1.Co to jest informatyka - dziedzina wiedzy zajmująca się problemem
przetwarzania i przesyłania danych.
2.Algorytm - jest to ciąg informacji służących wykonywaniu pewnego
zadania. W każdym algorytmie można wyróżnić szereg instrukcji które są
szczegółowym przepisem do wykonania procedury.
3.Języki programowania proceduralne i deklaratywne - wiążą się ze
strukturą i reprezentacją danych w komputerze, wykonywaniem działań i
operacji.
J.p. Proceduralne - zapisują procedury które komputer wykonuje
(procedura- moduł programu wykonujący określone zadania)
J.p. Deklaratywne - umożliwiają wyszukiwanie danych w dużych zbiorach.
4.Różnica między obliczeniami numerycznymi i symbolicznymi -
obliczenia numeryczne to przetwarzanie konkretnych liczb. Obliczenia
symboliczne – operacje wykonywane na wyrażeniach(symbolach)
matematycznych. Programy z grupy obliczeń symbolicznych nazywane są
programami algebry komputerowej. Np. Matlab.
5.Czym zajmuje się inżynieria oprogramowania - zajmuje się
doskonaleniem i optymalizacją oprogramowania. Dobre oprogramowanie
powinno być: zgodne z wymaganiami użytkownika, niezawodne, efektywne,
łatwe w konwersacji, ergonomiczne. Przyczyny powstania: duża złożoność
systemów operacyjnych, niepowtarzalność poszczególnych przedsięwzięć,
pozorna łatwość dokonywania poprawek.
6.Co to jest baza danych - zbiór informacji z pewnej dziedziny,
prowadzony w taki sposób, aby łatwo je można było analizować. Każdy zbiór
danych to baza danych, nie musi być komputerowa. Komputerowa baza
danych jest podzielona na rekordy. Najprostszą bazą danych jest tabela
składająca się z rekordów.
7.Siec komputerowa – system połączonych ze sobą urządzeń sieciowych
które pozwalają na wymianę informacji pomiędzy urządzeniami
przyłączonymi do tej sieci (wymiana danych wewnątrz sieci, korzystanie z 1
drukarki sieciowej, komunikacja użytkowników dzięki oprogramowaniu
sieciowemu). Rodzaje: LAN(lokalna), MAN(miejska), WAN(światowa).
8. Internet
- globalna sieć komputerowa, umożliwiająca wymianę
informacji dzięki jednolitemu sposobowi kodowania i przesyłu informacji
protokołem TCP/IPv4 obecnie lub w przyszłości TCP/IPv6. Intranet
-
wewnętrzna sieć lokalna w przedsiębiorstwie lub instytucji. Serwer WWW
udostępnia swoje zasoby wewnątrz przedsiębiorstwa lub instytucji.
9.KONWERSJA BIN-DEC-HEX (samemu)
10.Relacja pomiędzy ilościami informacji - 8bitów= 1bajt,
1kbajt=1024bitów, 1Mb=1024^2bajtów, 1Gb=1024^3bajtów.
11.Cyfrowe kodowanie informacji - dowolna informacja w komputerze
występuje tylko w postaci binarnej dlatego potrzebne są zatem reguły które
przekształcają różne postacie informacji na postać ciągu cyfr binarnych.
Proces przekształcenia informacji nazywamy kodowaniem, polega ono na
zamianie każdego kodu na kod binarny. Z kolei skróceniem kodu binarnego
jest kod hexadecymalny.
12.Co to jest kod ASCII- służy do kodowania tekstu i przesyłania go
między urządzeniami cyfrowymi oprócz znaków alfanumerycznych, koduje
także znaki sterujące pracę drukarki, przyporządkowuje znakom
alfanumerycznym i znakom sterującym ciąg złożony z 8 cyfr binarnych.
Kodowanie ASCI ma 83 znaków. Posługując się kodem ASCI możemy każdy
tekst zapisać jako ciąg bitów i na odwrót.
13.Porównanie kombinacyjnych i sekwencyjnych - Ukł.
kombinacyjny - układ w którym stan wyjść układu zależy wyłącznie od
stanu wejść. Ukł. sekwencyjny – układ w którym stan wyjść zależy od
stanu wejść oraz od poprzedniego stanu wyjść.
14.Układ synchroniczny i asynchroniczny - układem
asynchronicznym (niejednoczesnym) nazywamy taki układ cyfrowy
którego stan wyjść ustala się po kolei. Czas ustalania się stanu wyjść nie jest
sterowany. Układem synchronicznym nazywamy taki układ którego stan
każdego z wyjść ustalany jest taktem zegarowym. Eliminuje to błąd mogący
powstać gdy pojawia się impuls wejściowy a układ nie zdąży zadziałać na
skutek zbyt długiego czasu propagacji(zadziałania).
15.Do czego rejestr i rodzaje - układ cyfrowy służący do krótkotrwałego
zapamiętywania określonej porcji bitów danych. Na wejście podaję się
informację do zapamiętania w rejestrze. W tym momencie na wejście
sterujące podaje się sygnał sterujący który zapisuje informację z wejść.
Informacja przechowywana w rejestrze pojawia się na wyjściu. Rodzaje:
przesuwny (WE i WY) szeregowy, (WE i WY) równoległy, (WE)szeregowo-
(WY)równoległy, (WE)równoległo-(WY)szeregowy, synchroniczny,
asynchroniczny.
16.Co to jest magistrala - w systemie mikroprocesorowym należy
zapewnić przesyłanie informacji między różnymi układami w systemie
mikroprocesorowym, najprościej każdy układ połączyć z każdym, co jest
jednak fizycznie niemożliwe, więc tych połączeń jest mniej i droga którą
komunikują się dane układy nazywana jest magistralą. Składa się ona z 2
lub więcej układów będących nadajnikami lub(i) odbiornikami informacji.
