
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 89
4
Zawężanie
danych XML
Nauka XML-a, zarówno jako reprezentacji danych, jak i materiału wykorzystywanego przez apli-
kację w Javie, to proces wieloetapowy. Kolejne poznawane cechy XML-a lub technologii siostrza-
nych przyczyniają się do odkrywania całych pokładów wiedzy o tym języku. Istnieje wiele projektów
i specyfikacji związanych z XML-em; pojawia się pokusa „poznania wszystkiego”. A kiedy w końcu
wydaje nam się, że poznaliśmy wszystkie strony zagadnienia, pojawiają się nowe wersje... Im le-
piej jednak rozumiemy zasadę działania poszczególnych komponentów składających się na kraj-
obraz XML-a, tym lepiej przygotowani jesteśmy na wszelkie nowinki w naszym
programistycznym warsztacie. Pamiętając o tym, na jakiś czas porzucimy teraz język Java i
wrócimy do specyfikacji związanych z samym XML-em.
W rozdziałach 2. i 3. uzyskaliśmy wiedzę, która powinna wystarczyć do stworzenia poprawnie
sformatowanego dokumentu oraz do późniejszej manipulacji (w ograniczonym zakresie) tym do-
kumentem z poziomu Javy. Powinniśmy także rozumieć, jak przetwarzane są dokumenty XML i jak
w tym procesie można wykorzystać klasy SAX. W tym rozdziale zostanie omówione zawężanie do-
kumentów XML, a w następnym — wpływ zawężania na przetwarzanie takiego dokumentu w Javie.
Po co zawężać dane XML?
Wypada najpierw wytłumaczyć, do czego potrzebne są Czytelnikowi wiadomości dotyczące defi-
nicji DTD i schematów. Niektórzy użytkownicy XML-a twierdzą, że w ogóle nie ma potrzeby za-
wężania dokumentów XML i sprawdzania ich poprawności. Jak już powiedzieliśmy, poprawny
dokument XML spełnia wymogi zawężeń na niego narzuconych przez odpowiednią definicję DTD
lub schemat. Napisaliśmy również, że choć dokument jest poprawnie sformatowany, to nie musi
jeszcze być poprawny. Po cóż więc zadawać sobie trud tworzenia definicji DTD lub schematu,
który narzuca dodatkowe reguły na dane XML?
Komentarze w programach
Jako programujący w Javie, Czytelnik zapewne potrafi już dokumentować swój kod za pomocą
narzędzia Javadoc lub komentarzy w samym kodzie. Prawdopodobnie wie także, jak ważne jest
dokumentowanie własnej pracy — być może na kogoś spadnie obowiązek czytania naszego kodu,

90
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 90
poprawiania, czy po prostu zrozumienia. Komentowanie kodu jest jeszcze ważniejsze w proje-
ktach open source. Być może zdarzyło nam się kiedyś, że poganiani terminami nie byliśmy zbyt
rozlewni w komentowaniu programu. A trzy miesiące później programista, któremu powierzono
zadanie kontynuowania projektu, zasypywał nas telefonami o przeznaczenie danego fragmentu
kodu. Dobrze, jeśli jeszcze pamiętaliśmy; gorzej, jeśli dawno już zapomnieliśmy, jak udało nam
się zrobić „tę sztuczkę”. Właśnie w takich chwilach poznajemy wartość dokumentacji.
Dane XML to z pewnością nie kod. W wyniku zagnieżdżania i innych reguł składniowych niemal
zawsze łatwiej jest zrozumieć dokument XML niż fragment kodu w Javie. Jednakże nie należy
zakładać, że to, jak my widzimy naszą reprezentację danych, będzie identycznie postrzegane przez
innych. Świetnie obrazuje to plik XML z przykładu 4.1.
Przykład 4.1. Dwuznaczny plik XML
<?xml version="1.0" encoding="ISO-8859-2"?>
<strona>
<ekran>
<nazwa>Sprzedaż</nazwa>
<kolor>#CC9900</kolor>
<font>Arial</font>
</ekran>
<zawartosc>
<p>Tu idzie cała zawartość.</p>
</zawartosc>
</strona>
Przeznaczenie powyższego pliku wydaje się zupełnie oczywiste. Za jego pomocą aplikacja otrzy-
muje informacje o sposobie wyświetlenia konkretnego ekranu u klienta. Podany jest kolor, rodzaj
czcionki oraz zawartość ekranu. Gdzież tutaj dwuznaczność? Cóż, staje się ona ewidentna dopiero
po obejrzeniu innego dokumentu wykorzystywanego w tej samej aplikacji (przykład 4.2).
Przykład 4.2. Mniej dwuznaczny plik XML
<?xml version="1.0" encoding="ISO-8859-2"?>
<strona>
<ekran>
<nazwa>Sprzedaż</nazwa>
<kolor>#CC9900</kolor>
<font>Arial</font>
</ekran>
<ekran>
<nazwa>Komunikaty</nazwa>
<kolor>#9900FF</kolor>
<font>Arial</font>
</ekran>
<ekran>
<nazwa>Nowości</nazwa>
<kolor>#EECCEE</kolor>
<font>Helvetica</font>
</ekran>
<zawartosc>
<p>Tu idzie cała zawartość.</p>
</zawartosc>
</strona>
I nagle nasza interpretacja pierwszego pliku nie wydaje się już poprawna. Element
ekran
nie mo-
że reprezentować bieżącego ekranu, bo w drugim przykładzie widzimy aż trzy takie elementy.

Po co zawężać dane XML?
91
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 91
W rzeczywistości aplikacja tworzy na górze strony odsyłacze do dostępnych ekranów i właśnie
element
ekran
opisuje, jak odsyłacze te mają wyglądać — podana jest nazwa odsyłacza, kolor
fragmentu ekranu i czcionka. W pierwszym przypadku tak się złożyło, że był tylko jeden ekran, do
którego tworzono odsyłacz, i stąd to zamieszanie. Tylko autor dokumentu XML lub programista
aplikacji od razu zrozumieliby, o co tutaj chodzi.
Zawężanie dokumentów XML umożliwia udokumentowanie takich dwuznacznych sytuacji. Gdy-
byśmy wiedzieli, że w danej stronie XML dozwolony jest tylko jeden element
ekran
, moglibyś-
my bezpiecznie poczynić takie założenie, jakie zrobiliśmy odnośnie pierwszego przykładu. Gdy-
byśmy jednak wiedzieli, że dozwolonych jest wiele elementów
ekran
, to nawet patrząc tylko na
pierwszy przykład moglibyśmy trafniej odgadnąć przeznaczenie dokumentu. Innymi słowy, po-
prawnie sformatowany dokument XML zawiera słowa występujące w słowniku. Słowa te mają
pewne znaczenia, ale mogą być wykorzystywane w różny sposób. Jako przykład weźmy słowa:
„Lis kot bieg chleb ser”. Poprawność (ang. validity) dokumentu daje nam gwarancje, że „słowa” te
(elementy i atrybuty dokumentu XML) zostaną złożone w sensowny sposób: „Lisy i koty biegną
w kierunku chleba z serem”.
Udokumentowanie „poprawnych” czy „właściwych” połączeń elementów i atrybutów to właśnie za-
danie definicji DTD lub schematu. Umożliwiają one samodokumentowanie się danych XML — teraz
już nie tylko my będziemy wiedzieli, co właściwie chcieliśmy przekazać za pomocą danych XML.
Przenośność
Zawężanie XML-a pomaga nie tylko zrozumieć sposób reprezentacji danych innym osobom; po-
maga także zrozumieć dane innym aplikacjom. Wspomnieliśmy o tym już wcześniej — jeśli weź-
miemy dwie dowolne aplikacje, to nie możemy zakładać, że korzystają one ze wspólnych zasobów.
Mówiąc inaczej, program, który utworzył dokument XML w jednej aplikacji, może nie być do-
stępny w drugiej; ta druga aplikacja „nie rozumie” logiki, według której powstał dokument XML.
Druga aplikacja musi więc określić sama, jaki typ danych jest przekazywany za pośrednictwem
dokumentu XML. Nie mając żadnych wskazówek, druga aplikacja mogłaby tylko zakładać, co
„autor miał na myśli” — i często byłyby to założenia błędne.
Przypomina to nieco problemy z językiem C, których starali się uniknąć twórcy Javy. Java, nieza-
leżna od platformy i nie polegająca na kodzie własnym, jest obecnie najbardziej przenośnym ję-
zykiem programowania. Wynika to stąd, że nałożono szereg zawężeń na to, co Java może robić
i zawężenia te działają na wszystkich platformach. Takie szczegóły implementacyjne jak zarządza-
nie pamięcią czy wątkami pozostawiono do rozwiązania poszczególnym platformom, ale interfejs
do obsługi tych zadań przez programistę jest zawsze taki sam.
Zawężanie dokumentów za pomocą definicji DTD lub schematów gwarantuje podobną przenoś-
ność w języku XML. Przypomnijmy sobie pierwszy z dwóch powyższych przykładów — gdyby
inna aplikacja mogła uzyskać dostęp do zasobu opisującego dozwolone formaty przetwarzanych
danych, mogłaby przetworzyć te dane za pomocą narzędzi XML-a. Ponieważ zawężenia doku-
mentu nie zostały zakodowane bezpośrednio w aplikacji (pierwszej czy drugiej), logika aplikacji
nie zmieni się po zmianie formatu dokumentu. Definicja DTD lub schemat mógłby ulec zmianie,
ale ponieważ pracujemy na tekstowym opisie zawężeń, aplikacja mogłaby natychmiast wyko-
rzystać dokument o zmienionej strukturze, bez konieczności modyfikacji samej aplikacji. W ten
sposób uzyskuje się przenośność danych XML bez konieczności ingerencji w kod aplikacji — tak
jak próbuje się unikać kodu własnego w programach w Javie.
Czy to na potrzeby dokumentacji, przenośności pomiędzy aplikacjami i systemami, czy po prostu
ze względu na bardziej restrykcyjne sprawdzanie poprawności danych XML, zawężanie przydaje

92
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 92
się w niemal wszystkich przypadkach. Przeciwnicy zawężania mają rację właściwie tylko w jed-
nym — sprawdzanie poprawności danych ma duży wpływ na wydajność całego procesu. Jednakże
w wielu strukturach publikacji, np. takich jak Apache Cocoon, można określić, czy dany dokument
ma być sprawdzany pod kątem poprawności, czy nie. Oznacza to, że tworzenie dokumentu można
przeprowadzać przy włączonym sprawdzaniu poprawności i wyłączyć je dopiero wtedy, gdy stru-
ktura dokumentu została już solidnie przetestowana. Aplikacje otrzymujące dane również mogą
sprawdzać lub nie sprawdzać poprawności dokumentu. W razie potrzeby zawsze jest to możliwe,
bo dokument ten zawierać będzie odwołanie do definicji DTD lub schematu. A więc możliwe jest
korzystanie ze sprawdzania składni bez jednoczesnego zmniejszania wydajności aplikacji. Wcześ-
niej należy jednak sprawdzić, czy funkcja włączania-wyłączania sprawdzania jest dostępna w wy-
korzystywanej strukturze publikacji.
W systemach produkcyjnych sprawdzanie poprawności oznacza wyższą jakość aplikacji typu fir-
ma-firma (ang. business-to-business). Sprawdzanie poprawności daje gwarancję, że dane otrzyma-
ne z innych aplikacji — często takich, na które nie mamy wpływu — są poprawnie sformatowane.
Dzięki temu unikamy błędów wynikających z niepoprawnego formatu danych wejściowych. Tutaj
definicje DTD i schematy są wprost nieocenione.
Definicje typu dokumentu
Jak już to zostało powiedziane, dokument XML ma niewielką wartość bez towarzyszącej mu defi-
nicji DTD. XML w wydajny sposób opisuje dane, a DTD przygotowuje te dane do użycia w wielu
różnych programach poprzez zdefiniowanie ich struktury. W tej części książki zajmiemy się kon-
strukcjami DTD. W funkcji przykładowego pliku XML znów zostanie wykorzystany fragment spi-
su treści niniejszej książki, dla którego zbudujemy definicję DTD.
Zadaniem definicji DTD jest określenie sposobu formatowania danych. Zdefiniowany musi zostać
każdy element dozwolony w danym dokumencie XML, sposoby występowania i zagnieżdżania
elementów, a także zewnętrzne encje. Tak naprawdę w definicji DTD można określić jeszcze wie-
le innych aspektów dokumentu, ale tutaj skoncentrujemy się na tych podstawowych. Poznamy
konstrukcje oferowane przez DTD — za ich pomocą zawęzimy nasz przykładowy plik z rozdziału
2. Ponieważ do pliku tego będziemy się często odwoływali w tym rozdziale, warto przytoczyć go
tutaj jeszcze raz (przykład 4.3).
Przykład 4.3. Plik XML zawierający spis treści
<?xml version="1.0" encoding="ISO-8859-2"?>
<?xml-stylesheet href="XSL\JavaXML.html.xsl" type="text/xsl"?>
<?xml-stylesheet href="XSL\JavaXML.wml.xsl" type="text/xsl"
media="wap"?>
<?cocoon-process type="xslt"?>
<!DOCTYPE JavaXML:Ksiazka SYSTEM "DTD\JavaXML.dtd">
<!-- Java i XML -->
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<JavaXML:Title>Java i XML</JavaXML:Title>
<JavaXML:Spis>
<JavaXML:Rozdzial tematyka="XML">
<JavaXML:Naglowek>Wprowadzenie</JavaXML:Naglowek>
<JavaXML:Temat podrozdzialy="7">Co to jest?</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="3">Jak z tego korzystać?</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="4">Dlaczego z tego korzystać?</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="0">Co dalej?</JavaXML:Temat>

