X L V I I I K O N F E R E N C J A N AU K O W A
KOMITETU INŻ YNIERII LĄ DOWEJ I WODNEJ PAN
I KOMITETU NAUKI PZITB
Opole – Krynica
2002
Janusz KASPERKIEWICZ
1
ANALIZA BAZ DANYCH NA TEMAT MATERIAŁ Ó W BETONOPODOBNYCH
1. O potrzebie automatyzacji analizy danych inżynierskich
Opracowanie niniejsze poś więcone jest prawidłowemu postępowaniu przy naborze danych oraz
moż liwoś ciom ich automatycznej eksploatacji.
Rozwój nowych technologii powoduje cią gły napływ rozproszonych, nieuporzą dkowa-
nych informacji, które trudno jest wykorzystać ograniczają c się tylko do tradycyjnych metod
analizy, polegają cych np. na budowaniu modeli empirycznych i poszukiwaniu prostych kore-
lacji. W dziedzinie tworzyw betonopodobnych dotyczy to zwłaszcza tzw. "wysokich technolo-
gii", takich jak stosowanie betonów wysokiej wartoś ci (BWW), betonów samopoziomują cych
się czy kompozytów zawierają cych mikrowłókna.
Nowe składniki i technologie pojawiają się obecnie w coraz krótszych odstępach czasu,
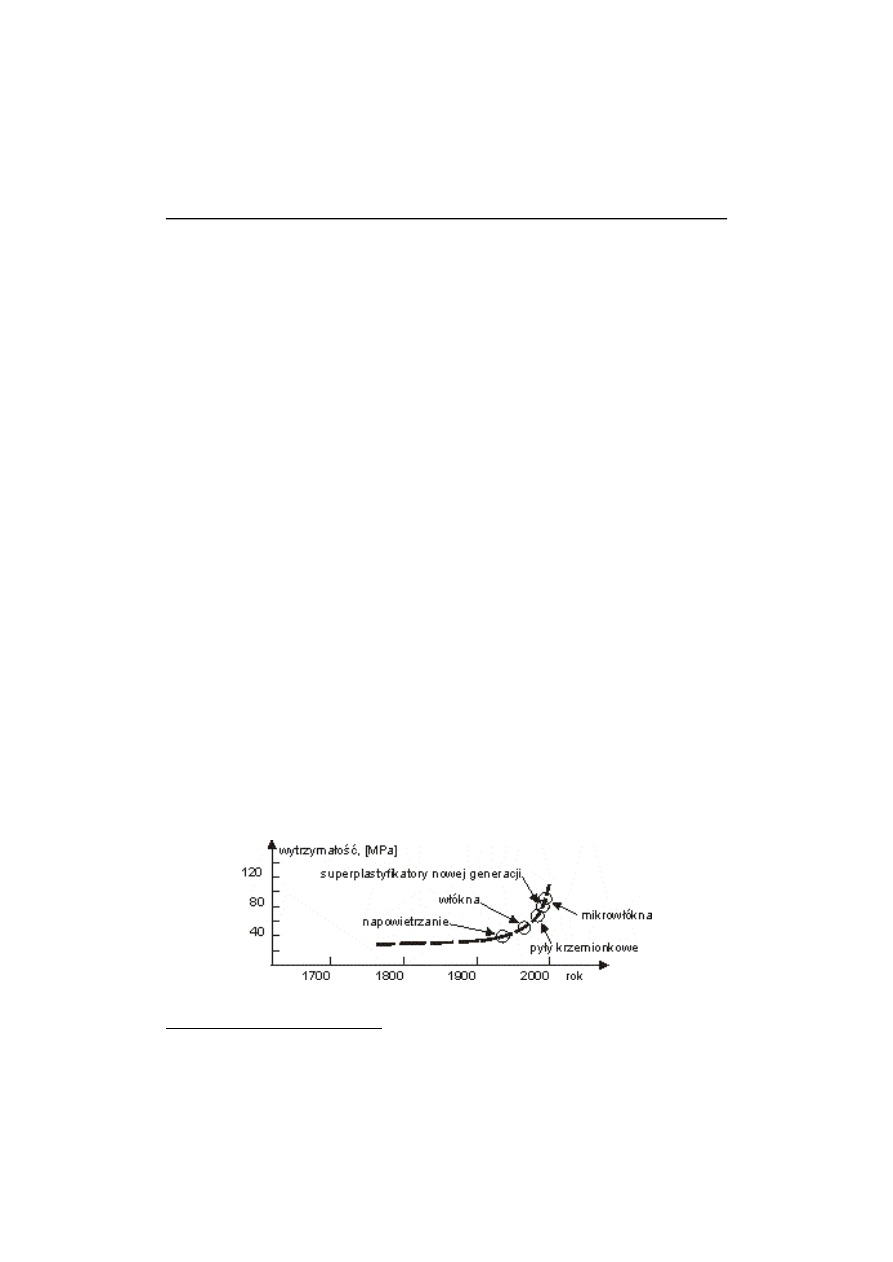
wpływają c na podobnie szybki wzrost oczekiwań i standardów. Wykres poniż ej –rys. 1 – ma
ilustrować dynamikę zachodzą cych zmian na przykładzie betonu. Wytrzymałoś ć betonu stanowi
tu jedynie przykład, a spostrzeż enie dotyczy takż e innych cech podobnych kompozytów.
