Pojęcie przerwania. Organizacja układu przerwań. Priorytety przerwań. Pojęcie procedury obsługi przerwania. Maskowanie przerwań.
Pojęcie przerwania:
Jest to zdarzenie zewnętrzne które powoduje przerwanie aktualnie wykonywanego programu po to aby obsłuzyć to zdarzenie.
Struktura logiczna maszyny EW
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
mag A |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
wel |
wyl |
|
|
|
as |
|
sa |
|
wea |
|
||
il |
|
|
|
|
|
|
|
|
|
|
|
||
|
L |
|
|
|
|
|
|
A |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
wyad |
weak |
Z |
AK |
|
|
PaO |
pisz |
|||
|
|
|
|
dod |
|
|
|
|
|
|
czyt |
||
|
|
|
|
ode |
JAL |
|
wyak |
|
|
|
|||
|
|
I |
AD |
przep |
|
|
|
|
S |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
wei |
|
|
weja |
|
|
wes |
wys |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
mag S |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
jedn |
wewy |
wywe |
strt |
wyg |
|
|
wex |
wyx |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
system we/wy |
|
|
X |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
Organizacja układu przerwań:
System przerwan zawiera:
rejestr zgłoszeń(RZ) przyjmuje on zgloszenia nadchodzące z lini zgłoszen. Zerowany sygnałem rint na najstarszej zgłoszonej pozycji przyjetej do obsługi.
rejestr maski(RM) służy do programowego maskowania zgl. przyjetych do rej. zgl.Informacja wprowadzana jest do tego rej. z magistrali A.
układ hierarhi-wybiera najstarsze z niezamaskowanych zgłoszen(wg ustalonego priorytetu) przyjetych do RZ
układ samoblokady-zabezpiecza przed powtarzaniem się generacji zgloszeń na danym poziomie przed zakonczeniem obsługi przerwania.
rejestr przerwań(RP - pamieta zgłoszenie przyjęte do obsługi. Informacja jest wprowadzana do rej. RP za pośrednictwem sygnału eni. Poszczególne pozycje rejestru przerwań sa zerowane z wyjść rej.RZ.
układ generacji sygnału INT- wypracowuje ten sygnał jako sumę wyjść rej. przerwań lub sumę sygnałów wychodzących z układu samoblokady. Sygnał INT dochodzi do układu sterującego komputera jako sygnał stanu sygnalizujący fakt zgłoszenia przerwania
układ hierarhi przerwań przyjętych do obsługi- wybiera najstarsze spośród przerwań przyjetych do obsługi
układ generacji adresu przerwania-wypracowuje adres przerwania na podstawie numeru poziomu ustalonego na wyjsciu układu hierarhii przerwań przyjetych do obsł. Adres ten przesyłany jest na magA procesora przez układ bramek sterowanych sygnałem wyap
Priorytety przerwań:
Priorytety przerwań są ustalane systemowo. to które przerwanie zostanie obsłużone jako pierwsze jest rozwiązywane na zewnątrz mikroprogramu, stosuje się do tego dwa różne podejścia: koder priorytetowy lub łańcuch ustalania priorytetów (Daisy chain).
Jako pierwsze zostaje przyjęte przerwanie o największym priorytecie
Jeżeli jest więcej przerwań układ priorytetowy zezwala na przyjęcie tylko zgłoszenia o najwyższym priorytecie.
Pojęcie procedury obsługi przerwania:
Obsługa przerwania w cyklu rozkazowym musi zapewnic zapamietanie stanu procesora w chwili przerwania oraz przejscie do realizacji programu obsługi przerwania.
Czynności realizowane w trakcie obsługi przerwania:
wykonywanie własciwego rozkazu
testowanie sygnałów zgłoszeń przerwan(eni)
jeśli brak zgłoszeń przerwań->przejź do punktu g)
schowanie śladu(zawartości rej. L) w odpowiednim miejscu w pamięci:
(L) -> S :wyl, wes;
(AP) -> A :wyap, wea;
(S) -> A :pisz;
wyznaczenie adresu nowego rozkazu:
(AP) -> L :wyap, wel;
(L) + 1 -> L :il;
kasowanie zgłoszenia przerwania (sygnał rint);
przygotowanie do pobrania następnego rozkazu:
(L) -> A :wyl, wea;
Program obsługi przerwania jest wywoływany w momencie wystąpienia zewn. zgłoszenia. Natomiast powrót z tego prg następuje po napotkaniu w jego treści rozkazu powrotu PWR - zadaniem tego rozkazu jest odtworzenie stanu komputera jaki był w momencie wystąpienia przerwania.
