A. Podstawowe zasady działania komputera
1. Omówić koncepcję programu w modelu komputera wg von Neumanna.
Realizacja przetwarzania w procesorze wymaga skierowania do odpowiednich podzespołów
procesora odpowiednich sygnałów. A żeby to było możliwe, program musi być
przekształcony na poprawną sekwencję sygnałów, oddziałujących na sprzęt. Program musi
być bezpośrednio dostępny, by od razu po zakończeniu jednej operacji, można było zacząć
niezwłocznie drugą. Wynika z tego między innymi fakt, że program przechowywany w
pamięci musi być zakodowany w postaci binarnej. Sam program składa się z ciągu poleceń,
zakodowanych w sposób zrozumiały dla procesora. Ponadto, program może się sam
modyfikować traktując obszar instrukcji jako dane, a po przetworzeniu tych instrukcji
(danych) – zacząć je wykonywać.
2. Wyjaśnić znaczenie terminu lista rozkazów procesora.
Jest to podstawowy zbiór operacji procesora. Operacje takie są rozkazami, albo instrukcjami.
Każdy rozkaz ma przypisany kod 0-1. Przekazanie instrukcji takiego kodu w formie bajtu
01000010 powoduje zwiększenie o 1 liczby EDX, a przekazanie bajtu 01001010 –
zmniejszenie liczby o 1. Do zbioru podstawowych operacji należą 4 działania arytmetyczne,
operacje logiczne na bitach (negacja, suma, iloczyn), operacje przesyłania, operacje
porównania.
3. Na czym polega różnica między pamięcią fizyczną i pamięcią wirtualną w komputerze?
Rozkazy odczytujące dane z pamięci operacyjnej zawierają informacje o adresie danej w
pamięci. W wielu procesorach ten adres ma postać adresu fizycznego i jednoznacznie
wskazuje komórkę pamięci, gdzie znajduje się potrzebna dana. W kontekście systemów
wielozadaniowych jest to niepraktyczne, dlatego z czasem wyłoniła się koncepcja pamięci
wirtualnej, będącej iluzją pamięci fizycznej. Zbiór wszystkich adresów w pamięci wirtualnej
nosi nazwę wirtualnej przestrzeni adresowej. Transformacja adresów wirtualnych na fizyczne
jest procesem dość skomplikowanym, ale problemy te zostały rozwiązane z czasem i
wydłużenie działania programu nie przekracza kilku %.
4. Jaką rolę w trakcie wykonywania programu przez procesor pełni wskaźnik instrukcji
( licznik rozkazów)?
Jest to rejestr, który informuje o położeniu kolejnej instrukcji, więc ma bardzo duży wpływ na
precyzję procesu pobierania kolejnych instrukcji z pamięci operacyjnej i ich realizowania.
Natychmiast po tym procesor musi pobierać z pamięci następną instrukcję.
5. Omówić klasę rozkazów (instrukcji) procesora, które mają zdolność do zmiany
naturalnego porządku wykonywania rozkazów.
Do zmiany naturalnego porządku używane są rozkazy sterujące, nazywane zazwyczaj
rozkazami skoku, których zadaniem jest sprawdzenie pewnego warunku, np. czy znacznik ZF
zawiera wartość 1. Zmiana jest realizowana poprzez zwiększenie, lub zmniejszenie
zawartości wskaźnika instrukcji (rejestru EIP). Taką zmianę wykonują też rozkazy sterujące
bezwarunkowe. Wtedy nie muszą być spełnione żadne warunki.
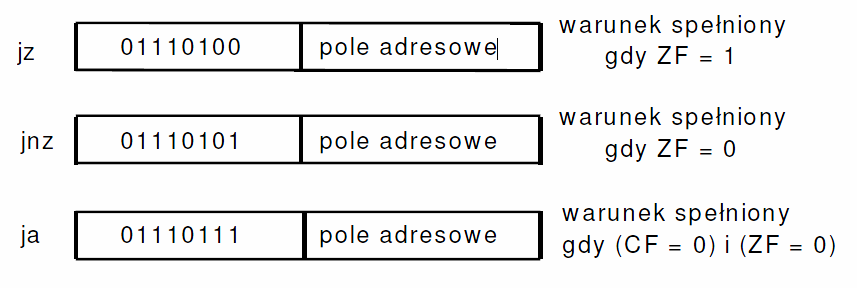
6. Omówić funkcje znaczników CF i ZF w rejestrze stanu procesora (rejestrze
znaczników).
