnieniu protokołu TCP/IP, który okazał się być niezawodnym protokołem dla Internetu.
Scharakteryzuj krótko pakiet protokołów TCP/IP.
Pakiet protokołów TCP/IP jest zbiorem protokołów definiujących czteropoziomową hierarchię stosowaną w Internecie. TCP i IP są nazwami jedynie dwóch protokołów z tego zestawu. Protokół TCP definiuje pewną wersję warstwy transportowej. TCP/IP udostępnia dwa sposoby implementacji warstwy transportowej. Drugi sposób definiuje protokół UDP. W zależności od wymaganej jakości usług, oprogramowanie z warstwy aplikacji może decydować, której warstwy transportowej użyje do przesyłania danych: TCP czy UDP.
Czym różnią się od siebie TCP i UDP?
TCP najpierw ustanawiam połączenie i dopiero zaczyna transmisję oczekując potwierdzenia odebrania danych w przypadku jego braku wznawia transmisję. Natomiast UDP nie oferuje retransmisji oraz nie zestawia najpierw połączenia tylko transmituje od razu dane pod wskazany adres.
Są dwie główne różnice pomiędzy TCP a UDP . Pierwsza polega na tym, że warstwa transportowa oparta na TCP przed przesłaniem danych wysyła do warstwy transportowej komunikat informujący o zamiarze przesłania danych i identyfikujący oprogramowanie z warstwy aplikacji, które ma odebrać. Następnie oczekuje na potwierdzenie tego komunikatu dopiero wówczas rozpoczyna przesyłanie. TCP przed wysłaniem danych ustanawia połączenie. Warstwa oparta na UDP nie ustanawia takiego połączenia. Wysyła ona po prostu dane pod podany adres i więcej się nim nie zajmuje. Dlatego UDP nazywa się protokołem bezpołączeniowym. Druga różnica: warstwy transportowe TCP komunikują się ściśle ze sobą w celu uzyskania pewności, że wszystkie segmenty dotarły do miejsca przeznaczenia. Protokół TCP jest niezawodny, podczas gdy UDP nie oferuje takiej retransmisji, jest protokołem zawodnym.
Wyjaśnij i krótko scharakteryzuj najważniejsze zagrożenia przy korzystaniu z komputera podłączonego do Internetu?
Komputer przyłączony do Internetu staje się dostępny dla wielu potencjalnych użytkowników. Wiążą się z tym problemy, które można podzielić na dwie grupy; pierwsza dotyczy nieuprawnionego dostępu do informacji, druga wandalizmu. Często zdarza się ze nasze tajne i pilnie strzeżone hasła staja się obiektem kradzieży, przez co wpadają w niepowołanie ręce przysparzając nam spore problemy. Sposobów kradzieży haseł jest naprawdę bardzo wiele np.: - wykorzystanie luk w systemie operacyjnym i uzyskanie zapisanych w nim informacji o hasłach - napisaniu programu, który symuluje proces rejestrujący na komputerze lokalnym. Mimo licznych zabezpieczeń, które strzegą tego by nasze hasla pozostaly tylko nasza własności korzystając z Internetu musimy zwracać ogromna uwagę na to by uchronić się przed takimi niemiłymi sytuacjami.
Jakie znasz sposoby zapobiegania najważniejszym zagrożeniem przy korzystaniu z komputera podłączonego do Internetu?
