
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 1/48
Łagodne wprowadzenie do Message Passing
Interface (MPI)
Szymon Łukasik
Zakład Automatyki PK
szymonl@pk.edu.pl
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 3/48
Czym jest MPI?
MPI to standard przesyłania wiadomo´sci (komunikatów)
pomi ˛edzy procesami programów równoległych działaj ˛
acych na
jednym lub wi ˛ecej komputerach.
Implementowany jest najcz˛e´sciej w postaci bibliotek, do
wykorzystania w programach tworzonych w Fortranie, C, C++,
Ada.
Pierwsza wersja standardu MPI: MPI-1, ukazała si ˛e w maju
1994 r., druga (i obecnie obowi ˛
azuj ˛
aca) MPI-2 w 1998 roku.
Standard MPI ma status public-domain i jest dost ˛epny w sieci
Internet pod adresem www.mpi-forum.org
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 4/48
Własno ´sci MPI
■
architektura programu - niezale˙zne procesy operuj ˛
ace na
ró˙znych danych (MIMD),
■
zapewnia przeno´sno´s´c programów, mo˙zliwo´s´c stosowania
zarówno dla multiprocesorów jak i multikomputerów,
■
udost ˛epnia mechanizmy komunikacji jeden - jeden oraz
grupowej,
■
pozwala na tworzenie (intra- i inter-) komunikatorów,
■
zapewnia mo˙zliwo´s´c definiowania nowych typów danych,
■
umo˙zliwia wykonywanie oblicze ´n i operacji globalnych,
■
pozwala na definiowanie topologii procesów
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 5/48
MPI-2
Najnowszy standard umo˙zliwia:
■
równoległe operacje wej´scia-wyj´scia,
■
zdalne operacje na pami ˛eci,
■
dynamiczne zarz ˛
adzanie struktur ˛
a procesów bior ˛
acych
udział w obliczeniach.
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 6/48
Implementacje MPI
MPICH2
wieloplatformowa (gridy: MPICH-G2), ogólnodost ˛epna
www: http://www-unix.mcs.anl.gov/mpi/mpich
LAM/MPI
projekt zawieszony, ogólnodost ˛epna
www: http://www.lam-mpi.org
Open MPI
kontynuacja LAM/MPI, ogólnodost ˛epna
www: http://www.open-mpi.org
WMPI
„folklor” - dla Windows, płatna
www: http://www.criticalhpc.com/
HP-MPI, IBM-MPI, SGI-MPI
implementacje specjalizowane
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 7/48
Omówienie wa˙zniejszych funkcji MPI

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 8/48
U˙zyta notacja i uwagi ogólne
■
definicje podano w składni j ˛ezyka C,
■
IN/OUT/INOUT
przy argumencie oznacza parametr
wej´sciowy, wyj´sciowy i modyfikowany przez funkcj ˛e,
■
comm
to komunikator, który odpowiada oddzielnej strukturze
komunikacji, specyfikuje on grup ˛e procesów, które do niego
nale˙z ˛
a
■
MPI_COMM_WORLD
to specyficzny komunikator grupuj ˛
acy
wszystkie procesy, które wł ˛
aczyły si ˛e do systemu MPI od
jego uruchomienia
■
src,dest
definiuj ˛
a numery procesów ´zródłowych i
docelowych komunikatu
■
tag
okre´sla znacznik typu komunikatu
■
gdy długo´s´c danych jest krótsza od bufora, pozostałe pola
bufora nie s ˛
a nadpisywane.

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 9/48
Podstawowe funkcje
■
Inicjalizacja biblioteki:
OUT int MPI_Init(IN int *argc, IN char ***argv);
■
Zako ´nczenie oblicze ´n:
OUT int MPI_Finalize(void);
■
Numer bie˙z ˛
acego procesu w danym komunikatorze:
OUT int MPI_Comm_rank(IN MPI_Comm comm, OUT int
*rank);
■
Ilo´s´c procesów w komunikatorze:
OUT int MPI_Comm_size(IN MPI_Comm comm, OUT int
*size);
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 10/48
Komunikacja blokuj ˛
aca jeden do jednego
■
Wysyłanie danych:
OUT int MPI_Send(IN void* buf, IN int count, IN
MPI_Datatype datatype, IN int dest, IN int tag, IN
MPI_Comm comm);
■
Odbieranie:
OUT int MPI_Recv(OUT void* buf, IN int count, IN
MPI_Datatype datatype, IN int source, IN int tag,
IN MPI_Comm comm, OUT MPI_Status *status);
Uwagi:
■
w odwołaniach mo˙zna u˙zy´c stałych
MPI_ANY_SOURCE
i
MPI_ANY_TAG
■
MPI_STATUS
jest struktur ˛
a o polach
MPI_SOURCE
,
MPI_TAG
,
MPI_ERROR
; sprawdzanie ilo´sci odebranych danych realizuje
MPI_Get_count
■
testowanie czy wiadomo´s´c nie nadeszła -
MPI_Probe

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 11/48
Przykład - kom. blokuj ˛
aca
# include < s t d i o . h>
# include <mpi . h>
void main ( i n t argc , char
∗
argv )
{
i n t myrank ;
MPI_Status s t a t u s ;
double a [ 1 0 0 ] ;
M P I _ I n i t (& argc , &argv ) ;
MPI_Comm_rank (MPI_COMM_WORLD, &myrank ) ;
i f ( myrank == 0 )
MPI_Send ( a , 100 , MPI_DOUBLE, 1 , 17 , MPI_COMM_WORLD) ;
else i f ( myrank == 1 )
MPI_Recv ( a , 100 , MPI_DOUBLE, 0 , 17 , MPI_COMM_WORLD, & s t a t u s ) ;
M P I _ F i n a l i z e ( ) ;
}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 12/48
Typy danych MPI
Typ MPI
Typ C
MPI_CHAR
signed char
MPI_SHORT
signed short int
MPI_INT
signed int
MPI_LONG
signed long int
MPI_UNSIGNED_CHAR
unsigned char
MPI_UNSIGNED_SHORT
unsigned short int
MPI_UNSIGNED
unsigned int
MPI_UNSIGNED_LONG
unsigned long int
MPI_FLOAT
float
MPI_DOUBLE
double
MPI_LONG_DOUBLE
long double
MPI_BYTE
brak
MPI_PACKED
brak

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 13/48
Pakowanie danych
■
Pakowanie danych do bufora:
OUT int MPI_Pack(IN void* inbuf, IN int incount,
IN MPI_Datatype datatype, OUT void *outbuf, IN int
outsize, INOUT int *position, IN MPI_Comm comm);
■
Rozpakowywanie:
OUT int MPI_Unpack(IN void* inbuf, IN int insize,
INOUT int *position, OUT void *outbuf, IN int
outcount, IN MPI_Datatype datatype, IN MPI_Comm
comm);
Uwaga:
position
jest wska´znikiem do bufora ci ˛
agłego (przy
wysyłaniu - bufora nadawczego
outbuf
, przy odbieraniu -
bufora odbiorczego
inbuf
) przesuwanym automatycznie
przez funkcje.

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 14/48
Przykład - pakowanie
i n t p o s i t i o n , i , j , a [ 2 ] ;
char b u f f [ 1 0 0 0 ] ;
. . . .
