
52
OBRONA
HAKIN9 4/2009
Z
anim zostanie zaprezentowana filozofia
działania oraz konkretne przykłady
konfiguracji systemu Bacula, warto
zastanowić się nad kilkoma podstawowymi
kwestiami. Przede wszystkim – czym jest
kopia zapasowa (backup) i czym różni się ona
od archiwizacji? Kopia zapasowa jest kopią
danych, która ma służyć do ich odtworzenia
w przypadku utraty lub uszkodzenia danych
oryginalnych. Archiwizacja z kolei jest procesem
tworzenia kopii zapasowych danych w celu ich
przechowywania przez dłuższy czas (np. kilka
lat). Chęć (bądź konieczność) wykonywania kopii
archiwalnych wynikać może między innymi z
potrzeby składowania danych dla celów własnej ich
analizy w przyszłości lub z obowiązku nałożonego
przez przepisy prawa. Oprócz tego archiwizacja
wykonywana jest również wtedy, gdy oryginalne dane
nie są aktualnie potrzebne do pracy, a zajmowana
przez nie przestrzeń dyskowa może zostać
wykorzystana do przechowywania innych danych.
Oczywiście pojawia się pytanie, po co
wykonywać kopie zapasowe danych albo
raczej: w jakich sytuacjach kopia zapasowa
może okazać się przydatna? Odpowiedź na to
pytanie jest bardzo prosta, szczególnie dla osób,
którym przytrafiła się utrata danych. Jedną z
najczęstszych sytuacji, w których konieczne jest
odzyskanie danych z kopii zapasowej, jest błąd
człowieka, czyli przypadkowe usunięcie istotnych
danych. Często dane są celowo usuwane przez
użytkownika. Kolejne sytuacje motywujące do
MARCIN KLAMRA
Z ARTYKUŁU
DOWIESZ SIĘ
jak skonfigurować system
kopii zapasowych Bacula do
centralnego wykonywania kopii
zapasowych heterogenicznego
środowiska,
w jaki sposób przy niewielkim
nakładzie pracy zapewnić sobie
wykonywanie kopii zapasowych
cennych danych stacji roboczej.
CO POWINIENEŚ
WIEDZIEĆ
czym jest kopia zapasowa,
jaki sprzęt jest wykorzystywany
do wykonywania kopii
zapasowych,
znać strategie rotacji nośników,
znać podstawy konfiguracji
systemów Windows oraz Linux.
tworzenia kopii danych to awarie sprzętu (np.
uszkodzenie dysku twardego) lub kradzież sprzętu.
Jak można przypuszczać, istnieją różne
typy kopii zapasowych. W zależności od
przeznaczenia kopii zapasowej można wyróżnić
kopie zapasowe danych, kopie zapasowe
systemu oraz archiwizację danych. Kopia
zapasowa danych służy do zapisania duplikatu
tylko danych użytkowników, poczty, baz danych,
stron WWW – a więc wszystkich danych, które
zostały utworzone z wykorzystaniem systemu
operacyjnego i działających w nim aplikacji.
Kopia zapasowa systemu służy do wykonania
duplikatu całego systemu plików wraz z systemem
operacyjnym i plikami aplikacji. Jest to kompletny
obraz całego systemu i jako taki może posłużyć
nie tylko do odzyskania danych użytkowników,
ale również do odzyskania całego systemu
w momencie nieodwracalnego uszkodzenia
serwera (np. pożaru). Tego typu kopia pozwala
na uruchomienie całego systemu na innym
sprzęcie w bardzo krótkim czasie (tzw. bare metal
restore). Archiwizacja jest z kolei kopią danych
służącą do długoterminowego przechowywania.
W odróżnieniu od kopii zapasowej, która
przechowywana jest przez krótki okres (zależnie
od przyjętej polityki – od kilku dni do jednego
roku), archiwizacja służy do przechowywania
danych przez dłuższy czas (np. kilka lub
kilkanaście lat).
Oprócz typów kopii zapasowych możemy
także wyróżnić kilka ich rodzajów: kopie pełne,
Stopień trudności
System kopii
zapasowych
Bacula
Wykonywanie kopii zapasowych jest operacją niezbędną w każdym
środowisku, w którym przetwarza się dane. Proces wykonywania
kopii zapasowych jest monotonny i powinien być wykonywany
automatycznie. Spełnienie tego warunku wymaga posiadania
stosownego sprzętu i oprogramowania.
53
SYSTEM KOPII ZAPASOWYCH BACULA
HAKIN9
4/2009
różnicowe i przyrostowe. Kopia pełna
wykonuje duplikat wszystkich danych
niezależnie od czasu, kiedy były ostatnio
kopiowane. W razie utraty lub uszkodzenia
danych kopia ta pozwala na najszybsze
odtworzenie danych. Niestety, ze względu
na jej kompletność wymaga nośnika
o największej pojemności. Co więcej,
wykonywanie kopii pełnej w największym
stopniu obciąża duplikowany system i
jest najbardziej czasochłonne spośród
wszystkich rodzajów kopii. Kopia różnicowa
służy do wykonania duplikatu danych
zmodyfikowanych od czasu wykonywania
ostatniej kopii pełnej. Ilość danych, jaką
trzeba zapisać w wyniku wykonywania tej
kopii, jest znacznie mniejsza niż dla kopii
pełnej, dzięki czemu wymaga nośnika o
niższej pojemności, wykonuje się szybciej
i w mniejszym stopniu obciąża duplikowany
system. Kopia przyrostowa wykonuje
duplikat danych zmodyfikowanych
od czasu wykonywania ostatniej kopii
(mogła to być kopia pełna, różnicowa lub
przyrostowa). Ilość danych koniecznych
do zapisania jest najmniejsza, a co za
tym idzie – czas potrzebny na wykonanie
kopii jest najkrótszy, lecz odzyskanie
danych z tego typu kopii trwa najdłużej.
Konieczne jest bowiem częściowe
odzyskanie danych z kopii pełnych,
różnicowych i przyrostowych. Kompromis
pomiędzy czasem wykonywania kopii a
czasem odtwarzania danych w przypadku
awarii uzyskuje się poprzez umiejętne
zastosowanie wszystkich trzech rodzajów
kopii (np. kopia pełna wykonywana w
pierwszym dniu miesiąca, kopia różnicowa
wykonywana w pierwszym dniu tygodnia,
a kopia przyrostowa wykonywana w
pozostałe dni).