Urabialnoś ć betonu, jego ś cieralnoś ć czy mrozoodpornoś ć , ulegały polepszeniu stosunkowo
powoli w czasie pierwszych 150 lat historii nowoczesnego budownictwa. Natomiast w drugiej
połowie XX wieku nastą piło niemal jednoczesne pojawienie się nowych składników (np.
domieszki napowietrzają ce, plastyfikatory i superplastyfikatory, pyły krzemionkowe, włókna
i mikrowłókna), nowe metody projektowania, nowe techniki wykonawcze (takie jak pompo-
wanie, naparzanie, próż niowanie, torkret, wirowanie, wyciskanie), nowe oddziaływania,
(obcią ż enia) oraz nowe techniki badawcze (automatyczna analiza obrazów, badanie cienkich
szlifów, SEM, rezonans magnetyczny, badania akustyczne, itd.).
Rys. 1. Dynamika zmian na przykładzie wytrzymałoś ci betonu
1
Prof., dr inż . hab., Instytut Podstawowych Problemów Techniki PAN, Warszawa

36
Rozwój technologii powoduje, ż e zasoby wiedzy rosną niemal wykładniczo w czasie
(rys. 1), i niezbędne są bardziej efektywne narzędzia do ich eksploatacji.
Rozwią zaniem problemu jest wyzyskanie metod zautomatyzowanych, okreś lanych często
jako "metody sztucznej inteligencji". Konieczne jednak jest wówczas zachowanie pewnej
dyscypliny i pewnego formalizmu sposobów zbierania danych, co gwarantuje moż noś ć ich
późniejszego, skutecznego wykorzystywania.
Referat dotyczy racjonalnego tworzenia baz danych oraz niektórych wymagań, co do ich
formy tak, aby łatwa była ich analiza i eksploatacja z pomocą rozmaitych technik komputacyjnych.
Prezentację oparto na prostym przykładzie niewielkiego zbioru danych z zakresu
mrozoodpornoś ci betonu konstrukcyjnego. Pokazano poprawny sposób przygotowywania
danych oraz efekty ich analizy za pomocą dwóch wybranych metod z zakresu ML (ML -
Machine Learning – Uczenie Maszyn).
Nowoś ć pracy stanowi zademonstrowana moż liwoś ć efektywnego uż ycia omawianych
metod nawet w wypadku danych niezbyt licznych, a nawet niekompletnych.
2. Wnioskowanie na podstawie przykładó w
Uczenie i wnioskowanie na podstawie przykładów jest podstawowym elementem szeregu
technik obliczeniowych, utoż samianych najczęś ciej z terminem "sztuczna inteligencja", chociaż
bardziej adekwatne byłoby skromniejsze okreś lenie "metody komputacyjne". Uczenie takie
stanowi waż ny cel kompletowania i zajmowania się bazami danych. Niestety, wbrew
naturalnemu oczekiwaniu większoś ć informacji powstają cych w cyklach produkcyjnych i
wykonawczych w rozmaitych działach budownictwa i inż ynierii lą dowej, kolekcjonowana jest
raczej ze względów prawno-administracyjnych, a nie w celu dalszej eksploatacji naukowej.
Uwidacznia się to natychmiast, gdy tylko zaistnieje potrzeba przedstawienia ich w formie
elektronicznej, kiedy to trzeba mozolnie wpisywać dane z dzienników budowy czy z wytwórni
do elektronicznych arkuszy kalkulacyjnych.
Nawet pomimo takich ograniczeń technologowie dysponują obecnie dostępem do coraz
większej iloś ci masowych danych, często i pozornie słabo ze sobą powią zanych. Na dodatek
cią gle napływają dane nowe, pochodzą ce z róż nych oś rodków, publikacji, raportów czy atestów,
a oczywistą staje się koniecznoś ć moż liwie szybkiego i wiarygodnego analizowania wszystkich
takich informacji równocześ nie.