Maskowanie przerwań:
Sam program obsługi przerwania też może zostać przerwany, jeśli są w nim rozkazy przerywalne. Aby się przed tym zabezpieczyć jako pierwszy rozkaz tego programu powinien wystąpić rozkaz maskowania przerwań MAS. Zadaniem tego rozkazu jest wpisanie części adresowej do rej maski RM [(AD) -> RM]
Realizacja rozkazu w wersji przerywalnej na przykładzie rozkazu dodawania. (gosc ktory to pisal byl na bani) - zjebane.. patrz ksiazka str 126
I
II
III
IVa IVb
V
VI
VII
Wspólnie dla wszystkich rozkazów
Niezmieniona II faza rozkazu DOD
III faza rozkazu DOD z dodatkowym sygnałem eni (pojebalo sie gosciowi cos!!! )
IV a. IV faza rozkazu DOD w wersji: „brak przerwania”
IV b. IV faza rozkazu DOD w wersji: „przerwanie”
V. Cykl obsługi przerwania
VI. Cykl obsługi przerwania
VII Cykl obsługi przerwania
Różnica między wresją przerywalną a nieprzerywalną rozkazu polega na tym, że w wersji przerywalnej w III fazie wystepuje dodatkowo sygnał eni. Sprawdza on stan przerzutnika INT. Jeżeli INT = 0, bieg fazy IV pozostaje bez zmian. Jeżeli INT = 1, faza IV ulega modyfikacji, występuje w niej sygnał wyap, a po jej zakończeniu zostają zrealizowane trzy dodatkowe fazy cyklu obsługi przerwania.
Czynności realizowane w cyklu obsługi przerwania:
( AP ) -> A : wyap, wea
( L ) -> S : wyls, wes
( S ) -> ( A ) : pisz
( AP ) -> L : wyap, wel
( L ) + 1 -> L : il
( L ) -> A : wyl, wea
Pojęcia informacji elementarnej i bloku informacji. Wymiana informacji elementarnej. Obwód wymiany jako pośrednik między jednostką centralną a urządzeniami zewnętrznymi. Konstrukcja przykładowego obwodu wymiany.
Informacja - zbiór informacji elementarnych.
Informacja elementarna - słowo maszynowe.
Blok - zbiór uporządkowanych słów .
Aby umożliwić wymianę informacji przez urządzenia cyfrowe należy zbudować interfejs łączący te urządzenia. Urządzenia cyfrowe A i B można połączyć na 2 sposoby:
urządzenia A i B mają wspólny układ sterujący US (np. procesor maszyny W i pamięć
operacyjną PaO). Interfejs składa się wtedy z linii danych, adresów i linii sterujących.
US sterujący procesora W steruje przesyłem inf. Między tymi urządzeniami.
urządzenia A i B mają włąsne oddzielne układy sterujące US. Linie sterujące muszą
przenosić sygnały od A do B jak i w drugą stronę. Konieczna jest synchronizacja. W skład interfejsu mogą wchodzić również linie adresowe-jeśli ich nie ma to połączenie nazywamy dedykowanym.
Budowa obwodu wymiany dla maszyny W
RO- Rejestr odbiorczy inf. RN- Rejestr nadawczy inf.
RS - Rejestr stanu RR - Rejestr rozkazu
Połączenie magistrali danych obwodu wymiany OW z magistralą S umożliwia zapisanie stanu tych magistrali do rejestrów RS I RN. Przesyłami między magistralą OW a rejestrami steruje US obwodu wymiany (US-OW).
Powiązania między US jednostki centralnej a US obwodu wymiany:
Łączą je 2 linie synchronizacji - PR(początek cyklu wymiany) i GT(koniec cyklu) oraz
4 linie sterowania - sow( sterowanie dla obw. wymiany), iow(inf. dla obw. wymiany), ows(przekazanie do komp. stanu obw.wym) i owi(przekazanie do komp. inf.).
