
Bazy danych – zbiorcze pytania i odpowiedzi
1. Elementy DBMS
DMBS – Data Base Management System, System zarządzania bazą danych, jest to cześd
systemu bazy danych (który składa się z DBMSu i Bazy danych), elementami DBMS są:
Moduł Zarządzania Transakcjami
Moduł Zarządzania Pamięcią
Procesor Zapytao
Dane/Metadane
2. Dana jest relacja, ustalamy jej klucz oraz wskazujemy funkcjonalnośd przechodnią
(przechodnią zależnośd funkcyjną?)
Kluczem relacji (kluczem głównym) nazywamy taki z kluczy kandydujących, który składa się z
najmniejszej ilości atrybutów i najlepiej określa poszczególne krotki. Klucz taki musi
jednoznacznie identyfikowad każdą z krotek, nie może się powtarzad (musi byd unikalny) i nie
może byd pusty (nie może mied wartości NULL).
Zależnośd funkcyjna – wystąpienie danej wartości A zależy od wystąpienia wartości B
Przechodnia zależnośd funkcyjna – wartośd A zależy od B a wartośd B zależy od C, więc A jest
przechodnio zależne funkcyjnie od C
3. Mnożenie tablicowe zapytaniem SQL
SELECT a.wartosc, b.wartosc, a.wartosc*b.wartosc AS wynik FROM a JOIN b ON a.id=b.id
4. Moduł Ben-Zvi, gdzie występuje i do czego służy
Jest to moduł występujący w temporalnych bazach danych, czyli bazach danych
przechowujących oprócz rekordów dane dotyczące czasu kiedy dane były poprawne, a kiedy
nie, przydatne jeśli wyniki operacji na danych zależą od ich aktualności lub przedawnieniu.
Na moduł ten składa się 5 znaczników czasu:
Tes – czas kiedy dane zaczęły byd aktualne
Trs – czas kiedy zarejestrowano, że dane są aktualne
Tee – czas kiedy dane przestały byd aktualne
Tre – czas kiedy zarejestrowano, że dane nie są aktualne
Td – czas kiedy dane przestały byd aktualne w bazie