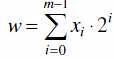
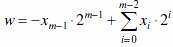
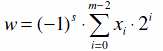

Warunek spełniony – liczba umieszczona w polu adresowym jest dodawana do rejestru EIP
Warunek niespełniony – wskaźnik instrukcji EIP jest zwiększany o liczbę bajtów
zajmowanych przez rozkaz skoku.
7. Czym różnią się rozkazy sterujące warunkowe od bezwarunkowych?
Rozkazy bezwarunkowe służą do zmiany porządku wykonywania instrukcji (w
przeciwieństwie do warunkowych – nie wykonują żadnego sprawdzenia, przyjmują, że
testowany warunek jest zawsze spełniony).
8. Omówić podstawowe zasady modyfikacji adresowych.
Adres komórki pamięci, na której wykonywana jest operacja podaje się w polu adresowym
rozkazu. Dodatkowo można zażądać, aby adres podany w polu adresowym został doraźnie
zwiększony o liczbę podaną w jednym z rejestrów procesora – ten mechanizm to modyfikacja
adresowa. Rozkaz wykona działanie na komórce pamięci o adresie stanowiącym sumę liczby
podanej w polu adresowym i zawartości rejestru.
9. Omówić technikę wyodrębniania zawartości pól bitowych.
B. Kodowanie danych i instrukcji
1. Omówic różne rodzaje kodowania liczb binarnych w komputerze.
W przypadku liczb całkowitych bez znaków stosowany jest naturalny kod binarny, wartość
liczby określa
, gdzie m oznacza liczbę bitów rejestru lub komórki pamięci.
W przypadku liczb ze znakiem, kodowanych w systemie U2, wartość liczby określa formuła:
, gdzie m oznacza liczbę bitów rejestru lub komórki pamięci.
W przypadku kodowania w systemie BCD, każdy upakowany bajt zawiera dwie cyfry
dziesiętne, za to nie upakowany bajt zawiera jedną cyfrę dziesiętną (4 starsze bity są
wyzerowane).
Liczby zmiennoprzecinkowe kodujemy za pomocą mantysy i wykładnika.
mantysa * 2^wykładnik, gdzie wartość bezwzględna mantysy należy do przedziału [1,2).
2. Podac w przyblizeniu zakresy liczb, które moga kodowane w postaci binarnej jako
liczby bez znaku na 16 lub 32 bitach.
liczby 16-bitowe <0, 65535>
liczby 32-bitowe <0, 4 294 967 295>
3. Na czym polega kodowanie liczb w systemie znak–moduł?
W tym systemie kodowania skrajny lewy bit określa znak liczby, a pozostałe – wartość
bezwzględną liczby. Jest to sposób stosowany w głównie w arytmetyce
zmiennoprzecinkowej. Kodowanie to opisuje poniższe wyrażenie:
m – liczba znaków rejestru lub komórki pamięci, a s – wartość bitu znaku.
4. W komórkach pamieci operacyjnej o
adresach 0x00430F74 i 0x00430F75 została
zapisana liczba 259 w postaci 16-bitowej liczby
binarnej. Podac zawartosci tych komórek w
postaci
binarnej
przy
założeniu,
że
w
komputerze stosowana jest konwencja mniejsze
niżej (ang. little endian). W komputerze
stosowana jest pamiec o organizacji bajtowej.
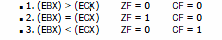

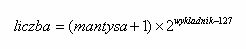
5. Omówic technike porównywania liczb stałoprzecinkowych stosowana w procesorach
zgodnych z architektura IA 32.
W architekturze IA 32 operacje porównania wykonywane są poprzez odejmowanie
porównywanych wartości i testowanie zawartości znaczników CF, ZF, OF i SF. Jeżeli
procesor wykonał odejmowanie dwóch liczb znajdujących się w rejestrach EBX i ECX, to
wartość CF i ZF będą następujące:
6. Dlaczego obliczenia na liczbach stałoprzecinkowych sa kłopotliwe, jesli działania
wykonywane sa na wartosciach bardzo dużych i bardzo małych?
W przypadku obliczeń na bardzo małych i dużych wartościach wymaga przyjęcia formatu,
który będzie w stanie przedstawić bardzo dużą część całkowitą (np. 24 bity), ale także bardzo
małą część ułamkową (np. 40 bitów). Łącznie daje to 64 bity, czyli 8 bajtów. Wiele z tych
bitów zostaje zatem wypełniona zerami. Dla bardzo dużych liczb będzie to 40 bitów, a dla
bardzo małych – 24 bity.