Definicje typu dokumentu
93
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 93
</JavaXML:Rozdzial>
<JavaXML:Rozdzial tematyka="XML">
<JavaXML:Naglowek>Tworzenie dokumentów XML</JavaXML:Naglowek>
<JavaXML:Temat podrozdzialy="0">Dokument XML</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="2">Nagłówek</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="6">Zawartość</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="1">Co dalej?</JavaXML:Temat>
</JavaXML:Rozdzial>
<JavaXML:Rozdzial tematyka="Java">
<JavaXML:Naglowek>Przetwarzanie kodu XML</JavaXML:Naglowek>
<JavaXML:Temat podrozdzialy="3">Przygotowujemy się</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="3">Czytniki SAX</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="9">Procedury obsługi
zawartości</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="4">Procedury obsługi błędów</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="0">
Lepszy sposób ładowania parsera
</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="4">"Pułapka!"</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="0">Co dalej?</JavaXML:Temat>
</JavaXML:Rozdzial>
<JavaXML:PodzialSekcji/>
<JavaXML:Rozdzial tematyka="Java">
<JavaXML:Naglowek>Struktury publikacji WWW</JavaXML:Naglowek>
<JavaXML:Temat podrozdzialy="4">Wybór struktury</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="4">Instalacja</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="3">
Korzystanie ze struktury publikacji
</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="2">XSP</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="3">Cocoon 2.0 i dalej</JavaXML:Temat>
<JavaXML:Temat podrozdzialy="0">Co dalej?</JavaXML:Temat>
</JavaXML:Rozdzial>
</JavaXML:Spis>
<JavaXML:Copyright>&OReillyCopyright;</JavaXML:Copyright>
</JavaXML:Ksiazka>
Określanie elementów
Najpierw zajmiemy się określaniem, które elementy są w naszym dokumencie dozwolone. Chcemy,
aby definicja DTD umożliwiała autorom umieszczanie w naszym dokumencie takich elementów
jak
JavaXML:Ksiazka
i
JavaXML:Spis
, ale nie
JavaXML:jas
czy
JavaXML:malgo-
sia
. Określenie zestawu dozwolonych elementów oznacza nadanie takiemu dokumentowi zna-
czenia semantycznego; innymi słowy określamy dopuszczalny (sensowny) kontekst. Najpierw
należy więc stworzyć listę dopuszczalnych elementów. Najprostszym sposobem jest przejrzenie
dokumentu i odnotowanie każdego wykorzystanego elementu. Dobrze jest także zdefiniować
przeznaczenie poszczególnych znaczników. Co prawda na określenie przeznaczenia elementów
nie pozwala bezpośrednio DTD (chyba że za pomocą komentarzy — to całkiem niezłe rozwiąza-
nie), ale coś takiego uprościłoby pracę autora DTD. W tabeli 4.1 przedstawiono pełne zestawienie
elementów dokumentu contents.xml.

94
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 94
Tabela 4.1. Elementy dozwolone w naszym dokumencie XML
Nazwa elementu
Znaczenie
JavaXML:Ksiazka
element główny
JavaXML:Tytul
tytuł dokumentowanej książki
JavaXML:Spis
oznacza spis treści książki
JavaXML:Rozdzial
rozdział książki
JavaXML:Naglowek
nagłówek (tytuł) rozdziału
JavaXML:Temat
tematyka rozdziału
JavaXML:PodzialSekcji
podział pomiędzy rozdziałami oznaczający nową część książki
JavaXML:Copyright
informacje o prawach autorskich
Teraz poszczególne elementy możemy zdefiniować w DTD. Wykonujemy to za pomocą następu-
jących konstrukcji:
<!ELEMENT [Nazwa elementu] [Definicja/typ elementu]>
Konstrukcja
[Nazwa elementu]
to faktyczna nazwa elementu, taka jak w tabelce powyżej.
Powinna ona, podobnie jak w tabeli, zawierać przedrostek przestrzeni nazw. W DTD nie istnieje
pojęcie elementu z przedrostkiem przestrzeni nazw ani odwzorowania przestrzeni nazw według
identyfikatora URI. Nazwa elementu ma postać albo samej nazwy (gdy nie użyto przestrzeni
nazw), albo nazwy poprzedzonej przedrostkiem i dwukropkiem.
Najbardziej użytecznym fragmentem jest konstrukcja
[Definicja/typ elementu]
. Tutaj
definiujemy element, nadając mu „typ” i określając, czy są to „czyste dane”, czy też typ złożony
z danych i innych elementów. Najmniej restrykcyjnym typem elementu jest ten określony za po-
mocą słowa kluczowego
ANY
. Wtedy element może zawierać dane tekstowe, elementy zagnież-
dżone, lub też dowolną (prawidłową) kombinację ich obu. Ta wiedza umożliwia już zdefiniowanie
wszystkich elementów dokumentu XML, choć może w niezbyt użyteczny sposób. W przykładzie 4.4
jest przedstawiony początek definicji DTD naszego dokumentu XML.
Przykład 4.4. „Gołe” definicje elementów w DTD
<!ELEMENT JavaXML:Ksiazka ANY>
<!ELEMENT JavaXML:Tytul ANY>
<!ELEMENT JavaXML:Spis ANY>
<!ELEMENT JavaXML:Rozdzial ANY>
<!ELEMENT JavaXML:Naglowek ANY>
<!ELEMENT JavaXML:Temat ANY>
<!ELEMENT JavaXML:PodzialSekcji ANY>
<!ELEMENT JavaXML:Copyright ANY>
Oczywiście, taka prosta definicja DTD, nie opisująca ani atrybutów, ani encji, jest niezbyt przy-
datna. Określony jest każdy dozwolony element, ale nie ma mowy ani o typach tych dokumentów,
ani o dozwolonym zagnieżdżaniu. Można stworzyć dokument zgodny z tą DTD, a jednak zupełnie
bezsensowny (przykład 4.5).
Przykład 4.5. Dokument zgodny z DTD, ale bezużyteczny
<?xml version="1.0" encoding="ISO-8859-2"?>
<?xml-stylesheet href="XSL\JavaXML.html.xsl" type="text/xsl"?>
<?xml-stylesheet href="XSL\JavaXML.wml.xsl" type="text/xsl"
media="wap"?>
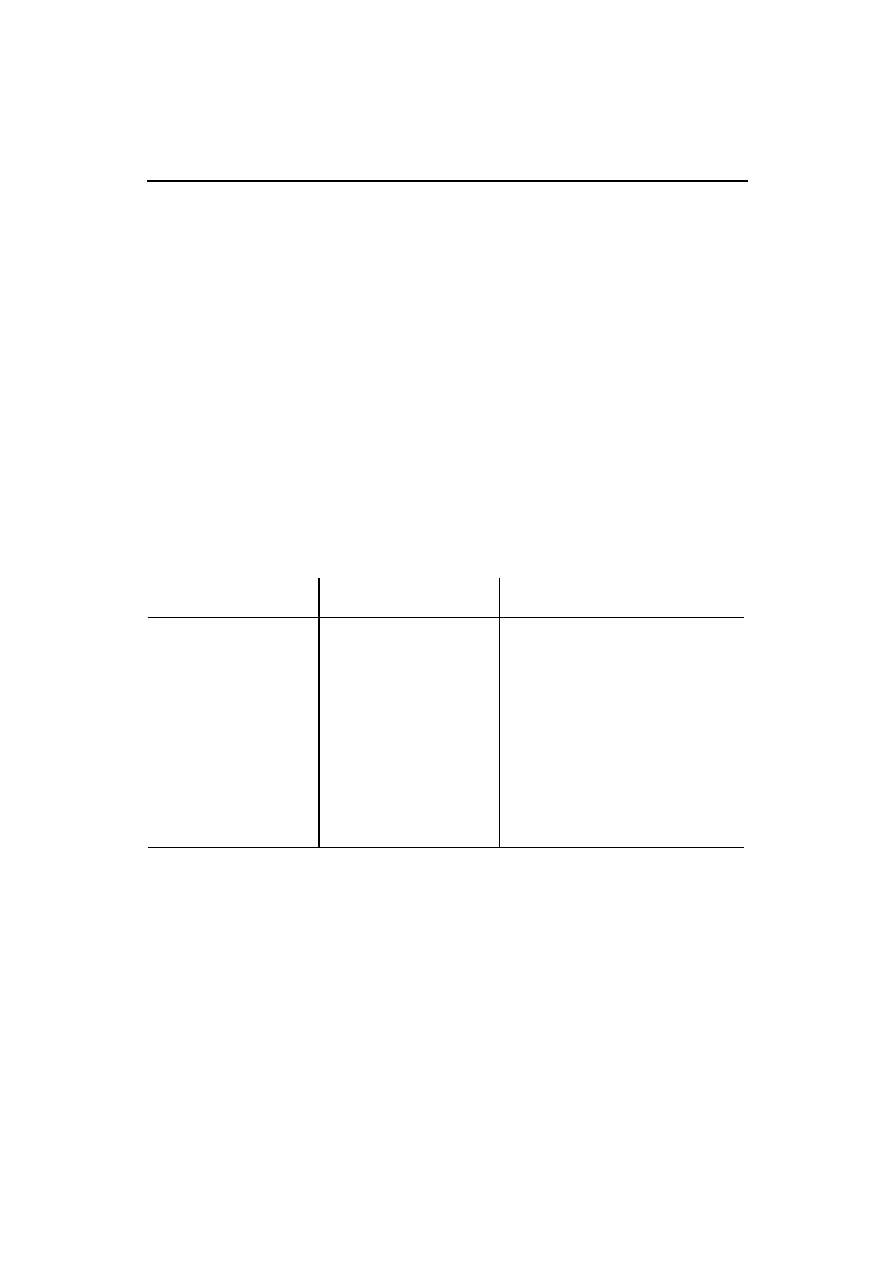
Definicje typu dokumentu
95
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 95
<?cocoon-process type="xslt"?>
<!DOCTYPE JavaXML:Ksiazka SYSTEM "DTD\JavaXML.dtd">
<JavaXML:Temat>
<JavaXML:Ksiazka>Oto moja książka</JavaXML:Ksiazka>
<JavaXML:Copyright>
<JavaXML:Rozdzial>Rozdział pierwszy</JavaXML:Rozdzial>
</JavaXML:Copyright>
<JavaXML:PodzialSekcji>A tu inna część</JavaXML:PodzialSekcji>
</JavaXML:Temat>
W powyższym fragmencie zostały użyte wyłącznie elementy dozwolone w DTD, a jednak jego
struktura nie jest poprawna. Wynika to stąd, że nasza definicja DTD nie określa, w jaki sposób
mogą być zagnieżdżane elementy i które z nich mogą zawierać dane tekstowe.
Zagnieżdżanie elementów
Jedną z najważniejszych cech struktury dokumentu XML jest zagnieżdżanie elementów. Naszą
wcześniejszą tabelkę rozszerzymy teraz o informację o dozwolonym zagnieżdżaniu elementów.
W ten sposób powstanie hierarchia elementów, którą następnie zdefiniujemy w DTD. Spójrzmy na
tabelę 4.2.
Tabela 4.2. Hierarchia elementów
Nazwa elementu
Dozwolone zagnieżdżone
elementy
Znaczenie
JavaXML:Ksiazka
JavaXML:Tytul
JavaXML:Spis
JavaXML:Copyright
element główny
JavaXML:Tytul
brak
tytuł dokumentowanej książki
JavaXML:Spis
JavaXML:Rozdzial
JavaXML:PodzialSekcji
oznacza spis treści książki
JavaXML:Rozdzial
JavaXML:Naglowek
JavaXML:Temat
rozdział książki
JavaXML:Naglowek
brak
nagłówek (tytuł) rozdziału
JavaXML:Temat
brak
tematyka poruszana w rozdziale
JavaXML:PodzialSekcj
i
brak
podział pomiędzy rozdziałami oznaczający
nową część książki
JavaXML:Copyright
brak
informacje o prawach autorskich
Teraz możemy już określić sposób zagnieżdżania w DTD. Robimy to za pomocą następującej
konstrukcji:
<!ELEMENT [Nazwa elementu] ([Zagniezdzony element] [,Zagniezdzony
element]...)>
W tym przypadku typem elementu staje się lista elementów rozdzielonych przecinkami. Istotna
jest kolejność elementów, z czego wynika dalsze zawężenie dokumentu XML. W ten sposób gwa-
rantujemy, że np. element
copyright
znajdzie się na końcu książki, albo że tytuł występuje
przed spisem. Teraz możemy naszą definicję DTD wzbogacić o opis zagnieżdżania (przykład 4.6).
Przykład 4.6. Definicja DTD określająca hierarchię elementów

