
1
Hurtownie danych i eksploracja
danych – wprowadzenie
Tadeusz Pankowski
www.put.poznan.pl/~pankowsk/
2
Motywacja
• Tradycyjne systemy baz danych
ukierunkowane są na realizację wiele
małych i prostych zapytań.
• Aplikacje analityczne używają małej liczby
zapytań ale bardzo kosztownych czasowo i
bardzo złożonych.
• Powstały nowe architektury do efektywnej
obsługi zapytań „analitycznych”.

3
Hurtownie danych
• Najpowszechniejsza forma integracji danych
• Źródłowe danych kopiowane są do pojedynczej
bazy danych (
hurtowni danych, magazynu
),
która powinna być utrzymywana w stanie
aktualnym.
• Zwykle stosuje się periodyczną rekonstrukcję
hurtowni, najczęściej nocą.
• Hurtownia najczęściej używana jest do obsługi
zapytań analitycznych.
4
OLTP
• Większość operacji w bazie danych to
transakcje typu OLTP (
Online Transaction
Processing
).
• Krótkie, proste, bardzo częste zapytania i/lub
modyfikacje, z których każda odnosi się do małej
liczby krotek.
• Na przykład: odpowiedzi na zapytania w
aplikacjach internetowych, sprzedaż wprowadzana
w kasach sklepowych, sprzedawanie biletów
kolejowych, przelewy bankowe.

