
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 131
6
Przekształcanie
kodu XML
Jeśli Czytelnik bierze udział w tworzeniu systemów wewnętrznych lub projektuje systemy, to już
na tym etapie czytania powinien doceniać możliwości XML-a. Język reprezentujący dane w spo-
sób niezależny od producenta, prosty w przetwarzaniu, przenośny i obsługiwany z poziomu Javy
— czy to właśnie ten format danych rozwiąże wszystkie problemy ze współpracą pomiędzy apli-
kacjami? Możliwe. Jeśli jednak Czytelnik jest programistą zawartości, budowniczym aplikacji, lub
też zaangażowany jest w prezentację aplikacji, może odczuwać zniecierpliwienie — po przeczy-
taniu pięciu rozdziałów nie wie jeszcze, jak generować zawartość dla klientów z wykorzystaniem
XML-a, jak separować prezentacje od danych.
W tym rozdziale zostanie rozpoczęte omawianie przekształcania danych XML. Jest to obszerny
temat obszerny.
Najpierw zostaną przedstawione cele i sposoby przekształcania danych XML. W następnym roz-
dziale przedstawiony zostanie procesor Java XSLT, który pobiera dokument XML i generuje róż-
ne rodzaje zawartości — często różniące się w sposób zasadniczy od pierwotnych danych XML.
Czytelnik dowie się również, jak w tym procesie wykorzystywany jest obiektowy model dokumentu
(DOM). Przekształcanie XML-a jest tak obszernym tematem, że nie sposób omówić tutaj wszy-
stkich dostępnych konstrukcji składniowych. Referencyjne podejście do przekształcania przedstawione
jest w książce XML Pocket Reference Roberta Ecksteina (O'Reilly & Associates). Przekształcaniu
XML-a poświęcono również sporą część serwisu WWW grupy W3C: http://www.w3.org/Style/XSL/.
Cel
Przed przystąpieniem do omawiania procesu przekształcania danych XML, warto powiedzieć
kilka słów o samym celu przekształcania. Podobnie jak w przypadku omawiania istoty zawężania
danych XML, dobre zrozumienie przekształcania umożliwi poprawne wykonywanie tego procesu.
Przekształcanie nie jest rozwiązaniem ostatecznym w zakresie prezentacji danych i nie wszędzie
powinno być wykorzystywane; jednak są sytuacje, w których przekształcanie oszczędzi wiele go-
dzin naszej pracy.

132
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 132
W następnych dwóch rozdziałach skoncentrujemy się na sposobie, w jaki dane XML mogą zostać
przedstawione różnym klientom. Jednakże niekoniecznie oznacza to, że będziemy zajmować się
prezentacją danych samemu użytkownikowi... właściwie o tym nie powiemy prawie nic! Jeśli
Czytelnik czuje się teraz nieco zagubiony, to nic nie szkodzi. Najpierw przypomnijmy sobie, co
rozumiemy pod pojęciem klienta.
Klient klienta mojego klienta
Najczęściej klienta lub aplikację klienta opisuje się jako użytkownika końcowego. Ale pogląd, że
klientem aplikacji jest po prostu człowiek siedzący przed przeglądarką WWW lub interfejsem GUI
jest nieścisły. Powiedzieliśmy już o tym, jak różne mogą być klienty korzystające z aplikacji; teraz
rozszerzymy tę definicję jeszcze bardziej. Weźmy na przykład mechanizm bazy danych. Dane
w bazie rzadko wyświetlane są bezpośrednio użytkownikowi, bez wcześniejszego sformatowania
ich przez inny program. Czy możemy więc powiedzieć, że z bazy nie korzystają żadne klienty? A co
z aplikacją przetwarzającą dane o pogodzie z innej strony HTML i wyświetlającą je użytko-
wnikowi w nowym formacie? Czy aplikacja ta ma dwa klienty? A np. system X Windows, gdzie
wyświetlany obraz generowany jest na serwerze, a aplikacja zdalna jest klientem? Oczywiste jest,
że definicja klienta jest bardzo pojemna.
Na potrzeby niniejszej książki klientem będziemy nazywali wszystko to, co korzysta z danych
aplikacji, programu lub mechanizmu. Klientem w tym pojęciu byłby więc program korzystający
z opisanej wyżej bazy danych, a także użytkownik, który przegląda sformatowane dane. Program
formatujący dane o pogodzie jest klientem; są nimi także użytkownicy korzystający ze sformato-
wanych danych. Jak widać, granica między pojęciami „użytkownik” a „program” zaciera się.
W wielowarstwowym systemie, w którym uruchomiono bazę danych, pojemnik Enterprise
JavaBean, mechanizm serwletów i strukturę publikacji istnieją cztery, pięć lub więcej klientów!
Czytelnik winien zrozumieć, że w przypadku XML-a nie rozróżniamy pomiędzy klientem a pro-
gramem korzystającym z danych. Pozwala to nam postrzegać przekształcanie danych w sposób
bardziej użyteczny — jeśli aplikacja A wymaga danych (w formacie A) od aplikacji B (przecho-
wującej dane w formacie B), musimy te dane przekształcić (ang. transform). W przekształcaniu
biorą udział dwa formaty, natomiast same dane pozostają nienaruszone. Kiedy znamy już nową
definicję klienta, to możemy jeszcze od procesu tego oddzielić szczegółowe informacje o aplikacji
wykorzystującej dane. Jeśli aplikacja C wykorzystuje sformatowane dane aplikacji B w formacie
C, musi się odbyć kolejne przekształcanie. Nie jest istotne, czy formaty te to HTML, SQL, XML
zgodny z różnymi DTD, czy coś jeszcze zupełnie innego. Nie jest również istotne to, czy klient
jest kolejnym programem, użytkownikiem czy systemem własnym. Przekształcanie to po prostu
przekładanie z jednego formatu na drugi. Wszystkie te informacje pomogą Czytelnikowi zrozu-
mieć, dlaczego przekształcanie danych XML jest tak ważne.
Ja nie rozumiem chińskiego ...
Jak można się domyślać, najważniejszym celem przekształcania danych XML jest doprowadzenie
ich do takiej postaci, aby były czytelne dla danego klienta. Czasami można to osiągnąć poprzez
przekształcenie dokumentu XML zgodnego z pewną definicją DTD na dokument zgodny z inną
definicją (lub schematem). Innym razem konieczne jest uzyskanie zupełnie innych dokumentów
z dokumentu bazowego. Tak czy inaczej, potrzebne tutaj będą informacje dotyczące zawężania
i sprawdzania poprawności danych XML. Nawet jeśli aplikacja „zna” format danych, to nie będzie
go mogła jeszcze zinterpretować — do tego konieczne są definicje DTD, schematy lub inne zawę-