96
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 96
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ELEMENT JavaXML:Tytul ANY>
<!ELEMENT JavaXML:Spis (JavaXML:Rozdzial, JavaXML:PodzialSekcji)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek, JavaXML:Temat)>
<!ELEMENT JavaXML:Naglowek ANY>
<!ELEMENT JavaXML:Temat ANY>
<!ELEMENT JavaXML:PodzialSekcji ANY>
<!ELEMENT JavaXML:Copyright ANY>
Choć niektóre elementy — te, które zawierają przetwarzane dane — nie uległy zmianie, stworzy-
liśmy hierarchię, która nadaje znaczenie zawężonemu dokumentowi. Wcześniejszy bezsensowny
przykład teraz traktowany byłby już jako niepoprawny. Wciąż jednak jest tutaj sporo problemów
związanych z dozwolonymi typami danych w pozostałych elementach.
Przetwarzane dane
Typ elementu wykorzystywany do określania danych tekstowych to
#PCDATA
. Nazwa tego typu
wywodzi się ze słów Parsed Character Data (przetwarzane dane tekstowe). Za jego pomocą ozna-
czamy elementy zawierające dane tekstowe, które mają być w zwyczajny sposób traktowane przez
parser XML. Zastosowanie tego typu wyklucza jednak możliwość obecności w elemencie innych,
zagnieżdżonych elementów. Tego typu sytuacje zostaną przedstawione dalej. Tymczasem możemy
już zmienić elementy określające tytuł, nagłówek i temat — w nich mogą być zawarte dane teksto-
we (przykład 4.7).
Przykład 4.7. Definicja DTD opisująca hierarchię elementów i elementy zawierające dane tekstowe
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis (JavaXML:Rozdzial, JavaXML:PodzialSekcji)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek, JavaXML:Temat)>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ELEMENT JavaXML:PodzialSekcji ANY>
<!ELEMENT JavaXML:Copyright ANY>
Elementy puste
Oprócz elementów zawierających dane tekstowe oraz tych, które zawierają inne elementy, mamy
jeden element,
JavaXML:PodzialSekcji
, który nie ma zawierać żadnych danych. Oczywiś-
cie, można by określić, że element ten zawiera przetwarzane dane tekstowe i nigdy ich tam nie
wstawiać, ale nie tak należy korzystać z zawężeń. Lepiej jawnie określić, że element ma być pusty
— w ten sposób zapobiegamy przypadkowym błędom. Tym razem odpowiednie słowo kluczowe
to
EMPTY
. Nie musi ono pojawiać się w nawiasach, ponieważ określa pewien typ i nie może być
łączone z innymi elementami, na co — jak wkrótce zobaczymy — pozwalają właśnie nawiasy.
Wprowadźmy więc kolejną poprawkę do definicji DTD (przykład 4.8).
Przykład 4.8. Definicja DTD z określonym elementem EMPTY

Definicje typu dokumentu
97
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 97
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis (JavaXML:Rozdzial, JavaXML:PodzialSekcji)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek, JavaXML:Temat)>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ELEMENT JavaXML:PodzialSekcji EMPTY>
<!ELEMENT JavaXML:Copyright ANY>
Encje
Ostatnim elementem, który należy uściślić, jest
JavaXML:Copyright
. Jak już to było wspom-
niane, element ten faktycznie zawiera encję odwołującą się do innego pliku, który w tym miejscu
ma zostać zawarty. Kiedy dokument XML „zobaczy”
&OReillyCopyright;
, będzie usiłował
odnaleźć encję
OReillyCopyright
w DTD, która w naszym przypadku powinna stanowić
odwołanie do zewnętrznego pliku. Plik ten zawiera informacje o prawach autorskich wszystkich
książek udokumentowanych za pomocą języka XML. Zadaniem DTD jest określenie miejsca
położenia pliku oraz sposobu uzyskania dostępu do niego. Tutaj zakładamy, że plik z prawami
autorskimi znajduje się na dysku lokalnym i że do niego właśnie będziemy się odwoływali. Encje
określane są w ramach definicji DTD za pomocą następującego zapisu:
<!ENTITY [Nazwa encji] "[Znaki podstawiane/identyfikator]">
Zauważmy, że umożliwia się podanie zestawu znaków podstawianych (zamiast pliku zewnętrz-
nego). To właśnie w ten sposób określane są „sekwencje unikowe” w dokumentach XML:
<!ENTITY & "&">
<!ENTITY < "<">
<!ENTITY > ">">
...
Tak więc jeśli nasza informacja o prawach autorskich byłaby krótka, moglibyśmy napisać:
<!ENTITY &OReillyCopyright;
"Copyright O'Reilly and Associates, 2000">
Jednakże my zamierzamy użyć dłuższego tekstu, a więc wygodniej będzie pobrać go z zewnętrz-
nego pliku. W ten sposób możemy z niego korzystać w wielu dokumentach bez konieczności
duplikowania danych w poszczególnych definicjach DTD. Wymaga to podania identyfikatora za-
sobu systemowego, dlatego korzystamy tutaj z następującego zapisu:
<!ENTITY [Encja] SYSTEM "[URI]">
Tak jak w przypadku dokumentu XML, URI może być zarówno zasobem lokalnym, jak i siecio-
wym. W naszym przypadku odwołujemy się do pliku znajdującego się na serwerze zewnętrznym,
więc musimy zastosować adres URL:
<!ENTITY OReillyCopyright SYSTEM
"http://www.oreilly.com/catalog/javaxml/docs/copyright.xml">
Dzięki takiemu zapisowi parser XML rozpozna referencję OReillyCopyright w dokumencie i odpo-
wiednio przetłumaczy ją w czasie przetwarzania. Z tego właśnie powodu musieliśmy ten fragment
oznaczyć jako komentarz w rozdziale 3. W następnym rozdziale usuniemy symbole komentarza
i zobaczymy, w jaki sposób parser sprawdzający poprawność składni obsłuży tę encję z wykorzys-
taniem definicji DTD.

98
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 98
Na koniec w elemencie zawierającym encję musimy podać, że oczekujemy w tym miejscu prze-
twarzanych danych tekstowych:
<!ELEMENT JavaXML:Copyright (#PCDATA)>
Powtórz to, a...
Ostatnią ważną konstrukcją, jaką omówimy w związku z definicjami DTD, jest opis grupowania,
wielokrotnego występowania i dopuszczalnych kombinacji w ramach elementu. Innymi słowy,
chodzi tu np. o sytuacje, w których element X może wystąpić tylko raz, lub też po elemencie Y
musi wystąpić element Z. To niezwykle istotne konstrukcje DTD. Domyślnie, jeśli nie podaliśmy
w elemencie specjalnych modyfikatorów, element może wystąpić dokładnie raz:
<!ELEMENT MojElement (ZagniezdzonyElement, InnyElement)>
W tym przypadku
ZagniezdzonyElement
ma wystąpić tylko raz, a po nim koniecznie musi
znajdować się
InnyElement
. Jeśli struktura dokumentu XML jest inna, to dokument ten nie jest
poprawny. Aby zmienić to domyślne zawężenie, można zastosować specjalne modyfikatory.
Zero, jeden lub więcej
Najczęściej do elementu dodawany jest operator rekurencji. Umożliwia on określenie, czy dany
element ma się pojawić zero lub więcej razy, jeden lub więcej razy, wcale lub (ustawienie
domyślne) dokładnie raz. W tabeli 4.3 przedstawione są operatory rekurencyjne i ich znaczenia.
Tabela 4.3. Operatory rekurencyjne
Operator
Opis
[Domyślnie]
musi wystąpić dokładnie raz
?
musi wystąpić raz albo wcale
+
musi wystąpić przynajmniej raz (1 ... n razy)
*
może wystąpić dowolną liczbę razy (0 ... n razy)
Modyfikatory dodawane są na końcu nazwy elementu. W naszym poprzednim przykładzie, aby ze-
zwolić na jedno lub więcej wystąpień elementu
ZagniezdzonyElement
, a potem na tylko jedno
(lub wcale) wystąpienie elementu
InnyElement
, należałoby użyć następującej konstrukcji:
<!ELEMENT MojElement (ZagniezdzonyElement+, InnyElement?)>
Wtedy taki zapis XML byłby zupełnie poprawny:
<MojElement>
<ZagniezdzonyElement>Jeden</ZagniezdzonyElement>
<ZagniezdzonyElement>Dwa</ZagniezdzonyElement>
</MojElement>
W definicji DTD, którą tworzymy, z taką sytuacją mamy do czynienia w przypadku elementu
JavaXML:Rozdzial
. Chcemy, aby nagłówek rozdziału (
JavaXML:Naglowek
) mógł wystą-
pić raz lub wcale, chcemy również pozwolić na wystąpienie jednego lub więcej elementów
Ja-
vaXML:Temat
. Wykorzystujemy modyfikatory rekurencyjne:
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>

