
ITA-102 Hurtownie Danych
Marcin Gorawski, Michał Jan Gorawski
Moduł 9
Wersja 1.0
Data Mining I
Spis treści
Data Mining I ........................................................................................................................................ 1
Informacje o module ............................................................................................................................ 2
Przygotowanie teoretyczne ................................................................................................................. 3
Podstawy teoretyczne.................................................................................................................. 3
Laboratorium podstawowe .................................................................................................................. 6
Problem 1 (czas realizacji 25 min) ................................................................................................ 6
Problem 2 (czas realizacji 15min) - .............................................................................................. 7
Laboratorium podstawowe ................................................................................................................ 11
Problem 2 (czas realizacji 25 min) – kontynuacja modułu 1 ...................................................... 11
Laboratorium rozszerzone ................................................................................................................. 12
Zadanie 1 (czas realizacji 30 min) ............................................................................................... 12
Zadanie 1 (czas realizacji 60 min) ............................................................................................... 12
Marcin Gorawski, Michał Jan Gorawski
Moduł IX
ITA-102 Hurtownie Danych
Data Mining I
Strona 2/12
Informacje o module
Opis modułu
W module poznasz zaawansowane zastosowania modeli eksploracji danych.
Dowiesz się czym jest Data Mining (Eksploracja Danych), w jakich
przypadkach można ją wykorzystać, jakie są korzyści wykorzystania tych
struktur oraz jak korzystać z Data Miningu w SQL Server 2008.
Cel modułu
Przekazanie informacji na temat modeli służących do określenia
potencjalnych odbiorców akcji reklamowej, oraz metody porównań różnych
algorytmów.
Uzyskane kompetencje
Po zrealizowaniu modułu będziesz:
• wiedział czym jest Data Mining i do czego jest wykorzystywany
• potrafił stworzyć modele Dataminingowe w SQL Server 2008
Wymagania wstępne
Przed przystąpieniem do pracy z tym modułem powinieneś:
• wiedział teorię Ekstrakcji Danych
• potrafić utworzyć modele i przeanalizować modeleEkstrakcji danych
• rozumiał zasady tworzenia i analizy modeli Ekstrakcji Danych
Zgodnie z mapą zależności przedstawioną na Rys. 1, przed przystąpieniem
do realizacji tego modułu należy zapoznać się z materiałem zawartym
w modułach 3, 4, 5.
Rys. 1 Mapa zależności modułu

Marcin Gorawski, Michał Jan Gorawski
Moduł IX
ITA-102 Hurtownie Danych
Data Mining I
Strona 3/12
Przygotowanie teoretyczne
Podstawy teoretyczne
Początek dziedziny odkrywania wiedzy (ang. Knowledge Discovery in Databases KDD) poprzez
eksplorację danych (ang. Data Minig DM) sięgają 5000 lat wstecz, kiedy to ludzie kultury
sumeryjskiej gromadzili zapisy podatkowe na glinianych tabliczkach. Od tego czasu, rozwijano
techniki gromadzenia i analizy tego typu informacji. Poniżej przykłady KDD.
Analizy korporacyjne i sterowanie ryzykiem
• Planowanie finansowe i ewolucja aktywów:
• Analiza i predykcja przepływu pieniędzy.
• Analiza żądań warunkowych zapewniających rozwój aktywów.
• Analiza przekrojowo-profilowana i szeregów czasowych ( finansowe wskaźniki, analiza
trendów, etc).
• Konstruowanie zasobów:
• Sumaryzacja - porównywanie zasobów i ich zużycia.
• Konkurencja:
• Monitor konkurencji i kierunki rynku (CI: inteligentna konkurencja).
• Segmentowanie klientów w klasy i klasy bazujące na procedurach wyceny.
• Ustawienie strategii wyceny dla wysoce konkurencyjnego rynku.
Zarządzanie rynkiem
• Lokowanie danych do analizy:
• transakcje kart kredytowych, karty lojalności klienta, kupony dyskontowe, zgłoszenia
skarg klientów, badania stylu życia (publicznego).
• Marketing ukierunkowany - poszukiwanie klasterów „modelu’ klientów, którzy dzielą pewne
charakterystyki np.: zainteresowań, poziom dochodu, przyzwyczajeń, itp.;
• Określenie wzorców nadprogramowo kupowania dla klienta -Konwersja pojedynczego
rachunku bankowego na rachunek wspólny : skojarzenie, etc.
• Analiza przekrojowa rynku:
• Skojarzenia/korelacje pomiędzy sprzedażami produktu.
• Predykcja bazująca na skojarzonej informacji.