Składniki
133
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 133
żenia dokumentu. Wtedy dopiero aplikacja „zrozumie”, jakiej konwersji można dokonać i jakie
struktury danych są obecne w dokumencie źródłowym.
Problemy pojawiają się wtedy, gdy wzrasta liczba permutacji współpracujących ze sobą aplikacji;
innymi słowy, im więcej jest składników biorących udział w wymianie danych, tym więcej możli-
wości przekształcania tych danych. Każdy komponent musi znać zawężenia innych komponentów.
Dlatego właśnie stworzono zestaw specyfikacji i standardów służących do przekształcania danych
XML. Powstała warstwa pośrednia, niezależna od poszczególnych komponentów aplikacji, która
umożliwia konwersję danych z jednego formatu lub stylu na inny; samym komponentom pozo-
stawia się czuwanie nad logicznym przetwarzaniem danych. Tę powłokę pośrednią będziemy
nazywali procesorem. Procesor ma za zadanie pobrać jeden lub więcej dokumentów, określić ich
formaty i zawężenia i dokonać przekształcenia (transformacji), po której powstają dane w nowym
formacie (a to może nawet oznaczać rozdzielenie ich na wiele plików). Dokument wynikowy
może potem zostać użyty przez inny komponent. Oczywiście, ta aplikacja może z kolei przekazać
dane do innego procesora, który przekaże dokument w jeszcze innym formacie trzeciemu kom-
ponentowi i tak dalej. W ten sposób aplikacje nie znające tego samego „języka” mogą się ze sobą
porozumiewać. Poniżej omówione zostaną „podzespoły” biorące udział w tym procesie.
Składniki
Przekształcanie danych XML jest bardzo przydatne, ale wcale nie łatwe w implementacji. Nie
określono sposobów przekształcania w oryginalnej specyfikacji XML 1.0; zamiast tego powstały
trzy oddzielne zalecenia dotyczące przekształcania. Jeden z tych sposobów (XPath) jest również
wykorzystywany w specyfikacji XPointer, ale na pewno najważniejszym celem opisywanych niżej
komponentów jest przekształcanie XML-a z jednego formatu na inny.
Te trzy specyfikacje są ze sobą ściśle powiązane (i niemal zawsze wykorzystywane wspólnie),
więc zwykle opisuje się je razem. Powstały opis jest prostszy w zrozumieniu, ale niekoniecznie
poprawny technicznie. Innymi słowy, termin XSLT, oznaczający dokładnie „przekształcenia XSL”,
często stosowany jest jako określenie zarówno rozszerzalnych arkuszy stylów (XSL), jak i specy-
fikacji XPath. Podobnie, za pomocą terminu XSL określa się często wszystkie te trzy technologie.
Tutaj zalecenia te zostaną rozdzielone. Jednak w celu uproszczenia będziemy używać skrótów
XSL i XSLT przemiennie — określając za ich pomocą cały proces przekształcania. Nie jest to mo-
że zgodne z wytycznymi wspomnianych specyfikacji, ale na pewno zgodne z ich duchem i pro-
stsze w zrozumieniu.
Rozszerzalny język arkuszy stylów (XSL)
XSL to rozszerzalny język arkuszy stylów (ang. Extensible Stylesheet Language). Służy do two-
rzenia arkuszy stylów. To obszerna definicja, którą można rozbić na dwie części:
• XSL to język służący do przekształcania dokumentów XML;
• XSL to zbiór słów XML służących do formatowania dokumentów XML.
Te definicje są do siebie podobne. Jedna z nich opisuje przekształcanie z jednego formatu XML na
inny; druga odnosi się do samej prezentacji zawartości dokumentu. Mówiąc prościej, XSL opisuje,
jak przekształcać dokument z formatu A na format B. Składniki tego języka opisują sposób
takiego przekształcania.
134
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 134
XSL a drzewa
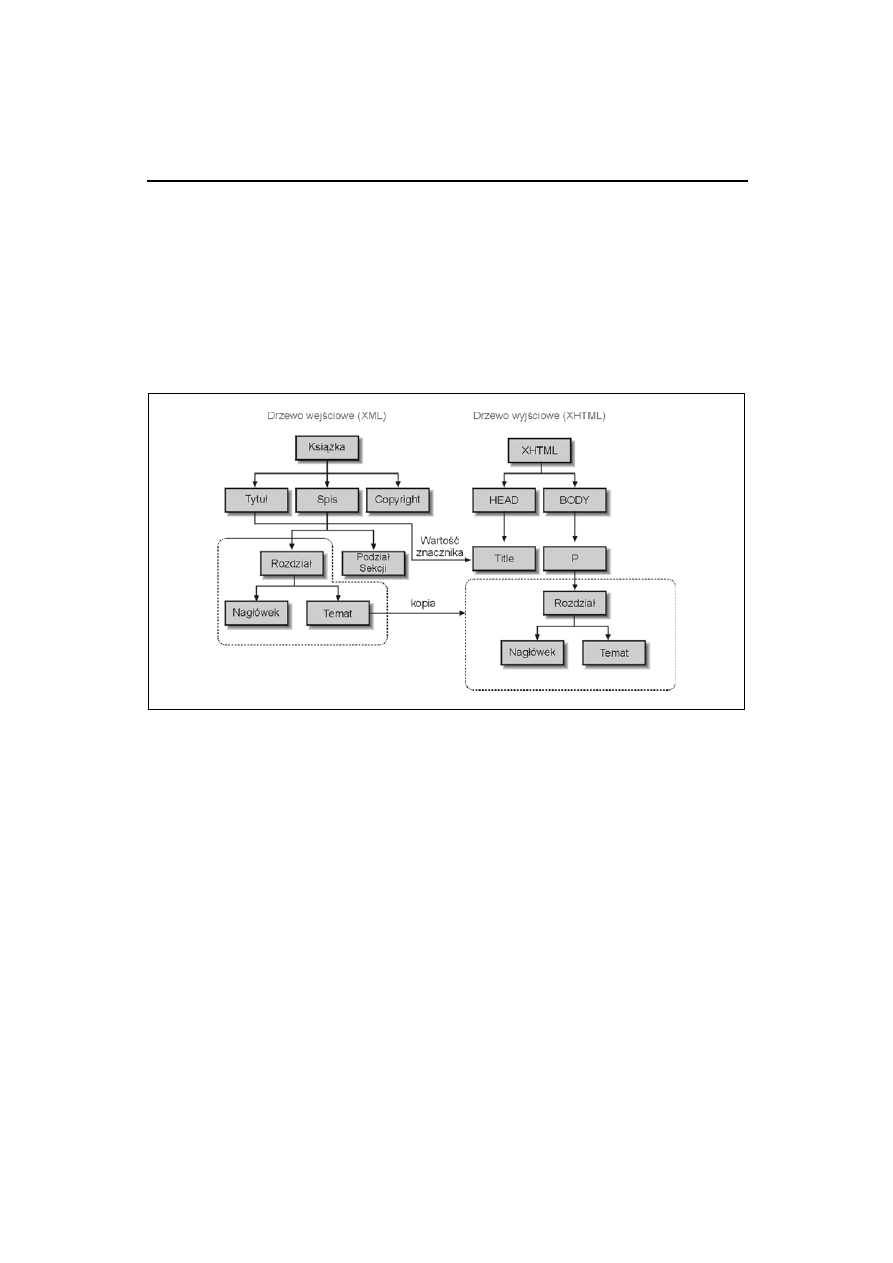
Aby zrozumieć istotę XSL, trzeba przede wszystkim uświadomić sobie, że wszystkie dane biorące
udział w przetwarzaniu XSL mają strukturę drzewiastą (patrz rysunek 6.1). Nawet same reguły de-
finiowane za pomocą arkuszy XSL umieszczane są w takiej strukturze. Dzięki temu przetwa-
rzanie dokumentów XML (także posiadających strukturę drzewiastą) jest bardzo proste. Za
pomocą szablonów dopasowuje się element główny przetwarzanego dokumentu XML. Następ-
nie dalsze reguły („liście”) stosuje się na dalszych elementach („liściach”) dokumentu XML, aż do
tych położonych najniżej. Elementy mogą być przetwarzane, przekształcane za pomocą stylów,
ignorowane, kopiowane lub w inny sposób „obrabiane” na dowolnym etapie tego procesu.
Rysunek 6.1. Operacje na drzewach w XSL
Struktura drzewiasta ma tę zaletę, że umożliwia grupowanie dokumentów XML. Jeśli element A
zawiera elementy B i C i nastąpi jego przeniesienie lub skopiowanie to elementy w nim zawarte
będą podlegały tej samej operacji.
Dzięki temu obsługa dużych porcji danych za pomocą arkusza XSL jest spójna i przejrzysta. O budo-
wie takiego drzewa powiemy więcej w następnej części, przy okazji omawiania standardu XSLT.
Obiekty formatujące
Niemal cała specyfikacja XSL to definicje obiektów formatujących. Obiekt formatujący oparty jest
na dużym modelu określanym — jak łatwo się domyślić — nazwą modelu formatującego. W ra-
mach modelu zdefiniowano zestaw obiektów, które przekazywane są na wejście programu forma-
tującego. Program taki „aplikuje” obiekty formatujące na całym albo na części dokumentu;
w rezultacie powstaje nowy dokument składający się z wszystkich lub tylko z części danych orygi-
nalnego dokumentu XML, ale już w nowym formacie, odpowiadającym obiektom wykorzystanym
przez program formatujący. Jest to, jak widać, koncepcja bardzo luźno zdefiniowana; dlatego też
w ramach specyfikacji XSL starano się stworzyć bardziej konkretny model, z którym obiekty
miałyby być zgodne. Innymi słowy, istnieje obszerny zestaw właściwości i słów kluczowych,

Składniki
135
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 135
które można wykorzystać w obiektach formatujących. Mamy tutaj typy obszarów podlegających
wizualizacji, właściwości linii, czcionek, grafiki i innych obiektów wizualnych, obiekty formatują-
ce typu „inline” i blokowe oraz wiele innych konstrukcji składniowych.
Obiekty formatujące są szczególnie intensywnie wykorzystywane przy konwersji tekstowych da-
nych XML na formaty binarne, takie jak pliki PDF lub dokumenty binarne w rodzaju Microsoft
Word. Przy przekształcaniu danych XML na innegy format tekstowy obiekty te rzadko wykorzystuje
się jawnie. Ponieważ większość aplikacji używanych w przedsiębiorstwach jest obecnie przynaj-
mniej częściowo oparta na architekturze WWW, a w funkcji klienta wykorzystywana jest przeglą-
darka WWW, skoncentrujemy się głównie na przekształcaniu do formatu HTML-a lub XHTML-a.
Będzie to wymagało jedynie pobieżnego omówienia obiektów formatujących; temat obiektów for-
matujących jest jednak na tyle obszerny, że zasługuje na oddzielną książkę lub witrynę WWW.
Więcej informacji na ten temat można znaleźć w specyfikacji XSL pod adresem http://www.w3.-
org/TR/WD-xsl.
Transformacje XSL (XSLT)
Drugim istotnym elementem opisywanego zagadnienia są transformacje XSL. Językiem opisują-
cym konwersję dokumentu z jednego formatu na drugi jest XSLT. Składnia XSLT opisuje głównie
te transformacje, które nie generują danych binarnych. Chodzi tu na przykład o przekształcanie
dokumentu XML do HTML-a lub WML-a (Wireless Markup Language). Faktycznie, specyfikacja
XSLT opisuje składnię arkuszy XSL w sposób bardziej jawny niż sama specyfikacja XSL!
Podobnie jak w przypadku XSL, XSLT to zawsze poprawnie sformatowany i poprawny dokument
XML. Dozwolone konstrukcje opisane są w odpowiedniej definicji DTD. W celu korzystania
z XSLT konieczne jest więc nauczenie się jedynie nowej składni — a nie całkowicie nowych
struktur, jak to ma miejsce w przypadku definicji DTD. Podobnie jak w przypadku XSL, XSLT
oparty jest na hierarchii drzewiastej — elementy zagnieżdżone to „liście” lub „potomki”. XSLT
udostępnia mechanizm dopasowania wzorców występujących w oryginalnym dokumencie XML
(za pośrednictwem wyrażeń XPath, które wkrótce zostaną przedstawione), a następnie stosowania
formatowania na znalezionych w ten sposób danych. Formatowanie może polegać po prostu na
wysłaniu danych pozbawionych nazw elementów XML na wyjście albo na wstawieniu ich do zło-
żonej tabeli HTML i wyświetleniu w różnych kolorach. XSLT udostępnia również rozmaite popular-
ne operatory, takie jak instrukcje warunkowe, możliwość kopiowania fragmentów drzewa dokumentu,
zaawansowane dopasowania wzorca oraz dostęp do elementów XML poprzez ścieżki absolutne
i względne. Wszystko to upraszcza proces przekształcania dokumentu XML na nowy format.
Język XML Path (XPath)
XPath to ostatni element używany w procesie przekształcania XML-a. XPath to mechanizm umoż-
liwiający odwoływanie się do różnych nazw elementów i atrybutów w dokumencie XML. Jak
wspomnieliśmy wcześniej, wiele specyfikacji XML korzysta z technologii XPath, ale tutaj sku-
pimy się jedynie na wykorzystaniu jej w ramach XSLT. Przy złożonej strukturze, jaką może mieć
dokument XML, zlokalizowanie konkretnego elementu lub grupy elementów może sprawiać trud-
ności — tym większe, że nie można zakładać istnienia definicji DTD lub innych zawężeń opisujących
strukturę dokumentu. Musi istnieć możliwość przekształcania zarówno dokumentów podlegają-
cych, jak i nie podlegających sprawdzaniu poprawności. Adresowanie elementów w XPath odby-
wa się za pomocą składni odpowiadającej strukturze drzewiastej dokumentu XML oraz operującym
na niej procesom i konstrukcjom XSLT.