MPI_Comm_rank (MPI_COMM_WORLD, &myrank ) ;
i f
( myrank == 0 )
{
/ / NADAWCA
p o s i t i o n = 0 ;
MPI_Pack (& i , 1 , MPI_INT , b u f f , 1000 , & p o s i t i o n , MPI_COMM_WORLD) ;
MPI_Pack (& j , 1 , MPI_INT , b u f f , 1000 , & p o s i t i o n , MPI_COMM_WORLD) ;
MPI_Send ( b u f f , p o s i t i o n , MPI_PACKED, 1 , 0 , MPI_COMM_WORLD) ;
}
else
/ / ODBIORCA
MPI_Recv ( a , 2 , MPI_INT , 0 , 0 , MPI_COMM_WORLD)

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 15/48
Typy u˙zytkownika
Do definiowania własnych typów słu˙zy rodzina funkcji
MPI_TYPE
:
OUT int MPI_Type_contiguous(IN int count, IN
MPI_Datatype oldtype, OUT MPI_Datatype *newtype);
OUT int MPI_Type_vector(IN int count, IN int
blocklength, IN int stride, IN MPI_Datatype oldtype,
OUT MPI_Datatype *newtype);
OUT int MPI_Type_struct(IN int count, IN int
*array_of_blocklengths, IN MPI_Aint
*array_of_displacements, IN MPI_Datatype
*array_of_types, OUT MPI_Datatype *newtype);
Aby u˙zywa´c nowego typu danych nale˙zy dokona´c operacji:
OUT int MPI_Type_commit (INOUT MPI_datatype
*datatype);
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 16/48
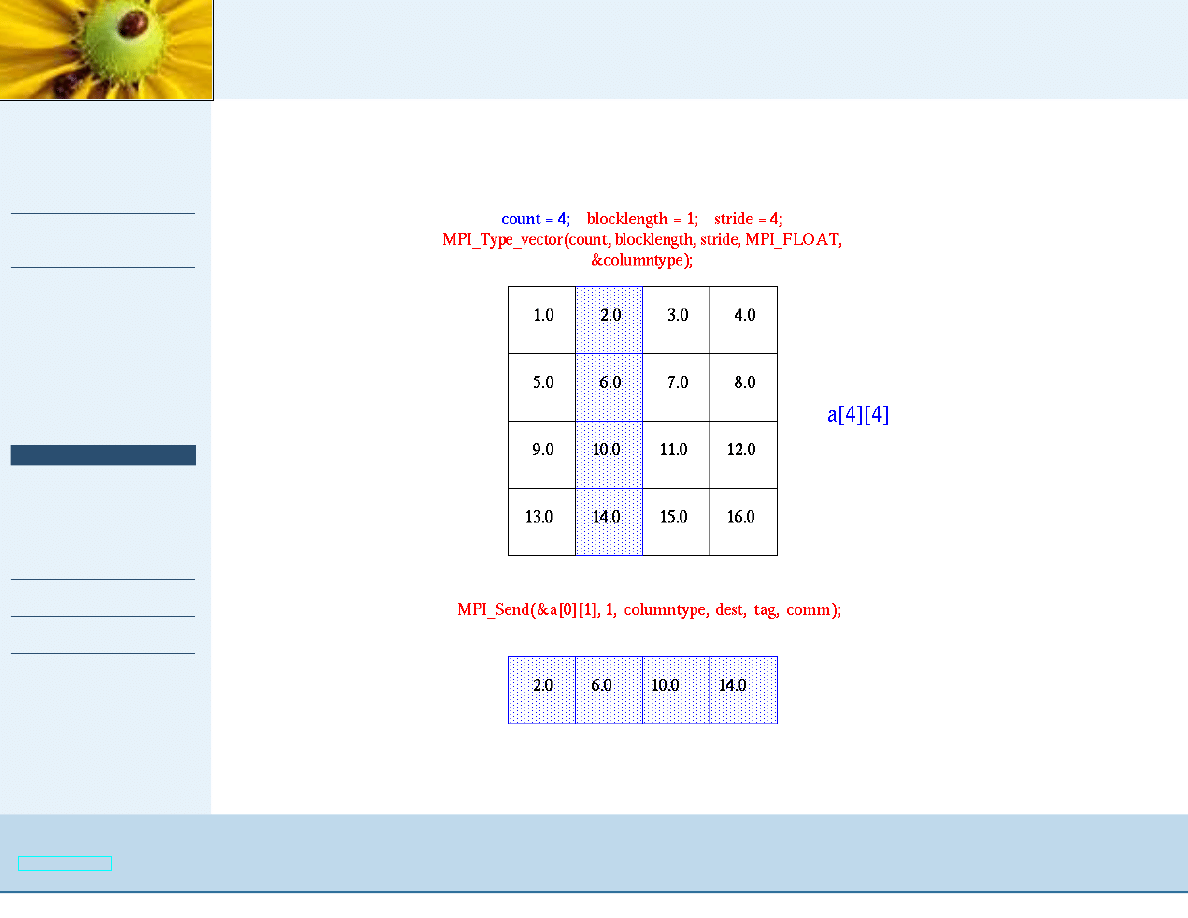
Przykład - typy u˙zytkownika

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 17/48
Przykład - typy u˙zytkownika
# include " mpi . h "
# d e f i n e SIZE 4
i n t main ( argc , argv )
i n t argc ;
char
∗
argv [ ] ;
{
i n t numtasks , rank , source =0 , dest , t a g =1 , i ;
f l o a t a [ SIZE ] [ SIZE ] =
{ 1 . 0 , 2 . 0 , 3 . 0 , 4 . 0 ,
5 . 0 , 6 . 0 , 7 . 0 , 8 . 0 ,
9 . 0 , 1 0 . 0 , 1 1 . 0 , 1 2 . 0 ,
1 3 . 0 , 1 4 . 0 , 1 5 . 0 , 1 6 . 0 } ;
f l o a t b [ SIZE ] ;
MPI_Status s t a t ;
MPI_Datatype columntype ;
M P I _ I n i t (& argc ,& argv ) ;
MPI_Comm_rank (MPI_COMM_WORLD, &rank ) ;
MPI_Comm_size (MPI_COMM_WORLD, &numtasks ) ;

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 18/48
Przykład - typy u˙zytkownika
MPI_Type_vector ( SIZE , 1 , SIZE , MPI_FLOAT , &columntype ) ;
MPI_Type_commit(& columntype ) ;
i f
( numtasks == SIZE )
{
i f
( rank == 0 )
{
f o r ( i = 0 ; i < numtasks ;
i ++)
MPI_Send(&a [ 0 ] [ i ] , 1 , columntype , i , tag , MPI_COMM_WORLD) ;
}
MPI_Recv ( b , SIZE , MPI_FLOAT , source , tag , MPI_COMM_WORLD, & s t a t ) ;
p r i n t f ( " rank=%d
b=%3.1 f %3.1 f %3.1 f %3.1 f \ n " ,
rank , b [ 0 ] , b [ 1 ] , b [ 2 ] , b [ 3 ] ) ;
}
else
p r i n t f ( " Must s p e c i f y %d p r o c e s s o r s . T e r m i n a t i n g . \ n " , SIZE ) ;
M P I _ F i n a l i z e ( ) ;
}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 19/48
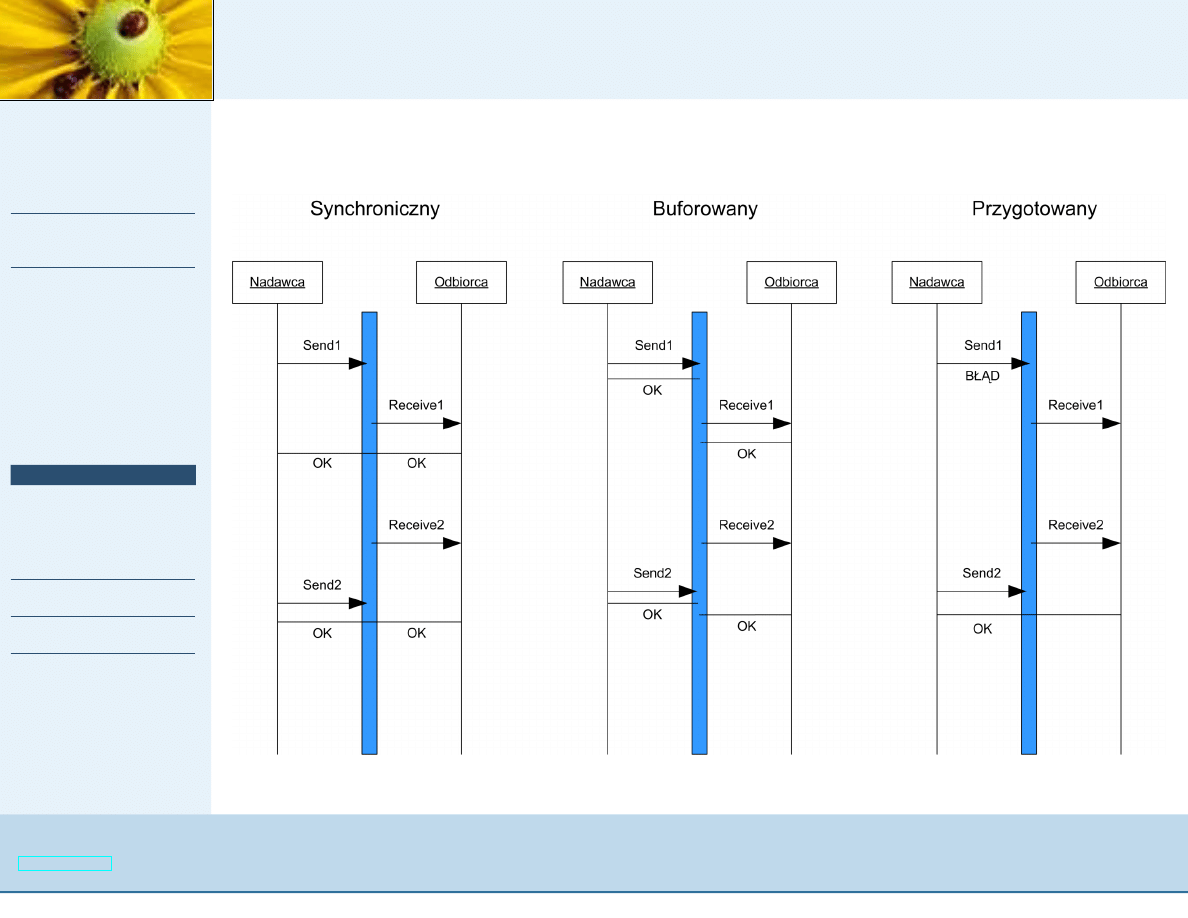
Tryby komunikacji
Polecenia
MPI_Send
i
MPI_Recv
realizuj ˛
a tryb standardowy -
wysyłanie MO ˙
ZE (ale nie musi) by´c buforowane (brak
oczekiwania na odpowiednie
MPI_Recv
).
