
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 155
7
Czerpanie z XML-a
W poprzednim rozdziale Czytelnik nauczył się tworzyć arkusze stylów XSL dla posiadanych do-
kumentów XML. W niniejszym rozdziale temat ten będzie kontynuowany. Czytelnik dowie się,
jak dokument i arkusz stylów są przetwarzane i przekształcane na dane wyjściowe. Podobnie jak
w poprzednich rozdziałach, tym razem przyjrzymy się poznanym strukturom języka XML z pun-
ktu widzenia Javy. Omówimy procesory XSLT, interfejsy API Javy do obsługi wejścia XML
w formacie drzewiastym oraz powiemy, czym różnią się te interfejsy od opisywanego już SAX-a.
Najpierw przeanalizujemy sposób, w jaki wykonywane są w komputerze transformacje. Stworzy-
my w ten sposób „wirtualny plac zabaw”, gdzie będziemy mogli eksperymentować z własnymi
konstrukcjami XSL i XSLT. Spróbujemy również dodać nieco bardziej złożone formatowanie
do arkusza stylów, który stworzyliśmy w ostatnim rozdziale. Ponadto zaczniemy dokładniej anali-
zować sposób działania procesora XSLT; na końcu szczegółowo omówimy, jakiego rodzaju i forma-
tu danych wejściowych oczekuje taki procesor. Tym samym rozpoczniemy dyskusję o obiektowym
modelu dokumentu (DOM) — alternatywnym względem SAX-a sposobie uzyskiwania dostępu do
danych XML. Na koniec odejdziemy od tematu parserów, procesorów i interfejsów API, spróbuje-
my natomiast poskładać wszystkie elementy „układanki XML” w jedną całość. Będzie to wstęp do
pozostałej części książki — spróbujemy bardziej przekrojowo opisać różne typy aplikacji XML
i sposoby wykorzystania wzorców projektowych i struktur XML do własnych potrzeb.
Przed lekturą dalszej części książki Czytelnik powinien zrozumieć nie tylko tematykę niniejszego
rozdziału, ale także to, jakich tematów ten rozdział nie porusza. Czytelnik nie znajdzie tutaj opisu
tworzenia procesora XSLT (podobnie jak wcześniej nie znalazł receptury tworzenia parsera XML).
Opisywane tutaj zagadnienia są bardzo ważne — w zasadzie kluczowe — do korzystania z proce-
sora XSLT; to także świetny wstęp do ewentualnego zaangażowania się w rozbudowę istniejących
procesorów XSLT, takich jak Xalan grupy Apache. Jednakże parsery i procesory to programy nie-
zwykle złożone i próba wyjaśnienia ich wewnętrznych mechanizmów zajęłaby resztę książki,
a może i całą następną! My natomiast zajmiemy punkt widzenia programisty aplikacji lub ar-
chitekta programów w Javie; postaramy się wykorzystać istniejące już narzędzia i w razie koniecz-
ności rozbudować je do własnych potrzeb. Innymi słowy, zanim zabierzemy się za programowanie
procesorów, powinniśmy nauczyć się ich używać!

156
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 156
Uzyskiwanie danych wyjściowych
Jeśli Czytelnik śledził przykłady z ostatniego rozdziału, powinien być już przygotowany na prze-
kazanie arkusza i dokumentu XML do procesora. W przypadku większości procesorów jest to
dość prosta czynność. Zgodnie z przyjętą taktyką korzystania z najlepszych w branży produktów
typu open source, użyjemy procesora Apache Xalan (można go pobrać i uzyskać o nim informacje
pod adresem http://xml.apache.org). Nad Xalanem pracują najtęższe umysły — programiści firm
Lotus, IBM, Sun, Oracle i innych. Ponadto procesor ten świetnie współpracuje z opisywanym we
wcześniejszych rozdziałach parserem Apache Xerces. Jeśli jednak Czytelnik posiada już inny proce-
sor, to także nie powinien mieć problemów ze znalezieniem informacji, dotyczących uruchamiania
przykładów opisywanych w tym rozdziale, a wynik działania programu powinien być identyczny
lub bardzo podobny do uzyskiwanego w książce.
Najpierw spróbujemy uruchomić procesor XSLT z wiersza poleceń. Często robi się to na potrzeby
testowania, usuwania błędów i tworzenia zawartości dokumentów w trybie offline. Warto pamię-
tać, że w wielu „poważnych” witrynach WWW zawartość tworzona jest właśnie offline, często
w godzinach nocnych lub raz w tygodniu, dzięki czemu w czasie żądania pobrania strony nie ma
spadku wydajności związanego z dynamicznym przetwarzaniem XML-a na HTML lub inny język
znaczników. Uruchamiany w ten sposób procesor pomoże nam również w przeanalizowaniu róż-
nych warstw transformacji XML. Dokumentacja używanego procesora powinna zawierać instru-
kcje dotyczące sposobu uruchamiania go z wiersza poleceń. W przypadku procesora Apache Xalan
polecenie ma następującą postać
D:\prod\JavaXML> java org.apache.xalan.xslt.Process
-IN [Dokument XML]
-XSL [Arkusz stylu XSL]
-OUT [Plik wyjściowy]
Xalan, jak każdy inny procesor, umożliwia podanie także wielu innych opcji w wierszu poleceń,
ale my będziemy korzystali głównie z tych trzech powyższych. Xalan domyślnie korzysta z par-
sera Xerces, a więc w ścieżce dostępu do klas będą musiały się znaleźć zarówno klasy parsera, jak
i procesora. W wierszu poleceń można zażądać zmiany parsera XML, ale w Xalanie obsługa par-
sera Xerces jest najbardziej zaawansowana. Jeśli przekształcanie odbywa się w powyższy sposób,
nie trzeba odwoływać się do arkusza stylu z poziomu dokumentu; procesor XSLT sam zastosuje
arkusz stylu podany w wierszu poleceń. Wewnętrzne deklaracje arkuszy stylów zostaną użyte do-
piero w rozdziale 9., Struktury publikacji WWW. Tak więc do zbudowania polecenia uruchamia-
jącego nasz procesor potrzebujemy nazwy dokumentu XML i arkusza XSL (w tym przypadku
znajdującego się w podkatalogu). Ponieważ w wyniku mamy uzyskać plik HTML, jako plik wyjś-
ciowy podajemy contents.html:
D:\prod\JavaXML> java org.apache.xalan.xslt.Process
-IN contents.xml
-XSL XSL/JavaXML.html.xsl
-OUT contents.html
Uruchomienie takiego polecenia w odpowiednim katalogu spowoduje, że Xalan rozpocznie proces
transformacji. Uzyskamy wynik podobny do tego przedstawionego w przykładzie 7.1.
Przykład 7.1. Przekształcanie pliku XML za pomocą procesora Apache Xalan
D:\prod\JavaXML> java org.apache.xalan.xslt.Process
-IN contents.xml
-XSL XSL/JavaXML.html.xsl
-OUT contents.html
Pobieranie danych wejściowych
157
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 157
========== Parsing file:D:/prod/JavaXML/XSL/JavaXML.html.xsl =========
Parse of file:D:/prod/JavaXML/XSL/JavaXML.html.xsl took 1161 milliseconds
========= Parsing contents.xml ==========
Parse of contents.xml took 311 milliseconds
=============================
Transforming...
transform took 300 milliseconds
XSLProcessor: done
Po ukończeniu przetwarzania powinno być możliwe otworzenie uzyskanego pliku contents.html
w edytorze lub przeglądarce WWW. Jeśli Czytelnik postępował zgodnie z instrukcjami w ostatnim
rozdziale, to w przeglądarce powinna zostać wyświetlona strona widoczna na rysunku 7.1.
Rysunek 7.1. Strona HTML uzyskana po transformacji danych XML
Teraz Czytelnik wie już, jak wprowadzać zmiany i testować dane wynikowe plików XML i arkuszy
XSL. Procesor Xalan uruchomiony z wiersza poleceń posiada także pożyteczną funkcję odnajdy-
wania błędów w plikach XML lub XSL i podawania numerów wierszy, w których one wystąpiły
— to jeszcze bardziej upraszcza usuwanie błędów i testowanie plików.
Pobieranie danych wejściowych
Poza powodami, o których już wspomnieliśmy, jest jeszcze jedna istotna przyczyna, dla której nie
będziemy zajmować się omawianiem wewnętrznych mechanizmów procesora — dane wejściowe
i wyjściowe procesora są o wiele bardziej zajmujące! Widzieliśmy już, jak można przetwarzać do-
kument przyrostowo za pomocą interfejsów i klas SAX. W procesie tym w prosty sposób decy-
dujemy, co zrobić z napotkanymi elementami, jak obsłużyć określone atrybuty i jakie czynności
powinny zostać podjęte w przypadku napotkania błędów. Jednakże korzystanie z takiego modelu
w pewnych sytuacjach rodzi również problemy. Jedną z takich sytuacji jest przekazywanie danych
wejściowych dla procesora XSLT.

