1
MSI-w5/1
Metody sztucznej inteligencji
Politechnika Śląska
Katedra Podstaw Konstrukcji Maszyn
Rok akademicki 2003/2004
Wykład 6
Materiały dydaktyczne (na prawach rękopisu)
dla studentów Wydziału Mechanicznego Technologicznego
Wszystkie ilustracje pochodzą z S. Russel, P. Norvig, Artificial
Intelligence - A modern approach, Prentice Hall, 1995
MSI-w5/2
Uczenie (się) ze wzmocnieniem
(RL=Reinforcement learning)
MSI-w5/3
Uczenie indukcyjne
(na przykładach)
• Uczenie indukcyjne:
– Środowisko dostarcza przykładów - pary
(wejście-wyjście)
– Zadanie polega na nauczeniu się funkcji, która
mogłaby być uogólnieniem tych przykładów
• Można uczyć się na przykładach, gdy:
– Nauczyciel dostarcza poprawnych wartości
– Lub predykcje uzyskiwane poprzez
zastosowanie funkcji mogą być zweryfikowane
w następnym kroku działania agenta
MSI-w5/4
Przykład: gra w szachy (1)
• Uczenie indukcyjne jest niekorzystne:
– Przykłady dostarczane przez nauczyciela:
(sytuacja na szachownicy; najlepszy ruch dla tej sytuacji)
– Ile może być takich przykładów?
• Gdy brak nauczyciela, agent może
losowo
wybierać
posunięcia i budować model predykcyjny: jak
będzie wyglądać szachownica po wykonaniu jego
ruchu i w jaki sposób partner
prawdopodobnie
odpowie na ten ruch
Gdy agent nie wie, który ruch jest dobry, a który zły,
trudno mu zdecydować, który ruch wybrać
MSI-w5/5
Przykład: gra w szachy (2)
• W grze w szachy istnieje sprzężenie
zwrotne:
– Gdy jest nauczyciel, może ocenić ruch
– Gdy go nie ma, na końcu partii wiadomo, czy
agent wygrał, czy nie
• Takie sprzężenie nazywa się
nagrodą
lub
wzmocnieniem
• W szachach nazywane jest
stanem
terminalnym
w sekwencji historii stanów
MSI-w5/6
Uczenie ze wzmocnieniem (RL)
• Istota:
wykorzystanie nagród w celu wyuczenia przez
agenta skutecznego działania
• Trudność:
agent nie wie
:
– jaka akcja jest właściwa
– jaka nagroda jest przypisana do której akcji
• Nagroda jest
specjalnym rodzajem percepcji
• W wielu złożonych dziedzinach jest jedynym
wykonalnym sposobem wyuczenia agenta działań
o wysokim poziomie

2
MSI-w5/7
RL: Sformułowanie problemu
• Agent działający w swoim środowisku
odbiera percepcje