Definicje typu dokumentu
99
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 99
Ta prosta zmiana czyni naszą reprezentację rozdziału w XML bardziej realistyczną. Musimy także
dokonać zmian w definicji elementu
JavaXML:Spis
. Może się w nim pojawić jeden lub więcej
rozdziałów, a potem, ewentualnie, podział sekcji. Podział jest opcjonalny, bo książka może się
składać wyłącznie z rozdziałów. Rekurencję rozdziałów i podziałów sekcji zapiszemy następująco:
<!ELEMENT JavaXML:Spis (JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)>
Wciąż jednak definicja DTD „nie wie”, że po elemencie
JavaXML:PodzialSekcji
może wy-
stąpić więcej rozdziałów. Chcemy, aby cała ta struktura mogła pojawić się kilkakrotnie. Po rozdziale
podział sekcji, potem znów rozdziały i znów podziały sekcji. Musimy zastosować grupowanie.
Grupowanie
Grupowanie umożliwia rozwiązywanie problemów takich jak ten z zagnieżdżaniem elementów
wewnątrz
JavaXML:Spis
. Często rekurencja dotyczy bloku elementów, a nie jednego elementu.
Dlatego operatory rekurencji można dodawać także do grup elementów. Grupę elementów two-
rzymy poprzez ujęcie elementów w nawiasy. Jeśli w tej chwili Czytelnikowi przypomniały się
zajęcia z języka LISP, to niech się nie zamartwia — w naszych przykładach wszystko będzie do-
syć proste, a liczba nawiasów nie wymknie się spod kontroli. Oczywiście, zagnieżdżanie nawia-
sów jest dozwolone. Tak więc, aby stworzyć grupę elementów, zastosujemy następującą konstrukcję:
<!ELEMENT PrzykladGrupowania ((Grupa1El1, Grupa1El2),
(Grupa2El1, Grupa2El2))>
Do każdej grupy (a nie tylko do poszczególnych jej elementów) można dopisać modyfikator. W opi-
sywanym scenariuszu musimy tak zmienić zapis, aby możliwe było wielokrotne wystąpienie gru-
py zawierającej elementy rozdziału i podziału sekcji:
<!ELEMENT JavaXML:Spis (JavaXML:Rozdzial+,JavaXML:PodzialSekcji?)+>
Teraz dozwolone są już różne kombinacje — kilka rozdziałów plus jeden podział sekcji i to wszy-
stko powtórzone wiele razy lub też nie powtórzone wcale. Możliwy jest także przypadek, w któ-
rym wystąpią same tylko rozdziały, bez podziałów sekcji. Jednakże tutaj sprawa nie jest zupełnie
jasna (według naszego opisu w DTD). Lepiej byłoby określić, że pojawić się może jeden lub
więcej rozdziałów lub taka struktura. Zachowanie DTD się nie zmieni, ale z pewnością definicja
będzie bardziej czytelna. Aby to uzyskać, należy wprowadzić pojęcie „lub”.
To lub tamto
W definicjach DTD możliwe jest stosowanie pojęcia „lub”, oznaczanego symbolem kreski pio-
nowej. Symbol ten jest często wykorzystywany w połączeniu z grupowaniem. Częstym, choć nie-
koniecznie udanym przykładem użycia operatora „lub” jest umożliwienie wystąpienia wewnątrz
elementu pewnego innego elementu (elementów) lub danych:
<!ELEMENT ElementKumulujacy (#PCDATA|(Element 1, Element2))>
W przypadku tej definicji DTD oba poniższe fragmenty będą poprawne:
<ElementKumulujacy>
<Element1>Jeden</Element1>
<Element2>Dwa</Element2>
</ElementKumulujacy>
<ElementKumulujacy>
Dane tekstowe
</ElementKumulujacy>

100
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 100
Nie zaleca się jednak stosowania takiego rozwiązania, gdyż wówczas staje się niejasne znaczenie
elementu zamykającego. Zazwyczaj element powinien zawierać dane tekstowe, dane przetwarzane
lub inne elementy — ale nie wszystko razem.
W naszym dokumencie zależy nam na bardziej przejrzystej reprezentacji elementu
JavaXML:
Spis
. Zastosujemy następujące rozwiązanie:
<!ELEMENT JavaXML:Spis ((JavaXML:Rozdzial+)|
(JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)+)>
Teraz jest już jasne, że może pojawić się tutaj albo pewna liczba rozdziałów, albo rozdziały, po
których następuje podział sekcji. W ten sposób tworzy się przejrzyście udokumentowaną definicję,
a jednocześnie zapewnia odpowiednie zawężenie dokumentu XML.
Teraz nasze elementy XML są już poprawnie określone i zawężone. Definicja przedstawiona w przy-
kładzie 4.9 powinna działać bezproblemowo na naszym przykładowym dokumencie. Pozostały
nam jeszcze definicje argumentów, które omawiamy poniżej.
Przykład 4.9. Opis elementów w definicji DTD
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis ((JavaXML:Rozdzial+)|
(JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)+)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ELEMENT JavaXML:PodzialSekcji EMPTY>
<!ELEMENT JavaXML:Copyright (#PCDATA)>
<!ENTITY OReillyCopyright SYSTEM
"http://www.oreilly.com/catalog/javaxml/docs/copyright.xml">
Definiowanie atrybutów
Po tym dość dokładnym omówieniu sposobu definiowania elementów możemy przejść do definio-
wania atrybutów. Ponieważ tutaj nie będziemy mieli do czynienia z zagnieżdżaniem, czynność ta
jest nieco prostsza niż opisywanie elementów. Nie będziemy też potrzebowali operatorów reku-
rencji, ponieważ o tym, czy obecność danego atrybutu jest wymagana, mówi określone słowo klu-
czowe. Definicje atrybutów przyjmują następującą formę:
<!ATTLIST [Element zamykajacy]
[Nazwa atrybutu] [typ] [modyfikator]
...
>
Pierwsze dwa parametry, nazwa elementu i atrybutu, nie powinny sprawiać trudności. Za pomocą
jednej konstrukcji
ATTLIST
dowolnemu elementowi możemy przypisać wiele atrybutów. Taki
schemat jak powyżej zostanie dodany teraz do naszej definicji DTD, dzięki czemu lepiej będzie
przedstawiona struktura opisywania atrybutów. Najlepiej definicje atrybutów dodawać zaraz po
opisie elementu (to kolejny krok w kierunku utworzenia samodokumentującego się opisu DTD).
Spójrzmy na przykład 4.10.
Przykład 4.10. Definicja DTD opisująca elementy i zawierająca ogólny szkielet opisów atrybutów
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,

Definicje typu dokumentu
101
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 101
JavaXML:Spis,
JavaXML:Copyright)>
<!ATTLIST JavaXML:Ksiazka
xmlns:JavaXML [typ] [modyfikator]
>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis ((JavaXML:Rozdzial+)|
(JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)+)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ATTLIST JavaXML:Rozdzial
tematyka [typ] [modyfikator]
czesc [typ] [modyfikator]
>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ATTLIST JavaXML:Temat
podRozdzialy [typ] [modyfikator]
>
<!ELEMENT JavaXML:PodzialSekcji EMPTY>
<!ELEMENT JavaXML:Copyright (#PCDATA)>
<!ENTITY OReillyCopyright SYSTEM
"http://www.oreilly.com/catalog/javaxml/docs/copyright.xml">
Teraz zdefiniujmy typy dozwolone dla poszczególnych atrybutów.
Typy atrybutów
Wartością wielu atrybutów będą dane tekstowe. To najprostszy typ wartości atrybutu, ale też naj-
mniej zawężony. Typ ten określamy za pomocą słowa kluczowego
CDATA
(Character Data — da-
ne tekstowe). Jest to ta sama konstrukcja
CDATA
, która w samym dokumencie XML reprezentuje
dane wchodzące w skład „sekwencji unikowej”. Typ ten jest zazwyczaj używany wtedy, gdy atry-
but może przyjąć dowolną wartość i służy jako komentarz lub dodatkowa informacja o danym
elemencie. Wkrótce Czytelnik przekona się, że lepszym rozwiązaniem jest zdefiniowanie zestawu
wartości dozwolonych dla atrybutu danego elementu. W naszym dokumencie typem tekstowym
jest atrybut
xmlns
. Co prawda
xmlns
to słowo kluczowe XML oznaczające deklarację prze-
strzeni nazw, ale wciąż jest to atrybut, którego poprawność ma zostać sprawdzona — i musi zostać
opisany w definicji DTD. Atrybut
podRozdzialy
elementu
JavaXML:Temat
przyjmuje także
wartość tekstową:
<!ATTLIST JavaXML:Ksiazka
xmlns:JavaXML CDATA [modyfikator]
>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis ((JavaXML:Rozdzial+)|
(JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)+)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ATTLIST JavaXML:Rozdzial
tematyka [typ] [modyfikator]
>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ATTLIST JavaXML:Temat
podRozdzialy CDATA [modyfikator]
>
Następny typ atrybutu (jeden z najczęściej używanych) to wyliczenie. Umożliwia określenie kon-
kretnych wartości atrybutu. Wartości nie wymienione w wyliczeniu powodują, że dokument XML
jest niepoprawny. Rozwiązanie to przydaje się wszędzie tam, gdzie zestaw wartości atrybutu zna-

102
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 102
my już w czasie tworzenia dokumentu i umożliwia on bardzo ścisłe zawężenie definicji elementu.
Taki typ ma nasz atrybut
tematyka
, ponieważ dozwolone są dla niego jedynie wartości „Java”
lub „XML”. Wartości dozwolone umieszczane są w nawiasach i rozdzielane znakiem operatora
„lub”, podobnie jak przy określaniu zagnieżdżania elementów:
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ATTLIST JavaXML:Rozdzial
tematyka (XML|Java) [modyfikator]
>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
Być albo nie być ...
W definicji atrybutu należy jeszcze określić, czy atrybut ten jest w danym elemencie wymagany.
Służą do tego trzy słowa kluczowe:
#IMPLIED
,
#REQUIRED
lub
#FIXED
. Atrybut niejawny
(ang. implied) nie jest wymagany. Takim modyfikatorem można określić atrybut
podRozdzia-
ly
, jako że nie jest on wymagany do stworzenia poprawnego dokumentu:
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ATTLIST JavaXML:Temat
podRozdzialy CDATA #IMPLIED
>
Jeśli chodzi o atrybut
xmlns
, to chcemy zagwarantować, żeby autor zawartości zawsze określał
przestrzeń nazw dla danej książki. W przeciwnym razie nasze przedrostki określające przestrzeń
nazw na nic by się nie zdały. W takim przypadku należy zastosować słowo
#REQUIRED
(wy-
magany). Gdyby atrybut ten nie został zawarty w elemencie
JavaXML:Ksiazka
, dokument nie
byłby poprawny:
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ATTLIST JavaXML:Ksiazka
xmlns:JavaXML CDATA #REQUIRED
>
Ostatnie słowo kluczowe,
#FIXED
, nie jest zbyt często używane w aplikacjach. Najczęściej sto-
suje się je w systemach bazowych; określa ono, że użytkownik nie może nigdy zmienić wartości
danego atrybutu. Format jest tutaj następujący:
<!ATTLIST [Nazwa elementu]
[Nazwa atrybutu] #FIXED [Stala wartosc]
>
Ponieważ atrybut ten nie przydaje się w aplikacjach dynamicznych (nie jest możliwa jego zmiana),
nie będziemy się nim tutaj zajmować.
Do omówienia pozostał jeszcze atrybut
tematyka
. Wymieniliśmy wszystkie możliwe wartości,
jakie może przyjmować, ale ponieważ w tej książce koncentrujemy się głównie na Javie, chcie-
libyśmy, aby autor nie musiał jawnie definiować atrybutu jako „Java” w tych rozdziałach, w któ-
rych rzeczywiście Java jest głównym tematem. W książce składającej się z dwudziestu czy
trzydziestu rozdziałów ciągłe wpisywanie atrybutu może okazać się męczące. Wyobraźmy sobie
listę książek w bibliotece naukowej, w której jako temat każdej książki należałoby podać „nauka”!
Duplikowanie danych wydłuża proces, a więc wymaganie podawania atrybutu za każdym razem
nie jest dobrym rozwiązaniem. Chcemy więc przypisać atrybutowi pewną domyślną wartość, kie-
dy żadna wartość nie zostanie podana przez autora (i nie załatwia tego słowo
#IMPLIED
, które
powoduje, że atrybutowi nie zostaje przypisana żadna wartość). Domyślną wartość można określić