158
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 158
SAX działa sekwencyjnie
Model sekwencyjny oferowany przez interfejs SAX nie umożliwia uzyskania swobodnego dostępu
do dokumentu XML. Innymi słowy, korzystając z SAX-a pobieramy informacje o dokumencie XML
wtedy, kiedy robi to parser — i podobnie jak parser informacje te tracimy. Kiedy pojawia się ele-
ment 2., to nie można uzyskać dostępu do informacji w elemencie 4., ponieważ nie został on
jeszcze przetworzony. Natomiast kiedy pojawi się element 4., to nie możemy powrócić do elemen-
tu 2. Oczywiście, mamy prawo zachować informacje napotkane w procesie przetwarzania, ale za-
kodowanie tego typu przypadków specjalnych może być bardzo trudne. Przeciwną skrajnością jest
stworzenie reprezentacji dokumentu XML w pamięci. Wkrótce okaże się, że parser DOM postępuje
właśnie w ten sposób; tak więc wykonywanie tego w interfejsie SAX byłoby bezcelowe, a praw-
dopodobnie także wolniejsze i bardziej kłopotliwe.
SAX a elementy siostrzane
Innym zadaniem trudnym do wykonania w interfejsie SAX jest przechodzenie z elementu na ele-
ment „w poziomie”. Dostęp do elementów poprzez SAX jest w dużym stopniu hierarchiczny i se-
kwencyjny. Uzyskujemy dostęp do krańcowego elementu węzła, potem przechodzimy z powrotem
„w górę” drzewa i znów schodzimy do innego elementu na dole hierarchii. Nie ma przejrzystego
odniesienia do „poziomu” hierarchii, na którym aktualnie się znajdujemy. Identyfikację poziomów
można co prawda wdrożyć poprzez wprowadzenie wyszukanych liczników, ale ogólnie SAX nie
jest do tego typu operacji przystosowany. Nie ma zaimplementowanego pojęcia elementu siostrza-
nego, następnego elementu na tym samym poziomie; nie ma też możliwości sprawdzenia, które
elementy są zagnieżdżone w których.
Procesor XSLT musi znać elementy siostrzane danego elementu; co ważniejsze, musi znać jego
elementy potomne. Spójrzmy na taki fragment szablonu XSL:
<xsl:template match:"elementMacierzysty">
<!-- Tutaj zawartość drzewa wynikowego -->
<xsl:apply-templates select="elementPotomny1|elementPotomny2" />
<!-- Tutaj dalsza zawartość drzewa wynikowego -->
</xsl:template>
Szablony nakładane są poprzez konstrukcję
xsl:apply-templates
, ale to nakładanie odby-
wa się na konkretnym zestawie węzłów, pasującym do podanego wyrażenia XPath. W powyższym
przykładzie szablon powinien być nałożony jedynie na
elementPotomny1
lub
elementPo-
tomny2
(są one rozdzielone operatorem LUB wyrażeń XPath, czyli kreską poziomą). Ponadto,
ponieważ wykorzystujemy ścieżkę względną, wspomniane elementy muszą być bezpośrednio
potomne względem elementu
elementMacierzysty
. Określenie i zlokalizowanie tych węz-
łów w reprezentacji dokumentu XML oferowanej przez SAX byłoby niezwykle trudne. Dzięki hie-
rarchicznej reprezentacji dokumentu w pamięci czynność ta jest bardzo łatwa — i jest to kolejny
powód, dla którego tak często korzysta się z modelu DOM jako wejścia dla procesorów XSLT.
Przyczyny korzystania z SAX-a
Wszystkie te „wady” SAX-a skłaniają zapewne Czytelnika do zastanawiania się, dlaczego w ogóle
korzysta się z interfejsu SAX. Warto więc tutaj przypomnieć, że powyższe problemy odnoszą się
do konkretnego zastosowania danych XML, w tym przypadku przetwarzania poprzez XSL. Otóż
„wady” te są jednocześnie... zaletami SAX-a! Czy to nie wydaje się zagmatwane? Wkrótce okaże
się, że nie tak bardzo.

Obiektowy model dokumentu (DOM)
159
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 159
Wyobraźmy sobie, że przetwarzamy spis treści czasopisma National Geographic w postaci danych
XML. Dokument taki często osiąga 500 wierszy długości, czasem więcej. Teraz wyobraźmy sobie
indeks książki O'Reilly w postaci pliku XML. Setki słów z numerami stron, odsyłaczami itd. Wszy-
stko to przykłady w miarę małych, spójnych aplikacji XML. W miarę wzrostu dokumentu XML
rośnie obszar zajmowanej przez niego pamięci, jeśli korzystamy z drzewa DOM. Weźmy teraz
pod uwagę sytuację, w której dokument XML staje się tak wielki, że jego reprezentacja w modelu
DOM zaczyna wpływać na wydajność aplikacji. I wyobraźmy jeszcze sobie, że te same wyniki
można uzyskać poprzez przetworzenie dokumentu wejściowego sekwencyjnie, za pomocą SAX-a
— przy wykorzystaniu jednej dziesiątej lub jednej setnej zasobów systemowych.
Powyższy przykład obrazuje, że podobnie jak w Javie istnieje wiele sposobów wykonania tego
samego zadania, tak i w różny sposób można uzyskać dane dokumentu XML. W wielu scenariu-
szach SAX stanowi lepszy wybór — oferuje szybkie przetwarzanie i przekształcanie. W innych
przypadkach zwycięża DOM — zapewnia prosty, przejrzysty interfejs danych określonego forma-
tu. To my, programiści, musimy zastanowić się nad celem budowania aplikacji i wybrać odpowie-
dnią metodę (albo opracować sposób współdziałania obydwu metod). Jak zwykle umiejętność
podjęcia właściwej decyzji wynika ze znajomości dostępnych rozwiązań. Mając to na uwadze,
przyjrzyjmy się takiemu właśnie nowemu rozwiązaniu.
Obiektowy model dokumentu (DOM)
W przeciwieństwie do interfejsu SAX, obiektowy model dokumentu wywodzi się z kręgów kon-
sorcjum W3C. SAX to oprogramowanie będące własnością publiczną, stanowiące owoc długich
dyskusji na liście adresowej XML-dev. Natomiast DOM jest samym w sobie standardem, tak jak
XML. DOM nie został również opracowany wyłącznie dla Javy; jego zadaniem jest reprezentacja
zawartości i modeli dokumentów we wszystkich językach i narzędziach programistycznych. Ist-
nieją interfejsy DOM dla JavaScriptu, Javy, CORBA i innych języków. Jest to więc specyfikacja
neutralna językowo i platformowo.
Kolejna różnica polega na tym, że DOM jest dostarczany jako „poziomy”, a nie wersje. DOM
Level One (DOM poziomu pierwszego) ma status przyjętego zalecenia W3C, a pełną specyfikację
możemy przejrzeć pod adresem http://www.w3.org/TR/REC-DOM-Level-1/. Level One opisuje
funkcje i sposób nawigacji po zawartości dokumentu. Dokument w modelu DOM nie musi być
dokumentem XML — może to być HTML bądź dowolny inny rodzaj zawartości! Level Two
(DOM poziomu drugiego), ukończony w roku 2000, uzupełnia Level One o moduły i opcje dla
poszczególnych modeli zawartości, takich jak XML, XSL czy CSS (kaskadowe arkusze stylów).
W ten sposób „uzupełniane są luki” pozostawiane przez bardziej ogólne narzędzia Level One. Bie-
żący dokument kandydujący do oficjalnego zalecenia W3C znajduje się pod adresem http://www.-
w3.org/TR/DOM-Level-2/. Trwają już prace nad modelem Level Three (DOM poziomu trzeciego),
udostępniającym kolejne narzędzia dla specyficznych typów dokumentów — np. procedury obsłu-
gi sprawdzania poprawności dla XML-a.
DOM a Java
Aby móc korzystać z modelu DOM w określonym języku programowania, należy zastosować
interfejsy i klasy oraz zaimplementować sam model DOM. Ponieważ wykorzystywane metody nie
są określone w samej specyfikacji DOM (specyfikacja ta charakteryzuje jedynie model dokumen-
tu), konieczne było opracowanie interfejsów języka reprezentujących konceptualną strukturę mo-
delu DOM — zarówno dla Javy, jak i innych języków. Interfejsy te umożliwiają manipulację
dokumentami w sposób określony właśnie w specyfikacji DOM.

