424 2

424
10. Optymalizacja
było najlepiej dopasowane do m punktów pomiarowych (tifyd 9
go
Nie można zastosować tu wprost metod z rozdziału 4, gdyż y (/, x) zależy niełiniow ^ parametrów x2, x5. Postawione zadanie można opisać jako rozwiązywanie nielwiJ^^ układu nadokreślonego
y(tf,x)asy{ (i~l .2,...»m).
Jeśli pomiary mają równe wagi, to aproksymacja średniokwadratowa wymaga minimali zacji funkcji
(io.5.n ?«= Y
i- I
Przykład 10.5.2. Niech llf f2.....będą elementami próby pobranej z populacji
i niech/(r.«) będzie gęstością dla pewnej cechy tych elementów, gdzie a jest nieznanym wektorem parametrów. Zgodnie z zasadą największej wiarcgodności, a określa się znajdując maksimum funkcji
?(*)= FI/('!>«)•
Można to zrobić analitycznie tylko dla szczególnych rodzajów gęstości.
Rozważymy najpierw ogólne zadanie minimalizacji, jak w' drugim przykładzie, i założymy, żc pochodne cząstkowe można wyrazić w postaci analitycznej. (Specjalne techniki dla układów nadokreślonych będą podane w § 10.5.4). Zadanie redukuje się więc do rozwiązywania układu (zwykle nieliniowego)
(10.5.2) *(*)«<?,
gdzie g(x)={dęfćxl, c<p/tlx2,..., cyjdxjiT jest gradientem funkcji <p. Można tu stosować metody z § 6.9, np. metodę Newtona opisaną wzorem
(10.5.3) x¥+1*=xy-H(xy)g(x,),
gdzie H(x) jest macierzą odwrotną do jakobianu G(x) funkcji g:
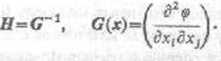
Macierz (7(jc) nazywa się też hesjanem funkcji <p. Zauważmy, że macierze G i H są symetryczne. Warunkiem dostatecznym na to, żeby rozwiązanie x równania (10.5.2) dawało minimum funkcji ę, jest nieujemna określoność macierzy G(x). To wTaz z możliwo®^ obliczania wartości funkcji <p stwarza korzystniejszą sytuację w porównaniu z dewoto)’101 układami nieliniowymi. Zauważmy, że obliczanie funkcji g jest zazwyczaj znacznie koszto* wniejsze niż obliczanie ę i że obliczanie G wymaga jeszcze wrięccj pracy, szczególniesvłe • ’ gdy n jest duże.
Przypomnijmy sobie, że zaletą metody Newtona jest jej zbieżność kwadratowa, zaleta jest okupiona następującymi wadami (zob. też § 10.5.3):
Wyszukiwarka
Podobne podstrony:
10 M. Piegza i in. uzyskując od +2 do +7 punktów, w najmniejszym stopniu hamując wzrost B. cinerea 6
Rys. 6. Dopasowanie funkcji kwadratowej do punktów pomiarowych z Rys. 4. Wykonanie ćwiczenia 1.
DIETETYK schudniesz 4kg w miesiąc przepisy dopasowane do Ciebie plan diety na 7,10 lub 14 dni etap a
10 NAJLEPSZYCH PROGRAMÓW DO ZARZĄDZANIA ZADANIAMI
424 10. ZASTOSOWANIA UKŁADÓW PRZEKSZTAŁTNIKOWYCH a obwód wzbudzenia tego silnika — z przekształtnika
424 (10) - 424 - 424 » wówcza3 Gdy R" » (1 + tR)R » 1,1 kQ oraz C" » (1 + tc)C - 1#1 . 10~
15286 skanuj0031 mnie chronić. Niezwykłym doznaniem było usłyszeć, jak ona 10 przeżywała, nic biorąc
str (2) 22 Najlepszą porą do zakładania rozsadników jest u nas 10— 25 marzec. Jeżeli założymy rozsa
Silniki i pozycjonery Festo obejmuje szeroki asorty- skokowych, optymalnie dopasowanych do wszystkic
25 (424) 25 2.6.c. Nałożenie diagramu C na diagram B (do przykładu 2.6)
10 000 000Cześć Piotr,Należysz do najlepszych fotografów w Mapach Google Twoje zdjęcia uzyskały 10 0
choroszyB4 424 kości skrawania i dla zakresu od 2 do 6 m/min parametr Ra mieści się w przedziale od
Pierwsze wrażenie po wejściu do biura nie było najlepsze, co prawda pani siedząca za biurkiem przywi
więcej podobnych podstron