C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
165
Rozdział 8.
Struktura sieciowych
systemów operacyjnych
υ
Funkcje oprogramowania dla sieci LAN.
υ
Oprogramowanie klienta PC.
υ
Typy serwerów.
υ
Struktura oprogramowania serwera.
υ
System to sieciowy system operacyjny.
„Protokoły” raz jeszcze
Objaśnienie pojęcia
protokoły sieciowe
pojawia się w tej książce
kilkukrotnie, jednak za każdym razem w nieco innym kontekście.
Protokoły
sieciowe
to umowy dotyczące pakowania, rozliczania i transmisji danych w
sieci. Producenci i organizacje branżowe opracowują umowy, a
poszczególne firmy starają się napisać oprogramowanie, które będzie
zgodne z tymi umowami. Niektóre próby są bardziej udane inne mniej, ale
po kilku miesiącach stosowania metody „prób i błędów” (często prób
wykonywanych i błędów doświadczanych przez nabywców pierwszych
wersji oprogramowania) producenci są w stanie zaoferować prawidłowo
działające programy. W protokołach nie ma nic tajemniczego. Są one po
prostu porozumieniami dotyczącymi tego, co
i jak powinno działać.
Niniejszy rozdział stanowi poszerzony przegląd koncepcji sieciowych systemów
operacyjnych opisanych w rozdziale 4., „Praktyczny przewodnik po sieciach LAN”.
Opisane tu zostaną funkcje różnych rodzajów oprogramowania serwerów,
klienckich stacji roboczych i stanowiących podstawę wszystkiego protokołów
komunikacyjnych. W następnym rozdziale zostaną przedstawione bardziej
166
Sieci komputerowe dla każdego
166
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
szczegółowe informacje dotyczące produktów, takich jak Windows, NetWare i
Unix.
Ważną cechą systemów sieci LAN, takich jak Ethernet, ARCnet i Token-Ring,
które zostały opisane w poprzednich rozdziałach, jest całkowita niezależność
sprzętu sieciowego od oprogramowania sieciowego. Kiedyś firmy takie jak IBM i
Digital wiązały systemy sieciowe z konkretnymi systemami operacyjnymi, jednak
ich konkurenci przeforsowali międzynarodowe, otwarte standardy. Dzisiaj
rzadkością jest sytuacja, w której określony sprzęt sieciowy wymusza stosowanie
określonego oprogramowania. W szczególności zawdzięczamy to powszechnej
popularności Ethernetu.
W rozdziale 7. opisano podstawy standardów Ethernet, ARCnet i Token-
Ring.
Rozdział 6. zawiera wszystkie informacje na temat okablowania.
Informacje o współpracy kart sieciowych z komputerami PC zawiera
rozdział 5.
W dalszej części tej książki Czytelnik może zapoznać się z systemami
NetWare i Microsoft Windows NT.
Funkcje oprogramowania dla sieci LAN
W tym miejscu warto przypomnieć cztery koncepcje, z którymi Czytelnik już
zetknął się we wcześniejszych rozdziałach:
υ
Głównym celem oprogramowania sieciowego jest umożliwienie
współużytkowania zasobów – na przykład drukarek, dysków twardych i
łączy komunikacyjnych – pomiędzy klientami sieci.
υ
Podstawową funkcją oprogramowania sieciowego jest sprawienie, aby
odległe zasoby były dostępne jak zasoby lokalne.
υ
Oprogramowanie sieciowe realizuje te same funkcje niezależnie od systemu
operacyjnego. Nazwy produktów i protokołów mogą się zmieniać, ale idea
jest taka sama do Windows, dla Uniksa, dla MacOs i dla innych systemów
operacyjnych.
Wszystkie systemy są sieciowe...mniej więcej
Najważniejsze współczesne systemy operacyjne to Microsoft Windows
2000, NetWare, Sun Solaris, Linux i różne odmiany Uniksa. Faktem jest,
że systemy operacyjne Windows 98 i MacOS firmy Apple mają
wbudowane możliwości sieciowe i pewne podstawowe moduły
funkcjonalne, jednak funkcje sieciowe w tych systemach mają charakter

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
167
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
167
drugorzędny względem ich podstawowych funkcji.
υ
Do formatowania, adresowania i niezawodnego przesyłania danych
poprzez sieci system operacyjny używa warstw oprogramowania o
określonych regułach zachowania, zwanych protokołami.
Sieciowy system operacyjny nie jest jednym programem, ale raczej zestawem
programów. Niektóre z tych programów działają na komputerach w roli serwerów
różnego rodzaju, inne z kolei pełnią rolę klientów. Obecnie moduły programowe
które realizują funkcje sieciowe wydają się integralną częścią systemów
operacyjnych
w rodzaju Microsoft Windows 95/98 czy Sun Solaris, jednak ich zadania są w
dalszym ciągu odrębne.
Oprogramowanie sieciowe na serwerach umożliwia równoczesny dostęp wielu
użytkowników do napędu dysków, drukarek i innych urządzeń, takich jak modemy,
interfejsy komunikacyjne czy telefaksy a jednocześnie steruje tym dostępem.
Oprogramowanie sieciowe na stacjach klienckich przechwytuje żądania usług
generowane przez programy użytkowe, a następnie przeadresowuje je do
odpowiedniego serwera w celu realizacji.
Oprogramowanie klienta PC
Komputery korzystające z zasobów sieciowych powszechnie nazywa się
klientami
(client). Komputer-klient używa dysków twardych, łączy komunikacyjnych i
drukarek podłączonych do serwera, tak jakby były one podłączone lokalnie. W
niektórych sieciowych systemach operacyjnych stacje klienckie mogą również
działać jako serwery, ale dzisiaj wiele komputerów w sieciach LAN działa jako
pewna forma serwera. Biurowy PC może udostępniać innym klientom PC w sieci
swój napęd CD-ROM, drukarkę czy port komunikacyjny.
Oto kilka istotnych punktów pozwalających zrozumieć, w jaki sposób
oprogramowanie sieciowe wykonuje swoje zadania:
υ
klienty PC używają wspólnych zasobów udostępnianych przez serwery,
υ
klient PC nie zawsze wymaga specjalnych aplikacji,
υ
specjalne programy (readresatory) kierują żądania do serwerów,
υ
oprogramowanie warstwy transportowej przesyła dane przez kabel,
υ
istnieje wiele rodzajów serwerów.
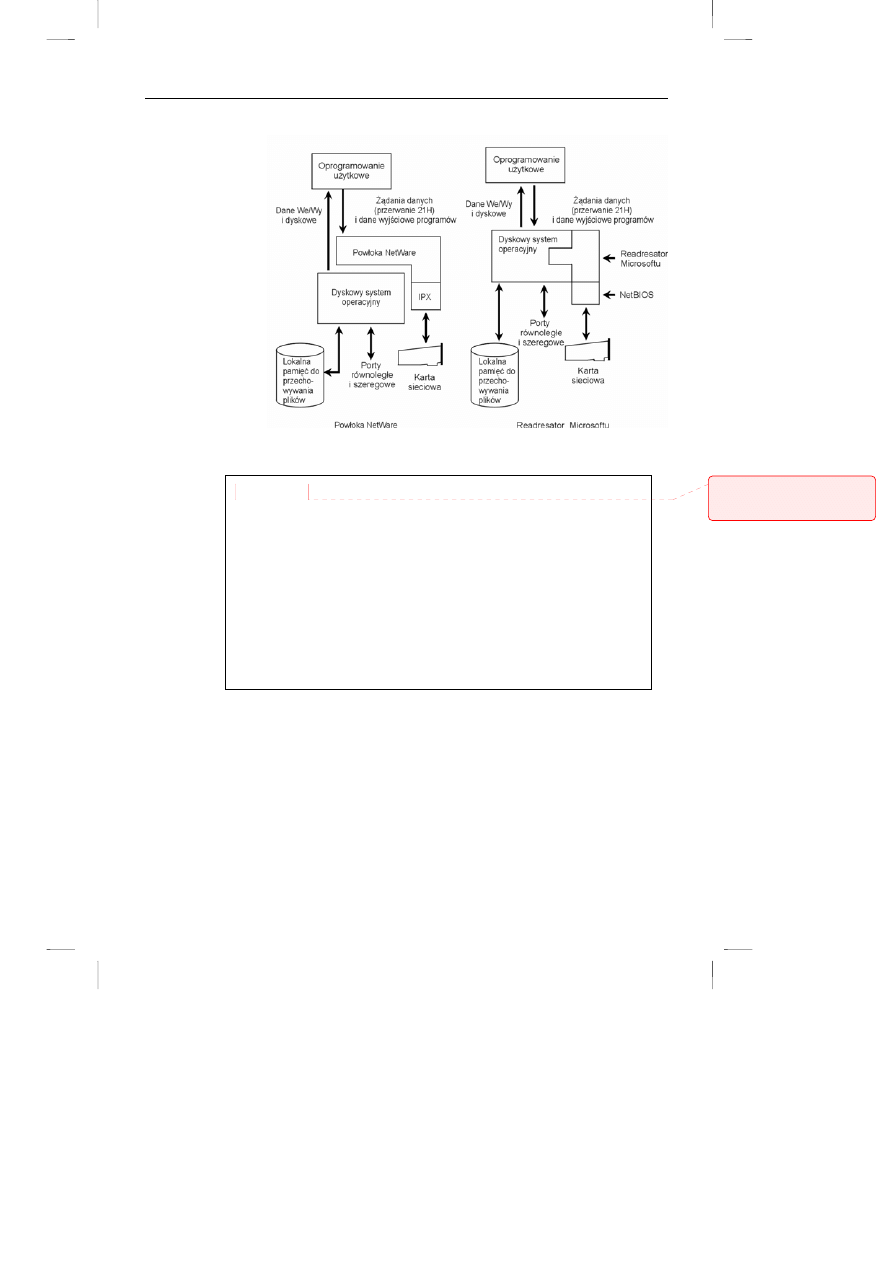
Punkty te zostały szczegółowo objaśnione w poniższych podrozdziałach. Na rysunku
8.2 przedstawiono graficznie warstwy oprogramowania sieciowego w sieciach
Microsoftu, Novella i sieciach TCP/IP. Z uwagi na ilość odwołań do tego rysunku w
treści niniejszego rozdziału, najlepiej będzie zaznaczyć odpowiednią stronę zakładką.
168
Sieci komputerowe dla każdego
168
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Kiedy serwer nie jest serwerem?
Pojęcia
serwer
i
klient
opisują funkcję komputera w sieci; nie mówią one
nic na temat mocy lub pojemności komputera pełniącego daną funkcję.
Ponadto terminy te nie wykluczają się nawzajem; często jakiś komputer
działa jako serwer pewnego rodzaju – w szczególności jako serwer
wydruków – i jednocześnie jako klient. Producenci sprzętu sprzedają
produkty zaprojektowane do pełnienia funkcji serwera, ale nie są
faktycznie serwerami, dopóki ich napędy i porty nie zostaną udostępnione
klientom sieci. Funkcja jest ważniejsza niż sprzęt.
Readresator
Mapowanie dysków
Funkcja wiązania zasobów z współużytkowanymi napędami dysków lub
portami nazywa się
mapowaniem
(
mapping
to inaczej
przypisanie
lub
odwzorowanie
). Z punktu widzenia aplikacji mapowane dyski działają tak
samo, jak dyski lokalne.
Oprogramowanie przeadresowujące w każdym komputerze-kliencie umożliwia
korzystanie z zasobów dostępnych w siecipodobnie, jak z zasobów lokalnych, a
także daje dostęp do programów znajdujących się na innych komputerach i pozwala
komunikować się z poszczególnymi użytkownikami sieci. Polecenia systemu
operacyjnego lub niektóre funkcje programów użytkowych, które odnoszą się do
dysków oznaczonych na przykład D:, E: lub F: (przy założeniu, że są to tak zwane
dyski sieciowe, czyli zasoby udostępniane przez inne komputery w sieci – przyp.
tłum.), są przeadresowywane i kierowane poprzez sieć do odpowiednich serwerów
plików. Podobnie działają programy, które wysyłają dane wyjściowe na drukarkę i
używają do tego celu portu wymienionego na liście obok lokalnych portów
komputera.
Readresator i elementy programowe przesyłające dane wyjściowe readresatora
poprzez sieć to moduły systemu operacyjnego stacji klienckiej. Readresator działa
w ramach systemu operacyjnego tak, że pewne typy żądań programów użytkowych
lub bezpośrednio użytkownika są kierowane do realizacji poprzez kartę sieciową
a nie do lokalnych dysków twardych lub portów We/Wy. To administrator systemu
za pomocą poleceń menu lub z wiersza poleceń programuje readresator, tak aby
żądania adresowane do napędu dysków o odpowiednim oznaczeniu literowym lub
do określonego portu We/Wy były przeadresowywane do określonych zasobów
sieciowych.