Posiadają c wiarygodny i uporzą dkowany zbiór danych, na podstawie znanych przykładów
trenują cych moż na klasyfikować zestawy danych nowych lub pojedyncze nowe rekordy do
rozpoznanych już wcześ niej klas, co otwiera moż liwoś ci szacowania (predykcji) właś ciwoś ci
dotyczą ce materiałów o zbliż onych cechach, które to materiały nie były jeszcze pod danym
względem badane.
Zadania, o jakich tu mowa, dają się realizować wyłącznie dzięki postępowi komputeryzacji.
Należ y pamiętać , ż e wnioskowanie na podstawie przykładów moż e być poprawne jedynie
w odniesieniu do atrybutów (cech, właś ciwoś ci) objętych zakresem przykładów trenują cych.
Wszelkie próby ekstrapolacji wyników poza taki zakres są zawsze bardzo ryzykowne.
3. Struktura bazy danych
Dane, z jakimi styka się technolog konstrukcji betonowych próbują cy uogólnić nowe
osią gnięcia, np. celem oceny i akceptacji nowych propozycji rynkowych, pochodzą z
rozmaitych źródeł. Opisy kolekcji danych w kontekś cie szeroko rozumianych metod sztucznej
inteligencji pojawiają się w cią gle jeszcze stosunkowo nielicznych opracowaniach, a do kwestii
formalizmu i poprawnego kształtowania takich zbiorów przykładana jest niedostateczna uwaga.
Zbiory danych, z jakich moż na korzystać w celach projektowania, i optymalizacji
materiałów konstrukcyjnych powstają w wyniku:
37
§
obserwacji stanów naturalnych elementów konstrukcji (in situ)
§
obserwacji podczas badań laboratoryjnych
§
realizacji pracochłonnych obliczeń o znanym algorytmie
§
symulowania procesów technologicznych o założ onych cechach rozkładu
§
procesów automatycznego przekształcania obrazów materiału
Analiza danych, co przyjęło się w nomenklaturze angielskiej okreś lać jako "górnictwo danych"
(data mining), obejmuje liczne dziedziny wiedzy, najczęś ciej bardzo odległe od inż ynierii
lą dowej. Poniż ej mowa jest o znacznie zawęż onym zakresie badań materiałowych, reali-
zowanych z pomocą rozmaitych metod, poczynają c od metod statystycznego rozpoznawania
struktur – np. 0, poprzez rozmaite realizacje sztucznych sieci neuronowych, np. 0, kończą c na
metodach z zakresu uczenia maszynowego, np. 0, 0.
Bazę danych w niniejszym tekś cie definiuje się jako odpowiednio uporzą dkowany zbiór
rekordów o ustalonej strukturze. Od luźnych notatek z rzeczywistych obserwacji bazę róż ni jej
sformalizowanie. Dobrym obyczajem jest rozpoczęcie pracy nad analizą danych od opracowania
tablicy charakteryzują cej strukturę bazy. Dotyczą cy omawianych dalej prób przykład pokazano
poniż ej – tab. 1.
Tablica 1. Charakterystyka atrybutów bazy danych
opis atrybutu jedn.
symbol
typ
funkcja min max
zakres
zmienn.
lub lista
uwagi
1
2
3
4
5
6
7
8
9
1 etykieta
rekordu
[ - ]
Key
label inf
np. numer
serii próbek
2 gęstoś ć
[kg/m
3
] gest
con
input
2250 2520 270
badanie
normowe
3 wytrz. 28d na
ś cisk.
[MPa] wytrz
con
input
20
120
100
badanie
normowe
4 porowatoś ć
[ % ]
porow
con
input
0.1
12.0 11.9
wg szlifu
5 wskaźnik
rozmieszcz.
porów
[mm]
L-factor con
input
0.01 0.6
0.59
wg szlifu
6 pow. porów [mm
-1
] alfa
lin
input
10
60
50
wg szlifu
7 klasa mrozo-
odpornoś ci
MrzOdp nom output -
-
odporny
nieodporny
metoda
Boras
Niezależ nie od sposobu faktycznego jej przechowywania na noś nikach elektronicznych
bazę danych moż na wyobrazić sobie jako tablicę, w której dokładnie ustalony jest zbiór
moż liwych wartoś ci poszczególnych pól. Ustalanie zawartoś ci pól następuje przez podanie
zakresu w wypadku zmiennych liczbowych, lub przez podanie katalogu (listy) moż liwych
wartoś ci, w wypadku zmiennych jakoś ciowych. Pola tablicy wypełniają liczby lub oznaczenia
alfanumeryczne, co oznacza, ż e jej elementami składowymi mogą być nie tylko liczby, ale i
łańcuchy tekstowe (łańcuchy alfanumeryczne - strings). Jednym z dopuszczalnych oznaczeń
moż e być takż e symbol braku informacji (tutaj przedstawiany jako '?').
