
11. MPI: Definicja standardu
11. MPI: Definicja standardu
Cz
Cz
ęść
ęść
III
III
Lesław Sieniawski © 2010

Operacje grupowe
Operacje grupowe
Operacje grupowe
=
anga
ż
uj
ą
ce wszystkie procesy
danego komunikatora
- domy
ś
lnie, procesy nale
żą
do
MPI_COMM_WORLD
- programista odpowiada za to,
ż
e wszystkie procesy
komunikatora uczestnicz
ą
w operacjach grupowych
Rodzaje operacji grupowych
:
-
synchronizacja
(czekanie na osi
ą
gni
ę
cie zadanego punktu)
-
przesyłanie danych
(ró
ż
ne rodzaje)
-
wspólne obliczenia
(redukcje)

Operacje grupowe (2)
Operacje grupowe (2)
Zasady ogólne
:
- operacje grupowe s
ą
blokuj
ą
ce
- operacje grupowe nie korzystaj
ą
z etykiet
komunikatów
- operacje na podzbiorach procesów wymagaj
ą
uprzedniego utworzenia grup i przekształcenia ich
w nowe komunikatory
- nie mo
ż
na stosowa
ć
własnych typów danych
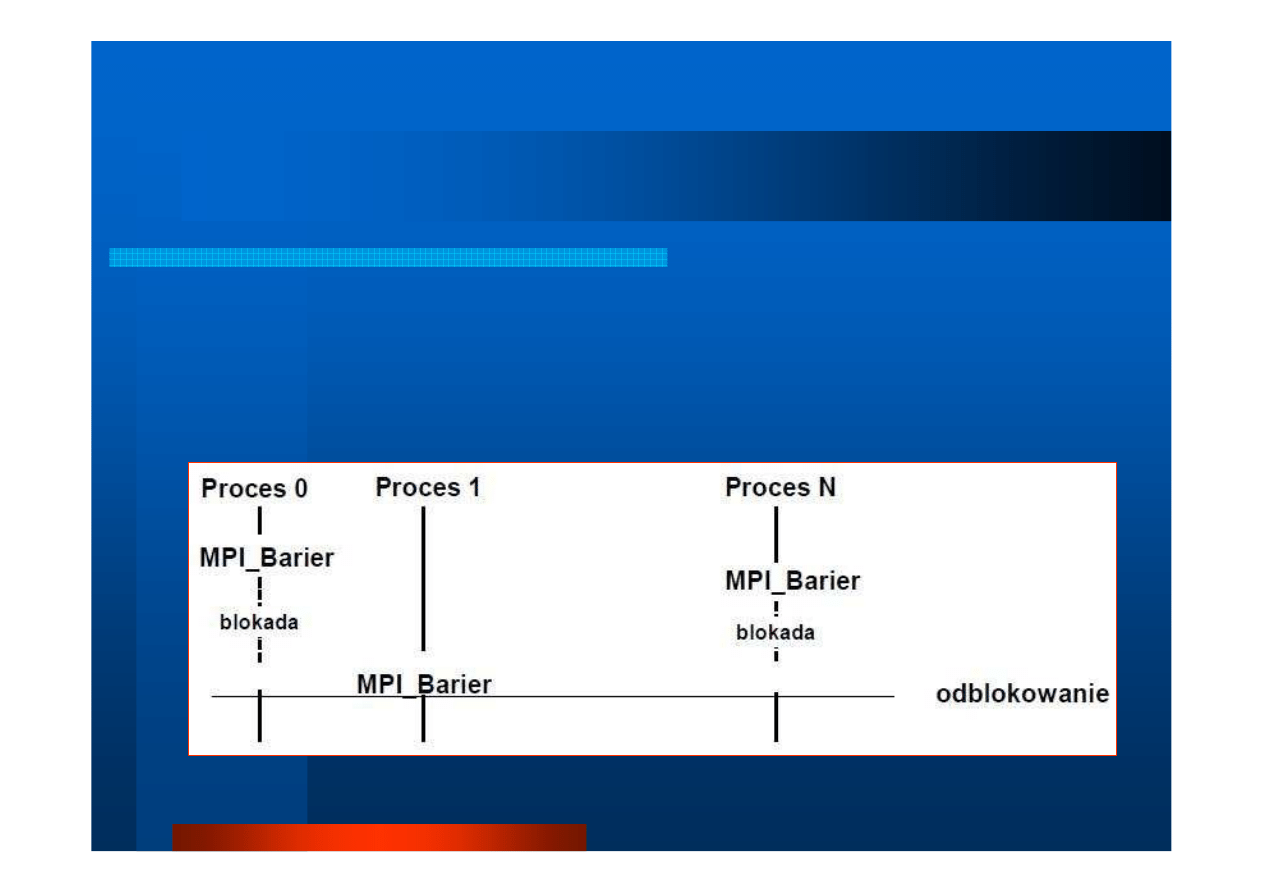
Operacje grupowe (3)
Operacje grupowe (3)
int MPI_Barrier (MPI_Comm comm)
zatrzymanie bie
żą
cego procesu a
ż
do chwili, gdy wszystkie
procesy komunikatora
comm
wywołaj
ą
t
ę
funkcj
ę
[
ź
ródło: jedrzej.ulasiewicz.staff.iiar.pwr.wroc.pl/Progr-Wspol-i-Rozprosz/wyklad/MPI14.pdf
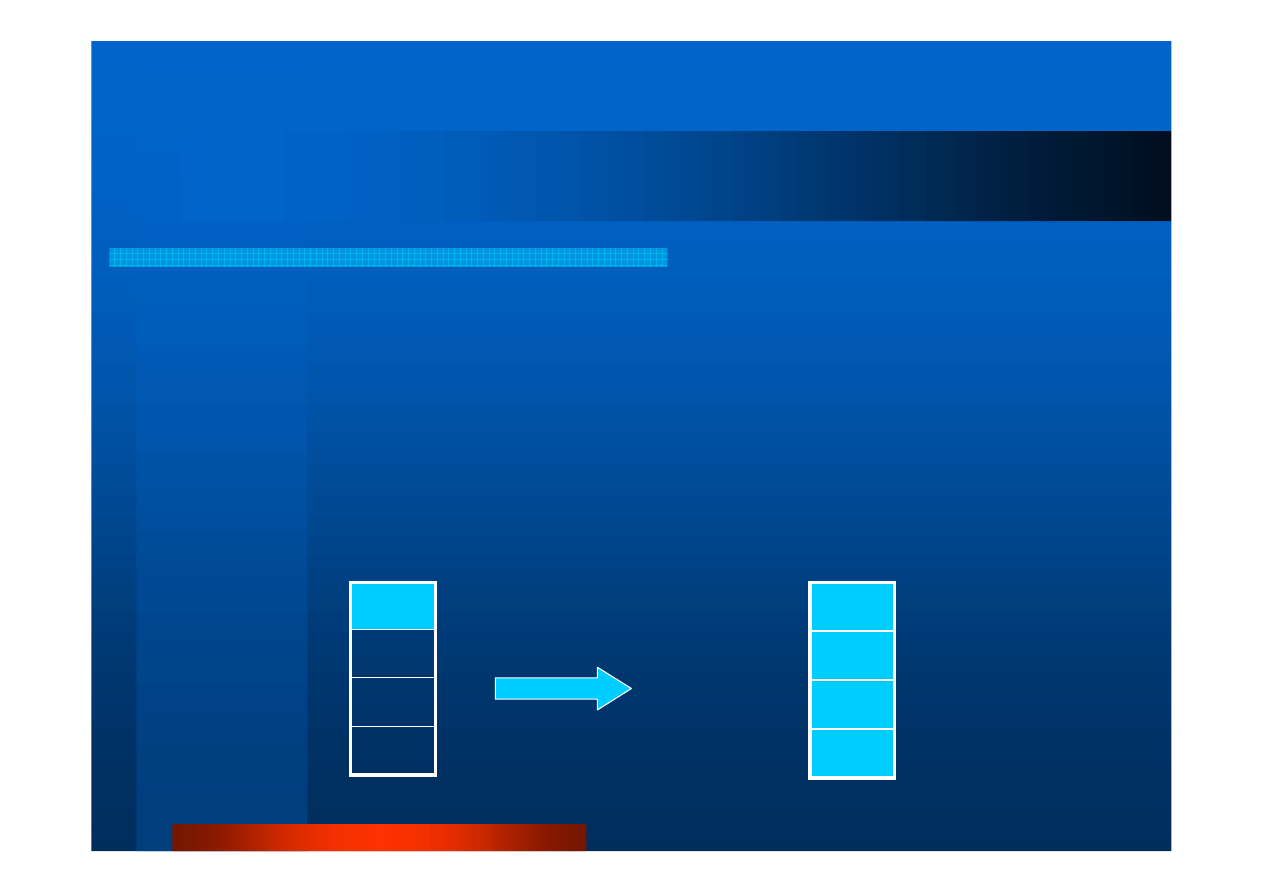
Operacje grupowe (4).
Operacje grupowe (4).