KDD odwołuje się do całościowego procesu odkrywania użytecznej wiedzy z danych, podczas, gdy
DM to szczególny krok w tym procesie – aplikacja specyficznych algorytmów ekstrakcji wiedzy z
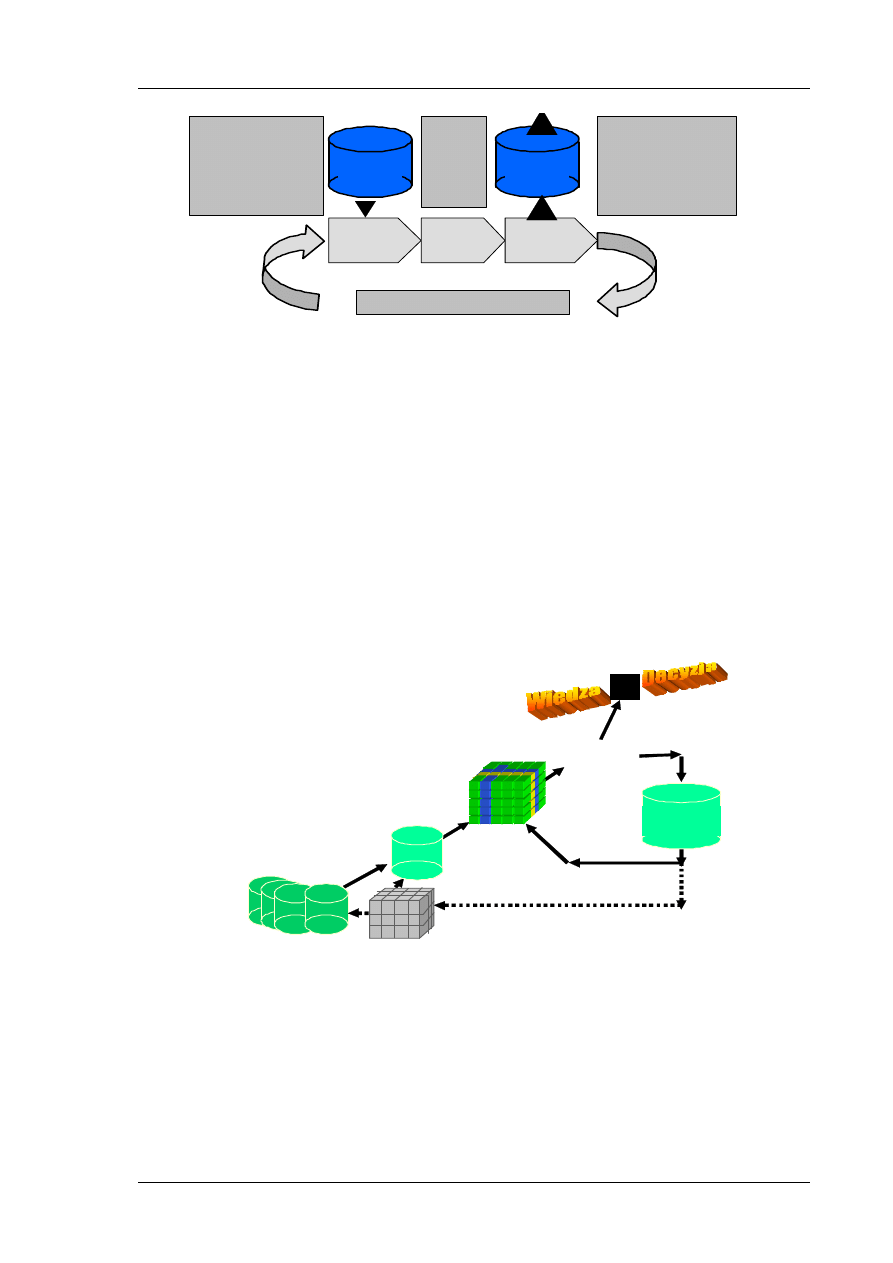
danych. Rys. 1 prezentuje ogólny schemat procesu KDD z użyciem algorytmów DM. Zauważmy, że
proces ten jest dość skomplikowany - wieloiteracyjny i wieloeksperymentalny.
Marcin Gorawski, Michał Jan Gorawski
Moduł IX
ITA-102 Hurtownie Danych
Data Mining I
Strona 4/12
Rys. 1. Schemat procesu KDD z użyciem algorytmów DM
Największym wyzwaniem dla DM jest bardzo duży rozmiar kolekcji danych. Obecne obserwacje
pokazują, że rozmiar danych rośnie podobnie jak moc obliczeniowa komputerów – podwaja się co
12 miesięcy. Ma to ogromny wpływ na ewolucję algorytmów DM z powodu tak szybko rosnących
ilościami danych.
Pod pojęciem eksploracji danych (DM) rozumiemy:
• Ekstrakcję niejawnych, wcześniej nieznanych i potencjalnie użytecznych informacji z danych.
• Ekstrakcję i analizę dużej liczby danych, przy pomocy środków automatycznych lub pół
automatycznych w celu okrycia znaczących wzorców i reguł.
• Technika używana do znajdowania struktur i związków w dużych zbiorach danych.
Eksploracją danych nie jest dedukcyjnym przetwarzaniem zapytań, systemem eksperckim czy
standardowym programem statystycznym.
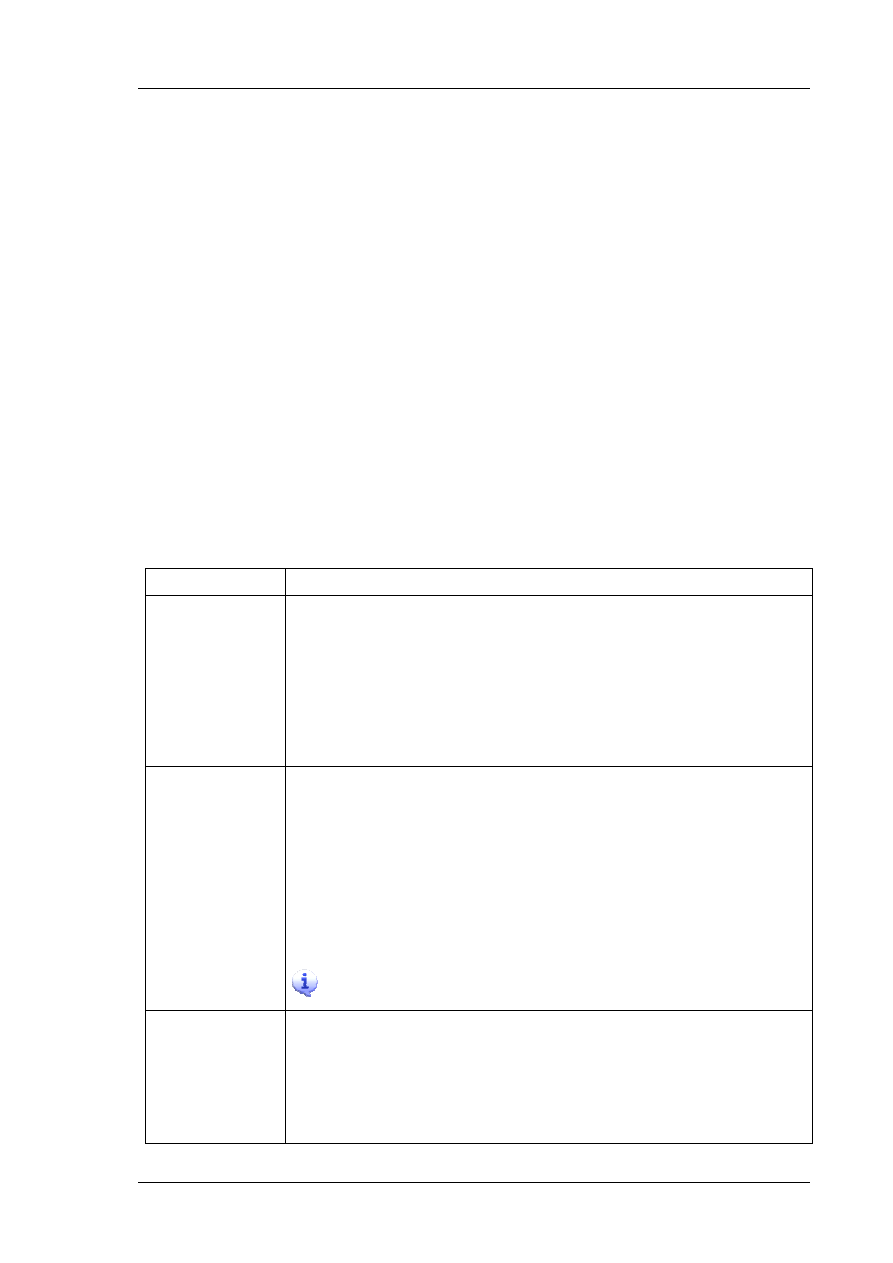
Rys. 2. Schemat procesu KDD z użyciem algorytmów DM i hurtowni danych
Linia procesu KDD z użyciem algorytmów DM i hurtowni danych (DW) składa się z najpierw z
wyboru modelu DM (metod (taksonomia) a następnie z ich użycia w DW (rys.102/9/2). Metody DM
mają na celu odkrycie wiedzy w hurtowniach danych, która przybiera formę wzorców, związków i
faktów, które wcześniej nie były oczywiste. Wybrana metoda DM jest nierozerwalnie związana z
wykrytymi wzorcami. Nie oczekuje się, że wszystkie te metody będą działały równie dobrze na
wszystkich zbiorach danych. Wizualizacja zbiorów danych może być połączona z, lub użyta przed
P R E P R O C E S S IN G
D o s t ę p i S e le kc ja
C z y s z c z e n ie
W z bo g a c a n ie
In te g r a c ja
T ra n s fo rm a c ja
R e d u k c ja
D y s k r e t y z a c ja
O c e n a e ks p e rt ó w
P r z e tw a rz a n ie
w s t ę p ne
D M
E k s p lo ra c ja
d a n yc h
P rz e tw a rz a nie
k o ń c o w e
B A Z A
D A N Y C H
B A Z A
W IE D Z Y
P O S T P R O C E S S IN G
W iz u a liz a c ja
R a po r t ow a n ie
A n a liz a w y n ik ó w
A s ym ila c ja
D e c y z ja @ A k c ja
P o m i a r r e z u lta t ów
In t e rp r e ta c ja
M
O
D
E
L
E
D
M
A
L
G
O
R
Y
T
M
Y
T
A
K
S
O
N
O
M
IA
C z ys z c z en ie da n yc h