17.U2(kod uzupełnień do dwóch) obecnie najpopularniejszy sposób
zapisu liczb całkowitych oraz ułamkowych przedstawionych w formacie
stałoprzecinkowym na bitach. Operacje dodawania i odejmowania są w nim
wykonywane tak samo jak dla liczb binarnych bez znaku. Nazwa kodu wzięła
się ze sposobu obliczania liczb przeciwnych. Dla liczb n-bitowych wartości
przeciwne uzyskujemy odejmując liczbę od dwukrotnej wagi najstarszego
bitu (2·2n–1 = 2n).
18.Dekodery i kodery priorytetu. Dekoder - układ kombinacyjny
posiadający n wejść oraz k wyjść (k=2n). Jego działanie polega na
zamianie kodu binarnego (o długości n), lub każdego innego kodu, na kod
"1 z k". Koder priorytetu – układ kodera z następującymi zmianami: na
wejściu kodera może pojawić się więcej niż 1 wyróżniony sygnał, każde
wejście ma przypisany swój priorytet. Na wyjściu pojawia się zakodowany
numer tego wejścia wyróżniony sygnałem który posiada najwyższy priorytet.
19. Podział pamięci półprz. RAM- pamięć ulotna służy do zapisu i
odczytu. Tą pamięć dzielimy na: DRAM- są to pamięci wolne, tanie, łatwe w
miniaturyzacji stosuje się je jako RAM w komputerach; SDRAM- szybkie,
drogie stosuje się je jako pamięci podręczne (cache) w procesorach. ROM -
pamięć nieulotna przeznaczone tylko do odczytu. Dzieli się ją na: ROM-tylko
do odczytu, PROM - jednorazowego zapisu, EPROM – kasowalna(UV) pamięć
tylko do odczytu, EEPROM - pamięć kasowalna i programowalna
elektrycznie(Flash).
20.Laczenie pamięci - zwiększenie liczby slów, zwiększenie liczby adresów,
zwiększenie długości slow, zwiększenie ilości linii w szynie adresowej
21. Skracanie czasu dostępu do pamięci. Skracanie czasu dostępu do
pamięci polega na zwiększaniu częstotliwości taktowania pamięci poprzez
podnoszenie taktowania szyny FSB. Niektóre płyty główne umożliwiają
modyfikację timingów z jakimi pamięć pracuje (CAS Latency(CL), RAS-to-
CAS Delay(tRCD), RAS Precharge Time(tRP), Cycle Time(Tras), Command
Rate(CR), xxxMHz). Wraz ze zmianą częstotliwości pracy magistrali
procesorów parametry pamięci ulegają zmianom.
22.Na czym polega odświeżanie pamięci – Odświeżanie pamięci polega
na okresowym odświeżaniu zawartości pamięci, ponieważ w przeciwnym
przypadku dane mogą zaniknąć (kondensatory się rozładują). Odświeżanie
musi następować w regularnych odstępach czasu oraz bezpośrednio po
każdej operacji odczytu i polega na ponownym zapisie odczytanej wartości w
tych samych komórkach pamięci.
23. SDRAM - pamięć dynamiczna, synchroniczna, zbudowana na
kondensatorach i tranzystorach. Synchroniczna, ponieważ działa ona zgodnie
z przebiegiem taktu zegara procesora.
DRAM - ulotna pamięć półprzewodnikowa o dostępie swobodnym,
której bity są reprezentowane przez stan naładowania kondensatorów. Nie
wymagają stałego zasilania, a jedynie okresowego odświeżania zawartości,
przez co zużywają mniej energii. Komórka pamięci dynamicznej składa się z
mniejszej liczby elementów niż analogiczna komórka pamięci statycznej.
Powyższe cechy pozwalają na większe upakowanie elementów w układach
scalonych, niższe koszty produkcji, budowa układów pamięci o większych
pojemnościach.
24.ROM i rodzaje – pamięć tylko do odczytu. Rodzaje: PROM -
jednorazowego zapisu, EPROM – kasowalna(UV) pamięć tylko do odczytu,
EEPROM - pamięć kasowalna i programowalna elektrycznie(Flash).
25. Specjalizowany układ cyfrowy
– nie wymaga programu, układ może
realizować tylko jeden (konkretny) algorytm przetwarzania informacji
prowadząc do wyników przetwarzania. System mikroprocesorowy, do
przetworzenia informacji wymaga wprowadzonych danych i szczegółowego
zbioru instrukcji zwanych programem który realizuje proces przetwarzania
danych prowadząc do otrzymania wyników. System mikroprocesorowy jest
zdolny do szerszego i bardziej uniwersalnego przetwarzania danych, zależnie
od wprowadzonego programu.
