
409
W dzisiejszych czasach trudno sobie wyobrazić dziedzinę szero-
ko rozumianej telekomunikacji, w której cyfrowe przetwarzanie sy-
gnałów DSP (Digital Signal Processing) nie miałoby zasadniczego
znaczenia. Odnosi się to do wszystkich warstw systemu telekomuni-
kacyjnego: od urządzeń przetwarzających obrazy, dźwięki, dane
alfanumeryczne na sygnały (i odwrotnie), przez sieci telekomunika-
cyjne przenoszące i komutujące te sygnały, aż po systemy urzą-
dzeń, zapewniających dostarczanie różnorakich treści, zwanych po-
wszechnie usługami. Można tu wymienić takie przykłady, jak: mode-
my telefoniczne, systemy cyfrowego szerokopasmowego dostępu
abonenckiego DSL (Digital Subscriber Line), dostępu radiowego,
rozpoznawanie mowy i mówców, telewizja cyfrowa wysokiej roz-
dzielczości, telefonia komórkowa i satelitarna czy związana z więk-
szością wymienionych systemów – kryptografia. Trzeba podkreślić,
że tak szerokie zastosowanie techniki cyfrowej w telekomunikacji
znalazło zastosowanie dopiero w momencie opanowania technolo-
gii wytwarzania na wielką skalę scalonych układów specjalizowa-
nych ASIC (Application Specific Integrated Circuits). Coraz większą
popularnością w tym zakresie cieszą się procesory sygnałowe – mi-
krokomputery skonstruowane specjalnie do cyfrowego przetwarza-
nia sygnałów. Obecnie z procesorami sygnałowymi w wielu zastoso-
waniach mogą konkurować układy programowalne i reprogramo-
walne.
Dynamiczny rozwój cyfrowych technik telekomunikacyjnych daje
się zauważyć zwłaszcza w systemach multimedialnych. Ogólnie
można powiedzieć, że telekomunikacyjny system multimedialny to
zespół środków technicznych i procesów, umożliwiających przekaz
i prezentację wiadomości za pomocą przynajmniej dwóch, wzajem-
nie zsynchronizowanych, środków przekazu, takich jak: mowa, mu-
zyka, ruchomy obraz, tekst, grafika itp. Powszechnie jest on utożsa-
miany z takimi usługami, jak: wideotelefonia, wideokonferencja, wi-
deo na żądanie (lub prawie na żądanie), telepraca, teleedukacja,
telezakupy itd. W takim systemie wyróżnia się trzy podstawowe ele-
menty funkcjonalne: serwer usług multimedialnych, terminale multi-
medialne oraz sieć dostępu do usług. Zadaniem sieci jest przenie-
sienie sygnałów dotyczących usług – oferowanych przez serwery –
do terminali, a także wymiana danych między serwerami. Płaszczy-
zna transportowa takiej sieci jest na ogół bardzo dobrze rozwinięta
i przystosowana do przenoszenia sygnałów cyfrowych z dużą szyb-
kością. Najczęściej są w niej stosowane kable światłowodowe
i szybkie techniki transmisyjne: SDH, ATM, Frame-Relay itp. Najbar-
dziej krytycznym elementem tego systemu jest abonencka sieć do-
stępowa, przenosząca sygnały multimedialne od węzłów sieci trans-
portowej do terminalu i na odwrót. Ze względu na istniejącą infra-
strukturę kablową tej sieci (najczęściej symetryczna para
przewodów miedzianych, tzw. skrętka), stało się konieczne opraco-
wanie systemów umożliwiających transmisję cyfrową do (i od) abo-
nenta z dużą szybkością.
W tej części sieci powszechnie przyjmowana szerokość pasma
podstawowego 300 Hz – 3400 Hz nie wynika z własności linii trans-
misyjnej, lecz z przepustowości filtrów stosowanych (dla transmisji
telefonicznej) w punktach styku z siecią transportową. Wspomniana
skrętka umożliwia (oczywiście po usunięciu filtrów) wykorzystanie
pasma do 1 MHz, a jedynym ograniczeniem szybkości transmisji cy-
frowej jest długość kabla i jakość jego wykonania. Efektywne zwięk-
szenie wykorzystania pasma do transmisji dwukierunkowej osiąga
się przez stosowanie odpowiednich kodów liniowych oraz przez sto-
sowanie cyfrowej kompensacji (kasowania) echa (Echo Canceller)
w układach rozgałęźnych po stronie abonenta i po stronie sieci.
Na przykład w sieciach ISDN dla dostępu podstawowego
(2B + D) do transmisji o szybkości 144 kbit/s (2 kanały po 64 kbit/s
+ 16 kbit/s dla kanału sygnalizacyjnego) wykorzystuje się kod linio-
wy 2B1Q (2-Binary 1-Quatenary) oraz technikę kompensacji echa.
Sprowadza się ona do wytworzenia w nadajniku przez adaptacyjny
filtr cyfrowy sygnału identycznego z przebiegiem echowym i odjęcia
go od całkowitego sygnału odbieranego.
Podobną zasadę kasowania echa stosuje się w systemach dostę-
powych DSL. Opracowano (i dalej się rozwija) systemy HDSL (High
data rate Digital Subscribe Line), ADSL (Asymmetric Digital Sub-
scribe Line), VDSL (Very high data rate Digital Subscribe Line) o róż-
nych przepływnościach i różnych technikach kodowania.
Kodowanie liniowe i cyfrowe kasowanie echa w systemach do-
stępowych i sieciach ISDN to niewielka część szerokiego zakresu
stosowania cyfrowego przetwarzania sygnałów. Ogromne znacze-
nie mają techniki kodowania sygnałów telefonicznych i wizyjnych,
umożliwiające zmniejszenie przepływności kanałów służących do
ich przenoszenia, a także wykrywanie i ewentualnie korekcję błędów
transmisji. Wystarczy powiedzieć, że w systemach radiokomunikacji
ruchomej szybkość strumienia sygnału mowy zmniejsza się
z 64 kbit/s (w systemach PCM) do szybkości poniżej 10 kbit/s.
W społeczeństwie informacyjnym wiele dziedzin życia gospodar-
czego i kulturalnego korzysta z elektronicznego przekazywania da-
nych. Ogromnego znaczenia nabiera zatem poufność, a nawet taj-
ność przekazywanych informacji. Z coraz większym przekonaniem
przyjmowany jest pogląd, że ochrona danych będzie odgrywała
podstawową rolę w funkcjonowaniu przyszłych systemów informa-
cyjnych. Dotyczy ona głównie aplikacji telekomunikacyjnych, takich
jak telefonia bezprzewodowa i komórkowa, faksy, pagery, płatna te-
lewizja, komercyjne produkty audio/wideo itp. Jednak najważniej-
szym obszarem, w którym decydujące znaczenie mają mechanizmy
ochrony informacji, jest komunikacja cyfrowa, a w szczególności
sieć internetowa.
Mechanizmy ochrony komunikacji cyfrowej są realizowane za po-
mocą specjalnych protokołów bezpieczeństwa i w formie algoryt-
mów kryptograficznych stały się częścią wielu standardowych roz-
wiązań, jak IPSec (protokół internetowy), SSL (Secure Socket
Layer), szyfrowane komórki sieci ATM oraz różnych standardów
ANSI dla bankowości. Eksplozja wzrostu usług internetowych w za-
kresie handlu i biznesu, w tym operacji finansowych i obrotu kapita-
łowego, spowodowała, że realizacja mechanizmów zabezpieczenia
przed nieuprawnionym dostępem do informacji stała się ogromnym
wyzwaniem.
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
Tadeusz ŁUBA*, Krzysztof JASIŃSKI*, Bogdan ZBIERZCHOWSKI*
Programowalne układy
przetwarzania sygnałów
i informacji – technika cyfrowa
w multimediach i kryptografii
*
Instytut Telekomunikacji Politechniki Warszawskiej
e-mail: luba@tele.pw.edu.pl, kjasio@tele.pw.edu.pl,
bogdan@tele.pw.edu.pl
Jak widać, zakres zastosowań układów cyfrowych w telekomuni-
kacji będzie coraz większy i niedobrze byłoby, gdyby w rozwoju tej
techniki i jej ogromnych rynkowych możliwości nie uczestniczyły fir-
my polskie. Zrozumienie tych szans jest szczególnie istotne w dobie
rewolucyjnego rozwoju technologii układów programowalnych [26].
Dotychczasowe sukcesy polskich firm w komercyjnych aplikacjach
techniki cyfrowej w telekomunikacji potwierdzają tę tezę. Doskona-
łym przykładem może tu być firma ADB Polska, założona przed pię-
ciu laty przez pracowników naukowych Politechniki Zielonogórskiej.
Z dużym powodzeniem opracowuje ona i sprzedaje w milionach
sztuk – również na rynki zagraniczne – urządzenia telewizji cyfrowej.
W artykule opisano podstawowe właściwości układów programo-
walnych oraz możliwości ich zastosowania w przetwarzaniu sygna-
łów i informacji. Omówiono przykłady eksperymentalnych i przemy-
słowych aplikacji multimedialnych oraz realizacje algorytmów kryp-
tograficznych. Przedstawiono nową ofertę na rynku cyfrowych
układów telekomunikacyjnych – produkty wirtualne. Wskazano tak-
że na ogromne znaczenie syntezy logicznej w tych zastosowaniach.
ROLA UKŁADÓW PROGRAMOWALNYCH
W ROZWOJU TECHNIKI CYFROWEJ
DLA POTRZEB PRZETWARZANIA
SYGNAŁÓW I INFORMACJI
W technice cyfrowej w ostatnich latach obserwuje się ogromne
zmiany w metodach projektowania układów i systemów cyfrowych
oraz w technologiach wykonywania urządzeń cyfrowych. Z punktu
widzenia technologii jest to postęp od układów katalogowych i płyt-
ki drukowanej do specjalizowanych układów ASIC i specjalizowa-
nych procesorów ASIP (Application Specific Instruction Set Proces-
sors) o złożoności sięgającej milionów bramek. W szczególności
udoskonalenia procesu technologicznego, polegające na reduko-
waniu wymiarów elementów półprzewodnikowych i zwiększaniu
liczby warstw metalizowanych połączeń, a także nowe techniki pro-
gramowania umożliwiły opracowanie generacji struktur FPLD (Field
Programmable Logic Devices) z możliwością reprogramowania i re-
konfiguracji [21], [30]. Te cechy układów FPLD umożliwiają imple-
mentacje algorytmów DSP, niekiedy znacznie lepsze w porównaniu
z implementacjami na procesorach sygnałowych.
Obecnie produkowane układy FPLD, w zależności od struktury,
klasyfikuje się na układy matrycowe – CPLD (Complex PLD) oraz
układy komórkowe – FPGA.
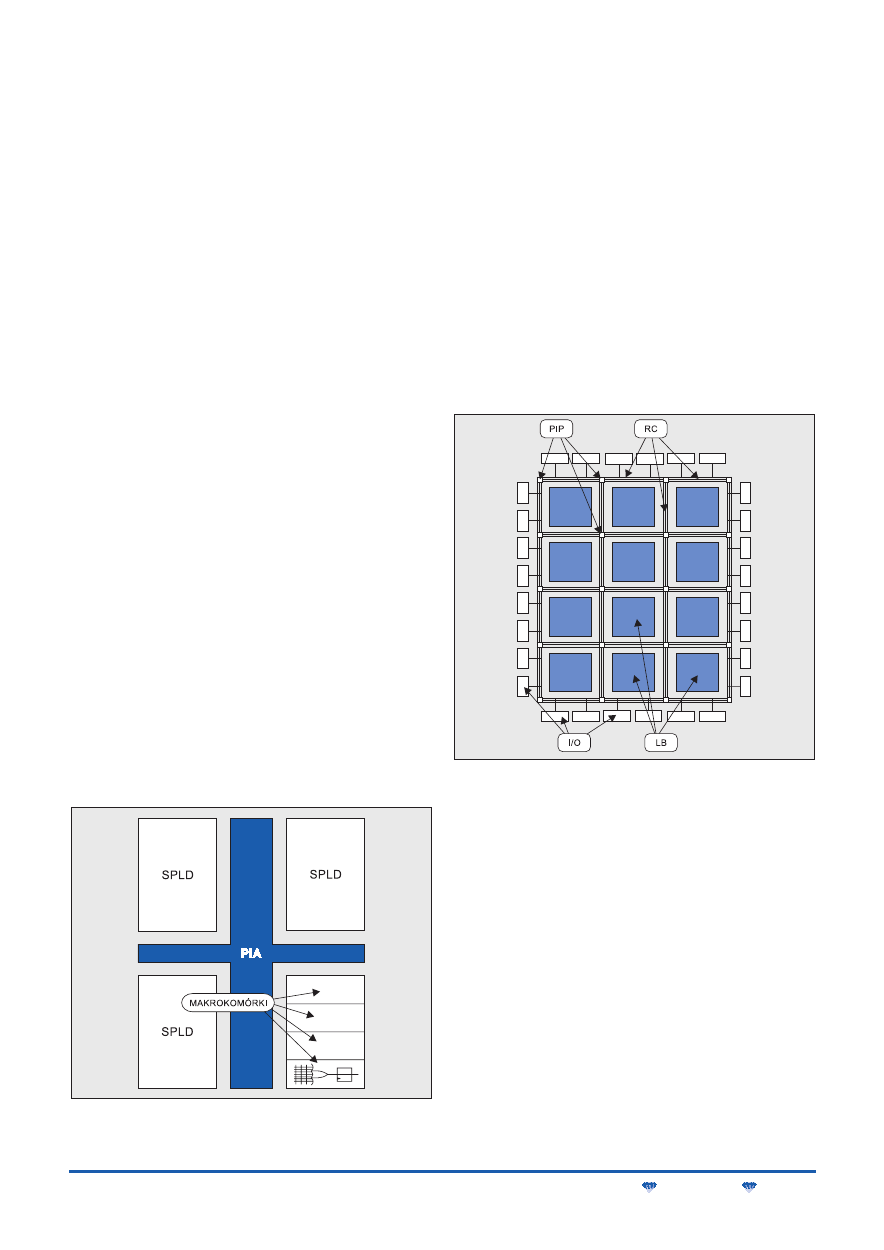
Elementem charakterystycznym dla architektury CPLD jest wyko-
rzystanie w układach wielu struktur typu PAL (Programmable Array
Logic) zgrupowanych w bloki SPLD (Simple PLD). Bloki te są ze so-
bą połączone szybką, programowaną matrycą połączeniową, jak to
pokazano na rys. 1. Jej zadaniem jest przesyłanie sygnałów między
wejściami zewnętrznymi a wewnętrznymi blokami logicznymi oraz
między tymi blokami.
