Metody Analizy Rynku
Rynek notbooków
1.Prezentacja i omówienie danych będących podstawą analizy.
Celem powyższego projektu jest analiza rynku notbookow przeznaczonych dla klientów nie będących użytkownikami instytucjonalnymi - firmy o specjalistycznych potrzebach (np. komputery przystosowane do obróbki grafiki).
Do opisu notbookow wybraliśmy 6 zmiennych:
Procesor (jednostka MHz)
Typ procesora (100 - Pentium III, 200 - Celeron)
Monitor/Wyświetlacz (przekątna, jednostka -cale)
RAM (jednostka MB)
Dysk (jednostka GB)
Modem (1- posiada modem, 0 - bez modemu)
Cena (jednostka - zł)
Do analizy powyższego projektu wykorzystywaliśmy pakiet STATISTICA wersja 6.0
Poniżej przedstawiam dane będące podstawa analizy w powyższym projekcie.
|
NAZWA |
|
PROCESOR |
TYP_PROC |
MONITOR |
RAM |
DYSK |
MODEM |
CENA |
1 |
Aristo F |
|
700.000 |
Pentium |
15.100 |
64.000 |
10.000 |
TAK |
8421.000 |
2 |
Aristo S |
|
600.000 |
Celeron |
13.300 |
64.000 |
10.000 |
TAK |
5965.000 |
3 |
HP OmniB |
|
1000.000 |
Pentium |
14.000 |
128.000 |
20.000 |
NIE |
8748.000 |
4 |
Satelite |
|
600.000 |
Celeron |
14.000 |
32.000 |
6.000 |
TAK |
5028.000 |
5 |
LiveBook |
|
650.000 |
Pentium |
14.100 |
64.000 |
10.000 |
NIE |
9630.000 |
6 |
IBM Thin |
|
900.000 |
Pentium |
14.100 |
128.000 |
20.000 |
TAK |
7981.000 |
7 |
Acer Tra |
|
800.000 |
Celeron |
14.100 |
128.000 |
10.000 |
TAK |
5389.000 |
8 |
Aristo T |
|
600.000 |
Pentium |
12.100 |
64.000 |
10.000 |
TAK |
7223.000 |
9 |
Armada 1 |
|
800.000 |
Pentium |
14.100 |
64.000 |
10.000 |
TAK |
6158.000 |
10 |
Armada E |
|
900.000 |
Pentium |
14.100 |
128.000 |
20.000 |
NIE |
7717.000 |
11 |
HP OmniB |
|
600.000 |
Celeron |
12.100 |
64.000 |
10.000 |
TAK |
9118.000 |
12 |
N600C |
|
1066.000 |
Pentium |
14.100 |
128.000 |
20.000 |
TAK |
9007.000 |
13 |
Portege |
|
650.000 |
Pentium |
13.300 |
64.000 |
12.000 |
TAK |
8836.000 |
14 |
Satellit |
|
600.000 |
Celeron |
14.100 |
128.000 |
10.000 |
TAK |
8164.000 |
15 |
Satellit |
|
650.000 |
Celeron |
13.300 |
64.000 |
6.000 |
TAK |
7380.000 |
16 |
Satellit |
|
650.000 |
Celeron |
12.100 |
64.000 |
6.000 |
TAK |
5924.000 |
17 |
ThinkPad |
|
700.000 |
Celeron |
15.000 |
64.000 |
20.000 |
TAK |
7166.000 |
18 |
Acer Tra |
|
800.000 |
Pentium |
14.100 |
128.000 |
10.000 |
NIE |
7888.000 |
19 |
Aristo P |
|
600.000 |
Pentium |
12.100 |
64.000 |
6.000 |
TAK |
7676.000 |
Ocena jednorodności danych
W celu zweryfikowania hipotezy o jednorodności danych - w sensie nie występowania obserwacji nietypowych mogących zniekształcić wyniki analizy (szczególnie takie miary jak współczynnik korelacji). Metoda Cambella przypisuje każdej obserwacji wagę z przedziału [0,1], która określa stopień typowości danych. W pierwszej iteracji zakładamy że wszystkie obserwacje są tak samo dobre, a więc przypisujemy im wagi równe 1. W kolejnych iteracjach wagi są modyfikowane w zależności od odległości Mahalnobisa każdej obserwacji od środka odległości próby. Proces ten jest kontynuowany jest aż do ustabilizowania się wag. Dodatkowe informacje na temat tej metody można uzyska w książce prof. Witolda Miszczaka - „Statystyczne Metody Analizy Danych”. Analiza do powyżswego opracowania została wykonana za pomocą programu do Analizy szeregów finasowych - „NEUROINTREST” ver.1.0 Autorstwa Tomasz Oczadłego. W dodatku nr.1 dołączam kod źródłowy realizujący omawianą metodę w jezyki C++.