Rozg
Rozg
ł
ł
aszanie
aszanie
int MPI_Bcast(void *buffer,\
int count, MPI_Datatype datatype,\
int root, MPI_Comm comm)
rozgłaszanie komunikatu (ang. broadcast) z bufora
buffer
przez dowolny proces
root
do wszystkich procesów
komunikatora
comm
;
count
i
datatype
– liczba elementów
i typ wysyłanych danych
A
Proces 0
Proces 1
Proces P
A
A
A
A
Proces 0
Proces 1
Proces P
MPI_Bcast
Stan PO wykonaniu
procedury

#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <mpi.h>
/*
Oprac. LS na podstawie:
http://d3s.mff.cuni.cz/~ceres/sch/mwy/text/ch06s07s05.php
*/
int main (int iArgC, char *apArgV [])
{
int iRank;
int iLength;
int iSize;
char *pMessage;
char acMessage [] = "Hello World !";
MPI_Init (&iArgC, &apArgV);
MPI_Comm_rank (MPI_COMM_WORLD, &iRank);
MPI_Comm_size (MPI_COMM_WORLD, &iSize);
if (iRank == 0)
{ iLength = sizeof (acMessage);
MPI_Bcast (&iLength, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast (acMessage, iLength, MPI_CHAR, 0, MPI_COMM_WORLD);
printf ("Process 0: Message '%s' sent to %d recipient(s).\n", acMessage, iSize-1);
}
else
{
MPI_Bcast (&iLength, 1, MPI_INT, 0, MPI_COMM_WORLD);
pMessage = (char *) malloc (iLength);
MPI_Bcast (pMessage, iLength, MPI_CHAR, 0, MPI_COMM_WORLD);
printf ("Process %d: Message received '%s'\n", iRank, pMessage);
}
MPI_Finalize ();
return (0);
}
Program #1.
Program #1.
Broadcast
Broadcast

Kompilacja i uruchomienie. Program #1
Kompilacja i uruchomienie. Program #1
[root@p205 openMPI]#
mpicc broadcast.c -o broadcast
[root@p205 openMPI]#
