
SPRAWOZDANIE Z ĆWICZENIA
LABORATORYJNEGO NR 3
Przedmiot: Systemy dialogowe
Temat: Urządzenie automatycznego rozpoznawania
sygnału mowy metodą rozpoznawania wzorców
Prowadzący: dr inż. Andrzej Wiśniewski
Wykonał: Wojciech Węgrecki
Grupa: I9G2S1

1) Założenia:
-
mały słownik wyrazów rozpoznawanych: 10 słów,
-
jednostka fonetyczna: całe słowo.
Do rozpoznania wybrałem 10 przypadkowych słów:
budzik
gazeta
książka
kubek
motor
plecak
pociąg
rower
samochód
telefon
2) Przygotowad dane:
- sformułowad słownik wyrazów rozpoznawanych;
- dokonad rejestracji wszystkich słów (każde słowo 15-krotnie, w
oddzielnym pliku .wav);
- do rejestracji przyjąd: f
s
= 22050 Hz, 16 bitów/próbka, kodowanie
PCM, mono;
Wszystkie słowa wymienione w punkcie 1 nagrałem w oddzielnych plikach z
wyżej wymienionymi parametrami. Zostały nazwane w jednoraki sposób –
SłowoNr.wav np. budzik1.wav.
3) Zdefiniowad wzór testowy
Wzorzec słów został zdefiniowany jako wektor, przetrzymujący średnie
charakterystyczne wielkości dla poszczególnych słów. Użyte wartości dla
każdego słowa to:
Energia sygnału
2
1
( )
N
n
E
s n

Długośd sygnału
Liczba przejśd przez zero
2
1
|
[ ( )]
[ (
1)] |
2
N
n
PPZ
sign z n
sign z n
Współczynniki FFT
Współczynniki LPC
Podsumowując wzór mojego wektora wygląda w następujący sposób:
WZOR = [Energia sygnału, długość sygnału, liczba przejść przez zero,
współczynniki FFT, współczynniki LPC]
Wszystkie składowe wzorca zostały obliczone za pomocą kodu:
E=sum(s.^2);
L=length(s);
z1=2:L;
z2=1:L-1;
PPZ = sum(abs(sign(s(z1))-sign(s(z2))))/2;
FFT = sum(fft(s));
LPC=sum(abs(lpc(s,1300)));
WZOR = [E L PPZ FFT LPC];
4) Opracowad procedurę uczenia - utworzyd wzorce słów:
- zdefiniowad wzorzec,
- określid ciąg uczący,
- dokonad estymacji parametrów wzorców
Następnym krokiem było przygotowanie wzorców – czyli etap nauki naszego
programu. Program pobiera pliki *.wav (pierwsze 5 nagrane w etapie
przygotowania danych) i wylicza wzorce zgodnie ze wzorem przedstawionym w
punkcie 3. Aplikacja z naszych pięciu wzorców wylicza jeden, który jest średnia
arytmetyczną wszystkich.
1
2
3
4
5
5
WZOR
WZOR
WZOR
WZOR
WZOR
WZORZEC

5) Opracowad procedurę rozpoznawania
Do rozpoznawania zostało użytych 10 pozostałych nagrao. Przebieg procedury
rozpoznawania wygląda następująco: wartości poszczególnych składowych
dźwięku podanego przez nas na wejściu są porównywane z wartościami
składowych we wzorcu każdego ze słów. Rozpoznanym wyrazem zostaje ten
którego różnica jego parametrów z parametrami wzorca określonego wyrazu
jest najmniejsza. Dodatkowym elementem usprawniającym działanie słownika
było wprowadzenie przeze mnie wag. Każdy z elementów wzorca po odjęciu
jest przemnażany przez wartośd, która jest swojego rodzaju ważnością każdej
składowej. Wartości te zostały wyznaczone doświadczalnie tak, aby
zmaksymalizowad wynik rozpoznania wyrazów. Największe znaczenie w moim
programie mają współczynniki LPC, a najmniejszą długośd, gdyż wszystkie słowa
są podobnej długości. Aby móc zweryfikowad wyniki rozpoznania
poszczególnych słów, wartośd dla każdego z nich zapisywana jest w
odpowiednich polach macierzy rozpoznanie_pojedyn. Aby obliczyd całkowitą
skutecznośd programu wystarczyło zsumowad pierwszy wiersz tej macierzy.
