Definicje
Statystyka jest nauką traktującą o ilościowych modelach badania zjawisk (procesów) masowych (Sobczak95)
Statystyka matematyczna zajmuje się metodami wnioskowania o całej zbiorowości na podstawie zbadania pewnej jej części zwanej próbką lub próbą (Greń68).
Wnioskowanie statystyczne będące przedmiotem statystyki matematycznej może występować w dwu wariantach zastosowań:
*jako estymacja, czyli szacowanie parametrów rozkładu badanej cechy w populacji generalnej,
*jako weryfikacja (testowanie) hipotez statystycznych dotyczących rozkładu badanej cechy w populacji (zbiorowości generalnej).
Zarówno w estymacji jak i przy weryfikacji hipotez statystycznych zakłada się, iż populacja generalna z której pobieramy próbę losową, jest nieskończona. Przypadek skończonej liczby elementów rozpatruje się w części statystyki zwanej metodą reprezentacyjną.
Zbiorowością statystyczną (zwaną również populacją) nazywa się zbiór dowolnych elementów(nieidentycznych z punktu widzenia badanej cechy) objętych badaniem statystycznym.
Jednostki wchodzące w skład zbiorowości statystycznych charakteryzują się pewnymi właściwościami - zwanych cechami, które mogą być stałe i zmienne.
Cechy stałe określają jednostki (przez nie zbiorowość) pod względem rzeczowym(co?), czasowym(kiedy), oraz przestrzennym (gdzie). Cechy stałe są wspólne wszystkim jednostkom zbiorowości. Nie podlegają one badaniu a jedynie decydują o zaliczeniu jednostek do określonej zbiorowości.
Cechy zmienne to właściwości, którymi różnią się poszczególne jednostki statystyczne. Dzielimy je na jakościowe (niemierzalne) i ilościowe (mierzalne).
Cech jakościowych nie można zmierzyć, lecz tylko określić(np. pochodzenie społeczne, płeć, rasa, kolor włosów, uroda). Cechy ilościowe dadzą się wyrazić przy pomocy liczb o różnych mianach, np. wzrost (w cm), wiek (w latach), zyski (w zł), produkcja (w szt., tonach, mb itp.). Cechy ilościowe dzielimy na ciągłe i skokowe.
Cechy ciągłe stanowią wyniki pomiarów wartości cech w przedziale jej kształtowania się w populacji np. wzrost, waga ciała, dochód miesięczny na członka gospodarstwa domowego, czy jednostkowe spożycie dóbr w przedziale czasu.
Cechy skokowe charakteryzują się występowaniem całkowitoliczbowych reprezentacji np.: liczba dzieci w rodzinie, liczba studentów w grupie, ilość osób na mieszkanie, liczba prosiąt w miocie.
Próba, próbka - część, tj. podzbiór populacji podlegający bezpośrednio badaniu ze względu na ustaloną cechę, w celu wyciągnięcia wniosków o kształtowaniu się wartości tej cechy w populacji.
Liczebność próby - liczba jednostek, elementów populacji generalnej wybranych do próby. Liczebność próby oznacza się zwykle przez n. Gdy n![]()
30, mówimy o małej próbie.
Próba losowa - próba, której dobór z całej populacji dokonany jest w drodze losowania, tzn. w taki sposób, że jedynie przypadek decyduje o tym który element został wylosowany a który nie.
Próba reprezentacyjna - próba, której struktura pod względem badanej cechy nie różni się istotnie od struktury populacji generalnej. Próba reprezentacyjna jest jak gdyby „miniaturą” populacji generalnej, daje więc podstawę do wysuwania prawidłowych o niej wniosków. Uzyskiwaniu prób reprezentacyjnych sprzyja dobór właściwego schematu losowania próby.
Schemat losowania próby - praktyczny sposób losowania elementów populacji generalnej do próby, uwzględniający możliwości techniczne, koszt i efektywność uzyskiwanych wyników. Metoda reprezentacyjna zajmuje się szczegółowo różnymi schematami losowania próby.
Losowanie niezależne - schemat losowania próby ze zwracaniem każdego wylosowanego elementu w trakcie losowania, tak że jeden element może być wylosowany więcej niż jeden raz.
