
Metodologia a
statystyka

Zmienna losowa
Zmienne które mierzymy w badaniach, to zmienne
losowe. Przed wykonaniem pomiaru nie wiemy,
jaka będzie jej wartość, ale prawdopodobieństwo
wylosowania z populacji różnych wartości może
być różne. Prawdopodobieństwo to określone jest
przez rozkład zmiennej w populacji
Populacja: zbór wszystkich elementów podlegających
badaniu statystycznemu (np. wszystkich ludzi albo
wszystkich wyników pomiaru inteligencji testem
Wechslera)
Próba losowa: podzbiór elementów wylosowanych z
populacji

Rozkład zmiennej
Pojęcie rozkładu zmiennej
Prawdopodobieństwo / częstość wystąpienia
poszczególnych wartości zmiennej
Dla zmiennych dwuwartościowych będzie to
prawdopodobieństwo wystąpienia każdej
wartości, np. orzeł i reszka w rzucie monetą
(jeżeli moneta jest „prawdziwa”, to p(o) = p(r) =
0,5), albo proporcja płci w całej populacji
Europejskiej (p(m)=0,48, p(k)=0,52). Są to tzw.
rozkłady dwumianowe.
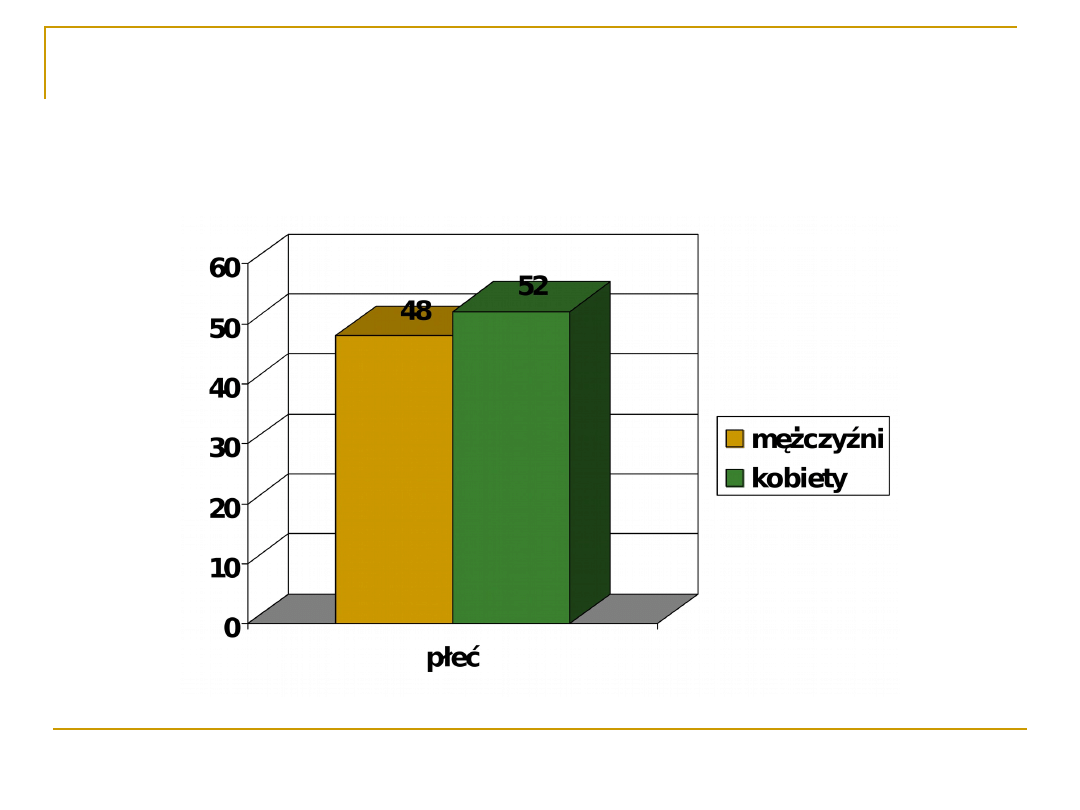
Rozkład płci w populacji
europejskiej