(wrażenia)
• Niektóre percepcje
są odwzorowywane na
ujemne
lub
dodatnie użyteczności
• Następnie agent
decyduje
,
które działanie
podjąć
MSI-w5/8
Podstawy RL: jak mogą zmieniać
się zadania uczenia (1)
• Środowisko:
– dostępne
- agent identyfikuje stany poprzez
percepcje
– niedostępne
- agent utrzymuje pewien stan
wewnętrzny próbując monitorować środowisko
• Agent
posiada wiedzę o środowisku
i wynikach jego działań
LUB
agent
musi wyuczyć się tego modelu wraz
z informacją o użyteczności
MSI-w5/9
Podstawy RL: jak mogą zmieniać
się zadania uczenia (2)
• Nagrody mogą być otrzymywane:
– tylko w stanie terminalnym
(końcowym)
– w każdym stanie
• Nagrody mogą być
– składnikami bieżącej wartości użyteczności
,
którą agent stara się maksymalizować
– wskazówkami co do bieżącej użyteczności
MSI-w5/10
Podstawy RL: jak mogą zmieniać
się zadania uczenia (3)
• Agent może działać jako uczeń :
– Pasywny
, biernie obserwujący świat „dziejący
się obok” i próbujący nauczyć się użyteczności
„bycia w różnych stanach”
– Aktywny
, który musi ponadto działać stosując
wyuczoną informację, oraz może stosować
swój własny generator problemów który
sugeruje specjalne działania poznawcze
(eksploracja nieznanych części otoczenia)
MSI-w5/11
Podstawowe warianty RL-agenta
• Agent uczy się funkcji użyteczności na
podstawie stanów (lub historii stanów), a
następnie używa jej do wyboru akcji które
maksymalizują oczekiwaną użyteczność ich
wyników
• Agent uczy się funkcji akcja-wartość, która
daje oczekiwaną użyteczność podjęcia
danej akcji w danym stanie (Q-learning)
MSI-w5/12
Uczenie pasywne w znanym
środowisku
• Pasywny RL-agent w znanym, dostępnym
środowisku (reprezentacja za pomocą
stanów)
• Środowisko generuje przejścia stanów,
a agent stara się nauczyć użyteczności tych
stanów
• Założenie: agentowi dostarczono model M
i,j
podający prawdopodobieństwo przejścia ze
stanu i do stanu j
3
MSI-w5/13
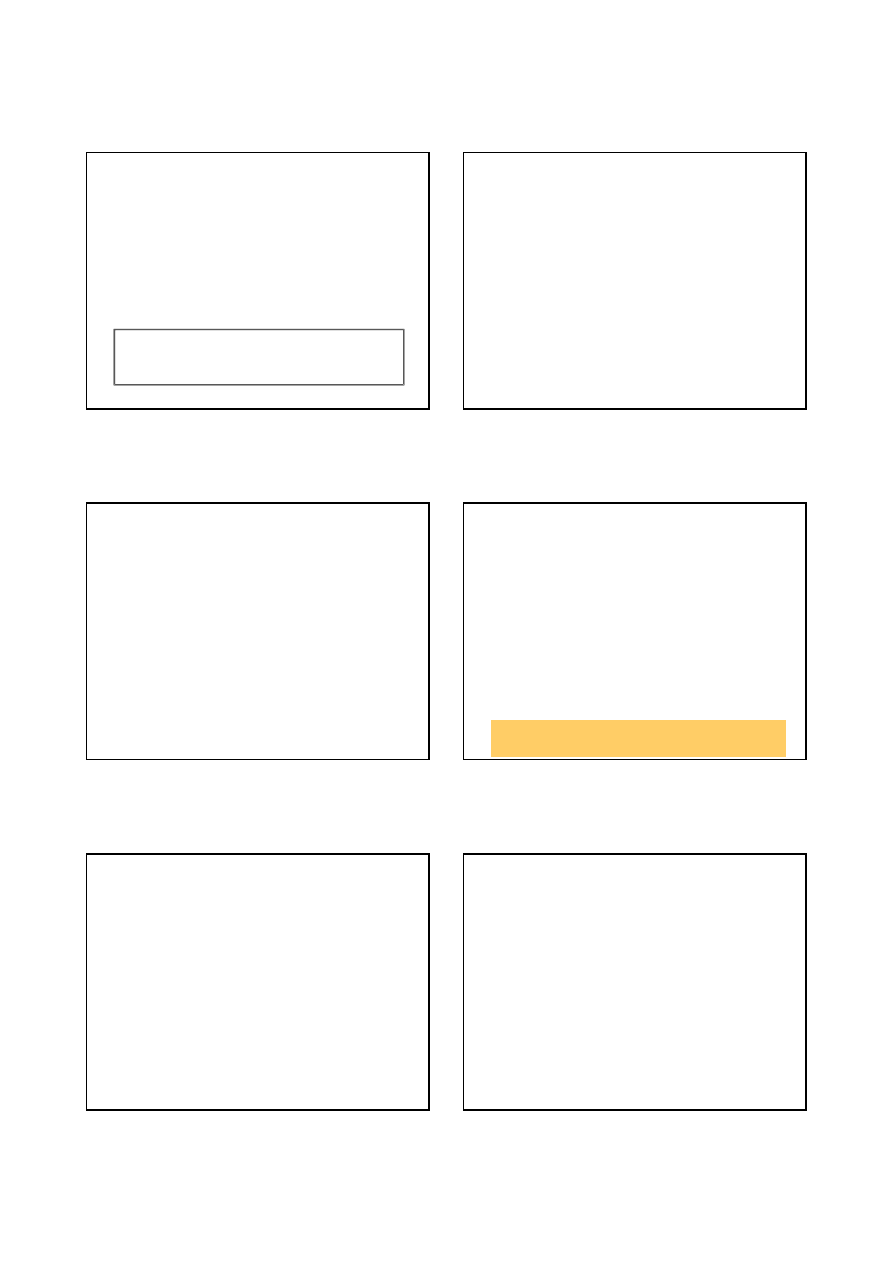
Proste środowisko stochastyczne
Założenie upraszczające:
użyteczność sekwencji jest sumą nagród
zgromadzonych dla wszystkich stanów tej sekwencji (tj. funkcja
użyteczności jest addytywna).
