
www.vlsilab.polito.it
www.polito.it
Networks-on-Chip
Sergio Tota and Mario R. Casu
VLSI Laboratory

S. Tota and M.R. Casu
Seminar contents
The Premises
Homogenous and Heterogeneous
Systems-on-Chip and their interconnection
networks
The Network-on-Chip approach
Examples
Our THIN contribution (Sergio’s speech)
Back to the coffee corner…

S. Tota and M.R. Casu
The premises
The System-on-Chip (SoC) today
Heterogeneous ~10 IP’s
Homogeneous (MP-SoC) ~ 10 uP (with exceptions)
On-Chip BUS (AMBA, Core Connect, Wishbone, …)
IP and uP are sold with proprietary Bus IF
Near and long-term forecast
100 IP/uP: Busses are non scalable!
Physical Design issues: signal integrity, power
consumption, timing closure
Clock issues: Is time for the Globally Asynchronous
paradigm? (Still locally synchronous)
Need for “more regular” design
S. Tota and M.R. Casu
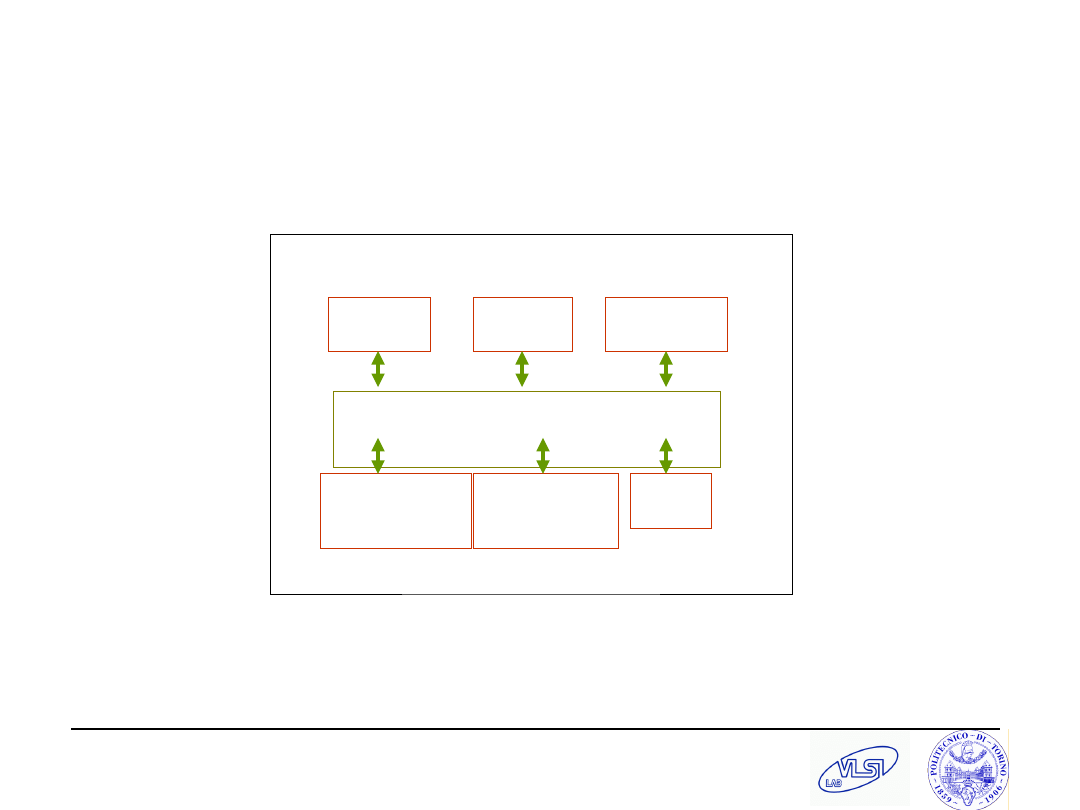
Heterogeneous Today’s SoC
CPU
DSP
MEM
Embedded
FPGA
Dedicated
IP
Interconnection network
(BUS)
I/O
S. Tota and M.R. Casu
Maya (Rabaey’00)
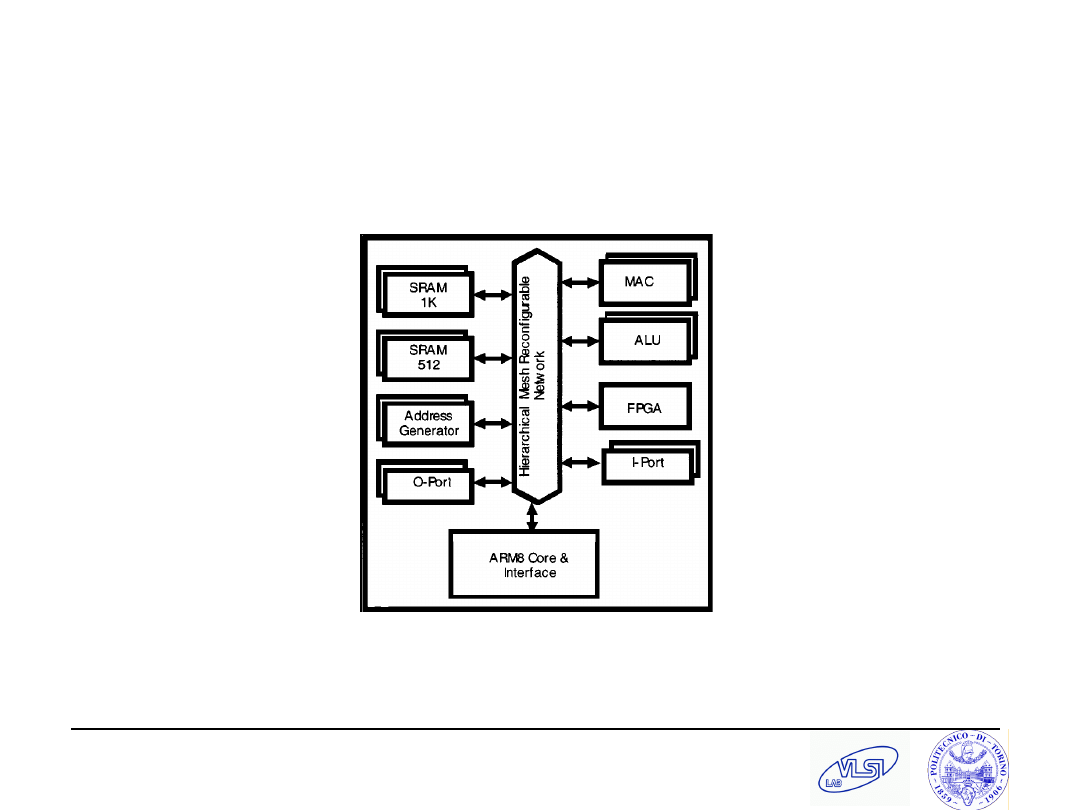
S. Tota and M.R. Casu
Maya (Rabaey’00)
S. Tota and M.R. Casu
Maya (Rabaey’00)
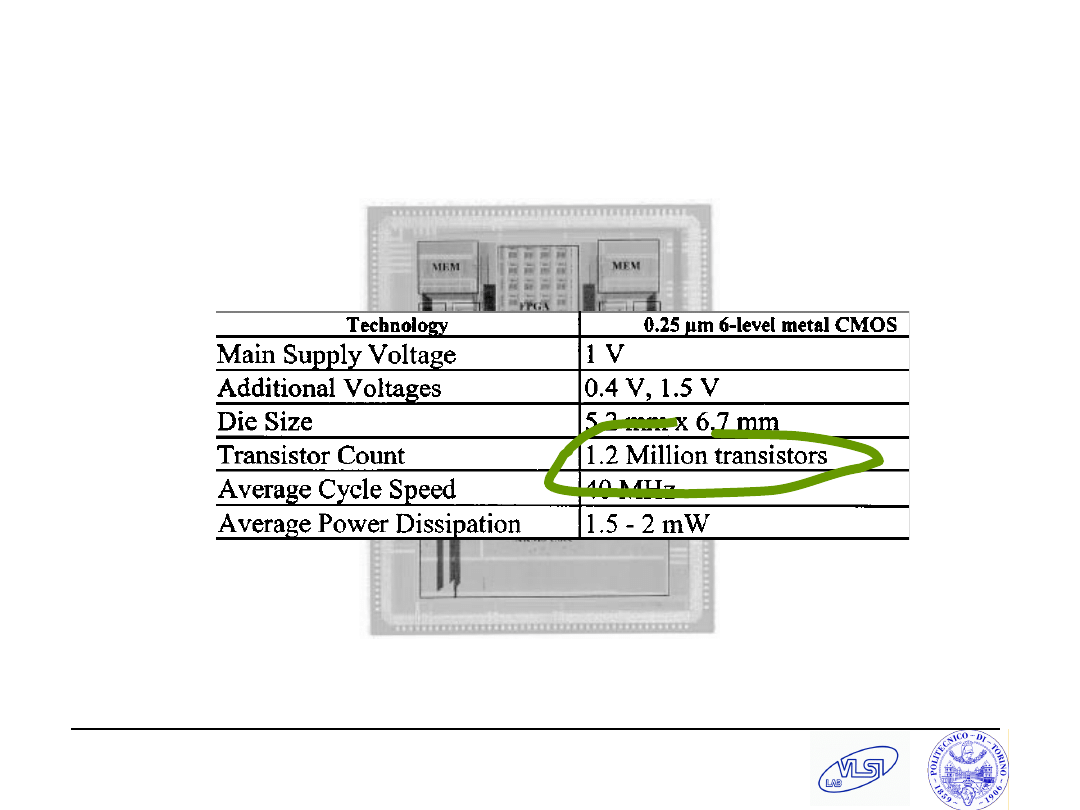
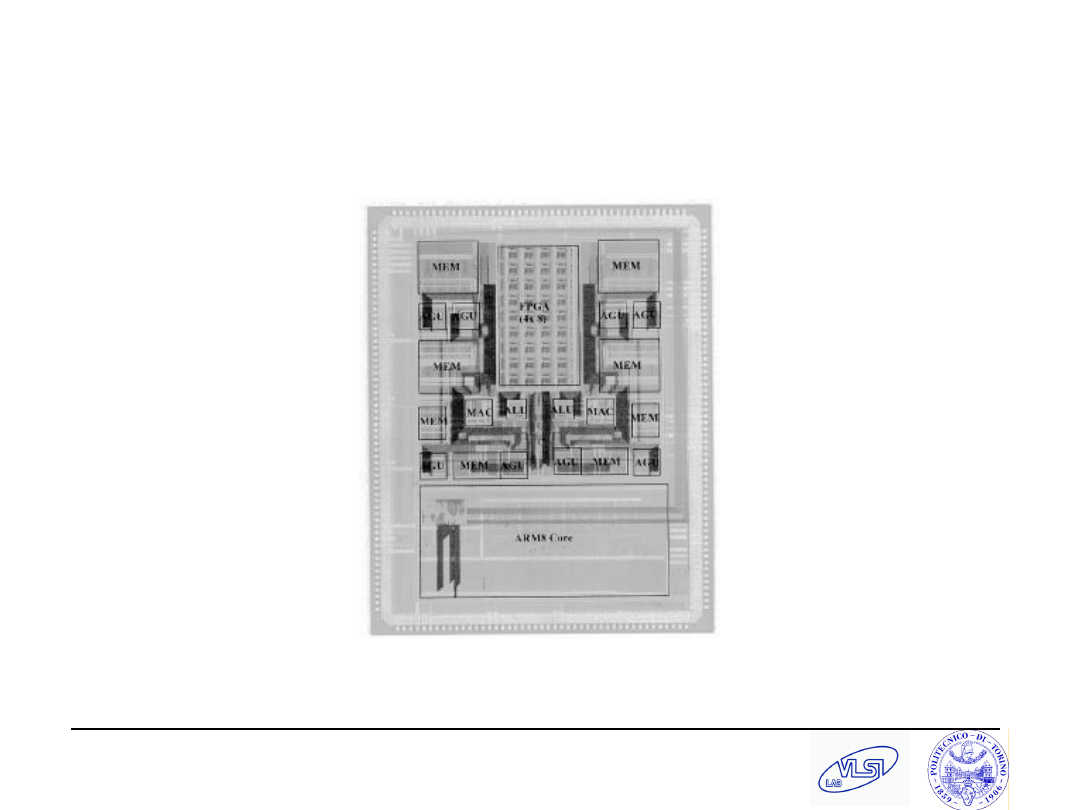
S. Tota and M.R. Casu
Maya (Rabaey’00)
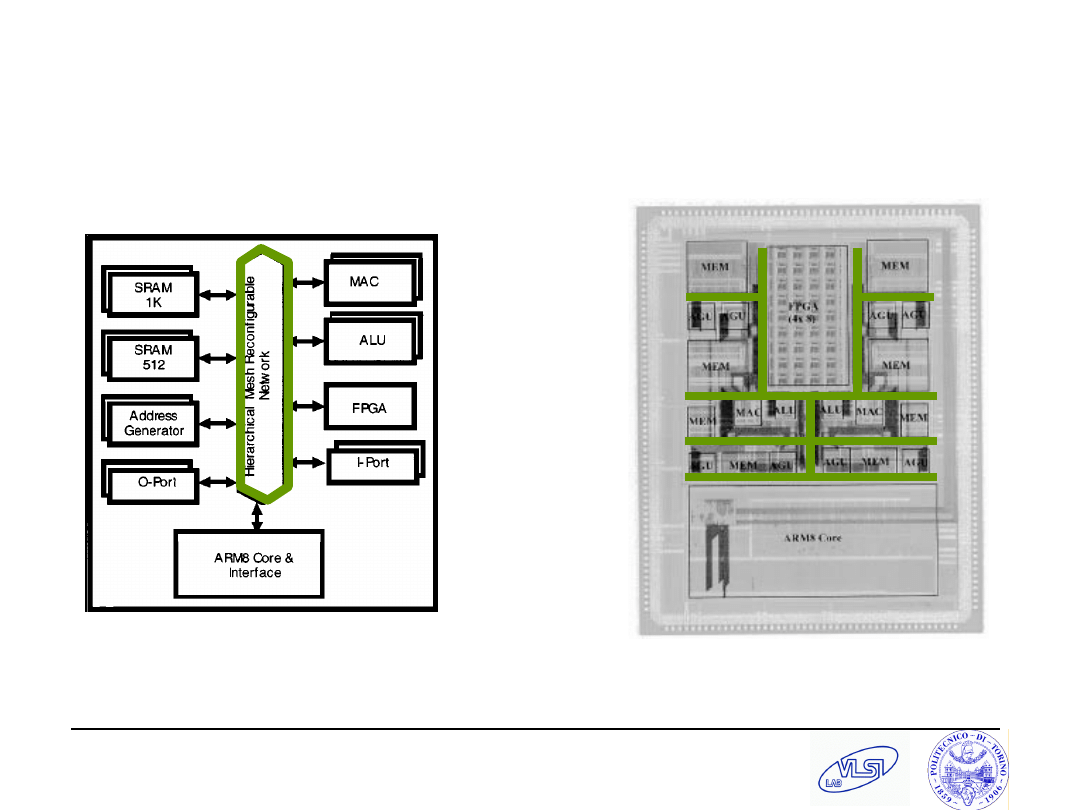
S. Tota and M.R. Casu
Maya (Rabaey’00)
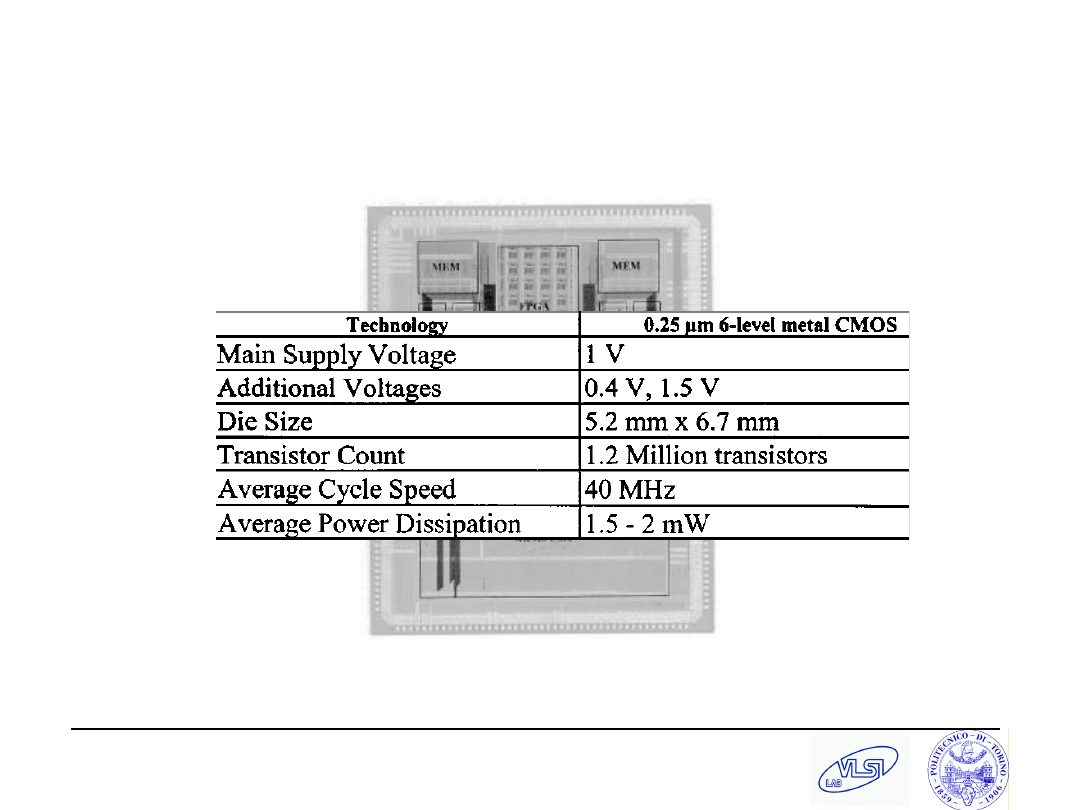
S. Tota and M.R. Casu
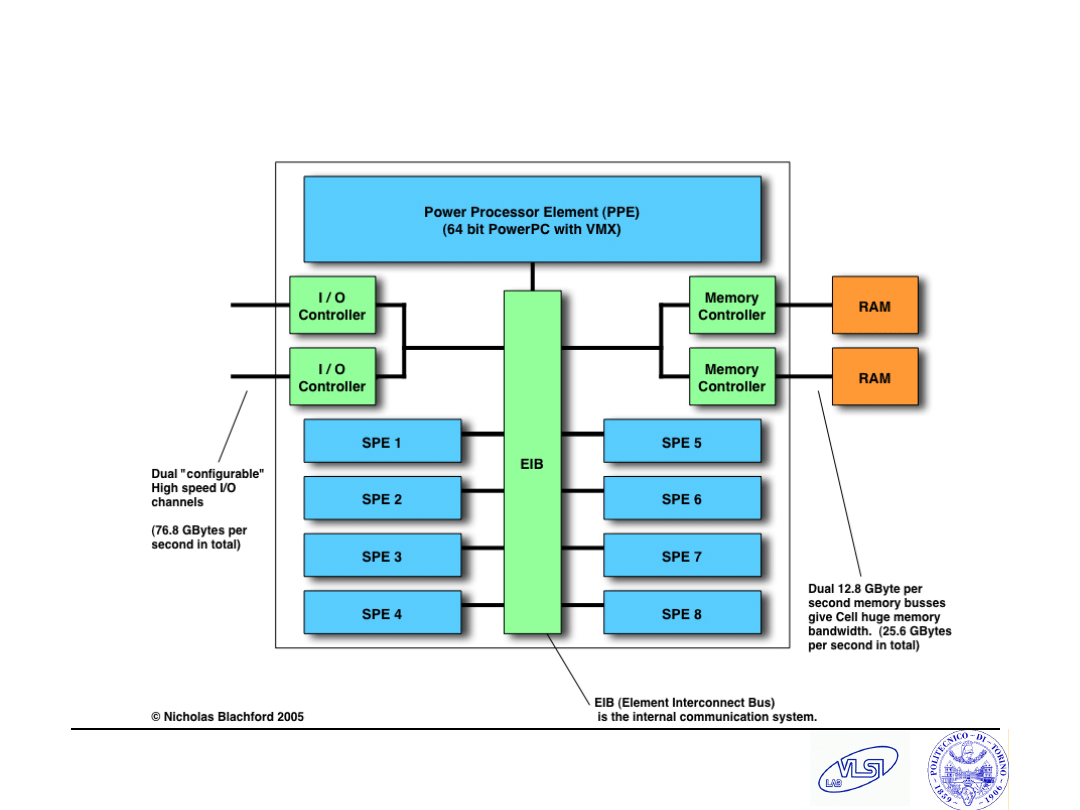
The Cell Processor