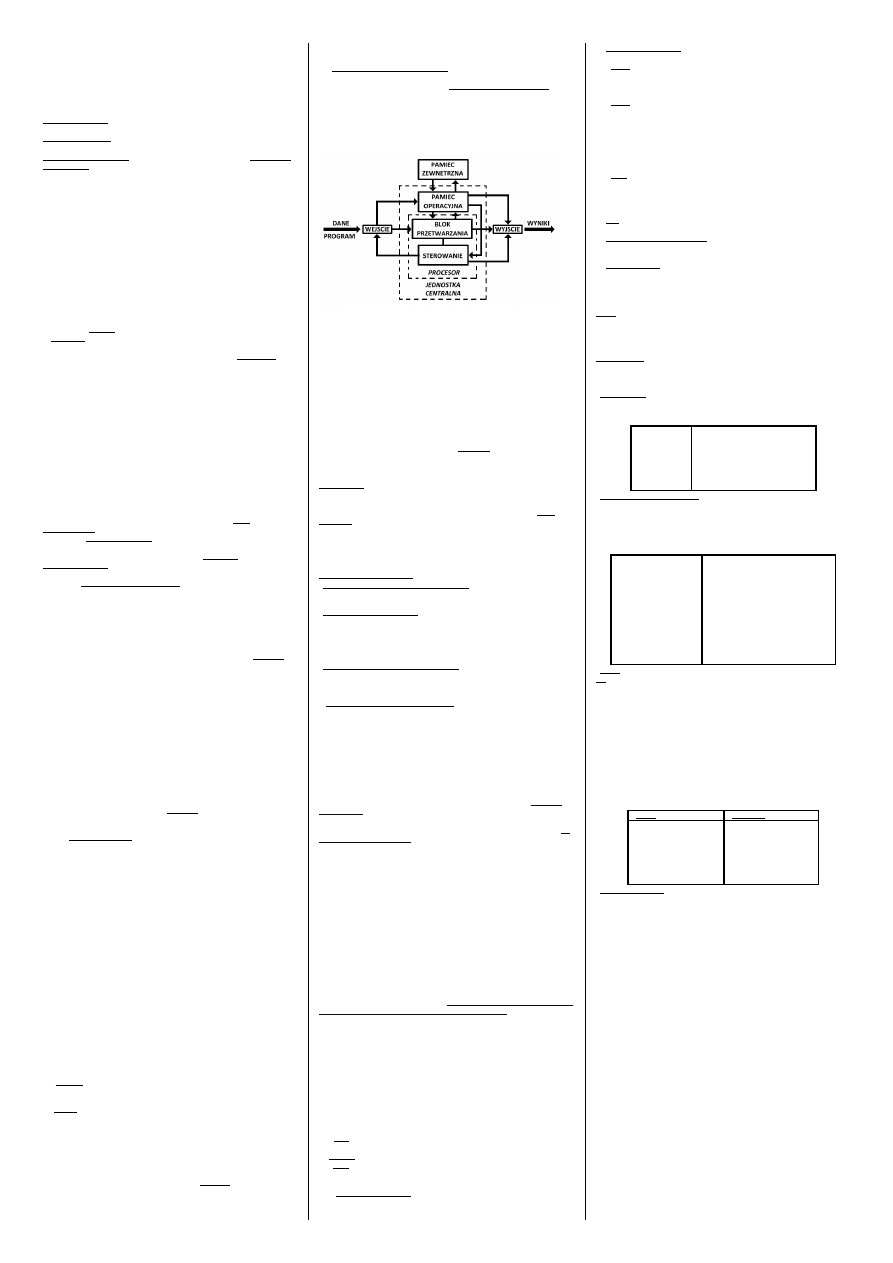
26.Schemat blokowy systemu mikroprocesorowego:
+omów poszczególne części(każdy to musi znać)
27.J
ednostka arytmetyczno logiczna ALU - jednostka ta wykonuje operacje
takie jak: dodawanie, odejmowanie, przyrównanie bitów, porównanie
wartości 2 słów, operacje iloczynowe i sumy algebraiczne, negacji,
alternatywy, wyboru rodzaju operacji dokonujemy sygnałem sterującym.
Układ nie ma pamięci własnej, dlatego współpracuje z rejestrem.
28. Struktura mikroprocesora – w każdym mikroprocesorze możemy
wyróżnić następujące elementy: ALU, interpreter rozkazów, rejestry, szynę
danych i szynę adresową.
29.Przykładowe rejestry mikroprocesora: rejestry danych, rejestry
adresowe, licznik rozkazów, rejestr instrukcji, wskaźnik stosu.
30. Magistrala – zespół linii oraz układów przełączających służących do
przesyłania sygnałów między połączonymi urządzeniami w systemach
mikroprocesorowych, złożony z trzech współdziałających szyn: sterująca -
mówi, czy sygnał ma zostać zapisany, czy odczytany, adresowa - mówi,
z(do) jakiej komórki pamięci sygnał ma zostać odczytany(zapisany),
danych - tą magistralą przepływają dane. Przykłady: PCI, PCI Express,
PCMCIA, USB, AGP, COM…
31. Cykl adresowy - przy realizacji jakiegokolwiek rozkazu procesora z
pamięci następują: wczytywanie do układu sterowania, realizacji rozkazu.
Faza pobrana: 1.odczytujemy rozkaz z licznika rozkazu, a dokładniej
odczytuje się adres komórki z nowym kodem rozkazu, adres ten jest
przesyłany magistralą danych, 2.pobranie kodu rozkazu z pamięci i
umieszczenie go w IR, 3.modyfikacja licznika rozkazu IPC=PC+1. Faza
wykonana: 1.zdekodowanie kodu rozkazu 2.wysyłanie sygnałów sterujących
realizujących dany rozkaz.
32. Zadania i rodzaje WE/WY. Układy pośredniczące w wymianie
informacji miedzy pamięcią, procesorem, a urządzeniami zewnętrznymi.
Układy we/wy mogą być dedykowane tylko do pracy z konkretnym
urządzeniem np. mysz PS/2, lub pracować z wieloma urządzeniami np. USB.
Wyróżniamy układy we/wy :
*Współadresowe z pamięcią operacyjna (traktuje się te układy jako
pewien zespól rejestrów, które są wybierane za pomocą adresów np. karta
grafiki-w celu wyświetlenia grafiki.
*Izolowane-obiekt we/wy wybierany jest poprzez podanie uprzedniego
sygnału sterującego. Przestrzeń adresowa układu we/wy i pamięć może się
pokrywać, o wyborze decyduje sygnał sterujący (sterowanie dysku IDE).
33. Tryb DMA - technika pozwalająca niektórym urządzeniom uzyskiwać
bezpośredni dostęp do modułów pamięci operacyjnej, a więc bez
pośrednictwa procesora, nie zajmując jego mocy obliczeniowej.
*Adresowanie w trybie rzeczywistym - adresy mają 20 bitów.
Natomiast rejestry mają 16 bitów. Zatem by uzyskać fizyczny adres komórki
pamięci zawartość rejestru segmentowego mnoży się razy 16 i dodaje
przesunięcie (OFFSET).
*Adresowanie w trybie chronionym - rejestry segmentowe
zawierają selektory, które wskazują na pole w tablicy deskryptorów. Z
wskazanego elementu tablicy deskryptorów procesor pobiera 32-bitowy
adres bazowy, który sumowany jest z przesunięciem. Tak powstaje adres
liniowy, który przy włączonym mechanizmie stronicowania zostaje poddany
transformacji na adres fizyczny.
