
Bazy danych XML
Wydział Informatyki EWSIE
mgr inż. Piotr Greniewski
Wykład: Bazy danych II – arkusze DTD

2
Wprowadzenie
XML (ang. Extensible Markup Language, w
wolnym tłumaczeniu Rozszerzalny Język
Znaczników) - uniwersalny język
formalny przeznaczony do reprezentowania
różnych danych w strukturalizowany sposób.
XML jest niezależny od platformy, co
umożliwia łatwą wymianę dokumentów
pomiędzy różnymi systemami i znacząco
przyczyniło się do popularności tego języka w
dobie Internetu. XML jest rekomendowany
oraz specyfikowany przez organizację W3C.

3
Poprawność dokumentów XML
Mówimy o dokumencie, że jest poprawny
składniowo (ang. well-formed), jeżeli jest zgodny z
regułami składni XML. Reguły te obejmują m.in.
konieczność domykania wszystkich znaczników.
Dokument niepoprawny składniowo nie może być
przetworzony przez parser XML.
Mówimy o dokumencie, że jest poprawny
strukturalnie (ang. valid), jeżeli jest zgodny z
definicją dokumentu, tzn. dodatkowymi regułami
określonymi przez użytkownika. Do precyzowania
tych reguł służą specjalne języki.
Najpopularniejszymi są DTD, XML
Schema oraz RELAX NG.

4
Przykładowy dokument XML
<?xml version="1.0" standalone="no"?>
<pracownik>
<osoba>
<imie>Alan</imie>
<nazwisko>Starski</nazwisko>
<profesja>operator</profesja>
<profesja>scenarzysta</profesja>
</osoba>
<osoba>
<imie>Janko</imie>
<nazwisko>Muzykant</nazwisko>
<profesja>muzyk</profesja>
<profesja>pasterz</profesja>
</osoba>
</pracownik>

5
Prawidłowo wygenerowany dokument
XML
version - określa wersję specyfikacji XML,
encoding – deklaruje zestaw znaków używanych
w dokumencie XML, wartością domyślną jest
kodowanie unicode „UTF-8”.
standalone – określa tryb dokumentu XML, może
przyjmować wartość yes lub no. Jeśli ustawimy
wartość na yes to będzie oznaczało, że
dokument nie zawiera innych plików, które
muszą zostać przetworzone wraz z dokumentem.
Może to być np. zewnętrzny arkusz stylów lub
definicja DTD
;
<?xml version="1.0" encoding="iso-8859-2" standalone="no"?>

6
Prawidłowo wygenerowany dokument
XML
musi zawierać jeden element główny zwany root, w
naszym przypadku elementem głównym jest element o
nazwie newsy;
każdy element musi zaczynać się znacznikiem początku
elementu np. <data> oraz kończyć identycznym
znacznikiem końca elementu np. </data>, wyjątek
stanowią elementy puste (<element-pusty />), czyli takie
które nie zawierają żadnych danych, ani innych elementów,
mogą zawierać atrybuty;
nazwy elementów mogą zawierać znaki alfanumeryczne
(litery a-z, A-Z oraz cyfry 0-9), znaki ideograficzne (ą, ó, ń
jednak należy unikać takich konstrukcji) oraz 3 znaki
interpunkcyjne (podkreślenie _, łącznik -, kropka .). Znak
dwukropka zarezerwowany jest dla identyfikacji
przestrzeni nazw, której nazwa dopisywana jest przed
nazwą elementu np. <przestrzeń1:element>,

7
Prawidłowo wygenerowany dokument
XML
nazwy elementów nie mogą zaczynać się od znaku
łącznika -, kropki, cyfry,
elementy można zagnieżdżać w sobie i wtedy każdy
element znajdujący się wewnątrz innego elementu jest
nazywany „dzieckiem” tego elementu, a element
wewnątrz którego znajdują się inne elementy zwany
jest „rodzicem” tych elementów, element <newsy> jest
rodzicem elementu <news>, element <news> jest
dzieckiem elementu <newsy>, a zarazem rodzicem
elementów <data>, <autor>, <e-mail>, <tresc>.
Nie można stosować konstrukcji takiego typu:
<news><data></data><tresc></news></tresc>,
ponieważ element <tresc> nie jest prawidłowo
zagnieżdżony w elemencie <news>;