160
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 160
Oczywiście, w tej książce najbardziej interesuje nas interfejs dla Javy. Dowiązania dla tego języka
(ang. bindings), określane nazwą DOM Level Two Java bindings, można pobrać ze strony
http://www.w3.org/TR/DOM-Level-2/java-binding.html. Klasy, które powinniśmy dodać do ścieżki
dostępu do klas, znajdują się w pakiecie org.w3c.dom (i podpakietach). Jednakże zanim je pobie-
rzemy z sieci, warto zerknąć do posiadanego parsera XML i procesora XSLT. Podobnie jak pakiet
SAX, DOM jest często dostarczany wraz z tymi narzędziami. W ten sposób mamy również zagwa-
rantowane, że parser, procesor i posiadana wersja DOM poprawnie współpracują ze sobą.
Większość procesorów nie generuje samodzielnie danych wejściowych DOM. Korzystają w tym
celu z parsera XML, któremu powierza się zadanie wygenerowania drzewa DOM. Dlatego często
to parser XML, a nie procesor XSLT będzie posiadał wymagane klasy DOM. Ponadto w ten sposób
zapewnia się niezależność obu narzędzi — zawsze można zamienić parser albo procesor na produkt
innego producenta. Ponieważ domyślnie Apache Xalan wykorzystuje parser Xerces do przetwarzania
i generowania modelu DOM, zajmiemy się tutaj obsługą DOM z poziomu tego narzędzia.
Uzyskanie parsera DOM
Aby zorientować się w sposobie działania modelu DOM, powiemy teraz, w jaki sposób procesor
Apache Xalan i inne programy wymagające danych wejściowych w formacie DOM otrzymują do-
kument XML w strukturze drzewiastej DOM. W ten sposób poznamy pierwsze dowiązania języka
Java do modelu DOM i wyjaśnimy koncepcje leżące u podstaw obsługi dokumentów XML po-
przez model DOM.
Model DOM nie określa, w jaki sposób tworzone jest drzewo DOM. Autorzy specyfikacji skon-
centrowali się na strukturze i interfejsach API służących do manipulacji tym drzewem; pozosta-
wiono dużą dowolność implementacji parsera DOM. W przeciwieństwie do klasy SAX
XMLRe-
ader
, dynamicznie ładującej implementację, w przypadku DOM to my musimy jawnie zaimpor-
tować i stworzyć egzemplarz klasy parsera DOM określonego producenta. Na początek stwórzmy
nowy plik w Javie o nazwie DOMParserDemo.java. Zbudujemy prosty program przetwarzający
z wykorzystaniem modelu DOM; będzie on wczytywał dokument XML i wyświetlał jego zawar-
tość na ekranie. Zacznijmy od nakreślenia szkieletu naszej przykładowej klasy (przykład 7.2).
Przykład 7.2. Klasa DOMParserDemo
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;
/**
* <b><code>DOMParserDemo</code></b> pobiera plik XML i wyświetla
* jego zawartość za pomocą modelu DOM.
*
* @author Brett McLaughlin
* @version 1.0
*/
public class DOMParserDemo {
/**
* <p>
* Tutaj przetwarzamy plik i drukujemy dokument
* za pomocą modelu DOM.
* </p>
*
* @param uri <code>String</code> URI pliku do przetworzenia.
*/

Obiektowy model dokumentu (DOM)
161
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 161
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
// parser.parse(uri)
} catch (Exception e) {
System.out.println("Błąd w przetwarzaniu: " + e.getMessage());
}
}
/**
* <p>
* Obsługa wiersza poleceń programu.
* </p>
*/
public static void main(String[] args) {
if (args.length != 1) {
System.out.println("Użycie: java DOMParserDemo [XML URI]");
System.exit(0);
}
String uri = args[0];
DOMParserDemo parserDemo = new DOMParserDemo();
parserDemo.performDemo(uri);
}
}
Struktura jest podobna do tej wykorzystywanej wcześniej w klasie
SAXParserDemo
, ale tym ra-
zem importujemy bezpośrednio klasę Apache Xerces
DOMParser
i tworzymy jej egzemplarz.
Faktyczną metodę
parse()
opatrzyliśmy tymczasem komentarzami; zanim zajmiemy się prze-
twarzaniem struktury DOM, musimy omówić zagadnienia związane z wyborem parsera określone-
go producenta.
Należy pamiętać, że powyższy przykład jest bardzo prosty i działa w wielu aplikacjach, ale nie jest
przenośny na inne implementacje parsera, tak jak to było w przypadku SAX-a. Może pojawić się
pokusa użycia konstrukcji Javy w rodzaju
Class.forName(parserClass).newInstan-
ce()
i pobrania za jej pomocą klasy parsera odpowiedniego producenta. Jednakże inne imple-
mentacje modelu DOM zachowują się rozmaicie — czasem metoda
parse()
zwraca obiekt
org.w3c.dom.Document
(o którym powiemy niżej), a czasem konieczne jest wywołanie tej
metody z różnymi parametrami (
InputSource
,
InputStream
,
String
,
URI
itd.). Innymi
słowy, drzewo DOM jest konstrukcją przenośną, natomiast metoda uzyskania tego drzewa — już
nie, chyba że programista zastosuje dość złożone klasy i metody dynamiczne.
Dane wyjściowe modelu DOM
Jak pamiętamy, w interfejsie SAX działanie parsera skoncentrowane było wokół cyklu życia pro-
cesu — metody wsteczne oferowały „punkty zaczepienia” danych. Działanie modelu DOM skon-
centrowane jest natomiast na danych wyjściowych procesu przetwarzania. Danych nie można
użyć, dopóki cały dokument nie zostanie przetworzony i dodany do wyjściowej struktury drzewia-
stej. Dane wyjściowe z procesu przetwarzania, które mają zostać wykorzystane przez interfejsy

162
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 162
DOM, mają postać obiektu
org.w3c.dom.Document
. Obiekt ten działa jako „procedura
obsługi” drzewa, w którym znajdują się nasze dane XML; z punktu widzenia hierarchii elemen-
tów, o której cały czas mówimy, obiekt ten znajduje się jeden poziom „ponad” elementem głów-
nym dokumentu XML. Innymi słowy, każdy element naszego wejściowego dokumentu XML jest
bezpośrednio lub pośrednio potomny względem niego.
Niestety, standaryzacja modelu DOM dotyczy samej obróbki danych, ale nie sposobu ich uzyskania.
Powstało więc kilka mechanizmów uzyskiwania obiektu
Document
po przetwarzaniu. W wielu
implementacjach, np. w starszych wersjach parsera IBM XML4J, obiekt
Document
był zwracany
przez metodę
parse()
. Kod wykorzystujący tego typu implementację wyglądałby następująco:
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
Document doc = parser.parse(uri);
} catch (Exception e) {
e.printStackTrace();
System.out.println("Błąd w przetwarzaniu: " + e.getMessage());
}
}
Większość nowszych parserów, takich jak Apache Xerces, korzysta z innych sposobów. W celu
zachowania standardowego interfejsu w parserach SAX i DOM metoda
parse()
jest typu void,
podobnie jak ta, którą poznaliśmy przy okazji omawiania SAX-a. Dzięki temu w aplikacji można
korzystać z klasy parsera DOM i SAX zamiennie; jednakże wiąże się to z koniecznością stworze-
nia nowej metody, służącej do uzyskania obiektu
Document
będącego wynikiem przetwarzania
XML. W parserze Apache Xerces metoda ta nosi nazwę
getDocument()
. Jeśli więc korzysta-
my z tego parsera, to aby uzyskać drzewo wynikowe DOM z procesu przetwarzania, uzupełniamy
nasz przykładowy kod następująco:
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
parser.parse(uri);
Document doc = parser.getDocument();
} catch (Exception e) {
e.printStackTrace();
System.out.println("Błąd w przetwarzaniu: " + e.getMessage());
}
}
Należy również pamiętać o zaimportowaniu odpowiedniej klasy DOM:
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;