nagroda do otrzymania
= suma nagród do otrzymania począwszy
od danego stanu a skończywszy na stanie terminalnym
MSI-w5/14
Przykład sekwencji trenujących
(1,1)
→(1,2)→(1,3)→(1,2)→(1,3)→(1,2)→(1,1)→(2,1)→(3,1)→(4,1)→(4,2) -1
(1,1)
→(1,2)→(1,3)→(2,3)→(3,3)→(4,3) +1
(1,1)
→(1,2)→(1,1)→(1,2)→(1,1)→(2,1)→(3,1)→(3,2)→(4,2) -1
(1,1)
→(1,2)→(1,1)→(1,2)→(1,3)→(2,3)→(1,3)→(2,3)→(3,3)→(4,3) +1
(1,1)
→(2,1)→(3,1)→(2,1)→(1,1)→(1,2)→(1,3)→(2,3)→(3,3)→(4,3) +1
(1,1)
→(2,1)→(1,1)→(1,2)→(1,3)→(2,3)→(3,3)→(3,2)→(4,2) -1
W każdym ciągu trenującym agent zaczyna w stanie (1,1)
i odbiera sekwencję przejść stanów dopóki nie osiągnie
jednego ze stanów terminalnych (4,2) lub (4,3), w
których otrzymuje nagrodę
Celem jest
wykorzystanie informacji o nagrodach do
nauczenia się oczekiwanej użyteczności
U(i) stanu
nieterminalnego i
MSI-w5/15
Program pasywnego RL-agenta
function PASSIVE-RL-AGENT(e) returns działanie
static: U, tablica estymat funkcji użyteczności
N, tablica częstości dla stanów
M, tablica prawdopodobieństw przejścia ze stanu do stanu
percepts, sekwencja (początkowo pusta)
Dodaj e do percepts
Zwiększ N[STAN[e]]
U
←
UPDATE
(U, e, percepts, M, N)
if TERMINALNY?[e] then percepts
← pusta sekwencja
return działanie Obserwuj
Różne wersje algorytmu
zależą od funkcji UPDATE
MSI-w5/16
Aktualizacja tabeli wartości
funkcji użyteczności
• Agent aktualizuje bieżące wartości funkcji
użyteczności po każdym przejściu stanów
• Stosowane algorytmy UPDATE:
– Naiwna aktualizacja (NU)
– Adaptacyjne programowanie dynamiczne (ADP)
– Uczenie na podstawie chwilowych różnic (TD)
• Od wyboru algorytmu aktualizacji funkcji
użyteczności zależą właściwości agenta RL
MSI-w5/17
Naiwna aktualizacja (1)
• Pochodzi z adaptacyjnej teorii sterowania
(Widrow & Hoff, 1960), zwane LMS=least mean
squares
• Założenie: dla każdego stanu w sekwencji
trenującej zaobserwowane dla tej sekwencji
reward-to-go dostarcza bezpośredniej informacji o
oczekiwanym reward-to-go
• Na końcu każdej sekwencji algorytm oblicza
zaobserwowane reward-to-go dla każdego stanu i
aktualizuje wartość estymowaną dla tego stanu
MSI-w5/18
Naiwna aktualizacja (2)
• Estymaty użyteczności uzyskane z
zastosowaniem algorytmu LMS
minimalizują błąd średniokwadratowy ze
względu na zaobserwowane dane
• Dla funkcji użyteczności reprezentowanej
za pomocą tablicy aktualizacja tej tablicy
dokonywana jest za pomocą obliczania
wartości średniej bieżącej (ruchomej)
4
MSI-w5/19
Naiwna aktualizacja (3)
function LMS-UPDATE(U, e, percepts, M, N) returns aktualne U
if TERMINALNY?[e] then
reward-to-go
← 0
for each e
i
in percepts (zaczynając od końca) do
reward-to-go
← reward-to-go + REWARD[e
i
]
U[STATE[e
i
]]
← RUNNING-AVERAGE(
U[STAN[e
i
]] , reward-to-go, N[STAN[e
i
]] )
end
--------------------------------------------------------
reward-to-go = nagrody do zebrania
RUNNING-AVERAGE = średnia bieżąca
MSI-w5/20
Naiwna aktualizacja (4)
• Zastosowanie algorytmu LMS jest równoważne
nauczeniu się funkcji użyteczności bezpośrednio
z przykładów
:
(stan; nagroda do odebrania)
• Takie podejście sprowadza RL do
standardowego problemu uczenia indukcyjnego
• Funkcja użyteczności może być także
reprezentowana np. przez sztuczną sieć
neuronową
MSI-w5/21
Naiwna aktualizacja (5)
• Wada:
LMS nie wykorzystuje informacji zawartej w
tym, że użyteczności stanów są od siebie zależne
!