W z b og ac a ni e da n yc h
B a z y da n yc h
O bs z ar Po śr ed ni
W s tę pn e prz e tw a rz a nie d a n yc h
M od e le ED
E
E
k
k
s
s
p
p
l
l
o
o
r
r
a
a
c
c
j
j
a
a
D
D
a
a
n
n
y
y
c
c
h
h
Ew o lu c ja
W z o rcó w
B A Z A
W IE D Z Y
H
H
u
u
r
r
t
t
o
o
w
w
n
n
i
i
a
a
d
d
a
a
n
n
y
y
c
c
h
h
E ks tra k cj a da n yc h
@
D M

Marcin Gorawski, Michał Jan Gorawski
Moduł IX
ITA-102 Hurtownie Danych
Data Mining I
Strona 5/12
modelowaniem i może wspomagać wybór metody oraz wskazywać, jakie wzorce mogą być
prezentowane
Wyróżniamy następujące podejście w metodach DM:
• Kierowanie weryfikacją:
• Analiza zapytań,
• Analiza statystyczna.
• Nadzorowane kierowanie odkryciami:
• Predykacja,
• Klasyfikacja.
• Nienadzorowane kierowanie odkryciami:
• Sieci neuronowe map samo-organizujących się,
• Asocjacja,
• Klasteryzacja,
• Wykrywanie odchyleń.
Metody kierowania weryfikacją wymagają, aby użytkownik postawił pewną hipotezę a odpowiedzi
na zapytania i raportowanie lub analiza statystyczna potwierdzają następnie tę hipotezę. Statystyka
w DM jest w pewnym stopniu niedoceniana w porównaniu do mniej tradycyjnych technik takich
jak: sieci neuronowe, algorytmy genetyczne i klasyfikacja regałowa. Wiele z tych mniej tradycyjnych
technik posiada swoją statystyczną interpretację. Metody statystyczne są najbardziej użyteczne dla
zagadnień dobrze ustrukturyzowanych. Wiele problemów DM nie zalicza się do tej klasy - techniki
statystyczne załamują się lub wymagają zbyt dużych nakładów, żeby być efektywne.
Nadzorowane kierowanie odkryciami polega na odkryciu związków między wejściami i wyjściami
systemu. Związki te mogą być wykorzystywane do predykcji, estymacji lub klasyfikacji. Do uczenia
sieci wykorzystywany jest znany zbiór trenujący par wejść/wyjść z dołączonymi etykietami
wskazującymi klasę obserwacji, a nowe dane są klasyfikowane w oparciu o niego. Metody
nadzorowanego kierowania odkryciami to predykacja oraz klasyfikacja. Metody predykcyjne
budują wzorce przewidując nieznane wartości atrybutów na podstawie znanych wartości innych
atrybutów. Główną metodą predykcji jest regresja liniowa i wielokrotna lub nie liniowa (sieci
neuronowe z propagacją wsteczną). Klasyfikacja to proces dwuetapowy, który tworzy konstrukcja
modelu (opisywanie predefiniowanych klas) oraz użycie modelu do predykcji (klasyfikacja przyszłych
lub nieznanych obiektów). Wyróżniamy metody klasyfikacji związane z:
• sieciami neuronowymi z propagacją wsteczną,
• sieciami Bayesowskimi,
• k-najbliższymi sąsiadami
• wnioskowaniem opartym o przypadki,
• algorytmami genetycznymi,
• zbiorami przybliżonymi,
• zbiorami rozmytymi.