Inne tryby to:
■
Buforowany (
MPI_Bsend
i
MPI_Brecv
) - wysyłanie odbywa
si ˛e niezale˙znie od tego czy została wywołana funkcja
odbieraj ˛
aca ; zwraca sterowanie natychmiast, niezale˙znie od
wyst ˛
apienia funkcji odbioru,
■
Synchroniczny (prefix S) - wysyłanie niezale˙znie od tego czy
została wywołana funkcja odbieraj ˛
aca ; zwraca sterowanie
po odebraniu wiadomo´sci
■
Przygotowany (prefix R) - wiadomo´s´c mo˙ze by´c wysłana
dopiero wtedy, gdy została wywołana funkcja odbieraj ˛
aca, w
przeciwnym wypadku funkcja wysyłaj ˛
aca zwraca bł ˛
ad.

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 21/48
Komunikacja nieblokuj ˛
aca
Funkcja zwraca sterowanie od razu nie czekaj ˛
ac na wykonanie
operacji.
OUT int MPI_IXsend(IN void *buf, IN int count, IN
MPI_Datatype dtype, IN int dest, IN int tag, IN
MPI_Comm comm, OUT MPI_Request *request);
OUT int MPI_IXrecv(OUT void *buf, IN int count, IN
MPI_Datatype dtype, IN int source, IN int tag, IN
MPI_Comm comm, OUT MPI_Request *request);
Uwaga:
X={,B,S,R}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 22/48
Komunikacja nieblokuj ˛
aca
request
jest wska´znikiem realizacji ˙z ˛
adania którego stan
mo˙zna sprawdzi´c funkcjami - blokuj ˛
ac ˛
a i nieblokuj ˛
ac ˛
a:
OUT int MPI_Wait(INOUT MPI_Request *request, OUT
MPI_Status *status);
OUT int MPI_Test(INOUT MPI_Request *request, OUT int
*flag, OUT MPI_Status *status);
Uwaga:
flag=TRUE
gdy opisywana wska´znikiem
request
operacja
została zako ´nczona.
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 23/48
Przykład - kom. nieblokuj ˛
aca
typedef s t r u c t {
char data [ MAXSIZE ] ;
i n t d a t a s i z e ;
MPI_Request req ;
} B u f f e r ;
B u f f e r b u f f e r [ ] ;
MPI_Status s t a t u s ;
. . .
MPI_Comm_rank (comm, &rank ) ;
MPI_Comm_size (comm, & s i z e ) ;
i f ( rank ! = s i z e
−
1)
{
/
∗
i n i c j a l i z a c j a
−
p r o d u c e n t a l o k u j e swój b u f o r
∗
/
b u f f e r = ( B u f f e r
∗
) m a l l o c ( s i z e o f ( B u f f e r ) ) ;
while ( 1 )
{
/
∗
main l o o p
∗
/
/
∗
p r o d u c e n t w y p e ł n i a b u f o r danych i zwraca i c h i l o ´s ´c
∗
/
produce ( b u f f e r
−
>data , & b u f f e r
−
>d a t a s i z e ) ;
/
∗
po czym j e wysyła