35.Tablica deskryptorów - w trybie chronionym procesora x86 struktura
ulokowana w dedykowanym segmencie, zawierająca deskryptory
wszystkich segmentów znajdujących się w pamięci operacyjnej. Dysponując
rozmiarem tablicy deskryptorów można określić maksymalny rozmiar pamięci
wirtualnej, którą może zaadresować pojedynczy proces.
36.Różnice w adresowaniu rzeczywistym a wirtualnym -
W trybie
rzeczywistym procesor 80286 jest kompatybilny z 8086 na poziomie kodu
wynikowego, co oznacza, że procesor może wykonywać skompilowane
programy z systemu 8086 bez dokonywania w nich jakichkolwiek zmian. W
trybie adresów wirtualnych zgodność programowa z procesorem ’86 dotyczy
tylko postaci źródłowych programów. Program wynikowy dla 8086 będzie
błędnie wykonywany przez ‘286 pracujący w trybie adresów wirtualnych.
37.Praca wielozadaniowa w systemie jednoprocesowym - w tym
samym czasie jest wykonywanych kilka zadań współbieżnie, każde na innym
etapie zaawansowania. Na ogół jeden proces jest realizowany przez
określony czas, po czym ustępuje miejsca innemu procesowi, który również
jest realizowany przez określony czas. System realizuje wielozadaniowość
drogą przełączania procesora pomiędzy poszczególnymi zadaniami, dzięki
czemu każde zadanie zyskuje na swoje potrzeby pewną ilość czasu. Na
platformach jednoprocesorowych to przełączanie procesora pomiędzy
poszczególnymi procesami.
38.Cel stosowania pamięci cache i współpraca z mikroprocesorem –
coraz szybsze procesory wymagają coraz szybszych układów pamięciowych.
Doszło do sytuacji w której procesor musiał odczekać kilka cyklów
zegarowych zanim otrzymał dane z pamięci.
W celu usunięcia tego
ograniczenia wprowadzona została pamięć podręczna stanowiąca bufor o
krótkim czasie dostępu. Zastosowanie jej zaowocowało zwiększeniem
wydajności obliczeniowej procesorów. Sterownik cache cały czas monitoruje
czy potrzebna informacja jest przechowywana w buforze. Jeżeli tak to mamy
do czynienia z cache hit tzn. dane nie muszą być wyszukiwane i pobierane
od początku ponieważ znajdują się już w pamięci cache i mogą być więc
bezpośrednio wysłane do CPU, co znacznie zwiększa wydajność. W drugim
przypadku mamy do czynienia z cache miss czyli należy pobrać nie obecne w
cach'u adresy i dane potrzebne procesorowi. W tym celu konieczny jest
dostęp do pamięci (wolniejszej) gdzie owe dane są przechowywane i
pobranie ich co w rezultacie spowalnia pracę CPU i owocuje spadkiem
wydajności komputera.
39.Praca potokowa procesora - polega na jednoczesnym przetwarzaniu
kilku zadań. Na każdy takt przypada jedno rozpoczęcie zadania, jedno
przetworzenie wszystkich zadań i jedno zakończenie zadania. Pozwala to na
maksymalnie efektywne wykorzystanie magistrali procesora oraz
zwiększenie wydajności procesora.
40.*FSB(Front Side Bus) - magistrala łącząca procesor z kontrolerem
pamięci.
*FCore - częstotliwość rdzenia procesora (fsb x mnożnik).
*DDR(Double Data Rate) - 2x większa przepustowość(FSBx2).
41.Złożoność algorytmu –zależność między mocą obliczeniową a
rozmiarami wprowadzonych danych z zakresu danego zagadnienia.
42. *Algorytm iteracyjny - algorytm, który uzyskuje wynik przez
powtarzanie danej operacji określoną ilość razy.
*Algorytm rekurencyjny – algorytm, którego wynik zależy od swojego
poprzedniego wyniku (funkcja, która odwołuje się do samej siebie).
43.*NWD – Podajemy 2 liczby. Sprawdzamy czy obie cyfry są podzielne
przez kolejne cyfry rozpoczynając od 2. Iloczyn otrzymanych cyfr da NWD.
36,18|2; 18,9|3; 6,3|3; 2,1|STOP bo nie ma już wspólnych dzielników czyli
NWD(36,18)=2x3x3
*F(n):
F(n)= 1) 0
dla n=0
2) 1
dla n=1
3) F(n-1)+F(n-2)
dla n>1
Ciąg Fibonacciego wyraża się rekurencyjnym wzorem: F(n)=F(n-2)+F(n-1),
gdy F(1)=1 oraz F(2)=1.
Łatwo obliczyć, że:
F(3)=F(1)+F(2)=1+1=2
F(4)=F(2)+F(3)=1+2=3 itd.
*2^n – Przyjmujemy założenia dla n: Gdy n należy do l. całkowitych
n<0, n=0, n>0, gdy n należy do l. wymiernych… Przyjmijmy że algorytm
odnosi się do liczb całkowitych to: Gdy n=0 to n^0=1, gdy n>0 to wynik to
n krotny iloczyn cyfry 2, czyli gdy n=3 to wynik=2*2*2. Gdy n<0 to wynik to
1/(n krotny iloczyn cyfry 2).
*n! – Podaj n, gdy n=0 to wynik=1, gdy n>0 to wynik =1*2*3*…*n
czyli iloczyn kolejnych liczb naturalnych kończąc na n.
*czy n jest liczbą pierwszą – sprawdzam czy n przy dzieleniu przez
wszystkie liczby z zakresu od 2 do n-1 daje resztę z dzielenia, jeśli tak to n
jest liczbą pierwszą.
*równanie kw. Mam równanie w postaci Ax^2+Bx+C=0. Sprawdzam
jakie współczynniki ma równanie. Jeżeli A=0 to nie jest to równanie
kwadratowe. Jeśli A≠0 i Δ=0 to x= -B/2A, jeśli A≠0 i Δ>0 to x1=(-B-
sqrΔ)/2A; x2=(-b+sqrΔ)/2A, jeśli A≠0 i Δ<0 to brak rozwiązań.