Niezależnie od wykonania, ważnymi parametrami matrycy połą-
czeniowej, będącej krytycznym fragmentem układów CPLD, są:
zdolność łączeniowa i czas propagacji sygnału. Pod pojęciem zdol-
ności łączeniowej rozumie się możliwość łączenia dowolnych ele-
mentów struktury programowalnej. Producenci układów rozwiązują
związane z tym problemy w różny sposób, czego efektem są różno-
rodne architektury matryc połączeniowych, w „dużych” układach
CPLD – także wielopoziomowe. Architektura matrycy połączeniowej
i technologia zastosowana do jej realizacji mają duży wpływ na czas
propagacji sygnału. We współczesnych układach CPLD czas propa-
gacji sygnału przez matrycę połączeniową nie przekracza zazwyczaj
0,8... 3 ns (m. in. matryce GRP firmy Lattice, PIA – Altera, PIM – Cy-
press, ZIA – Xilinx). Dostępne są także układy, w których czas pro-
pagacji skrócono do ok. 100... 200 ps (ZIA, AIM – Xilinx).
Grupą układów programowalnych o architekturze i budowie ele-
mentarnych komórek logicznych, znacznie odmiennej od architektu-
ry i budowy komórek układów SPLD i CPLD, są struktury FPGA
(Field Progammable Gate Array). Na rys. 2 pokazano ułożenie komó-
rek logicznych oraz traktów połączeniowych, charakterystyczne dla
większości układów FPGA.
410
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Rys. 1. Struktura CPLD. Oznaczenia: PIA (Programmable Inter-
connect Array) – matryca połączeniowa, SPLD – prosta struktura PLD
typu PAL
O
O
Rys. 2. Struktura FPGA. Oznaczenia: PIP (Programmable Intercon-
nect Point) – programowalne punkty połączeniowe, RC (Routing
Channels) – trakty połączeniowe, I/O – bloki wejściowo-wyjściowe, LB
(Logic Blocks) – bloki logiczne
Praktycznie wszystkie obecnie produkowane układy programo-
walne są wyposażone w reprogramowalne matryce pamięciowe.
Najczęściej są stosowane dwa rodzaje matryc: z komórkami pamię-
ci SRAM (Static RAM) i trwałej EEPROM, a coraz rzadziej PROM lub
EPROM. Układy reprogramowalne CPLD i FPGA oferuje na świecie
kilku producentów. Są to zarówno układy z matrycami SRAM, jak
i EEPROM. Nieulotne matryce EEPROM charakteryzują się ograni-
czoną liczbą dopuszczalnych cykli reprogramowania, zazwyczaj od
100 do 1000, gwarantują natomiast długi czas przechowywania za-
pisanych w nich konfiguracji (do 100 lat) bez zasilania.
W aplikacjach wymagających dużej pojemności logicznej są sto-
sowane przede wszystkim struktury FPGA, w których rolę elementu
pamięciowego spełnia komórka pamięci nietrwałej SRAM. Po każ-
dorazowym włączeniu zasilania niezbędne jest wprowadzenie da-
nych o konfiguracji, czyli tzw. inicjalizacja konfiguracji matrycy. Pro-
ces rekonfiguracji we wszystkich układach FPGA przebiega podob-
nie, przy czym – w zależności od typu układu – czas inicjalizacji
struktury waha się od 1ms (układy serii AT6000) aż do 320 ms (ukła-
dy FLEX10K). Dzięki wykorzystaniu standardowych interfejsów sze-
regowych SDI (Serial Data Interface) w układach FPGA oraz JTAG-
ISP w układach CPLD, dane konfiguracyjne można „załadować” do
411
struktury programowalnej za pomocą lokalnego sterownika lub spe-
cjalnego interfejsu programującego. Strumień danych konfiguracyj-
nych jest zwykle przechowywany w standardowej pamięci stałej
o dowolnej organizacji lub w specjalnej pamięci szeregowej.
Ze względu na właściwości matryc pamięciowych, do stosowania
w aplikacjach rekonfigurowalnych są predestynowane układy
FPGA.
Głównym celem rekonfiguracji systemu jest dostosowanie struk-
tury funkcjonalnej, dostępnej w ramach jego architektury podstawo-
wej, do wymagań realizowanych algorytmów. W przypadku realiza-
cji algorytmów, które „nie mieszczą” się w całości w strukturze sys-
temu, istnieje konieczność ich rozłożenia na sekwencje podzadań
realizowanych kolejno w odpowiednich konfiguracjach. Warunkiem
niezbędnym do realizacji całego algorytmu jest zdolność systemu
rekonfigurowalnego do wymiany danych konfiguracyjnych wraz
z przekazaniem wyników uzyskanych w bieżącej konfiguracji do
kontynuowania obliczeń w następnej konfiguracji. Taki sposób re-
konfiguracji systemu podczas jego działania jest wyróżniany termi-
nem run-time.
Obecnie stosuje się kilka metod rekonfiguracji układów FPGA
[40]. Najprostszym implementacyjnie, ale niezbyt efektywnym spo-
sobem rekonfiguracji, jest zmiana konfiguracji (tzw. kontekstu) całej
struktury programowalnej. Polega ona na szeregowym wprowadze-
niu strumienia nowych danych konfiguracyjnych. Wadą tej metody
jest konieczność przerwania pracy całego układu, co w konsekwen-
cji może obniżyć wydajność całego systemu. Układy wyposażone
w taki mechanizm rekonfiguracji są nazywane jednokontekstowymi.
Większość obecnie produkowanych układów FPGA można uważać
za układy jednokontekstowe o różnych czasach rekonfiguracji.
Bardziej efektywnym sposobem rekonfiguracji jest rekonfiguracja
częściowa. Jest ona możliwa pod warunkiem przerwania pracy ukła-
du, podobnie jak w przypadku układów jednokontekstowych, cho-
ciaż dzięki możliwości wymiany tylko niezbędnej części danych kon-
figuracyjnych średni czas rekonfiguracji może być – zależnie od
przyjętego sposobu przydziału zadań – znacznie krótszy.
Do najbardziej znanych układów rekonfigurowalnych należą
struktury AT40K/KA/KAL, AT6000 oraz FPSLIC AT94 (wszystkie
wymienione rodziny są to układy FPGA, produkowane przez firmę
Atmel [13]) oraz Virtex/Virtex II i Virtex E (produkowane przez firmę
Xilinx).
Ogromną zaletą układów AT40K/KA/KAL oraz AT6000 jest możli-
wość ich częściowej rekonfiguracji bez konieczności „wyłączania”
pozostałej, nie poddawanej rekonfiguracji, części układu. Uzyskanie
tak dobrego efektu użytkowego jest możliwe dzięki zaawansowane-
mu mechanizmowi wymiany danych konfiguracyjnych CacheLogic,
w który wyposażono wszystkie układy obydwu rodzin.
Zupełnie inną architekturę i nieco inne walory użytkowe mają
układy AT94, nazywane w nomenklaturze producenta także FPSLIC
(Field Programmable System Level Integrated Circuit). Integrują one
bowiem w jednej strukturze rekonfigurowalną matrycę FPGA oraz 8-
bitowy mikrokontroler RISC. Budowa, właściwości (w tym możli-
wość częściowej rekonfiguracji) i podstawowe parametry matryc re-
konfigurowalnych są identyczne jak dla matryc stosowanych w ukła-
dach AT40K. Możliwości użytkowe układów AT94K znacznie
zwiększa fakt zintegrowania w ich strukturze szybkiego mikrokontro-
lera o architekturze RISC, którego wydajność dochodzi do 40 MIPS.
Szczegółowy opis architektury układów FPSLIC można znaleźć m.
in. w artykule [40].
Do stosowania w aplikacjach nie wymagających częściowej re-
konfiguracji struktury układu doskonale nadają się układy z rodzin
Virtex oraz APEX, które należą obecnie do grupy najwyżej zaawan-
sowanych technologicznie układów FPGA. O ich dużych zaletach
decydują m. in. mechanizmy sprzętowej implementacji pamięci róż-
nego typu (w tym FIFO oraz DualPort FIFO), możliwość łączenia blo-
ków logicznych w bloki funkcjonalne bez wykorzystywania lokal-
nych zasobów połączeniowych, a także krótki czas rekonfiguracji.
Jednak nie tylko z tych powodów układy FPGA mają przeważają-
ce zalety w implementacjach algorytmów DSP. Decydującym czyn-
nikiem w coraz powszechniejszym zastosowaniu układów FPGA do
syntezy układów DSP jest ich specyficzna, ziarnista i potokowa
struktura wewnętrzna. Zalety tej struktury objawiają się już na pozio-
mie najprostszych – ale wyjątkowo typowych w DSP – układów
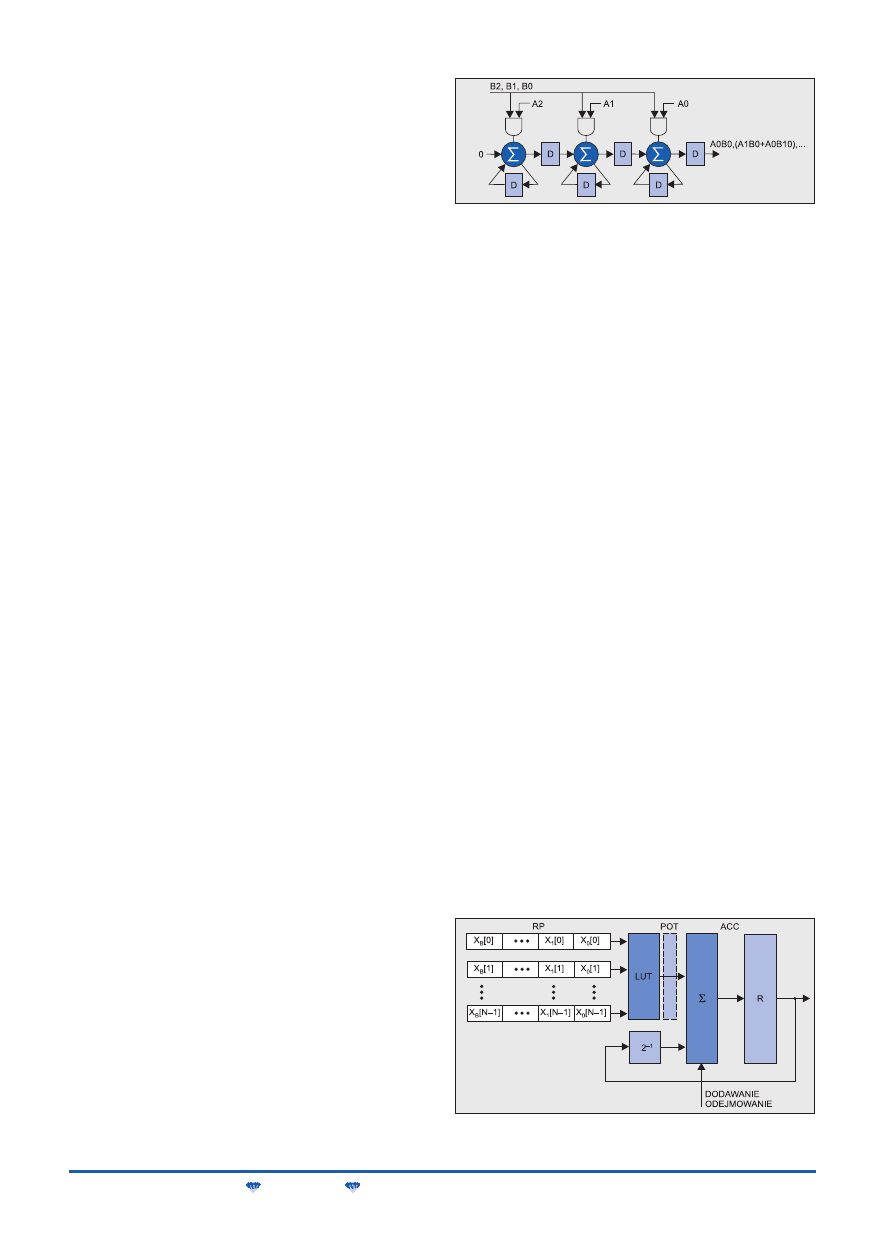
mnożenia skalarnego z akumulacją. Na rys. 3 pokazano uproszczo-
ną strukturę mnożenia szeregowego, realizowanego w jednowymia-
rowej matrycy systolicznej. Każde ogniwo tego układu można bez-
pośrednio zrealizować w pojedynczych komórkach struktur FPGA,
a niezależność tej struktury od liczby bitów przetwarzanych słów jest
dodatkową zaletą decydującą o wydajności i skalowalności realizo-
wanych algorytmów. Układy szeregowego mnożenia bitowego znaj-
dują zastosowanie w realizacjach filtrów typu FIR [26], [36].