Tab. Wyniki analizy metodą Cambella - dane podstawowe - bez Typ_Proc, i Modem 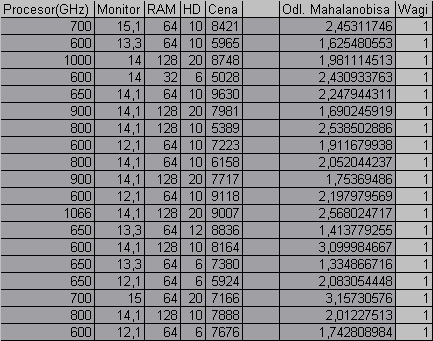
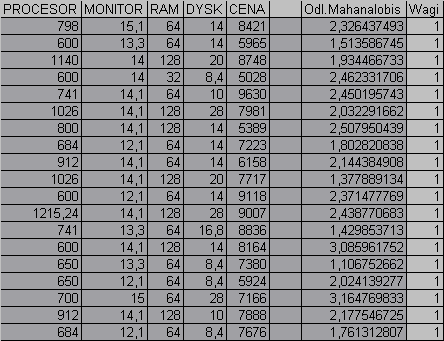
Tab. Wyniki analizy metodą Cambella - dane zmodyfikowane - patrz rozdzial 3.
Wyniki analizy:
Po przeanalizowaniu powyżej tabeli widzimy, iż wszystkim danym zostały przypisane wagi o wartości równej jeden. Można, więc na tej podstawie wyciągnąć wniosek iż analiza odległości pomiędzy poszczególnymi obserwacjami w przestrzeni zmiennych nie wykazuje większych odchyleń które można by było uznać za nietypowe. Na tej podstawie można wyciągnąć wniosek o jednorodności danych ( w sensie typowości).
2. Opis metody pobierania próby.
Pobierając próbę do powyższych badań marketingowych korzystaliśmy z zasobów Internetu. Kilkanaście znanych firm zajmujących się produkcją sprzętu komputerowego udostępniła nam swoją ofertę. Oferta dotyczyła znajdujących się w sprzedaży notbookow klasy średniej. Należy tutaj podkreślić, iż notboki te zawierały się w cenach od 5 - 20 tys.zł. W naszych badaniach celowo ominęliśmy notbooki klasy powyżej 20 tys.zł. wynika to z faktu iż są to najczęściej maszyny przeznaczone dla firm lub użytkowników o wyższych wymaganiach. Natomiast naszym celem jest analiza rynku z punktu widzenia przeciętnego klienta a nie firmy czy osoby zajmującej się profesjonalnie np. grafiką i wymagającego bardzo specjalistycznego sprzętu.. Dlatego też przyjęcie powyższych założeń w naszym przypadku wydaje być się sensownym.
Podczas procesu doboru próby wykorzystaliśmy metodę doboru losowego. W tym celu wykorzystaliśmy tablice losowe (liczby wygenerowane przez funkcje rand()). Każdej z dostępnych obserwacji przypisaliśmy jakąś liczbę losową z przedziału [0,10]. Wybraliśmy te obserwacje których numery wpadły do przedziału od [3,7].
3. Wyznaczenie współczynników korealcji
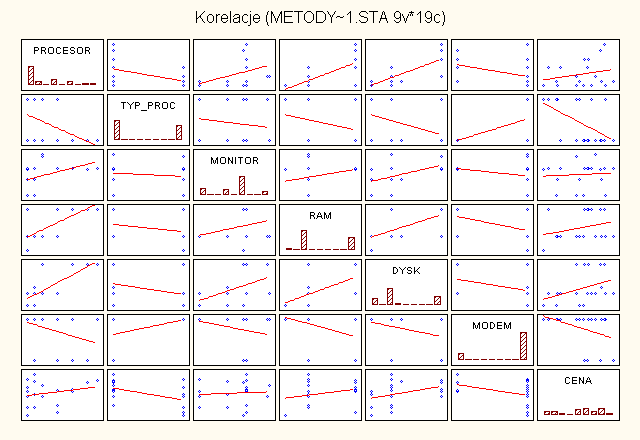
Wykres. Wykres rozrzutu z liniami regresji dla zmiennych.
Tab. Współczynniki korelacji. Na czerwono podkreślone wsp. Z poziomem istotności poniżej 0,05.