• Struktura przejść pomiędzy stanami narzuca bardzo
silne dodatkowe więzy:
Użyteczność danego stanu jest średnią ważoną
(wagi=prawdopodobieństwa) użyteczności
następników tego stanu plus nagrody przypisanej do
tego stanu
• Zignorowanie tej informacji powoduje
bardzo wolną
zbieżność użyteczności do ich wartości dokładnych
MSI-w5/22
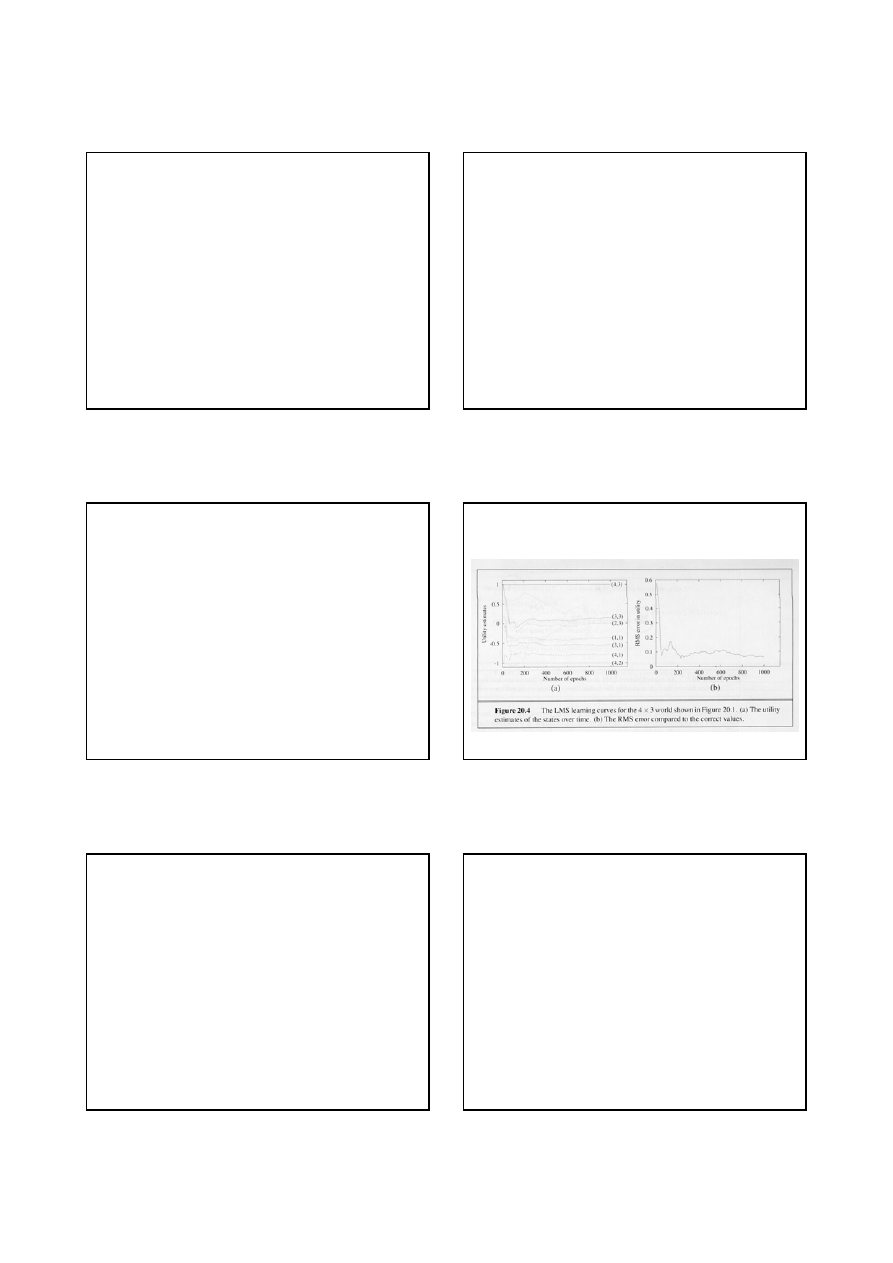
Naiwna aktualizacja (6)
Ponad 1000 sekwencji potrzeba, by agent uzyskał
użyteczności bliskie wartościom poprawnym!!
MSI-w5/23
Adaptacyjne programowanie
dynamiczne (1)
• Użyteczności U(i) oblicza się rozwiązując układ
równań:
gdzie:
R(i)- nagroda przypisana do stanu i
M
ij
- prawdopodobieństwo wystąpienia
przejscia ze stanu i do stanu j
• Wartości dokładne użyteczności zawiera Rys. 20.1(c)
( ) ( )
( )
∑
+
=
j
ij
j
U
M
i
R
i
U
MSI-w5/24
Adaptacyjne programowanie
dynamiczne (2)
• Ponieważ agent jest pasywny, nie dokonuje
żadnej maksymalizacji wartości ze względu
na akcje
• ADP dobrze wykorzystuje doświadczenie
• ADP stanowi odniesienie dla innych
algorytmów RL
• Dla dużych przestrzeni stanów ADP jest
trudny do rozwiązania
5
MSI-w5/25
Uczenie na podstawie
chwilowych różnic (1)
• Istota:
wykorzystać zaobserwowane przejścia
pomiędzy stanami, aby poprawić wartości
użyteczności dla zaobserwowanych stanów by
były one zgodne z równaniami więzów
:
gdzie α - parametr prędkości uczenia
• Częstość aktualizacji zależy od
prawdopodobieństwa przejścia pomiędzy
stanami
( )
( )
( ) ( ) ( )
(
)
i
U
j
U
i
R
i
U
i
U
−
+
+
←
α
MSI-w5/26
Uczenie na podstawie
chwilowych różnic (2)
function TD-UPDATE(U, e, percepts, M, N) returns tablica U
if TERMINALNY?[e] then
U[STAN[e]]
←RUNNING-AVERAGE(U[STAN[e],
NAGRODA[e], N[STAN[e]])
else if percepts zawiera więcej niż jeden element then
e’
← przedostatni element ciągu percepts
i, j
← STAN[e’], STAN[e]
U[i]
← U[i] + α(N[i])(NAGRODA[e’] + U[j] - U[i])
MSI-w5/27
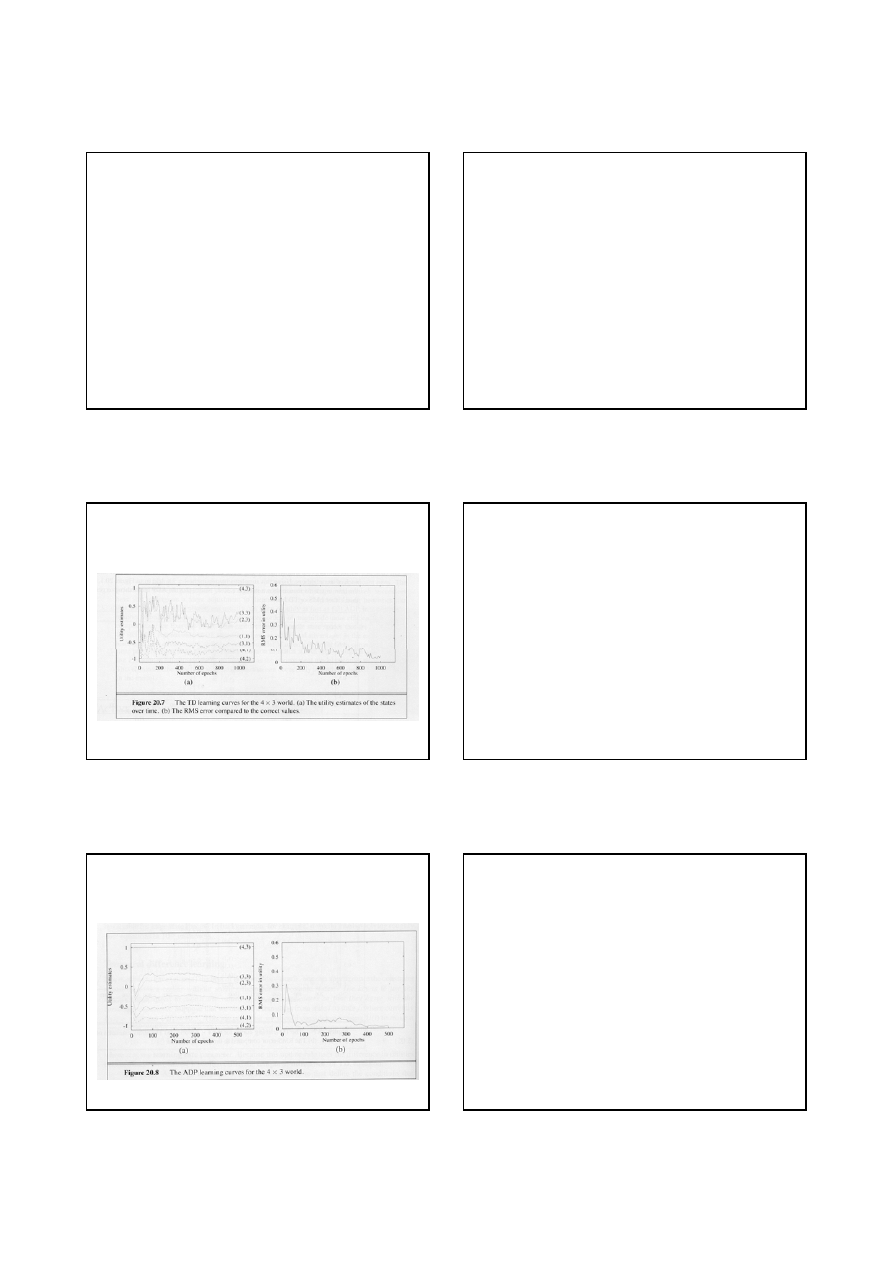
Uczenie na podstawie
chwilowych różnic (3)
Choć TD generuje bardziej zaszumione wartości użyteczności,
błąd średniokw. jest istotnie mniejszy niż dla LMS
MSI-w5/28