Komórkowa budowa struktur FPGA, a w szczególności możli-
wość grupowania często wykorzystywanych bloków tablic odwzoro-
wań (tablic prawdy) LUT (Look Up Table) w wielowyjściowe pamię-
ci, znakomicie ułatwia realizację układów arytmetyki rozproszonej
DA (Distributed Arithmetic) [26]. Strukturę układu DA pokazano na
rys. 4. Zaletą architektury DA jest wygodna i efektywna implementa-
cja w strukturach FPGA. Przeprowadzone eksperymenty [36] wska-
zują, że równoległe i rozproszone układy mnożące implementowa-
ne w strukturach FPGA są 6 razy szybsze przy zaledwie 2,5-krotnym
zwiększeniu zasobów sprzętowych.
Rekonfigurowalne układy FPGA, które zapoczątkowały nową erę
w dziedzinie projektowania układów DSP, stanowią również dosko-
nałe medium implementacyjne do realizacji algorytmów szyfrują-
cych w różnych zastosowaniach, takich jak protokoły bezpieczeń-
stwa komunikacji w sieciach, ochrona i potwierdzanie autentycz-
ności informacji i dokumentów oraz do realizacji maszyn wyszukują-
cych klucze w kryptoanalizie.
Głównym atutem układów rekonfigurowalnych jako medium kon-
strukcyjnego jest ich zdolność „adaptacyjna”, polegająca na możli-
wości dostosowania architektury logicznej do typu, kształtu i właści-
wości realizowanych funkcji. Do efektywnego wykorzystania
możliwości tych układów, zarówno pod względem optymalizacji lo-
gicznej, jak też parametrów fizycznych (szybkość, moc, powierzch-
nia) jest potrzebna gruntowna znajomość funkcji i własności imple-
mentowanych algorytmów. Środkiem do osiągnięcia tak określone-
go celu jest wiedza o sposobach odwzorowywania podstawowych
operacji i funkcji algorytmu w strukturę podstawową matrycy rekon-
figurowalnej oraz wybór logicznej reprezentacji danych, odpowied-
niej do specyfikacji algorytmu architektury.
Większość algorytmów szyfrowania można przedstawić za po-
mocą grafu przepływu danych, który jest zbudowany zaledwie z kil-
ku różnych komponentów, realizujących mniej lub bardziej złożone
operacje arytmetyczne i funkcje logiczne. Poniżej przedstawiono li-
stę najczęściej stosowanych operacji i funkcji.
M
Proste operacje arytmetyczne, takie jak dodawanie i odejmowa-
nie.
M
Operacje na krótkich słowach binarnych o nietypowych długo-
ściach.
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Rys. 3. Jednowymiarowa systoliczna matryca sumatora; D – prze-
rzutnik
O
O
Rys. 4. Architektura DA. Oznaczenia: RP – rejestry przesuwające,
POT – rejestr potokowy, R – rejestr wyjściowy
M
Operacje mnożenia – mnożenie ogólne (dowolne wartości ope-
randów), mnożenie modularne, mnożenie z obcięciem wyniku, mno-
żenie przez stałą, mnożenie z użyciem kodowania nadmiarowego
operandów etc.
M
Równoległe operacje logiczne.
M
Sekwencje operacji logicznych.
M
Tablice odwzorowań LUT, np. nieliniowe typu S-box.
M
Operacje rotacji i przesunięcia.
Dla każdej z wymienionych operacji można wyznaczyć efektyw-
ne odwzorowanie w strukturze matrycy rekonfigurowalnej. Zastoso-
wanie takich „wzorów” realizacyjnych do projektowania algorytmów
kryptograficznych pozwala lepiej wykorzystać walory systemów re-
konfigurowalnych.
EKSPERYMENTALNE I PRZEMYSŁOWE
APLIKACJE MULTIMEDIALNE
Wraz z wprowadzeniem rekonfigurowalnych struktur logicznych
pojawiły się nowe możliwości ich zastosowań w dziedzinie przetwa-
rzania obrazów i dźwięku. Pierwszą architekturą komputera konfigu-
rowanego ze strukturami FPGA była wirtualna maszyna, pomyślana
jako programowalna pamięć aktywna PAM (Programmable Active
Memory); miała ona formę rekonfigurowalnego koprocesora stero-
wanego standardowym procesorem. Rola procesora sprowadzała
się do zarządzania konfiguracją macierzy układów FPGA, które peł-
niły funkcje koprocesora, i współpracy z tym koprocesorem, analo-
gicznie jak w konwencjonalnych komputerach.
Przykładami zastosowania platformy PAM do realizacji specjali-
zowanych maszyn liczących są między innymi: system DECPeRLe
zaprojektowany przez Digital Equipment Corporation’s Paris Re-
search Laboratory [38] i system SPLASH, opracowany w Super-
computer Research Center [3].
Systemy PeRLe-0 i PeRLe-1 cechuje wielka efektywność rozwią-
zywania zadziwiająco szerokiej klasy problemów obliczeniowych.
Są one zbudowane z macierzy dwuwymiarowej układów FPGA
komunikującej się z otoczeniem zewnętrznym za pomocą szyny
o dużej przepływności.
Oprócz 16 układów macierzy 4x4 FPGA system zawiera 1 MB
pamięci statycznej RAM na każdej z krawędzi macierzy FPGA. Układ
został zaprojektowany do przyspieszenia realizacji zadań wymaga-
jących dużych mocy obliczeniowych przy założeniu, że części reali-
zowanego algorytmu, które stanowią jego „wąskie gardło”, będą
przekazywane do wykonania układowi. Do specyfikacji zadań zosta-
ło zaprojektowane specjalne środowisko programowe [4], które
łączy w sobie cechy kompilatorów złożonych języków programowa-
nia oraz systemów do projektowania sprzętu. Lista problemów, któ-
re efektywnie rozwiązywano za pomocą DEC PeRLe, zawiera wiele
istotnych zadań z dziedziny przetwarzania obrazu i dźwięku, jak na
przykład: mnożenie dużych liczb całkowitych, kompresja danych,
rozwiązywanie równań Laplace’a, synteza dźwięku, rozpoznawanie
wzorca, splot w dziedzinie dwuwymiarowej, kompresja obrazu.
Innym przykładem wysoko wyspecjalizowanej maszyny liczącej
jest system SPLASH zaprojektowany w Supercomputer Research
Center [3], [8] oraz jego następca SPLASH-2. Podobnie jak system
DEC PeRLe, współpracuje on ze stacją roboczą, przyspieszając jej
działanie w tych sytuacjach, gdy nie może ona uporać się z zada-
niem wymagającym dużych mocy obliczeniowych. Architektura
SPLASH-2 została zaprojektowana jako macierz systoliczna na po-
jedynczej płytce o 16 elementach obliczeniowych, z których każdy
zawiera układ FPGA oraz lokalną pamięć. Analogicznie jak w przy-
padku PeRLe, stworzono środowisko programistyczne, dające moż-
liwość tworzenia aplikacji. Miało ono wbudowany symulator języka
VHDL [1], [2], język opisu logiki LDG [9] oraz model programowy
SIMD [10]. Za pomocą systemu SPLASH uruchomiono i przetesto-
wano wiele aplikacji. Otrzymane wyniki świadczą o jego dużej efek-
tywności. Lista przykładowych problemów rozwiązanych za pomocą
systemu SPLASH-2 zawierała m. in. następujące zadania: wyszuki-
wanie tekstu, przetwarzanie obrazów, ustalanie zmiennego przecin-
ka oraz splot w dziedzinie dwuwymiarowej.
Eksperymenty przeprowadzone z
architekturami PeRLe
i SPLASH pokazały, że pojedyncza platforma obliczeniowa zbudo-
wana z układów FPGA może zapewnić imponującą efektywność dla
bardzo szerokiej rodziny zastosowań. Tak wysoki poziom efektyw-
ności był możliwy do osiągnięcia dzięki zaprojektowaniu dla każde-
go z wymienionych problemów specjalizowanej architektury. Me-
chanizmy rekonfiguracji gwarantują, że z wykorzystaniem tego sa-
mego sprzętu można realizować niezliczoną liczbę różnych
architektur logicznych. Osiągnięcie wysokiej efektywności syste-
mów PeRLe i SPLASH było możliwe dzięki:
M
wyspecjalizowaniu bloków funkcjonalnych;
M
wykorzystaniu współbieżności;
M
optymalizacji procesów i interfejsów komunikacyjnych;
M
wyspecjalizowaniu układów wejściowo-wyjściowych.
Niewątpliwie eksperymenty te stały się bezpośrednią przyczyną
zastosowania układów programowalnych w komercyjnych (przemy-
słowych) aplikacjach telekomunikacyjnych. Typowym przykładem
mogą być satelitarne systemy telemetryczne firmy TSI TelSys [16],
w których rekonfigurowalna matryca składająca się z 12 układów
APEX20K100 spełnia rolę rekonfigurowalnego systemu DSP, auto-
matycznie dostosowującego się do protokołu transmisyjnego śle-
dzonej misji satelitarniej (EOS, SBIRS-High, DRTS, Heliosat).
Możliwość rekonfiguracji układów CPLD wykorzystała firma LG
Information & Telecommunications. W jej ofercie znajdują się urzą-
dzenia stosowane w systemach komórkowych CDMA (Code Divi-
sion Multiple Access), W-CDMA (Wideband CDMA) oraz WLL (Wire-
less Local Loop). We współpracy z firmą Hanaro Telecom [12] firma
LGIE wdrożyła do produkcji modemy W-CDMA, w których zastoso-
wano po cztery układy EPF10K100. Zastosowanie układów rekonfi-
gurowalnych wiąże się z możliwością szybkiego i w miarę bezpro-
blemowego dostosowania toru obróbki sygnału do modyfikacji
wprowadzanych w zaleceniach ITU, które mają na celu m. in. zwięk-
szenie przepływności kanałów transmisyjnych, przy jednoczesnym
zawężeniu zajmowanego pasma.
Układy rekonfigurowalne znalazły zastosowanie także we współ-
czesnych telewizyjnych systemach retransmisyjnych, czego przykła-
dem może być rodzina procesorów wizyjnych D1 firmy Snell & Wil-
cox [12]. Według danych producenta, zastosowanie układów rekon-
figurowalnych spowodowało obniżenie kosztu wykonania takiego
procesora o ok. 30% w stosunku do klasycznych rozwiązań opar-
tych na procesorach sygnałowych.