Nienadzorowane kierowanie odkryciami. Często zadaniem DM jest odkrycie struktur w zbiorze
danych, bez jakiejkolwiek wiedzy wstępnej o nim. Stąd uczenie nienadzorowane, gdzie występują
nieznane etykiety danych w zbiorze trenującym, a celem jest wykrycie istnienia klas lub klasterów
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
w danych. Do tego zadania można wykorzystać klasę sieci neuronowe
organizującymi się. Nienadzorowane kierowanie odkryciami
• sieci neuronowe: mapy samo
• asocjacje,
• klasteryzacja,
• wykrywanie odchyleń
Laboratorium podstawowe
Problem 1 (czas realizacji 25 min)
Ćwiczenie prezentuje sposób stworzenia projektu dla Data Miningu. Krok po kroku opisane zostały
definiowanie źródła danych, widoku źródła danych i jego modyfikacji.
Zadanie
Tok postępowania
1.
Stworzenie
nowego projektu
Analysis Services
w SS BIDS (SQL
Server Business
Intelligence
Development
Studio)
• Uruchom Business Intelligence Development Studio
• Stwórz
Services Project Template.
• Wpisz nazwę projektu
2.
Stworzenie
źródła danych
(Data Source)
• W Solution Explorer klikn
New Data Source
• Wyb
•
•
•
• Jako sposób logowania wybierz
• Wybierz
3.
Stworzenie
widoku źródła
danych (Data
Source View)
• W Solution Explorer klik
•
•
• Na stronie
•
Gorawski
Strona 6/12
adania można wykorzystać klasę sieci neuronowe
Nienadzorowane kierowanie odkryciami zapewniają:
e: mapy samo-organizujące się,
ykrywanie odchyleń.
Laboratorium podstawowe
Problem 1 (czas realizacji 25 min)
prezentuje sposób stworzenia projektu dla Data Miningu. Krok po kroku opisane zostały
źródła danych, widoku źródła danych i jego modyfikacji.
Tok postępowania
Uruchom Business Intelligence Development Studio
Stwórz nowy projekt Analysis Services File->New
Services Project Template.
Wpisz nazwę projektu AdventureWorks.
W Solution Explorer kliknij ppm na katalogu DataSource
New Data Source.
Wybierz New aby dodać nowe połączenie do bazy
Provider: Native OLE\DB\Microdoft OLE DB Provider for SQL Server
Select or enter a database name: AdventureWorksDW
Server Name: localhost.
Jako sposób logowania wybierz Use the service account
Wybierz Finish i zamknij edytor.
Nowe źródło danych, baza danych AdventureWorksDW
folderze Data Sources.
W Solution Explorer kliknij ppm i wybirz opcję New Data Source View
Select a Data Source : AdventureWorksDW
Select or enter a database name: AdventureWorksDW
Na stronie Select Tables and Views wybierz następujące tabele:
dbo.ProspectiveBuyer
Moduł IX
Data Mining I
zwane mapami samo-
prezentuje sposób stworzenia projektu dla Data Miningu. Krok po kroku opisane zostały
Uruchom Business Intelligence Development Studio (BIDS).
>New->Projects-> Analysis
DataSource i wybierz opcję
aby dodać nowe połączenie do bazy Adventure Works.
Microdoft OLE DB Provider for SQL Server
Select or enter a database name: AdventureWorksDW
Use the service account
AdventureWorksDW pojawia się w
opcję New Data Source View
Select or enter a database name: AdventureWorksDW
następujące tabele:
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
•
•
•
•
• Wybie
4.
Modyfikacja
widoku źródła
danych (Data
Source View)
• Kliknij
• W panelu widoku źródła danych wyb
vAssocSeqLineItems
Problem 2 (czas realizacji
Ćwiczenie prezentuje sposób użycia różnych modeli danych na przykładzie fikcyjnej firmy
Adventure Works. Firma ma zamiar zwiększyć sprzedaż rowerów kierując ofertę do konkretnych
klientów za pomocą kampanii pocztowej. Analizując cechy znanych klientów można zauważyć
pewne zależności wskazujące potencjalnych nowych klientów, oraz określić prawdopodobieństw
zakupienia towarów danej firmy przez potencjalnego klienta. Dodatkowo możliwe jest logiczne
grupowanie istniejących klientów, za pomocą zależności np. demograficznych bądź nabywczych.
Baza danych Adventure Works DW
przykład) zawiera informacje o
Zadanie
Tok postępowania
1.
Stworzenie
struktury
eksploracji danych
dla modelu
Targeted Mailing
• W
Structures
• Jako metodę definicji (
relacyjną bazę lub hurtownię danych (
or data warehouse
• Jako metodę eksploracji danych (
wyb
• Aby określić typy tabel (
kolumnie
Gorawski
Strona 7/12
dbo.vAssocSeqLineItems
dbo.vAssocOrders
dbo.vTargetMailing
dbo.vTimeSeries
Wybierz Finish i zamknij kreatora
Widok źródła danych pozwala modyfikować strukturę danych aby były
one bardziej znaczące dla projektu. Używając widoków można: wybrać
tabele najistotniejsze dla tworzonego projektu, stworzyć relacje
pomiędzy tabelami oraz dodać kolumny obliczeniowe bez potrzeby
modyfikowania oryginalnego źródła danych
Aby stworzyć zaplanowane w ćwiczeniu modele
sequence clustering muszisz utworzyć związek jeden
pomiędzy tabelami vAssocSeqOrders i vAssocSeqLineItems
to na uczynienie tabeli vAssocSeqLineItems
vAssocSeqOrders na potrzeby w/w modeli.