Realizuje to poniższy kod:
rozpoznanie_pojedyn=zeros(2,10);
waga=[1 0.2 3 10 77];
for
i=1:10
for
j=6:15
[s,fs]=wavread(strcat(deblank(A(i,:)),int2str(j)));
E=sum(s.^2);
L=length(s);
z1=2:L;
z2=1:L-1;
PPZ = sum(abs(sign(s(z1))-sign(s(z2))))/2;
FFT = sum(fft(s));
LPC=sum(abs(lpc(s,1300)));
WZOR = [E L PPZ FFT LPC];
pom=zeros(10,1);
for
z=1:10
pom(z,1)=sum(abs(WZORZEC(z,:)-WZOR).*waga);
end
;
[C,I]=min(pom);
if
(I==i)
rozpoznanie_pojedyn(1,i)=rozpoznanie_pojedyn(1,i)+1;
else
rozpoznanie_pojedyn(2,i)=rozpoznanie_pojedyn(2,i)+1;
end
;
end
;
end
;
rozpoznanie_laczne=sum(rozpoznanie_pojedyn(1,1:10));
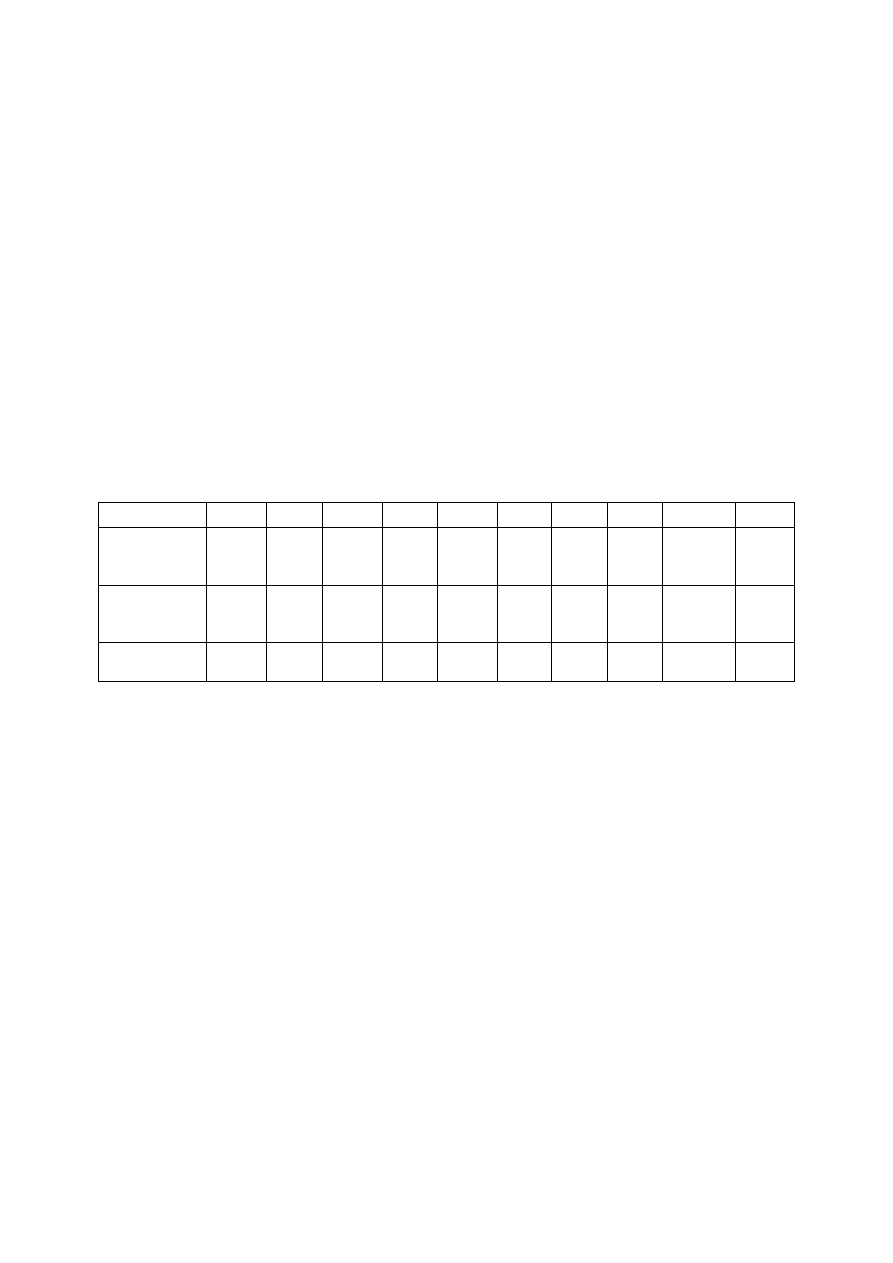
disp(strcat(
'Procentowe
rozpoznanie:'
,int2str(rozpoznanie_laczne),
'%'
));
disp(rozpoznanie_pojedyn);
6) Dokonad weryfikacji i testowania urządzenia:
- określid ciąg testowy
- wyznaczyd statystyki rozpoznawania (estymatory
prawdopodobieostwa poprawnego rozpoznania, analiza błędów
rozpoznawania)
- zaproponowad kierunki zmian w celu poprawienia jakości
zbudowanego urządzenia ARM
Mój program osiągnął wynik rozpoznania 87%, co jest dosyd dobrym wynikiem.
Poniżej przedstawiam tabelę przedstawiającą wyniki dla poszczególnych słów:
Budzik
Gazeta
Książka Kubek
Motor
Plecak
Pociąg
Rower
Samochód Telefon
Liczba
prawidłowo
rozpoznanych
10
8
10
9
10
5
7
9
10
9
Liczba
błędnie
rozpoznanych
0
2
0
1
0
5
3
1
0
1
Procent
rozpoznania
100% 80%
100% 90% 100% 50%
70%
90%
100%
90%
Najsłabiej rozpoznanymi słowami są „plecak” i „pociąg”. Wynika to z tego, że są
to słowa brzmiące podobnie i mogły byd mylone ze sobą. Początek i koniec obu