7. Poniżej podano reprezentacje binarna dwóch 32-bitowych liczb binarnych
zmiennoprzecinkowych (format float) x i y. Która z tych liczb jest wieksza? Wskazówka: w formacie 32-bitowym wykładnik jest przesuniety o 127.
8. Dlaczego w formatach liczb zmiennoprzecinkowych zgodnych z norma 754 nie
wystepuje bit znaku wykładnika.
Pomija się go, ponieważ z warunku normalizacji dla liczb różnych od zero, bit ten jest zawsze
równy 1.
9. Jakie działania wykonuje asembler w pierwszym i drugim przebiegu asemblacji?
Pierwszy przebieg – asembler stara się wyznaczyć ilości bajtów zajmowane przez
poszczególne rozkazy i dane. Jednocześnie asembler rejestruje w słowniku symboli wszystkie
pojawiające się definicje symboli (zmiennych i etykiet).
Drugi przebieg – asembler tworzy kompletną wersję tłumaczonego programu określając
adresy wszystkich rozkazów w oparciu o informacje zawarte w słowniku symboli.
C. Operacje stosu i podprogramy
1. W jaki sposób interpretuje sie zawartosc rejestru wskaznika stosu ESP w
procesorach zgodnych z architektura IA–32?
Rejestr ESP wskazuje wierzchołek stosu, czyli obszar 4- lub 2-bajtowy, w którym
przechowywana jest ostatnio zapisana dana. Na stosie mogą być zapisywane wyłącznie
wartości 16- i 32-bitowe.
2. Co oznacza sformułowanie: "stos rosnie w kierunku malejacych adresów"?
Oznacza to, że pierwszą daną na stosie zapisujemy na największym adresie, a potem
wierzchołek jest przesuwany tak, że jego adres jest coraz mniejszy. Lokacje bardziej odległe
od wierzchołka stosu mają większe adresy.
3. Omówic drogi i sposoby przekazywania parametrów do podprogramów.
Istnieją dwa podstawowe sposoby przekazywania parametrów do podprogramów:
- przekazywanie przez wartość – do podprogramu jest bezpośrednio przekazywana wartość.
- przekazywanie przez adres – podprogramu przekazywany jest adres lokacji pamięci, w
którym znajduje się wymagana wartość.
Drogi przekazywania parametrów: przez rejestry, przez stos, przez ślad, przez bufory.
4. Omówic zasady działania rozkazów CALL i RET.
CALL – odpowiedzialny za zapamiętywanie śladu. Występuje w wersji z adresowaniem
bezpośrednim i pośrednim. wywołuje podprogram i zostawia ślad na stosie.
RET – po zakończeniu wykonywania podprogramu zdejmuje z wierzchołka stosu ślad
zostawiony przez CALL i wraca do programu głównego.
5. W jakim celu rozkaz wywołania podprogramu pozostawia s lad na stosie?
Ślad jest zostawiany, ponieważ program musi wiedzieć, do którego miejsca w programie
głównym ma wrócić po wykonaniu podprogramu. [adres powrotu]
6. W jaki sposób w programie wywołuje sie funkcje usługowe systemu operacyjnego?
Funkcje usługowe OSu mogą zostać wywołane w programach napisanych w językach
wysokiego poziomu, jak również w programach napisanych w asemblerze. Wywołanie usługi
systemu operacyjnego lub funkcji bibliotecznej realizowane jest za pomocą rozkazu CALL.
7. Wyjasnic znaczenie terminu interfejs programowania aplikacji (ang. API – Application
Programming Interface).
Jest to interfejs określający sposób porozumiewania się OSu z programem. Zawiera on
szczegółowe informacje o wymaganych parametrach i sposobach przekazywania ich do
podprogramów systemowych.
D. Sterowanie urzadzeniami zewnetrznymi
1. Wyjasnic różnice w sposobie komunikacji procesora z urzadzeniami zewnetrznymi
poprzez pamiec współadresowalna i poprzez porty.
Sterowanie pracą urządzeń jest realizowane za pomocą podzespołów tworzących układy
wej/wyj. Stosowane są 2 metody dostępu do zawartości rejestrów układów wej/wyj:
- rejestry są udostępniane jako zwykłe komórki pamięci w przestrzeni adresowej pamięci.
[współadresowane układy wejścia/wyjścia - 1]
- rejestry dostępne są w odrębnej przestrzeni adresowej zwanej przestrzenią adresową portów.
[izolowane wej-wyj - 2]
1- można odczytywać i zapisywać rejestry urządzenia tak samo jak zwykłe komórki pamięci,
np. za pomocą instrukcji MOV.