Kliknij podwójnie widok źródła danych Adventure Works DW.d
W panelu widoku źródła danych wybirz kolumnę
vAssocSeqLineItems
•
Przeciągnij kolumnę do tabeli vAssocSeqOrders
OrderNumber
Stworzyłeś nowy związek jeden-do-wielu pomiędzy tabelami
vAssocSeqOrders i vAssocSeqLineItems
(czas realizacji 15min) -
Ćwiczenie prezentuje sposób użycia różnych modeli danych na przykładzie fikcyjnej firmy
. Firma ma zamiar zwiększyć sprzedaż rowerów kierując ofertę do konkretnych
klientów za pomocą kampanii pocztowej. Analizując cechy znanych klientów można zauważyć
pewne zależności wskazujące potencjalnych nowych klientów, oraz określić prawdopodobieństw
zakupienia towarów danej firmy przez potencjalnego klienta. Dodatkowo możliwe jest logiczne
grupowanie istniejących klientów, za pomocą zależności np. demograficznych bądź nabywczych.
Adventure Works DW (instalowana wraz z produktem SQL Serve
przykład) zawiera informacje o istniejących i potencjalnych klientach firmy.
Tok postępowania
Pierwszym krokiem jest stworzenie w BIDS nowej struktury eksploracji
danych oraz modelu drzewa decyzyjnego.
W Solution Explorer kliknij ppm na struktury eksploracji (
Structures) i wybierz New Mining Structures.
Jako metodę definicji (Select the Definition Method
relacyjną bazę lub hurtownię danych (From existing relational database
or data warehouse) i wybierz Next.
Jako metodę eksploracji danych (Select a Data Mining Technique
wybierz drzewo decyzyjne (Microsoft Decision Trees
Aby określić typy tabel (Specify the Table Types) zaznacz pole
kolumnie vTargetMail i wybierz Next
Moduł IX
Data Mining I
Widok źródła danych pozwala modyfikować strukturę danych aby były
one bardziej znaczące dla projektu. Używając widoków można: wybrać
tabele najistotniejsze dla tworzonego projektu, stworzyć relacje
kolumny obliczeniowe bez potrzeby
Aby stworzyć zaplanowane w ćwiczeniu modele market basket i
tworzyć związek jeden-do-wielu
vAssocSeqLineItems. Pozwoli
vAssocSeqLineItems zagnieżdżoną tabelą
Adventure Works DW.dsv
kolumnę OrderNumber z tabeli
vAssocSeqOrders do kolumny
wielu pomiędzy tabelami
Ćwiczenie prezentuje sposób użycia różnych modeli danych na przykładzie fikcyjnej firmy
. Firma ma zamiar zwiększyć sprzedaż rowerów kierując ofertę do konkretnych
klientów za pomocą kampanii pocztowej. Analizując cechy znanych klientów można zauważyć
pewne zależności wskazujące potencjalnych nowych klientów, oraz określić prawdopodobieństwo
zakupienia towarów danej firmy przez potencjalnego klienta. Dodatkowo możliwe jest logiczne
grupowanie istniejących klientów, za pomocą zależności np. demograficznych bądź nabywczych.
(instalowana wraz z produktem SQL Server 2005 jako
Pierwszym krokiem jest stworzenie w BIDS nowej struktury eksploracji
ppm na struktury eksploracji (Mining
inition Method) wybierz istniejącą
From existing relational database
Select a Data Mining Technique)
Microsoft Decision Trees) i wybierz Next.
) zaznacz pole Case przy
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
• Aby określić dane treningowe (
Key
• Wybierz
• Jako kolumny wejściowe (
Next
•
•
•
•
•
•
•
•
•
•
•
•
• Aby wybrać zawartość kolumn i typ danych (Specify Columns’ Content
and DataType) wyb
• Na stronie (
testing data
• Jako
cas’ów w zbiorze danych testowych)
• Wybierz
•
•
•
• Za
2.
Przetwarzanie
modelu ekstrakcji
danych
• W BIDS rozwiń menu
• Jeżeli pokaże się okno o potrzebie konwersji projektu kliknij
• Kliknij
•
Wybierz
3.
Analiza
modelu opartego
o drzewa
decyzyjne
• Dwukrotnie kliknij na
• Wybierz zakładkę
• Wybierz zakładkę
informujące o konieczności przebudowania projektu należy kliknąć
Gorawski
Strona 8/12
Aby określić dane treningowe (Specify the Training Data
Key przy kolumnie CustomerKey.
Wybierz pola Input i Predictible przy kolumnie BikeBuyers
Po zaznaczeniu, że kolumna jest przewidywana (predictible)
uaktywnia się przycisk Suggest. Wybranie przycisku powoduje
uruchomienie okna Suggest Related Columns, w którym wyświetlone
są kolumny o bliskiej relacji z kolumną przewidywaną.
Jako kolumny wejściowe (Input) wybierz następujące kolumny i
Next:
Age
CommutateDistance
EnglishEducation
EnglishOccupation
• FirstName
• Gender
• GeographyKey
HouseOwnerFlag
LastName
MartialStatus
NumberCarsOwned
NumberChildrenAtHome
Region
TotalChildren
YearlyIncome
Aby wybrać zawartość kolumn i typ danych (Specify Columns’ Content
and DataType) wybierz Wykryć (Detect) a następnie
Na stronie (Split data into training and testing sets)
testing data (procent danych testowych), zostaw domyślną wartość 30.
Jako Maximum number of cases in testing data set
cas’ów w zbiorze danych testowych), wpisz 1000.
Wybierz Next
Mining structure name: TargetedMailing
Mining model name : TM_Decision_Tree
Zaznacz pole Allow drill through i wybierz Finish
W BIDS rozwiń menu Mining Models i wybierz Process
Jeżeli pokaże się okno o potrzebie konwersji projektu kliknij
Kliknij Run i poczekaj na informację o zakończeniu procesu.
Wybierz Close.
Dwukrotnie kliknij na TargetedMailing.dmm
Wybierz zakładkę Mining Models
Na tej zakładce możesz sprawdzić jakie kolumny są używane w
modelu. Możesz ustawiać kolumny ignorowane, przez co właściwości
modelu zmieniają się.
Wybierz zakładkę Mining Model Viewer, jeżeli pojawi się okienko
informujące o konieczności przebudowania projektu należy kliknąć
Moduł IX
Data Mining I
Specify the Training Data) zaznacz pole
BikeBuyers
Po zaznaczeniu, że kolumna jest przewidywana (predictible)
. Wybranie przycisku powoduje
, w którym wyświetlone
przewidywaną.
następujące kolumny i wybierz
Aby wybrać zawartość kolumn i typ danych (Specify Columns’ Content
) a następnie Next.