Przy zastosowaniu powyższej strategii
otrzymujemy system, w którym kopia
wykonywana jest jeden raz dziennie. Czas
RPO (ang. Recovery Point Objective) w tej
strategii wynosi 24 godziny. Wielkość ta
jest czasem opisującym pesymistyczny
docelowy stan odtworzenia, czyli w
najgorszym razie dane po odtworzeniu nie
będą starsze niż sprzed czasu określonego
przez wskaźnik RPO. Przedstawiona
strategia chroni użytkowników przed utratą
danych zmodyfikowanych od poprzedniego
dnia pracy (zakładający wykonywanie kopii
wieczorem lub nad ranem). Gdyby jednak
istotna była ochrona danych o krótszym
czasie RPO, należy zastosować inną
strategię. Jeżeli czas RPO ma być mierzony
w sekundach, wtedy konieczne jest
zastosowanie systemu zapewniającego
ciągłą ochronę danych (ang. Continuous
Data Protection).
Kolejnymi istotnymi, wartymi poruszenia
sprawami są automatyzacja i centralizacja
procesu wykonywania kopii zapasowych.
Automatyzacja jest właściwie wymagana
w niezawodnym systemie tworzenia
kopii zapasowych. Ze względu na swoją
monotonność i powtarzalność nie ma
sensu – a co więcej, jest to niewskazane –
by angażować do tego procesu człowieka.
Może on zawieść, popełnić błąd czy
zapomnieć o wykonaniu kopii zapasowej.
Przy wykorzystaniu odpowiedniego,
poprawnie skonfigurowanego
oprogramowania oraz należytego
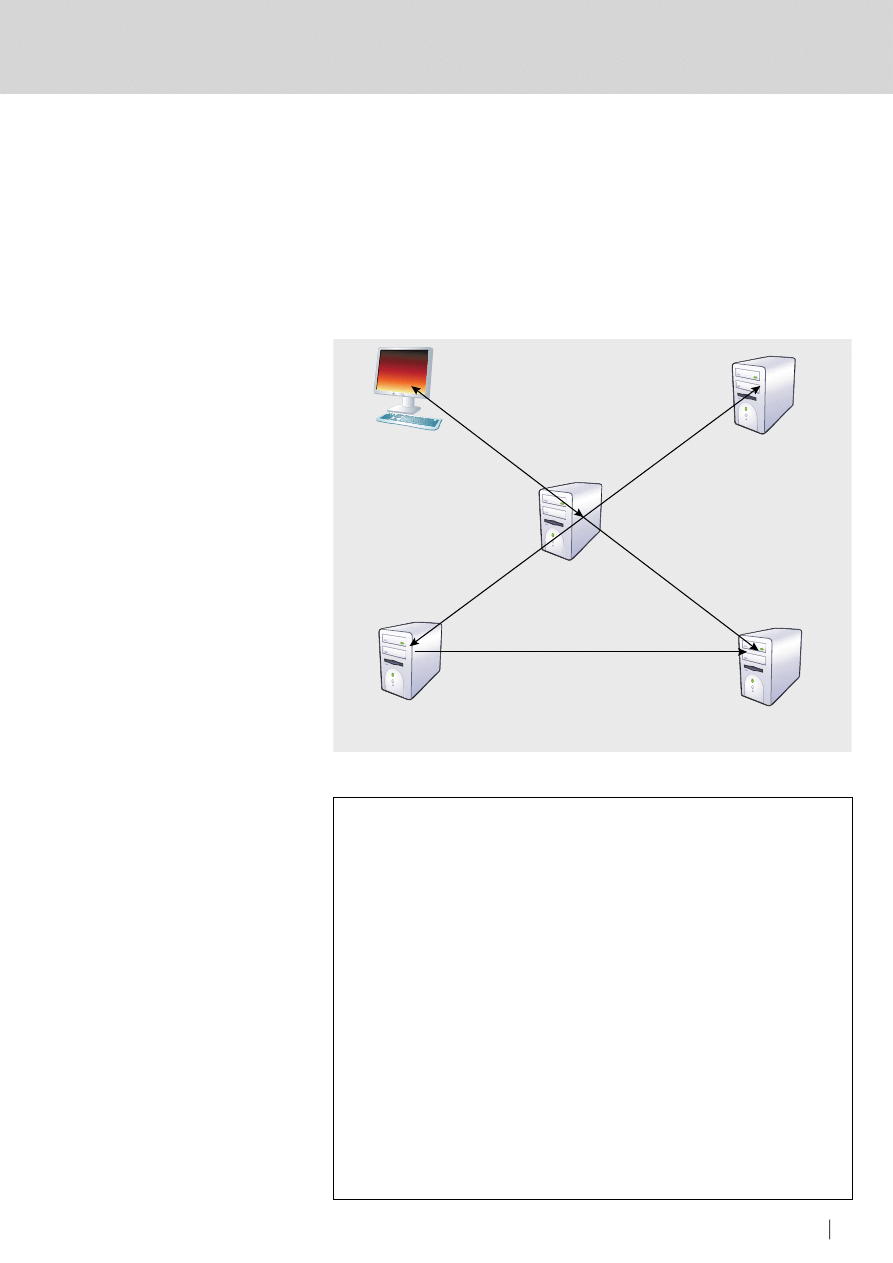
Rysunek 1.
Zależności pomiędzy modułami systemu Bacula
�������������
�������������
����������
�������������
��������������
��������
�����������������
�������������������
�������������
������������������
��������������
Listing 1.
Konfiguracja modułu Console
Director
{
Name
=
host
-
dir
DIRport
=
9101
address
=
host
.
domena
Password
=
"fdsIDSVNew8sfd"
}
Listing 2.
Konfiguracja modułu Storage – sekcja Storage
Storage
{
Name
=
host
-
sd
SDPort
=
9103
WorkingDirectory
=
"/var/bacula/working"
Pid
Directory
=
"/var/run"
Maximum
Concurrent
Jobs
=
20
}
Listing 3.
Konfiguracja modułu Storage – sekcja Director
Director
{
Name
=
host
-
dir
Password
=
"UIIadsksd89"
}

OBRONA
54
HAKIN9 4/2009
SYSTEM KOPII ZAPASOWYCH BACULA
55
HAKIN9
4/2009
sprzętu proces tworzenia kopii zapasowej
może zostać w pełni zautomatyzowany.
Takim oprogramowaniem może być
system Bacula. Odpowiedni sprzęt to
taki, który zarówno w procesie tworzenia
kopii zapasowej, jak i w procesie
odtwarzania danych nie wymaga
żadnej interwencji człowieka, np. w
postaci konieczności umieszczenia
odpowiedniego nośnika w napędzie. Tego
typu sprzętem mogą być na przykład
wszelkiego rodzaju autoloadery, a więc
urządzenia posiadające magazyny taśm
i automatycznie ładujące odpowiednie
taśmy do napędu streamera. Przy
założeniu odpowiedniej strategii
wykonywania kopii oraz konfiguracji
oprogramowania interwencja człowieka
nie będzie konieczna nigdy bądź bardzo
rzadko (np. wymiana uszkodzonych
nośników danych czy wymiana całego
magazynu nośników po ich zapełnieniu np.
raz na miesiąc).