∗
/
MPI_Send ( b u f f e r
−
>data , b u f f e r
−
>d a t a s i z e , MPI_CHAR, s i z e
−
1,tag , comm ) ;
}
}
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 24/48
Przykład - kom. nieblokuj ˛
aca
else
{
/
∗
rank == s i z e
−
1; kod konsumenta
∗
/
/
∗
konsument a l o k u j e jeden b u f o r d l a ka ˙zdego producenta
∗
/
b u f f e r = ( B u f f e r
∗
) m a l l o c ( s i z e o f ( B u f f e r )
∗
( s i z e
−
1));
f o r ( i = 0 ; i < s i z e
−
1; i ++)
/
∗
r o z p o c z n i j o d b i ó r od ka ˙zdego producenta
∗
/
MPI_Irecv ( b u f f e r [ i ] . data , MAXSIZE , MPI_CHAR, i , tag ,
comm, &( b u f f e r [ i ] . req ) ) ;
f o r ( i = 0 ; ;
i = ( i +1)%( s i z e
−
1))
{ /
∗
główna p ˛e t l a
−
o c z e k i w a n i e
∗
/
MPI_Wait ( & ( b u f f e r [ i ] . req ) , & s t a t u s ) ;
/
∗
sprawd ´z i l e danych d o t a r ł o
∗
/
MPI_Get_count (& s t a t u s , MPI_CHAR, &( b u f f e r [ i ] . d a t a s i z e ) ) ;
/
∗
o p r ó ˙z n i j b u f o r i r o z p o c z n i j nowy proces o d b i o r u
∗
/
consume ( b u f f e r [ i ] . data , b u f f e r [ i ] . d a t a s i z e ) ;
MPI_Irecv ( b u f f e r [ i ] . data , MAXSIZE , MPI_CHAR, i , tag ,
comm, &( b u f f e r [ i ] . req ) ) ;
}
}
}
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 25/48
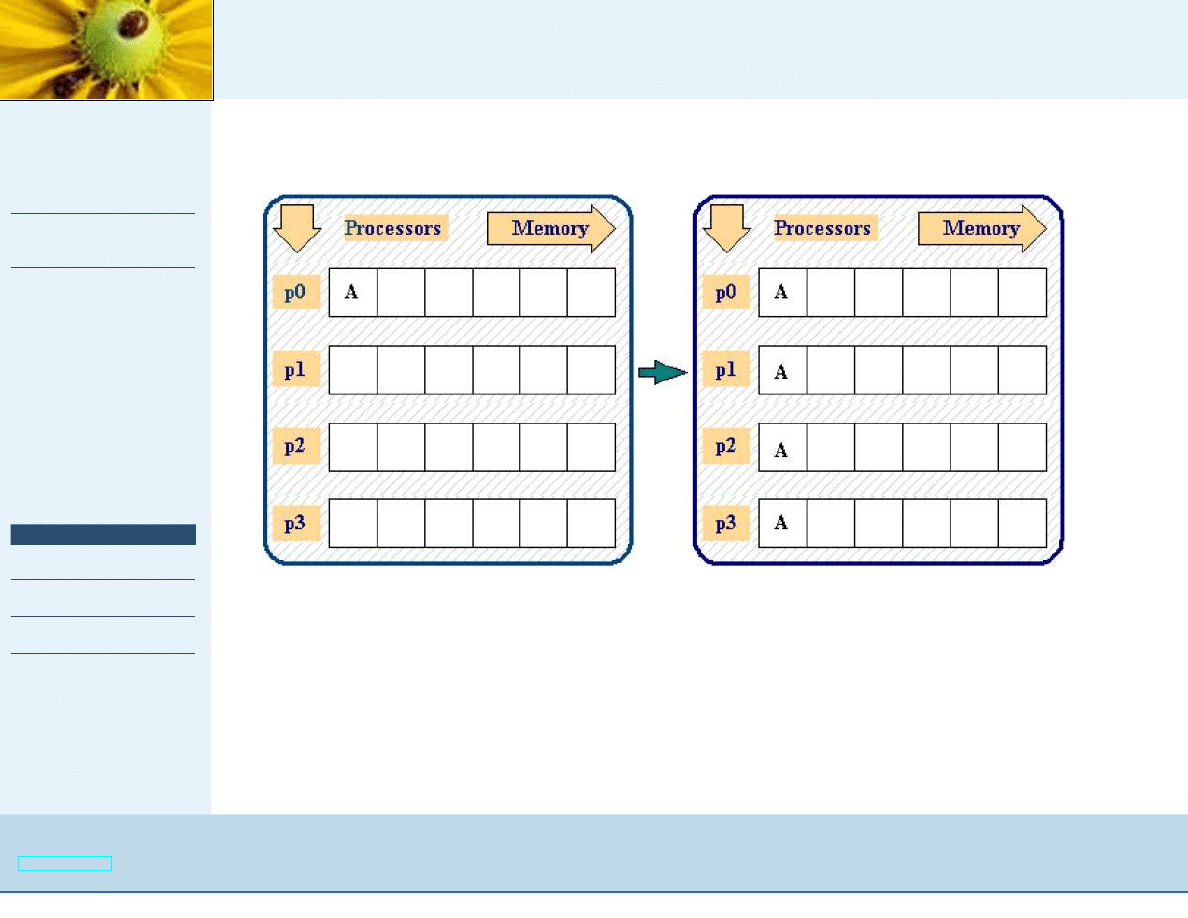
Komunikacja grupowa
OUT int MPI_Bcast (INOUT void* buffer, IN int count, IN
MPI_Datatype datatype, IN int rank, IN MPI_Comm comm);
UWAGA: Synchronizacja w operacjach grupowych odbywa si ˛e za
pomoc ˛
a barier:
OUT MPI_Barrier(IN MPI_Comm comm)
;
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 26/48
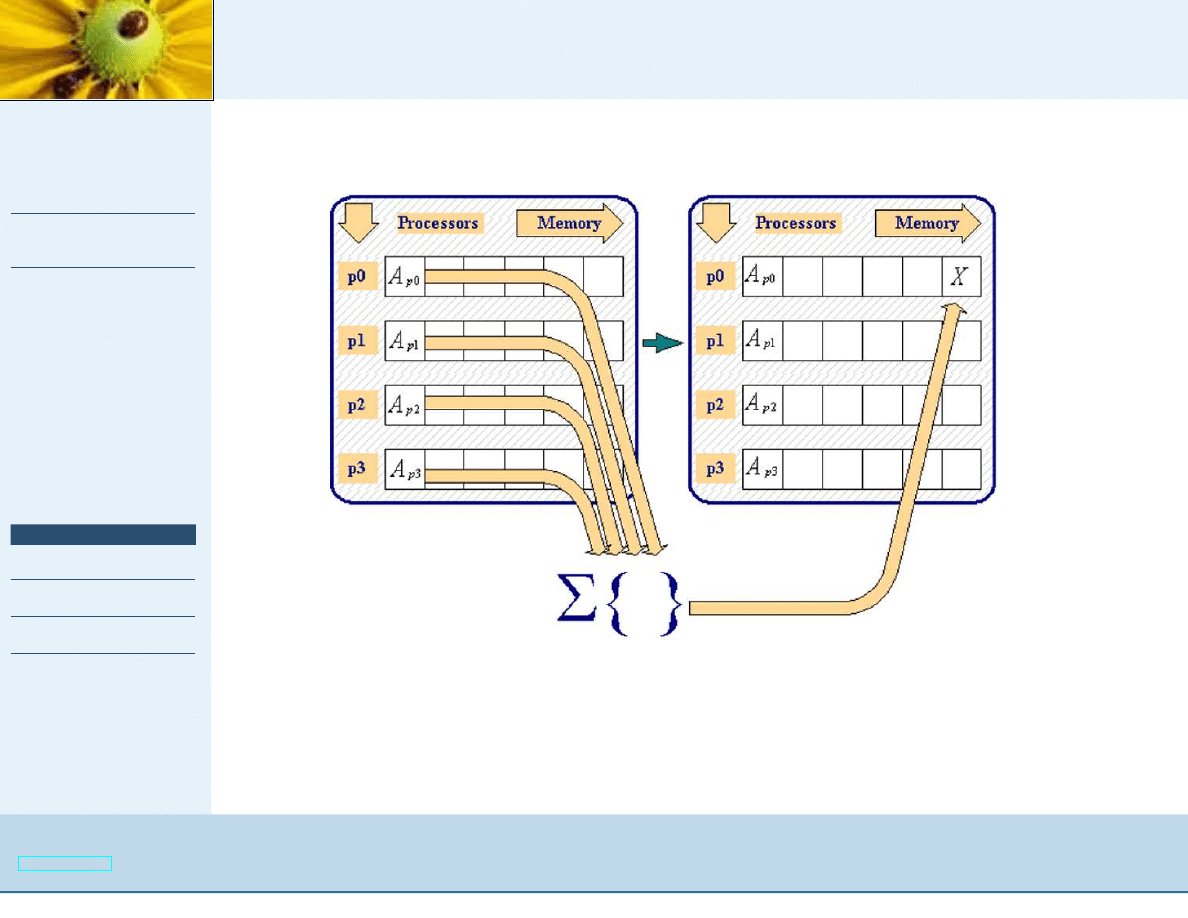
Komunikacja grupowa
OUT int MPI_Reduce (IN void* send_buffer, OUT void*
recv_buffer, IN int count, IN MPI_Datatype datatype, IN
MPI_Op operation, IN int rank, IN MPI_Comm comm);
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 27/48
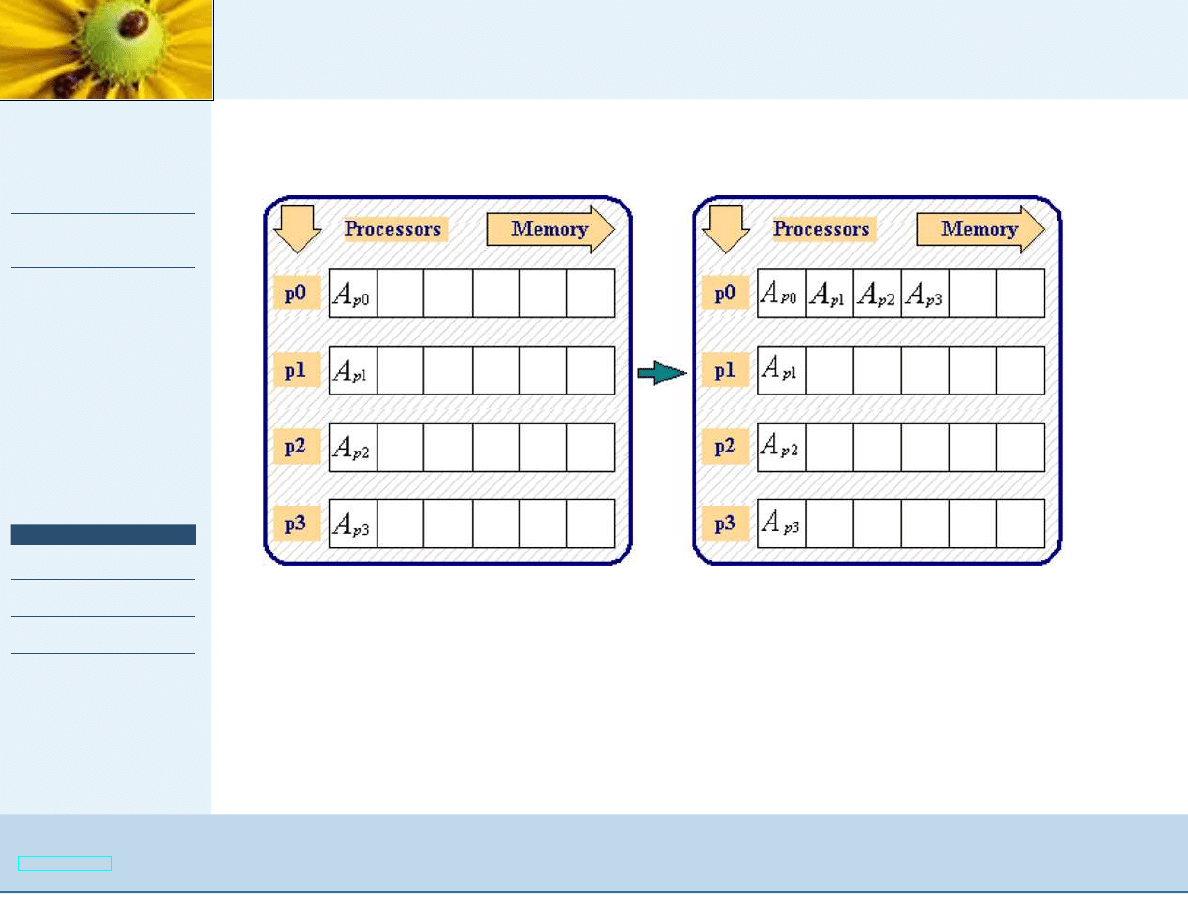
Komunikacja grupowa
OUT int MPI_Gather (IN void* send_buffer, IN int
send_count, IN MPI_datatype send_type, OUT void*
recv_buffer, IN int recv_count, IN MPI_Datatype recv_type,
IN int rank, IN MPI_Comm comm);
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 28/48