Losowanie zależne - schemat losowania próby bez zwracania każdego wylosowanego elementu populacji generalnej, tak że jeden element populacji może zostać wylosowany do próby tylko jeden raz.
Losowanie nieograniczone - losowanie elementów do próby od razu z całej populacji, co nie występuje w losowaniu warstwowym.
Losowanie warstwowe - losowanie próby oddzielnie z każdej części tzw. Warstwy populacji generalnej, na które została ona podzielona przed losowaniem.
Losowanie indywidualne - losowanie oddzielne poszczególnych elementów populacji generalnej do próby w odróżnieniu np. od losowania zespołowego, w którym losuje się do próby pewne naturalne zespoły populacji generalnej np. gospodarstwa domowe.
Wyniki próby - zaobserwowane wartości badanej cechy u tych elementów populacji generalnej które zostały wybrane do próby. Wyniki próby losowej o liczebności n stanowią wartości n- wymiarowej zmiennej losowej. Wyniki dużej próby grupuje się zwykle w klasy, tworząc szereg rozdzielczy.
Przestrzeń próby - zbiór wszystkich możliwych wyników próby o liczebności n.
Rozkład populacji - rozkład wartości badanej cechy w całej zbiorowości.
Parametry populacji - parametry rozkładu badanej cechy w populacji. Charakteryzują one ten rozkład. Do najczęściej używanych parametrów należą tzw. momenty. Parametry dzielimy zwykle na następujące grupy:
*miary skupienia (np. średnia arytmetyczna, mediana),*miary rozrzutu (np. wariancja i odchylenie standardowe współczynnik zmienności),*miary asymetrii, *miary korelacji (przy badaniu populacji ze względu na wiele cech współczynniki regresji i korelacji).
Statystyka z próby - zmienna losowa będąca dowolną funkcją wyników próby losowej, np. średnia arytmetyczna wyników próby x, statystyka pozycyjna rzędu 0,5, czyli mediana
Rozkład statystyki - teoretyczny rozkład prawdopodobieństwa zmiennej losowej będącej statystyką. Rozkład ten zależy zwykle od rozkładu populacji i schematu losowania n- elementowej próby.
Asymptotyczny rozkład statystyki - graniczny rozkład prawdopodobieństwa zmiennej losowej będącej statystyką, wyznaczony przy założeniu, że liczebność losowej próby n![]()
![]()
.
Rozkład dwupunktowy (rozkład zerojedynkowy) - teoretyczny rozkład prawdopodobieństwa zmiennej losowej skokowej X o funkcji prawdopodobieństwa określanej wzorem![]()
P(X=k) = ![]()
![]()
p![]()
q![]()
dla k = 0 lub k = 1 (0![]()
p![]()
, q = 1 - p
Rozkładu tego używa się w statystyce przy badaniu cech jakościowych.
Rozkład dwumianowy - rozkład prawdopodobieństwa zmiennej losowej skokowej X o funkcji prawdopodobieństwa określonej wzorem
P(X=k)=![]()
dla k=0, 1, 2,..., n (0![]()
p![]()
1, q = 1 - p)
Rozkład Poissona - rozkład prawdopodobieństwa zmiennej losowej skokowej X o funkcji prawdopodobieństwa określonej wzorem
P(X=k) = ![]()
dla k = 0, 1, 2,... (![]()
).
Rozkład normalny - najważniejszy w statystyce rozkład zmiennej losowej ciągłej X o funkcji gęstości prawdopodobieństwa określonej wzorem
f(x) = 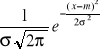
dla -![]()
(![]()
Często rozkład normalny oznacza się symbolem N(m,![]()
), gdzie m jest wartością oczekiwaną (średnią ), a ![]()
odchyleniem standardowym w tym rozkładzie, tj. m=E(X), ![]()
= D![]()
(X).
Rozkład normalny standaryzowany - rozkład normalny N(0,1), tzn. funkcji gęstości określonej wzorem
![]()
.
Wykresem tej funkcji gęstości jest tzw. krzywa Gaussa. Zmienna losowa U mająca rozkład N(0,1) nosi nazwę standaryzowanej lub unormowanej zmiennej normalnej.