W celu udaremnienia wysiłków tych, którzy bawią się w zgadywankę haseł, systemy operacyjne projektuje się tak, aby informowały o próbach rejestracji w systemie za pomocą niepoprawnego hasła. Wiele systemów operacyjnych podaje także po rozpoczęciu nowej sesji informacje, kiedy ostatnio korzystano z konta. Dzięki temu użytkownicy mogą wykrywać nieuprawnione użycie ich konta. Bardziej wyrafinowany sposób obrony przed poławiaczami haseł polega na tym, że w razie podania niepoprawnego hasła system operacyjny udaje, że rejestracja się powiodła (nazywa się to bocznym wejściem, ang. trapdoor) i kontynuuje działanie, próbując namierzyć włamywacza. Innym sposobem ochrony danych przed nieuprawnionym dostępem jest szyfrowanie danych - wtedy nawet w wypadku zdobycia danych przez włamywacza, są one bezpieczne. Opracowano wiele różnych technik szyfrowania. Jednym z popularnych sposobów szyfrowania komunikatów przesyłanych w sieci jest szyfrowanie z kluczem publicznym (ang. public-key encryption) Umożliwia on wielu nadawcom bezpieczne wysyłanie komunikatów do centralnego odbiorcy. Szyfrowanie z kluczem publicznym wymaga użycia dwóch wartości zwanych kluczami. Jeden klucz, zwany kluczem publicznym, stosuje się do kodowania wiadomości. Jest on znany wszystkim uprawnionym do tworzenia komunikatów. Drugi klucz, zwany kluczem prywatnym, jest potrzebny do odszyfrowania komunikatu. Jest on znany tylko osobie, która ma odebrać komunikat.
Czym różnią się wirusy od robaków?
Wirus jest segmentem programu, który dokleja się do innych programów w systemie. Wirus może wykonywać złośliwe działania, które są łatwo zauważalne lub po prostu szukać innych programów do których dołącza kopie samego siebie. Gdy spełniony zostanie odpowiedni warunek (np. konkretna data) wirus dokonuje aktu wandalizmu. Robak to niezależny program, który rozpowszechnia się po sieci. Tak jaki i wirusy robaki się powielają i dokonują aktu wandalizmu.
Wykład 4
Wyjaśnij krótko filozofię budowy dokumentów hipertekstowych z wykorzystaniem HTML.
HTML jest to język znakowy, określa formatowanie tekstu. W HTML jest możliwość umieszczania odnośników do innych dokumentów oraz możliwość umieszczania w dokumentach odnośników do innych obiektów (grafiki, apletów, obiektów). Tekst będzie sformatowany i wyświetlony bez względu na typ komputera n jakim go napisano, poleceniami formatującymi są znaczniki. Standard znaczników i innych formatów stosowanych w WWW zostało określone przez konsorcjum W3C.
Co to jest drzewo dokumentów?
Drzewo dokumentów jest to drzewo elementów umieszczonych w dokumencie źródłowym. Każdy element w takim drzewie ma dokładnie jednego rodzica, oprócz elementu podstawowego, czyli korzenia drzewa (root).
Omów najważniejsze sposoby tworzenia stron WWW
edytory WYSIWYG (np.: Mozilla Nvu Adobe Dreamweaver, Agobe GoLive, MS Expression Web, MS Front Page, …)
- łatwość obsługi
- generują stosunkowo „słabej” jakości kod
- przydatne przy dużych projektach
„tekstowe” edytory HTML (Pajączek, AceHTML, PSPad,…)
- dokładniejsze
- tylko dla osób znających HTML'a
- dzisiejsze oferują wiele ułatwień (kolorowane składni, biblioteki skryptów, wbudowany podgląd, generowanie bardziej złożonych elementów kodu)
Omów proces umieszczania stron w Internecie?
Trzeba posiadać konto na serwerze w Internecie. Zwykle wystarczy skopiować pliki witryny do odpowiedniego katalogu. Zwyczajową nazwą katalogu przeznaczonego do publikacji strony w Internecie jest public_html umieszczony w katalogu domowym użytkownika. Zwykle są one również dostępne po podaniu adresu: adres_serwera/~nazwa_konta_użytkownika/nazwapliku
Trzeba pamiętać o tym aby folder z plikami był publiczne dostępny.
Co to są znaczniki? Jaką rolę pełnią znaczniki w dokumencie hipertekstowym? Do czego służą atrybuty znaczników? Jak definiujemy atrybuty znaczników?
Znaczniki mają postać słów umieszczonych w nawiasach <>, np.<h1>
- Reprezentują strukturę dokumentu
- Zakres działania znaczników <p>...</p>(znacznik końcowy zawiera ukośnik, sformatowanie obowiązuje od znacznika początkowego do końcowego)
Nie rozróżnia się dużych i małych liter <b> i <B> oznaczają to samo (nowe wersje standardów np.. xhtml zalecają używanie małych liter).