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
169
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
169
Na przykład w sieci z systemem NetWare Novella, w celu przeadresowania żądań
do dysku F: na podkatalog KONTA na dysku o nazwie WOLUMEN1, znajdującym
się na serwerze SERWER1, należy użyć następującego polecenia:
MAP F: = SERWER1/WOLUMEN1:KONTA
W systemie NetWare polecenia tego rodzaju są zwykle częścią systemowego
skryptu logowania przypisanego poszczególnym użytkownikom. Skrypty takie –
centralnie administrowane – dają każdemu użytkownikowi indywidualny obraz
zasobów sieciowych. Tworzenie i utrzymywanie różnych skryptów logowania dla
różnych kategorii użytkowników to ważne zadanie administratorów sieci. W
systemach z graficznym interfejsem użytkownika, takich jak Windows czy MacOS,
zasoby udostępniane w sieci wybiera się, klikając myszką ich ikonę, by następnie
zaznaczyć odpowiednie polecenie menu, jednak w procesie tym wykorzystuje się tę
samą koncepcję
mapowania
odległych zasobów literami lokalnych napędów
dysków lub nazw portów.
Oprogramowanie warstwy transportowej
Dodatkowa warstwa programowa w kliencie zajmuje się przesłaniem żądania
usługi zgłoszonego przez aplikację z readresatora do karty sieciowej i dalej do sieci.
Oprogramowanie to składa się z trzech części:
υ
interfejsu do programowania aplikacji (application programming interface
– API),
υ
części do komunikacji sieciowej, posługującej się określonym protokołem,
υ
sterowników dostosowanych do karty sieciowej.
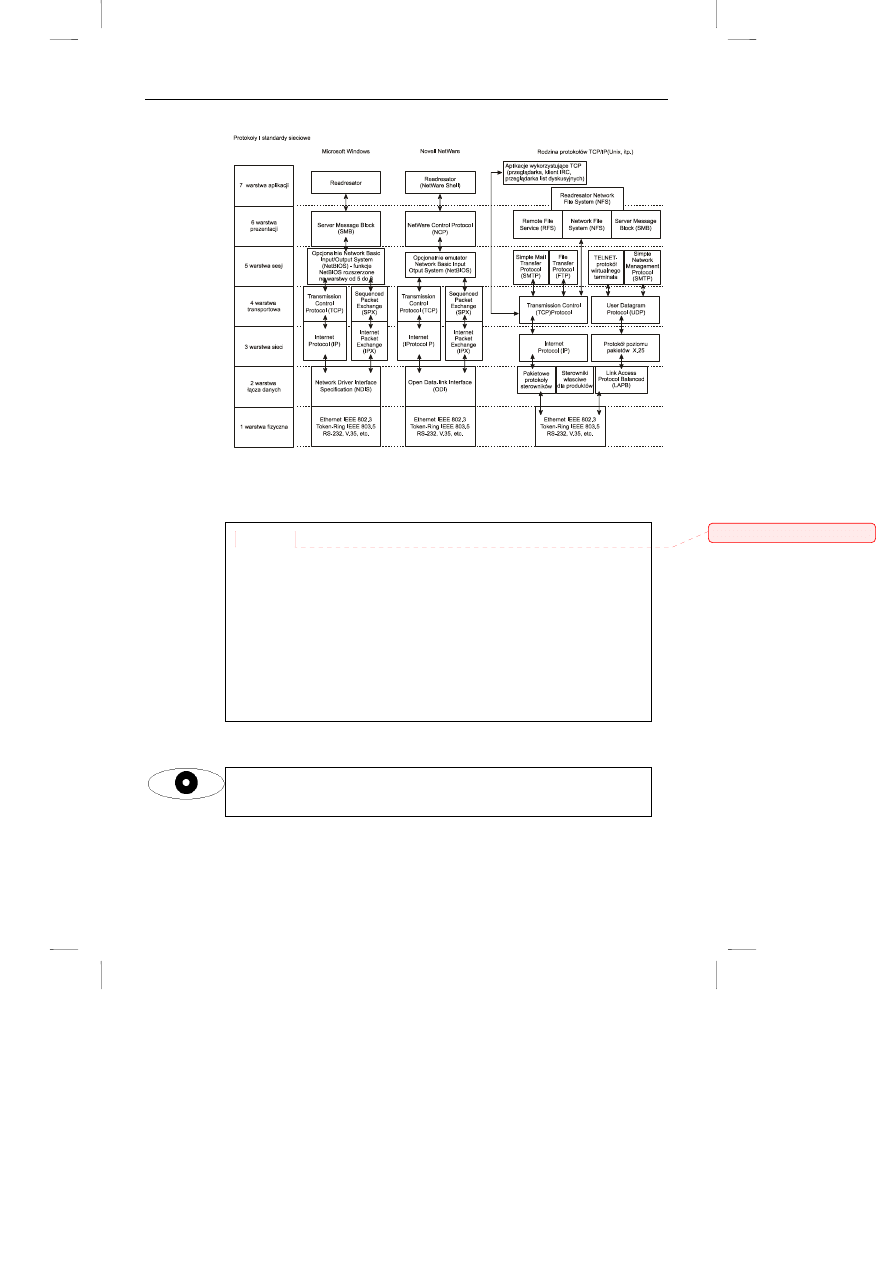
Rysunek 8.1 przedstawia powiązanie pomiędzy readresatorem a oprogramowaniem
warstwy transportowej. Rysunek 8.2 pokazuje w jaki sposób systemy Windows,
NetWare i Unix wpasowują się w siedmiowarstwowy model OSI.
170
Sieci komputerowe dla każdego
170
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Rysunek 8.1.
Związek pomiędzy
readresatorem
a oprogramowaniem
warstwy
transportowej.
Powiązania pomiędzy readresatorem a oprogramowaniem warstwy
transportowej
Novell nazywa swoje oprogramowanie przeadresowujące na stacji
klienckiej „powłoką” (shell), aby podkreślić, że otacza ono system
operacyjny i przechwytuje wszelkie żądania danych, a także komendy z
programów użytkowych i bezpośrednio z klawiatury. Microsoft instaluje
readresatora klienta Windows razem z innymi modułami
oprogramowania sieciowego, takimi jak moduły warstwy transportowej.
Shell Novella i readresator Microsoftu kierują odebrane komunikaty do
karty sieciowej poprzez oprogramowanie warstwy transportowej, na
przykład NetBIOS, TCP lub SPX/IPX Novella. Każdy sterownik jest
skonfigurowany odpowiednio do marki i modelu karty sieciowej.
Interfejs do programowania aplikacji
(API) to w rzeczywistości specyfikacja
określająca, w jaki sposób programy użytkowe (na przykład edytory tekstu,
programy graficzne, arkusze kalkulacyjne) współdziałają z dyskowym lub
sieciowym systemem operacyjnym. Specyfikacja ta określa między innymi
przerwania programowe
wysyłane przez program w celu zgłoszenia żądania usługi
oraz format danych zawartych w żądaniu.
Komentarz: Podpis rysunku
przeniosłem do ramki na
marginesie
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
171
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
171
Rysunek 8.2.
Systemy
Windows,
NetWare, Unix
w modelu OSI
Protokoły i standardy sieciowe
Każda z głównych rodzin systemów operacyjnych zbudowana jest z
modułów realizujących pewne usługi. Struktura tych modułów jest
interesująca z teoretycznego punktu widzenia, ale ma również ważne
znaczenie praktyczne. Określa bowiem co z czym współpracuje! Istnieje
wiele dziwnych hybryd, o których Czytelnik mógł słyszeć, na przykład
SMB Microsoftu działających z TCP/IP lub SNMP z IPX. Jednak
najrozsądniej jest trzymać się protokołów sieciowych pochodzących z
jednej rodziny. Należy zwrócić uwagę, że Internet wymusił przyjęcie
rodziny TCP/IP jako rodzimych protokołów w systemach Microsoftu i
Novella.
Wyczerpujące informacje na temat sterowników i kart sieciowych można
znaleźć w rozdziale 5.
Standardowe aplikacje
Komentarz: j.w.
172
Sieci komputerowe dla każdego
172
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Bogu dzięki za Y2K!
Pluskwa milenijna to bodaj najlepsza rzecz, jaka kiedykolwiek przytrafiła
się w branży oprogramowania. Zanim sprawa stała się głośna, szefowie
działów informatyki często tolerowali archaiczne aplikacje biznesowe (na
przykład bezpośrednio używające adresów sprzętowych), ponieważ wciąż
jeszcze działały. Problem roku 2000 dał motywację do przepisania wielu
złych programów.
Kiedy program użytkowy potrzebuje dostępu do pliku na dysku, tworzy blok
danych zawierających parametry żądania. W systemie operacyjnym Windows
standardowe aplikacje umieszczają adresy takich bloków danych w specjalnym
rejestrze
i generują
przerwanie 21
(szesnastkowo). W odpowiedzi na przerwanie system
operacyjny odczytuje adres, a następnie odpowiedni blok danych. Tak postępują
wszystkie współczesne, „dobrze ułożone” programy. Tylko starsze, „źle ułożone”
omijają usługę Windows i bezpośrednio „odpytują” dysk twardy. Wszystkie takie
programy, które są jeszcze gdziekolwiek używane powinno się zastąpić ich
współczesnymi odpowiednikami.
Jeśli system operacyjny używa readresatora, program ten sprawdza, czy żądania
aplikacji nie dotyczą zasobów sieciowych. Załóżmy na przykład, że aplikacja żąda
odczytania danych z dysku G:, a readresator został zaprogramowany tak, aby mógł
rozpoznać dysk G: jako określoną część konkretnego napędu dyskowego serwera w
sieci. Wówczas readresator kieruje to żądanie poprzez sieć do właściwego celu.
Udostępnianie zasobów w sieci zawsze wiąże się z ryzykiem potencjalnego
konfliktu. Przyjmijmy, że dwóch użytkowników pracuje nad tym samym
dokumentem WYDATKI.TXT. Pojedyncza kopia dokumentu jest zapisana na
udostępnianym dysku serwera. Jeśli edytory tekstu obydwu użytkowników nie są
dostosowane do współpracy z oprogramowaniem sieciowym, możliwe jest, że obaj
będą mogli jednocześnie otworzyć ten sam plik. W przypadku typowych
programów do obróbki tekstów otworzenie pliku oznacza wczytanie zawartości
pliku do pamięci operacyjnej komputera lokalnego.
Załóżmy, że pierwszy użytkownik dokona zmian w pliku i zapisze go, podczas gdy
drugi użytkownik wciąż ma ten plik otwarty. Jeśli zatem drugi użytkownik
wprowadzi zmiany i zapisze plik, ta czynność spowoduje, że wersja zapisana przez
pierwszego użytkownika zostanie zastąpiona wersją drugiego użytkownika, co
znaczy, że praca pierwszego użytkownika poszła na marne (o ile nie zapisał swoich
zmian pod inną nazwą).
Istnieje kilka sposobów rozwiązania tego problemu. Po pierwsze – użytkownicy
mogą pracować na różnych kopiach tego dokumentu zapisanych w swoich
prywatnych podkatalogach, a zmiany mogą wprowadzać ręcznie do pliku
wynikowego.
Nie potrzeba specjalnych aplikacji

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
173
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
173
Nie od rzeczy będzie przypomnieć, że do pracy w sieci używa się
najczęściej standardowych aplikacji. To oprogramowanie sieciowe ma
sprawić, aby dla tych aplikacji zasoby sieciowe, na przykład napędy
dysków, drukarki i inne, nie różniły się niczym od zasobów lokalnych.
Zainstalowanie sieci wcale nie znaczy, że trzeba również wymienić
oprogramowanie użytkowe. Chociaż niektóre aplikacje wykorzystują sieć
w specjalny sposób (najlepszym przykładem są przeglądarki internetowe),
zwykłe aplikacje będą również działać w sieci.
Po drugie – mogą oni skoordynować swoją pracę i nie otwierać tego samego pliku
równocześnie. I na koniec – mogą oni zaktualizować swoje edytory tekstów, tak
aby były one w stanie rozpoznawać komunikaty sieciowego systemu operacyjnego.
W większości jednak edytory tekstu sprzedawane w ciągu kilku ostatnich lat są
w stanie stwierdzić, kiedy inna aplikacja już korzysta z danego pliku i ostrzec
każdego, kto będzie próbował otworzyć taki plik. Najczęściej aplikacje proponują
w takiej sytuacji otworzenie pliku używanego przez kogoś innego w trybie tylko-do-
odczytu, co uniemożliwia użytkownikom dokonywanie jednoczesnych zmian w tym
samym pliku.
Współużytkowanie danych
Sprawy jeszcze bardziej się komplikują, jeśli chcemy, aby jednoczesny dostęp do
tych samych plików miało wielu użytkowników. Rozważmy jednak na
począteksytuację, w której pliki są udostępniane podobnie jak książki w bibliotece
zgodnie
z zasadą – jeden użytkownik w danej chwili.
Kiedy program użytkowy otwiera plik danych, może jednocześnie ustawić pewne
ograniczenia dotyczące równoczesnego korzystania z tego pliku przez inne
aplikacje. Programiści mają do wyboru kilka różnych sposobów realizacji tej
funkcji. Program może na przykład otworzyć plik w trybie wyłączności (odmawiając
wszelkim innym aplikacjom możliwości odczytu i zapisu pliku w tym samym czasie)
albo w innych trybach, które pozwalają na odczyt lub zapis (czy nawet jedno i drugie)
pliku przez inne aplikacje, ale w określonych warunkach. Możliwe jest również
zezwolenie na otworzenie pliku w trybie, w którym wszystko jest dozwolone dla
wszystkich aplikacji i w dowolnym czasie.
Przy otwieraniu pliku programiści mogą zastosować dowolny z tych warunków.
Najczęściej używanym trybem współużytkowania dla operacji sieciowych jest tryb
określony opcją 2 Deny Write, ponieważ umożliwia on zmianę pliku tylko jednemu
klientowi PC, podczas gdy pozostali mogą tylko ten plik odczytywać.
Jeśli kolejni użytkownicy potrzebują możliwości modyfikacji plików, wszystkie
programy powinny używać opcji 4, a programiści muszą sięgnąć do specjalnych
technik, aby zapobiec zniszczeniu danych.