Split data into training and testing sets),jako Percentage of
, zostaw domyślną wartość 30.
Maximum number of cases in testing data set (maksymalna ilość
Process
Jeżeli pokaże się okno o potrzebie konwersji projektu kliknij Yes
i poczekaj na informację o zakończeniu procesu.
Na tej zakładce możesz sprawdzić jakie kolumny są używane w
ustawiać kolumny ignorowane, przez co właściwości
, jeżeli pojawi się okienko
informujące o konieczności przebudowania projektu należy kliknąć Yes.
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
• Wybierz zakładkę
4.
Mapowanie
kolumn
• Wybierz zakładkę
• Na zakładce Column Mapping sprawdz kolumny w oknie
Structure.
• W oknie
wybierztabelę
•
Sprawdz jakie kolumny z
vTargetMail
5.
Macierz
klasyfikacji
• Przełączyć na zakładkę
Gorawski
Strona 9/12
Na tej zakładce możesz zaobserwować w jaki sposó
wejściowe wpływają na parametr wyjściowy modelu. Przy drzewie
decyzyjnym możesz ocenić które kolumny mają największy wpływ na
ostateczną decyzję o kupnie roweru.
Wybierz zakładkę Decision Tree.
Drzewo składa się z wielu hierarchicznie połączon
decyzyjnych. W każdym węźle jest warunek jaki musi być spełniony.
Po zatrzymaniu kursora myszki nad węzłem, pokazuje się informacja
szczegółowa o danej grupie. Po prawej stronie nad diagramem masz
możliwość wybrania z listy rozwijanej liczby po
wyświetlane. Jeżeli chcesz wyświetlić węzły potomne dla danego
węzła, to musisz podwójnie kliknąć w kwadrat po prawej stronie węzła
(jeżeli węzeł jest zwinięty, to w środku jest plus, jeżeli węzeł jest
rozwinięty to w środku jest minus).
Wybierz zakładkę Mining Accurancy Chart.
Na zakładce Column Mapping sprawdz kolumny w oknie
Structure.
W oknie Select Input Table(s) naciśnij przycisk
wybierztabelę vTargetMail.
Sprawdz jakie kolumny z TargetMailing wiążą się z kolumnami tabeli
vTargetMail.
Przełączyć na zakładkę Classification Matrix
Jak można zinterpretować otrzymaną macierz?
W kolumnach są wartości rzeczywiste, natomiast w wierszach
wartości wynikające z predykcji. Wartość 7157 w krotce (0,0) oznacza,
że w danych testowych tyle przypadków zostało zaklasyfikowanych
dobrze do grupy osób nie zainteresowanych kupnem roweru. Wartość
2240 w krotce (1,0) oznacza, że tyle przypadków zostało
zaklasyfikowanych do grupy osób które nie są zainteresowane, choć w
rzeczywistości jest inaczej. Wartość (0,1) to liczba przypadków
zaklasyfikowanych jako osoby zainteresowane kupieniem roweru,
choć w rzeczywistości tak nie jest. Ostatnią krotką jest (1,1) gdzie
mamy przypadek poprawnego zaklasyfikowania osób które chcą kupić
rower.
Całkowity błąd predykcji można wyznaczyć poprzez podzielenie sumy
przypadków leżących we wszystkich krotkach poza główną przekątną
do sumy liczb we wszystkich krotkach macierzy.
Błąd predykcji dla kupna roweru należy rozumieć jako liczbę osób
które nie przyjmą oferty do liczby wszystkich osób do których zostanie
wysłana oferta. Ten błąd jest dla nas ważniejszy, ponieważ on
decyduje o ostatecznym zysku z kampanii (przykładowo, jeżeli na 100
osób do których zostanie wysłana oferta tylko 5 skorzysta z niej, to
zysk ze sprzedaży rowerów może być mniejszy od całkowitego kosztu
wysyłania ofert). W naszym przypadku błąd dotyczy tylko tych krotek,
dla których wartość predykcji wynosiła 1.
Moduł IX
Data Mining I
Na tej zakładce możesz zaobserwować w jaki sposób parametry
wejściowe wpływają na parametr wyjściowy modelu. Przy drzewie
decyzyjnym możesz ocenić które kolumny mają największy wpływ na
Drzewo składa się z wielu hierarchicznie połączonych węzłów
decyzyjnych. W każdym węźle jest warunek jaki musi być spełniony.
Po zatrzymaniu kursora myszki nad węzłem, pokazuje się informacja
szczegółowa o danej grupie. Po prawej stronie nad diagramem masz
możliwość wybrania z listy rozwijanej liczby poziomów jakie są
wyświetlane. Jeżeli chcesz wyświetlić węzły potomne dla danego
węzła, to musisz podwójnie kliknąć w kwadrat po prawej stronie węzła
(jeżeli węzeł jest zwinięty, to w środku jest plus, jeżeli węzeł jest
Na zakładce Column Mapping sprawdz kolumny w oknie Mining
naciśnij przycisk Select Case Table i
wiążą się z kolumnami tabeli
Jak można zinterpretować otrzymaną macierz?
W kolumnach są wartości rzeczywiste, natomiast w wierszach
predykcji. Wartość 7157 w krotce (0,0) oznacza,
danych testowych tyle przypadków zostało zaklasyfikowanych
dobrze do grupy osób nie zainteresowanych kupnem roweru. Wartość
krotce (1,0) oznacza, że tyle przypadków zostało
upy osób które nie są zainteresowane, choć w
rzeczywistości jest inaczej. Wartość (0,1) to liczba przypadków
zaklasyfikowanych jako osoby zainteresowane kupieniem roweru,
choć w rzeczywistości tak nie jest. Ostatnią krotką jest (1,1) gdzie
oprawnego zaklasyfikowania osób które chcą kupić
Całkowity błąd predykcji można wyznaczyć poprzez podzielenie sumy
przypadków leżących we wszystkich krotkach poza główną przekątną
do sumy liczb we wszystkich krotkach macierzy.
na roweru należy rozumieć jako liczbę osób
które nie przyjmą oferty do liczby wszystkich osób do których zostanie
wysłana oferta. Ten błąd jest dla nas ważniejszy, ponieważ on
decyduje o ostatecznym zysku z kampanii (przykładowo, jeżeli na 100
ych zostanie wysłana oferta tylko 5 skorzysta z niej, to
zysk ze sprzedaży rowerów może być mniejszy od całkowitego kosztu
wysyłania ofert). W naszym przypadku błąd dotyczy tylko tych krotek,
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
6.