Amerykańska firma Metalithic Systems jest producentem profe-
sjonalnego, studyjnego sprzętu audio, w tym wielu cyfrowych
konsol mikserskich. W 1999 roku inżynierowie tej firmy opracowali
412
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
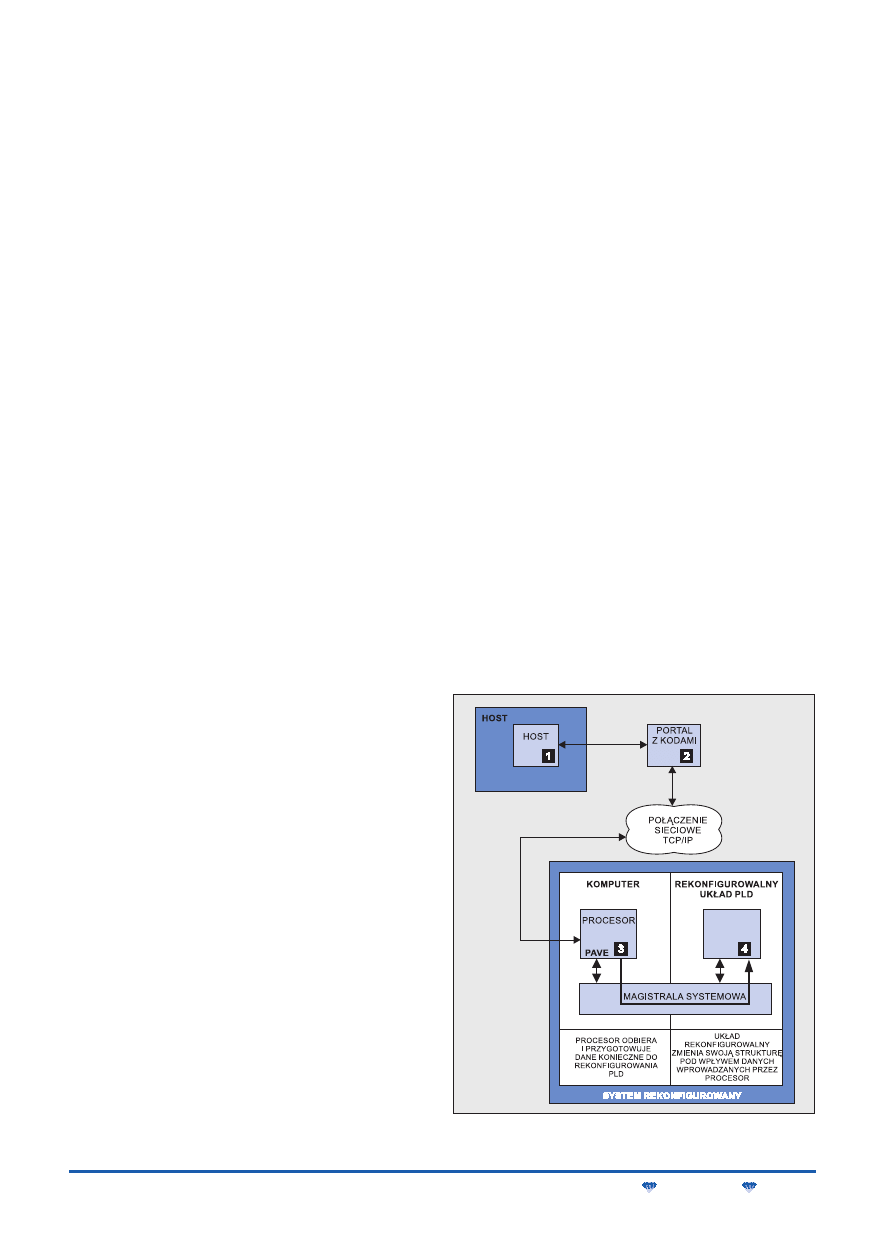
Rys. 5. Schemat blokowy systemu ze zdalnie rekonfigurowanym
blokiem sprzętowym; 1, 2, 3, 4 – etapy rekonfiguracji
413
128-kanałową konsolę, wykonaną na układach Spartan firmy Xilinx,
w której możliwość rekonfiguracji układów wykorzystano do budowy
różnego rodzaju efektów audio, w tym cyfrowego pogłosu i kompre-
sji szumów [15].
Szczególnym przykładem w grupie opracowań komercyjnych
jest propagowana od 1998 roku przez firmę Xilinx idea budowania
sprzętu rekonfigurowanego przez Internet – IRL (Internet Reconfigu-
rable Logic), co schematycznie pokazano na rys. 5 [17].
Pierwsze komercyjne aplikacje IRL opracowały i wdrożyły w 1999
roku firmy Bosch i Siemens, które testują możliwości stosowania
układów zdalnie rekonfigurowalnych w aplikacjach samochodo-
wych [17]. Na początku 2001 roku, w wyniku prac prowadzonych
wspólnie z LG Electronics oraz konsorcjum: Xilinx, Celoxica oraz
WindRiver, powstały – wykorzystujące układy Virtex E – zdalnie re-
konfigurowalne: odtwarzacz MP3 oraz internetowy telefon VoIP
[14]. Urządzenia te mają zostać wdrożone do masowej produkcji
przed końcem 2003 roku.
UKŁADY PROGRAMOWALNE
W KRYPTOGRAFII
Wśród pierwszych implementacji szyfrów blokowych w układach
programowalnych szczególnie interesujące były dwa opracowania.
Pierwsze powstało w Szwajcarskim Federalnym Instytucie Technicz-
nym w Lozannie pod akronimem CryptoBooster [25]. CryptoBooster
spełnia funkcje rekonfigurowalnego, modułowego koprocesora
kryptograficznego, który współpracuje z głównym komputerem jako
akcelerator operacji kryptograficznych. Próbnym modułem wykona-
nym w tej architekturze była realizacja symetrycznego szyfru bloko-
wego IDEA. Przeprowadzone testy wykazały, że pod względem
szybkości i przepustowości koprocesor nadaje się do zastosowań
w szybkich sieciach, jak ATM, SONET i GigaEthernet.
Drugi przykład to projekt wykorzystujący rekonfigurowalny proce-
sor PipeRench opracowany w Carnegie Mellon University [37]. Ory-
ginalna warstwowa architektura procesora PipeRench, zaprojektowa-
na w CMU, została zoptymalizowana pod względem implementacji
kryptograficznych. Jej głównymi cechami są: wirtualizacja, potokowa
organizacja ścieżki danych i zerowy pozorny czas rekonfiguracji. Wir-
tualizacja umożliwia implementację algorytmów nie mieszczących
się w całości w fizycznej strukturze systemu. W architekturze
PipeRench zrealizowano szereg algorytmów, jak CRYPTON, IDEA,
RC6 i Twofish.
Na podstawie analizy wielu zastosowań sprzętowych [5] realiza-
cji algorytmów kryptograficznych można określić funkcje i wymaga-
nia, jakie powinien spełniać elastyczny system kryptograficzny. Są
to:
M
możliwość zmiany algorytmu w trakcie pracy,
M
możliwość wprowadzania nowych algorytmów,
M
duża szybkość przetwarzania danych,
M
łatwa obsługa interfejsu użytkownika,
M
modyfikowalność oprogramowania sterującego (upgradable
firmware),
M
modyfikowalność sprzętu.
Traktując powyższe warunki jako założenia do konstrukcji syste-
mu kryptograficznego, współpracującego z głównym komputerem
PC na zasadzie koprocesora, można zaproponować konstrukcję,
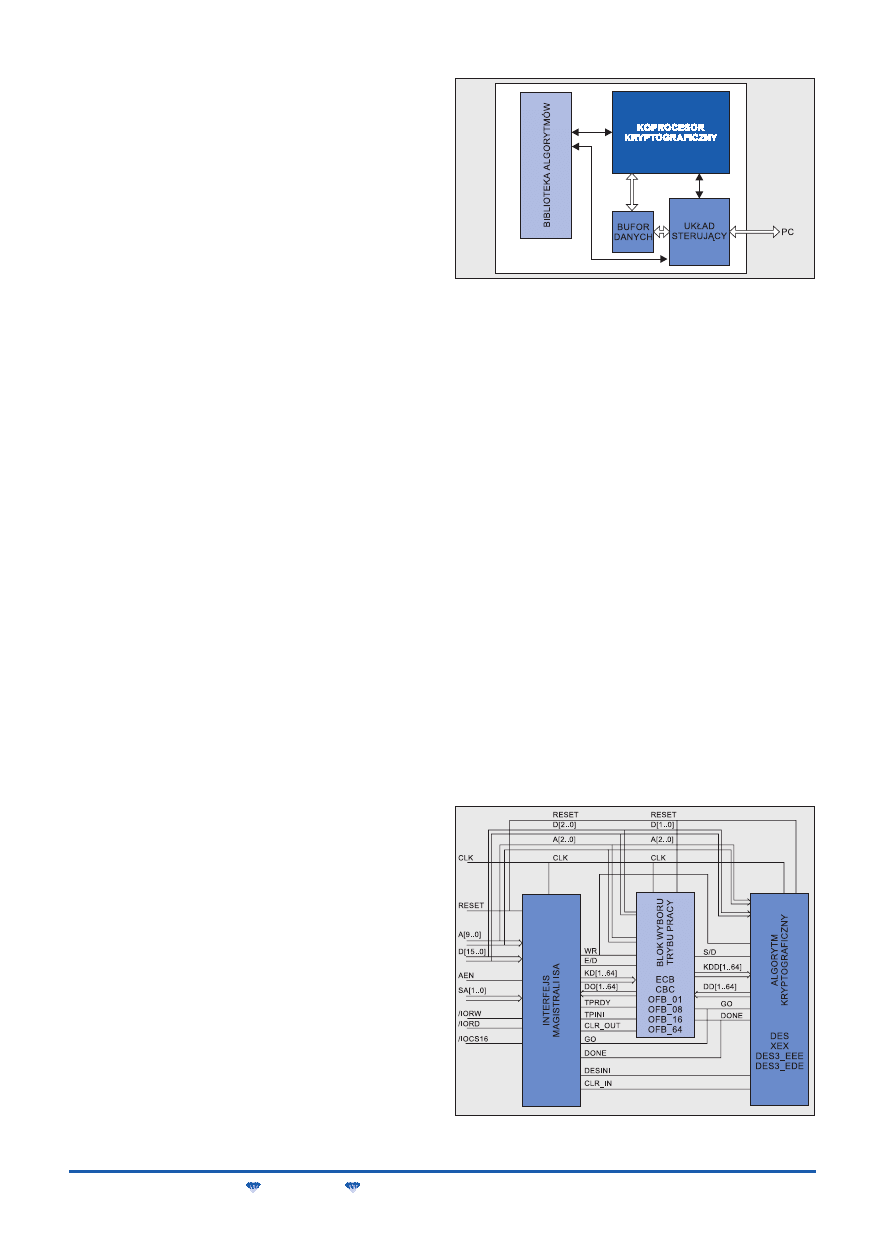
której uproszczona architektura jest przedstawiona na rys. 6. Zasad-
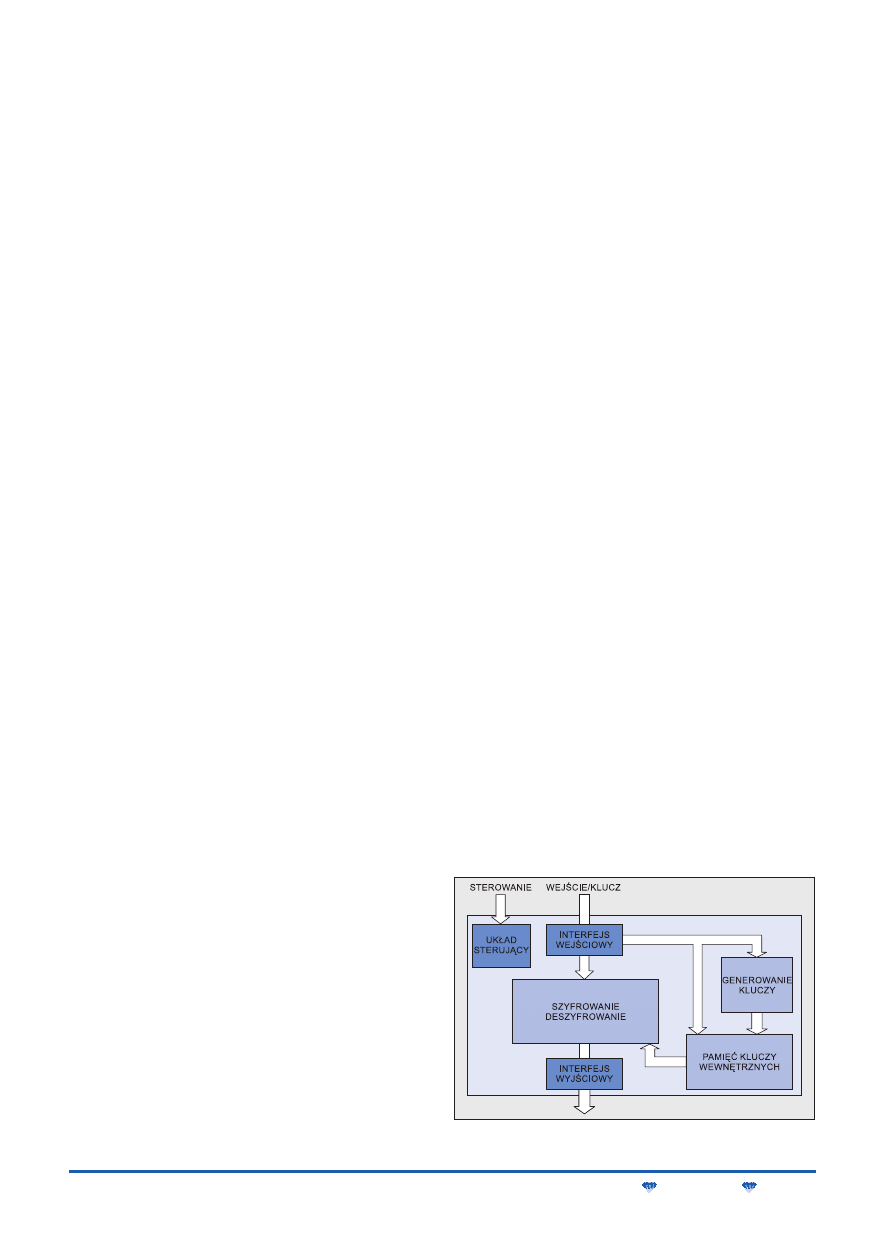
niczymi blokami takiego systemu są:
M
koprocesor kryptograficzny z pamięcią buforową,
M
układ sterujący,
M
biblioteka algorytmów.
