HISTORIA POWSTANIA I ROZWOJU JĘZYKA C
Powstanie języka C jest ściśle związane z systemem operacyjnym Unix. Prace projektowe nad C rozpoczęto w 1971 r. w Laboratoriach Bella (AT&T) w celu ponownego napisania w nim jądra systemu (wcześniejsze wersje jądra były pisane w asemblerze). Zostało to dokonane w 1973 r. i od tamtej pory wszystkie jądra systemów uniksowych (również Linuksa) są pisane w języku C. Jedynymi fragmentami jądra, które muszą być pisane w języku maszynowym, są sterowniki urządzeń fizycznych. Kompilator języka C jest dostępny w każdym systemie uniksowym. Język C w pewnym stopniu opiera się na wcześniejszym języku B (mało rozpowszechnionym), ale typami danych i strukturami sterującymi zdradza też pokrewieństwo z wcześniej istniejącymi językami strukturalnymi (Algol - koniec lat 50-tych, Pascal - 1971 r. - prawie jednocześnie!). Początkowo język C był nazywany językiem programowania systemowego (prawdopodobnie głównie dlatego, że było to jego pierwsze zastosowanie) - udostepnia mechanizmy uważane za niskopoziomowe, takie jak operowanie na poszczególnych lokatach pamięci (nawet w pewnym stopniu na rejestrach procesora), wywoływanie niskopoziomowych funkcji systemu operacyjnego, a także daje dość zwięzły i wydajny kod wynikowy po kompilacji (kosztem pewnej utraty czytelności programu źródłowego). Obecnie język C jest uważany za język ogólnego użytku i jego stosowalność i rozpowszechnienie wykracza daleko poza programowanie sytemowe. Co więcej, stał się on podstawą do opracowania języków obiektowych wysokiego poziomu - C++ i Java (duże fragmenty kodów źródłowych programów w C mogą być przenoszone do nich bez zmiany). Rozpowszechnienie języka C spowodowało potrzebę jego standaryzacji (aby jak najwięcej programów było przenośnych pomiędzy różnymi typami komputerów i systemów operacyjnych). Standard został opracowany przez ANSI (American National Standardization Institute) w latach 1983 - 88 i obejmuje zarówno składnię i semantykę instrukcji C oraz typy danych, jak i pewną liczbę najważniejszych bibliotek funkcji. Przedmiotem naszego wykładu będzie język ANSI C.
CHARAKTERYSTYCZNE CECHY JĘZYKA C
Język C, podobnie jak cały system Unix, jest wytworem typowo „inżynierskim”. Oznacza to, że zawiera wiele pomysłowych elementów, które zwiększają sprawność programów w nim napisanych i ułatwiają zespołowe tworzenie większych fragmentów oprogramowania, ale definicje jego składni i semantyki nie zawsze wykazują się „matematyczną precyzją” i elegancją. Minimalnie wcześniejszy od języka C język Pascal, choć pod większością względów do niego podobny (struktura blokowa, typy danych, instrukcje sterujące, definiowanie funkcji), jest językiem typowo „akademickim”. Ma precyzyjnie i elegancko zdefiniowaną składnię, co bardzo ułatwia wyszukiwanie błędów i formalne (zautomatyzowane) dowodzenie poprawności programów. Jego semantyka jest prawie wolna od niejednoznaczności. Wadą jest natomiast niezbyt efektywny (na ogół) kod maszynowy powstały w wyniku kompilacji oraz niezbyt poręczne narzędzia do składania większych całości z fragmentów programów.
Kompilatory języka Fortran są w stanie generować kod wynikowy o podobnej efektywności, co kompilatory języka C, ale składnia Fortranu jest dużo bardziej prymitywna. Dla programistów przyzwyczajonych do Pascala zaskakujące może się wydać pojęcie wyrażenia oraz pojęcie instrukcji przypisania (podstawienia) w języku C. Dowolne wyrażenie arytmetyczne, po którym został umieszczony średnik, staje się instrukcją (nawet jeśli ta instrukcja nie zmienia wartości żadnej zmiennej), na przykład 2 + 2 ; jest poprawną instrukcją w języku C! Z drugiej strony, każda instrukcja (w szczególności instrukcja przypisania) jest traktowana jako wyrażenie posiadające pewną wartość, która może być użyta w instrukcji nadrzędnej, na przykład w instrukcji x = y = z ; przypisanie y = z jest traktowane z jednej strony jako instrukcja zmieniająca wartość zmiennej y, a z drugiej strony jako wyrażenie, którego wartość może być przypisana zmiennej x. W języku C operatorem przypisania jest = (nie := jak w Pascalu). Operatorem porównania jest = =. Średnik pełni rolę znaku kończącego instrukcję (należącego do niej), a nie separatora pomiędzy instrukcjami. Odpowiednikiem pary begin, end jest para nawiasów klamrowych { , }.
Dostępnymi typami złożonymi danych są tablice oraz struktury (struktury odpowiadają pascalowemu pojęciu rekordu). Nie ma typu zbiorowego. Pliki są traktowane w inny sposób, niż w Pascalu - nie są złożonym typem danych i nie mają narzuconej przez deklarację struktury zapisu (na przykład plik liczb całkowitych lub plik rekordów) - są „bezpostaciowymi” ciągami bajtów zakończonymi znacznikiem końca plików (tak w Pascalu są dostrzegane „pliki ogólne” - file, na których dokonujemy operacji zapisów i odczytów blokowych).
Operacje na plikach nie są udostępnione w samym języku ANSI C, ale w tak zwanej bibliotece standardowej, do której został przerzucony ciężar wykonywania bardziej złożonych operacji. W przeciwieństwie do pascalowych łańcuchów, których długość może wynosić co najwyżej 255 znaków (jest zapisywana w bajcie zerowym łańcucha), łańcuchy w C mogą mieć teoretycznie dowolną długość (w praktyce zależy to od implementacji). Podobnie jak pliki, kończą się one pewnym ustalonym znakiem (znakiem pustym o kodzie 0). Z tego powodu typowe operacje na łańcuchach, takie jak kopiowanie czy porównywanie, również nie są elementem języka ANSI C, ale są udostępniane w bibliotece standardowej. W przeciwieństwie do Pascala, w którym odróżnia się pojęcia procedury i funkcji, w języku C istnieją wyłącznie funkcje (czyli podprogramy obliczające wyniki określonych typów). Wręcz sam program główny w C jest również funkcją o zastrzeżonej nazwie main. Chcąc wyrazić w języku C, że funkcja nie zwraca żadnego wyniku, jako typ wyniku przyjmujemy void (pusty). Argumenty funkcji w C mogą być przekazywane wyłącznie przez wartość (nie ma odpowiednika var w Pascalu). Jeśli chcemy, żeby argumentem funkcji był jakiś duży, złożony obiekt danych (np. struktura), używamy zmiennej wskaźnikowej (wskaźniki mają w języku C dużo większe znaczenie, niż w Pascalu). Funkcje w C mogą być jednostkami kompilacji (to znaczy, mogą być umieszczane w oddzielnych plikach i niezależnie kompilowane). Umiejętność łączenia funkcji w biblioteki i wykorzystywania bibliotek w programach powinna być jedną z podstawowych umiejętności (i nawykiem) programisty używającego C.
Jest zalecane (jako element dobrego stylu programowania), żeby deklaracje zmiennych lokalnych umieszczać na początku funkcji, ale nie jest to obowiązkiem - deklaracja zmiennej musi jedynie pojawić się przed pierwszym użyciem tej zmiennej w jakiejkolwiek instrukcji. Sam język ANSI C nie ma wbudowanych żadnych bardziej złożonych operacji (na przykład porównywania łańcuchów lub tablic) ani żadnych operacji na zasobach systemu operacyjnego, w szczególności zaś operacji na standardowym wejściu i wyjściu. Wniosek: jeśli program w C ma cokolwiek pisać lub czytać, niezbędne jest dołączenie do niego przynajmniej jednej biblioteki (zazwyczaj jest to stdio - standard input and output). Biblioteki statyczne dołącza się przy użyciu dyrektywy dla kompilatora #include (odpowiednika pascalowego uses). Interesującą możliwością dostępną dla programistów w C jest możliwość stosowania tak zwanego przetwarzania wstępnego (preprocessing) tekstu źródłowego programu, zanim zostanie on poddany właściwej kompilacji. W praktyce oznacza to, że na pierwotnym tekście programu może być automatycznie wykonany cały szereg typowych funkcji edytorskich - zastępowanie jednych ciągów znaków innymi, wstawianie przygotowanych wcześniej fragmentów tekstu i temu podobne. Bardzo użyteczna jest możliwość warunkowego (conditional) przetwarzania tekstu, na przykład w zależności od wykrytej wersji systemu operacyjnego - znacznie ułatwia to przenoszenie oprogramowania pomiędzy różnymi systemami.
Przykład
Prosty program, który wyświetla ustalony napis.
#include <stdio.h>
main( )
{
printf(”ABC \n”);
return;
}
W powyższym programie instrukcja printf wyprowadza napis ABC na standardowe wyjście. Znak \n jest znakiem nowej linii. Instrukcja return; powinna kończyć wykonywanie każdej funkcji (też main), ale nie jest konieczna - bez niej kompilator też będzie w stanie prawidłowo przetłumaczyć ten program.
Tak, jak w przypadku programów w Pascalu, nadanie tekstowi pewnej struktury może poprawić jego czytelność (ale nie jest obowiązkowe). Stosowane są różne style formowania tekstów programów.
Przykład
Program, który wczytuje liczbę całkowitą i wyświetla jej podwojenie.
#include <stdio.h>
main( )
{
int k;
scanf(”%d”,&k);
printf(”%d \n”,2*k);
return;
}
Pomiędzy znakami ” ” umieszczony jest tak zwany format wczytywanej / wyświetlanej liczby. Format %d wskazuje, że będzie to liczba całkowita dziesiętna.
Przykład
Program, który wczytuje dwie liczby rzeczywiste i wyświetla ich sumę.
#include <stdio.h>
main( )
{
float x,y;
printf(”Podaj dwie liczby rzeczywiste oddzielone spacją: ”);
scanf(”%f %f”,&x,&y);
printf(”Oto ich suma: %f \n”, x + y);
return;
}
Format %f jest formatem liczby rzeczywistej pojedynczej długości (float).
KOMPILACJA PROGRAMÓW W C W SYSTEMACH UNIKSOWYCH
Pliki z programami źródłowymi powinny mieć rozszerzenie c.
Podstawowym (i najprostszym) poleceniem kompilacji pliku o nazwie plik.c jest cc plik.c (w Linuksie poza cc można używać równoważnego polecenia gcc), które w przypadku pomyślnym generuje plik wykonywalny o nazwie a.out umieszczony w tym samym katalogu, zaś w przypadku niepomyślnym wyświetla listę komunikatów o błędach. Jeśli chcemy, żeby plik wynikowy miał dowolną inną ustaloną przez nas nazwę (rozszerzenie out nie jest obowiązkowe), możemy użyć polecenia o postaci cc plik.c -o nazwa. Polecenie cc umożliwia również jednoczesną kompilację i połączenie w całość kilku plików źródłowych zawierających różne fragmenty (ale nie dowolne) jednego programu. Do przeprowadzania bardziej skomplikowanych kompilacji i łączeń zalecany jest program make współpracujący z zawierającym polecenia dla niego plikiem makefile. W przypadku pomyślnego przebiegu kompilacji kompilator cc nie wyświetla żadnego komunikatu, zwraca jedynie sterowanie do linii poleceń. W przypadku błędów wyprowadza na standardowe wyjście błędów (czyli zazwyczaj na ekran, tak jak standardowe wyjście) od razu całą listę wykrytych błędów wraz z podanymi numerami linii programu, w których występują (kompilator Pascala zatrzymuje się po wykryciu pierwszego błędu).
System Unix nie oferuje standardowo tak wygodnego środowiska do śledzenia wykonywania skompilowanych programów, jak Turbo. Istnieją jednak pewne programy (na przykład lint), które w pewnym stopniu mogą pełnić taką rolę.
TYPY PROSTE. STAŁE I ZMIENNE
Podstawowe typy danych wystepujące w języku C to:
char - typ znakowy;
int - typ całkowity;
float - typ rzeczywisty pojedynczej precyzji;
double - typ rzeczywisty podwójnej precyzji.
Deklaracje typów mogą być poprzedzone kwalifikatorami:
short - może poprzedzać int;
long - może poprzedzać int i double;
unsigned - może poprzedzać cher i int (z kwalifikatorem short lub long lub bez kwalifikatora).
Jeśli jakiekolwiek kwalifikatory odnoszą się do typu int, samo słowo klucz int może być pominięte.
Liczby bajtów implementacji poszczególnych typów zależą od sprzętu, na którym pracuje kompilator języka C. Standard ANSI C gwarantuje jedynie minima: short i int - co najmniej 2 bajty; long - co najmniej 4 bajty;
Ponadto musi zawsze zachodzić: sizeof (short typ) <= sizeof (typ) <= sizeof (long typ) oraz sizeof (float) <= sizeof (double)
Kwalifikator unsigned nie wpływa na długość reprezentacji, powoduje jedynie, że zamiast kodu uzupełnieniowego stosowany jest kod naturalny zapisu liczb.
Przykład
unsigned char a, b, c;
short m, n;
long double x, y, z;
Nazwy zmiennych i stałych symbolicznych mogą składać się jedynie z liter (uwaga: małe i duże litery są rozróżniane !), cyfr i znaku podkreślenia. Nazwa musi zaczynać się od litery lub znaku podkreślenia (ale nie zaleca się tworzenia nazw rozpoczynających się od znaku podkreślenia, gdyż takie nazwy często występują w funkcjach bibliotecznych i może wystąpić zjawisko przesłonięcia). Stałe symboliczne są deklarowane podobnie, jak zmienne, ale ich deklaracje są poprzedzane słowem kluczowym const, a po deklaracji następuje podanie wartości.
Przykład
const int k = 1654;
const float p = 27.341;
Uwaga. Skutki próby zmiany przez instrukcje programu wartości stałej symbolicznej są zależne od implementacji.
Typami stałych literalnych (występujących w instrukcjach konkretnych wartości) są domyślnie char, int i double. Programista może w pewnym stopniu „wymusić” przyporządkowanie określonego typu poprzez zastosowanie w zapisie odpowiednich znaków.
Przykład
'a' - jest stałą znakową (char);
'\0' - jest stałą znakową reprezentującą kod ASCII 0 (znak końca łańcucha)
674 - jest stałą typu int;
674L - jest stałą typu long int (można pisać l zamiast L);
0X674 - jest stałą typu int traktowaną jako liczba szesnastkowa (o wartości dziesiętnej 1652);
12.345 - jest stałą typu double;
12.345F - jest stałą typu float (można pisać f zamiast F).
Podobnie, jak w Pascalu, w języku C istnieją też stałe łańcuchowe (napisy), traktowane jako tablice znakowe zawierające ciągi znaków zakończone znakiem pustym. ”ABCD” jest pięcioznakowym łańcuchem zawierającym znaki 'A', 'B', 'C', 'D' i '\0'.
OPERATORY I WYRAŻENIA. PRZYPISANIE
W języku C istnieje standardowy zestaw operatorów arytmetycznych, logicznych, porównania i bitowych, których oznaczenia tylko częściowo pokrywają się z oznaczeniami używanymi w Pascalu.
1) Operatory arytmetyczne:
+ dodawanie
- odejmowanie
* mnożenie
/ dzielenie
% obliczenie reszty z dzielenia
Operacje arytmetyczne mogą być wykonywane na argumentach zarówno całkowitych, jak i zmiennoprzecinkowych, tylko operator % może być stosowany wyłącznie do pary argumentów całkowitych. W przypadku wykonywania dzielenia pary liczb całkowitych wynik jest automatycznie zaokrąglany (dla pary liczb dodatnich w dół, w innych przypadkach zależy to od implementacji).