8
Prawidłowo wygenerowany dokument
XML
każdy element może zawierać atrybuty, które definiuje się w
znaczniku początku elementu np. atrybutem elementu <news
potw=”yes”> jest atrybut o nazwie potw oraz wartości yes.
Wartości atrybutów podaje się w cudzysłowach.
informacje, które zawiera element muszą być zapisane
pomiędzy znacznikiem początku i końca elementu,
w danych, atrybutach oraz nazwach elementów nie mogą
pojawiać się niektóre znaki. Przykładem może być znak
mniejszości (<), lub ampersand (&). Znaków tych nie można
używać, ponieważ parsery XML „widząc” np. znak mniejszości
wewnątrz elementu stwierdzą, że jest to początek znacznika i
dokument zostanie błędnie zinterpretowany. Specyfikacja XML
daje możliwość używania takich znaków z wykorzystaniem
predefiniowanych odniesień jednostki. Jeśli np. chcemy
wstawić znak mniejszości (<) wpisujemy zamiast niego
sekwencję < znak ampersand - & znak większości (>)
>

9
Prawidłowo wygenerowany dokument
XML
jeżeli nie chcemy używać predefiniowanych odniesień
jednostek możemy część danych, które zawierają np. kod
html lub xml zapisać w sekcji danych znakowych, która nie
będzie przetwarzana przez analizator składni XML.
Znacznik początku sekcji danych znakowych to: <!
[CDATA[, a znacznik końca: ]]>
w dokumencie XML możemy wykorzystywać komentarze,
które zaczynają się znakami: <!--, a kończą: -->. Przykład:
<!-- To jest komentarz -->,
specyfikacja XML zezwala na wstawianie instrukcji
przetwarzania, które są wykorzystywane do przeniesienia
informacji do aplikacji. Instrukcje przetwarzania
rozpoczynają się znakami: <?, a kończą: ?>. Przykładem
takiej instrukcji może być odniesienie do arkusza stylów,
który jest powiązany z dokumentem XML: <?xml-
stylesheet type="text/xsl" href="newsy.xsl"?>.

10
Dokument DTD
DTD (ang. Document Type Definition), definicja typu dokumentu –
rodzaj dokumentu definiujący formalną strukturę
dokumentów HTML, XML, XHTML lub innych z rodziny SGML. Definicje
DTD mogą być zawarte w pliku dokumentu, którego strukturę definiują,
przeważnie jednak zapisane są w osobnym pliku tekstowym, co pozwala
na zastosowanie tego samego DTD dla wielu dokumentów.
DTD określa składnię konkretnej aplikacji XML lub SGML,
np. XHTML, EAD, TEI lub innej, zdefiniowanej dla potrzeb użytkownika.
Zazwyczaj DTD definiuje każdy dopuszczalny element dokumentu, jego
zbiór atrybutów i dopuszczalne wartości. DTD określa także
zagnieżdżanie i wymagalność poszczególnych elementów w
dokumencie. W praktyce DTD przeważnie składa się z definicji
ELEMENT i definicji ATTLIST.
W praktyce DTD używanego typu dokumentów SGML jest najczęściej
"zaszyte" w oprogramowaniu obsługującym dany typ dokumentów (np.
w przypadku języka HTML w przeglądarkach i programach do pisania
stron WWW) i użytkownicy tych dokumentów oraz nawet osoby
tworzące te dokumenty nie mają bezpośredniego dostępu do DTD, z
którego korzystają.