Do realizacji operacji we-wy są konieczne 4 rozkazy:
WYP - (AK)->RO //akumulator do rej. RO a później do urz. zewn.(UZ)
WPR - (RN)-> AK //do ak. dane z rej. RN (wprow. do RN z UZ)
STE - (AK)->RR //do rej. RR rozkaz ustalający rodzaj pracy UZ (rozruch, stop)
TES - (RS)->AK //do ak. zawartość rej. RS(stan UZ w postaci zakodowanej)
Możliwości realizacji rozkazu WYP
praca przy zablokowanej jednostce centralnej - po wysłaniu z AK na mag. S i wpisaniu do rej. RO praca zegara jednostki centralnej wstrzymywana do momentu nadejścia sygnału GT oznaczającego przejęcie danych przez UZ. Jest to rozwiązanie bardzo nieekonomiczne ( oczekiwanie na GT może być kilkaset razy dłuższe od realizacji jednego cyklu rozkazowego jednostki centralnej). -> protokół z potwierdzeniem
Wykorzystując układ przerwań - zakończenie rozkazu WYP bez potwierdzenia wejścia danych do UZ (sygn. GT). Jednocześnie wstrzymanie następnego rozkazu WYP do czasu nadejścia sygnału GT. Wykorzystuje się układ przerwań co umożliwia wykorzystanie czasu oczekiwania na realizację rozkazów innego program, który może być wykonywany równolegle z wyprow. danych na UZ. -> protokół bez potwierdzenia
Realizacja rozkazów wejścia/wyjścia na przykładzie rozkazu wyprowadzania znaku na urządzenie zewnętrzne.
Układ bezpośredniego dostępu do pamięci (DMA), konstrukcja i działanie.
DMA (Direct Memory Access) stosuje się do wymiany informacji blokowej, odciąża procesor od sterowania transmisją każdego słowa
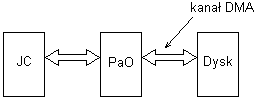
Struktura komputera opartego na dysku
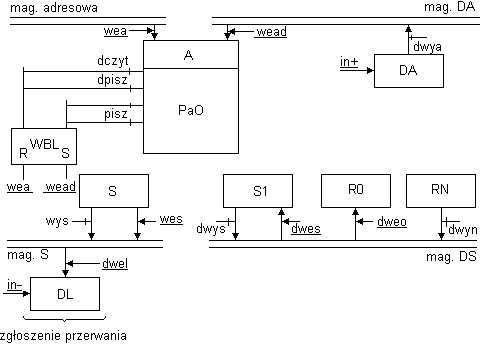
Dla maszyny W rozbudowanej o układ DMA struktura przedstawia się następująco:
S - dla procesora; S1 - dla układu DMA
DA - rejestr adresowy (zawiera adresy kolejnych komórek bloku, który trzeba odczytać z dysku i zapisać do pamięci)
DL - rejestr licznika słów (przechowuje ilość znaków, które zostały do transmisji; „0” powoduje przerwanie)
WBL - przerzutnik wzajemnej blokady:
wea - rezerwuje następny takt dla procesora
wead - rezerwuje następny takt dla układu DMA
wea i wead - nie występują równocześnie, gdyż sygnał zegara przechodzi przez DMA, który go wychwytuje
przerzutnik blokuje czytanie i pisanie w zależności od tego jaki był sygnał wea, wead
wea |
|
|
|
|
|
||
|
|
|
|
|
|
||
pisz |
|
|
|
|
|
Dochodzi do pamięci |
|
|
|
|
|
|
|
||
wead |
|
|
|
|
|
|
|
|
|
|
|
|
|
||
czyt |
|
|
|
|
|
||
Chodzi o wydłużenie taktu ukrywając zegar przed procesorem (2 cykle dostępu do pamięci mieszczą się w dwóch taktach, a pojedynczy cykl zajmuje normalnie dwa takty)
Praca kanału DMA polega na wprowadzeniu do komórki pamięci o adresie określonym zawartością rejestru RN lub wyprowadzeniu z pamięci zawartości komórki o adresie określonym zawartością rejestru DA do rejestru R0
Rozwój dróg obiegu adresów i danych w maszynach wyższych generacji. Metody adresacji.
Adres pod którym znajduje się wartość argumentu w pamięci operacyjnej Pao, nazywamy adresem efektywnym.
Rodzaje adresowania:
natychmiastowe - polega na tym, że w części adresowej rozkazu zostaje umieszczona wprost wartość argumentu.
bezpośrednie - polega na tym ,że w części adresowej rozkzu umieszczony jest adres komórki pamięci, w której znajduje się poszukiwana dana.
Pośrednie - polega na tym, że w części adresowej rozkazu umieszczony jest adres komórki pamięci, w której znajduje się dopiero właściwy adres danej.