Koprocesor kryptograficzny wykonuje wszelkie operacje zwią-
zane z szyfrowaniem i deszyfrowaniem danych. Po włączeniu zasi-
lania koprocesor rezydujący w strukturach FPGA nie jest jeszcze
zaprogramowany. Na sygnał wyboru algorytmu, wydany przez
użytkownika za pośrednictwem interfejsu, układ sterujący przepi-
suje do koprocesora z biblioteki algorytmów odpowiedni zbiór
konfiguracyjny. Po skonfigurowaniu koprocesor jest gotowy do
pracy. Transmisja danych szyfrowanych i deszyfrowanych pomię-
dzy systemem a komputerem odbywa się za pośrednictwem ma-
gistrali ISA. Tą samą drogą, z komputera do systemu, są przeka-
zywane nowe zbiory modyfikujące lub rozszerzające bibliotekę al-
gorytmów.
Naszkicowana wyżej koncepcja elastycznego systemu krypto-
graficznego została wykorzystana przez autorów przy opracowaniu
prototypu wieloalgorytmowego koprocesora kryptograficznego, któ-
ry zrealizowano w ramach prac badawczych w Instytucie Telekomu-
nikacji PW. Prototyp koprocesora został wykonany w formie karty do
komputerów klasy PC. Schemat blokowy karty koprocesora,
uwzględniający szczegółowo sygnały magistrali ISA, jest przedsta-
wiony na rys. 7. Karta wymaga wstępnej inicjalizacji kilku wewnętrz-
nych rejestrów, których zawartość ustawia się przez interfejs progra-
mowy w komputerze. Ich wartości definiują szczegółowo następują-
ce funkcje i parametry karty:
M
wybór algorytmu kryptograficznego – DES, X_DES_X,
DES3_EEE, DES3_EDE;
M
tryb pracy algorytmu – ECB, CBC, OFB_64, CFB_01, CFB_08,
CFB_16, CFB_64;
M
tryb współpracy z magistralą ISA – normal lub pipeline;
M
funkcje karty – szyfrowanie/deszyfrowanie, wpisywanie kluczy
i wektora stanu początkowego.
Przed rozpoczęciem cyklu szyfrowania/deszyfrowania są testo-
wane wybrane komórki rejestru stanów w celu ustalenia prawidłowo-
ści przeprowadzonej inicjalizacji. Aby zapobiec lub przynajmniej
utrudnić ataki hackerów, wprowadzono dodatkowe mechanizmy
ochronne zapewniające bezpieczeństwo kluczy i bloków danych za-
równo jawnych, jak i zaszyfrowanych. Zastosowane mechanizmy
wykrywają pewne odstępstwa od oczekiwanych prawidłowych se-
kwencji instrukcji inicjujących proces szyfrowania/deszyfrowania
i blokują reakcje koprocesora na sygnał startu GO lub niszczą za-
wartość rejestrów kluczy i rejestru stanu początkowego.
Algorytm DES został zaprojektowany według amerykańskiej nor-
my FIPS 46, zaś tryby pracy opracowano na podstawie normy FIPS
81. Algorytmy DES-EDE i DES-EEE, mimo iż nie są aktualnie ujęte
w normach, należą obecnie do najczęściej używanych szyfrów
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Rys. 6. Architektura elastycznego systemu kryptograficznego
O
O
Rys. 7. Schemat blokowy wieloalgorytmowego koprocesora kryp-
tograficznego
w protokołach bezpieczeństwa stosowanych w sektorze bankowym
na całym świecie. Tryby pracy, pozwalające dopasować właściwości
szyfru do wymagań otoczenia, są zgodne z międzynarodowymi nor-
mami ISO/IEC 8372 i ISO/IEC 10116.
Główna część projektu została wyspecyfikowana w języku
AHDL dla środowiska MAX+PLUS II firmy ALTERA, z przeznacze-
niem dla rodziny układów rekonfigurowalnych FLEX 10K. W proto-
typie wykorzystano układ FLEX 10K30. Eksperymenty symulacyjne
przeprowadzone z algorytmem DES, uwzględniające zastosowanie
w koprocesorze układu FLEX 10K50, wykazały, że maksymalna
częstotliwość zegara systemowego może wynosić około 70 MHz.
Odpowiada to maksymalnej szybkości przetwarzania rzędu 190
Mbit/s. Dla algorytmu potrójny DES osiągalna szybkość wynosi
około 66 Mbit/s.
NOWY STANDARD SZYFROWANIA:
ALGORYTMY – ANALIZA I WYBÓR
OPTYMALNYCH IMPLEMENTACJI
Przedstawione powyżej przykłady implementacji algorytmów
kryptograficznych były jedną z wielu prób poszukiwania optymal-
nych realizacji nowych algorytmów szyfrujących, które w XXI wieku
mogłyby zastąpić dotychczasowy światowy standard DES.
Wydarzeniem o przełomowym znaczeniu – kamieniem milowym
w dziedzinie ochrony systemów informacyjnych i bezpieczeństwa
w sieciach teleinformatycznych – stał się konkurs zorganizowany
przez amerykański NIST (National Institute of Standards and Tech-
nology). Wyłoniona w ostatniej rundzie konkursu grupa najlepszych
algorytmów kryptograficznych została poddana niezwykle gruntow-
nym badaniom teoretycznym i szczegółowej analizie ich walorów
praktycznych, zwłaszcza implementacji sprzętowych wybranej gru-
py szyfrów pod względem oceny ich wydajności i przydatności
w przyszłych systemach kryptograficznych. Analizowane implemen-
tacje szyfrów zostały zrealizowane w kilku ośrodkach akademickich
na podstawie tych samych założeń funkcjonalnych, wspólnej meto-
dologii i wspólnych narzędzi projektowania, tej samej technologii
i tych samych architektur układów rekonfigurowalnych. Za podsta-
wę oceny implementacji zgłoszonych na forum III Konferencji Kan-
dydatów AES (Advanced Encryption Standard) posłużyły przyjęte
i uzgodnione wcześniej miary parametrów związanych z szybkością
przetwarzania i złożonością realizacji.
Głównymi kryteriami przyjętymi przez NIST do oceny i kwalifika-
cji szyfrów w konkursie na nowy standard były: bezpieczeństwo,
efektywność w realizacjach sprzętowych i programowych oraz ela-
styczność. Spośród tych czterech parametrów efektywność realiza-
cji sprzętowej okazała się szczególnie ważnym czynnikiem, umożli-
wiającym zróżnicowanie konkurujących algorytmów, przy założeniu,
że:
M
porównanie było oparte na zbiorze obiektywnych i zgodnie ak-
ceptowanych miar,
M
istniały dostrzegalne różnice pomiędzy „kandydatami”,
M
ustalono wyraźną zgodność pomiędzy wynikami uzyskanymi
przez niezależne grupy.
W celu osiągnięcia większej jednolitości i czytelności porównań
wyników otrzymanych przez różne grupy, zaproponowano zgodną
terminologię, która może być użyta do opisu różnych architektur
i parametrów wydajności szyfrów blokowych.
Wybór technologii
Algorytmy kryptograficzne mogą być realizowane zarówno w for-
mie programu, jak i sprzętu. Implementacje programowe są projek-
towane i kodowane przy użyciu języków programowania, takich jak
C, C
++
, Java czy asembler, a następnie wykonywane w uniwersal-
nych mikroprocesorach, procesorach sygnałowych lub kartach inte-
ligentnych. Implementacje sprzętowe są projektowane i specyfiko-
wane za pomocą języków opisu sprzętu, takich jak VHDL i Verilog
HDL i realizowane z wykorzystaniem jednej z dwóch technologii:
specjalizowanych układów scalonych typu ASIC lub rekonfigurowal-
nych matryc logicznych FPGA.
Do porównania i oceny wymienionych technologii pod względem
ich przydatności do zastosowań kryptograficznych można posłużyć
się zestawieniem parametrów użytkowych, własności funkcjonal-
nych i charakterystyki procesu projektowania.
Do grupy parametrów użytkowych, które mają istotny wpływ na
efektywność przetwarzania danych, należą: możliwość przetwarza-
nia równoległego i potokowego, zmienna długość słowa i szybkość
działania. Do najważniejszych właściwości funkcjonalnych, decydu-
jących o elastyczności i bezpieczeństwie implementacji kryptogra-
ficznej, zalicza się: możliwość wymiany algorytmu w trakcie pracy
(algorithm agility), zabezpieczenie przed penetracją (tamper resi-
stance) i kontrolę dostępu do kluczy. Charakterystykę procesu pro-
jektowania określają między innymi: języki specyfikacji, długość
cyklu projektowania, koszty narzędzi do projektowania, koszty testo-
wania, utrzymania i modyfikacji. Z porównania parametrów użytko-
wych wynika, że układy ASIC i FPGA mają wyraźną przewagę nad
implementacją programową pod względem efektywności przetwa-
rzania. Istotna różnica pomiędzy technologią ASIC i FPGA dotyczy
szybkości działania układów FPGA, które są wolniejsze, co wynika
z opóźnień wprowadzanych przez elementy programowalnych połą-
czeń i proces rekonfiguracji. Pod względem funkcjonalnym następu-
je większe zróżnicowanie: największe bezpieczeństwo zapewnia
ASIC, natomiast wadą jest całkowity brak możliwości modyfikacji.
W przypadku układów ASIC i FPGA proces projektowania jest po-
dobny w sposobie specyfikacji (język opisu sprzętu), weryfikacji (sy-
mulator) i testowania (płyta prototypowa). Zasadnicza różnica po-
między nimi polega na tym, że układy FPGA nie wymagają projektu
warstwy fizycznej (layout), wytwarzania i testowania defektów fizycz-
nych. Konsekwencją tego są: znacznie krótszy cykl projektowania
i dużo tańsze narzędzia do projektowania i testowania. Z porównań
wynika, że implementacje oparte na FPGA mają przewagę nad tech-
nologią ASIC pod względem kosztów i długości cyklu opracowania
prototypu, możliwości wielokrotnego i szybkiego rekonfigurowania
i możliwości eksperymentalnego testowania dużej liczby różnych ar-
chitektur. Ponadto implementacje na układach FPGA zapewniają
znacznie wyższy stopień zgodności i wiarygodności porównań. Są
bowiem weryfikowane na podstawie dokładnych symulacji funkcjo-
nalno-czasowych gotowych struktur i eksperymentalnego testowa-
nia prototypu.
Założenia, porównywane parametry
i zasady projektowania
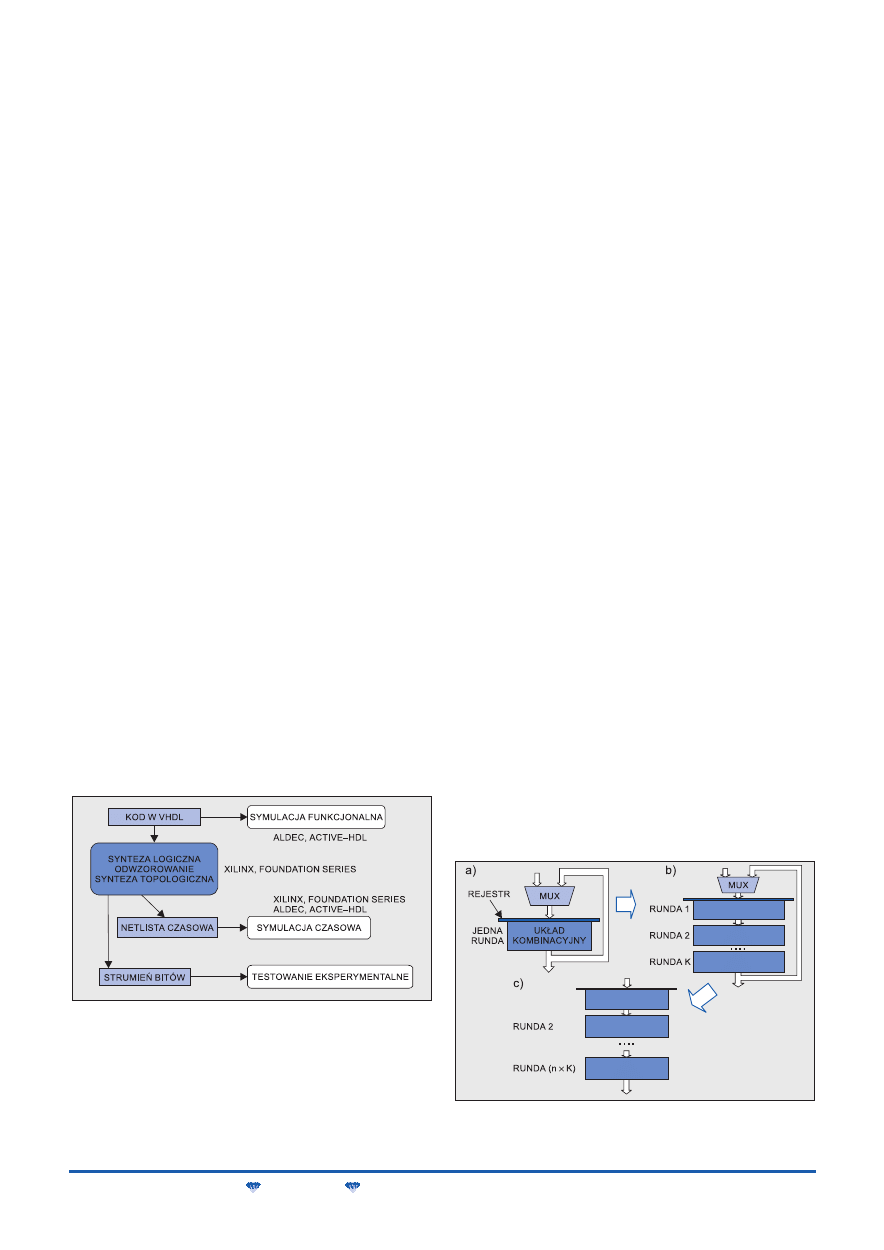
Ogólny model sprzętowej implementacji symetrycznych szyfrów
blokowych jest pokazany w formie schematu blokowego na rys. 8.