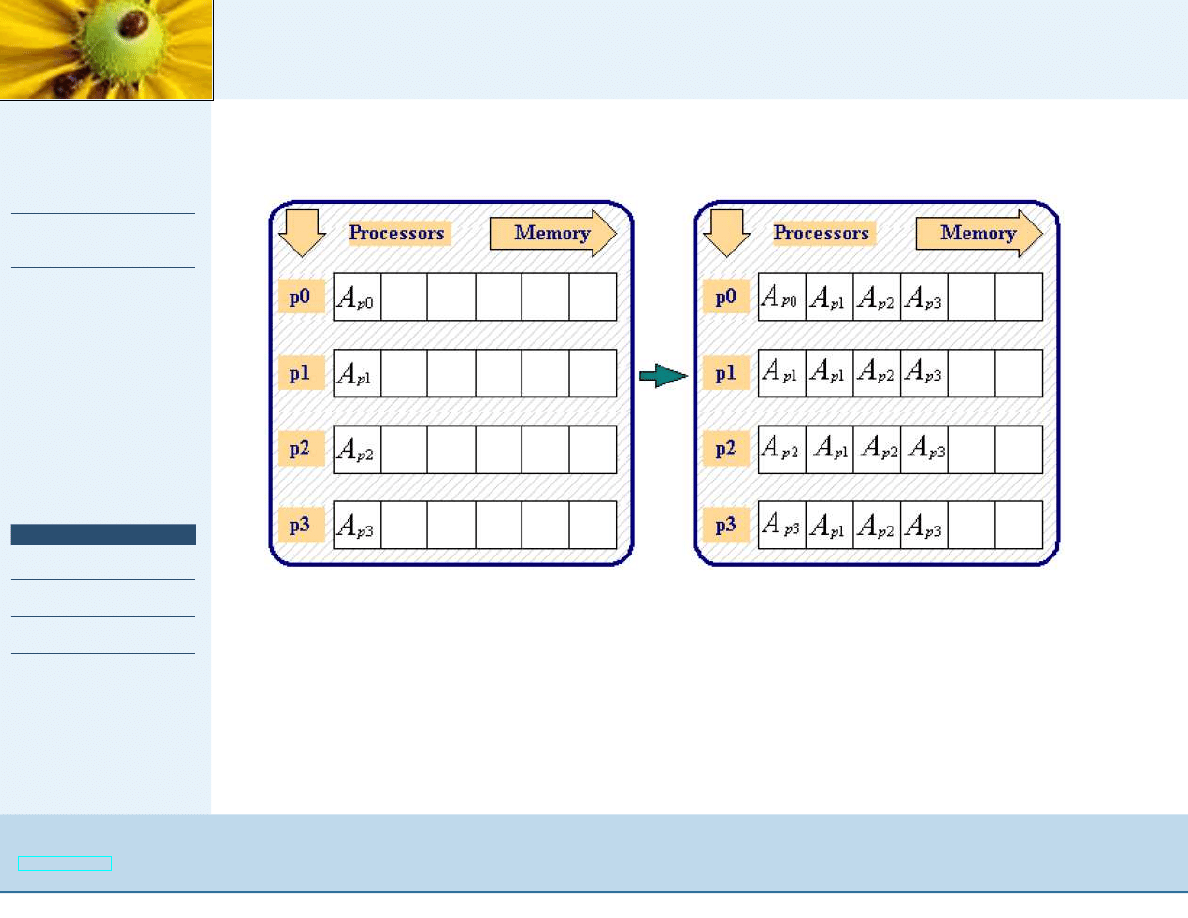
Komunikacja grupowa
OUT int MPI_Allgather (IN void *sendbuf, IN int sendcount,
IN MPI_Datatype sendtype, OUT void *recvbuf, IN int
recvcount, IN MPI_Datatype recvtype, MPI_Comm comm);
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 29/48
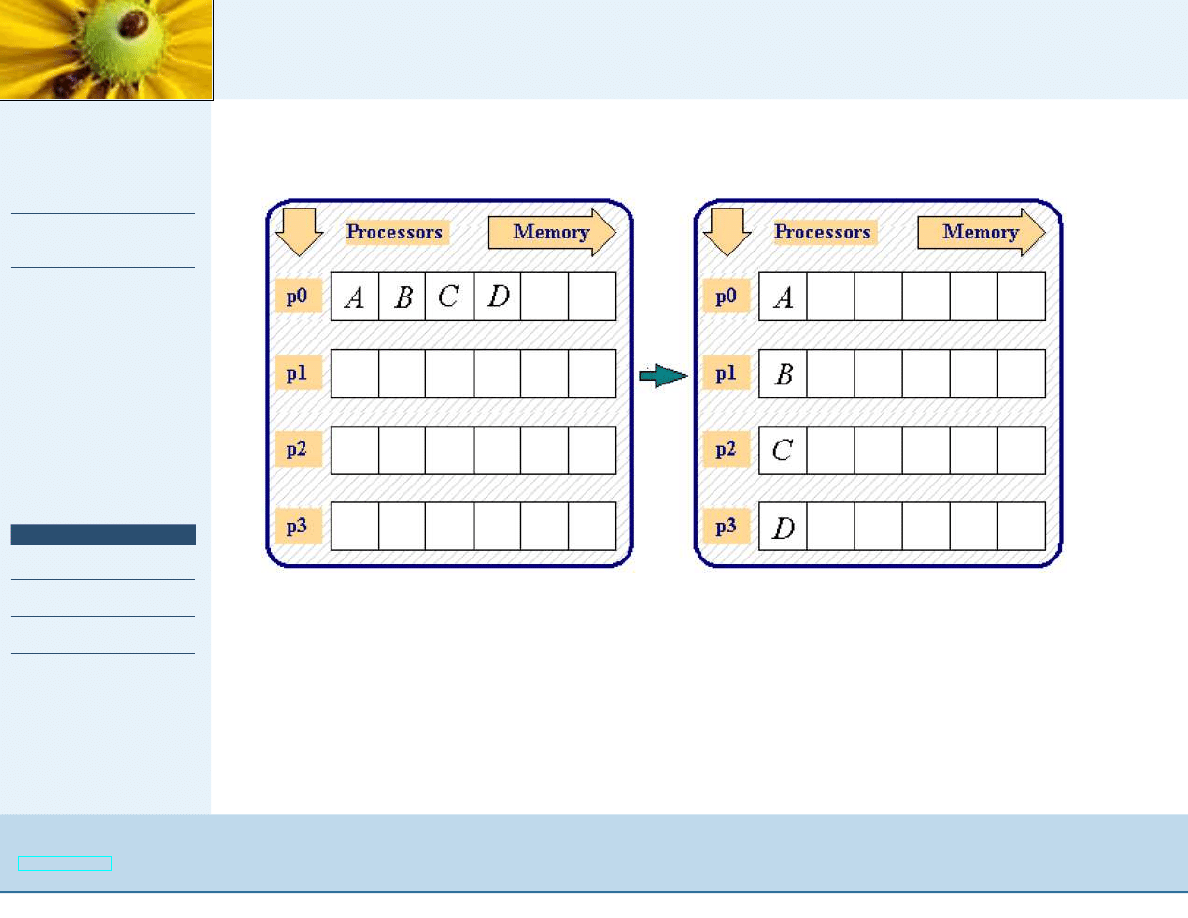
Komunikacja grupowa
OUT int MPI_Scatter (IN void *sendbuf, IN int sendcnt, IN
MPI_Datatype sendtype, OUT void *recvbuf, int recvcnt, IN
MPI_Datatype recvtype, IN int root, IN MPI_Comm comm);


Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 31/48
Równoległe we-wy
Realizacja:
■
zapis do pliku jest analogi ˛
a nadawania komunikatu do
systemu plików
■
odczyt z pliku jest analogi ˛
a odbierania komunikatu z systemu
plików
■
MPI-2 zawiera analogie do operacji Uniksowych:
open
,
close
,
seek
,
read
i
write
.
Funkcje:
MPI_File_open();
MPI_File_write();
MPI_File_read();
MPI_File_set_view();
MPI_File_close();
MPI_File_seek();
MPI_File_write_shared();

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 32/48
Przykład: równoległy zapis do pliku
# include " mpi . h "
# include < s t d i o . h>
# d e f i n e BUFSIZE 100
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t i , myrank , b u f [ BUFSIZE ] ;
M P I _ F i l e t h e f i l e ;
M P I _ I n i t (& argc , &argv ) ;
MPI_Comm_rank (MPI_COMM_WORLD, &myrank ) ;
f o r ( i = 0 ; i <BUFSIZE ;
i ++) b u f [ i ] = myrank
∗
BUFSIZE + i ;
MPI_File_open (MPI_COMM_WORLD, " t e s t f i l e " , MPI_MODE_CREATE
| MPI_MODE_WRONLY, MPI_INFO_NULL , & t h e f i l e ) ;
M P I _ F i l e _ s e t _ v i e w ( t h e f i l e , myrank
∗
BUFSIZE
∗
s i z e o f ( i n t ) , MPI_INT ,
MPI_INT , " n a t i v e " , MPI_INFO_NULL ) ;
M P I _ F i l e _ w r i t e ( t h e f i l e , buf , BUFSIZE , MPI_INT , MPI_STATUS_IGNORE ) ;
M P I _ F i l e _ c l o s e (& t h e f i l e ) ;
M P I _ F i n a l i z e ( ) ;
r e t u r n 0 ;
}
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 33/48
Przykład: równoległy odczyt pliku
# include ”mpi . h ”
# include < s t d i o . h>
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t myrank , numprocs , b u f s i z e ,
∗
buf , count ;
MPI_File t h e f i l e ;
MPI_Status s t a t u s