Adres efektywny = ((AD))
Przy adresowaniu pośrednim wielokrotnym występuje n-krotne powtórzenie
adresowania pośredniego
Adres efektywny = (....(AD)....)
względne - polega na tym, że adres efektywny tworzymy przez dodanie zawartości częsci
adresowej rozkazu do zawartośći specjalnego rejestru bazowego B
Adres efektywny = (B) + (AD)
Adresowanie względne można również wykonywać wykorzystując jako przesunięcie stan
licznika rozkazów L. Zawartość części adresowej dodaje się wówczas do stanu licznika
rozkazów L lub odejmuje od niego. Tak więc:
Adres efektywny = (L) +(AD) lub (L)-(AD)
stronicowanie - polega na podzieleniu pamięci operacyjnej na obszary, które można objąć adresowaniem bezpośrednim(ograniczona liczba bitów części adr. rozk.). Załóżmy, że jedna komórka PaO tworzy jeden wiersz. Adres efektywny kompletowany jest jako
połączenie adresu wiersza na danej stronie i adresu strony branego z wydzielonej części
licznika rozkazów L. Jeżeli np. w części adr. mamy n bitów to możemy nimi zaadresować
stronę o pojemności 2^n wierszy, a adres strony określić stanem m bitów licznika rozk. L znajdujących się powyżej jego n pierwszych bitów. W ten sposób możęmy zaadresować łącznie 2^m. stron każda po 2^n wierszy -> łącznie 2^(m.+n) wierszy. Młodsze n bitów L podaje wiersz na stronie a starsze m. bitów podaje nr strony.
indeksowe - polega na tym, że adres efektywny otrzymuje się na podstawie zawartości części adresowej rejestru rozkazów i specjalnego rejestr, zwanego rejestrem indeksowym. Zawartość tego rejestru nazywa się indeksem. Rejestr indeksowy może sprzętowo lub programowo zwiększać (zmniejszać) swoją zawartość o 1.
Adres efektywny = (AD)+(X)
Adresowanie indeksowe wykorzystujemy gdy np. operujemy zmiennymi zebranymi w tablicy. Adres tablicy umieszczany w części adresowej rozkazu, zaznaczając że jest to adresowanie indeksowe. Adres efektywny tworzymy dodając zawartość rej. X. Na początku rejestr X zerujemy. Przy każdym przebiegu pętli zwiększamy go o 1 i w ten sposób poruszamy się po tablicy do wyczerpania jej wierszy.
Różnica między adresowaniem względnym i indeksowym polega na tym, że adresowanie względne zostaje ustalone a priori zawartością rejestru bazowego - PREINDEKSACJA, a adresowanie indeksowe powoduje cykliczne zwiększanie adresu elementu tablicy, liczonego względem jej początku - POSTINDEKSACJA.
mieszane - polega na złożeniu kilku z wyżej wymienionych trybów adresowania. Przykładowo połączenie adresowania względnego i pośredniego możemy zapisać
Adres efektywny=((B)+(AD))
ROZWINIĘTE DROGI OBIEGU DANYCH I ADRESÓW
Wprowadzono bogatszą listę sygnałów sterujących jednostką arytmetyczno-logiczną. Wynik operacji np. dodawania może być przesłany bezpośrednio do któregoś z rejestrów Rn -> wynik nie musi przechodzić przez akumulator.
Rozwinięte drogi obiegu danych i adresów stwarzają możliwość realizacji bogatszej listy rozkazów niż ta rozpatrywana w przypadku jednostki o prostej strukturze.
Możliwe więc będzie przede wszystkim wprowadzenie rozkazów realizujących adresowanie bezpośrednie, pośrednie, względne, indeksowe. Jak również rozkazów takich jak : operacje na słowach podwójnej długości, skok ze śladem czy wyjście z pętli.
Komputer Super W, realizacja dwuargumentowego rozkazu dodawania, skoku ze śladem, końca pętli, dodawania z podwójną precyzją w komputerze Super W
Schemat jednostki centralnej komputera Super W został przedstawiony na końcu pytania 17 więc nie ma chyba sensu go tu powtarzać.
W skrypcie przedstawiony został jeszcze graf Komputera Super W:
Rozkaz skoku ze śladem:
Zadaniem tego rozkazu jest przerwanie aktualnie wykonywanego programu, schowanie
adresu komórki pamięci , od której należy go kontynuować, przystąpienie do realizacji innego fragmentu programu rozpoczynającego się od adresu wskazanego w części adresowej
rozkazu AD. W wykorzystanym tu wariancie adres powrotu jest chowany do R1. Inną możliwością byłoby zapisanie adresu powrotu do 1 komórki podprogramu.