5
OLAP
• Coraz większe znaczenie mają zapytania
typu OLAP (
Online Analytical Processing
)
• Mniejsza liczba zapytań, ale dużo bardziej
złożonych – wykonanie ich może trwać wiele
godzin.
• Wykonywanie zapytań nie wymaga absolutnie
najbardziej aktualnego stanu bazy danych.
• Określane są niekiedy jako
eksploracja
danych
(ang.
data mining
).
6
OLAP - Przykłady
1. Amazon analizuje zakupy dokonywane przez
klientów w celu opracowania indywidualnego
ekranu dla każdego klienta z produktami
najbardziej go interesującymi.
2. Analitycy hipermarketu poszukują towarów,
których sprzedaż w danym regionie wzrasta.
3. Bank próbuje opracować kryteria pozwalające
ocenić wiarygodność kredytobiorców.
7
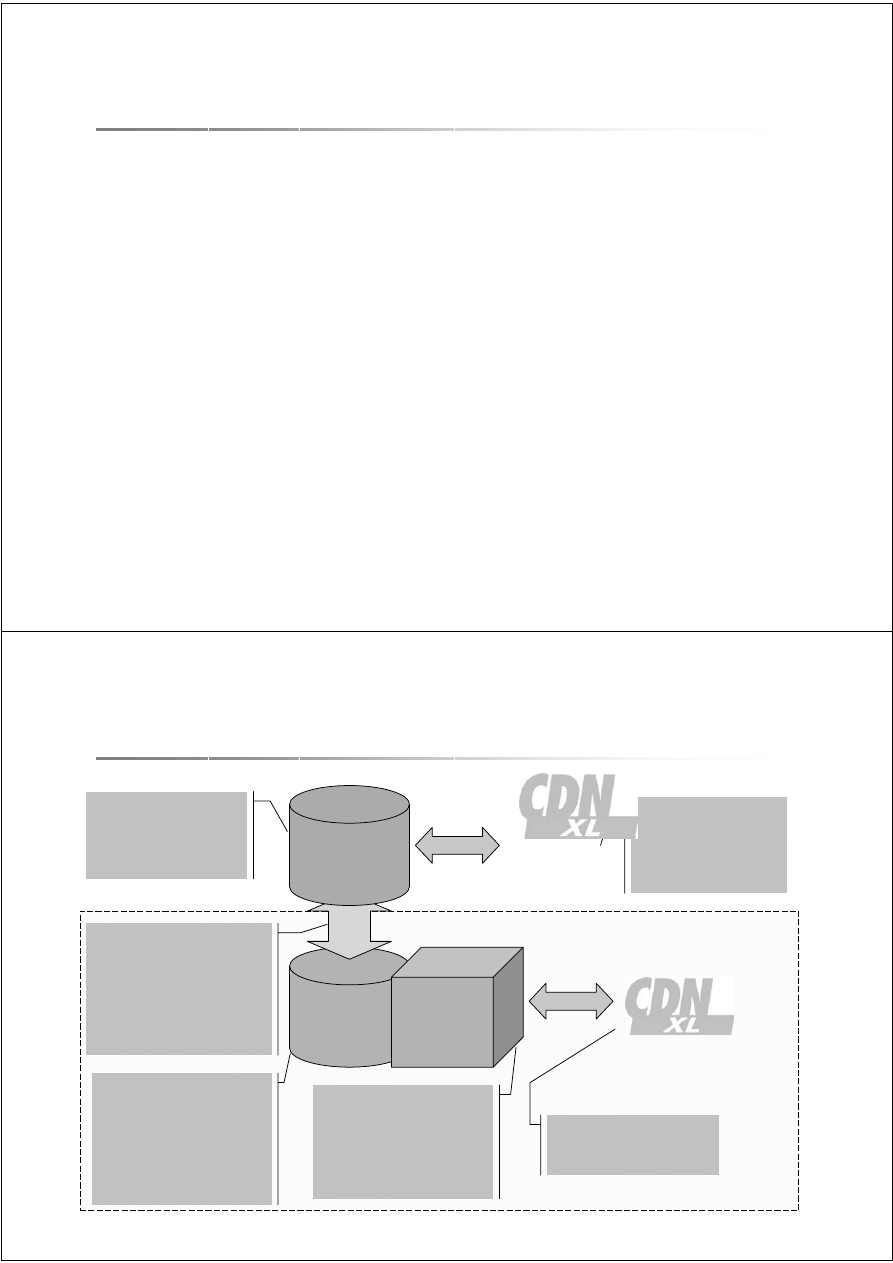
Ogólna architektura
• Bazy danych w poszczególnych oddziałach
obsługują zapytania typu OLTP.
• Lokalne bazy danych kopiowane są do
centralnej hurtowni danych.
• Analitycy używają hurtowni danych do
operacji typu OLAP.
8
Hurtownia
Danych
OLAP
Podstawowa baza
danych systemu
CDN XL (OLTP)
SQL Server 2000
Wystawianie
dokumentów,
ksi
ę
gowo
ść
,
obieg dokumentów,
bie
żą
ce analizy
Baza zawieraj
ą
ca dane
przetransformowane
z bazy OLTP
Struktura
zoptymalizowana dla
potrzeb analiz
SQL Server 2000
Baza wielowymiarowa
umo
ż
liwiaj
ą
ca szybkie
przetwarzanie zapyta
ń
obejmuj
ą
cych szerokie
zakresy danych
Analysis Server 2000
Przegl
ą
darka analiz
wielowymiarowych
Funkcje bud
ż
etuj
ą
ce
DTS
OLTP
Transformacje
przenosz
ą
ce dane z
bazy OLTP do hurtowni
i bazy OLAP
Wykonywane cyklicznie
(np. codziennie w nocy)
SQL Server 2000
PLATFORMA
BUSINESS INTELLIGENCE
System hurtowni danych (ComArch)

9
• Umiejscowienie zdarzeń
• Każde zdarzenie gospodarcze
odzwierciedlone dokumentem
ma swoje miejsce w zdefiniowanej
przestrzeni wielowymiarowej
• Każde zdarzenie można opisać
przez określenie jego pozycji
na osi każdego z wymiarów
• Przykład: Faktura zakupu
• Czas = 28.02.2002, Kontrahent = MICROSOFT
• Dokument FZ, Seria = SPKR, Status = Zatw.
• Produkt = Windows XP, Osoba = SŁUPIK
• Lokalizacja = Kraków, Centrum = CXL.Produkcja
• Działalność = Licencje, Projekt = XL.Controlling
Pr
od
uk
ty
Czas
Kontrahe
nci
Opis analityczny (ComArch)
10
Schematy gwiazdy
•
Schemat gwiazdy
(ang.
star schema
) jest
najczęściej stosowaną metodą organizacji
danych w hurtowni danych. W jego skład
wchodzą:
1. Tabeli faktów
(ang.
fact table
): bardzo duży zestaw
faktów takich na przykład jak sprzedaż, najczęściej
tylko do dołączania.
2. Tabele wymiarów
(ang.
dimension tables
): nieduże i
najczęściej statyczne tabele zawierające informacje
o jednostkach związanych z faktami, na przykład z
faktem sprzedaży związane są jednostki: klient,
miejsce, towar, moment czasu.