5. Normalizacja:
I postad normalna – atrybuty są atomowe (niepodzielne)
II postad normalna – wszystkie atrybuty są w pełni zależne od klucza głównego relacji
( od całości tego klucza)
III postad normalna – brak przechodnich zależności funkcjonalnych
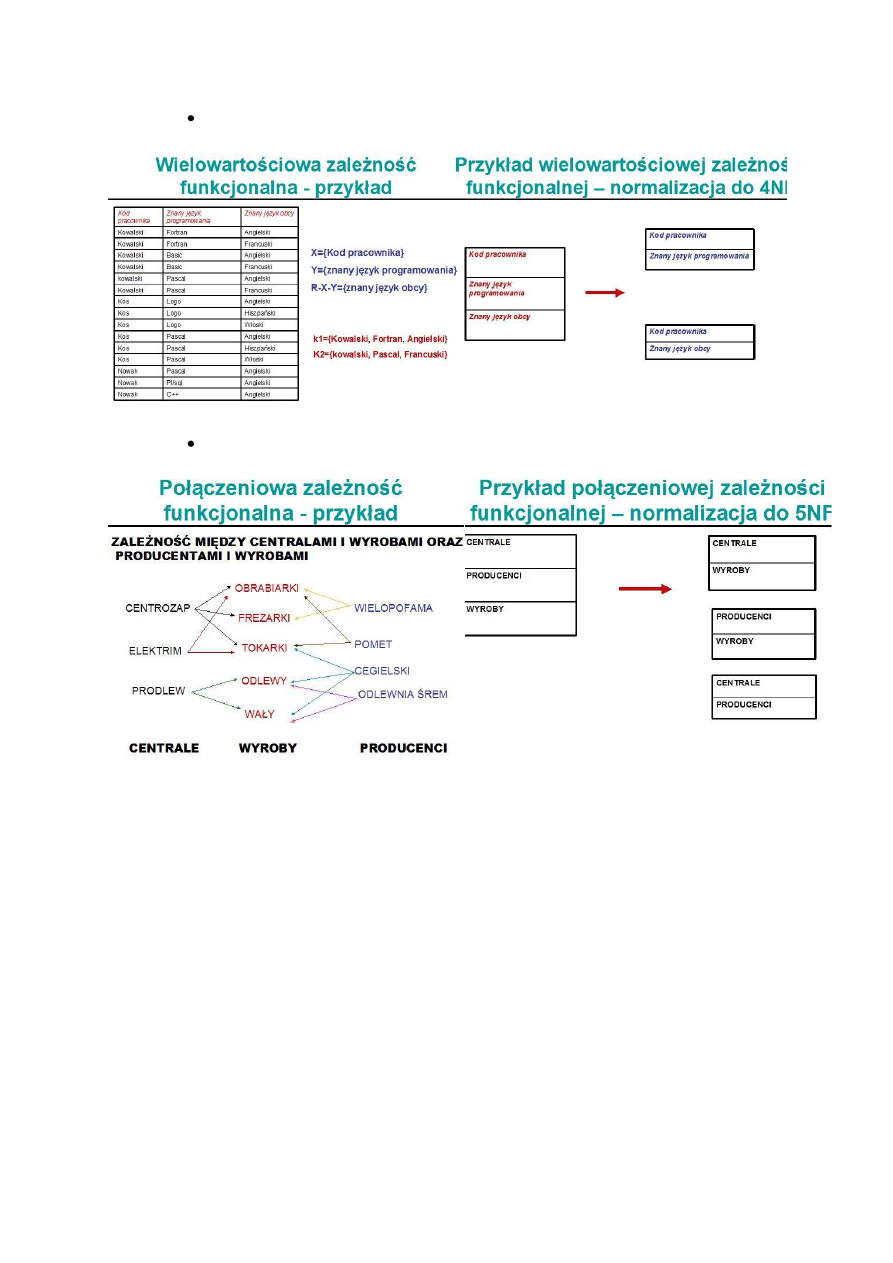
IV postad normalna – brak wielowartościowych zależności funkcjonalnych
V postad normalna – brak połączeniowych zależności funkcjonalnych
6. Co to jest ROLLBACK WORK
ROLLBACK WORK jest poleceniem SQLa służącym do anulowania zmian wprowadzonych do
bazy. Zmiany wprowadzane do bazy za pomocą komend UPDATE, INSERT, DELETE nie są
wprowadzane na stałe do fizycznych danych, dopóki nie zostanie wydane polecenie COMMIT
WORK, ROLLBACK WORK jest poleceniem, które działa odwrotnie, tzn. nie potwierdza
wprowadzonych zmian.
7. Baza danych, a hurtownia danych
Baza danych to zbiór danych do których można odwoływad się za pomocą zapytao w formie
transakcji, otrzymujemy w wyniku dane wybrane z danych bazy. Jest to rodzaj systemu OLTP
(Online Transaction Processing). Poprzez transakcje rejestruje się zmiany stanów rzeczy.
Hurtownie danych są zbiorami narzędzi, które pośredniczą pomiędzy systemami OLTP, a
systemami OLAP (Online Analitycal Processing), które pozwalają na analizę danych. HD są
narzędziami pomagającymi w procesie decyzyjnym podejmowad w odpowiednim czasie, z

odpowiednim kosztem dobre decyzje. Hurtownie danych operują na bazach danych
(zazwyczaj na więcej niż jednej), HD zawierają dane archiwalne, statystyki, ostatnie wyniki
analiz.
8. ACID – co to i do czego jest stosowane
ACID to zbiór reguł, które powinny byd spełniane przez transakcje, jest stosowany w
modułach MZT systemów DBMS.
