
1
Konrad Cichy
Informatyka Stosowana
Stopień 2, rok 1
NIESTACJONARNE
Sprawozdanie
Laboratorium nr 1
Optymalizacja algorytmu mnożenia macierzy przez wektor
/*=========================================================================
Usuniecie skokow w danych
===========================================================================*/
{
//napisz swoj kod
int
i, j;
memset((
void
*)y, 0, n*
sizeof
(
double
));
for
(j=0;j<n;j++){
for
(i=0;i<n;i++){
y[i]+=a[i+n*j]*x[j];
}
}
}
void
matvec_opt_2(
double
* a,
double
* x,
double
* y,
int
n)
/*============================================================================
Rozwijanie petli
=============================================================================*/
{
memset((
void
*)y, 0, n*
sizeof
(
double
));
//napisz swoj kod
int
i, j;
int
rest = n%4;
register
int
reg;
for
(j=0;j<n;++j)
{
reg =x[j];
for
(i=0;i<rest;++i)
{
y[i]=y[i]+a[i+n*j]*reg +x[i+n*j];
}
for
( i=rest;i<n;i+=4)
{
y[i]=y[i]+a[i+n*j]*reg;
y[i+1]=y[i+1]+a[i+n*j+1]*reg;
y[i+2]=y[i+2]+a[i+n*j+2]*reg;
y[i+3]=y[i+3]+a[i+n*j+3]*reg;
}
}
}
2
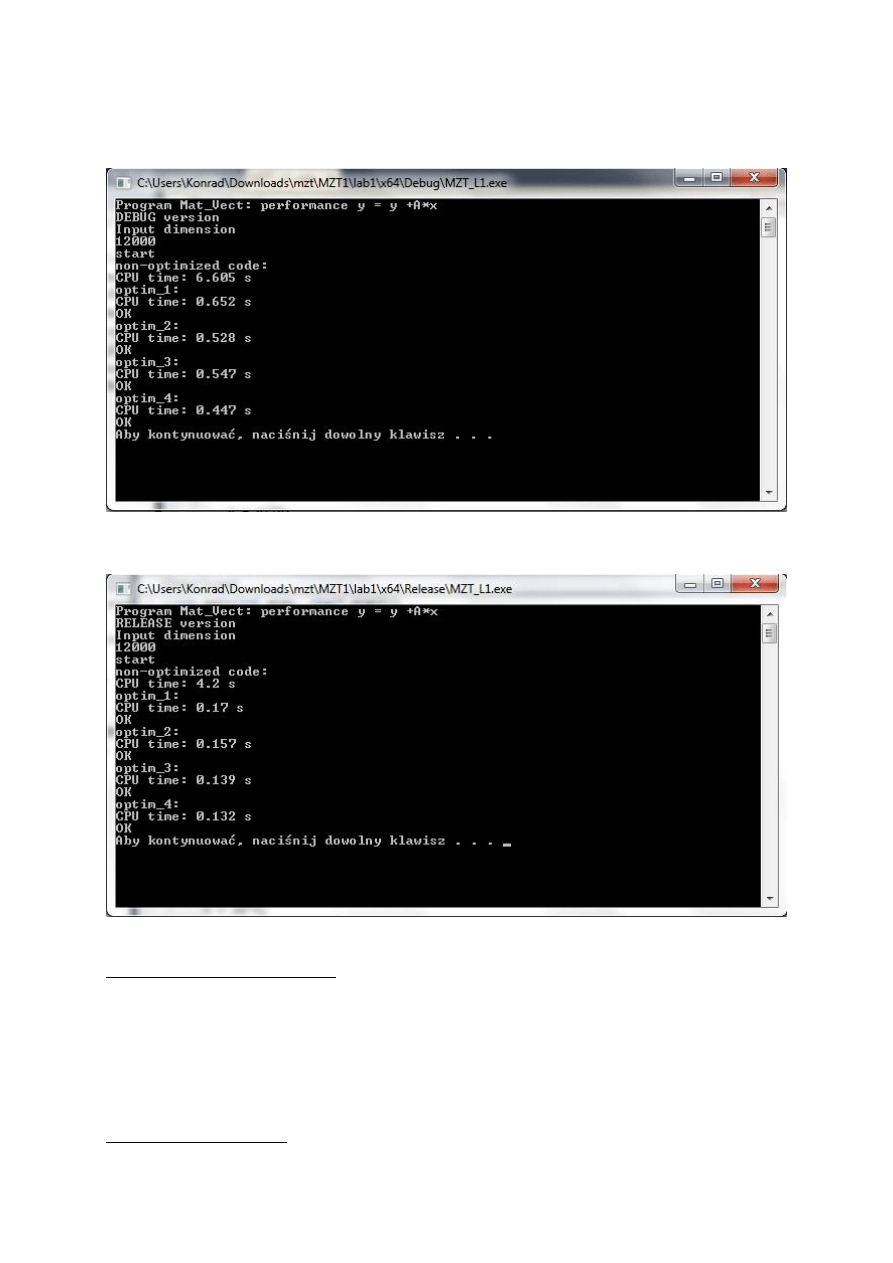
Wyniki:
Dla wersji Debug(parametr wejściowy 12000):
Dla wersji release(parametr wejściowy 12000):
Różnice wersji Debug i Release
Wersja Release:
–
jest o wiele szybsza
–
wiele systemów sprawdzania jest wyłączona
–
plik wykonywalny jest wiele mniejszy
–
systemy optymalizacji są wyłączone
Podsumowanie i wnioski
3
Udało się spełnić postawione zadanie, program został wysoce zoptymalizowany,
największy zysk czasowy dało rozwinięcie pętli, z czego płynie jasny wniosek, co najbardziej
wpływa na niską wydajność niektórych programów. Testy były wykonane na procesorze i5-
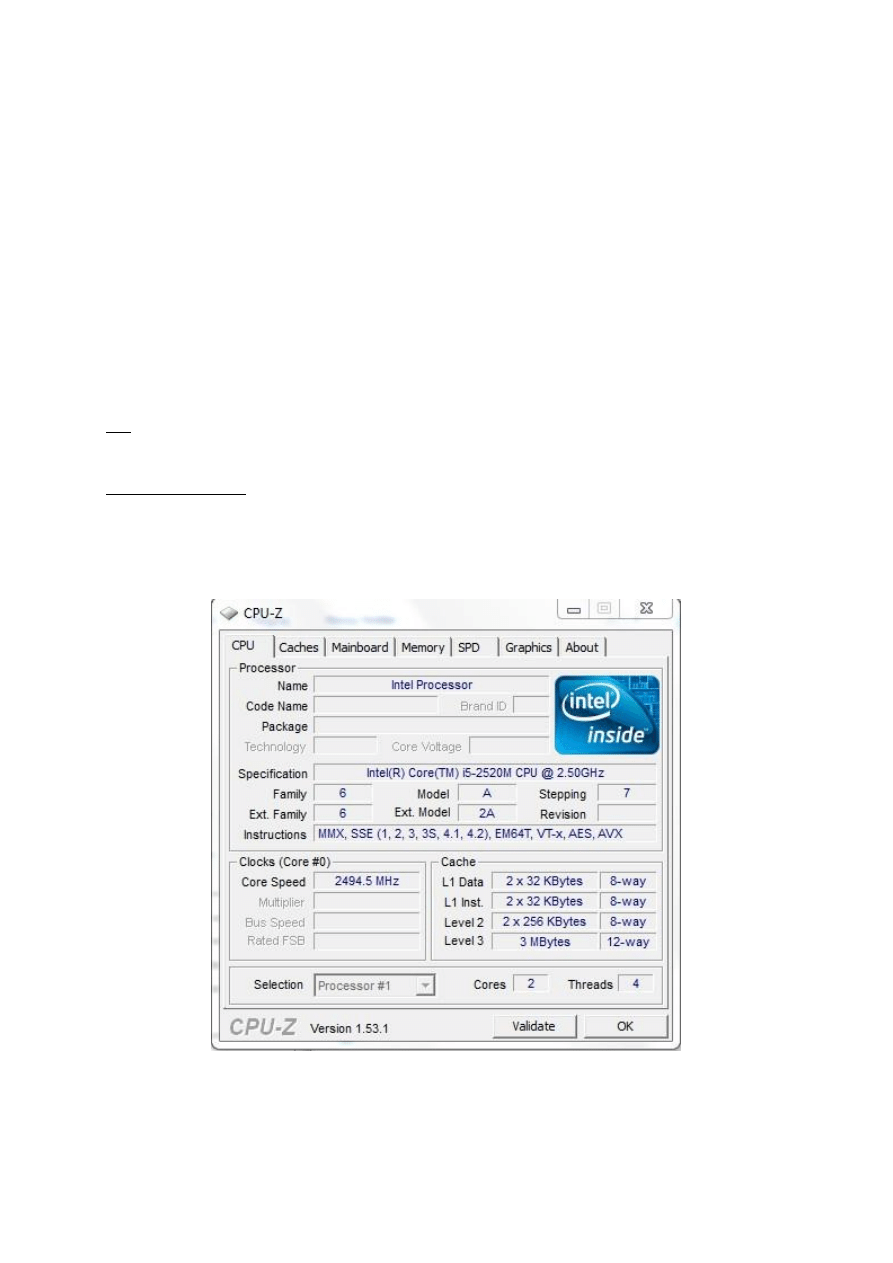
2520M CPU @ 2,50GHz (Cores : 2 , Threads: 4).
Laboratorium nr 2
Cel
Porównanie różnych metod mnożenia macierzy przez wektor.
Przebieg ćwiczenia
Porównanie metody klasycznej z HP, dla jednego wątku dla porcji danych 1936.