MPI_Offset f i l e s i z e ;
M P I _ I n i t (& argc , &argv ) ;
MPI_Comm_rank (MPI_COMM_WORLD, &myrank ) ;
MPI_Comm_size (MPI_COMM_WORLD, &numprocs ) ;
MPI_File_open (MPI_COMM_WORLD, " t e s t f i l e " , MPI_MODE_RDONLY, MPI_INFO_NULL , & t h e f i l e ) ;
M P I _ F i l e _ g e t _ s i z e ( t h e f i l e , & f i l e s i z e ) ; /
∗
w b a j t a c h
∗
/
f i l e s i z e = f i l e s i z e
/ s i z e ( i n t ) ; /
∗
w l i c z b i e
i n t s
∗
/
b u f s i z e = f i l e s i z e
/ numprocs + 1 ; /
∗
l o k a l n a l i c z b a do odczytu
∗
/
b u f = ( i n t
∗
) m a l l o c ( b u f s i z e + s i z e o f ( i n t ) ) ;
M P I _ F i l e _ s e t _ v i e w ( t h e f i l e , myrank
∗
b u f s i z e
∗
s i z e o f ( i n t ) ) , MPI_INT , MPI_INT ,
" n a t i v e " , MPI_INFO_NULL ) ;
MPI_File_read ( t h e f i l e , buf , b u f s i z e , MPI_INT , & s t a t u s ) ;
MPI_Get_count (& s t a t u s , MPI_INT , &count ) ;
p r i n t f ( " process %d read %d i n t s \ n " , myrank , count ) ;
M P I _ F i l e _ c l o s e (& t h e f i l e ) ;
M P I _ F i n a l i z e ( ) ;
r e t u r n 0 ;
}
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 34/48
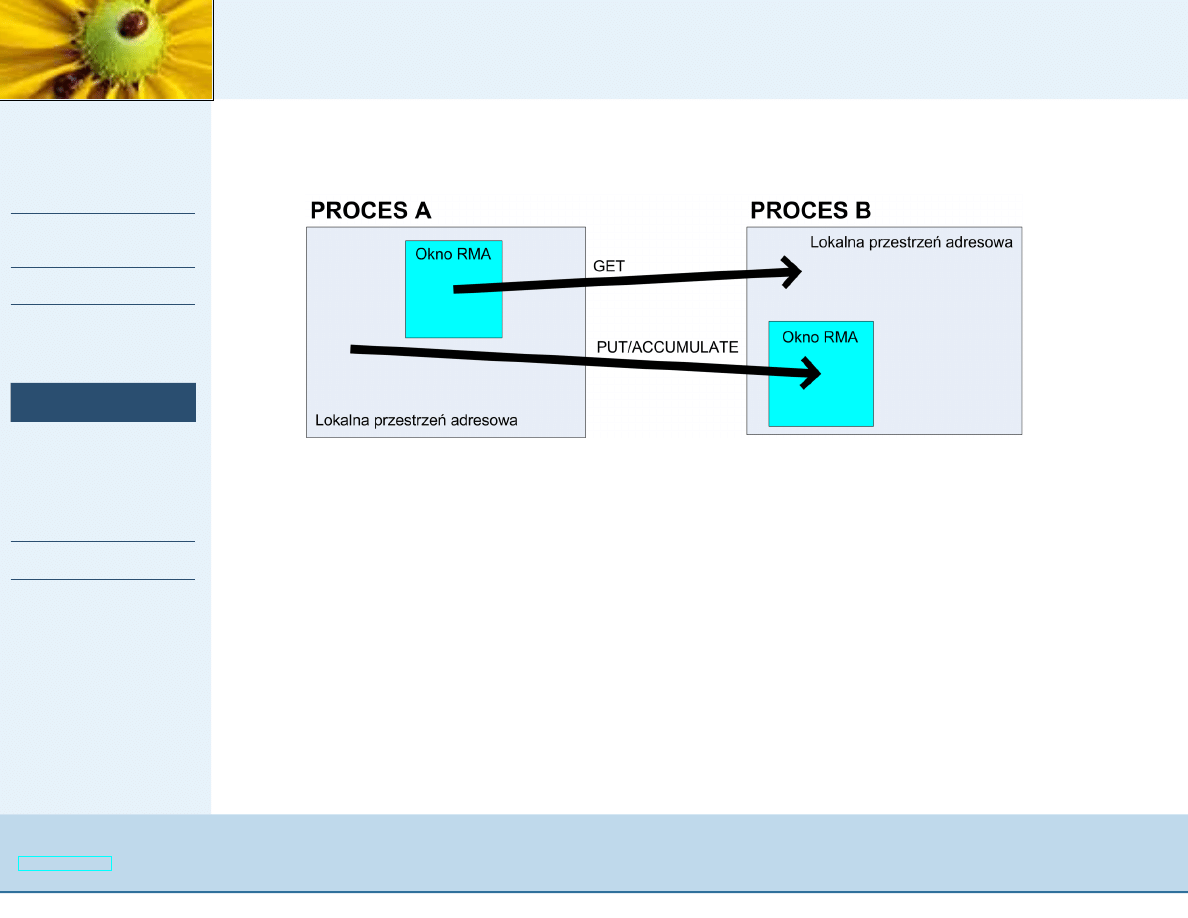
Zdalne operacje na pami ˛eci (RMA)
Zdalne operacje na pami ˛eci
6=
pami ˛e´c dzielona:
■
MPI-2: dane s ˛
a przesyłane z jednej przestrzeni adresowej do
drugiej za pomoc ˛
a pary operacji
sendreceive
■
Pami ˛e´c dzielona: procesy maj ˛
a dost ˛ep do wspólnej puli
pami ˛eci i mog ˛
a wprost wykonywa´c operacje na pami ˛eci
Realizacja:
■
oddzielenia synchronizacji od przesyłania danych w celu
zwi ˛ekszenia efektywno´sci,
■
powstałe rozwi ˛
azanie jest oparte na idei okien zdalnego
dost ˛epu do pami ˛eci (okno - to porcja przestrzeni adresowej
ka˙zdego procesu dost ˛epna dla innych).
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 35/48
RMA
Operacje na oknach:
■
pobieranie zawarto´sci okna
MPI_Get
■
zapisywanie do okna
MPI_Put
■
zmiana zawarto´sci okna
MPI_Accumulate
A wszystko: synchronizowane przez
MPI_Win_Fence

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 36/48
Przykład: RMA
/
∗
o b l i c z a n i e p i za pomoc ˛
a całkowania numerycznego , w e r s j a RMA
∗
/