2- konieczne jest zdefiniowanie odrębnych rozkazów przesyłania, działających w przestrzeni
adresowej portów; dla IA-32 tę rolę pełnią rozkazy IN i OUT.
2. W jakim celu przed rozpoczeciem obsługi przerwania sprzetowego na stosie
zapisywany jest s lad ?
Ślad jest zapisywany na stosie, aby procesor, który dostał sygnał przerwania podczas
wykonywania bieżącego programu, mógł bez problemów później wrócić do wykonywania
tego zadania, po wykonaniu zadania zleconego w momencie otrzymania sygnału przerwania.
3. Omówic podstawowe elementy systemu przerwan stosowanego w komputerach PC.
Procesor po otrzymaniu sygnału przerwania przerywa wykonywanie bieżącego programu i
rozpoczyna wykonywanie innego programu, związanego z obsługą zdarzenia. Ponieważ po
pewnym czasie procesor wróci do wykonywania przerwanego programu, procesor zapisuje na
stosie ślad, zawierający adres rozkazu, który miał zostać wykonany jako następny, ale na
razie nie jest ze względu na przerwanie. Po wykonaniu tych działań procesor wraca do
wykonywania przerwanego programu. W komputerach system przerwań obsługiwany jest
przez układ APIC, który wspomaga też pracę wieloprocesową. System przerwań jest
realizowany jedynie przez OS.
4. Jaka role w obsłudze przerwan sprzetowych pełni tablica deskryptorów przerwan?
Tablica deskryptorów przerwań zawiera adresy podprogramów obsługi przerwań sprzętowych
wysyłanych przez różne urządzenia komputera. Zawiera także adresy podprogramów
obsługujących wyjątki procesora, a także adresy podprogramów systemowych, które
wywoływane są z poziomu aplikacji za pomocą rozkazu INT.
5. Na czym polega różnica miedzy przerwaniami sprzetowymi a wyjatkami
generowanymi przez procesor?
Wyjątki to przerwania, które są generowane przez sam procesor i nie są zależne od działań
użytkownika.
E. Hierarchia pamieci
1. W jakim podzespole komputera wykorzystuje sie obserwacje znane jako zasada
lokalnos ci?
Pamięć podręczna procesora.
2. Co oznaczaja terminy trafienie i chybienie w odniesieniu do pamieci podrecznej?
Trafienie – cache hit – potrzebna informacja została odnaleziona w pamięci podręcznej.
Chybienie – cache miss – potrzebnej informacji nie ma w pamięci podręcznej. Jest ona wtedy
pobierana z pamięci głównej, przy czym jednocześnie jest zapisywana do podręcznej w
postaci całego bloku.
3. Na czym polega technika dostepu do pamieci podrecznej z odwzorowaniem
bezposrednim?
W tej technice nie występuje konieczność jednoczesnego porównywania wielu etykiet. 32-
biotwy adres pamięci jest dzielony na 3 pola: 16-bitowe pole etykiety, 12-bitowe pole obszaru
(nr linii) i 4-bitowe pole słowa (adres wewnątrz bloku). Na podstawie pola obszaru
wyznaczany jest numer linii w pamięci podręcznej. Jeśli pole etykiety wewnątrz linii pamięci
podręcznej i pole etykiety w adresie są identyczne, to nastąpiło trafienie.
4. Omówic schemat współdziałania różnych rodzajów pamieci w komputerze znany jako
hierarchia pamie ci.
5. W jaki sposób implementuje sie pamiec wirtualna za pomoca stronicowania.
Głównym elementem implementacji pamięci wirtualnej jest tablica transformacji adresów,
która zarządzana jest przez OS. Cała pamięć podzielona jest na obszary zwane stronami
(4KB, 4MB). Dla każdego adresu wirtualnego w tablicy transformacji istnieje wiersz, który
zawiera adres fizyczny przyporządkowany adresowi wirtualnemu lub informację, że podany
adres aktualnie nie jest odwzorowany w pamięci fizycznej, a potrzebna dana jest na dysku.
6. Omówic własnosci typowych pamieci dyskowych.
Stanowią pamięć nielotną, w której przechowywane są programy i dane przez bardzo długie
okresy. Stanowią także pamięć potrzebną do implementacji pamięci wirtualnej. Pojemności
zbliżają się do 1TB. Informacje zapisywane są przez zespół ruchomych głowic w postaci
współśrodkowych okręgów zwanych ścieżkami. Ścieżki o tym samym promieniu stanowią
cylinder. Rozpoczęcie przesyłania danych wymaga przesunięcia głowic do odpowiedniego
cylindra (4-10ms), a następnie oczekiwania, aż informacja będzie dostępna do odczytu/zapisu
(4-11ms). Szybkość zależy od standardu, ale typowa prędkość to 25MB/s.