Centralizacja jest z kolei wskazana
ze względu na łatwość zarządzania oraz
wysoki stopień wykorzystania zbioru
urządzeń i nośników danych służących
do zapisywania kopii zapasowych. Warto
zainwestować w urządzenie wyższej
klasy, zapewniające większą pojemność,
niż w kilka urządzeń o mniejszych
pojemnościach. Przy zastosowaniu
odpowiedniego oprogramowania (jakim
jest Bacula) istnieje możliwość centralnego
wykonywania jednoczesnych kopii na jedno
urządzenie składujące z różnych systemów
operacyjnych. Jedynym wymaganiem jest
odpowiednie skonfigurowanie systemu
kopii zapasowych.
System Bacula służy do wykonywania
kopii zapasowych zarówno małych, jak
i dużych systemów komputerowych.
Jego używanie nie jest jednak zawsze
uzasadnione. W przypadku wykonywania
kopii zapasowych pojedynczej stacji
roboczej czasami warto posłużyć się
narzędziami i metodami znacznie
prostszymi – co nie znaczy, że mniej
skutecznymi.
Przykładowym narzędziem tego typu
jest rsnapshot, dostępny dla użytkowników
systemu Linux. Transfer danych w ramach
lokalnego systemu wykonywany jest przy
pomocy narzędzia rsync, do transferu
danych do innej maszyny wykorzystywany
jest rsync oraz ssh. Rsnapshot podczas
pierwszego uruchomienia wykonuje kopię
pełną wskazanych danych. Podczas
kolejnych uruchomień wykorzystywany
jest mechanizm linków twardych. Na
nowo kopiowane są tylko pliki nowo
utworzone lub zmienione. Dla wszystkich
pozostałych tworzone są linki twarde do
plików znajdujących się w kopii pełnej.
Zastosowanie tego mechanizmu zapewnia
niewielki rozmiar kolejnych kopii, szybkość
działania oraz łatwość odtwarzania danych
z kopii. Wykonywanie kopii może być
regularnie uruchamiane z wykorzystaniem
demona cron, nawet w stosunkowo
niewielkich odstępach czasu (np. co
godzinę). Rozwiązanie to idealnie nadaje
się do zabezpieczania danych, na których
aktualnie pracuje użytkownik.
Bacula jest systemem
centralnego zarządzania tworzeniem
i przechowywaniem, ale także
wykonywaniem kopii zapasowych
danych i systemu. Ze względu na
dostępność wersji dla różnych systemów
operacyjnych doskonale nadaje się do
pracy w środowiskach heterogenicznych.
Oprogramowanie Bacula dostępne jest
dla systemów Unix, Linux, Windows (tylko
oprogramowanie klienckie) oraz Mac OS.
Pozwala to na centralne, jednoczesne
wykonywanie kopii zapasowych dla
wszystkich wyżej wymienionych systemów
operacyjnych. System Bacula pozwala
na zapisywanie kopii zapasowych na
różnego rodzaju nośnikach (dyski, napędy
optyczne, taśmy) i jednoczesną obsługę
wielu nośników (np. wykorzystywanie kilku
streamerów do zapisu danych). Informacje
na temat wykonywanych kopii oraz
dostępnych nośników przechowywane
są w bazie danych. Bacula potrafi
współpracować z różnymi bazami
danych (mySQL, SQLite, postgresql), co
czyni ten system bardzo elastycznym
w zastosowaniu. Dodatkowo Bacula
doskonale współpracuje z urządzeniami
Listing 4.
Konfiguracja modułu Storage – sekcja Autochanger
Autochanger
{
Name
=
"zmieniacz"
Device
=
"Ultrium"
Changer
Command
=
"/usr/local/bacula/etc/mtx-changer %c %o %S %a %d"
Changer
Device
=
/
dev
/
sg1
}
Listing 5.
Konfiguracja modułu Storage – sekcja Device
Device
{
Name
=
"Ultrium"
Device
Type
=
Tape
Media
Type
=
LTO
-
4
Drive
Index
=
0
AutoChanger
=
yes
Archive
Device
=
/
dev
/
nst0
LabelMedia
=
No
;
Random
Access
=
No
;
AutomaticMount
=
Yes
;
RemovableMedia
=
Yes
;
AlwaysOpen
=
Yes
;
Spool
Directory
=
/
backup
Maximum
Spool
Size
=
100
g
}
Listing 6.
Konfiguracja modułu Director – sekcja Director
Director
{
Name
=
host
-
dir
DIRport
=
9101
QueryFile
=
"/etc/query.sql"
WorkingDirectory
=
"/var/bacula/working"
PidDirectory
=
"/var/run"
Maximum
Concurrent
Jobs
=
5
Password
=
"jfkbwf8FDSwef"
Messages
=
Daemon
}

OBRONA
54
HAKIN9 4/2009
SYSTEM KOPII ZAPASOWYCH BACULA
55
HAKIN9
4/2009
pozwalającymi na automatyczną
wymianę nośników danych (autoloadery),
także wyposażonych w czytniki kodów
kreskowych, co sprzyja automatyzacji
procesu wykonywania kopii zapasowych.
Pozwala to także na odtworzenie systemu
po awarii (bare metal recovery). Wszystkie
wymienione wyżej cechy sprawiają, że
system Bacula nadaje się do zastosowania
w wielu środowiskach wymagających
wykonywania kopii zapasowych.
Bacula jest rozwiązaniem
modułowym. Składa się z kilku
elementów funkcjonalnych wykonujących
poszczególne zadania. Każdy z modułów
może działać na oddzielnej maszynie,
można je także zainstalować na jednym
hoście. Jest to możliwe dzięki temu,
że komunikacja pomiędzy modułami
odbywa się z wykorzystaniem protokołów
sieciowych. Taka architektura systemu
czyni go uniwersalnym. Na Rysunku 1.
przedstawione są zależności pomiędzy
poszczególnymi modułami.
Pierwszym, podstawowym modułem
jest
Director
. Jest to moduł centralny,
pełniący nadzór nad całym procesem
tworzenia i odzyskiwania kopii zapasowych.
To właśnie w tym module definiuje się
harmonogram wykonywania kopii (co
i kiedy ma zostać skopiowane), gdzie
dane mają zostać zapisane (na którym
z dostępnych urządzeń zapisać kopię)
oraz gdzie zapisać informacje na temat
wykonywanych kopii i wykorzystanych
nośników danych.
Kolejnym modułem jest
Catalog
.
Jest to standardowa baza danych, w
której przechowywane są wszystkie
dane związane z procesem tworzenia
kopii zapasowych. Są to między innymi
informacje o tym, co zostało skopiowane,
kiedy, na jakim nośniku zostało zapisane,
jak również informacje na temat
dostępnych nośników i ich stanie (np.
nośnik pełny, pusty, uszkodzony itp.).