136
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 136
Najprościej odwołać się do dowolnego elementu lub atrybutu w dokumencie XML poprzez
podanie ścieżki do tego elementu względem elementu bieżącego (przetwarzanego w danej chwili).
Innymi słowy, jeśli element B jest elementem bieżącym, a w nim zagnieżdżone są elementy C i D,
to te dwa ostatnie najprościej zlokalizujemy za pomocą ścieżki względnej. Przypomina to ścieżki
względne w strukturze katalogów systemu operacyjnego. W XPath zdefiniowano również sposób
adresowania elementów względem elementu głównego. Konieczne jest tutaj odwołanie się do ele-
mentu nie znajdującego się w zakresie nazwy elementu bieżącego; innymi słowy — elementu nie
zagnieżdżonego w obecnie przetwarzanym elemencie. W XPath zdefiniowano wreszcie składnię
dopasowywania wzorca („znajdź element, którego elementem macierzystym jest E i którego ele-
mentem siostrzanym jest F”). W ten sposób zapełniono lukę pomiędzy ścieżkami absolutnymi
i względnymi. We wszystkich wyrażeniach można również korzystać z atrybutów (i stosować na
nich podobne dopasowania). W przykładzie 6.1 reprezentowane są różne sposoby użycia Xpath.
Przykład 6.1. Wyrażenia XPath
<!-- Dopasuj element JavaXML:Ksiazka względem elementu bieżącego -->
<xsl:value-of select="JavaXML:Ksiazka" />
<!-- Dopasuj element JavaXML:Spis zagnieżdżony w elemencie JavaXML:Ksiazka -->
<xsl:value-of select="JavaXML:Ksiazka/JavaXML:Spis" />
<!-- Dopasuj element JavaXML:Spis z wykorzystaniem ścieżki absolutnej -->
<xsl:value-of select="/JavaXML:Ksiazka/JavaXML:Spis" />
<!-- Dopasuj atrybut tematyka elementu bieżącego -->
<xsl:value-of select="@tematyka" />
<!-- Dopasuj atrybut tematyka elementu JavaXML:Rozdzial -->
<xsl:value-of select="JavaXML:Rozdzial/@tematyka" />
Ponieważ często dokument wejściowy nie ma ustalonej struktury, może się okazać, że wyrażenie
XPath przetwarza puste dane wejściowe, jeden element lub atrybut wejściowy, lub też wiele ele-
mentów i atrybutów wejściowych. Ta pożyteczna możliwość wiąże się z wprowadzeniem szeregu
dodatkowych pojęć. Wynik przetwarzania wyrażenia XPath określa się mianem zestawu węzłów
(ang. node set). To nie powinno Czytelnika dziwić, ponieważ termin „węzeł” był już używany
wcześniej. Koncepcja ta jest zbieżna z hierarchiczną strukturą drzewiastą, często opisywaną poję-
ciami „liści” lub właśnie „węzłów”. Wynikowy zestaw węzłów może być następnie przekształcony,
skopiowany, zignorowany lub poddany innym dozwolonym operacjom. Oprócz wyrażeń umożli-
wiających wybór zestawów węzłów, XPath udostępnia również funkcje operujące na zestawach
węzłów, takie jak
not()
i
count()
. Funkcje te pobierają zestaw węzłów (zazwyczaj w postaci
wyrażenia XPath) i poddają je dalszym przeliczeniom. Wszystkie wyrażenia i funkcje stanowią
część specyfikacji i implementacji XPath; pojęcie XPath jest jednak również używane do opisania
wyrażenia zgodnego z samą specyfikacją. Nie jest to (podobnie jak w XSL i XSLT) zawsze tech-
nicznie poprawne, ale upraszcza opisywanie XSL i XPath.
Opis składni tych trzech komponentów jako takiej byłby po prostu kopiowaniem specyfikacji.
Dlatego po raz kolejny posłużymy się naszym przykładowym dokumentem XML. Stworzymy
fragment dokumentu HTML na podstawie poznanego już spisu treści w formacie XML. Pozwoli
nam to zaznajomić się z językami XSL, XSLT i XPath w kontekście praktycznego zastosowania.

Składnia
137
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 137
Składnia
Skoro już znamy funkcje poszczególnych fragmentów układanki o nazwie „przekształcanie XML”,
spróbujmy poukładać je w całość. Rozpoczniemy od naszego pierwotnego dokumentu XML re-
prezentującego fragment spisu treści niniejszej książki. Za zadanie postawimy sobie uzyskanie
sformatowanego według naszego uznania dokumentu HTML. Operacje tego typu przeprowadza
się niezwykle często. My zastosujemy jedynie proste formatowanie, ale możliwości są tutaj
ogromne — ograniczeniem jest tylko wiedza i doświadczenie programisty. W poniższych ćwi-
czeniach zbudujemy arkusz stylu, który zastosujemy na naszym dokumencie XML i przy okazji
omówimy najistotniejsze konstrukcje XSLT oraz sposób ich działania w aplikacjach XML.
Ponieważ niniejszy rozdział stanowi wprowadzenie do technologii XSLT, nie będziemy omawiać
bardziej złożonych przekształceń z jednego formatu XML na inny. Przekształcenia takie, typowe
w dużych aplikacjach typu firma-firma, często zależą od konkretnego zastosowania i reguł panu-
jących w danym przedsiębiorstwie. Przekształcenia tego typu zostaną omówione w dalszych roz-
działach. Konstrukcje stosowane w przekształceniu będą identyczne — inny będzie jedynie wynik
ich działania.
XSL to XML
Dowolny arkusz stylów XSL musi być przede wszystkim zgodny ze specyfikacją XML. Należy
pamiętać, że XSL posiada swoje własne konstrukcje, ale tak naprawdę składają się one na jeden
konkretny zasób słów zdefiniowanych w XML-u. Oznacza to, że arkusz XSL musi być poprawnie
sformatowany, musi zawierać deklarację XML i muszą w nim być zadeklarowane wykorzysty-
wane przestrzenie nazw. W przestrzeni nazw XSL (z przedrostkiem
xsl
) zdefiniowano elementy
konieczne do przeprowadzenia transformacji (przekształcania). Każdy element arkusza „obsługu-
jący” przekształcanie będzie więc rozpoczynał się przedrostkiem
xsl
. Na przykład element głów-
ny każdego arkusza stylu XSL powinien nosić nazwę
xsl:stylesheet
. Ta przestrzeń nazw
nie tylko umożliwia identyfikację przestrzeni XSL przez parser i procesor, ale również upraszcza
przeglądanie arkusza XSL — widzimy, które elementy służą do transformacji, a które nie.
Oprócz deklaracji XML i wspomnianego elementu głównego, musimy wstawić odwołanie do
przestrzeni nazw
xsl
. To nie powinno już stanowić dla Czytelnika niespodzianki — jeśli wsta-
wiamy przedrostki jakiejś przestrzeni nazw, to parser musi znać identyfikator URI dla tej prze-
strzeni. Najnowszą wersję specyfikacji przestrzeni nazw XSL znaleźć można na stronach W3C,
pod adresem http://www.w3.org/1999/XSL/Transform. W dokumentacji procesora XSL należy
sprawdzić typ wersji XSL. Oprócz przestrzeni nazw XSL, będziemy się również odwoływali do
elementów w naszym spisie treści XML, należących do przestrzeni
JavaXML
— jej deklarację
musimy więc również zawrzeć w arkuszu stylu, taką samą jak w dokumencie XML. Należy pa-
miętać, że deklaracje te są wykorzystywane jedynie jako sposób przypisania wybranej przestrzeni
nazw, nie reprezentują natomiast schematu, definicji DTD czy jakichkolwiek innych faktycznych
danych. Z tej początkowej deklaracji, elementu głównego i deklaracji przestrzeni nazw możemy
już utworzyć prosty szkielet arkusza XSL (przykład 6.2).
Przykład 6.2. Szkielet arkusza XSL
<?xml version="1.0" encoding="ISO-8859-2"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
version="1.0"
>

138
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 138
</xsl:stylesheet>
Czytelnik winien zauważyć, że dodano atrybut
version
, który obecnie jest wymagany w arku-
szach XSL. Powyższy arkusz stylów jest już poprawny, ale jeszcze zupełnie bezużyteczny. Nie
zdefiniowaliśmy żadnych reguł dopasowujących elementy wejściowych danych XML. Zadanie to
zostanie wykonane w następnym podrozdziale.
Szablony XSL
Podstawowym zadaniem arkuszy XSL jest wyszukiwanie określonych elementów lub grup ele-
mentów w wejściowym dokumencie XML i stosowanie do nich reguł lub zestawów reguł. W języku
Javy możemy to wyrazić następująco: wywołujemy akcesor np.
pobierzWezly(kryteria)
i
wykonujemy obliczanie (transformację) na wartości, którą zwraca. Proces ten jest wykonywany
za pośrednictwem szablonu XSL. Szablon to zestaw reguł, jakie należy zastosować w danych XML
odpowiadających określonej ścieżce XPath. A więc teraz zaczynamy wykorzystywać wszystkie te
komponenty, które zostały opisane wcześniej. Szablon definiujemy za pomocą elementu XSL
template
. Po dodaniu przedrostka przestrzeni nazw będzie to, oczywiście, element
xsl:tem-
plate
. Element ten powinien zawierać atrybut
match
(dopasuj). Wartość atrybutu jest wyraże-
niem XPath, dopasowującym zero lub więcej elementów przetwarzanego dokumentu XML.
<xsl:template match="[Wyrażenie XPath]">
<!-- Tutaj wstawiamy swoje reguły i sposób formatowania -->
</xsl:template>
Jak widać, jedyną trudnością w procesie tworzenia szablonu jest sformułowanie wyrażenia XPath
dopasowującego element lub elementy XML, które chcemy „obrabiać”. Najprościej zastosować
względne wyrażenie XPath. Podobnie jak podajemy katalog lib/ względem katalogu głównego,
możemy określać elementy po prostu podając ich nazwę — o ile tylko znajdujemy się „o stopień
wyżej” w hierarchii. Procesor XSLT „ustawia” nas na samym szczycie hierarchii elementów, a więc
element główny dokumentu określamy podając jego nazwę:
<?xml version="1.0" encoding="ISO-8859-2"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
version="1.0"
>
<xsl:template match="JavaXML:Ksiazka">
<!-- Teraz możemy już zająć się formatowaniem danych XML -->
</xsl:template>
</xsl:stylesheet>
W tym przypadku dopasowywany jest dokładnie jeden element, ale możliwe jest również dopa-
sowanie wielu lub też żadnego elementu danych wejściowych. Takie sytuacje zostaną omówione
w dalszej kolejności.
Kiedy już element jest dopasowany, wypadałoby coś z nim zrobić. W szablonie mamy dostęp do
wszystkich elementów znajdujących się wewnątrz dopasowanego elementu. Wracając do przykła-
du z katalogami, możemy powiedzieć, że zmieniliśmy katalog bieżący na lib/. Teraz możemy
odwoływać się za pomocą zwykłych nazw do elementów niższego poziomu (
JavaXML:Tytul
i
JavaXML:Spis
); odwołania do wszelkich innych elementów wymagają bardziej złożonych