Standaryzacja rozkładu normalnego - zamiana rozkładu normalnego N(m,![]()
) na rozkład normalny standaryzowany N(0,1). Odbywa się ona poprzez odjęcie średniej m i podzielenie przez odchylenie standardowe ![]()
, tzn. jeżeli X ma rozkład N(m,![]()
), to U=(X-m)/ ![]()
ma rozkład N(0,1).
Rozkład normalny n - wymiarowy - rozkład prawdopodobieństwa n - wymiarowego wektora losowego x o funkcji gęstości określonej wzorem
f(x)=(2 ![]()
)![]()
![]()
exp{-![]()
,
Gdzie ![]()
jest wektorem wartości oczekiwanych, a ![]()
![]()
jest macierzą wariancji i kowariancji. Wyznacznik I![]()
I nosi nazwę wariancji uogólnionej. Często rozkład ten jest oznaczany symbolem N(![]()
,![]()
).
Z pośród innych rozkładów statystycznych najważniejsze znaczenie posiadają: *rozkład ![]()
,
*rozkład t Studenta,
*rozkład F Snedecora.
Estymator - dowolna statystyka Z służąca do oszacowania nieznanej wartości parametru ![]()
populacji generalnej.
Rozkład estymatora - rozkład prawdopodobieństwa statystyki będącej estymatorem parametru ![]()
.
Parametry rozkładu estymatora - najważniejsze to wartość oczekiwana E(Z) oraz wariancja D![]()
(Z) w rozkładzie statystyki Z będącej estymatorem jakiegoś parametru ![]()
w populacji
Błąd przeciętny szacunku - pierwiastek z wariancji, tzn. odchylenie standardowe D(Z) w rozkładzie estymatora Z za pomocą którego szacuje się parametr ![]()
w populacji generalnej.
Estymacja punktowa - metoda szacunku nieznanego parametru ![]()
populacji, polegająca na tym, że jako wartość parametru ![]()
przyjmuje się wartość estymatora Z tego parametru, otrzymaną z danej n - elementowej próby losowej.
Estymator nieobciążony - estymator Z spełniający równość E(Z)=0, oznaczającą, że estymator Z szacuje parametr ![]()
bez błędu systematycznego.
Estymator efektywny - estymator Z o możliwie małej wariancji D![]()
(Z). Stosowanie estymatora efektywnego oznacza popełnienie małego błędu przeciętnego szacunku D(Z).
Metoda największej wiarygodności - metoda znajdowania estymatora parametru ![]()
, polegająca na tym, że za estymator przyjmuje się taką wartość parametru ![]()
, dla której wiarygodność (prawdopodobieństwo lub gęstość prawdopodobieństwa) danej próby losowej jest największa. Estymatory uzyskane metodą największej wiarygodności mają wiele pożądanych cech.
Estymacja przedziałowa - estymacja parametru ![]()
polegająca na budowaniu tzw. przedziału ufności dla tego parametru.
Przedział ufności - losowy przedział wyznaczony za pomocą rozkładu estymatora, a mający tę własność, że z dużym, z góry danym prawdopodobieństwem, pokrywa wartość szacowanego parametru ![]()
. Zapisujemy go zwykle w postaci P(a![]()
)= 1 - ![]()
, gdzie a i b noszą nazwę dolnej i górnej granicy(końca) przedziału ufności, a prawdopodobieństwo 1-![]()
jest dane z góry.
Współczynnik ufności - prawdopodobieństwo 1- α występujące po prawej stronie wzoru na przedział ufności, a oznaczające prawdopodobieństwo, z jakim parametr θ jest pokryty tym przedziałem. Współczynnik ufności w praktyce wybiera się jako dowolnie duże prawdopodobieństwo. Najczęściej przyjmowanymi wartościami za 1- α są liczby: 0,90; 0,95; 0,99. Im bliższy 1 jest współczynnik ufności, tym szerszy (więc o mniejszej użyteczności) otrzymuje się przedział ufności. Dlatego też bez specjalnej potrzeby nie należy przyjmować zbyt wysokich wartości współczynnika ufności.
Hipoteza statystyczna - jakiekolwiek przypuszczenie dotyczące rozkładu populacji generalnej.
Hipoteza parametryczna - hipoteza statystyczna precyzująca wartość parametru w rozkładzie populacji generalnej znanego typu.