174
Sieci komputerowe dla każdego
174
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Przy otwieraniu pliku współczesne aplikacje używają jednego z trybów SHARE
(współużytkowanie). Poniżej wymieniono opcje tego trybu dostępne dla
programistów:
Numer opcji
Opis
0 Compatibility
(Zgodność)
1
Deny Read/Write (Zablokuj odczyt/zapis)
2
Deny Wite (Zablokuj zapis)
3
Deny Read (Zablokuj odczyt)
4
Deny None (Nic nie blokuj)
Jeśli aplikacja nie została zaprojektowana z myślą o tworzeniu współużytkowanych
plików danych, potrzebna jest procedura programistyczna, która będzie otwierała
pliki danych, uniemożliwiając innym programom dostęp do tych plików. Pliki
utworzone przez taką aplikację będą dostępne w sieci dla pojedynczych
użytkowników na zasadzie „kto pierwszy, ten lepszy”; tak jak książki w bibliotece.
Równoczesny wielodostęp
System zarządzania bazą danych (Database Management System – DBMS) to
najpowszechniejszy przykład równoczesnego wielodostępu do plików w sieci LAN.
Baza danych składa się z plików zawierających rekordy. Aby móc przeczytać
rekordy w tych plikach, program działający na kliencie PC musi otworzyć kilka
takich plików. W tym samym czasie inny program może również otworzyć jeden
z takich plików, aby zapisać nowe rekordy. Rzecz jasna, kiedy jedna stacja
sieciowa próbuje odczytać rekordy, a inna w tym samym czasie je zapisuje,
pojawienie się problemów wydaje się nieuchronne.
Jednak z pomocą przychodzi tu możliwość zablokowania przez aplikację tylko
pewnego zakresu bajtów z pliku na wyłączny użytek tej aplikacji. Na przykład, jeśli
w systemie Windows program użytkowy wysyła przerwanie systemu operacyjnego
21 hex i wywołanie funkcji 5C hex (nie należy tego mylić z przerwaniem 5C hex,
które wywołuje NetBIOS), może przekazać systemowi informację o tym, ile bajtów
danego pliku należy zablokować do wyłącznego użytku. Po zablokowaniu tych
bajtów przez system operacyjny, żaden inny program nie będzie miał do nich
dostępu.
Każda próba dostępu do zablokowanego segmentu danych zakończy się wysłaniem
przez system operacyjnym komunikatu o błędzie do aplikacji, która taką próbę
podejmie.
Pakiety systemów DBMS z wbudowanymi własnymi językami programowania
udostępniają programistom tę funkcję blokującą za pomocą wewnętrznego
polecenia o nazwie RLOCK (Record Lock – zablokuj rekordy – przyp. tłum.).
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
175
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
175
Zazwyczaj programiści używają polecenia RLOCK, aby spowodować
zablokowanie przez aplikację określonej liczby rekordów, które muszą być
ponownie zapisane. Jednak system DBMS konwertuje to polecenie na polecenie
zablokowania przez system operacyjny odpowiedniego zakresu bajtów w pliku
bazy danych.
Ukryty DBMS
Współczesne systemy zarządzania bazami danych są ukryte za
aplikacjami napisanymi w językach C, Java lub w językach właściwych
dla systemów DBMS. I chociaż użytkownicy systemów wprowadzania
zamówień, systemów zarządzania klientami czy systemów spedycyjnych
nie dostrzegają w nich systemów DBMS, to jednak są one ich częścią.
Technologia DBMS jest dojrzała i ważna w zastosowaniach
biznesowych. Jednak sieciowy system DBMS z obsługą wielu
użytkowników to wciąż bardzo skomplikowane oprogramowanie.
Serwer baz danych to serwer aplikacji
Obecnie często słyszy się lub czyta o
serwerach aplikacji
. Można się także
spotkać z określeniem
serwer baz danych
. Są to określenia funkcjonalne.
Serwer baz danych jest praktycznie zawsze serwerem aplikacji, a serwer
aplikacji jest najprawdopodobniej serwerem baz danych. Na najwyższym
poziomie zarówno serwer aplikacji, jak i serwer baz danych można nazwać
serwerami plików
.
W przypadku aplikacji dla wielu użytkowników korzystającej z bazy danych,
programista lub system zarządzania bazą danych musi przekazać systemowi
operacyjnemu informację o tym, które bajty powinny zostać zablokowane, aby
zapobiec dostępowi do pliku w momencie, gdy jakaś aplikacja zapisuje w nim dane.
Jeśli to programista musi użyć w tym celu polecenia, na przykład RLOCK, mówi
się, że program ma
jawne
blokowanie rekordów. Jeśli natomiast system DBMS jest
na tyle „mądry”, że może automatycznie poinformować system operacyjny o
potrzebie zablokowania zakresu bajtów na czas zapisywania rekordu przez
aplikację, a o programie można powiedzieć, że ma
niejawne
blokowanie rekordów.
W systemach wielodostępnych, trzeba również znaleźć wyjście z sytuacji, gdy
aplikacja próbuje odczytać zakres bajtów zablokowany przez inny program.
Niektóre systemy zarządzania bazami danych wysyłają do takiej aplikacji
komunikat
Record locked
(rekord zablokowany). Programista musi taki
komunikat przewidzieć i znaleźć metodę obsłużenia go.
Istnieją różne możliwości obsługi komunikatu
Record locked
. Programista może
zdecydować się na stworzenie pętli, w której aplikacja po krótkiej przerwie ponowi
próbę dostępu. Może również zakończyć aplikację lub wyświetlić na ekranie
komunikat z pytaniem do użytkownika o decyzję w sprawie dalszych kroków.

176
Sieci komputerowe dla każdego
176
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Niektóre systemy DBMS automatycznie ponawiają próby dostępu. Funkcja ta jest
zwykle połączona z ograniczeniem maksymalnej długości czasu blokady rekordów.
Tak więc rzeczywista aplikacja – na przykład sieciowy system zarządzania bazą
danych, która umożliwia kilku operatorom dostęp do danych magazynowych i ich
aktualizację – musi zawierać fragment kodu, który poinstruuje system operacyjny
o konieczności zablokowania zakresu bajtów w danym pliku, jaki odpowiada
rekordowi lub polu, które w danej chwili są aktualizowane. Twórca aplikacji
systemu DBMS musi również opracować procedurę, obsługującą komunikat
systemu operacyjnego o zablokowaniu danych i przekazującą operatorowi
informację o tym, kto próbuje zmieniać pole, które jest właśnie modyfikowane.
Otwieranie plików w trybie wielodostępu lub w trybie wyłączności oraz obsługa
konfliktów przy jednoczesnym dostępie do danego segmentu danych to problemy, z
którymi muszą sobie radzić twórcy aplikacji sieciowych.
Najbardziej skomplikowana sytuacja ma miejsce wtedy, gdy kilka aplikacji otwiera
jednocześnie kilka różnych plików. Ponieważ rekordy w różnych plikach są ze sobą
w różny sposób powiązane, może dojść do sytuacji, w której dwie aplikacje
jednocześnie zablokują te same dane w celu realizacji swoich zadań. W literaturze
fachowej pojawia się wtedy
zakleszczenie
(deadlock). Zakleszczenie można
przerwać na wiele sposobów (na przykład – używając limitu czasu), ale każdy z
nich powoduje spowolnienie przetwarzania.
Niektóre systemy zarządzania bazami danych nie korzystają z funkcji blokowania
plików i bajtów systemu operacyjnego, ale przejmują je i realizują w bardziej
elegancki sposób, który jednocześnie pozwala uniknąć zakleszczeń. Aplikacje w
systemach tego typu mogą na czas tworzenia lub aktualizacji danych pozostawić
komunikat w specjalnym pliku rejestru, a po zakończeniu operacji usunąć go. Inne
aplikacje przed dostępem do danych sprawdzają ten plik rejestru. Jeśli jedna
aplikacja (aplikacja A) chce odczytać rekord, który właśnie jest aktualizowany
przez inną aplikację (aplikację B), musi poczekać. Jeśli czas oczekiwania
przekroczy określony limit, użytkownik aplikacji B zobaczy komunikat z
informacją o tym, kto zablokował rekord. Od tej chwili to użytkownik będzie
musiał rozstrzygnąć problem.
Użycie pliku rejestru jest „elegancką” metodą obsługi wspólnego dostępu do
danych, ale jednocześnie zwiększa obciążenie sieci i serwera. Każda aplikacja
przed każdym dostępem do danych musi uzyskać dostęp do pliku rejestru.
Aplikacje, które zapisują zmiany w pliku danych muszą wpisać odpowiednią
pozycję w rejestrze przed operacją oraz usunąć ją po zakończeniu. Skutkiem jest to,
że w sieci krąży większa ilość pakietów, a serwer musi obsłużyć znacznie więcej
żądań dostępu do dysku niż w przypadku ochrony danych metodami systemu
operacyjnego.
Żadna z metod zabezpieczenia danych nie jest idealna. Trzeba znać wady i zalety
obydwu podejść. Ważne, że teraz w sieciach pecetów dostępne są odpowiednie
metody, które umożliwiają wielu użytkownikom jednoczesny dostęp do tych samych
danych.