wypowiadane są tak samo. Poza tym na wynik ten mógł mied wpływ słabej
jakości mikrofon używany do nagrywania oraz fakt, że nagrania nie były
wykonywane w pomieszczeniu wyciszonym od dźwięków zewnętrznych.
Według mnie, aby poprawid jakośd ARM należałoby lepiej określid wzorce,
które później miałyby byd rozpoznawane. Pięciokrotne wypowiedzenie jednego
słowa nie daje nam rzetelnych wyników. Żeby osiągnąd lepsze rezultaty
należałoby wyciągnąd średnią z dużo większej ilośd wzorców. Oprócz tego aby
zwiększyd rozpoznawanie trzeba by było dodad kilka składowych do wzorca. W
profesjonalnych programach do rozpoznawania mowy wykorzystywanych jest
znacznie więcej współczynników (np. funkcje autokorelacji, moc sygnału,
współczynniki cepstralne). Wszystkie wyżej wymienione zabiegi wraz z lepszej
jakości mikrofonem i pomieszczeniem do nagrywania mogłyby dad dużo lepsze
wyniki rozpoznawania wyrazów.
Wyszukiwarka
Podobne podstrony:
I9G2S1 Węgrecki Wojciech Lab3
I9G2S1 Węgrecki Wojciech sprawozdanie, WAT, SEMESTR V, systemy dialogowe, SDial, SD cwiczenia 5
I9G2S1 Węgrecki Wojciech sprawozdanie lab5
I9G2S1 Węgrecki Wojciech Lab4
I9G2S1 Wegrecki sprawozdanie, WAT, SEMESTR V, podstawy symulacji
I9G2S1 Joanna Rutkowska lab3
I9G2S1 Joanna Rutkowska lab3
I9G2S1 Skrzypczynski Węgrecki lab2
I9G2S1 Skrzypczynski Wegrecki l Nieznany
I9G2S1 Skrzypczynski Węgrecki lab2
I9G2S1 Skrzypczynski Węgrecki lab1, WAT, SEMESTR V, podstawy bezpieczenstwa informacji
4 ŚMIERĆ ŚWIĘTEGO WOJCIECHA
lab3
lab3 kalorymetria
Instrukcja Lab3
lab3 6
więcej podobnych podstron