Według tego schematu zostały zrealizowane wszystkie szyfry
z ostatniej rundy konkursu AES. Schemat ten składa się z następu-
jących części:
M
modułu szyfrowania/deszyfrowania, w którym są kodowane i de-
kodowane bloki danych wejściowych,
M
bloku generacji kluczy pochodnych, w którym wyznacza się zbiór
kluczy wewnętrznych na podstawie jednego klucza zewnętrznego,
M
pamięci kluczy wewnętrznych, w której są przechowywane klu-
cze utworzone w bloku generacji kluczy lub dostarczone przez inter-
fejs wejściowy z zewnątrz,
414
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Rys. 8. Schemat blokowy realizacji sprzętowej szyfrów blokowych
415
M
interfejsu wejściowego, służącego do wprowadzania danych wej-
ściowych i kluczy oraz do buforowania danych wejściowych oczeku-
jących na kodowanie/dekodowanie,
M
interfejsu wyjściowego, używanego do buforowania danych prze-
tworzonych i przesyłania ich do zewnętrznej pamięci,
M
jednostki sterującej, w której są wytwarzane sygnały sterujące
pracą pozostałych bloków.
W celu ujednolicenia procedury projektowania implementacji
szyfrów, przyjęto wstępnie następujące założenia:
M
długość klucza 128 bitów, co upraszcza porównywanie i analizę
M
generowanie kluczy pochodnych na zewnątrz,
M
długość bloku danych 128 bitów,
M
dzielenie zasobów funkcjonalnych pomiędzy część szyfrującą
i deszyfrującą.
Poniżej przedstawiono definicje parametrów używanych do po-
równywania szyfrów z punktu widzenia efektywności ich implemen-
tacji sprzętowych.
Szybkość szyfrowania (deszyfrowania) jest określana jako licz-
ba bitów zaszyfrowanych (zdeszyfrowanych) w jednostce czasu.
Jednostką szybkości jest Mbit/s.
Czas opóźnienia szyfrowania (deszyfrowania) (latency) jest
zdefiniowany jako czas niezbędny do zaszyfrowania (zdeszyfrowa-
nia) jednego bloku danych jawnych lub zaszyfrowanych. Jeżeli
w aplikacji podczas jednej sesji są szyfrowane/deszyfrowane duże
porcje danych, to szybkość wyznacza całkowity czas wykonywania
tych operacji i jest najlepszą miarą szybkości szyfru.
Drugi ważny parametr to powierzchnia zajmowana przez układ,
gdyż jest głównym czynnikiem określającym jego koszt. Przyjmuje
się, że z grubsza koszt układu scalonego jest wprost proporcjonal-
ny do jego powierzchni. Dla ścisłości należy jednak uwzględnić
koszt obudowy, na który ma wpływ liczba wyprowadzeń. W pew-
nych aplikacjach mogą wystąpić ograniczenia maksymalnej dostęp-
nej powierzchni do realizacji modułu kryptograficznego, wynikające
z kosztów dostępnej technologii wytwarzania, zużywanej mocy lub
kombinacji tych czynników, np. w inteligentnych kartach z mikrokon-
trolerem.
W układach ASIC powierzchnia wymagana do implementacji jest
zwykle wyrażana w
µ
m
2
, choć są też używane dwie miary względne:
liczba tranzystorów i liczba bramek logicznych. Wartości tych trzech
miar są ze sobą ściśle skorelowane, ale relacje te trudno określić.
W implementacjach FPGA jedyną uznaną miarą wielkości układu
jest liczba komórek logicznych.
Struktura tworzenia projektu w środowisku CAD do implementa-
cji algorytmów w układach FPGA jest pokazana na rys. 9. Wszystkie
szyfry AES zostały w pierwszym kroku opisane w języku VHDL, a na-
Tryby pracy
Symetryczne szyfry blokowe są używane w kilku trybach opera-
cyjnych, które z punktu widzenia implementacji sprzętowej można
podzielić na dwie kategorie:
M
tryby bez sprzężenia zwrotnego, takie jak tryb elektronicznej
książki kodowej (ECB) i tryb licznikowy,
M
tryby ze sprzężeniem zwrotnym, jak tryb wiązania bloków zaszy-
frowanych (CBC), tryb sprzężenia zwrotnego szyfrogramu (CFB)
i tryb sprzężenia zwrotnego wyjściowego (OFB).
W trybach bez sprzężenia zwrotnego szyfrowanie każdego kolej-
nego bloku danych może być wykonane niezależnie od przetwarza-
nia innych bloków. W trybach ze sprzężeniem zwrotnym nie jest
możliwe rozpoczęcie szyfrowania następnego bloku danych przed
zakończeniem kodowania bloku bieżącego i wszystkie bloki muszą
być szyfrowane sekwencyjnie. To ograniczenie nie dotyczy operacji
deszyfrowania, która może być wykonywana równolegle na kilku
blokach szyfrogramu we wszystkich trybach. Zgodnie z obecnymi
standardami bezpieczeństwa, szyfrowanie jest wykonywane przede
wszystkim z użyciem trybów sprzężenia zwrotnego, jak CBC i CFB,
zaś tryby bez sprzężenia zwrotnego są głównie stosowane do szy-
frowania kluczy podczas ich dystrybucji. Te wymagania bezpieczeń-
stwa uniemożliwiają wykorzystanie w pełni efektywności implemen-
tacji sprzętowych opartych na równoległym przetwarzaniu wielu blo-
ków danych.
Podstawowe architektury
Wybierając architekturę dla implementacji szyfrów w strukturach
FPGA, wystarczy ograniczyć się do dwóch typów: bazowej architek-
tury iteracyjnej i architektury z rozwiniętą (częściowo lub w pełni) pę-
tlą. Podstawową architekturę sprzętową stosowaną do implementa-
cji jednostki szyfrującej/deszyfrującej typowego szyfru blokowego
z tajnym kluczem pokazano na rys. 10a. Jedną rundę szyfru zreali-
zowano jako układ kombinacyjny, uzupełniony rejestrem i multiplek-
serem. W pierwszym cyklu zegara wejściowy blok danych jest poda-
wany przez multiplekser i zapisywany w rejestrze. W każdym kolej-
nym cyklu zegara jest realizowana operacja jednej rundy
szyfrowania, a jej rezultat podawany zwrotnie do układu przez mul-
tiplekser i zapisywany następnie w rejestrze. Architektura bazowa
ma dwie cechy charakterystyczne:
M
w tym samym czasie jest kodowany tylko jeden blok danych,
M
liczba cykli zegara, koniecznych do zaszyfrowania jednego bloku
danych, jest równa liczbie rund szyfru.
Architektura z częściowo rozwiniętą pętlą jest przedstawiona na
rys. 10b. Jedyna różnica w porównaniu z bazową architekturą itera-
cyjną polega na tym, że część kombinacyjna układu realizuje K rund
szyfrowania zamiast jednej. Liczba K musi być podzielnikiem całko-
witej liczby rund. Liczba cykli zegara koniecznych do zaszyfrowania
jednego bloku danych jest K-krotnie mniejsza od liczby rund. Mini-
malny okres zegara wzrasta ze współczynnikiem nieco mniejszym
niż K.
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Rys. 9. Środowisko projektowe CAD
stępnie zweryfikowane przy użyciu symulatora Active-HDL z firmy
ALDEC. Do korekcji błędów i weryfikacji kodów źródłowych wyko-
rzystano wektory testowe i pośrednie wyniki przetwarzania z opubli-
kowanych wcześniej implementacji programowych. Przedstawione
raporty zawierają powierzchnię, szybkość i inne dane o implementa-
cji oraz zbiory danych do symulacji czasowej i do skonfigurowania
układu.
O
O
Rys. 10. Podstawowe architektury szyfrów w trybach ze sprzęże-
niem zwrotnym: a) bazowa architektura iteracyjna, b) z częściowo
rozwiniętą pętlą, c) z pętlą w pełni rozwiniętą
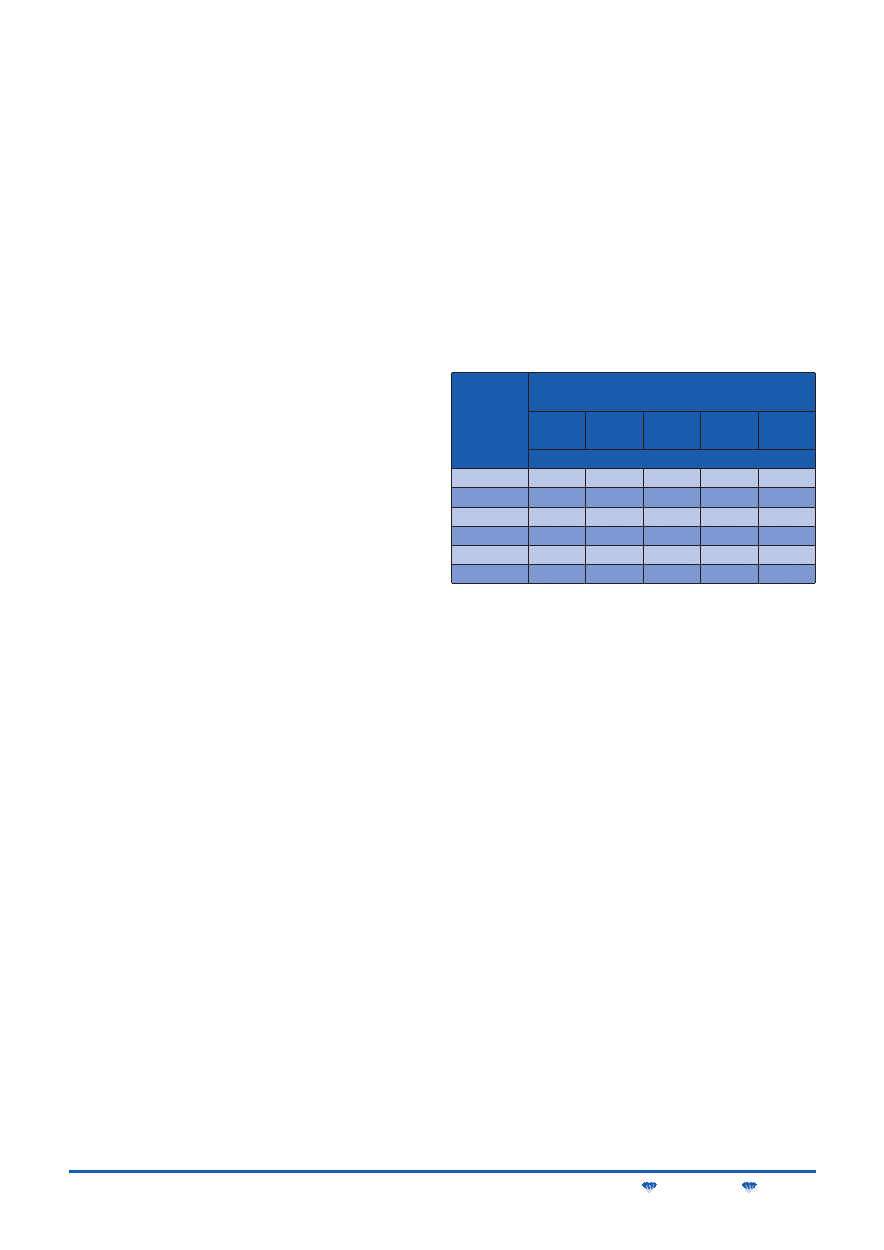
Architektura z rozwiniętą w pełni pętlą jest pokazana na rys. 10c.