S. Tota and M.R. Casu
The Cell Processor
S. Tota and M.R. Casu
The Cell Processor
Fclock > 4 GHz.
Memory bandwidth: 25.6 GBytes per second.
I/O bandwidth: 76.8 GBytes per second.
Performance:
256 GFLOPS (Single precision at 4 GHz).
256 GOPS (Integer at 4 GHz).
25 GFLOPS (Double precision at 4 GHz).
235 square mm.
235 million transistors.
Power consumption estimated at 60 - 80 W @
4GHz

S. Tota and M.R. Casu
Cell’s Element Interconnect
Bus
From the trenches: D. Krolak, IBM
“Well, in the beginning, early in the development
process, several people were pushing for a
crossbar switch
, and the way the bus is
architected, you could actually pull out the EIB and
put in a crossbar switch
if you were willing to
devote more silicon space on the chip to wiring
.
We had to find a balance between connectivity
and area, and there just wasn't enough room to
put a full crossbar switch in. So we came up with
this ring structure which we think is very
interesting.
It fits within the area constraints and
still has very impressive bandwidth
.”
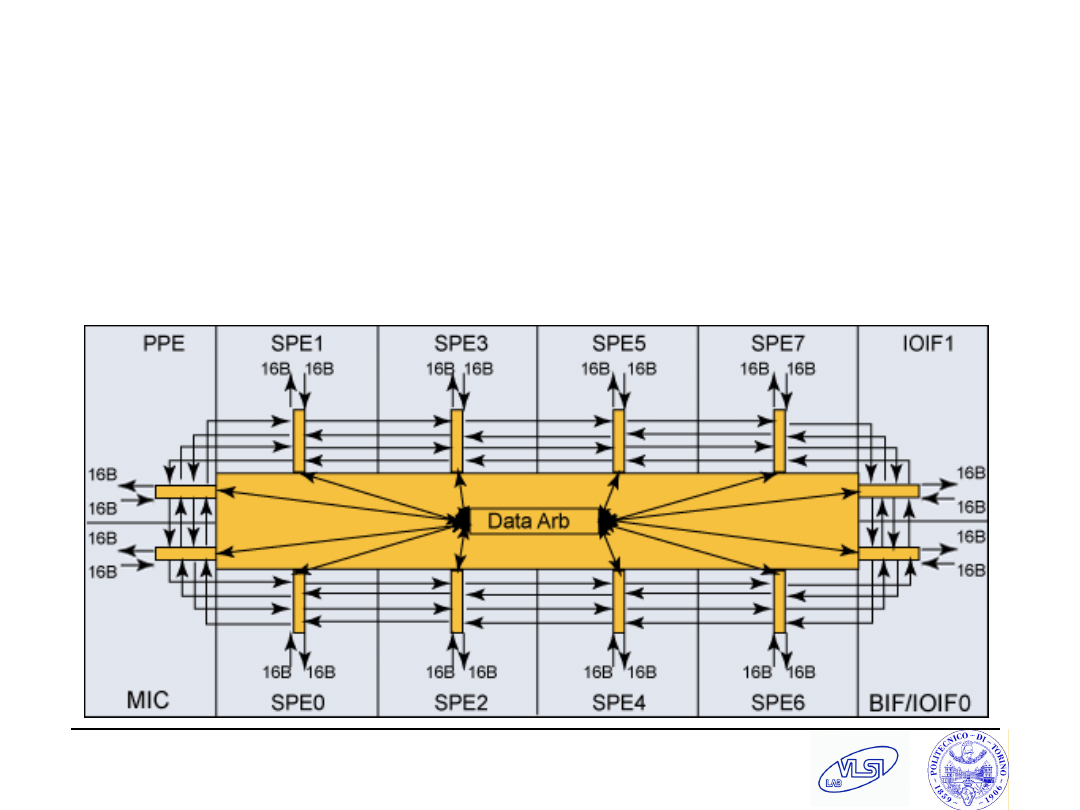
S. Tota and M.R. Casu
Cell’s Element Interconnect
Bus
4 rings (2 ckwise + 2 counter-ckwise)
No token rings, still request/grant
arbitrations
S. Tota and M.R. Casu
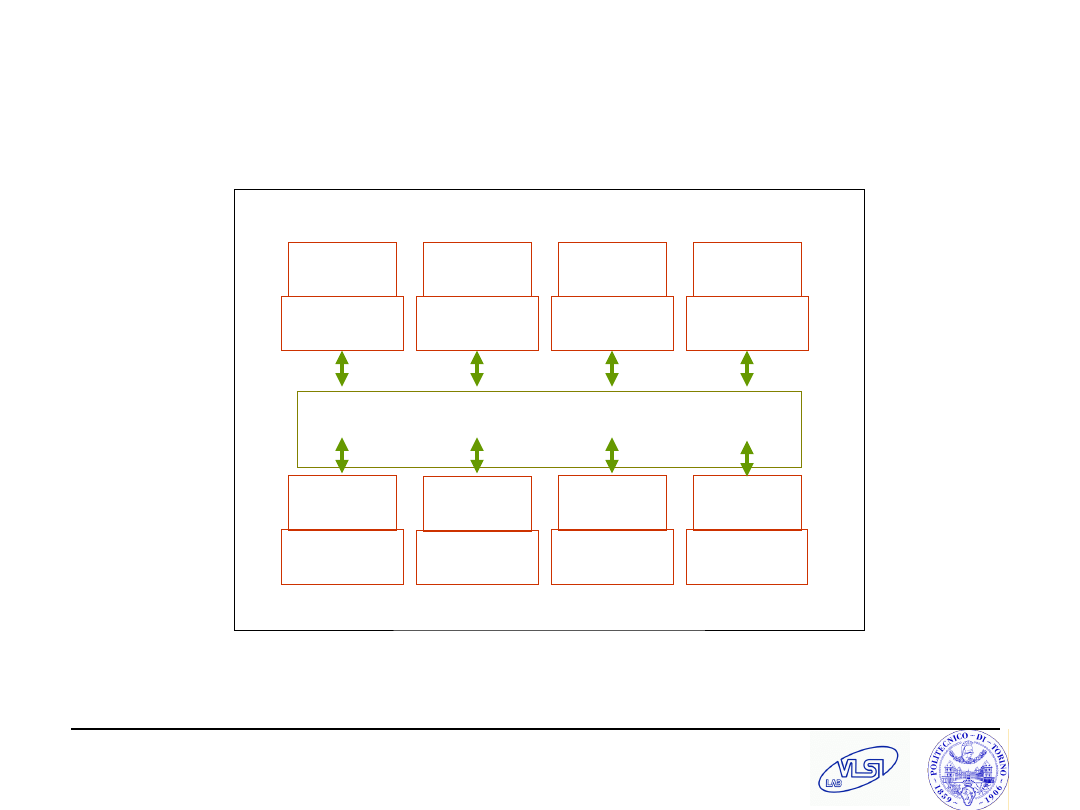
Homogeneous SoC (MP-SoC)
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
CPU
MEM
Interconnection network (BUS,
XBAR)
S. Tota and M.R. Casu
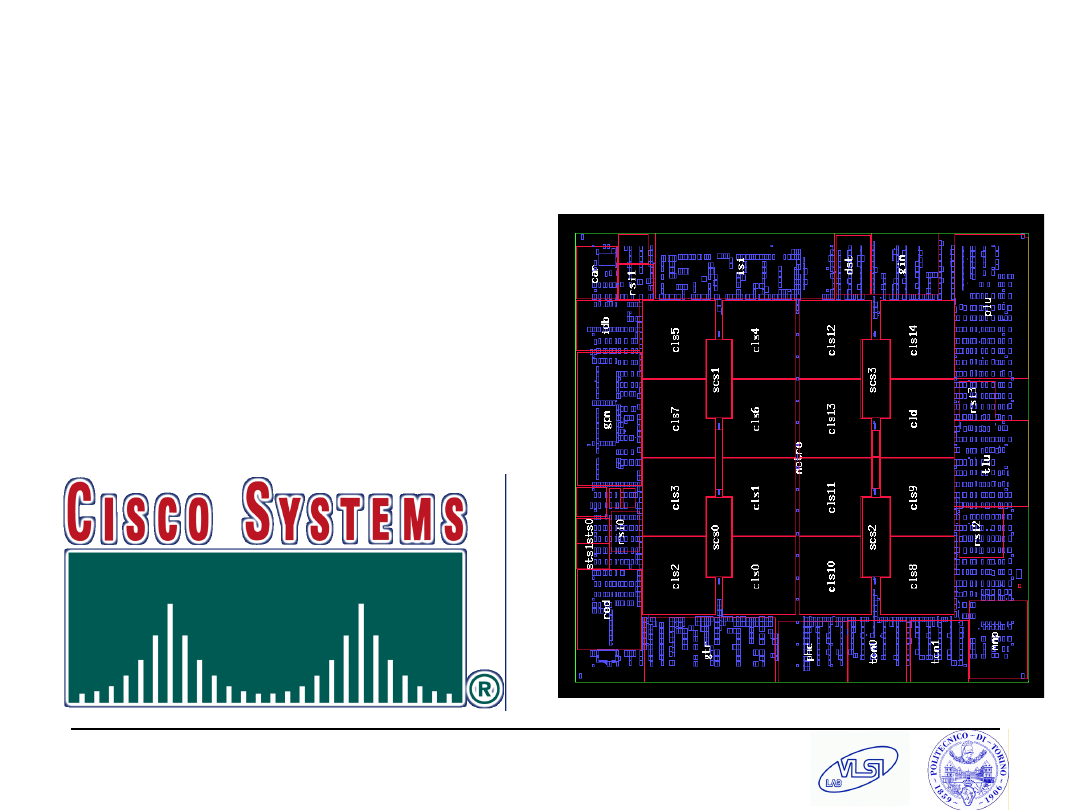
MP-SoC: Cisco CRS-1 Router
CRS-1 Router uses 188
extensible network
processors per “Silicon
Packet Processor” chip
S. Tota and M.R. Casu
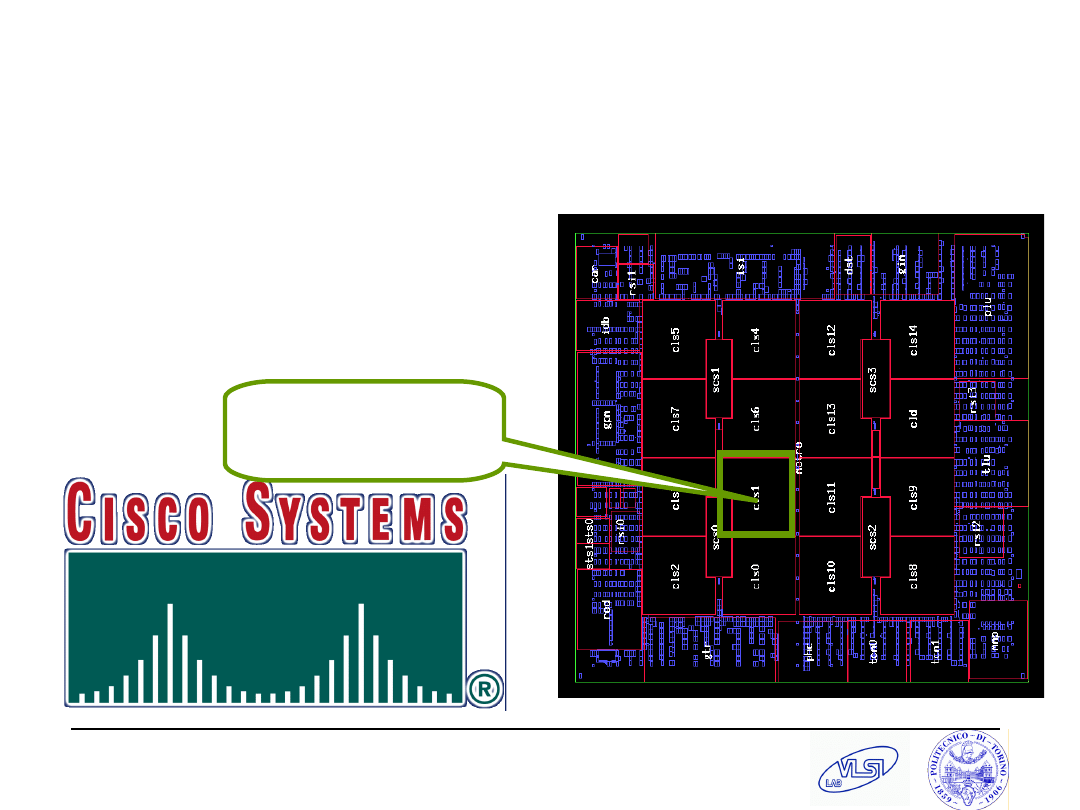
MP-SoC: Cisco CRS-1 Router
CRS-1 Router uses 188
extensible network
processors per “Silicon
Packet Processor” chip
16 PPE Clusters
of 12 PPEs
each
S. Tota and M.R. Casu
Very long wires
1 ns (1 GHz)
0.1 ns (10 GHz)
A
B
A
B
Year 2005
Year 2010

S. Tota and M.R. Casu
Bus pros (
) and cons ()
Every unit attached adds parasitic capacitance,
therefore electrical performance degrades with growth.
Bus timing is difficult in a deep submicron process.
Bus arbiter delay grows with the number of masters.
The arbiter is also instance-specific.
Bandwidth is limited and shared by all units attached.
Bus latency is zero once arbiter has granted control.
The silicon cost of a bus is near zero.
Any bus is almost directly compatible with most
available IPs, including software running on CPUs.
The concepts are simple and well understood.