Pasywne uczenie w nieznanym
otoczeniu (1)
• ADP można skutecznie stosować także w
tym przypadku (otoczenie wolno ewoluuje)
• Agent uczy się modelu środowiska poprzez
bezpośrednie obserwacje przejść stanów
reprezentowanych przez tablicę M
• Wartości tablicy M buduje się na podstawie
znajomości liczby przejść danego stanu w
stany sąsiadujące z tym stanem
MSI-w5/29
Pasywne uczenie w nieznanym
otoczeniu (2)
ADP jest zbieżne dużo szybciej niż LMS i TD
MSI-w5/30
Aktywne uczenie się
w nieznanym otoczeniu (1)
• Pasywny RL-agent ma ustaloną strategię
działania i nie musi troszczyć się o to, jaką
akcję wybrać
• Aktywny RL-agent musi rozważać:
– Jaką akcję wybrać
– Jakie mogą być wyniki tej akcji
– Jak wyniki tej akcji mogą wpłynąć na
otrzymane nagrody
6
MSI-w5/31
Aktywne uczenie się
w nieznanym otoczeniu (2)
• Model środowiska musi uwzględniać
prawdopodobieństwa M
ij
a
przejścia ze stanu i
do innego stanu j, gdy jest dana akcja a
• Racjonalny RL-agent maksymalizuje swoją
użyteczność:
• Agent musi wybierać akcję w każdym kroku,
do czego potrzebuje miary osiągów
( ) ( )
( )
∑
+
=
j
U
M
i
R
i
U
a
ij
a
max
MSI-w5/32
Eksploracja (1)
• Problem - jaką akcję powinien w danej
sytuacji podjąć agent (wynik działania
PERFORMANCE-ELEMENT)
• Akcja ma dwa rodzaje skutków:
– Zwiększa nagrody dla bieżącej sekwencji stanów
– Ma wpływ na odebrane percepcje, a przez to na
zdolność agenta do uczenia się
i
otrzymywania
nagród dla przyszłych sekwencji
MSI-w5/33
Eksploracja (2)
• Dwa skrajne podejścia do zadania wyboru
kolejnej akcji:
– Losowy wybór z nadzieją, że agent w końcu
zbada całe środowisko (wacky=stuknięty)
– Zachłanne (greedy) podejście maksymalizujące
użyteczność z wykorzystaniem bieżących estymat
MSI-w5/34
Eksploracja (2)
• Losowy wybór
– umożliwia nauczenie dobrych estymat użyteczności dla
wszystkich stanów
– nigdy nie poprawia osiągów w zakresie dodatnich nagród
• Zachłanne podejście
– Zwykle znajduje ścieżkę do nagrody +1
– Ale potem trzyma się tej ścieżki i nigdy nie nauczy się
użyteczności dla innych stanów (nie osiągnie perfekcji,
ponieważ nie znajdzie lepszej ścieżki - zadowala się