Tablica danych zbudowana jest z wierszy i kolumn. W wypadku danych czysto
numerycznych tablica odpowiada prostoką tnej macierzy znanej z algebry liniowej. Wygodnie
jest jednak korzystać z oczywistej analogii i baza danych utoż samiana jest w tekś cie poniż ej z
macierzą o wymiarach m×n. Macierz danych ma m wierszy i n+1 kolumn, (etykiety są kolumną
dodatkową ). Liczby m i n okreś lają odpowiednio liczby rekordów w danej bazie (m) i liczbę
występują cych atrybutów (n). W podanym przykładzie w tab. 1 i tab. 2 – poniż ej, mowa jest o
macierzy o wymiarach 25×6.
38
Każ dy rekord jest pojedynczym wynikiem obserwacji, moż e takż e stanowić uś rednienie
z kilku obserwacji. Przykład układu prostej bazy zestawionej celem demonstracji w tym
opracowaniu pokazany jest poniż ej – tab. 2.
Tablica 2. Fragment (począ tek i koniec) macierzy rozważ anej bazy danych;
w pierwszym wierszu dołączono objaś nienia kolumn; symbole atrybutów wg tab. 1
Key
gest
wytrz
porow
L-factor
alfa
MrzOdp
1
2333
49.3
4.8
0.22
28
odporny
2
2348
50.0
4.2
?
?
nieodporny
3
2369
52.7
5.6
?
?
nieodporny
4
2351
57.2
5.6
?
?
nieodporny
5
2359
53.1
4.4
0.20
44
nieodporny
...
...
...
...
...
...
...
23
2371
?
?
?
38
odporny
24
2371
?
?
0.50
?
nieodporny
25
2371
?
?
0.10
?
odporny
Do celów demonstracji 25 rekordów bazy danych uzyskano bą dź z badań własnych, bą dź z
monografii 0 i 0. Ponieważ poszczególne źródła były niekompatybilne, dlatego na 125 pól w
macierzy danych występowało aż 56 braków (ok. 42% całoś ci), oznaczonych symbolem '?'.
Listę moż liwych typów atrybutów pokazano w tab. 3.
Tablica 3. Moż liwe typy atrybutów
typ
symbol
przykład
1 cią gły
con
x
Î
{ x: x > 3.15 AND x ≤ 14.00 }
2 cykliczny
cyc
x
Î
{ wiosna, lato, jesien, zima }
3 identyfikator
label
dowolny, zgodny z wymaganiami systemu
4 liniowy
lin
x
Î
{ 1, 7, 8, 11, 72, 356, 1435 }
5 logiczny
log
x
Î
{ FALSE, TRUE }
6 nominalny
nom
x
Î
{ bazalt, granit, wapień, pospółka-A, pospółka-C }
7 strukturalny
str
x
Î
{ r2-4, r2-8, r8-10, r10plus }
8 wyłączony
ign
- moż e zastą pić dowolny inny typ atrybutu
Atrybuty dzielą się na objaś niają ce i objaś niane, oznaczane w (tab.1) jako - odpowiednio - input
i output. Jak widać baza pomyś lana została tak aby na podstawie wybranych informacji na temat
próbki betonu stwardniałego – są to: gęstoś ć betonu, jego wytrzymałoś ć na ś ciskanie, zawartoś ć
powietrza oraz dwa parametry wynikają ce z analizy struktury napowietrzenia, np. zgodnie z
PrPN-EN 480-11, 0, okreś lić moż na było czy beton będzie mrozoodporny czy też nie, przy
badaniu mrozoodpornoś ci metodą złuszczania powierzchniowego (metoda Boras).
Wybrany przykład jest bardzo prosty i jednoznaczny. Jest on takż e stosunkowo
niekorzystny, jako ż e baza zawierała zarówno niewiele danych (tylko 25 rekordów) jak i duż y
procent pól pustych (45% ubytków).
Atrybuty objaś niają ce dzielić się mogą dodatkowo na atrybuty podstawowe lub pierwotne
(np. zawartoś ci w mieszance wody i cementu) oraz atrybuty pochodne (derived; np. stosunek
w/c w tej samej mieszance). Liczba tych ostatnich jest właś ciwie nieograniczona.

39
Należ y dodać , ż e dodatkowo, jeś li zachodzi potrzeba przejś cia ze zmiennych nominalnych
(jakoś ciowych) na iloś ciowe, będzie się to wią zało z trudnymi do przewidzenia skutkami.