Trzecim modułem jest
File
. Moduł
ten jest komponentem klienckim. Instaluje
się go na każdej maszynie, która ma
podlegać procesowi wykonywania kopii
zapasowej. Zadaniem tego modułu jest
przesyłanie danych do modułu
Storage
w
celu zapisania ich kopii. Pracą tego modułu
steruje moduł Director.
Wspomniany przed chwilą komponent
Storage to czwarty moduł Baculi. Jego
zadaniem jest zapisywanie danych na
dostępnym nośniku.
Piątym, ostatnim, modułem
jest
Console
– komponent konsoli
administratora. Z poziomu tego modułu
administrator może zarządzać systemem
kopii zapasowych oraz wykonywać
poszczególne zadania, takie jak zlecanie
wykonania kopii zapasowej poza
zdefiniowanym harmonogramem czy
odzyskiwanie danych. Konsola służy także
do monitorowania pracy całego systemu.
Dostępne są zarówno wersje tekstowe, jak i
graficzne konsoli zarządzającej.
W całym systemie kopii zapasowych
może wystąpić tylko jeden moduł
Director
. Pozostałe komponenty
mogą pojawiać się wielokrotnie. O ile
w przypadku modułu
File
wydaje się
to być oczywiste (można wykonywać
kopie danych z wielu maszyn), o tyle w
przypadku pozostałych modułów już tak
nie jest. Moduł
Catalog
może pojawić
się wielokrotnie, jeśli administrator
chce dane o poszczególnych kopiach
przechowywać w różnych bazach
danych. Komponent
Storage
może
pojawić się wielokrotnie, jeśli w całym
systemie kopii dostępne jest więcej niż
jedno urządzenie pozwalające na zapis
kopii danych, a do tego podłączone
jest np. do innej maszyny. Podobnie
Listing 7.
Konfiguracja modułu Director – sekcja JobDefs
JobDefs
{
Name
=
"Linux Backup"
Enabled
=
yes
Type
=
Backup
Level
=
Incremental
Client
=
host
-
fd
FileSet
=
"Full Set Host"
Schedule
=
"MonthlyCycle"
Storage
=
host
-
sd
Messages
=
Standard
Pool
=
Default
Spool
Data
=
yes
Maximum
Concurrent
Jobs
=
10
Priority
=
10
}
Listing 8.
Konfiguracja modułu Director – sekcja Job
Job
{
Name
=
"Host2 Backup"
JobDefs
=
"Linux Backup"
Client
=
host2
-
fd
FileSet
=
"Full Set Host2"
Write
Bootstrap
=
"/usr/local/bacula/bootstrap/Host2.bsr"
}
Listing 9.
Konfiguracja modułu Director – sekcja FileSet
FileSet
{
Name
=
"Full Set Host2"
Include
{
Options
{
signature
=
MD5
}
File
=
/
File
=
/
var
}
Exclude
{
File
=
/
proc
File
=
/
tmp
File
=
/
var
/
spool
/
squid
File
=
/.
journal
File
=
/.
fsck
}
}

OBRONA
56
HAKIN9 4/2009
SYSTEM KOPII ZAPASOWYCH BACULA
57
HAKIN9
4/2009
konsol zarządzających może być wiele.
Systemem może zarządzać więcej niż
jeden administrator.
Instalacja systemu Bacula nie jest
skomplikowana. W przypadku systemu
Windows można ze strony projektu
pobrać wersję instalacyjną modułu
File
(dla okienek dostępny jest tylko
ten komponent). W systemach Unix lub
Linux możliwa jest instalacja zarówno z
przygotowanych pakietów (wchodzących
w skład poszczególnych dystrybucji),
jak również kompilacja ze źródeł. W
przypadku konieczności kompilacji
odsyłam do dokumentacji zawartej w
pakietach źródłowych. W trakcie instalacji
lub konfiguracji ze źródeł tworzone są
przykładowe pliki konfiguracyjne.
Konfigurację systemu Bacula
najlepiej rozpocząć od końca, czyli od
skonfigurowania modułu
Console
, a
następnie modułów
Storage
,
File
i
Director
(konfiguracja modułu
Catalog
znajduje się w pliku konfiguracyjnym
modułu
Director
). Dzięki takiemu
podejściu nie będzie konieczne ustawiczne
powracanie do pliku konfiguracyjnego
modułu
Director
. Dodanie bowiem
kolejnego klienta lub kolejnego modułu
odpowiedzialnego za zapisywanie kopii na
nośnikach wymaga modyfikacji konfiguracji
modułu
Director
.
Konfiguracja
modułu Console
Konfiguracja modułu
Console
(Listing
1) sprowadza się do określenia modułu
Director
, którym dana konsola ma
zarządzać. W pliku konfiguracyjnym
(bconsole.conf ) znajduje się nazwa
modułu (wykorzystywana tylko w plikach
konfiguracyjnych), adres maszyny, na której
zainstalowany został moduł
Director
,
numer portu, na którym oczekuje na
połączenia oraz hasło.
Konfiguracja modułu Storage
Konfiguracja modułu Storage (plik
bacula-sd.conf ) jest znacznie bardziej
rozbudowana. Składa się z kilku sekcji:
Storage
– sekcja ta opisuje moduł,
Director
– definiuje moduł zarządzający,
opcjonalna sekcja
Autochanger
opisująca urządzenie zmieniające
(o ile oczywiście jest dostępne) oraz
sekcja
Device
opisująca urządzenie
zapisujące kopie zapasowe. Oprócz tego
występują jeszcze sekcje informujące o
tym, gdzie i w jaki sposób przesyłane są
komunikaty. Konfiguracja tych sekcji dla
wszystkich modułów jest taka sama i na
tyle oczywista, że jej opis zostanie tutaj
pominięty.
Na Listingu 2. przedstawiona jest
konfiguracja sekcji
Storage
. W sekcji tej
definiuje się nazwę modułu
Storage
,
numer portu, na którym oczekuje na
połączenia, katalog roboczy aplikacji,
katalog, w którym zapisana jest informacja
o numerze PID, oraz wielkość definiująca
liczbę jednoczesnych zadań, jakie mogą
zapisywać dane do modułu
Storage
.
Zadania definiowane są w konfiguracji
modułu
Director
.
Konfiguracja sekcji
Director
(Listing
3) zawiera jedynie nazwę modułu
zarządzającego oraz hasło. Określa, który
moduł
Director
ma prawo komunikować
się z modułem
Storage
.