Definicje typu dokumentu
103
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 103
poprzez wpisanie jej w cudzysłowach zamiast wpisania słowa kluczowego modyfikatora. Jeśli ty-
pem atrybutu jest wyliczanie (
enumeration
), wartość ta powinna być jednym z wymienionych
łańcuchów znaków. Zdefiniujmy więc nasz atrybut
tematyka
:
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ATTLIST JavaXML:Rozdzial
tematyka (XML|Java) "Java"
>
Nasza definicja DTD jest już gotowa! Składnia definicji DTD może wydawać się nieco
dziwaczna, ale mam nadzieję, że Czytelnikowi nie sprawiło trudności śledzenie kolejnych etapów
definiowania elementów, atrybutów i encji. Nie omówiliśmy oczywiście wszystkich zagadnień
związanych z definicjami DTD, ponieważ niniejsza książka nie traktuje o samym XML-u, ale o
Javie i XML-u. Mam jednak nadzieję, że przykładowa definicja DTD jest zrozumiała i że
Czytelnik będzie potrafił stworzyć proste definicje dla własnych dokumentów. Zanim przejdziemy
do omawiania schematów, spójrzmy raz jeszcze na gotową definicję DTD (przykład 4.11).
Przykład 4.11. Gotowa definicja DTD
<!ELEMENT JavaXML:Ksiazka (JavaXML:Tytul,
JavaXML:Spis,
JavaXML:Copyright)>
<!ATTLIST JavaXML:Ksiazka
xmlns:JavaXML CDATA #REQUIRED
>
<!ELEMENT JavaXML:Tytul (#PCDATA)>
<!ELEMENT JavaXML:Spis ((JavaXML:Rozdzial+)|
(JavaXML:Rozdzial+, JavaXML:PodzialSekcji?)+)>
<!ELEMENT JavaXML:Rozdzial (JavaXML:Naglowek?,JavaXML:Temat+)>
<!ATTLIST JavaXML:Rozdzial
tematyka (XML|Java) "Java"
>
<!ELEMENT JavaXML:Naglowek (#PCDATA)>
<!ELEMENT JavaXML:Temat (#PCDATA)>
<!ATTLIST JavaXML:Temat
podRozdzialy CDATA #IMPLIED
>
<!ELEMENT JavaXML:PodzialSekcji EMPTY>
<!ELEMENT JavaXML:Copyright (#PCDATA)>
<!ENTITY OReillyCopyright SYSTEM
"http://www.oreilly.com/catalog/javaxml/docs/copyright.xml">
Po dokładnym przyjrzeniu się tej definicji DTD można uznać, że jest ona zbyt złożona. Struktura
definicji DTD rządzących organizacją plików XML zupełnie nie przypomina samych plików
XML. Struktura DTD jest odmienna od struktury schematu, arkusza stylu XSL i niemal każdego
innego dokumentu związanego z językiem XML. Definicje DTD opracowano jako część specyfi-
kacji XML 1.0. Niektóre decyzje projektowe podjęte w ramach tej specyfikacji odbiły się piętnem
na użytkownikach i programistach korzystających z XML. Podstawy definicji DTD w standardzie
XML oparte są w dużej części na SGML-u — specyfikacji o wiele starszej. Jednakże struktura
definicji DTD z czasów SGML-a stanowi niezbyt dobry wybór w odniesieniu do XML-a. Te róż-
nice strukturalne stara się naprawić standard XML Schema, który skoncentrowany jest właśnie na
XML-u i nie narusza stylu poprawnego programowania. Schematy XML Schema zostaną wkrótce
omówione. Najprawdopodobniej schematy całkowicie zastąpią definicje DTD, ale zastępowanie to
przebiega powoli — w wielu aplikacjach XML został już wdrożony w systemach produkcyjnych,
w których są używane dokumenty zawężane definicjami DTD. To dlatego właśnie zrozumienie
definicji DTD jest tak istotne — nawet jeśli mają one odejść do lamusa.

104
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 104
Czego brak w definicji DTD?
Co ciekawe, aż całą sekcję poświęcić trzeba sprawom, które nie zostały ujęte w definicji DTD.
W DTD podać trzeba wszystkie elementy i zdefiniować wszystkie atrybuty dokumentu XML, ale
nie muszą się tam znaleźć instrukcje przetwarzania (PI). Co więcej, w ogóle nie ma możliwości
określenia instrukcji PI, podobnie jak deklaracji XML znajdującej się na samym początku doku-
mentu XML. Definicja DTD rozpoczyna się wraz z pierwszym wystąpieniem pierwszego elemen-
tu w pliku XML. Takie podejście może się wydawać naturalne — po co określać, że dokument ma
zawierać taką, a nie inną instrukcję przetwarzani?. Odpowiedzią jest przenośność.
Są powody, dla których określanie instrukcji przetwarzania przydałoby się w definicjach DTD. Na
przykład możliwa jest sytuacja, w której autor zawartości chciałby mieć gwarancję, że jego doku-
ment XML zostanie zawsze przekształcony — a więc wymaga instrukcji opisującej arkusz stylu
xml-stylesheet
. Ale który arkusz chcemy wykorzystać? To trzeba również określić. A jaki
mechanizm ma wykonać przekształcenia? Cocoon? Servlet Jamesa Clarka? Inna struktura? To
wszystko również trzeba zdefiniować. Jednak kiedy wszystko zostanie dokładnie określone, doku-
ment utraci przenośność. Będzie mógł być wykorzystany już tylko do jednego konkretnego celu
i w jednej specyficznej strukturze publikacji. Nie będzie go łatwo przenieść na inną platformę,
strukturę czy aplikację. Dlatego instrukcje PI i deklaracje XML pozostają niezawężone w ramach
definicji DTD. Zajmujemy się tylko elementami i atrybutami dokumentu, począwszy od elementu
głównego.
XML Schema
XML Schema to nowy projekt roboczy grupy W3C, uwzględniający dotychczasowe problemy
i ograniczenia definicji DTD. Umożliwia on bardziej precyzyjną reprezentację zawężeń struktury
XML i, co istotne, wykorzystuje w tym celu sam język XML. Schematy to właściwie dokumenty
XML — dobrze sformatowane i poprawne. Mogą więc być obsługiwane przez parsery i inne apli-
kacje „znające XML” w sposób podobny jak zwykłe dane XML. Nie trzeba stosować specjalnych
technik, jak przy obsłudze definicji DTD.
Ponieważ XML Schema to jeszcze „młoda” i niepełna specyfikacja, zostanie omówiona pokrótce.
Szczegóły implementacji mogą w każdej chwili ulec zmianie; jeśli więc Czytelnik ma problemy
z omawianymi przykładami, może przejrzeć najnowszą wersję projektu pod adresami http://www.-
w3.org/TR/xmlschema-1/ i http://www.w3.org/TR/xmlschema-2/. Należy także pamiętać, że wiele
parserów XML nie obsługuje schematów XML, bądź też obsługuje je tylko częściowo. Stopień
obsługi XML Schema opisany jest w instrukcji parsera.
Istnieje różnica pomiędzy dokumentem poprawnym a dokumentem poprawnym z punktu widzenia
schematu. XML Schema nie stanowi części specyfikacji XML 1.0, a więc dokument zgodny z da-
nym schematem może być niepoprawny. Tylko dokument XML zgodny z definicją DTD określo-
ną w deklaracji
DOCTYPE
może być uważany za poprawny. W związku z tym w środowisku użyt-
kowników XML-a rodzą się wątpliwości dotyczące sposobu obsługi sprawdzania poprawności
poprzez XML Schema. Ponadto, nawet jeśli dokument posiada odpowiadający mu schemat, to nie
znaczy jeszcze, że jego poprawność będzie sprawdzana — ponieważ XML Schema nie jest opi-
sany w specyfikacji XML 1.0, aplikacja lub parser wcale nie muszą dokonywać takiego sprawdza-
nia (bez względu na poziom obsługi schematów przez parser). Dlatego zawsze trzeba sprawdzić,
czy parser będzie sprawdzał poprawność dokumentu, oraz jak obsługuje schematy. Na potrzeby
przejrzystości opisu będziemy zakładać, że sprawdzanie poprawności to jedno pojęcie, obejmujące

XML Schema
105
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 105
zarówno schematy, jak i definicje DTD; znaczenie tego pojęcia będzie zaś musiało być interpreto-
wane w odpowiednim kontekście. Na ewentualne dwuznaczności zawsze będziemy zwracali uwagę.
Najważniejsze przy budowaniu schematu jest to, że w trakcie tego procesu powstaje po prostu
nowy dokument XML. W przeciwieństwie do definicji DTD, korzystających z zupełnie odmien-
nego formatu opisu elementów i definiowania atrybutów, schemat jest zwyczajnym dokumentem
XML. Składnia nie będzie więc znacząco odbiegała od tej opisanej w rozdziale 2. Co ciekawe,
sam schemat XML jest zawężony za pomocą definicji DTD. Jeśli to wydaje się nieco osobliwe, to
należy przypomnieć, że przed powstaniem XML Schema jedynym sposobem zawężania dokumen-
tów było właśnie zastosowanie definicji DTD. Aby poprzez XML Schema można było sprawdzać
poprawność, trzeba najpierw określić zawężenia samego schematu, korzystając z „zewnętrznego
mechanizmu”. A tym zewnętrznym mechanizmem musi być definicja DTD. Jednak już po stwo-
rzeniu tej początkowej definicji wszystkie inne dokumenty XML w ogóle nie będą korzystały z DTD.
Ta nieco dziwna kolej rzeczy jest zjawiskiem dość pospolitym w ewoluującym świecie specyfika-
cji — nowe wersje powstają na bazie starych.
Przestrzeń nazw schematu
Można oczekiwać, że dokumenty XML Schema rozpoczynają się standardową deklaracją XML,
po czym następuje odwołanie do przestrzeni nazw schematu. I tak jest w rzeczywistości. Ponadto
istnieją standardy nazywania elementu głównego. Przyjęło się, że element główny nosi nazwę
schema
. Przy tworzeniu elementu głównego buduje się również definicje przestrzeni nazw — po-
dobnie jak to robiliśmy w naszym przykładowym dokumencie XML. Przede wszystkim konieczne
jest podanie domyślnej deklaracji przestrzeni nazw:
<xsd:schema xmlns:xsd="http://www.w3.org/1999/XMLSchema">
Jak to zostało przedstawione w rozdziale 2., pominięcie identyfikatora po atrybucie
xmlns
powo-
duje zastosowanie w dokumencie domyślnej przestrzeni nazw. W naszym wcześniejszym doku-
mencie XML definicja przestrzeni nazw odpowiadała konkretnie przestrzeni
JavaXML
:
<JavaXML:Ksiazka xmlns:JavaXML="http://www.w3.org/1999/XMLSchema">
W ten sposób informowaliśmy parser XML, że wszystkie dokumenty z przedrostkiem
JavaXML
należą do tej konkretnej przestrzeni nazw, skojarzonej z podanym adresem URL. W naszym doku-
mencie XML dotyczyło to wszystkich elementów, bo wszystkie opatrzone były tym przedrost-
kiem. Ale przecież mogły tam pojawić się także elementy bez takich przedrostków. Elementy takie
nie są, oczywiście, skazane na niebyt — one również muszą zostać przypisane jakiejś przestrzeni
nazw. Przypisuje się im przestrzeń domyślną, która nie jest zdefiniowana w dokumencie. Można
zdefiniować ją za pomocą dodatkowej deklaracji przestrzeni nazw w elemencie głównym:
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml"
xmlns="http://www.jakisInnyUrl.com"
>
Spowodowałoby to, że dowolny element nie poprzedzony przedrostkiem
JavaXML
lub innym ko-
jarzony byłby z domyślną przestrzenią nazw, identyfikowaną za pomocą adresu http://www.jakisIn-
nyUrl.com. Tak więc w następującym fragmencie dokumentu elementy
Ksiazka
,
Spis
i
Tytul
skojarzono z przestrzenią
JavaXML
, zaś
element1
i
element2
z domyślną przestrzenią nazw:
<JavaXML:Ksiazka xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml"
xmlns="http://www.jakisInnyUrl.com"
>
<JavaXML:Tytul>Mój tytuł</JavaXML:Tytul>