2) Operatory porównania:
= = równe
! = różne
> większe
> = większe lub równe
< mniejsze
< = mniejsze lub równe
Wartością wyrażenia relacyjnego (wynikiem porównania) jest 1, jeśli jest ono prawdziwe, zaś 0, jeśli jest ono fałszywe.
3) Operatory logiczne
&& i (and)
| | lub (or)
! nie (not)
Uwaga. W przeciwieństwie do Pascala, w języku C nie istnieje predefiniowany typ logiczny danych. Operacje logiczne wykonywane są na wartościach arytmetycznych stałoprzecinkowych, przy czym wartość 0 traktowana jest jako fałsz (false), zaś każda wartość niezerowa jako prawda (true). Wynikiem zarówno operacji porównania, jak i operacji logicznych może natomiast być tylko 0 lub 1.
4) Operatory bitowe
& koniunkcja bitowa
| alternatywa bitowa
^ bitowa różnica symetryczna
<< przesunięcie w lewo
>> przesunięcie w prawo
~ negacja bitowa (dopełnienie jedynkowe)
Operacje bitowe mogą być wykonywane tylko na wartościach stałoprzecinkowych (ze znakiem lub bez znaku). Operator ~ jest jednoargumentowy, pozostałe są dwuargumentowe. Przesuwanie w lewo lub w prawo wartości bez znaku oraz przesuwanie w lewo wartości ze znakiem powoduje wypełnienie zwolnionych bitów zerami, przesuwanie w prawo wartości ze znakiem powoduje wypełnienie zerami lub jedynkami - zależnie od implementacji. Wartość stojąca po prawej stronie znaku << oraz >> określa liczbę pozycji, o którą ma nastąpić przesunięcie, i musi być nieujemna. Operatorem podstawienia (przypisania) wartości jest w języku C operator =. Instrukcja podstawienia ma zatem postać zmienna = wyrażenie;. Interesującą cechą języka C jest możliwość traktowania instrukcji podstawienia jednocześnie jako wyrażenia, którego wartość jest równa obliczonej wartości wyrażenia po prawej stronie znaku =.
Oznacza to, że instrukcja podstawienia może być wbudowywana w bardziej złożone wyrażenia i instrukcje i pełnić jednocześnie dwie role: nadawać wartość zmiennej i umożliwiać jednoczesne wykonanie innej instrukcji (w szczególności innego podstawienia).
Przykład y = (x = 5) + 2;. W wyniku wykonania tej instrukcji zmienna x otrzyma wartość 5, a zmienna y otrzyma wartość 7. Tego rodzaju podwójne wykorzystanie operacji przypisania jest jedną z typowych „sztuczek technicznych” w języku C. Zaletą ich jest powodowanie większej zwięzłości zapisu programu źródłowego i optymalizowanie kodu wynikowego powstałego po kompilacji, natomiast wadą jest zmniejszanie czytelności programu źródłowego i utrudnianie wyszukiwania błędów.
5) Operatory zwiększania i zmniejszania wartości (o jeden)
Są operatorami jednoargumentowymi, które mogą być stosowane wyłącznie do zmiennych typów całkowitych i stanowią szczególny przypadek operatorów przypisania. Mogą być stosowane jako operatory przedrostkowe (przed zmienną) lub przyrostkowe (po zmiennej).
+ + zmienna; - zwiększ wartość zmiennej o 1 przed jej wykorzystaniem
- - zmienna; - zmniejsz wartość zmiennej o 1 przed jej wykorzystaniem
zmienna + +; - zwiększ wartość zmiennej o 1 po jej wykorzystaniu
zmienna - -; - zmniejsz wartość zmiennej o 1 po jej wykorzystaniu
Przykład 1
Instrukcja C + +; jest funkcjonalnie równoważna instrukcji C = C + 1; (ale jest nieco szybciej wykonywana).
Przykład 2
W wyniku wykonania ciągu instrukcji: x = 0; y = (+ + x) + 2; zmienna x uzyska wartość 1, zaś zmienna y uzyska wartość 3 (gdybyśmy zastosowali (x + +), zmienna y uzyskałaby wartość 2).
5) Pozostałe operatory przypisania
Poza wcześniej omówionymi instrukcjami są dostępne również instrukcje o postaci zmienna op = wyrażenie; gdzie op jest jednym z operatorów dwuargumentowych: + - * / % << >> & ^ |
Powyższa instrukcja jest funkcjonalnie równoważna instrukcji zmienna = zmienna op wyrażenie; (ale jest od niej nieco szybciej wykonywana).
Przykład
Instrukcja x + = 2; jest równoważna instrukcji x = x + 2;
Podobnie jak wcześniej omówione instrukcje przypisania, powyższe instrukcje również mogą być traktowane jako wyrażenia o wartościach równych wartościom nadawanym zmiennym.
6) Wyrażenia warunkowe
Instrukcja o postaci zmienna = warunek?wyrażenie1:wyrażenie2 jest funkcjonalnie równoważna instrukcji if (warunek) zmienna = wyrażenie1; else zmienna = wyrażenie2; (ale jest od niej nieco szybciej wykonywana). Podkreślone wyrażenie jest nazywane wyrażeniem warunkowym i, podobnie jak inne wyrażenia, posiada przypisaną wartość (równą wartości nadanej zmiennej).
Przykład
Instrukcja x = (a > b) ? a : b; przypisuje zmiennej y wartość równą większej spośród wartości a oraz b.
Kolejność wykonywania obliczeń w wyrażeniach.
Operator Łączność
( ) [ ] -> . lewostronna najwyższy priorytet
! ~ ++ -- + - * & (typ) sizeof prawostronna
* / % lewostronna
+ - lewostronna
<< >> lewostronna
< <= > >= lewostronna
== != lewostronna
& lewostronna
^ lewostronna
| lewostronna
&& lewostronna
| | lewostronna
?: prawostronna
= += -= *= ?= %= ^= |= <<= >>= prawostronna
, lewostronna najniższy priorytet
(Niektóre operatory mogą mieć różne interpretacje - zależnie od kontekstu).
2. INSTRUKCJE STERUJĄCE
W języku C instrukcje sterujące są podobne do analogicznych instrukcji w Pascalu (ale nie są dokładnie takie same !).
1) Instrukcja warunkowa
if (wyrażenie)
instrukcja1
else
instrukcja2
Przykład
if (x >= 0)
y = x;
else
y = -x; /* Zmiennej y jest przypisana wartość bezwzględna x */
Przykład
Obliczanie pierwiastków trójmianu kwadratowego.
/* Dane liczby rzeczywiste a, b, c, gdzie a nie jest równe 0 */
delta = b*b - 4*a*c;
if (delta < 0)
printf (”Nie ma pierwiastkow”);
else if (delta = = 0)
printf (”x = %f \ n”, - b / (2 * a));
else printf (”x1 = %f , x2 = %f \ n”, (- b - sqrt (delta)) / (2 * a), (- b + sqrt (delta)) / (2 * a));
Uwaga
W przypadku zagnieżdżenia instrukcji if (jak w powyższym przykładzie) drugie else jest związane z bardziej wewnętrzną (drugą) instrukcją if. Gdyby zewnętrzna instrukcja if miała zawierać człon else, zaś wewnętrzna nie, należałoby stosować nawiasy klamrowe { } grupujące instrukcje.
2) Instrukcja wyboru
switch (wyrażenie)
{
case stała_1: ciąg_instrukcji_1
.....................
case stała_n: ciąg_instrukcji_n
default: ciąg_instrukcji
}
Działanie jest podobne jak instrukcji case w Pascalu. Stałe mogą być dane wyrażeniami stałymi. Ciąg instrukcji nie musi być ujęty w nawiasy klamrowe, może być też pusty. Człon default instrukcji (podobnie jak else w Pascalu) nie jest obowiązkowy.
Uwaga
Najbardziej istotną różnicą dzielącą sposób wykonania instrukcji switch od instrukcji case w Pascalu jest to, że po wykonaniu ciągu instrukcji po odpowiedniej etykiecie wyboru sterowanie nie przechodzi do pierwszej instrukcji po nawiasie klamrowym zamykającym całą instrukcję switch, ale do ciągu instrukcji po następnej etykiecie wyboru. Jeśli chcemy uniknąć takiej sytuacji, powinniśmy na końcu każdego ciągu instrukcji umieszczać instrukcję przerywającą wykonywanie instrukcji wyboru - zazwyczaj jest to instrukcja break.
Przykład
/* c - wczytany znak, powinien to być znak działania arytmetycznego */
switch (c)
{
'+': printf (”Wybrales dodawanie \ n”); break;
'-': printf (”Wybrales odejmowanie \ n”); break;
'*': printf („Wybrales mnozenie \ n”); break;
'/': printf (”Wybrales dzielenie \ n”); break;
default: printf(”To nie jest wlasciwy znak \ n”); break;
}
3) Instrukcja pętli while
while (wyrażenie)
instrukcja
Działanie jest dokładnie takie samo, jak działanie instrukcji while w Pascalu.
Przykład
Dana jest liczba rzeczywista r. Ile kolejnych wyrazów szeregu 1/1 + 1/2 + 1/3 + ... trzeba zsumować, aby suma przekroczyła r ?
suma = 0;
i = 0;
while (suma <= r)
suma += (float) 1/++i;
Uwaga: dla ujemnych wartości r wynik będzie 0 (wnętrze pętli nie będzie ani razu wykonane).
4) Instrukcja pętli do
do
instrukcja
while (wyrażenie);
Działanie jest takie samo, jak działanie instrukcji repeat w Pascalu poza interpretacją wyrażenia, które w instrukcji repeat jest traktowane jako warunek wyjścia z pętli, zaś w instrukcji do - jako zanegowany warunek wyjścia z pętli.
Przykład
Obliczenie liczby pozycji binarnych (bitów) danej liczby naturalnej n.
liczbit = 0;
do
liczbit ++ ;
while ((n /= 2) > 0); /* do zapisu liczby 0 potrzebny jest jeden bit */
5) Instrukcja pętli for
for (wyrażenie1; wyrażenie2; wyrażenie3)
instrukcja
Działanie pętli for jest inne, niż odpowiadającej jej instrukcji for w Pascalu. Ma ona szersze zastosowania, niż tylko odliczanie kolejnych obiegów pętli przy użyciu kolejnych wartości zmiennej. Instrukcja for w języku C jest funkcjonalnie równoważna instrukcji
wyrażenie1;
while (wyrażenie2)
{
instrukcja
wyrażenie3;
}
Uwaga: na ogół wyrażenie2 ma postać warunku, a wyrażenie1 i wyrażenie3 są przypisaniami, ale formalnie nie musi tak być - w języku C nawet napis 2+2; jest uważany za instrukcję!(pustą).
Przykład
Dla danej liczby naturalnej n obliczyć n!
silnia = 1;
for (i = 1; i <= n; i ++)
silnia *= i;
Pętla for w języku C może służyć nie tylko do iteracyjnych obliczeń o z góry znanej liczbie powtórzeń.
Przykład
Zapis przy użyciu for równoważny rozwiązaniu wcześniejszego przykładu dla while:
suma = 0;
for (i = 0; suma <= r ; suma += (float) 1 / ++ i);
W programach reaktywnych (czyli takich, które teoretycznie mogą działać dowolnie długo, na przykład w serwerach) może być zastosowana pętla nieskończona o postaci: for ( ; ; ) instrukcja.
6) Pozostałe instrukcje sterujące
break; Wyskok z najbardziej zagnieżdżonej (wewnętrznej) spośród aktualnie wykonywanych instrukcji złożonych;
continue; Przerwanie wykonywania wnętrza najbardziej zagnieżdżonej (wewnętrznej) spośród aktualnie wykonywanych pętli i przejście do początku jej następnego obiegu
goto etykieta; Przeskok (bezwarunkowy) do miejsca w programie oznaczonego etykietą.
Powyższe instrukcje są rzadko stosowane (wyjątek: omówione wyżej zastosowanie instrukcji break w instrukcji switch), gdyż psują naturalną strukturę programu i zwiększają prawdopodobieństwo wystąpienia trudno wykrywalnych błędów.
3. TABLICE
Postać deklaracji tablicy (zmiennej tablicowej):
typ_elementu nazwa [ rozmiar_1 ] [ rozmiar_2 ] ... [ rozmiar_n ] ;
Poszczególne rozmiary muszą być dane wyrażeniami stałymi typu całkowitego o wartościach dodatnich.
Przykład
int dane [ 8 ]; float macierz [ 6 ] [ 10 ];
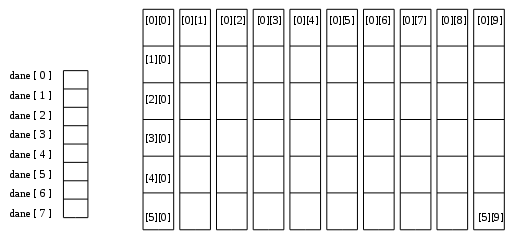
Każda ze współrzędnych elementu tablicy musi być wyrażeniem typu całkowitego o wartości w przedziale [ 0, rozmiar - 1 ].
W instrukcjach programu operujemy na elementach tablic tak, jak na zmiennych typów prostych, podając nazwę tablicy i współrzędną (współrzędne) elementu w tej tablicy.
Przykład
int tab [10] [20];
int x, y;
unsigned short i, j;
..............
x = tab [5] [15] + tab [6] [18] ;
..............
i = 7;
j = 9;
y = x * tab [ i ] [ j ] + 12 ;
..............
printf ( ”%d \ n”, tab [ i + 1 ] [ j + 2 ] );
..............
W języku C najczęściej używane są tablice jednowymiarowe. Macierze wielowymiarowe powinny być postrzegane jako tablice jednowymiarowe o elementach typu złożonego (tablice tablic). Typowe algorytmy wykonywane na tablicach jednowymiarowych często sprowadzają się do „przebiegnięcia” przez wszystkie elementy tablicy i wykonania na każdym z nich ustalonej operacji (zapisu, odczytu bądź zmiany wartości).
Przykład
Wczytać ciąg 20 znaków i wyświetlić je w odwrotnej kolejności.
...............
char tab [20];
int i;
...............
for (i=0 ; i < 20 ; i++)
tab [i] = getchar ( );
for (i=19 ; i >= 0 ; i--)
putchar (tab [i]);
W przypadku użycia tablicy dwuwymiarowej typową instrukcją operującą na niej jest, podobnie jak w Pascalu, podwójna pętla for.
Przykład
Generowanie kwadratowej tablicy liczb losowych.
.............
int tab [10] [10] ;
int i , j ;
.............
for (i=0 ; i < 10 ; i++)
for (j=0 ; j < 10 ; j++)
tab [i] [j] = rand ( ) ;
............
W języku C nie ma instrukcji umożliwiającej bezpośrednie przypisanie jednej tablicy innej tablicy o takim samym rozmiarze i typie elementów (instrukcja taka istnieje w Pascalu i BASIC-u). Przypisanie takie jest jednak bardzo łatwo zrealizować:
Przykład
.............
int a [10], b [10];
int i;
.............
for (i=0 ; i < 10 ; i++)
b [i] = a [i] ;
............
Podobnie byłoby zrealizowane przypisanie tablicy wielowymiarowej. We wprowadzanym z wejścia standardowego ciągu znaków (zakończonym znakiem końca pliku EOF) zliczane są wystąpienia każdej z dużych liter 'A' ... 'Z'.
Przykład
............
int Litery ['Z' - 'A'+1];
int i ;
char c ;
...........
for (i=0 ; i < 'Z' - 'A'+1 ; i++)
Litery [i] = 0 ;
while ((c = getchar ( )) != EOF)
if (c >= 'A' && c <= 'Z')
++Litery [c - 'A'];
...........
Klasyczną operacją wykonywaną na elementach tablicy jednowymiarowej jest ich sortowanie (układanie zgodnie z pewną relacją liniowego porządku). Poniższy fragment programu realizuje jeden z najprostszych algorytmów sortowania.