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
177
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
177
Najlepszą radą dla każdego administratora sieci lub bazy danych jest wybór
programów z rozbudowanym systemem pomocy technicznej. Często może się
zdarzyć potrzeba skorzystania z telefonicznej pomocy eksperta w celu rozwiązania
problemu. Koszty sprzętu, oprogramowania i instalacji sieci lokalnej to tylko
otwierający gambit w sieciowej grze. Aby zainstalować, skonfigurować i zarządzać
aplikacjami sieciowymi potrzebne, jest mocne wsparcie.
Wykorzystanie warstwy transportowej
Warstwa oprogramowania sieciowego poniżej readresatora jest nazywana warstwą
transportową. Zadaniem tego oprogramowania jest przygotowanie do przesyłki
żądania usługi, które jest prawidłowe w odniesieniu do wszystkich serwerów, na
jakich działa ten sam system operacyjny.
Zadanie to jest realizowane zgodnie z określonym protokołem. Program warstwy
transportowej adresuje pakiety do konkretnej funkcji komputera obsługującego,
niekoniecznie do określonego komputera.
Protokół warstwy transportowej o nazwie
Sequenced Packet Exchange
(SPX)
opracował Novell, a Microsoft zaadoptował specyfikację warstwy transportowej
zwaną
Network Basic Input/Output System
(NetBIOS). Chociaż te dwa protokoły są
wciąż bardzo popularne w sieciach LAN, coraz powszechniejsze zastosowanie
znajduje inny protokół warstwy transportowej o nazwie
Transmission Control
Protocol
(TCP). Popularność Internetu oraz przydatność TCP w połączeniu z
protokołem
Internet Protocol
(IP) są źródłem wzrastającego wciąż zainteresowania
sieciami opartymi na TCP/IP.
Oprogramowanie warstwy transportowej, we współczesnych sieciach najczęściej
protokoły TCP lub SPX, wykorzystują do określenia dokładnego adresu dla
przetwarzanych danych funkcję zwaną
usługa katalogową
(directory service).
Oprogramowanie to dysponuje pewnymi metodami identyfikacji każdej usługi w
sieci. Jeden z rodzajów usług związanych z nazwami, którego może używać
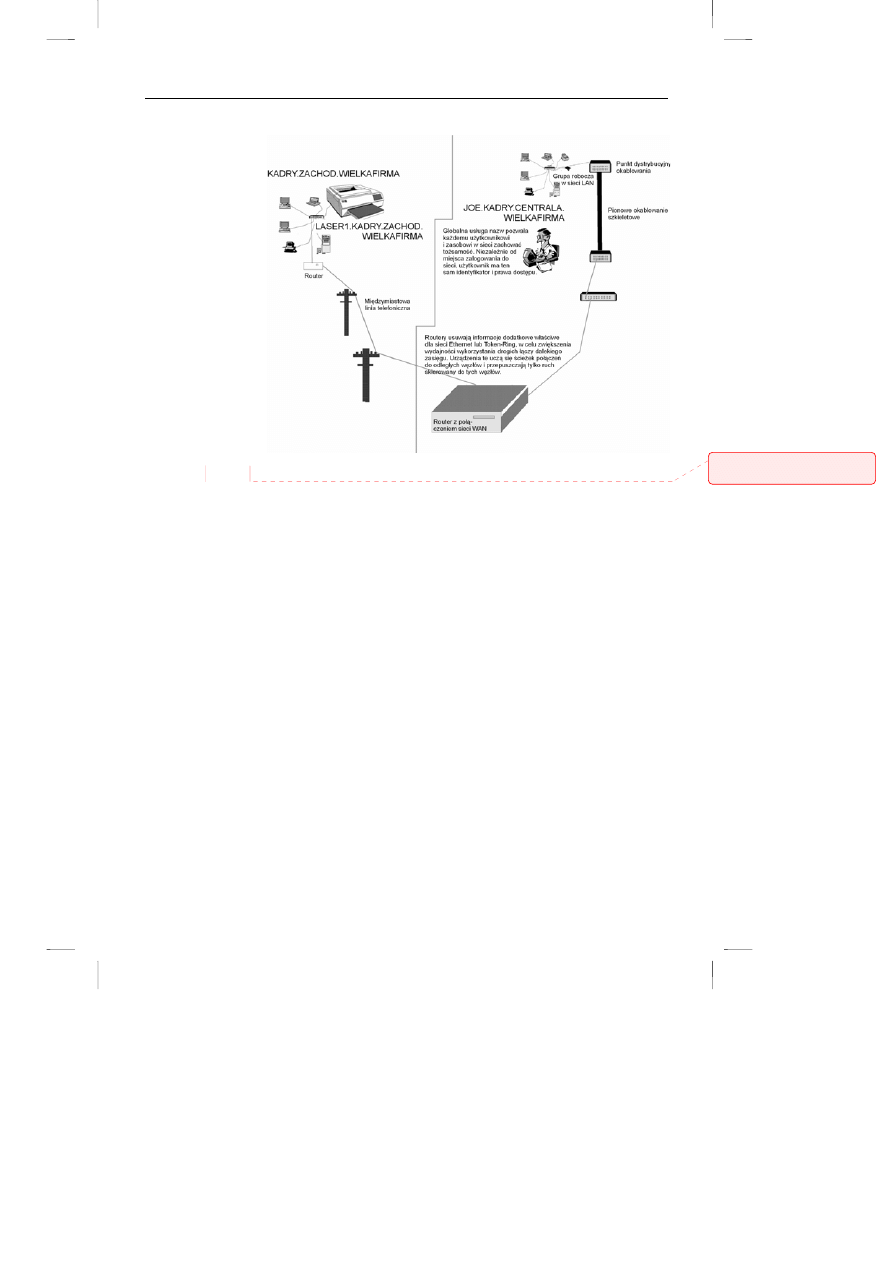
oprogramowanie warstwy transportowej przedstawiono na rysunku 8.3.
178
Sieci komputerowe dla każdego
178
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Rysunek 8.3.
Przykładowe
wykorzystanie usług
katalogowych
Usługa nazw powinna zapewnić precyzyjną, ale jednocześnie elastyczną metodę
identyfikacji usług, zasobów i użytkowników w sieci rozległej. W tym przypadku
nazwy łączą w sobie informacje geograficzne i korporacyjne.
Należy zwrócić uwagę, że na komputerach w sieci – na przykład na serwerach
plików – często można uruchomić kilka rodzajów usług (tak jak w budynku może
być wiele mieszkań czy wiele pomieszczeń biurowych).
Oprócz przetworzenia żądań usług w odpowiednio zaadresowane pakiety,
oprogramowanie warstwy transportowej odpowiada również za to, by pakiety
dotarły do celu. W poprzednim rozdziale dowiedzieliśmy się, że ethernetowe
datagramy nie dają pewności co do skutecznej realizacji przesyłki. Również
protokoły warstwy sieci (na przykład IP lub IPX) nie gwarantują dostawy. To
zazwyczaj oprogramowanie warstwy transportowej (SPX, NetBIOS lub TCP) jest
odpowiedzialne za rozpoznanie niepowodzenia przesyłki i zainicjowanie kolejnej
próby.
Aplikacje transportowe
W przypadku oprogramowania warstwy transportowej metodę wysyłania żądań do
sieci i odbierania ich stamtąd oferuje readresator, który jest elementem
standardowego interfejsu API (a także pewne klasy programów użytkowych,
odwołujących się bezpośrednio do oprogramowania warstwy transportowej). Na
przykład interfejs API protokołu NetBIOS interpretuje przerwanie programowe 5C
hex jako żądanie obsługi danych przez NetBios. Jednak coraz więcej aplikacji –
zwłaszcza w sieciach TCP/IP – ignoruje lokalny system operacyjny i z żądaniem
usług zwraca się bezpośrednio do oprogramowania warstwy transportowej.
Komentarz: niech podpis
rysunku pozostanie w tekście
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
179
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
179
Przykładami programów, które zgłaszają żądania bezpośrednio do protokołu TCP są
programy poczty elektronicznej, przeglądarki WWW, programy klienta IRC,
przeglądarki grup dyskusyjnych, programy do transmisji plików i wiele innych
specjalistycznych programów.
Oprogramowanie warstwy transportowej (TCP lub SPX) „śledzi” obsługę pakietów
skierowanych pod określony adres, ale sposób dostarczenia pakietów pod ten adres
to już sprawa oprogramowania warstwy sieci.
Podróże w warstwie sieci
Oprogramowanie warstwy sieci zaopatruje przesyłkę z danymi w dodatkowe
informacje potrzebne do przemierzenia sieci. Opakowanie w protokole IP jest
solidniejsze niż w protokole IPX, dzięki czemu pakiety IP lepiej nadają się do
routingu w dużych sieciach. Protokół IPX rozgłasza komunikaty o statusie, które w
dużych sieciach generują dużo dodatkowego ruchu, a które nie są potrzebne w
schemacie adresowania właściwym dla protokołu IP.
Protokoły warstwy sieci również dysponują pewnymi metodami identyfikacji
każdego funkcjonalnego węzła w sieci. Schemat adresowania używany w protokole
IP jest bardzo złożony, ale obejmuje wiele milionów węzłów. Natomiast schemat
adresowania w protokole IPX jest bardziej ograniczony, ale również bardziej
podatny na automatyzację, łatwiejszy w użyciu i bardziej wydajny.
Spedytor, dok załadunkowy i ciężarówka
Zamiast utwierdzać się w przekonaniu, że to wszystko jest zbyt
skomplikowane, lepiej przyjrzeć się prostej analogii. Oprogramowanie
warstwy transportowej działa jak pracownik działu spedycji
w firmie. Klient (program użytkowy) zostawia przesyłkę do wysłania.
Spedytor (protokół warstwy transportowej, np. TCP lub SPX) wypisuje
na przesyłce adres odbiorcy i miejsce dostawy. Zwykle spedytor załącza
również prośbę o potwierdzenie odbioru przez adresata. Protokół warstwy
sieci (na przykład IP lub IPX) pełni rolę nadzorcy doku załadunkowego,
który zna drogę przesyłki z doku załadunkowego do miejsca dostawy.
Dodatkowe opakowanie przesyłki, o ile jest potrzebne do wysyłki,
zapewnia warstwa łącza danych, a warstwa fizyczna zabiera przesyłkę w
drogę. Warstwa ta zostawia przesyłkę w doku załadunkowym miejsca
odbioru (Ethernet) lub prosi
o potwierdzenie odbioru (Token-Ring). Czy to nie jest proste?
TCP/IP nie nadaje się dla sieci LAN!
Stos protokołów TCP/IP nie był projektowany z myślą o krótkich,
„impulsowych” blokach danych przesyłanych w sieciach lokalnych.
Pakiety TCP/IP są jak 18-kołowe ciągniki siodłowe, przeznaczone do
transportu potężnych ładunków poprzez burzliwe terytoria sieci
rozległych. Są one zbyt duże dla niewielkich, uporządkowanych i