Obiektowy model dokumentu (DOM)
163
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 163
Aby dowiedzieć się, w jaki sposób można uzyskać rezultat przetwarzania, należy zajrzeć do doku-
mentacji posiadanego parsera. W następnym rozdziale przyjrzymy się interfejsowi API JAXP fir-
my Sun oraz innym, bardziej ustandaryzowanym sposobom uzyskiwania dostępu do drzewa DOM
z dowolnej implementacji parsera. Jak widać, istnieją pewne różnice pomiędzy sposobami uzyski-
wania opisywanych danych, natomiast uzyskane dane są zawsze takie same, a więc nie powinniśmy
mieć dalszych kłopotów w przypadku używania innego parsera.
Zastosowanie drzewa DOM
Skoro już uzyskaliśmy ten „drzewiasty” obiekt, spróbujmy wykorzystać go do czegoś pożytecz-
nego. Na przykład, „przejdziemy” przez strukturę, do której mamy dostęp, i wyświetlimy dane
XML. W tym celu najprościej pobrać wstępny obiekt
Document
i przetworzyć każdy węzeł, oraz
— rekursywnie — wszystkie jego węzły potomne. Jeśli Czytelnik kiedykolwiek miał do czynienia
ze strukturami drzewiastymi, ta czynność nie powinna stanowić problemu. W celu zrozumienia
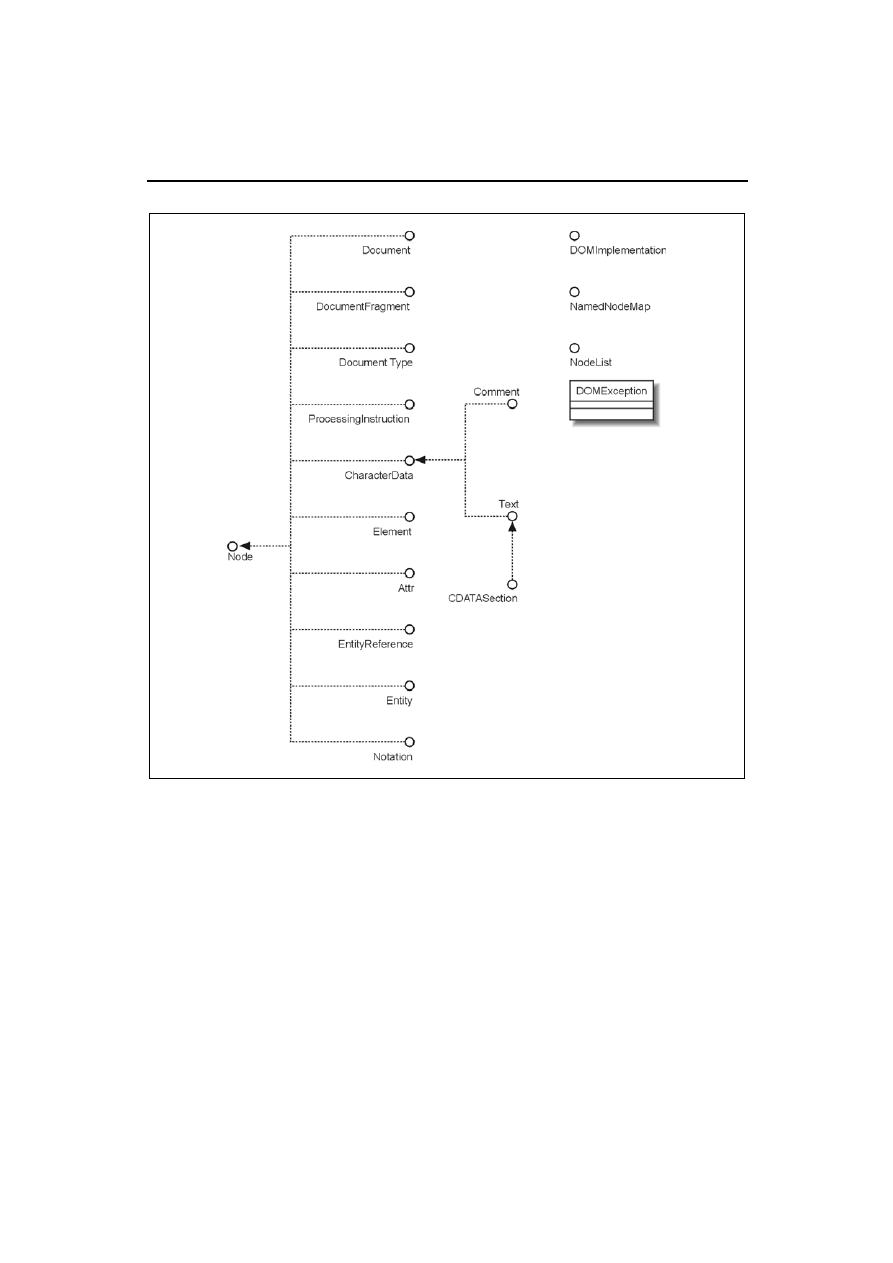
zasady działania całego procesu, należy przyjrzeć się podstawowym obiektom, przez które zostaną
udostępnione nasze dane XML. Poznaliśmy już obiekt
Document
; ten oraz inne podstawowe
interfejsy obiektów DOM zostały zaprezentowane na rysunku 7.2 (są tam również rzadziej wyko-
rzystywane interfejsy). Za pomocą tych właśnie interfejsów będziemy przetwarzali dane w drze-
wie DOM.
Warto dobrze przyjrzeć się przedstawionym interfejsom. Szczególną uwagę należy poświęcić in-
terfejsowi
Node
— stanowi on interfejs bazowy wszystkich innych. Widząc tego typu strukturę,
powinniśmy natychmiast pomyśleć o rozpoznawaniu typu obiektu w czasie pracy programu. In-
nymi słowy, możliwe jest napisanie metody pobierającej węzeł, rozpoznającej, jakiego typu stru-
kturę DOM ten węzeł stanowi i wyświetlającej węzeł w odpowiedni sposób. W ten sposób
możemy wyświetlić całe drzewo DOM za pomocą jednej metody. Kiedy węzeł jest już wy-
świetlony, korzystamy z dostępnych metod „przenoszących” nas do następnego elementu siostrza-
nego, pobierających atrybuty (jeśli jest to element) i obsługujących wszelkie możliwe sytuacje
specjalne. Następnie, wykonując iterację po węzłach potomnych, rekurencyjnie uruchamiamy me-
todę na każdym z tych węzłów, dopóki nie wyświetlimy całego drzewa DOM — oto prosty
i przejrzysty sposób obsługi drzew DOM.
Do dzieła
Ponieważ sam obiekt
Document
stanowi węzeł
Node
modelu DOM, możemy przekazać go w po-
staci niezmienionej do metody wyświetlającej. Zanim stworzymy szkielet takiej metody, musimy
jednak dodać odpowiednie instrukcje importujące:
import org.w3c.dom.Document;
import org.w3c.dom.Node;
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;
Następnie dodajemy sygnaturę naszej metody, pobierającej i wyświetlającej obiekt DOM Node:
164
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 164
Rysunek 7.2. Model klasy UML podstawowych interfejsów i klas DOM Level 2
/**
* <p>
* Tutaj wyświetlamy węzeł DOM i przechodzimy
* przez wszystkie węzły potomne.
* </p>
*
* @param node <code>Node</code> obiekt do wyświetlania.
* @param indent <code>String</code> białe znaki do wyświetlania
* przed <code>Node</code>
*/
public void printNode(Node node, String indent) {
// Rozpoznajemy typ węzła
// Wyświetlamy węzeł
// Przetwarzamy rekurencyjnie węzły potomne
}