# include " mpi . h "
# include <math . h>
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t n , myid , numprocs ,
i ;
double PI25DT = 3.141592653589793238462643;
double mypi , p i , h , sum , x ;
MPI_Win nwin , p i w i n ;
M P I _ I n i t (& argc , &argv ) ;
MPI_Comm_size (MPI_COMM_WORLD,& numprocs ) ;
MPI_Comm_rank (MPI_COMM_WORLD,& myid ) ;
i f
( myid == 0 )
{
MPI_Win_create (&n , s i z e o f ( i n t ) , 1 , MPI_INFO_NULL , MPI_COMM_WORLD, &nwin ) ;
MPI_Win_create (& p i , s i z e o f ( double ) , 1 , MPI_INFO_NULL , MPI_COMM_WORLD, &p i w i n ) ;
}
else
{
MPI_Win_create (MPI_BOTTOM, 0 , 1 , MPI_INFO_NULL , MPI_COMM_WORLD, &nwin ) ;
MPI_Win_create (MPI_BOTTOM, 0 , 1 , MPI_INFO_NULL , MPI_COMM_WORLD, &p i w i n ) ;
}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 37/48
Przykład: RMA
while ( 1 )
{
i f
( myid == 0 )
{
p r i n t f ( " E n t e r t h e number o f i n t e r v a l s : ( 0 q u i t s ) " ) ;
s c a n f ( "%d " ,& n ) ;
p i = 0 . 0 ;
}
MPI_Win_fence ( 0 , nwin ) ;
i f
( myid ! = 0 ) MPI_Get (&n , 1 , MPI_INT , 0 , 0 , 1 , MPI_INT , nwin ) ;
MPI_Win_fence ( 0 , nwin ) ;
i f
( n == 0 ) break ;
else
{
h = 1 . 0 / ( double ) n ;
sum = 0 . 0 ;
f o r ( i = myid + 1 ; i <= n ;
i += numprocs )
{
x = h
∗
( ( double ) i
−
0 . 5 ) ;
sum += ( 4 . 0 / ( 1 . 0 + x
∗
x ) ) ;
}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 38/48
Przykład: RMA
mypi = h
∗
sum ;
MPI_Win_fence ( 0 , p i w i n ) ;
MPI_Accumulate(& mypi , 1 , MPI_DOUBLE , 0 , 0 , 1 , MPI_DOUBLE , MPI_SUM , p i w i n ) ;
MPI_Win_fence ( 0 , p i w i n ) ;
i f
( myid == 0 )
p r i n t f ( " p i i s a p p r o x i m a t e l y %.16 f , E r r o r i s %.16 f \ n " , p i , f a b s ( p i
−
PI25DT ) ) ;
}
}
MPI_Win_free (& nwin ) ;
MPI_Win_free (& p i w i n ) ;
M P I _ F i n a l i z e ( ) ;
r e t u r n 0 ;
}

Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 39/48
Dynamiczna struktura obliczeniowa
■
MPI-2 umo˙zliwia dynamiczne tworzenie procesów w trakcie
pracy poprzez funkcj ˛e
MPI_Comm_Spawn
.
■
Maksymaln ˛
a ilo´s´c procesów okre´sla parametr
MPI_UNIVERSE_SIZE
.
■
Procesy wywołuj ˛
acy i wywołany ł ˛
aczy interkomunikator -
podawany jako argument w
MPI_Comm_Spawn
oraz
otrzymywany w procesie wywołanym przez
MPI_Comm_get_parent
.