106
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 106
<JavaXML:Spis>
<element1>
<element2 />
</element1>
</JavaXML:Spis>
</JavaXML:Ksiazka>
Ponieważ w naszym schemacie opisujemy inny dokument, wszystkie elementy związane z kon-
strukcjami samego XML Schema powinny należeć do domyślnej przestrzeni nazw — i dlatego po-
dajemy na początku jej deklarację. Jednakże konstrukcje te oddziaływają na przestrzeń nazw
w zawężanym dokumencie XML. Innymi słowy, konstrukcje XML Schema stanowią część prze-
strzeni nazw XML Schema, ale wykorzystywane są do zawężenia elementów w innych przestrze-
niach nazw — w tych, które opisują dokument lub dokumenty XML opisywane przez ten schemat.
W naszym przykładzie dotyczyłoby to przestrzeni nazw
JavaXML
. Tak więc do elementu
sche-
ma
trzeba dodać następującą deklarację:
<schema xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
>
Teraz jeszcze należy „poinformować” schemat, że przedmiotem zawężania jest druga przestrzeń
nazw. W tym celu należy zastosować atrybut
targetNamespace
(docelowa przestrzeń nazw),
którego działanie jest zgodne z nazwą:
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
>
W ten sposób otrzymaliśmy definicje dwóch przestrzeni nazw (domyślna oraz
JavaXML
) oraz
określiliśmy przedmiot zawężania w postaci drugiej przestrzeni nazw (
JavaXML
). A skoro jest
już zdefiniowany element główny, można rozpocząć nakładanie zawężeń na tę przestrzeń nazw.
Należy pamiętać jeszcze o jednej rzeczy: w świecie protokołu HTTP i serwerów WWW możliwe
jest, że adres URL skojarzony z daną przestrzenią nazw może być prawdziwym adresem; w na-
szym przypadku, gdybyśmy do przeglądarki wpisali http://www.oreilly.com/catalog/javaxml, otrzy-
malibyśmy odpowiedź HTML. Ale zwracany dokument tak naprawdę nie jest wykorzystywany;
adres URL wcale nie musi być osiągalny — służy wyłącznie jako element kojarzony z prze-
strzenią nazw. Nie zawsze jest to łatwo zrozumieć, dlatego Czytelnik nie powinien zaprzątać sobie
głowy tym, na co wskazuje podany identyfikator URI; ważniejsze jest skoncentrowanie się na
deklarowanej przestrzeni nazw oraz na sposobie, w jaki wykorzystywana jest ona w dokumencie.
Uwaga! Zagadnienia omawiane w dalszej części rozdziału nie są proste, więc Czytelnik nie
powinien przejmować się ewentualnymi trudnościami z ich zrozumieniem. Koncepcje związane ze
schematami XML Schema nie są „łatwe i przyjemne”, a cała ta specyfikacja jest dopiero w fazie
rozwoju. Wielu autorów zawartości korzysta z technologii XML Schema, my zaś staramy się tutaj
zrozumieć ją — to subtelna, ale istotna różnica. Dzięki zrozumieniu zagadnień związanych z XML
Schema Czytelnik będzie potrafił bardziej efektywnie projektować dokumenty XML i tworzyć
lepsze aplikacje. Szczególnie złożoną sprawą jest sposób wykorzystania w schematach definicji
DTD i przestrzeni nazw; na szczęście większość pozostałych konstrukcji nie jest już tak skompli-
kowana. Tak więc warto teraz zrelaksować się, napić kawy i uważnie, bez pośpiechu kontynuować
lekturę. To na pewno zaowocuje w przyszłości.
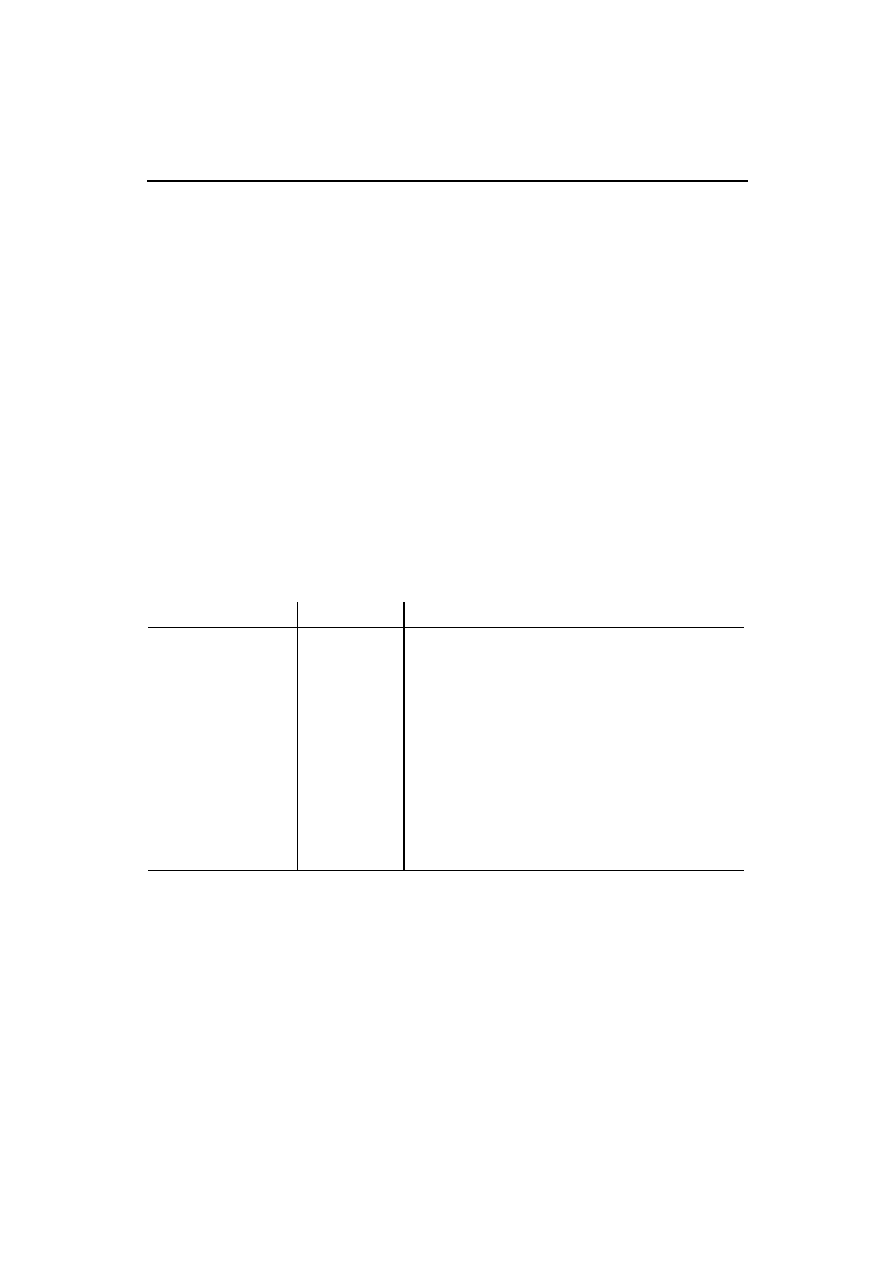
XML Schema
107
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 107
Określanie elementów
Zagadnienie określania elementów zostało już poruszone przy omawianiu definicji DTD. W sche-
matach określanie elementów okaże się nieco bardziej logiczne. Proces ten dość dokładnie od-
zwierciedla strukturę deklaracji w Javie (plus kilka dodatkowych opcji). Do określania elementów
posłużymy się elementem...
element
:
<element name="[Nazwa elementu]"
type="[Typ elementu]"
[Opcje...]
>
[Nazwa elementu]
określa element w zawężanym dokumencie XML. Jednakże w przeci-
wieństwie do definicji DTD, nie powinno być tutaj przedrostka przestrzeni nazw. Czytelnik winien
przypomnieć sobie uwagi na temat docelowej przestrzeni nazw. Zostało tam powiedziane, że prze-
strzenią docelową (ang. target) jest
JavaXML
, a więc specyfikacje wszystkich elementów, a także
typy zdefiniowane przez użytkownika, są kojarzone i przypisywane właśnie tej docelowej prze-
strzeni nazw. To przyczynia się do utworzenia bardziej przejrzystego dokumentu XML Schema,
ponieważ najpierw definiowane są wszystkie elementy, a potem narzuca się przestrzeń nazw.
Konstrukcja
[Typ elementu]
to albo wstępnie zdefiniowany typ danych w schemacie, albo
typ zdefiniowany przez użytkownika. W tabeli 4.4 zestawiono typy danych obsługiwane przez
bieżącą wersję standardu XML Schema.
Tabela 4.4. Typy danych w XML Schema
Typ
Podtypy
Znaczenie
string
NMTOKEN,
language
łańcuchy znaków
boolean
brak
binarna wartość logiczna (prawda lub fałsz)
float
brak
32-bitowy typ zmiennoprzecinkowy
double
brak
64-bitowy typ zmiennoprzecinkowy
decimal
integer
standardowy zapis dziesiętny, dodatni i ujemny
timeInstant
brak
połączenie daty i czasu, wskazujące konkretny moment
w czasie
timeDuration
brak
czas trwania
recurringInstant
date, time
specyficzny czas, powtarzający się przez okres
timeDuration
binary
brak
dane binarne
uri
enumeration
jednolity identyfikator zasobów (URI).
W naszych przykładach wykorzystamy tylko niektóre typy. Widać jednak od razu, że wybór jest
tutaj większy niż w DTD.
Zaczynamy od dołu
Możliwe jest także tworzenie złożonych typów danych, definiowanych przez użytkownika. Typy
takie budowane są z kombinacji elementów. Na przykład można określić, że typ
Ksiazka
składa
się z elementu
Tytul
,
Spis
i
Copyright
(zwróćmy uwagę, że przy opisywaniu elementów nie
jest już podawany przedrostek przestrzeni nazw — w schematach najpierw odczytywana jest tylko
nazwa elementu, dopiero potem definiuje się odpowiednią przestrzeń). Te zaś elementy mogą

108
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 108
znów być typami zdefiniowanymi przez użytkownika, składającymi się z dalszych elementów.
Tak powstaje piramida hierarchii; na jej spodzie znajdują się elementy o podstawowych typach
XML Schema; wyżej — warstwy elementów zdefiniowanych przez użytkownika; na samej górze
— element główny.
Taka struktura wymusza określony sposób działania — najlepiej zaczynać budowanie schematu od
określenia elementów znajdujących się u podstaw tej hierarchii — czyli tych, które można zdefi-
niować jako standardowe typy XML Schema. Sytuacja jest więc tutaj nieco inna niż w definicjach
DTD, gdzie zazwyczaj postępuje się zgodnie z kolejnością elementów w dokumencie XML. Ale
dzięki temu budowanie schematu jest prostsze. Jeśli spojrzymy na nasz dokument XML, to mo-
żemy określić, które elementy stanowią typy „prymitywne” — (patrz tabela 4.5).
Tabela 4.5. Elementy „prymitywne”
Nazwa elementu
Typ
Tytul
string
Naglowek
string
Temat
string
Teraz elementy te można wpisać do schematu (przykład 4.12). Aby budowany schemat nie utracił
przejrzystości, zostaną w nim pominięte deklaracje XML i
DOCTYPE
; znajdą się one w wersji
ostatecznej, ale teraz tylko zmniejszałyby czytelność przykładów.
Przykład 4.12. Schemat z elementami „prymitywnymi”
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
>
<element name="Tytul" type="string" />
<element name="Naglowek" type="string" />
<element name="Temat" type="string" />
</schema>
Zbyt proste? Cóż, to jest proste. Po zdefiniowaniu tych „podstawowych”, czy też „prymitywnych”
elementów możemy przejść do budowania elementów bardziej złożonych.
Typy danych definiowane przez użytkownika
Podobnie jak w przypadku elementów niepodzielnych, elementy bardziej złożone należy budować
także „od dołu” piramidy. Niemal zawsze oznacza to, że programista rozpoczyna tworzenie od ele-
mentów najgłębiej zagnieżdżonych i posuwa się „w górę”, aż do elementu głównego. W naszym
przypadku najbardziej zagnieżdżone są
Naglowek
i
Temat
. Ponieważ elementy te już zostały
określone jako prymitywne, można przenieść się o poziom wyżej — do elementu
Rozdzial
. To
właśnie będzie pierwszy element zdefiniowany przez użytkownika. W definicji musi zostać zawar-
ta informacja, że składa się on z jednego elementu
Naglowek
oraz jednego lub więcej elementów
Temat
. Typy złożone definiujemy za pomocą elementu
complexType
:
<complexType name="[Nazwa typu">
<[Specyfikacja elementu]>
<[Specyfikacja elementu]>