S. Tota and M.R. Casu
What are NoC’s?
According to
Wikipedia
:
“Network-on-a-chip (NoC) is a new paradigm
for System-on-Chip (SoC) design. NoC
based-systems accommodate multiple
asynchronous clocking that many of today's
complex SoC designs use.
The NoC solution
brings a networking method to on-chip
communications
and claims roughly a
threefold performance increase over
conventional bus systems.”
Imprecise…
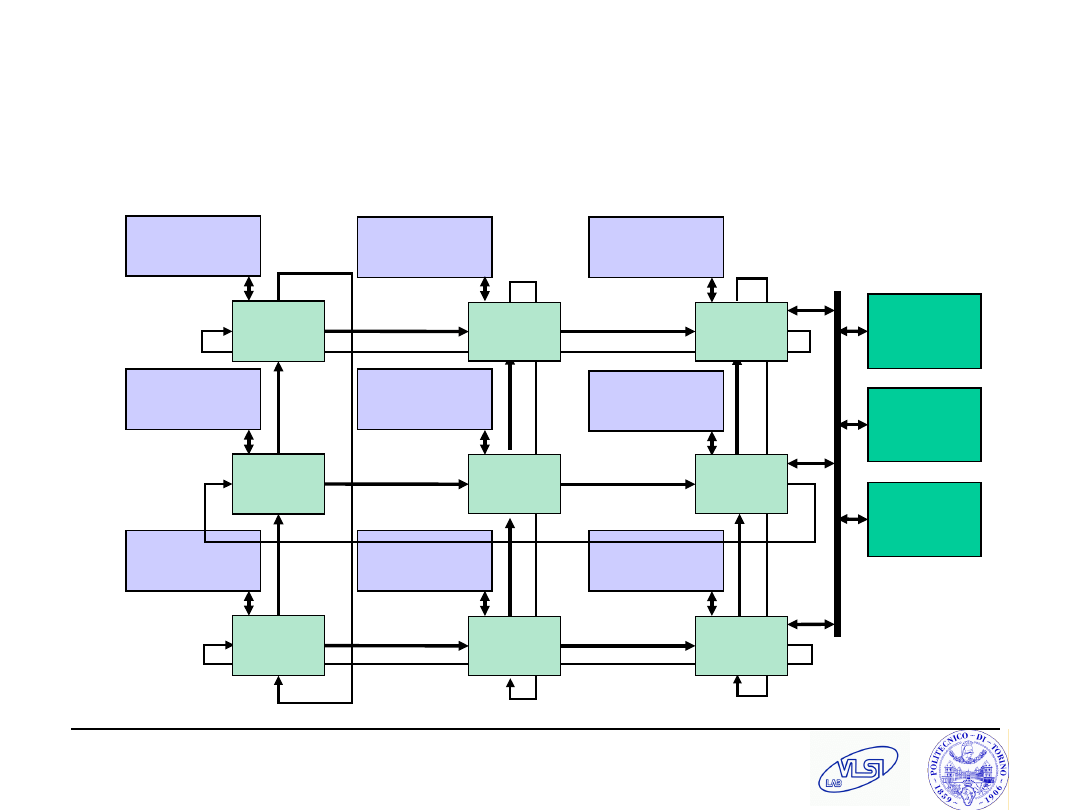
S. Tota and M.R. Casu
Processor
Master
Global
Memory
Slave
Global I/O
Slave
Global I/O
Slave
Processor
Master
Processor
Master
Processor
Master
Processor
Master
Processor
Master
Processor
Master
Processor
Master
Processor
Master
Routing
Node
Routing
Node
Routing
Node
Routing
Node
Routing
Node
Routing
Node
Routing
Node
Routing
Node
Routing
Node
NoC exemplified

S. Tota and M.R. Casu
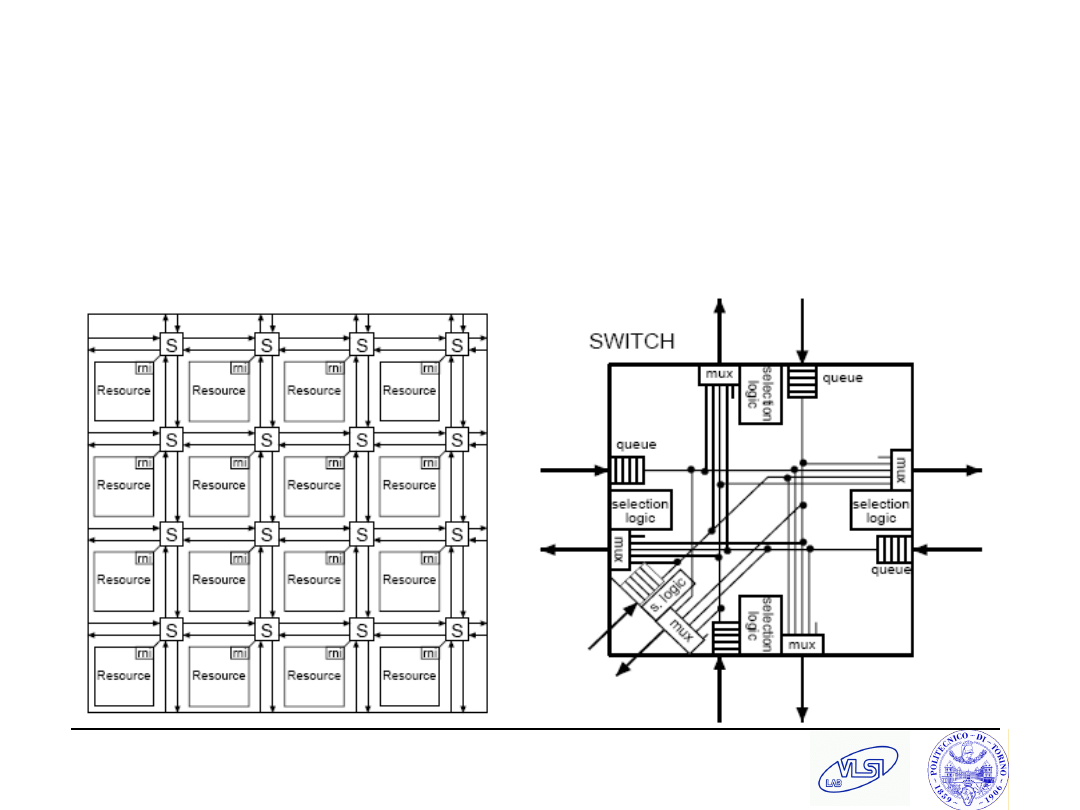
Basic Ingredients of a NoC
N Computational
Resources
Processing Elements (PE)
1 Connection
Topology
1
Routing
technique
M N
Switches
N
Network Interfaces

S. Tota and M.R. Casu
For the Connoisseurs…
1
Addressing
system
1 Switch-level
Arbitration
policy
1 Communication
Protocol
1
Programming
model
Message passing
Shared Memory
Bon appetit!

S. Tota and M.R. Casu
NoC: Good news
Only point-to-point one-way wires are
used, for all network sizes.
Aggregated bandwidth scales with
the network size.
Routing decisions are distributed and
the same router is re-instanciated, for
all network sizes.
NoCs increase the wires utilization
(as opposed to ad-hoc p2p wires)

S. Tota and M.R. Casu
There’s no free lunch…
Internal network contention causes (often
unpredictable) latency.
The network has a significant silicon area.
Bus-oriented IPs need smart wrappers.
Software needs clean synchronization in
multiprocessor systems.
System designers need reeducation for
new concepts.