Obiektowy model dokumentu (DOM)
165
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 165
Kiedy szkielet metody jest już we właściwym miejscu, możemy uruchomić metodę na początkowym
obiekcie
Document
i przetwarzać rekursywnie dopóty, dopóki nie zostanie wyświetlone całe drze-
wo. Jest to możliwe właśnie dlatego, że interfejs
Document
to część wspólnego interfejsu
Node
:
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
parser.parse(uri);
Document doc = parser.getDocument();
// Wyświetlamy dokument z drzewa DOM
printNode(doc);
} catch (Exception e) {
System.out.println("Błąd w przetwarzaniu: " + e.getMessage());
}
}
Teraz możemy już skompilować plik programu w Javie. Nie uzyskamy żadnych danych wyjściowych,
ale przekonamy się chociaż, że stworzenie aplikacji wykorzystującej wejście DOM z parsera XML
jest dość proste. W dalszej części spróbujemy nieco uatrakcyjnić nasz program demonstracyjny.
Rozpoznawanie typu węzła
Wewnątrz metody wyświetlającej musimy przede wszystkim rozpoznać typ węzła. Moglibyśmy
wykorzystać w tym celu metodologię Javy (
instanceof
i refleksja), ale dowiązania DOM dla
Javy znacznie upraszczają ten proces. W interfejsie
Node
zdefiniowano metodę pomocniczą
getNodeType()
, zwracającą wartość typu całkowitego. Wartość ta porównywana jest z zesta-
wem stałych zdefiniowanych również w ramach interfejsu
Node
i w ten sposób rozpoznajemy typ
węzła. Takie rozwiązanie w sposób naturalny pasuje do konstrukcji
switch
Javy — za jej po-
mocą możemy w naszej metodzie rozbić wydruk na logiczne części. Typ węzła porównujemy
z najczęściej spotykanymi typami; co prawda istnieje szereg innych typów (patrz rysunek 7.2), ale
te wymienione poniżej są najbardziej popularne, a opisywane rozwiązania w razie potrzeby można
zastosować także do pozostałych.
public static void printTree(Node node) {
// Wybieramy czynność do wykonania na podstawie typu węzła
switch (node.getNodeType()) {
case Node.DOCUMENT_NODE:
// Wyświetlamy zawartość obiektu Document
break;
case Node.ELEMENT_NODE:
// Wyświetlamy element i jego atrybuty
break;
case Node.TEXT_NODE:
case Node.CDATA_SECTION_NODE:
// Wyświetlamy dane tekstowe
break;
case Node.PROCESSING_INSTRUCTION_NODE:
// Wyświetlamy instrukcję przetwarzania (PI)

166
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 166
break;
case Node.ENTITY_REFERENCE_NODE:
// Wyświetlamy encję
break;
case Node.DOCUMENT_TYPE_NODE:
// Wyświetlamy Wyświetlamy deklarację DTD
break;
}
}
Warto zauważyć, że węzły
CDATASection
i
Text
obsługujemy za pomocą jednej instrukcji
case
.
W tym przykładzie nie będzie nas bowiem interesować, czy w oryginalnym dokumencie tekst
znajduje się w części
CDATA
, czy nie; chcemy go tylko wyświetlić. Teraz w odpowiednich blo-
kach kodu możemy dodać instrukcje wyświetlające i przetwarzające rekurencyjnie.
Typy węzłów DOM
Skoro wiemy już, jak wygląda i działa model DOM, wystarczy tylko poznać składnię dla poszcze-
gólnych typów węzłów — w ten sposób uzyskamy solidną wiedzę o działaniu modelu. Innymi
słowy, teraz możemy już traktować dowiązania Javy dla DOM-a tak jak inne interfejsy API — np.
pakiety JNDI czy rozszerzenia serwletów. Zazwyczaj najtrudniejszą częścią nauki języka jest po-
znanie zasady jego działania; opanowanie składni wymaga już tylko materiałów referencyjnych
i przykładowego kodu. W tej części przedstawimy taki właśnie przykładowy kod. Wyświetlimy
najczęściej spotykane typy węzłów oraz przyjrzymy się przetwarzaniu drzewa DOM. Później jako
materiał referencyjny można wykorzystać dokumentację online modelu DOM, znajdującą się pod
adresem http://www.w3.org/DOM; podobną rolę pełni dodatek A, zawierający materiały
referencyjne dla interfejsów SAX, DOM i JDOM (o tym ostatnim powiemy w następnym
rozdziale).
Węzeł Document
Ponieważ
Document
to część samego węzła
Node
, możemy używać go wymiennie z innymi ty-
pami węzłów. Stanowi on jednak swoisty „przypadek specjalny”, ponieważ zawiera element główny
i definicję DTD dokumentu oraz szereg innych specjalnych informacji nie należących do hierar-
chii elementów XML. Dlatego przetwarzając ten węzeł, musimy uzyskać element główny i prze-
kazać go funkcji wyświetlającej. Wyświetlimy również prostą deklarację wersji, tak aby dokument
wyjściowy utrzymywał zgodność ze specyfikacją XML:
case Node.DOCUMENT_NODE:
System.out.println("<xml version=\"1.0\">\n");
Document doc = (Document)node;
printTree(doc.getDocumentElement());
break;
Ponieważ chcemy uzyskać dostęp do metody specyficznej dla obiektu
Document
, najpierw
musimy wykonać rzutowanie implementacji
Node
przekazanej do metody wyświetlającej na
interfejs
Document
. Później można już uzyskać element główny dokumentu wejściowego XML
za pomocą metody
getDocumentElement()
i przekazać go do metody wyświetlającej, roz-
poczynając rekurencyjne przetwarzanie drzewa DOM.
Niestety, model DOM Level 2 (podobnie jak SAX 2.0) nie udostępnia deklaracji XML.

Obiektowy model dokumentu (DOM)
167
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 167
Wydaje się, że nie jest to duży problem, ale tylko dopóki nie zdamy sobie sprawy, że
w deklaracji tej zawarta jest również informacja o kodowaniu dokumentu. DOM Level
3 ma rozwiązać to niedopatrzenie (wersję roboczą specyfikacji udostępniono we wrze-
śniu 2000 r. — przyp. tłum.). Do czasu rozwiązania problemu należy unikać stosowa-
nia mechanizmu DOM w tym celu.
Elementy DOM
Oczywiście, najbardziej typowym zadaniem wykonywanym w aplikacji będzie pobranie węzła
DOM
Element
i wyświetlenie jego nazwy, atrybutów i wartości, a następnie jego elementów
potomnych. Jak można oczekiwać, wszystko to wykonuje się w bardzo prosty sposób metodami
DOM. Najpierw pobieramy nazwę elementu (metoda
getNodeName()
wchodząca w skład in-
terfejsu
Node
) i wyświetlamy ją. Chwilowo pominiemy obróbkę atrybutów i wydrukujemy nawias
zamykający elementu. Następnie odnajdujemy elementy potomne względem bieżącego i również wy-
świetlamy ich nazwy. Elementy potomne węzła
Node
są udostępniane poprzez metodę
get-
ChildNodes()
, zwracającą egzemplarz DOM
NodeList
.
Większość interfejsów API Javy wykorzystuje
Vector
,
Hashtable
lub inne zbiory klas
obsługujące przetwarzanie list. DOM zwraca natomiast specjalny interfejs,
NodeList
.
Nie możemy oczekiwać, że zaczniemy obsługiwać atrybuty poprzez metody Javy, do
których jesteśmy przyzwyczajeni — korzystając z DOM-a, będziemy musieli zaznajo-
mić się z nowymi strukturami.
Uzyskanie długości takiej listy jest zadaniem banalnym; podobnie jest z iteracją po elementach po-
tomnych, wywoływaniem na nich metod wyświetlających i kontynuacją algorytmu
rekurencyjnego. Na koniec wstawiamy znacznik zamykający elementu.
Najpierw dodajemy wymagany interfejs DOM:
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;
Teraz wymagane klasy i interfejsy są dostępne „po imieniu” — możemy więc dodać opisane wyżej
fragmenty kodu. Uzyskujemy nazwę implementacji
Node
, drukujemy ją w formacie XML, dru-
kujemy jej elementy potomne (za pomocą wartości
null
sprawdzając, czy elementy takie istnie-
ją) i zamykamy element. Poniższy kod nie obsługuje jeszcze atrybutów, ale powinien wyświetlić
elementy XML z całego drzewa DOM:
case Node.ELEMENT_NODE:
String name = node.getNodeName();
System.out.print("<" + name);
// Wyświetlamy atrybuty
System.out.println(">");
// Rekurencyjne przetwarzanie elementów potomnych
NodeList children = node.getChildNodes();
if (children != null) {
for (int i=0; i<children.getLength(); i++) {
printTree(children.item(i));
}
}