Skok bezwzględny ze śladem SOB AD
1) Pobranie instrukcji ((A))->S
(S)->I
2)obliczenie i schowanie adresu powrotu (R0)+1->R1
3) przygotowanie adresu nowego rozkazu
nowego fragmentu programu (AD)->R0
(AD)->A
Rozkaz końca pętli:
Rozkaz umieszczany na końcu pętli. Jego zadaniem jest inkrementowanie zawartości rejestru indeksowego i porównanie jego wartości z zadaną (sprawdzenie warunku).Jeśli warunek nie spełniony to skok pod adres AD.
Rozkaz końca pętli SKX X Ri AD
// przyjmujemy, żę rejestr Ri jest indeksowym a zadana wartość jest w rej. R(i+1)
Warunkiem wyjścia z pętli jest (Ri)-(R(i+1))<0
pobranie i zdekodowanie rozkazu ((A))->S
(S)->I
2) obliczenie wartości indeksu (Ri)+1->Ri
3)sprawdzenie warunku pętli (Ri)-(R(i+1))<0
Jeśli nie, to (R0)+1->R0,A
Jeśli tak, to (AD)->R0,A
Rozkaz dodawania z podwójną precyzją:
Postać symboliczna mogłaby wyglądać następująco:
2DOD Ri AD
Rozkaz dodaje do zawartości rejestrów Ri i R(i+1) zawartości słów o adresach w pamięci (AD) i (AD)+1 a wyniki umieszcza z powrotem w rejestrach. Starsze części dodawanych liczb znajdują się w rejestrze Ri oraz w pamięci pod adresem (AD).
Pobranie i zdekodowanie rozkazu: ((A))->S
(S)->I
2) Wykonanie operacji na młodszych słowach (AD)+1->A
((A))->S
przeniesienie zostaje umieszczone w przerzutniku D (S) + (R(i+1))->R(i+1)
3) Wykonanie operacji na starszych słowach (AD)->A
((A))->S
(D)+(S)+(Ri)->Ri
4) Obliczenie adresu nowego rozkazu (R0)+1->R0
R0->A
Kod maszynowy, programowanie w języku symbolicznym, składnia programu w języku asemblera, przebieg procesu asemblacji.
Kod maszynowy:
Zapis programu jako sekwencji rozkazów prostych (tzn. rozpoznawanych bezpośrednio przez procesor) kodowanych jako ciągi bitów.
Dla 8-bitowej maszyny W struktura rozkazu może mieć postać:
1 słowo 8-bit |
||||||||
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Kod rozkazu |
Adres argumentu (4-bit) |
|||||||
W ten sposób można zakodować 24 = 16 rozkazów korzystających z 24 = 16 komórek pamięci.
Język symboliczny:
Zapis programu w kodzie maszynowym za pomocą skrótów (mnemoników) symbolizujących poszczególne kody rozkazów oraz etykiet oznaczających adresy w pamięci.
Adresowanie za pomocą etykiet nazywamy adresowaniem pośrednim (logicznym). Pozwala ono na uruchamianie programu na różnych systemach korzystających z tej samej listy rozkazów.
W kodzie mogą występować również tzw. pseudorozkazy. Są to polecenia dla asemblera, że w danej komórce pamięci ma się znajdować np. przechowywana wartość lub, że w danym miejscu kod się kończy.
Na przykładzie asemblera maszyny W:
Rozkazy oznaczamy np. przez DOD, ODE, POB, ŁAD
Pseudorozkazy to np. RPA, RST, KON
Składnia programu w języku asemblera:
[ <etykieta> ] < nazwa_rozkazu_lub_pseudorozkazu > [ < argument > ]
Przebieg procesu asemblacji:
Wyszukanie linia po linii wszystkich adresów logicznych (etykiet) i przyporządkowanie im adresów fizycznych.
Zakładamy, że pierwsza linia kodu znajduje się w komórce `0', a każda linia zajmuje 1 komórkę pamięci.
Powstaje tablica przypisań adresów fizycznych do etykiet (dalej: tablica adresów).
Interpretacja linia po linii wszystkich rozkazów i pseudorozkazów programu.
W przypadku RPA lub RST (dla maszyny W) w danej komórce pamięci pozostawiane jest miejsce na zapamiętywaną wartość (zmienną).
W przypadku innych rozkazów wpisuje się w danej komórce pamięci kod rozkazu wg tabeli rozkazów procesora i adres fizyczny wg tabeli adresów (z p.1).
Operacje te wykonuje się aż do napotkania (dla maszyny W) pseudorozkazu KON.
Makroasembler, przykłady użycia makrodefinicji, segmentacja.