Sekwencje tekstu pomiędzy znacznikami mogą zawierać inne znacznik. Każdy znacznik może posiadać atrybuty. Atrybuty znaczników określają dodatkowe właściwości znacznika Atrybuty i ich wartości umieszcza się po nazwie atrybutu ale przed zamykającym znakiem >. Wartość musi być zamknięta pomiędzy znakami ` ' np. <znacznik atrybut1="wartość 1" atrybut2="wartość 2"
atrybut3="wartość 3">
...
</znacznik>
Podaj i omów strukturę dokumentu HTML.
Struktura dokumentu HTML:
Prolog - określa wersję dokumentu
Znaczniki dokumentu - pomiędzy znacznikami <html> </html> (pomiędzy nimi umieszczony jest cały dokument)
Nagłówek - pomiędzy znacznikami <head> </head> (określa własności dokumentu)
Treść - pomiędzy znacznikami <body> </body> (zawiera treść dokumentu)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<HTML>
<HEAD>
…
informacje nagłówkowe
…
</HEAD>
<BODY>
…
właściwa treść (ciało) dokumentu
…
</BODY>
</HTML>
Podaj składnię i przedstaw sposób umieszczania typowych informacji w nagłówku dokumentu.
Tytuł dokumentu (tekst sekwencji pojawi się w nazwie okienka przeglądarki lub zakładki) <title> Technologie informacyjne </title>
Dane dodatkowe:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-2">
- znacznik zamykający jest zabroniony
- określa dodatkowe informacje o dokumencie, interpretowane przez serwery i przeszukiwarki
- pozwala na określenie strony kodowej dokumentu (wymagane)
Inne znaczniki meta:
<meta name="author" content="Tomasz Ciszewski">
<meta name="keywords" content="HTML, wykład, znaczniki META">
<meta name="description" content="Wykład o HTML">
<meta name="copyright" content="Politechnika Radomska 2007">
<meta name="date" content="2007-05-04">
Jak w dokumentach HTML umieszczamy komentarze?
Komentarz rozpoczyna się znakiem <!-- a kończy -->
Czym różnią się znaczniki formatujące fizyczne i logiczne? Podaj po kilka przykładów dla obu rodzajów znaczników.
Znaczniki formatujące fizycznie pozwalają autorowi dokumentu na narzucenie określonego wyglądu tekstu np. pogrubienie, pochylenie. Natomiast znaczniki formatujące logiczne umożliwiają wskazanie że dany fragment tekstu powinien być traktowany odmiennie lecz decyzję o sposobie wyróżnienia tekstu pozostawiają programowi klienta http.
Znaczniki fizyczne:
<b> - pogrubienie
<i> - pochylenie
<u> - podkreślenie
<font> - arbitralna zmiana czcionki
<small> - zmniejszenie rozmiaru czcionki
<big> - zwiększenie czcionki
<tt> - czcionka o stałej szerokości
<s> - przekreślenie
<sub> - indeks górny
<Sup> - indeks dolny
Znaczniki logiczne:
<strong> - mocne wyróżnienie
<em>- wyróżnienie
<Cite> - cytat
<dfn> - definicja
<code> - fragment kodu programu
<kbd> - tekst do wprowadzania
<samp> - przykład
<var> - zmienna
<abbr> - skrót
<acronym> -akronimJakie znasz atrybuty fizyczne czcionki? Podaj przykład ich stosowania.
Atrybuty fizyczne czcionki:
znacznik <FONT> (wycofany w HTML 4.0)
- określenie rozmiaru:
bezwzględnie przez liczbę: 1,2,3, 4, 5, 6, 7
względnie: +1, +2, +3, +4, -1, -2, -3, -4
- określenie koloru:
przez nazwę: Black, Green, Silver, itd..
przez wartości RGB: #RRGGBB
- określenie kroju czcionki:
pozwala na zmianę kroju przez podanie nazwy czcionki, Uwaga! Należy pamiętać, że nie na każdym systemie musi istnieć dana czcionka.