Przykład
.............
int a [ 100 ] ;
............
for ( i = 0 ; i < 99 ; i++ )
for ( j = i + 1 ; j < 100 ; j++ )
if ( a [i] > a [j] )
{
x = a [i] ;
a [i] = a [j] ;
a [j] = x ;
}
............
Podobnie jak w Pascalu, rozmiary tablicy muszą być określone przy użyciu stałych. Stałe mogą być stałymi symbolicznymi o wartościach zdefiniowanych na początku programu.
Przykład
#include <stdio.h> /*Mnożenie dwóch macierzy prostokątnych*/
#define ROZM1 10
#define ROZM2 30
#define ROZM3 20
main ( )
{
float a [ROZM1] [ROZM2], b [ROZM2] [ROZM3], c[ROZM1] [ROZM3]
...........
for (i=0 ; i < ROZM1 ; i++)
for (j=0 ; j < ROZM3 ; j++)
{ c [i] [j] = 0 ;
for (k=0 ; k < ROZM2 ; k++)
c [i] [j] += a [i] [k] * b [k] [j]; }
Łańcuchy w języku C są dowolnymi ciągami znaków zakończonymi znakiem pustym '\ 0' (kod ASCII 0). W przeciwieństwie do Pascala, gdzie długość łańcucha ograniczona jest do 255 znaków i pamiętana w bajcie o numerze 0, tj. początkowym bajcie łańcucha, w języku C długość łańcucha może być (teoretycznie) dowolna i nigdzie nie jest zapamiętywana (ale może być obliczona). Łańcuchy zapisywane są w pamięci w tablicach znaków - nie istnieje oddzielny typ łańcuchowy danych (odpowiednik string w Pascalu).
Przykład
Zapisanie i odczytanie łańcucha.
...............
char napis [ 21 ];
...............
printf (”Napisz cos (co najwyzej 20 znakow): ”);
scanf (”%20s”, napis);
printf (”Napisales: % s \ n”, napis);
..............
Uwaga: stosowanie formatu ”% s” w funkcji scanf jest niezalecane, gdyż system operacyjny nie kontroluje długości wprowadzanych łańcuchów. Taki program może stanowić „dziurę” w systemie !
Większość podstawowych operacji na łańcuchach (obliczanie długości, porównywanie alfabetyczne, kopiowanie do innego miejsca w pamięci, znajdowanie wzorca itp.) jest zaimplementowana w bibliotece standardowej (plik nagłówkowy <string.h>). Czasem jednak zachodzi potrzeba implementacji mniej typowego algorytmu.
Przykład
Sprawdzić, czy w łańcuchu zapisanym w tablicy (o rozmiarze określonym stałą MAX) występuje gdziekolwiek taki sam znak na dwóch sąsiednich pozycjach.
.................
char s [ MAX ];
unsigned i, jest;
................
jest = 0;
for (i = 0; i < MAX-1; i++)
if (s [ i ] = = s [ i + 1 ] )
jest = 1;
// wartość jest = 0 oznacza, że nie występuje, zaś wartość jest = 1, że występuje.
4. STRUKTURY I UNIE
Pojęcie struktury jest odpowiednikiem pojęcia rekordu w Pascalu. Struktury służą do tego, aby w jednej złożonej danej można było przechowywać zbiór wartości różnych typów - na przykład liczby całkowite i rzeczywiste, napisy itd. Typowe zastosowania mają charakter „biurokratyczny” - struktury są zazwyczaj elementami wykazów danych osobowych, list płac, wykazów przechowywanych towarów itp.
Postać deklaracji typu strukturalnego oraz zmiennych tego typu:
struct nazwa_typu
{
typ_1 nazwa_pola_1;
typ_2 nazwa_pola_2;
...........
typ_n nazwa_pola_n;
} zmienna_1, zmienna_2, ... , zmienna_k ;
Uwaga
1) Typy poszczególnych pól mogą być zarówno proste, jak i złożone - mogą to być na przykład znaki, liczby, tablice lub wcześniej zdefiniowane struktury.
2) Nazwa typu struktury nie jest konieczna - podajemy ją tylko wtedy, gdy przewidujemy późniejsze ponowne wykorzystanie zdefiniowanego typu - na przykład jako fragmentu bardziej złożonej struktury.
3) Nie jest konieczne podawanie od razu nazw zmiennych danego typu - można zadeklarować je później, korzystając z wcześniej podanej definicji typu struktury.
Przykład
struct pracownik
{
char nazwisko [20];
char imie [15];
int rok;
float pensja;
} /* definiuje tylko typ, nie deklarując żadnych zmiennych */
Przykład
Mając zdefiniowaną prostszą strukturę:
struct data
{
int rok;
short miesiac, dzien;
}
możemy przy jej użyciu zdefiniować strukturę bardziej złożoną:
struct towar
{
char nazwa [30];
int liczba_szt;
float cena_jedn;
struct data data_prod, data_wazn;
}
Na strukturach w języku C operujemy podobnie, jak na rekordach w Pascalu. Dostępne jest zarówno operowanie na całych strukturach (przypisanie, użycie jako argumentu funkcji i jako typu wyniku funkcji), jak też na poszczególnych polach (stosując zapis zmienna . pole).
Przykład
Operowanie na pojedynczych polach:
.........
struct pracownik dyrektor, kierownik;
.........
kierownik . pensja += 500; /* podwyżka uposażenia */
.........
if (dyrektor . rok < 1938) ......./* na emeryturę */
Przykład
Operowanie na całych strukturach:
.........
dyrektor = kierownik; /* awans */
Operowanie na bardziej złożonych strukturach odbywa się zgodnie z intuicją:
Przykład
..........
struct towar mydlo;
.........
if (mydlo . liczba_szt > 1000) mydlo . cena_jedn - = 1.20; /* przecena */
........
if (mydlo . data_wazn . rok < 2001) ......... /* przeterminowane */
Podobnie, jak w Pascalu, w języku C również nie ma sensu używanie w programach wyłącznie pojedynczych zmiennych strukturowych, gdyż mogłyby być zastąpione odpowiednią liczbą zmiennych prostszych typów. Przeważnie struktury występują jako elementy tablic struktur lub plików struktur.
Przykład
Wyszukiwanie na liście płac:
.........
struct pracownik lista [150];
........
for (i = 0; i < 150; i ++)
if (lista [i] . pensja < MIN) lista [i] .pensja = MIN; /* wyrównanie do płacy minimalnej */
........
Typowymi operacjami wykonywanymi na tablicach struktur są: wyszukiwanie według podanego klucza (unikalnej zawartości jednego z pól), sortowanie według zawartości jednego lub kilku pól i temu podobne operacje charakterystyczne dla baz danych i arkuszy kalkulacyjnych. Unie odpowiadają pascalowemu pojęciu wariantów w rekordzie, ale w przeciwieństwie do tego, co jest w Pascalu, w języku C unie stanowią odrębny typ danych złożonych. Deklaracja typu unijnego i zmiennych jest bardzo podobna do deklaracji struktury:
union nazwa_typu
{
typ_1 nazwa_pola_1;
typ_2 nazwa_pola_2;
...........
typ_n nazwa_pola_n;
} zmienna_1, zmienna_2, ... , zmienna_k ;
Unia posiada zarezerwowane w pamięci tylko jedno pole o rozmiarze równym największemu z rozmiarów odpowiadających typom typ_1 ... typ_n . Interpretacja zawartości tego pola jako danej jednego z tych typów jest zależna od instrukcji, która ją wykorzystuje - prawidłowe użycie jest zależne od odpowiedzialności programisty. Różnica pomiędzy pojęciem struktury a unii jest analogiczna do różnicy pomiędzy pojęciem połączenia szeregowego a połączenia równoległego elementów.
struct dane
{
}
union dane
{
}
Przykład
Typową sytuacją jest, kiedy interpretacja zawartości unii będącej jednym z pól (nadrzędnej)
struktury zależy od zawartości innego pola tej struktury:
........
struct podatnik
{
long pesel;
char nazwisko [20];
short l_dzieci;
union ma_dzieci
{
int wiek;
float zarobki;
}
} /* To jest raczej abstrakcyjny przykład */
Na polach unii operujemy w taki sam sposób, jak na polach rekordu (używając operatora'.' ). W języku C nie ma możliwości „upakowywania” danych w pamięci tak, aby poszczególne dane zajmowały niecałkowite wielokrotności jednego bajta w pamięci (w Pascalu - teoretycznie - możliwość taką stwarza użycie słowa kluczowego packed). Praktycznie stosowaną namiastką tej możliwości są tak zwane pola bitowe, czyli zwyczajne dane różnych typów (na przykład int lub char) na których wykonujemy operacje bitowe.
Przykład
.......
char flagi;
.......
flagi | = O_EXCLUSIVE | O_APPEND; /* odpowiednie bity otrzymały wartość 1 */
.......
gdzie O_EXCLUSIVE i O_APPEND zostały wcześniej zdefiniowane jako jednobajtowe liczby naturalne będące potęgami dwójki.
Powyższy przykład jest związany z tworzeniem nowego pliku w systemie Unix.
5. ZMIENNE WSKAŹNIKOWE
Każda dana (typu prostego lub złożonego) zapisana w pamięci operacyjnej komputera jest scharakteryzowana przez dwa parametry:
1) wartość (zapisaną w pamięci w postaci ciągu bajtów o określonej długości);
2) adres (wyznaczający położenie pierwszego bajtu w pamięci).
Wartość danej (zawartość pamięci) zajmuje w pamięci liczbę bajtów, która zależy od typu danej (np. wartości typu char zajmują pojedyncze bajty, liczba typu int zajmuje (w systemach linuksowych) cztery bajty itd.). Adresy danych mają ustaloną wielkość, która zależy od typu procesora i przyjętego trybu adresowania - w systemach linuksowych na procesorach zgodnych z procesorem Intel są to cztery bajty.
Nazwy zmiennych używanych przez nas do tej pory były związane z wartościami zapisywanymi w pamięci. Deklaracja: int x ; oznaczała, że x w treści programu będzie utożsamiane z zawartością pewnych czterech kolejnych bajtów.
Operacja: x + + ; w treści programu oznacza zatem zwiększenie liczby zapisanej w tych bajtach o 1.
Natomiast deklaracja: int * a ; oznacza, że a w treści programu będzie utożsamiane z adresem początkowego spośród czterech kolejnych bajtów zawierających liczbę typu int.
Operator & służy do obliczania adresu przyporządkowanego pewnej zmiennej przez kompilator.
Jeśli zostały podane deklaracje: int x ; int * a ; to w wyniku przypisania: a = & x ; wartością zmiennej a stanie się adres zmiennej x.
Operator * służy do obliczania wartości aktualnie zapisanej pod pewnym adresem. Przy powyższych deklaracjach, w wyniku przypisania: x = * a; wartością zmiennej x stanie się liczba typu int zapisana pod adresem przechowywanym w zmiennej a.
Uwaga
Operator & nie może być stosowany do wyrażeń. Może być stosowany tylko do zmiennych. Operator * może być stosowany do wyrażeń (których wartość jest traktowana jako adres). Ponieważ wszystkie wskaźniki (adresy) w danym systemie mają tę samą wielkość (niezależną od wielkości wskazywanej danej), teoretycznie ta sama zmienna wskaźnikowa mogłaby wskazywać dane różnych typów w pamięci, np. int * a ; float r ; ..............; a = & r ; ŹLE !
Należy jednak przypuszczać, że takie podstawienie jest wynikiem błędu programisty. Kompilator wykrywa tego rodzaju sytuacje i wyświetla ostrzeżenie (warning), niemniej dokonuje kompilacji i tworzy wynikowy plik wykonywalny. W niektórych przypadkach programista może świadomie chcieć używać zmiennych wskaźnikowych do wskazywania w pamięci danych różnych typów i wielkości. W takim przypadku powinien zaznaczyć to w programie wykorzystując odpowiednie operatory rzutowania (konwersji typu danej). W powyższym przykładzie miałoby to postać a = (int *) & r;
W tym przypadku kompilator nie wyświetli ostrzeżenia (choć instrukcja wygląda na nielogiczną). Głównym zastosowaniem zmiennych wskaźnikowych jest tworzenie dynamicznych struktur danych, czyli takich struktur danych, dla których miejsce w pamięci nie jest przydzielane statycznie przez kompilator, ale może być przydzielane i zwalniane w trakcie wykonywania programu. Do przydzielania porcji pamięci wykonywanemu programowi służy funkcja malloc, zaś do zwalniania przydzielonych wcześniej porcji pamięci - funkcja free (aby móc ich używać, należy na początku programu włączyć plik nagłówkowy < stdlib.h > ). Z użyciem powyższych funkcji związane jest istnienie w języku C typu wskaźnikowego „ogólnego użytku” (void *), wskazującego na nieokreślony („pusty”) typ danej void. Typ void został wprowadzony w języku ANSI C dla zwiększenia „składniowej elegancji” języka, głównie aby zwiększyć czytelność deklaracji funkcji. Typ wskaźnikowy void * powinien zawsze być zrzutowany na typ
konkretnej zmiennej wskaźnikowej występującej w programie. Jedną z możliwych wartości zmiennej dowolnego typu wskaźnikowego jest wskaźnik pusty NULL (stała standardowa o wartości 0). W programach wskaźnik NULL jest używany do oznaczania końców struktur dynamicznych („adres nieistniejący”). Funkcja malloc otrzymuje argument liczbowy, określający liczbę bajtów pamięci, na którą program zgłasza zapotrzebowanie. Wynikiem funkcji malloc jest wskaźnik typu void * do początku przydzielonego obszaru pamięci o danym rozmiarze, jeśli system operacyjny był w stanie taką porcję pamięci przydzielić, zaś NULL, jeśli nie był w stanie jej przydzielić. Funkcja free jako argument otrzymuje wskaźnik do porcji pamięci wcześniej przydzielonej przez pewne wywołanie funkcji malloc. Wynikiem jej działania jest zwolnienie danej porcji pamięci (przekazanie jej z powrotem do dyspozycji systemu operacyjnego). Funkcja nie tworzy żadnej wartości wynikowej (wynik jest typu void).
Uwaga
1) Jeśli argumentem funkcji free jest wartość NULL, funkcja nie wykonuje żadnej czynności.
2) Jeśli argumentem funkcji free jest adres w pamięci nie będący wynikiem wcześniejszego dynamicznego przydziału pamięci przez system (w wyniku wykonania funkcji malloc lub innej funkcji przydzielającej pamięć) lub adres już wcześniej zwolniony przez inne wywołanie free, wynik działania funkcji free jest nieokreślony (może to prowadzić do trudno wykrywalnych błędów lub zawieszenia wykonywania programu).
Przykład
Wczytanie łańcucha o nieznanej (ale ograniczonej) długości.
# define MAX 100
..........
char *a ;
..........
a = (char *) malloc (MAX + 1) ;
scanf ( ” %100s ”, a) ;
..........
Uwaga
Powyższy przykład mógłby zawierać na początku deklarację tablicy char a [101]; zamiast deklaracji jedynie zmiennej wskaźnikowej char *a; w takim przypadku zmiennej a byłaby przydzielona porcja pamięci o wielkości 101 bajtów niezależnie od tego, czy w trakcie wykonywania programu okazałaby się ona potrzebna, czy nie. Struktury dynamiczne mają często postać list wiązanych lub drzew. Najprostszym i jednym z najczęściej spotykanych przypadków jest lista jednostronnie wiązana.
Typowe operacje wykonywane na liście wiązanej to:
0) utworzenie nowej (pustej) listy ;
1) dopisanie elementu do listy ;
2) usunięcie elementu z listy ;
3) wyświetlenie aktualnej zawartości listy.
Przykład
Fragment typowej implementacji listy jednostronnie wiązanej.
..........
struct element
{
int key ;
struct element * next ;
} * start, * new ;
..........