Składnia
139
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 139
wyrażeń XPath. Zanim jednak się tym zajmiemy, spróbujmy uzyskać jakikolwiek wynik zastosowa-
nia arkusza. Np. zdanie „Witaj świecie!” uzyskamy po prostu wpisując je w szablonie:
<xsl:template match="JavaXML:Ksiazka">
Witaj świecie!
</xsl:template>
Oczywiście, taki wynik nie jest zbyt imponujący — chcemy przecież uzyskać dostęp do naszych
danych, a nie wysyłać z arkusza XSL zwykły tekst. Najprościej uzyskamy pożądany efekt poprzez
wykorzystanie domyślnego „zachowania” arkusza XSL. Skoro dopasowaliśmy element główny, to
do szablonu została załadowana cała hierarchia elementów dokumentu XML. Dalej możemy zażą-
dać, aby na danych zastosowane zostały wszystkie inne szablony naszego arkusza stylu. To może
nie brzmi zbyt rozsądnie (przecież nie zdefiniowaliśmy żadnych innych szablonów); jednak
w takim przypadku procesor XSLT przetwarza całą hierarchię elementów i po napotkaniu każdego
węzła („liścia”) dodaje dane do strumienia wynikowego transformacji. W wyniku tego wszystkie
dane dokumentu XML są drukowane hierarchicznie, bez stosowania jakiegokolwiek formatowa-
nia. Odpowiednia konstrukcja XSL nosi nazwę
xsl:apply-templates
. Jeśli nie zostaną po-
dane żadne atrybuty, element ten spowoduje, że procesor dopasuje wszystkie elementy podrzędne
względem bieżącego za pomocą wszystkich szablonów w arkuszu:
<xsl:template match="JavaXML:Ksiazka">
<xsl:apply-templates />
</xsl:template>
Jednak taki zapis jest wciąż bezużyteczny — są to przecież dane bez żadnego formatowania. My
chcemy zastosować znaczniki HTML i stworzyć stronę WWW. Podobnie jak w przypadku tekstu
„Witaj świecie!”, standardowe znaczniki HTML wystarczy po prostu wstawić. Do tekstu wyniko-
wego dodajemy więc znaczniki
head
i
body
, a następnie wstawiamy dane XML „wewnątrz”
tych znaczników — właśnie za pomocą omówionego wyżej elementu
xsl:apply-templa-
tes
. W ten sposób wykonaliśmy pierwszy krok w kierunku stworzenia faktycznego dokumentu
HTML. Wprowadźmy więc do naszego arkusza stylu zmiany wskazane w przykładzie 6.3.
Przykład 6.3. Tworzenie wyjściowego pliku HTML
<?xml version="1.0" encoding="ISO-8859-2"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
version="1.0"
>
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title>Moja strona HTML!</title>
</head>
<body>
<xsl:apply-templates />
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Wynikowy plik HTML wyglądałby tak, jak w przykładzie 6.4.
Przykład 6.4. Plik HTML powstały z przykładu 6.3 i pliku XML ze spisem treści

140
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 140
<html xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<head>
<title>Moja strona HTML!</title>
</head>
<body>
Java i XML
Wprowadzenie
Co to jest?
Jak z tego korzystać?
Dlaczego z tego korzystać?
Co dalej?
Pisanie w XML-u
Dokument XML
Nagłówek
Zawartość
Co dalej?
<!-- Dalsze rozdziały zostały wycięte w celu skrócenia wydruku -->
Przykładowy współdzielony plik z opisem praw autorskich.
</body>
</html>
Nareszcie coś zaczyna się dziać. Na razie nie musieliśmy korzystać z wyszukanych funkcji XSL-a,
ale już widać efekt w postaci wyjściowych danych HTML, i to przy niewielkim wysiłku z naszej
strony. Można zauważyć, że elementy, których specjalne znaczenie w arkuszu powinno być zniesio-
ne (np. nawiasy trójkątne), zostały bezproblemowo przeniesione do drzewa wyjściowego. Dzieje
się tak, ponieważ w samym arkuszu XSL elementy nie wchodzące w skład specyfikacji XSL
(np.
head
i
body
) są wstawiane do drzewa wyjściowego bezpośrednio. To umożliwia nam do-
dawanie znaczników bez konieczności znoszenia ich specjalnego znaczenia.
Zanim przejdziemy dalej, powiemy jeszcze o tym, jak dopasować w szablonie specyficzny ele-
ment. Załóżmy, że chcemy, aby tytuł dokumentu HTML był identyczny z zawartością elementu
JavaXML:Tytul
. Dobrze byłoby, gdyby nie trzeba było tworzyć oddzielnego szablonu dla tego
elementu — nie ma tutaj żadnego formatowania, więc byłoby to działanie na wyrost. My chcemy
tylko uzyskać wartość elementu i „wpleść” ją w nasz HTML. Jak łatwo się domyślić, coś takiego
można zrobić za pomocą jednej prostej konstrukcji — mianowicie
xsl:value-of
. Konstrukcja
ta, zamiast przetwarzać dalej wyrażenie XPath, powoduje uzyskanie wartości dopasowanych przez
XPath elementów. Wyrażenie XPath podawane jest jako wartość atrybutu
select
tego elementu.
Wkrótce Czytelnik przekona się, że atrybut ten stosowany jest w wielu elementach XSL i że zawsze
służy do podawania ścieżki XPath. W naszym arkuszu chcemy dopasować element
JavaXML:
Tytul
, będący podrzędnym względem elementu bieżącego — czyli znów nie musimy w wy-
rażeniu XPath stosować jakichś specjalnych zabiegów. Po prostu wstawiamy tam nazwę elementu:
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title><xsl:value-of select="JavaXML:Tytul" /></title>
</head>
<body>
<xsl:apply-templates />

Składnia
141
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 141
</html>
</xsl:template>
Zanim przejdziemy do bardziej skomplikowanych struktur i wyrażeń, warto wspomnieć o jeszcze
jednej rzeczy. W ostatnim przykładzie dopasowaliśmy element
JavaXML:Tytul
. Jednak wy-
branie wartości tego elementu nie oznacza usunięcia go z hierarchii elementów stanowiącej dane
wejściowe procesora XSLT. To nieco osobliwe — nie tylko wartość elementu pojawi się w tytule
dokumentu; zostanie ona powielona w jego treści, w wyniku działania
xsl:apply-tem-
plates
. Jeśli to zachowanie wydaje się Czytelnikowi niewłaściwe, warto zauważyć, że dane
wejściowe procesora są nienaruszalne — nie można ich zmienić, a jedynie określić, w jaki sposób
mają być przetwarzane i jakie informacje należy do nich dodać. Aby uniknąć przetwarzania ja-
kiegoś elementu, musimy stworzyć wyrażenie XPath nie obejmujące go albo spowodować, aby
szablon dopasowywał element, ale nie generował żadnych danych wyjściowych. Innymi słowy,
musimy stworzyć szablon jawnie dopasowujący element
JavaXML:Tytul
i zrobić tak, aby po
jego napotkaniu nie były tworzone żadne dane wyjściowe:
<xsl:template match="JavaXML:Tytul" />
Kiedy wszystkie szablony w ramach szablonu elementu głównego zostaną już zastosowane,
dopasowany — i zignorowany — zostanie także powyższy element. Mam nadzieję, że Czytelnik
spostrzegł, że to rozwiązanie jest nieeleganckie i zastanawia się, jak stworzyć wyrażenie XPath
ignorujące określony element. O tym wszystkim powiemy!
Struktury sterujące
XSL, jak każdy dobry język przetwarzania, udostępnia struktury sterujące. Nie przypominają one
może instrukcji sterujących Javy czy C, ale bardzo pomagają w sterowaniu przetwarzaniem drze-
wa wejściowego w procesorze XSLT. Przyjrzymy się najpopularniejszym z nich i zobaczymy, jak
za ich pomocą określić dane, do których mamy mieć dostęp, oraz jak ustalić kolejność i sposób
uzyskiwania tego dostępu.
Filtrowanie w XPath
Omawianie struktur sterujących XSL zaczniemy od omówienia sterowania przetwarzaniem drze-
wa dokumentów. Czynność ta nie wymaga stosowania żadnej specjalnej konstrukcji, ale łatwo ją
wykonać za pomocą wyrażeń XPath. Na przykład, jeśli zbudujemy wyrażenie XPath mówiące, że
element opisujący tytuł ma nie być dublowany, to będzie to równie sprawna struktura sterująca,
jak „typowe” struktury sterujące, o których powiemy dalej. Problem elementu
JavaXML:Tytul
można rozwiązać w prosty sposób. Pamiętamy, że zestaw węzłów zwróconych z wyrażenia XPath
jest przetwarzany hierarchicznie; innymi słowy, procesor XSLT „nie widzi” wszystkich elemen-
tów dokumentu XML naraz. Rozpoznaje wszystkie elementy na określonym poziomie zagnieżdże-
nia, a następnie przetwarza w głąb struktury drzewiaste poszczególnych elementów. W przypadku
naszego dokumentu elementy postrzegane przez procesor XSLT znajdujące się w dokumencie
głównym to te zagnieżdżone dokładnie o jeden poziom niżej:
JavaXML:Tytul
,
JavaXML:
Spis
oraz
JavaXML:Copyright
. Chcemy wyłączyć z przetwarzania
JavaXML:Tytul
.
Najprościej wykorzystać tutaj funkcję XPath
not()
. Służy ona do generowania zestawu węzłów
nie pasujących do podanego wyrażenia XPath. Najpierw dodajemy atrybut umożliwiający
wprowadzenie wyrażenia XPath do szablonów. Na razie wystarczy podać atrybut
select
z gwiazdką
— czyli wybieramy wszystkie węzły potomne węzła bieżącego. Nazwiemy to wybieraniem osi, na
której będziemy przeprowadzać operację — tutaj wybieramy oś potomną. Oczywiście, w ten spo-
sób nie rozwiązujemy do końca naszego problemu, ale początek mamy już za sobą:

142
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 142
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title><xsl:value-of select="JavaXML:Tytul" /></title>
</head>
<body>
<xsl:apply-templates select="*" />
</body>
</html>
</xsl:template>
Teraz musimy dokładnie dopasować zestaw wynikowy. Na końcu kryterium wyboru dodamy na-
wiasy kwadratowe, w których wstawimy wyrażenie opisujące zestaw węzłów i zwracające węzły
do przetworzenia. W naszym przykładzie w miejscu tym pojawi się funkcja
not()
, a następnie
węzły osi potomnej, których nie chcemy przetwarzać:
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title><xsl:value-of select="JavaXML:Tytul" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(tutajWyrażenie)]" />
</body>
</html>
</xsl:template>
Wyrażenie, które teraz wstawimy, powinno zawierać nazwę (wraz z przedrostkiem przestrzeni)
ignorowanego elementu, czyli tutaj
JavaXML:Tytul
. Jednakże to wciąż nie wszystko. Ponie-
waż wybieramy węzły znajdujące się na określonej osi, musimy poinformować procesor XSLT,
skąd pochodzi węzeł, do którego się odwołujemy. To dziwne — dlaczego programista ma sam po-
dawać miejsce pochodzenia węzła? Zauważmy jednak, że często wybierana oś nie jest osią potom-
ną, a więc konieczne jest podanie „punktu odniesienia” — nawet w naszym prostym przykładzie.
W tym celu używamy słowa kluczowego
self
. Dzięki niemu procesor dowiaduje się, że węzły
umieszczone po tym słowie są potomne względem węzła bieżącego (
JavaXML:Ksiazka
). Do
oddzielenia słowa kluczowego od elementów (w naszym przypadku jednego elementu) używamy po-
dwójnego dwukropka (jeden dwukropek pozostaje zarezerwowany jako separator przestrzeni nazw).
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title><xsl:value-of select="JavaXML:Tytul" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::JavaXML:Tytul)]" />
</body>
</html>
</xsl:template>
Jeśli to wydaje się Czytelnikowi zagmatwane, nie powinien się przejmować — to jest zagmatwa-
ne! Zestawy węzłów, osie i transformacje to wcale nie banalna sprawa. Te zagadnienia warte są
osobnej publikacji. Tymczasem Czytelnik powinien starać się zrozumieć jak najwięcej z powyż-
szego opisu i odnotować, co wciąż pozostaje niejasne. Po przeczytaniu tego i następnego rozdziału
Czytelnik może znaleźć dodatkowe wyjaśnienia na stronach W3C (http://www.w3.org). Może
również przejrzeć i dołączyć się do listy adresowej http://www.mulberrytech.com.

Składnia
143
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 143
Pętle
XSL udostępnia również konstrukcje do sterowania przetwarzaniem, analogiczne do standardo-
wych programistycznych struktur sterujących. Pierwszą konstrukcją sterującą, jaką omówimy, jest
xsl:for-each
. Doskonale nadaje się ona do iteracji po danych w ramach jednego typu elemen-
tu. Na przykład — nasz spis treści zawiera szereg rozdziałów. Przetwarzając kolejne rozdziały,
chcemy wydrukować ich tytuły. Aby to osiągnąć, tworzymy nowy szablon w pliku XSL, dopaso-
wujący element JavaXML:Spis. Tak powstaje baza, w której zbudujemy pętlę (inaczej nie mieli-
byśmy gdzie jej wstawić). Moglibyśmy dodawać kolejne elementy do pierwszego szablonu
JavaXML:Ksiazka
, ale wtedy nasz arkusz szybko zapełniłby się złożonymi wyrażeniami
XPath, odwołującymi się do węzłów leżących wiele warstw niżej. Tworząc nowy szablon dla
elementu
JavaXML:Spis
, umożliwiamy budowanie wyrażeń XPath, w których „bazą” jest
właśnie
JavaXML:Spis
, a nie
JavaXML:Ksiazka
. Wyrażenia XPath pozostają dzięki temu
proste, a cały arkusz stylu — czytelny.
Po przejściu do nowego szablonu można wydrukować nagłówek informujący, że teraz wyświetlo-
ny zostanie spis treści — wystarczy bezpośrednio wstawić odpowiedni fragment kodu HTML. Na-
stępnie dodajemy linię poziomą (
<hr>
), oddzielającą tytuł od zawartości:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr>
</xsl:template>
Zanim jednak stworzymy pętlę, musimy rozwiązać jeden problem związany z powyższym fra-
gmentem. Jeśli Czytelnik nie widzi błędu, winien przypomnieć sobie, że plik XSL musi zawsze być
poprawnie sformatowanym dokumentem XML. Nawet kiedy dodajemy statyczne fragmenty kodu
HTML, to muszą one być zgodne z powyższą zasadą (co w praktyce czyni te fragmenty danymi
XHTML!). A więc przy przetwarzaniu powyższego fragmentu zgłoszony zostałby błąd, ponieważ
znacznik
<hr>
nie posiada odpowiadającego mu znacznika zamykającego. Z punktu widzenia
XML-a nie jest to nic zaskakującego, ale jeśli Czytelnik jest przyzwyczajony do HTML-a, to tutaj
natrafia na coś nowego. Proste rozwiązanie polega na stworzeniu pustego zapisu w znaczniku,
ignorowanego przez przeglądarki przetwarzające wynikowy HTML:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
</xsl:template>
Do takich zapisów trzeba się po prostu przyzwyczaić — z biegiem czasu stają się one równie
naturalne jak pisanie w mniej formalnym standardzie HTML. Skoro ten drobny szczegół mamy
już za sobą, możemy budować pętlę. Konstrukcja
xsl:for-each
pobiera wyrażenie XPath
(wstawione w atrybut
select
) opisujące węzeł, po którym następować będzie iteracja. W na-
szym przypadku życzymy sobie, aby wyrażenie zwracało wszystkie elementy
JavaXML:Roz-
dzial
. Tyle potrafimy już zrobić:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
<xsl:for-each select="JavaXML:Rozdzial">
</xsl:for-each>

144
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 144
</xsl:template>
Teraz wystarczy dodać zawartość. Każdy przetwarzany węzeł na czas kolejnej iteracji pętli staje
się węzłem bieżącym hierarchii. Oznacza to, że aby odwołać się do elementów i atrybutów za-
gnieżdżonych w elemencie
JavaXML:Rozdzial
, należy potraktować je jako podrzędne wzglę-
dem tego elementu, a nie elementu przetwarzanego w szablonie (
JavaXML:Spis
). My chcemy
wydrukować nagłówek każdego rozdziału. Aby wynik wyglądał ładniej, każdy nagłówek będzie
stanowił element nieponumerowanej listy HTML:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
<ul>
<xsl:for-each select="JavaXML:Rozdzial">
<li><xsl:value-of select="JavaXML:Naglowek" /></li>
</xsl:for-each>
</ul>
</xsl:template>
Wynikowy kod HTML zaczyna już wyglądać obiecująco! Informacje o tym, jak taką zawartość
stworzyć w mechanizmie serwletów, Czytelnik znajdzie w rozdziale 9. Wynikowy kod HTML
wygląda następująco:
Przykład 6.5. Dane HTML powstałe w wyniku zastosowania zmodyfikowanego arkusza XSL
<html xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<head>
<title>Java i XML</title>
</head>
<body>
<center>
<h2>Spis treści</h2>
</center>
<hr>
<ul>
<li>Wprowadzenie</li>
<li>Pisanie w XML-u</li>
<li>Przetwarzanie XML-a</li>
<li>Struktury publikacji WWW</li>
</ul>Przykładowy współdzielony plik z opisem praw autorskich.</body>
</html>
Czytelnik prawdopodobnie chciałby już się dowiedzieć, w jaki sposób faktycznie została przepro-
wadzona ta transformacja; o tym powiemy jednak dopiero w następnym rozdziale, po omówieniu
konstrukcji XSL. Przed używaniem procesora XSLT należy poznać składnię XSL-a — to będzie
procentowało na dalszym etapie nauki.
Czytelnik może teraz zadawać sobie pytanie: dlaczego właściwie w stylach XSL korzystamy z pętli?
Czy nie prościej byłoby stworzyć nowy szablon dla elementu, który zamierzamy sformatować
(np.
JavaXML:Rozdzial
) i obsłużyć formatowanie w ramach tego szablonu? Tak, byłoby to
prostsze (i robiliśmy to już wcześniej w przypadku wspomnianego elementu), ale problemem staje
się wtedy czytelność kodu. W naszym arkuszu doskonale widać, do czego służy pętla — na pewno
jest to rozwiązanie czytelniejsze, niż gdybyśmy tworzyli szablony dla każdego elementu
Java-
XML:Naglowek
oddzielnie. W prosty sposób daje się także wyświetlić tylko te dane, które
chcemy uwidocznić — w naszym przypadku nagłówek. Nie musimy pokazywać innych zagnież-
dżonych w szablonie elementów (np.
JavaXML:PodzialSekcji
), ale rozdziały są wykorzys-