Poniżej zrzut ekranu z programu CPU-Z:
Pierwsze testy zostały uruchomione z parametrem N=1936, standardowo ustawionym
rozmiarem l_block=176 oraz z wykorzystaniem 1 wątku:

4
Times
Metoda Classic
HP
Block_cache(ib, kb,
jb::i,k,j)
Block_cache,
register (2x2), pack
(BLAS 1989)
Block_cache (kb,
jb=1, ib), block
XMM registers
(2x4xk) SSE2, SSe3,
pack A, B
time_1
Duration: 76,425
OPS: 1,45126e+010
Performance:189.89
Duration: 7,785
OPS: 1,45126e+010
Performance:1864.18
Duration: 5.008
OPS: 1,45126e+010
Performance:2897.89
Duration: 6.708
OPS: 1,45126e+010
Performance:2136.48
Duration: 1,888
OPS: 1,45126e+010
Performance:7686,77
time_2
Duration: 76,596
OPS: 1,45126e+010
Performance:189.47
Duration: 7,675
OPS: 1,45126e+010
Performance:1890.92
Duration: 4.695
OPS: 1,45126e+010
Performance:3091.08
1906.34
Duration: 6.490
OPS: 1,45126e+010
Performance:2236,15
Duration: 1,607
OPS: 1,45126e+010
Performance:9030,88
time_3
Duration: 76,628
OPS: 1,45126e+010
Performance:189.39
Duration: 7,613
OPS: 1,45126e+010
Performance:1906.34
Duration: 4.758
OPS: 1,45126e+010
Performance:3050.15
Duration: 6,412
OPS: 1,45126e+010
Performance:2263,35
Duration: 1,638
OPS: 1,45126e+010
Performance:8859,97
AVG
AVERAGE:
Duration:76,549
Performance:189.58
AVERAGE:
Duration:7.691
Performance:1887,12
AVERAGE:
Duration:4,820
Performance:3013.04
AVERAGE:
Duration:6,536
Performance:2211,99
AVERAGE:
Duration:1,711
Performance:8525,87

5
Dla metod Block_cache(ib,kb,jb::i,k,j), Block_cache, registers(2x2), Block_cache(kb, jb=1,
ib) zostały wyznaczone następujące optymalne wartości parametru l_block przy parametrze
N=2000:
Block_cache(ib,kb,jb::i,k,j) :
l_block=105
Duration: 6,069s
Performance: 2542,57 Mflops
Block_cache, registers(2x2), pack (BLAS 1989) :
l_block=128
Duration: 4,773s
OPS: 1,41558e+010
Performance: 3168,08 Mflops

6
Blocka_cache(kb, jb=1, ib) :
l_block=124
Duration: 1,841
OPS: 1,56191e+010
Performance: 8484,01
Obserwacje
Porównując metodę HP z metodą klasyczną można zaobserwować jak istotny jest brak
skoków danych, algorytm HP pozbawiony tej wady, której eliminacja sprowadza się jedynie
do zamiany kolejności pętli jest szybszy kilkukrotnie.
Kolejna metoda – blokowanie cache’u jest lepsza od metody HP, ponieważ zapisuje trzy bloki
jednocześnie w pamięci cache.
Badanie następnej metody, wykorzystującej blokowanie rejestrów nie przyniosła
oczekiwanych rezultatów, ponieważ program nie zwiększył swojej wydajności.
Znaczącą poprawę przyniosło natomiast zastosowanie metody wykorzystującej rejestry
wektorowe (SSE2), pozwalające wykonywać dwie operacje mnożenia, dodawania
jednocześnie.
Wyszukiwarka
Podobne podstrony:
MZT KC Sprawozdanie z labolatorium 1 2, pk niestac 2st IIsem, MZT, sprawka, spr 1 i 2
SPRAWOZDANIE Z LABOLATORIUM Z FIZYKI I BIOFIZYKI cw.5, biotechnologia inż, sem2, FiB, laborki, spraw
SPRAWOZDANIE Z LABOLATORIUM Z FIZYKI I BIOFIZYKI cw.6, sprawka
75, LAB 75!, Sprawozdanie z labolatorium
FIZ 10, Sprawozdanie z labolatorium fizycznego
WYDZIA~1, Labolatoria fizyka-sprawozdania, !!!LABORKI - sprawozdania, Lab, !!!LABORKI - sprawozdania
Ćwiczenie nr 50b, sprawozdania, Fizyka - Labolatoria, Ćwiczenie nr50b
Doświadczalne spr p. Malusa, sprawozdania, Fizyka - Labolatoria, Ćwiczenie nr70
Fizyka 25a, Labolatoria fizyka-sprawozdania, !!!LABORKI - sprawozdania, 25 - Interferencja fal akust
Jednomodowe czujniki interferencyjne, Studia, sprawozdania, sprawozdania od cewki 2, Dok 2, Dok 2, P
Labolatorium 2 sprawozdanie
Mechanika gruntów - Ćwiczenie 1 - Sprawozdanie 1, Budownictwo S1, Semestr III, Mechanika gruntów, La
Ćwiczenie nr 82, sprawozdania, Fizyka - Labolatoria, Ćwiczenie nr82
Zastosowanie kompesatorów prądu stałego v3, Politechnika Lubelska, Studia, Studia, Sprawozdania, ME
Fizyka - sprawozdanie 49, Biotechnologia, Fizyka, Labolatorium
więcej podobnych podstron