Jest to przykład rekurencyjnej definicji typu danych (definicja struktury element w swojej treści odwołuje się do siebie samej). Pożyteczną funkcją umożliwiającą obliczenie, jakiej wielkości porcja pamięci będzie potrzebna dla danej dowolnego typu, jest funkcja sizeof (formalnie jest to operator, a nie funkcja). Argumentem sizeof może być dowolne wyrażenie lub nazwa typu (standardowego lub zdefiniowanego w programie). Z użyciem wskaźników na struktury związany jest operator ->. Umożliwia on bardziej czytelny zapis programu. Jeśli zmienna w jest wskaźnikiem do pewnej struktury, a pole jest nazwą jednego z pól tej struktury, to zamiast zapisu
* w . pole
możemy stosować zapis
w -> pole
Korzystając z przykładu na poprzedniej stronie, instrukcję zwiększenia o 5 wartości pola key struktury wskazywanej przez wskaźnik start można zapisać w postaci
start -> key += 5;
(operatory . oraz -> mają wyższe priorytety, niż operatory przypisania).
6. WSKAŹNIKI I TABLICE
W języku C istnieje silny związek pomiędzy wskaźnikami i tablicami. Do pewnego stopnia adresowanie lokat w tablicy przy użyciu indeksów w tablicy i przy użyciu wskaźników (adresów) może być stosowane zamiennie. Język C umożliwia tworzenie wyrażeń arytmetycznych o wartościach typu wskaźnikowego (czyli udostępnia tak zwaną arytmetykę adresów). Jest to ważna cecha odróżniająca język C od Pascala.
Przykład
..........
int a [ 10 ] ; /* tablica a składa się z elementów a [ 0 ] ... a [ 9 ] */
int * pa ; /* wskaźnik na typ elementów tablicy */
..........
Przy powyższych deklaracjach przypisanie
pa = & a [ 0 ] ;
(wskazanie na początkowy element tablicy) jest równoważne przypisaniu
pa = a ;
(wskazanie na początek tablicy). Nazwa tablicy jest więc w tym kontekście związana z adresem jej początku.
Dodanie liczby naturalnej do adresu pa jest równoważne utworzeniu adresu jednego z dalszych elementów tablicy. Wyrażenie wskaźnikowe
pa + 5
jest równoważne wyrażeniu
& a [ 5 ] ;
Wynika z tego (przez zastosowanie do obu wyrażeń operatora * ), że wyrażenie
* (pa + 5)
jest równoważne wyrażeniu
a [ 5 ]
Co ciekawsze, nazwa tablicy również może posłużyć do skonstruowania analogicznego wyrażenia o wartości będącej adresem. Wyrażenie
a + 5
też jest równoważne wyrażeniu
& a [ 5 ]
zaś wyrażenie
* (a + 5)
jest także równoważne wyrażeniu
a [ 5 ]
Nazwa tablicy nie jest jednak traktowana jako zmienna wskaźnikowa ( i nie wszystkie operacje można na niej wykonać) - należy ją raczej postrzegać jako stałą wskaźnikową. Przykładowo, o ile zmiennej pa można przypisać nową wartość, na przykład
pa += 7 ;
o tyle analogiczna operacja na nazwie tablicy a będzie potraktowana jako błędna:
a += 7 ; ŹLE !
Uwaga
Zwiększenie wartości zmiennej wskaźnikowej tak, aby „wskazywała poza obszar tablicy” może dać w programie skutki nieokreślone. Wyjątkiem jest wskazanie na pierwszą pozycję po ostatnim elemencie tablicy (może służyć do porównywania adresów).
Uwaga Nazwa tablicy nie w każdym kontekście traktowana jest jako stała wskaźnikowa. Przykładowo, operator sizeof traktuje nazwę tablicy jako nazwę zmiennej typu złożonego, nie jako adres. Następujący fragment programu:
...........
char a [ 50 ] ;
printf ( ” % d \ n ” , sizeof (a) );
..........
wyświetli liczbę 50, a nie liczbę 4 (wielkość adresu w systemach komputerowych 32-bitowych).
Arytmetyka adresów
Z punktu widzenia implementacji adresy są czterobajtowymi liczbami naturalnymi, ale z punktu widzenia kompilatora języka C żaden typ wskaźnikowy nie jest zgodny z żadnym typem liczbowym w sensie możliwości bezpośredniej konwersji. Jedynym wyjątkiem jest liczba 0 (fizyczna reprezentacja stałej symbolicznej NULL), która zawsze może być potraktowana jako stała adresowa (choć z punktu widzenia czytelności programu wskazane jest stosowanie nazwy NULL). Na wskaźnikach można wykonywać następujące operacje:
- dodawanie liczby całkowitej do wskaźnika;
- odejmowanie liczby całkowitej od wskaźnika;
- porównywanie i odejmowanie dwóch wskaźników do elementów tej samej tablicy;
- przypisanie wskaźnika do zmiennej wskaźnikowej tego samego typu.
Zawsze można wykonać przypisanie wartości NULL zmiennej wskaźnikowej, dodawanie i odejmowanie NULL oraz porównanie z NULL.
Dość dziwnym może wydać się fakt, że nazwy zmiennych wskaźnikowych mogą być traktowane tak, jak nazwy tablic, czyli mogą występować w połączeniu z indeksami. Co więcej, w niektórych sytuacjach indeksy te mogą być liczbami ujemnymi.
Przykład
int a [ ] = {7, 12, 5, 8}; // wstępnie wypełniona tablica liczb całkowitych
int *p; // wskaźnik na liczbę całkowitą
......................
p = a + 1; // p zawiera adres liczby 12 w tablicy a
printf ( ”% d \n”, *p ); // będzie wyświetlona liczba 12
printf ( ”%d \n”, p[0] ); // też będzie wyświetlona liczba 12
printf ( ”%d \n”, *(p + 1) ); // będzie wyświetlona liczba 5
printf ( ”%d \n”, p[1] ); // też będzie wyświetlona liczba 5
printf ( ”%d \n”, *(p - 1) ); // będzie wyświetlona liczba 7
printf ( ”%d \n”, p[-1] ); // też będzie wyświetlona liczba 7
Stosowanie adresów zamiast indeksów w tablicach może uprościć zapis programu i przyspieszyć jego działanie. Klasyczny przykład [ Kernighan, Ritchie ] pokazuje różnicę obu sposobów zapisu dla przypadku kopiowania łańcuchów (czyli tablic znakowych).
Wersja indeksowa:
.........
int i;
.........
i = 0;
while ( s [ i ] = t [ i ] ) /* znaki z t [ ] są kopiowane do s [ ] do napotkania \0 */
i ++ ;
.........
Wersja wskaźnikowa:
.........
while ( *s ++ = *t ++ ) ;
.........
Ponieważ operatory ++ , -- , oraz * mają ten sam priorytet oraz własność prawostronnej łączności, w poprzednim i poniższym przykładzie nie są potrzebne dodatkowe nawiasy.
Przykład
Obsługa stosu zrealizowanego w tablicy. Zmienna wskaźnikowa p pełni rolę wskaźnika stosu.
........
*p ++ = w ; /* wstaw wartość w na szczyt stosu i zwiększ wskaźnik stosu o 1 */
........
w = *-- p ; /* zmniejsz wskaźnik stosu o 1 i pobierz wskazaną wartość do w */
W powyższym przykładzie wskaźnik stosu wskazuje adres pierwszej wolnej lokaty ponad stosem (szczytu stosu).
W przypadku, gdy chcemy operować na ciągu elementów o różnych długościach, wygodnie jest utworzyć tablicę wskaźników do tych elementów. Typowym przypadkiem jest tworzenie listy łańcuchów o różnych długościach. Implementacja przy użyciu dwuwymiarowej tablicy znaków jest nieoszczędna, gdyż nie wszystkie wiersze tablicy są w pełni wykorzystane:
1 A L A \0 char tab [ M ] [ N ] ;
2 M A \0
3 K O T A \0
Dla długich łańcuchów lepsza byłaby następująca implementacja:
1 A L A \0 char *tab [ M ] ;
2 M A \0
3 K O T A \0
Ta implementacja posiada również tę zaletę, że sortowanie listy łańcuchów nie wymaga przepisywania z miejsca na miejsce całych łańcuchów, a jedynie operowania na wskaźnikach do nich (dużo szybsze). Należy zdawać sobie sprawę z różnicy między definicją wstępnie wypełnionej tablicy znakowej:
char tablicaznakow [ ] = ”napis”;
a definicją stałej łańcuchowej:
char *wsknaznaki = ”napis”;
W pierwszym przypadku będzie utworzona sześciobajtowa zmienna o nazwie tablicaznaków, która będzie miała stałe miejsce w pamięci i wstępnie wpisaną wartość (którą później w programie można zmieniać).
tablicaznakow: n a p i s \0
W drugim przypadku będzie utworzona sześciobajtowa stała napisowa oraz zmienna wskaźnikowa, która wstępnie ma wpisany adres tej stałej (w programie później można wpisywać do tej zmiennej inne adresy).
wsknaznaki: n a p i s \0
Jednym z ważnych zastosowań tablic wskaźników jest przechowywanie argumentów wywołania programu. Podobnie, jak wiele poleceń podawanych w linii komend otrzymuje jeden lub więcej argumentów (przykład: cp plik1 plik2 ), programy w języku C również mają możliwość pobierania argumentów z linii komend. Należy w tym celu utworzyć następujący nagłówek głównej funkcji programu:
main ( int argc, char *argv [ ] ) /* argc - argument count */
/* argv - argument vector */
Wymienione nazwy zmiennych mogą być używane w programie. Uwaga: *argv [ 0 ] jest nazwą skompilowanego programu.
Przykład
Aby wyświetlić wszystkie argumenty podane w linii komend, można wykonać instrukcję:
while ( -- argc > 0 )
printf ( ” % s \ n ” , *++ argv ) ;
Nazwa programu nie będzie w tym przypadku wyświetlona (zaczynamy od argv [ 1 ] ).
7. FUNKCJE
W języku Pascal istnieją dwa rodzaje podprogramów: funkcje i procedury. W języku C istnieją tylko funkcje. Funkcja otrzymuje od wywołującego ją programu (lub innej funkcji) ciąg argumentów (być może pusty - void) i oblicza pewien wynik (jeśli ma nic nie przekazywać z powrotem do wywołującego programu, typem wyniku również może być void). Podział podprogramów na funkcje i procedury w Pascalu jest dość sztuczny i jest związany głównie z tym, że wartości zwracane przez funkcje mogą być tylko jednego z typów prostych. W języku C struktury mogą być zarówno argumentami, jak i wynikami działania funkcji, natomiast nazwy tablic są traktowane jako nazwy stałych wskaźnikowych (czyli wielkości typu prostego). W Pascalu odróżniamy przekazywanie argumentów przez wartość i przez referencję. W języku C istnieje tylko ten pierwszy sposób, co oznacza, że funkcja rozpoczynając działanie tworzy prywatne kopie wartości przekazywanych jako argumenty wywołania i przyporządkowuje je nazwom swoich argumentów formalnych, traktując je jako swoje zmienne lokalne. Możliwość przekazywania argumentów przez referencję jest w języku C (szeroko) zastępowana przekazywaniem wskaźników. Przyczyny stosowania podprogramów:
1) możliwość wielokrotnego użycia podprogramu w wywołującym go programie;
2) możliwość tworzenia bibliotek podprogramów, które mogą być potem wykorzystywane przez wiele programów;
3) możliwość tworzenia dobrze zorganizowanego, czytelnego oprogramowania o hierarchicznej strukturze;
4) możliwość łatwego wprowadzania poprawek i ulepszeń w pojedynczych podprogramach (bez ingerowania w treść pozostałych);
5) możliwość stosowania rekursji (czyli techniki programowania bazującej na wywoływaniu podprogramu przez ten sam podprogram).
Ważną zaletą kompilatorów języka C jest możliwość niezależnej kompilacji funkcji, co ułatwia tworzenie bibliotek funkcji oraz tworzenie złożonego oprogramowania zapisanego przed kompilacją w wielu plikach źródłowych.
Ogólna postać definicji funkcji:
typ_wyniku nazwa_funkcji ( lista argumentów )
{
deklaracje
instrukcje
}
Lista argumentów jest listą par o postaci: typ nazwa oddzielonych przecinkami. Jeżeli funkcja ma zwracać pewną wartość (wynik), musi ona być zgodna z zadeklarowanym typem wyniku. Wartość jest zwracana wskutek wykonania instrukcji o postaci return wyrażenie ; .
Uwaga:
1) wyrażenie może być ujęte w nawiasy, ale nie musi;
2) jeśli funkcja ma nie zwracać żadnego wyniku (tylko przekazywać sterowanie z powrotem do
programu wywołującego), wystarczy umieścić w niej instrukcję return ; (bez wyrażenia);
3) jeśli w funkcji nie występuje return, sterowanie jest przekazywane po dojściu do ostatniego „}”.
Przykład
Funkcja obliczająca potęgę liczby całkowitej o wykładniku naturalnym k .
int power ( int k, unsigned int n )
{
int p;
for (p = 1; n > 0; - - n)
p = p * k;
return p;
}
Przykład użycia wyżej zdefiniowanej funkcji w programie głównym:
...........
int p, x;
...........
p = power (x, 4) + 2 * power (x, 3) ;
...........
n
W powyższym przykładzie każde wywołanie funkcji power powodowało (czasowe) utworzenie kopii obydwóch argumentów. W przypadku, gdy argumentem jest tablica, działanie funkcji odnosi się do oryginalnej zawartości tej tablicy (która może ulec zmianie w wyniku wykonania funkcji).
Przykład
Zwiększenie n początkowych elementów tablicy o 1.
void inctab ( int a[ ], int n );
{
while (- - n >= 0) a[n] ++ ;
}
Wywołanie tej funkcji przez program spowoduje zwiększenie wartości elementów tablicy, której nazwa zostanie podana w wywołaniu.
Uwaga
Na liście argumentów formalnych w nagłówku definicji funkcji podajemy nazwy tablic nie podając rozmiarów tych tablic (gdyż i tak jedyną przekazywaną do funkcji wartością jest wskaźnik do początku tej tablicy). W przypadku operowania na złożonych typach danych, funkcje często zwracają wskaźniki do danych. Wiele standardowych funkcji w C operuje na łańcuchach.
Przykład
Funkcja zwracająca wskaźnik do pierwszego wystąpienia danego znaku w danym łańcuchu (lub NULL, jeśli znak w łańcuchu nie występuje).
char *find (char c, char * s) ;
{
while (c != *s && *s) s++ ;
if (*s) return s ; else return NULL ;
}
Funkcja ta może być na przykład wykorzystana do wyświetlenia podłańcucha rozpoczynającego się od pierwszego wystąpienia danego znaku:
........
printf(”%s \ n”, find ( `P', str)) ; // przy założeniu, że znak `P' na pewno występuje w str
Struktury mogą być zarówno danymi, jak i wynikami wykonania funkcji.
Przykład
Funkcja obliczająca średnią arytmetyczną trzech pól struktury.
struct dane {float pierwsza, druga, trzecia ;} ;
............
float srednia ( struct dane d )
{ return ( d . pierwsza + d . druga + d . trzecia ) / 3 ; }
............
Tego rodzaju przekazanie danych do funkcji niepotrzebnie pochłania pamięć na utworzenie ich kopii. Wersja wskaźnikowa tej samej funkcji (przekazujemy wskaźnik, dana d jest tylko odczytywana):
..........
float srednia ( struct dane *d )
{return ( d -> pierwsza + d -> druga + d -> trzecia ) / 3 ; }
Język C udostępnia możliwość tworzenia funkcji rekurencyjnych (czyli funkcji, które wywołują same siebie w swojej treści).