Sekcja
Autochanger
(Listing 4)
określa urządzenie zmieniające. Pierwszym
elementem konfiguracji tej sekcji jest
nadanie nazwy zasobowi zmieniającemu
nośniki (jest to zresztą ogólna zasada
konfiguracji systemu Bacula – każdy
zasób posiada swoja nazwę, którą
można się później posługiwać w innych
sekcjach konfiguracji). Drugi element
określa urządzenie zapisujące dane, które
obsługiwane jest poprzez to urządzenie
zmieniające (tutaj podaje się nazwę
zasobu
Device
). Dalej zdefiniowane jest
polecenie służące do zmiany taśm (jest to
skrypt wchodzący w skład systemu Bacula)
oraz urządzenie w systemie reprezentujące
zmieniarkę.
Ostatnia sekcja konfiguracji
modułu
Storage
(
Device
) definiuje
urządzenie zapisujące dane. Na Listingu
5 przedstawiona jest konfiguracja
napędu taśmowego LTO-4. Zgodnie
z ogólną zasadą, określona zostaje
nazwa zasobu (proszę zauważyć, że
wykorzystana ona jest w konfiguracji
zasobu
Autochanger
), dalej określony
jest typ urządzenia (możliwe wartości
to
File
,
Tape
,
Fifo
oraz
DVD
), dalej typ
nośnika (jest to też nazwa umowna),
numer napędu w urządzeniu (urządzenie
może posiadać więcej niż jeden
napęd), określenie, czy urządzenie
obsługiwane jest przez zmieniarkę,
określenie urządzenia w systemie.
Kilka kolejnych parametrów definiuje
odpowiednio, czy nośniki danych mają
być automatycznie nazywane (nie jest
to konieczne, gdy wykorzystywana
jest określona pula nazwanych przez
administratora nośników), czy urządzenie
jest urządzeniem o swobodnym dostępie
do danych (nośniki dyskowe, DVD), czy
dostępie sekwencyjnym (taśmy, kolejki
FIFO), czy nośnik ma być automatycznie
montowany, czy urządzenie posiada
wymienne nośniki (taśmy, DVD), czy
urządzenie ma być zawsze dostępne
do zapisu (chyba, że zostanie jawnie
domontowane poprzez wydanie
polecenia w konsoli zarządzającej).
Ostatnie dwa parametry przykładowego
Listing 10.
Konfiguracja modułu Director – sekcja Schedule
Schedule
{
Name
=
"MonthlyCycle"
Run
=
SpoolData
=
yes
Level
=
Full
1
st
sun
at
23
:
05
Run
=
SpoolData
=
yes
Level
=
Differential
2
nd
-
5
th
sun
at
23
:
05
Run
=
SpoolData
=
yes
Level
=
Incremental
mon
-
sat
at
23
:
05
}
Listing 11.
Konfiguracja modułu Director – sekcja Client
Client
{
Name
=
host2
-
fd
Address
=
host2
FDPort
=
9102
Catalog
=
MyCatalog
Password
=
"
daf8SSD9ikv
”
File
Retention
=
90
days
Job
Retention
=
6
months
AutoPrune
=
yes
}
OBRONA
56
HAKIN9 4/2009
SYSTEM KOPII ZAPASOWYCH BACULA
57
HAKIN9
4/2009
pliku konfiguracyjnego określają, gdzie
znajduje się katalog tymczasowego
przechowywania kopii zapasowej oraz
jaką posiada pojemność. Tymczasowe
przechowywanie kopii jest istotne w
przypadku korzystania z napędów
taśmowych, a szczególnie w przypadku
jednoczesnego zapisu danych z kilku
serwerów.
Chodzi tutaj przede wszystkim o
uniknięcie zjawiska naciągania się taśmy.
Gdyby kopia zapasowa zapisywana była
bezpośrednio na taśmę, wtedy napęd
musiałby co chwilę (gdy nadejdzie pakiet
danych) rozpędzać się i zatrzymywać
(gdy pakiet ten zostanie zapisany). W
przypadku wykorzystywania tymczasowego
przechowywania kopii zjawisko to jest
minimalizowane, gdyż w prezentowanym
przypadku zapis następuje w porcjach
po 100 gigabajtów danych. Gdy jeszcze
wykorzystywany jest do tego jednoczesny
zapis danych z kilku serwerów, wtedy
przy bezpośrednim zapisie na taśmę
dane byłyby bardzo poszatkowane. Na
taśmie zapisany zostałby jeden pakiet
danych z serwera A, jeden z serwera
B itd. Odzyskiwanie tak zapisanych
danych byłoby bardzo czasochłonne,
a do tego bardzo obciążałoby napęd
taśmowy i sam nośnik (duża ilość operacji
przewijania i odczytu). Wykorzystanie
katalogu tymczasowego przechowywania
pozwala na posegregowanie danych z
różnych serwerów w duże zbiory przed ich
zapisaniem.
Konfiguracja modułu File
Moduł
File
odpowiedzialny jest za
wysłanie kopii danych określonych przez
moduł zarządzający do urządzenia
zapisującego wskazanego przez moduł
zarządzający. Moduł
File
jest więc
komponentem w pełni zależnym od
modułu
Director
i jako taki nie ma
najmniejszego wpływu na konfigurację
całego systemu Bacula. W związku z tym
w pliku konfiguracyjnym (bacula-fd.conf )
tego elementu systemu kopii zapasowych,
poza częścią określającą adresata
wszelkich komunikatów, zdefiniowane
są tylko dwie sekcje. Są nimi sekcja
FileDaemon
, która jest niemal identyczna,
jak sekcja
Storage
modułu o tej samej
nazwie oraz sekcja
Director
, która
jest identyczna, jak w module
Storage
.
Znaczenie tych sekcji jest również takie
samo, jak w przypadku komponentu
Storage
.
Konfiguracja
modułu Director
Moduł
Director
ze względu na
nadzorczy charakter posiada najbardziej
rozbudowaną konfigurację. W pliku
konfiguracyjnym (bacula-dir.conf ) znajdują
się następujące sekcje:
Director
– definiująca moduł nadzorczy (jedyna
sekcja, która może pojawić się tylko
raz, pozostałe mogą występować
wielokrotnie),
JobDefs
– predefiniuje
wartość poszczególnych parametrów
wspólnych dla zdefiniowanych później
zadań,
Job
– definiuje zadanie, którym
może być wykonywanie kopii zapasowej lub
odzyskiwanie danych,
FileSet
– określa
zbiór plików, które mają zostać skopiowane,
Schedule
– określa harmonogram
wykonywania zadań,
Client
– definiuje
maszyny, które podlegają procesowi
wykonywania kopii,
Catalog
– określa
parametry dostępu do bazy danych,
w której zapisywane są informacje
o wykonywanych zadaniach (jest to
konfiguracja modułu
Catalog
),
Storage
– opisuje dostępne moduły
Storage
,
wreszcie
Pool
– definiuje zbiór dostępnych
nośników danych.