Hipoteza nieparametryczna - hipoteza statystyczna precyzująca typ rozkładu populacji generalnej.
Hipoteza zerowa - podstawowa hipoteza statystyczna sprawdzana danym testem. Oznacza się ją zwykle symbolem H0.
Hipoteza alternatywna - hipoteza statystyczna konkurencyjna w stosunku do hipotezy zerowej w tym sensie, że jeżeli odrzuca się hipotezę zerową, to przyjmuje się hipotezę alternatywną. Oznacza się ją H1.
Błąd pierwszego rodzaju - możliwy do popełnienia przy weryfikacji hipotezy statystycznej błąd polegający na odrzuceniu hipotezy prawdziwej.
Błąd drugiego rodzaju - możliwy do popełnienia przy sprawdzaniu hipotezy statystycznej błąd polegający na przyjęciu hipotezy fałszywej.
Poziom istotności - prawdopodobieństwo popełnienia błędu pierwszego rodzaju w postępowaniu testującym hipotezę. Poziom istotności oznacza się zwykle symbolem α i obiera się z góry, zwykle jako małe prawdopodobieństwo. Do najczęściej przyjmowanych poziomów istotności należą prawdopodobieństwa 0,1; 0,05; 0,001. Odrzucenie sprawdzanej hipotezy na poziomie istotności np. α = 0,05 oznacza, że ryzyko popełnienia błędu pierwszego rodzaju przy tej decyzji wynosi tylko 5% (inaczej mówiąc, co najwyżej 5 razy na 100 takich decyzji popełniać będziemy błąd).
Test statystyczny - reguła postępowania, która na podstawie wyników próby ma doprowadzić do decyzji przyjęcia lub odrzucenia postawionej hipotezy statystycznej. Przy pomocy testu weryfikujemy zatem hipotezę statystyczną.
Moc testu - prawdopodobieństwo podjęcia decyzji prawidłowej przy weryfikacji hipotezy statystycznej danym testem, a polegającej na odrzuceniu hipotezy fałszywej.
Test istotności - najczęściej używany w praktyce statystycznej typ testu, pozwalający na odrzucenie hipotezy z małym ryzykiem popełnienia błędu (mierzonym poziomem istotności α). Ze względu na to, że w teście istotności uwzględnia się jedynie błąd pierwszego rodzaju, a nie rozpatruje się szansy popełnienia błędu drugiego rodzaju, to w wyniku tego testu możliwa jest decyzja odrzucenia hipotezy zerowej lub nie ma podstaw do jej odrzucenia (co nie oznacza jej przyjęcia).
Wyszukiwarka
Podobne podstrony:
Wykład 1-1.03.2011, Notatki UTP - Zarządzanie, Semestr II, Statystyka
ściąga 2 egzamin, Notatki UTP - Zarządzanie, Semestr II, Technologie informacyjne
ściąga 1 egzamin, Notatki UTP - Zarządzanie, Semestr II, Technologie informacyjne
WykłD 4 - 05.04.2011, Notatki UTP - Zarządzanie, Semestr II, Statystyka
Wykład 3 - 22.03.2011, Notatki UTP - Zarządzanie, Semestr II, Statystyka
ściąga 3 egzamin, Notatki UTP - Zarządzanie, Semestr II, Technologie informacyjne
Zagadnienia NoO, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
Wykład 9 - 10.05.2011, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
Ściąga ZO, Notatki UTP - Zarządzanie, Semestr IV, Zachowania organizacyjne
Wykład 3 - 17.03.2011, Notatki UTP - Zarządzanie, Semestr II, Prawo
Wykład 1-03.03.2011, Notatki UTP - Zarządzanie, Semestr II, Zarządzanie zasobami ludzkimi
Wykład 10 - 17.05.2011, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
Prawo 2 - 10.03.2011, Notatki UTP - Zarządzanie, Semestr II, Prawo
Wykład 11, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
wykład 3-08.03.2011, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
Wykład 5 - 31.03.2011, Notatki UTP - Zarządzanie, Semestr II, Nauka o organizacji
Wykład 3 - 01.04.2011, Notatki UTP - Zarządzanie, Semestr II, Zarządzanie jakością
więcej podobnych podstron