Po przeanalizowani zarówno wykresu jak i tabeli możemy stwierdzić, iż największa korelacja cechują się zmienne RAM - Procesor, HD(Dysk Twardy - pojemność) - Procesor. Natomiast z cena najbardziej jest skorelowana zmienna - typ procesora, (Pentium, Celeron). Jednak wartość ta wynika z faktu, iż jest to zmienna przyjmująca tylko dwie wartości, co zaburza oszacowanie współczynnika korelacji z metoda Persona. Z drugiej strony nie możemy analizować tylko częstotliwości procesorów abstrahując od ich typu.
Dlatego też dokonamy pewnego przekształcenia danych. Mianowicie częstotliwości procesorów typu Pentium przemnożymy przez stałą 1.14, Natomiast typy Celeron zostawimy nienaruszone, jednocześnie redukując zbiór zmiennych o zmienna typ procesora. Dodatkowo dokonamy również modyfikacji Zmiennej HD z punktu widzenia drugiej zmiennej Modem.
Wszystkie pojemności Dysków (HD) nottboków wyposażonych w modem zostaną przemnożone przez wartości 1.4. Wynika to z faktu, iż użytkownik nottboka, który posiada modem może przechowywać swoje dane na serwerach (na zasadzie dysków zewnętrznych), oraz ma dostęp do dużej liczby informacji („poprzez modem”), które normalnie musiałby przechowywać na swoim dysku.
Dane po zmodyfikowaniu
|
NAZWA |
PRODUCEN |
PROCESOR |
MONITOR |
RAM |
DYSK |
CENA |
1 |
Aristo F |
Aristo |
798.000 |
15.100 |
64.000 |
14.000 |
8421.000 |
2 |
Aristo S |
Aristo |
600.000 |
13.300 |
64.000 |
14.000 |
5965.000 |
3 |
HP OmniB |
HP |
1140.000 |
14.000 |
128.000 |
20.000 |
8748.000 |
4 |
Satelite |
Toshiba |
600.000 |
14.000 |
32.000 |
8.400 |
5028.000 |
5 |
LiveBook |
Fujitsu/ |
741.000 |
14.100 |
64.000 |
10.000 |
9630.000 |
6 |
IBM Thin |
IBM |
1026.000 |
14.100 |
128.000 |
28.000 |
7981.000 |
7 |
Acer Tra |
Acer |
800.000 |
14.100 |
128.000 |
14.000 |
5389.000 |
8 |
Aristo T |
Aristo |
684.000 |
12.100 |
64.000 |
14.000 |
7223.000 |
9 |
Armada 1 |
Compaq |
912.000 |
14.100 |
64.000 |
14.000 |
6158.000 |
10 |
Armada E |
Compaq |
1026.000 |
14.100 |
128.000 |
20.000 |
7717.000 |
11 |
HP OmniB |
HP |
600.000 |
12.100 |
64.000 |
14.000 |
9118.000 |
12 |
N600C |
Compaq |
1215.240 |
14.100 |
128.000 |
28.000 |
9007.000 |
13 |
Portege |
Toshiba |
741.000 |
13.300 |
64.000 |
16.800 |
8836.000 |
14 |
Satellit |
Toshiba |
600.000 |
14.100 |
128.000 |
14.000 |
8164.000 |
15 |
Satellit |
Toshiba |
650.000 |
13.300 |
64.000 |
8.400 |
7380.000 |
16 |
Satellit |
Toshiba |
650.000 |
12.100 |
64.000 |
8.400 |
5924.000 |
17 |
ThinkPad |
IBM |
700.000 |
15.000 |
64.000 |
28.000 |
7166.000 |
18 |
Acer Tra |
Acer |
912.000 |
14.100 |
128.000 |
10.000 |
7888.000 |
19 |
Aristo P |
Aristo |
684.000 |
12.100 |
64.000 |
8.400 |
7676.000 |
Nowe oszacowania współczynników korelacji.
Wykres. Wykres rozrzutu z liniami regresji dla zmiennych
Tab. Współczynniki korelacji. Na czerwono podkreślone wsp. Z poziomem istotności poniżej 0,05.
Po przeanalizowani zarówno wykresu jak i tabeli możemy stwierdzić, iż największa korelacja cechują się znowu zmienne RAM - Procesor, HD(Dysk Twardy - pojemność) - Procesor. Natomiast z cena najbardziej jest skorelowana zmienna Procesor, oraz Dysk (HD). Oszacowania te nie można jednak przyjąć za istotne na poziomie 5%.

Tab. Dokładne oszacowania korelacji zmiennych z Cena
Współczynniki istotności zarówno dla Procesora jak i HD w porównaniu do innych cech są najniższe. Aby potwierdzić powyższe przypuszczenia, co do istnienia zależności liniowych pomiędzy tymi dwoma zmiennymi należałoby zwiększyć liczebność próby. My jednak nie będziemy tego robić i założymy istotność oszacowana współczynników korelacji.