Operacji takich należ y unikać . Inną komplikacją jest obecnoś ć w strukturze danych całych
rekordów niepewnych lub niepewnych wartoś ci niektórych składowych. Opisywanie ich
wymaga dołączenia dalszych atrybutów. W każ dym zbiorze danych dopuszczać trzeba ponadto
ewentualnoś ć występowania outliersów – i to zarówno outliersów rekordów jak i outliersów
atrybutów. Ich usunięcie, ewentualnie zaakceptowanie moż na oprzeć wyłącznie na analizie
statystycznej.
Efektywnoś ć niektórych programów typu ML zależ eć moż e od kolejnoś ci analizowania
rekordów i od uporzą dkowania atrybutów. Optymalne uporzą dkowanie wybrać moż na z
pomocą zaawansowanych technik statystycznych, np. GCA – technika pozwalają ca ustalić które
atrybuty są "bliż ej siebie" w sensie wyraźniejszej korelacji dodatniej lub ujemnej. Innym
rozwią zaniem jest stosowanie metody prób.
Dopuszczać należ y współobecnoś ć w bazie atrybutów aktywnych i nieaktywnych. W
wielu sytuacjach warto przechowywać informację o atrybutach pozbawionych oczywistego
wpływu na interesują ca uż ytkownika cechę, ponieważ dana informacja przydatna moż e okazać
się dopiero później.
Waż nym elementem bazy danych jest jej licznoś ć , jednoznacznoś ć i wiarygodnoś ć . Tę
ostatnią moż na jednak ocenić wyłącznie na podstawie oszacowania eksperta.
W opisie struktury bazy poza okreś leniem atrybutów w sensie ich treś ci podać trzeba
(tab. 1): jednostki (kolumna 2), oznaczenia symboliczne, niezbędne przy definiowaniu
przekształceń (kolumna 3), typ atrybutu (kolumna 4), funkcję w procesie predykcji (kolumna 5)
oraz zakresy dopuszczalnych wartoś ci (kolumny 6-8).
4. Techniki i narzędzia porzą dkowania i analizowania baz danych
Przy przygotowaniu i porzą dkowaniu danych najpierw stosuje się procedury statystyczne. M.in.
umoż liwiają one wstępne badanie danych, identyfikację rekordów nietypowych, (outliers), a
takż e uzupełnianie pól brakują cych.
Przeszukiwanie danych celem wygenerowania reguł decyzyjnych realizuje się
następnie za pomocą metod sztucznej inteligencji, Szczególną cechą tych metod jest
okolicznoś ć , ż e w wielu z nich występują jednostki wnioskują ce (inference machines),
których sposób funkcjonowania sprawdzić moż na wyłącznie poprzez odpowiednie
eksperymenty na zbiorach danych. Jednostki te zawierają pewne "czarne skrzynki",
których stanów w procesie rozpoznawania nie analizuje się, a jedynie korzysta z nich po
wytrenowaniu, jako z narzędzi poszukiwanego odwzorowywania, np. przestrzeni
zmiennych wejś ciowych na wyjś ciowe.
Zestaw narzędzi komputacyjnych z zakresu omawianych tu badań charakteryzuje
tab. 4. Z poś ród wzmiankowanych w tej tablicy narzędzi, w przykładzie poniż szym
zastosowano dwa rozwią zania z zakresu uczenia się maszyn - ML - Machine learning;
pozycje 4 i 5.
5. Przykład: reguły wykryte metodami ML
Reguły decyzyjne wygenerowano w odniesieniu do zbiorów wg tab. 1 i tab. 2 metodą tworzenia
pokryć zbioru danych. Program pozwala wyspecyfikować wielkoś ci współczynnika rozmiesz-
czenia włókien (L z kreską ), gęstoś ci stwardniałego betonu (gest), oraz współczynnika
charakteryzują cego powierzchnię porów widzianych na szlifie próbki (alfa), warunkują ce
przynależ noś ć rekordu do jednej z dwóch klas mrozoodpornoś ci: "odporny" lub "nieodporny".
40
Tablica 4. Narzędzia obliczeniowe stosowane w próbach klasyfikacji i aproksymacji
właś ciwoś ci kompozytów betonopodobnych
cele rozwią zanie algorytm
ocena
1
MatLab-
NeuralNet
works
sztuczne sieci neuronowe ze
wsteczną propagację błędu
wyłącznie kompletne bazy danych;
atrybuty iloś ciowe; kiepska
aproksymacja przy opisach
niecią głych
2
SSN ART.