168
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 168
System.out.println("</" + name + ">");
break;
Proste, prawda? Równie łatwo wykonuje się iterację po atrybutach węzła DOM
Element
. Tym
razem wykorzystujemy metodę
getAttributes()
, również zdefiniowaną w interfejsie
Node
.
W ten sposób uzyskujemy listę atrybutów XML, zwróconą w postaci klasy
NamedNodeMap
.
Interfejs ten wykorzystywany jest do gromadzenia węzłów o niepowtarzalnych nazwach, tak więc
idealnie nadaje się do przechowywania atrybutów elementu XML. Kolejną czynnością jest iteracja
po uzyskanej w ten sposób liście i wyświetlenie nazwy i wartości każdego atrybutu. Jest to
procedura podobna do tej, za pomocą której dokonywaliśmy iteracji po węzłach potomnych
elementu; do uzyskania wartości do wyświetlenia używamy metod
getNodeName()
i
getNodeValue()
. Wykonamy to zadanie poniżej (należy pamiętać o dodaniu instrukcji
importującej dla
NamedNodeMap
):
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;
...
case Node.ELEMENT_NODE:
String name = node.getNodeName();
System.out.print("<" + name);
NamedNodeMap attributes = node.getAttributes();
for (int i=0; i<attributes.getLength(); i++) {
Node current = attributes.item(i);
System.out.print(" " + current.getNodeName() +
"=\"" + current.getNodeValue() +
"\"");
}
System.out.println(">");
// Rekurencyjne przetwarzanie elementów potomnych
NodeList children = node.getChildNodes();
if (children != null) {
for (int i=0; i<children.getLength(); i++) {
printTree(children.item(i));
}
}
System.out.println("</" + name + ">");
break;
No i sporą część pracy mamy już za sobą! Te kilkaset wierszy kodu pozwala nam „przejść” przez
całe drzewo DOM i wyświetlić elementy i atrybuty. To właśnie ta prostota (szczególnie w porów-
naniu z SAX-em) powoduje, że DOM jest tak popularny w aplikacjach obsługujących dane XML.
Oczywiście — o czym już wspominaliśmy i do czego jeszcze wrócimy — nie zawsze jest to
rozwiązanie najlepsze; jednak na pewno udostępnia prostą reprezentację danych XML, do których
programista ma bardzo łatwy dostęp.

Obiektowy model dokumentu (DOM)
169
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 169
Formatowanie
Jeśli jeszcze tego nie zrobiliśmy, skompilujmy plik źródłowy i spróbujmy uruchomić go z argu-
mentem w postaci pliku spisu treści. Powinniśmy uzyskać wynik działania podobny do fragmentu
pokazanego w przykładzie 7.3.
Przykład 7.3. Wynik działania programu DOMParserDemo
D:\prod\JavaXML> java DOMParserDemo D:\prod\JavaXML\contents.xml
Przetwarzanie pliku XML: contents.xml
<xml version="1.0">
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<JavaXML:Tytul>
</JavaXML:Tytul>
<JavaXML:Spis>
<JavaXML:Rozdzial tematyka="XML">
<JavaXML:Naglowek>
</JavaXML:Naglowek>
<JavaXML:Temat podRozdzialy="7">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="3">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="4">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="0">
</JavaXML:Temat>
</JavaXML:Rozdzial>
...
Wynik jest zgodny z oczekiwaniami, wciąż jednak uzyskane informacje nie są ani przejrzyste, ani
zbyt przydatne. Bardzo trudno stwierdzić, gdzie elementy zaczynają się, a gdzie kończą — nie ma
wcięć, które były w oryginalnym dokumencie. Jak pamiętamy, białe znaki występujące pomiędzy
elementami są „obcinane” i zazwyczaj ignorowane przez parsery, tak więc tutaj musimy ponownie
je dodać. W tym celu przekażemy prosty łańcuch z „wcięciami” do metody wyświetlającej. Wcię-
cia będą dodawane w miarę rekurencyjnego przechodzenia po drzewie DOM:
/**
* <p>
* Tutaj drukujemy węzeł DOM i przechodzimy
* przez wszystkie węzły potomne.
* </p>
*
* @param node <code>Node</code> obiekt do wyświetlania.
* @param indent <code>String</code> białe znaki do wyświetlania
* przed <code>Node</code>
*/
public void printNode(Node node, String indent) {
// Wybieramy czynność do wykonania na podstawie typu węzła
switch (node.getNodeType()) {
case Node.DOCUMENT_NODE:
System.out.println("<xml version=\"1.0\" encoding=\"ISO-8859-
2\">\n");

170
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 170
Document doc = (Document)node;
printNode(doc.getDocumentElement(), "");
break;
case Node.ELEMENT_NODE:
String name = node.getNodeName();
System.out.print(indent + "<" + name);
NamedNodeMap attributes = node.getAttributes();
for (int i=0; i<attributes.getLength(); i++) {
Node current = attributes.item(i);
System.out.print(" " + current.getNodeName() +
"=\"" + current.getNodeValue() +
"\"");
}
System.out.println(">");
// Rekurencyjne przetwarzanie elementów potomnych
NodeList children = node.getChildNodes();
if (children != null) {
for (int i=0; i<children.getLength(); i++) {
printNode(children.item(i), indent + " ");
}
}
System.out.println(indent + "</" + name + ">");
break;
case Node.TEXT_NODE:
case Node.CDATA_SECTION_NODE:
// Wyświetlamy dane tekstowe
break;
case Node.PROCESSING_INSTRUCTION_NODE:
// Wyświetlamy instrukcję przetwarzania (PI)
break;
case Node.ENTITY_REFERENCE_NODE:
// Wyświetlamy encję
break;
case Node.DOCUMENT_TYPE_NODE:
// Wyświetlamy deklarację DTD
break;
}
}
Teraz jeszcze wykonamy małą zmianę polegającą na przekazaniu naszej metodzie początkowego
wcięcia w postaci łańcucha pustego:
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
parser.parse(uri);
Document doc = parser.getDocument();
// Wyświetlamy dokument z drzewa DOM
// z wcięciem w postaci łańcucha pustego
printNode(doc, "");

Obiektowy model dokumentu (DOM)
171
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 171
} catch (Exception e) {
System.out.println("Błąd w przetwarzaniu: " + e.getMessage());
}
}
Po tych niewielkich zmianach dane wynikowe prezentują się o wiele bardziej estetycznie (przy-
kład 7.4).
Przykład 7.4. Wynik działania programu DOMParserDemo po zastosowaniu wcięć
D:\prod\JavaXML> java DOMParserDemo D:\prod\JavaXML\contents.xml
Przetwarzanie pliku XML: contents.xml
<xml version="1.0" encoding="ISO-8859-2">
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<JavaXML:Tytul>
</JavaXML:Tytul>
<JavaXML:Spis>
<JavaXML:Rozdzial tematyka="XML">
<JavaXML:Naglowek>
</JavaXML:Naglowek>
<JavaXML:Temat podRozdzialy="7">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="3">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="4">
</JavaXML:Temat>
<JavaXML:Temat podRozdzialy="0">
</JavaXML:Temat>
</JavaXML:Rozdzial>
...
Teraz można już dodać wartości tekstowe zawarte w elementach.
Węzły tekstowe
Czytelnik być może zastanawia się teraz, gdzie w książce zawarte są informacje dotyczące węzłów
o wartościach typu całkowitego, numerycznych czy boolowskich. Otóż w niniejszej książce nie
ma ich wcale. Jak pamiętamy, wszystkie dane XML w elementach zwracane są przez wywołanie
SAX
characters()
. Już to powinno podpowiedzieć Czytelnikowi, że parser XML „postrzega”
wszystkie dane jako tekst i że to aplikacja dokonuje w razie potrzeby konwersji typów. Tak więc
aby wyświetlić wartości elementów w DOM-ie, należy skupić uwagę na interfejsach
Text
i
CDA-
TASection
. Wyświetlanie wartości jest całkiem proste — korzystamy ze znanej już metody
getNodeValue()
interfejsu DOM
Node
:
case Node.TEXT_NODE:
case Node.CDATA_SECTION_NODE:
System.out.print(node.getNodeValue());
break;
Po dodaniu tego fragmentu przetwarzanie modelu DOM jest już niemal kompletne. Zanim jednak
przejdziemy dalej, przyjrzyjmy się kilku rzadziej używanym, ale równie przydatnym interfejsom
DOM (i odpowiadającym im typom
Node
):
ProcessingInstruction
,
DocumentType
i
EntityReference
— wszystkie występują w naszym dokumencie.