C++
44.Instrukcje: przypisania, warunkowa, warunkowa zagnieżdżona,
instrukcje do realizacji pętli obliczeń, instrukcja wyboru, break,
continua, skoku, typedef – składnia (przykłady).
*Przypisania - w językach programowania to instrukcja w której do pewnej
lokacji (l-wartości) przypisuje się wartość, która będzie w nim
przechowywana.
np. int x=5; a=20; d=a+x;
*Warunkowa - umożliwia wykonanie pewnej instrukcji w zależności od
wartości wyrażenia. Wszystkie wartości różne od 0 są w języku C++
traktowane jako prawda, równe 0 jako fałsz. Wyrażenia logiczne są liczone
tylko do momentu, w którym można określić jego wartość.
if (warunek)
{instrukcja}
else
{instrukcja}
int a=4;
if (a > 5)
cout<<”a jest wieksze od 5”;
else if
cout<<”a jest mniejsze od 5”;
else
cout<<”a jest rowne 5”;
*Warunkowa zagnieżdżona - instrukcja if...else... wykonuje serię testów
aż wystąpi jedna z poniższych sytuacji:
-jeden z warunków w instrukcji if lub else if jest prawdziwy. W tym wypadku
wykonują się instrukcje występujące po tym warunku
- żaden z testowanych warunków nie jest prawdziwy. Program wykonuje
instrukcję z ostatniej instrukcji else (jeżeli występuje)
-jeżeli warunek jest spełniony, po prostu wykonuje instrukcje. Np.
if (warunek)
{if(warunek2)
{ instrukcja1}
else {instrukcja2}
}
else {instrukcja3}
char c ;
clrscr () ;
cout << "Podaj znak" ;
cin >> c ;
if (c >= 'A' && c <= 'Z')
cout << "litera duza\n" ;
else if (c >= 'a' && c <= 'z')
cout << "litera mala\n" ;
else if (c >= '0' && c <= '9')
cout << "cyfra/n" ;
else
cout << "inny znak\n" ;
*Pętle
for (inicjacja; warunek; instrukcja1) instrukcja2 ;
{
double a = 10 ;
int n ;
cout << "Podaj liczbe z zakresu [1..30]: " ;
cin << n ;
if (n > 0 && n <= 30)
{
for (int i = 1 ; i <= n ; i++) a += (double)i ;
cout << n << " != " << a << '\n' ;
}
else cout << "Liczba z poza zakresu" ;
return 0 ;
}
dodatkowo pętle:
while
do-while
while (zmienna < 100)
{
instrukcja_1;
instrukcja_2;
instrukcja_3;
}
do
{
instrukcja_1;
instrukcja_2;
instrukcja_3;
}
while (zmienna > 10);
*Wyboru – switch
- instrukcja wymaga wartości całkowitej, wartość ta może być stałą
zmienną, wywołaniem funkcji lub wyrażeniem. Switch nie działa ze
zmiennoprzecinkowymi typami danych.
- wartość występująca po każdej etykiecie case musi być stałą.
- C++ nie zezwala na użycie etykiet case z zakresem wartości, każda
wartość musi występować w oddzielnej etykiecie case.
- po każdej grupie wykonywanych instrukcji, trzeba użyć instrukcji break.
Powoduje ona wyjście programu z instrukcji switch. Jeżeli nie użyje się
instrukcji break program przejdzie do wykonania instrukcji po kolejnych
etykietach case.
- zbiór instrukcji dla każdej etykiety lub etykiet musi być zawarty w
nawiasach klamrowych.
- instrukcja po etykiecie default jest wykonywana gdy nie natrafiono na
żadną etykietę else.
Przykład:
char c ;
clrscr () ;
cout << "Podaj znak" ; cin >> c ;
switch (c)
{
case "A":
case "B":
…
cout << "Duza litera" ;
break ;
case "a":
case "b":
…
cout << "Mala litera" ;
case "0":
case "1":
…
cout << "Cyfra" ;
break ;
default :
cout << "Inny znak" ;
}
*Cd 44 instrukcja Break
– umożliwia wyjście z pętli Instrukcja ta
powoduje przejście programu do końca aktualnej pętli. Składnia dla pętli for:
for (inicjalizacja, test, uaktualnienie)
{
//sekwencja instrukcji nr 1
if (warunek wyjścia z pętli) break ;
//sekwencja instrukcji nr 2
}
//sekwencja instrukcji nr 3
Przykład:
char s [8], FindChar ;
// Podaj ciąg
znaków (string) s
for (i = 0 ; i < strlen (s) ; i++) // strlen() - zwraca długość
łańcucha
if (s [i] == findchar) break ;
// znak do wyszukiwania
FindChar
if (i < strlen (s)) cout << " " << i << '\n' ;
*continue
- Instrukcja ta kończy działanie przebiegu kodu pętli - czyli jeżeli
gdzieś w pętli wystąpi instrukcja continue to program pomija instrukcje
występujące po niej i przystępuje do ponownego sprawdzenia warunku.
Instrukcja ta powoduje przedwczesne, bezwarunkowe zakończenie
wykonania wewnętrznej instrukcji pętli i podjęcie próby realizacji następnego
cyklu pętli.
*Instrukcje skoku - goto
Instrukcja goto jest postrzegana przez programistów jako spadek po
BASIC'u, ponieważ za jej pomocą możemy wykonywać skoki do
deklarowanej etykiety. Większość domorosłych programistów uważa, że jej
stosowanie jest przykładem złej znajomości rzeczy, ale tak na prawdę,
użycie goto w uzasadnionym przypadku ma swój sens. Konstrukcja goto jest
prosta:
goto nazwa_etykiety; // a w kodzie programu umieszczamy:
nazwa_etykiety;
instrukcje_etykiety;
Ograniczenia instrukcji goto nie pozwalają jej na przeskoczenie definicji
zmiennej, po każdej etykiecie musi wystąpić co najmniej jedna instrukcja.
Instrukcja ta może przydać się choćby do natychmiastowego opuszczenia
wielokrotnie zagnieżdżonej pętli. Ponadto goto nie może spowodować
przejścia do wykonania instrukcji znajdującej się poza funkcją zawierającą
goto.