S. Tota and M.R. Casu
Facts about NoC’s
It is a way to
decouple computation from
communication
The design is
layered
(physical, network,
application…): Taming complexity is made
easier
Communication between processing
elements in NoC takes place by encapsulating
data in
packets
The elementary packet piece to which switch
and routing operations apply is the
flit
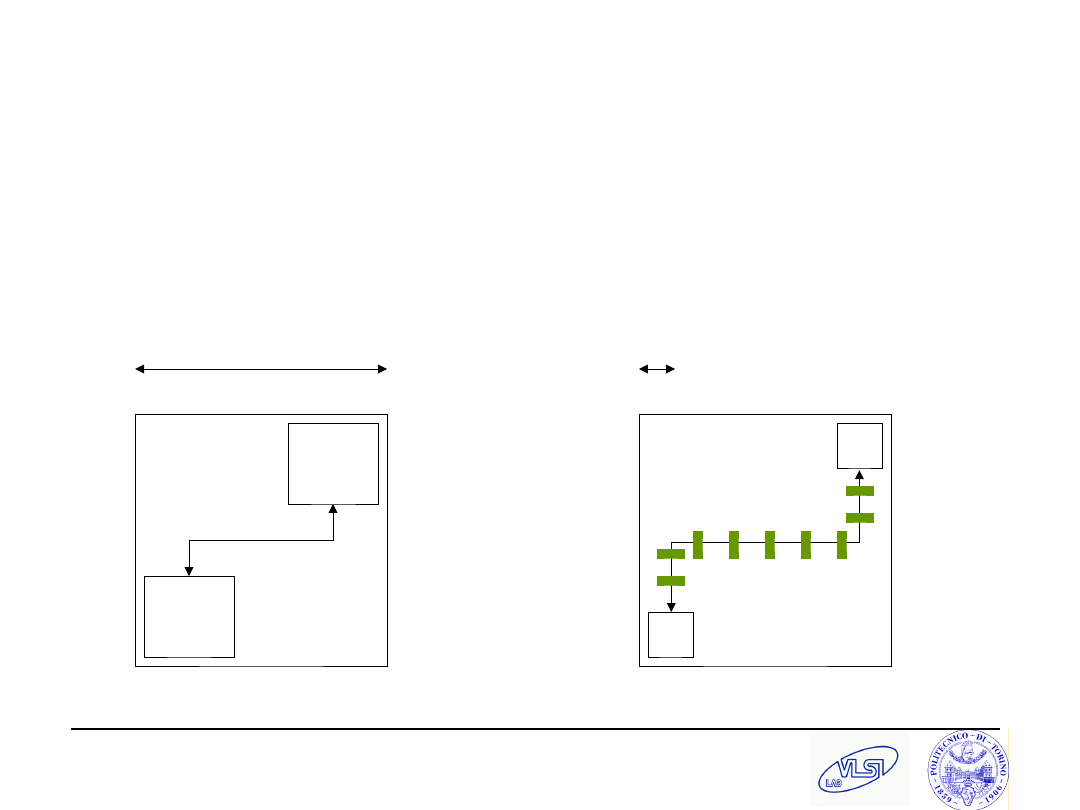
S. Tota and M.R. Casu
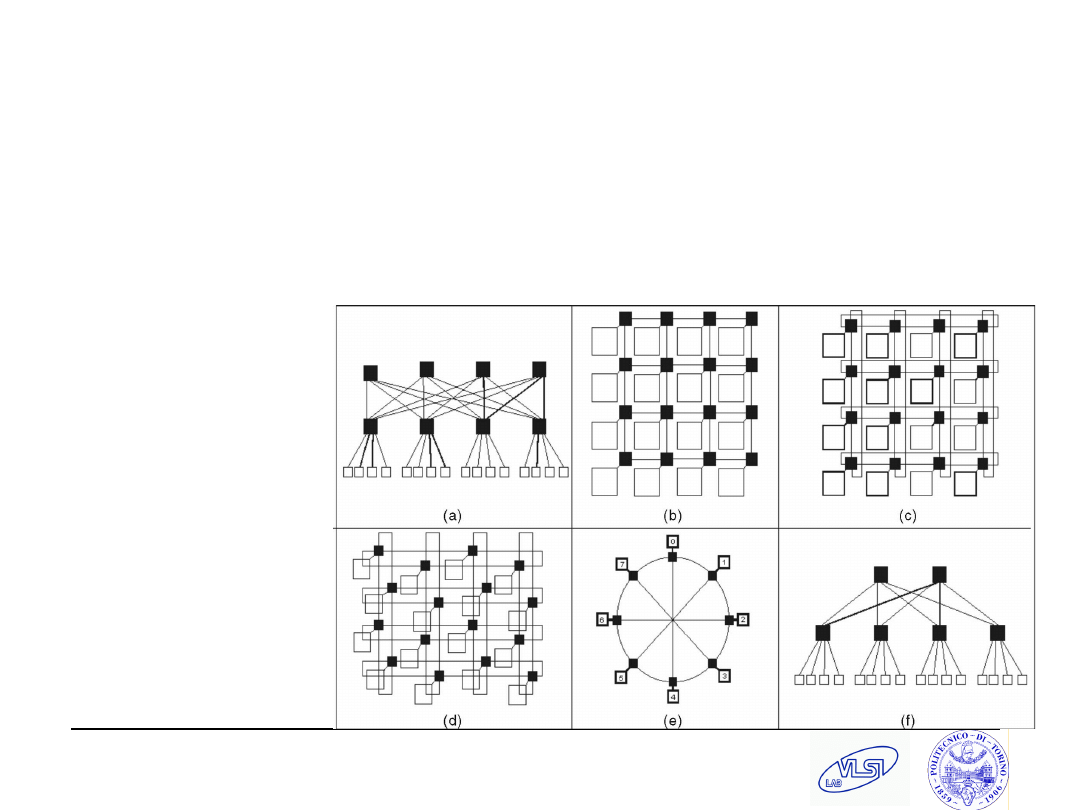
Topologies
Heritage of networks with new constraints
Need to accommodate interconnects in a 2D layout
Cannot route long wires (clock frequency bound)
a)
SPIN,
b)
CLICHE’
c)
Torus
d)
Folded
torus
e)
Octagon
f)
BFT.
S. Tota and M.R. Casu
Topologies
Heritage of networks with new constraints
Need to accommodate interconnects in a 2D layout
Cannot route long wires (clock frequency bound)

S. Tota and M.R. Casu
Switching
Again, techniques inherited from Computer
and Communication Networks
New constraints in silicon:
area and power
Use
as few buffers as possible
Store & Forward and Virtual-Cut-Through
Need buffers size for an entire packet, unsuited!
Limited buffer size in
Wormhole
Deflection Routing
, a.k.a. “Hot Potato”
Virtual channels
Increase buffer size…

S. Tota and M.R. Casu
Routing
Deterministic vs. Adaptive
Simplify/Complicate routing logic
Easy/Uneasy deadlock free
Prone/Robust to congestion
2D dimension order routing (XY)
most used static routing in NoC (e.g.
with Wormhole and Mesh)