znalezioną ścieżką, która daje jakieś gwarantowane
nagrody)
MSI-w5/35
Eksploracja (3)
MSI-w5/36
Eksploracja (4)
• Optymistyczna estymata użyteczności U
+
(nagród do zebrania):
N(a, i) - ile razy próbowano akcję a w stanie i
• Przykładowa funkcja f(u, n):
( )
( )
( ) ( )
+
←
∑
+
+
j
a
ij
a
i
a
N
j
U
M
f
i
R
i
U
,
,
max
( )
<
=
+
razie
przeciwnym
w
gdy
,
u
N
n
R
n
u
f
e
Optymistyczna ocena
najwyższej możliwej nagrody
w jakimkolwiek stanie
Minimalna liczba prób
dla pary (akcja, stan)
7
MSI-w5/37
Eksploracja (5)
MSI-w5/38
Uczenie funkcji akcja-wartość (1)
• Istotne znaczenie w RL:
– Wystarczają do podejmowania decyzji
bez
wykorzystania modelu
– Mogą być wyuczone bezpośrednio poprzez
sprzężenie zwrotne z nagrodą
• Gdy Q(a,i)=wartość wykonania akcji a w
stanie i :
( )
( )
i
a
Q
i
U
a
,
max
=
MSI-w5/39
Uczenie funkcji akcja-wartość (2)
• Podejście bez modelu umożliwia TD:
obliczane po każdym przejściu ze stanu i do j
• Podejście
bez wykorzystania modelu
, bardzo
skuteczne
( )
( )
( )
(
) ( )
−
′
+
+
←
′
i
a
Q
j
a
Q
i
R
i
a
Q
i
a
Q
a
,
,
max
,
,
α
MSI-w5/40
Uczenie funkcji akcja-wartość (3)
MSI-w5/41
Uczenie funkcji akcja-wartość (4)
• WAŻNE PYTANIE -
czy i kiedy warto
budować model
?
• Odpowiedź intuicyjna: gdy środowisko
staje się coraz bardziej skomplikowane, np.
– szachy
– warcaby
warto budować model tego środowiska
MSI-w5/42
Uogólnienia w RL (1)
• Dotychczas wszystkie rozpatrywane funkcje
(U, M, R, Q) reprezentowano tabelarycznie
• Co zrobić, gdy liczba stanów jest ogromna
(szachy - 10
50
)?!!
• Funkcyjna reprezentacja użyteczności, np.
Zamiast 10
50
wartości trzeba określić n wag
( )
( )
( )
( )
i
f
w
i
f
w
i
f
w
i
U
n
n
+
+
+
=
K
2
2
1
1

8
MSI-w5/43
Uogólnienia w RL (2)
• Zalety:
– niesłychana kompresja wiedzy o problemie
– Możliwość uogólniania: na podstawie
stanów, które agent zbadał, wnioskuje o
stanach, których nie zbadał
• Modele można zbudować jako:
– Drzewa decyzyjne
– Sieci neuronowe
– ...
MSI-w5/44
Uogólnienia w RL (3)
• Zastosowania do gier:
– Program grający w szachy (Samuel, 1959)
• liniowa funkcja użyteczności
• 16 wag (!!!)