Konfiguracja sekcji
Director
(Listing
6) zawiera definicje nazwy modułu
zarządcy, numer portu, na którym oczekuje
na połączenia od modułów
Console
,
określenie pliku, w którym znajdują się
definicje zapytań SQL kierowanych
do bazy danych w celu wykonywania
poleceń administratora (plik zawarty jest
w dystrybucji systemu Bacula), katalog,
w którym moduł zostaje uruchomiony,
wskazanie miejsca, gdzie przechowywana
jest informacja PID, liczbę zadań, jakie
nadradca może jednocześnie uruchomić,
hasło służące do łączenia się z nadradcą
z poziomu konsoli administratora (powinno
być takie samo, jak w konfiguracji modułu
Console
) oraz określenie sposobu obsługi
wszelkich komunikatów niepowiązanych
Listing 12.
Konfiguracja modułu Director – sekcja Storage
Storage
{
Name
=
host
-
sd
Address
=
host
SDPort
=
9103
Password
=
" 7cPIehqKR3BhRT6ak"
Device
=
"zmieniacz"
Media
Type
=
LTO
-
4
AutoChanger
=
yes
Maximum
Concurrent
Jobs
=
20
}
Listing 13.
Konfiguracja modułu Director – sekcja Catalog
Catalog
{
Name
=
MyCatalog
dbname
=
"bacula"
dbuser
=
"bacula"
dbpassword
=
"Df98vdf34f"
;
DB
Address
=
127.0
.
0.1
DB
Port
=
5432
}
Listing 14.
Konfiguracja modułu Director – sekcja Pool
Pool
{
Name
=
Default
Maximum
Volumes
=
16
Storage
=
host
-
sd
Pool
Type
=
Backup
Recycle
=
yes
Recycle
Oldest
Volume
=
yes
AutoPrune
=
yes
Volume
Retention
=
365
days
}

OBRONA
58
HAKIN9 4/2009
z żadnym zadaniem (parametr
Daemon
określa, że będą obsługiwane przez moduł
Director
).
Sekcja
JobDefs
definiuje wspólne
dla wszystkich zadań parametry.
W definicji poszczególnych zadań
można później wykorzystać te zasoby
i ewentualnie redefiniować niektóre z
parametrów. Parametry, jakie można
definiować w tej sekcji (co wydaje się
oczywiste) są takie, jak dla sekcji Job.
W przykładowej definicji zasobu (Listing
7) kolejno określone zostały: nazwa
zbioru definicji, czy dane zadanie ma
być automatycznie uruchamiane z
wykorzystaniem harmonogramu, typ
zadania (możliwe wartości to Backup,
Restore, Verify i Admin), poziom
wykonywanej kopii zapasowej (można
podać
Full
,
Differential
bądź
Incremental
), określenie maszyny, która
będzie podlegała temu zadaniu, ustalenie
zbioru plików, jakie będą kopiowane,
definicja harmonogramu, przy którego
użyciu zadanie będzie automatycznie
uruchamiane, określenie modułu typu
Storage
, który zostanie wykorzystany
do zapisu kopii danych, sposób obsługi
komunikatów generowanych przez
zadanie, zbiór nośników, na których
zapisana zostanie kopia danych, to, czy
dane mają być przed zapisem na nośnik
tymczasowo przechowywane, liczbę
jednoczesnych zadań tego typu (jeśli w
konfiguracji sekcji
Director
wartość
ta jest mniejsza, parametr podany
tutaj nie jest brany pod uwagę), i na
koniec – priorytet określający kolejność
wykonywania zadań.
W prezentowanej tutaj konfiguracji w
sekcji
Director
określona jest możliwość
jednoczesnego wykonywania do 5 zadań.
Priorytet pozwala zdefiniować, które
zadania wykonywane będą wcześniej
(gdyby było ich więcej niż 5).
Sekcja
Job
służy do zdefiniowania
zadania. Może korzystać z sekcji typu
JobDefs
i dookreślić dodatkowe parametry
lub je redefiniować. W przykładowej
definicji (Listing 8) określona zostaje
nazwa zadania, zbiór predefiniowanych
wartości, z których korzysta zadanie,
następuje redefinicja klienta oraz zbioru
plików względem zbioru predefiniowanych
wartości i podana zostaje ścieżka do
pliku, w którym zapisany zostanie plik typu
bootstrap.
Pliki bootstrap wykorzystywane są
do odzyskiwania kopii zapasowych w
przypadku utracenia bazy danych, w
której zapisana jest informacja, na jakiej
taśmie znalazły się składowane pliki.
Plik bootstrap zawiera informacje o
tym, skąd odzyskać pliki, by przywrócić
dane do stanu, w jakim znajdowały się
w trakcie ostatnio wykonywanej kopii.
W przypadku kopii pełnej w pliku tym
zapisywana jest pełna informacja o
odzyskaniu danych. Gdy wykonywana
jest kopia różnicowa lub przyrostowa, na
końcu pliku dopisywane są informacje
o różnicach względem kopii pełnej.
Pliki tego typu, jako niezbędny element
odzyskiwania systemu po awarii, muszą
być zapisywane na nośniku niezależnym
od maszyny, na której pracuje moduł
Director
i
Catalog
. Najczęściej pliki
te zapisywane są na innej maszynie do
podmontowanego zdalnego folderu.
Sekcja
FileSet
definiuje zbiór
danych, jaki ma być kopiowany. Może
także określać wykonanie dodatkowych
operacji. Sekcja ta składa się z dwóch
podsekcji:
Include
oraz
Exclude
. W
podsekcji
Include
określa się pliki, jakie
mają zostać skopiowane, z kolei w sekcji
Exclude
wskazuje się pliki, jakich kopiować
nie należy. W wyniku scalenia dwóch tak
Listing 15.
Odzyskanie danych na żądanie
*
run
A
job
name
must
be
specified
.
The
defined
Job
resources
are
:
1
:
Host1
Backup
2
:
Host2
Backup
3
:
Host3
Backup
Select
Job
resource
(
1
-
3
):
Listing 16.
Wybór danych do odzyskania
cwd
is
:
/
$
ls
boot
/
etc
/
home
/
root
/
usr
/
var
/
$
mark
etc
332
files
marked
.
$
done
Listing 17.
Uruchomienie procesu odzyskiwania danych
*
restore
Automatically
selected
Catalog
:
MyCatalog
Using
Catalog
"MyCatalog"
First
you
select
one
or
more
JobIds
that
contain
files
to
be
restored
.
You
will
be
presented
several
methods
of
specifying
the
JobIds
.
Then
you
will
be
allowed
to
select
which
files
from
those
JobIds
are
to
be
restored
.