Makroasembler to język stworzony po to aby umożliwić stworzenie dodatkowych rozkazów .Te dodatkowe rozkazy będą nazywane makroinstrukcjami(makrodefinicjami).
Przykład:
Potrzebujemy rozkazu, który wykona następujące operacje:
(N1) + (N5) -> N7 - zawartość komórki N1 doda do zaw. kom. N5 i umieści w N7
(N3) + (N1) -> N4 - zawartość komórki N3 doda do zaw. kom. N1 i umieści w N4
(N1) + (N4) -> N8 - zawartość komórki N1 doda do zaw. kom. N4 i umieści w N8
Gdyby chcieć napisać taki rozkaz w asemblerze otrzymamy:
POB N1
DOD N5
ŁAD N7
(jakieś inne rozkazy)
POB N3
DOD N1
ŁAD N4
(jakieś inne rozkazy)
POB N1
DOD N4
ŁAD N8
Aby uprościć dany rozkaz można zastosować makroinstrukcję:
MAKRO BAS X, Y, Z
POB X
DOD Y
ŁAD Z
KON MAKRO
X Y Z to parametry formalne natomiast KON MAKRO jest instrukcją makroasemblera oznaczającą koniec definicji makroinstrukcji, a
MAKRO nazwa <lista parametrów formalnych>
Jest instrukcją makroasemblera, oznaczającą początek instrukcji.
Teraz jeśli na początku programu zdefiniujemy naszą makroinstrukcję to nasz rozkaz można zapisać:
BAS N1 N2 N7
(jakieś inne rozkazy)
BAS N3 N1 N2
(jakieś inne rozkazy)
BAS N1 N4 N8
Wywołanie podprogramu tym różni się od makroinstrukcji że makroinstrukcja wygeneruje w programie wynikowym całą swoją definicje i program zwiększy nieco swoją objętość, a wywołanie podprogramu polega tylko na przekazaniu sterowania w inne miejsce pamięci i oczekiwanie na powrót po jego wykonaniu.
Segmentacja polega na podziale programu na oddzielne moduły (segmenty) o pewnych określonych zadaniach funkcjonalnych.
Celem takiego podziału jest umożliwienie pracy nad jednym programem wielu programistom. Każdy moduł może być opracowywany, tłumaczony i uruchamiany oddzielnie.
Cechą charakterystyczną segmentacji jest to, że w poszczególnych segmentach (punkty wejścia) oraz mogą występować adresy symboliczne (części adresowe), dla których etykiety występują w innym segmencie(nazwy zewnętrzne)
Powiązania międzysegmentowe
Etykieta Kod Argument
...... PAM1
......
ET1 ...... Etykieta Kod Argument
..... ET2
PAM1 .....
..... ET1
SEGMENT 1
SEGMENT 2
Etykieta Kod Argument
....
ET2 ....
....
SEGMENT 3
Przykład do rysunku wyżej:
Segment 1 ma jeden punkt (wejścia etykieta ET1) i jedną nazwę zewnętrzną - PAM1.
Segment 2 ma punkt wejścia PAM1 i dwie nazwy zewnętrzne ET1 ET2.
Segment 3 ma tylko 1 punkt wejścia (etykieta ET2)
Teraz zdeklarujemy punkty wejścia i nazwy zewnętrzne na początku każdego segmentu:
Segment 1
WNZ: PAM1 (Wykaz Nazw Zewnętrznych)
WPW: ET1 (Wykaz Punktów Wejścia)
Segment 2
WNZ: ET2, ET1
WPW: PAM1
Segment 3
WNZ:
WPW: ET2
Makroasembler, jeśli będzie posiadał taką informację, to oczywiście nie zakomunikuje błędu,
Jeśli trafi na nazwę zewnętrzną, ale też nie będzie wiedział, jaką wartość należy wstawić zamiast nazwy zewnętrznej. Makroasembler, jeśli trafi na nazwy zewnętrzne, wypełni je wartościami pustymi i dołączy do segmentu informację o tym, gdzie należy powstawiać brakujące adresy, dołączy też listę punktów wejścia w danym segmencie.
Po skompilowaniu tych 3 segmentów otrzymamy 3 programy których samodzielnie nie uruchomimy. Aby je połączyć potrzebny jest program łączący (tak tak to jest jak dobrze przypuszczacie linker ;] ).
Program na tej bazie otrzymanych informacji z makroasemblera skojarzy punkty wejścia z nazwami zewnętrznymi, powstawia brakujące adresy, sprawdzi czy nie wystąpiły odwołania do niezdeklarowanych nazw zewnętrznych. Po uzupełnieniu tych informacji w każdym segmencie, połączy segmenty ze sobą tak, aby utworzyły jeden program.