4. Wybrać dwa największe współczynniki korelacji i dla par je reprezentujących narysować mapy pozycjonowania produktów.
Poniżej przedstawiamy tabelę zawierająca statystyki opisowe dla wybranych cech opisujących nottboki. W dalszej kolejności prezentowane są wykresy rozrzutu dla wybranych cech w stosunku do Ceny. Na wykresach umieszczono również linie regresji wraz z przedziałami ufności dla regresji.
Tab. Statystyki opisowe danych zmodyfikowanych 
Wykres. Wykres pozycjny dla Ceny w stosunku do Dysku.
Wykres. Wykres pozycjny dla Ceny w stosunku do Procesora.
.
5. Wyznaczyć średnią cenę oraz średnie wartości i nanieść proste odpowiadające tym punktom na wykresy.
.
6. Porównaj mapy z punktu widzenia stabilności.
Poniższy rysunek wskazuje przesunięcia punktów z wykresu Cena - Dysk w porównaniu z Cena - Procesor. Oprócz notbooka ThinkPad A212 firmy IBM nie nastąpiły znaczne zmiany w obszarach.
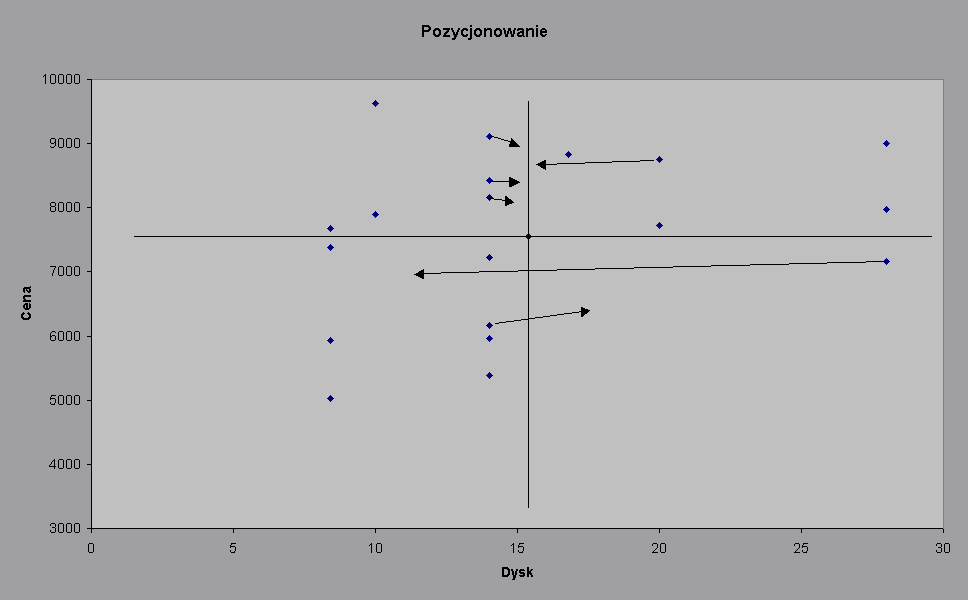
Analizując powyższy wykres oraz wykresy wcześniejsze można stwierdzić, iż produkty można podzielić na trzy klasy. W ramach dwóch klas można stwierdzić, iż istnieją outsiderzy.
Pierwsza klasa to nottbooki o wysokiej cenie w porównaniu do oferowanych szybkości procesora (zmodyfikowanej o typ procesora) oraz pojemności dysku twardego (zmodyfikowanej o modem). Klasą tą będą na pewno zainteresowaniu konsumenci z grupy snobistycznych oraz koneserskich. Do grupy tej zaliczają się m.in. notbooki: LiveBook C6555 (Fjitsu/Siemens), HP OmniBook XE3 (HP), Portege 7220 CT. Następną grupę stanowią nottboki o wmiarę niskiej użyteczności (GHx, GB) ale charakteryzujące się niską ceną. Klas ta jeżeli chodzi o konsumentów jest przeznaczona przede wszystkim dla lusdzi oszczędnych i- „ciułaczy”. Do klasy tej zaliczają się m.in.: Satelite 1710 CDS (Toshiba), Aristo Sirion (Aristo),. Ostatnik klasa to dobre notbboki ,droższe aczkolwiek nie nie tak jak te z pierwszej klasy. W naszej grupie . Zaliczyć tutaj można: Compaq N600C(Compaq), Armada E500 (Compaq), Armada 110(Compaq), Acer TravelMate (Acer) .Jak widzimy w tej klasie górują notbooki firmy Compaq.