Rozkłady dla zmiennych
wielowartościowych i ciągłych
Wraz ze wzrostem liczby możliwych
wartości zmiennej rozkład zazwyczaj
przestaje mieć charakter liniowy
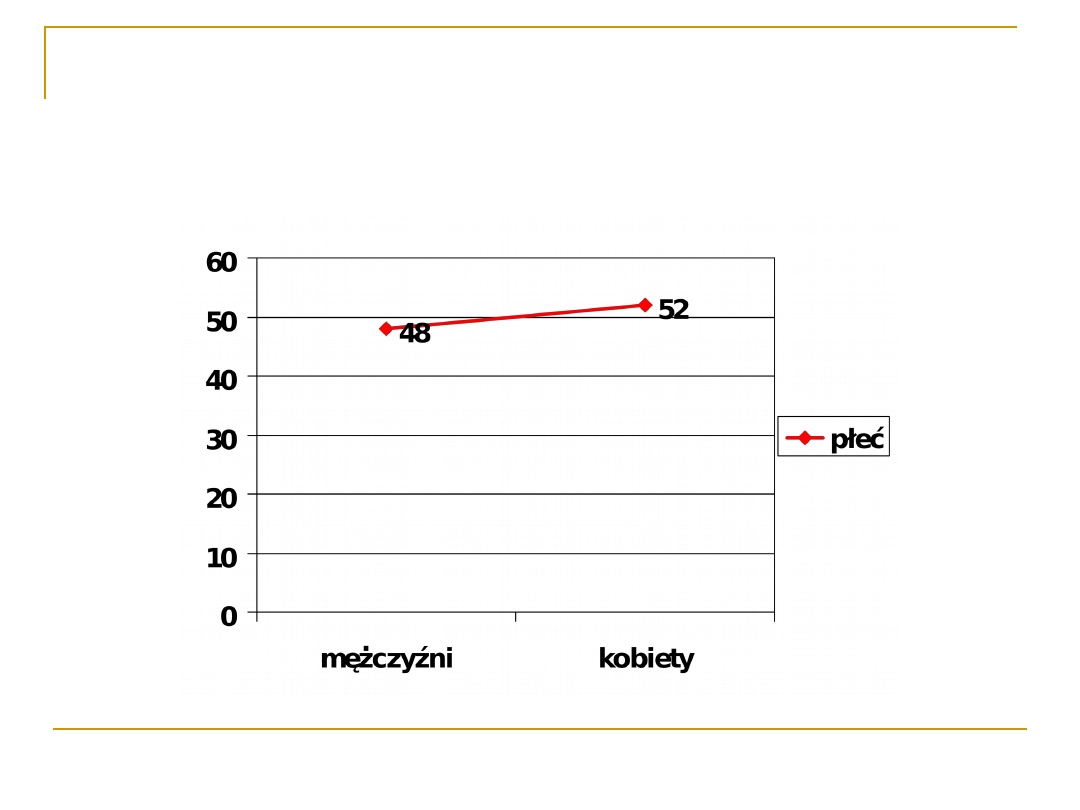
Rozkład płci w populacji
europejskiej
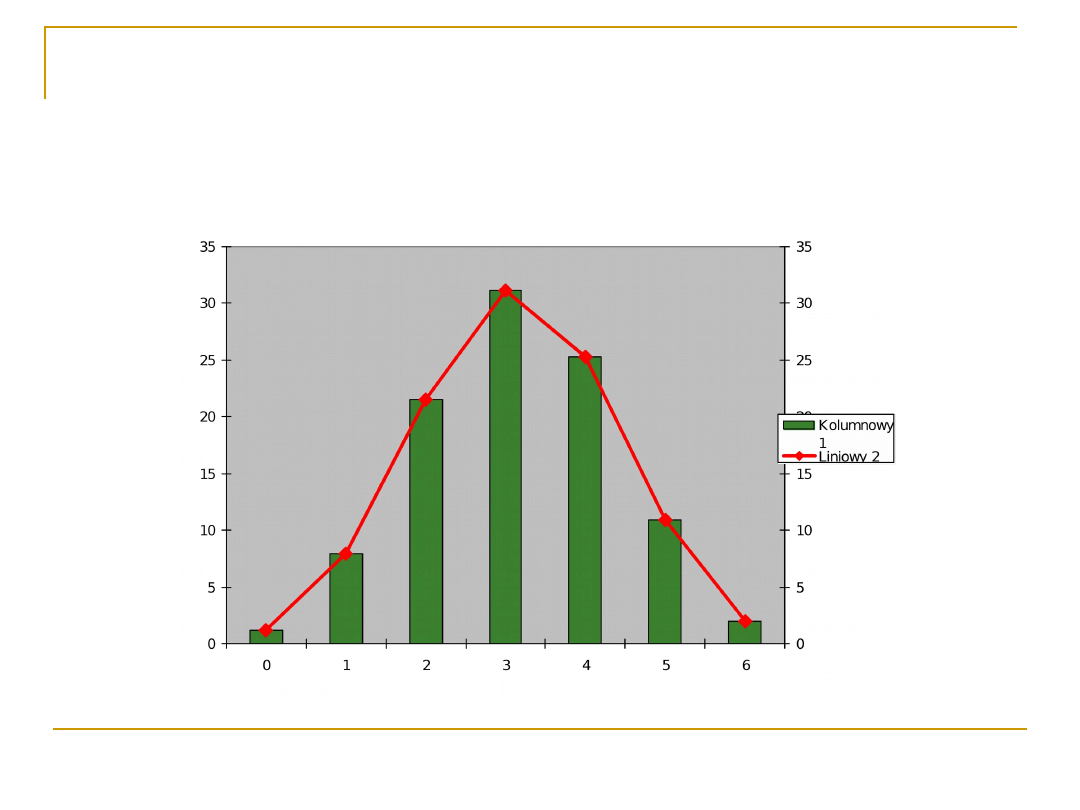
Rozkład liczby dziewcząt w
rodzinach z 6 dzieci