To
select
the
JobIds
,
you
have
the
following
choices
:
1
:
List
last
20
Jobs
run
2
:
List
Jobs
where
a
given
File
is
saved
3
:
Enter
list
of
comma
separated
JobIds
to
select
4
:
Enter
SQL
list
command
5
:
Select
the
most
recent
backup
for
a
client
6
:
Select
backup
for
a
client
before
a
specified
time
7
:
Enter
a
list
of
files
to
restore
8
:
Enter
a
list
of
files
to
restore
before
a
specified
time
9
:
Find
the
JobIds
of
the
most
recent
backup
for
a
client
10
:
Find
the
JobIds
for
a
backup
for
a
client
before
a
specified
time
11
:
Enter
a
list
of
directories
to
restore
for
found
JobIds
12
:
Cancel
Select
item
:
(
1
-
12
):

SYSTEM KOPII ZAPASOWYCH BACULA
59
HAKIN9
4/2009
zdefiniowanych grup plików powstaje zbiór
danych do skopiowania. W przykładowej
konfiguracji (Listing 9) w sekcji
Include
określona została jeszcze podsekcja
Options
, pozwalająca na wymuszenie
dodatkowych działań. W tym przypadku
oprócz wykonania kopii plików obliczona
i zapisana zostanie także wartość MD5
dla każdego z plików. Może być ona
wykorzystywana do weryfikacji danych
w momencie ich odzyskiwania. Każde
określenie folderu należy rozumieć jako
określenie rekursywne.
Podsekcja
Exclude
jest bardzo
przydatnym narzędziem. Można bowiem
w sekcji
Include
wyspecyfikować jako
zbiór plików katalog główny systemu
(np. /), a w sekcji
Exclude
usunąć
zbędne jego pliki lub katalogi (np. /tmp).
Podobnie w systemie Windows warto
pamiętać o tym, że nie jest konieczne
wykonywanie kopii np. pliku pagefile.sys
czy pamięci podręcznej przeglądarek
internetowych dla wszystkich użytkowników,
jak również wszelkiego rodzaju plików
tymczasowych. Odpowiednie zaplanowanie
i skonfigurowanie zbioru plików pozwoli na
znaczną oszczędność czasu i przestrzeni
przechowywania danych.
Sekcja
Schedule
określa
harmonogram wykonywania kopii
zapasowych. Na Listingu 10. przedstawiony
jest harmonogram, który w pierwszą
niedzielę miesiąca wykonuje kopię pełną,
w pozostałe niedziele miesiąca wykonuje
kopię różnicową, a w pozostałe dni – kopię
przyrostową. Kopie wykonywane są zawsze
w nocy (od godz. 23:05). Zastosowanie
takiego harmonogramu powoduje, że
dodatkowe obciążenie systemu wynikające
z wykonywania kopii zapasowych
generowane jest w czasie, w którym
większość użytkowników nie pracuje.
Dodatkowo w harmonogramie określone
zostało, że dane mają być tymczasowo
przechowywane przed zapisaniem na
docelowym nośniku.
W harmonogramie określone zostały
różne poziomy kopii. Tymczasem w definicji
zadania podany został poziom kopii
przyrostowy. Jeżeli w harmonogramie
określony jest inny poziom kopii zapasowej,
wtedy wykonany zostanie poziom określony
przez harmonogram. W specyfikacji
harmonogramu można redefiniować także
inne parametry zadań.
Sekcja
Client
definiuje maszynę, która
ma podlegać wykonywanemu zadaniu.
Zgodnie z przykładem (Listing 11) definiuje
się nazwę klienta, którą wykorzystuje się w
definicjach zadań, adres maszyny (może
to być nazwa domenowa lub adres IP),
numer portu, na którym nasłuchuje na
połączenia od modułu
Director
, moduł
Catalog
, w którym przechowywane
mają być informacje o kopiach danych
tego klienta, hasło, przy którego pomocy
moduł
Director
może komunikować
się z klientem. Ostatnie trzy dyrektywy
służą do określenia polityki usuwania z
Catalog'u danych o wykonywanych dawniej
zadaniach. W przykładowej konfiguracji
określono, że dane o plikach mają być
usuwane po 3 miesiącach, dane o
wykonywanych zadaniach po pół roku oraz
że usunięcie tych danych powinno nastąpić
automatycznie.
Sekcja
Storage
określa dostępny
moduł typu
Storage
oraz wykorzystywane
w ramach modułu urządzenie zapisujące
dane. Jak pokazano na Listingu 12, w sekcji
tej definiuje się jej nazwę (wykorzystywana
w definicji zadań), adres maszyny, na której
pracuje moduł
Storage
, numer portu, na
którym oczekuje na połączenia, hasło,
nazwę urządzenia (w przypadku urządzenia
zmieniającego podaje się nazwę właśnie
tego urządzenia, a nie napędu), typ
nośnika danych, określenie, czy urządzenie
jest urządzeniem zmieniającym, oraz
ilość jednoczesnych zadań, jakie mogą
przesyłać dane do tego modułu. Jeżeli w
definicji modułu
Storage
zdefiniowana jest
inna wartość, wtedy obowiązuje ta niższa.
Sekcja
Catalog
zawiera konfigurację
modułu o tej samej nazwie. Sprowadza
się to do podania nazwy katalogu
oraz parametrów pozwalających na
nawiązanie komunikacji z bazą danych.
W prezentowanym przypadku (Listing
13) wykorzystywana była baza danych
postgresql.
PROMISE
R
E
K
L
A
M
A

OBRONA
60
HAKIN9 4/2009
Ostatnią omawianą sekcją konfiguracji
modułu
Director
jest sekcja
Pool
.
Definiuje ona zbiór nośników oraz
sposób przechowywania informacji o ich
wykorzystaniu. W przykładowej konfiguracji
(Listing 14) w sekcji tej zdefiniowana została
nazwa zbioru nośników, ich liczba, moduł
Storage
, który wykorzystuje ten zbiór
nośników, typ zbioru nośników (obecnie
poprawna jest tylko wartość
Backup
), to,
czy nośniki mogą być nadpisywane, fakt, że
nadpisywanie nośników rozpocznie się od
najstarszego, oraz że usuwanie informacji
o wykorzystywaniu nośników nastąpi
automatycznie po upływie 365 dni od ich
użycia. Dopiero po upływie tego czasu
możliwe będzie nadpisanie nośników.
Po dokonaniu konfiguracji
wszystkich elementów systemu
konieczne jest uruchomienie demonów
odpowiadających za działanie
poszczególnych modułów. Skrypty
startowe dostarczane są wraz z
dystrybucją systemu Bacula. Konieczna
jest także wcześniejsza konfiguracja
bazy danych. Wraz z systemem Bacula
dostarczane są niezbędne skrypty do
tego celu. Opis całej operacji znajduje
się w dokumentacji systemu.