Języki wyższego poziomu, kompilatory. Przykłady kompilacji fragmentów programu w języku wysokiego poziomu. Algorytm kompilacji wyrażenia arytmetycznego
Język wysokiego poziomu to taki, który charakteryzuje się zbiorem zasad składni, instrukcji, dzięki którym powstaje kod źródłowy programu. Procesor jest w stanie wykonywać program w kodzie maszynowym, jednakże tworzenie programów w tym języku jest praktycznie niemożliwe. Dlatego programista używa języka zrozumiałego dla człowieka, który następnie jest kompilowany do postaci maszynowej.
Kompilacja jest procesem tłumaczenia programu z języka wyższego rzędu na język asemblera (j. symboliczny) bądź bezpośrednio do kodu binarnego.
Kompilacja obejmuje:
analizę tekstu programu źródłowego (pod względem poprawności)
analiza leksykalna - jest to wydzielenie dopuszczalnych symboli w języku i zweryfikowanie ich poprawności.
analiza syntaktyczna - to wydzielenie i zweryfikowanie procesu dopuszczalnych konstrukcji w tłumaczonym programie.
syntezę tekstu programu wynikowego i rozmieszczenie tego programu w PaI
generacja kodu
optymalizacja
gospodarka pamięcią
Poprawne zakończenie procesu tłumaczenia jest uwarunkowane poprawnym zakończeniem procesów analizy i syntezy
Algorytm kompilacji wyrażenia arytmetycznego.
Pobieramy kolejne symbole i wykonujemy różne operacje. Umieszczamy na stosie. Jeśli trafimy na operator, to pobieramy odpowiednie argumenty, obliczamy wartości
i umieszczamy je na stosie. Pod koniec procesu na stosie będzie znajdować się jeden argument - wynik
Przykład działania powyższego algorytmu:
a+b*c+d, gdzie a=1, b=2, c=3, d=4
dla notacji Łukasiewicza wyrażenie przedstawia się następująco : abc*+d+
wejście |
|
Stos |
||
a (1) |
|
1 |
|
|
|
|
1 |
2 |
|
c (3) |
|
1 |
2 |
3 |
|
|
1 |
6 |
|
+ |
|
7 |
|
|
d (4) |
|
7 |
4 |
|
+ |
|
11 |
|
|
0 |
|
|
|
|
Przykład kompilacji fragmentów programu w języku wysokiego poziomu
1. Translacja do języka asemblera wyrażenia : a = b * c - d / e
|
POB b |
|
POB d |
|
POB T1 |
|
POB T3 |
POB b |
|
MNO c |
|
DZI e |
|
ODE T2 |
|
ŁAD a |
MNO c |
|
ŁAD T1 |
|
ŁAD T2 |
|
ŁAD T3 |
|
|
ŁAD T1 |
|
|
|
|
|
|
|
|
POB d |
|
|
e |
|
|
|
|
|
DZI e |
|
|
/ |
|
|
|
|
|
ŁAD T2 |
C |
|
d |
|
T2 |
|
|
|
POB T1 |
* |
|
- |
|
- |
|
|
|
ODE T2 |
B |
|
T1 |
|
T1 |
|
T3 |
|
|
= |
|
= |
|
= |
|
= |
|
|
A |
|
a |
|
a |
|
a |
|
ŁAD a |
2. W tym przypadku kompilator wykona translację do notacji Łukasiewicza
a * b + a * ( b + c * d )
wejście stos wyjście
a a
* * a
b * a b
+ + a b *
a + a b * a
* + * a b * a
( + * ( a b * a
b + * ( a b * a b
+ + * ( + a b * a b
c + * ( + a b * a b c
* + * ( + * a b * a b c
d + * ( + * a b * a b c d
) + * a b * a b c d * +
wynik: a b * a b c d * + * +
Rola i funkcje systemu operacyjnego. Synchronizacja i komunikacja między procesami. Pojęcie zasobów systemu.
System operacyjny:
Oprogramowanie pośredniczące pomiędzy sprzętem (komputerem i urządzeniami zewnętrznymi), a aplikacjami (programami użytkowymi).