*Typedef- Język C++ umożliwia zdefiniowanie swoich własnych typów
danych poprzez
zastosowanie instrukcji typedef. Instrukcja ta jest środkiem, dzięki któremu
program może
rozszerzyć podstawowe typy danych języka C. Ogólna postać instrukcji
typedef jest na-
stępująca,
typedef deklaracja_typu;
gdzie deklaracja_typu jest identyczna jak deklaracja zmiennej, poza tym że
zamiast nazwy_
zmiennej jest użyta nazwa typu. Na przykład instrukcja
typedef int count;
przykład:
main()
{
typedef int group[10]; /* Utworzenie nowego typu
'group' */
group totals; /* Przypisanie nowego typu
danych zmiennej */
for (i = 0; i < 10; i++)
totals[i] = 0;
return (0);
}
45.Jakie znasz typy standardowe?
Typ Boolean
Typ Integer
Typ Float
Typ Character
*bool - przechowuje informacje typu: prawda lub fałsz. Zajmuje 1 bajt
pamięci.
*char - typ znakowy. Można za jego pomocą przechowywać znaki w kodzie
ASCII (American Standard Code for Information Interchange) lub innym
stosowanym na danej maszynie.
*short - short integer, czyli krótki całkowity. Zmienne typu short są
zapisywane na dwóch bajtach.
*int - integer, czyli całkowity. Zapisywany jest na czterech bajtach.
*long - long integer, czyli dla odmiany długi całkowity, na 4 bajtach.
*float - typ zmiennoprzecinkowy pojedynczej precyzji, 4 bajty.
*double - typ zmiennoprzecinkowy zapisywany na 8 bajtach (większa
dokładność)
*long double - można zapisać duże liczby z ogromną dokładnością (10
bajtów)
*void - typ pusty oznaczający brak wartości (stosowany w ANSI C). Żadna
zmienna nie może być typu void. Tylko parametry przekazywane do funkcji
mogą być typu void (oznacza wtedy, że do funkcji nic się nie przekazuje) lub
zwracane przez funkcję (funkcja nic nie zwraca). Oprócz tego typ void może
być stosowany przy tworzeniu pewnych typów złożonych.
*unsigned - typ bez znaku (tylko wartości dodatnie)
46.W jaki sposób możesz zdefiniować typy pochodne (własne)?
Typy pochodne – tworzymy na podstawie typów fundamentalnych za
pomocą operatorów deklaracji
* - wskaźnik danego typu – int *w;
& - referencja do danego typu
[] – tablice danego typu
() – funkcja zwracająca dany typ, o parametrach danego typu
47.Jakie znasz zakresy ważności zmiennej (obiektu)?
- czas życia obiektu - od momentu gdy obiekt został zdefiniowany do
momentu, kiedy przestaje istnieć,
- zakres ważności nazwy – zakres w którym nazwa jest znana kompilatorowi,
- zakres lokalny – od punktu deklaracji do końca bloku,
- zakres globalny – dla nazwy zadeklarowanej poza klasą lub funkcją, zasięg
od punktu deklaracji do końca pliku zawierającego tą deklarację,
- zakres klasy – nazwa widziana tylko przez metody klasy, klas pochodnych i
zaprzyjaźnionych
48. Definiowanie(utworzenie) zmiennej. Podczas definiowania najpierw
podajemy typ zmiennej, później jej nazwę oraz jej wartość.
typ zmienna = wartość;
W ten sposób zdefiniowaliśmy zmienną, którą zainicjalizowaliśmy określoną
wartością początkową.
49.Co to jest enum?
Typ wyliczeniowy enum.
Typ wyliczeniowy jest bardzo sprytnym rozwiązaniem polepszającym
czytelność kodu oraz
zmniejszającym ilość błędów w programie. Stosuje się go w wypadku, gdy
znamy ilość pewnych
stanów układu, oraz jeśli jesteśmy je w stanie wyliczyć. Klasycznym
przypadkiem może być typ
użyty do wyliczenia dni tygodnia:
enum dni_tygodnia = {poniedzialek=1, wtorek, sroda,
czwartek, piatek, sobota, niedziela};
Taka konstrukcja jest jednak mało przydatna. Najlepiej typ enum połączyć z
instrukcją typedef, w wyniku której otrzymujemy nowy typ:
typedef enum { poniedzialek=1, wtorek, środa, czwartek,
piątek, sobota, niedziela}dniTygodnia;
50.Struktura programu w języku C++
Struktura programu:
#include <iostream> // dyrektywa preprocesora dołączająca standardową
// bibliotekę wejścia - wyjścia
using namespace std; // wybór przestrzeni nazw
int main() //główny program
{
double a = 3;
double b, c;
cout << "Wprowadz liczbe: "; // wypisujemy na ekran tekst
cin >> b; // wprowadzamy dane do zmiennej b
c = a * b; // obliczanie wartości wyrażenia arytmetycznego
// wyprowadzanie tekstu na ekran
cout << endl << a << " * " << b << " = " << c;
return 0;
}
51.Operatory arytmetyczne, relacji, logiczne, bitowe.
Operatory relacji:
*operator „>” oznacza: większy od..
4 > 2; //prawda
3 > 8; //fałsz
Całe wyrażenie ma wartość prawda, gdy warunek jest prawdziwy
*operator „<” czyli: mniejszy od..
21 < 15; //fałsz
11 < 23; //prawda
Wyrażenie jest prawdziwe tylko wtedy, gdy wartość stojąca po lewej stronie
jest mniejsza od wartości będącej po stronie prawej.
*operator „>=” większy lub równy od..
2 >= 3; //fałsz
14 >= 13; //prawda
Wyrażenie jest prawdziwe tylko wtedy, gdy wartość stojąca po lewej stronie
jest większa lub równa wartości będącej po stronie prawej.
*operator „<=” mniejszy lub równy od
21 <= 3; //fałsz
10 <= 18; //prawda
Wyrażenie jest prawdziwe tylko wtedy, gdy wartość stojąca po lewej stronie
jest mniejsza lub równa wartości będącej po stronie prawej.