180
Sieci komputerowe dla każdego
180
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
szybkich środowisk sieci LAN. Ale z powodu popularności Internetu
i korporacyjnych intranetów, menedżerowie chcą używać protokołów
TCP/IP także w sieciach LAN. Wprawdzie – z uwagi na dość duże pasmo
sieci lokalnych – nieefektywność wniesiona przez dodatkowe informacje
związane z TCP/IP nie jest poważnym problemem.
Należy jednak mieć świadomość, że wraz z wyborem TCP/IP dla sieci
LAN pojawią się problemy z adresowaniem i bezpieczeństwem, których
nie było w przypadku alternatywnych protokołów, takich jak IPX,
przeznaczonych wyłącznie dla sieci LAN.
Typy serwerów
W sieci mogą występować trzy podstawowe typy serwerów: serwery plików,
serwery wydruków i serwery komunikacyjne. W każdej konkretnej sieci może
występować kilka serwerów z każdego rodzaju.
Należy pamiętać, że termin
serwer
jest tu używany w kontekście funkcjonalnym i
odnosi się do urządzenia, które pełni rolę serwera w sieci. W tabeli 8.1 wymieniono
typy i podtypy serwerów sieciowych.
Tabela 8.1 Typy serwerów sieciowych
Serwery plików
Serwery wydruków
Serwery komunikacyjne
Serwery baz danych
Na pececie z podłączoną drukarką Serwery
faksów
Serwery napędów CD-ROM Urządzenia specjalne
Bramy do systemów mainframe
Serwery aplikacji
Bramy poczty elektronicznej
Serwery WWW
Routery sieci IP
Serwery
protokołów YCP/IP
i Internetu
Serwery
DNS
Serwery
LDAP
Serwery
DHCP
Serwery
buforujące strony WWW
Niekiedy serwery plików, wydruków i serwery komunikacyjne działają na tym
samym komputerze w sieci, ale czasem zadania te są rozdzielone na różne
komputery. Serwer uniwersalny może zaoferować wspólny dostęp do plików, łącza
komunikacyjne do systemu mainframe oraz łącza dalekiego zasięgu pomiędzy
serwerami używającymi technologii X.25. Ogólny obraz serwerów i stacji
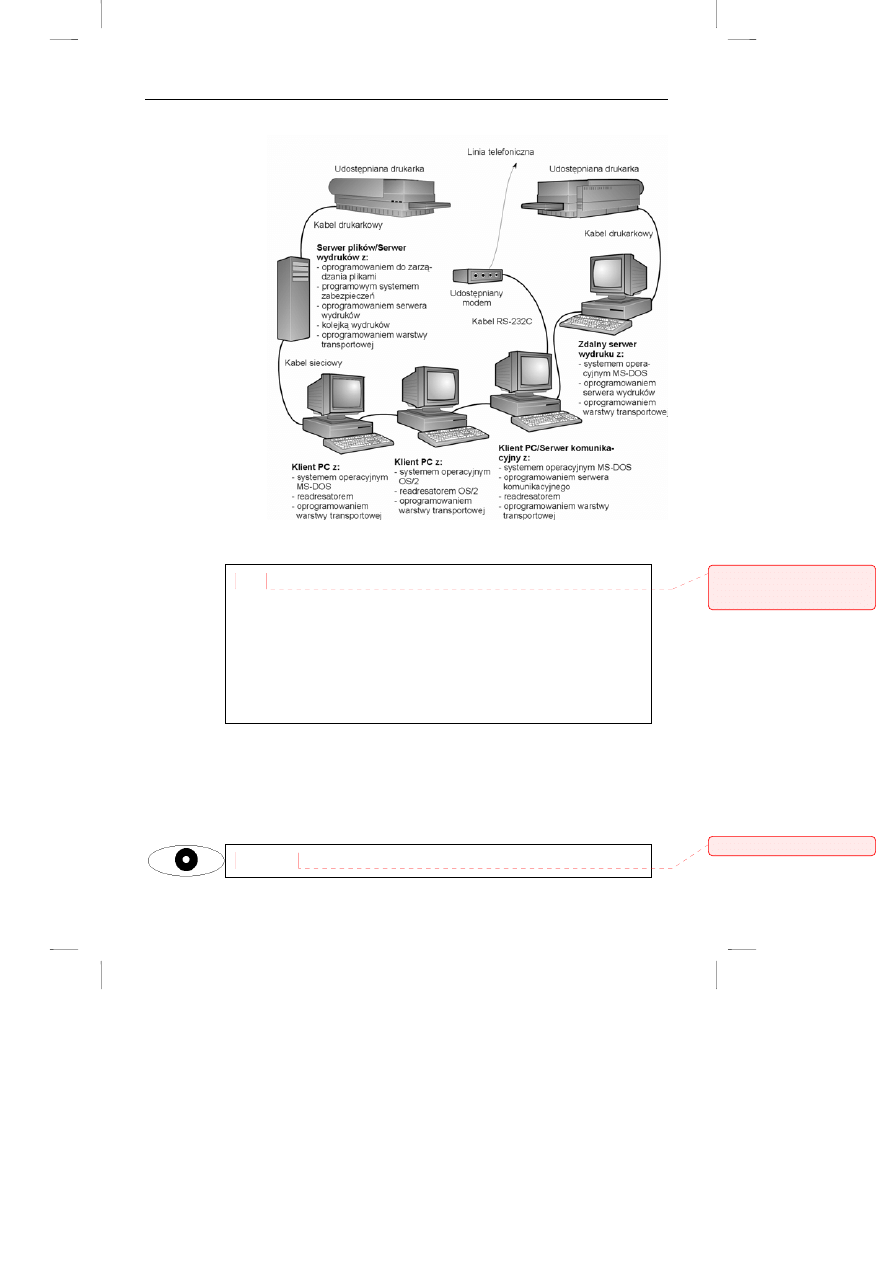
klienckich w praktycznej sieci pokazano na rysunku 8.4.
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
181
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
181
Rysunek 8.4.
Różne role
komputerów PC
w sieci
Rola komputera PC w sieci
Komputer PC może pełnić w sieci różne role. Na tym rysunku
przedstawiono sieć z trzema serwerami: serwerem plików, który pełni
również rolę serwera wydruków, serwera komunikacyjnego, który
udostępnia modem oraz zdalnego serwera wydruków. Na serwerze
komunikacyjnym można również uruchamiać standardowe aplikacje, tak
jak na komputerze osobistym, zawsze jednak trzeba się liczyć z pewnym
kompromisem, gdy chodzi o wydajność komputera, który jednocześnie
pełni rolę stacji roboczej i serwera usług sieciowych.
Firmy takie jak Microsoft i Sun projektują swoje systemy operacyjne tak, aby
komputery w sieci mogły pełnić rolę serwerów różnych usług, nawet wtedy, gdy są
one wykorzystywane do pracy ze standardowymi aplikacjami. Linux i inne,
„czystsze” wersje Uniksa zwykle działają w ten sam sposób. Jednak w systemie
sieciowym NetWare Novella komputery działające jako serwery są wyłączone z
innych zastosowań.
Informacje o serwerach drukowania można znaleźć w rozdziale 5.
Komentarz: podpis rysunku
przeniosłem do ramki na
marginesie
Komentarz: dopisałem See Also
182
Sieci komputerowe dla każdego
182
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Serwery Internetowe zostaną opisane w rozdziale 12.
Funkcje serwera plików
Serwer plików
udostępnia klientom PC przestrzeń na swoim dysku twardym. Serwer
plików obsługuje żądania odczytu i zapisu danych, które są kierowane przez
readresatory z programów użytkowych każdego klienta PC oraz rozstrzyga
jednoczesne żądania dostępu do tych samych danych.
Strzeż się specjalnych wertykalnych aplikacji
Najważniejsze oprogramowanie jest najczęściej przyczyną
najpoważniejszych problemów. Aplikacje wertykalne to programy
stworzone specjalnie do obsługi określonej działalności w ramach firmy.
Mogą one służyć do obsługi magazynu towarów dla sklepu lub części
zapasowych dla warsztatu naprawczego, mogą też śledzić „rezerwacje”
pokoi hotelowych lub planować dostawy surowców dla linii
produkcyjnej. W większości przypadków są one dziełem osób, które
więcej wiedzą o danej dziedzinie niż o programowaniu. Często ci,
nadzwyczaj wydajni, neofici robią rzeczy niemądre. W szczególności
używają w swoich programach usług obsługi plików właściwych dla
NetWare lub „markowych” wersji Uniksa. Ten brak roztropności ze
strony programistów może związać
użytkownika
z takim właśnie systemem operacyjnym. Dlatego należy sprawdzić
wszystkie aspekty każdej wirtualnej aplikacji firmowej i upewnić się, że
jest ona napisana dla usług uniwersalnych.

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
183
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
183
Serwery baz danych
i
serwery aplikacji
, to podzbiór kategorii serwerów plików,
który obejmuje serwery, na jakich działa dodatkowe oprogramowanie – zazwyczaj
system zarządzania bazą danych – i które najczęściej wykonują pewne zadania
porządkowe na rzecz komputera klienta. Te serwery
zaplecza
(back-end) baz
danych są podstawą modelu obliczeniowego klient-serwer, który stał się podstawą
wielu aplikacji przeznaczonych dla przedsiębiorstw. W rzeczywistości określenie
klient-serwer
ma kilka znaczeń. W najstarszej definicji mówi się po prostu o
technologii sieciowej, która wykorzystuje dedykowany serwer tak, jak robi to na
przykład system NetWare. Przeciwieństwem tej technologii jest sieć
równy-z-
równym
(peer-to-peer), która jest realizowana na przykład w systemach Windows
95/98. Dwie nowsze definicje pojęcia klient-serwer oparte są na różnych
architekturach sieciowych: architekturze serwera baz danych (wspomnianej
wcześniej), która wykorzystuje procesor zaplecza bazy danych i architekturze
serwera aplikacji.
W modelu bazy danych klient-serwer klient PC wysyła żądania danych do
programu zwanego
motorem bazy danych
(database engine), który działa na
komputerze pełniącym rolę serwera plików. Najważniejsi dostawcy motorów baz
danych to Oracle, IBM, Sybase i Microsoft. W tej architekturze serwer plików
(serwer DBMS/serwer aplikacji) działa jako wydajny procesor bazy danych, który
wykonuje specjalne polecenia – często formułowane w stworzonym przez IBM
języku SQL (Structured Query Language) – wysyłane z programów zapytań
działających na klientach PC w sieci. Procesor bazy danych odbiera proste żądanie
zestawienia danych ze stacji klienta i wykonuje złożony fragment kodu niezbędny
do uzyskania i skompilowania informacji z „surowej” bazy danych. Ponieważ
motor bazy danych działa na komputerze, który pełni rolę serwera plików,
programy zapytań nie muszą pobierać całych plików poprzez sieć w celu
odpowiedniego przetworzenia danych na kliencie PC. W tej architekturze
minimalizuje się obciążenie sieci, jednak odbywa się to kosztem zaspokojenia
wysokich wymagań dotyczących wydajności komputera obsługującego bazę
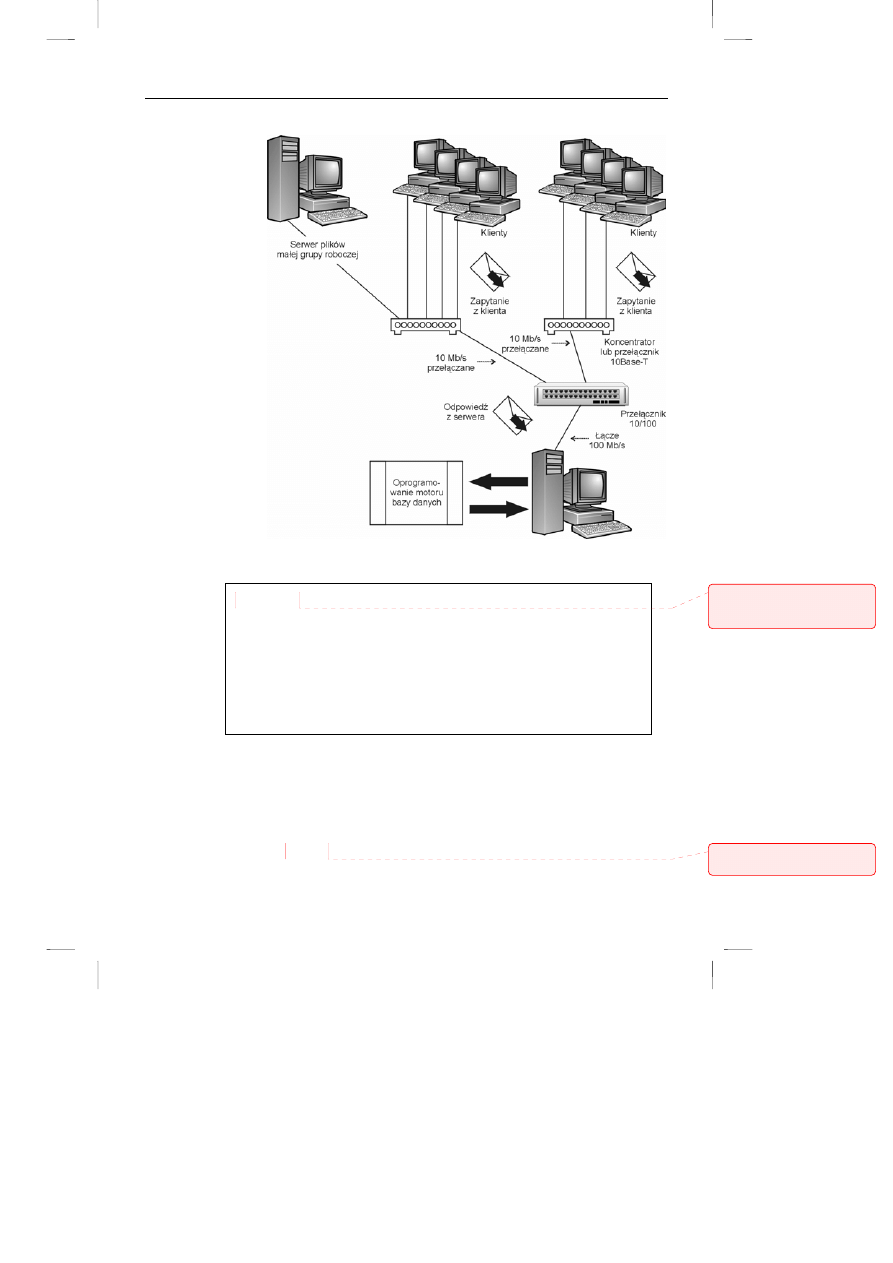
danych (patrz rysunek 8.5).
184
Sieci komputerowe dla każdego
184
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Rysunek 8.5.
Architektura
klient-serwer
Komputer PC obsługujący bazę danych
W architekturze klient-serwer aplikacje działające na kliencie żądają
danych uporządkowanych i zestawionych w określony sposób. Motor bazy
danych na serwerze otwiera potrzebne tabele z danymi, sortuje je, wybiera i
wykonuje inne funkcje a potem zwraca kompletną odpowiedź.
Rozwiązanie alternatywne polega na przesłaniu przez sieć do klienta
dużych ilości danych podstawowych. Może to być praktyczne tylko w
przypadku rzadkiego dostępu do niewielkich ilości danych.
Z podejściem tym kontrastuje starsza technologia baz danych, która wciąż jest
używana przez programy obsługujące nieduże bazy danych i z niewielką ilością
zapytań. W tym scenariuszu programy bazy danych działające na każdej stacji
pobierają dane z serwera poprzez sieć i przetwarzają je lokalnie na każdym
komputerze. Chociaż ta starsza technologia jest znacznie mniej wydajna, okazuje
się również mniej skomplikowana i wymaga mniej nakładów inwestycyjnych niż
wykonywanie motoru bazy danych na serwerze.
Komentarz: podpis rysunku
przeniosłem do ramki na
marginesie
Komentarz: MERYTORYCZN
E: motor bazy danych???
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
185
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
185
Architektura serwera aplikacji
to określenie, które niesie kilka znaczeń. Tak jak
w modelu klient-serwer może ono oznaczać jeden wydajny komputer, na którym
działa część aplikacji – na przykład baza danych lub program graficzny, taki jak X
Windows – i który obsługuje żądania dotyczące tej aplikacji zgłaszane przez
programy działające na klientach PC. Do komunikacji obydwa programy używają
techniki nazywanej
wywoływaniem odległych procedur
(Remote Procedure Call –
RPC). Wywołania RPC to w efekcie wstępnie ustalone, skrócone żądania
wykonania określonej czynności. IBM, opracowując architekturę
Advanced
Program to Program Communictaions
(APPC), utorował drogę do rozwoju
architektury serwera baz danych i serwera aplikacji. IBM stworzył APPC po to, aby
komputery PC mogły używać oprogramowania i sprzętu systemów mainframe
według modelu klient-serwer. W miarę spadku zainteresowania systemami
mainframe, IBM przekształcił APPC w
APPN
(Advanced Peer-to-Peer
Networking). Tym samym technologia klient-serwer, która powstała, aby
przedłużyć życie systemów mainframe stała się obecnie katalizatorem sprzedaży
zaawansowanych komputerów PC i AS/400.
Istotą serwera aplikacji jest
aplikacja rozproszona
. W powszechnym rozumieniu
aplikacje rozproszone to te, które przekraczają granice pomiędzy różnymi typami
komputerów i różnymi systemami operacyjnymi.
Open Software Foundation
–
organizacja założona przez IBM, HP i Digital – ustanowiła standardy dla
rozproszonego środowiska komputerowego
(Distributed Computing Environment –
DCE). Produkty środowiska DCE udostępniają standardowe wywołania programów
używane pomiędzy aplikacjami, tak że mogą one dzielić między sobą dostępną moc
obliczeniową. Środowisko DCE obejmuje protokoły bezpieczeństwa i protokoły
administracyjne, które umożliwiają programom tego środowiska rozpoznawanie się
nawzajem i komunikowanie ze sobą. DCE jest złożoną architekturą, a swoich sił na
tym polu próbuje wiele firm. Microsoft dołączył do DCE ze swoją architekturą
łączenia i osadzania obiektów
(Object Linking and Embeding – OLE), czyli
zestawem narzędzi programistycznych, które umożliwiają różnym aplikacjom
współużytkowanie określonych typów modułów informacyjnych zwanych
obiektami
.
Inna organizacja –
Object Management Group
, opracowała zestaw specyfikacji
podobnych do DCE, zwanych
Common Object Request Broker Architecture
(CORBA). Specyfikacje te dotyczą mniej więcej tych samych zagadnień co DCE,
jednak znacznie bardziej opierają się one na obiektach programowania wizualnego.
Na marginesie powyższej dyskusji należy wspomnieć, że termin klient-serwer niesie
różne znaczenia dla różnych osób. Strategowie gigantów takich jak IBM, Microsoft
i Novell, sądzą, że model obliczeniowy klient-serwer to ważny element ich
przyszłości, ale każda organizacja patrzy na zaangażowaną w ten model technologię
pod nieco innym kątem.
Sieciowe systemy operacyjne dla serwerów plików opisano w rozdziale
9.
Dużo więcej informacji na temat łączności pecetów z komputerami
AS/400 i z systemami mainframe można znaleźć w rozdziale 14.
186
Sieci komputerowe dla każdego
186
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Funkcje serwera wydruków
Komputery działające jako
serwery wydruków
udostępniają drukarki do wspólnego
użytku w sieci. Serwery wydruków przyjmują zadania drukowania z aplikacji
działających na stacjach klienckich i przechowują je w postaci plików w
specjalnym podkatalogu zwanym
buforem wydruków
(print spool) na dysku
twardym. Po zapisaniu całego zadania drukowania w buforze wydruków plik z tym
zadaniem czeka w kolejce na pierwszą wolną drukarkę lub na zwolnienie się
określonej drukarki, dla której jest przeznaczony.
Dysk z buforem wydruków może znajdować się na innym komputerze, działającym
jako serwer plików, jednak taka organizacja powoduje generowanie dodatkowego
ruchu sieciowego; z komputera, na którym działa aplikacja do serwera wydruków,
a stąd do serwera plików i ewentualnie z powrotem do serwera wydruków w celu
wydrukowania. W praktyce albo przypisuje się funkcję serwera wydruków serwerowi
plików, albo wyposaża się serwer wydruków we własny dysk twardy.
Oprogramowanie sieciowe dostarczane ze współczesnymi wersjami Windows
umożliwia każdemu komputerowi w sieci jednoczesne pełnienie roli serwera
plików, serwera wydruków, a także zezwala na uruchamianie na tym komputerze
programów użytkowych. System NetWare Novella ułatwia połączenie funkcji
serwera plików i serwera wydruków na jednym komputerze lub przypisanie funkcji
serwera wydruków osobnemu komputerowi. Na serwerach plików NetWare nie
można uruchomić typowych aplikacji, ale oprogramowanie serwera wydruków
można zainstalować na dowolnej stacji sieciowej używanej do uruchamiania
aplikacji.
Więcej alternatywnych rozwiązań problemu drukowania w sieci opisano
w rozdziale 3.
Zalety serwerów wydruków
Największą zaletą sieci z dedykowanymi serwerami wydruków jest możliwość
dowolnej przestrzennej aranżacji urządzeń sieciowych, która jest zgodna z
oczekiwaniami użytkowników. Jeśli natomiast połączy się funkcje serwera plików i
serwera wydruków, drukarkę sieciową trzeba będzie umieścić w pobliżu sprzętu
serwera, głównie z powodu ograniczeń w długości kabla biegnącego do portu
równoległego. Jako że komputer pełniący rolę serwera plików w solidnej sieci ma
wiele dość hałaśliwych napędów dysków, wydajne wentylatory i prawdopodobnie
sporych rozmiarów zasilacz UPS, zwykle lokuje się go w nieco bardziej oddalonym
miejscu,
a często – ze względów bezpieczeństwa – w zamkniętym pomieszczeniu. Trzeba
zwykle sporo pogłówkować lub mieć dużo szczęścia, aby znaleźć lokalizację
odpowiednią dla sprzętu serwera plików i wygodną dla użytkowników, chcących
odebrać swoje wydruki z drukarki.
Udostępnianie drukarek poprzez dogodnie zlokalizowane stacje robocze, które
działają jako serwery wydruków, wydaje się dobrą metodą rozwiązania problemu