Rozkład normalny
W miarę jak rośnie liczba wartości (np.
wielkość rodziny w której badamy liczbę
córek), rozkład dąży do pewnego
idealnego rozkładu ciągłego. Dla
rozkładów olbrzymiej większości
zmiennych losowych przybliżeniem jest
rozkład normalny, w którym
prawdopodobieństwo odpowiada części
powierzchni pod krzywą Gaussa (krzywą
dzwonową)
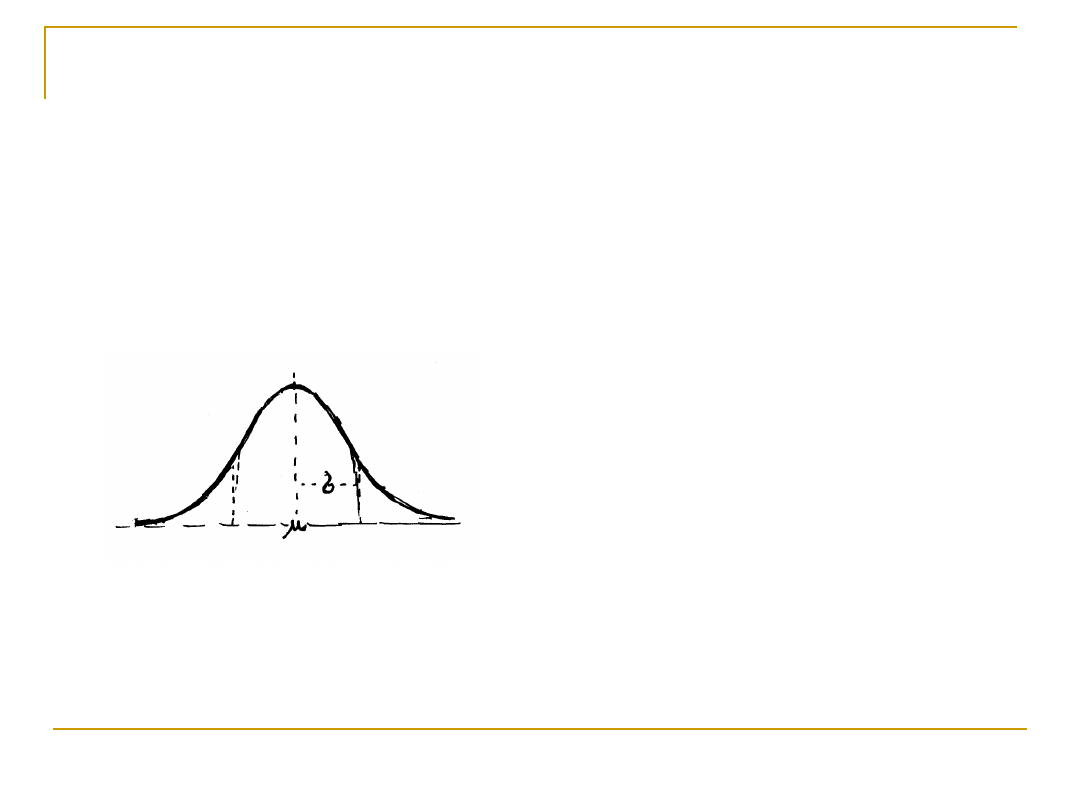
Rozkład normalny II
Rozkład normalny jest
symetryczny, średnia (μ)
jest zarazem modalną i
medianą, a
prawdopodobieństwo
wyznaczane jest przez
odległość od średniej w
jednostkach odchylenia
standardowego (σ), np.
w odległości 2 odchyleń
od średniej mieści się
95,6% wszystkich
przypadków