Przykład
Przepis rekurencyjny obliczania potęgi o wykładniku naturalnym:
1 jeśli n = 0
k = (k * k) jeśli n > 0, parzyste
k * k jeśli n > 0, nieparzyste
Funkcja realizująca powyższy przepis:
int binpower ( int k , unsigned int n )
{
if ( n = = 0 ) return 1 ;
else if ( n % 2 = = 0 ) return binpower ( k * k , n / 2 ) ;
else return k * binpower ( k , n - 1) ;
}
n2n
Argumentami wywołania funkcji mogą być inne funkcje. Korzystamy często z takiej możliwości wtedy, gdy konstruujemy bardziej uniwersalne algorytmy, które mogą (w zależności od dokonanego wyboru) realizować jedno z kilku obliczeń o podobnym charakterze.
Przykład
W zależności od podanych argumentów wywołania funkcja może obliczać najmniejszy lub największy element w danej tablicy:
float min ( float x, float y )
{ if (x < y) return x;
else return y; }
float max ( float x, float y )
{ if (x > y) return x;
else return y; }
float choice ( float a[ ], unsigned n, float comp ( float, float ) )
{
float best, *next;
best = *a;
for ( next = a + 1; next < a + n; next + + )
best = comp ( best, *next );
return best;
}
Przyjmując, że dla wartości int c równej 0 ma być obliczona najmniejsza wartość w tablicy tab zawierającej k elementów, zaś dla wartości c równej 1 - największa wartość, przykładowe wykorzystanie funkcji choice w programie może być następujące:
..................
printf (”Wynik: %f \ n”, choice ( tab, k, c = = 0 ? min : max ) );
.................
Ważną cechą języka C jest możliwość przekazywania wskaźników do funkcji jako argumentów wywołania innej funkcji. Umożliwia to tworzenie bardzo ogólnych algorytmów, które mogą operować na różnych typach danych. Przykładowo, jeden i ten sam algorytm sortowania może posortować liczby rzeczywiste, jeśli użyjemy w nim funkcji porównującej liczby rzeczywiste, lub łańcuchy, jeśli jako argument podamy funkcję porównującą łańcuchy. Należy zwrócić uwagę na priorytet operatorów przy tworzeniu wskaźników do funkcji:
int *f ( ) ; /* f jest funkcją zwracającą wskaźnik do liczby całkowitej */
zaś
int ( *p ) ( ) ; /* p jest wskaźnikiem do funkcji zwracającej wartość całkowitą */
W sytuacji, gdy konstruujemy ogólny algorytm i nie jesteśmy w stanie z góry określić, na jakich typach danych będzie on operował, i jaki będzie typ obliczonego wyniku (może zależeć to od innych funkcji wywoływanych przez daną funkcję), często stosujemy typ void * jako „wskaźnik ogólny” (odpowiada on pascalowemu typowi pointer). Z wartości zapisanej w pamięci i wskazywanej przez zmienną typu void * możemy zrobić użytek, jeśli dokonamy rzutowania ogólnego wskaźnika na wskaźnik na konkretny typ (tak, jak to było zrobione dla przypadku funkcji malloc).
Przykład
Przy założeniu, że dana jest funkcja numcmp służąca do porównywania dwóch liczb rzeczywistych i zwracająca wynik -1, 0 lub 1, analogicznie, jak funkcja standardowa strcmp, można utworzyć ogólny algorytm sortowania, mogący służyć zarówno do posortowania tablicy liczb rzeczywistych, jak i tablicy (wskaźników do) łańcuchów.
Prototyp funkcji sortującej:
void sort ( void *a, unsigned n, int (*comp)(void *, void *))
Przykładowe wywołanie tej funkcji:
sort ( (void *) tablica, k, (int (*)(void *, void *))( liczby ? numcmp : strcmp ) );
8. STRUKTURA PROGRAMU I KLASY PAMIĘCI
Program w języku C składa się z jednej lub więcej funkcji. Wśród nich zawsze musi istnieć dokładnie jedna wyróżniona funkcja o zastrzeżonej nazwie main, od której rozpoczyna się (i w której się kończy) wykonywanie programu. Funkcja ta odpowiada pascalowemu pojęciu programu (głównego). W przeciwieństwie do Pascala, w języku C nie jest możliwe definiowanie funkcji wewnątrz innych funkcji (w szczególności nie można tego robić wewnątrz funkcji main). Definicje funkcji tworzą zatem ciąg, przy czym jeśli jedna z funkcji wywołuje w swojej treści inną funkcję, kompilator powinien być wcześniej „uprzedzony” o jej istnieniu (czyli powinien wcześniej przejść przez jej definicję lub deklarację jej użycia). Ogromną zaletą języka C jest możliwość oddzielnej kompilacji poszczególnych funkcji. W praktyce oznacza to, że pojedyncze funkcje lub grupy funkcji mogą być umieszczane w oddzielnych plikach i niezależnie kompilowane. Pliki będące wynikami takiej kompilacji nazywane są plikami pośrednimi (object file). Nie nadają się one do bezpośredniego wykonania - ich zbiór musi być przekształcony na jeden plik wykonywalny (executable file) przez operację łączenia (link). Poszczególne pliki źródłowe (source file) mają nazwy z rozszerzeniem c. Polecenie kompilacji grupy plików źródłowych do postaci pośredniej: cc - c nazwa_1.c nazwa_2.c ... nazwa_n.c
Wynikiem prawidłowo przebiegającej kompilacji jest zbiór plików pośrednich o nazwach nazwa_1.o,
nazwa_2.o , ... , nazwa_n.o .
Podstawowe polecenie kompilacji (polecenie cc bez żadnych opcji) może przyjmować jako swoje argumenty zarówno nazwy plików źródłowych, jak i wynikowych, na przykład: cc pierwszy.c drugi.o trzeci.c.
Polecenie takie wykonuje wszystkie brakujące kompilacje do kodów pośrednich, a na koniec łączenie do wspólnego pliku wykonywalnego a.out .
Uwaga: nie można rozdzielać jednej funkcji pomiędzy kilka plików źródłowych !
Korzyści wynikające z możliwości kompilacji programu zapisanego w wielu oddzielnych plikach źródłowych:
- możliwość rozdzielenia pracy nad programem na wielu programistów ;
- możliwość niezależnego sprawdzenia poprawności składniowej poszczególnych fragmentów ;
- brak konieczności rekompilacji całości programu w przypadku wprowadzenia poprawek w jednej tylko jego części ;
- możliwość tworzenia skompilowanych bibliotek funkcji, które będą mogły być wykorzystane ponownie poprzez włączenie do innych programów.
Uwaga
Kompilator nie musi sprawdzać zgodności typu wyniku oddzielnie skompilowanej funkcji z typem oczekiwanym przez jej wywołanie w innej funkcji. Jeśli nazwa wywoływanej funkcji nie jest znana w pliku zawierającym funkcję wywołującą, kompilator przyjmuje domniemanie, że typem wyniku funkcji wywoływanej jest int. Chcąc mieć pewność zgodności zdefiniowanego typu funkcji z jej wywołaniem w innym pliku, należy stosować deklarację funkcji w tym pliku. Powyższy problem wiąże się z bardziej ogólnym problemem zasięgu nazw. Każda nazwa zmiennej zadeklarowana wewnątrz funkcji powinna być unikalna w obrębie tej funkcji (nie powinna służyć do dwóch różnych celów). Zmienną taką nazywamy zmienną wewnętrzną (internal) lub zmienną lokalną w danej funkcji (do zmiennych wewnętrznych zaliczamy też argumenty formalne wymienione w nagłówku danej funkcji). Mówimy, że zasięgiem nazwy zmiennej wewnętrznej jest obszar funkcji, w której została ona zadeklarowana (a dokładniej: obszar funkcji od miejsca deklaracji tej zmiennej do jej końca). Poza zmiennymi wewnętrznymi funkcji mogą istnieć też zmienne zewnętrzne (external), nazywane również zmiennymi globalnymi. Ich nazwy mają zasięg od miejsca ich deklaracji w pliku źródłowym do końca tego pliku. Zmienne zewnętrzne mogą być wykorzystywane wewnątrz funkcji w ich zasięgu - są w nich „widoczne” i zachowują swoje wartości pomiędzy kolejnymi momentami ich użycia w funkcjach. W przeciwieństwie do nich zmienne wewnętrzne są „powoływane do życia” tylko na czas wykonywania funkcji, w której są zadeklarowane, a ich wartości nie są przechowywane pomiędzy kolejnymi wywołaniami tej funkcji. Zasadniczo zmienne wewnętrzne funkcji powinny być deklarowane na początku funkcji (przed instrukcjami). Takie zmienne mają przydzieloną pamięć na cały czas wykonywania danej funkcji. Jest jednakże również możliwe deklarowanie zmiennych na początku każdego wewnętrznego bloku funkcji (fragmentu ujętego w odrębne nawiasy klamrowe { ................. } ). Takie zmienne są „powoływane do życia” nie na cały czas wykonywania funkcji, lecz jedynie na czas wykonywania bloku, w którym ich deklaracje zostały umieszczone. Za każdym razem po wejściu do bloku pamięć jest im przydzielana na nowo, toteż nie należy liczyć na to, że wartości tych zmiennych „przetrwają” pomiędzy opuszczeniem bloku a ponownym wejściem do niego w czasie wykonywania programu.
Uwaga
Zasadniczo należy starać się, aby wszystkie nazwy zmiennych używane w danym programie były unikalne (aby każda występowała tylko w jednej roli). Jeśli jedną i tą samą nazwę nadamy zmiennej wewnętrznej i zmiennej zewnętrznej (lub zmiennej zadeklarowanej na początku funkcji i zmiennej zadeklarowanej w jednym z jej wewnętrznych bloków), kompilator nie potraktuje tego jako błąd, ale w trakcie wykonywania programu będzie zachodziło zjawisko przesłaniania polegające na tym, że w czasie wykonywania danej funkcji (danego bloku) obowiązująca będzie „bardziej wewnętrzna” deklaracja zmiennej, a dostęp do wartości zmiennej „bardziej zewnętrznej” będzie uniemożliwiony. Formalnie program w języku C składa się ze zbioru obiektów zewnętrznych, którymi są wszystkie użyte w tym programie funkcje oraz zmienne zewnętrzne. Każda definicja funkcji oraz deklaracja zmiennej zewnętrznej wiąże się z przydziałem przez kompilator pamięci danemu obiektowi na cały czas wykonywania programu. Taki przydział pamięci nazywany jest przydziałem statycznym. W przeciwieństwie do obiektów zewnętrznych, zmienne wewnętrzne mają pamięć przydzielaną dynamicznie, czyli tylko na czas wykonywania danej funkcji (i odbieraną, kiedy funkcja nie jest wykonywana). W opisie języka C używane jest pojęcie klasy pamięci danego obiektu. Obiekty zewnętrzne mają statyczną klasę pamięci, a zmienne wewnętrzne - dynamiczną. Szczególnym przypadkiem dynamicznej klasy pamięci jest klasa rejestrowa. Jeśli deklaracja zmiennej wewnętrznej zostanie poprzedzona słowem kluczowym register, zmienna taka jest traktowana jako przeznaczona do częstego używania w programie i kompilator stara się wyprodukować taki kod wynikowy, aby wartość tej zmiennej była (jeśli to możliwe) przechowywana w rejestrach procesora, aby przyspieszyć wykonywanie programu (nie wszystkie kompilatory uwzględniają taki postulat). Istnieje możliwość spowodowania, żeby zmienne wewnętrzne uzyskały statyczną klasę pamięci. W tym celu należy ich deklaracje poprzedzić słowem kluczowym static. Takie zmienne zachowują swoje wartości pomiędzy kolejnymi wywołaniami funkcji (pomiędzy wywołaniami pamięć nie jest im odbierana).
Słowo kluczowe static można stosować również do obiektów (zmiennych i funkcji) zewnętrznych. Zasadniczo nazwy zmiennych zewnętrznych i funkcji mają zasięg tylko do końca pliku źródłowego, w którym zostały zdefiniowane. Nazwy funkcji mogą być wywoływane w innych funkcjach (w innych plikach), ale przez domniemanie typ wyniku jest przyjmowany jako int. Aby można było oddzielnie skompilować (a następnie połączyć w całość) fragmenty programu korzystające z różnych wspólnych definicji obiektów zewnętrznych (umieszczonych w różnych plikach), należy w plikach korzystających z tych definicji umieszczać deklaracje użycia tych obiektów w funkcjach w danym pliku (odpowiada to pascalowej deklaracji forward). Deklaracja wygląda podobnie do definicji, ale pomijamy w niej rozmiary tablic, nazwy argumentów funkcji i wartości inicjujące zmienne, a na początku umieszczamy słowo kluczowe extern.
Przykład
Jeśli w jednym pliku mamy zdefiniowaną pewną funkcję:
............
float ff ( int a )
{
............... /* deklaracje zmiennych wewnętrznych i instrukcje */
}
............
to aby mogła ona być użyta (wywołana) w funkcji zdefiniowanej w innym pliku, musimy w tym pliku umieścić na początku deklarację:
...........
extern float ff ( int ) ;
Słowo kluczowe static umieszczone przed nazwą obiektu zewnetrznego powoduje, że zasięg tej nazwy zostaje ograniczony do pliku, w którym została ona zdefiniowana - bez względu na jej deklaracje i użycie w innych plikach. Oznacza to, że obiekt ten będzie w innych plikach niewidoczny, a jego nazwa może być tam używana do innych celów. Zarówno zmienne zewnętrzne, jak i wewnętrzne mogą być inicjowane, czyli mieć przyporządkowane wartości początkowe. Jeśli zmienne nie są jawnie zainicjowane w programie, to domyślnie zmienne zewnętrzne oraz statyczne wewnętrzne są inicjowane zerami, natomiast w przypadku zmiennych dynamicznych zależy to od implementacji (należy zakładać, że mogą zawierać wartości przypadkowe). Zmienne zewnętrzne i statyczne wewnętrzne muszą być inicjowane wyrażeniami stałymi, zmienne dynamiczne mogą być inicjowane również wyrażeniami zmiennymi, których wartość może być obliczona w momencie ich inicjacji.
Przykład
Inicjacja zmiennej indywidualnej:
float x = 2.1583 ;
Inicjacja tablicy:
int primes [ ] = { 2 , 3 , 5 , 7 , 11 , 13 } ;
Inicjacja struktury:
struct { int number ; char *name } person = { 7 , ”Smith” } ;
W przypadku budowy dużego programu składającego się z wielu fragmentów umieszczonych w oddzielnych plikach, ale wykorzystujących wspólne obiekty zewnętrzne (zmienne lub funkcje), zalecane jest utworzenie pliku nagłówkowego zawierającego wszystkie deklaracje wspólnych funkcji i zmiennych . Jeśli taki plik jest włączony do wszystkich plików zawierających składowe programu, pozwala to uniknąć trudno wykrywalnych błędów wynikających z niezgodności sposobów użycia wspólnych obiektów z ich definicjami. Tradycyjnie pliki nagłówkowe otrzymują rozszerzenie h (header). Do włączania plików nagłówkowych służy dyrektywa dla kompilatora # include .
Przykład
Zawartość pewnego pliku nagłówkowego:
int MAX = 1000 ;
int MIN = 0 ;
float avg ( int , float [ ] ) ;
char *error ( int ) ;
9. PREPROCESOR JĘZYKA C
Przed wykonaniem właściwej kompilacji programu źródłowego kompilator przegląda jego treść i wyszukuje w niej dyrektywy (polecenia dla kompilatora). Dyrektywy nie podlegają kompilacji - stanowią instrukcje, jak kompilacja powinna być przeprowadzona. Dokładniej, mówią one, jakie operacje na tekście źródłowym powinny wstępnie być wykonane (dając w wyniku również tekst). Polecenia dla kompilatora rozpoczynają się od znaku # i powinny być umieszczane w oddzielnych liniach. Operacje wstępnego przetworzenia tekstu (preprocessing) mają typowo „edytorski” charakter - wstawienia lub usunięcia pewnego ciągu znaków, lub zamiany jednego ciągu znaków na inny. Korzyści ze wstępnego przetwarzania:
- ułatwienie pracy programistów (możliwość stosowania własnych skrótów);
- możliwość stosowania plików nagłówkowych;
- możliwość kompilacji warunkowej (co wiąże się z przenośnością oprogramowania).