Składnia
145
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 145
tywane do formatowania w ramach listy (
<ul></ul>
) tworzonej w szablonie
JavaXML:Spis
.
Gdybyśmy rzeczywiście stworzyli szablon dla rozdziałów, musielibyśmy pamiętać, że zawartość
szablonu musi być elementem listy (
<li></li>
). To mało eleganckie. Podobnie jak w przy-
padku innych aspektów języka XML, możliwość zrobienia czegoś nie oznacza jeszcze, że jest to
do końca poprawne. Tak więc odpowiedź brzmi: owszem, byłoby prościej stworzyć szablon, ale
nie jest to dobre rozwiązanie.
Wybór elementów do przetwarzania
Oprócz stosowania pętli, często przydaje się także możliwość przetwarzania tylko tych węzłów,
które spełniają pewne kryteria. Programistom od razu przychodzi tutaj na myśl konstrukcja typu
if-then
, obecna w większości języków. W języku XSL zachowanie takie symulujemy konstrukcją
xsl:if
, zwracającą tylko te węzły, które odpowiadają wymogom zarówno wyrażenia XPath, jak
również kryteriom użytkownika. Przydaje się to wszędzie tam, gdzie konieczne jest przeanalizo-
wanie wszystkich danych pewnego typu i gdzie chcemy wyświetlić lub sformatować w określony
sposób jedynie podzbiór tych danych. W naszym przykładzie oddzielimy rozdziały dotyczące Javy
od tych poświęconych głównie XML-owi. Informacje o tematyce rozdziału pobierzemy z atrybutu
tematyka
, już obecnego w naszym dokumencie XML. Atrybutem uzupełniającym konstrukcję
xsl:if
jest
test
. Wynikiem obliczenia wyrażenia
test
powinna być wartość „prawda” lub
„fałsz”. W pierwszym przypadku element
xsl:if
będzie obliczany, w drugim ignorowany. Nic
trudnego, prawda? Spójrzmy na nasz przykład. Za pomocą opisywanej konstrukcji wyświetlimy
teraz tylko te rozdziały, które zawierają atrybut
tematyka
o wartości „Java”:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
<ul>
<xsl:for-each select="JavaXML:Rozdzial">
<xsl:if test="@tematyka='Java'">
<li><xsl:value-of select="JavaXML:Naglowek" /></li>
</xsl:if>
</xsl:for-each>
</ul>
</xsl:template>
Mamy tutaj kilka nowych rzeczy. Nowy jest sposób odwołania do atrybutu XML. Zamiast nazwy
(jak w przypadku elementów), jako przedrostek wstawiamy znak
@
. Dzięki temu procesor XSLT
„wie”, że odwołujemy się do atrybutu, a nie do elementu. Spójrzmy także na wartość dosłowną
„Java”, wstawioną w apostrofy (czyli jako tekst statyczny). W przypadku dwóch rozdziałów,
w których wyrażenie nie jest prawdziwe (rozdziały 1. i 2.), nagłówek nie jest drukowany; pozo-
stałe dwa, spełniające zadane kryteria, są przetwarzane i drukowane na ekranie.
To dość typowy i przydatny sposób „podejmowania decyzji” w czasie transformacji; jednak w przy-
padku naszego dokumentu — wciąż nie najlepszy. Zamiast tylko pokazywać rozdziały o XML-u
lub o Javie, możemy zażyczyć sobie wyświetlania nazwy rozdziału, a potem jego tematyki w na-
wiasach. Owszem, moglibyśmy osiągnąć to za pomocą konstrukcji
xsl:if
, ale konieczne byłoby
użycie dwóch pętli; pierwsza sprawdzałaby, czy tematyką poszczególnych rozdziałów jest XML,
a druga sprawdzałaby, czy tematyką jest Java. Nie tylko odbiłoby się to na wydajności, ale rów-
nież spowodowało wyświetlenie rozdziałów w złej kolejności — rozdziały o XML-u byłyby
pierwsze, a te o Javie — ostatnie. Chcemy więc przeprowadzić podobny test, ale tak, aby zadana
czynność wykonywana była w obu przypadkach. Służy do tego element
xsl:choose
. Pozwala
on na przetestowanie warunku i wykonanie pewnej czynności, gdy warunek został spełniony, a in-

146
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 146
nej, jeśli nie został. Element ten otacza blok czynności do wykonania w obu przypadkach. We-
wnątrz bloku wstawiany jest element
xsl:when
(„jeśli”), w którym za pomocą atrybutu
test
określa się rodzaj testu do przeprowadzenia. Test ten jest identyczny z podanym w atrybucie ele-
mentu
xsl:if
. Wewnątrz tego elementu wstawia się instrukcje przetwarzania, jakie mają zostać
wykonane, gdy test zwróci wartość „prawda”. Różnica polega na tym, że jest jeszcze element
xsl:otherwise („w przeciwnym razie”), zawierający instrukcje przetwarzania wykonywane, gdy
warunek nie zostanie spełniony. Ten element zachowuje się podobnie jak słowo kluczowe
de-
fault
w instrukcji
switch
Javy. Do naszego przykładu wprowadzimy teraz drobne poprawki
— za każdym razem drukowana będzie nazwa elementu i, na podstawie testu, wyświetlana odpo-
wiednia tematyka:
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
<ul>
<xsl:for-each select="JavaXML:Rozdzial">
<xsl:choose>
<xsl:when test="@tematyka='Java'">
<li><xsl:value-of select="JavaXML:Naglowek" /> (Tematyka: Java)</li>
</xsl:when>
<xsl:otherwise>
<li><xsl:value-of select="JavaXML:Naglowek" /> (Tematyka: XML)</li>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</ul>
</xsl:template>
Należy sobie zdać sprawę z faktu, że powyższy przykład działa tylko dlatego, że dla atrybutu
tematyka
istnieją tylko dwie wartości. Trzeba także pamiętać, że moglibyśmy po prostu wysłać
wartość tego atrybutu na ekran. Oczywiście, ale w ten sposób nie dowiedzielibyśmy się nic nowe-
go o XSL-u! A mówiąc poważnie, element
xsl:choose
bardzo przydaje się do sterowania prze-
twarzaniem zestawu węzłów zwróconego z wyrażenia XPath, szczególnie gdy pewien podzbiór
węzłów musi zostać wyizolowany i potraktowany w inny sposób. Nasz wynikowy plik HTML
coraz bardziej przypomina rzeczywisty spis treści (przykład 6.6).
Przykład 6.6. Wynikowy plik HTML po zastosowaniu instrukcji sterujących
<html xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<head>
<title>Java i XML</title>
</head>
<body>
<center>
<h2>Spis treści</h2>
</center>
<hr>
<ul>
<li>Wprowadzenie (Tematyka: XML)</li>
<li>Pisanie w XML-u (Tematyka: XML)</li>
<li>Przetwarzanie XML-a (Tematyka: Java)</li>
<li>Struktury publikacji WWW (Tematyka: Java)</li>
</ul>Przykładowy współdzielony plik z opisem praw autorskich.</body>
</html>

Składnia
147
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 147
Struktury sterujące umożliwiają wykonanie wielu różnych zadań; przydają się również do zrozu-
mienia bardziej złożonych wyrażeń XPath oraz testów. W następnych rozdziałach Czytelnik dowie
się, jak za pomocą języka XSL przetwarzać i tworzyć elementy i atrybuty uzupełniające te już
obecne na wejściu procesora.
Elementy i atrybuty
Teraz czytelnik powinien już rozumieć, jak dużą kontrolę nad dokumentem XML daje nam arkusz
XSL. Nie powinno być zaskoczeniem, że można również definiować własne atrybuty i elementy.
Mogą one służyć do obliczeń lub po prostu zostać dodane do danych wyjściowych. Najczęściej
wykorzystuje się takie elementy w zaawansowanych szablonach i przy przetwarzaniu parametrów,
tego tematu nie będziemy jednak obszernie omawiali. Aby dowiedzieć się więcej o tych bardziej
zaawansowanych zastosowaniach arkuszy XSL, warto zapisać się na listę adresową XSL, na której
tematyka ta jest często poruszana. Informacje o liście uzyskamy pod adresem http://www.mulber-
rytech.com/xsl/xsl-list.
Jednym z typowych powodów, dla których tworzy się elementy i atrybuty w arkuszu stylów, jest
konieczność zbudowania dynamicznych odwołań HTML wewnątrz danych XML. Aby to zade-
monstrować, do naszego arkusza dodamy sekcję zawierającą informacje o materiałach dodatkowych
(być może nie nadaje się to do spisu treści, ale służy jako doskonały przykład!), zagnieżdżoną w ele-
mencie
JavaXML:Ksiazka
(należy pamiętać o wyłączeniu sprawdzania poprawności — w prze-
ciwnym razie zostaną złamane zasady zdefiniowane w DTD!):
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
dataPublikacji="czerwiec 2000">
<JavaXML:Tytul>Java i XML</JavaXML:Tytul>
<!-- Tutaj rozdziały -->
<JavaXML:Dodatkowe>
<JavaXML:Dodatkowa>
<JavaXML:Nazwa>Grupa W3C</JavaXML:Nazwa>
<JavaXML:Url>http://www.w3.org/Style/XSL</JavaXML:Url>
</JavaXML:Dodatkowa>
<JavaXML:Dodatkowa>
<JavaXML:Nazwa>Lista XSL</JavaXML:Nazwa>
<JavaXML:Url>http://www.mulberrytech.com/xsl/xsl-list</JavaXML:Url>
</JavaXML:Dodatkowa>
</JavaXML:Dodatkowe>
<!-- Copyright -->
</JavaXML:Ksiazka>
Aby obsłużyć taki fragment, trzeba dodać nowy szablon do arkusza stylu. Można również dodać
formatowanie HTML oraz pętlę przebiegającą po odsyłaczach w dokumencie — wszystko to już
potrafimy:
<xsl:template match="JavaXML:Dodatkowe">
<p>
<center><h3>Pożyteczne informacje dodatkowe</h3></center>
<ol>
<xsl:for-each select="JavaXML:Dodatkowa">
<li><!-- Tu powinien pojawić się URL --></li>
</xsl:for-each>
</ol>
</p>