11
Schemat gwiazdy - przykład
• Przypuśćmy, że w hurtowni danych chcemy
pamiętać informacje o każdej zapłacie kartą
płatniczą, takie jak: miejsce transakcji,
numer karty, dzień, godzina, kwota.
• Tabela faktów jest wówczas relacją:
Zapłata(IdKasy, IdKarty, Dzień, Godzina, Kwota)
12
Przykład c.d.
• Tabele wymiarów zawierają informacje o
wymiarach: miejsce (kasa sklepu), karta i
dzień; wymiar godzina można potraktować
jako standardowy. Wymiary opisane są w
tabelach:
Kasa(IdKasy, Miasto, Województwo)
Karta(IdKarty, Rodzaj, IdPosiadacza,
DataWażności)
Dzień(Dzień, Miesiąc, Kwartał, Rok)

13
Atrybuty tabeli faktów
• W tabeli faktów wyróżniamy dwa rodzaje
atrybutów:
1. Atrybuty wymiarów
: są kluczami w tabelach
wymiarów.
2. Atrybuty zależna
: determinowane przez
atrybuty wymiarów, np. Kwota.
14
Sposoby pamiętania danych
1. ROLAP
= “relational OLAP”:
Dostosowanie relacyjnego SZBD do
zarządzania schematami gwiazdowymi
(stosowane są specjalne indeksy).
2. MOLAP
= “multidimensional OLAP”:
Używa wyspecjalizowanego SZBD
zarządzającego wielowymiarowym
modelem danych o postaci kostek danych,
“data cube.”

15
Techniki ROLAP
1. Indeksy bitmapowe
: dla każdej
wartości kluczowej tabeli wymiarów
(np. IdKasy) tworzony jest wektor
binarny mówiący, które krotki z tabeli
faktów mają tę wartość.
2. Materializowane widoki
: pamiętają
odpowiedzi na niektóre istotne
zapytania (widoki) i przechowywane
są w hurtowni danych.
16
Typowe zapytania OLAP
• Zapytania OLAP najczęściej obejmują „star join”,
tzn. naturalne złączenie tabeli faktów z wszystkimi
lub z większością tabel wymiarów.
• Przykład:
SELECT *
FROM Zapłata,Kasa,Karta,Dzie
ń
WHERE Zapłata.IdKasy = Kasa.IdKasy AND
Zapłata.IdKarty = Karta.IdKarty AND
Zapłata.Dzie
ń
= Dzie
ń
.Dzie
ń

17
Typowe zapytania OLAP –c.d.
• Typowe zapytanie OLAP:
1. Zaczyna się operacją „star join”.
2. Na podstawie danych wymiarowych wybiera
interesujące krotki.
3. Wybrane krotki grupuje według jednego lub
wielu wymiarów.
4. Agreguje pewne atrybuty.
18
Zapytanie OLAP - przykład
• Dla każdej kasy w Poznaniu znajdź ogólną
symę zapłaconych kwot poszczególnymi
kartami Visa Electron.
1. W operacji selekcji stosujemy warunek:
Kasa.Adres = ‘Poznań’
AND
Karta.Rodzaj = ‘Visa Electron’
2. Grupowanie: według
IdKasy
,
IdKarta
3. Agregacja: Sumowanie
Kwota
.

19
Przykład: SQL
SELECT Z.IdKasy,Z.IdKarty,sum(Z.Kwota)
FROM Zapłata Z, Kasa M,Karta K
WHERE Z.IdKasy = M.IdKasy AND
Z.IdKarty = K.IdKarty AND
M.Miasto = ‘Pozna
ń
’ AND
K.Rodzaj=‘Visa Electron’
GROUP BY Z.IdKasy,Z.IdKarty
20
Używanie zmaterializowanych
widoków
• Bezpośrednie wykonanie rozważanego
zapytania z tabeli Zapłata i tabel wymiarów
może trwać bardzo długo.
• Jeśli utworzymy zmaterializowany widok,
który będzie zawierał wystarczająco dużo
informacji, żądaną odpowiedź to możemy
otrzymać dużo szybciej.