Zmiana koloru czcionki:
<font color="red">To jest czerwone</font>
<font color="rgb(200, 200, 200)">Jakiś szary kolor</font>
<font color="#A450F76">Jakiś kolor</font>
Zmiana rozmiaru czcionki:
<font size="1">Roz1</font>
<font size="2">Roz2</font>
<font size="3">Roz3</font>
<font size="4">Roz4</font>
<font size="5">Roz5</font>
<font size="6">Roz6</font>
<font size="7">Roz7</font>
Zmiana kroju czcionki:
<font face="Arial">Arial</font>
<font face="Verdana">Verdana</font>
<font face="Courier">Courier</font>
<font face="Impact">Impact</font>
<font face="Times New Roman">Times New Roman</font>
<font face="Lucida Console">Lucida Console</font>
W jaki sposób budujemy wykazy punktowe (nienumerowane)?
lista umieszczana jest pomiędzy znacznikami <ul></ul> każdy punkt listy musi zostać umieszczony pomiędzy <li></li> lista może zawierać listy zagnieżdżone można określić rodzaj wypunktowania przez podanie własności w stylu
Jak tworzymy listy numerowane?
Lista numerowana umieszczana jest pomiędzy znacznikami <ol> </ol>.
Każdy punkt listy musi zostać umieszczony pomiędzy <li> </li>. Można dodatkowo określić rodzaj wypunktowania przez podanie właściwości
- a - małe litery
- A - duże litery
- i - małe liczby rzymskie
- I - duże liczby rzymskie
- 1 - liczy arabskie
Można ręcznie określić numer danego punktu przez podanie wartości value.
Jak w dokumentach HTML umieszczamy tabelę?
Tabela <TABLE> </TABLE> Definicja tabeli musi być umieszczona między tymi dwoma znacznikami, które stanowią jej delimitery. W ich ramach umieszczone są definicje rzędów, definicje komórek w rzędach, konkretne dane w komórkach, tytuł tabeli oraz nagłówki wierszy i kolumn.
Jak w dokumentach HTML osadzamy grafikę?
Osadzanie grafiki w dokumentach HTML:
<img src=”nazwa pliku z grafiką” width=”szerokość” height=”wysokość”alt=”opis” align=”połoŜenie”>
znacznik <img> pozwala umieścić w danym miejscu grafikę
- znacznik zamykający jest zabroniony
- określenie pliku z grafika może zawierać pełny URL, ściekę względną, bądź bezwzględną do pliku np:
src="img/tlo.gif"
src="/usr/tciszewski/public_html/img/ul_close.gif "
src=http://www.pr.radom.net/img/cda.gif
Najczęściej używane są pliki gif, jpg, png, rzadziej bmp.
Jak w dokumentach HTML umieszczamy odsyłacze? Podaj przykłady dla najważniejszych rodzajów odsyłaczy.
odnośniki do innych stron html - wymagany znacznik zamykający
<a href=”url_strony”>napis na stronie</a>
odnośniki do oznaczonych miejsc na stronie
<a name=”oznaczenie_miejsca”></a>
<a href=”#oznaczone_miejsce”>napis na stronie</a>
bądź
<a href=”url_strony#oznaczone_miejsce”>napis na stronie</a>
Odnośniki poczty elektronicznej
<a href=”mailto:informatyka@pr.radom.net”>napis na stronie</a>
Dlaczego warto używać CSS do formatowania treści dokumentu HTML?
Rozdziela proces powstawania treści i układu graficznego strony, Dzięki niemy kod jest czytelniejszy i zajmuj mniej miejsca. Daje możliwość łatwej modyfikacji strony - wystarczy zmienić kod w miejscu gdzie został zdefiniowany styl.
Jakie znasz metody umieszczania CSS w dokumentach HTML? Który z tych sposobów jest Twoim zdaniem najlepszy? Dlaczego?
Są 3 sposoby:
Po pierwsze za pomocą kodu CSS możemy zmienić wygląd każdego elementu oddzielnie. Wystarczy w jego definicji wpisać atrybut style= a następnie w cudzysłowach umieścić definicję CSS.