148
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 148
</xsl:template>
Pozostaje teraz utworzyć odsyłacz HTML. Powinien on zawierać wartość elementu
JavaXML:
Nazwa
jako etykietę oraz
JavaXML:Url
jako adres. Ale jak dodać to do zdefiniowanego zna-
cznika? Musimy uzyskać coś takiego:
<a href="[wartość elementu Url]">[wartość elementu Nazwa]</a>
Trik polega na tym, że atrybut na wyjściu musi składać się z elementu znajdującego się na wejściu
procesora. Dobrym sposobem osiągnięcia takiego rezultatu jest zastosowanie konstrukcji
xsl:
element
i
xsl:attribute
— pozwalają one ustawić wartości odpowiednich elementów
i atrybutów. Pierwsza z nich zawiera atrybut
name
, w którym podawana jest nazwa budowanego
elementu. Innymi słowy, zapis
<xsl:element name="mojElement">Cze••!</xsl:
element>
spowoduje wyświetlenie
<mojElement>Cze••!</mojElement>
. Do definicji
możemy także dodać znaczniki
<xsl:attribute>
, działające w analogiczny sposób. Tak więc
następujący arkusz XSL:
<xsl:element name="mojElement">
<xsl:attribute name="mojAtrybut">
Java
</xsl:attribute>
jest świetna!
</xsl:element>
zostałby przetworzony do postaci wynikowej:
<mojElement mojAtrybut="Java">jest świetna!</mojElement>
W elementach
xsl:element
i
xsl:attribute
mogą pojawić się złożone wyrażenia, co
umożliwia tworzenie naprawdę dowolnych „wplecionych” wartości. I teraz wiemy już, jak
rozwiązać nasz problem z adresami URL:
<xsl:template match="JavaXML:Dodatkowe">
<p>
<center><h3>Pożyteczne informacje dodatkowe</h3></center>
<ol>
<xsl:for-each select="JavaXML:Dodatkowa">
<li>
<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select="JavaXML:Url" />
</xsl:attribute>
<xsl:value-of select="JavaXML:Nazwa" />
</xsl:element>
</li>
</xsl:for-each>
</ol>
</p>
</xsl:template>
Potrafimy już wstawiać wartości elementów i tworzyć atrybuty, które potem interpretowane są
jako odsyłacze w HTML-u. Wynik transformacji, przedstawiony w przykładzie 6.7, jest zgodny
z naszymi oczekiwaniami:
Przykład 6.7. Wynikowy plik HTML zawierający „pożyteczne informacje”
<html xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<head>
<title>Java i XML</title>
</head>

Składnia
149
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 149
<body>
<center>
<h2>Spis treści</h2>
</center>
<hr>
<ul>
<li>Wprowadzenie (Tematyka: XML)</li>
<li>Pisanie w XML-u (Tematyka: XML)</li>
<li>Przetwarzanie XML-a (Tematyka: Java)</li>
<li>Struktury publikacji WWW (Tematyka: Java)</li>
</ul>
<p>
<center>
<h3>Pożyteczne informacje dodatkowe</h3>
</center>
<ol>
<li>
<a href="http://www.w3.org/Style/XSL">Grupa W3C</a>
</li>
<li>
<a href="http://www.mulberrytech.com/xsl/xsl-list">Lista XSL</a>
</li>
</ol>
</p>Przykładowy współdzielony plik z opisem praw autorskich.</body>
</html>
Dane... po prostu dane
Można dowieść, że w idealnej sytuacji w dowolnym dokumencie XML wystarczy przeprowadzić
tylko jedną transformację. Można także twierdzić, że dokument XML powinien zawierać czyste
dane, bez jakiegokolwiek znacznika formatującego lub elementu, który powinien pozostać nie-
przetworzony. Niestety, sytuacje idealne zdarzają się rzadko. Czasem elementy dokumentu XML
są wykorzystywane jako dane. Jeśli to wydaje się dziwne, to nic nie szkodzi — to jest dziwne dla
wielu osób. Ale prawdopodobnie niejeden Czytelnik dobrze już wie, o co tutaj chodzi. Wielo-
krotnie zdarza się, że chcemy stworzyć kod HTML wewnątrz dokumentu XML i powiedzieć
procesorowi XSLT: „Tego HTML-a proszę mi nie ruszać!”. Zdarza się tak w sytuacji, gdy trzeba
łączyć w łańcuchy różne arkusze stylów lub generować elementy, które mają pozostać nieprzetwo-
rzone i wykorzystane w innej aplikacji „znającej XML”. Sytuacja taka ma również miejsce w przy-
padku danych, które mają zostać wyświetlone na ekranie bez przetwarzania. Jednym słowem — jeśli
jeszcze na taką sytuację Czytelnik się nie natknął, to prędzej czy później mu się to przydarzy!
Ostatnią konstrukcją, jaką omówimy w związku z przetwarzaniem XSLT, jest konstrukcja zabraniająca
przetwarzania! Najlepiej posłużyć się przykładem. Zamiast korzystać z encji odwołującej się do praw
autorskich, wstawmy w tym miejscu dane HTML. Dane te mogą być pobrane z innego pliku lub też
mogą zostać wygenerowane poza naszą kontrolą. Innymi słowy, otrzymujemy dane HTML, na któ-
re nie mamy wpływu — a to zdarza się często. Dodajmy więc do naszego dokumentu XML kod
HTML:
<JavaXML:Copyright>
<center>
<table cellpadding="0" cellspacing="1" border="1" bgcolor="Black">
<tr>
<td align="center">
<table bgcolor="White" border="2">
<tr>
<td>
<font size="-1">

150
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 150
Copyright O'Reilly and Associates, 2000
</font>
</td>
</tr>
</table>
</td>
</tr>
</table>
</center>
</JavaXML:Copyright>
I to mamy teraz obsłużyć w transformacji XSL. Po bezpośrednim przetworzeniu otrzymalibyśmy
tekst „Copyright O'Reilly and Associates, 2000” bez jakiegokolwiek formatowania. Nie powinno
to Czytelnika dziwić, jeśli przypomni sobie opis sposobu dopasowania w szablonie. Trzeba pamię-
tać, że jeśli dla elementu nie podano szablonu, dane wynikowe nie będą zawierały nic, a drzewo
wejściowe jest przetwarzane dopóty, dopóki nie zostaną znalezione jakieś dane do wydrukowania.
To, co zostało dostarczone do procesora jako znaczniki HTML, jest traktowane jako XML i wszy-
stkie znaczniki typu
center
,
table
itd. są ignorowane — pozostają tylko dane tekstowe, nie-
sformatowane i niezmienione. Na szczęście istnieje proste rozwiązanie tego problemu. Aby pewne
elementy oznaczyć jako dane, wystarczy użyć konstrukcji
xsl:copy-of
. Działa ona identycz-
nie jak
xsl:value-of
, pobierając wyrażenie XPath poprzez wartość atrybutu
select
. Jednak
zamiast dawać w wyniku wartości zwróconego zestawu węzłów, przekazuje taki zestaw bezpośre-
dnio z wejścia na wyjście. Cała zawartość zestawu węzłów nie jest przetwarzana.
<xsl:template match="JavaXML:Copyright">
<xsl:copy-of select="*" />
</xsl:template>
Zawartość elementu
JavaXML:Copyright
(wraz z całym kodem HTML) jest przekazywana
bez zmian. Nie znaczy to jednak, że możemy teraz dowolnie łamać zasady XML-a! Zawartość
tego węzła jest przetwarzana dokładnie tak samo, jak dowolne inne dane XML, zanim w ogóle nastąpi
transformacja. Innymi słowy, korzystanie ze znaku
&
lub elementów bez znaczników zamykają-
cych (np.
<br>
) jest niedozwolone. Ale możliwość bezpośredniego przesłania danych na wyjście
w celu ewentualnego dalszego przetwarzania jest bardzo przydatna wszędzie tam, gdzie dane te
nie są XML-em lub gdzie konieczne jest zastosowanie wielu arkuszy stylów i nie wszystkie ele-
menty mają być przetwarzane przez jeden styl. Teraz spójrzmy na gotowy arkusz XSL z dodanym
nowym szablonem (przykład 6.8):
Przykład 6.8. Gotowy arkusz XSL
<?xml version="1.0" encoding="ISO-8859-2"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
version="1.0"
>
<xsl:template match="JavaXML:Ksiazka">
<html>
<head>
<title><xsl:value-of select="JavaXML:Tytul" /></title>
</head>
<body>
<xsl:apply-templates select="*[not(self::JavaXML:Tytul)]" />
</body>
</html>
</xsl:template>

Składnia
151
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 151
<xsl:template match="JavaXML:Spis">
<center>
<h2>Spis treści</h2>
</center>
<hr />
<ul>
<xsl:for-each select="JavaXML:Rozdzial">
<xsl:choose>
<xsl:when test="@tematyka='Java'">
<li><xsl:value-of select="JavaXML:Naglowek" /> (Tematyka: Java)</li>
</xsl:when>
<xsl:otherwise>
<li><xsl:value-of select="JavaXML:Naglowek" /> (Tematyka: XML)</li>
</xsl:otherwise>
</xsl:choose>
</xsl:for-each>
</ul>
</xsl:template>
<xsl:template match="JavaXML:Dodatkowe">
<p>
<center><h3>Pożyteczne informacje dodatkowe</h3></center>
<ol>
<xsl:for-each select="JavaXML:Dodatkowa">
<li>
<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select="JavaXML:Url" />
</xsl:attribute>
<xsl:value-of select="JavaXML:Nazwa" />
</xsl:element>
</li>
</xsl:for-each>
</ol>
</p>
</xsl:template>
<xsl:template match="JavaXML:Copyright">
<xsl:copy-of select="*" />
</xsl:template>
</xsl:stylesheet>
Tabele HTML zostały przekazane na wyjście bez zmian; wynikowy dokument HTML można obej-
rzeć w przykładzie 6.9.
Przykład 6.9. Wynikowy dokument HTML ze skopiowaną zawartością XHTML
<html xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<head>
<title>Java i XML</title>
</head>
<body>
<center>
<h2>Spis treści</h2>
</center>
<hr>
<ul>
<li>Wprowadzenie (Tematyka: XML)</li>
<li>Pisanie w XML-u (Tematyka: XML)</li>
<li>Przetwarzanie XML-a (Tematyka: Java)</li>
<li>Struktury publikacji WWW (Tematyka: Java)</li>