Wykres
przewidywanego
zysku
następujące wartości:
•
•
•
•
• Zbadaj
12, 14)
7.
Zmiany
kolumn w modelu
• Wybierz zakładkę
• Dla kolumn
wartość
• Przejdź do zakładki
Gorawski
Strona 10/12
Jaki jest całkowity błąd predykcji drzewa decyzyjnego, a także jaka
część osób odrzuci ofertę z kampanii.
•
Wybierz zakładkę Lift Chart.
•
Z rozwijanej listy Chart Type wybierz
następujące wartości:
Population: 50000
Fixed Cost: 5000
Individual Cost: 10
Revenue per Individual: 15
Jak można zinterpretować otrzymany wykres?
Zbadaj kształt wykresu dla różnych wartości Individual Cost
12, 14) – w tym celu naciśnij przycisk Settings i wpis
Dlaczego przy ustawieniu Individual Cost powyżej wartości 15 wykres
zysku nie posiada wartości dodatnich?
Wybierz zakładkę Mining Models.
Dla kolumn First Name, Last Name, Region zaznacz w
wartość Ignore zamiast Input.
Przejdź do zakładki Mining Accurancy Chart | Classification Matrix
Oblicz na nowo całkowity błąd predykcji i błąd dla kupna roweru. Czy
otrzymane wyniki są lepsze czy gorsze od poprzednio uzyskanych?
Moduł IX
Data Mining I
błąd predykcji drzewa decyzyjnego, a także jaka
Profit Chart. Wpisać
Jak można zinterpretować otrzymany wykres?
Individual Cost. (3, 5, 10,
i wpisz wybrane wartości.
powyżej wartości 15 wykres
zaznacz w pozycji rozwijanej
Classification Matrix.
Oblicz na nowo całkowity błąd predykcji i błąd dla kupna roweru. Czy
otrzymane wyniki są lepsze czy gorsze od poprzednio uzyskanych?
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
Laboratorium podstawowe
Problem 2 (czas realizacji 25 min)
Ćwiczenie prezentuje tworzenie różnych modeli dla vTargetMail.
Zadanie
Tok postępowania
1.
Algorytm
naiwny Bayes-
owski
• Przejdź na zakładkę
wybierz
• Jako
Bayes.
• Przy pojawieniu się okienka ostrzegającego wybierz
• Z menu kontekstowego dla
wybrać ten model, możesz kliknąć ppm na pierwszym wierszu w nowo
utworzonej kolumnie (czyli na
• Przejdź
• Sprawdź dla których atrybutów jest największa różnica pomiędzy liczbą
osób zainteresowanych kupnem roweru.
• Przejź na zakładkę
• Sprawdź jakie wartości dla określonych atrybutów
predykcji.
• Przejź na zakładkę
2.
Algorytm
oparty o Sztuczne
Sieci Neuronowe
• Przet
Process
Gorawski
Strona 11/12
Laboratorium podstawowe
acji 25 min) – kontynuacja modułu 1
Ćwiczenie prezentuje tworzenie różnych modeli dla vTargetMail.
Tok postępowania
Przejdź na zakładkę Mining Models, z menu kontekstowego (ppm)
wybierz New Mining Model.
Jako Model name wpisz TM_Bayes, jako Algorithm name wybrać
Bayes.
Niektóre typy danych nie są wspierane przez różne metody. Dla wyżej
wybranego algorytmu kolumny Age, Geography Key
zostaną pominięte, ponieważ nie mają wartości dyskretnych tylko
ciągłe.
Przy pojawieniu się okienka ostrzegającego wybierz
Z menu kontekstowego dla TM_Bayes wybierz opcję
wybrać ten model, możesz kliknąć ppm na pierwszym wierszu w nowo
utworzonej kolumnie (czyli na Microsoft Neural Network
Przejdź na zakładkę Mining Model Viewer | Attribute Profiles
Sprawdź dla których atrybutów jest największa różnica pomiędzy liczbą
osób zainteresowanych kupnem roweru.
Przejź na zakładkę Attribute Characteristics.
Sprawdź jakie wartości dla określonych atrybutów
predykcji.
Przejź na zakładkę Mining Accurancy Chart | Classification Matrix
Czy aktualnie stworzony model jest lepszy czy gorszy od drzew
decyzyjnych?
Zmienić kolumny wejściowe dla tego modelu, czy można w ten
sposób poprawić wyniki dla tego algorytmu?
•
Przejdź na zakładkę Mining Models, z menu kontekstowego
(ppm) wybierz New Mining Model.
•
Jako Model name wpisz Neural_Network
name wybierz Neural Network.
Podobnie jak w poprzednim przypadku, niektóre kolumny zostaną
automatycznie wyłączone.
Jakie kolumny nie mogą być użyte przez sieć neuronową?
Przetwórz model – z menu kontekstowego dla tego modelu wyb
Process.
Zmień kolumny wejściowe dla tego modelu, czy można w
poprawić wyniki dla tego algorytmu?
Moduł IX
Data Mining I
, z menu kontekstowego (ppm)
, jako Algorithm name wybrać Naive
Niektóre typy danych nie są wspierane przez różne metody. Dla wyżej
Geography Key i Yerly Income
zostaną pominięte, ponieważ nie mają wartości dyskretnych tylko
Przy pojawieniu się okienka ostrzegającego wybierz Yes.
wybierz opcję Process. Aby
wybrać ten model, możesz kliknąć ppm na pierwszym wierszu w nowo
Microsoft Neural Network).
Attribute Profiles.
Sprawdź dla których atrybutów jest największa różnica pomiędzy liczbą
Sprawdź jakie wartości dla określonych atrybutów wpływają na wynik
Mining Accurancy Chart | Classification Matrix.