21
Zmaterializowany widok - przykład
•
Jakie widoki mogą pomóc w uzyskaniu
odpowiedzi na rozważane zapytanie?
•
Widok powinien:
•
Key issues:
1. Łączyć co najmniej tabele Zapłata, Kasa, Karta.
2. Musi być pogrupowany co najmniej według IdKasy i
IdKarty.
3. Musi zawierać wszystkie kasy z Poznania i wszystkie
karty Visa Electron.
4. Musi zawierać kolumny IdKasy i IdKarty.
22
Hurtownie danych a eksploracja
danych
• Czym jest eksploracja danych
• Eksploracja danych w procesie odkrywania
wiedzy
• Metody i techniki eksploracji danych
• Znaczenie eksploracji danych

23
Czym jest eksploracja danych?
• Eksploracja danych oznacza wydobywanie wiedzy z dużych
zbiorów danych.
• Eksploracja –
badanie
,
przeszukiwanie;
np.
dziewiczych
obszarów Afryki
(Słownik poprawnej polszczyzny PWN
1976).
• Eksplorować –
przemierzać jakiś teren w celach
badawczych
;
eksplorować dziewiczą puszczę
(jak wyżej)
• Cel eksploracji danych – wydobycie wiedzy z danych (ang.
knowledge mining from data
).
• Jeden z istotnych etapów w procesie odkrywania wiedzy w
bazach danych
Knowledge Discovery in Databases
(KDD) –
niekiedy rozumiany jest jako synonim KDD.
24
Eksploracja danych w procesie odkrywania wiedzy
w bazach danych (KDD)
1.
Czyszczenie danych (
data cleaning
) – usuwanie zanieczyszczeń i
niespójności w danych.
2.
Integracja danych (
data integration
) – łączenie danych pochodzących
z różnorodnych źródeł.
3.
Selekcja danych (
data selection
) – wybieranie tych danych z bazy
danych, które są istotne dla zadań analizy.
4.
Transformacja danych (
data transformation
) – przekształcanie i
konsolidowanie danych do postaci przydatnej dla eksploracji, na
przykład ich sumowanie i/lub agregowanie (np. w hurtowni danych).
5.
Eksploracja danych (
data mining
) – stosowanie „inteligentnych” metod
w celu odkrycia istotnych zależności zwanych
wzorcami
(
patterns
).
6.
Ocena wzorców (
pattern evaluation
) – identyfikacja naprawdę
interesujących wzorców w oparciu o pewne miary ważności.
7.
Reprezentacja wiedzy (
knowledge presentation
) – przedstawienie