6. Klasyfikacja.
W celu wyznaczenia grup skorzystamy z algorytmu aglomeracji. Algorytm ten ma na celu łączenie obiektów (np. notbooków) w coraz to większe wiązki, z zastosowaniem pewnej miary podobieństwa lub odległości. Wynikiem tego typu grupowania jest hierarchiczne drzewo. Hierarchiczny wykres drzewkowy rozpoczynając od dolnej strony wykresu, gdzie każdy obiekt stanowi swoją własną klasę. Wyobraźmy sobie teraz, że bardzo małymi krokami "osłabiamy" nasze kryterium tego, na ile jest on lub nie jest wyjątkowy. Innymi słowy, obniżamy próg stanowiący o decyzji przypisania dwóch lub więcej obiektów do tego samego skupienia. Tym sposobem wiążemy ze sobą coraz to więcej obiektów i agregujemy je w coraz to większe skupienia elementów coraz bardziej różniących się od siebie. W końcu, na ostatnim etapie, wszystkie obiekty zostają ze sobą połączone. Przy każdym węźle na wykresie (gdzie uformowało się nowe skupienie) możemy odczytać odległość, w której odpowiednie elementy zostały powiązane ze sobą tworząc nowe pojedyncze skupienie. Jeśli dane mają wyrazistą "strukturę" w tym sensie, że istnieją skupienia podobnych do siebie obiektów, to często struktura ta znajdzie odbicie na hierarchicznym drzewie w postaci oddzielnych gałęzi. Pomyślna analiza przy pomocy metody łączenia daje możliwość wykrywania skupień (gałęzi) i ich interpretacji.
W naszym przypadku miarą danej klasy jest jej środek ciężkości. Metoda środków ciężkości [Unweighted pair-group centroid] polega na tym, iż środek ciężkości skupienia jest średnim punktem w przestrzeni wielowymiarowej zdefiniowanej przez te wymiary. W metodzie tej, odległość między dwoma skupieniami jest określona jako różnica między środkami ciężkości.
Inna ciekawą metodą jest Metoda Warda. Ta metoda różni się od większości pozostałych metod, ponieważ do oszacowania odległości między skupieniami wykorzystuje podejście analizy wariancji. Krótko mówiąc, metoda ta zmierza do minimalizacji sumy kwadratów dowolnych dwóch skupień, które mogą zostać uformowane na każdym etapie.
Do pomiaru odległości pomiędzy przypadkami zastosowaliśmy kwadrat odległości euklidesowej. Odległość euklidesową podnosi się do kwadratu, aby przypisać większą wagę obiektom, które są bardziej oddalone. W przypadku metody Warda wykorzystaliśmy odległość euklidesową by zbyt dużej zbieżności algorytmu.
Wykres. Drzewo grupowania hierarchicznego
Wykres. Drzewo grupowania hierarchicznego Metoda Warda.
Na podstawie wykonanych analizy możemy wyróznić, trzy podstawowe grupy:
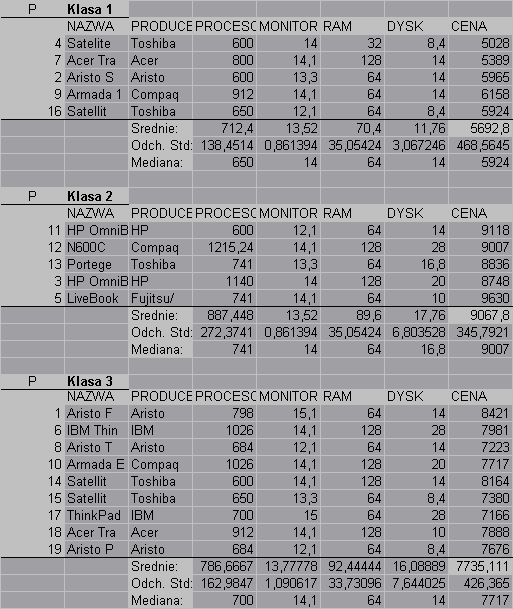
Charakteryzacja klas z punktu widzenia konsumenta.