11
Przykładowy dokument DTD (standalone)
<!ELEMENT pracownik (osoba*)>
<!ELEMENT osoba (imie,nazwisko,profesja*)>
<!ELEMENT imie (#PCDATA)>
<!ELEMENT nazwisko (#PCDATA)>
<!ELEMENT profesja (#PCDATA)>
<?xml version="1.0" encoding="iso-8859-2" standalone="yes"?>
<!DOCTYPE pracownik SYSTEM "pracownik.dtd">
<pracownik>
</pracownik>

12
Przykładowy dokument DTD (not
standalone)
<?xml version="1.0" encoding="iso-8859-2" standalone="no"?>
<!DOCTYPE pracownik [
<!ELEMENT pracownik (osoba*)>
<!ELEMENT osoba (imie,nazwisko,profesja*)>
<!ELEMENT imie (#PCDATA)>
<!ELEMENT nazwisko (#PCDATA)>
<!ELEMENT profesja (#PCDATA)>
]>
<pracownik>
<osoba>
<imie>Alan</imie>
<nazwisko>Starski</nazwisko>
<profesja>operator</profesja>
<profesja>scenarzysta</profesja>
</osoba>
</pracownik>

13
Kontrola poprawności dokumentu
Przeglądarki stron www w zasadzie nie
kontrolują poprawności dokumentu, a tylko
sprawdzają je pod względem właściwej
konstrukcji.
Pisząc własne pliki xml i dtd potrzebujemy
sprawdzenia poprawności plików (xml) z
definicją (dtd).
Można to zrealizować za pomocą pakietu DOM
w języku PHP.
Inną metodą jest użycie interaktywnych
parserów dostępnych w internecie.

14
Kontrola poprawności dokumentu
Obiektowy model dokumentu (Document Object
Model, DOM) – sposób reprezentacji złożonych
dokumentów XML i HTML w postaci modelu obiektowego.
Model ten jest niezależny od platformy i języka
programowania.
Standard W3C DOM definiuje zespół klas i interfejsów,
pozwalających na dostęp do struktury dokumentów oraz jej
modyfikację poprzez tworzenie, usuwanie i modyfikację
tzw. węzłów (ang. nodes).
Dla większości języków programowania istnieją biblioteki
obsługujące DOM dla plików XML. Najbardziej
zaawansowane z nich toApache Xerces i MS XML. Standard
W3C definiuje interfejsy DOM tylko dla
języków JavaScript i Java.
Język PHP 5.x posiada sprawnie działającą bibliotekę DOM

15
Kontrola poprawności dokumentu
Klasa DOMDocument posiada wiele funkcji do
obróbki dokumentów XML.
Metoda load() ładuje dokument do pamięci
komputera
Metoda validate() sprawdza poprawność dokumentu.
Metoda zwraca true w przypadku poprawnej walidacji
false gdy jest niepoprawna.
<?php
$dom = new DOMDocument();
$dom->load('order.xml');
if ($dom->validate())
{echo 'Walidacja dokumentu jest poprawna';}
else {echo 'Walidacja dokumentu jest błędna';}
?>

16
Elementy i ich deklaracje
Każdy element używany w prawidłowym
dokumencie musi być zadeklarowany w definicji
DTD tego elementu za pomocą deklaracji
elementu.
Nazwą elementu może być dowolna nazwa XML.
Model zawartości określa jakie elementy potomne
może lub musi posiadać ten element i w jakiej
kolejności powinny one występować.
Mogą być złożone wielopoziomowo.
<!ELEMENT nazwa_elementu (model_zawartosci)>
17
Model zawartości #PCDATA
Najprostrzy model zawartości deklarowany za
pomocą słowa kluczowego #PCDATA określa,
że element nie zawiera elementów potomnych
żadnego typu.
Element może jedynie zawierać analizowane
dane znakowe.
<!ELEMENT numer_telefonu(#PCDATA)>
18
Elementy potomne
Innym prostym modelem zawartości jest model,
który określa, że dany element musi mieć
dokładnie jeden element potomny danego typu.
Poniższa deklaracja informuje, że element faks
musi zawierać dokładnie jeden element numer
telefonu.
Element faks nie może zawierać niczego innego
niż element numer telefonu i musi zawierać
dokładnie jeden numer telefonu
<!ELEMENT faks(numer_telefonu)>
<!ELEMENT numer_telefonu(#PCDATA)>