*operator „==” służy do porównywania dwóch wartości. Gdy wartości są
równe wyrażenie jest prawdą i odwrotnie.
42 == 42; //prawda
4 == 14; //fałsz
Jeśli liczby są takie same wyrażenie jest prawdziwe.
*operator „!=” służy do porównywania dwóch wartości. Gdy wartości są
jednakowe wyrażenie jest fałszem i odwrotnie.
28 != 28; //fałsz
6 != 11; //prawda
Operatory logiczne:
Operatory te służą do obliczania wartości "prawda" lub "fałsz". Warunek
prawdziwy daje wartość 1 natomiast fałszywy 0.
*Negacja logiczna zamienia prawdę w fałsz, a fałsz w prawdę. Np. jeżeli
wyrażenie: a==b jest prawdziwe i do niego
zastosujemy wyrażenie !(a==b) to w wyniku otrzymamy fałsz.
Składnia:
!argument
*Iloczyn logiczny
Wynikiem iloczynu logicznego jest prawda tylko wtedy gdy oba argumenty
też są prawdziwe. Jeżeli tylko jeden jest
fałszywy to wynikiem jest fałsz.
Składnia:
argument1 && argument2
*Suma logiczna
Wynikiem sumy logicznej jest prawda wtedy jeżeli przynajmniej jeden
argument jest prawdziwy. Tylko jeżeli oba są fałszywe to wynikiem jest
fałsz. Np:
01001010 - zmienna1
00101001 - zmienna2
01101011 - wynik
Składnia:
argument1 || argument2
*Równość
Wynikiem jest prawda w tedy gdy wartości obu argumentów są takie same.
Składnia:
argument1 == argument2
*Nierówność
Wynikiem jest prawda w tedy gdy wartości obu argumentów są różne.
Składnia:
argument1 != argument2
Operator arytmetyczne:
*Operator if
Jest to jedyny w języku C++ operator, w którym śa wymagane 3
argumenty. Ma on następującą składnię:
warunek ? wyrażenie1 : wyrażenie2
Zawsze na początku jest obliczany warunek. Jeżeli jest on prawdziwy ( !=
0 ) to jest obliczany wrażenie1 a jeżeli warunek jest równy 0 to jest
obliczane wyrażenie2.
*Operator zwiększania
Dodaje on liczbę 1 do zmiennej przy której ten operator występuje. Jest to
skrót ot wyrażenia:
a = a + 1;
//lub
a += 1;
Składnia:
++zmienna
zmienna++
*Operator zmniejszania
Odejmuje on liczbę 1 do zmiennej przy której ten operator występuje. Jest
to skrót ot wyrażenia:
a = a - 1; lub
a -= 1;
Składnia:
--zmienna
zmienna--
Operatory bitowe :
*Przesuwanie bitów w lewo
Zakładamy że operacja dzieje się na zmiennych typu unsigned char. Jeżeli
zmienna ma wartość przedstawioną w
postaci binarnej:
00100100
to wynikiem takiej operacji zmienna << 2 będzie wynik:
10010000
to polecenie przesuwa bity w lewo o dwie pozycje. Argument traci bity które
w wyniku przesunięcia znajdą się poza nim. po prawej stronie na miejsce
brakujących bitów wstawia zera. Składnia:
zmienna << liczba bitów
*Przesuwanie bitów w prawo .
Jeżeli zmienna ma wartość przedstawioną w
Zakładamy że operacja dzieje się na zmiennych typu unsigned char
postaci binarnej:
00100100
to wynikiem takiej operacji zmienna >> 1 będzie wynik:
00010010
to polecenie przesuwa bity w lewo o jedną pozycję. Argument traci bity
które w wyniku przesunięcia znajdą się poza nim. po lewej stronie na
miejsce brakujących bitów wstawia zera. Składnia:
zmienna >> liczba bitów
*Negacja bitowa
Negacja bitowa zamienia w zmiennej wszystkie zera na jedynki i jedynki na
zera. Jeżeli mamy zmienną o wartości 10011010 to jej negacja bitowa
wygląda tak: 01100101
Składnia:
~zmienna
CD51Koniunkcja bitowa
CD51 *Koniunkcja bitowa
Koniunkcja bitowa jest to mnożenie pojedynczych bitu. Koniunkcja daje
wynik jeden na danej pozycji, gdy w we wszystkich zmiennych na tej pozycji
jest jedynka. Jeżeli tylko na jednym miejscu jest 0 to wynikiem jest 0.
Przykład:
01101011 - zmienna1
11001101 - zmienna2
01001001 - wynik
Składnia:
zmienna1 & zmienna2
*Różnica symetryczna
Wynikiem różnicy symetrycznej jest na danej pozycji jedynka tylko w tedy
gdy tylko w jednej zmiennej na danej pozycji jest jedynka. W przeciwnym
wypadku jest 0.
01101011 - zmienna1
11001101 - zmienna2
10100110 - wynik
Składnia:
zmienna1 ^ zmienna2
*Alternatywa bitowa
Wynikiem alternatywy bitowej jest na danej pozycji jedynka w tedy gdy
przynajmniej w jednej zmiennej na danej pozycji jest jedynka. W
przeciwnym wypadku jest 0.
01101011 - zmienna1
11001101 - zmienna2
11101111 - wynik
Składnia:
zmienna1 | zmienna2
52.Na czym polega inkrementacja i dekrementacja zmiennej?
Inkrementacja/dekrementacja polega na dodaniu/odjęciu od zmiennej
jedynki
#include <iostream>
using namespace std;
int main()
{
int a = 5;
cout << a << endl;
cout << ++a << endl; //preinkrementacja
cout << a++ << endl; //postinkrementacja
cout << a << endl;
return 0;
}
Powyższy program wypisze nam na ekranie:
5
6
6
7
Jak widać na powyższych przykładach rozróżniamy 2 typy inkrementacji -
tzw. preinkrementację i postinkrementację. Obie powodują zwiększenie
wartości zmiennej o 1 jednak jest między nimi pewna różnica. Otóż operator
preinkremencacji
(++a)
zwraca wartość już zwiększoną o 1 (w tym przypadku będzie to 6) natomiast
operator postinkrementacji
(a++)
zwraca wartość zmiennej przed procesem inkrementacji (tutaj zwróci
wartość 6 natomiast wartość zmiennej 'a' będzie już wynosić 7).