152
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 152
</ul>
<p>
<center>
<h3>Pożyteczne informacje dodatkowe</h3>
</center>
<ol>
<li>
<a href="http://www.w3.org/Style/XSL">Grupa W3C</a>
</li>
<li>
<a href="http://www.mulberrytech.com/xsl/xsl-list">Lista XSL</a>
</li>
</ol>
</p>
<center xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<table cellpadding="0" cellspacing="1" border="1" bgcolor="Black">
<tr>
<td align="center">
<table bgcolor="White" border="2">
<tr>
<td>
<font size="-1">
Copyright O'Reilly and Associates, 2000
</font>
</td>
</tr>
</table>
</td>
</tr>
</table>
</center>
</body>
</html>
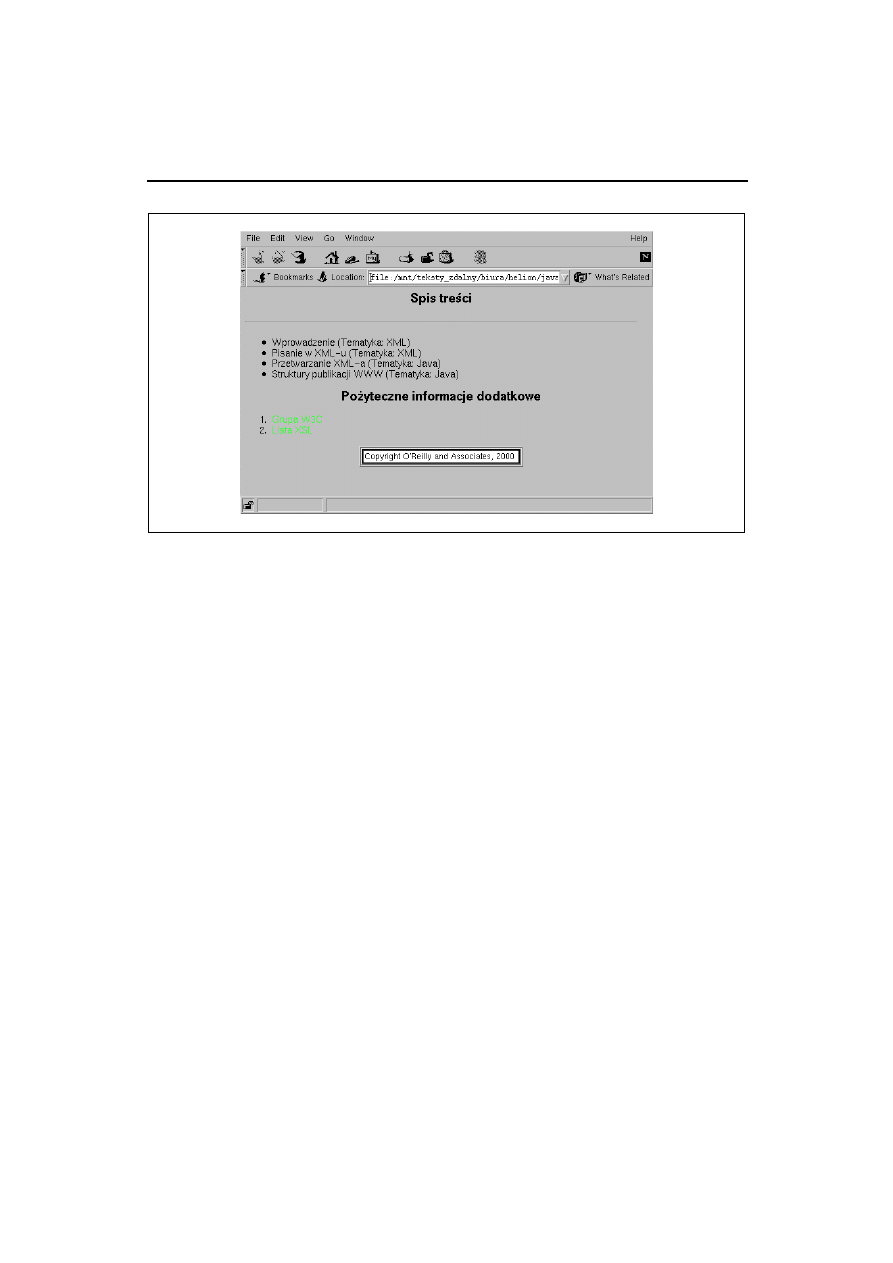
Rysunek 6.2, będący zapowiedzią rozdziału o procesorze XSLT, przedstawia otrzymany plik
HTML w takiej postaci, w jakiej będzie on widoczny w przeglądarce.
Składnia
153
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 153
Rysunek 6.2. Wynikowa strona HTML w przeglądarce WWW
Kiedy tekst nie wystarcza ...
Przekształcanie danych XML na inny format jest przydatne i często stosowane. Jednak czasami to
nie wystarcza. Powiedzieliśmy, że dane XML można przekształcić na niemal dowolne formaty, a nie
tylko na formaty tekstowe w rodzaju HTML i WML. Na przykład XML można przetworzyć i prze-
kształcić na format PDF (Portable Document Format), który to format odczytywany jest później
np. za pomocą programu Adobe Acrobat. Do takich binarnych przekształceń wykorzystuje się
obiekty formatujące. Wspomnieliśmy o nich krótko już wcześniej, przy okazji omawiania spe-
cyfikacji XSL. Ponieważ w wyniku działania XSL musi powstać poprawnie sformatowany XML,
nie jest możliwe, aby procesor XSLT bezpośrednio zwrócił dane binarne. Obiekty formatujące
umożliwiają zdefiniowanie zestawu elementów i atrybutów XML, które wykorzystuje się do re-
prezentacji obszarów (ang. areas) formatu wyjściowego. Obszar jest następnie wykorzystywany
przez procesor obiektów formatujących i przekształcany na format binarny. Jako przykład roz-
ważmy następujący fragment arkusza XSL, przekształcający XML z wykorzystaniem obiektów
formatujących:
<xsl:template match="JavaXML:Tytul">
<fo:block font-size="24pt" text-align-last="centered"
space-before.optimum="24pt">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
Wynik transformacji elementu
JavaXML:Title
, którego wartość to „Java i XML”, miałby na-
stępującą postać:
<fo:block font-size="24pt" text-align="centered"
space-before.optimum="24pt">
Java i XML
</fo:block>

154
Rozdział 6. Przekształcanie kodu XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\06-08.doc — strona 154
Powyższy zapis jest sam w sobie nieco zagadkowy i na pewno nie jest fragmentem dokumentu
PDF. Jednakże procesor obiektów formatujących, taki jak FOP autorstwa grupy Apache XML
(http://xml.apache.org), może przekształcić taki fragment na binarne dane PDF. Uzyskalibyśmy
wtedy tytuł „Java i XML” umieszczony na środku strony, wpisany czcionką o podanej wielkości.
Ten sam fragment XML można byłoby przekształcić na dokument programu Word lub na arkusz
kalkulacyjny Star Office — o ile tylko istniałyby odpowiednie procesory.
W arkuszu XSL generowane są „obszary” XML z wykorzystaniem obiektów formatujących; te re-
prezentacje danych można potem przekształcać w celu uzyskania odpowiedniej postaci binarnej.
Jednocześnie zachowany jest format XML, zarówno w postaci oryginalnej, jak i w przekształco-
nych dokumentach — dane te są więc cały czas przenośne. Tak więc ustalenie tego, czy wystarcza
uzyskanie danych tekstowych, czy nie, nic nie zmienia w samej technice przetwarzania XSL
— zmieniają się tylko przekształcane obiekty. Wciąż mamy jeden dokument źródłowy, z którego
można uzyskać wiele dokumentów wynikowych.
Co dalej?
Mamy już pełny, działający arkusz XSL. Czytelnik powinien już potrafić przetwarzać i przekształ-
cać dane XML oraz tworzyć nowe dane w arkuszu XSL. Aby jednak rzeczywiście zrealizować
współpracę standardów XML i XSL, potrzebny jest nam procesor XSLT. Procesor taki, w naszym
przypadku napisany w Javie, zajmie się faktyczną transformacją i stworzy dane wynikowe — do-
kument XML z narzuconymi stylami XSL. W następnym rozdziale zostanie omówiona obsługa
takiego właśnie procesora XSLT — zarówno standardowa, z wiersza poleceń, jak i z poziomu
programu w Javie. Przedstawiony zostanie również obiektowy model dokumentu (DOM); służy on
do generowania danych XML w formacie odpowiednim dla danych wejściowych procesora XSLT.
W zakończeniu rozdziału 7. zostaną podsumowane poznane dotychczas wiadomości dotyczące
przetwarzania XML-a — Czytelnik zobaczy, w jaki sposób łączą się one w jedną całość i są wyko-
rzystywane w większych aplikacjach XML.
Wyszukiwarka
Podobne podstrony:
06 08 artykul1pid 6497 Nieznany (2)
9 wyklad, 1 06 08 id 48416 Nieznany
acad 06 id 50513 Nieznany (2)
MD wykl 06 id 290158 Nieznany
08 2HBZ25RJBN6D4ITZUMZK4SZDSTJD Nieznany
bns kalisz 02 06 id 90842 Nieznany (2)
egzamin 2 termin 27 06 2005 id Nieznany
06 Projektowanie i organizowani Nieznany (2)
2008 10 06 praid 26459 Nieznany
newsletter 19 06 id 317919 Nieznany
mat fiz 2003 12 06 id 282350 Nieznany
06 1ogloszenieid 6229 Nieznany (2)
ZF 06 id 589761 Nieznany
06 Rozdzial III Nieznany
zest 06 id 587842 Nieznany
DGP 2014 06 23 rachunkowosc i a Nieznany
Ekonometria dr Barczak 16.06.08, UE ROND - UE KATOWICE, Rok 2 2011-2012, semestr 4, Ekonometria, Egz
Fizjologia Cwiczenia 06 id 1743 Nieznany
06 7id 6116 Nieznany (2)
więcej podobnych podstron