Drugą możliwością jest umieszczenie globalnego (określającego wygląd wielu elementów) arkusza stylów w sekcji <head> dokumentu HTML.
Trzecim sposobem jest umieszczenie arkusza stylów w osobnym pliku i wskazanie tegoż pliku w każdym dokumencie HTML który ma być sformatowany wg podanego wzorca.
Najlepszym sposobem jest sposób trzeci ponieważ aby zmienić jakiś element naszej witryny dokonujemy modyfikacji tylko w jednym miejscu - w pliku z arkuszem CSSOmów budowę stylu CSS?
Konstrukcja stylu CSS jest bardzo prosta, składa się z dwu elementów - selektora przy pomocy, którego określamy, któremu ze znaczników HTML nadajemy formatowanie oraz umieszczonych w nawiasach klamrowych poleceń formatujących.
Polecenia formatujące składają się z dwóch części - cechy (własności) oraz przypisanej jej wartości. Przykład
Co to jest grupowanie selektorów ? Jakie są korzyści z grupowania selektorów?
Jeśli chcemy te same cechy przypisać kilku selektorom możemy skorzystać z możliwości ich grupowania. Aby ustawić pogrubiony tekst dla tytułów h1, h2 i h3 korzystamy z zapisu
h1, h2, h3 {font-weight: bold;}
Do czego służą klasy selektorów. Jak je definiujemy? Jak korzystamy z klas selektorów?
Klasy selektorów służą do nadawania różnym akapitom różnych wyglądów
Definiujemy je tworząc definicję stylów w której selektorami są nazwy znaczników i oddzielone od nich kropkami nazwy klas np.:
p { tu są różne parametry}
p.koniec {tu są różne parametry}
Aby w kodzie określonym znacznikom przypisać przynależność do klasy do znacznika dodajemy atrybut class z wartością określającą nazwę klasy w ””
<p class=”koniec”>tu jest tekst</p>
Do czego w CSS służą wolne klasy?
Specyfikacja CSS przewiduje możliwość nadawania wyglądu klasom niezwiązanym z żadnym elementem HTML. Służy do tego specjalny selektor *, zastępuje wszystkie elementy HTML. Dzięki temu możemy stworzyć np. klasę *.czerwony, którą możemy następnie przypisać dowolnemu znakowi HTML.
Na czym polega dziedziczenie stylów?
Dziedziczenie stylów polega na tym, ze elementy leżące niżej w hierarchii elementów HTML dziedziczą styl elementu lezącego wyżej w hierarchii chyba, że nadamy im inne formatowanie. Tak wiec, jeśli ustawimy wielkość czcionki na 14 i nie nadamy innym komórkom niżej w hierarchii osobnego stylu to będą one miały właśnie rozmiar 14.
Wykład 5
Dlaczego warto korzystać z XML
Jeśli masz potrzebę zapisywania określonych danych o określonej strukturze , XML okaże się najlepszym narzędziem, bez względu jakie by te dane nie były W przeciwieństwie do np. HTML, XML nie ma ograniczonej liczby znaczników, bo pozwala przechowywać dowolne dane i to w jak najbardziej wygodny dla nas sposób, bo sami go określamy. Sami określamy strukturę danych, która może być tabelaryczna, ale może także tworzyć drzewo.W ten sposób bnie jesteś, jako twórca zbiorów XML w żaden sposób ograniczony.Na tym przede wszystkim polega wyższość XML nad innymi formatami zapisu danych.
Jak definiujemy elementy i atrybuty w XML?
Definicja elementu:
<?xml version =”1.0” standalone=”yes”?>
<przykład>
<typ> jakaś właściwość</typ>
Witaj świecie!
</przykład>
Definicja atrybutu:
<?xml version =”1.0” standalone=”yes”?>
<przykład typ= ”jakaś właściwość”>
Witaj świecie!
</przykład>
Do czego w XML służą sekcje CDDATA? Jak je definiujemy?