• program gra jak dobry szachista
– Sieć neuronowa do gry w trik-traka
(backgammon - 10
120
stanów ) (1992)
• 40 węzłów w warstwie ukrytej
• po 200 000 gier (2 tygodnie trenowania) program
osiągnął poziom standardowego gracza
MSI-w5/45
Algorytmy genetyczne
i programowanie ewolucyjne
MSI-w5/46
Ewolucja w świecie organizmów
żywych
• Doprowadza do wykształtowania się
udanych
organizmów
, bo:
– Organizmy niedopasowane do otoczenia wymierają
– Organizmy dopasowane mogą się reprodukować
• Potomstwo jest podobne do rodziców
• Gdy środowisko powoli ewoluuje,
organizmy
dopasowują się do zmian
, także ewoluując
• Czasem występują losowe mutacje:
– W większości przypadków mutanty szybko wymierają
– Niektóre mutacje prowadzą do nowych udanych gatunków
MSI-w5/47
Algorytm genetyczny
function GENETIC-ALGORITHM(populacja, FITNESS-FN)
returns osobnik
inputs:populacja, zbiór osobników
FITNESS-FN, funkcja określająca dopasowanie osobnika
repeat
rodzice
← SELECTION(populacja, FITNESS-FN)
populacja
← REPRODUCTION(rodzice)
until jakiś osobnik nie jest wystarczająco dopasowany
return najlepszy osobnik w populacja, ze względu na FITNESS-FN
MSI-w5/48
Algorytm genetyczny (GA) w AI
• Działa dobrze w sztucznych systemach
• Osobnikiem może być:
– Kompletna funkcja realizowana przez agenta,
wtedy FITNESS-FN jest miarą osiągów agenta lub
funkcją nagrody
– Funkcja składowa agenta, wtedy FITNESS-FN jest
składową krytyki
– . . .

9
MSI-w5/49
GA jako RL
• Ponieważ proces ewolucyjny uczy funkcji agenta
bazując na sporadycznych nagrodach
(potomstwo!!) udzielonych przez funkcję selekcji,
ma on cechy RL
• GA
nie wykorzystuje relacji
występujących pomiędzy
nagrodami i akcjami podejmowanymi przez agenta
lub stanami środowiska
• Działanie GA polega na
prostym przeszukiwaniu
przestrzeni osobników
w celu znalezienia osobnika
maksymalizującego FITNESS-FN
MSI-w5/50
Przeszukiwanie w GA
• Jest równoległe (każdy osobnik jest
niezależny)
• Ma charakter hill-climbing (robi się małe
zmiany genetyczne w osobnikach i używa
najlepszych potomków)
• Problem:
– Czy zajmować się głównie najlepszymi, ignorując
słabych?
Grozi utknięcie w lokalnym maksimum!!
– Don’t kill infeasible individuals!
MSI-w5/51
Problemy implementacji GA
• Jak określić FITNESS-FN?
• Jak reprezentować osobniki?
• Jak selekcjonować osobniki (do reprodukcji)?
• W jaki sposób osobniki reprodukują się?
MSI-w5/52
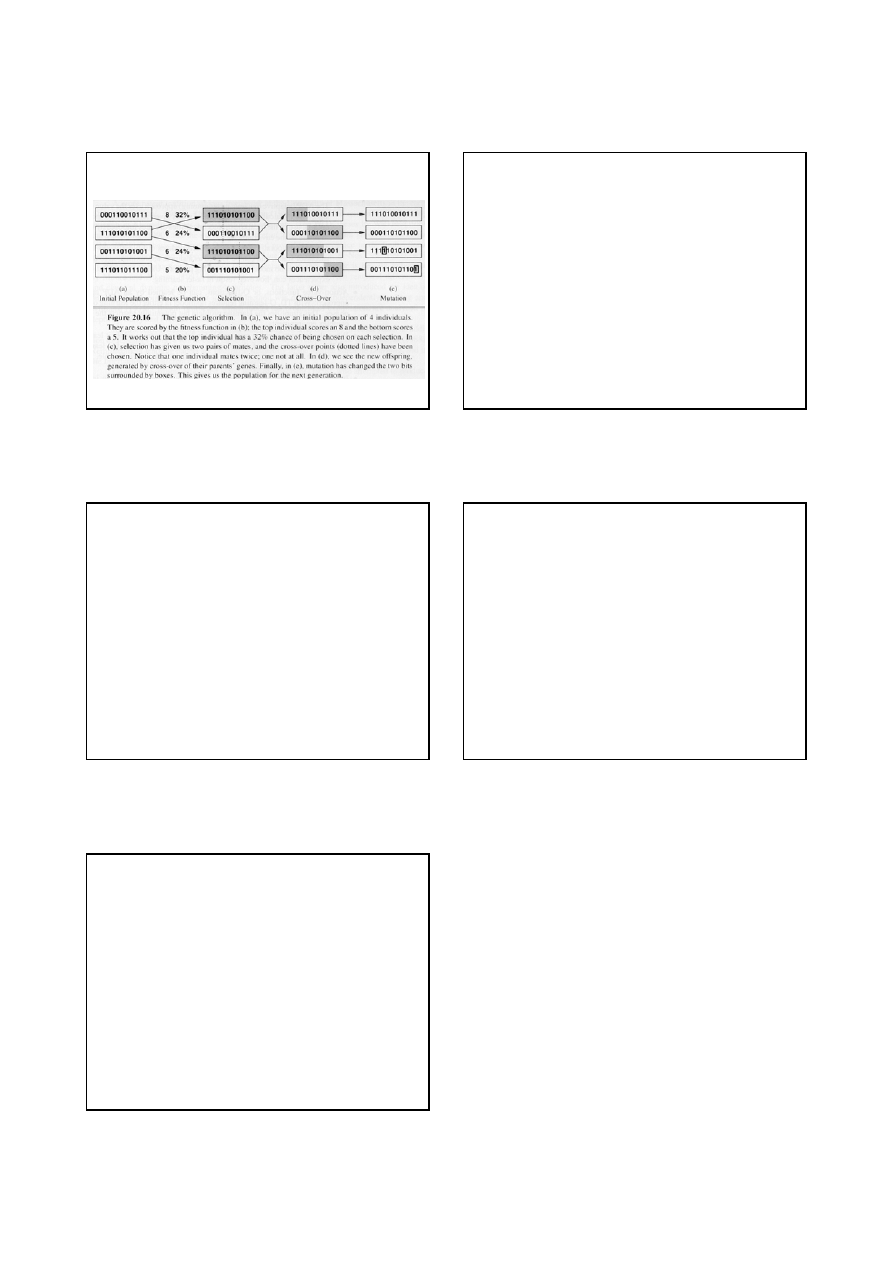
Reprezentowanie osobników
• Klasyczny GA:
– chromosomy zbudowane z genów
