img060

Jest to tak zwany test dla par danych. Wykorzystujemy w nim statystykę t
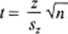
gdzie:
(5.12)
z — wartość średnia różnic zh
sz — oszacowanie odchylenia standardowego różnic według znanego wzoru
'z

(5.13)
Statystyka (5.12) ma rozkład / o n- 1 stopniach swobody. Dalsze postępowanie znamy. Korzyścią ze stosowania tego testu jest wyeliminowanie wpływu różnic między poszczególnymi obiektami (np różnic osobniczych między pacjentami), dlatego też wynik testu można uważać za bardziej obiektywny.
Jeżeli tylko są możliwości, należy stosować test dla par. a nie poprzednio omówiony test porównywania dwóch średnich. Jeżeli jednak musimy porównywać dwie średnie, a dodatkowym utrudnieniem jest niemożność przyjęcia założenia o równości wariancji w obu populacjach (por. punkt 5.7), z których wylosowano próby, to gdy obie próby mają dużą liczebność (/i1, n2> 100) można wykorzystywać statystykę u
u

(5.14)
(oznaczenia jak we wzorach (5.9) i (5.10)) mającą w przybliżeniu rozkład normalny standaryzowany. Jeżeli zaś dysponujemy małymi próbami lub próby znacznie różnią się liczebnością, to lepiej stosować statystykę /:
t
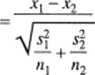
(5.15)
która ma w przybliżeniu rozkład f-Studenta o liczbie stopni swobody v danej wzorem
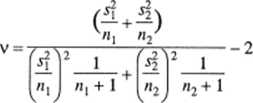
(5.16)
60
Wyszukiwarka
Podobne podstrony:
prigogine19 Dylemat Epikura po prostu niemożliwe. Jest to tak zwany problem małych mianowników, o kt
Nieżyt nosa NIEŻYT NOSA (RHINITIS) Panie, kichanie to nie na zdrowie Jest to tak zwany katar, czyli
SNB13904 udaremnione. Nie jest to związek specyficzny tylko dla opieki i wychowania, j istota i sens
s 14 15 14 ROZDZIAŁ 1 ka, śvjata, przyrody. Jest to tak zwane prawo natury. Szkoły prawa natu ry pow
Scan0161 SHY Vj Boy Nie jest to łatwe zadanie nawet dla eksperta. Każdy, kto kiedyś kupił konia, ma
skanuj0050 (22) 58 w obiegu. Był to tak zwany system waluty złotej. Obok złotych monet funkcjonowały
IMG$28 A więc Jest to postać przemiany połitropowej, dla w m-“*. llJ Ta posta
IMGW12 (3) 204 WACŁAW BERENT grch wzbogaca ... Mam i drugi zbiorek, tak zwany „filantropijny . dla
więcej podobnych podstron