XML Schema
109
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 109
...
</complexType>
Naszemu elementowi przypisujemy nowy typ. Dla elementu
Rozdzial
stworzymy typ
Typ-
Rozdzial
:
<complexType name="TypRozdzial">
...
</complexType>
Powstały w ten sposób typ staje się, oczywiście, częścią docelowej przestrzeni nazw
JavaXML
.
Tak więc aby przypisać ten typ naszemu elementowi
Rozdzial
, użyjemy następującej specyfi-
kacji dokumentu:
<element name="Rozdzial" type="JavaXML:TypRozdzial" />
Teraz, jakąkolwiek strukturę określimy wewnątrz typu
TypRozdzial
, będzie ona zawężała ele-
ment
Rozdzial
. Należy zauważyć, że typ elementu określany jest jako
JavaXML:Typ-
Rozdzial
, a nie po prostu jako
TypRozdzial
. Typ ten był tworzony w ramach docelowej
przestrzeni nazw,
JavaXML
. Jednak elementy, jakie wykorzystujemy w schemacie (
element
,
complexType
itd.), nie mają przedrostka przestrzeni nazw, ponieważ należą do przestrzeni do-
myślnej schematu. Gdybyśmy więc próbowali określić typ jako
TypRozdzial
, parser przeszu-
kałby przestrzeń domyślną (tę odnoszącą się do schematu), a nie znajdując tam naszego elementu,
zgłosiłby wyjątek. Aby parser „wiedział”, gdzie szukać definicji typu, należy wskazać poprawną
przestrzeń nazw — w tym przypadku
JavaXML
.
Ogólną strukturę Czytelnik już zna, pora zająć się szczegółami. W przypadku tego elementu trzeba
zdefiniować w schemacie dwa elementy, które są w tym typie zagnieżdżane. Ponieważ już zostały
określone dwa zagnieżdżane elementy (prymitywne
Naglowek
i
Temat
), należy się do nich do-
wołać w nowym typie:
<complexType name="TypRozdzial">
<element ref="JavaXML:Naglowek" />
<element ref="JavaXML:Temat" />
</complexType>
Atrybut
ref
informuje parser XML, że definicja danego elementu znajduje się w innej części
schematu. Tak jak przy określaniu typu i tutaj również trzeba wskazać parserowi przestrzeń nazw,
w jakiej znajdują się elementy (zazwyczaj jest to przestrzeń docelowa). Ale można tutaj dopatrzyć
się pewnej nadmiarowości i „przegadania”. Dwa elementy definiujemy jako prymitywy, a potem
się do nich odwołujemy — to daje cztery linijki. Elementy te jednak nie są wykorzystywane nig-
dzie indziej w naszym dokumencie, a więc czy nie logiczniej byłoby zdefiniować element od razu
wewnątrz typu? Nie trzeba byłoby wtedy odwoływać się do elementu i wymuszać na czytających
nasz schemat przeszukiwanie dokumentu w celu odnalezienia elementu wykorzystanego tylko raz.
Tak można zrobić. Specyfikacja elementu może zostać zagnieżdżona w typie zdefiniowanym przez
użytkownika, a więc nieco przerobimy teraz nasz schemat — tak, aby był bardziej czytelny:
<element name="Tytul" type="string" />
<element name="Rozdzial" type="JavaXML:TypRozdzial" />
<complexType name="TypRodzial">
<element name="Naglowek" type="string" />
<element name="Temat" type="string" />
</complexType>
Oprócz usunięcia niepotrzebnych wierszy, pozbyliśmy się także niepotrzebnych odwołań do prze-
strzeni nazw
JavaXML
. To na pewno zwiększy czytelność, szczególnie wśród odbiorców nie

110
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 110
mających doświadczenia w pracy z XML-em. Znając sposób tworzenia typów definiowanych przez
użytkownika, możemy teraz określić pozostałe elementy, tak jak w przykładzie 4.13.
Przykład 4.13.
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/"
>
<element name="Ksiazka" type="JavaXML:TypKsiazka" />
<complexType name="TypKsiazka">
<element name="Tytul" type="string" />
<element name="Spis" type="JavaXML:TypSpis" />
<element name="Copyright" type="string" />
</complexType>
<complexType name="TypSpis">
<element name="Rozdzial" type="JavaXML:TypRozdzial" />
<element name="PodzialSekcji" type="string" />
</complexType>
<complexType name="TypRozdzial">
<element name="Naglowek" type="string">
<element name="Temat" type="string">
</complexType>
</schema>
Dzięki temu każdy użyty element XML zostanie zdefiniowany, a schemat będzie czytelny. Nie
znaczy to jednak, że wszystkie problemy zostały rozwiązane.
Typy niejawne i pusta zawartość
Do tej pory korzystaliśmy wyłącznie z typów nazwanych, często określanych mianem jawnych. Typ
jawny to taki, w którym podano nazwę typu; element wykorzystujący ten typ zazwyczaj znajduje się
w innym miejscu pliku. To bardzo obiektowe podejście — ten sam typ jawny może być zastosowany
dla różnych elementów. Jednakże istnieją sytuacje, kiedy taka struktura jest rozwiązaniem na wyrost;
innymi słowy, typ jest tak specyficzny względem elementu, że jego nazywanie nie jest potrzebne.
W naszym przykładzie definicję elementu
Rozdzial
moglibyśmy skonsolidować poprzez zdefinio-
wanie typu w samej definicji elementu. Służą do tego typy niejawne, zwane także nienazwanymi:
<complexType name="TypSpis">
<element name="Rozdzial">
<complexType>
<element name="Naglowek" type="string" />
<element name="Temat" type="string" />
</complexType>
</element>
<element name="PodzialSekcji" type="string" />
</complexType>
Zastosowanie typu niejawnego powoduje, że schemat jest jeszcze bardziej czytelny. Jednakże żaden
inny element nie może być tego samego typu, co zdefiniowany w ten sposób typ niejawny — chyba
że zdefiniowano kolejny typ niejawny. Innymi słowy, typów niejawnych używamy tylko wtedy,
gdy jesteśmy zupełnie pewni, że typ ten nie będzie wykorzystywany przez wiele elementów.

XML Schema
111
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 111
Typy niejawne mogą także służyć do podawania informacji o definiowanych elementach. Na przy-
kład, do tej pory definiowaliśmy element
PodzialSekcji
jako
string
. Faktycznie nie jest to
określenie zbyt precyzyjne, ponieważ element ten ma być pusty. Aby określić element jako pusty,
użyjemy typu niejawnego:
<element name="PodzialSekcji">
<complexType content="empty" />
</element>
To może wydawać się dziwne — dlaczego nie można po prostu przypisać temu elementowi „pus-
tego” (ang. empty) typu danych? Czy twórcy specyfikacji XML Schema coś przeoczyli? Wręcz
przeciwnie — we wcześniejszych wersjach specyfikacji istniał typ danych empty, ale go usunięto.
Zrobiono tak, aby wymóc definicje typu elementu. Aby to zrozumieć, zauważmy, że większość
pustych elementów może przyjmować atrybuty do określania danych:
<img src="obrazki/takiGif.gif" />
<komentarz tekst="A tu komentarz" />
W takich przypadkach określenie elementu jako
empty
nie pozwoliłoby na intuicyjne określenie,
jakie atrybuty są w nim dozwolone. Sprawa jest natomiast prosta, jeśli użyjemy typu elementu:
<element name="img">
<complexType content="empty">
<attribute name="src" type="string" />
</complexType>
</element>
Sposoby definiowania atrybutów zostaną omówione dalej. Tymczasem warto pamiętać, że typy
niejawne pomagają budować schemat w sposób bardziej intuicyjny oraz umożliwiają definiowanie
właściwości elementu — np. tego, że jest pusty.
Ile?
Oprócz powyższych, w definicji elementu należy określić rodzaj rekurencji (lub zdefiniować jej
brak). Schemat zachowuje się tutaj podobnie jak DTD — jeśli elementu nie opatrzono modyfikato-
rami, może pojawić się tylko raz. Jak już wcześniej wspomniano, nie zawsze akurat tak musi być.
Nasza książka może mieć wiele rozdziałów, ale może nie mieć podziału sekcji; niektóre rozdziały
mogą mieć nagłówki, a inne nie. Musimy umieć zdefiniować te wszystkie szczegóły w naszym sche-
macie. Podobnie jak w definicji DTD, służy do tego odpowiedni mechanizm. Ale w przeciwieństwie
do DTD stworzono intuicyjny zestaw atrybutów (zamiast nieco zagadkowych operatorów rekurencji
typu
?
,
+
czy
*
). W XML Schema wykorzystuje się atrybuty
minOccurs
i
maxOccurs
:
<element name="[Nazwa elementu]"
type="[Typ elementu]"
minOccurs="[Ile razy najmniej może się pojawić]"
maxOccurs="[Ile razy najwięcej może się pojawić]"
>
Jeśli atrybuty te nie zostaną określone, przyjmują domyślną wartość 1 — czyli jeden dozwolony
element na definicję. Jeśli maksymalna wartość nie jest określona, wykorzystuje się symbol wielo-
znaczny. Konstrukcje te pozwalają w prosty sposób narzucić zawężenia związane z rekurencją
(przykład 4.14).
Przykład 4.14. Schemat XML z definicjami elementów
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"

112
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 112
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<element name="Ksiazka" type="JavaXML:TypKsiazka" />
<complexType name="TypKsiazka">
<element name="Tytul" type="string" />
<element name="Spis" type="JavaXML:TypSpis" />
<element name="Copyright" type="string" />
</complexType>
<complexType name="TypSpis">
<element name="Rozdzial" maxOccurs="*">
<complexType>
<element name="Naglowek" type="string" minOccurs="0" />
<element name="Temat" maxOccurs="*">
</complexType>
</element>
<element name="PodzialSekcji" minOccurs="0" maxOccurs="*">
<complexType content="empty" />
</element>
</complexType>
</schema>
Zdefiniowaliśmy jeden element główny,
Ksiazka
, typu
TypKsiazka
. Element ten zawiera trzy
bezpośrednio potomne elementy:
Tytul
,
Spis
i
Copyright
. Z tych trzech dwa są prymityw-
nymi łańcuchami XML, a trzeci (
Spis
) to kolejny typ zdefiniowany przez użytkownika,
Typ-
Spis
. Typ ten zawiera z kolei element potomny
Rozdzial
, który może pojawić się raz lub
więcej razy, oraz element potomny
PodzialSekcji
, który wcale nie musi się pojawić. Element
Rozdzial
zawiera dwa elementy zagnieżdżone,
Naglowek
i
Temat
. Każdy z nich jest prymi-
tywnym łańcuchem XML;
Naglowek
może pojawić się zero lub więcej razy, a
Temat
jeden lub
więcej razy. Element
PodzialSekcji
może wystąpić zero lub więcej razy i jest elementem pu-
stym. Teraz w schemacie zdefiniowane są już wszystkie elementy — pozostaje dodać atrybuty.
Definiowanie atrybutów
Proces definiowania atrybutów jest o wiele prostszy od definiowania elementów, przede wszy-
stkim dlatego, że nie trzeba zwracać uwagi na tyle spraw, co w przypadku elementów. Domyślnie
atrybut nie musi występować, a zagnieżdżanie w ogóle atrybutów nie dotyczy. Choć istnieje wiele
zaawansowanych konstrukcji, których można użyć do zawężania atrybutów, my przyjrzymy się
tylko tym podstawowym, koniecznym do zawężenia omawianego dokumentu XML. W razie po-
trzeby zastosowania tych trudniejszych konstrukcji Czytelnik powinien zajrzeć do specyfikacji
XML Schema.
Czego brakuje?
Przy zawężaniu atrybutów na potrzeby dokumentu XML wchodzą w grę pewne pominięcia; wszy-
stkie mają związek z różnymi definicjami przestrzeni nazw opisywanego dokumentu. Dokument
XML, jak to już było powiedziane, musi zawierać definicje przestrzeni nazw w odniesieniu do
schematu oraz definicje przestrzeni nazw „na własne potrzeby” — tj. odnoszące się do jego zawartości.
Definicje te tworzy się za pomocą atrybutu
xmlns:[PrzestrzenNazw]
elementu głównego.
Atrybuty te nie powinny być definiowane w schemacie. Próba zdefiniowania każdej dozwolonej prze-
strzeni nazw dałaby bardzo zagmatwany schemat. Położenie deklaracji przestrzeni nazw nie musi
być stałe; można ją przemieszczać, o ile tylko pozostaje dostępna dla wszystkich odpowiednich
elementów. Dlatego w schemacie zezwala się na pominięcie definicji atrybutów przestrzeni nazw.