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 40/48
Przykład: dynamiczny model master-slave
/
∗
master
∗
/
# include " mpi . h "
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t w o r l d _ s i z e , u n i v e r s e _ s i z e ,
∗
u n i v e r s e _ s i z e p , f l a g ;
MPI_Comm everyone ;
/
∗
i n t e r k o m u n i k a t o r
∗
/
char worker_program [ 1 0 0 ] ;
M P I _ I n i t (& argc , &argv ) ; MPI_Comm_size (MPI_COMM_WORLD, &w o r l d _ s i z e ) ;
i f ( w o r l d _ s i z e ! = 1 ) e r r o r ( " Top heavy w i t h management " ) ;
M P I _ A t t r _ g e t (MPI_COMM_WORLD, MPI_UNIVERSE_SIZE , &u n i v e r s e _ s i z e p , & f l a g ) ;
i f
( ! f l a g )
{
p r i n t f ( " T h i s MPI does n o t s u p p o r t UNIVERSE_SIZE . How many \ n \ processes t o t a l ? " ) ;
s c a n f ( "%d " , &u n i v e r s e _ s i z e ) ;
}
else
u n i v e r s e _ s i z e =
∗
u n i v e r s e _ s i z e p ;
i f ( u n i v e r s e _ s i z e == 1 ) e r r o r ( " No room t o s t a r t workers " ) ;
/ / uruchamiamy procesy s l a v e
−
mozemy w c z e s n i e j sprecyzowa ´c l i n i ˛e polece ´n
choose_worker_program ( worker_program ) ;
MPI_Comm_spawn ( worker_program , MPI_ARGV_NULL, u n i v e r s e _ s i z e
−
1, MPI_INFO_NULL ,
0 , MPI_COMM_SELF, &everyone , MPI_ERRCODES_IGNORE) ;
/
∗
Tu kod r ó w n o l e g ł y . Komunikator " everyone " mo˙ze by ´c u ˙zywany do k o m u n i k a c j i z
∗
uruchomionymi procesami o rank 0 , . . . , MPI_UNIVERSE_SIZE
−
1 w " everyone "
∗
/
M P I _ F i n a l i z e ( ) ; r e t u r n 0 ; }
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 41/48
Przykład: dynamiczny model master-slave
/
∗
s l a v e
∗
/
# include " mpi . h "
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t s i z e ;
MPI_Comm p a r e n t ;
M P I _ I n i t (& argc , &argv ) ;
MPI_Comm_get_parent (& p a r e n t ) ;
i f ( p a r e n t == MPI_COMM_NULL )
e r r o r ( " No p a r e n t ! " ) ;
MPI_Comm_remote_size ( parent , &s i z e ) ;
i f ( s i z e ! = 1 )
e r r o r ( " Something ’ s wrong w i t h t h e p a r e n t " ) ;
/
∗
Tu kod r ó w n o l e g ł y . Master j e s t procesem o rank 0 w MPI_Comm p a r e n t
∗
Procesy s l a v e mog ˛
a komunikowa ´c s i ˛e ze sob ˛
a przez MPI_COMM_WORLD.
∗
/
M P I _ F i n a l i z e ( ) ;
r e t u r n 0 ;
}


Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 43/48
MPI a j ˛ezyk C++
■
W standardzie MPI u˙zyto "konserwatywnego" podej´scia do
implementacji w C++ - wi ˛ekszo´s´c funkcji jest metodami klasy
MPI
.
■
Wi ˛ekszo´s´c zmiennych charakterystycznych dla MPI (takich
jak statusy, ˙z ˛
adania, pliki) jest obiektami w C++.
■
Je˙zeli funkcja jest naturalnie powi ˛
azana z obiektem to
stanowi ona jego metod ˛e.
■
Funkcje tworz ˛
ace obiekty zwracaj ˛
a je - zamiast kodu bł ˛edu.
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 44/48
Przykład: MPI, a C++
i n t main ( i n t argc , char
∗
argv [ ] )
{
i n t b u f s i z e ,
∗
buf , count ;
char f i l e n a m e [ 1 2 8 ] ;
MPI : : S t a t u s s t a t u s ;
MPI : : I n i t ( ) ;
i n t myrank = MPI : :COMM_WORLD. Get_rank ( ) ;
i n t numprocs = MPI : :COMM_WORLD. Get_size ( ) ;
MPI : : F i l e
t h e f i l e = MPI : : F i l e : : Open ( MPI : : COMM_WORLD, " t e s t f i l e " ,
MPI : : MODE_RDONLY, MPI : : INFO_NULL ) ;
MPI : : O f f s e t
f i l e s i z e = t h e f i l e . Get_size ( ) ;
/ / w b a j t a c h
f i l e s i z e = f i l e s i z e
/ s i z e o f ( i n t ) ;
/ / w i n t
b u f s i z e = f i l e s i z e
/ numprocs + 1 ;
/ / do p r z e c z y t a n i a l o k a l n i e
b u f = ( i n t
∗
) m a l l o c ( b u f s i z e
∗
s i z e o f ( i n t ) ) ;
t h e f i l e . Set_view ( myrank
∗
b u f s i z e
∗
s i z e o f ( i n t ) ,
MPI_INT , MPI_INT , " n a t i v e " , MPI : : INFO_NULL ) ;
t h e f i l e . Read ( buf , b u f s i z e , MPI_INT , & s t a t u s ) ;
count = s t a t u s . Get_count ( MPI_INT ) ;
c o u t << " process " << myrank << " read " << count << " i n t s " << e n d l ;
t h e f i l e . Close ( ) ;
MPI : : F i n a l i z e ( ) ;
r e t u r n 0 ;
}
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 45/48
U˙zytkowanie MPICH w ZA
■
W laboratorium 102 Zakładu Automatyki dost ˛epnych jest 6
komputerów pracuj ˛
acych pod kontrol ˛
a systemu
operacyjnego Debian Linux, z zainstalowan ˛
a bibliotek ˛
a
MPICH i kompilatorem GCC.
■
Komputery posiadaj ˛
a nazwy domenowe za-51, za-52, itd.
■
Dla uruchamiania programów równoległych przygotowano
konta mpilab1, mpilab2, ... przypisane do ka˙zdego z
komputerów (hasło: mpilab).
■
Katalogi domowe s ˛
a dzielone przez NFS mi ˛edzy wszystkimi
maszynami (nie ma zatem potrzeby kopiowania kodów,
mo˙zna stosowa´c metody równoległego we/wy).
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 46/48
U˙zytkowanie MPICH w ZA
Kroki uruchamiania programu:
■
kompilacja
mpicc.mpich -g -o binary_file_name
source_file.c
(w przypadku C++ -
mpiCC
)
■
przygotowanie ´srodowiska - stworzy´c plik zawieraj ˛
acy nazwy
u˙zywanych komputerów i ilo´s´c procesów na ka˙zdym z nich
np.
za-51
za-52
za-54
■
uruchomienie programu - poprzez wywołanie
mpirun
np.
mpirun.mpich -machinefile plik_z_maszynami -n
ilosc_procesów binary_file
Szymon Łukasik, 8 listopada 2006
Łagodne wprowadzenie do MPI - p. 47/48
Gdzie szuka ´c informacji?
Szczególnie polecane s ˛
a strony danej implementacji MPI,
specyfikacja samego standardu (www.mpi-forum.org) oraz:
■
„MPI: The Complete Reference”, M. Snir, S. Otto, S.
Huss-Lederman, D. Walker, J. Dongarra,
(http://www.netlib.org/utk/papers/mpi-book/mpi-book.html)
■
„Rozszerzenia standardu MPI: MPI-2”, materiały
szkoleniowe PCSS,
(http://szkolenia.man.poznan.pl/kdm/presentations/
MPI-2/rozszerzenia standardu MPI - MPI-2.pdf )
Document Outline
- Wstep
- Omówienie wazniejszych funkcji MPI
- Uzyta notacja i uwagi ogólne
- Podstawowe funkcje
- Komunikacja blokujaca jeden do jednego
- Przyklad - kom. blokujaca
- Typy danych MPI
- Pakowanie danych
- Przyklad - pakowanie
- Typy uzytkownika
- Przyklad - typy uzytkownika
- Przyklad - typy uzytkownika
- Przyklad - typy uzytkownika
- Tryby komunikacji
- Tryby komunikacji
- Komunikacja nieblokujaca
- Komunikacja nieblokujaca
- Przyklad - kom. nieblokujaca
- Przyklad - kom. nieblokujaca
- Komunikacja grupowa
- Komunikacja grupowa
- Komunikacja grupowa
- Komunikacja grupowa
- Komunikacja grupowa
- Glówne funkcje MPI-2
- Uzupelnienia
- Zakonczenie
Wyszukiwarka
Podobne podstrony:
Napęd Elektryczny wykład
wykład5
Psychologia wykład 1 Stres i radzenie sobie z nim zjazd B
Wykład 04
geriatria p pokarmowy wyklad materialy
ostre stany w alergologii wyklad 2003
WYKŁAD VII
Wykład 1, WPŁYW ŻYWIENIA NA ZDROWIE W RÓŻNYCH ETAPACH ŻYCIA CZŁOWIEKA
Zaburzenia nerwicowe wyklad
Szkol Wykład do Or
Strategie marketingowe prezentacje wykład
Wykład 6 2009 Użytkowanie obiektu
wyklad2
wykład 3
wyklad1 4
więcej podobnych podstron