Zadania:
obsługa sprzętu (np. edytor tekstu wysyła polecenie `drukuj' i dane do druku,
a S.O. przekształca je na kod zrozumiały dla drukarki)zarządzanie pamięcią operacyjną i zasobami systemu
zarządzanie procesami
System operacyjny czasu rzeczywistego:
wszystkie współczesne systemy operacyjne
każde zadanie (proces) ma skończony czas trwania (jeśli zostanie przekroczony - tzw. timeout - zadanie zostaje przerwane)
Sposoby zarządzania procesami w systemach wielowątkowych:
`kto pierwszy ten lepszy' => każdy zgłaszający się proces zostaje umieszczony na końcu kolejki (więc nawet bardzo krótkie lub ważne procesy będą musiały czekać na zakończenie wcześniej zgłoszonych)
kolejka priorytetowa => każdemu procesowi jest przyporządkowany przez s.o. priorytet (w momencie zgłoszenia lub zaprogramowany wcześniej) w zależności od ważności dla systemu lub szacowanego czasu trwania, a kolejka jest zmieniana dynamicznie w zależności od priorytetów procesów zgłaszanych (ważne i/lub krótkie procesy są wykonywane wcześniej, ale te mniej ważne lub długie mogą ulec zagłodzeniu, tzn. nigdy `nie dojdą do głosu')
zmodyf. kolejka priorytetowa => j.w., ale z uwzględnieniem czasu oczekiwania procesu w kolejce (zmniejsza znacząco ryzyko zagłodzenia procesu)
Synchronizacja i komunikacja:
synchronizacja => przekazywanie kontroli nad systemem (zasobami) pomiędzy procesami (przy pomocy systemu operacyjnego)
komunikacja => przekazywanie danych między procesami
Na rysunku:
Zasoby systemu:
Wszystkie urządzenia sprzętowe lub procedury i podprogramy biblioteczne udostępniane przez system operacyjny aplikacjom (procesom, programom użytkowym).
Podział:
zasoby podzielne => takie zasoby, które bądź mogą być powielone, aby kilka procesów mogło z nich korzystać jednocześnie (1), bądź skonstruowane tak, że ich niepodzielność jest niewidoczna na zewnątrz (wewnętrznie zastosowany time-sharing) (2)
przykład 1: biblioteki systemowe (np. wyświetlanie okienek w Windows)
przykład 2: procesor komputera
zasoby niepodzielne => takie zasoby, których w żaden sposób nie można podzielić między dwa procesy; zawsze jeden proces musi zakończyć pracę z zasobem, aby drugi mógł z niego skorzystać
przykład: skaner, drukarka, dysk (przy czym 2 ostatnie w nowych systemach operacyjnych są buforowane w taki sposób, że aplikacje wysyłają żądanie dostępu i dane, tak, jakby zawsze urządzenia te były zawsze dostępne - obsługą oczekiwania na zasób zajmuje się już później s.o.)
Podstawy informatyki - egzamin ustny 2002
(I) Zakończyłem pracę. Powiedz P2, że mam dla niego dane.
SYSTEM OPERACYJNY
PROCES 1
(II) Jak będę miał czas, to mu powiem.
(IV) O.K. Już odbieram.
(III) P1 zakończył pracę. Ma dla ciebie dane.
(V) Podobno masz dla mnie dane ?
(VI) DANE
PROCES 2
KOMUNIKACJA
SYNCHRONIZACJA
czyt, wys wei, il
czyt, wys, weja, dod, weak, wyap, wea
wyap, wyls, pisz, wes, wel, rint
il, pisz
wea, wyl
Czyt wys weja dod weak wyl wea
INT ?
Nie ma tej fazy!!!!
wyad, wea, eni
START
pobierz symbol
t
argument na stos
n
t pobierz arg. ze
Operator stosu, wyk. op
wynik na stos
n
n t pob. wynik
BŁĄD ! znak końca ze stosu STOP
Poprawny zapis, więc program wykona się - na stosie znajduje się wynik operacji
Wyszukiwarka
Podobne podstrony:
04 22 PAROTITE EPIDEMICA
POKREWIEŃSTWO I INBRED 22 4 10
Wykład 22
22 Choroby wlosow KONSPEKTid 29485 ppt
22 piątek
plik (22) ppt
MAKROEKONOMIA R 22 popyt polityka fiskalna i handel zagr
PREZENTACJA UZUP 22 XII
22 Tydzień zwykłyxxxx, 22 środa
Prawo budowlane wykł 22 02 13
22 WdK
2011 09 22 Rozkaz nr 904 MON instrikcja doświadczenie w SZ RP
22 04 2010
2003 06 22
000 Alfabetyczny indeks zawodów do KZiS (Dz U 28 08 14,poz 1145)st 22 12 2014
więcej podobnych podstron