mpirun -n 1 --mca btl tcp,self broadcast
Process 0: Message 'Hello World !' sent to 0 recipient(s).
[root@p205 openMPI]#
mpirun -n 4 --mca btl tcp,self broadcast
Process 0: Message 'Hello World !' sent to 3 recipient(s).
Process 2: Message received 'Hello World !'
Process 1: Message received 'Hello World !'
Process 3: Message received 'Hello World !'
[root@p205 openMPI]#
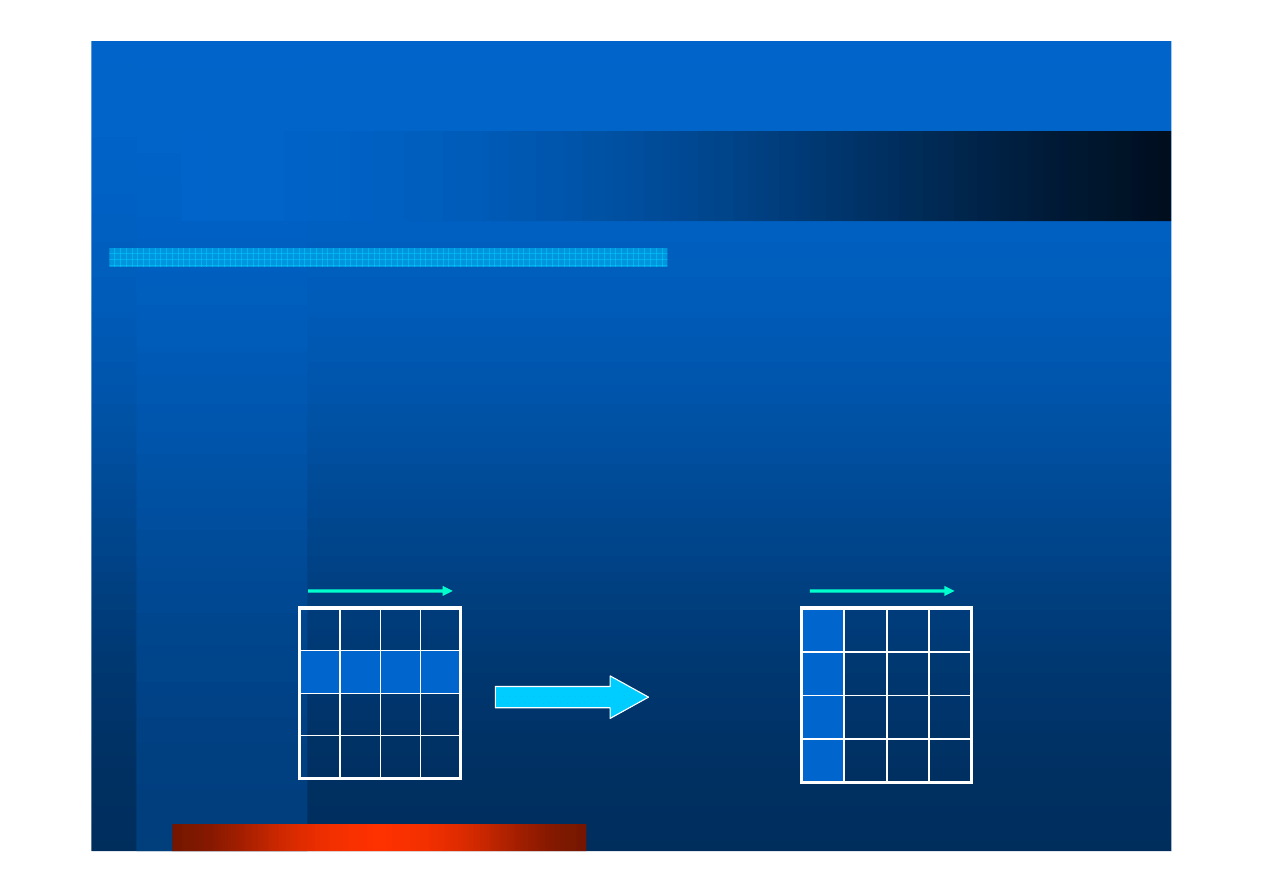
Operacje grupowe (5).
Operacje grupowe (5).
Rozsy
Rozsy
ł
ł
anie
anie
int MPI_Scatter( \
void *sendBuf,int sendCnt,MPI_Datatype sendType,\
void *recvBuf,int recvCnt,MPI_Datatype recvType,\
int root, MPI_Comm comm)
proces
root
dzieli dane z bufora nadawczego
sendBuf
na segmenty
o jednakowej długo
ś
ci
sendCnt
elementów i rozsyła je do buforów odbiorczych
recvBuf
wszystkich procesów komunikatora
comm
(ł
ą
cznie z procesem-
nadawc
ą
);
sendCnt/recvCnt
oraz
sendType/recvType
– odpowiednio
liczba elementów i typ danych wysyłanych/odbieranych
D
C
B
A
Proces 0
Proces 1
Proces P
Proces 0
Proces 1
Proces P
MPI_Scatter
Stan PO
wykonaniu
procedury
Dane
D
C
B
A
Dane
sendBuf
recvBuf

Operacje grupowe (6)
Operacje grupowe (6)
Przykładowe u
ż
ycie
MPI_Scatter()
…
MPI_COMM comm;
// komunikator
int grpSize;
// liczba procesów
int *sendBuf;
// wsk. bufora nadawczego
int rootProc;
// nr procesu nadawczego,
int recvBuf[80];
// bufor odbiorczy
…
MPI_Comm_size(comm, &grpSize);
// pobranie liczby procesów
sendBuf = (int *)malloc(grpSize*80+sizeof(int));
//utworz. bufora nadawczego i przypisanie wska
ź