Najważniejsze parametry
rozkładu
Kształt (ciągły/nieciągły,
symetryczny/niesymetryczny,
jednomodalny/wielomodalny,
płaski/spiczasty)
Miary położenia centralnego: średnia,
mediana, modalna
Miary rozrzutu: wariancja, odchylenie
standardowe

Próba reprezentatywna
To próba, której właściwości (częstości,
średnia, rozrzut wyników itp.) są
dobrym przybliżeniem parametrów
rozkładu w populacji
Np.:
kobiety stanowią ok. 52% próby
średnia wynik w teście inteligencji w próbie
wynosi ok. 100, a odchylenie standardowe
ok. 10

Jak uzyskać próbę
reprezentatywną
Można ją dobrać celowo, ale do tego trzeba
znać parametry rozkładu w populacji, a to jest
spełnione tylko dla nielicznych zmiennych
Można ją wybrać losowo, ponieważ PRAWO
WIELKICH LICZB mówi, że
wraz ze wzrostem
liczebności próby jej właściwości dążą do
parametrów rozkładu w populacji
. Tak więc
dostatecznie duża próba będzie przybliżeniem
rozkładu w populacji
Co to znaczy dostatecznie duża próba?
Jak dobrym przybliżeniem rozkładu w populacji jest
próba?

Duża próba
Brak jednoznacznego kryterium określającego, co to jest
dostatecznie duża próba, ponieważ zależy to
Od właściwości rozkładu w populacji, zwłaszcza rozrzutu
(wariancji). Im większa wariancja, tym większa próba będzie
potrzebna
Od celu badania – czy jest nim dokładne poznanie
parametrów rozkładu w populacji, czy tylko ogólnych
tendencji (np. kierunku różnic w zależności od innej
zmiennej)
Wielkości dopuszczalnego błędu
W badaniach eksperymentalnych często wystarcza próba ok. 24
osób
W sondażach preferencji politycznych (zakładany dopuszczalny
błąd ok. 3%) bada się zwykle próby ok. 1000 osób
Przy normalizacji testów psychologicznych próby mogą liczyć
nawet kilka lub kilkanaście tysięcy osób

Reprezentatywność próby
losowej
Próba losowa prawie nigdy nie będzie dokładnym
obrazem populacji
Prawdopodobieństwo tego, na ile dana właściwość próby
(np. średnia) odpowiada parametrowi rozkładu w
populacji, jest wyznaczane przez
rozkład z próby
, czyli
teoretyczny rozkład nieskończonej liczby losowań próby
o zadanej wielkości (N) z danej populacji. Rozkład z próby
zależy m. in. od wielkości próby i wariancji zmiennej w
populacji
Zgodnie z CENTRALNYM TWIERDZENIEM
GRANICZNYM
wraz ze wzrostem liczebności próby
rozkład z próby dąży do rozkładu normalnego o średniej
równej średniej (proporcji) w populacji i wariancji równej
wariancji w populacji podzielonej przez pierwiastek z
liczebności próby