172
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 172
Instrukcje przetwarzania
W ramach dowiązań DOM do Javy zdefiniowano interfejs do obsługi instrukcji przetwarzania wy-
stępujących w wejściowym dokumencie XML. To bardzo przydatne rozwiązanie, ponieważ in-
strukcje te są budowane według tego samego modelu znaczników co elementy i atrybuty XML,
a mimo to stanowią istotną część XML-a i powinna o nich wiedzieć aplikacja. W naszym przykła-
dowym dokumencie procesorowi XSLT przekazujemy instrukcje informujące o arkuszu stylów,
a strukturze publikacji (Apache Cocoon) — instrukcję informującą o tym, jakie przetwarzanie ma
zostać wykonane. Jeśli w pliku Czytelnika instrukcje PI są wciąż opatrzone komentarzami, to na-
leży je teraz usunąć:
<?xml version="1.0" encoding="ISO-8859-2"?>
<?xml-stylesheet href="XSL\JavaXML.html.xsl" type="text/xsl"?>
<?xml-stylesheet href="XSL\JavaXML.wml.xsl" type="text/xsl"
media="wap"?>
<?cocoon-process type="xslt"?>
<!DOCTYPE JavaXML:Ksiazka SYSTEM "DTD/JavaXML.dtd">
<!-- Java i XML -->
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
Węzeł PI w modelu DOM stanowi pewne odstępstwo od schematu, który poznaliśmy — aby za-
chować zgodność ze składnią interfejsu
Node
, metoda
getNodeValue()
zwraca wszystkie in-
strukcje w PI w postaci jednego łańcucha
String
. To pozwala w prosty sposób wyświetlić in-
strukcję PI na ekranie; wciąż jednak do pobrania nazwy PI musimy korzystać z metody
getNo-
deValue()
. Gdybyśmy pisali aplikację, która otrzymywałaby instrukcje PI z dokumentu XML,
skorzystalibyśmy raczej z interfejsu
ProcessingInstruction
; dzięki temu uzyskujemy dostęp
do takich samych danych, ale nazwy metod (
getTarget()
i
getData()
) są bardziej zgodne
z formatem PI. Mając to na uwadze, możemy już dodać kod wyświetlający instrukcje prze-
twarzania:
case Node.PROCESSING_INSTRUCTION_NODE:
System.out.println("<?" + node.getNodeName() +
" " + node.getNodeValue() +
"?>");
break;
Po skompilowaniu i uruchomieniu tak zmienionego programu znów może nas spotkać niespo-
dzianka — żadne instrukcje przetwarzania w dokumencie nie zostały wyświetlone na ekranie!
Dlaczego? Otóż kod w takiej postaci uzyskuje obiekt
Document
z parsera XML i przetwarza
tylko element główny wejściowych danych XML. Ponieważ instrukcje przetwarzania znajdują się
na tym samym „poziomie” co element główny — są one ignorowane. Aby to poprawić, musimy
zmienić część kodu obsługującą węzeł typu
Document
. Wprowadzimy fragment podobny do
tego, jakim obsługiwaliśmy elementy potomne w celu przetworzenia wszystkich struktur XML
„najwyższego poziomu”, a nie tylko elementu głównego:
case Node.DOCUMENT_NODE:
System.out.println("<xml version=\"1.0\" encoding=\"ISO-8859-
2\">\n");
// Rekurencyjne przetwarzanie elementów potomnych
NodeList nodes = node.getChildNodes();
if (nodes != null) {
for (int i=0; i<nodes.getLength(); i++) {
printNode(nodes.item(i), "");
}
}

Obiektowy model dokumentu (DOM)
173
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 173
/*
Document doc = (Document)node;
printNode(doc.getDocumentElement(), "");
*/
break;
Po wprowadzeniu tych zmian instrukcje PI powinny pojawić się na początku zwracanych danych,
zgodnie z oczekiwaniami. To kolejna subtelna cecha DOM, o której warto pamiętać — zawsze
należy uważać nie tylko na te węzły, które przetwarzamy, ale także na te, których nie prze-
twarzamy!
Typy dokumentów
Oprócz instrukcji PI, może okazać się konieczne uzyskanie deklaracji DTD — daje nam to infor-
macje, do jakich zawężeń odwołuje się dokument XML. Jednakże, ponieważ mogą istnieć identy-
fikatory publiczne i systemowe, a także inne dane specyficzne dla DTD, w celu uzyskania tych
dodatkowych danych musimy skorzystać z interfejsu
DocumentType
(w ramach naszego egzem-
plarza
Node
). Potem do pobrania nazwy z
Node
użyjemy metod pomocniczych;
Node
zwraca
element główny zawężanego dokumentu, identyfikator publiczny (jeśli istnieje) oraz identyfikator
systemowy definicji DTD, do której następuje odwołanie. Spróbujmy zrekonstruować odwołanie
do DTD w naszym dokumencie:
import org.w3c.dom.Document;
import org.w3c.dom.DocumentType;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
// Importujemy parser DOM określonego producenta
import org.apache.xerces.parsers.DOMParser;
...
case Node.DOCUMENT_TYPE_NODE:
DocumentType docType = (DocumentType)node;
System.out.print("<!DOCTYPE " + docType.getName());
if (docType.getPublicId() != null) {
System.out.print(" PUBLIC \"" + docType.getPublicId() +
"\" ");
} else {
System.out.print(" SYSTEM ");
}
System.out.println("\"" + docType.getSystemId() + "\">");
break;
Encje
Ostatni typ węzła, jaki omówimy, to interfejs
EntityReference
. Obsługuje on encje występu-
jące w dokumencie XML — takie jak ta opisująca prawa autorskie. Sposób drukowania tego typu
węzła nie stanowi niespodzianki:
case Node.ENTITY_REFERENCE_NODE:
System.out.print("&" + node.getNodeName() + ";");
break;
Niespodzianką mogą natomiast okazać się uzyskane w ten sposób dane. Definicja sposobu prze-
twarzania encji w modelu DOM zostawia dużą swobodę implementacji i sposób działania w dużym
stopniu zależy tutaj od parsera. Większość parserów XML tłumaczy i przetwarza encje, zanim

174
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 174
w ogóle dane XML „dostaną się” do drzewa DOM. Często więc spodziewamy się zobaczenia encji
w strukturze DOM, a zamiast tego widzimy tekst lub wartości. Aby sprawdzić, jak zachowuje się
nasz parser, opatrzmy komentarzami „HTML-ową” wersję elementu
JavaXML:Copyright
(wsta-
wiliśmy ją w poprzednim rozdziale) i zamieńmy ją na encję
OReillyCopyright
:
<!--
<JavaXML:Copyright>
<center>
<table cellpadding="0" cellspacing="1" border="1" bgcolor="Black">
<tr>
<td align="center">
<table bgcolor="White" border="2">
<tr>
<td>
<font size="-1">
Copyright O'Reilly and Associates, 2000
</font>
</td>
</tr>
</table>
</td>
</tr>
</table>
</center>
</JavaXML:Copyright>
-->
<JavaXML:Copyright>&OReillyCopyright;</JavaXML:Copyright>
Takie zachowania mogą stanowić przyczynę błędu w aplikacji. Cóż więc za pożytek z typu węzła
opisującego encję, jeśli i tak jest ona wcześniej przetwarzana przez parser? Otóż węzeł taki po-
wstał z myślą o tworzeniu nowego, a nie przetwarzaniu istniejącego dokumentu XML. To zagad-
nienie stanowić będzie treść kolejnego podrozdziału.
Mutacje drzewa DOM
Czytelnik obeznany z modelem DOM zapewne zauważył, że pominęliśmy jeden bardzo istotny
temat — możliwość zmiany drzewa DOM. Możliwe jest proste dodawanie węzłów do drzewa
DOM. Właściwie jeśli pominąć prostotę, ta zdolność modyfikacji i dodawania węzłów do drzewa
jest faktycznie jedną z najczęściej wykorzystywanych i najbardziej cenionych cech.
I w ten sposób powróciliśmy do kwestii transformacji XML-a. Dlaczego model DOM jest tak isto-
tny dla procesora XSLT? Otóż nie tylko chodzi tu o dane wejściowe, udostępniane w prosty spo-
sób; ważne jest także to, że procesor XSLT może tworzyć nowe drzewo DOM na potrzeby
dokumentu wyjściowego — a także w prosty sposób kopiować, modyfikować, dodawać i usuwać
węzły drzewa wejściowego. Takie przetwarzanie preferowane jest szczególnie w złożonych apli-
kacjach — często dane wejściowe przekazywane są na drzewo wyjściowe bez rzutowania klas czy
tworzenia nowych egzemplarzy obiektów — to istotnie zmniejsza złożoność i zwiększa wydajność
procesora XSLT. To dlatego poświęciliśmy tak dużo czasu modelowi DOM.
Omówienie mutowania, na które z pewnością czeka Czytelnik, zawarte jest w kolejnych roz-
działach. Teraz omówienie tego tematu oddaliłoby nas od tematu arkuszy XSL, ale w dalszych
rozdziałach powrócimy do zagadnień związanych z tworzeniem i modyfikacją XML-a. Zanim
jednak przejdziemy do bardziej zaawansowanych rozdziałów, należy omówić pułapki, jakie mogą
czyhać na programistę Javy korzystającego z potężnego interfejsu DOM.