Czy aktualnie stworzony model jest lepszy czy gorszy od drzew
Zmienić kolumny wejściowe dla tego modelu, czy można w ten
, z menu kontekstowego
Neural_Network, jako Algorithm
poprzednim przypadku, niektóre kolumny zostaną
Jakie kolumny nie mogą być użyte przez sieć neuronową?
z menu kontekstowego dla tego modelu wybierz
kolumny wejściowe dla tego modelu, czy można w ten sposób
Marcin Gorawski, Michał Jan Gorawski
ITA-102 Hurtownie Danych
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 30 min)
Otrzymałeś zadanie dokładnej analizy modelu
decyzyjne który jest prezentowany w laboratorium podstawowym. W tym celu musisz najpierw
zbudować ten model zgodnie z wskazówkami z laboratorium podstawowego a następnie Wykonać
następujące zadania: Na zakładce
decyzyjnym, które jednoznacznie wskazują (albo prawie jednoznacznie, np. 90%), że osoba z tej
grupy kupi lub nie kupi roweru, następnie przejdź zakładę Dependency Network i zinterpretuj jej
zawartość.
Kolejnym twoim zadaniem jest prze
wpływ mają wartości Population
zadaniem jest na zakładce
błąd predykcji dla kupna roweru. Czy zmiana kolumn wejściowych znacząco wpływa na błąd
predykcji?
Zadanie 1 (czas realizacji 60 min)
Firma Adventure Works w której pracujesz prowadzi szeroko zakrojoną akcję reklamową. Twoi
przełożeni są bardzo zainteresowanie wykorzyst
docelową do której należy skierować kampanie ulotkową. Twoim zadaniem jest porównanie
wszystkich dostępnych struktur dataminingowych dostępnych dla modelu
grupę docelową, oraz przeanalizuj
testowanych struktur są najbardziej odpowiednie dla testowanych danych? W ćwiczeniu skorzystaj
z tworzonego na laboratorim podstawowym projektu.
Gorawski
Strona 12/12
Porównaj opracowane modele. Które kolumny można
Laboratorium rozszerzone
Zadanie 1 (czas realizacji 30 min)
Otrzymałeś zadanie dokładnej analizy modelu Target Mail dataminingowego
który jest prezentowany w laboratorium podstawowym. W tym celu musisz najpierw
zbudować ten model zgodnie z wskazówkami z laboratorium podstawowego a następnie Wykonać
następujące zadania: Na zakładce Mining Model Viewer znaleźć po trzy ta
decyzyjnym, które jednoznacznie wskazują (albo prawie jednoznacznie, np. 90%), że osoba z tej
grupy kupi lub nie kupi roweru, następnie przejdź zakładę Dependency Network i zinterpretuj jej
Kolejnym twoim zadaniem jest przejść na zakładkę Mining Accuracy Chart/Lift Chart
Population i Fixed Cost na końcowy kształt wykresu.
a zakładce Mining Models tak dobrać kolumny wejściowe, aby zminimalizować
dla kupna roweru. Czy zmiana kolumn wejściowych znacząco wpływa na błąd
Zadanie 1 (czas realizacji 60 min)
Firma Adventure Works w której pracujesz prowadzi szeroko zakrojoną akcję reklamową. Twoi
przełożeni są bardzo zainteresowanie wykorzystaniem modeli dataminingowych aby określić grupę
docelową do której należy skierować kampanie ulotkową. Twoim zadaniem jest porównanie
wszystkich dostępnych struktur dataminingowych dostępnych dla modelu
przeanalizuj, porównaj i skrytykuj struktury dostępne dla modelu
testowanych struktur są najbardziej odpowiednie dla testowanych danych? W ćwiczeniu skorzystaj
z tworzonego na laboratorim podstawowym projektu.
Moduł IX
Data Mining I
opracowane modele. Które kolumny można zignorować?
dataminingowego opartego o drzewa
który jest prezentowany w laboratorium podstawowym. W tym celu musisz najpierw
zbudować ten model zgodnie z wskazówkami z laboratorium podstawowego a następnie Wykonać
naleźć po trzy takie ścieżki w drzewie
decyzyjnym, które jednoznacznie wskazują (albo prawie jednoznacznie, np. 90%), że osoba z tej
grupy kupi lub nie kupi roweru, następnie przejdź zakładę Dependency Network i zinterpretuj jej
Mining Accuracy Chart/Lift Chart i sprawdź jaki
na końcowy kształt wykresu. Ostatnim twoim
tak dobrać kolumny wejściowe, aby zminimalizować
dla kupna roweru. Czy zmiana kolumn wejściowych znacząco wpływa na błąd
Firma Adventure Works w której pracujesz prowadzi szeroko zakrojoną akcję reklamową. Twoi
aniem modeli dataminingowych aby określić grupę
docelową do której należy skierować kampanie ulotkową. Twoim zadaniem jest porównanie
wszystkich dostępnych struktur dataminingowych dostępnych dla modelu Target Mail. Określ
porównaj i skrytykuj struktury dostępne dla modelu TM. Które z
testowanych struktur są najbardziej odpowiednie dla testowanych danych? W ćwiczeniu skorzystaj
Wyszukiwarka
Podobne podstrony:
DSW 09 10 kl 2 cz II id 144072 Nieznany
MATERIALY DO WYKLADU CZ IV id Nieznany
Zwierzatka ze Zdrowego Zakatka tydzien pierwszy id 593875
pierwsza id 357471 Nieznany
fizyka cz 2 pdf id 176637 Nieznany
09 Karty umiejetnosci pierwszak Nieznany
09 Lekcja 1 cz 1
Jez niemiecki w klasach dwujez arkusz cz II id 221769
MATERIALY DO WYKLADU CZ III id Nieznany
09 Wnioskowanie w logice pierws Nieznany (2)
Automatyzacja zadania cz II id Nieznany
cz 7 sport id 127538 Nieznany
cz 1 pelna id 127130 Nieznany
II FILAR Cz III id 209872 Nieznany
DZIADY CZ III id 147073 Nieznany
pierwszpomoc id 357780 Nieznany
Cwiczenie 4 Metodyka cz II id 99491
m kawinski cz ii id 274819 Nieznany
więcej podobnych podstron