19
Sekwencje
Modele zawartości zawierające jeden element potomny
rzadko występują w praktyce.
Zazwyczaj występuje wiele elementów rozdzielonych
przecinkami i jest nazywane sekwencją.
Wskazuje ona, że elementy muszą występować w określonej
kolejności.
W naszym przykładzie najpierw dokładnie jedno imię a
potem dokładnie jedno nazwisko.
<!ELEMENT nazwa(imie,nazwisko)>
<!ELEMENT imie(#PCDATA)>
<!ELEMENT nazwisko(#PCDATA)>
<nazwa>
<imie>Jan</imie>
<nazwisko>Kowalski</nazwisko>
</nazwa>

20
Liczba elementów potomnych
Nie wszystkie wystąpienia danego elementu
mają dokładnie te same elementy potomne.
W modelu zawartości można dołączyć jeden z
trzech przyrostków w celu wskazania
krotności elementu
? – zezwala na zero lub jedno wystąpienie
* - zezwala na zero lub więcej wystąpień
+ - wymaga przynajmniej jednego wystąpienia
<!ELEMENT nazwa(imie,drugie_imie*,nazwisko+)
<!ELEMENT imie(#PCDATA)>
<!ELEMENT drugie_imie(#PCDATA)>
<!ELEMENT nazwisko(#PCDATA)>

21
Wybory
Czasami występuje sytuacja, że dany element
może mieć różne elementy potomne w zależności
od sytuacji.
Taką sytuację można wskazać za pomocą
wyboru
.
Wybór
jest to lista nazw elementów
rozdzielonych kreskami.
<?xml version="1.0" encoding="iso-8859-2" standalone="no"?>
<!ELEMENT nazwa (firma|czlowiek)>
<!ELEMENT dni_tyg(pon|wto|sro|czw|pia|sob|nie)>

22
Wybory
<?xml version="1.0" encoding="iso-8859-2"
standalone="no"?>
<!DOCTYPE klient [
<!ELEMENT klient (nazwa*)>
<!ELEMENT nazwa (firma|czlowiek)>
<!ELEMENT firma (nazwa_firmy,nip)>
<!ELEMENT nazwa_firmy (#PCDATA)>
<!ELEMENT nip (#PCDATA)>
<!ELEMENT czlowiek (imie,nazwisko)>
<!ELEMENT imie (#PCDATA)>
<!ELEMENT nazwisko (#PCDATA)>
]>

23
Wybory cd.
<klient>
<nazwa>
<firma>
<nazwa_firmy>Wedel SA</nazwa_firmy>
<nip>12345678</nip>
</firma>
</nazwa>
<nazwa>
<czlowiek>
<imie>Jan</imie>
<nazwisko>Kowalski</nazwisko>
</czlowiek>
</nazwa>
</klient>
http://localhost/work-xml/publikacja-xml/05-wybory/validate-dtd.php

24
Nawiasy okrągłe
<!ELEMENT okrag (srodek, (promien|srednica)>
Wybory, sekwencje i przyrostki mają dość
ograniczone możliwości. Można je z sobą łączyć.
Wybór lub sekwencję można umieszczać w
nawiasach. Nawiasy mogą posiadać przedrostki (? , *,
+). Pozycje wewnątrz nawiasów można zagnieżdżać
wewnątrz innych wyborów lub sekwencji
Jeśli chcemy zdefiniować okrąg na dwa sposoby:
środek i promień
środek i średnica

25
Zawartość mieszana
<!ELEMENT definicja (#PCDATA | termin)*>
<!ELEMENT paragraf (#PCDATA | nazwa | profesja |
przypis | wyroznienie | data)*>
W dokumentach opisowych pojedynczy element zawiera
zarówno elementy potomne, jak i dane znakowe bez
oznaczenia (czyli bez spacji).
Element definicja zawiera fragment tekstu oraz element
potomny termin. Nazywa się to
zawartością mieszaną
.
Do listy
zawartości mieszanej
można dodać dowolną
ilość innych elementów potomnych ale element
#PCDATA zawsze musi występować pierwszy.
Jest to jedyny sposób na wskazanie, że element zawiera
zawartość mieszaną
.