Uwaga! Pułapka!
175
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 175
Uwaga! Pułapka!
Podobnie jak w poprzednich rozdziałach, zostaną tutaj omówione najczęstsze pułapki czyhające na
programistów Javy zajmujących się XML-em, ze szczególnym uwzględnieniem modelu DOM.
Niektóre z poniższych uwag mają charakter bardziej informacyjny niż praktyczny, ale na pewno
przyczynią się do podejmowania właściwych decyzji odnośnie stosowania modelu DOM i pomogą
w zrozumieniu, co dzieje się „pod maską” naszych aplikacji XML.
Pamięć i wydajność w modelu DOM
Dużo czasu zajęło nam wcześniej omawianie powodów, dla których warto zdecydować się na
DOM lub SAX. Już wcześniej podkreślaliśmy, że korzystanie z modelu DOM wymaga wczytania
całego dokumentu XML do pamięci i przechowywania go tam w postaci struktury drzewiastej
— o tym trzeba koniecznie pamiętać! Niezwykle często zdarza się sytuacja, w której programista
ładuje cały zbiór złożonych dokumentów XML do procesora XSLT i zostawia je do przetworzenia
w trybie offline. Po powrocie komputer z systemem Windows wyświetla straszliwy „niebieski
ekran śmierci”, a Linux zalewa ekran komunikatami o braku pamięci. Powtórzmy więc jeszcze raz
— należy uważać na DOM przy przetwarzaniu dużych ilości danych!
Korzystanie z modelu DOM wymaga zaangażowania pamięci w ilości proporcjonalnej do rozmia-
ru i złożoności dokumentu XML. Nie ma sposobu obniżenia wymogów odnośnie pamięci. Co wię-
cej, same transformacje to „zasobożerne” operacje; w połączeniu z wymaganiami pamięciowymi
to naprawdę daje dużo do myślenia. Czyż więc programista nie powinien nigdy nie korzystać
z DOM-a? Oczywiście, powinien korzystać! Trzeba jednak zachować dużą ostrożność i uważać na
to, co przekazujemy do modelu. Jeśli operujemy na niewielkich, mniejszych niż megabajt doku-
mentach, prawdopodobnie żadne kłopoty nigdy nam się nie przydarzą. Większe dokumenty — pod-
ręczniki techniczne czy całe książki — mogą pochłonąć zasoby systemowe i wpłynąć na wydaj-
ność aplikacji.
Analizatory DOM zgłaszające wyjątki SAX
W naszych przykładach związanych z modelem DOM nie wspomnieliśmy o wyjątkach zgłaszanych
w wyniku przetwarzania dokumentu. Wynika to stąd, że — jak mówiliśmy — proces generowania
drzewa DOM pozostawiono implementacji parsera, a te różnią się przecież miedzy sobą. Jednakże
zawsze dobrze jest przechwytywać specyficzne wyjątki i odpowiednio na nie reagować. Odpo-
wiednia zmiana głównej pętli parsera może być nieco zaskakująca. Oto wersja dla Apache Xerces:
/**
* <p>
* Tutaj przetwarzamy plik i wyświetlamy dokument
* za pomocą modelu DOM.
* </p>
*
* @param uri <code>String</code> URI pliku do przetworzenia.
*/
public void performDemo(String uri) {
System.out.println("Przetwarzanie pliku XML: " + uri + "\n\n");
// Tworzymy egzemplarz implementacji parsera DOM danego producenta
DOMParser parser = new DOMParser();
try {
parser.parse(uri);
Document doc = parser.getDocument();

176
Rozdział 7. Czerpanie z XML-a
C:\WINDOWS\Pulpit\Szymon\Java i XML\07-08.doc — strona 176
// Wyświetlamy dokument z drzewa DOM
// z wcięciem w postaci łańcucha pustego
printNode(doc, "");
} catch (IOException e) {
System.out.println("Błąd wczytywania URI: " + e.getMessage());
} catch (SAXException e) {
System.out.println("Błąd przetwarzania: " + e.getMessage());
}
}
Niespodzianką nie jest
IOException
(wskazuje błąd w lokalizacji podanego URI, podobnie jak
w przykładzie SAX). Zastanawia coś innego — możliwość zgłoszenia wyjątku
SAXException
.
Nasz parser DOM zgłasza wyjątek SAX? Chyba zaimportowaliśmy nie te klasy! Nie, klasy są
właściwe. Pamiętajmy o tym, co mówiliśmy wcześniej — możliwe jest własnoręczne zbudowanie
struktury drzewiastej danych w dokumencie XML za pomocą SAX-a, ale DOM stanowi ciekawą
alternatywę. To prawda, ale nie wyklucza to jeszcze użycia interfejsu SAX. Rzeczywiście SAX
udostępnia wydajny i szybki sposób przetworzenia dokumentu; akurat w naszym przypadku doku-
ment jest przetwarzany przez SAX i wstawiany do struktury DOM. Ponieważ nie istnieje standard
rządzący sposobem tworzenia struktury DOM, takie rozwiązanie jest dopuszczalne, a nawet popu-
larne. Nie należy więc dziwić się, że importujemy i przechwytujemy
org.xml.sax.SAXExcep-
tion
w aplikacjach DOM.
Co dalej?
Rozdziały 1. – 7. stanowią pokaźny zbiór informacji o XML-u. Czytelnik powinien już potrafić po-
sługiwać się XML-em, definicjami DTD i schematami oraz XSLT. To najważniejsze technologie
w programowaniu z wykorzystaniem języka XML. W kolejnych rozdziałach pojawią się oczywiś-
cie jeszcze inne skróty i specyfikacje, ale omówione zagadnienia to klucz do korzystania z XML-a z
poziomu Javy. Oprócz specyfikacji zostały omówione także SAX i DOM, zatem Czytelnik potrafi
reprezentować większość danych XML w Javie. Można powiedzieć, że Czytelnik jest już ofi-
cjalnie programistą znającym Javę i XML!
W następnym rozdziale powrócimy do omawiania interfejsów SAX i DOM; wykażemy ich zalety
i wady. Przed zagłębieniem się w kodach aplikacji (czemu poświęcona jest reszta książki) zostanie
omówiony interfejs JDOM. Twórcy JDOM starali się naprawić problemy i dokuczliwości zwią-
zane z interfejsami SAX i DOM. Powstały w ten sposób interfejs API otwiera przed programistą
XML-a nowe możliwości.
Wyszukiwarka
Podobne podstrony:
ei 2005 07 08 s085 id 154185 Nieznany
chemia lato 12 07 08 id 112433 Nieznany
ei 2005 07 08 s033 id 154176 Nieznany
podst chemii 05 07 08 id 365984 Nieznany
chemia lato 07 07 08 id 112423 Nieznany
ei 2005 07 08 s050 id 154178 Nieznany
ei 2005 07 08 s084 id 154184 Nieznany
ei 2005 07 08 s052 id 154179 Nieznany
podst chemii 08 07 08 id 365991 Nieznany
ei 2005 07 08 s020 id 154175 Nieznany
chemia lato 05 07 08 id 112417 Nieznany
07 08 id 418350 Nieznany (2)
chemia lato 09 07 08 id 112430 Nieznany
ei 2005 07 08 s058 id 154180 Nieznany
chemia lato 08 07 08 id 112426 Nieznany
2015 04 09 08 21 07 01id 28637 Nieznany (2)
podst chemii 02 07 08 id 365977 Nieznany
ei 2005 07 08 s018 id 154174 Nieznany
ei 2005 07 08 s043 id 154177 Nieznany
więcej podobnych podstron