Konsekwencje Centralnego
Twierdzenia Granicznego
Jeżeli próba jest dostatecznie duża, to
nawet nie znając rozkładu w populacji (i
bez względu na jego kształt) możemy
przybliżyć rozkład z próby i określić
prawdopodobieństwo losowego błędu
oszacowania opartego na tej próbie.
Wykorzystano to w konstrukcji wielu
testów statystycznych.
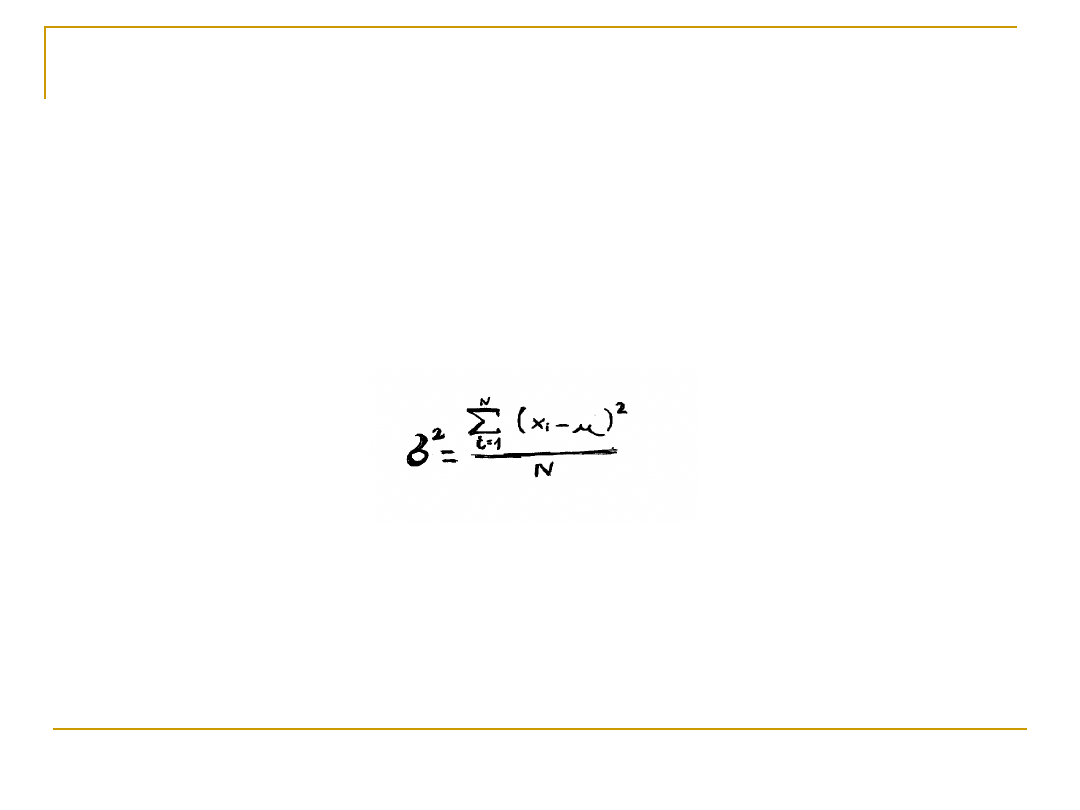
Wariancja
Wariancja jest parametrem rozkładu, który
określa rozrzut wartości zmiennej
Dla zmiennych przedziałowych wariancja
określona jest wzorem
Pierwiastek kwadratowy z wariancji nazywa
się odchyleniem standardowym, które jest
wygodną miarą przeciętnego odchylenia
wartości zmiennej od średniej w populacji

Podział wariancji na składniki
Wartość większości zmiennych wyznaczana jest przez
wiele czynników (dlatego też wiele zmiennych z mocy
Centralnego Twierdzenia Granicznego ma rozkład
normalny), przez co wartości zmiennej są zróżnicowane
(wariancja)
Typowa hipoteza badawcza mówi o tym, że część
wariancji zmiennej można wyjaśnić wariancją jednego
lub kilku wyróżnionych czynników – innych zmiennych
kontrolowanych w badaniu
Celem procedur statystycznych jest oddzielenie wariancji
wyjaśnionej przez inne kontrolowane zmienne (np.
zmienne niezależne) od wariancji powodowanej przez
czynniki niekontrolowane, czyli losowe, czyli od tzw.
wariancji niewyjaśnionej lub wariancji błędu

Podział wariancji, c.d.
W eksperymencie
wariancja wewnątrz grup pochodzi wyłącznie ze źródeł
losowych (niekontrolowanych; wariancja błędu) – o ile
spełniony został warunek randomizacji II
na różnice między grupami składa się przede wszystkim
wariancja wyjaśniona zmienną(-ymi) niezależną(-ymi)
oraz w pewnym (możliwym do oszacowania) stopniu
wariancja błędu
W schematach korelacyjnych obliczany jest zazwyczaj
współczynnik korelacji - miara tego, w jakim stopniu
zmiana wartości jednej zmiennej wiąże się z odpowiednią
zmianą wartości innej zmiennej. Najbardziej typowy
współczynnik korelacji r Pearsona podniesiony do
kwadratu określa proporcję wariancji wspólnej zmiennych
(wariancji wyjaśnionej)