nika
MPI_Scatter
(sendBuf,80,MPI_INT,recvBuf,80,MPI_INT,rootProc,comm);
//rozesłanie fragmentów danych po 80 liczb do procesów
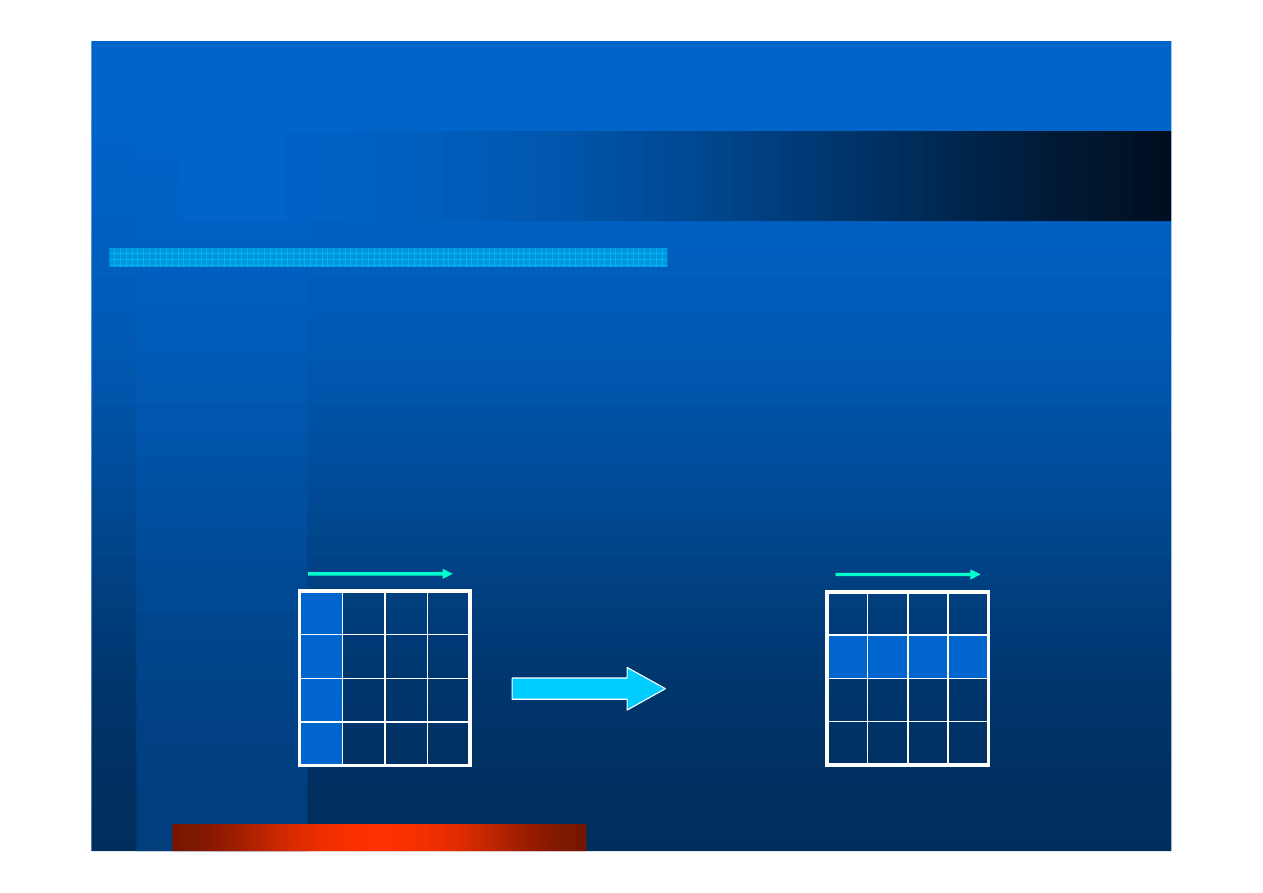
Operacje grupowe (7).
Operacje grupowe (7).
Gromadzenie
Gromadzenie
int MPI_Gather( \
void *sendBuf,int sendCnt,MPI_Datatype sendType,\
void *recvBuf,int recvCnt,MPI_Datatype recvType,\
int root, MPI_Comm comm)
procesy nale
żą
ce do komunikatora
comm
przesył
ą
j
ą
do procesu
root
fragmenty
danych o długo
ś
ci
sendCnt
jednostek typu
sendType
z bufora
sendBuf
; proces
root
gromadzi (scala) te dane i umieszcza w buforze
recvBuf
w kolejno
ś
ci
numeracji procesów
MPI_Gather
Stan PO
wykonaniu
procedury
Proces 0
Proces 1
Proces P
Dane
D
C
B
A
D
C
B
A
Proces 0
Proces 1
Proces P
Dane
sendBuf
recvBuf

Operacje grupowe (8)
Operacje grupowe (8)
Przykładowe u
ż
ycie
MPI_Gather()
…
MPI_COMM comm;
// komunikator
int grpSize;
// liczba procesów
int sendBuf[80];
// bufora nadawczy
int rootProc;
// nr procesu odbiorczego,
int procID;
// nr procesu bie
żą
cego
int *recvBuf;
// wsk. bufora odbiorczego
…
MPI_Comm_rank(comm, &procID);
if (procID == rootProc)
{ MPI_Comm_size(comm, &grpSize);
// pobranie liczby procesów
recvBuf = (int *)malloc(grpSize*80+sizeof(int));
//utworz. bufora nadawczego i przypisanie wska
ź
nika
}
MPI_Gather
(sendBuf,80,MPI_INT,recvBuf,80,MPI_INT,rootProc,comm);
//pobranie fragmentów danych po 80 liczb od wszystkich procesów
//i umieszczenie ich kolejno w buforze
recvBuf

Inne operacje grupowe.
Inne operacje grupowe.
