PRZEDZIAŁY UFNOŚCI
Szacowanie średniej w zbiorowości
a) ![]()
b) ![]()
![]()
![]()
Szacowanie odchylenia i wariancji w zbiorowości
(tylko gdy rozkład normalny)
a) ![]()
b)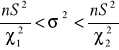
c)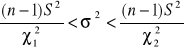
n>30 i m znane lub nieznane n≤30 i m znane n≤30 i m nieznane
Szacowanie wskaźnika struktury w zbiorowości
![]()
n≥100
Szacowanie współczynnika korelacji w zbiorowości
a) 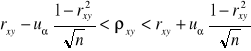
b) 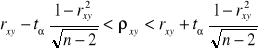
n>30 n≤30
Oznaczenia:
n- liczebność próby
uα- wielkość odczytywana z tablic rozkładu normalnego dla: Φ
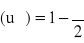
tα- wartość odczytywana z tablic dla zadanego α oraz liczby stopni swobody: k=n-1 (przedział ufności dla średniej) lub k=n-2 (przedział ufności dla współczynnika korelacji)
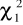
,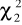
- wartości odczytywane z tablic rozkładu χ2 dla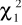
-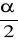
,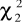
-(1-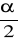
) oraz n- dla znanego m, albo (n-1)- gdy nieznana jest wartość mα- współczynnik istotności
β- współczynnik ufności: α+β=1
S- odchylenie standardowe odczytywane z próby
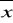
- wartość średniej w próbiem- średnia w całej zbiorowości
σ- odchylenie standardowe w całej badanej zbiorowości (dla n>30 przyjmuje się S=δ)
w- wskaźnik struktury (miernik prawdopodobieństwa w badanej, dużej próbie)
p- prawdopodobieństwo zajścia zdarzenia w zbiorowości
rxy- współczynnik korelacji w próbie
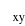
- współczynnik korelacji w zbiorowości
Przy danej wartości ![]()
dokonuje się przeliczenia na S ze wzoru: ![]()
BŁĄD OSZACOWANIA PRZEDZIAŁU
![]()
Oznaczenia:
G- górna wartość przedziału ufności
d- dolna wartość przedziału ufności
e- parametr wyznaczony z próby
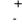
- odchylenie od wartości z próby, określające błąd oszacowania
WYZNACZANIE LICZEBNOŚCI PRÓBY DLA ZADANEJ DOKŁADNOŚCI

PrzyjPrzyjęte oznaczenia jak powyżej.
WERYFIKACJA HIPOTEZ STATYSTYCZNYCH
Testowanie hipotez o średniej w zbiorowości
1) Hipotezy o jednej średniej
a) ![]()
b) ![]()
![]()
![]()
2) Hipotezy o dwóch średnich
a) 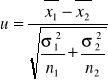
b) 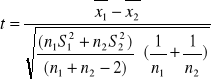
σ1, σ2 znane albo n1 i n2>30 n1 lub n2≤30 i δ1, δ2 nieznane, ale wiadomo, że δ1=δ2; rozkłady normalne
Testowanie hipotez o odchyleniu standardowym i wariancji w zbiorowości
(tylko gdy rozkład normalny)
3) Hipotezy o jednym odchyleniu (wariancji)
a)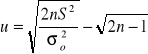
b) 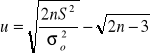
c)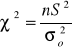
d) 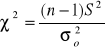
n>30 i m znane n>30 i m nieznane n≤30 i m znane n≤30 i m nieznane
4) Hipoteza o dwóch wariancjach
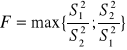
często przy badaniu hipotezy 2 w sytuacji b)
Testowanie hipotez o wskaźniku struktury w zbiorowości
5) Hipoteza o wskaźniku struktury.
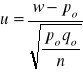
qo=1-po n≥100
6) Hipoteza o dwóch wskaźnikach struktury.
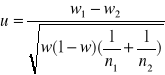
![]()
; n1, n2≥100
Testowanie hipotezy o istotności współczynnika korelacji
a) 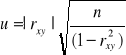
b) 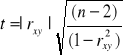
n>30 n≤30
Oznaczenia:
mo, σo, po (qo)- założone hipotetycznie wielkości odpowiednio: średniej, odchylenia, wskaźnika struktury
x1- ilość obserwacji posiadających daną cechę w I-szej próbie
x2- ilość obserwacji posiadających daną cechę w II-giej próbie
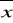
1- wartość średniej w I-szej próbie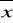
2- wartość średniej w II-giej próbieS1- odchylenie standardowe w I-szej próbie
S2- odchylenie standardowe w II-giej próbie
n1- liczebność I-szej próby
n2- liczebność II-giej próby
w1- wskaźnik struktury w I-szej próbie
w2- wskaźnik struktury w II-giej próbie
rxy- współczynnik korelacji
σ1- odchylenie standardowe w I-szej zbiorowości
σ2- odchylenie standardowe w II-giej zbiorowości
Pozostałe oznaczenia bez zmian
STOSOWANE STATYSTYKI
Rozkład normalny: uα- wielkość odczytywana z tablic rozkładu normalnego dla φ(uα)=...:
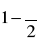
- przy testowaniu hipotezy o równości np. m=mo1-α- przy testowaniu hipotezy o większości np. m>mo
α- przy testowaniu hipotezy o mniejszości danego parametru w stosunku do zadanej wielkości np. m<mo