Dokładnie tak samo sprawa wygląda dla operatora dekrementacji -
predekrementacji (--a) i postdekrementacji (a--).
53.Podaj przykłady wykorzystania operatorów: sizeof, rzutowania.
*Operator sizeof
Operator sizeof przekazuje liczbę bajtów będącą rozmiarem wyrażenia lub
specyfikatora typu. Może on występować w jednej z dwóch postaci:
sizeof (specyfikator_typu);
sizeof wyrażenie;
*Operator rzutowania
Zmiana typu danych: operator rzutowania
Operator rzutowania służy do zmiany typu danych na inny:
(typ_danych)x;
gdzie typ_danych oznacza ten typ danych, na który ma zostać zamieniona
wartość zmiennej x.
Np. deklaracja:
(float)5;
spowoduje zmianę stałej całkowitej 5 (typu int) na stałą
zmiennoprzecinkową 5.0 (typu float).
54.W jaki sposób można przesyłać argumenty do funkcji –
porównaj te sposoby?
*Przesyłanie argumentów funkcji przez wartość: występują tutaj
argumenty formalne formalne i aktualne. Argumenty formalne to jest to, jak
na parametry mówi sobie w środku funkcja, natomiast argumenty aktualne
to te, co aktualnie stosujemy w konkretnym wywołaniu funkcji.
*Przesyłanie argumentów przez referencje: ( przez przezwisko) ,
przesyłanie argumentów przez referencje pozwala tej funkcji na
modyfikowanie zmiennych ( nawet lokalnych) znajdujących się poza ta
funkcja.
55.Na czym polega przeładowanie funkcji.
Przeładowanie funkcji: następuje wtedy, gdy w danym zakresie
ważności jest więcej niż jedna funkcja o tej samej nazwie. To, która z tych
funkcji zostanie wykonana, zależy od liczby lub typu argumentów, z którymi
dana funkcja jest wywoływana.
56. W jaki sposób definiuje się tablice i w jaki sposób przekazuje
się je do funkcji (przykłady)?
Tablica to ciąg obiektów tego samego typu, które zajmują ciągły obszar w
pamięci. Tablice są typem pochodnym czyli biorąc typ int tablica będzie typy
int.
Tablice przesyła się podając funkcji tylko adres początku tej tablicy. Nazwa
tablicy jest równocześnie adresem zerowego jej elementu.
definicja np. int liczba[20];
57.Co pojawi się na ekranie monitora w wyniku wykonania
fragmentu programu …..
58.Zdefiniuj i napisz do czego wykorzystuje się wskaźniki?
Wskaźnik to zmienna (zwana zmienna wskaźnikową) która zawiera adres
pierwszej komórki pamięci, w której przechowana jest inna zmienna. Jeśli
zmienna zajmuje więcej niż jedną komórkę pamięci to wskaźnik wskazuje na
pierwszą z tych komórek. Dla każdego wskaźnika określany jest jego typ.
Wskaźnik typu
int wskazuje na zmienną typu int. Dzięki temu, kompilator
wie ile komórek w pamięci zajmuje zmienna rozpoczynająca się w komórce,
na którą wskazuje wskaźnik. Nierozłącznie ze wskaźnikami związane są dwa
operatory. Są to operator wyłuskania, który jest zapisywany jako gwiazdka
(*) oraz operator pobrania adresu &. Oba te operatory są operatorami
przedrostkowymi (zapisuje się je przed zmienną) oraz jednoargumentowymi.
Zastosowanie wskaźników: wskaźniki stosuje się w różnych sytuacjach,
a mianowicie gdy chodzi nam o:
- ulepszenie pracy z tablicami
- funkcje mogą zmieniać wartość przesyłanych do nich argumentów
- dostęp do specjalnych komórek pamięci
- rezerwacje obszarów pamięci
int x=1; //deklaracja zmiennej int
int *wskaznik; //deklaracja wskaźnika na typ int
wskaznik = &x; //przypisanie adresu zmiennej wskaźnikowi
*wskaźnik = 99; //zapis równoważny z "x=99;"
Pierwsza linia przedstawionego kodu jest oczywista więc nie będziemy jej
spejcajlnie analizować. W drugiej lini zadeklarowaliśmy wskaźnik na typ int.
Zatem jak można się domyślać deklaracja wskaźnika wygląda następująco:
<modyfikator> <typ> *nazwa;
Zatem sama deklaracja wskaźnika na zmienną danego typu różni się od
deklaracji zmiennej jedynie dodatkowym znakiem '*' poprzedzającym nazwę
zmiennej.
KONIEC
Wyszukiwarka
Podobne podstrony:
2011 ODP Informatyka Sadzik prezent na swieta
2011 ODP Informatyka Sadzik prezent na swieta, Polibuda, I semestr, Informatyka
INFORMACJE DOTYCZĄCE PRZEDMIOTU wdr, 3 # SZKOŁA - prezentacje na lekcje, wdżwr
Prezentacja na zajęcia dostęp do informacji publicznej 9 10 2015 (1)
Prezentacja na informatykę o wirusach
Prezentacja na technologię informacyjną
Prezentacja na informatyke
Jak przygotować prezentację multimedialną, Ogrodnictwo 2011, Technologia informacyjna
Informacja dotyczaca sytuacji na lokalnym rynku pracy styczen 2011
Techniki zbierania informacji prezenatcja na zaliczenie
BFG prezentacja na 18 12 2011
Prezentacja na seminarium
internetoholizm prezentacja na slajdach
Bezrobocie prezentacja na WOS
Prezentacja na muzyke
Pozagałkowe zapalenie nerwu wzrokowego prezentacja na zajęcia
więcej podobnych podstron