26
Puste elementy
<!ELEMENT obraz EMPTY>
<obraz zrodlo=foto.jpg szer= "152" wys="345"
alt= " Widok z Zakopanego na Giewont" />
Niektóre elementy nie posiadają żadnej zawartości.
Nazywamy je elementami pustymi.
( oznaczamy je <element />)
Puste elementy deklarujemy przy pomocy słowa
kluczowego EMPTY, użytego w odniesieniu do modelu
zawartości
.
27
ANY
<!ELEMENT strona ANY>
Niedokładne definicje DTD definiują element ale
nie wskazują co może a czego nie może zawierać.
W takim przypadku jako modelu zawartości
należy użyć słowa ANY.
Poniższa deklaracja wskazuje, że strona może
zawierać zupełnie dowolną zawartość. Np.
zawartość mieszaną, elementy potomne, inne
elementy strona.
Należy pamiętać o zadeklarowaniu pojawiających
się elementów. Any nie umożliwia stosowania
elementów bez deklaracji.

28
Deklaracje atrybutów
<!ATTLIST obraz zrodlo CDATA #REQUIRED>
<obraz zrodlo=„National Geographic” />
Prawidłowy dokument, oprócz zadeklarowanych
elementów musi posiadać deklaracje atrybutów.
Atrybuty deklarujemy za pomocą ATTLIST. Za pomocą
jednej deklaracji można zadeklarować wiele atrybutów
dla elementu jednego typu.
Jeśli ten sam atrybut ma się powtarzać w wielu
elementach to trzeba go deklarować oddzielnie.
Poniższa deklaracja określa, że element obraz posiada
atrybut o nazwie zrodlo. Wartością tego atrybutu są dane
znakowe. Dla zapewnienia wartości elementu zrodlo w
dokumencie są wymagane wystąpienia elementu obraz.

29
Deklaracje atrybutów
<!ATTLIST obraz zrodlo
CDATA #REQUIRED
szerokosc CDATA #REQUIRED
wysokosc CDATA #REQUIRED
alt
CDATA #iMPLIED
>
W jednej deklaracji można zadeklarować wiele
atrybutów tego samego elementu.
W poniższym przykładzie zadeklarowano
atrybuty: zrodlo, szerokosc, wysokosc i alt
Wymagane są atrybuty zrodlo, szerokosc,
wysokosc. Atrybut alt jest opcjonalny

30
Typy atrybutów
CDATA
ciąg znaków
NMTOKEN
ciąg znaków mogących występować w
nazwach atrybutów i elementów
NMTOKENS
ciąg NMTOKEN oddzielanych spacjami
ID
identyfikator unikalny w dokumencie
IDREF
wskaźnik do ID innego elementu
IDREFS
ciąg IDREF oddzielany spacjami
ENTITY
nazwa encji (musi być zadeklarowana)
ENITIES
ciąg ENTITY oddzielany spacjami
(a|b|c)
typ wyliczeniowy
CDATA
ciąg znaków
W XML dozwolone jest tylko 10 typów atrybutów

31
Atrybut typu CDATA
Wartość atrybutu CDATA może zawierać dowolny ciąg tekstowy,
który będzie akceptowany jako prawidłowy atrybut XML.
Możemy go stosować wszędzie tam gdzie narzuca się
konkretnej postaci tekstu
<!ATTLIST pozycja
cena_zakupu
CDATA #REQUIRED
cena_detal
CDATA #REQUIRED
cena_min
CDATA #iMPLIED
>
<-- Wszystkie trzy atrybuty mają postać XX.YYzł -->
<pozycja cena_zakupu= "23.00zł" cena_detal= "30.00zł"
cena_min= "25.00zł">Marchew</pozycja>