sieci typu Fuzzy ARTMAP
wyłącznie atrybuty iloś ciowe;
3
aiNet
pseudo SSN oparta na doborze
optymalnej wartoś ci estymatora
wyłącznie atrybuty iloś ciowe; łatwy
w stosowaniu
4
ML
AQ 19
ML - tworzenie reguł na zasadzie
uczenia indukcyjnego
szerokie moż liwoś ci okreś lania
warunków pracy
5
ML
See5
ML - tworzenie reguł na podstawie
budowy drzew decyzyjnych
nazbyt proste reguły; duż a łatwoś ć
obsługiwania
6
MatLab-
Statistics
podstawowa analiza statystyczna,
regresja wielowymiarowa, PCA,
analiza skupisk
duż e moż liwoś ci jednak wyłącznie
odnoś nie baz z atrybutami czysto
iloś ciowymi
7
GradeStat
gradacyjna analiza danych
umoż liwiają ca ocenę i racjonalne
ich przygotowanie do badań ML
specjalistyczny program z IPI PAN
8
SPSS
statystyczne badania podstawowe,
analiza skupisk, składowych
głównych, etc.
kosztowny program, który w wersji
podstawowej nie udostępnia
moż liwoś ci typu SSN czy ML
9
Rosetta
zastosowanie teorii zbiorów
przybliż onych
niska przydatnoś ć , skutkiem
generowania nadmiernych iloś ci
bardzo specyficznych reguł
Wynik uzyskany przez program AQ19 ma formę skryptu 0:
który przekłada się na sformułowanie słowne (anglojęzyczne operatory "OR" i "AND" poniż ej
zastą piono przez - odpowiednio: "ALBO" i "ORAZ"):
jeż eli zachodzi warunek:
to analizowany beton należ y do klasy:
L-factor<0.27 ALBO
gest>2371.00 ORAZ porow>3.80 ALBO
gest>2371.00 ORAZ alfa
Î
(30, 44)
odporny
natomiast, przy warunku:
analizowany beton należ y do klasy:
porow<4.80 ALBO
gest>2371.00 ORAZ alfa
Î
(0, 24)
nieodporny
odporny-outhypo
# rule
1 [L-factor<0.27] (t:5, u:4, n:3, q:0.479619)
2 [gest>2371.00] [porow>3.80] (t:4, u:3, n:1, q:0.552 771)
3 [gest>2371.00] [alfa=30..44] (t:1, u:1, n:0, q:0.333333)
nieodporny-outhypo
# rule
1 [porow<4.80] (t:10, u:8, n:1, q:0.6835)
2 [gest>2371.00] [alfa=0..24] (t:3, u:1, n:0, q:0.433013)
41
Rule 4/1: (6.9/1.8, lift 1.6)
porow > 4.4
-> class odporny [0.681]
Rule 4/2: (7.2, lift 1.5)
porow <= 4.4
-> class nieodporny [0.891]
Na 25 analizowanych rekordów bazy reguły te odpowiadały 18 rozpoznaniom poprawnym
i 6 błędnym, przy czym wś ród poprawnie rozpoznanych rekordów aż 10 dotyczyło informacji
niepełnej (pola rekordów zawierały symbole '?').