ACID to:
Atomicity – atomowośd transakcji, albo transakcja wykona się w całości albo wcale
Consistency – spójnośd, po wykonaniu transakcji baza będzie dalej spójna
Isolation – izolacja, transakcje wykonują się niezależnie od siebie, zazwyczaj nie
powinny widzied zmian dokonywanych przez inne
Durability – trwałośd, w razie awarii systemu, system powinien się normalnie
uruchomid i posiadad prawidłowe dane
9. Dostęp do bazy na podstawie stempli czasowych
Każda transakcja przychodząca do bazy dostaje swój stempel czasowy zależny od taktów
zegara, transakcje operują na kopiach danych. Każdy obiekt w bazie posiada 2 stemple
czasowe, jeden ostatniej czytającej transakcji, drugi ostatniej aktualizującej transakcji. W
momencie zakooczenia transakcji jej stempel czasowy jest porównywany z wartościami
stempli czasowych obiektów na których transakcja operowała. W zależności od wartości
porównao transakcje są wykonywane ponownie lub nie.
10. Poprawnośd relacji
Relacja jest poprawna, jeśli jest w 5 FN.
11. Co oznacza PRIMARY KEY i do czego służy
PRIMARY KEY oznacza klucz główny tabeli, czyli atrybut lub grupę atrybutów wybraną
spośród kluczy kandydujących do jednoznacznej identyfikacji krotek tabeli (klucz główny nie
może się powtarzad w obrębie tabeli i nie może mied wartości NULL). PRIMARY KEY służy w
SQLu do określania kolumny (kolumn) tabeli, którą tworzymy, zawierającej klucz główny tej
tabeli.
12. Co to jest ścieżka
Ścieżka to zagnieżdżony ciąg atrybutów ułatwiający określanie predykatów w złożonej
hierarchii klas w obiektowych bazach danych. Obiekt przechowujący ciąg kolejnych nazw
zagnieżdżonych atrybutów nazywany jest zmienna ścieżkową, wyróżniamy zmienne skalarne
i zbiorowe.

13. Co to jest 2PL
2PL to mechanizm dynamicznego dwufazowego blokowania. Transakcje mogą zakładad dwa
typy zamków – S (do odczytu) i X (do aktualizacji). Jeśli na ziarno został nałożony zamek S to
blokowane są możliwości zakładania zamków X, jeśli na ziarno nałożono zamek X to
blokowane są możliwości założenia jakiegokolwiek innego zamka. Dzięki temu dane nie mogą
byd zaktualizowane w trakcie odczytu przez jakąś inną transakcję. Dodatkowo prowadzony
jest dziennik i graf czekania oraz ochrona prze zakleszczeniem.
14. Zapytanie SQL służące do zwiększenia pensji Janowi Kowalskiemu jeśli jego pensja jest
większa niż 2000
UPDATE tabela SET pensja=1.2*(SELECT pensja FROM tabela WHERE nazwisko=Kowalski AND
imie=Jan) WHERE nazwisko=Kowalski AND imie=Jan AND pensja>2000
15. Metody radzenia sobie z awariami w bazach danych.
Backup – tworzenie kopii bezpieczeostwa danych co pewien czas
Log – tworzenie dzienników operacji na bazie
Recovery – przywracanie bazy na podstawie backup’ów lub log’ów
Chechpoint – migawkowe zrzuty transakcji
Replication – tworzenie kopii na nośnikach fizycznie i geograficznie oddalonych
Rollback – cofanie zmian na podstawie log’ów
16. Federacyjne BD
Federacyjna BD to baza danych składająca się z wielu baz danych, które są autonomiczne, ale
połączone w przezroczystą całośd, tzn. użytkownik widzi je jako jedną bazę. Podbazy
zachowują pełną autonomię, pokazują dane poprzez perspektywy, przez co częśd danych
może byd ukrywana. Takie podejście zapewnia bezpieczeostwo, autonomię i efektywnośd.
17. Model hierarchiczny BD
W modelu tym rekordy logicznie uszeregowane są w drzewa, w których każdy rekord zawiera
zbiór rekordów, połączenia są tworzone poprzez zawieranie się. Dzięki zastosowaniu tego
modelu wyszukiwanie danych w bazie jest szybkie.