– chromosom jest łańcuchem elementów
zbudowanych ze skończonego alfabetu
– W skrajnym przypadku chromosom jest
łańcuchem bitów
• Możliwe jest stosowanie chromosomów,
których geny są
liczbami rzeczywistymi
MSI-w5/53
Strategia selekcji
• Zwykle strategia losowa (ruletka) z
prawdopodobieństwem wylosowania
odpowiadającym wartości FITNESS-FN
• Selekcja z powtórzeniami - dobry osobnik
ma szanse wielokrotnie być wylosowany
• Są inne strategie (rangowa, turniejowa, ...)
MSI-w5/54
Reprodukcja
• Losowe kojarzenie w pary
• Krzyżowanie tej pary w losowo wybranym
miejscu chromosomu (2 osobniki potomne)
• Mutacja dowolnego z genów (małe
prawdopodobieństwo mutacji)
10
MSI-w5/55
Przykład GA
MSI-w5/56
Podsumowanie (1)
• Omówiono dwa podejścia
– bazujące na modelu
– bez wsparcia modelowego
• Użyteczność stanu jest
oczekiwaną sumą
nagród
otrzymanych od danego stanu do
końca danej sekwencji stanów
MSI-w5/57
Podsumowanie (2)
• Użyteczność może być wyuczona poprzez:
– LMS: całkowita zaobserwowana suma nagród do
otrzymania stosowana jako bezpośrednie dane dla
wyuczenia tej użyteczności; model stosowany tylko do
wyboru akcji
– ADP: iteracyjnie oblicza dokładne użyteczności
stanów, gdy dany jest estymowany model; optymalnie
wykorzystuje informację o więzach
– TD: aktualizuje oceny użyteczności, by pasowały do
użyteczności dla następnych stanów; model dostarcza
surogatu doświadczenia
MSI-w5/58
Podsumowanie (3)
• Wyuczenie funkcji akcja-wartość
nie
wymaga modelu ani do uczenia, ani do
selekcji odpowiedniej akcji
• Gdy agent jest aktywny, musi wybierać
właściwe akcje, biorąc pod uwagę
estymowane wartości tych akcji
oraz
potencjalną możliwość wyuczenia
nowej
użytecznej wiedzy
MSI-w5/59
Podsumowanie (4)
• W „dużych” przestrzeniach stanów algorytmy
RL muszą bazować na reprezentacji
funkcyjnej, co umożliwia uogólnianie wejść
ponad stanami. Algorytm TD umożliwia
bezpośrednią korektę wag
• GA ma cechy RL, gdyż używa wzmocnienia
do zwiększenia udziału udanych osobników w
populacji. GA jest zdolny do uogólniania
dzięki mutacjom i krzyżowaniu osobników
Wyszukiwarka
Podobne podstrony:
MSI AiR w7 2004
MSI AiR w5 2004
MSI AiR w2 2004
MSI AiR w1 2004
MSI AiR w4 2004
MSI AiR w3 2004
MSI w6 2006 cz1
ti 1102 Transporter 2004 Heating and Air Conditioning
131 Jak to jest z powietrzem u góry How s the air up there Jay Friedman,Sep 9, 2004
2004 mx comp air
W6 Technika harmonogramów i CPM
w6 Czołowe przekładanie walcowe o zebach srubowych
AM1 W6
więcej podobnych podstron