XML Schema
113
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 113
Pora przypomnieć sobie wiadomości dotyczące definicji DTD. Aby zezwolić na deklaracje prze-
strzeni nazw w dokumencie XML, trzeba było wstawić taką definicję atrybutu jak poniżej:
<!ATTLIST JavaXML:Ksiazka
xmlns:JavaXML CDATA #REQUIRED
>
Aby można było korzystać z DTD, wystarczyło określić przestrzeń nazw w danym dokumencie
XML, bo definicje DTD nie posiadają „świadomości” istnienia przestrzeni nazw w XML. W sche-
matach XML Schema sprawa jest trochę bardziej skomplikowana.
Czytelnik wie już, że istnieją trzy różne atrybuty służące do określenia schematu dla dokumentu:
<?xml version="1.0"?>
<ksiazkaAdresowa xmlns:xsi="http://www.w3.org/1999/XMLSchema/instance"
xmlns="http://www.oreilly.com/catalog/javaxml/"
xsi:schemaLocation="http://www.oreilly.com/catalog/javaxml/
mySchema.xsd"
Gdyby Czytelnik miał napisać schemat w oparciu o poznane dotąd wiadomości o DTD, prawdopo-
dobnie zadeklarowałby, że
xmlns:xsi
,
xmlns
i
xsi:schema-Location
to poprawne atrybu-
ty elementu głównego. Jednakże deklaracje te można pominąć, ponieważ schematy są „świadome”
istnienia przestrzeni nazw i wystarczająco „inteligentne”, żeby nie wymagać wstawiania takich
deklaracji w zawężanym dokumencie XML.
Definicja
Atrybuty definiuje się za pomocą elementu XML Schema
attribute
(ciekawe, prawda?). In-
nymi słowy, oprócz elementu
element
, w schematach zdefiniowany jest element
attribute
,
za pomocą którego określa się atrybuty dozwolone dla bieżącej definicji elementu lub typu. Oto
format tego elementu:
<attribute nazwa="[Nazwa atrybutu]"
typ="[Typ atrybutu]"
[Opcje atrybutu]
>
Format ten jest podobny do definicji elementów — właściwie jest niemal identyczny. Przy defi-
niowaniu atrybutów dostępne są te same typy danych, co przy definiowaniu elementów. Oznacza
to, że dodanie atrybutów do naszego schematu nie będzie przedstawiało trudności. Dla każdego
elementu posiadającego zdefiniowany typ dodamy wymagane atrybuty wewnątrz definicji tego
typu. W przypadku elementów nie posiadających zdefiniowanego typu musimy typ taki dodać.
W ten sposób „poinformujemy” schemat, że atrybuty, które deklarujemy, „należą” do opisywane-
go typu elementu. W tych nowych typach elementów można określić typ zawartości za pomocą
atrybutu
content
elementu
complexType
— zachowując oryginalne zawężenia i dodając de-
finicje atrybutów. Po tych zmianach uzyskamy schemat taki jak w przykładzie 4.15.
Przykład 4.15. Schemat XML z definicjami atrybutów
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<element name="Ksiazka" type="JavaXML:TypKsiazka" />
<complexType name="TypKsiazka">
<element name="Tytul" type="string" />

114
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 114
<element name="Spis" type="JavaXML:TypSpis" />
<element name="Copyright" type="string" />
</complexType>
<complexType name="TypSpis">
<element name="Rozdzial" maxOccurs="*">
<complexType>
<element name="Naglowek" type="string" minOccurs="0" />
<element name="Temat" maxOccurs="*">
<complexType content="string">
<attribute name="podRozdzialy" type="integer" />
</complexType>
</element>
<attribute name="tematyka" type="string" />
</complexType>
</element>
<element name="PodzialSekcji" minOccurs="0" maxOccurs="*">
<complexType content="empty" />
</element>
</complexType>
</schema>
Po przyjrzeniu się elementowi
Temat
Czytelnik z pewnością zauważy, że na potrzeby zdefinio-
wania atrybutu
podRozdzialy
konieczne jest stworzenie nowego typu. Wewnątrz tego typu, za
pomocą atrybutu
content
, wymagamy, aby atrybut był typu
integer
. Z tego samego mecha-
nizmu korzystaliśmy wcześniej, przy przypisywaniu elementowi
PodzialSekcji
typu
empty
— w ten sposób zapewnialiśmy, że element ten pozostanie pusty. Pozostałe dodane atrybuty nie
wymagają już tak wielu modyfikacji, bo odpowiednie typy dla złożonych elementów już istniały.
Atrybuty wymagane, wartości domyślne i wyliczenia
Pozostaje już tylko „dostroić” definicje atrybutów. W definicjach DTD, w celu określenia, czy
atrybuty mają się pojawić oraz czy posiadają wartości domyślne (jeśli ich nie podano), używa-
liśmy słów kluczowych
#IMPLIED
,
#FIXED
i
#REQUIRED
. Podobnie jak w przypadku opera-
torów rekurencji w elementach, w schematach zdefiniowano prostszy sposób zapisu tego samego.
Jeśli atrybut jest wymagany, wykorzystuje się ten sam atrybut
minOccurs
, który używany był
przy definiowaniu elementów, przypisując mu wartość 1. W naszym przykładzie chcemy zdefi-
niować, że w elemencie
Rozdzial
istnieje atrybut o nazwie
sekcja
. Użyjemy takiego zapisu:
<attribute name="sekcja" type="string" minOccurs="1" />
Jak wspomnieliśmy, domyślnie każdy element wymagany jest w jednym egzemplarzu (domyślna
wartość
minOccurs
to 1). Atrybuty natomiast nie są wymagane (
minOccurs
ma wartość do-
myślną 0).
W XML Schema nie istnieje pojęcie wartości stałej atrybutów (
#FIXED
); jak to zostało powie-
dziane wcześniej, wartość ta jest wykorzystywana rzadko i nie stanowi zapisu „intuicyjnego”.
Przydaje się za to możliwość określenia wartości domyślnej i służy do tego atrybut
default
. Na
przykład, aby określić domyślną wartość atrybutu
tematyka
elementu
Rozdzial
jako „Java”,
skorzystamy z zapisu:
<attribute nazwa="tematyka" type="string" default="Java" />
Mam nadzieję, że Czytelnik zdążył już polubić prostotę XML Schema! Jest to standard bardziej
intuicyjny i przez to prostszy niż DTD. Kolejnym dowodem na to są wyliczenia.

XML Schema
115
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 115
Dla atrybutu
tematyka
określiliśmy za pomocą DTD tylko dwie możliwe wartości:
Java
i
XML
.
Skorzystaliśmy z operatora LUB (OR):
<!ATTLIST JavaXML:Rozdzial
tematyka (XML|Java) "Java"
>
Nie jest to może zapis trudny, ale nie jest też najbardziej intuicyjny. Dozwolone wartości nie są
nawet umieszczane w cudzysłowach — a to jest właśnie de facto standard reprezentacji wartości.
W XML Schema, aby uzyskać to samo, trzeba napisać więcej — ale za to zrozumienie zapisu jest
o wiele prostsze. Należy otworzyć definicję atrybutu, po czym skorzystać z elementu
simpleType
.
Element ten umożliwia zawężenie istniejącego typu danych (np.
string
) do podanych wartości.
W tym przypadku zależy nam na podaniu dwóch wartości (wyliczenia) i każdą z nich określimy za
pomocą elementu
enumeration
. Typ bazowy elementu określimy za pomocą słowa kluczowe-
go
base
. Zmieńmy więc definicję atrybutu
tematyka
:
<attribute name="tematyka" default="Java">
<simpleType base="string">
<enumeration value="XML" />
<enumeration value="Java" />
</simpleType>
</attribute>
Tak, tekstu jest więcej niż w przypadku bliźniaczej konstrukcji w DTD, a jednak powyższy zapis
jest prostszy w zrozumieniu, szczególnie dla nowych użytkowników standardu XML. Po wprowa-
dzeniu tej zmiany nasz schemat jest już gotowy; zawarto w nim wszystkie zawężenia, które są
zamieszczone w stworzonej wcześniej definicji DTD. Spójrzmy na przykład 4.16.
Przykład 4.16. Gotowy dokument XML Schema
<?xml version="1.0"?>
<schema targetNamespace="http://www.oreilly.com/catalog/javaxml/"
xmlns="http://www.w3.org/1999/XMLSchema"
xmlns:JavaXML="http://www.oreilly.com/catalog/javaxml/">
<element name="Ksiazka" type="JavaXML:TypKsiazka" />
<complexType name="TypKsiazka">
<element name="Tytul" type="string" />
<element name="Spis" type="JavaXML:TypSpis" />
<element name="Copyright" type="string" />
</complexType>
<complexType name="TypSpis">
<element name="Rozdzial" maxOccurs="*">
<complexType>
<element name="Naglowek" type="string" minOccurs="0" />
<element name="Temat" maxOccurs="*">
<complexType content="string">
<attribute name="podRozdzialy" type="integer" />
</complexType>
</element>
<attribute name="tematyka" default="Java">
<simpleType base="string">
<enumeration value="XML" />
<enumeration value="Java" />
</simpleType>
</attribute>
</complexType>

116
Rozdział 4. Zawężanie danych XML
C:\WINDOWS\Pulpit\Szymon\Java i XML\04-08.doc — strona 116
</element>
<element name="PodzialSekcji" minOccurs="0" maxOccurs="*">
<complexType content="empty" />
</element>
</complexType>
</schema>
Co dalej?
W niniejszym rozdziale Czytelnik poznał dwa sposoby zawężania dokumentów XML: zawężanie
z wykorzystaniem definicji DTD oraz sposób nowszy — zawężanie z wykorzystaniem XML Sche-
ma. Czytelnik zapewne dostrzegł już, jak ważne jest zawężanie dokumentów, szczególnie jeśli ma-
ją one być wykorzystane przez aplikacje. Jeśli aplikacja nie rozpoznaje typu informacji zawartych
w dokumencie, manipulacja i przetwarzanie takich danych stają się o wiele trudniejsze. W na-
stępnym rozdziale zostaną omówione klasy interfejsu SAX. Czytelnik dowie się, jak z programu
w Javie uzyskać dostęp do definicji DTD oraz schematów. Do parsera dodamy przykładowy pro-
gram, który zbudowaliśmy w rozdziale 3. — będzie on odczytywał zawężenia dokumentu i zwracał
błędy, jeśli dokument XML nie będzie poprawny; będzie również wykorzystywał odwołania wste-
czne dostępne w procesie sprawdzania poprawności składni.
Wyszukiwarka
Podobne podstrony:
2011 04 08 pytania odpowiedziid Nieznany (2)
2009 04 08 POZ 06id 26791 ppt
711[04] Z2 04 Wykonywanie konse Nieznany (2)
04 08 Lowiectwo cw7
AG 04 id 52754 Nieznany
08 2HBZ25RJBN6D4ITZUMZK4SZDSTJD Nieznany
04 Frytkiid 5022 Nieznany (2)
43 04 id 38675 Nieznany
04 pHid 5134 Nieznany (2)
umowy cywilnoprawne 25.04.08, Administracja UKSW Ist, umowy cywilnoprawne w administracji
04 klimarczykid 5049 Nieznany (2)
535 0a56c Art 10 orto 04 08 czamara
F 04 08 Release Notes
INF2 2009 Wykl 04 Zaoczne 4na1 Nieznany
04 Halasid 5030 Nieznany (2)
matma dyskretna 04 id 287940 Nieznany
311[10] Z1 04 Opracowywanie prz Nieznany
04 08 belki i ramy zadanie 08id 4924
04 08 Lowiectwo cw1
więcej podobnych podstron