18. Model sieciowy BD
W modelu tym rekordy powiązane są między sobą za pomocą wskaźników (pointer),
poszczególne rekordy wskazują na inne rekordy, występuje też specjalny wskaźnik tzw. nil lub
pusty, mówiący o koocu listy.

19. Typy danych w modelu relacyjnym
Typ łaocuchowy (string)
Typ numeryczny (numeric)
Typ logiczny (logical)
Typ walutowy
Typ daty/godziny
Autonumer
Hiperłącze
Typ notatnikowy (memo)
20. DDL
Data Definition Language – język definicji danych, podjęzyk języka zapytao do baz danych,
służący do definiowania danych, tworzenia tabel.
Przykłady:
CREATE TABLE
DROP TABLE
21. SQL: kasowanie tabeli, kasowanie kolumny, kasowanie rekordu
Kasowanie tabeli:
DROP TABLE tabela
Kasowanie kolumny: ALTER TABLE tabela DROP kolumna
Kasowanie rekordu:
DELETE FROM tabela WHERE cos=cos
22. Wymienid i opisad funkcje procesora DBMS
Obsługa zapytao – przetworzyd zapytanie i zwrócid jego wynik
Aktualizacja i modyfikacja danych i metadanych – na podstawie zapytao dokonuje
modyfikacji danych (pośredniczy) i schematów
Optymalizacja zapytao – przekształcenie zapytao tak, by były wykonane jak
najmniejszym kosztem
Jest punktem przechodnim do pozostałych modułów – jeśli zapytanie będzie
przechodziło do innego modułu DBMS to musi przejśd przez procesor zapytao
23. Wymienid funkcje i zadania DBMS:
Realizowanie zapytao do bazy
Kontrola redundancji danych (nadmiarowości)
Kontrola użytkowników i autoryzacja
Zarządzanie współbieżnością transakcji
Zarządzanie blokowaniem transakcji
Modyfikowanie, dodawanie, usuwanie danych
Planowanie wykonywania transakcji

Udostępnianie interfejsów
Realizowanie zabezpieczeo przed awariami
24. Model logiczny oparty na rekordach
Jest to schemat relacji pomiędzy rekordami, czyli zbiorami atrybutów. W schemacie tym
pokazane są rekordy i zależności między nimi, różne od fizycznego ułożenia danych, tzn. jak
połączenia są interpretowane, a nie jak faktycznie fizycznie wyglądają, np. czy dane są
ułożone w formie drzew. Jest to zbiór informacji o systemie.
25. Ziarnistośd
Rodzaj jednostki podlegającej operacjom kopiowania, odczytu, zapisu itp. Wyróżniamy ziarna
grube i miałkie, grube to np. bazy danych w całości, relacje, natomiast miałkie to pole, kilka
pól. Ziarnistośd ma również znaczenie przy zakładaniu zamków, czy zamki są zakładane na
całą bazę, czy tylko na dany rekord.
26. UNIQUE i NOT NULL
Są to modyfikatory występujące przy definiowaniu tabel, określające jakie cechy mają
spełniad wartości w danej kolumnie. UNIQUE mówi o tym, że wartości w kolumnie nie mogą
się powtarzad, natomiast NOT NULL mówi o tym że wartośd w kolumnie nie może byd NULL
(pusta). Wykorzystywane przede wszystkim przy kolumnach zawierających klucze główne
tabel.
27. Zalety federacyjnej BD
Autonomicznośd podbaz
Podbazy prezentują tylko dane wybiórcze poprzez perspektywy
Wysokie bezpieczeostwo
Możliwośd pracy na wielu BD jak na jednej
Możliwośd złączenia wielu BD oddalonych od siebie
Duża efektywnośd pracy
28. Time-split (raczej chodzi o TIME-SLICE)
Służy do dookreślenia przedziału czasowego w zapytaniach do temporalnych baz danych, tj.
poprzez to słowo kluczowe określamy z jakiego okresu czasu dane nas interesują.