Test statystyczny
Test statystyczny to oszacowanie prawdopodobieństwa, że uzyskany
wynik (np. różnica między grupą eksperymentalną i kontrolną, albo
korelacja między dwoma zmiennymi) powstał w wyniku błędu losowego
Do oszacowania tego prawdopodobieństwa trzeba znać niektóre
parametry rozkładu zmiennej (np. częstość występowania danej
wartości, tak jak w rozkładzie płci, średnią, wariancję i in.). Wariancję
błędu można oszacować na podstawie wariancji w próbie, wtedy jednak
nie można już wykorzystać próby do oszacowania innych parametrów
populacji (oszacowania nie byłyby niezależne - raz popełniony błąd
byłby „dziedziczony” w kolejnych obliczeniach). Zauważmy jednak, że
hipotezy badawcze przewidują istnienie różnic między grupami
eksperymentalnymi lub niezerową korelację między zmiennymi. Jeżeli
założymy, że wartość zmiennej niezależnej nie różnicuje wartości
zmiennej zależnej w populacji (albo, że w populacji nie ma korelacji
między zmiennymi), to ewentualne różnice między grupami (lub
korelacja) w przeprowadzonym badaniu wynikają wyłącznie z błędu
losowego. Jeżeli założenie o braku różnic (korelacji) nazywane hipotezą
zerową jest prawdziwe, to rozkład różnic (korelacji) jest rozkładem z
próby o średniej 0 (z założenia) i wariancji oszacowanej jako wariancja
z próby podzielona przez pierwiastek z N-1 (Centralne Twierdzenie
Graniczne; N –liczebność próby; odejmujemy 1 bo nie mamy pełnego
zaufania do oszacowania). W ten sposób znamy rozkład dla hipotezy
zerowej i możemy określić prawdopodobieństwo tego, że uzyskany
wynik pochodzi z tego rozkładu. Jeżeli prawdopodobieństwo to jest
niewielkie, to odrzucamy hipotezę zerową i tym samym, drogą
wnioskowania nie wprost przyjmujemy hipotezę badawczą

Test statystyczny c.d.
Co to znaczy niewielkie prawdopodobieństwo błędu?
Umowna wartość dopuszczalnego prawdopodobieństwa błędu
określa się jako poziom istotności testu. Najczęściej przyjmowany
jest poziom istotności alfa=0,05, ale zależy to między innymi od
celu badania, np. w badaniach eksploracyjnych lub pilotażowych
można zaakceptować wyższe prawdopodobieństwo błędu (np.
alfa=0,1), podczas gdy niektórych badaniach (np. przy
dopuszczaniu do użytku leków o silnym działaniu) przyjmuje się
bardziej restrykcyjny poziom istotności (np. 0,001)
Wynik, którego prawdopodobieństwo przy założeniu hipotezy
zerowej jest mniejsze od założonego poziomu istotności nazywamy
istotnym statystycznie. Wynik istotny statystycznie upoważnia do
odrzucenia hipotezy zerowej i pośrednio przyjęcia hipotezy
badawczej
Czasem wynik, dla którego prawdopodobieństwo losowego
uzyskania przekracza nieznacznie założony poziom istotności (np.
wynosi 0,08 przy alfa=0,05) nazywamy marginalnie istotnym, lub
istotnym na poziomie tendencji. Taki wynik nie upoważnia do
odrzucenia hipotezy zerowej, ale uzasadnia powtórzenie badania
np. z udziałem większej próby lub z poprawioną procedurą

Moc testu
Test statystyczny pozwala oszacować
prawdopodobieństwo fałszywości hipotezy zerowej, ale nie
jej prawdziwości. Możliwa, a nawet dość prawdopodobna
jest więc sytuacja, że hipoteza zerowa nie zostanie
odrzucona, pomimo że jest fałszywa. Błąd taki nazywamy
błędem drugiego rodzaju (błędem beta).
Prawdopodobieństwo odrzucenia fałszywej hipotezy
zerowej wynosi 1-beta i nazywane jest mocą testu. Mocy
testu nie daje się zwykle dokładnie określić, ale zależy ona
m. in. od:
Wielkości próby
Wariancji w populacji
Siły badanego związku pomiędzy zmiennymi
Różnych właściwości samego testu statystycznego
Sposobu postawienia hipotezy (hipoteza kierunkowa -
przewiduje kierunek zależności)