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
187
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
187
lokalizacji drukarki. O ile jednak koncepcja jednoczesnego wykorzystania PC jako
serwera wydruków i stacji roboczej ma swoje plusy, o tyle ma również
ograniczenia praktyczne. Wymaga to podzielenia zasobów na realizowane funkcje i
doprowadza do tego, że użytkownicy czekający na wydruki oraz osoba próbująca
korzystać z aplikacji na serwerze wydruków, narzekają na coraz wolniejszą obsługę.
Przerwania sprzętowe generowane w związku z obsługą portów szeregowych i
równoległych oraz konkurencyjne żądania dostępu do dysku twardego mogą zwolnić
nawet najszybszy komputer, jeśli będzie on miał pracować jednocześnie jako
serwer
i osobista stacja robocza.
Decyzja o tym, czy połączyć funkcję serwera wydruków z serwerem plików ze stacją
roboczą, czy wydzielić ją na odrębnym komputerze, zależy głównie od intensywności
drukowania w sieci. Jeśli objętość wydruków nie przekracza 30 do 50 stron zwykłego
tekstu na godzinę, połączenie serwera wydruków z serwerem plików ma sens. Jednak
większe obciążenia drukowaniem, a także problemy z lokalizacją drukarki mogą
dyktować wydzielenie dedykowanego serwera wydruku.
W miarę zwiększania się objętości wydruków ze stacji klienckich i wzrostu
komplikacji programów użytkowych, tylko użytkownikom korzystającym z
względnie prostych aplikacji nie będzie przeszkadzać wykorzystanie ich peceta do
świadczenia usług serwera wydruków w sieci. Powszechną praktyką jest
przygotowanie dedykowanego komputera jako sieciowego serwera wydruków i
umieszczenie go w dogodnej lokalizacji w biurze.
Należy pamiętać, że to podejście wymaga poświęcenia kompletnego komputera PC
z twardym dyskiem, monitorem i klawiaturą dla każdego serwera wydruków.
Specjalistyczne serwery wydruków
Pod koniec roku 1990 w pracowniach LAN Labs PC Magazine pojawiła się nowa
kategoria produktów. Na początku nazwaliśmy je
urządzeniami do współużytkowania
peryferiów
w sieci Ethernet
(Ethernet peripheral sharing devices). Ta długa nazwa
opisywała ich funkcję, ale było mało prawdopodobne, by zapadła w świadomość
potencjalnych nabywców. Po intensywnej burzy mózgów zdecydowaliśmy się na to,
aby nazwać je
serwerami funkcji specjalnych
.
Najlepszym przykładem takiego urządzenia jest sprzętowy serwer wydruków, ale
do tej klasy należy także serwer napędów CD-ROM i kilka innych
specjalizowanych urządzeń. Produkty te (patrz rysunek 8.6) są podłączane do kabla
sieciowego
i udostępniają drukarki klientom w całej sieci.

188
Sieci komputerowe dla każdego
188
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Rysunek 8.6.
Serwer wydruków
przeznaczony do
„cienkiego”
Ethernetu umożliwia
użytkownikom
korzystanie z drukarki
w dowolnym miejscu
w sieci
Współczesne serwery wydruków mogą pracować z różnorodnymi protokołami, dzięki
czemu klienty używające NetWare, Windows czy Uniksa mogą drukować na tej
samej drukarce. Najbardziej ekonomiczne serwery wydruków mają dwa lub trzy
porty drukarkowe, więc pozwalają za pomocą jednego urządzenia udostępnić w sieci
dwie lub trzy drukarki.
Procesory tych urządzeń wykorzystują specjalne oprogramowanie zapisane w
pamięci tylko – do – odczytu. Nie wymagają one podłączania monitora, dysku ani
klawiatury. Serwery funkcji specjalnych mogą korzystać z oprogramowania
serwera wydruków, działającego na serwerze NetWare, aby odbierać i składować
zadania drukowania, które następnie mogą wziąć z kolejki i przesłać siecią do
drukarki.
Funkcje serwera komunikacyjnego
Termin
serwer komunikacyjny
odnosi się do wielu zadań. Serwery komunikacyjne
mogą działać jak bramy do sieci rozległych z protokołem IP, takich jak Internet czy
korporacyjne intranety. Mogą one działać jako portale, umożliwiając klientom PC
wspólny dostęp do systemów mainframe poprzez kosztowne kanały
komunikacyjne. Mogą również pełnić rolę buforów dla drogich, szybkich
modemów udostępnianych w trybie „pierwszy-zgłoszony-pierwszy-obsłużony”.
W przeciwieństwie do serwerów wydruków, głównym problemem w przypadku
serwerów komunikacyjnych nie jest lokalizacja przestrzenna. Można je postawić
wszędzie tam, gdzie jest dostęp do linii telefonicznej. Znacznie ważniejsza jest moc
procesora. O ile serwery wydruków buforują zadania wydruku skierowane na
drukarkę, serwery komunikacyjne muszą obsłużyć w czasie rzeczywistym
połączenie pomiędzy klientami PC a kanałami komunikacyjnymi. To powoduje
poważne obciążenie komputera działającego jako serwer komunikacyjny.
Obsługa przerwań sprzętowych generowanych przez porty szeregowe i równoległe
wykorzystuje w znacznym stopniu moc procesora serwera komunikacyjnego.
Niewielu użytkowników mogłoby usatysfakcjonować działanie programów
użytkowych na komputerze, który jednocześnie pełni rolę serwera
komunikacyjnego. Tak więc najczęściej we współczesnych sieciach
Komentarz: uzupełniłem podpis