29. Opisad model logiczny hurtowni danych
Hurtownie danych to zbiór narzędzi pośredniczących między systemami OLTP (Online
Transaction Processing), a OLAP (Online Analytical Processing). Są narzędziami ułatwiającymi
podejmowanie dobrych decyzji w zarządzaniu, przy małych kosztach. Integrują dane z wielu
źródeł pozwalając na ich analizę, zawierają dane statystyczne i historyczne.

Model logiczny HD opiera się o warstwy (połączone ze sobą):
Warstwa najniższa – uporządkowane dane z baz danych i nieuporządkowane dane z
plików tekstowych oraz np. arkuszy kalkulacyjnych
Magazyn danych operacyjnych – dane w postaci baz danych, ulotne aktualne
Centralna hurtownia danych – zawiera ukierunkowane, nieulotne, zintegrowane bazy
danych
Lokalne hurtownie danych – zawiera dane silnie zagregowane, mogące służyd w
procesie decyzyjnym
Warstwa metadanych – dane statystyczne, dane o użytkownikach i o pozostałych
warstwach, dane kontrolne
30. DML
Data Manipulation Language – język manipulacji danych, podjęzyk języka zapytao do baz
danych. Pozwala na modyfikację, tworzenie i kasowanie danych.
Przykłady:
INSERT INTO
DELETE
31. Wady i zalety obiektowych BD
Wady:
Mało specjalistów
Niepełna specyfikacja
Brak optymalizacji zapytao
Niedopracowane mechanizmy obsługi
Nie wiadomo jakie koszta migracji dużych systemów
Zalety:
Lepsza reprezentacja rzeczywistości
Połączenie danych z operacjami na nich
Hermetyzacja
Dziedziczenie
Możliwośd tworzenia własnych typów danych
Wersjonowanie
Duża efektywnośd, która wciąż rośnie
32. SQL: zmiana nazwy kolumny i dodanie kolumny
Zmiana nazwy kolumny – ALTER TABLE tabela RENAME
COLUMN
stara_nazwa
nowa_nazwa
Dodanie kolumny – ALTER TABLE tabela ADD COLUMN kolumna char(64)
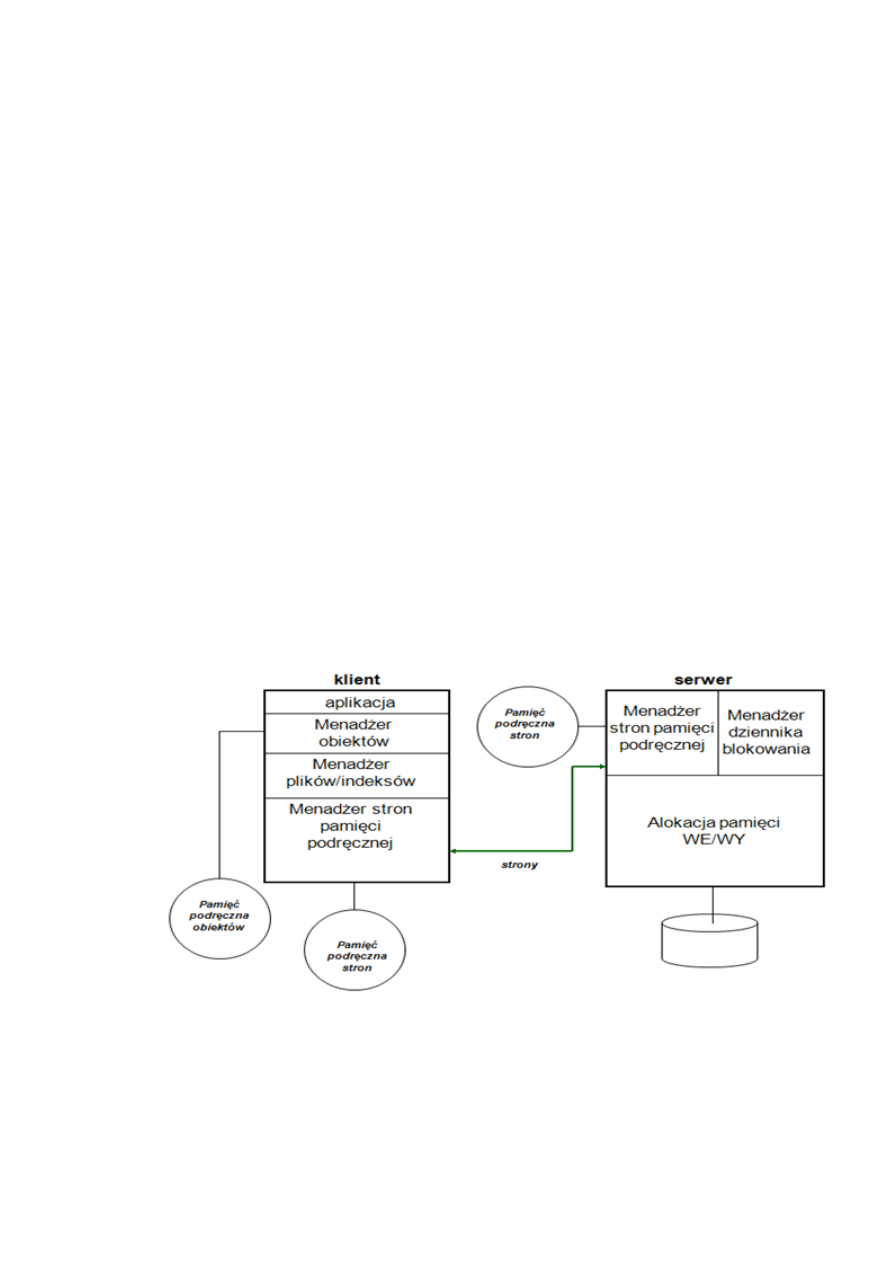
33. Opisad architekturę klient-broker-serwer