UWAGA!!!
Brak podstaw do odrzucenia hipotezy zerowej
nie oznacza że jest ona prawdziwa
inaczej:
Wynik nieistotny statystycznie nie upoważnia
do przyjęcia hipotezy zerowej
(choć w metodologii występują różne stanowiska w tej sprawie)
Metody statystyczne nie umożliwiają
testowania hipotez o braku związku jako
hipotez badawczych (można jednak wyznaczać
przedziały ufności dla H0, tzn. przy założonym
poziomie błędu wykazać, że maksymalna siła
efektu w populacji (różnica lub korelacja) nie
przekracza jakiejś (niewielkiej) wartości)

Poziom istotności a siła
badanego efektu
To, że wynik jest istotny statystycznie nie oznacza, że
uzyskany związek między zmiennymi jest silny. Nawet bardzo
słaby związek, jeżeli tylko próba była duża, może okazać się
istotny na bardzo restrykcyjnym poziomie istotności
Aby określić siłę związku trzeba oddzielnej miary. W
przypadku badań korelacyjnych jest nią współczynnik
korelacji, przybierający wartości z przedziału <-1,1>.
Istotność statystyczna współczynnika korelacji r oznacza tyle,
że z prawdopodobieństwem błędu = alfa ro (korelacja w
populacji) <0 jeżeli r<0 lub ro>0 jeżeli r>0, przy czym
istotność r przy założonym alfa (np. alfa=0,05) zależy tylko od
r i od N (wielkości próby). Sam współczynnik korelacji
interpretujemy natomiast jako miarę siły związku. |r|<0,5
uważamy za związek słaby, |r|>0,71 za bardzo silny
(zauważmy, że r
2
określa część wariancji jednej zmiennej
wyjaśnioną drugą zmienną, więc dla r=0,71 lub -0,71 r
2
=0,5,
czyli zmienność jednej zmiennej pozwala wyjaśnić aż połowę
zmienności drugiej zmiennej)

Wybór testu statystycznego
Wybór testu statystycznego zależy od
Jakich właściwości rozkładu dotyczy hipoteza (najczęściej
średniej lub korelacji)
Skali i rozkładu zmiennych
Schematu badania:
niezależne grupy czy powtarzany pomiar
liczby zmiennych i liczby grup/powtarzanych pomiarów
W schematach eksperymentalnych najczęściej używane
są test t-Studenta (różnice średnich), test dokładny
Fishera lub chi
2
gdy zmienna zależna jest wyrażona na
skali nominalnej, analizy wariancji gdy zmienna zależna
mierzona na skali interwałowej, a zmienna niezależna
przybiera więcej niż dwie wartości lub występuje więcej
niż jedna zmienna niezależna. Analiza wariancji pozwala
testować hipotezy o interakcyjnym wpływie zmiennych
niezależnych na zmienną zależną
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
Wyszukiwarka
Podobne podstrony:
prezentacja o metodologii
METODOLOGIA?DAŃ I STATYSTYKA
02 PREZENTACJA DANYCH STATYSTYCZNYCH
Pytania egzaminacyjne - Metodologia - Statystyka - 4, NIEPOSEGREGOWANE
4. Graficzne i tabelaryczne metody prezentacji danych statystycznych, licencjat(1)
Metody Metody prezentacji danych statystycznych, BHP Ula
Pytania egzaminacyjne Metodologia Statystyka 07
Pytania egzaminacyjne - Metodologia - Statystyka - 5, NIEPOSEGREGOWANE
praca semestralna - metody prezentacji danych statystycznych, SPIS TREŚCI
Pytania egzaminacyjne - Metodologia - Statystyka - 2, NIEPOSEGREGOWANE
Prezentacja danych statystycznych
Wyklad 1 Wplyw swiadomosci metodologicznej, Statystyka
Pytania egzaminacyjne Metodologia Statystyka 3
Metody opracowywania i prezentacji danych statystycznych
Praca kontrolna Metodologia?dania statystycznego
prezentacja o metodologii
więcej podobnych podstron