1484605993
6. Ćwiczenia
1. Rozważmy kolekcję 100 dokumentów, z których 8 jest uważanych za istotne (relevant) względem zapytania: {d2, d11, d16, d25, d46, d61, d79, d97). Podejście wykorzystane w celu wyszukania (retrieve) dokumentów w odpowiedzi na zapytanie zwróciło 10 dokumentów:
d1, d2. d10, d25, d40, d49, d51, d61, d76, d97
w formie rankingu. Oblicz miary „precision” oraz „recall" dla 5 i 10 pierwszych dokumentów w rankingu.
2. Załóżmy, że dla danego zapytania są 4 istotne dokumenty w kolekcji dokumentów. Wyniki algorytmu dla tego zapytania są następujące (R - relevant, N - non-relevant):
RNRNNNNNRR
Jakia jest wartość miary MAP dla tego systemu?
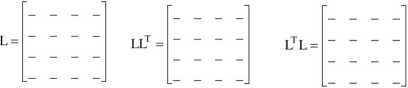
3. Oblicz wagi koncentratorów (h) i autorytetów (a) dla następującego grafu, korzystając z kalkulatora wartości i wektorów własnych znalezionego w sieci (calculator for eigenvalues and eigenvectors). Oblicz L, LLT oraz LTL.

4. Załóżmy, że początkowe zapytanie użytkownika jest następujące „cheap CDs cheap DVDs extremely cheap CDs". Użytkownik ocenia dwa pierwsze dokumenty D1 =„CDs cheap software cheap CDs" i D2=„cheap thrills DVDs" zwrócone przez system jako odpowiednio istotny i nieistotny. Zakładając wykorzystanie reprezentacji bag-of-words, jaka będzie postać zmodyfikowanego zapytania, jeśli wykorzystano metodę „Rocchio relevance feedback" z parametrami a=1, p=0.75 i y=0.25?
|
Q |
D1 |
D2 |
Q’ | |
|
cheap | ||||
|
CDs | ||||
|
DVDs | ||||
|
extremely | ||||
|
software | ||||
|
thrills |
Wyszukiwarka
Podobne podstrony:
100_H. Dźwigoł znaczenia współpracy między niezależnymi podmiotami jest uważany za jeden z
Ćwiczenia rewalidacyjne A 1. Połącz strzałkami pudełka, w których jest o jedną kolorową bombkę mnie
WSTĘP Przełom XX i XXI wieku jest uważany za początek ery ekologicznej. Obecnie najważniejszym wyzwa
PB030003 [1600x1200] Wstrzykowa analiza sekwencyjna• ZASADA TECHNIKI SIA Technika SIA jest uważana z
skanuj0010 5 1. Statyczna próba rozciągania1.1. Wprowadzenie Statyczna próba rozciągania jest uważan
20757 justy019 Reakcja ta jest katalizowana przez aspartazę i również jest odwracalna. Hydroliza moc
61Dydaktyka pedagogiczna jest uważana za najlepszą tego typu w naszym kraju. Świadczą o tym
Sponsoring •Sponsoring dopiero od niedawna jest uważany za równoprawny element promocji -
Med-Arb jest uważany za szczególnie interesujący mechanizm pojednawczego rozwiązywania sporów z
Obserwacja jest uważana za najbardziej wszechstronną technikę gromadzenia materiałów. Jest czynności
100Y12 Smakowitość Jest uważana za najbardziej subiektywną cechę określaną w hodowli ziemniaka jadal
G. Stanley Hall Jest uważany za twórcę naukowej psychologii rozwojowej. Jako pierwszy przeprowadził
8 (1313) Inżynieria genetyczna jest uważana za podstawowe narzędzie w rozwiązywaniu zasadniczych pro
więcej podobnych podstron