Redukcja
Redukcja
int MPI_Reduce ((void *)sendBuf,\
(void *)recvBuf, int cnt,\
MPI_Datatype dataType, MPI_Op opType,\
int root, MPI_Comm comm)
wykonanie przez proces
root
oblicze
ń
na danych zwróconych
przez wszystkie procesy komunikatora
comm
w buforach
sendBuf
; obliczenia polegaj
ą
na wykonaniu operacji typu
opType
na danych typu
dataType
o długo
ś
ci
cnt
, a wynik
umieszczany jest w buforze
recvBuf
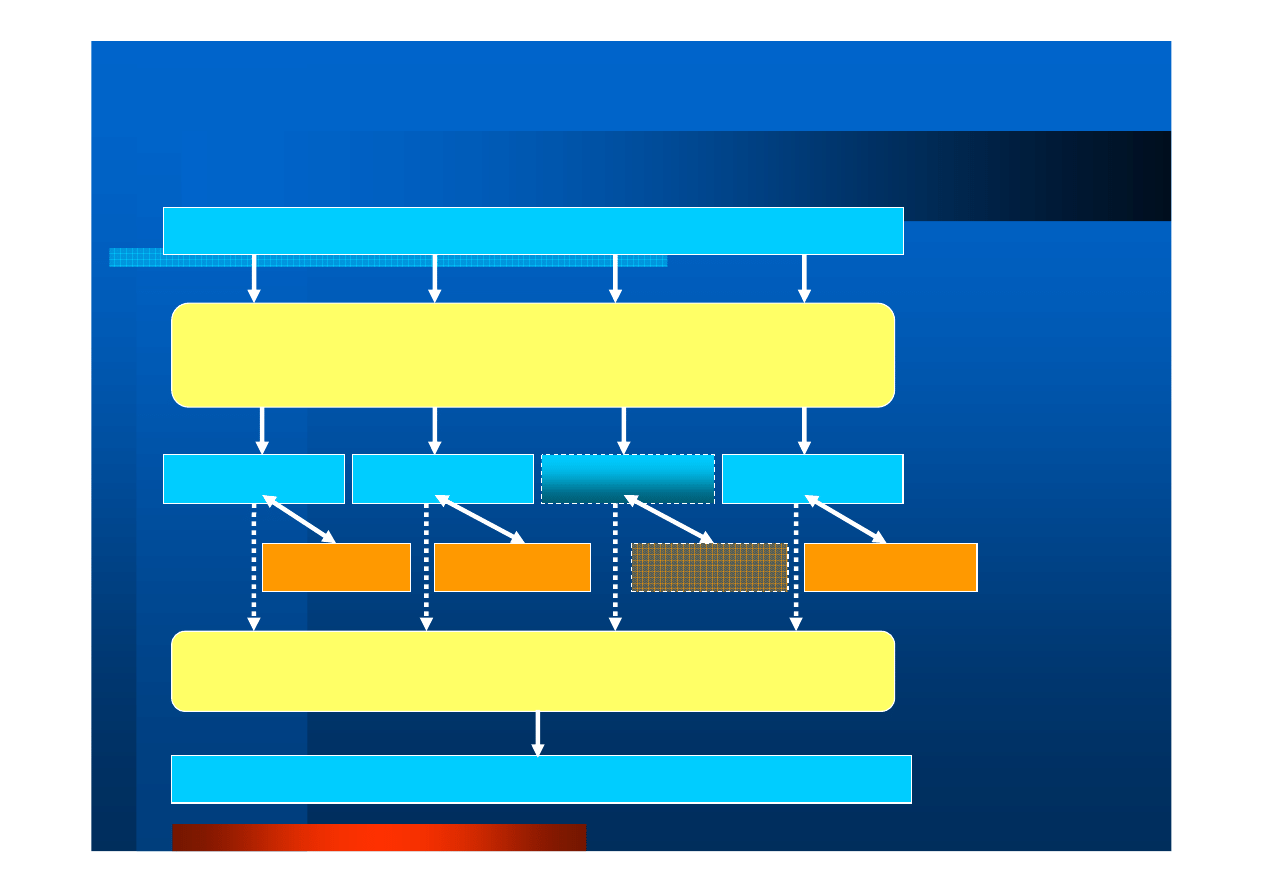
Schemat post
Schemat post
ę
ę
powania przy podziale domeny
powania przy podziale domeny
int buforDomeny[bufSize]
Domena wej
ś
ciowa
(uporz
ą
dkowany
zbiór danych)
buforFragmentu
buforFragmentu
buforFragmentu
Uporz
ą
dkowany
zbiór poddomen
MPI_Bcast(bufSize, 1, MPI_INT,…)
MPI_Scatter(buforDomeny,&bufSize,MPI_INT,…,\
buforFragmentu,…)
Operacja
rozpraszania:
- Wielko
ś
ci bufora,
- Danych wej
ś
ciowych
Obliczenia
lokalne
Obliczenia
lokalne
Obliczenia
lokalne
MPI_Gather(buforWynikowyDomeny,&bufSize,\
MPI_INT,…,buforFragmentu,…)
int buforWynikowyDomeny[bufSize]
Domena wynikowa
(uporz
ą
dkowany
zbiór wyników)
Operacja
scalania
Danych: np.