Schemat ten nie zawiera wejściowego multipleksera ani linii sprzę-
żenia zwrotnego. Dzięki temu jest możliwy niewielki wzrost szybko-
ści i zmniejszenie powierzchni układu w porównaniu z architekturą
o częściowo rozwiniętej pętli zawierającej taką samą liczbę rund.
Z przeglądu architektur wynika, że do implementacji szyfrów AES
w układach FPGA optymalny wybór stanowi bazowa architektura ite-
racyjna. Zapewnia ona maksymalny współczynnik szybkość/po-
wierzchnia dla trybów operacyjnych ze sprzężeniem zwrotnym
(CBC, CFB), używanych powszechnie do szyfrowania masowych
danych i gwarantuje szybkości i powierzchnie bliskie optymalnym.
Wydaje się bardzo prawdopodobne, że architektura ta będzie po-
wszechnie stosowana w większości aplikacji. Jest także względnie
łatwa do implementacji w podobny sposób dla wszystkich szyfrów
AES, dzięki czemu umożliwi bardziej miarodajne porównanie.
PRODUKTY WIRTUALNE
– NOWA OFERTA
NA RYNKU TELEKOMUNIKACJI
Wraz z wprowadzeniem struktur reprogramowalnych pojawiły się
jeszcze inne możliwości aplikacyjne. Wynikają one nie tylko z popra-
wy parametrów funkcjonalnych i czasowych oraz zmian w architek-
turze logicznej, ale również z samej istoty reprogramowalności. Je-
den z kierunków takich aplikacji określa koncepcja produktu wirtual-
nego – systemu, funkcji lub układu scalonego, które nie istnieją
w rzeczywistości materialnej, ale potencjalnie mogą być w każdej
chwili zrealizowane. Takie układy wirtualne to zarówno gotowe pro-
dukty o zmiennych funkcjach i właściwościach, jak również elastycz-
ne „klocki”, z których można konstruować większe systemy.
Powstał ogromny rynek wirtualnych produktów specjalizowa-
nych, tzw. rynek własności intelektualnej IP (Intellectual Property Bu-
siness) zawartej w układach zaprojektowanych w postaci kodów
źródłowych języków HDL. Działalnością taką zajmują się m.in. firmy:
ALTERA, XILINX INC., TILAB, CAST INC., inSILICON CORPORA-
TION, DIGITAL COMMUNICATION TECHNOLOGIES, IP SEMICON-
DUCTORS, a w Polsce DIGITAL CORE DESIGN. Typową ofertą tych
firm są właśnie układy DSP, a w szczególności: kodery FFT i DCT,
układy kryptograficzne, komutatory i rutery ATM, dekodery Viterbie-
go dla sieci LAN, skramblery i deskramblery itp.
Rynek produktów wirtualnych to jednocześnie ogromne wyzwa-
nie dla zaawansowanych metod optymalizacji logicznej. Wynika to
z faktu, że konkurencję na tym rynku będą wygrywać tylko najlepsze
produkty. Do ich realizacji zostaną wykorzystane zaawansowane
metody syntezy, niejednokrotnie występujące wyłącznie w specjali-
stycznym oprogramowaniu uniwersyteckim. Duża złożoność struk-
tur FPGA, a także ich nietypowe konstrukcje (komórki), spowodowa-
ły wzrost roli i znaczenia zaawansowanych procedur syntezy logicz-
nej.
Wpływ zaawansowanych procedur syntezy logicznej na jakość
implementacji sprzętowych układów przetwarzania informacji i sy-
gnałów jest szczególnie znaczący w algorytmach wykorzystujących
struktury tablicowe typu LUT. Struktury takie są powszechnie stoso-
wane w filtrach cyfrowych, układach transformacji falkowej [31],
w szczególności do realizacji wykorzystujących arytmetykę rozpro-
szoną [26], a także w algorytmach kryptograficznych, korzystają-
cych z tzw. bloków permutacyjno-podstawieniowych.
W Zakładzie Podstaw Telekomunikacji IT-PW opracowano
specjalistyczne oprogramowanie do optymalizacji implementacji
sprzętowych struktur typu LUT. Oprogramowanie to – nazwane
DEMAIN [21], [22], [27] – jest dostępne nieodpłatnie na
stronie internetowej Zakładu Podstaw Telekomunikacji IT-PW:
http://www.zpt.tele.pw.edu.pl. W systemie DEMAIN, jako główną
procedurę syntezy logicznej zorientowanej na struktury FPGA,
wykorzystuje się tzw. algorytm dekompozycji zrównoważonej. Sku-
teczność tego oprogramowania można ocenić na podstawie eks-
perymentów przeprowadzonych z realizacjami układów cyfrowych
wyposażonych w struktury specyfikowane tablicami LUT.
Eksperymenty te polegały na implementacji typowych układów
cyfrowych – głównie z dziedziny teleinformatyki – za pomocą róż-
nych systemów projektowania, a następnie na porównaniu ich reali-
zacji pod względem liczby użytych komórek odpowiedniej struktury
FPGA. Wymowa przeprowadzonych eksperymentów jest znacząca,
bowiem do projektowania użyto systemów renomowanych firm
światowych, takich jak Altera, Synopsys, Exemplar i Xilinx.
W szczególności zrealizowano i porównano następujące układy:
M
bin2bcd1 – konwerter kodu binarnego na BCD dla liczb z zakre-
su od 0 do 99,
M
bin2bcd2 – konwerter kodu binarnego na BCD dla liczb z zakre-
su od 0 do 355,
M
DESboxes – zespół skrzynek podstawieniowych szyfru DES,
M
rd88 – sbox z algorytmu kryptograficznego Rijndael,
M
DESaut – kombinacyjną część układu sekwencyjnego z imple-
mentacji algorytmu kryptograficznego DES,
M
5B6B – kombinacyjną część układu kodera 5B-6B.
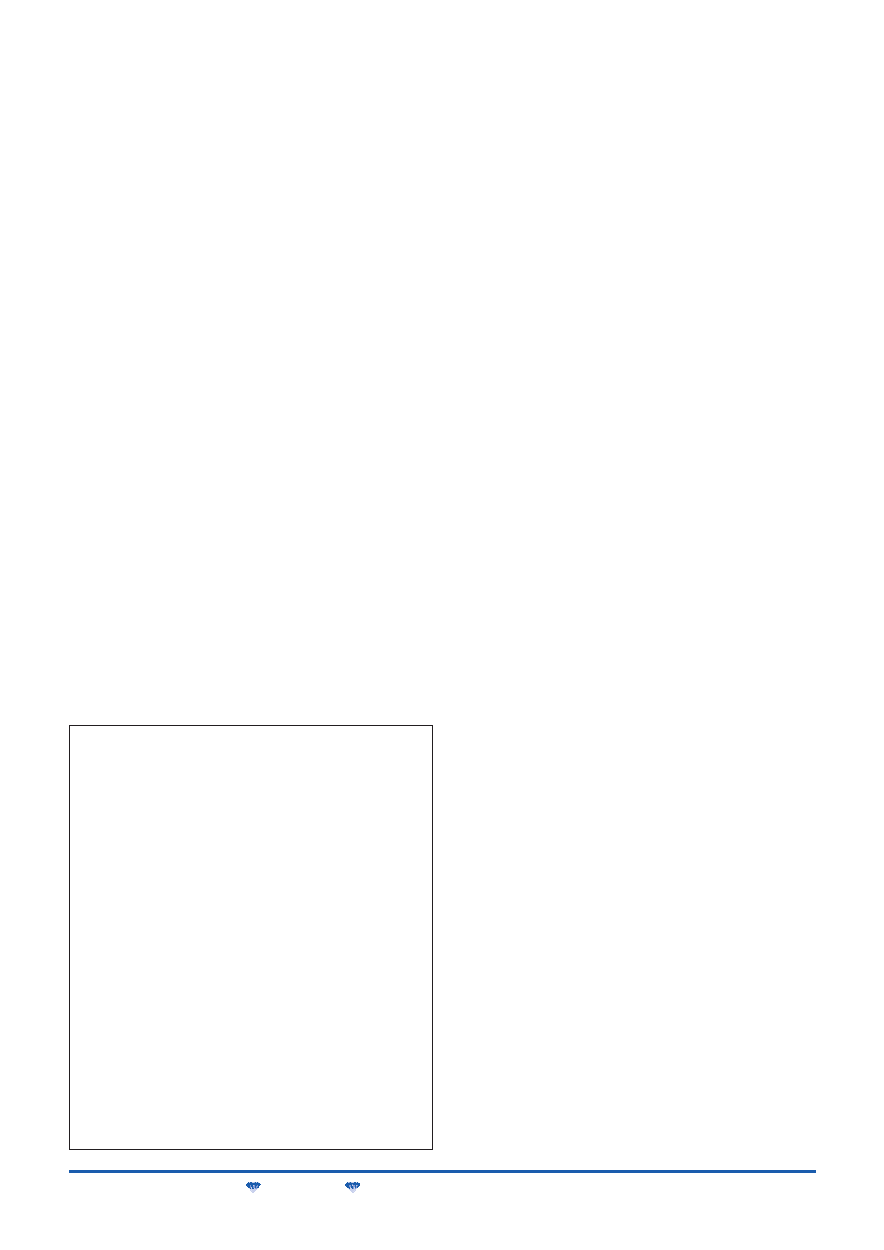
W tabeli 1 przedstawiono wyniki porównania metody wykorzystu-
jącej dekompozycję zrównoważoną, zaimplementowaną w systemie
DEMAIN, z metodami zaimplementowanymi w systemach: SIS,
FPGA Express, Leonardo Spectrum i MAX+PlusII. Przykładowe
układy zostały zaimplementowane w strukturach FPGA z rodziny
416
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
O
O
Tabela 1. Wyniki implementacji rzeczywistych układów przy użyciu
różnych narzędzi syntezy logicznej
Przykład
Architektura FPGA
EPF10K10LC84-3
DEMAIN
MAX
+Plus II
FPGA
Express
Leonardo
Spectrum
SIS
liczba komórek logicznych
bin2bcd1
13
131
30
30
–
bin2bcd2
39
505
225
120
136
DESboxes
184
585
486
192
–
rd88
167
332
341
245
248
DESaut
28
46
25
30
32
5B6B
41
92
100
49
51
FLEX. W tabeli podano liczbę komórek logicznych wymaganych do
implementacji poszczególnych układów. Z podanych rezultatów wy-
nika, że realizacja za pomocą metody wykorzystującej dekompozy-
cję zrównoważoną jest najoszczędniejsza pod względem liczby za-
jętych komórek i wygrywa nawet z realizacją osiągniętą za pomocą
uniwersyteckiego systemu SIS [35], opracowanego na Uniwersyte-
cie Kalifornijskim w Berkeley.
W szczególności warto zwrócić uwagę na implementację kon-
wertera kodu binarnego na kod BCD (wersja 1) oraz na implemen-
tacje skrzynek podstawieniowych (s-box) szyfrów DES i Rijndael.
Jak widać, wspomaganie procesu projektowania zaawansowanymi
procedurami syntezy logicznej prowadzi do rezultatów niemożli-
wych do uzyskania nawet za pomocą najlepszych systemów komer-
cyjnych. Trzeba również podkreślić, że na jakość powyższych imple-
mentacji w systemach komercyjnych nie mają wpływu nawet najlep-
sze kompilatory języków HDL. Konwerter BIN2BCD1 jest typowym
przykładem takiej sytuacji. Otóż konwerter ten można zaprojekto-
wać bądź to w strukturze zbudowanej z bloków funkcjonalnych we-
dług tzw. algorytmu +3
1)
, bądź też jako układ kombinacyjny realizu-
jący bezpośrednio tablicę LUT konwertera. W obu przypadkach
strukturę konwertera można zapisać w językach opisu sprzętu, np.
AHDL lub VHDL. Opisując realizację według algorytmu +3 w języku
VHDL i dokonując odpowiedniej kompilacji w systemie MAX+PLUS
II amerykańskiej firmy Altera, uzyskuje się realizację układu
BIN2BCD1 na 62 komórkach struktury FLEX 10K [23]. Ten sam
układ opisany tablicą prawdy (w specyfikacji VHDL instrukcjami
CASE) i skompilowany w tym samym systemie Altery zajmuje 131
komórek FLEX. Ale wprowadzając tablicę prawdy układu
BIN2BCD1 do systemu DEMAIN i dokonując odpowiedniej de-
kompozycji, uzyskuje się realizację tego samego konwertera na
zaledwie 13 komórkach struktury FLEX – czyli 10 razy lepiej.
Nie mniej intrygujące są wyniki implementacji skrzynek S-box
algorytmów kryptograficznych DES i Rijndael.