Pozwalają włączyć do dokumentu tekst, który ma być zignorowany przez parser. Jedyne, co parser ma prawo z sekcją CDATA zrobić, to przekazać jej zawartość. Mogą one zatem zawierać nawiasy kątowe oraz znaki ampersand (&) ,które w „zwykłej” zawartości tekstowej są niedozwolone.
<![CDATA[Hej! to & jest <właśnie> sekcjacdata.]]> Jak widać powyżej, sekcję taką rozpoczyna ciąg<![CDATA[,a kończy ]]>.
Ten ostatni ciąg jest jedyną niedozwoloną zawartością sekcji bo kiedy parser ją napotka, będzie oczywiście „myślał”, że to koniec sekcji CDATA.
Do czego w XML służą instrukcje przetwarzania? Jak je definiujemy?
Instrukcje przetwarzania pokrewne są sekcjom CDATA, ale lepiej nadają się do „przemycania” w dokumentach XML np. .skryptów. Funkcjonalność instrukcji przetwarzania jest tym większa, że pozwalają one na identyfikację swojej zawartości po prostu poprzez nazwę. Nazwa ta występuje na samym początku, po znakach <? i funkcjonuje dokładnie tak samo, jak nazwa każdego elementu.
<?javascriptalert("Tojest<tylko>przykład.");?>
<?phpfunctionprintsum($a,$b){echo$a+$b;}?>
Instrukcja przetwarzania kończy się ciągiem ?>.
Jak w XML umieszczamy komentarze?
Otoprzykład:
<!--<tekst> komentarza -->
Komentarz rozpoczyna ciąg<!—a kończy-->.Może on oczywiście zawierać zarówno nawiasy kątowe,jak i znaki ampersand.
Co to są encje tekstowe? Jakie znasz predefiniowanie encje?
Encje tekstowe są czymś w rodzaju szablonów tekstu, pozwalają uniknąć częstego wypisywanie tego samego teksu, są najlepszym sposobem na umieszczenie w kodzie „niedozwolonych znaków”.
Encje predefiniowane:
< oznacza <
> oznacza >
&apos to `
" to `'
& to &
Pokaż przykład organizacji danych przy pomocy XML.
Jakie znasz sposoby przekształcania danych XML w celu ich prezentacji w przeglądarce internetowej?
Dane XML możemy przekształcać za pomocą języka XLS na podstawie czegoś w rodzaju szablonu. Korzystając z tego narzędzia można przegrupowywać i wybierać dane. Można je także przygotować do wizualnego przeglądania. Opis graficzny XSL nie jest niestety obsługiwany przez żadną z powszechnie używanych przeglądarek internetowych, co oznacza, że do prezentacji danych używa się HTML-a, lub jego młodszego brata—XHTML-a. Cała rzecz opiera się na automatycznym umieszczaniu danych pobranych z dokumentu XML, w wynikowym pliku HTML. Taki plik HTML służy do prezentacji wybranych w trakcie przekształceń XSLT danych. Ta technika nadaje się wyśmienicie do prezentowania danych w Internecie. Z jednej strony umożliwiamy programom pobranie samych danych, z drugiej serwujemy czytelnikowi ładnie graficznie przygotowane dane. Co więcej, Dante można także zmusić do interakcji z użytkownikiem. Cały czas możemy przecież mieć do nich dostęp.Do czego służą arkusze XSL?
Arkusze stylów XSL mogą być osobnymi plikami, które za pomocą odpowiedniej deklaracji w prologu przypisuje się dokumentom z danymi. Oczywiście jednego arkusza stylów można używać do przekształceń wielu plików z danymi tworzącymi tę samą strukturę. Tak na prawdę, korzystając z tego, że arkusze stylów są „zorientowane” na elementy i inne „węzły” dokumentu XML, można wybiórczo przekształcać poszczególne „węzły” z danymi. Oczywiście najczęściej jest nim po prostu korzeń dokumentu.
Wyszukiwarka
Podobne podstrony:
2420
Bezugsquelle fuer RF 2420
2420
2420
2420
2420
2420
2420
2420 Regulator temperatury termostat
007 analiza ebmid 2420 ppt
2420
Recarga Toner HP 2400 2420
2420
więcej podobnych podstron