Wstawianie fragmentu tekstu umieszczonego w innym pliku umożliwia dyrektywa #include. Może ona mieć postać #include ” plik ” lub #include < plik >. W pierwszym przypadku plik z tekstem do wklejenia jest poszukiwany w katalogu bieżącym. W drugim przypadku (również w pierwszym, jeśli plik nie został znaleziony) jest poszukiwany w miejscu zależnym od implementacji (określonym w konfiguracji kompilatora).
Przykład
#include < ncurses. h >
podane na poczatku programu powoduje wklejenie w tym miejscu treści odpowiedniego pliku nagłówkowego biblioteki ncurses.
Dyrektywa #define umożliwia zastąpienie pojedynczego wyrazu dowolnym tekstem. Postać: #define wyraz dowolny_tekst. Zasięgiem dyrektywy #define jest obszar tekstu źródłowego od miejsca jej wystąpienia do końca pliku.
Przykład
Typowym zastosowaniem dyrektywy #define jest definiowanie stałych symbolicznych. Podanie na początku tekstu źródłowego programu dyrektywy: # define MAX 100 spowoduje, że we wszystkich miejscach wystąpienia w tekście nazwa MAX będzie zastąpiona liczbą 100. Jeśli zastępujący tekst jest zbyt długi, aby zmieścił się do końca linii, może być przenoszony do kolejnych linii przez umieszczenie na końcu linii znaku \ .
Uwaga
Zastępowaniu w tekście źródłowym mogą podlegać jedynie oddzielne wyrazy (nie fragmenty dłuższych wyrazów), które nie są ujęte w cudzysłów (nie są traktowane jako stała łańcuchowa). W powyższym przykładzie zastąpieniu nie uległby ani ciąg ”MAX” , ani fragment ciągu MAXIMUM.
Kolejne wprowadzane definicje mogą korzystać z wcześniej wprowadzonych definicji. Oznacza to, że na danym wyrazie może być wykonana cała seria (złożenie) przekształceń tekstowych, w kolejności określonej przez kolejność występowania przed nim dyrektyw #define. Jeśli w tekście podane są dwie dyrektywy nakazujące zastąpić jeden i ten sam wyraz różnymi tekstami, zachodzi zjawisko przesłaniania polegające na tym, że od podania pierwszej dyrektywy do podania drugiej dyrektywy następuje zastępowanie pierwszym tekstem, a poniżej drugiej dyrektywy - drugim tekstem. Działanie dyrektywy #define może od pewnego miejsca zostać unieważnione przez podanie #undef wyraz
Zastępowany ciąg znaków może na końcu zawierać ujęty w nawiasy okrągłe wykaz argumentów (pooddzielanych przecinkami). W takim przypadku zastępujący tekst jest traktowany jako wzorzec, w którym w trakcie przetwarzania tekstu źródłowego wszystkie wystąpienia argumentów formalnych są zastępowane argumentami aktualnymi.
Przykład
Jeśli na początku tekstu programu zostanie umieszczona dyrektywa
#define max (A , B) ((A) > (B)) ? (A) : (B)
instrukcja programu o postaci
x = max (p + q , r + s);
będzie zastąpiona instrukcją
x = ((p + q) > (r + s)) ? (p + q) : (r + s);
Stosując zastępowania z argumentami należy zachować dużą ostrożność ze względu na możliwość wystąpienia różnych „efektów ubocznych” (na przykład różnej od zamierzonej kolejności obliczania). Reguły wykonywania zastąpień w przypadku definicji z argumentami są dość skomplikowane. Jedna z reguł mówi, że jeżeli nazwa argumentu rozpoczyna się od znaku # , to jest ona (wraz ze znakiem # ) zastąpiona podanym tekstem ujętym w cudzysłów. Aby wynik zastąpienia był poprawnym łańcuchem, wszystkie znaki ” wewnątrz tekstu są zastępowane przez \” , zaś wszystkie znaki \ wewnątrz tekstu są zastępowane przez \\ . Jeśli w wyniku zastąpienia otrzymamy dwa łańcuchy (ciągi znaków zamknięte w cudzysłów) obok siebie, są one „sklejane” w jeden łańcuch. W ogólnym przypadku operację „sklejania” wartości dwóch sąsiadujących argumentów umożliwia operator ## . Łączy on „widzialne” fragmenty tekstów, a usuwa znaki niewidoczne w maszynopisie, na przykład spacje.
Przykład
Jeśli na początku została podana definicja
#define sklej (A , B) A ## B
to umieszczony poniżej w tekście programu napis
sklej (para , sol)
będzie zastąpiony napisem parasol.
Ważną możliwością udostępnianą przez preprocesor języka C jest możliwość kompilacji warunkowej. Polega ona na wybieraniu do kompilacji jedynie niektórych fragmentów programu źródłowego, w zależności od podanych wartości stałych.
Postać dyrektywy:
#if wyrażenie_1
...................
#elif wyrażenie_2
....................
....................
#elif wyrażenie_n
....................
#else
....................
#endif
Wyrażenia muszą być typu całkowitego i nie mogą zawierać zmiennych ani stałych wyliczeń. Fragment do kompilacji zostaje wybrany zgodnie z regułami obowiązującymi dla zwykłej instrukcji if. Jedną z typowych postaci wyrażenia stanowiącego warunek jest defined (nazwa). Wyrażenie takie ma wartość 1, jeśli wcześniej nazwa została zdefiniowana przy użyciu #define , zaś 0 w przeciwnym przypadku. Wyrażenie takie może również wystąpić pod znakiem negacji: ! defined (nazwa). Dla powyższego przypadku istnieją również skrótowe formy zapisu. Zamiast #if defined (nazwa) można pisać #ifdef nazwa , zaś zamiast #if ! defined (nazwa) można pisać #ifndef nazwa .
Przykład
Typowym zastosowaniem kompilacji warunkowej jest kompilacja fragmentu wybranego w zależności od wersji systemu operacyjnego (której nazwa wcześniej musiała zostać zdefiniowana).
...............
#if SYSTEM = = Linux
............... /* fragment przeznaczony do wykonywania pod Linuksem */
#else
............... /* fragment przeznaczony do wykonywania pod innymi systemami */
#endif
Pozostałe wiersze sterujące rozpoznawane przez preprocesor to: # line numer ”nazwa_pliku” (nakazuje kompilatorowi przyjęcie, że kolejny przeczytany wiersz tekstu źródłowego programu będzie miał podany numer, a bieżący plik źródłowy ma podaną nazwę - bywa to przydatne do celów diagnostycznych. Nazwa pliku może być pominięta);
# error napis
(nakazuje preprocesorowi wyświetlenie danego napisu jako komunikatu w trakcie przetwarzania);
# pragma napis
(nakazuje preprocesorowi wykonanie pewnej czynności zależnej od implementacji)
#
(pusty wiersz - nie wywołuje żadnego skutku)
Preprocesor zawiera kilka ustalonych nazw o przyporządkowanych wartościach. Definicje tych nazw nie mogą być zmieniane ani odwoływane przez programistę.
_ _LINE_ _ - dziesiętna stała całkowita zawierająca numer bieżącego wiersza programu źródłowego
_ _FILE_ _ - stała napisowa zawierająca nazwę kompilowanego pliku
_ _DATE_ _ - stała napisowa zawierająca datę bieżącej kompilacji programu
_ _TIME_ _ - stała napisowa zawierająca czas bieżącej kompilacji programu
_ _STDC_ _ - stała całkowita o wartości 1 zdefiniowana w tych implementacjach kompilatora, które są zgodne ze standardem ANSI C.
Chcąc uzyskać możliwość obejrzenia tekstu będącego wynikiem wstępnego przetworzenia tekstu źródłowego programu (na przykład w celu sprawdzenia prawidłowości rozmieszczenia w nim dyrektyw) należy podać polecenie cc -E plik.c.
Polecenie to wyprowadza przetworzony tekst na wyjście standardowe. W przypadku długich tekstów wygodnie jest użyć przekierowania do pliku (standardowo używana jest ta sama nazwa, co pliku źródłowego, z rozszerzeniem i ) cc -E plik.c > plik.i.
Do zarządzania większymi, bardziej złożonymi projektami programistycznymi używany jest program make współpracujący z zawierającym polecenia dla niego plikiem makefile . Polecenia te są również swojego rodzaju dyrektywami dla kompilatora, określającymi między innymi wzajemne zależności plików z fragmentami programów (co stanowi informację, które fragmenty należy rekompilować w przypadku wprowadzenia zmian w programie) oraz sposób traktowania dyrektyw dla kompilatora umieszczonych w treści programu źródłowego.
10. STANDARDOWE OPERACJE NA PLIKACH W JĘZYKU C
W języku ANSI C zbiór funkcji operujących na urządzeniach zewnętrznych nie jest częścią samego języka - tworzy on jedną ze standardowych bibliotek dołączonych do języka. Plikiem nagłówkowym tej biblioteki jest stdio.h (standard input and output). Sama biblioteka skojarzona z tym nagłówkiem jest największą spośród bibliotek ANSI C. Zbiór funkcji zawartych w tej bibliotece zakłada model systemu operacyjnego zgodny z wczesnymi wersjami systemu Unix - przyjmuje, że każdy program w momencie uruchomienia ma przydzielone trzy pliki standardowe, odpowiednio:
- stdin (standard input) - standardowe wejście;
- stdout (standard output) - standardowe wyjście;
- stderr (standard error) - standardowe wyjście błędów.
Przez domniemanie pliki te są skojarzone z terminalem użytkownika programu, czyli plik stdin odpowiada ciągowi znaków wprowadzanych z klawiatury, a pliki stdout i stderr - ciągom znaków wyprowadzanych na ekran terminala. W poleceniu uruchomienia programu użytkownik (używając znaków przekierowania < , > lub >>) może je zastąpić dowolnymi innymi plikami tekstowymi. Funkcje standardowej bibloteki wejścia-wyjścia są zorientowane na przetwarzanie plików tekstowych. Zakładają one następujący model pliku:
Wskaźnik położenia w pliku pełni rolę abstrakcyjnej „głowicy zapisująco-odczytującej”, która może
zapisywać lub odczytywać kolejne znaki w (z) pliku i przesuwać się przy tym od początku pliku aż do
napotkania jego znacznika końca EOF (End Of File).
Plik tekstowy składa się z ciągu znaków podzielonego na linie znakami zmiany linii (new line).
Uwaga
W zależności od systemu operacyjnego zmiana linii może być oznaczona jednym lub parą znaków. Zbiór funkcji bibliotecznych stdio stanowi dość bogatą kolekcję umożliwiającą zarówno korzystanie ze standardowego wejścia i wyjścia, jak i z innych plików (głównie tekstowych, ale również binarnych), zmianę bieżących przekierowań, tworzenie, usuwanie i zmianę nazw plików i wiele innych czynności. Ogólnym założeniem jest, że przed rozpoczęciem wykonywania operacji na pliku plik ten powinien zostać otwarty, a po zakończeniu wykonywania operacji powinien zostać zamknięty. Otwarcie pliku powoduje związanie z nim abstrakcyjnego obiektu zwanego strumieniem (lub wskaźnikiem do pliku). Nazwy stdin, stdout i stderr są nazwami stałych, symbolizujących strumienie standardowe (programista nie może przyporządkowywać im innych znaczeń). Pliki skojarzone ze strumieniami standardowymi są automatycznie otwierane w momencie rozpoczęcia wykonywania programu i automatycznie zamykane w momencie zakończenia jego wykonywania - programista nie musi umieszczać tych operacji w swoim programie. Poniżej zostaną omówione wybrane (najczęściej używane) funkcje z biblioteki stdio. Funkcje te nie uwzględniają specyficznych cech wpółczesnych uniksowych systemów plików (takich, jak na przykład prawa własności plików). Cechy te uwzględnione są przez biblioteki uniksowe nie należące do ANSI C. Z punktu widzenia biblioteki stdio strumień jest wskaźnikiem do obiektu danych predefiniowanego typu FILE (zmienna typu FILE zawiera wszystkie informacje potrzebne do bieżącej obsługi otwartego pliku, w szczególności informację o wskaźniku położenia). Plik tekstowy może być otwarty w jednym z następujących trybów:
”r” - otwarcie do czytania (plik musi istnieć, wskaźnik położenia na początku);
”w” - otwarcie do pisania (plik jest utworzony na nowo jako pusty);
”a” - otwarcie do dopisywania (jeśli plik nie istniał, jest utworzony, wskaźnik położenia na końcu);
”r+” - otwarcie do aktualizacji (do pisania i czytania, wskaźnik położenia na początku);
”w+” - otwarcie do aktualizacji (plik jest utworzony na nowo jako pusty);
”a+” - otwarcie do aktualizacji (jeśli plik nie istniał, jest utworzony, wskaźnik położenia na końcu).
W powyższych napisach oznaczających tryby otwarcia może dodatkowo być umieszczona na końcu litera b (przykładowo ”rb” lub ”r+b”), co oznacza, że otwarty plik ma być traktowany nie jako tekstowy, ale jako binarny.
FILE *fopen (const char *nazwa, const char *tryb)
Funkcja ta otwiera plik o podanej nazwie (jeśli plik nie jest umieszczony w katalogu bieżącym, nazwa powinna być poprzedzona ścieżką dostępu) w podanym trybie. Jeśli wywołanie funkcji powiedzie się, zwraca ona wskaźnik do obiektu pliku (strumień), zaś jeśli nie, zwraca NULL.
FILE *freopen (const char *nazwa, const char *tryb, FILE *strumień)
Funkcja zmienia przyporządkowanie używanego już wcześniej strumienia, przekierowując go do pliku o podanej nazwie otwartego w podanym trybie. Jeśli wywołanie funkcji powiedzie się, zwraca ona *strumień, jeśli nie, zwraca NULL. Funkcja ta używana jest głównie do przekierowywania w programie strumieni standardowych stdin, stdout i stderr.
int fclose (FILE *strumień)
Funkcja zamyka plik, z którym skojarzony jest dany strumień, zwraca 0 w przypadku sukcesu, zaś EOF w przypadku błędu.
int remove (const char *nazwa)
Funkcja usuwa (zamknięty) plik o podanej nazwie, zwraca 0 w przypadku sukcesu, zaś wartość niezerową w przypadku błędu.
int rename (const char *stara_nazwa, const char *nowa_nazwa)
Funkcja zmienia dotychczasową nazwę (zamkniętego) pliku na nową, zwraca 0 w przypadku sukcesu, zaś wartość niezerową w przypadku błędu.
int fflush (FILE *strumień)
Funkcja wypróżnia bufor skojarzony z danym (otwartym) plikiem, zwraca 0 w przypadku sukcesu, zaś EOF w przypadku błędu. Funkcja ta powinna być wywoływana pomiędzy zakończeniem pisania w pliku i rozpoczęciem czytania z tego pliku, jeśli operacje zapisywania były buforowane.
int fgetc (FILE *strumień)
Funkcja pobiera z otwartego pliku kolejny znak (unsigned char) i w przypadku sukcesu zwraca jego wartość zrzutowaną na int. W przypadku błędu (w szczególności w przypadku napotkania końca pliku) zwraca EOF.
int getchar (void)
Wywołanie tej funkcji jest równoważne wywołaniu fgetc (stdin).
char *fgets (char *s, int n, FILE *strumień)
Funkcja czyta co najwyżej n-1 znaków z pliku skojarzonego z danym strumieniem do tablicy s, po których umieszcza w tablicy znak \0. Czytanie może zakończyć się wcześniej w przypadku napotkania znaku nowej linii lub końca pliku. Funkcja zwraca s w przypadku przepisania wszystkich n-1 znaków, zaś NULL w każdym innym przypadku.
int fputc (int c, FILE *strumień)
Funkcja wpisuje znak (zrzutowany na int) do pliku skojarzonego z danym strumieniem, zwraca c w przypadku sukcesu, zaś EOF w przypadku błędu.
int putchar (int c)
Wywołanie tej funkcji jest równoważne wywołaniu fputc (int c, stdout).
int fputs (const char *s, FILE *strumień)
Funkcja wpisuje łańcuch s do pliku skojarzonego z danym strumieniem. Zwraca liczbę nieujemną w przypadku sukcesu, zaś EOF w przypadku błędu.