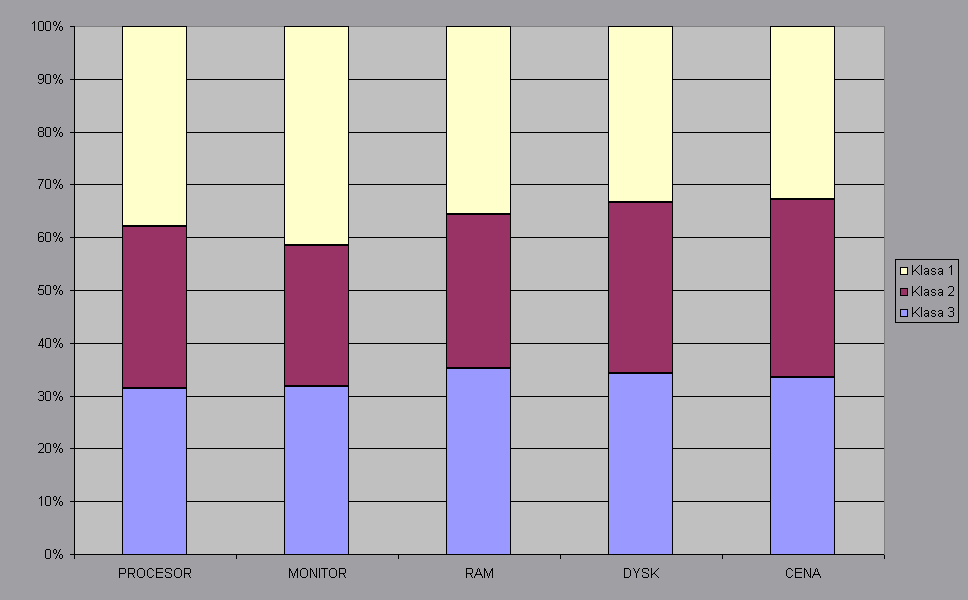
Wykres. Wykres porównawczy wartości średnich cech poszczegolnych klas.
Wykres. Wykres porównawczy średnich cen poszczegolnych klas.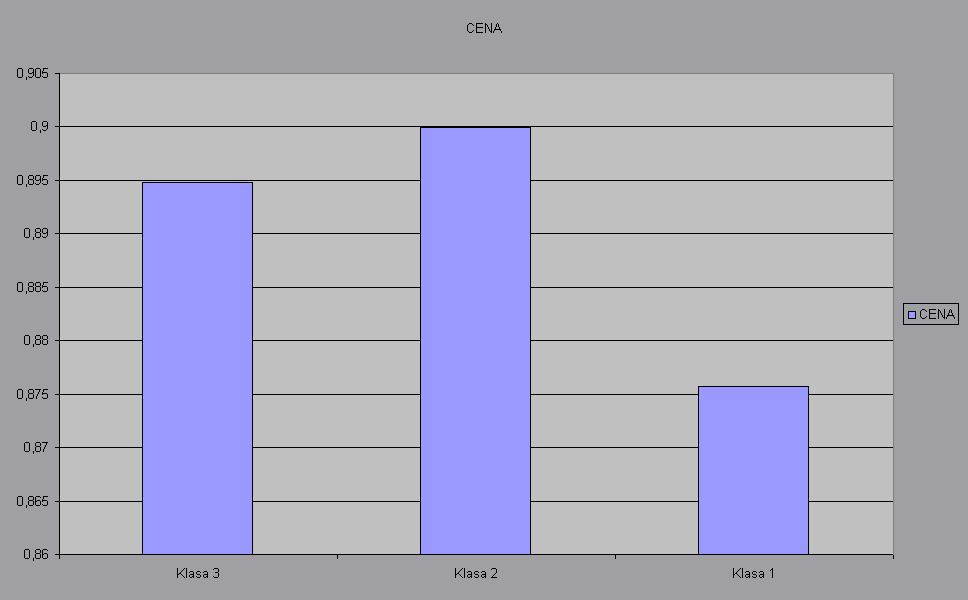
Analizując powyższe dwa wykresy, możemy stwierdzić iż notbooki należące do pierwszej klasy są najtańsze (w rozumieniu średnim). Cechują się małymi dyskami, małą pojemnością pamięci operacyjnej, aczkolwiek posiadają nie takie złe monitory. Klasa druga jest najdroższa klasą I zarazem nie charakteryzuje się niczym specjalnym. Głównie tutaj płaci się za markę. Do klasy tej zostały zaliczone komputery Compaa, Toshiby I IBM - czyli potentatów w tej dziedziny, co nie powinno dziwić.
Klasa trzecia to klasa trochę tańszych nottboków. Cechują się one najczęściej większa pamięcią operacyjną. Uważamy, iż klasa pierwsza jest przede wszystkim pomyślana o ludziach młodych nie mających dużych wymagań co do dysków twardych, zwracająca natomiast uwagę na procesor (zarówno szybkość jak i typ). Klasa druga to klasa dl ludzi snobistycznych, ceniących przede wszystkim markę a dopiero potem użytkowość. Oczywiście nie braliśmy pod uwagę cech, jaką jest jakosć wykonania, która tutaj prawdopodobnie górowałaby nad innymi klasami. Grupa trzecia to komputery dla ludzi o trochę większych wymaganiach niż klasa pierwsza, przy jednoczesnym zachowaniu racjonalności co do ceny.