Istotne jest, że wykorzystanie tak zrealizowanych bloków permu-
tacyjnych do budowy modułu rundy DES, a następnie modułu ścież-
–––––––-–
1)
Dokładny opis takiej realizacji można znaleźć w książce [21]
417
ki przepływu danych nie wymaga żadnych dalszych zmian w innych
plikach składowych projektu. Implementacje ścieżki przepływu da-
nych w strukturze rodziny FLEX10K program DEMAIN redukuje do
296 komórek logicznych. W porównaniu do 709 komórek niezbęd-
nych do realizacji tego bloku bez zastosowania programu DEMAIN
stanowi to ponad dwukrotną redukcję wymaganych zasobów. Opty-
malizacja z użyciem systemu DEMAIN poprawia także maksymalna
częstotliwość taktowania modułu DES. Wzrosła ona o ponad 51,5
MHz. Ponieważ do zaszyfrowania jednego bloku danych tekstu jaw-
nego potrzeba 16 cykli, szacunkowa szybkość szyfrowania P tego
modułu wynosi:
P = 51,5 MHz/16
×
64 bity = 206 Mbit/s.
Oznacza to prawie dwukrotny wzrost szybkości szyfrowania blo-
ku ścieżki przepływu danych.
Podobnie jak w przypadku bloku rundy zrealizowanego bez wy-
korzystania dekompozycji, rzeczywista szybkość układu realizujące-
go cały algorytm DES będzie zależała od sposobu realizacji pozo-
stałych modułów tego algorytmu, a więc modułu sterowania i modu-
łu generacji podkluczy.
Tak zoptymalizowany blok rundy umożliwia realizację całej ścież-
ki rozpływu danych w sposób potokowy. Specyfikację takiej realiza-
cji w języku AHDL podano w tabeli 2. Wykorzystano tu zmodyfiko-
wany blok rundy (desroundp). Modyfikacja polega na dodaniu na
wyjściu modułu odpowiedniego rejestru. Umieszczenie 16 bloków
tak zmodyfikowanych bloków rundy w łańcuchu zapewnia znacznie
efektywniejszą pracę układu, gdyż dane mogą być szyfrowane po-
tokowo. Układ wymaga 4346 komórek logicznych i może pracować
z szybkością P = 86,9 MHz
×
64 bity
≅
5 Gbit/s.
O dużej skuteczności systemu DEMAIN świadczy również reali-
zacja szyfru HIEROCRYPT, wykonana w ramach pracy magisterskiej
na Wydziale Cybernetyki WAT [34]. Efektem jego zastosowania by-
ła redukcja zasobów sprzętowych z ok. 22 tys. komórek logicznych
do 10 tys., a także 5-krotne przyśpieszenie działania układu. Praca
ta zdobyła I nagrodę w konkursie na najlepszą pracę magisterską,
zorganizowanym w ramach konferencji ENIGMA.
Przeprowadzone eksperymenty w pełni potwierdzają tezę, że ko-
mercyjne systemy projektowania układów cyfrowych niejednokrot-
nie realizują projekty dalekie od rozwiązań optymalnych pod wzglę-
dem zajętości zasobów sprzętowych. Sytuacja ta jest szczególnie
niepokojąca dla najnowszych układów reprogramowalnych typu
FPGA i FLEX. Przyczyna tego zjawiska tkwi w niedostosowaniu pro-
cedur syntezy logicznej, które w systemach komercyjnych są z re-
guły realizowane według klasycznych metod minimalizacji funkcji
boolowskich i nie uwzględniają metod dekompozycji funkcjonalnej
[22]. Zatem stosowanie zaawansowanych systemów uniwersytec-
kich niejednokrotnie może się przyczynić do sukcesu rynkowego,
w szczególności specyficznej techniki układów FPLD.
✽ ✽ ✽
Omówione w artykule zastosowania układów reprogramowal-
nych w cyfrowym przetwarzaniu sygnałów i kryptografii, dzięki moż-
liwości zmiany konfiguracji w trakcie pracy i elastycznemu wykorzy-
stywaniu zasobów sprzętowych, zapewniają ich wykorzystanie do
realizacji złożonych algorytmów obliczeniowych. W połączeniu
z możliwościami wspierania procesów optymalizacji komercyjnych
systemów zaawansowanymi systemami syntezy i optymalizacji lo-
gicznej stwarza to szansę dla rozwoju rodzimych opracowań urzą-
dzeń telekomunikacyjnych. Jest ona szczególnie widoczna w syste-
mach multimedialnych i kryptograficznych, dla których istotniejsze
są parametry techniczne, wynikające z istoty reprogramowania, niż
jednostkowy koszt produkcji.
LITERATURA
[1] Arnold J. M.: The Splash 2 software environment. In D. A. Buell and
K. L. Pocek, editors, Proceedings of IEEE Workshop on FPGAs for
Custom Computing Machines, Napa, CA, April, 1993
[2] Arnold M., Buell D. A. and Davis E. G.: VHDL programming on
Splash 2. In More FPGAs: Proceedings of the 1993 International
Workshop on Field-Programmable Logic and Applications, Oxford,
England, September 1993
[3] Arnold, D. A. Buell, and E. G: Davis. Splash 2. In Proceedings of the
4th Annual ACM Symposium on Parallel Algorithms and Architectu-
res, June 1992
[4] Bertin P. and Touati H.: PAM programming environments: Practice
and experience. In D. A. Buell and K. L. Pocek, editors, Proceedings
of IEEE Workshop on FPGAs for Custom Computing Machines, Na-
pa, CA, April 1994
[5] Connor T., Deng S., Marchant S.: Cryptographic Coprocesor with
Algorithm Agility, Worcester Polytechnic Institute, Worcester, March
1999
[6] Elbirt A. J., Yip W., Chetwynd B., Paar C.: An FPGA implementation
and performance evaluation of the AES block cipher candidate algo-
rithm finalists, Proc. 3
rd
Advanced Encryption Standard (AES) Can-
didate Conference, New York, April 13-14, 2000
[7] Gaj K., Chodowiec P.: Comparison of the hardware performance of
the AES candidates using reconfigurable hardware, Proc. 3
rd
Advan-
ced Encryption Standard (AES) Candidate Conference, New York,
April 13-14, 2000
[8] Gokhale M., Holmes W., Kopser A., Lucas S., Minnich R., Swelly D.,
and Lopresti D.: Building and using a highly parallel programmable
logic array. IEEE Computer, 24 (1), January 1991
[9] Gokhale M., Kopser A., Lucas S. and Minnich R.: The logic descrip-
tion generator. Technical Report SRC-TR-90-011, Suprtcomputer
Research Center (SRC), 1990
[10] Gokhale M. and Schott B.: Data Parallel C on a reconfigurable logic
array. Journal of Supercomputing, 9 (3), 1994
[11] Guccione S. A., Delon L., Downs D.: A reconfigurable content ad-
dressable memory, Parallel and Distributed Processing. Springer-
Verlag, Berlin, May 2000
[12] http://www.altera.com
[13] http://www.atmel.com
[14] http://www.windriver.com
[15] http://pw1.netcom.com
[16] http://www.tsi-telsys.com
[17] http://www.xilinx.com
[18] IEEE Computer Society, Proceedings of IEEE Workshop on FPGAs
for Custom Computing Machines, 1993-1996
[19] Jachna Z.: Analiza metod specyfikacji układów cyfrowych z punktu
widzenia optymalizacji logicznej i odwzorowania technologicznego.
Rozprawa doktorska, WAT, Warszawa 2002
[20] Jasiński K., Zbysiński P.: Rekonfigurowalny koprocesor systemowy:
uniwersalna platforma obliczeniowa, Przegląd Telekomunikacyjny
i Wiadomości Telekomunikacyjne, nr 10, 2000
[21] Łuba T., Zbierzchowski B.: Komputerowe projektowanie układów cy-
frowych. Wydawnictwa Komunikacji i Łączności, Warszawa 2000
[22] Łuba T.: Synteza układów logicznych, Wyższa Szkoła Informatyki
Stosowanej i Zarządzania, wyd. 2, poprawione i rozszerzone, War-
szawa 2001
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
OPTIONS BIT0 = MSB;
INCLUDE "iniperm";
INCLUDE "desroundp";
INCLUDE "invperm";
SUBDESIGN datapathp(
clk :
INPUT;
plaintext[1..64]
: INPUT;
subkey[1..16][1..48]
: INPUT;
encrypteddata[1..64]
: OUTPUT;
)
VARIABLE
ip
: iniperm;
round[1..16]
: desroundp;
invp
: invperm;
BEGIN
round[].clk = clk;
ip.IN[] = plaintext[];
round[1].R[] = ip.OUT[33..64];
round[1].L[] = ip.OUT[1..32];
round[1].K[] = subkey[1][];
FOR i IN 1 TO 15 GENERATE
round[i+1].R[] = round[i].NEXTR[];
round[i+1].L[] = round[i].NEXTL[];
round[i+1].K[] = subkey[i+1][];
END GENERATE;
invp.IN[] = (round[16].NEXTR[],round[16].NEXTL[]);
encrypteddata[] = invp.OUT[];
END;
O
O
Tabela 2. Specyfikacja rozpływu danych w języku AHDL

[23] Łuba T., Zbierzchowski B., Zbysiński P.: Układy reprogramowalne dla
potrzeb telekomunikacji cyfrowej. Przegląd Telekomunikacyjny
i Wiadomości Telekomunikacyjne, nr 5, 2002
[24] Łuba T. (red.), Rawski M., Tomaszewicz P., Zbierzchowski B.: Synte-
za układów cyfrowych. WKŁ Warszawa (przewidywany termin wyda-
nia – listopad 2003)
[25] Mosanya E. et al.: CryptoBooster: A Reconfigurable and Modular
Cryptographic Coprocesor, Proceedings of the Workshop on Cryp-
tographic Hardware and Embedded Systems, Worcester August
1999
[26] Meyer-Baese U.: Digital Signal Processing with Field Programmable
Gate Arrays, Springer Verlag, Berlin 2001
[27] National Security Agency, Initial plans for estimating the hardware
performance of AES submissions http://csrc.nist.gov/encryption/
aes/round2/round2.htm
[28] Nowicka M., Rawski M., Łuba T.: DEMAIN – an Interactive Tool for
FPGA-Based Logic Decomposition, Proceedings of the 6
th
Interna-
tional Conference Mixed Design of Integrated Circuits and Systems,
Kraków 1999
[29] IFAC Workshop on Programmable Devices and Systems (E. Hrynkie-
wicz – chairman), PDS2001, materiały konferencyjne, Gliwice 2001
[30] Pasierbiński J., Zbysiński P.: Układy programowalne w praktyce,
WKŁ, Warszawa 2001
[31] Rakowski W.: O implementacjach sprzętowych transformacji falko-
wej. Przegląd Telekomunikacyjny i Wiadomości Telekomunikacyjne,
nr 2–3, 2003
[32] Rawski M., Jóźwiak L., Łuba T.: Functional decomposition with an ef-
ficient input support selection for sub-functions based on information
relationship measures. Journal of Systems Architecture, 47, Elsevier
Science B. V., 2001
[33] Reprogramowalne układy cyfrowe (J. Sołdek – przewodniczący Ko-
mitetu Programowego), materiały IV Konferencji Naukowej, Szcze-
cin 2001
[34] Rogowski M.: Implementacja algorytmu HIEROCRYPT w strukturach
programowalnych. Praca magisterska, WAT, 2003
[35] Sentovich E., et al.: SIS: A system for Sequential Circuits Synt-
hesis. Electronics Research Laboratory Memorandum, No.
VCB/ERLM92/41, University of California, Berkeley, 1992
[36] Tessier R., Burlesson W.: Reconfigurable Computing for Digital
Signal Processing: A Survej. Journal of VLSI Signal Processing, 28,
2001
[37] Taylor R., Goldstein S.: A High-Perfomance Flexible Architecture for
Cryptography, Proceedings of the Workshop on Cryptographic Har-
dware and Embedded Systems, Worcester August 1999
[38] Vuillemin Bertin P., Roncin D., Shand M., Touati H., and Boucard P.:
Programmable active memories: Reconfigurable systems come of
age. IEEE Transactions on VLSI Systems, 4 (1), 1996
[39] Wiatr K.: Sprzętowe implementacje algorytmów przetwarzania obra-
zów w systemach wizyjnych czasu rzeczywistego. AGH, Kraków
2002
[40] Zbysiński P.: Rekonfigurowalne układy FPSLIC firmy Atmel, Elektroni-
zacja nr 7–8’2000
418
PRZEGLĄD TELEKOMUNIKACYJNY
ROCZNIK LXXVI
nr 8–9/2003
Wyszukiwarka
Podobne podstrony:
Abolicja podatkowa id 50334 Nieznany (2)
4 LIDER MENEDZER id 37733 Nieznany (2)
katechezy MB id 233498 Nieznany
metro sciaga id 296943 Nieznany
perf id 354744 Nieznany
interbase id 92028 Nieznany
Mbaku id 289860 Nieznany
Probiotyki antybiotyki id 66316 Nieznany
miedziowanie cz 2 id 113259 Nieznany
LTC1729 id 273494 Nieznany
D11B7AOver0400 id 130434 Nieznany
analiza ryzyka bio id 61320 Nieznany
pedagogika ogolna id 353595 Nieznany
Misc3 id 302777 Nieznany
cw med 5 id 122239 Nieznany
D20031152Lj id 130579 Nieznany
mechanika 3 id 290735 Nieznany
więcej podobnych podstron