32
Atrybut typu wyliczenie
Wyliczenie jest jedynym typem atrybutu, który nie
posiada słowa kluczowego XML. Zamiast tego model
zawartości stanowi listę wszystkich możliwych
zawartości atrybutu rozdzielonych pionowymi
kreskami.
Wszystkie wartości muszą być żetonami nazw XML.
<!ATTLIST data miesiac (styczen | luty | marzec |
kwiecien | maj | czerwiec | lipiec | sierpien |
wrzesien | pazdziernik | listopad | grudzień )
#REQUIRED >
<-- po zadeklarowaniu element data jest poprawny -->
<data miesiac= "styczen" />

33
Wartości domyślne atrybutów
Każda deklaracja ATTLIST, oprócz określenia
typu danych, zawiera deklarację wartości
domyślnej dla tego atrybutu:
#IMPLIED – atrybut jest opcjonalny, każde
wystąpienie może ale nie musi określać wartości
atrybutu. Nie jest określona wartość domyślna
#REQUIRED – Atrybut jest wymagany. Każde
wystąpienie musi określać wartość atrybutu. Nie jest
określona wartość domyślna.
#FIXED – Wartość atrybutu jest stała. Ten atrybut
posiada określoną wartość.
Literał – Rzeczywista wartość domyślna podana jest
jako ciąg znaków w cudzysłowie

34
Deklaracje encji ogólnych
XML oferuje pięc odwołań encji do
specjalnych zastosowań:
< - znak mniejszości, otwierający ostry nawias (<)
& - ampersand (&)
> - znak większości, zamykający nawias ostry (>)
" - zwykły, podwójny cudzysłów (")
' - apostrof, pojedynczy cudzysłów (')

35
Przestrzenie nazw
W XML łatwo można definiować nowe znaczniki, jednak
w miarę powstawania coraz liczniejszych aplikacji, pojawiać
się będzie problem nieprzewidziany przez twórców
pierwotnej wersji specyfikacji XML: konflikty nazw
znaczników.
Popularność zdobyły już dwie aplikacje XML: XHTML
stworzony na podobieństwo HTML 4.0 oraz MathML
umożliwiający wyświetlanie równań. XHTML jest przydatny,
gdyż pozwala stosować wszystkie znaczniki HTML 4.0,
natomiast MathML jest nieoceniony, jeśli chodzi
o prezentację równań. A co, jeśli trzeba wstawić równania
do strony sieciowej zapisanej w XHTML?
Jest to problem, gdyż część znaczników obu tych języków
tak samo się nazywa (powtarzają się między innymi
elementy var oraz select).

36
Przestrzenie nazw
Rozwiązaniem tego problemu są przestrzenie nazw.
Umożliwiają one uniknięcie konfliktów między
poszczególnymi zbiorami znaczników. Przestrzenie działają
w ten sposób, że nazwę znacznika i atrybutu poprzedza się
nazwą przestrzeni nazw z dwukropkiem; w ten sposób
faktycznie zmienia się sam znacznik i konflikty się już
nie pojawiają.
Przestrzenie nazw XML są jedną ze specyfikacji
towarzyszących samej rekomendacji XML. Specyfikację
przestrzeni nazw znajdziesz pod adresem
www.w3.org/TR/REC-xml-names/.
Z tego właśnie powodu zdecydowanie odradza się stosować
dwukropki w nazwach elementów, gdyż przez ich
umieszczanie można spowodować, że nazwy znaczników
nawet wzbogaconych przestrzenią nazw będą się powtarzały.

37
Tworzenie przestrzeni nazw
Oto przykład, w którym używamy aplikacji XML
przeznaczonej do katalogowania książek, gdzie
elementem głównym jest biblioteka. Do każdej książki
dodamy recenzje. Zaczynamy od opisania w tej aplikacji
książki:
<biblioteka>
<książka>
<tytuł>
Trzęsienia ziemi na śniadanie
</tytuł>
</książka>
</biblioteka>

38
Tworzenie przestrzeni nazw
Teraz chcemy do elementu książka dodawać swoje
komentarze. Zaczynamy od przypisania książkowej
aplikacji XML jej własnej przestrzeni nazw, do której
będziemy używać przedrostka książki:.
Aby zdefiniować przestrzeń nazw, używa się atrybutu
xmlns:przedrostek, gdzie przedrostek będzie używany
do identyfikacji naszej przestrzeni:
<biblioteka xmlns:książki="http://www.książki.com/spec">
<książka>
<tytuł>
Trzęsienia ziemi na śniadanie
</tytuł>
</książka>
</biblioteka>