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
189
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
189
oprogramowanie takiego serwera działa na komputerze dedykowanym do tych
zadań. Ze względu na rosnącą szybkość tak zwanych
procesorów sygnałowych
współczesne serwery komunikacyjne są często odrębnymi urządzeniami
zbudowanymi przy użyciu specjalizowanego sprzętu komunikacyjnego.
Serwery faksów
Serwery faksów
umożliwiają każdemu w sieci korzystanie ze sprzętu odbierającego
i wysyłającego faksy. Najczęściej funkcję tę wykonują komputery pełniące
jednocześnie rolę serwerów komunikacyjnych.
Serwery faksów świetnie sprawdzają się przy udostępnianiu modemów do połączeń
wychodzących, problemy jednak pojawiają się przy obsłudze faksów
przychodzących. Gdy serwer odbierze faks, to dokąd ma go skierować? Kiedyś
wyznaczony operator musiał czytać wszystkie faksy, jednak dzięki rozwojowi
technologii obecnie dostępnych jest pięć skutecznych technik wewnętrznego
kierowania faksów do poszczególnych użytkowników. Serwer faksów może
„przeczytać” linijkę tekstu, zareagować na tony DTMF (generowane przy
wciśnięciu przycisków telefonicznych), zidentyfikować linię, na którą przychodzi
faks, rozpoznać nadające go urządzenie lub rozpoznać schemat dzwonienia.
υ Odczyt linii tekstu
. Kierowanie faksów przychodzących na podstawie
odczytu linii tekstu wymaga użycia programu OCR do znalezienia
specjalnie sformatowanej linii zawierającej nazwisko adresata. Aby jednak
ta metoda działała, nadawca musi wiedzieć, jak sformatować faks.
υ Rozpoznawanie tonów DTMF
. Urządzenia rozpoznające tony DTMF
umożliwiają nadawcy – już po nawiązaniu połączenia – wygenerowanie
sygnałów wskazujących odbiorcę. Technika ta jest użyteczna, gdyż może
być zastosowana do wielu odbiorców, jednak jej minus satnowi
konieczność wykonania specjalnych czynności przez nadawcę.
υ Identyfikacja linii przychodzącej
. Jeśli serwer faksów korzysta z adaptera
dla wielu linii, może kierować faksy do poszczególnych użytkowników lub
grup roboczych na podstawie linii, na którą przyszedł faks.
υ Rozpoznawanie
urządzenia nadającego faks
. Rozpoznawanie numeru lub
identyfikatora (Customer Subscriber Identification – CSID) urządzenia
nadającego faks to użyteczna technika, ponieważ nie wymaga żadnych
specjalnych czynności po stronie nadawcy, ale jest ograniczona do
konkretnego telefaksu.
υ Rozpoznawanie schematu dzwonienia
. Schematy dzwonienia (distinctive
ringing) to przydatna opcja oferowana przez niektórych operatorów
telekomunikacyjnych. Polega ona na stosowaniu różnych schematów
dzwonienia dla kilku numerów używających jednej linii. Tak jak niektóre
modemy lub urządzenia faksowe mogą wykorzystywać schematy
dzwonienia do określenia czy powinny odebrać przychodzące połączenie,
tak serwery faksów mogą na tej podstawie kierować przychodzące faksy
do różnych skrzynek pocztowych. Technika ta nie wymaga żadnej

190
Sieci komputerowe dla każdego
190
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
dodatkowej wiedzy ani czynności po stronie dzwoniącego i pozwala mu
korzystać z dowolnego telefaksu.
Ostatnia możliwość to
bezpośrednie połączenia wewnętrzne
, które wykorzystują
sygnalizację pomiędzy firmą telekomunikacyjną a firmową centralą telefoniczną
umożliwiającą dodzwonienie się poprzez określone linie. Serwer faksów
interpretuje przychodzące połączenia i odpowiednio kieruje odebrane dokumenty.
Struktura oprogramowania serwera
Serwery umożliwiają zastosowania, które dostarczają funkcjonalnych i
ekonomicznych argumentów na rzecz instalacji sieci. Dodatkowym uzasadnieniem
konieczności budowy sieci LAN są możliwości wspólnego dostępu do informacji
oraz efektywność, jaką daje poczta elektroniczna lub planowanie pracy zespołów
roboczych. Rzecz jasna – do obsługi wielu zadań związanych z współużytkowaniem
zasobów serwery potrzebują specjalnego oprogramowania (sieciowego systemu
operacyjnego).
Oprogramowanie obsługujące serwery plików, wydruków czy serwery
komunikacyjne składa się z wielu różnych modułów. Na serwerach
komunikacyjnych działa oprogramowanie, które dokonuje translacji prędkości
transmisji w sieci na prędkość łącza komunikacyjnego, translacji alfabetów danych
i protokołów używanych przez połączenie zewnętrzne. Oprogramowanie serwerów
plików obejmuje wyrafinowane kolejki żądań i zazwyczaj obsługuje buforowanie
dysku. Funkcja buforowania dysku ładuje duże segmenty danych z dysku do
pamięci operacyjnej, aby szybko realizować żądania, dostarczając dane wprost z
szybkiej pamięci a nie z powolnego dysku.
Na serwerach działa oprogramowanie warstwy transportowej tego samego rodzaju
co na stacjach roboczych. Ponadto na serwerze działa oprogramowanie buforujące
żądania usług ze stacji sieciowych i ustawiające je w kolejkę. Oprogramowanie
serwera obejmuje najczęściej jakiś rodzaj zabezpieczeń, opartych na hasłach do
zasobów lub tabeli uprawnień przyznanych poszczególnym użytkownikom.
Oprogramowanie serwera plików można podzielić na trzy główne elementy:
υ System zarządzania plikami
, który zapisuje dane na przynajmniej jednym
dysku twardym i odczytuje je stamtąd.
υ System bufora dysku
, który gromadzi dane przychodzące i wychodzące
w pamięci RAM, dzięki czemu obsługa żądań jest szybsza niż wynikałoby
to z fizycznych możliwości dysku twardego.
υ System dostępu
, który kontroluje uprawnienia użytkowników do
korzystania z danych oraz obsługuje jednoczesny dostęp wielu aplikacji do
plików.

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
191
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
191
Wielozadaniowe systemy operacyjne dla sieci LAN (umożliwiające setkom węzłów
sieciowych dostęp do gigabajtów danych na pojedynczym serwerze) nadają tempo
i wyznaczają kierunek rozwoju branży sieci komputerowych oraz decydują, w jaki
sposób użytkownicy łączą się poprzez środowiska sieciowe i poza nimi.
Systemy te – na przykład – NetWare, Windows NT czy Unix – oferują elastyczne,
bezpieczne i niezawodne możliwości połączeń. Sieć komputerów PC zbudowana
w oparciu o jeden z tych systemów operacyjnych może z powodzeniem zastąpić
minikomputery w wielu organizacjach.
Funkcje zarządzania plikami
Podstawową funkcją oprogramowania do zarządzania plikami jest sterowanie
ruchem głowic dysków twardych i dostarczanie danych poprzez sieć do stacji
klienckich.
Do zwiększenia wydajności operacji na dysku twardym służy
algorytm windy
(elevator seeking). Aby odczytywać i zapisywać dane głowice dysku twardego
poruszają się do środka i na zewnątrz nad wirującym dyskiem. Każdy większy ruch
zajmuje czas rzędu milisekund. Oprogramowanie używające algorytmu windy
poprawia wydajność pracy dysku, ustawiając żądania w takiej kolejności, aby
dostęp do danych wymagał ruchu głowic w tym samym kierunku. Kolejność
napływu żądań nie ma w tym przypadku znaczenia; każde z nich jest realizowane z
uwzględnieniem najbardziej logicznego ruchu głowic. Umożliwia to takie
sterowanie głowicami, że poruszają się one ruchem posuwistym od krawędzi dysku
do jego środka i z powrotem.
Algorytm windy poprawia wydajność, znacznie redukując nagłe zmiany kierunku
ruchu głowic i minimalizuje czas wyszukiwania danych.
Szybszemu dostępowi do katalogów służy również technika indeksowania pozycji
katalogów zgodnie z określonym wzorem matematycznym, zwana
mieszaniem
katalogów
(directory hashing). Mieszanie katalogów ma charakter dwupoziomowy.
Pierwszy algorytm mieszający indeksuje katalogi danego wolumenu dyskowego,
a drugi pliki – tego wolumenu i podkatalogi. Mieszanie katalogów zmniejsza liczbę
odczytów katalogów po starcie serwera. Technikę tę z powodzeniem wykorzystano
w systemie NetWare i w innych systemach plików.
Systemy operacyjne serwerów wczytują zwykle do bufora pamięci dyskowej całą
strukturę katalogów na dyskach podłączonych do serwera. Operacja ta odbywa się
przy starcie serwera, a w trakcie jego pracy dokonywane są aktualizacje tej
struktury. W pierwszej kolejności aktualizowana jest kopia struktury katalogów
przechowywana w pamięci RAM, a w drugiej – o ile pozwala na to czas pomiędzy
obsługą żądań użytkowników – aktualizowane są dane na dyskach. Zapewnia to
szybkość realizacji operacji dyskowych, ale też niesie potencjalne zagrożenie. W
przypadku awarii zasilania lub jakiejkolwiek innej awarii serwera, która nastąpi
przed aktualizacją danych na dysku, może dojść do uszkodzenia plików.

192
Sieci komputerowe dla każdego
192
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Buforowanie dysku
Buforowanie dysku, które polega na wykorzystaniu pamięci RAM serwera do
przechowywania najczęściej używanych bloków danych z dysków serwera,
znacznie skraca czas dostępu do danych. Wczytanie danych z dysku twardego
zajmuje czas mierzony w setnych częściach sekundy. Pamięć RAM może
dostarczyć te dane
w czasie rzędu tysięcznych części sekundy. Przy współczesnych serwerach
obsługujących setki żądań na sekundę przyspieszenie dostarczania danych uzyskane
dzięki buforowaniu dysku staje się wyraźnie odczuwalne dla użytkowników stacji
roboczych.
Typowa wielkość bloku danych żądanego przez program użytkowy to 1 kB.
Natomiast system buforowania dysku wczytuje do pamięci RAM serwera
przynajmniej 4 kB danych z najbliższego sąsiedztwa danych żądanych. W celu
osiągnięcia maksymalnej skuteczności buforowania dysku administratorzy sieci
mogą skorzystać
z funkcji konfiguracyjnych oprogramowania buforującego i zmienić wielkość
wczytywanych bloków danych.
Buforowanie nie przyspiesza przetwarzania pierwszego żądania danych, ale jeśli
kolejne żądania będą dotyczyły danych, które znajdują się już w buforze, dane te
będą dostarczane znacznie szybciej, niż gdyby musiały być odczytane z dysku
twardego.
W wielu operacjach
wskaźnik trafień
bufora (liczba żądań zrealizowanych z bufora
w stosunku do ogólnej liczby żądań) przekracza 80 %.
Buforowanie dysku może również przyspieszyć operacje zapisu plików. Żądania
zapisu danych na dysku serwera trafiają do oznakowanych bloków bufora
dyskowego, które są systematycznie zapisywane na dysku w przerwach pomiędzy
obsługą żądań z sieci. Jednak buforowanie zapisu jest zwykle funkcją domyślnie
wyłączoną i dopiero administrator sieci może ją uruchomić, co jest spowodowane
jedną znaczącą wadą tej techniki. Jeśli zdarzy się poważna awaria dysku twardego
lub całego serwera albo jeśli wystąpi przerwa w zasilaniu, dane w buforze
czekające na zapis na dysku zostaną utracone. Dlatego potencjalny wzrost
wydajności systemu wynikający z buforowania zapisu należy zawsze oceniać pod
kątem potencjalnej straty danych w wyniku awarii.
Zwiększanie niezawodności systemu plików
Odporność na uszkodzenia
(fault tolerance), czyli zdolność do kontynuowania
pracy pomimo uszkodzenia istotnych podsystemów, to względnie nowy czynnik w
odniesieniu do sieci lokalnych. W miarę, jak coraz więcej użytkowników umieszcza
w sieci swoje najbardziej wartościowe aplikacje i dane, odporność na uszkodzenia
staje się coraz ważniejsza. Niektóre sieciowe systemy operacyjne – jak godne
uwagi wersje
System Fault Tolerant
(SFT) NetWare – mają funkcje jednoczesnego