Po uruchomieniu demonów
cały system zaczyna pracę. Kopie
zapasowe wykonywane są zgodnie z
harmonogramem, a przy wykorzystaniu
urządzenia zmieniającego nie jest
konieczna żadna ingerencja człowieka.
Należy jednak pamiętać o podstawowej
zasadzie. Samo wykonanie kopii
zapasowej nie daje pewności odzyskania
danych w niej zawartych. Konieczne jest
przeprowadzenie okresowych testów
odzyskania danych. Odzyskania danych
można dokonywać za pomocą konsoli
administratora (o ile nie zostało w
harmonogramie umieszczone zadanie
odzyskujące dane periodycznie). W
większości środowisk takie działanie
nie jest jednak uzasadnione, gdyż z
odzyskiwania danych nie korzystamy
periodycznie, a incydentalnie – w
przypadku awarii lub błędu.
Praca
z konsolą administratora
Z poziomu konsoli administratora
(narzędzie bconsole) można wykonywać
operacje uruchomienia zadania,
wykonania kopii danych na żądanie,
odzyskania danych oraz całą gamę
operacji monitorujących pracę systemu.
Poniżej zaprezentowane zostaną
przykłady uruchomienia zadania na
żądanie oraz odzyskania danych z
kopii.(Listing 15)
Do wykonania kopii zapasowej
danych poza zleconym harmonogramem
służy polecenie run konsoli systemu
Bacula.
Po wydaniu polecenia run pojawia
się lista możliwych do uruchomienia
zadań. Po wybraniu zadania, gdy pojawi
się pytanie OK to run? (yes/mod/
no):, należy wpisać yes. W każdym
momencie działania konsoli można
wykonać polecenie
messages
. Służy
ono do wyświetlenia komunikatów, jakie
przesyłane są przez poszczególne
moduły systemu. Komunikaty te mogą
być także wysyłane pocztą elektroniczna
do administratora (opis konfiguracji
obsługi komunikatów ze względu na
swoją prostotę został tutaj pominięty).
Opuszczenie konsoli następuje przez
wydanie polecenia
quit
. Można
to zrobić w dowolnym momencie
– nie jest konieczne oczekiwanie na
zakończenie wykonywania zadania.
Ponowne połączenie do konsoli i wydanie
polecenia messages spowoduje
wyświetlenie wszystkich komunikatów,
jakie zostały wygenerowane od
ostatniego wydania tego polecenia.
Proces odzyskania danych jest
bardziej skomplikowany, a to ze
względu na fakt, że nie korzysta się
ze zdefiniowanego zadania, co więcej
– nie zawsze odzyskuje się wszystkie
dane, najczęściej jest to tylko ich
pewien podzbiór. Konieczne jest w
takim razie określenie danych, które
mają zostać odzyskane. Do odzyskania
danych służy polecenie restore. W
sytuacji przykładowej, gdy dostępny
jest tylko jeden moduł
Catalog
, jest
on automatycznie wybierany. Kolejnym
krokiem jest wybór trybu odzyskiwania
danych. Najczęściej wykorzystywanym
jest tryb 5, a więc odzyskanie najnowszej
kopii danych.(Listing 16, 17)
Po wybraniu trybu pojawi się pytanie
o wybór klienta, dla którego dane będą
odzyskiwane oraz pytanie o wybór
zbioru plików (o ile dla danego klienta
zdefiniowano więcej niż jeden), z którego
dane mają być odzyskane. Po określeniu
tych parametrów zbudowane zostanie
drzewo plików znajdujących się w kopii.
Administrator zostanie przeniesiony
do trybu wyboru plików. W trybie tym
można posługiwać się standardowymi
poleceniami cd czy ls w celu przeglądania
zawartości kopii danych. Polecenie mark
służy do określenia plików i katalogów
(wraz z podkatalogami), które mają zostać
odzyskane z kopii. Polecenie unmark może
odznaczyć zaznaczone pliki. Polecenie
done powoduje opuszczenie trybu wyboru
plików i rozpoczęcie odzyskiwania danych.
Po wydaniu polecenia done
pojawi się podsumowanie zadania i
administrator ma wtedy możliwość
określenia dodatkowych parametrów
(np. zdecydowania, gdzie dane mają
zostać zapisane) i uruchomienia procesu
odzyskiwania danych.
Podsumowanie
Przedstawiony opis systemu Bacula
nie jest na pewno opisem kompletnym
(choćby zważywszy na obszerność samej
dokumentacji tego systemu – około 750
stron). Zaprezentowane zostało jedynie
przykładowe środowisko wraz z jego
konfiguracją. Mam jednak nadzieję, iż
opis ten pozwoli zapoznać się wstępnie z
tym naprawdę funkcjonalnym systemem
i zachęci do jego używania. W celu
uzyskania dodatkowych informacji na
temat użytkowania i konfiguracji systemu
odsyłam do strony internetowej projektu
oraz dokumentacji.
Marcin Klamra
Specjalista ds. bezpieczeństwa firmy CCNS SA, asystent
w Instytucie Teleinformatyki Politechniki Krakowskiej. Od
1999 roku zajmuje się zagadnieniami administracji
systemów komputerowych i bezpieczeństwem
w sieciach komputerowych. Na stałe związany z
firmą CCNS SA, w której zajmuje się rozwiązaniami
bezpieczeństwa sieciowego. Jako Certyfikowany Trener
WatchGuard Inc. prowadzi szkolenia w Autoryzowanym
Centrum Szkoleniowym WatchGuard, stworzonym przez
firmę CCNS SA.
Swoją wiedzę pogłębia uczestnicząc jako asystent
naukowy w pracach badawczych Instytutu Teleinformatyki
Politechniki Krakowskiej.
Kontakt z autorem: m.klamra@ccns.krakow.pl
W Sieci
• http://www.bacula.org,
• http://www.rsnapshot.org,
• http://www.finkproject.org.
Wyszukiwarka
Podobne podstrony:
Tworzenie kopii zapasowej systemu Windows 7
Tworzenie kopii zapasowej systemu Windows 7, DOC
2009 04 08 POZ 06id 26791 ppt
02 Leczenie bolu pooperacyjnego Szkola Bolu PTCh Machala W 2009 04 06[1]
Fakty i Mity 2009 04
04 system mikroprocesorowy i peryferia
2009 04 05 3052 14
Instalacja Windows XP i Vista(FORMATOWANIE),tworzenie kopii zapasowej
2009 04 GRUB [Poczatkujacy]
usuwania starych kopii zapasowych
2009 04 06 pra
2009.04.06 prawdopodobie stwo i statystyka
TIiK zadania 2009 04 17 VI pol
04 System Operacyjny
Zadania zaliczeniowe PODYPLOMOWI 2009, Studia, Systemy operacyjne
04 systemy pamięci krótkotrwałejid 4865 ppt
1 2009.04.06 matematyka finansowa
więcej podobnych podstron