Rozkład studenta- wartość t* odczytywana z tablic dla:
α oraz liczby stopni swobody k=(n-1), przy testowaniu hipotezy o równości średniej
2α oraz k=(n-1) dla testów jednostronnych (dla testu o mniejszości bierze się -t*)
α i k=(n1+n2-2) przy testowaniu hipotezy o równości dwóch średnich
2α i k=(n1+n2-2) przy testowaniu hipotezy o większości jednej średniej nad drugą
α oraz liczby stopni swobody k=(n-2), przy testowaniu hipotezy o istotności rxy,
Rozkład χ2*- wartości odczytuje się z tablic rozkładu dla:
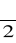
oraz 1-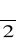
i k=n stopni swobody, w teście dwustronnym przy znanym m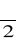
oraz 1-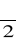
i k=n-1 stopni swobody, w teście dwustronnym dla nieznanego mα i k=n stopni swobody, przy testowaniu hipotezy o większości przy znanym m
α i k=(n-1) stopni swobody, gdy przy nieznanym m testowana jest hipoteza o większości
Rozkład Fishera-Snedecora. Wartość F* odczytywana jest z tablic rozkładu dla r1=(n1-1) i r2=(n2-1) stopni swobody, gdzie n1 jest liczebnością tej próby, w której było większe odchylenie)
WARUNKI PRZYJĘCIA HIPOTEZ
H0:- hipoteza o równości: |W|<T, lub w przypadku odrzucenia hipotezy o większości lub mniejszości badanego parametru od zadanej wielkości
H1: Hipoteza alternatywna do H0 przyjmowana w przypadku jej odrzucenia. Może dotyczyć:
różności, gdy |W|>T
większości, wtedy W>T
mniejszości: W<T
Oznaczenia:
W- wartości: u, t, χ2, F- wyznaczone ze wzorów dla danych empirycznych
T- wartości: uα, t*,χ2*, F*- odczytane z tablic
Test χ2
Stosowany gdy:
dane pochodzą z dużej próby (n>30)wylosowanej w sposób niezależny
dane są przedstawione w postaci szeregu rozdzielczego o r wariantach, liczebność dla każdego wariantu (ni≥5)
rozkład hipotetyczny jest ciągły lub skokowy
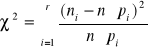
H0: X ma założony rozkład; przyjmuje się gdy χ2< χ2*
χ2*- odczytywane z tablic dla α oraz r-s-1
Test Kołmogarowa
Stosowany gdy:
dane pochodzą z dużej próby (n>30)wylosowanej w sposób niezależny
dane są przedstawione w postaci szeregu rozdzielczego o r przedziałach, liczebność w każdym przedziale (ni≥5)
rozkład hipotetyczny jest typu ciągłego
![]()
; ![]()
H0: X ma założony rozkład; przyjmuje się gdy λ< λ*
λ *- odczytywane z tablic Kołmogarowa dla zadanego Q=1-α
Oznaczenia:
n- liczebność próby
r- liczba wariantów (przedziałów)
s- liczba miar wyznaczonych z próby (s=0, jeśli nie trzeba było nic liczyć- wszystko było podane w założeniach; s= 1 jeśli liczono tylko średnią, jeśli liczono średnią i odchylenie s=2)
ni- liczebność w i-tym przedziale
nicum- liczebność skumulowana w i-tym przedziale
pi- prawdopodobieństwo teoretyczne obliczane ze wzorów lub odczytywane z tablic weryfikowanego rozkładu
F(x)- dystrybuanta empiryczna wyznaczona ze wzoru:
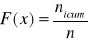
F*(x)- dystrybuanta teoretyczna obliczana ze wzorów lub odczytana z tablic weryfikowanego rozkładu dla danego xi
- 1 -
Wyszukiwarka
Podobne podstrony:
korelacja, Zarządzanie i inżynieria produkcji, Semestr 2, Statystyka, statystyka
rozkłady-wzory, Zarządzanie i inżynieria produkcji, Semestr 2, Statystyka, statystyka
a.opisowa, Zarządzanie i inżynieria produkcji, Semestr 2, Statystyka, statystyka
zarzadzanie piatek 1 czerwca, Zarządzanie i inżynieria produkcji, Semestr 2, Podstawy Zarządzania
Tabela[2], Zarządzanie i inżynieria produkcji, Semestr 4, Mechanika Stosowana
spr z ZP, Zarządzanie i inżynieria produkcji, Semestr 4, Zarządzanie personelem
zpiu kartkowa, Zarządzanie i inżynieria produkcji, Semestr 6, Zarządzanie produkcją i usługami
Przedszkole2, Zarządzanie i inżynieria produkcji, Semestr 6, Podstawy projektowania inżynierskiego,
cwiczenie scenariusze 2, Zarządzanie i inżynieria produkcji, Semestr 5, Zarządzanie strategiczne
Sprawozdanie 2 - Parametryzacja rysunków, Zarządzanie i inżynieria produkcji, Semestr 3, Grafika inż
PA.pojazd.w.labiryncie.1, Zarządzanie i inżynieria produkcji, Semestr 5, Podstawy automatyzacji
cwiczenie 6, Zarządzanie i inżynieria produkcji, Semestr 5, Zarządzanie strategiczne
Sprawozdanie 1 - Komputerowy zapis konstrukcji, Zarządzanie i inżynieria produkcji, Semestr 3, Grafi
sprawozdanie po liftingu nr7, Zarządzanie i inżynieria produkcji, Semestr 3, Metrologia
Wpływ rozwoju społeczeństwa informacyjnego na regulacje prawne, Zarządzanie i inżynieria produkcji,
Załącznik2, Zarządzanie i inżynieria produkcji, Semestr 4, Zarządzanie dok techn
więcej podobnych podstron