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
193
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
193
zapisu danych na kilku dyskach twardych, co zwiększa możliwości ich odtworzenia
w przypadku awarii jednego dysku.
Novell od kilku lat oferuje wersje SFT systemu NetWare z takimi funkcjami, jak
przeadresowywanie uszkodzonych bloków, kopia lustrzana dysku i dublowanie
dysku. Wersja SFT III NetWare jest skomplikowana i znacznie droższa od wersji
standardowej.
Przeadresowywanie uszkodzonych bloków
(bad block revectoring) – określane
przez Novella terminem
HotFix
– to technika, w której niewielki program
monitoruje działanie dysku twardego, wykrywając wszelkie nieprawidłowości
związane
z uszkodzeniami nośnika magnetycznego dysku. Kiedy zostanie wykryty problem
tego rodzaju, program próbuje odtworzyć dane dostępne w uszkodzonym fragmencie
i nadać im inną lokalizację, a także aktualizuje mapę adresów plików. Ponadto
program oznacza uszkodzony blok tak, aby nie był on wykorzystywany w
przyszłości.
W technice
kopii lustrzanej
(disk mirroring) używa się dwóch dysków – głównego
i podrzędnego. Najlepiej jeśli dysk podrzędny jest identyczny z dyskiem głównym,
a przynajmniej jest tego samego typu, jednak w takim przypadku musi mieć
większą pojemność niż dysk główny (dodatkowe miejsce nie będzie wykorzystane).
Uwaga na dublowanie
Dublowanie dysku znakomicie poprawia niezawodność, ale nie ma nic za
darmo. Zaleta ta musi być okupiona dodatkowym obciążeniem procesora
serwera, który powinien obsłużyć dwukrotnie więcej żądań
odczytu/zapisu. Aby dublowanie dysków miało sens w praktyce, trzeba
zaopatrzyć się w wysokiej jakości kontroler dysku twardego wyposażony
we własny procesor.
Wszystkie dane zapisywane na głównym dysku są również zapisywane na dysku
lustrzanym, jednak niekoniecznie w tej samej lokalizacji fizycznej. W przypadku
awarii dysku głównego jego funkcje przejmuje natychmiast dysk podrzędny, dzięki
czemu unika się utraty danych.
Inną podstawową cechą kopii lustrzanej jest możliwość odczytu danych z dysku
podrzędnego w przypadku błędów odczytu na dysku głównym. W stosunku do obu
dysków działają funkcje weryfikacji odczytu po zapisie oraz HotFix. Dlatego
uszkodzone bloki na dysku głównym zostaną oznaczone, a w prawidłowych
blokach zostaną zapisane odpowiednie dane odtworzone na podstawie danych z
dysku lustrzanego. W ten sposób zamyka się pętla odtwarzania z błędów odczytu i
zapisu.
Jeśli do konfiguracji stosowanej w lustrzanej kopii dysku dodać następną kartę
kontrolera dysku twardego, można wtedy mówić o
dublowaniu dysku
(disk
duplexing). Taka nadmiarowa konfiguracja jeszcze bardziej zwiększa
niezawodność. Dublowanie dysków ma ponadto wpływ na przepustowość sieci
lokalnej dzięki technice zwanej
przeszukiwaniem równoległym
(split seeks). Kiedy
194
Sieci komputerowe dla każdego
194
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
w tej samej chwili wystąpi wiele żądań odczytu, są one obsługiwane natychmiast
przez obydwa dyski, co praktycznie podwaja wydajność dysku i podnosi całkowitą
wydajność systemu. W przypadku pojedynczego żądania odczytu system
operacyjny określa najpierw, który z dysków może je szybciej zrealizować. Jeśli
oba są tak samo zajęte, NetWare kieruje je do napędu, którego bieżąca pozycja
głowicy jest najbliżej żądanych danych.
Podsumowując – kopia lustrzana dysku wymaga tylko jednej karty kontrolera i
wykorzystuje drugi dysk, który może natychmiast podjąć działanie w przypadku
awarii dysku głównego, eliminując tym samym groźbę utraty danych. Dublowanie
dysków wykorzystuje odrębne karty kontrolerów dla każdego z dysków i zwiększa
wydajność systemu, umożliwiając jednoczesne kierowanie żądań odczytu i zapisu
przez odrębne kanały do obu dysków. Technika ta pozwala także na kontynuowanie
pracy w przypadku awarii kontrolera dysku. Zarówno kopia lustrzana, jak i
dublowanie dysków przyczyniają się do zwiększenia odporności systemu na
uszkodzenia.
Łączenie w klastry
Chociaż opcje służące podwyższeniu niezawodności w systemie NetWare działają
dobrze, to jednak wymagają specjalnego oprogramowania i identycznego,
nadmiarowego sprzętu. Microsoft powołał konsorcjum, którego celem jest rozwój
technologii
łączenia w klastry
.
Nic nowego pod słońcem
O technice łączenia w klastry wiele się teraz mówi, jednak Autor już w
roku 1967 obsługiwał komputery firmy IBM, które używały
przełączników na lampach elektronowych i w których stosowano coś na
kształt klastrów.
Dwie identyczne maszyny mogły bowiem działać równolegle lub
w trybie „śledzenia” w celu natychmiastowego przejęcia funkcji
w wypadku awarii. Inne firmy – w szczególności Tandem (obecnie
należący do Compaqa) – oferowały sprzęt z kilkoma rodzajami obsługi
awarii. Klastry to nic nowego, ale klastry komputerów PC to nowość dla
Microsoft i Novella.
Celem techniki klastrowej jest łączenie serwerów w samoobsługowe i
samonaprawiające się grupy (klastry). Według założeń serwery w klastrach mogą
być modelami o różnych możliwościach i pochodzić od różnych producentów (choć
jest mało prawdopodobne, aby czołowi dostawcy sprzętu skierowali się ochoczo ku
pełnej wymienialności swoich komponentów). Podobny system klastrowy
opracowany przez Novella nosi nazwę Orion.
W koncepcji
klastrów aktywny-aktywny
każda maszyna w klastrze może
wykonywać rzeczywiste zadania, a także jest w stanie odtworzyć zasoby i zadania
dowolnej innej maszyny w klastrze.
Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
195
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
195
Teoretycznie nie ma potrzeby utrzymywanie rezerwowego serwera, który będzie
tylko czekał na awarię. Zamiast tego wszystkie serwery w klastrze komunikują się
ze sobą, aby w razie awarii jednego serwera móc przejąć jego funkcje. To
odtworzenie nie jest tak błyskawiczne, jak w przypadku pełnej kopii lustrzanej
zasobów sprzętowych, ale trwa nie więcej niż kilka sekund, a poza tym cały system
jest bardzo pojemny i znacznie bardziej dostępny finansowo.
Systemy zabezpieczeń
Idea współużytkowania zasobów i plików jest interesująca zarówno pod względem
ekonomicznym, jak i z uwagi na możliwość zwiększenia produktywności. Jednak
i tutaj obowiązuje zasada „co za dużo, to niezdrowo”. Oprogramowanie serwera
powinno dysponować jakąś metodą różnicowania żądań napływających ze stacji
klienckich i określania, czy dany użytkownik ma uprawnienia do żądanych danych
i usług. Nikt nie chce, aby nieupoważnieni pracownicy mieli dostęp do danych
osobowych albo do listy płac. Ponadto, aby zapobiec dowcipom i nieumyślnym
uszkodzeniom, często niezbędne jest ograniczenie aktywności użytkowników sieci
tylko do pewnych plików.
Oprogramowanie sieciowe wykorzystuje zwykle jeden lub dwa systemy
zabezpieczeń. Pierwszy system polega na przydzieleniu każdemu zasobowi
udostępnianemu w sieci nazwy sieciowej, która może określać dysk sieciowy,
podkatalog lub nawet pojedynczy plik. Z nazwą sieciową można powiązać hasło i
na jego podstawie decydować o prawach do odczytu/zapisu/tworzenia. Chociaż
system ten daje względnie łatwą możliwość ochrony zasobów, to jednak wymaga
od użytkownika pamiętania kilku haseł. Jeśli zarządzanie hasłami jest powodem
ciągłych problemów, skuteczność systemu zabezpieczeń jest zagrożona.
Odmienne podejście do kwestii bezpieczeństwa wykorzystuje koncepcję grup:
każdy użytkownik należy do przynajmniej jednej grupy, a każda z nich ma
określone uprawnienia. W takim systemie, stosowanym w NetWare, użytkownik
jest odpowiedzialny tylko za swoje hasło osobiste.
Największe „luki” w systemach bezpieczeństwa to ludzie
Oprogramowanie sieciowe może być wyposażone w wyszukane
mechanizmy zabezpieczające, jednak o ich skuteczności decyduje i tak
codzienna praktyka związana z bezpieczeństwem. Konieczne jest
wymuszenie odpowiedniego postępowania w zakresie haseł, fizyczne
zabezpieczenie sprzętu oraz rozbudzanie u pracowników świadomości
wagi spraw związanych z bezpieczeństwem. Największym zagrożeniem
nie są siejący zniszczenie crackerzy, ale niezadowoleni pracownicy i
konkurencja. Najczęściej o włamaniu do sieci nie wiadomo nic do czasu,
gdy w działalności firmy nie nastąpi jakaś poważna katastrofa.
W administrowaniu zadaniami związanymi z bezpieczeństwem nie wolno
zdawać się wyłącznie na oprogramowanie.

196
Sieci komputerowe dla każdego
196
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
Administrator sieci LAN może łatwo przenosić użytkowników z grupy do grupy,
zgodnie z zajmowanymi przez nich stanowiskami lub usuwać ich z grup, gdy
opuszczają oni firmę.
Oba systemy zabezpieczeń umożliwiają administratorowi przydzielenie lub
odebranie pojedynczym użytkownikom lub grupom użytkowników uprawnień do
odczytu, zapisu, tworzenia, usuwania, przeszukiwania i modyfikowania plików
danych.
Na przykład pracownikowi odpowiedzialnemu za wprowadzanie danych można
przydzielić tylko uprawnienia do modyfikowania plików księgowych, aby
uniemożliwić mu ich skopiowanie do własnych celów. Niektóre systemy
operacyjne oferują nawet możliwości uprawnień „tylko do wykonywania”, które
pozwalają uruchomić program, ale nie pozwalają go skopiować, ani nie dają do
niego żadnego innego dostępu. Odpowiednie zastosowanie różnych możliwości
zabezpieczeń pozwoli ochronić najcenniejsze informacje firmowe.
W aplikacjach o podwyższonym poziomie zabezpieczeń ważną funkcją jest
szyfrowanie haseł, zarówno zapisywanych na dysku, jak i podczas transmisji. O ile
wcześniej pracownik techniczny mógł za pomocą analizatora sieciowego
„podsłuchać” hasła i dane przesyłane w sieci, o tyle obecnie systemy operacyjne
oferują możliwości szyfrowania haseł na pohybel wszystkim, którzy chcieliby się
podłączyć do kabla.
I ostatnia uwaga na temat bezpieczeństwa: należy zastanowić się nad fizycznym
zabezpieczeniem każdego serwera. Najlepiej zamknąć je w osobnym
pomieszczeniu zamykanym na zamek szyfrowy.
System to sieciowy system operacyjny
Sieciowy system operacyjny składa się z wielu modułów i elementów. Często
podczas instalacji można wybrać opcje i konfiguracje, takie jak oprogramowanie
warstwy transportowej czy interfejsy API, które najlepiej pasują do danej
organizacji. Ale takie systemy interaktywne wymagają troskliwej opieki. W
następnym rozdziale zostaną przedstawione podstawy najpopularniejszych
sieciowych systemów operacyjnych ze szczególnym uwzględnieniem ich
praktycznych możliwości i ograniczeń.

Rozdział 8.
♦ Struktura sieciowych systemów operacyjnych
197
C:\Documents and Settings\Piotruś\Pulpit\sieci\Sieci komputerowe dla każdego\08.doc
197
Wyszukiwarka
Podobne podstrony:
08 2HBZ25RJBN6D4ITZUMZK4SZDSTJD Nieznany
06 08 4NUISS5FYYDYAMVPM5UYKTR64 Nieznany (2)
Podklad strunobetonowy PS 08 id Nieznany
09 rozdzial 08 4sgpmlmyclqg6hyv Nieznany (2)
02 08 AUM3QLLNN4ETLMSZBVTG6BEWL Nieznany (2)
07 08 GJCESOIYC7RKN6TD5XUQIWADT Nieznany (2)
05 08 CTR4YEAEUMGQHN7FSNWCCAV4G Nieznany (2)
00 08 4EYYVIPOLXVOTVKVZJ62QZLCZ Nieznany (2)
09 rozdzial 08 63dkeu7shlz4usq4 Nieznany
01 08 IROSLGFQBLIU57YFIQ3QRLJ33 Nieznany
04 08 Z43V27ZJWKAJHTDMPRYOFBKYR Nieznany (2)
03 08 3PCC6KQGGUBWQDLCKMB2U3UQM Nieznany (2)
08 rozdzial 08 GEXYYCBEP6PLNO2J Nieznany
08 2HBZ25RJBN6D4ITZUMZK4SZDSTJD Nieznany
Analiza ekon 08 w2 id 60028 Nieznany
ei 2005 07 08 s085 id 154185 Nieznany
2015 04 09 08 25 05 01id 28644 Nieznany (2)
chemia lato 12 07 08 id 112433 Nieznany
Literaturoznawstwo (08 04 2013) Nieznany
więcej podobnych podstron