Architektura ta opiera się o trzy aplikacje. Aplikację klienta który wyświetla wyniki i pozwala
wysyład zapytania do BD, brokera który odbiera zapytania i przekierowuje odpowiednio
przetworzone do serwera BD oraz wysyła wyniki otrzymane od serwera do klienta oraz
serwera który przetwarza zapytania od brokera. Broker jest swego rodzaju pośrednikiem,
który umożliwia zadawanie zapytao do wielu BD bez troszczenia się o ich różne
implementacje wewnętrzne.
34. MZT
MZT – Moduł zarządzania transakcjami, służy do kontroli transakcji i ich planowania. Musi
gwarantowad, że jeśli transakcja będzie wykonywana to będzie zgodna z ACID. Musi
planowad ich wykonanie, dbad o blokowanie i rozwiązywanie zakleszczeo, zabezpieczad przed
wzajemnym przeszkadzaniem.
35. AVG – co oznacza i przykład użycia
AVG jedna z funkcji agregujących, pozwalająca na wyznaczenie średniej wartości atrybutu w
grupie.
SELECT nazwa, AVG(pensja) FROM place GROUP BY nazwa
36. Architektura dostępu do serwera stron
Dostęp do serwera z BD odbywa się poprzez strony i dwie aplikacje wymieniające się nimi.
Jest aplikacja kliencka, która przetwarza dane (strony), pozwalająca na interakcję z
użytkownikiem i aplikacja serwerowa przetwarzająca strony i zarządzająca danymi/pamięcią.
Strony to zbiory danych.

37. Klucz potencjalny, funkcje klucza, podad dwa przykłady
Klucz potencjalny to kolumna lub grupa kolumn która jednoznacznie identyfikuje
poszczególne krotki tabeli, nie może się on powtarzad i nie może mied wartości NULL.
Spośród kluczy potencjalnych (kandydujących) wybierany jest jeden i staje się on kluczem
głównym. Funkcjami klucza jest identyfikacja rekordów tabeli, umożliwienie połączeo między
tabelami, umożliwienie wyszukiwania rekordów na postawie jego wartości.