Gather, Reduce

#include <mpi.h>
#include <math.h>
#include <stdio.h>
/*
Oprac. LS na podstawie
http://www.mcs.anl.gov/research/projects/mpi/usingmpi/examples/simplempi/main.htm
*/
int main(int argc, char *argv[])
{
int n, myid, numprocs, i, rc;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x, a;
double t_begin, t_end;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (1) // p
ę
tla dla wielokrotnych oblicze
ń
{ if (myid == 0)
{
printf("Enter the number of intervals: (0 quits)\n ");
scanf("%d",&n);
t_begin = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0) break;
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs)
{ x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x*x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
{ printf("pi is approximately %.16f, Error is %.16f\n", pi, fabs(pi - PI25DT));
t_end = MPI_Wtime();
printf("Time elapsed: %.12f [s]\n", t_end-t_begin);
}
}
MPI_Finalize();
return 0;
}
Program #2. Obliczanie
Program #2. Obliczanie
π
π
przez ca
przez ca
ł
ł
kowanie
kowanie

Kompilacja i uruchomienie. Program #2
Kompilacja i uruchomienie. Program #2
[root@p205 openMPI]#
./mcc MPI-pi
[root@p205 openMPI]#
./mrun 2 MPI-pi
Enter the number of intervals: (0 quits)
1000000
pi is approximately 3.1415926535899388, Error is 0.0000000000001457
Time elapsed: 0.034721136093 [s]
Enter the number of intervals: (0 quits)
1000000000
pi is approximately 3.1415926535900072, Error is 0.0000000000002141
Time elapsed: 12.683905124664 [s]
Enter the number of intervals: (0 quits)
0
[root@p205 openMPI]#
./mrun 8 MPI-pi
Enter the number of intervals: (0 quits)
1000000000
pi is approximately 3.1415926535898278, Error is 0.0000000000000346
Time elapsed: 3.210227966309 [s]
Enter the number of intervals: (0 quits)
0
[root@p205 openMPI]#

Skrypty
Skrypty
mcc
#!/bin/sh
# kompilacja mpicc
mpicc $1.c -o $1
mrun
#!/bin/sh
# lokalne uruchomienie programu MPI
# z maks. 2 parametrami:
#
mrun liczba_procesów program [par1 [par2]]
mpirun -n $1 --mca btl tcp,self $2 $3 $4

Inny przyk
Inny przyk
ł
ł
ad
ad