Porównanie według median
Wykres. Wykres porównawczy wartości median cen poszczegolnych klas
Wykres. Wykres porównawczy wartości median cech poszczegolnych klas.Dodatek 1
Kody źródłowy kasy realizującej analizy obserwacji nietypowych metodą Cambella.
#include "Nietypowe.h"
#include "Unit1.h"
#include <math.h>
#include "StatDll.h"
//---------------------------------------------------------------------------
#pragma package(smart_init)
//---------------------------------------------------------------------------
nietypowe::nietypowe(HWND _hwnd)
{
hwnd =_hwnd;
}
//---------------------------------------------------------------------------
// Usuwa tablice data z pamieci
//---------------------------------------------------------
void nietypowe::de_allocate(long double **data, int m)
{
for (int i = 0; i < m; i++)
delete[] data[i]; // STEP 1: DELETE THE COLUMNS
delete[] data; // STEP 2: DELETE THE ROWS
}
//---------------------------------------------------------------------------
// Usuwa tablice data z pamieci
//---------------------------------------------------------
void nietypowe::de_allocate(double **data, int m)
{
for (int i = 0; i < m; i++)
delete[] data[i];
delete[] data;
}
//---------------------------------------------------------------------------
// Oblicza odleglosc Mahalanobisa
//---------------------------------------------------------
// invcov[i][j] - macierz odwrotna do macierzy korelacji
// i - wiersze; j - kolumny;
// n - wymair macierzy kwadratowej.
//---------------------------------------------------------
double nietypowe::Mahanalobis(double *tab,long double **invert,double *average,int n)
{
double *sred;
double *temp;
double wynik = 0;
temp = new double[n];
sred = new double[n];
for(int i =0;i<n;i++) {
sred[i] = tab[i] - average[i];
temp[i] = 0;
}
for(int i =0;i<n;i++) {
for(int j = 0;j<n;j++) {
temp[i] = temp[i] + ((double)invert[i][j] * sred[j]);
}
}
for(int i =0;i<n;i++) {
wynik = wynik + (sred[i] * temp[i]);
}
delete[] sred;
delete[] temp;
return wynik;
}
//---------------------------------------------------------------------------
// Algorytm sortowania bombelkowego;
//---------------------------------------------------------
// tab[i][j] - tablica wejsciowa(welowymiarowa) do posortowaniania wzgledem tabsort;
// Uwaga!! i - columny, j - wiersze;
// n - wymair tablicy tab.
//---------------------------------------------------------
int nietypowe::sort(double **tab,double *tab1, double *tabsort,int n, int m,TComponent* Owner)
{
double x;
double k;
TProg *progr = new TProg(Owner);
k = n-1;
progr -> Setpar(n,0);
progr -> Show();
for(int i=1;i<n;i++)
{
progr -> Setpos(i);
for(int j= k;j>=i;j--)
{
if (tabsort[j-1] > tabsort[j])
{
x = tabsort[j-1];
tabsort[j-1] = tabsort[j];
tabsort[j] = x;
x = tab1[j-1];
tab1[j-1] = tab1[j];
tab1[j] = x;
for(int l = 0;l<m;l++) {
x = tab[l][j-1];
tab[l][j-1] = tab[l][j];
tab[l][j] = x;
}
}
}
}
progr -> Close();
return 1;
}
//---------------------------------------------------------------------------
// Oblicza srednia wazona.
//---------------------------------------------------------
// tab[i][j] - tablica wejsciowa(welowymiarowa) do posortowaniania wzgledem tabsort;
// Uwaga!! i - columny, j - wiersze;
// n - wymair tablicy tab.
//---------------------------------------------------------
double nietypowe::SredniaWazona(double *tab, double *wagi, int len)
{
double suma =0;
double sumaw = 0;
for(int i = 0;i<len;i++) {
suma = suma + (tab[i] *wagi[i]);
sumaw = sumaw + wagi[i];
}
suma = suma / sumaw;
return suma;
}
//---------------------------------------------------------------------------
// Oblicza kowariancje wazona.
//---------------------------------------------------------
// tab[i][j] - tablica wejsciowa(welowymiarowa) do posortowaniania wzgledem tabsort;
// Uwaga!! i - columny, j - wiersze;
// n - wymair tablicy tab.
//---------------------------------------------------------
long double nietypowe::CovWazona(double *tab1,double *tab2,double *wagi, int len)
{
long double suma =0;
long double sumaw = 0;
double srednia1 = SredniaWazona(tab1,wagi,len);
double srednia2 = SredniaWazona(tab2,wagi,len);
for(int i = 0;i<len;i++) {
suma = suma + (pow(wagi[i],2))*((tab1[i] - srednia1)*(tab2[i] - srednia2));
sumaw = sumaw + (pow(wagi[i],2));
}
sumaw = sumaw -1;
suma = suma / sumaw;
return suma;
}
//---------------------------------------------------------------------------
// Wyznacza macierz kowariancji wazona.