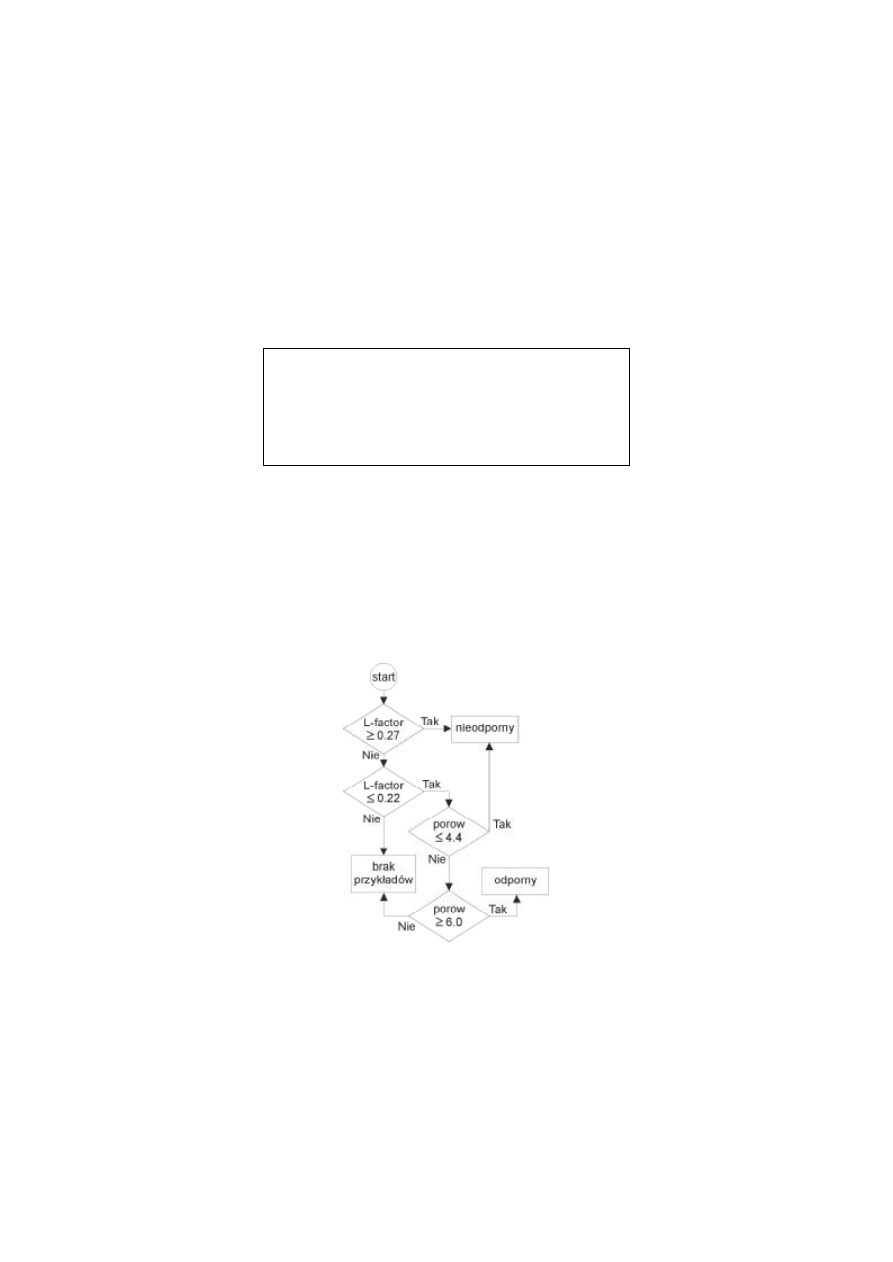
W wypadku programu zastosowania programu See5, działają cego na zasadzie tworzenia i
adaptacji drzew decyzyjnych 0, wynik działania programu pozwala narysować drzewo pokazane
dalej – rys. 3.
Przy odpowiednim nastawieniu program ten oprócz drzew decyzyjnych generuje również
reguły decyzyjne. Przykład pokazany jest w ramce poniż ej:
W zbiorze 25 rekordów (9 w klasie "odporny" i "16 w klasie "nieodporny"), podane powyż ej
reguły przy ocenie badanego zbioru 25 rekordów dają 10 poprawnych ocen "nieodporny", bez
ż adnej oceny błędnej oraz 5 poprawnych i dwie błędne oceny klasy "odporny". Reguła podana
w ramce powyż ej jest nazbyt prosta z punktu widzenia posługiwania się nią w praktyce,
natomiast przynależ noś ć konkretnego rekordu do danej kategorii oceniana jest w programie na
zasadzie głosowania ("komitet reguł"), co w efekcie daje wysoką jakoś ć kwalifikowania
poszczególnych rekordów do odpowiednich klas, 0 0.
Łatwo zauważ yć , ż e generowane przez oba programy w sposób automatyczny reguły
zgodne są z oceną danych przez eksperta. Reguły nie są analogiczne, moż na natomiast
podejmować próby ich łączenie (komplementarnoś ć ).
Rys. 2. Drzewo decyzyjne wygenerowane przez See5; dane wg tab. 1 i tab. 2
6. Wnioski koń cowe
Prawidłowo przygotowana i racjonalnie eksploatowana baza danych umoż liwia automatyczne
uzyskiwanie poprawnych predykcji z pomocą rozmaitych metod komputacyjnych (metod

42
sztucznej inteligencji). Postępowanie moż e być skuteczne nawet wówczas, jeż eli baza zawiera
znaczne ubytki informacji. W szczególnych wypadkach pozwoli to na łączenie baz wiedzy nie w
pełni kompatybilnych (tzn. o zróż nicowanych strukturach).
Otwarte jednak pozostaje wówczas zagadnienie odnoś nie oceny tego jak okreś lić
graniczny poziom takich ubytków w bazie danych, przy którym predykcja właś ciwoś ci
materiałów lub wykrywanie reguł pozostają jeszcze sensowne. Jest niewykluczone, ż e podobnie
jak przy zagadnieniach doboru architektury lub ustawiania parametrów sztucznych sieci
neuronowych, odpowiedź na powyż sze pytanie moż e być tylko oparta na odpowiednich
eksperymentach informatycznych, dają cych zadowalają cą przydatnoś ć uzyskiwanych wyników.