7. W jaki celu tworzone sa zespoły dysków RAID?
Macierze dyskowe umożliwiają tworzenie dużej i niezawodnej przestrzeni dyskowej za
pomocą niedrogich, standardowych dysków.
F. Zagadnienia zaawansowanej architektury komputerów
1. Omówic koncepcje leżace u podstaw konstrukcji procesorów o architekturze RISC.
- stosunkowo niewiele trybów adresowania
- formaty rozkazów stałej długości, łatwe do zdekodowania
- obszerny zbiór rejestrów ogólnego przeznaczenia
- rozkazy wykonują działania na argumentach zapisanych w rejestrach
- dostęp do pamięci operacyjnej umożliwiają tylko dwa rozkazy: load, store
- w niektórych procesorach RISC używane są oddzielne pamięci dla rozkazów i danych, z
których każda obsługiwana jest przez oddzielne magistrale adresowe i danych.
2. Scharakteryzowac trudnosci wykonywania rozkazów przez procesor w trybie
przetwarzania potokowego.
- jeżeli dwa etapy w tym samym czasie potrzebują dostępu do tego samego zasobu procesora,
to potok musi zostać zamrożony do czasu rozwiązania konfliktu
- realizacja niektórych etapów może powodować konflikty dostępu do pamięci
- jeżeli czasy trwania poszczególnych etapów mogą być niejednakowe, to na różnych etapach
wystąpi oczekiwanie
- w programie występują skoki warunkowe, które mogą zmienić kolejność wykonywania
instrukcji, a tym samym unieważnić kilka pobranych rozkazów
3. Omówic podstawowe zasady pracy systemów wielozadaniowych.
- poszczególne procesy wykonywane są w izolowanych obszarach pamięci operacyjnej
- realizacja wielozadaniowości wymaga dzielenia czasu procesora między uruchomione
zadania – system operacyjny udostępnia procesor wybranemu zadaniu na krótki odcinek
czasu
- po upływie tego czasu zadanie zostaje zatrzymane, a procesor wykonuje inne zadanie, znów
przez krótki odcinek czasu
4. Na czym polega różnica miedzy procesami cieżkimi a lekkimi?
Proces lekki – wątek, czyli fragment procesu. Proces ciężki – proces tradycyjny, który jest
równoważny zadaniu z jednym wątkiem.
5. Czym różnia sie procesory wielordzeniowe od wielowatkowych?
Procesory wielordzeniowe, podobnie jak wielowątkowe mają rozdzielne stan procesora i
obsługę przerwań dla każdego rdzenia (wątku dla wielowątkowych). Różnica polega na tym,
że procesor wielowątkowy ma wspólne jednostki wykonawcze dla wątków, kiedy procesor
wielordzeniowy ma rozdzielne jednostki wykonawcze dla każdego rdzenia, więc
wykonywanie działań jest o wiele szybsze. Wystarcz powiedzieć, ze każdy rdzeń może być
wielowątkowy. Każdy wątek nie może być wielordzeniowy. ;]
Wyszukiwarka
Podobne podstrony:
MIKROBIOLOGIA, III koło opracowanie
patomorfo 2 koło opracowane pytania
Koło opracowanie
na koło opracowanie(1), AM SZCZECIN, OWI
poprawione kwity, na koło opracowanie poprawione
ZARYS 2 KOLO OPRACOWANE, 2 rok, OGÓLNA TECHNOLOGIA ŻYWNOŚCI, egy, inne
Koło 4 Opracowanie krążeniowo oddechowy
pytania na koło, opracowane
1 kolo opracowanie2 (2)
na koło opracowanie poprawione, Akademia Morska Szczecin, Semestr VIII, Ochrona własności intelektua
1 kolo - opracowaniej, Zarządzanie PWR, Semestr 6, Analiza finansowa wspomagana komputerem
1 kolo opracowanie
wejscie-nerki, III rok, Patomorfologia, Patomorfologia, 5 koło, Opracowanie
kolo opracowanie odpowiedzi
kolo opracowanie silniory
Koło 5 Opracowanie pokarmowy, nerka, wątroba, trzustka
kolo opracowanie odpowiedzi
2007 MKM I kolo opracowanie
więcej podobnych podstron