Indeks jest dodatkową strukturą zaprojektowaną specjalnie w celu przyspieszenia
dostępu do danych. Jest on fizycznie i logicznie niezależny od danych, znajdujących się
w skojarzonej z nim tabeli lub klastrze. Poprawnie skonstruowane i odpowiednio używane
indeksy mogą w znaczny sposób zredukować operacje wejścia – wyjścia na plikach danych,
a tym samym zwiększyć wydajność systemu. Indeks prezentuje się w sposób niewidoczny dla
użytkownika, a więc jego zastosowanie bądź rezygnacja z jego wykorzystania nie wymaga
zmian w aplikacji. Niemniej jednak będąc świadomym jego istnienia, należy to wykorzystać
już na etapie tworzenia zapytań SQLa.
Indeks może być zbudowany na podstawie jednej lub wielu kolumn tabeli. Pożytek
ze stosowania indeksów w dużej mierze zależy od tzw. selektywności kolumn, na których jest
tworzony indeks.
Najlepszą selektywność posiadają indeksy unikalne.
Przykładem złej selektywności może być indeks zbudowany na kolumnie,
zawierającej wartości typu „tak – nie”, „prawda – fałsz”, tzn. w przypadku, gdy każda z tych
wartości występuje wiele razy.
Indeks nie zawsze musi być zbudowany na kolumnie, która umożliwia redukowanie
zbioru do jednego wiersza, np. indeks zbudowany na kolumnie, zawierającej nazwiska
pracowników zwraca wszystkie wiersze, posiadające w kolumnie nazwisko tą samą wartość.
W systemi Oracle można wyróżnić dwa główne typy indeksów:
- drzewiasty (B*tree).
- bitmapowy.
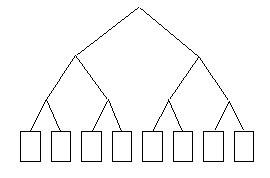
Indeks drzewiasty swoją budową przypomina drzewo, a przeszukiwania polegają na
przechodzeniu drogi od korzenia poprzez gałęzie do liści, gdzie znajdują się dane.
Indeks bitmapowy zbudowany na zasadzie map bitowych, tworzony jest dla każdej
unikalnej wartości kolumny w każdym wierszu.
W bazie danych Oracle najczęściej stosuje się indeksy drzewiaste.
W indeksie drzewiastym wszystkie liście znajdują się na tym samym poziomie.
Dojście do każdego z nich znajduje w praktyce tyle samo czasu niezależnie od wartości
wyszukiwanego klucza, dlatego też indeksy tego typu zapewniają wysoką wydajność, która
nie zależy od wielkości tabeli.
1z3
Metody dostępu do indeksu B*tree:
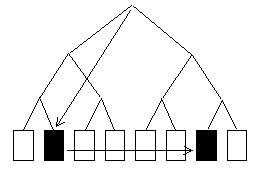
- przegląd unikalny (ang. unique scan) – wyszukiwanie następuje w dół od korzenia do
liścia, który w tym przypadku zawiera tylko jeden adres – ten liść. System Oracle wykonuje
przegląd unikalny wtedy i tylko wtedy, gdy warunek zapytania opiera się na kluczu
unikalnym lub kluczu głównym.
- przegląd zakresu (range scan) – w pierwszym etapie tego typu przeglądu standardową
ścieżką wyszukiwany jest liść, który zawiera początkową wartość zakresu, a następnie
następuje przegląd po liściach aż do napotkania wartości końcowej zakresu.
-
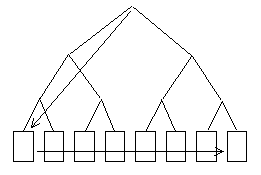
przegląd pełny (full scan) – odczyt następuje blok po bloku, a nawigacja po liściach. Jest
on używany także do sortowania.
- przegląd szybki pełny (fast full scan) – odczyt wielkoblokowy stosowany jest, gdy
zbędny jest dostęp do tabeli. W tej metodzie przeglądu to indeks jest traktowany jako wąska
tabela, zawierająca tylko kolumny będące jego kluczem.
2z3
CREATE INDEX indeks
ON {tabela(atrybut[, atrybut[...]]) | cluster klaster}
[potfree liczba]
[initrans liczba]
[maxtrans liczba]
[tablespace przestrzeń_tabeli]
Indeks bitmapowy zorientowany jest na zwiększenie szybkości przetwarzania typu
OLAP. Liczba bitów mapy odpowiada liczbie rekordów tabeli R, natomiast liczba map
bitowych dla danego atrybutu odpowiada liczbie różnych wartości tego atrybutu.
Reasumując należy stwierdzić, że nie można jednoznacznie powiedzieć, iż jeden typ
indeksu jest lepszy od drugiego typu. Każdy z nich najlepiej sprawdza się w zadaniach, do których został stworzony.
Indeks B*tree:
- skuteczny dla atrybutów z dużą dziedziną wartości.
- zapewnia efektywne wykonanie operacji koniunkcji.
- jego wielkość słabo zależy od wielkości dziedziny atrybutów.
- posiada bardzo wysoką współbieżność modyfikacji.
- zapewnia niski koszt pojedynczej modyfikacji.
- wykazuje stosunkowo wysoki koszt modyfikacji grupy wierszy (każda wartość
modyfikowana oddzielnie).
- główne zastosowanie to OLTP (ang. On - line Transaction Processing).
Indeks bitmapowy:
- skuteczny dla atrybutów z małą dziedziną wartości.
- zapewnia efektywne wykonanie operacji alternatywy i koniunkcji.
- jego wielkość silnie zależy od wielkości dziedziny atrybutów.
- posiada niską współbieżność modyfikacji.
- zapewnia wysoki koszt pojedynczej modyfikacji.
- wykazuje stosunkowo niski koszt modyfikacji grupy wierszy (każda wartość
modyfikowana oddzielnie).
- główne zastosowanie to OLAP (ang. On - line Analitic Processing).
3z3
Wyszukiwarka
Podobne podstrony:
wykl 8 Mechanizmy
Stomatologia czesc wykl 12
Wykł 1 Omówienie standardów
Wykl 1
KOMPLEKSY POLAKOW wykl 29 03 2012
Wykł 1B wstępny i kinematyka
Ger wykł II
Wykł BADANIA KLINICZNO KONTROLNE I PRZEKROJOWE
Wykł 05 Ruch drgający
podstawy prawa wykl, Prawo dz 9
łuszczyca wykł
Proj syst log wykl 6
WYKL 5b zmiana kształtu odlewu
Wykł ZP Wprowadzenie i Mierniki
więcej podobnych podstron