Przykłady:
Tabela składająca się z pól: PESEL , data urodzenia, data śmierci, imię, nazwisko
Klucz potencjalny – PESEL
Tabela składająca się z pól: uczelnia, wydział, numer albumu, imię, nazwisko
Klucz potencjalny – uczelnia+wydział+numer albumu
38. Różnica mnogościowa, opisad, przykład zapytania i wynik
Różnica mnogościowa to inaczej różnica kartezjaoska dwóch tabel. Różnicę można stosowad
jeśli w dwóch tabelach (lub projekcjach) jest zgodna liczba i nazwy kolumn, w wyniku
dostajemy te rekordy z tabeli pierwszej, które nie występują w tabeli drugiej.
SELECT imie, nazwisko FROM pracownicy EXCEPT (SELECT imie, nazwisko FROM klienci)
W wyniku otrzymamy wszystkich pracowników, którzy nie byli klientami
Podobnie suma mnogościowa – UNION
Iloczyn mnogościowy – INTERSECT
39. Słowny opis encji, czy jest poprawnie sformułowana, jakie występują zależności
Encja to zbiór atrybutów służących do opisania jakiegoś obiektu. Encje sformułowane są
poprawnie jeśli opisują obiekt w pełni oraz są znormalizowane, tzn. ich atrybuty są atomowe,
zależą w od klucza w pełni, nie występują przechodnie, wielowartościowe i połączeniowe
zależności funkcjonalne. Zależności między różnymi encjami mogą byd typu:
Jeden do jednego
Jeden do wielu
Wiele do wielu
40. Opisad meta dane w odniesieniu do HD
Metadane to dane o danych. W HD są to dane dotyczące użytkowników HD, statystyki użycia,
dane historyczne, raporty, słowniki danych (definicje baz i relacji), numery wersji itp.
Metadane w HD przechowywane są w osobnej warstwie (najwyższej), zwanej warstwą
metadanych i służą do kontrolowania działania systemu.
41. Architektury dostępu do relacyjnych baz danych
W związku z tym, że cholera wie o co chodzi w tym pytaniu to:
Dostęp do danych poprzez selekcje (wybieranie krotek spełniających kryteria),
projekcję (wybieranie kolumn spełniających kryteria) lub perspektywy (wybrane
krotki i kolumny z jednej lub wielu tabel)

W odniesieniu do rozproszonych BD:
o Klient – serwer
o Klient – multiserwer (wiele serwerów)
o Koleżeoska (p2p)
o Architektura oparta na oprogramowaniu pośredniczącym (nie ma klientów i
serwerów,
tylko
wymiana
przezroczysta
przez
oprogramowanie
pośredniczące)
42. OLTP i OLAP
OLTP – Online Transaction Processing, systemy przetwarzania transakcyjnego, w których
rejestrowane są zmiany stanu rzeczy w formie transakcji, charakteryzują się krótki i prostymi
transakcjami, operują na danych wyłączeni poprzez transakcje i mechanizmy z nimi związane,
nie wspomagają procesu analizy danych.
OLAP – Online Analytical Processing, systemy przetwarzania analitycznego, w których dane są
analizowane na podstawie np. poprzednich wyników zapytao, wielu źródeł itp. Pozwalają na
podejmowanie decyzji, są ważnym narzędziem decyzyjnym, dostarczają odpowiednich
narzędzi analitycznych.
Systemy OLTP i OLAP nie są ze sobą bezpośrednio zgodne, aby zgodnośd taką wprowadzid
stosuje się Hurtownie Danych.
Wyszukiwarka
Podobne podstrony:
,technika satelitarna,pyt&odp
pyt i odp andragogika 1
NERKI I FIZ STOSOWANA pyt odp
pyt odp
Socjologia pyt i odp
wyklad pyt i odp v1 1
Pedagogika Społeczna pyt. i odp., PEDAGOGIKA SPOŁECZ
pyt i odp, Audyt Wewnętrzny
WYZNANIOWE - pyt. i odp, Politologia
socjologia pyt i odp
mikro pyt i odp
III Źródła* Wprowadzenie do?finicji przez pyt i odp 7 04
Pyt Odp cienkoscienne
Wstep do socjologii pyt i odp skrypt
preparaty pyt + odp
Botanika egzamin pyt i odp, Uczelnia, Botanika systemowa
więcej podobnych podstron