S. Tota and M.R. Casu
Who first had the idea?
No clear parenthood. The most referred
papers according to
Google (#cit.)
Guerrier’00 (
204
), A Generic Architecture for
On-Chip Packet-Switched Interconnections
Dally’01 (
392
), Route Packets, Not Wires: On-
Chip Interconnection Networks
Benini’02 (
417
), Networks on Chips: A New SoC
Paradigm
Kumar’02 (
184
), A Network on Chip Architecture
and Design Methodology
S. Tota and M.R. Casu
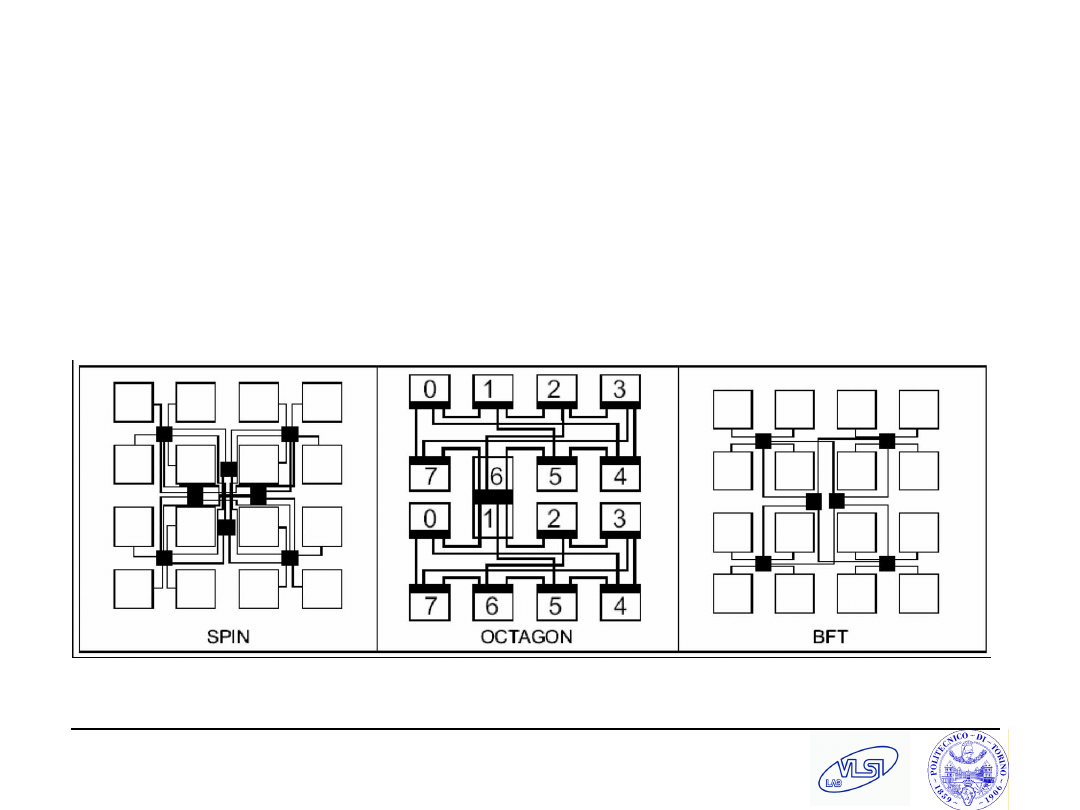
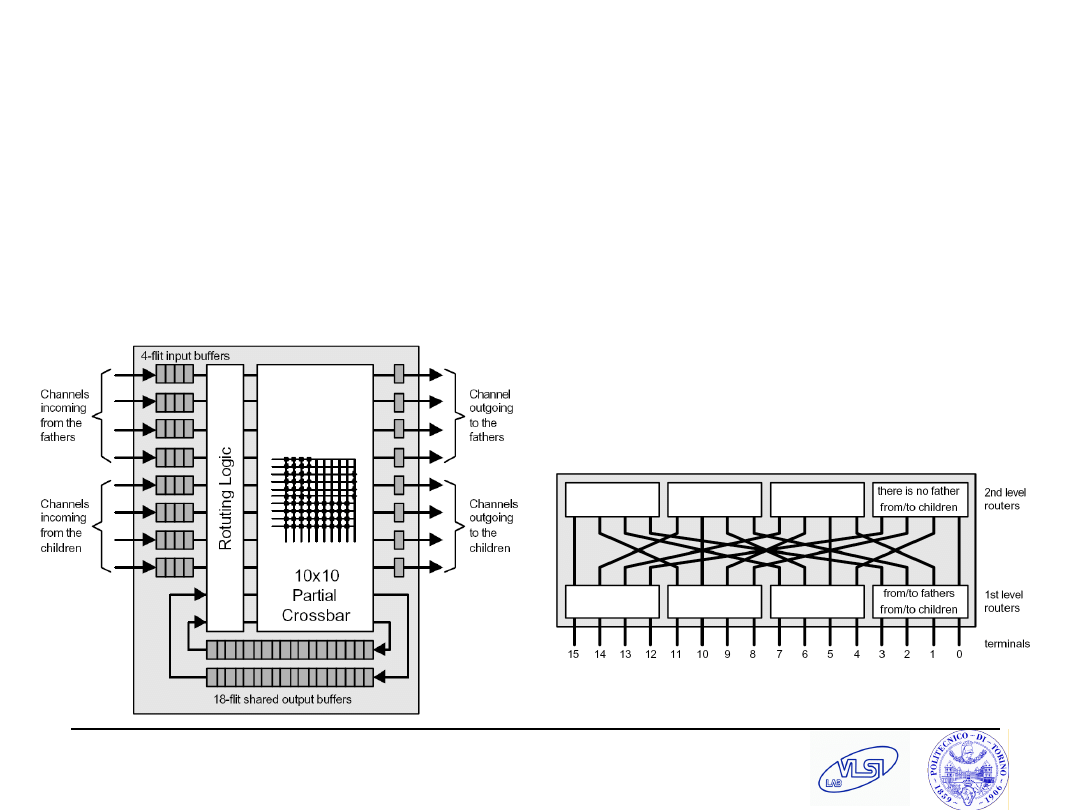
SPIN (Guerrier et al., DATE
’00/’03)
Wormhole switching, adaptive routing and credit-based flow control.
It is based on a fat-tree topology.
A flit is only one word (36 bits, 4 bits are for packet framing).
The input buffers have a depth of 4 words
S. Tota and M.R. Casu
Dally et al., DAC’01
2D folded torus topology
Wormhole routing and Virtual Channels (VC)
S. Tota and M.R. Casu
Kumar et al., ISLVLSI’02