Szkielet programu sortowania b
ą
belkowego
z wykorzystaniem MPI:
http://jedrzej.ulasiewicz.staff.iiar.pwr.wroc.pl/
Progr-Wspol-i-Rozprosz/wyklad/MPI14.pdf
(do uzupełnienie i sprawdzenia)

Topologie wirtualne
Topologie wirtualne
Standardowe uporz
ą
dkowanie procesów MPI
w grupie/komunikatorze – liniowe {0,1,…,N-1}
MPI dostarcza topologii
– Kartezja
ń
skiej
(procesy tworz
ą
macierz
wielowymiarow
ą
, mog
ą
identyfikowa
ć
swoje
poło
ż
enie i s
ą
siadów)
– Grafowej
(dowolny układ procesów)
Topologia
= uogólnienie komunikatora

Topologie wirtualne (2)
Topologie wirtualne (2)
Cel stosowania
:
– Wygoda
•
Lepsze odwzorowanie struktury aplikacji, np. dotycz
ą
cych
problemów 2D, 3D
– Efektywno
ś
c komunikacji
•
Odwzorowanie procesów w topologie wirtualn
ą
zachodzi
w implementacji MPI i nie jest widoczne dla programisty
•
Koszt komunikacji pomi
ę
dzy wirtualnie odległymi w
ę
złami
mo
ż
e by
ć
optymalizowany przez implementacj
ę
na
podstawie fizycznych wła
ś
ciwo
ś
ci maszyny
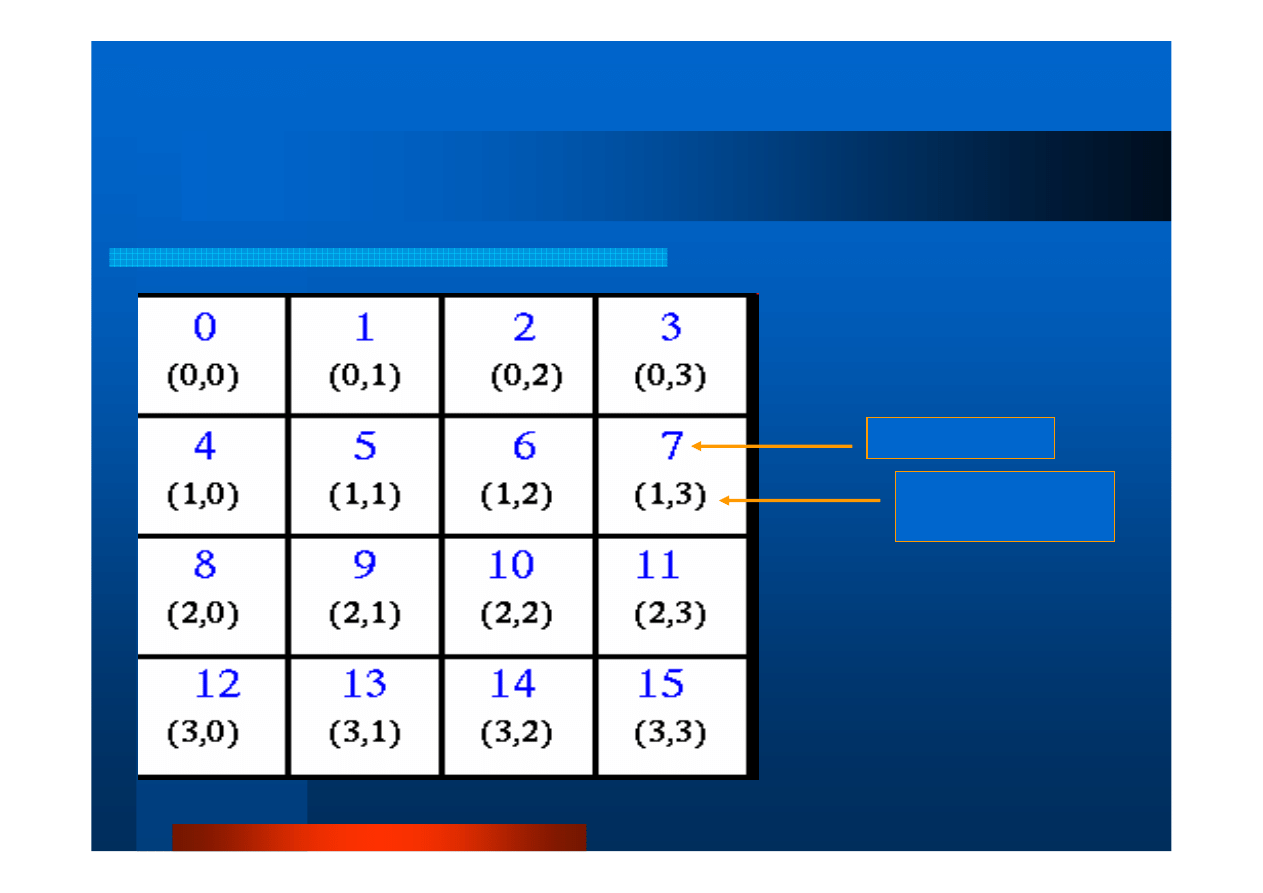
Topologie wirtualne (3)
Topologie wirtualne (3)
[źródło: https://computing.llnl.gov/tutorials/mpi/]
Przykład topologii kartezja
ń
skiej:
16 procesów tworzy macierz
2-wymiarow
ą
.
Numer procesu
Poło
ż
enie procesu
w macierzy
Wyszukiwarka
Podobne podstrony:
10 MPI Definicja standardu 2
9 MPI Definicja standardu
11 Rachunek kosztów standardowych
gatunek filmowy definicja (11)
11. Standard kaniulacji żyły, MEDYCZNE, ANASTEZOLOGIA i PIEL ANSTZJOLOGICZNE
Podstawowe definicje z zakresu budownictwa 11 12
Standardy (rozdz.11), Egzamin
Definicje procesu i pod procesowego (1) (1) 2015 04 10 11 33 26 017
11 Standardowe wkłady k k
Standard V 11
definicja i etapy, Wystawy, Dziecko w Sieci, Plansza 11 - uwodzenie w sieci
sprawdzian standaryzacja 11
Standardy Sprawozdawczosci Finansowej 6.11.10 - 15.01.11
11 1 1 Definicjeid 12328 ppt
Jawnosc i jej ograniczenia Standardy europejskie Tom 11
STANDARD 802 11 charakterystyka1
definicja czułości wg standardu ISO
(11) Obwieszczenie KE ws definicji rynku właściwego
więcej podobnych podstron