39
Tworzenie przestrzeni nazw
W celu zdefiniowania przestrzeni nazw przypisaliśmy
atrybutowi xmlns:przedrostek niepowtarzalny identyfikator,
który zwykle ma postać adresu URI (u nas był to po prostu
adres URL).
Pod tym adresem może (choć nie musi) znajdować się DTD
definiowanej przestrzeni nazw.
Teraz każdy znacznik i atrybut naszej nowej przestrzeni nazw
poprzedzamy przedrostkiem książki:
<książki:biblioteka
xmlns:książki="http://www.książki.com/spec">
<książki:książka>
<książki:tytuł>
Trzęsienia ziemi na śniadanie
</książki:tytuł>
</książki:książka>
</książki:biblioteka>

40
Tworzenie przestrzeni nazw
Teraz nazwy znaczników i atrybutów zostały zmienione – na przykład
z punktu widzenia procesora XML dawny <biblioteka> ma teraz
postać <książki:biblioteka> (jeśli znaczniki i atrybuty zdefiniowano
w DTD dokumentu, to trzeba zmienić ich definicje, aby podać
prawidłowe nazwy).
Teraz wszystkie znaczniki i atrybuty przestrzeni nazw książki należą
do osobnej przestrzeni nazw, można do dokumentu dodać drugą
przestrzeń, w której do książek dodawane będą komentarze.
Zaczynamy od utworzenia nowej przestrzeni nazw opinie:
<książki:biblioteka
xmlns:książki="http://www.książki.com/spec"
xmlns:opinie="http://www.gwiezdnypył.com/książki">
<książki:książka>
<książki:tytuł>
Trzęsienia ziemi na śniadanie
</książki:tytuł>
</książki:książka>
</książki:biblioteka>

41
Tworzenie przestrzeni nazw
Teraz w przestrzeni nazw opinie możemy dodać nowe
elementy nie zaburzając innych znaczników:
<książki:biblioteka
xmlns:książki="http://www.książki.com/spec"
xmlns:opinie="http://www.gwiezdnypył.com/książki">
<książki:książka>
<książki:tytuł>
Trzęsienia ziemi na śniadanie
</książki:tytuł>
<opinie:opinia>
Książka niezła, ale bez specjalnych wstrząsów.
</opinie:opinia>
</książki:książka>
</książki:biblioteka>

42
Tworzenie przestrzeni nazw
Można też używać w przestrzeni nazw opinie atrybutów,
byle tylko były też poprzedzone przedrostkiem:
<książki:biblioteka
xmlns:książki="http://www.książki.com/spec"
xmlns:opinie="http://www.gwiezdnypył.com/książki">
<książki:książka>
<książki:tytuł>
Trzęsienia ziemi na śniadanie
</książki:tytuł>
<opinie:opinia opinie:ID="1000034">
Książka niezła, ale bez specjalnych wstrząsów.
</opinie:opinia>
</książki:książka>
</książki:biblioteka>

43
Tworzenie przestrzeni nazw
I do tego właśnie służą przestrzenie nazw –
rozdzielają znaczniki, nawet znaczniki o takich
samych nazwach.
Jak widać, swobodnie można w jednym
dokumencie używać wielu przestrzeni nazw –
po prostu należy w zawierającym całość
elemencie umieścić odpowiednie atrybuty
xmlns w elementach potomnych
Tak naprawdę za pomocą atrybutu xmlns
można przedefiniować przestrzeń nazw
w elemencie potomnym na inną niż używana
w elemencie go zawierającym.