Chip-Level Integration of Communicating Heterogeneous Elements, CLICHÉ’
2D Mesh Topology
Message Passing
S. Tota and M.R. Casu
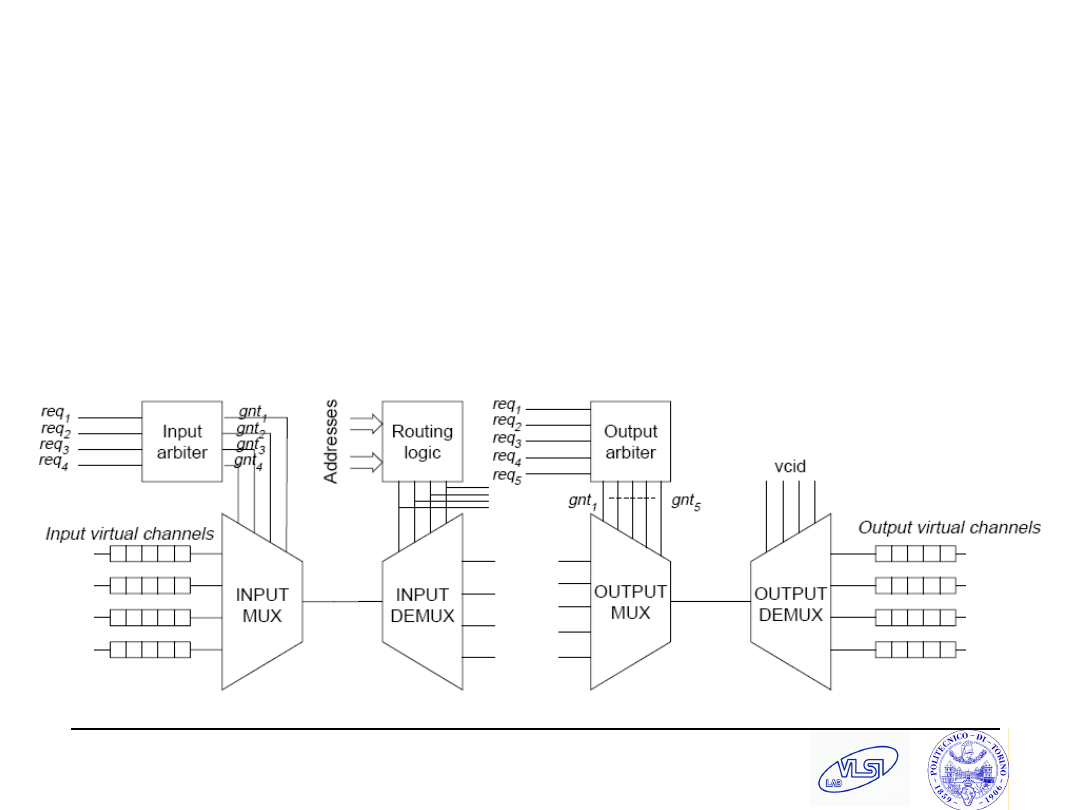
Pande et al., TCOMP’05
Butterfly Fat Tree
Wormhole, Virtual channels
Header flits: 3 ck cycles latency (input arbitration, routing, output arbitration)
“Body” flits: 3 ck cycles (input arbitration, switch traversal, output arbitration
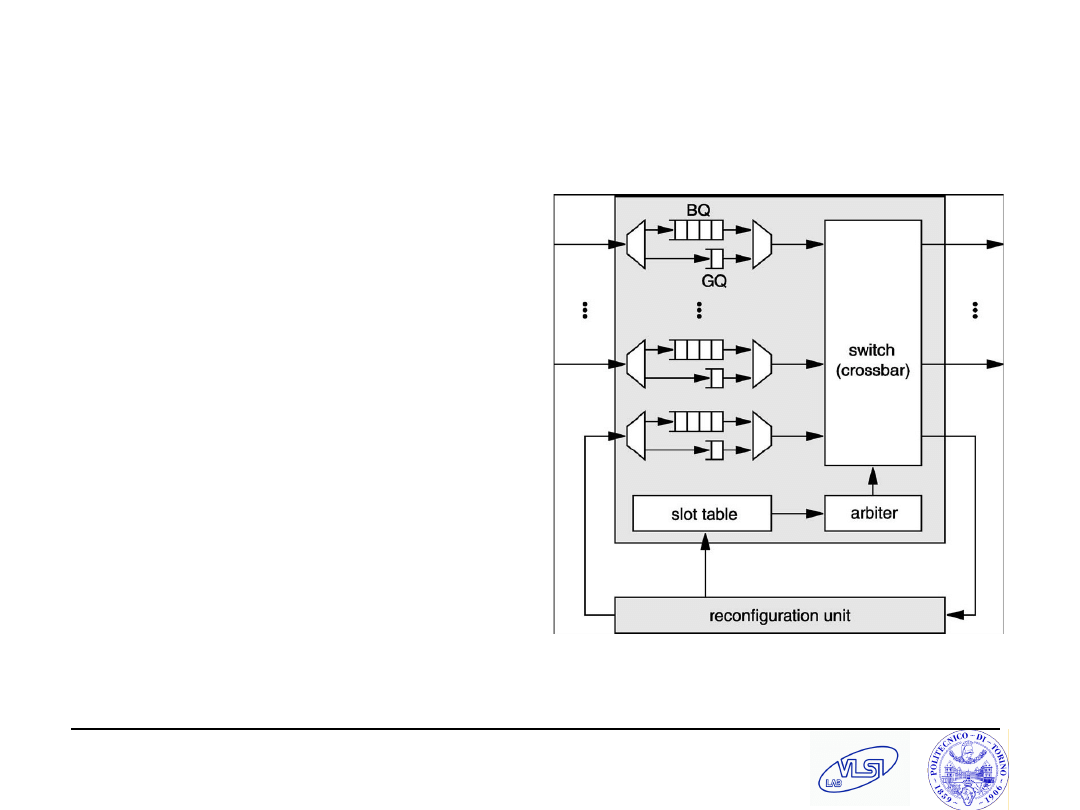
S. Tota and M.R. Casu
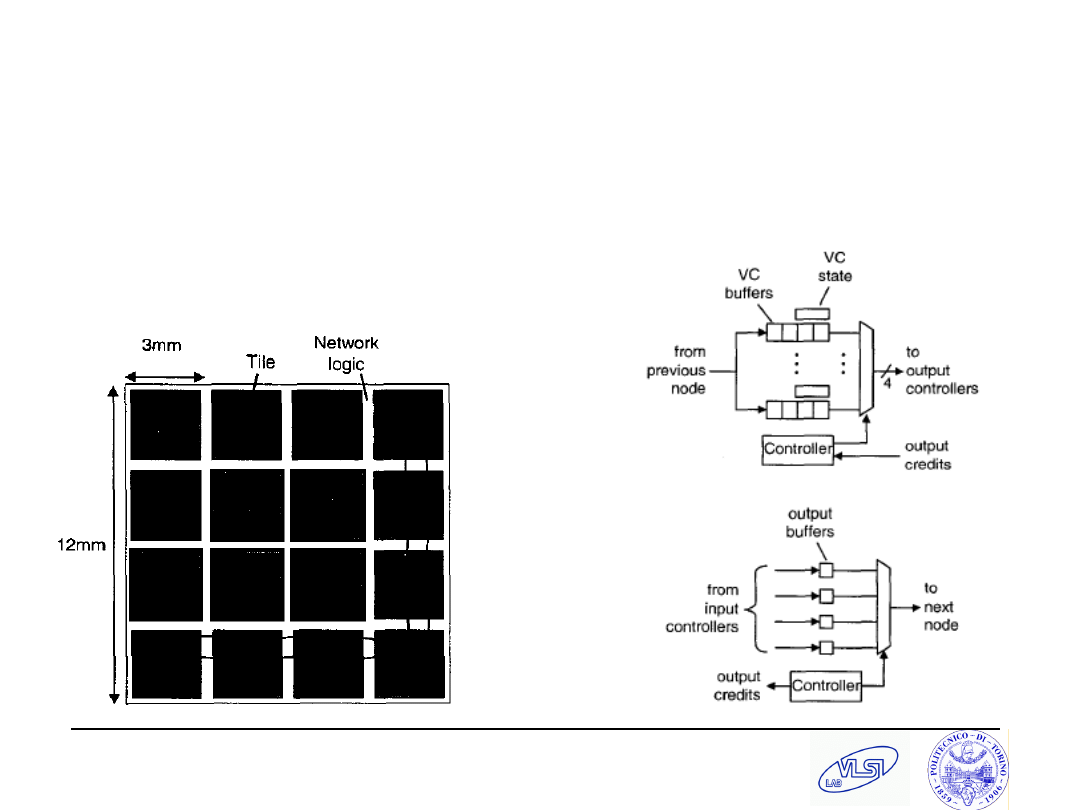
Goossens et al., IEE CDT’03
Both VCT and WH, GT and BE,
IQ and VOQ
GT uses TDM to avoid
contention and create virtual
circuits. In each time slot a
block of 3 flits is transferred
from In “j” to Out “k” in a S&F
fashion.
BE uses Matrix Scheduling
GT connections set up by BE
special system packets
Prototype with WH and IQ
5 ports
0.13 um, 0.26 mm
2
, 500/166
MHz
Flit size = 3 words, each 32
bits
80 Gb/s aggregate bandwidth