Przykład
Wpisanie ustalonego tekstu do pliku w bieżącym katalogu.
#include <stdio.h>
main ( )
{ /* Uwaga: ten program nie przewiduje sytuacji błędnych ! */
FILE *f;
buf [ ] = ”Ala ma kota\n”;
f = fopen ( ”plik”,”w” );
fputs ( buf, f );
fclose ( f );
return;
}
Uwaga
Funkcja fopen nie determinuje praw dostępu do nowo utworzonego pliku w systemach uniksowych! Aby zabezpieczyć plik przed niepożądanym dostępem w trakcie wykonywania programu lub zaraz po jego zakończeniu, należy wcześniej ustawić maskę trybu pliku poleceniem systemowym umask.
11. FORMATOWANE WEJŚCIE I WYJŚCIE
W bibliotece stdio istnieją funkcje umożliwiające wprowadzanie i wyprowadzanie liczb i napisów w określonym formacie. Format jest wzorcem określającym sposób zapisu danego obiektu - system zapisu liczb (dziesiętny, ósemkowy, szesnastkowy), dokładność (liczbę znaków), wyrównanie (do lewej lub do prawej) i inne atrybuty. Funkcje umożliwiają zapis (odczyt) do (z):
- dowolnego pliku;
- wejścia / wyjścia standardowego;
- tablicy.
Tablica musi mieć przydzielone wystarczająco dużo miejsca w pamięci.
int fprintf ( FILE *strumień, const char *format, ciąg_argumentów )
Ciąg argumentów może składać się z 0, 1, 2 ... wyrażeń rozmaitych typów, których wartości są wpisywane do otwartego pliku skojarzonego z danym strumieniem. Wartości są wpisywane zgodnie z podanym formatem. Funkcja zwraca liczbę wpisanych znaków w przypadku pomyślnego wykonania, zaś liczbę ujemną w przypadku błędu.
int printf ( const char *format, ciąg_argumentów)
Wywołanie tej funkcji jest równoważne wywołaniu fprintf ( stdout, ... ).
int sprintf (char *s, const char *format, ciąg_argumentów )
Funkcja ta działa podobnie, jak dwie poprzednie funkcje, ale wyjściowy ciąg znaków kierowany jest do tablicy s i kończony znakiem '\0' (w przypadku pomyślnym znak ten nie jest wliczany do liczby wypisanych znaków zwracanej przez funkcję). Łańcuch będący formatem może zawierać:
- zwykłe znaki (które są wpisywane bezpośrednio do ciągu wyjściowego);
- znaki składające się na specyfikację przekształcenia, które wpływają na postać wyprowadzanych wartości argumentów.
Specyfikacja przekształcenia musi zaczynać się od znaku % i kończyć jednym z możliwych znaków przekształcenia. Pomiędzy znakiem % a znakiem przekształcenia mogą wystąpić:
a) modyfikatory:
- dosunięcie wypisanej wartości argumentu do lewego krańca jego pola;
+ wypisanie wartości liczbowej zawsze ze znakiem;
spacja poprzedzenie wartości spacją, jeśli wartość nie jest poprzedzona znakiem;
0 uzupełnienie liczby wiodącymi zerami do pełnego rozmiaru pola;
# alternatywna (względem standardowej) postać liczby;
b) liczba określająca minimalny rozmiar pola (jeśli zapis wartości argumentu jest krótszy, będzie dopełniony odstępami lub (w zależności od modyfikatora) zerami;
c) kropka oddzielająca liczbę określającą rozmiar pola od liczby określającej precyzję;
d) liczba określająca precyzję (dla liczb zmiennoprzecinkowych - liczbę cyfr po kropce dziesiętnej, dla liczb całkowitych - minimalną liczbę cyfr);
e) modyfikator długości:
h argument jest typu short lub unsigned short ;
l argument jest typu long lub unsigned long ;
L argument jest typu long double.
Zamiast liczby określającej rozmiar pola lub precyzję można wpisać * - wtedy ta liczba jest obliczana jako wartość kolejnego argumentu (powinna być typu int). Możliwe jest zastąpienie znakami * obu tych liczb.
Tabela znaków przekształcenia:
int fscanf ( FILE *strumień, const char *format, ciąg_argumentów )
Ciąg argumentów może składać się z 0, 1, 2, ... argumentów będących wskaźnikami. Wartości są pobierane z danego pliku i przypisywane kolejnym argumentom aż do wyczerpania formatu lub wystąpienia błędu. Funkcja zwraca liczbę pobranych wartości w przypadku pomyślnego wykonania, zaś EOF w przypadku błędu.
int scanf ( const char *format, ciąg_argumentów )
Wywołanie tej funkcji jest równoważne wywołaniu fscanf (stdin, ... ) .
int sscanf ( char *s, const char *format, ciąg_argumentów )
Funkcja ta działa podobnie, jak dwie poprzednie funkcje, ale znaki wejściowe są pobierane z tablicy s (ciąg znaków jest zakończony '\0', nie EOF ). Format jest ciągiem znaków zawierającym specyfikacje przekształceń. W formacie mogą wystąpić:
- spacje i znaki tabulacji (są ignorowane);
- zwykłe znaki (które odpowiadają kolejnym ignorowanym znakom z ciągu wejściowego);
- specyfikacje przekształceń.
Specyfikacje przekształceń rozpoczynają się od znaku % i kończą znakiem przekształcenia. Pomiędzy nimi mogą wystąpić:
a) znak * oznaczający wstrzymanie przypisania (zignorowanie danej);
b) liczba ograniczająca rozmiar pola;
c) znak h, l lub L (interpretowane tak, jak w przypadku poprzedniej grupy funkcji).
Przyjęte jest założenie, że w ciągu znaków pobieranych z wejścia występują pola (ciągi zwykłych znaków stanowiące zapisy kolejnych danych), które są pooddzielane separatorami (pojedynczymi znakami lub ciągami znaków spacji, znaków tabulacji i znaków zmiany linii).
Tabela znaków przekształcenia:
Uwaga
W przypadku pobierania znaków z wejścia standardowego podłączonego do terminala (nie do pliku) istotną rzeczą z punktu widzenia użytkownika programu jest to, czy terminal pracuje w trybie znakowym (bez buforowania), czy w trybie z buforowaniem znaków. W zależności od tego program może pobierać pojedyncze znaki (natychmiast po naciśnięciu klawisza) lub całe linie znaków (dopiero po naciśnięciu <Enter>). Użytkownik terminala uniksowego ma możliwość zmiany trybu jego pracy.
12. PRZEGLĄD POZOSTAŁYCH BIBLIOTEK STANDARDOWYCH JĘZYKA ANSI C
1) Klasyfikowanie znaków ( plik nagłówkowy <ctype.h> )
Funkcje w tym zbiorze przyjmują jako argument wartość znakową (zrzutowaną na int), zwracają wartość niezerową, jeśli argument jest znakiem określonego rodzaju, zaś zero, jeśli nie jest.
Przykład
int isalpha (int c) - zwraca wartość niezerową, jeśli c jest literą (małą lub dużą)
int isdigit (int c) - zwraca wartość niezerową, jeśli c jest cyfrą
Dodatkowo w tym zbiorze umieszczone są dwie funkcje konwersji:
int tolower (int c) - zamienia duże litery na odpowiednie małe litery
int toupper (int c) - zamienia małe litery na odpowiednie duże litery
2) Operowanie na łańcuchach ( plik nagłówkowy <string.h> )
Funkcje w tym zbiorze dzielą się na dwie grupy:
- funkcje operujące na łańcuchach dowolnej długości (zakończonych znakiem '\0');
- funkcje operujące na ciągach znaków o długości określonej jednym z argumentów funkcji.
Przykład
char *strcpy (char *s, char *t) - kopiuje łańcuch z t do s (łącznie ze znakiem '\0')
int strcmp (char *s, char *t) - porównuje leksykograficznie („alfabetycznie”) łańcuchy t i s, zwraca wartość ujemną, jeśli s < t, zero jeśli s = t, wartość dodatnią, jeśli s > t
void *memcpy ( void *s, void *t, size_t n ) - kopiuje dokładnie n znaków z miejsca wskazywanego przez t do miejsca wskazywanego przez s (przy założeniu, że oba fragmenty pamięci nie zachodzą na siebie)
Uwaga
Miejsce w pamięci przeznaczone na wynik działania funkcji musi być wcześniej zarezerwowane (na przykład przy użyciu funkcji malloc).
3) Funkcje matematyczne ( plik nagłówkowy <math.h> )
Zbiór ten zawiera typowe funkcje dostępne w językach programowania (poza funkcjami obliczającymi wartość bezwzględną liczby całkowitej oraz obliczającymi parę (iloraz, reszta) dla liczb całkowitych, które zostały umieszczone w stdlib.h).
Argumenty funkcji trygonometrycznych oraz wartości funkcji odwrotnych do nich są podawane w radianach.
Przykład
double sin ( double x ) - oblicza sinus wartości x
double asin ( double x ) - oblicza wartość arcus sinus x (dla x w przedziale [-1, 1] )
double exp (double x) - oblicza wartość e
double pow ( double x, y ) - oblicza x (dla x = 0 wartość y musi być dodatnia, dla x < 0 wartość y musi być całkowita)
double fabs ( double x ) - oblicza wartość bezwzględną liczby x
4) Funkcje narzędziowe ( plik nagłówkowy <stdlib.h> )
W tym zbiorze umieszczone są funkcje konwersji typów danych, funkcje przydzielające i zwalniające pamięć (na przykład poznane wcześniej funkcje malloc i free) oraz inne funkcje nie zaklasyfikowane do którejś z pozostałych bibliotek standardowych.
Przykład
double atof ( const char *s) - zamienia łańcuch s na reprezentowaną przez niego liczbę typu double (dokładniej: zamienia najdłuższy możliwy podłańcuch początkowy na liczbę, zaś jeśli zamiana jest w ogóle niemożliwa, funkcja zwraca 0)
int rand ( void ) - funkcja zwraca pseudolosową liczbę całkowitą z przedziału [0, RAND_MAX], gdzie wartość RAND_MAX zależy od implementacji (musi wynosić co najmniej 32767)
void exit ( int status ) - zakończenie działania programu i przekazanie do procesu rodzicielskiego wartości status (zwyczajowo przyjmuje się, że wartość 0 oznacza zakończenie pomyślne)
int system ( const char *s ) - wykonanie przez interpreter polecenia systemowego zapisanego w łańcuchu s jeśli s jest łańcuchem pustym, funkcja umożliwia testowanie, czy interpreter poleceń jest dostępny)
char *getenv ( const char *nazwa ) - zwraca wartość zmiennej (o podanej nazwie) środowiska bieżącego procesu
void *bsearch ( const void *klucz, const void *tablica, size_t n, size_t rozmiar,
int (*cmp) ( const void *wart_klucza, const void *wart_danej ) ) - przeszukuje uporządkowaną rosnąco tablicę o danej liczbie i rozmiarze elementów przy zastosowaniu funkcji porównującej cmp (zwraca NULL w przypadku niepowodzenia)
void qsort ( void *tablica, size_t n, size_t rozmiar, int (*cmp) (const void *, const void * ) ) - wykonuje sortowanie danej tablicy o danej liczbie i rozmiarze elementów, przy zastosowaniu funkcji cmp porównującej dwa elementy tablicy
int abs ( int n ) - oblicza wartość bezwzględną argumentu całkowitego n
5) Makro diagnostyczne ( plik nagłówkowy <assert.h> )
Jedynym elementem tego zbioru jest funkcja realizowana jako makro:
void assert ( int wyrażenie ) - funkcja ta oblicza wartość danego wyrażenia, i w przypadku, gdy jest ona równa 0, wpisuje do standardowego wyjścia błędów (stderr) odpowiedni komunikat, a następnie kończy działanie programu „w trybie awaryjnym” (przez wykonanie funkcji abort ze stdlib.h).
6) Obsługa zmiennych list argumentów ( plik nagłówkowy <stdarg.h> )
Zbiór ten zawiera zmienne i funkcje (makra), które pozwalają definiować i wykorzystywać w programie funkcje o zmiennych długościach list argumentów i o zmiennych typach tych argumentów.
7) Obsługa skoków odległych ( plik nagłówkowy <setjmp.h> )
Skoki odległe są skokami w kodzie programu na odległość większą, niż w obrębie aktualnie wykonywanego podprogramu. W programach napisanych w językach wyższego poziomu służą zazwyczaj do „przyspieszonego” powrotu do programu głównego (z pominięciem ciągu wyjść z powywoływanych podprogramów).
8) Obsługa sygnałów (asynchronicznych) ( plik nagłówkowy <signal.h> )
Sygnały są logicznym modelem fizycznych przerwań, które mogą być generowane przez system asynchronicznie (w chwili nieoczekiwanej przez program). W zależności od rodzaju sygnału i jego implementacji domyślną reakcją procesu na otrzymanie sygnału może być zawieszenie procesu lub zignorowanie sygnału. Proces może „zabezpieczyć się” przed nieoczekiwanym sygnałem przez ustanowienie funkcji obsługi przerwania, do której automatycznie następuje przeskok w chwili otrzymania sygnału przez proces wykonujący dany program.
Uwaga: w systemie Unix istnieje sygnał „nieprzechwytywalny” (odpowiadający poleceniu kill -9).
9) Obsługa daty i czasu ( plik nagłówkowy <time.h> )
W zbiorze tym zdefiniowane są typy arytmetyczne, struktury oraz funkcje obsługujące datę oraz czas. Uwzględniają one czas lokalny (też zmianę czasu z zimowego na letni i odwrotnie) i zdefiniowany dla sieci komputerowej Skoordynowany Czas Uniwersalny (jednakowy na całym świecie).
Struktura czasu kalendarzowego:
int tm_sec; liczba sekund (0 ... 59)
int tm_min; liczba minut (0 ... 59)
int tm_hour; liczba godzin (0 ... 23)
int tm_mday; dzień miesiąca (1 ... 31)
int tm_mon; liczba miesięcy (0 ... 11)
int tm_year; liczba lat (od roku 1900)
int tm_wday; dzień tygodnia - licząc od niedzieli (0 ... 6)
int tm_yday; liczba dni od początku roku (0 ... 365)
int tm_isdst; znacznik letniej zmiany czasu (dodatni - letni, zero - zimowy, ujemny - brak)
10) Ograniczenia implementacji ( pliki nagłówkowe <limits.h> i <float.h> )
Te zbiory zawierają jedynie definicje stałych określajacych rozmiary typów: <limits.h> typów całkowitych, zaś <float.h> typów zmiennoprzecinkowych.
Przykład
INT_MIN - minimalna wartość dla typu int
INT_MAX - maksymalna wartość dla typu int
FLT_MAX - maksymalna liczba zmiennoprzecinkowa pojedynczej precyzji
DBL_MAX - maksymalna liczba zmiennoprzecinkowa podwójnej precyzji
Uwaga
W programach należy stosować stałe symboliczne, a nie literały, aby oprogramowanie było przenośne.