//---------------------------------------------------------
// tab[i][j] - tablica wejsciowa (wielowymiarowa);
// Uwaga!! i - columny
// n - wymair tablicy tab.
//---------------------------------------------------------
void nietypowe::CovMatrixWeight(long double **coltab,double **tab,double *wagi,int row, int col)
{
for(int i=0;i<col;i++) {
for(int j=i;j<col;j++) {
coltab[i][j] = CovWazona(tab[i],tab[j],wagi,row);
coltab[j][i] = coltab[i][j];
}
}
}
//---------------------------------------------------------------------------
// Zwraca wektor z Odleglosci Mahalanobisa dla metody Cambella.
//---------------------------------------------------------
// tab[i][j] - tablica wejsciowa (wielowymiarowa);
// Uwaga!! i - columny
// row - ilosc danych dla col zmiennych.
//---------------------------------------------------------
int nietypowe::Cambell(double **tab,double **Mah,int row, int col)
{
long double **CovTab;
long double **InCovTab;
double *average;
double *wektor;
double *wagi, *Swagi;
double det;
double X,Y,wsp,temp;
//Deklaraja tablic.
wagi = new double[row];
Swagi = new double[row];
CovTab = new long double*[col];
InCovTab = new long double*[col];
for(int i = 0;i<col;i++) {
CovTab[i] = new long double[col];
InCovTab[i] = new long double[col];
}
wektor = new double[col];
average = new double[col];
for(int i = 0;i<row;i++) {
wagi[i] = 1;
}
X = sqrt(col) + sqrt(2);
do {
for(int i = 0;i<col;i++) {
average[i] = SredniaWazona(tab[i],wagi,row);
}
//Oblicza wazona macierz kowariancji.
CovMatrixWeight(CovTab,tab,wagi,row,col);
InwertMatrix(CovTab,InCovTab,col,det);
if(det == 0) {
ShowMessage("Macierz nie jest macierza osobliwa. Nie mozna wyznaczyc macierzy odwrotnej.");
return 0;
}
Y = 0;
for(int i = 0;i<row;i++) {
for(int j = 0;j<col;j++) {
wektor[j] = tab[j][i];
}
Mah[0][i] = Mahanalobis(wektor,InCovTab,average,col);
Mah[0][i] = sqrt(Mah[0][i]);
if (Mah[0][i] > X) {
temp = (Mah[0][i] - X);
temp = pow(temp,2);
wsp = X * exp(((-2.0)*temp)/(5));
}
else {
wsp = Mah[0][i];
}
Swagi[i] = wsp / Mah[0][i];
Y = Y + fabs(wagi[i] - Swagi[i]);
wagi[i] = Swagi[i];
}
} while (Y > 0.00001);
for(int i = 0;i<row;i++) {
Mah[1][i] = wagi[i];
}
de_allocate(CovTab,col);
de_allocate(InCovTab,col);
delete[] average;
delete[] wektor;
delete[] wagi;
delete[] Swagi;
return 1;
}
Wyszukiwarka
Podobne podstrony:
Analiza niezawodności (22 strony) S234QDM4K3MRHZS77PXWBRAUG5HEGVTBYTHKUZA
Analiza ekonomiczna teoria (26 strony) id 60090 (2)
Konsolidacja w energetyce (22 strony) HADCHNCLENTU6437CRMABG7K7YC2BXRPT4CB2ZI
Zarządzanie logistyką (22 strony)
Zarządzanie logistyką (22 strony)
Zarządzanie logistyką (22 strony)
Rekrutacja i selekcja (22 strony)
Strategia działania firmy zakłady mięsne (22 strony) (2)
Reakcje na zmiany w organizacji (22 strony) 73EHGSZEPNSNKOIRPV5LPM2HFGGG5KRPSOVDD6A
Analiza ekonomiczna firm (49 strony)
od Elwiry, Prawo handlowe - zagadnienia (22 strony) , 1
biznes plan ogrodnik (22 strony) XMR3NFHSLVU52SKJPJ3IGSP4SUFQ6JE3XZHQFGQ
ocena kondycji finansowej przedsiębiorstwa (22 strony) SRNT65WZBRZGDK5DDNHQ7VEBEUB56T2BA4UFGGY
Handel Zagraniczny, Międzynarodowe ugrupowania gospodarcze (22 strony)
więcej podobnych podstron