3582277771
tych operacji jest znaczne zmniejszenie czasu wykonywania tej samej pracy przez jeden węzeł. Algorytm MapReduce najczęściej używany jest przy czasochłonnych operacjach na dużych zbiorach danych. Mniejsze znaczeniem ma poziom skomplikowania zadania, w praktyce są to zazwyczaj łatwe problemy.
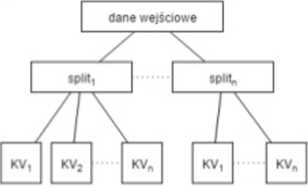
2.3 Diagram przedstawiający pierwszy etap fazy mapowania dane wejściowe - dowolne dane ładowane z pliku spkt - pofragmentowane dane wejściowe
KV • zbiory par klucz wartość dla danego splitu. ulegających mapowaniu w dalszym etapie Szczegółowy opis kroków przedstawia się następująco:
• InputFormat dzieli dane wejściowe z pliku wejściowego, wynikiem tego działania są InputSpUts, które reprezentują dane do późniejszej analizy.
• RecordReader przygotowuje dane dla następnego kroku w formie grupy par klucz-wartość.
• Hadoop MapReduce framewoik dla każdego InputSpUt tworzy map task. który następnie przydzielany jest do węzła.
• każdy map task wykonuje zaimplementowaną i dostarczaną przez aplikację funkcję map.
• każdy węzeł może mieć przydzielone więcej niż jeden task, wykonywane one są równolegle na wszystkich węzłach klastra.
InputSplits • rekordy danych powstałe na etapie dzielenia zbioru danych wejściowych na mniejsze części.
InputFormal • klasa odpowiedzialna za generowanie InputSplits. dostarcza także RecordReader oraz opisije specyfikację wejścia (typy danych dla par klucz-wartość).
RecordReader - generuje zbiór par klucz-wartość z każdego InputSplit, które następnie są wejściem dla map task.
map task - określenie na zadanie przydzielane węzłom klastra. którego celem jest wykonanie funkcji mapującej nadanych wejściowych.
< keyl,valuel > —> map-> < key2,vdue2 > (2.9)
Powyższy wzór ukazuje bardzo uproszczony schemat tej fazy. Wyjściem jest plik wynikowy, którego format reprezentowany jest również przez parę klucz-wartość. jednakże typy danych niekoniecznie muszą pokrywać się z tymi na wejściu.
17
Wyszukiwarka
Podobne podstrony:
stronne badania nad mechanizmem zachowania się. Zadanie tych uwag jest znacznie skromniejsze: chodzi
szybko ulegają rozluźnieniu. Najbardziej ujemną cechą tych ochraniaczy jest znaczne ścienienie ich
Jeśli jeden z argumentów przy operacjach jest skalarem, to zawsze wykonywane są operacje tablicowe,
71711 skanuj0181 18 1. Co to jest strategia i zarządzanie strategiczne kowana w tej samej pozycji ni
15 Ściąga z SQL 4.4. Różnica relacji Argumentem różnicy jest para relacji. Dwie relacje z tej samej
Pielęgnacja: Pielęgnacja: ukierunkowana jest na zmniejszanie grubości warstwy rogowej i regulację pr
14580 IMG?40 (2) rowywaru* czasu na tej samej drodze, zawracając plamkę do początku drogi W tym celu
Zdjęcie0294 KISIcnIJ, aby dodać tytuł Jozoli następujące po sobie przypisy dotyczą tej samej pracy.
page0046 36 nie do tej samej pracy, zawaliła się jeszcze po raz drugi. Wtedy ogarnęło wszystkich prz
page0060 58 XENOFONT. ściA). Jakże więc stało się, że jego synowie, chowani według tej samej metody
- podczas cytowania tej samej pracy kilka razy po sobie stosujemy, np. Tamże,
osobnika przedstawia dana sytuacja. W tej samej pracy znajdujemy również podkreślenie znaczenia, jak
Filozofia, kulturoznawstwo, europeistyka różne nazwy tej samej pracy wwiV.demotywatory.pl
Herold naczynia621 po 1 minucie. W razie choroby niedokrwiennej tętnic obwodowych zmniejszenie I śni
298 (42) jem wewnętrznym jest ogromna. Ona już nie ma czasu dla tej siebie malutkiej, ponieważ
nej jest więc miejscem zatrudnienia osób ze znacznie zmniejszoną wydolnością wysiłkową (fizyczną lub
więcej podobnych podstron