S. Tota and M.R. Casu
Common properties
Data integrity
, meaning that data is
delivered uncorrupted
Lossless
data delivery, which means no
data is dropped in the interconnect
In-order
data delivery, which specifies
that the order in which data is delivered is
the same order in which it has been sent
Throughput and Latency
services that
offer time related bounds.

S. Tota and M.R. Casu
What is new?
Yes you are very right, no new concepts
Amazing application of network ideas to the chip
context
But ideas need to be re-contextualized
Old constraints
Latency, bandwidth
New constraints are very tight
Area, Power, Clocks
Differences of fine-grain NoC with large-grain Networks
Today links are 100% reliable. Might become false for ultra-
scaled technologies and globally asynchronous NoC
For many applications, lowest latency is more important than
highest bandwidth

S. Tota and M.R. Casu
Simulation Issues
Stochastic traffic generators
Ease of implementation/simulation
Fast simulation
MP-SoC loop interactions ignored?
Self-similar traffic used by some
Trace-Based Simulation
Need for extensive pre-simulation
Long simulations (days-weeks)
Accurate results
Stay tuned for Sergio’s speech…

S. Tota and M.R. Casu
Applications
Main NoC feature: high communication
bandwidth
Desirable feature for MP-SoC: low
communication
latency
The twos are often contrasting requirements:
“Bandwidth problems can be cured with money.
Latency problems are harder because the speed of
light is fixed—you can’t bribe God.” —Anonymous
Desperately seeking benchmarks and
killer
applications
Networking!!!
Multimedia?

S. Tota and M.R. Casu
The THIN NoC
What we think will make a NoC sexy
enough for chip designers
Least switch area and power
Fast and low latency switch
Ideally one single clock cycle latency and cutting edge
clock frequency Fck (technology limited)
Large bandwidth
= high Fck X high data
parallelism
Need for a
lightweight
NoC design
T
orino
H
awaii
I
nterconnection
N
etwork
Joint work with Hawaii University at Manoa,
Dept. Electrical Engineering

S. Tota and M.R. Casu
Some References
J. Rabaey et al., “A 1-V heterogeneous reconfigurable DSP IC for wireless
baseband digital signal processing,” IEEE Journal of Solid State Circuits, Vol.
35, No. 11, Nov. 2000, pp. 1697 - 1704
P. Guerrier and A. Greiner, “A Generic Architecture for On-Chip Packet-
Switched Interconnections,” Proc. Design and Test in Europe (DATE), pp. 250-
256, Mar. 2000.
A. Adriahantenaina et al., “SPIN: a Scalable, Packet Switched, On-chip Micro-
network,” Proc. Design and Test in Europe (DATE), Mar. 2003.
L. Benini and G. De Micheli, “Networks on Chips: A New SoC Paradigm,”
Computer, vol. 35, no. 1, Jan. 2002, pp. 70-78.
S. Kumar et al., “A network on chip architecture and design methodology,” in
Proc. ISVLSI, 2002.
W. J. Dally and B. Towles, “Route packets, not wires: on-chip interconnection
networks,” in Proc. Design Automation Conf., 2001.
K. Goossens et al., “Trade-offs in the design of a router with both guaranteed
and best-effort services for networks on chip,” IEE Proc.-Comput. Digit. Tech.,
Vol. 150, No. 5, Sep. 2003, pp. 294-302.
P.P. Pande et al., “Performance Evaluation and Design Trade-offs for Network-
on-Chip Interconnect Architectures,” IEEE Trans. Computers, vol. 54, no. 8,
Aug. 2005, pp. 1025-1040.
Document Outline
- Networks-on-Chip
- Seminar contents
- The premises
- Heterogeneous Today’s SoC
- Maya (Rabaey’00)
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- The Cell Processor
- Slide 11
- Slide 12
- Cell’s Element Interconnect Bus
- Slide 14
- Homogeneous SoC (MP-SoC)
- MP-SoC: Cisco CRS-1 Router
- Slide 17
- Very long wires
- Bus pros () and cons ()
- What are NoC’s?
- NoC exemplified
- Basic Ingredients of a NoC
- For the Connoisseurs…
- NoC: Good news
- There’s no free lunch…
- Facts about NoC’s
- Topologies
- Slide 28
- Switching
- Routing
- Who first had the idea?
- SPIN (Guerrier et al., DATE ’00/’03)
- Dally et al., DAC’01
- Kumar et al., ISLVLSI’02
- Pande et al., TCOMP’05
- Goossens et al., IEE CDT’03
- Common properties
- What is new?
- Simulation Issues
- Applications
- The THIN NoC
- Some References
Wyszukiwarka
Podobne podstrony:
2006 05 R odp
doczekalska wielkojezycznosc eps 2006 05 014
kolokwium 2006 05 30
2006 05 Krita–edytor grafiki bitmapowej [Grafika]
Wystapienie 2006 05 18
Święty Pustelnik z Libanu (o ojcu Charbel) Miłujcie się 2006 05
2006 05 mapa
2006 05 Antywzorce w zarządzaniu projektami informatycznymi [Inzynieria Oprogramowania]
Przebieg ćwiczeń hmp, Przebieg ćwiczeń - HMP 23 maja 2006-05-23
GWT Working with the Google Web Toolkit (2006 05 31)
Zdrowie publiczne - [forum] - Giełda 2006-05-01, zdrowie publiczne
LM 2006 05
Podstawy zarządzania - wyk - 2006-05-20, Inteligencja - jest kwalifikowana na 6 grup
2006 05 P
2006 05 Simple Event Correlator (SEC) w monitorowaniu logów bezpieczeństwa
2006 05 R odp
2006 05 05 zajecia 10
laboratorium artykul 2006 05 3461
więcej podobnych podstron