Zestawianie bazy danych należ y poprzedzić formalnym sporzą dzeniem opisu tej struktury,
tak jak pokazano w przykładzie (tab. 1). W miarę moż liwoś ci bazę należ y konstruować biorą c
pod uwagę moż liwoś ci jej przyszłej rozbudowy, przestrzegają c zwłaszcza zasad poprawnoś ci
identyfikacji, w tym jednoznacznoś ci i niezmiennoś ci nazewnictwa. Wskazana jest nawet
rejestracja szczegółów "na zapas", ponieważ nakład pracy przy uzupełnianiu bazy danych moż e
być porównywalny z nakładem pracy przy tworzeniu całej bazy od począ tku.
Literatura
[1] WEBB A., Statistical pattern recognition. ARNOLD, London 1999, 454 ss.
[2] KASPERKIEWICZ J., ALTERMAN D., Wykorzystanie metod sztucznej inteligencji
przy projektowaniu mieszanek betonowych. Referaty XLVII Konferencji Naukowej KILW
PAN I KN PZITB, Opole-Krynica 2001, t.1 – Materiały budowlane, 331-338
[3] QUINLAN J.R., C4.5: Programs for machine learning. Morgan Kaufmann Publishers,
San Mateo, California 1993, 302 ss.
[4] MITCHELL T.M., Machine learning. WCB/MacGraw-Hill, Boston MA 1997, 414 ss.
[5] NEVILLE A.M., Właściwości betonu. Polski Cement, Kraków 2000, 874 ss.
[6] FAGERLUND G., Trwałość konstrukcji betonowych. Arkady, Warszawa 1997, 93 ss.
[7] ZAŁ OCHA D., KASPERKIEWICZ J., Automatyzacja wyznaczania charakterystyki
napowietrzenia betonu w ś wietle normy PrPN-EN 480-11. Referaty XLVII Konferencji
Naukowej KILW PAN I KN PZITB, Opole-Krynica 2001, t.1 – Mat.budowl., 437-444.
[8] MICHALSKI R.S., KAUFMAN K.A., The AQ19 system for machine learning and
patterndiscovery: a general description and user’s guide, George Mason University,
MLI 01-2, March 2001, 39 ss.
[9] CICHOSZ P., Systemy uczą ce się. WNT, Warszawa 2000, 894 ss.
ANALYSIS OF DATABASES IN CONCRETE-LIKE MATERIALS
Summary
Rapid progress in technology of concrete and of similar composite materials imposes changing from the
conventional methods of data analysis (like constructing specific models of materials or models of
processes, based on a small number of precisely designed experiments) to automatic analysis, enabling
quick processing of large databases obtained from laboratories or building sites by machine learning
(ML), artificial neural networks and similar computing tools. Database preparation procedure is shortly
explained and an example of correct rule generation process with help of two ML programs (AQ19 and
See5) is presented. The experiment gave correct predictions of concrete frost resistance class (estimated by
Boros method), in spite of the base being of minimal size (25 records of 5 attributes) and having 45%
voids (empty spaces) in its structure.
Wyniki uzyskano z pomocą finansowania ze ś rodków KBN – Projekt KBN: 8 T11F 01317-Predykcja
właś ciwoś ci kompozytów betonopodobnych przy zastosowaniu metod uczenia się maszyn oraz
NATO – Projekt 97 1888 SfP-Concrete Diagnosis.
Wyszukiwarka
Podobne podstrony:
Analiza baz danych na temat materiałów betonopodobnych
cwiczonko drugie z baz danych na stopieniek
cwiczonko drugie z baz danych na stopieniek
cwiczonko drugie z baz danych na stopieniek
3 Szkup Jabłońska M Analiza opinii społecznych na temat wy
Litania Loretańska w quenya, Tolkien, Inne teksty na temat twórczości, Nieposegregowane materiały o
materiały do pracy na temat stresu
Wariacje na temat ziół, materiały farmacja, Materiały 4 rok, LPN
Analiza ankiety na temat zadowolenia ze studiów
Materia dodatkowy nt Baz Danych encr
Czy neutrina mogą nam coś powiedzieć na temat asymetrii między materią i antymaterią we Wszechświeci
Materiały na temat Umowy Czarterowej i Klauzul
Analiza reklamy zestawu witamin „VIGOR”, materiały na studia, szkoła - prace, analiza reklam
Biblijne przesłanie w pracach Tolkiena, Tolkien, Inne teksty na temat twórczości, Nieposegregowane m
Analiza tekstu na perswazję, Materiały, Perswazja
Analiza ankiety na temat czytelnictwa i wykorzystania zbiorów bibliotecznych, Bibliotekoznawstwo, Bi
Materialy na temat Konosamentu Nieznany
Ankieta dla nauczyciela na temat procesu dydaktycznego, Materiały dydaktyczne EFS
Ankieta na temat oczekiwań rodziców względem nauczycieli, materiały szkolne, wychowawcze
więcej podobnych podstron