13. PRZYKŁADY BIBLIOTEK NIESTANDARDOWYCH W JĘZYKU C
Poza standardową biblioteką ANSI C (dostępną zawsze, jeśli kompilator jest zgodny ze standardem ANSI) istnieje wiele bibliotek niestandardowych, utworzonych dla konkretnych systemów operacyjnych i zależnych od ich zasobów. Każda z takich bibliotek zawiera zbiór definicji typów danych, stałych oraz funkcji i wymaga dołączenia do programu odpowiedniego pliku nagłówkowego. Poniżej zostaną podane przykłady zastosowań bibliotek charakterystycznych dla systemów linuxowych (zgodnych z bibliotekami utworzonymi dla systemów unixowych). Biblioteki takie mogą być zarówno łączone statycznie (dołączane do programu na etapie jego konsolidacji i przechowywane w jego przestrzeni adresowej przez cały czas jego wykonywania), jak i łączone dynamicznie (dołączane w trakcie wykonywania programu w miarę potrzeb). Zarówno funkcje ze standardowej biblioteki ANSI C, jak i funkcje z bibliotek niestandardowych posiadają swoje opisy podane w dokumentacji wbudowanej (manual). Instalacja nowej biblioteki w systemie wiąże się między innymi z umieszczeniem zbioru opisów jej funkcji w odpowiednim katalogu w systemie plików. Do wykonywania podstawowych operacji na standardowym wejściu/wyjściu oraz plikach służą funkcje związane z plikami nagłówkowymi < fcntl.h > oraz < unistd.h > (może też być potrzebne dołączenie < sys / types.h > oraz < sys / stat.h > ).
int open (const char *nazwa, int flagi, mode_t uprawnienia);
Funkcja ta jest odpowiednikiem funkcji fopen w standardzie ANSI C, ale uwzględnia atrybuty plików specyficzne dla systemów unixowych, w szczególności prawa dostępu. Argumentami funkcji są:
- nazwa otwieranego pliku (istniejącego lub tworzonego);
- flagi (czyli pojedyncze bity mające swoje nazwy symboliczne) decydujące o sposobie otwarcia pliku;
- prawa dostępu do tworzonego pliku (jeśli plik już istnieje, ten argument jest ignorowany).
Funkcja zwraca tak zwany deskryptor pliku (niedużą liczbę naturalną) w przypadku pomyślnego otwarcia pliku, zaś wartość -1 w przypadku błędu. Deskryptor pliku pełni podobną rolę do strumienia zwracanego przez funkcję fopen - odwołują się do niego funkcje zapisu, odczytu i zamknięcia pliku. Pierwsza z flag musi być jedną z trzech określających sposób wykorzystywania otwartego pliku:
O_RDONLY - plik tylko do odczytu;
O_WRONLY - plik tylko do zapisu;
O_RDWR - plik zarówno do zapisu, jak i do odczytu.
Do tej flagi możę być dołączonych (za pomocą operatora | alternatywy bitowej) 0, 1, 2 lub więcej innych flag, na przykład:
O_CREAT - plik ma być utworzony jako nowy;
O_EXCL - w połączeniu z poprzednią flagą oznacza, że funkcja open ma zwrócić błąd, jeśli plik już istnieje (przydatne na przykład do utworzenia pliku zamkowego - lockfile);
O_TRUNC - jeśli plik już istnieje, to ma być skrócony do 0;
O_APPEND - wskaźnik pliku ma być ustawiony na jego końcu (domyślnie jest na początku).
Prawa dostępu mogą być podawane w postaci liczbowej, ale zalecane jest stosowanie nazw symbolicznych i ewentualne składanie ich przy użyciu operatora alternatywy bitowej. Przykłady:
S_IRWXU - prawa r,w,x dla właściciela pliku;
S_IROTH - prawo r dla innych.
int close (int deskryptor);
Funkcja ta służy do zamknięcia pliku o deskryptorze zwróconym wcześniej przez wywołanie funkcji open. Zwraca 0 w przypadku pomyślnym, zaś -1 w przypadku błędu.
ssize_t read (int deskryptor, void *bufor, size_t liczba_bajtów);
Funkcja czyta z pliku o podanym deskryptorze co najwyżej liczba_bajtów bajtów do bufora o podanym adresie początku. Zwraca liczbę faktycznie przeczytanych bajtów (być może 0) w przypadku pomyślnym, zaś -1 w przypadku błędu.
ssize_t write (int deskryptor, const void *bufor, size_t liczba_bajtów);
Funkcja zapisuje do pliku o podanym deskryptorze co najwyżej liczba_bajtów bajtów z bufora o podanym adresie początku. Zwraca liczbę faktycznie zapisanych bajtów w przypadku pomyślnym, zaś -1 w przypadku błędu.
Uwaga: zarówno funkcja read, jak i funkcja write ma zapewnioną niepodzielność wykonania !
Oddzielną grupę funkcji związanych z plikiem nagłówkowym < unistd.h > są funkcje służące do zarządzania procesami. Przykłady takich funkcji:
pid_t getpid (void); - zwraca identyfikator procesu, który wywołał tę funkcję;
pid_t getppid (void); - zwraca identyfikator procesu rodzicielskiego;
pid_t fork (void); - tworzy nowy proces wykonujący współbieżnie ten sam program, w przypadku pomyślnym zwraca identyfikator nowo utworzonego procesu procesowi, który wywołał tę funkcję, zaś 0 nowemu procesowi, w przypadku niepomyślnym zwraca -1.
Przykład
.................
if ((id = fork ( )) < 0 ) printf (”Nie udalo sie utworzyc nowego procesu \n”);
else if (id = = 0) printf (”Jestem procesem potomnym dla procesu %d\n”, getppid ( ));
else printf (”Jestem procesem rodzicielskim dla procesu %d \n”, id);
................
W przypadku pomyślnym komunikaty wyświetlane w powyższym przykładzie mogą pojawiać się na ekranie w przypadkowej kolejności (zależy ona od procesu szeregującego wykonywanie procesów). Systemy unixowe posiadają na ogół bibliotekę funkcji „pseudograficznych” pozwalających operować na terminalu tekstowym w bardziej urozmaicony sposób, niż tylko przez wypisywanie kolejnych linii tekstu - przemieszczać swobodnie kursor na obszarze ekranu, tworzyć okna złożone ze znaków z rozszerzonego kodu ASCII, używać różnych kolorów i innych atrybutów czcionek i ich tła i temu podobne (tak, jak na przykład w mniejszym zakresie moduł crt, a w większym Turbo Visio w Pascalu). Możliwość stosowania funkcji z tej biblioteki zależy oczywiście od właściwości terminala tekstowego i poprawnie skonstruowane programy powinny zaczynać pracę od testowania tych możliwości). Typowa biblioteka unixowa nazywa się curses, zaś jej linuxowy odpowiednik - ncurses. Używanie biblioteki ncurses wymaga włączenia pliku nagłówkowego < ncurses.h > do treści programu i użycia opcji -lncurses w poleceniu kompilacji. Podstawowe funkcje to: initscr ( ) - inicjująca działanie pakietu i udostępniająca pusty ekran, oraz endwin ( ) - kończąca działanie pakietu i przywracająca poprzedni ekran. Przykładem programu użytkowego utworzonego przy pomocy ncurses jest Midnight Commander. Systemy unixowe dysponujące graficznymi stacjami roboczymi pozwalają na programowanie interfejsów graficznych przy użyciu podstawowej biblioteki Xlib (stanowiącej bezpośredni interfejs programisty do unixowego protokołu graficznego X protocol ), jak również przy użyciu bibliotek graficznych wyższych poziomów (na ogół wywodzących się od pierwotnej biblioteki Xt - skrót nazwy X toolkit ). Xlib udostępnia funkcje operujące na podstawowych obiektach graficznych - punktach, liniach prostych i krzywych, wielokątach, kołach i innych. Umożliwia też wyświetlanie tekstów o rozmaitych atrybutach w trybie graficznym. Przypomina nieco pascalowy moduł graph, ale jest od niego dużo bardziej skomplikowana. Biblioteki graficzne wyższych poziomów udostępniają bardziej złożone obiekty graficzne - okienka dialogowe, menu rozwijalne, suwaki i wiele innych. Umożliwiają szybkie tworzenie profesjonalnych interfejsów programów, ale posługiwanie się nimi wymaga przyswojenia na początku dość dużego zasobu wiedzy (złożone obiekty graficzne posiadają bardzo wiele atrybutów, których wartości trzeba określić w momencie ich tworzenia).
Unixowy protokół graficzny (X protokół) jest protokołem wysokiego poziomu (warstwy prezentacji) służącym do przesyłania informacji graficznej pomiędzy programem użytkowym (X klientem), a programem obsługującym terminal graficzny (X serwerem).
Model logiczny pary X klient - X serwer
Uwaga.
1) Konfiguracja oprogramowania jest odwrotna, niż zazwyczaj (serwer w terminalu, klient w komputerze głównym).
2) Terminal graficzny może być zarządzany przez tylko jeden X serwer, w komputerze głównym może być uruchomionych wielu klientów.
3) Ogólny model jest modelem sieciowym: wiele komputerów i wiele terminali może być połączonych w sieć, dowolny proces na dowolnym komputerze (być może pełniącym jednocześnie rolę terminala graficznego) może łączyć się z dowolnym X serwerem, jeśli tylko posiada odpowiednią autoryzację.
4) Autoryzacja (prawo do komunikowania się) może być przydzielana przez właściciela procesu X serwera wybranym użytkownikom sieci, wybranym komputerom lub wszystkim użytkownikom. W Unixie służy do tego polecenie xhost.
5) Wielu klientów może komunikować się współbieżnie z jednym X serwerem i rywalizować o generowane przez niego sygnały. Programy klientów powinny być tak konstruowane, żeby nie dezorganizowały sobie wzajemnie pracy.
Najważniejsze funkcje i struktury danych
Funkcje Xlib operują na standardowych strukturach danych, do których dostęp jest możliwy zazwyczaj tylko za ich pośrednictwem. Struktury te są logicznym obrazem fragmentów sprzętu, na którym operuje X serwer: {Uwaga: do tej pory nie istnieją polskie odpowiedniki wielu nazw angielskich}
terminal graficzny (display) - odpowiada pojęciu graficznej stacji roboczej (z urządzeniami we/wy)
ekran (screen) - odpowiada obrazowi na ekranie monitora
okno (window) - odpowiada oknu (zwykle jednemu z wielu) wyświetlanemu na ekranie
mapa pikselowa (pixmap) - odpowiada obszarowi w pamięci operacyjnej przechowującemu obraz, który może być wyświetlony w oknie
rysowisko (drawable) - wspólna nazwa dla okien i map pikselowych
i wiele innych.
Istotnym pojęciem jest pojęcie zdarzenia, które może dotyczyć zarówno użycia klawiatury lub wskaźnika (myszy), jak i rozwoju wydarzeń na ekranie - przesłonięcia/odsłonięcia okna, zmiany okna aktywnego i innych. Program klienta może być wykonywany w trybie asynchronicznym (z kolejkowaniem zdarzeń poszczególnych rodzajów) lub w trybie synchronicznym (wielokrotnie wolniejszym, wykorzystywanym głównie do celów diagnostycznych). Aby móc wykonywać operacje na oknach, X serwer musi komunikować się z zarządcą okien (window manager). Proces ten jest specjalnym klientem X serwera (zazwyczaj wykonywanym na tym samym komputerze, co X serwer), który musi być aktywny przez cały czas działania X serwera. Decyduje on o wszystkich szczegółach technicznych związanych z wyświetlaniem okien, które nie są ujęte w specyfikacji X protokołu.
Uwaga.
Programy X klientów mogą decydować o tym, czy chcą, czy też nie chcą korzystać z usług zarządcy okien (i wyświetlać obraz w postaci „surowych” okien nieprzemieszczalnych po ekranie).
Display *XOpenDisplay (char *nazwa); zwraca: wskaźnik do struktury typu Display w przypadku sukcesu;
wskaźnik pusty (NULL) w przypadku błędu.
nazwa - łańcuch pusty lub o postaci:
adres:numer.ekran gdzie
adres - adres sieciowy komputera (o postaci zależnej od używanego protokołu warstwy transportowej, w przypadku protokołu TCP może być cyfrowy lub symboliczny (jeśli dostępny jest serwer nazw), może też być pusty - wtedy dobierany jest jeden z protokołów w dziedzinie Unixa)
numer - numer terminala graficznego (zazwyczaj podajemy tu 0, większe liczby mogą się pojawić, jeśli jeden komputer steruje kilkoma „nieinteligentnymi” graficznymi stacjami roboczymi)
ekran - numer monitora domyślnego w zestawie graficznej stacji roboczej (tę część wraz z kropką pomijamy, jeśli stacja robocza ma tylko jeden monitor)
Działanie: ustanawia połączenie między procesem wywołującym tę funkcję a X serwerem o podanym adresie i zapisuje uzyskane informacje o X serwerze w strukturze, do której zwraca wskaźnik. W przypadku, jeśli zamiast nazwy został podany łańcuch pusty, pobiera nazwę domyślną zapisaną w zmiennej środowiska DISPLAY.
Uwaga.
Niektóre systemy unixowe tworzą automatycznie zmienną DISPLAY już w momencie zalogowania się na nie (na przykład przy użyciu telnetu), niektóre należy skłonić do tego odpowiednim poleceniem (najlepiej umieszczonym w skrypcie logowania).
void XCloseDisplay (Display *terminal);
terminal - wskaźnik do struktury zwrócony przez funkcję XOpenDisplay
Działanie: zapamiętuje niektóre ustawienia (na życzenie programisty) i zrywa połączenie z X serwerem.
Istnieje cała seria funkcji służących do testowania struktury utworzonej przez funkcję XOpenDisplay (co umożliwia dostosowanie działania programu do możliwości X serwera). Żeby można było cokolwiek wyświetlić na ekranie terminala, należy otworzyć na nim okno. Okazuje się to nadspodziewanie skomplikowaną czynnością, bo trzeba określić mnóstwo różnych atrybutów - rozmiary okna, szerokość ramki, kolory ramki i tła, czy korzystamy z usług zarządcy okien, czy okno ma samo odtwarzać brakujące fragmenty po odsłonięciu itd. Możemy też zasugerować początkowe położenie okna na ekranie (co w przypadku korzystania z usług zarządcy okien niekoniecznie musi być spełnione). Niektóre z tych atrybutów określamy oddzielnymi funkcjami, a niektóre podajemy jako argumenty funkcji tworzącej okno (XCreateWindow). Dalsze czynności są jeszcze bardziej skomplikowane (określenie palety kolorów, kontekstu graficznego itd.). Początkującym programistom może trochę ułatwić pracę korzystanie z wartości domyślnych (funkcje Default Screen, DefaultVisual, XCreateSimpleWindow i inne).
Wyszukiwarka
Podobne podstrony:
wyklad podstawy wprogramowania Janusz Ratajcza, PWr, Programowanie 1
wykład z podstawy programowania, BHP z elementami ergonomii
Podstawy fizyki 3-program-09, SKRYPTY, NOTATKI, WYKŁADY, Podstawy Fizyki 3, wykład
Wykład 4 Podstawy prawne finansów publicznych
Idea holizmu - wykład 2, podstawy pielęgniarstwa
wykłady z podstaw ekonomii
Konspekt wykładów z Podstaw automatyki wykład 5
Zagadnienia egzaminacyjne PF3-09, SKRYPTY, NOTATKI, WYKŁADY, Podstawy Fizyki 3, wykład
1 wykład Podstawowe pojęcia i przedmiot ekonomi
Wykład 1 - Podstawy organizacji, zarządzanie bhp
Wykład -Podstawy turystyki, Turystyka i Rekreacja, Podstawy turystyki
ZFP wykład 4, podstawy finansów przedsiębiorstwa
Projektowanie baz danych Wykłady Sem 5, pbd 2006.01.07 wykład03, Podstawy projektowania
wykład 3 - podstawy zarządzania - 10.01.2010
wykłady, Podstawy kinezjologi, Podstawy kinezjologi
więcej podobnych podstron