odkrytej wiedzy użytkownikowi za pomocą technik wizualizacji i
reprezentacji wiedzy.
25
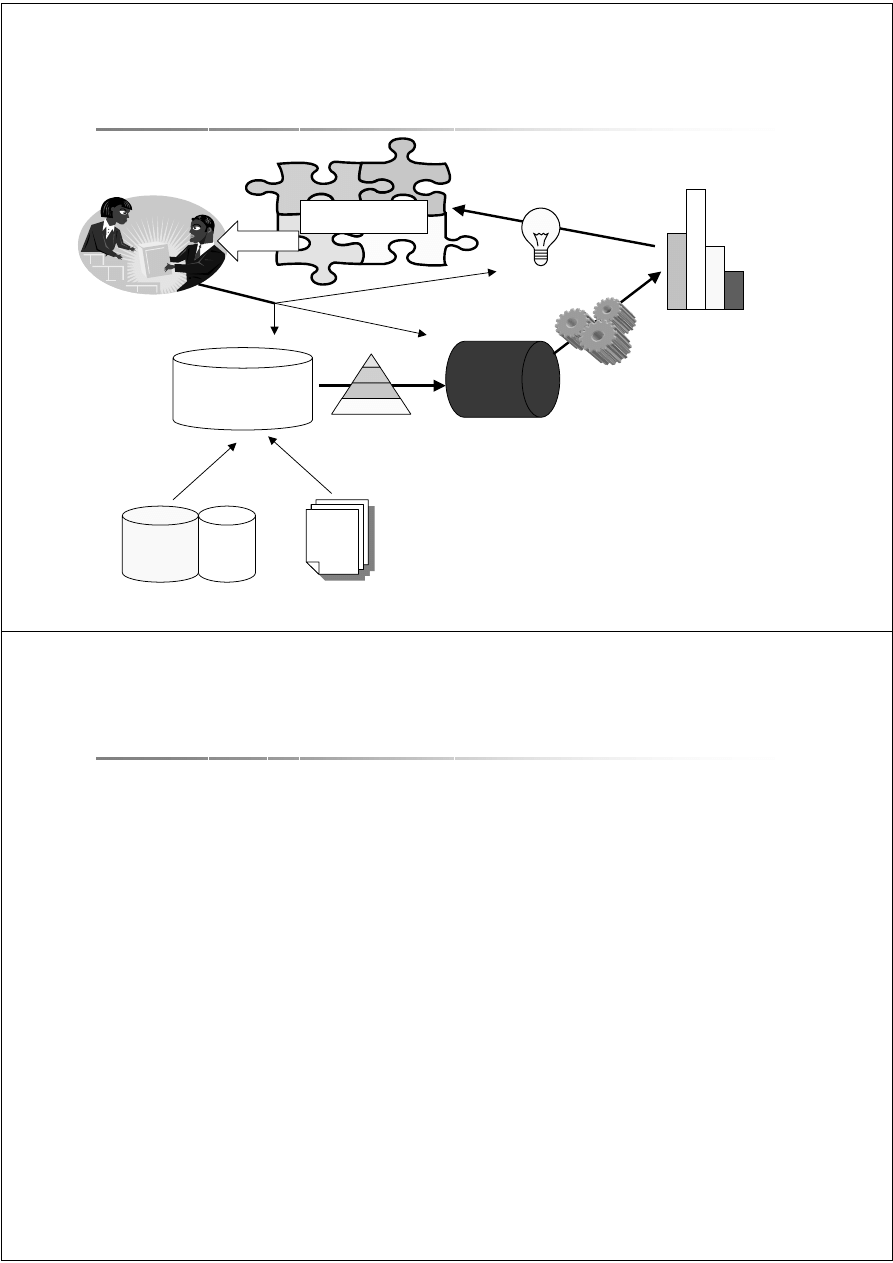
Eksploracja danych jako etap w procesie
odkrywania wiedzy
Bazy
danych
Pliki
danych
Hurtownia
danych
Wzorce
Czyszczenie i
integracja
Selekcja i
transformacja
Eksploracja
danych
Ocena i
prezentacja
Wiedza
U
ż
ytkownik
26
Metody i techniki eksploracji danych
¾ Eksploracja danych obejmuje szereg technik z różnych dyscyplin,
takich jak:
• technologie baz danych
• statystyka
• uczenie maszynowe
• techniki obliczeń wielkiej skali
• rozpoznawanie wzorców
• sieci neuronowe
• wizualizacja danych
• wyszukiwanie informacji
• przetwarzanie obrazów i dźwięku
• analiza danych przestrzennych
27
Znaczenie eksploracji danych
1. Wynikiem eksploracji danych powinno być odkrycie
interesującej wiedzy, regularności i uzyskanie informacji
na wysokim poziomie ogólności, która może być
prezentowana z różnych punktów widzenia.
2. Odkryta wiedza powinna być użyteczna dla podejmowania
decyzji, sterowania procesami, zarządzania informacją a
także do udzielania odpowiedzi na różne zapytania.
3. Eksploracja danych może być przeprowadzana na każdym
rodzaju repozytorium danych: relacyjnych bazach danych,
hurtowniach danych, bazach transakcji, plikach, sieci
WWW, przestrzennych bazach danych, bazach
multimedialnych, arkuszach kalkulacyjnych, strumieniach
danych, itp. itd.
Wyszukiwarka
Podobne podstrony:
Przedmiot PRI i jego diagnoza przegląd koncepcji temperamentu
Bliźniuk G , interoperacyjność przegląd, marzec 2008
PRZEGLĄD METOD OSZUSZANIA MURÓW
Przegląd rozwiązań konstrukcyjnych wtryskarek (ENG)
Przegląd kuferków
Przeglad oferty Micro Automation Sets
Przegląd układu tłokowo – korbowego silnika MAN B&W – L 2330 H
67 Starostka Patyk Przeglad barier
Przegląd systematyczny roślin
Prolactinoma przeglad lekarski id 401350
!!! Pełen przegląd Kulikowska 16(3)
Automatyczna regulacja zasięgu reflektorów przegląd podzespołów
14 04 Remonty przeglady i naprawy maszynid 15614
Recenzja przeglądów teatralnych osób niepełnosprawnych
więcej podobnych podstron