44
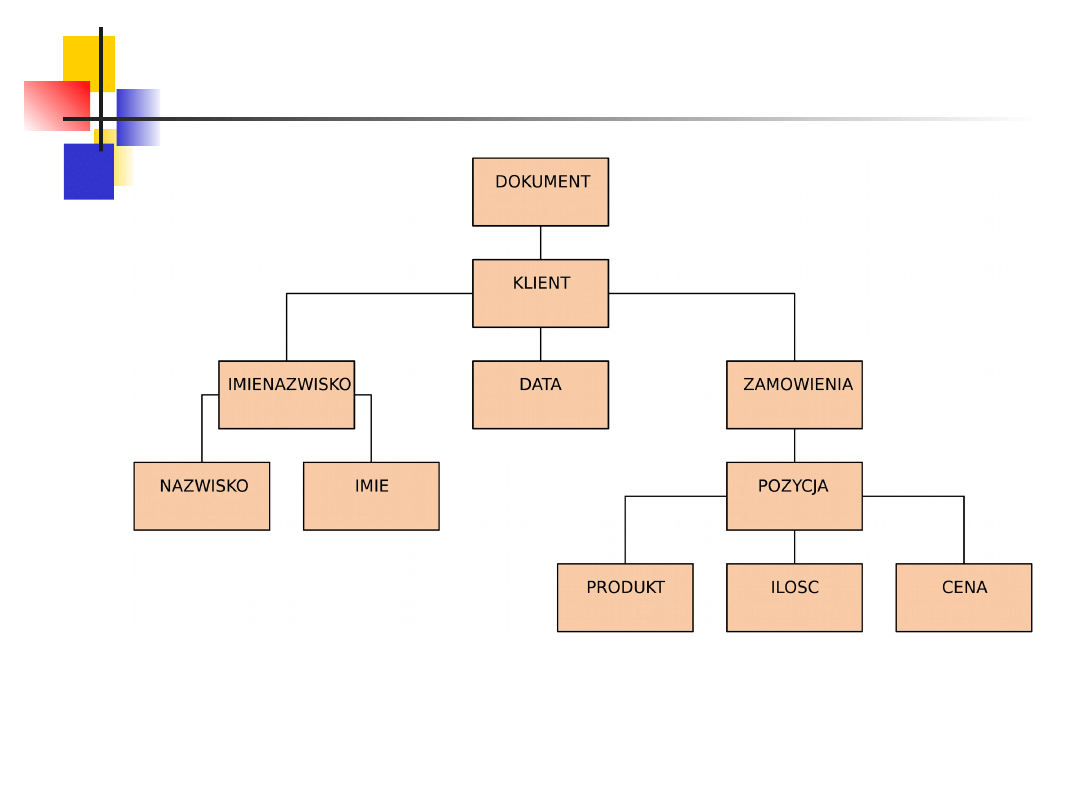
Ćwiczenie – zamówienie (order) – opis
słowny
Budujemy dokument XML do przechowywania zamówień
klientów. Zamówienie klienta zawiera:
Imię
Nazwisko
Data
Pozycja zamówienia
Pozycja zamówienia składa się z:
Produkt
Ilość
Cena
Należy stworzyć dokument XML zawierający diagram
DTD. Sprawdzić jego poprawność formalną oraz
zobrazować go na przeglądarce za pomocą arkusza XLS.
45
Ćwiczenie – zamówienie (order) diagram
zależności
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
Wyszukiwarka
Podobne podstrony:
03 Sejsmika04 plytkieid 4624 ppt
05 xml domid 5979 ppt
10 XML appsid 11206 ppt
03 Zmiennelosowe ciagle2011id 4560 ppt
03 Patologia sutkaid 4246 ppt
03 Uczenie sieid 4517 ppt
0 Owibpie 03 12 2012id 1730 ppt
04 xml xslid 5313 ppt
03 NIKOTYNIZM PREZENTACJAid 4243 ppt
03 Źródła prawaid 4231 ppt
03 Stratygrafia sejsmicznaid 4258 ppt
03 cwiczenie3 macierze2id 4342 ppt
03 Makrootoczenie przedsiębiorstwaid 4178 ppt
2009 06 03 POZ 11id 26815 ppt
03 podstawy RBDid 4615 ppt
03 Spor o uniwersaliaid 4201 ppt
03 Liczby w komputerzeid 4175 ppt
więcej podobnych podstron